Induction Networks for Few-Shot Text Classification
Ruiying Geng1,2, Binhua Li2, Yongbin Li2 *, Xiaodan Zhu3, Ping Jian1 *, Jian Sun2
1School of Computer Science and Technology, Beijing Institute of Technology
2 Alibaba Group, Beijing
3 ECE, Queen’s University
{ruiying.gry,binhua.lbh,shuide.lyb,jian.sun}@alibaba-inc.com
zhu2048@gmail.com pjian@bit.edu.cn
摘要
当数据不足或需要适应没有见过的类别时,文本分类往往会遇到困难。 对于这些具有挑战性的场景,最近的研究使用元学习来模拟这项 few-shot 任务,few-shot 任务的意思是将新的查询与样本数量很小的支持集进行比较。 但是,这种基于样本的比较可能会受到同一类中各种表达的严重干扰。 因此,我们应该能够学习支持集中每个类的一般表示,然后将其与新查询进行比较。 在本文中,我们提出了一种新颖的归纳网络,通过在元学习中创新地利用动态路由算法来学习这种广义的类表示。 通过这种方式,我们发现该模型能够更好地归纳和泛化。 我们在经过充分研究的情感分类数据集(英语)和真实世界的对话意图分类数据集(中文)上评估了提出的模型。 实验结果表明,在两个数据集上,所提出的模型均明显优于现有的最新方法,证明了类别的泛化在few-shot文本分类中的有效性。
1 引言
深度学习在计算机视觉,语音识别和自然语言处理等许多领域都取得了巨大的成功(Kuang et al., 2018)。 但是,对于大型标签数据集,监督式深度学习众所周知是贪婪的,这由于注释成本而将深度模型的可推广性限制为新类。 另一方面,人类很容易就能以很少的实例或刺激快速学习新的概念类别。 这一明显的差距为进一步研究提供了沃土。
Few-shot 学习通过从非常少的带有标签的样本中识别新的类别来致力于解决数据不足问题。 只有一个或几个样本的限制对深度学习中标准的微调方法带来挑战。 早期研究(Salamon and Bello, 2017)应用数据扩充和正则化技术来缓解因数据稀疏而导致的过拟合问题,但是程度有限。 相反,研究人员探索了元学习(Finn et al., 2017)在人类学习的启发下将分布分配到类似任务上。 当前few-shot学习方法通常遵循测试和训练条件必须匹配的原则,将训练过程分解为辅助元学习阶段,该阶段包括许多元任务。 他们通过将元任务从小批次转换为小批次来提取一些可迁移的知识。 这样,few-shot模型可以仅通过一个带有标签的小型支持集对新类进行分类。
然而,现有的few-shot学习方法仍然面临许多重要问题,包括强先验条件(Fei-Fei et al., 2006),任务之间复杂的梯度转移(Munkhdalai and Yu, 2017)以及对目标问题进行微调(Qi et al., 2018)。 Snell et al. (2017) 和 Sung et al. (2018)提出的方法将非参数方法和元学习相结合,为其中一些问题提供了潜在的解决方案。 非参数方法可以使新样本快速被吸收,而不会遭受灾难性的过度拟合。 这样的非参数模型仅需要学习样本的表示和度量标准。 但是,相同类别的实例是相互关联的,并且具有统一的分数和特定的分数。 在以前的研究中,通过简单地将支持集中样本的表示形式相加或取平均值来计算类级别表示形式。 这样做可能会在同一类别的各种形式的样本所带来的噪声中丢失基本信息。 请注意,few-shot 学习算法不会在支持集上进行微调。 当增加支持集的大小时,更大的数据大小所带来的改进也将因更多的样本噪声而减弱。
相反,我们通过在类级别上进行归纳来探索一种更好的方法:忽略无关的细节,并从同一类中具有各种语言形式的样本中封装一般语义信息。 结果,需要一种透视图体系结构,其可以重构支持集的分层表示并且将样本表示动态地诱导为类表示。
最近,(Sabour等人,2017)提出了胶囊网络,它具有解决上述问题的令人兴奋的潜力。 胶囊网络使用执行动态路由的“胶囊”来编码构成视点不变知识的部分和整体之间的固有空间关系。 遵循类似的精神,我们可以将样本视为部分,将类视为整体。 我们提出了归纳网络,其目的是基于动态路由过程,对从小型支持集中的样本中学习广义类级别表示的能力进行建模。 首先,编码器模块为查询和支持样本生成表示形式。 接下来,归纳模块执行动态路由过程,其中矩阵变换可以看作是从样本空间到类空间的映射,然后类表示的生成全都取决于按协议进行的路由而不是任何参数,这为所提出的模型提供了强大的归纳能力,可以处理看不见的类。 通过将样本的表示形式视为输入胶囊,将类的类别视为输出胶囊,我们希望识别出与样本级噪声无关的类的语义。 最后,对查询和类之间的交互进行建模-关系模块比较它们的表示,以确定查询是否与类匹配。 整体模型定义了基于情节的元训练策略,具有端到端的元训练能力,具有通用性和可伸缩性,可以识别看不见的类别。
