语音模型预训练以用于端到端口语理解
Loren Lugosch1, Mirco Ravanelli1, Patrick Ignoto2,Vikrant Singh Tomar2, Yoshua Bengio1,3
1 Université de Montréal / Mila, 2Fluent.ai
3 CIFAR Fellow
{lugoschl, mirco.ravanelli, yoshua.bengio}@mila.quebec
{patrick.ignoto, vikrant}@fluent.ai
摘要
传统的口语理解(SLU)系统将语音映射到文本,然后将文本映射到意图,而端到端SLU系统通过单个可训练模型将语音直接映射到意图。 在没有大量训练数据的情况下,使用这些端到端模型很难实现高精度。 我们提出了一种降低端到端SLU数据需求的方法,该方法首先对模型进行预训练以预测单词和音素,从而学习SLU的良好特征。 我们引入一个新的SLU数据集Fluent Speech Commands,并表明当用整个数据集以及仅使用一小部分子集用于训练时,我们的方法都可以提高性能。 我们还描述主要的实验,以评估模型将其推广到训练期间未听到的新短语的能力。
1 简介
口语理解(SLU)系统推断口语的意思或意图 [1]。 这对于语音用户接口至关重要,在语音用户接口中,说话者的话语需要转换为动作或查询。 例如,对于语音控制的咖啡机,语音“make me a large coffee with two milks and a sugar, please”可能的意图表示为 {drink: "coffee", size: "large", additions:[{type: "milk", count: 2}, {type: "sugar", count: 1}]}。
传统的 SLU 流水线由两个模块组成:自动语音识别(ASR)模块,用于将语音映射到文本记录;自然语言理解(NLU)模块,用于将文本记录映射到说话者的意图 [2, 3, 4]。 开始流行的另一种方法是端到端SLU [5, 6, 7, 8, 9]。 在端到端SLU中,一个可训练的模型将语音音频直接映射到说话者的意图,而无需显式生成文本记录(图1)。 与传统的SLU流水线不同,端到端SLU:
- 直接优化关注的指标(意图识别准确性),
- 不会在估算文本上浪费建模工作,从而产生更紧凑的模型,并避免涉及搜索算法、语言模型、有限状态转换器等容易出错的中间步骤,
- 能够利用可能与推断意图有关但在文字记录中不存在的话语特征,例如韵律。
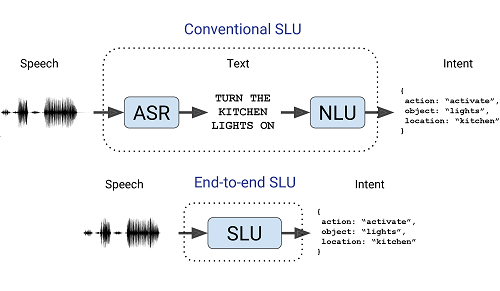
深度学习使端到端模型成为可能,深度学习可自动学习输入信号的层次表示 [10, 11, 12, 13, 14]。 语音很自然地以分层方式表示:波形→音素→语素→单词→概念→含义。 但是,由于语音信号即使对于单个说话者来说也是高维且高度可变的,因此在没有大量训练数据的情况下,难以训练深度模型并学习这些分层表示。
计算机视觉 [15, 16],自然语言处理 [17, 18, 19, 20, 21]和ASR [22, 23, 24, 25] 社区通过在有更多训练数据的相关任务上预训练深度模型,攻克了监督训练数据有限的问题,并取得了巨大成功。 继他们之后,我们在本文中提出一种高效的基于ASR的预训练方法,并表明它可以用来提高端到端SLU模型的性能,特别是当训练数据量非常小的时候。
我们的贡献如下:
2 相关工作
三篇描述端到端SLU的关键论文分别由 Qian 等人 [5], Serdyuk 等人 [6]和 Chen 等人 [7]所写。 Serdyuk 等人 在 [6] 中没有使用任何预训练。 Qian 等人 在 [5] 中使用自动编码器初始化 SLU 模型。 Chen 等人 [7] 预训练 SLU 模型的第一级以识别字素;然后将第一级的 softmax 输出馈送到第二级分类器。 本文提出的模型与他们的模型相似,但是消除 softmax 瓶颈的限制,使用其它训练目标,这将在后面描述。
