我们提出高斯误差线性单元(GELU),一种高性能的神经网络激活函数。 随机正则法将神经元的一个输入随机应用等值映射或零值映射,GELU 非线性是对随机正则法用数学期望进行的一种变换。 GELU 非线性根据输入的幅度调整输入权重,不像 ReLU 按符号对输入进行门控。 我们将 GELU 非线性与 ReLU 和 ELU 激活进行实验评估,发现在所考虑的计算机视觉、自然语言处理和语音等所有任务中,GELU 非线性的性能都有所提升。
1 简介
早期的人工神经元使用二元阈值单元(Hopfield,1982;McCulloch & Pitts,1943)。 这些固定的二元值通过 sigmoid 激活来平滑,从而使神经元具有“发射率”的解释并可以进行反向传播训练。 但是,随着网络变得越来越深,sigmoid 的训练被证明比非平滑、概率性较弱的 ReLU(Nair & Hinton,2010)效果要差,后者根据输入的符号进行门控。 尽管具有较少的统计数据,但 ReLU 在工程上仍然是一种竞争性解决方案,通常比 sigmoid 更快、更好地收敛。 在 ReLU 成功的基础上,最近的一个名为 ELU 的修改(Clevert 等人,2016)允许类似于 ReLU 的非线性输出负值,这有时会提高训练速度。 总的来说,激活选择仍然是神经网络结构上必要的决策,以免网络成为深度线性分类器。
深度非线性分类器可以过好地拟合它们的数据以至于网络设计者经常需要选择随机正则化方法,如在隐藏层中加入噪声或应用 dropout (Srivastava 等人,2014),而这种选择仍然与激活函数互相独立。 一些随机正则方法可以使网络的行为像一个网络的融合,即一个 pseudo 融合(Bachman 等人,2014),并可以导致精度的明显提高。 例如,随机正则化方法 dropout 通过零乘法随机更改一些激活决策来创建 pseudo 融合。 因此非线性和 dropout 共同决定神经元的输出,但是这两项创新仍然是相互独立的。 而且,两者都不归于另一个,因为流行的随机正则化方法与输入无关,并且这种正则化方法有助于非线性激活。
