打赏本站
微信
 支付宝
支付宝

支付宝
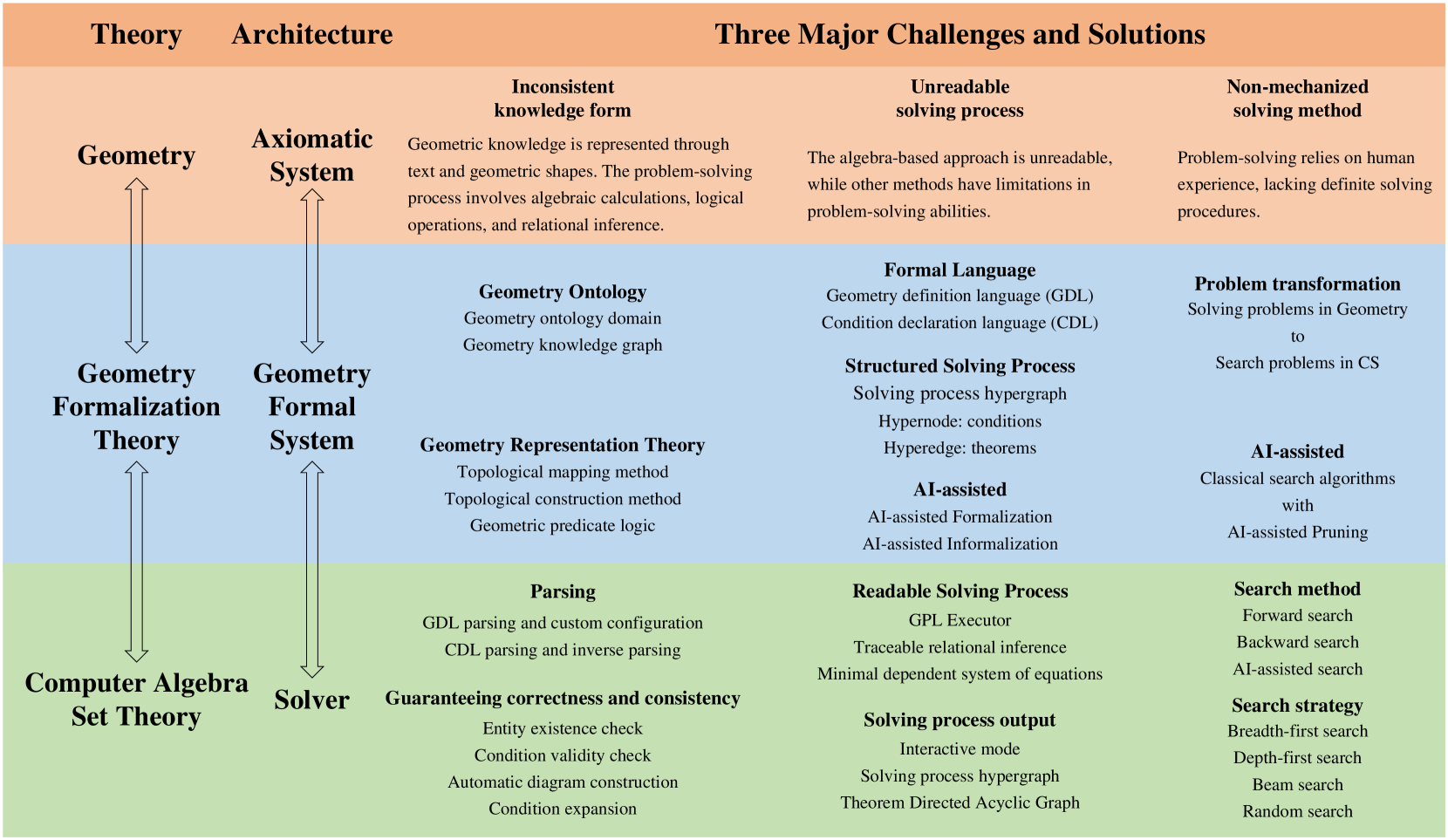
这是我们过去三年来完成的一系列工作中的第一篇论文。在本文中,我们构建了一个一致的形式平面几何系统。这将成为 IMO 级平面几何挑战和可读的人工智能自动推理之间的重要桥梁 ...