最近,Haghani 等人 在 [8] 中比较 SLU 四种类型的序列到序列模型,包括直接模型(无预训练的端到端)和多任务模型(使用共享的编码器,其输出由单独的 ASR 解码器和 SLU 解码器提取)。 尽管我们在SLU训练期间不使用或不需要 ASR 目标,但本文提出的模型与他们的多任务模型有些相似。
上面列出的工作需要非常高的 SLU 资源 — [8],例如 Google Home [26] 数据集包含 2400 万个带有标签的语音。 相比之下,Renkens 等人 在 [9] 考虑训练数据有限的端到端 SLU 问题,并发现胶囊网络 [27]与传统的神经网络模型相比,更容易从头开始学习端到端SLU。 但是,他们没有考虑在其它语音数据上预训练的影响。
先前的所有工作都是在封闭源数据集或数据集太小而无法测试关于普遍化所需数据量的假设的数据集上进行的。 端到端SLU实验缺少良好的开源数据集,这使得大多数人很难对此主题进行高质量,可重复的研究。 因此,我们创建了一个新的SLU数据集,即“ Fluent语音命令”数据集,Fluent.ai与本文一起发布了该数据集。
3 数据集
本节介绍Fluent语音命令的结构和创建。
3.1 音频和标签
该数据集由16 kHz单通道.wav音频文件组成。 每个音频文件都包含一个英语口语命令的记录,该命令可能用于智能家居或虚拟助手,例如“放音乐”或“调高厨房的温度”。
每个音频带有三个slot标记:动作,对象和位置。 插槽采用多个值之一:例如,“位置”插槽可以采用“无”,“厨房”,“卧室”或“盥洗室”值。 我们将槽值的组合称为语音的意图。 数据集共有 31 个意图。 我们不区分领域、意图和槽值预测,类似于部分 SLU [28]。
数据集可用作多标签分类任务,其目标是预测动作,对象和位置标签。 由于这些插槽实际上并不是彼此独立的,因此更谨慎的方法是对插槽之间的关系进行建模,例如使用自回归模型,如 [8]。 我们在本文中使用更简单的多标签分类方法,以避免在训练自回归模型时有时会遇到的问题,相反我们将注意力集中在与使用更简单模型进行泛化相关的问题上。 另外一种方法,可以“展平”这 31 个不同的意图并将其用作单标签分类任务的 31 个不同的标签。
对于每种意图,都有多种可能的说法:例如,意图{action: "activate", object: "lights", location: "none"} 可以用“turn on the lights”、“switch the lights on”、“lights on”等表达。 这些短语是在数据收集之前通过询问 Fluent.ai 的员工,包括英语为母语和非母语的人,以各种表达特定意图的方式决定的。 共有 248 个不同的词组。
3.2 数据收集
数据是使用众包收集的。 记录每个说话者说两次每个意图的措辞。 记录的短语以随机顺序出现。 参与者同意发布数据并提供有关他们自己的统计信息。 有关这些匿名说话者的统计信息(年龄范围、性别、说话能力等)与数据集一起包括在内。
数据由另一组众包来源验证。 众包人员认为无法理解或包含错误短语的所有音频均已删除。 表1中显示说话人的总数、语句数目和音频的小时数。
3.3 数据集拆分
话语被随机分为训练音段,有效音段和测试音段,使得没有一个说话者出现在多个音段中。 尽管我们的代码可以选择仅包含不同集合中某些特定词语的数据,以测试模型识别训练期间未听到的词语的能力,但每个分组都包含每种意图的所有可能词语。 数据集的每个拆分都有一个.csv文件,该文件列出了该拆分中的所有.wav文件的发言人ID,文件路径,转录和插槽。
3.4 相关数据集
在这里,我们回顾了一些相关的公共数据集,并展示了Fluent Speech Commands填补的空白。
Google Speech Commands数据集 [29] (又名“Fluent Speech Commands”)是 30 个单字语音命令(“yes”, “no”, “stop”, “go”等)的免费数据集。 此数据集适用于关键字发现实验,但不适用于SLU。