在这项工作中,我们引入一种新的非线性激活函数,即高斯误差线性单元(GELU)。 它与随机正则化方法有关,因为它是对 Adaptive Dropout 的一种修改(Ba & Frey,2013)。 它对神经元的输出更具有概率的观点。 我们发现,这种新型的非线性激活函数在计算机视觉、自然语言处理和自动语音识别等任务中与用 ReLU 或 ELU 的模型效果相当或有所超越。
2 GELU 的公式
我们的激活函数的灵感来源于组合 dropout、zoneout 和 ReLU 各自的特性。 首先请注意,ReLU 和 dropout 都产生一个神经元的输出,ReLU 将输入确定性地乘以 0 或 1,dropout 将输入随机性地乘以 0。 另外,一种称为 zoneout 的新 RNN 正则化方法将输入随机地乘以 1(Krueger 等人,2016)。 我们通过将输入乘以 0 或 1 来合并此功能,但是 0 和 1 的值随机确定的同时还取决于输入。 具体来说,我们可以将神经元输入 x 乘以 m∼ Bernoulli(Φ(x)),其中 Φ(x) =P(X≤x),X∼N(0,1) 是标准正态分别的累积分布函数。 我们选择这种分布是因为神经元输入倾向于遵循正态分布,尤其是在批归一化的情况下。 在这种设置下,随着 x 的减小,输入被“丢弃”的可能性更高,因此应用于 x 的变换是既随机的又与输入有关。 以这种方式屏蔽输入保留不确定性但保持对输入值的依赖性。 随机选择等同于对输入进行随机零变换或恒等变换。 这很像 Adaptive Dropout(Ba & Frey,2013),但是 adaptive dropout 与非线性一起使用并使用逻辑分布而非标准正态分布。 我们发现,仅使用这种随机正则化方法就可以训练具有竞争性的 MNIST 和 TIMIT 网络,而无需使用任何非线性。
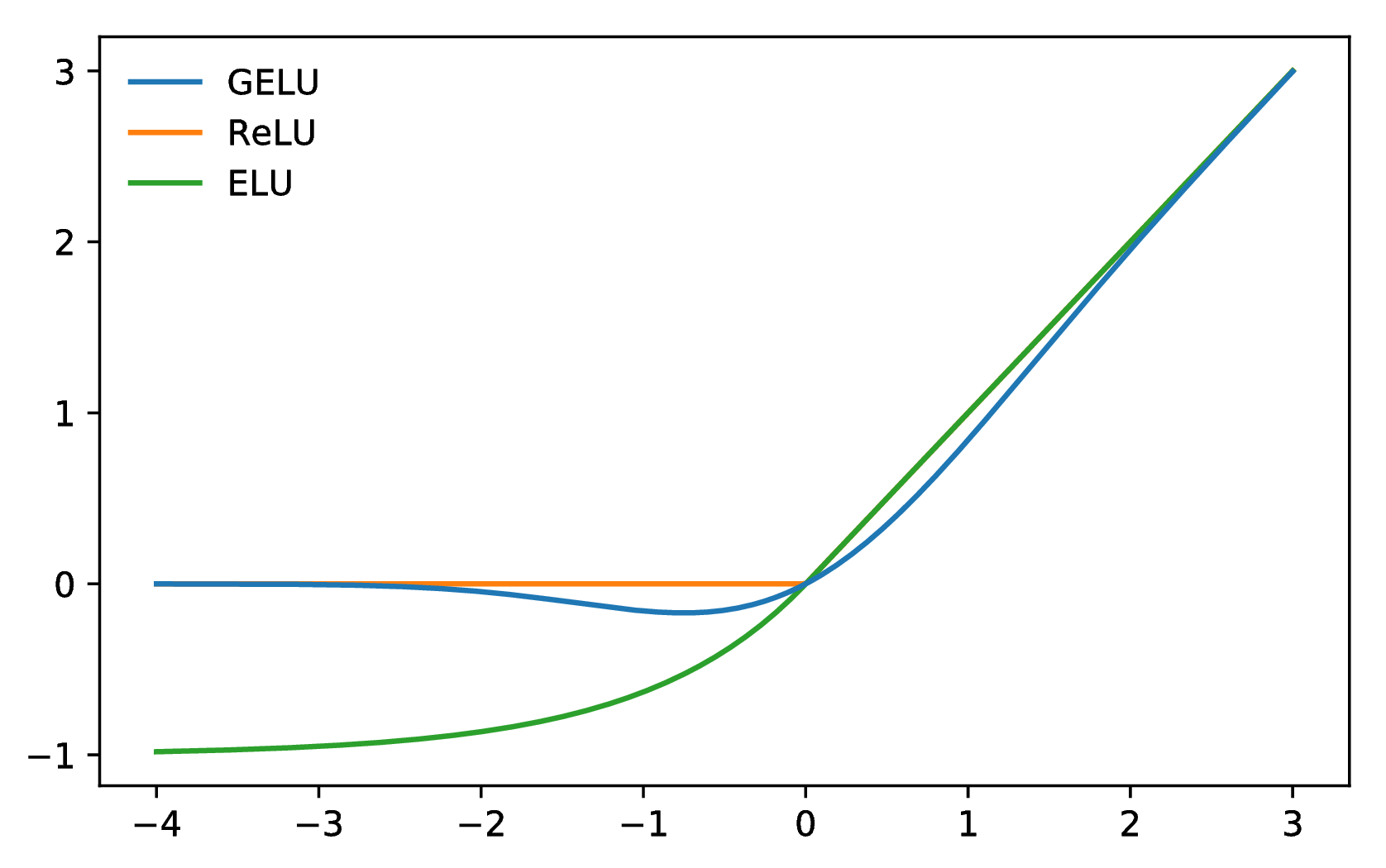
图 1:GELU (μ = 0,σ = 1)、ReLU 和 ELU
(α = 1)。
我们经常需要神经网络输出一种确定性结果,这引入我们新的非线性。 这个非线性是输入 x 上随机正则化方法用数学期望进行的一种变换 , 即 Φ(x)×Ix+ (1−Φ(x))×0x=xΦ(x)。 不严格地说,这个表达式表示我们以比其它输入大多少倍缩放 x 。 由于高斯累积分布函数通常是使用误差函数计算的,因此我们将高斯误差线性单位(GELU)定义为
