一个用于意图分类和范围外意图预测的评估数据集
Stefan LarsonAnish MahendranJoseph J. PeperChristopher Clarke
Andrew LeeParker HillJonathan K. KummerfeldKevin Leach
Michael A. LaurenzanoLingjia TangJason Mars
Clinc, Inc.
Ann Arbor, MI, USA
stefan@clinc.com
摘要
面向任务的对话系统需要知道查询何时超出其支持的意图范围,但当前文本分类语料仅定义涵盖每个样本的标签集。 我们引入一个新的数据集,其中包含意图范围外的查询,即不属于系统支持的任何意图的查询。 这带来新的挑战,因为模型不能假定推理时的每个查询都属于系统支持的意图类型。 我们的数据集还涵盖 10 个领域中的 150 个意图类型,满足面向任务的生产环境必须处理的广度。 我们以几种不同的识别范围之外的意图方式,在此数据集上评估一系列基准分类器。 我们发现,虽然分类器在范围内意图分类方面表现良好,但它们很难识别范围外查询。 我们的数据集和评估填补了该领域的重要空白,为任务驱动的对话系统中更严格、更现实地基准化文本分类提供了一种方式。
1简介
面向任务的对话系统已经无处不在,为数十亿人提供了使用自然语言与计算机交互的手段。 此外,最近谷歌的DialogFlow或亚马逊的Lex等平台和工具的涌入,使得这些平台和工具更容易被全球各个行业和人口群体所利用。 开发此类系统的工具首先指导开发人员收集意图分类的训练数据:根据用户的查询确定用户希望执行的固定操作集的任务。 用于评估此任务性能的公共数据集相对较少,而存在的公共数据集通常仅涵盖极少数意图(例如,Coucke et al. (2018),其中有 7 个意图)。 此外,这些资源并不便于分析超出范围的查询:用户可以合理地进行的查询,但不属于系统支持的意图范围。

图 1:用户(蓝色、右侧)与任务驱动的个人财务对话系统(灰色、左侧)之间的示例交互。 系统在 1 中正确标识用户的查询,但在 2 中,用户的查询被错误地标识为范围内,并且系统给出不相关的响应。 在 3 中,用户的查询被正确标识为范围外,系统提供回退响应。
图 1 显示了用户与任务驱动的个人财务对话系统之间的查询-响应交换示例。 在第一个用户系统交换中,系统将用户的意图正确标识为范围内 BALANCE 查询。 在第二次和第三次交换中,用户使用范围外输入进行查询。 在第二个交换中,系统错误地将查询标识为内窥镜,并产生不相关的响应。 在第三个交换中,系统正确地将用户的查询分类为范围外,并生成回退响应。
对于面向任务的对话系统来说,范围外查询是不可避免的,因为大多数用户不会完全了解系统的能力,这些能力受意图类别固定数目的限制。
因此,正确识别范围外情况对于部署的系统至关重要,既要避免执行错误操作,也一方面还要确定潜在的未来发展方向。 然而,在分析和评价意向分类系统方面很少注意这一问题。
本文通过分析意图分类性能,重点进行外在处理,填补了这一空白。 为此,我们构建了一个新的数据集,包含 23,700 个短查询和非结构化查询,其样式与面向任务系统的实际用户相同。 这些查询涵盖 150 个意向,以及不属于 150 个范围内意图中的任何一个范围外查询。
我们评估数据集上的一系列基准分类器和范围外处理方法。 BERT(Devlin 等人,2019 年)可产生最佳范围内精度,即使在我们限制训练数据或引入类别不平衡时,其得分也达到 96% 或更高。 但是,所有方法都难以识别范围外查询。 即使为训练提供大量范围外的样本,也存在重大性能差距,最佳系统得分为 66% 的范围外召回。 我们的结果表明,虽然当前的模型在已知类上工作,但它们很难进行超范围查询,尤其是在数据不丰富的情况下。 此数据集将使人们能够在今后的工作中解决对话系统研发中的这一关键差距。 本文介绍的所有数据均可在 https://github.com/clinc/ 查看到。
2数据集
我们引入了包含 23,700 个查询的新众包数据集,包括 22,500 个范围内查询,涵盖 150 个意图,这些查询可以分为 10 个常规域。 数据集还包括 1,200 个范围外查询。 表 1 显示了数据示例。1
2.1 范围内数据收集
我们使用使用范围范围众包任务收集的查询中定义意图,这促使众工以与人工智能助手交互的方式提供与主题域相关的问题和命令。 我们手动将任务范围生成的数据分组到意图中。 为了收集每个意图的额外数据,我们使用 Kang 等人(2018 年)提出的短语和情景众包任务。2 对于每个意图,有 100 个训练查询,这是预算有限的团队在开发任务驱动的对话系统时可以收集内容的典型情况。 除了 100 个训练查询外,每个意图还有 20 个验证和 30 个测试查询。
2.2 范围外数据收集
以两种方式收集范围外查询。 首先,使用人工错误:为 150 个意图之一编写的查询实际上与任何意图不匹配。 其次,使用范围和场景任务,并根据 Quora、维基百科和其他地方找到的主题区域使用提示。 为了帮助确保这些额外的范围外数据的丰富性,每个任务提示都贡献最多四个查询。 由于我们使用相同的众包方法来收集范围外数据,因此这些查询在风格上与范围外查询类似。