ATIS是一个SLU数据集,由与旅行计划3 相关的话语组成。 该数据集只能从语言数据联盟昂贵地获得。
Grabo,Domotica和Patcor数据集是由KU Leuven 4 开发并用于机器人控制和纸牌游戏的口头命令的三个相关数据集 [9]. 这些数据集是免费的,但只有少数说话者和短语。
免费的基于音频的Snips SLU数据集 [30] 非常接近我们想要的 该数据集具有多种多样的短语,但音频却更少,只有2946种英语发音和1138种法语发音,而“流利语音命令”则为30043种。
与这些数据集相比,Fluent语音命令同时基于音频,相当大且免费,并且包含多个与每个意图相对应的多字命令,每个字词都有多个记录。
4 模型和预训练策略
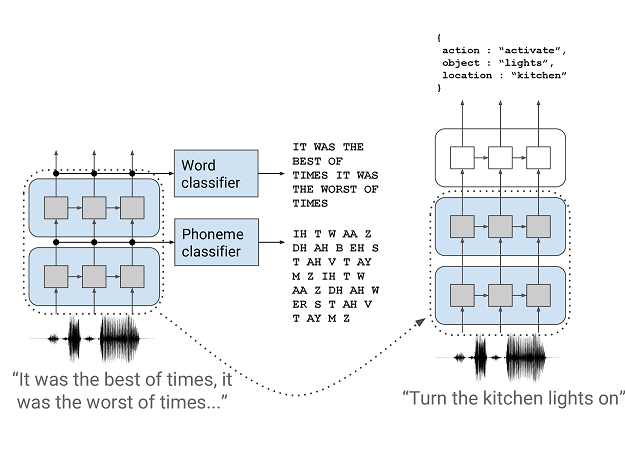
使用上一节中描述的数据集,我们测试了我们提出的模型和预训练策略(图2)的性能,在此进行描述。 该模型是一个由一堆模块组成的深度神经网络,其中第一个模块经过预训练以预测音素和单词。 丢弃单词和音素分类器,然后在监督的SLU任务中对整个模型进行端到端训练。 在这里,我们论证并提供有关这些设计决策的更多详细信息。
4.1 要使用哪个ASR目标?
使用各种目标来训练ASR模型,包括音素,字素,单词或最近的整个单词 [31,32,33]. 我们选择整个单词作为预训练目标,因为这是典型的NLU模块所期望的输入。 庞大的词汇表ASR数据集包含太多独特词(LibriSpeech [34] 有超过200,000个),以高效地为每个分配输出;我们只会为10,000个最常见的单词分配标签。 这使得许多预训练数据没有任何标签,从而浪费了数据。 通过使用音素作为中间的预训练目标 [35,20,36],我们可以在没有单词标签的语音段上进行预训练。 此外,我们发现使用音素作为中间目标可加快词级预训练 [37,38,39].
我们使用蒙特利尔强制对准器 [40] to obtain word- and phoneme-level alignments for LibriSpeech, and we pre-train the model on the entire 960 hours of training data using these alignments5 ,6 . 使用力对齐的标签还有另一个好处,即可以使用短随机农作物而不是整个语音进行预训练,从而减少了对模型进行预训练所需的计算和内存。
4.2 音素模块
第一个模块将音频信号作为输入,并输出h 音素,这是一系列经过预训练以预测音素的隐藏表示形式。 音素级对数使用线性分类器计算:
 | (1) |
音素模块是使用SincNet层实现的 [41,42],它处理原始输入波形,然后处理多个卷积层和递归层,并进行合并(以减少序列长度)和丢弃。 可以在我们的代码中找到更详细的超参数。
4.3 Word模块
第二个模块将h 音素作为输入,并输出h word。 与音素级模块类似,它使用具有辍学和合并功能的循环层,并使用另一个线性分类器进行了预训练以预测整个单词目标:
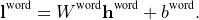 | (2) |
请注意,此模块的输入是h phoneme,而不是l phoneme,同样,输出到下一个阶段是h word,而不是l word。 有两个很好的理由转发h而不是l。首先是我们不想从模型中消除自由度:l的大小由目标数量确定,这反过来又会确定下一层的大小模型的 第二个原因是计算l word需要乘以并存储一个大的权重矩阵(≈ 250万个参数),并在之后丢弃该矩阵预训练,我们节省了内存和计算量。
4.4 意图模块

未预先训练的第三个模块将h word映射到预测的意图。 根据意图表示的结构,意图模块可以采用各种形式。 由于在这项工作中我们使用固定的三时隙意图表示,因此我们使用循环层来实现该模块,然后通过最大池将循环层的输出序列压缩为与不同时隙值相对应的logits的单个向量, 如同 [6].
4.5 解冻时间表
尽管经过预训练的模型可以很好地用作冻结特征提取器,但可能最好“解冻”其权重,并通过反向传播对SLU任务进行微调。 类似于ULMFiT [18],我们发现逐渐解冻预训练的图层比立即解冻所有效果更好。 我们在每个时期解冻一层,然后在预定层停止,这是一个超参数。
5 实验
在这里,我们报告有关Fluent语音命令的三个实验的结果:使用完整的数据集,使用数据集的子集以及使用措辞的子集。
5.1 完整数据集
我们首先给出了整个SLU训练集的训练模型。 这些模型使用以下方法之一:1)不进行预训练(随机初始化),2)不进行解冻的预训练,3)仅逐渐解冻单词层,或4)逐渐解冻词层和音素层。 我们在此报告的“准确性”指的是所有话语的准确度,也就是说,如果预测意图与甚至在一个时隙中的真实意图都不同,则认为该预测是错误的。
这些模型随时间的验证准确性如图3a所示。 当仅冻结预训练模型的单词层时,可获得最佳结果。 这可能是因为完全未冻结的模型开始忘记了在预训练过程中获得的更一般的语音知识。 对于测试集,冻结模型和部分未冻结模型的性能大致相同(表2,“完整”列),这可能是因为测试集比验证集“更容易”。 在所有情况下,预先训练的模型都优于随机初始化的模型。
5.2 部分数据集
为了模拟较小的数据集,我们随机选择了训练集的10%,并使用它代替了整个训练集。 图3b显示了随时间推移的验证准确性(在整个验证集上,而不是子集上)。 对于整个数据集,也观察到类似的趋势:解冻单词图层效果最佳。 随机初始化的模型与预先训练的模型之间的最终测试准确性差距越来越大(表2,“ 10%”列);预训练模型的最终测试准确性仅略有下降,这进一步凸显了我们提出的方法的优势。
5.3 推广到新的词语
如果新词出现在测试数据中却从未出现在训练数据中,该怎么办? 这是一个重要的问题,因为在收集培训数据时试图想象特定意图的每种可能措辞通常是不切实际的。
为了对此进行测试,我们在三个特定的短语上训练了模型,分别是“打开灯”,“关闭灯”和“打开灯”(总共273种发音),并在这些相同的短语和新词组:“关灯”。 如果模型错误地推断出包含“开关”的话语始终与打开灯相对应,则将错误地猜测“关闭灯”与打开灯相对应。如果模型推断单词“ off”的存在对应于关闭灯,则它将推广为新短语。 随机初始化的模型无法适应这种微小的训练集,即使学习率非常低且没有正则化也是如此。 预先训练的模型能够推广到新的措词(验证集的准确率达到97%,其中包含新短语的示例比训练短语的示例更多)。
但是,在许多情况下,我们的模型无法正确概括。 例如,如果仅使用包含“卧室”和“盥洗室”的示例训练模型,然后在包含“浴室”的示例中进行测试,则模型将猜测与“卧室”相对应的意图,因为“卧室”听起来更像是“浴室”而不是“洗手间”,即使“洗手间”是正确的含义。 在基于文本的NLU中,可以使用词嵌入来处理这种情况,词嵌入以这样的方式表示词:具有相似含义的词具有相似的矢量表示 [2,43]. 可以教导模型的预训练部分以输出“嵌入类”词表示,以便意图模块可以识别具有同义词的短语的含义。
6 结论
在本文中,我们为端到端SLU模型提出了一种预训练方法,引入了Fluent语音命令数据集,并使用该数据集显示了我们的预训练技术可提高大型和小型SLU训练集的性能。 将来,我们计划继续使用Fluent Speech Commands来探索端到端SLU的局限性,例如SLU数据集中未发现的新措辞和同义词,以查看是否可以克服这些局限性。
7 致谢
我们要感谢以下为研究资金和计算提供支持的机构:NSERC,CalculQuébec,Compute Canada,Canada Research Chairs和CIFAR。
感谢Mila的Dima Serdyuk和Kyle Kastner,以及Fluent.ai的Farzaneh Fard,Luis Rodriguez Ruiz,Sam Myer,Mohamed Mhiri和Arash Rad与我们就这项工作进行了有益的讨论。
8 参考
[1] G. Tur and R. D. Mori, Spoken Language Understanding: Systems for Extracting Semantic Information from Speech. Wiley, 2011.