| GELU(x) = xP(X ≤ x) = xΦ(x). |
我们可以近似 GELU 为
0.5x(1 + tanh[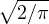 (x + 0.044715x3)]) (x + 0.044715x3)])
|
或
| xσ(1.702x). |
我们可以使用 (μ,σ2) 的累积分布函数并让 μ 和 σ 为可学习的参数,但是本工作中我们简单地让 μ= 0 和 σ= 1。 因此,在以下实验中,我们不会引入任何新的超参数。 在下一节中,我们将表明 GELU 在许多任务上都超过 ReLU 和 ELU 的性能。
3 GELU 实验
我们在 MNIST 分类(具有 10 个类别、60k 训练和 10k 测试样本的灰度图像)、MNIST 自动编码、Tweet 词性标注(1000 个训练、327 个验证和 500 个测试 Tweet)、TIMIT 帧识别(3696 个训练、1152 个验证和 192 个测试音频句子)和 CIFAR-10/100 分类(具有 10/100 类别、50k 训练和 10k 测试的彩色图像)上评估 GELU、ELU 和 ReLU。 我们不评估类似 LReLU 这样的非线性激活,因为它与 ReLU 相似(请参见 Maas 等人 (2013)了解 LReLU)。
3.1 MNIST 分类
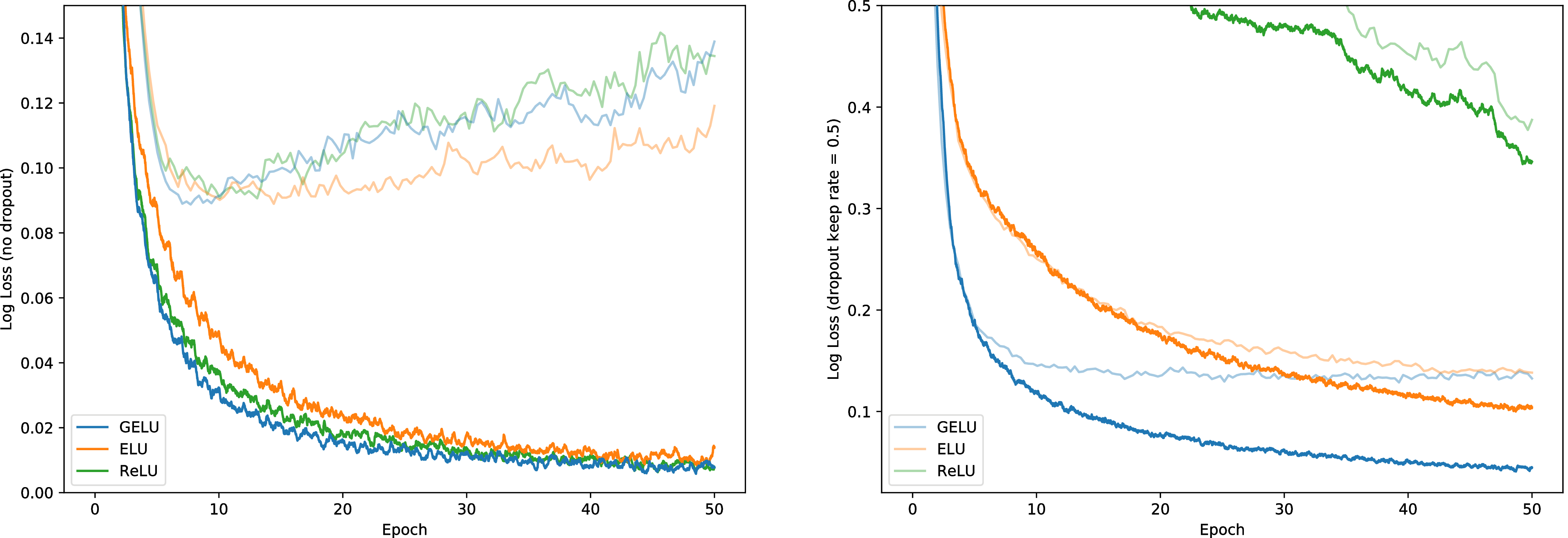
让我们通过复现以下实验来验证这种非线性激活能否与先前的激活函数竞争: Clevert 等人 (2016)。 为此,我们使用 GELU(μ = 0,σ = 1)、ReLU 和 ELU(α= 1)训练一个完全连接的神经网络。 每个 8 层、128 个神经元宽的神经网络都使用大小为 128 的批次训练 50 个周期。 此实验与 Clevert 等人的实验不同点在于我们使用的是 Adam 优化器(Kingma & Ba,2015),而不是没有动量的随机梯度下降,并且我们还展示我们还展示了非线性如何很好地应对 dropout。 权重使用单位范数行初始化,因为这会对每个非线性的性能产生积极影响(Hendrycks & Gimpel,2016;Mishkin & Matas,2016; Saxe 等人,2014)。 请注意,我们在来自训练集的 5k 验证样本上调整学习率 {10−3,10−4,10−5} 并取五次运行的中位数结果。 使用这些分类器,我们在图 3 中展示使用 GELU 分类器对噪声输入的鲁棒性。 图 2 显示,不管有没有 dropout,GELU 训练集上的对数损失中值往往最低。 因此,尽管 GELU 的启发来源于一个不同的随机过程,但与 dropout 相适应。

3.2 MNIST 自动编码器
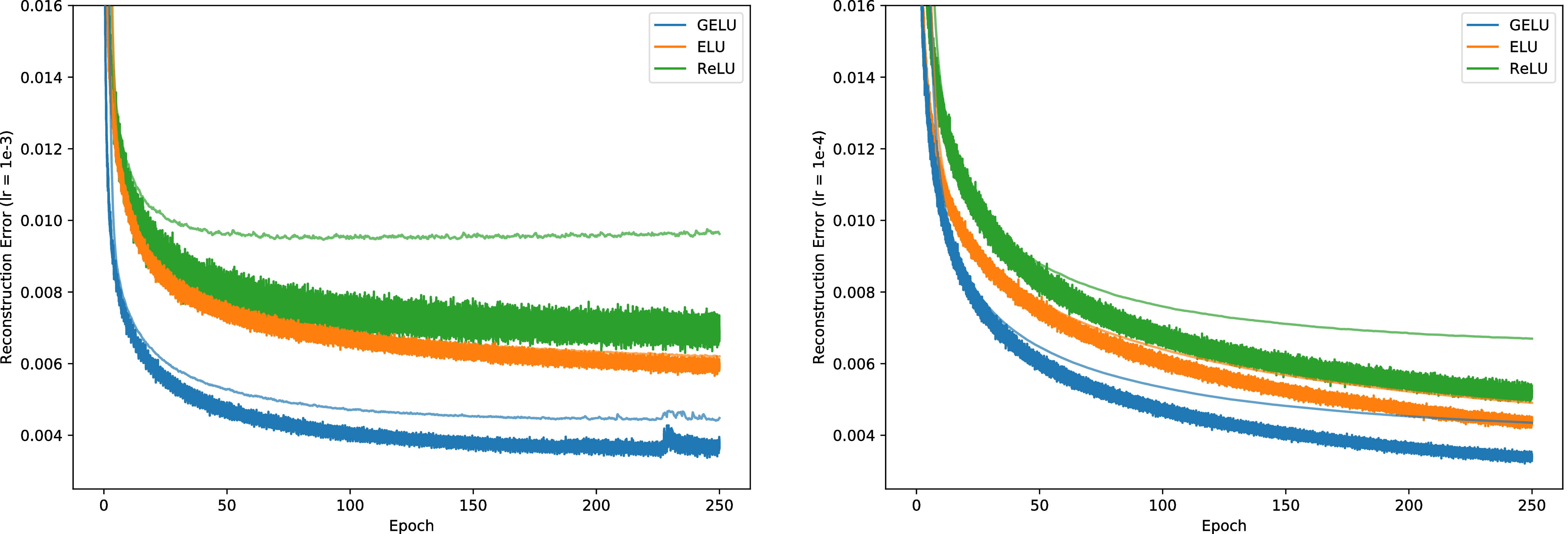
现在,我们考虑一种自我监督的设置,并在MNIST上训练深度自动编码器(Desjardins等人,2015)。 为此,我们使用一个网络,该网络的顺序依次为1000、500、250、30、250、500、1000层。 我们再次使用Adam优化器和64的批处理大小。 我们的损失是均方损失。 我们的学习率在 10−3 to 10−4 之间变化。 我们还尝试了 0.01 的学习率,但 ELU 不收敛,GELU 和 RELU 的收敛性很差。 图 4 中的结果表明 GELU 适应不同的学习率,并且明显优于其他非线性激活。
3.3 Twitter POS 标注
自然语言处理中的许多数据集相对较小,所以一个激活函数要从为数不多的样本中很好概括非常重要。 为了应对这一挑战,我们在带有 POS 标签的推文(Gimpel 等人,2011;Owoputi 等人,2013)上比较这几个非线性激活,其中包含 25 个标签。 推文标记网络只是一个两层网络,其预训练词向量在 5600 万条推文的语料库上进行训练(Owoputi 等人,2013)。 输入是要标记的单词的向量及其左、右相邻单词的向量的连接。 网络每层具有 256 个神经元,dropout 保持率为 0.8,用 Adam 优化,在学习率 {10−3,10−4,10−5} 上调优。 针对每个学习速率我们对每个网络进行五次训练,GELU 的测试集中位数错误为 12.57%,ReLU 的测试集中位数错误为 12.67%,而 ELU 的测试集中位数错误为 12.91%。
3.4 TIMIT 帧分类
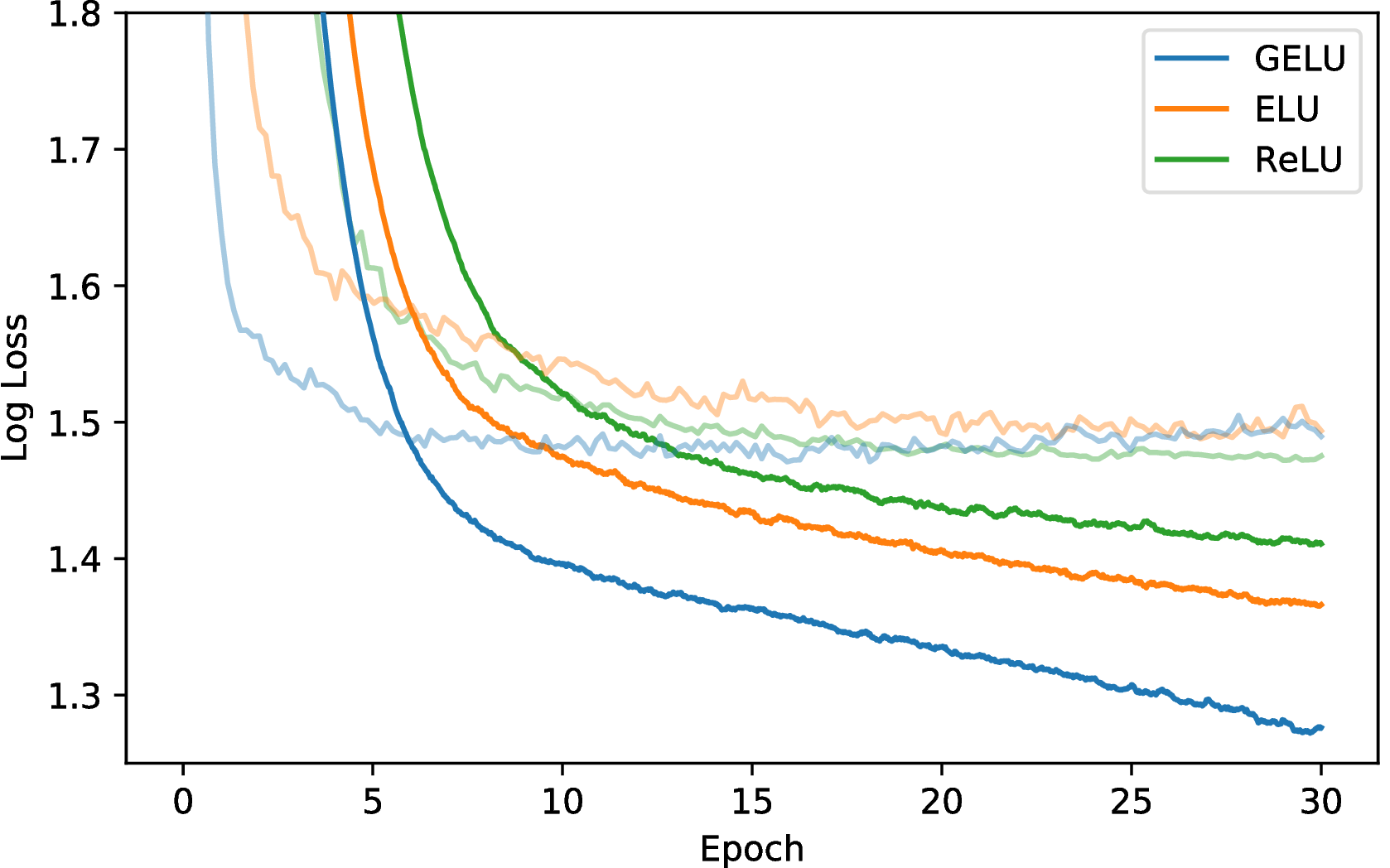
我们的下一个挑战是使用TIMIT数据集进行电话识别,该数据集可在无噪声的环境中录制680个扬声器。 该系统是一个五层、宽度为 2048 个神经元的分类器(Mohamed 等人,2012),具有 39 个输出电话标签,丢弃率为 0.5(Srivastava,2013)。 该网络以11帧为输入,并且必须使用26 MFCC,每帧能量和微分特征来预测中心帧的电话。 我们在学习率{10−3,10−4,10−5} 上调优并使用 Adam 进行优化。 每个设置运行五次后,我们得到图 5 的中值曲线,在最低验证集误差下选择的中值测试集误差对于 GELU 为 29.3%,对于 ReLU 为 29.5%,对于 RELU 为 29.6%。
3.5 CIFAR-10/100 分类
接下来,我们证明对于更复杂的体系结构,GELU 非线性激活再次优于其他非线性激活。 我们分别在浅层和深层卷积神经网络上使用 CIFAR-10 和 CIFAR-100 数据集(Krizhevsky,2009)来评估此激活函数。
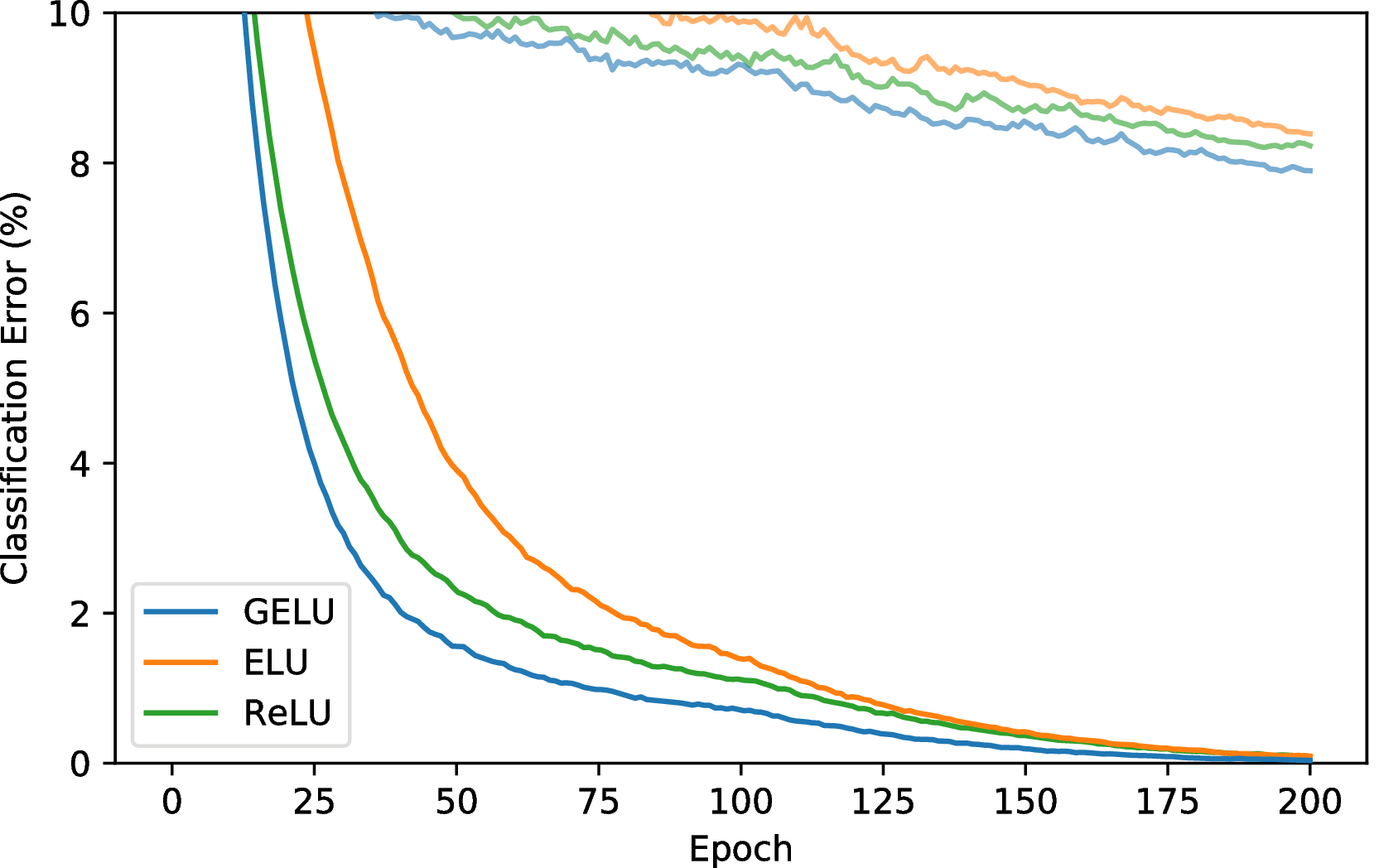
我们的浅层卷积神经网络是一个9层网络,具有Salimans和Kingma(2016)的体系结构和训练过程,同时使用批量归一化来加快训练速度。 A部分描述了该体系结构,最近在CIFAR-10上获得了最新技术,而没有进行数据增强。 没有数据增强被用来训练该网络。 我们调整学习初始速率{ 10 - 3 , 10 - 4 , 10 t11 > − 5 }并带有5k验证示例,然后根据来自的学习率再次训练整个训练集交叉验证。 该网络使用Adam优化了200个时代,在第100个时代,学习率线性下降到零。 结果显示在图6中,每条曲线均为三个运行的中值。 最终,GELU获得了7.89%的中位数错误率,ReLU获得了8.16%,而ELU获得了8.41%。
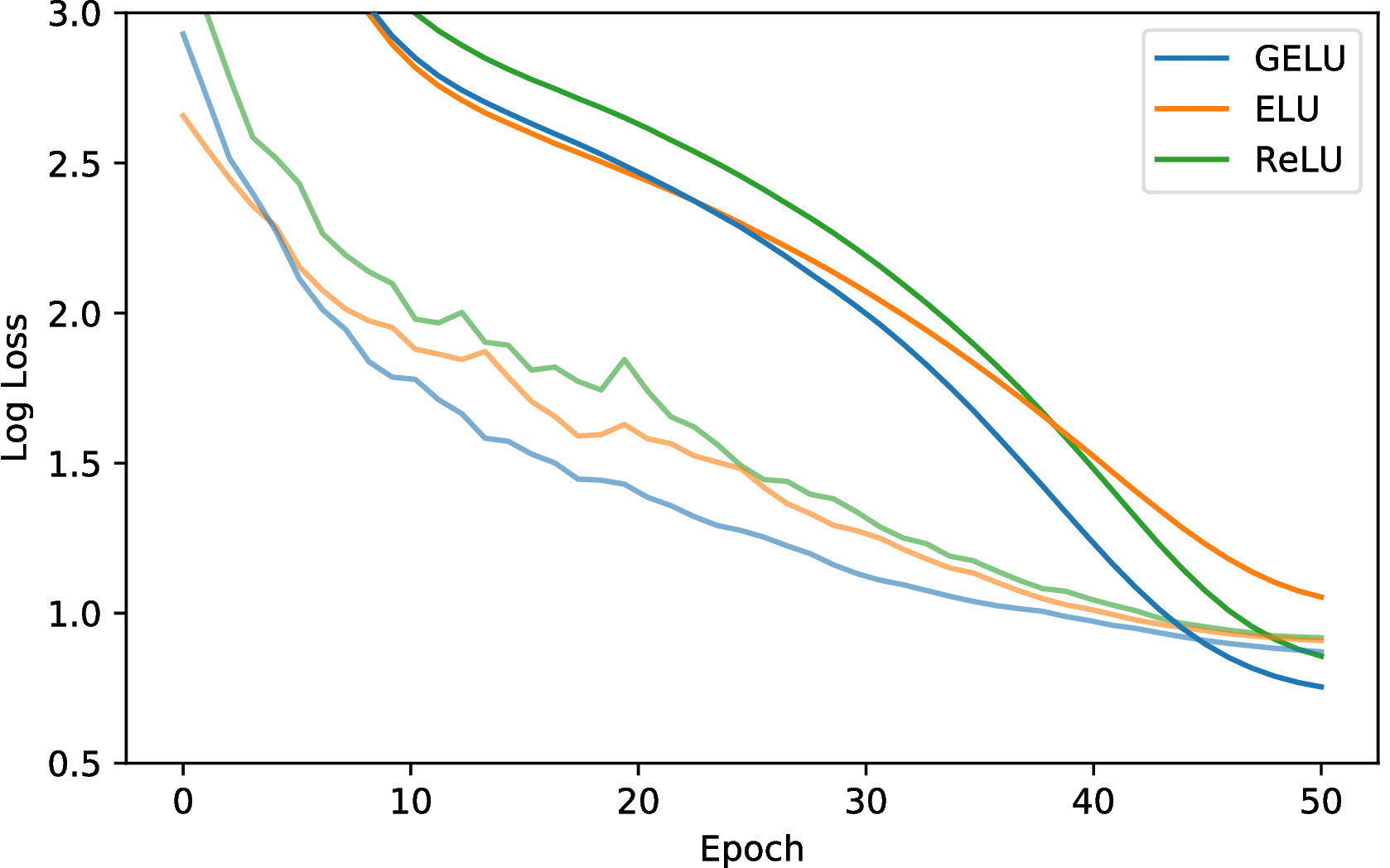
接下来,我们考虑在CIFAR-100上有40个层的宽残差网络,并且扩展因子为4(Zagoruyko&Komodakis,2016)。 我们按照(Loshchilov&Hutter,2016)(T 0 = 50 t4> ,η = 0 。 1),具有涅斯特罗夫动量,且丢球保持概率为0.7。 一些人指出,ELU在残差网络中具有爆炸梯度(Shah等人,2016),而在残差块末尾进行批归一化可以缓解这种情况。 因此,我们使用Conv-Activation-Conv-Activation-BatchNorm块架构来对ELU进行慈善。 在三个运行中,我们获得了图7的中值收敛曲线。 同时,GELU实现的中位数误差为20.74%,ReLU获得21.77%(不进行上述更改,带有ReLU的原始40-4 WideResNet获得22.89%(Zagoruyko&Komodakis ,2016)),那么ELU的比例为22.98%。
4 讨论
在多个实验中,GELU 优于以前的非线性激活,但在其他方面与 ReLU 和 ELU 相似。 例如,当 σ → 0 且 μ = 0,则 GELU 成为 ReLU。 此外,ReLU和GELU渐近相等。 实际上,GELU 可以看作是平滑 ReLU 的一种方法。 要看清这一点,回忆一下 ReLU = max(x,0) = x (x > 0) (其中 为指示函数),而 GELU 为 xΦ(x) 如果 μ = 0,σ = 1。 然后,CDF 是 ReLU 使用的元函数的平滑近似,例如 sigmoid 平滑二元阈值激活的方式。 与 ReLU 不同,GELU 和 ELU 可以为负也可以为正。 In fact, if we used the cumulative distribution function of the standard Cauchy distribution, then the ELU (when α = 1∕π) is asymptotically equal to xP(C ≤ x),C ∼ Cauchy(0,1) for negative values and for positive values is xP(C ≤ x) if we shift the line down by 1∕π. 这些是先前非线性的一些基本关系。
但是,GELU有几个显着差异。 该非凸,非单调函数在正域中不是线性的,并且在所有点处都显示出曲率。 同时,凸和单调激活的ReLU和ELU在正域中是线性的,因此可以缺少曲率。 因此,与ReLU或ELU相比,增加的曲率和非单调性可使GELU更容易地近似复杂函数。 另外,由于ReLU ( x )= x ( t5> x> 0)和GELU ( x )= x Φ( x )如果μ = 0 ,σ = 1,我们可以看到ReLU根据其符号对输入进行门控,而GELU根据其输入比其他输入大多少来对其输入进行加权。 另外,重要的是,鉴于GELU是随机正则化函数的期望,因此具有概率解释。
我们还有两个使用 GELU 的实用技巧。 首先,我们建议在进行 GELU 训练时使用动量优化器,这是深度神经网络的标准。 其次,使用高斯分布的累积分布函数的近似值非常重要。 sigmoid 函数σ(x) = 1∕(1 + e−x) 是正态分布累积分布函数的近似。 但是,我们发现 Sigmoid 线性单位(SiLU)xσ(x) 的性能比 GELU 差,但通常比 ReLU 和 ELU 好。 没有使用 xσ(x) 来近似 Φ(x),我们使用 0.5x(1 +tanh[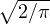 (x+ 0.044715x3)]) (Choudhury, 2014)1 或 xσ(1.702x)。 两者都是快速、易于实现的近似值,我们在本文的每个实验中都使用前者。
(x+ 0.044715x3)]) (Choudhury, 2014)1 或 xσ(1.702x)。 两者都是快速、易于实现的近似值,我们在本文的每个实验中都使用前者。
5 结论
对于本文评估的众多数据集,GELU 始终超过 ELU 和 ReLU 的准确性,使其成为以前各种非线性激活的一种可行替代方案。
致谢
我们要感谢NVIDIA公司捐赠了本研究中使用的多个TITAN X GPU。
参考
Jimmy Ba and Brendan Frey. Adaptive dropout for training deep neural networks. In Neural Information Processing Systems, 2013.
Philip Bachman, Ouais Alsharif, and Doina Precup. Learning with pseudo-ensembles. In Neural Information Processing Systems, 2014.
Amit Choudhury. A simple approximation to the area under standard normal curve. In Mathematics and Statistics, 2014.
Djork-Arné Clevert, Thomas Unterthiner, and Sepp Hochreiter. Fast and accurate deep network learning by exponential linear units (ELUs). In International Conference on Learning Representations, 2016.
Guillaume Desjardins, Karen Simonyan, Razvan Pascanu, and Koray Kavukcuoglu. Natural neural networks. In arXiv, 2015.
Kevin Gimpel, Nathan Schneider, Brendan O′Connor, Dipanjan Das, Daniel Mills, Jacob Eisenstein, Michael Heilman, Dani Yogatama, Jeffrey Flanigan, and Noah A. Smith. Part-of-Speech Tagging for Twitter: Annotation, Features, and Experiments. Association for Computational Linguistics (ACL), 2011.
Dan Hendrycks and Kevin Gimpel. Adjusting for dropout variance in batch normalization and weight initialization. In arXiv, 2016.
John Hopfield. Neural networks and physical systems with emergent collective computational abilities. In Proceedings of the National Academy of Sciences of the USA, 1982.
Diederik Kingma and Jimmy Ba. Adam: A Method for Stochastic Optimization. International Conference for Learning Representations, 2015.
Alex Krizhevsky. Learning Multiple Layers of Features from Tiny Images, 2009.
David Krueger, Tegan Maharaj, János Kramár, Mohammad Pezeshki, Nicolas Ballas, Nan Rosemary Ke1, Anirudh Goyal, Yoshua Bengio, Hugo Larochelle, Aaron Courville, and Chris Pal. Zoneout: Regularizing RNNs by randomly preserving hidden activations. In Neural Information Processing Systems, 2016.
Ilya Loshchilov and Frank Hutter. SGDR: Stochastic gradient descent with restarts. arXiv, 2016.
Andrew L. Maas, Awni Y. Hannun, , and Andrew Y. Ng. Rectifier nonlinearities improve neural network acoustic models. In International Conference on Machine Learning, 2013.
Warren S. McCulloch and Walter Pitts. A logical calculus of the ideas immanent in nervous activity. In Bulletin of Mathematical Biophysics, 1943.
Dmytro Mishkin and Jiri Matas. All you need is a good init. In International Conference on Learning Representations, 2016.
Abdelrahman Mohamed, George E. Dahl, and Geoffrey E. Hinton. Acoustic modeling using deep belief networks. In IEEE Transactions on Audio, Speech, and Language Processing, 2012.
Vinod Nair and Geoffrey E. Hinton. Rectified linear units improve restricted boltzmann machines. In International Conference on Machine Learning, 2010.
Olutobi Owoputi, Brendan O’Connor, Chris Dyer, Kevin Gimpel, Nathan Schneider, and Noah A. Smith. Improved part-of-speech tagging for online conversational text with word clusters. In North American Chapter of the Association for Computational Linguistics (NAACL), 2013.
Tim Salimans and Diederik P. Kingma. Weight normalization: A simple reparameterization to accelerate training of deep neural networks. In Neural Information Processing Systems, 2016.
Andrew M. Saxe, James L. McClelland, and Surya Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. In International Conference on Learning Representations, 2014.
Anish Shah, Sameer Shinde, Eashan Kadam, Hena Shah, and Sandip Shingade. Deep residual networks with exponential linear unit. In Vision Net, 2016.
Nitish Srivastava. Improving neural networks with dropout. In University of Toronto, 2013.
Nitish Srivastava, Geoffrey E. Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: A simple way to prevent neural networks from overfitting. In Journal of Machine Learning Research, 2014.
Sergey Zagoruyko and Nikos Komodakis. Wide residual networks. British Machine Vision Conference, 2016.
A 用于 CIFAR-10 实验的神经网络结构
| 网络层类型 | # channels | x,y dimension
|
| raw RGB input | 3 | 32 |
| ZCA whitening | 3 | 32 |
| Gaussian noise σ = 0.15 | 3 | 32 |
| 3 × 3 conv with activation | 96 | 32 |
| 3 × 3 conv with activation | 96 | 32 |
| 3 × 3 conv with activation | 96 | 32 |
| 2 × 2 max pool, stride 2 | 96 | 16 |
| dropout with p = 0.5 | 96 | 16 |
| 3 × 3 conv with activation | 192 | 16 |
| 3 × 3 conv with activation | 192 | 16 |
| 3 × 3 conv with activation | 192 | 16 |
| 2 × 2 max pool, stride 2 | 192 | 8 |
| dropout with p = 0.5 | 192 | 8 |
| 3 × 3 conv with activation | 192 | 6 |
| 1 × 1 conv with activation | 192 | 6 |
| 1 × 1 conv with activation | 192 | 6 |
| global average pool | 192 | 1 |
| softmax output | 10 | 1 |