范围外数据难以收集,需要对范围内意图非常熟悉,才能苦苦确保没有范围外查询样本被错误地标记为在范围内(反之亦然)。 实际上,以范围外为目标的提示收集大约只有 69% 的查询,产生了范围外查询。 在收集的 1200 个范围外查询中,100个用于验证,100个用于训练,剩下 1000 个用于测试。
2.3 数据预处理和分区
对于收集的所有查询,所有词符都变成小写,并且删除所有句子结尾的标点符号。 此外,删除并替换所有重复的查询。
为了减少范围内数据中的偏见,我们将来自给定众体工作者的所有查询置于单个拆分(训练、验证或测试)中。 这样可以避免一个众包工作人员的潜在相似问题,例如,最终在训练和测试组中,这将使训练和测试分配不切实际地相似。 我们注意到,这是Geva等人(2019年)同时提出的一项建议。 我们还将此过程用于范围外集,只不过我们根据任务提示而不是工作程序将数据拆分为训练/验证/测试。
| 领域 | 意图 | 查询 |
| 银行 | 转账 | 把100美元从我的积蓄转移到我的支票上 |
| 工作 | PTO 请求 | 让我知道如何提出休假请求 |
| META | 更改语言 | 将语言设置切换到德语 |
| 自动和通勤 | 距离 | 告诉英里,它会从圣迭戈到达拉斯维加斯 |
| 旅行 | 旅行建议 | 哪些网站有看到时,在埃文斯 |
| 家 | 待办事项列表更新 | 核所有项目在我的待办事项列表 |
| 实用 | 文本 | 给妈妈发短信说我在路上了 |
| 厨房和餐饮 | 食品过期 | 在冰箱里吃3天后,米饭还好 |
| 闲聊 | 讲笑话 | 你能告诉我一个关于政客的笑话吗? |
| 信用卡 | 奖励余额 | 我的发现卡上的奖励有多高 |
| 范围外 | 范围外 | 我的运动队表现如何 |
| 范围外 | 范围外 | 创建标记为妈妈的联系人 |
| 范围外 | 范围外 | 我的地址的扩展邮政编码是多少? |
表 1:来自数据集的示例查询。 范围外查询在样式上与范围内查询类似。
2.4 数据集变体
除了完整的数据集之外,我们还考虑三个变体。 首先,Small,其中每个范围内的意图只有 50 个训练查询,而不是 100 个。 其次,Imbalanced,其中意图有 25、50、75 或 100 个训练查询。 第三,OOS+,其中有250个而不是100个范围外的训练样本。 这些旨在表示数据供应有限或不均衡的生产方案。
3基准评估
为了量化新数据集带来的挑战,我们评估了一系列分类器模型3和范围外预测方案的性能。
3.1 分类器模型
SVM: 具有袋词句子表示的线性支持向量机。
MLP: 以USE嵌入(Cer等人,2018年)为输入的多层感知器。
FastText: 一个浅神经网络,平均 n-grams 嵌入(Joulin等人,2017年)。
CNN: 一个卷积神经网络,词嵌入以 GloVe 初始化同时动态训练(Pennington et al., 2014)。
BERT: 一个神经网络,训练来预测文本中的省略单词,然后根据我们的数据进行微调(Devlin等人,2019年)。
Platforms: 存在几个平台用于开发面向任务的代理。 我们考虑谷歌的 DialogFlow4 和 用 spacy-sklearn 的 Rasa NLU5。
3.2 范围外预测
我们使用三种基准方法来预测一个查询是否在范围外:(1) oos-train,我们用范围外训练数据训练一个额外(即第151个)意图;(2)oos-threshold,我们使用分类器概率估计的阈值;(3)oos-binary,一个两阶段的过程,我们首先将查询分类为在范围内或范围外,然后将其分类为150个意图之一(如果分类为在范围内)。
为降低范围内查询样本与范围外查询样本(即 OOS+ 的 15,000 个查询与 250 个查询)之间的类别不平衡的严重性,使用 oos-binary 时我们研究两种策略:一种是我们对范围内数据进行不足采样,在所有意图之间均衡采样 1,000 个范围内查询训练(与 250 个范围外相比),另一种是从维基百科采样的 14,750 个句子来增强 250 个 OOS+ 范围外训练查询。
从开发的角度来看,oos-train 和 oos-binary 方法都需要仔细管理范围外训练集,并且该集可以针对各个系统进行定制。 oos-threshold 方法是一个更通用的决策规则,可应用于生成概率的任何模型。 在我们的评估中,范围外阈值被选择为在所有意图中产生最高验证分数的值,将范围外视为其自身意图。
3.3 指标
我们考虑所有方案的两个性能指标:(1) 对 150 个意图的准确性,以及 (2) 在范围外查询上的 recall。 我们使用 recall 来评估范围外,因为我们更感兴趣的是此类查询预测为范围内的情况,因为这意味着系统为用户提供了完全错误的响应。 精度错误问题不大,因为回退响应将提示用户重试,或通知用户系统受支持的领域范围。
| 范围内精度 | 范围外召回 | |||||||