[2] G. Mesnil, Y. Dauphin, K. Yao, Y. Bengio, L. Deng, D. Hakkani-tur, and X. He, “Using Recurrent Neural Networks for Slot Filling in Spoken Language Understanding,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015.
[3] A. Coucke, A. Saade, A. Ball, T. Bluche, A. Caulier, D. Leroy, C. Doumouro, T. Gisselbrecht, F. Caltagirone, T. Lavril, M. Primet, and J. Dureau, “Snips Voice Platform: an embedded Spoken Language Understanding system for private-by-design voice interfaces,” arXiv:1805.10190v3, 2018.
[4] A. L. Gorin, G. Riccardi, and J. H. Wright, “How may I help you?” Speech Communication, vol. 23, no. 1-2, pp. 113–127, 1997.
[5] Y. Qian, R. Ubale, V. Ramanarayanan, and P. Lange, “Exploring ASR-free end-to-end modeling to improve spoken language understanding in a cloud-based dialog system,” ASRU, 2017.
[6] D. Serdyuk, Y. Wang, C. Fuegen, A. Kumar, B. Liu, and Y. Bengio, “Towards end-to-end spoken language understanding,” ICASSP, 2018.
[7] Y.-P. Chen, R. Price, and S. Bangalore, “Spoken language understanding without speech recognition,” ICASSP, 2018.
[8] P. Haghani, A. Narayanan, M. Bacchiani, G. Chuang, N. Gaur, P. Moreno, R. Prabhavalkar, Z. Qu, and A. Waters, “From Audio to Semantics: Approaches to end-to-end spoken language understanding,” arXiv:1809.09190, 2018.
[9] V. Renkens and H. Van hamme, “Capsule Networks for Low Resource Spoken Language Understanding,” Interspeech, 2018.
[10] I. Goodfellow, Y. Bengio, and A. Courville, Deep Learning. MIT Press, 2016.
[11] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998.
[12] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,” NeurIPS, 2012.
[13] A. Graves and N. Jaitly, “Towards End-to-End Speech Recognition with Recurrent Neural Networks,” ICML, 2014.
[14] D. Amodei, R. Anubhai, E. Battenberg, C. Case, J. Casper, B. Catanzaro, J. Chen, M. Chrzanowski, A. Coates, G. Diamos et al., “Deep Speech 2: End-to-End Speech Recognition in English and Mandarin,” ICML, 2015.
[15] J. Yosinski, J. Clune, Y. Bengio, and H. Lipson, “How transferable are features in deep neural networks?” NeurIPS, 2014.
[16] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” ICLR, 2015.
[17] A. M. Dai and Q. V. Le, “Semi-supervised sequence learning,” NeurIPS, 2015.
[18] J. Howard and S. Ruder, “Universal language model fine-tuning for text classification,” ACL, 2018.
[19] A. Radford and T. Salimans, “Improving Language Understanding by Generative Pre-Training,” Technical report, OpenAI, 2018.
[20] V. Sanh, T. Wolf, and S. Ruder, “A hierarchical multi-task approach for learning embeddings from semantic tasks,” AAAI, 2019.
[21] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional Transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
[22] D. Wang and T. Zheng, “Transfer learning for speech and language processing,” APSIPA, 2015.
[23] G. Dahl, D. Yu, L. Deng, and A. Acero, “Context-dependent pre-trained deep neural networks for large vocabulary speech recognition,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 20, no. 1, pp. 30–42, 2012.
[24] J. Kunze, L. Kirsch, I. Kurenkov, A. Krug, J. Johannsmeier, and S. Stober, “Transfer Learning for Speech Recognition on a Budget,” ACL, 2017.
[25] P. Ghahremani, V. Manohar, H. Hadian, D. Povey, and S. Khudanpur, “Investigation of transfer learning for ASR using LF-MMI trained neural networks,” ASRU, 2017.
[26] B. Li, T. N. Sainath, A. Narayanan, J. Caroselli, M. Bacchiani, A. Misra, I. Shafran, H. Sak, G. Pundak, K. K. Chin et al., “Acoustic Modeling for Google Home,” Interspeech, 2017.
[27] S. Sabour, N. Frosst, and G. E. Hinton, “Dynamic routing between capsules,” NeurIPS, 2017.
[28] Y.-Y. Wang, L. Deng, and A. Acero, “Spoken language understanding,” IEEE Signal Processing Magazine, vol. 22, no. 5, pp. 16–31, 2005.
[29] P. Warden, “Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition,” arXiv:1804.03209v1, 2018.
[30] A. Saade, A. Coucke, A. Caulier, J. Dureau, A. Ball, T. Bluche, D. Leroy, C. Doumouro, T. Gisselbrecht, F. Caltagirone, T. Lavril, and M. Primet, “Spoken Language Understanding on the Edge,” arXiv:1805.10190v3, 2018.
[31] H. Soltau, H. Liao, and H. Sak, “Neural Speech Recognizer: Acoustic-to-Word LSTM Model for Large Vocabulary Speech Recognition,” arxiv:1610.09975, 2016.
[32] K. Audhkhasi, B. Ramabhadran, G. Saon, M. Picheny, and D. Nahamoo, “Direct Acoustics-to-Word Models for English Conversational Speech Recognition,” Interspeech, 2017.
[33] K. Audhkhasi, B. Kingsbury, B. Ramabhadran, G. Saon, and M. Picheny, “Building competitive direct acoustics-to-word models for english conversational speech recognition,” ICASSP, 2018.
[34] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, “LibriSpeech: An ASR corpus based on public domain audio books,” ICASSP, 2015.
[35] S. Fernández, A. Graves, and J. Schmidhuber, “Sequence Labelling in Structured Domains with Hierarchical Recurrent Neural Networks,” IJCAI, 2007.
[36] R. Caruana, “Multitask learning,” Machine learning, vol. 28, no. 1, pp. 41–75, 1997.
[37] T.-S. Nguyen, S. Stueker, and A. Waibel, “Using multi-task learning to improve the performance of acoustic-to-word and conventional hybrid models,” arXiv:1902.01951, 2019.
[38] R. Sanabria and F. Metze, “Hierarchical multitask learning with CTC,” SLT, 2018.
[39] K. Krishna, S. Toshniwal, and K. Livescu, “Hierarchical Multitask Learning for CTC-based Speech Recognition,” arXiv:1807.06234, 2018.
[40] M. McAuliffe, M. Socolof, S. Mihuc, M. Wagner, and M. Sonderegger, “Montreal Forced Aligner: Trainable text-speech alignment using Kaldi,” Interspeech, 2017.
[41] M. Ravanelli and Y. Bengio, “Speaker recognition from raw waveform with SincNet,” SLT, 2018.
[42] ——, “Interpretable convolutional filters with SincNet,” NeurIPS Workshop on Interpretability and Robustness for Audio, Speech and Language (IRASL), 2018.
[43] T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” arXiv preprint arXiv:1301.3781, 2013.