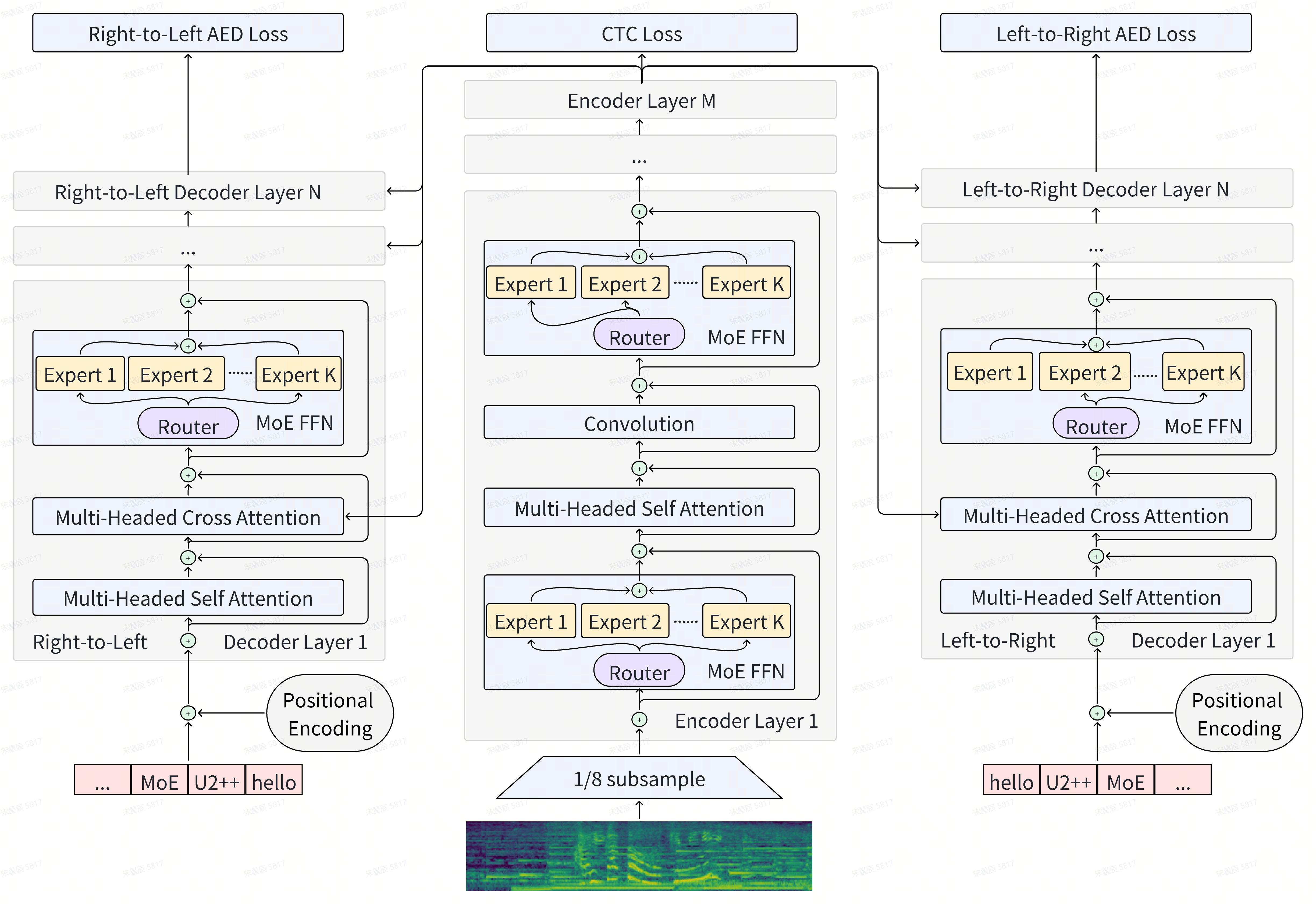
规模化开辟了自然语言处理的新领域,但成本很高。作为回应,通过学习仅激活训练和推理中的参数子集,专家混合 (MoE) 已被提议作为通往更大、能力更强的语言模型的节能途径,并且这种向新一代基础的转变模型正在获得发展势头,特别是在自动语音识别(ASR)领域。最近将 MoE 纳入 ASR 模型的工作具有复杂的设计,例如通过补充嵌入网络路由框架、提高专家的多语言能力,以及利用专用辅助损失来进行专家负载平衡或 ...
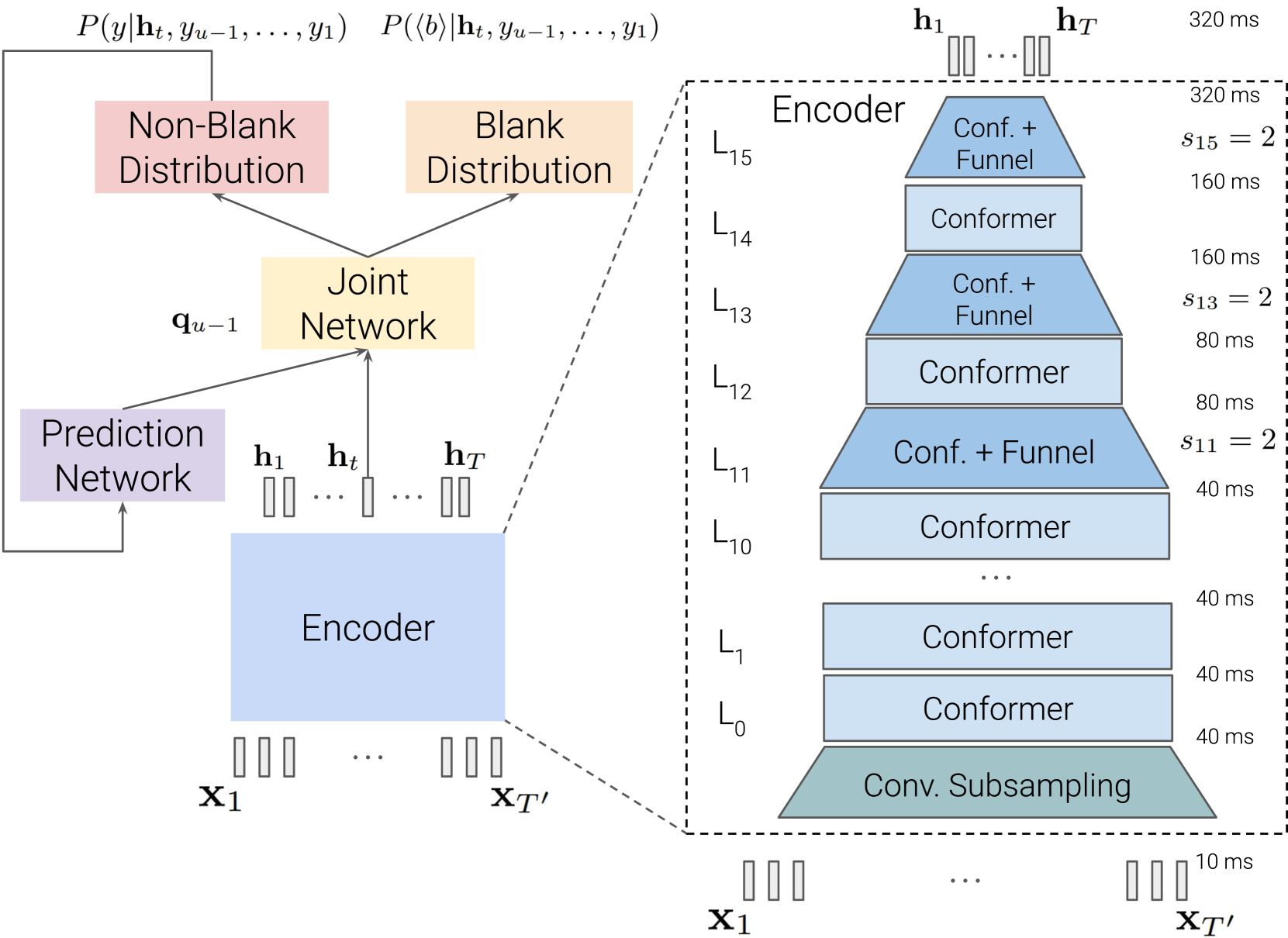
随着大规模通用语音模型 (USM) 的最新发展,端到端自动语音识别 (ASR) 模型的质量得到了革命性的提升。然而,由于巨大的内存使用和计算成本,部署这些大规模 USM 的成本极其昂贵。因此,模型压缩是在现实场景中在预算范围内适应基于 USM 的 ASR 的一个重要研究课题 ...

我们提出了一种基于离散潜在代码生成框架的大掩模多元图像修复方法。我们的方法通过仅在图像的可见位置执行计算来学习潜在先验,离散化为标记。这是通过一个限制性部分编码器来实现的,该编码器预测每个可见块的 Token 标签,一个双向变换器,仅通过查看这些 Token 来推断丢失的标签,以及一个专用合成网络,该网络将 Token 与部分图像先验耦合以生成相干的即使在极端的掩模设置下也能获得多元化的完整图像 ...

端到端 (E2E) 自动语音识别 (ASR) 模型的准确性随着规模的扩大而不断提高,有些模型现在已达到数十亿个参数。然而,这些模型的广泛部署和采用需要计算高效的解码策略。在目前的工作中,我们研究了一种这样的策略:在编码器中应用多个帧缩减层将编码器输出压缩为少量输出帧 ...
因果关系揭示了现实场景中数据分布背后的基本原理,大型语言模型 (LLM) 理解因果关系的能力直接影响其在解释输出、适应新证据和生成反事实方面的功效。随着 LLM 的激增,对这种能力的评估越来越受到关注。然而,由于缺乏全面的基准,现有的评估研究变得简单、单一和同质化 ...

尽管神经辐射场 (NeRF) 在物体和小空间有限区域上展示了令人印象深刻的视图合成结果,但它们在“无界”场景中表现不佳,在“无界”场景中,相机可能指向任何方向,内容可能存在于任何距离。在这种情况下,现有的类似 NeRF 的模型通常会产生模糊或低分辨率的渲染(由于附近和远处物体的细节和比例不平衡),训练速度很慢,并且由于任务的固有模糊性可能会出现伪影。从一小组图像重建大场景。我们提出了 mip-Ne ...

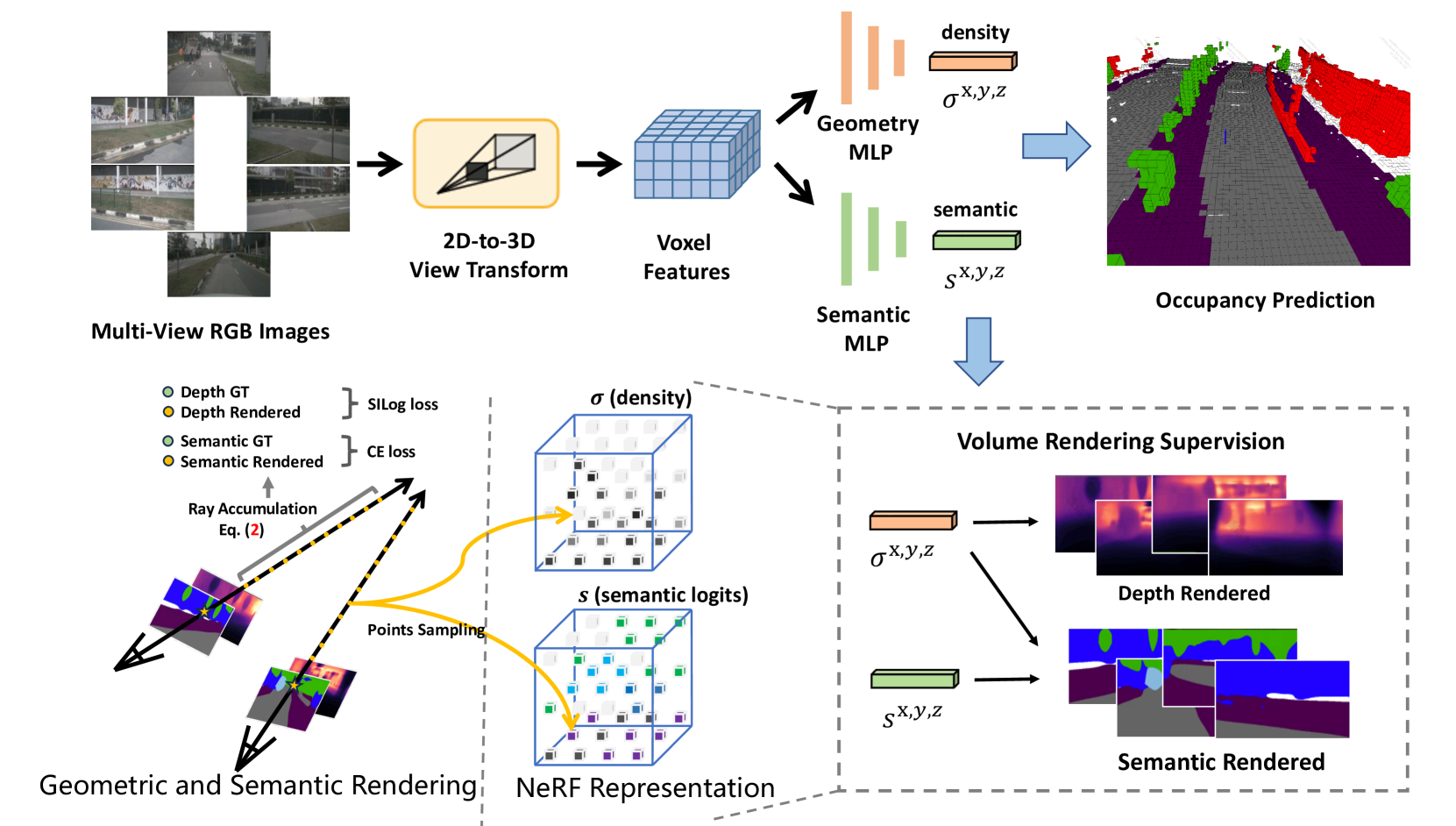
在本技术报告中,我们介绍了名为 UniOCC 的解决方案,用于 CVPR 2023 的 nuScenes 开放数据集挑战赛中以视觉为中心的 3D 占用预测赛道。现有的占用预测方法主要侧重于使用 3D 占用优化 3D 体积空间上的投影特征标签。然而,这些标签的生成过程复杂且昂贵(依赖于3D语义注释),并且受体素分辨率的限制,它们无法提供细粒度的空间语义 ...