| 分类器 | Full | Small | Imbal | OOS+ | Full | Small | Imbal | OOS+ |
| FastText | 89.0 | 84.5 | 87.2 | 89.2 | 9.7 | 23.2 | 12.2 | 32.2 |
| SVM | 91.0 | 89.6 | 89.9 | 90.1 | 14.5 | 18.6 | 16.0 | 29.8 |
| CNN | 91.2 | 88.9 | 89.1 | 91.0 | 18.9 | 22.2 | 19.0 | 34.2 |
| DialogFlow | 91.7 | 89.4 | 90.7 | 91.7 | 14.0 | 14.1 | 15.3 | 28.5 |
| Rasa | 91.5 | 88.9 | 89.2 | 90.9 | 45.3 | 55.0 | 49.6 | 66.0 |
| MLP | 93.5 | 91.5 | 92.5 | 94.1 | 47.4 | 52.2 | 35.6 | 53.9 |
| BERT | 96.9 | 96.4 | 96.3 | 96.7 | 40.3 | 40.9 | 43.8 | 59.2 |
oos-train
| 范围内精度 | 范围外召回 | |||||||
| 分类器 | Full | Small | Imbal | OOS+ | Full | Small | Imbal | OOS+ |
| SVM | 88.2 | 85.6 | 86.0 | — | 18.0 | 13.0 | 0.0 | — |
| FastText | 88.6 | 84.8 | 86.6 | — | 28.3 | 6.0 | 33.2 | — |
| DialogFlow | 90.8 | 89.2 | 89.2 | — | 26.7 | 20.5 | 38.1 | — |
| Rasa | 90.9 | 89.6 | 89.4 | — | 31.2 | 1.0 | 0.0 | — |
| CNN | 90.9 | 88.9 | 90.0 | — | 30.9 | 25.5 | 26.9 | — |
| MLP | 93.4 | 91.3 | 92.5 | — | 49.1 | 32.4 | 13.3 | — |
| BERT | 96.2 | 96.2 | 95.9 | — | 52.3 | 58.9 | 52.8 | — |
oos-threshold
表 2:使用 oos-train(上半部分)和 oos-threshold (下半部分)预测方法,在每个数据条件下的基准分类器结果。
4结果
4.1 oos-train 结果
表 2 显示了数据集四个变体中所有模型的结果。 首先,BERT 始终是范围内的最佳方法,其次是 MLP。 其次,跨范围的查询性能在所有方法中都远远低于范围内的查询性能。 对较少数据(小和不平衡)进行训练可生成在范围内查询上性能稍差的模型。 在评估范围外时,趋势大多相反,在小型和不平衡训练条件下,召回率会上升。 在这两种情况下,范围内训练集的大小减小,而范围外训练查询的数量保持不变。 这表明可以通过增加范围外训练查询的相对数量来提高范围外性能。 我们在 OOS+ 设置中就做到这一点(在 OOS® 环境中,模型在完整训练集以及 150 个其他范围外查询上进行了培训),并看到范围外的性能显著提高,但相对于范围内精度而言仍然很低。
4.2 oos-threshold 结果
使用 oos 阈值方法的示波器精度与 oos-train 大致相当。 在 Full 上,范围外调用往往要高得多,但几个模型在有限的数据集上受到很大影响。 BERT 和 MLP 是性能最高的执行者,对于多个型号,阈值方法提供了不稳定的结果,尤其是 FastText 和 Rasa。
| 范围内精度 | 范围外召回 | |||
| 分类器 | under | wiki aug | under | wiki aug |
| DialogFlow | 84.7 | — | 37.3 | — |
| Rasa | 87.5 | — | 37.7 | — |
| FastText | 88.1 | 87.0 | 22.7 | 31.4 |
| SVM | 88.4 | 89.3 | 32.2 | 37.7 |
| CNN | 89.8 | 90.1 | 25.6 | 39.7 |
| MLP | 90.1 | 92.9 | 52.8 | 32.4 |
| BERT | 94.4 | 96.0 | 46.5 | 40.4 |
表3:OOS+上oos-binary实验的结果,其中我们使用维基百科(wiki aug)中的句子比较了采样不足(下)和扩增的性能。 对于 DialogFlow 和 Rasa 分类器来说,wiki aug 方法太大了。
4.3 oos-binary 结果
表 3 使用 oos-binary 方案比较分类器的性能。 与使用表 2 所示的 oos-train 和 oos 阈值方法对完整数据集进行定型训练相比,使用不足采样方案的所有模型在范围内精度都会受到影响。 但是,与"完全"(而非 OOS®)上的 oostrain 相比,范围外召回情况有所改善。 与弱抽样相比,增强范围外训练集似乎有助于提高范围内和范围外性能,但范围外性能仍然薄弱。