我们工作的具体贡献如下:
• 我们提出将归纳网络用于 fewshot 文本分类。 为了处理几次学习任务中的样本多样性,就我们所知,我们的模型是第一个模型,该模型显式地建模了从小型支持集中推导类级别表示的能力。
•建议的归纳模块将动态路由算法与典型的元学习框架结合在一起。 矩阵转换和路由过程使我们的模型能够很好地泛化以识别看不见的类。
•我们的方法在两个镜头很少的文本分类数据集中优于当前的最新模型,其中包括经过深入研究的情感分类基准和现实世界中的对话意图分类数据集。
2 相关工作
2.1 Few-Shot 学习
关于少拍学习的开创性工作可以追溯到2000年代初(Fe-Fei等,2003; Fei-Fei等,2006)。 作者将生成模型与复杂的迭代推理策略结合在一起。 最近,许多方法都使用了元学习(Finn等人,2017; Mishra等人,2018)策略,从某种意义上说,它们从一组辅助任务中提取了一些可转让的知识,从而帮助他们学习很好地针对少数问题解决问题,而不会遭受过度拟合的困扰。 通常,这些方法可以分为两类。
基于优化的方法这种类型的方法旨在学习根据从littleshot示例计算出的梯度来优化模型参数。 Munkhdalai和Yu(2017)提出了元网络,该元网络跨任务学习了元级知识,并通过快速参数化转移了归纳偏差,从而实现了快速概括。 Mishra等。 (2018)引入了一种称为SNAIL的通用元学习架构,该架构使用了时间卷积和软注意力的新颖组合。
距离度量学习这些方法不同于上述方法,在学习目标少击球问题时会带来一些复杂性。 基于度量的几次射击学习的核心思想类似于最近邻和核密度估计。 一组已知标签的预测概率是支持集样本的标签的加权总和。 Vinyals等。 (2016年)产生了通过余弦距离测量的加权K最近邻分类器,称为匹配网络。 Snell等。 (2017)提出了原型网络,该网络学习了一个度量空间,可以通过计算平方的欧几里德距离来对每个类别的原型表示进行分类。 与固定度量指标不同,关系网络学会了一种深度距离度量标准,可以将查询与给定示例进行比较(Sung等人,2018年)。
近来,已经提出了一些专门针对少拍文本分类问题的研究。 徐等。 (2018)通过元学习研究了终身域词嵌入。 Yu等。 (2018)认为最优元模型可能会因任务而异,他们通过将元任务聚类为几个定义的聚类来采用多指标模型。 Rios和Kavuluru(2018)开发了针对多标签文本分类的快照文本分类模型,该模型在标签空间上存在已知结构。 徐等。 (2019)提出了一个开放世界的学习模型来处理产品分类问题中看不见的类。 我们从不同的角度解决了几次学习问题,并提出了一种动态路由归纳方法来封装样本中的抽象类表示形式,从而在两个数据集上实现了最新的性能。
2.2 Capsule 网络
胶囊网络最早由Sabour等人提出。 (2017),这使网络能够稳健地学习部分-整体关系中的不变量。 近年来,胶囊网络在自然语言处理领域进行了探索。 Yang等人(2018年)成功地将胶囊网络应用于大型标记数据集的完全监督文本分类问题。 与他们的工作不同,我们研究很少拍摄的文本分类。 Xia等人(2018年)重用了类似于Yang等人(2018年)的监督模型进行意向分类,其中扩展了基于胶囊的架构,以计算目标意图和源意图之间的相似性。 与他们的工作不同,我们建议采用诱导网络进行少镜头学习,其中我们建议使用胶囊和动态路由从基于样本的样本中学习广义的类级表示。 动态路由方法使我们的模型在很少镜头的文本分类任务中更好地进行概括。
3 问题定义
3.1 Few-Shot分类
很少射击分类(Vinyals等人,2016年;Snell 等人,2017 年)是一项任务,其中必须调整分类器以适应培训中未见的新课程,只需给出每个新课程的几个示例。 我们有一个大型标记训练集与一套C类训练。 然而,经过培训后,我们的最终目标是在测试集上生成分类器,其中只有一组不相交的新类 C测试,只有一个小的标记支持集可用。 如果支持集包含每个 C 唯一类的 K 标记示例,则目标很少射砂问题称为 C 向 K 射标问题。 通常,K 太小,无法训练受监督的分类模型。 因此,我们的目标是在训练集上执行元学习,并提取可转移的知识,使我们能够在支持集上提供更好的很少镜头学习,从而更准确地对测试集进行分类。
3.2 训练过程
训练程序必须仔细选择,以匹配测试时间的推理。 利用训练集的一个有效方法是将训练过程分解为辅助元学习阶段,并通过基于单集的训练模拟很少的镜头学习设置,如 Vinyals 等人(2016 年)中提出的。 我们构建了一个元集来计算梯度,并在每次训练迭代中更新模型。 元集由首先从训练集中随机选择类子集,然后选择每个选定类中的示例子集作为支持集 S 和其余示例的子集作为查询集 Q。 元训练过程明确学习从给定的支持集 S 中学习,以尽量减少查询集 Q 的损失。 我们将此策略称为基于单集的元训练,详细信息显示在算法 1 中。 值得注意的是,训练模型的可能元任务呈指数级,因此很难过度拟合。 例如,如果数据集包含 159 个训练类,则会有 \( (^{159}_{5}) \) 个可能的 5-way 任务。
算法 1 基于 Episode 的元训练
1: for each episode iteration do
2: Randomly select C classes from the class space of the training set;
3: Randomly select K labeled samples from each of the C classes as support set \( S = \{(x_s , y_s)\}^m_{s=1} (m = K × C) \), and select a fraction of the reminder of those C classes’ samples as query set \( Q = \{(x_q, y_q)\}^n_{q=1} \)
4: Feed the support set S to the model and update the parameters by minimizing the loss in the query set Q;
5: end for
4 模型
图 1(3-way 2-shot模型的情况)中所示的Induction 网络由三个模块组成:编码器模块、Induction模块和关系模块。 在本节的其余部分中,我们将展示这些模块在每个元集中的工作方式。
4.1 编码器模块
这个模块是一个具有 self-attention 的双向循环神经网络,如 Lin et al. (2017) 中所述。 给定一个由单词嵌入序列表示的输入文本 x = (w1, w2, ..., wT)。 我们使用双向LSTM处理文本:
\( \overrightarrow {h_t} \space = \space \overrightarrow {LSTM} (w_t, h_{t-1}) \) (1)
\( \overleftarrow {h_t} \space = \space \overleftarrow {LSTM} (w_t, h_{t+1}) \) (2)
And we concatenate \( \overrightarrow {h_t} \) with \( \overleftarrow {h_t} \) to obtain a hidden state \( {h_t} \). 设每个单向 LSTM 的隐藏状态大小为 u。 为简单起见,我们标记所有的 T 个 hts 为 H = (h1, h2, ..., hT)。 我们的目标是将可变长度的文本编码为固定大小的嵌入。 我们通过选择 H 中这 T 个 LSTM 隐藏矢量的线性组合来实现这一点。 计算线性组合需要 self-attention 机制,该机制将整个 LSTM 隐藏状态 H 作为输入,并输出权重向量 a:
\( a = softmax(W_{a2}tanh(W_{a1}H^T)) \) (3)
here \( W_{a1} ∈ R^{d_a×2u} \) and \( W_{a2} ∈ R^{d_a} \) are weight matrices and da is a hyperparameter. 文本的最终表示形式 e 是 H 的加权总和:
\( e = \sum_{t=1}^T a_t · b_t \) (4)
4.2 归纳模块
本节介绍我们提出的动态路由归纳算法。 我们将根据等式 4 获得的支持集 S 的向量 e 称作样本向量 es,而查询集 Q 的向量 e 称作查询向量 eq。 最重要的步骤是提取支持集中每个类别的表示形式。 归纳模块的主要目的是设计从样本矢量 \(e_{ij}^s\) 到类向量 ci的非线性映射:
\( \{e_{ij}^s ∈ R^{2u}\}_{i=1...C,j=1...K} \rightarrow \{c_{i} ∈ R^{2u}\}_{i=1}^C \).
在本模块中,我们以输出胶囊数量为 1 的情形应用动态路由算法 (Sabour et al., 2017)。 为了接受我们模型中任意 way 任意 shot 输入,在支持集中的所有样本向量上采用权重共享的变换。 支持集中的所有样本向量共享相同的变换权重 Ws ∈ R2u×2u 和偏置 bs,因此模型足够灵活,能够处理任何规模的支持集。 每个样本的预测向量 \( \hat e_{ij}^s \) 的计算方式为:
\(\hat e_{ij}^s = squash(W_se_{ij}^s + b_s)\) (5)
其中 squash 是贯穿整个向量的非线性挤压函数,使向量的方向保持不变,但减小其大小。 给定输入向量 x,squash 定义为:
\( squash(x) = \frac{||x||^2}{1+||x||^2} \frac{x}{||x||} \) (6)
等式 5 编码底层样本特征和高层类别特征之间重要的不变语义关系(Hinton et al., 2011)。 为了确保类别向量自动概况此类别的样本特征向量,动态路由以迭代方式应用。 在每次迭代中,这个过程动态地修正连接强度,并通过"路由 softmax"确保类别 i 和这个类别中所有支持样本之间的耦合系数 di 之和为 1:
\( d_i = softmax(b_i) \)(7)
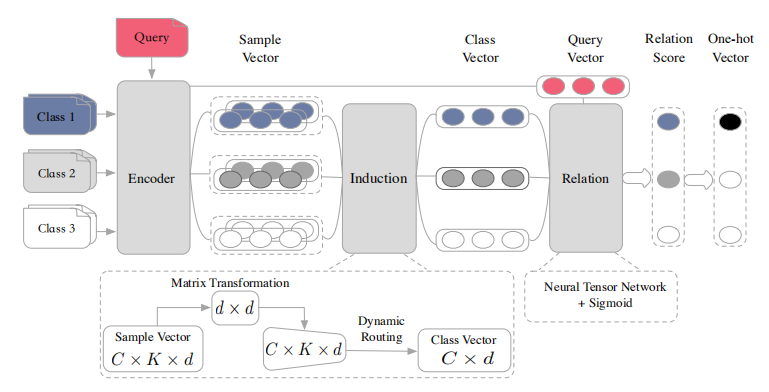
图 1:带有一个查询样本的 C-way K-shot (C = 3,K = 2)归纳网络架构
其中 bi 是耦合系数的 logits ,并在第一次迭代中初始化为 0。 给定每个样本预测矢量 \( \hat e_{ij}^s \),每个类别的候选向量量 \( \hat c_i \) 是 类别 i 中所有样本预测向量 \( \hat e_{ij}^s \) 的加权总和:
\( \hat c_i = \sum_{j} d_{ij} \space · \space \hat e_{ij}^s \)(8)
然后应用非线性"挤压"函数,以确保路由过程的矢量输出长度不超过 1:
\( c_i = squash(\hat c_i) \)(9)
每次迭代的最后一步是通过"协议路由"方法调整耦合系数 bij的日志。 如果生成的类候选矢量具有具有一个样本预测矢量的大标量输出,则存在自上而下的反馈,该反馈会增加该样本的耦合系数,并降低其他样本的耦合系数。 这种类型的调整对于很少的镜头学习场景是非常有效和可靠的,因为它不需要还原任何参数。 每个 bij的更新时间:
\( b_{ij} = b_{ij} \space + \space \hat e_{ij}^s \space · \space c_i \)(10)
从形式上讲,我们将归纳方法称为动态路由归纳,并在算法 2 中总结。
4.3 Relation 模型
在归纳模块生成类向量 ci后,查询集中的每个查询文本由编码器模块编码为查询向量 eq,下一个基本过程是测量每对查询和类之间的相关性。 关系模块的输出称为关系分数,表示 ci和 eq之间的相关性,这是 0 和 1 之间的标量。 具体来说,我们在本模块中使用神经张量层(Socher等人,2013年),在建模两个向量之间的关系方面显示出了很大的优势(Wan等人,2016年;耿等人,2017年)。 本文选择它作为交互函数。 张量层输出关系矢量,如下所示:
算法 2 Dynamic Routing Induction
需要: 支持集 S 中的样本向量 (e_[ij]s _) 并初始化耦合系数的日志 [(b_[ij] ]) = 0
Ensure: class vector \( c_i \)
1: for all samples j = 1, ..., K in class i:
2: \( \space \space \space \space \hat e^s_{ij} \space = \space squash(W_se^s_{ij} + b_s) \)
3: for iter iterations do
4: \( \space \space \space \space d_i \space = \space softmax(b_i) \)
5: \( \space \space \space \space \hat c_i \space = \space \sum_j d_{ij} \space · \space \hat e_{ij}^s \)
6: \( \space \space \space \space c_i = squash(\hat c_i) \)
7: \( \space \space \space\space \)for all samples j = 1, ..., K in class i:
8: \( \space \space \space \space \space \space \space \space b_{ij} = b_{ij} \space + \space \hat e_{ij}^s \space · \space c_i \)
9: end for
10: Return \( c_i \)
\( v(c_i, e^q) = f(c_i^T M^{[1:h]}e^q) \)(11)
其中 Mk ∈ R2u×2u, k ∈ [1, ..., h] 是张量参数的一个切片,f 是称为 RELU 的非线性激活函数(Glorot 等人,2011 年)。
i-th 类和 q-th 查询之间的最终关系分数 riq由 sigmoid 函数激活的完全连接层计算。
\( r_{iq} = sigmoid(W_rv(c_i, e^q) + b_r) \)(12)
4.4 目标函数
我们使用平均平方误差(MSE)损失来训练我们的模型,将关系分数 riq 回归到真实的 yq:匹配具有相似性 1,不匹配具有相似性 0。 在一个 episode 中,给定 C 个类别的查询集 S 和 支持集 \( Q = \{ (x_q, y_q)\}_{q=1}^n\),损失函数定义为:
\( L(S, Q) = \sum^C_{i=1} \sum^n_{q=1} (r_{iq} - 1(y_q == i))^2 \)(13)
从概念上讲,我们预测关系分数,这可以被视为回归问题,而地面真理在空间 [0, 1] 内。
三个模块的所有参数都通过反向传播共同训练。 Adagrad(Duchi等人,2011年)用于每个训练插曲中的所有参数。 由于其通用性,我们的模型不需要对从未见过的类进行任何微调。 诱导和比较能力与训练情节一起在模型中积累。
5 实验
我们通过在两个很少拍摄的文本分类数据集上进行实验来评估我们的模型。 所有实验都使用 Tensorflow 实现。
5.1 数据集
亚马逊评论情绪分类(ARSC)和 Yu et al. (2018) 一样,我们使用多领域情绪分类 (Blitzer et al., 2007) 数据集的多个任务。 该数据集包含亚马逊上 23 种产品的英文评论。 对于每个产品域,有三个不同的二进制分类任务。 然后,这些存储桶总共形成 23 × 3 = 69 个任务。 继 Yu 等人 (2018) 之后,我们从 4 个域(书籍、DVD、电子和厨房)中选择 12(4 + 3) 任务作为测试集,只有五个示例作为测试集中每个标签的支持集。 我们在此数据集上创建 5 镜头学习模型。
| 训练集 | 测试集 | |
|---|---|---|
| Class Num | 159 | 57 |
| Data Num | 195,775 | 2,279 |
| Data Num/Class | € 77 | 20 × 77 |
表1:ODIC详情
| 模型 | 平均 Acc |
|---|---|
| Matching Networks (Vinyals et al., 2016) | 65.73 |
| Prototypical Networks (Snell et al., 2017) | 68.17 |
| Graph Network (Garcia and Bruna, 2017) | 82.61 |
| Relation Network (Sung et al., 2018) | 83.07 |
| SNAIL (Mishra et al., 2018) | 82.57 |
| ROBUSTTC-FSL (Yu et al., 2018) | 83.12 |
| Induction Networks (ours) | 85.63 |
表2:在 ARSC 上的平均精度(%)的比较
对话框系统 (ODIC) 的开放域意图分类我们通过在真实对话平台上获取日志数据来创建此数据集。 企业提交的各种对话任务具有大量意图,但许多意图只有几个标记样本,这是一个典型的少镜头分类应用程序。 遵循很少镜头的学习任务的定义,我们将 ODIC 划分为训练集和测试集,并确保两组的标签没有交集。 设置分区的详细信息如表 1 所示。
5.2 实验设置
基线 本节将介绍实验中的基线模型,如下所示。
• 匹配网络:使用基于公制注意力方法的几杆学习模型(Vinyals等人,2016年)。
• 原型网络:一种基于指标的深层方法,使用样本平均值作为类原型(Snell等人,2017年)。
• 图形网络:基于图形的少镜头学习模型,在采样级别上实现任务驱动的消息传递算法(Garcia 和 Bruna,2017)。
• 关系网络:使用神经网络作为距离度量并汇总支持集中的样本向量作为类矢量(Sung 等人,2018 年)的几个镜头学习模型。
• SNAIL:一类简单和通用的元学习者架构,使用时间卷积和软注意力的新组合(Mishra等人,2018年)。
• ROBUSTTC-FSL:此方法通过对任务进行聚类来组合几种基于指标的方法(Yu等人,2018年)。
| 模型 | 5-way Acc. | 10-way Acc. | ||
|---|---|---|---|---|
| 5-shot | 10-shot | 5-shot | 10-shot | |
| Matching Networks (Vinyals et al., 2016) | 82.54±0.12 | 84.63±0.08 | 73.64±0.15 | 76.72±0.07 |
| Prototypical Networks (Snell et al., 2017) | 81.82±0.08 | 85.83±0.06 | 73.31±0.14 | 75.97±0.11 |
| Graph Network (Garcia and Bruna, 2017) | 84.15±0.16 | 87.24±0.09 | 75.58±0.12 | 78.27±0.10 |
| Relation Network (Sung et al., 2018) | 84.41±0.14 | 86.93±0.15 | 75.28±0.13 | 78.61±0.06 |
| SNAIL (Mishra et al., 2018) | 84.62±0.16 | 87.31±0.11 | 75.74±0.07 | 79.26±0.09 |
| Induction Networks (ours) | 87.16±0.09 | 88.49±0.17 | 78.27±0.14 | 81.64±0.08 |
表3:平均精度比较(%)在 ODIC 上
在 u 等人(2018 年)中报告了 ARSC 的基线结果,并在 ODIC 上实现了具有相同文本编码器模块的基线模型。
实施详情我们使用 300 维手套嵌入(Pennington 等人,2014 年)用于 ARSC 数据集和由 Li 等人(2018 年)为 ODIC 培训的 300 维中文单词嵌入。 我们设置 LSTM u = 128 的隐藏状态大小,并将注意力维度 da = 64 设置为隐藏状态大小。 动态路由算法中使用的迭代数迭代器为 3。 关系模块是一个神经张量层,h = 100 后跟由 sigmoid 激活的完全连接层。 我们在 Yu 等人 (2018) 之后在 ARSC 上构建双向 5 镜头模型,并构建基于单集的元训练,使用 C = [5, 10] 和 K = [5, 10] 在 ODIC 上进行比较。 除了作为支持集的 K 示例文本外,查询集在每个培训集中的每个 C 采样类都有 20 个查询文本。 这意味着,例如,有20 × 5 × 5 × 5 × 125 文本在一个训练情节的 5 路 5 镜头实验。
评价方法在前几项研究之后,我们通过几枪分类精度来评估性能(Snell等人,2017年;Sung等人,2018年。 为了客观地评估建议的模型与基线,我们计算平均几针分类精度在ODIC超过600随机选择的情节从测试集。 我们每集对每节课的 10 个测试文本进行采样,以评估 5 次拍摄和 10 次拍摄场景。 请注意,对于 ARSC,测试支持集由 Yu 等人 (2018) 固定。 因此,我们只需要为每个目标任务运行一次测试集。 将 12 个目标任务的平均精度与 Yu 等人(2018 年)之后的基线模型进行比较。
5.3 实验结果
整体性能表2给出了关于ARSC的实验结果。 建议的感应网络实现了 85.63% 的精度,比现有的最先进的模型 ROBUSTTC-FSL 提高了 3%。 我们之所以有所改进,是:ROBUSTTC-FSL 通过在样本级别集成多个指标来构建一般度量方法,这面临着在同一类不同表达式之间消除噪声的困难。 此外,ROBUSTTC-FSL 使用的基于任务群集的方法必须在相关性矩阵上找到,当应用于任务快速变化的实际场景时,这种方法效率很低。 然而,我们的归纳网络在元学习框架中经过培训,具有更灵活的概括性,因此其归纳能力可以通过不同的任务积累。
我们还使用实际意图分类数据集 ODIC 来评估我们的方法。 实验结果列在表3中。 我们可以看到,我们提出的感应网络在所有四个实验中都实现了最佳的分类性能。 在距离度量学习模型(匹配网络、原型网络、图形网络和关系网络)中,所有学习都发生在以采样级别表示特征和测量距离。 我们的工作构建了一个归纳模块,侧重于按类别分类的表示水平,我们声称该模块对支持集中样本的变化更为可靠。 我们的模型还优于最新的基于优化的方法 — SNAIL。 表 3 所示的感应网络和 SNAIL 之间的差异在 99% 显著性水平的配对下具有统计显著性。 此外,我们的模型与 10 次拍摄方案中的其他基线之间的性能差异比 5 次拍摄场景的性能差异更为显著。 这是因为在 10 镜头方案中,对于基线模型,更大的数据大小带来的改进也会因采样级噪声增加而减少。
| 迭 代 | 精度 | |
|---|---|---|
| Routing+Relation | 3 | 85.63 |
| Routing+Relation | 2 | 85.41 |
| Routing+Relation | 1 | 85.06 |
| Routing + Cosine | 3 | 84.67 |
| Sum +Relation | - | 83.07 |
| Attention + Relation | - | 85.15 |
表4:ARSC数据集感应网络消融研究
消融研究为了分析感应模块和关系模块不同组件的影响,我们进一步报告ARSC数据集上的消融实验,如表4所示。 我们可以看到,当我们使用 3 次迭代(对应于表 2 中报告的最佳结果)时,可实现最佳性能(多轮迭代没有进一步提高性能),并且该表显示了路由组件的有效性。 我们还更改了感应模块与总和和自我注意,并改变了关系模块与后因距离。 性能的变化验证了关系模块和归纳模块的好处。 注意与关系通过自我注意机制对诱导能力进行模型,但能力受到所学注意力参数的限制。 相反,提出的动态路由感应方法通过根据输入的支撑集自动调整耦合系数来捕获类级信息,更适合于很少的学习任务。
5.4 进一步分析
进一步分析了变换的效果,可视化了查询文本向量,显示了感应网络的优势。
转换的效果图 2 显示了 5 向 10 镜头方案下支持样本向量前后的 t-SNE(Maaten 和 Hinton,2008 年)的可视化。 我们从 ODIC 测试集中随机选择包含 50 个文本(每类 10 个文本)的支持集,并获取示例矢量 [(e_]{i}{1},...5,j=1...10 =编码器模块和样本预测向量后 [(\\\\\\e_\\\\\\\\\\\\\\\\\\\\\\\\\\\\,...\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\5,j=1...10==)转换后。 我们可以看到,矩阵变换后的向量更加可分离,证明了矩阵变换对较低层次采样特征和较高级别类特征之间的语义关系进行编码的有效性。
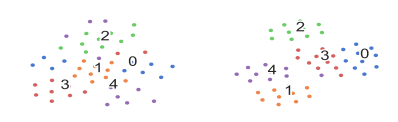
(a) 转换前(b) 转换后
图 2:5 路 10 镜头下转换的效果。 (a) 矩阵变换前的支持样本向量。 (b) 矩阵变换后的支持样本向量。

(a) Relation Network (b) Induction Networks
图3:查询文本矢量可视化,由(a) 关系网络和 (b) 感应网络学习。
查询文本矢量可视化我们还发现,我们的归纳模块不仅在生成有效的类级功能方面效果良好,还有助于编码器学习更好的文本矢量,因为它可以在反向传播期间为实例和特征提供不同的权重。 图 3 显示了 T-SNE(Maaten 和 Hinton,2008 年)对来自同一随机选择的五个类的文本矢量的可视化,这些文本矢量由关系网络和我们的感应网络学习。 显然,感应网络所学的文本向量在语义上比关系网络的载体更分离。
6 结论
本文提出了诱导网络,一种用于少镜头文本分类的新型神经模型。 我们建议从支持集诱导类级表示,以处理少数学习任务中的样本多样性。 归纳模块将动态路由算法与元学习框架相结合,路由机制使我们的模型更通用地识别看不见的类。 实验结果表明,该模型优于现有的最先进的少镜头文本分类模型。 我们发现,矩阵转换和路由过程都一致地有助于完成很少的学习任务。
致谢 作者感谢EMNLP-IJCNLP2019的组织者和审查者提出的有益建议。 本研究工作得到国家重点研究发展计划的支持。 2017YFB1002103,国家自然科学基金,授权号 61751201,北京市科委研究基金会,授权号 Z181100008918002。
引文
John Blitzer, Mark Dredze, and Fernando Pereira. 2007. Biographies, bollywood, boom-boxes and blenders: Domain adaptation for sentiment classification. In Proceedings of the 45th annual meeting of the association of computational linguistics, ages 440–447.
John Duchi, Elad Hazan, and Yoram Singer. 2011. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 12(Jul):2121–2159.
Li Fe-Fei et al. 2003. A bayesian approach to unsupervised one-shot learning of object categories. In Computer Vision, 2003. Proceedings. Ninth IEEE International Conference on, pages 1134–1141. IEEE.
Li Fei-Fei, Rob Fergus, and Pietro Perona. 2006. Oneshot learning of object categories. IEEE transactions on pattern analysis and machine intelligence, 28(4):594–611.
Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 1126–1135. JMLR. org.
Victor Garcia and Joan Bruna. 2017. Few-shot learning with graph neural networks. CoRR, abs/1711.04043.
Ruiying Geng, Ping Jian, Yingxue Zhang, and Heyan Huang. 2017. Implicit discourse relation identification based on tree structure neural network. In 2017 International Conference on Asian Language Processing (IALP), pages 334–337. IEEE.
Xavier Glorot, Antoine Bordes, and Yoshua Bengio. 2011. Deep sparse rectifier neural networks. In Proceedings of the fourteenth international conference on artificial intelligence and statistics, pages 315– 323.
Geoffrey E Hinton, Alex Krizhevsky, and Sida D Wang. 2011. Transforming auto-encoders. In International Conference on Artificial Neural Networks, pages 44–51. Springer.
Shaohui Kuang, Junhui Li, Ant´onio Branco, Weihua Luo, and Deyi Xiong. 2018. Attention focusing for neural machine translation by bridging source and target embeddings. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), volume 1, pages 1767–1776.
Shen Li, Zhe Zhao, Renfen Hu, Wensi Li, Tao Liu, and Xiaoyong Du. 2018. Analogical reasoning on chinese morphological and semantic relations. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 138–143.
Zhouhan Lin, Minwei Feng, Cicero Nogueira dos Santos, Mo Yu, Bing Xiang, Bowen Zhou, and Yoshua Bengio. 2017. A structured self-attentive sentence embedding. arXiv preprint arXiv:1703.03130.
Laurens van der Maaten and Geoffrey Hinton. 2008. isualizing data using t-sne. Journal of machine learning research, 9(Nov):2579–2605.
Nikhil Mishra, Mostafa Rohaninejad, Xi Chen, and Pieter Abbeel. 2018. A simple neural attentive metalearner. In Proceedings of ICLR.
Tsendsuren Munkhdalai and Hong Yu. 2017. Meta networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 2554–2563. JMLR. org.
Jeffrey Pennington, Richard Socher, and Christopher Manning. 2014. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 1532–1543.
Hang Qi, Matthew Brown, and David G Lowe. 2018. Low-shot learning with imprinted weights. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5822–5830.
Anthony Rios and Ramakanth Kavuluru. 2018. Fewshot and zero-shot multi-label learning for structured label spaces. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3132–3142.
Sara Sabour, Nicholas Frosst, and Geoffrey E Hinton. 2017. Dynamic routing between capsules. In Advances in Neural Information Processing Systems, pages 3856–3866.
Justin Salamon and Juan Pablo Bello. 2017. Deep convolutional neural networks and data augmentation for environmental sound classification. IEEE Signal Processing Letters, 24(3):279–283.
Jake Snell, Kevin Swersky, and Richard Zemel. 2017. Prototypical networks for few-shot learning. In Advances in Neural Information Processing Systems, pages 4077–4087.
Richard Socher, Danqi Chen, Christopher D Manning, and Andrew Ng. 2013. Reasoning with neural tensor networks for knowledge base completion. In Advances in neural information processing systems, pages 926–934.
Flood Sung, Yongxin Yang, Li Zhang, Tao Xiang, Philip HS Torr, and Timothy M Hospedales. 2018. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1199–1208.
Oriol Vinyals, Charles Blundell, Tim Lillicrap, Daan Wierstra, et al. 2016. Matching networks for one shot learning. In Advances in Neural Information Processing Systems, pages 3630–3638.
Shengxian Wan, Yanyan Lan, Jiafeng Guo, Jun Xu, Liang Pang, and Xueqi Cheng. 2016. A deep architecture for semantic matching with multiple positional sentence representations. In AAAI, volume 16, pages 2835–2841.
Congying Xia, Chenwei Zhang, Xiaohui Yan, Yi Chang, and Philip Yu. 2018. Zero-shot user intent detection via capsule neural networks. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing,
Hu Xu, Bing Liu, Lei Shu, and P Yu. 2019. Openworld learning and application to product classification. In The World Wide Web Conference, pages 3413–3419. Acm。
Hu Xu, Bing Liu, Lei Shu, and Philip S Yu. 2018. Lifelong domain word embedding via meta-learning. arXiv preprint arXiv:1805.09991.
Min Yang, Wei Zhao, Jianbo Ye, Zeyang Lei, Zhou Zhao, and Soufei Zhang. 2018. Investigating capsule networks with dynamic routing for text classification. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3110–3119.
Mo Yu, Xiaoxiao Guo, Jinfeng Yi, Shiyu Chang, Saloni Potdar, Yu Cheng, Gerald Tesauro, Haoyu Wang, and Bowen Zhou. 2018. Diverse few-shot text classification with multiple metrics. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1206–1215.