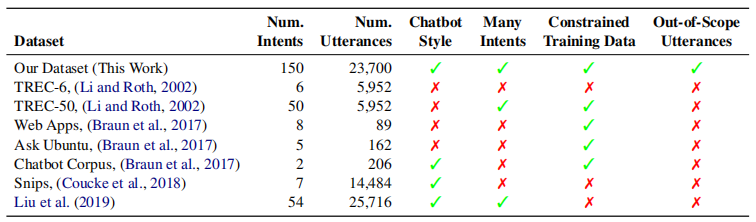
表 4:分类数据集属性。 我们数据集具有最广泛的意图和专门收集的范围外查询。 我们认为"聊天机器人风格"查询是简短的,可能是非结构化的问题和命令。
5之前的工作
在大多数其他分析和数据集中,没有考虑范围外数据的概念,而是输出旨在涵盖所有可能查询的类别(例如,TREC (Li and Roth, 2002))。 Hendrycks and Gimpel (2017) 最近的工作考虑一个类似问题,他们称之为分布外检测。 它们使用训练期间排除的其他数据集或类来形成分发外样本。 这意味着范围外样本来自一组与分布样本有很大区别的相干类。 Lin and Xu (2019) 进行了类似的实验以评估未知的意图发现模型。 相反,我们的范围外查询涵盖广泛的现象,并且风格相似,并且通常与范围内查询的主题类似,表示用户在部分了解系统功能的情况下可能说的话。
表 4 将数据集与其他简短查询意图分类数据集进行比较。 Snips(Coucke 等人,2018 年)数据集和 Liu 等人 (2019) 中显示的数据集与我们工作的范围内部分最相似,具有相同类型的对话代理请求。 和我们一样,这两个数据集都是使用众包启动的。 但是,Snips 数据集只有少量意图,虽然每个意图中有大量样本。 Snips 确实呈现低数据变体,每个意图有 70 个训练查询,其中性能略有下降。 Liu 等人 (2019) 中提供的数据集具有大量意向类,但也包含每个意向类的各种示例(每个意图查询数从 24 个到 5,981 个不等,因此在所有情况下都不受约束)。
Braun 等人(2017 年)创建了具有受限训练数据的数据集,但意图很少,这带来了非常不同的挑战类型。 我们还包括 TREC 查询分类数据集(Li 和 Roth,2002),这些数据集具有大量标签,但它们描述的是所需的响应类型(例如,距离、城市、缩写),而不是我们考虑的操作意图。 此外,TREC 只包含问题和没有命令。 关键是,表 4 中总结的其他数据集都没有提供一种评估外窥镜性能的可行方法。
对话状态跟踪挑战(DSTC)数据集是另一个相关资源。 具体来说,DSTC 1(Williams et al., 2013)、DSTC 2(Henderson et al., 2014a)和DSTC 3(Henderson et al., 2014b)包含"聊天机器人风格"查询,但数据集侧重于状态跟踪。 此外,这些数据集中的大多数(如果不是所有)查询都在范围内。 相反,我们的分析重点是在范围内和范围外查询上,这些查询对虚拟助理确定其能否提供可接受的响应提出质疑。
6结论
本文使用由仔细收集的范围外数据组成的新数据集分析了意图分类和范围外预测方法。 我们的发现表明,某些模型(如 BERT)在范围内分类方面表现更好,但所有被调查的方法都难以识别范围外查询。 包含更多范围外训练数据的模型往往会改进范围外的性能,但此类数据成本高昂且难以生成。 我们相信,我们的分析和数据集将开发更好、更强大的对话系统。
本文介绍的所有数据集都可以在 https://github.com/clinc/oos-eval 中找到。
引文
Daniel Braun, Adrian Hernandez-Mendez, Florian Matthes, and Manfred Langen. 2017. Evaluating natural language understanding services for conversational question answering systems. In Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue (SIGDIAL).
Daniel Cer, Yinfei Yang, Sheng-yi Kong, Nan Hua, Nicole Limtiaco, Rhomni St. John, Noah Constant, Mario Guajardo-Cespedes, Steve Yuan, Chris Tar, Brian Strope, and Ray Kurzweil. 2018. Universal sentence encoder for English. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (EMNLP).
Alice Coucke, Alaa Saade, Adrien Ball, Th´eodore Bluche, Alexandre Caulier, David Leroy, Cl´ement Doumouro, Thibault Gisselbrecht, Francesco Caltagirone, Thibaut Lavril, Ma¨el Primet, and Joseph Dureau. 2018. Snips voice platform: an embedded spoken language understanding system for privateby-design voice interfaces. CoRR, abs/1805.10190.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL).
Mor Geva, Yoav Goldberg, and Jonathan Berant. 2019. Are We Modeling the Task or the Annotator? An Investigation of Annotator Bias in Natural Language Understanding Datasets. arXiv e-prints, page arXiv:1908.07898.
Matthew Henderson, Blaise Thomson, and Jason D. Williams. 2014a. The second dialog state tracking challenge. In Proceedings of the 15th Annual Meeting of the Special Interest Gorup on Discourse and Dialogue (SIGDIAL).
Matthew Henderson, Blaise Thomson, and Jason D. Williams. 2014b. The third dialog state tracking challenge. In Spoken Language Technology Workshop (SLT).
Dan Hendrycks and Kevin Gimpel. 2017. A baseline for detecting misclassified and out-of-distribution examples in neural networks. In Proceedings of International Conference on Learning Representations (ICLR).
Armand Joulin, Edouard Grave, Piotr Bojanowski, and Tomas Mikolov. 2017. Bag of tricks for efficient text classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics (EACL).
Yiping Kang, Yunqi Zhang, Jonathan K. Kummerfeld, Parker Hill, Johann Hauswald, Michael A. Laurenzano, Lingjia Tang, and Jason Mars. 2018. Data collection for dialogue system: A startup perspective.
In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL).
Xin Li and Dan Roth. 2002. Learning question classifiers. In Proceedings of the 19th International Conference on Computational Linguistics (COLING).
Ting-En Lin and Hua Xu. 2019. Deep unknown intent detection with margin loss. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL).
Xingkun Liu, Arash Eshghi, Pawel Swietojanski, and Verena Rieser. 2019. Benchmarking natural language understanding services for building conversational agents. In Proceedings of the Tenth International Workshop on Spoken Dialogue Systems Technology (IWSDS).
Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP).
Jason Williams, Antoine Raux, Deepak Ramachandran, and Alan Black. 2013. The dialog state tracking challenge. In Proceedings of the 14th Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL).