1 . 引言
深度神经网络已成为计算机视觉应用的实际模型。 它们的成功部分归因于其明显的可扩充性,即根据经验观察到的在较大的数据集上训练会产生更好的性能 [25, 17, 35, 46, 34, 18]。 深度网络通常通过有监督的学习来实现其强大的性能,这需要标记的数据集。 由于标注数据通常需要人工,因此使用较大的数据集所带来的性能优势可能会付出巨大的代价。 当必须由专家(例如,医疗应用中的医生)进行标记时,此成本可能会特别高。
半监督学习(SSL)是一种在大量数据上训练模型而无需大量标签的有效方法。 SSL 通过提供一种利用未标记数据的方法来减轻对标记数据的需求。 由于通常可以用最少的人力来获得未标记的数据,因此 SSL 所带来的任何性能提升通常都成本很低。 这使得有大量为深度网络设计的 SSL 方法 [28, 39, 21, 43, 3, 45, 2, 22, 38]。
一类流行的SSL方法可以粗略地看成是为每个未标记图像生成一个人工标签然后训练模型以在输入该未标记图像作为输入时预测该人工标签。 例如,伪标签 [22](也称为自训练 [27, 46, 37, 40])使用模型预测的类别作为要进行训练的标签。 同样,一致性正则化 [39,21] 在随机修改输入或模型函数后,使用模型的预测分布获得人工标签。

在这项工作中,我们继续最先进方法的趋势,结合多种机制来生产人工标签 [3, 45, 2, 28]。 我们引入 FixMatch,它同时使用一致性正则化和伪标签生成人工标签。 至关重要的是,基于弱 增强的未标记图像(例如仅使用翻转和移位的数据增强)来生成人工标签,当把相同图像的强 增强版本输入到模型时将使用这个标签。 受 UDA [45] 和 ReMixMatch [2] 的启发,我们利用 CutOut [13]、CTAugment [2] 和 RandAugment [10] 强增强,所有增强都会产生给定图像的严重变形的版本。 遵循伪标签 [22] 的方法,仅当模型将高概率分配给可能的类别之一时,我们才保留它为人工标记。 FixMatch 的示意图显示在图 1 中。
虽然 FixMatch 包含现有技术的简单组合,但我们仍然表明,它在最常研究的 SSL 基准测试中获得了最先进的性能。 例如,FixMatch 在 250 个标签样本的 CIFAR-10 上取得 94.93% 的准确率,之前标准实验最先进的结果 93.73%[2] 来自于 [31]。 我们还通过将其应用于极少标签的场景中来探索我们方法的局限性,在每个类别只有 4 个标签的 CIFAR-10 上获得 88.61% 的准确率。 由于 FixMatch 与现有方法相似,但可实现明显更好的性能,因此我们进行了广泛的消融研究,以确定哪些因素对其成功最重要。 我们的消融研究还包括一些基本的实验选择,当新的 SSL 方法提出时,这些实验选择通常会被忽略或未报告(例如 optimizer 或学习速率调度),因为我们发现它们会对性能产生巨大影响。
在以下部分中,我们介绍 FixMatch 及其构建的基础想法。 在第 3 节中,我们讨论 FixMatch 与现有 SSL 算法的关系。 第 4 节和第 5 节分别包括我们的实验结果和消融研究。 最后,我们在第 6 章中总结对未来工作的展望。
2 . FixMatch
总体而言,FixMatch 算法是 SSL 两种常见方法的简单组合:一致性正则化和伪标签。 它的主要创新之处在于这两种方法的结合以及在执行一致性正则化时分别使用弱增强和强增强。 在本节中,我们将首先回顾一致性正则化和伪标签,然后再详细描述 FixMatch 算法。 我们还描述其它帮助 FixMatch 实验成功的因素,如正则化。
对于 L 类分类问题,我们定义 X =  (xb,pb) : b∈(1,…,B)
(xb,pb) : b∈(1,…,B)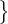 为批次大小为 B 的有标签样本,其中 xb 为训练样本以及 pb 为 one-hot 标签。
设 U =
为批次大小为 B 的有标签样本,其中 xb 为训练样本以及 pb 为 one-hot 标签。
设 U = 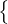 ub : b ∈ (1,…,μB)
ub : b ∈ (1,…,μB)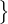 为批次大小为 μB 的未标记样本,其中 μ 为超参数决定 X 和 U 的相对大小。 设 pm(y∣x) 为模型输入 x 预测的类别分布。 我们将两个概率分布 p 和 q 之间的交叉熵表示为 H(p,q)。 作为 FixMatch 的一部分,我们执行两种类型的增强:强和弱,分布用 A(⋅) 和 α(⋅) 表示。 我们将在第2.3节中描述用于 A 和 α 增强的形式。
为批次大小为 μB 的未标记样本,其中 μ 为超参数决定 X 和 U 的相对大小。 设 pm(y∣x) 为模型输入 x 预测的类别分布。 我们将两个概率分布 p 和 q 之间的交叉熵表示为 H(p,q)。 作为 FixMatch 的一部分,我们执行两种类型的增强:强和弱,分布用 A(⋅) 和 α(⋅) 表示。 我们将在第2.3节中描述用于 A 和 α 增强的形式。
2.1 . 背景
一致性正则化 是许多最新 SSL 算法的重要组成部分。 一致性正则化通过依赖以下假设来利用未标记的数据:模型在输入相同图像的受扰动版本时应输出相似的预测。 这个想法最早在 [39,21] 中提出,其模型通过标准监督分类损失以及无标签数据上的以下损失函数训练
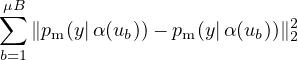 | (1) |
请注意,α 和 pm 都是随机函数,因此 等式 (1) 中的两个项会有不同的值。 这种思想的扩展包括使用对抗变换代替 α [28]、使用平均或过去模型的预测作为等式 (1) 中的 pm [43, 21]、使用交叉熵损失代替平方损失 ℓ2 [28, 45, 2]、使用更强的变换形式 [45, 2] 以及使用在一个更大的 SSL 管道中使用一致性正则 [3, 2]。
伪标签 利用这样的想法,即我们应该使用模型本身来获取无标签数据的人工标签。 这个想法是在数十年前引入的 [27,40]。 伪标签特指使用“硬”标签(即模型输出的 argmax)并仅保留最大类别的概率高于预定义阈值的人工标签 [22]。 设 qb =pm(y|ub),伪标签在无标签数据上使用以下损失函数:
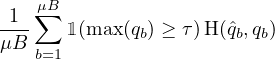 | (2) |
其中 ˆqb=argmax(qb),τ 是阈值超参数。 请注意,为简单起见,我们假设应用于概率分布的 argmax 会产生有效的“one-hot”概率分布。 硬标签的使用使伪标签与熵最小化密切相关 [16, 38],其促使模型的预测在无标签数据上具有较低的熵(即高置信度)。
2.2 . 我们的算法:FixMatch
FixMatch 的损失函数仅由两个交叉熵损失项组成:应用于标记数据的监督损失 ℓs 和非监督损失 ℓu。 具体来说,ℓs 只是弱增强有标签样本的标准交叉熵损失:
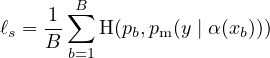 | (3) |
对于无标签的数据,1 FixMatch 为每个样本计算一个人工标签,然后将其用于标准交叉熵损失。 为获得人工标签,给定一个弱 增强的无标签图像,我们首先计算模型预测的类别分布:qb =pm(y∣α(ub))。 然后,我们使用 ˆqb=argmax(qb) 作为伪标签,我们强制 ub 强 增强版本的交叉熵损失基于模型输出:
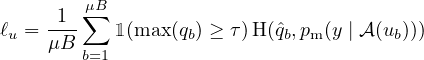 | (4) |
其中 τ 是表示阈值的标量超参数,我们保留在该阈值之上的伪标签。 总之,通过 FixMatch 最小化的损失只是 ℓs + λuℓu,其中,λu 是一个固定的标量超参数,表示无标签损失的相对权重。 我们在补充材料的算法 1中给出 FixMatch 的完整算法。
注意,等式 (4)与等式(2) 中的伪标签损失相似。 关键的区别在于,人工标签是根据弱增强的图像计算出来的,而对于强增强的图像,损失是相对于模型的输出而言的。 这引入一种一致性正则化形式,正如我们将在第 5 部分中展示的那样,这对于 FixMatch 的成功至关重要。 我们还注意到,在现代 SSL 算法中,随着训练增加无标签损失项的权重 (λu) 很常见 [43, 21, 3, 2, 31]。 我们发现对于 FixMatch 来说这是不必要的,这可能是由于 max(qb) 在训练中通常小于 τ。 随着训练的进行,模型的预测变得置信度更高,max(qb) > τ 的情况更加常见。 这表明伪标签可能会“免费”产生自然的课程。 过去已使用类似的理由来忽略视域适应 [14] 中的低置信度预测。
2.3 . FixMatch中的增强
FixMatch 利用两种增强:“弱”和“强”。 在我们所有的实验中,弱增强是一种标准的翻转移动增强策略。 具体来说,我们在除 SVHN 之外的所有数据集上以 50% 的概率随机水平翻转图像,并且我们以最多 12.5% 的概率垂直和水平随机转换图像。
对于“强”增强,我们尝试两种基于 AutoAugment [9] 的方法。 AutoAugment 通过使用强化学习从 Python Imaging Library 2 中的转换来学习强化策略。 这需要标注数据来学习增强管道,因此在有限的标注数据的 SSL 设置中使用会有问题。 结果,各种自动增强的变体提出,它们不需要使用有标签的数据提前学习增强策略。 我们试验两个这样的变体:RandAugment [10] 和 CTAugment [2]。 请注意,除非另有说明,否则我们在 Cutout [13] 之后使用这两种策略之一。
给定一系列转换(例如颜色反转、平移、对比度调整等),RandAugment 为批次中的每个样本随机选择转换。 按照最初的建议,RandAugment 使用一个固定的全局幅度来控制所有扭曲的严重性 [10]。 这个幅度是必须在验证集上优化的超参数,例如使用网格搜索。 我们发现,在每个训练步骤(而不是使用固定的全局值)中,从预定义的范围内采样随机幅度,对于半监督训练效果更好,类似于UDA 中使用的 [45] 方式。
CTAugment [2] 并非随机设置变换幅度,而是在训练过程中在线学习它们。 为此,将一个很广范围的变换幅度值划分为多个 bin(和 AutoAugment [9] 中一样),每个 bin 分配一个权重(最初设置为 1)。 所有样本都由两个变换组成的流水线进行增强,这两个变换是随机均匀采样进行。 对于给定的变换,以根据(标准化的)bin 权重的概率随机采样幅度箱。 为了更新量值 bin 的权重,通过两个变换来增强标记的样本,这些变换的量值 bin 被随机地均匀采样。 然后根据模型的预测与真实标签的接近程度来更新大小仓权重。 有关 CTAugment 的更多详细信息,请参见 [2]。
2.4 . 其他重要因素
半监督性能可能会受到使用的 SSL 算法以外因素重要影响,因为正则化数量之类的考虑因素在标签较少的场景中尤其重要。 为图像分类而训练的深度网络的性能可能在很大程度上取决于结构、优化器,训练的调度等事实,这使情况更加复杂。 引入新的SSL算法时通常不会强调这些因素。 我们没有最小化这些因素的重要性,而是努力量化它们的重要性,并强调哪些因素对效果有重大影响。 大多数分析是在第5节中进行。 在本节中,我们确定几个关键的考虑因素。
首先,如上所述,我们发现正则化尤为重要。 在我们所有的模型和实验中,我们都使用简单的权重衰减正则化。 我们还发现,使用 Adam 优化器 [19] 导致性能更差,从而使用标准带动量的 SGD [42, 33, 29]。 我们没有发现标准动量和 Nesterov 动量之间存在实质性差异。 对于学习率调整,我们使用余弦学习率衰减 [23] 将学习率设置为
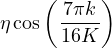 | (5) |
其中η是初始学习速率,k是当前训练步骤,而K是训练步骤的总数。 请注意,这种调整通过遵循余弦曲线,有效地将学习率从 η 衰减到接近 0。 最后,我们使用模型参数的指数移动平均值报告最终性能。
| 算法 | 人工标签增强 |
预测 增强 |
人工标签后处理 | 注 |
| TS [39]/Π-Model [36] | 弱 | 弱 | 没有 | |
| Temporal Ensembling [21] | 弱 | 弱 | 没有 | 在训练中使用较早的模型 |
| Mean Teacher [43] | 弱 | 弱 | 没有 | 使用 EMA 参数 |
| Virtual Adversarial Training [28] | 没有 | 对抗性 | 没有 | |
| UDA [ 45 ] | 弱 | 强 | 锐化 | 忽略低置信度的人工标签 |
| MixMatch [ 3 ] | 弱 | 弱 | 锐化 | 平均多个人工标签 |
| ReMixMatch [ 2 ] | 弱 | 强 | 锐化 | 对多个预测的损失求和 |
| FixMatch | 弱 | 强 | 伪标签 |
3 . 相关工作
半监督学习是一个成熟的领域,具有多种多样的方法。 在对相关工作的回顾中,我们仅关注与 FixMatch 相关的方法。 [51, 52, 5] 提供了对该领域的更广泛介绍。
伪标签或自我训练背后的想法已经存在了几十年 [40, 27]。 自我训练的普遍性(即使用模型的预测来获得未标记数据的人工标签)已使其应用于多种多样的领域,包括 NLP [26]、对象检测 [37]、图像分类 [22, 46]、领域适应性 [53] 等,仅举几例。 伪标签是指一种特定的变体,其中模型预测被转换为硬标签,并且仅在分类器具有足够的把握[22]时才保留。 一些研究表明,伪标签本身与其它现代 SSL 算法不具备竞争力 [31]。 但是,最近的 SSL 算法使用伪标签作为其流水线的一部分,以产生更好的结果 [1, 32]。 同样,如上所述,伪标签带来的一种熵最小化形式 [16] 已被用作许多强大的 SSL 技术 [28] 的一个组成部分。
一致性正则化首先以“Regularization With Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning” 被提出(简称Transformation/Stability 或 TS )[39] 或“Π-Model” [36]。 早期扩展包括在生成人工标签时使用模型参数 [43] 的指数移动平均值或使用以前的模型检查点 [21]。 已经使用了多种方法来产生随机扰动,包括数据增强[14],随机正则化(例如 Dropout [41] ) [39, 21] 和对抗扰动 [28]。 最近,研究表明,使用强数据增强可以产生更好的结果 [45, 2]。 这些强增强的样本几乎可以肯定不在数据分布范围之内,而事实证明,这对SSL [11] 可能具有潜在的好处。
在上述工作中,FixMatch与最近的两种算法最为相似:无监督数据增强(UDA)[45] 和 ReMixMatch [2]。 UDA 和 ReMixMatch 都使用一个弱增强的样本生成人工标签,并与强增强的样本保持一致。 它们都没有使用伪标签,但是都“锐化”人工标签来鼓励模型产生高可信度的预测。 当人工标签的预测类别分布中的最高概率高于阈值时,UDA 还特地强制一致性。 FixMatch 的阈值伪标签与锐化具有类似的效果。 另外,ReMixMatch 对无标签数据损失的权重进行了退火,我们从 FixMatch 中省略了这一点,因为我们认为伪标签中使用的阈值具有类似的作用(如2.2 节所述)。 这些相似之处表明 FixMatch 实质上可以看作是 UDA 和 ReMixMatch 的简化版本,在这里我们结合了两种常用技术(伪标签和一致性正则化),同时去除了许多组件(锐化、UDA 的训练信号退火、分布对齐和 ReMixMatch 的旋转损失等)。
由于 FixMatch 的核心方法是两种现有技术的简单组合,因此它也与许多先前提出的 SSL 算法具有很大的相似性。 我们在表 1中对每种技术进行了简要的比较,其中列出了用于人工标签的增强,模型的预测以及应用于人工标签的任何后处理。 下一节将对这些不同算法及其构成方法进行更全面的实验比较。
| CIFAR-10 | CIFAR-100 | SVHN
| |||||||
| 方法 | 40个标签 | 250个标签 | 4000个标签 | 400个标签 | 2500个标签 | 10000个标签 | 40个标签 | 250个标签 | 1000个标签 |
| Π-Model | - | 54.26 ± 3.97 | 14.01 ± 0.38 | - | 57.25 ± 0.48 | 37.88 ± 0.11 | - | 18.96 ± 1.92 | 7.54 ± 0.36 |
| Pseudo-Labeling | - | 49.78 ± 0.43 | 16.09 ± 0.28 | - | 57.38 ± 0.46 | 36.21 ± 0.19 | - | 20.21 ± 1.09 | 9.94 ± 0.61 |
| Mean Teacher | - | 32.32 ± 2.30 | 9.19 ± 0.19 | - | 53.91 ± 0.57 | 35.83 ± 0.24 | - | 3.57 ± 0.11 | 3.42 ± 0.07 |
| MixMatch | 47.54 ± 11.50 | 11.05 ± 0.86 | 6.42 ± 0.10 | 67.61 ± 1.32 | 39.94 ± 0.37 | 28.31 ± 0.33 | 42.55 ± 14.53 | 3.98 ± 0.23 | 3.50 ± 0.28 |
| UDA | 29.05 ± 5.93 | 8.82 ± 1.08 | 4.88 ± 0.18 | 59.28 ± 0.88 | 33.13 ± 0.22 | 24.50 ± 0.25 | 52.63 ± 20.51 | 5.69 ± 2.76 | 2.46 ± 0.24 |
| ReMixMatch | 19.10 ± 9.64 | 5.44 ± 0.05 | 4.72 ± 0.13 | 44.28 ± 2.06 | 27.43 ± 0.31 | 23.03 ± 0.56 | 3.34 ± 0.20 | 2.92 ± 0.48 | 2.65 ± 0.08 |
| FixMatch(RA) | 13.81 ± 3.37 | 5.07 ± 0.65 | 4.26 ± 0.05 | 48.85 ± 1.75 | 28.29 ± 0.11 | 22.60 ± 0.12 | 3.96 ± 2.17 | 2.48 ± 0.38 | 2.28 ± 0.11 |
| FixMatch(CTA) | 11.39 ± 3.35 | 5.07 ± 0.33 | 4.31 ± 0.15 | 49.95 ± 3.01 | 28.64 ± 0.24 | 23.18 ± 0.11 | 7.65 ± 7.65 | 2.64 ± 0.64 | 2.36 ± 0.19 |
4 . 实验
我们在几种标准 SSL 图像分类基准上评估 FixMatch 的效果。 特别地,我们在 CIFAR-10 [20], CIFAR-100 [20], SVHN [30], STL-10 [8] 和 ImageNet [12] 上用不同数量的有标签数据和增强策略进行试验。 在许多情况下,由于 FixMatch 在标签稀缺的情况下显示出希望,因此我们使用比以前考虑的更少的标签进行实验。 请注意,除 ImageNet 之外,我们在所有数量的有标签样本和数据集上使用相同的超参数集(λu=1, η=0.03, β=0.9, τ=0.95, μ=7, B=64, K=220)3。 补充材料中报告了超参数的完整列表。 我们在第5节中进行了广泛的消融研究,以弄清 FixMatch 的不同组件和超参数的重要性,包括不是 SSL 算法明确组成部分的因素如优化器和学习率。
4.1 . CIFAR-10、CIFAR-100 和 SVHN
首先,我们将FixMatch与标准CIFAR-10,CIFAR-100和SVHN基准上的各种现有方法进行比较。 根据[31]的建议,我们重新实现了所有现有基准,并使用相同的代码库执行了所有实验。 特别是,我们在所有的 SSL 方法上使用相同的网络结构(参数为1.5M 的 Wide ResNet-28-2 [47])和训练协议,包括优化器、学习率调整、数据预处理。 对于基线,我们主要考虑与 FixMatch 类似和/或最新的方法:Π-Model [36], Mean Teacher [43], Pseudo-Label [22], MixMatch [3], UDA [45] 和 ReMixMatch [2]。 除了 [2] 以外,以前的工作在这些基准上考虑的每个类别的有标签数据不少于 25 个。 我们还考虑为每个数据集的每个类别仅提供 4 个有标签图像的场景。 据我们所知,我们是第一个在 CIFAR-100 上以 400 个标签样本运行任何 实验的。
我们在表 2中报告所有基准以及 FixMatch 的性能。 我们对有标签数据的 5 个不同“fold”进行训练,计算准确率的均值和方差。 因为 Π-Model、Mean Teacher 和 Pseudo-Labeling 在每个类别具有 250 个标签时的性能较差,我们直接省略了每个类别具有 4 个标签的结果。 MixMatch、ReMixMatch 和 UDA 在 40 和 250 个标签上表现都相当不错,但是我们发现 FixMatch 明显优于这些方法而且更简单。 例如,FixMatch 在 CIFAR-10 每个类别有 4 个标签的情况下取得平均错误率 11.39%。 作为参考,在 [31] (使用相同的网络结构)中研究的方法中,每个类别 400 个标签的情况下,最低的错误率为 13.13%。 尽管我们省略了诸如自我监督损失之类的各种组件,但我们的结果也可以与 ReMixMatch [2] 取得的最新结果相媲美。
除了 ReMixMatch 在 CIFAR-100 上略微好一些之外,我们的结果在所有数据集上都是最好的。 为了了解 ReMixMatch 为什么比 FixMatch 具有更好的效果,我们尝试了 FixMatch 的一些变体,这些变体将 ReMixMatch 的各个组件复制到 FixMatch 中。 我们发现最重要的原因是分布对齐(DA),它鼓励模型以相等的概率产生所有类别。 FixMatch 与 DA 的组合在 400 个标签的样本上达到 40.14% 的错误率,这明显优于 ReMixMatch 取得的 44.28% 。
我们发现,除了在每个类中有 4 个标签的场景中,在大多数情况下,使用 CTAugment 和 RandAugment 的 FixMatch 的性能是相似的。 这可能是由于这些结果具有特别高的差距。 例如,对于 CIFAR-10,每类 4 个标签的 5 个不同 fold 的方差为 3.35%,这明显高于每个类别 25 个标签的 0.33%。 如表 4所示,当每个类别的有标签数量极少时,随机种子也将极大地影响错误率。
4.2 . STL-10
STL-10 数据集包含 10个类别 5,000 个有标签的图像,尺寸为 96×96 ,和 100,000 无标签的图像。 无标签的图像集中存在分布不当的图像,这使其成为对 SSL 效果的更现实、更具挑战性的测试。 我们分别在 1,000 有标签图像的五个预定义折叠上测试 SSL 算法。 遵循 [3],我们使用 WRN-37-2 网络(包含 23.8M 个参数)。 与表3中一样,FixMatch 尽管非常简单,但却可以实现 ReMixMatch [2] 的最新效果。
4.3 . ImageNet
我们还在 ImageNet 上对 FixMatch 进行了评估,以验证它在更大、更复杂的数据集上的性能是否良好。 遵循 [45],我们使用 10% 的训练数据作为有标签的样本,将其余训练数据视为无标签的样本。 我们还使用 ResNet-50 网络结构和 RandAugment [10] 作为本实验的强增强。 我们将额外的实验细节放在小节C中。FixMatch 取得 top-1 错误率 28.54±0.52%,比 UDA [45] 高出 2.68%。 我们的 top-5 错误率是 10.87 ± 0.28%。 虽然 S4L [48] 在半监督 ImageNet 上拥有最好的效果,其错误率为 26.79% ,但是它在第一阶段之后利用两个额外的训练阶段(伪标签再训练和监督微调)将错误率从30.27% 降到很低。 FixMatch 在其第一阶段之后的表现优于 S4L,并且通过将这些技术并入 FixMatch,有可能获得类似的性能提升。
4.4 . 勉强监督学习
为了测试我们提出的方法的局限性,我们将 FixMatch 应用于 CIFAR-10,每个类别仅 1 个样本。 我们进行了两组实验。
首先,我们通过每个类别随机选择一个样本来创建四个数据集。 我们对每个数据集进行四次训练,并达到 48.58% 和 85.32% 之间的测试准确率,中位数为 64.28%。 但是,数据集内的差异要小得多;例如,在第一个数据集中训练的四个模型的准确率都在 61% 和 67% 之间,第二个数据集的准确率在 68% 和 75% 之间。
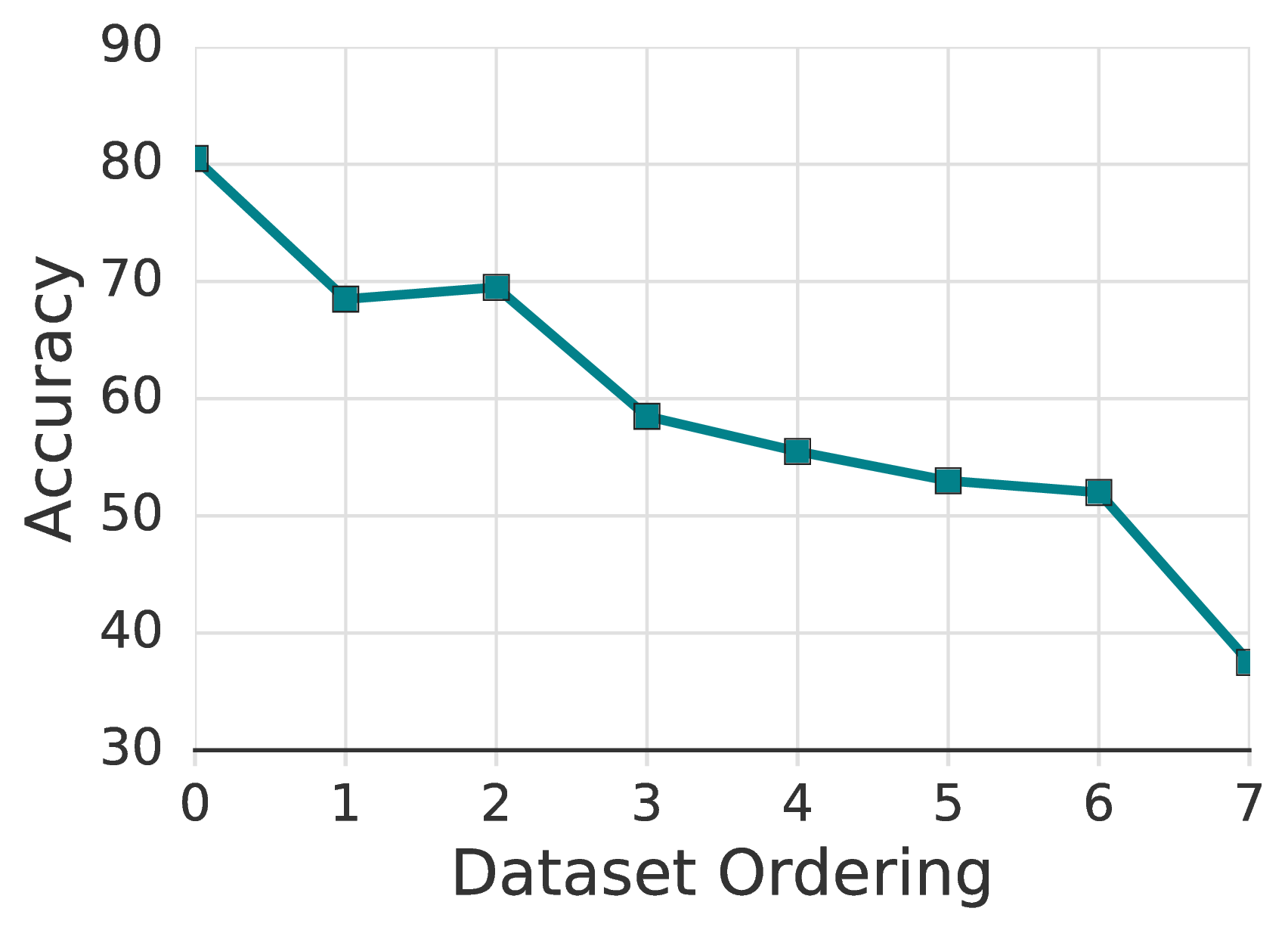
我们假设这种可变性是由给定数据集中标记的示例的质量引起的,选择低质量的示例可能会使模型更难以有效地学习某些特定的类。 为了测试这一点,我们构建了八个新的训练数据集,并举例说明了“原型”(即,基础类的代表)。 具体来说,我们从[4]中对CIFAR-10训练集进行排序,从最有代表性的示例到最少代表性的示例进行排序。 在使用所有标记数据训练了许多CIFAR-10模型之后,确定了此示例排序。 因此,我们没有将其设想为实际选择用于SSL的示例的实用方法,而是通过实验验证了更具代表性的示例更适合于低标签训练。 我们将此排序平均分为八个存储桶(因此,所有最具代表性的示例都在第一个存储桶中,所有异常值在最后一个存储桶中)。 然后,我们通过从同一存储桶中随机选择每个班级的一个带标签的示例来创建八个带标签的训练集。
使用相同的超参数,仅在最典型的示例上训练的模型就达到了78%准确性的中位数(最大84%准确性);分布中间的训练达到65%的准确性;并且仅对异常值的训练无法完全收敛,准确性10%。 图2显示了该分组的完整标签训练数据集,其中FixMatch达到了78%的中值准确度。 进一步的分析在附录B.3中进行。


| Ablation | FixMatch | Only CutOut | No CutOut |
| Error | 4.84 | 6.15 | 6.15 |
5 . 消融研究
由于FixMatch包含两种现有技术的简单组合,因此我们进行了广泛的消融研究,以更好地理解为什么它能够获得最新的结果。 回想一下,我们在表2和表3中报告了每种实验方案的5倍均值和标准差,作为我们的主要结果。 但是,由于我们在消融研究中的实验数量众多,因此我们专注于从CIFAR-10中分离250个标签进行研究,仅使用CTAugment报告结果。 请注意,在这个特定的数据集上,使用默认参数的 FixMatch 可以达到 4.84% 的错误率。 我们在补充材料中提供完整的结果。
5.1 . 锐化和阈值化
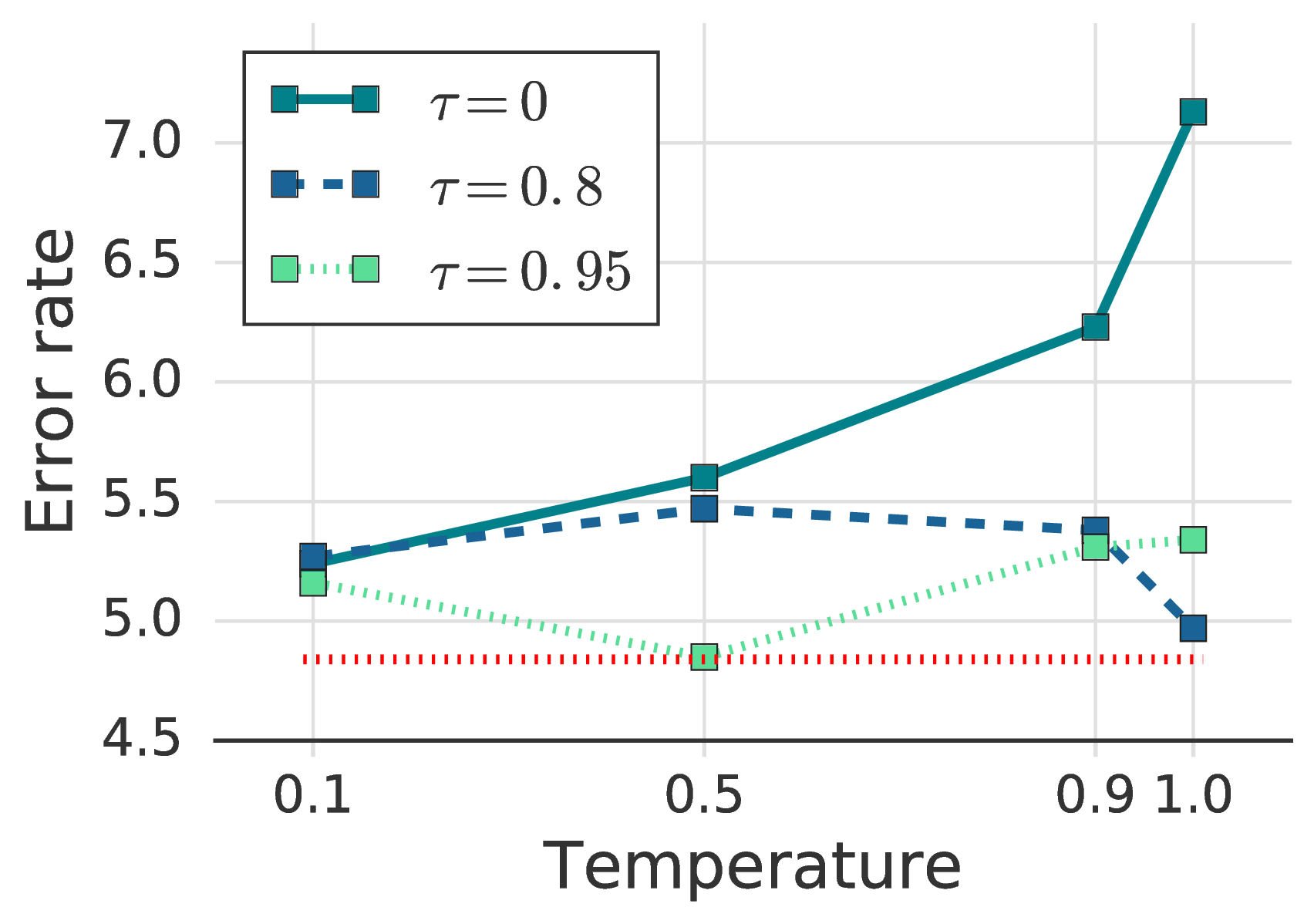
一种“软”版本的伪标签可以设计成通过锐化预测分布而不是使用 one-hot 标签。 这种设计出现在 UDA 中并且引起普遍关注,因为其它方法如 MixMatch 和 ReMixMatch 也使用锐化(尽管没有阈值)。 使用锐化代替 argmax 会引入超参数:温度 T [2, 45]。
我们研究了温度 T 和置信度阈值 τ 之间的相互作用。 请注意,FixMatch 中的伪标记被恢复为 T → 0。 结果显示在图 3b和图 3c中。 阈值 0.95 显示最低的错误率,尽管将其提高到 0.97 或 0.99 不会损害性能。 另一方面,使用较小的阈值时,精度下降超过1.5%。 另一方面,使用置信度阈值时,锐化没有表现出明显的性能差异。 总而言之,我们观察到将伪标签交换为锐化和阈值处理将引入新的超参数,同时不会获得更好的性能。
5.2 . 增强策略
我们对各种强大的数据增强策略进行了消融研究,因为数据增强在FixMatch中起着关键作用。 具体来说,我们选择了RandAugment [10]和CTAugment [2]先进的SSL算法,例如UDA [45]和ReMixMatch [3]。 在CIFAR-10,CIFAR-100和SVHN上,我们观察到两个策略(表2)之间的结果具有可比性,而在表3中,我们观察到显着的收益。使用CTAugment。
如2.3中所述,在RandAugment和CTAugment中都强烈增强后,默认情况下会使用CutOut [13]。 因此,我们在表7中测量CutOut的效果。 我们发现CutOut和CTAugment都需要获得最佳性能。删除任何一个都会导致错误率的可比增长。
我们还研究了伪标记生成和预测的弱和强增强的不同组合(即,图1中的上下路径)。 当我们用强增强替换用于标签猜测的弱增强时,我们发现模型在训练的早期就出现了分歧。 这表明需要使用弱扩充数据来生成伪标签。 使用弱增强代替强增强来生成模型的训练预测峰值达到45%的准确性,但不稳定,并逐渐崩溃到12%,这表明强数据增强对于训练中模型预测的重要性。 此观察结果与监督学习[9]中的观察结果非常吻合。
5.3 . 无标签数据的比例
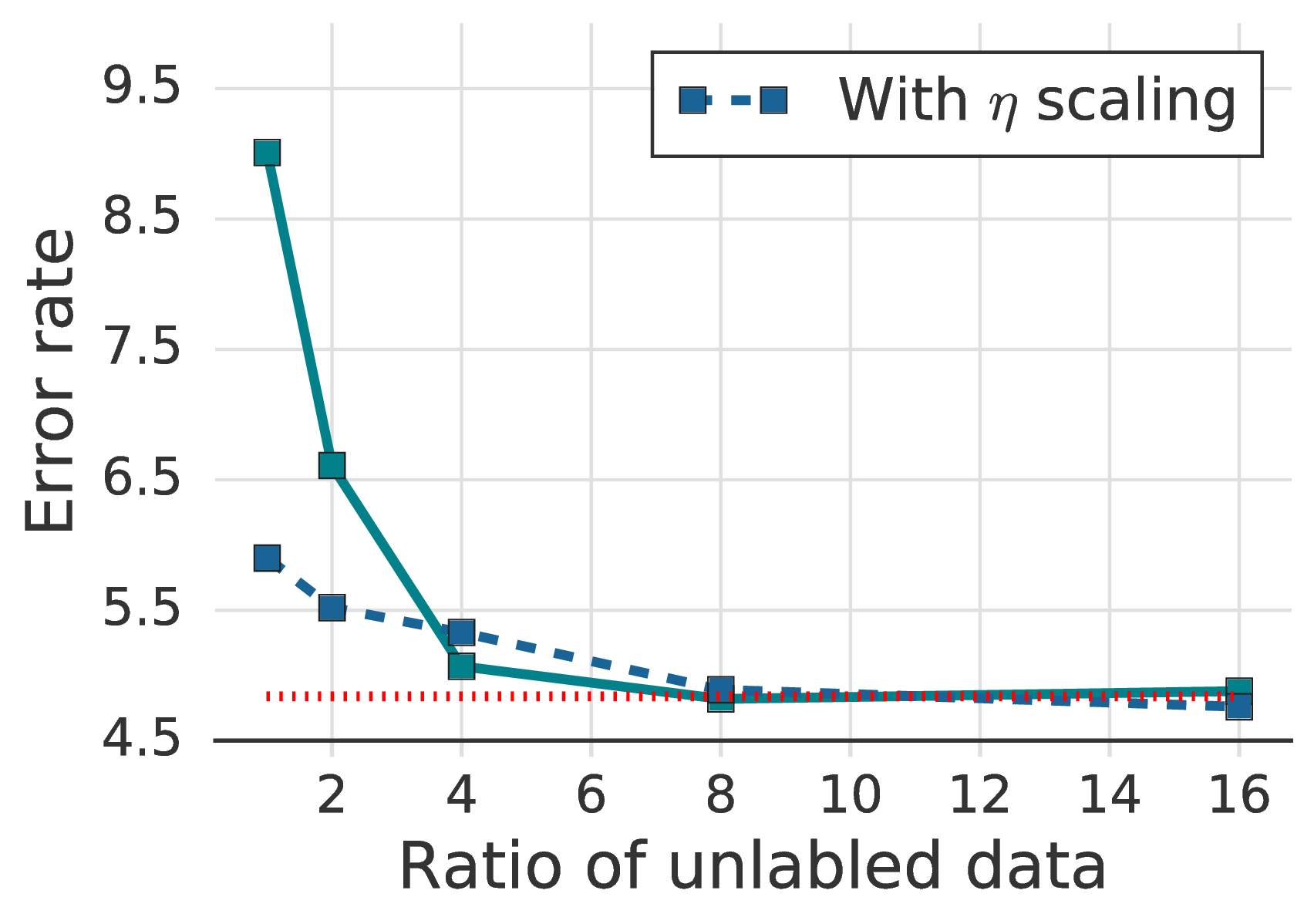
在图 3a中我们绘制具有不同比率的无标签数据(μ)的 FixMatch 错误率。 通过使用大量无标签的数据,我们发现错误率显着下降,这与 UDA [45] 中的发现一致。 此外,将学习率 η 随批次大小线性缩放(一种用于大批次监督训练的技术 [15])对于 FixMatch,尤其是当 μ 较小时有效。
5.4 . 优化器和学习率调整
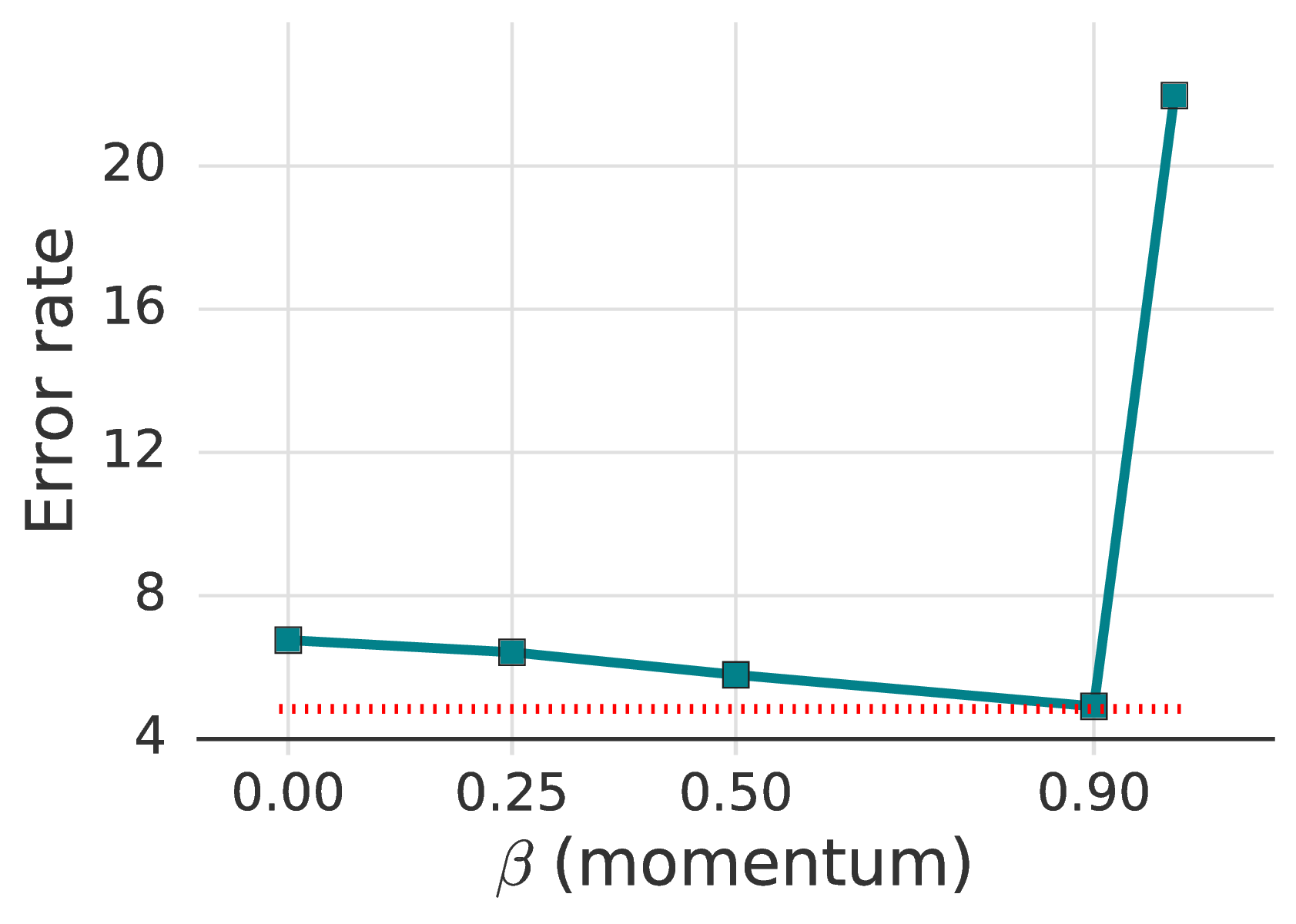
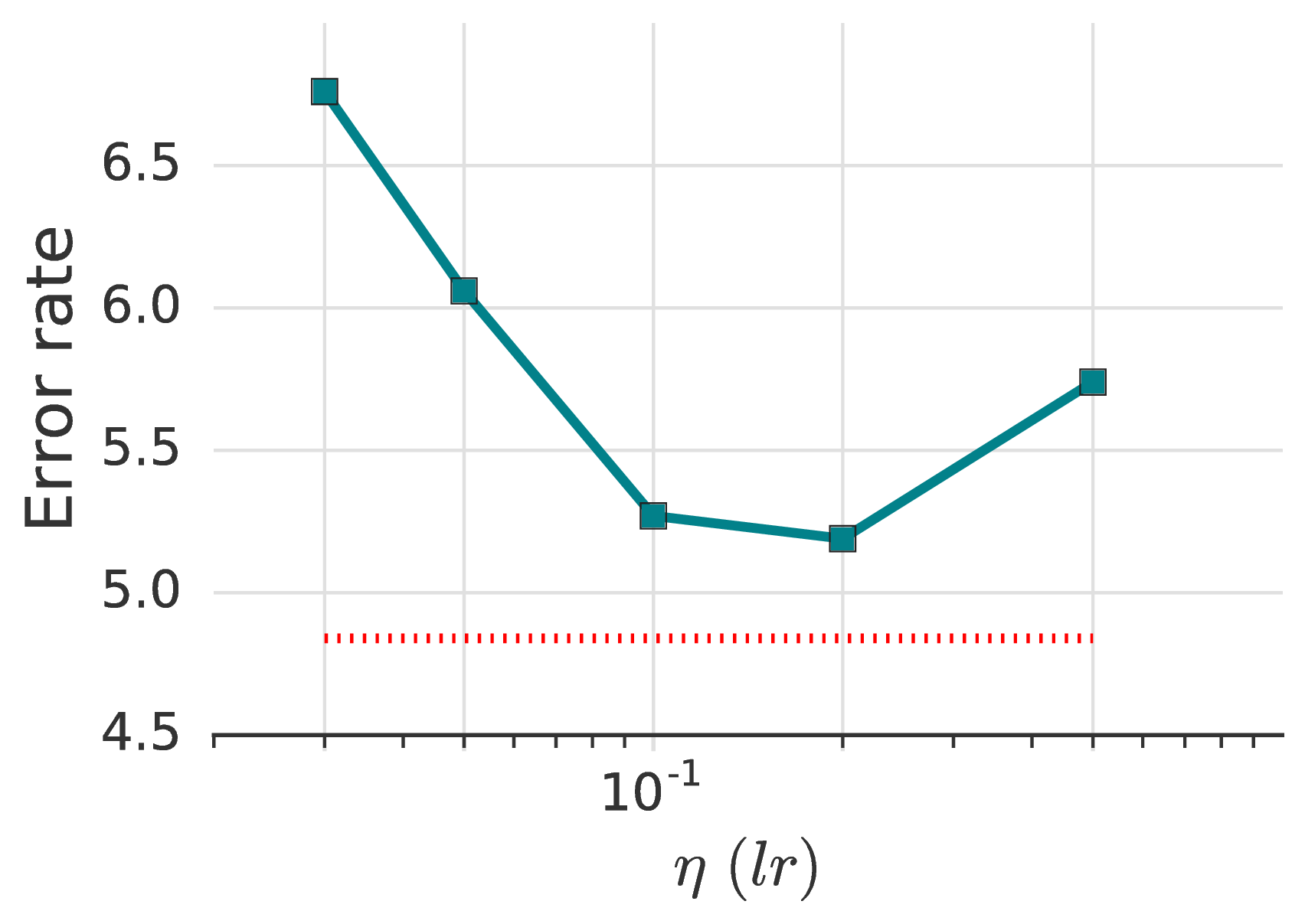
尽管以前的SSL著作很少研究不同的优化器及其超参数,但我们发现它们会对性能产生很大影响。 如表 5所示,动量为 0.9 的 SGD 效果最好。 没有动量,我们可以达到的最佳错误率是 5.19% ,而有动量时为 4.84。 我们发现,动量的 Nesterov 变体 [42] 对于取得 5% 以下的误差不是必需的。 对于 Adam [19],我们探索的 η、β1、β2 参数组合均未显得很有效果。 有关更多详细信息,请参见补充材料中的表9。
在最近的工作中 [23] ,使用余弦学习速率衰减是一个流行的选择。 在我们的实验中,线性学习率的衰减也差不多。 注意,对于余弦学习速率衰减,选择适当的衰减速率很重要。 最后,不使用衰减会导致准确率变差(降低 0.86%)。
5.5 . 权重衰减
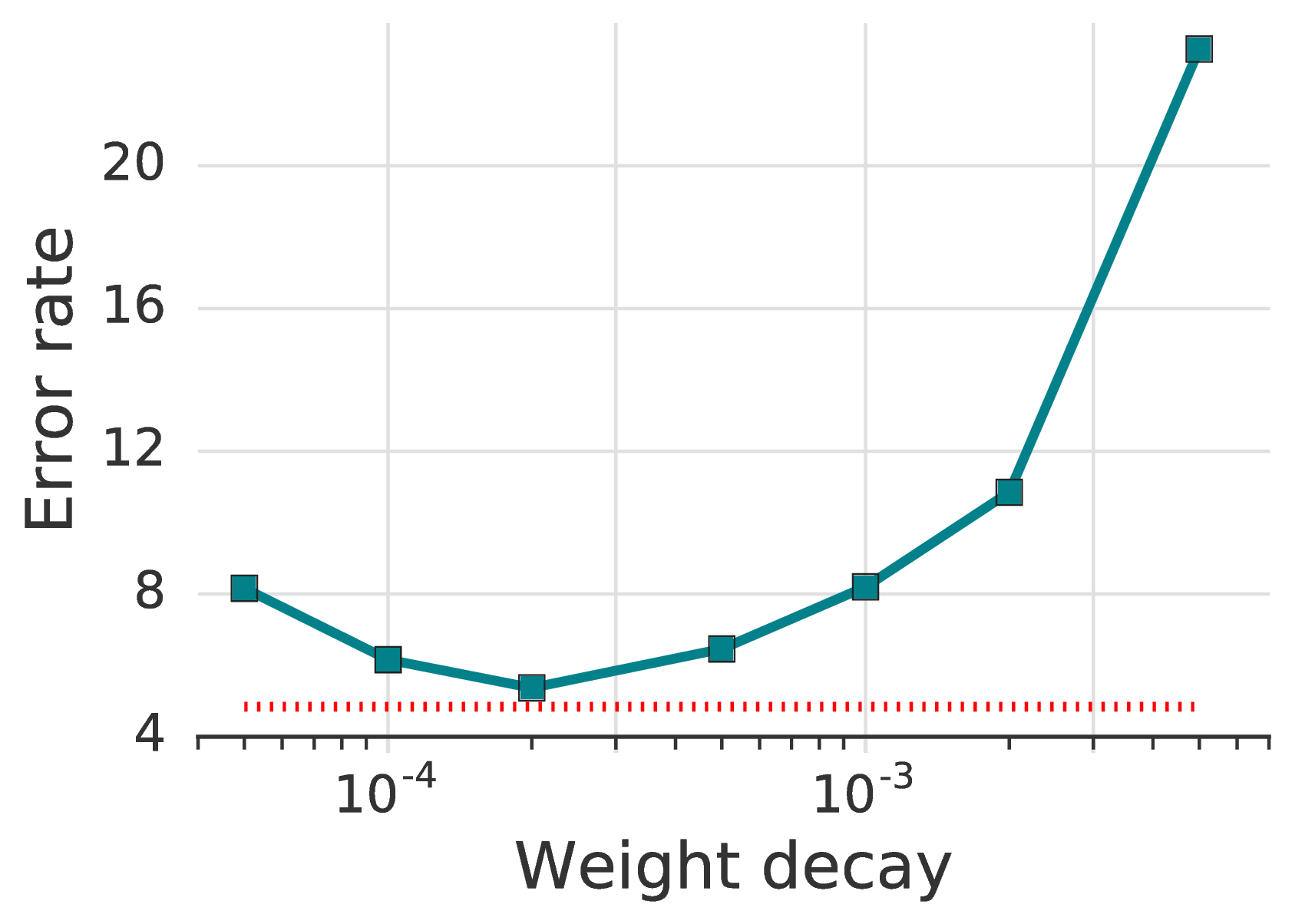
我们发现,调整权重衰减对于低标签场景极为重要:如图 3d所示,选择仅比最佳值大或小一个数量级的值可能会下降十个百分点或更多。
6 . 结论
最近在半监督学习中取得了迅速的进步。 不幸的是,这种进步的大部分是以越来越复杂的学习算法为代价的,这些算法具有复杂的损失项和众多难以调整的超参数。 我们引入FixMatch,这是一种更简单的半监督学习算法,可在许多数据集中实现最新的结果。 我们还展示了 FixMatch 如何开始弥合低标签半监督学习与少样本学习甚至是聚类之间的差距:每个类别只有一个标签时,我们获得了令人惊讶的高准确率。 只需在有标签和无标签的数据上使用标准的交叉熵损失,用几行代码就可以编写 FixMatch 的训练目标。
由于这种简单性,我们能够研究该算法的几乎所有方面,以了解其工作原理。 我们发现,要获得良好的结果,尤其是在标签受限的情况下,某些设计选择通常没有强调 — 最重要的是权重衰减和优化器的选择。 这些因素的重要性意味着,即使按照[31]中的建议控制模型架构,也无法始终在不同的实现中直接比较相同的技术。
总体而言,我们相信,这种简单但高效的半监督机器学习算法的存在将有助于使机器学习能够部署在越来越多的标签昂贵或难以获得的实际领域中。
致谢 我们感谢谢 Qizhe Xie、Avival Oliver 和 Sercan Arik 对本文的反馈。
参考资料
[1] Eric Arazo, Diego Ortego, Paul Albert, Noel E. O’Connor, and Kevin McGuinness. Pseudo-labeling and confirmation bias in deep semi-supervised learning. arXiv preprint arXiv:1908.02983, 2019.
[2] David Berthelot, Nicholas Carlini, Ekin D. Cubuk, Alex Kurakin, Kihyuk Sohn, Han Zhang, and Colin Raffel. Remixmatch: Semi-supervised learning with distribution matching and augmentation anchoring. In Eighth International Conference on Learning Representations, 2020.
[3] David Berthelot, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital Oliver, and Colin A Raffel. Mixmatch: A holistic approach to semi-supervised learning. In Advances in Neural Information Processing Systems 32. 2019.
[4] Nicholas Carlini, Úlfar Erlingsson, and Nicolas Papernot. Distribution density, tails, and outliers in machine learning: Metrics and applications. arXiv preprint arXiv:1910.13427, 2019.
[5] Olivier Chapelle, Bernhard Scholkopf, and Alexander Zien. Semi-Supervised Learning. MIT Press, 2006.
[6] Jinghui Chen and Quanquan Gu. Closing the generalization gap of adaptive gradient methods in training deep neural networks. arXiv preprint arXiv:1806.06763, 2018.
[7] Dami Choi, Christopher J Shallue, Zachary Nado, Jaehoon Lee, Chris J Maddison, and George E Dahl. On empirical comparisons of optimizers for deep learning. arXiv preprint arXiv:1910.05446, 2019.
[8] Adam Coates, Andrew Ng, and Honglak Lee. An analysis of single-layer networks in unsupervised feature learning. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, 2011.
[9] Ekin D. Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, and Quoc V. Le. Autoaugment: Learning augmentation strategies from data. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
[10] Ekin D. Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V. Le. Randaugment: Practical automated data augmentation with a reduced search space. arXiv preprint arXiv:1909.13719, 2019.
[11] Zihang Dai, Zhilin Yang, Fan Yang, William W. Cohen, and Ruslan R. Salakhutdinov. Good semi-supervised learning that requires a bad GAN. In Advances in Neural Information Processing Systems, 2017.
[12] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database. In IEEE Conference on Computer Vision and Pattern Recognition, 2009.
[13] Terrance DeVries and Graham W Taylor. Improved regularization of convolutional neural networks with cutout. arXiv preprint arXiv:1708.04552, 2017.
[14] Geoffrey French, Michal Mackiewicz, and Mark Fisher. Self-ensembling for visual domain adaptation. In Sixth International Conference on Learning Representations, 2018.
[15] Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv preprint arXiv:1706.02677, 2017.
[16] Yves Grandvalet and Yoshua Bengio. Semi-supervised learning by entropy minimization. In Advances in neural information processing systems, 2005.
[17] Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md. Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou. Deep learning scaling is predictable, empirically. arXiv preprint arXiv:1712.00409, 2017.
[18] Rafal Jozefowicz, Oriol Vinyals, Mike Schuster, Noam Shazeer, and Yonghui Wu. Exploring the limits of language modeling. arXiv preprint arXiv:1602.02410, 2016.
[19] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Third International Conference on Learning Representations, 2015.
[20] Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009.
[21] Samuli Laine and Timo Aila. Temporal ensembling for semi-supervised learning. In Fifth International Conference on Learning Representations, 2017.
[22] Dong-Hyun Lee. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In ICML Workshop on Challenges in Representation Learning, 2013.
[23] Ilya Loshchilov and Frank Hutter. SGDR: Stochastic gradient descent with warm restarts. In Fifth International Conference on Learning Representations, 2017.
[24] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In Sixth International Conference on Learning Representations, 2018.
[25] Dhruv Mahajan, Ross Girshick, Vignesh Ramanathan, Kaiming He, Manohar Paluri, Yixuan Li, Ashwin Bharambe, and Laurens van der Maaten. Exploring the limits of weakly supervised pretraining. In Proceedings of the European Conference on Computer Vision (ECCV), 2018.
[26] David McClosky, Eugene Charniak, and Mark Johnson. Effective self-training for parsing. In Proceedings of the main conference on human language technology conference of the North American Chapter of the Association of Computational Linguistics. Association for Computational Linguistics, 2006.
[27] Geoffrey J. McLachlan. Iterative reclassification procedure for constructing an asymptotically optimal rule of allocation in discriminant analysis. Journal of the American Statistical Association, 70(350):365–369, 1975.
[28] Takeru Miyato, Shin-ichi Maeda, Shin Ishii, and Masanori Koyama. Virtual adversarial training: a regularization method for supervised and semi-supervised learning. IEEE transactions on pattern analysis and machine intelligence, 2018.
[29] Yurii Evgen’evich Nesterov. A method of solving a convex programming problem with convergence rate o(k̂2). Doklady Akademii Nauk, 269(3), 1983.
[30] Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y. Ng. Reading digits in natural images with unsupervised feature learning. In NIPS Workshop on Deep Learning and Unsupervised Feature Learning, 2011.
[31] Avital Oliver, Augustus Odena, Colin A Raffel, Ekin Dogus Cubuk, and Ian Goodfellow. Realistic evaluation of deep semi-supervised learning algorithms. In Advances in Neural Information Processing Systems, pages 3235–3246, 2018.
[32] Hieu Pham and Quoc V Le. Semi-supervised learning by coaching. Submitted to the 8th International Conference on Learning Representations, 2019. https://openreview.net/forum?id=rJe04p4YDB.
[33] Boris T Polyak. Some methods of speeding up the convergence of iteration methods. USSR Computational Mathematics and Mathematical Physics, 4(5), 1964.
[34] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners, 2019.
[35] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683, 2019.
[36] Antti Rasmus, Mathias Berglund, Mikko Honkala, Harri Valpola, and Tapani Raiko. Semi-supervised learning with ladder networks. In Advances in Neural Information Processing Systems, 2015.
[37] Chuck Rosenberg, Martial Hebert, and Henry Schneiderman. Semi-supervised self-training of object detection models. In Proceedings of the Seventh IEEE Workshops on Application of Computer Vision, 2005.
[38] Mehdi Sajjadi, Mehran Javanmardi, and Tolga Tasdizen. Mutual exclusivity loss for semi-supervised deep learning. In IEEE International Conference on Image Processing, 2016.
[39] Mehdi Sajjadi, Mehran Javanmardi, and Tolga Tasdizen. Regularization with stochastic transformations and perturbations for deep semi-supervised learning. In Advances in Neural Information Processing Systems, 2016.
[40] H Scudder. Probability of error of some adaptive pattern-recognition machines. IEEE Transactions on Information Theory, 11(3), 1965.
[41] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research, 15(1), 2014.
[42] Ilya Sutskever, James Martens, George Dahl, and Geoffrey Hinton. On the importance of initialization and momentum in deep learning. In International conference on machine learning, 2013.
[43] Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Advances in neural information processing systems, 2017.
[44] Ashia C Wilson, Rebecca Roelofs, Mitchell Stern, Nati Srebro, and Benjamin Recht. The marginal value of adaptive gradient methods in machine learning. In Advances in Neural Information Processing Systems, pages 4148–4158, 2017.
[45] Qizhe Xie, Zihang Dai, Eduard Hovy, Minh-Thang Luong, and Quoc V. Le. Unsupervised data augmentation for consistency training. arXiv preprint arXiv:1904.12848, 2019.
[46] Qizhe Xie, Eduard Hovy, Minh-Thang Luong, and Quoc V. Le. Self-training with noisy student improves ImageNet classification. arXiv preprint arXiv:1911.04252, 2019.
[47] Sergey Zagoruyko and Nikos Komodakis. Wide residual networks. In Proceedings of the British Machine Vision Conference (BMVC), 2016.
[48] Xiaohua Zhai, Avital Oliver, Alexander Kolesnikov, and Lucas Beyer. S4l: Self-supervised semi-supervised learning. In The IEEE International Conference on Computer Vision (ICCV), October 2019.
[49] Guodong Zhang, Chaoqi Wang, Bowen Xu, and Roger Grosse. Three mechanisms of weight decay regularization. arXiv preprint arXiv:1810.12281, 2018.
[50] Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin, and David Lopez-Paz. MixUp: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412, 2017.
[51] Xiaojin Zhu. Semi-supervised learning literature survey. Technical Report TR 1530, Computer Sciences, University of Wisconsin – Madison, 2008.
[52] Xiaojin Zhu and Andrew B Goldberg. Introduction to semi-supervised learning. Synthesis lectures on artificial intelligence and machine learning, 3(1), 2009.
[53] Yang Zou, Zhiding Yu, BVK Vijaya Kumar, and Jinsong Wang. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training. In Proceedings of the European Conference on Computer Vision (ECCV), pages 289–305, 2018.
A . 算法
我们在算法1中介绍了FixMatch的完整算法。

B . 综合实验结果
B.1 . 超参数
如第4部分所述,我们在CIFAR-10,CIFAR-100,SVHN和STL-10上使用了几乎相同的FixMatch超参数。 请注意,对于这些数据集,我们使用了类似的网络体系结构,不同的是,CIFAR-100使用了更多的卷积过滤器来处理更大的标签空间,STL-10使用了更多的卷积来处理更大的输入图像。 在这里,我们在表8中提供了超参数的完整列表。 请注意,我们在第5部分(5.1,μ中的τ 第5.3,lr和β(动量)在第5.4部分,体重下降在第5.5部分中)。
B.2 . 优化器的完整消融结果
我们在表9中提供了有关优化器的完整消融结果。 首先,我们研究了动量(β)对SGD优化器的影响。 我们发现,性能对β较为敏感,并且当β设置得太大时模型无法收敛。 另一方面,β的较小值仍然可以正常工作。 当 β 较小时,提高学习速度可改善性能,尽管它们不如使用 β=0.9 获得的最佳性能好。 Nesterov动量的误差率比标准动量SGD的误差率略低,但差异不大。
根据 [44, 24] 的研究,我们没有发现 Adam 的表现优于动量 SGD。 尽管使用 Adam 训练的模型的最佳错误率仅比动量 SGD 的最佳错误率大 0.53%,但我们发现其性能对学习率的变化比动量 SGD 更为敏感(例如,当将学习率提高到 0.002 时,错误率增加 8% 以上)。 沿着该方向进行的其他探索以使Adam更具竞争力,包括使用权重衰减[24,49]代替L2权重正则化和更好的方法超参数[6,7]的探索。
| 优化器 | 超参数 | Error | ||
| SGD | η = 0.03 | β = 0.90 | Nesterov | 4.84 |
| SGD | η = 0.03 | β = 0.999 | Nesterov | 84.33 |
| SGD | η = 0.03 | β = 0.99 | Nesterov | 21.97 |
| SGD | η = 0.03 | β = 0.50 | Nesterov | 5.79 |
| SGD | η = 0.03 | β = 0.25 | Nesterov | 6.42 |
| SGD | η = 0.03 | β = 0 | Nesterov | 6.76 |
| SGD | η = 0.05 | β = 0 | Nesterov | 6.06 |
| SGD | η = 0.10 | β = 0 | Nesterov | 5.27 |
| SGD | η = 0.20 | β = 0 | Nesterov | 5.19 |
| SGD | η = 0.50 | β = 0 | Nesterov | 5.74 |
| SGD | η = 0.03 | β = 0.90 | 4.86 | |
| Adam | η = 0.002 | β1 = 0.9 | β2 = 0.00 | 29.42 |
| Adam | η = 0.002 | β1 = 0.9 | β2 = 0.90 | 14.42 |
| Adam | η = 0.002 | β1 = 0.9 | β2 = 0.99 | 15.44 |
| Adam | η = 0.002 | β1 = 0.9 | β2 = 0.999 | 13.93 |
| Adam | η = 0.0008 | β1 = 0.9 | β2 = 0.999 | 7.35 |
| Adam | η = 0.0006 | β1 = 0.9 | β2 = 0.999 | 6.12 |
| Adam | η = 0.0005 | β1 = 0.9 | β2 = 0.999 | 5.95 |
| Adam | η = 0.0004 | β1 = 0.9 | β2 = 0.999 | 5.44 |
| Adam | η = 0.0003 | β1 = 0.9 | β2 = 0.999 | 5.37 |
| Adam | η = 0.0002 | β1 = 0.9 | β2 = 0.999 | 5.57 |
| Adam | η = 0.0001 | β1 = 0.9 | β2 = 0.999 | 7.90 |
B.3 . 用于勉强监督学习的有标签数据
在 图 2 的基础上,我们可视化通过排序机制 [4] 获得的完整有标签训练图像,用于图 5中勉强监督学习。 每行包含来自10个不同类别的CIFAR-10的10张图像,并用作一次FixMatch的完整标记训练数据集。 第一行包含每个类别的原型图像最多,而底行则包含最少的原型图像。 我们为每个数据集训练两个模型,并计算两个模型之间的平均准确度,并将其绘制在图 6中。 观察到,在训练最佳范例时,我们可以获得80%以上的准确性。







B.4 . 与监督基准的比较
在表10和表11中,我们展示了仅使用带有强数据增强功能的带标签数据训练的模型的性能,以突出显示在FixMatch中使用无标签数据的有效性。
| CIFAR-10 | CIFAR-100 | SVHN
| |||||||
| 方法 | 40个标签 | 250个标签 | 4000个标签 | 400个标签 | 2500个标签 | 10000个标签 | 40个标签 | 250个标签 | 1000个标签 |
| 监督(RA) | 64.01 ± 0.76 | 39.12 ± 0.77 | 12.74 ± 0.29 | 79.47 ± 0.18 | 52.88 ± 0.51 | 32.55 ± 0.21 | 52.68 ± 2.29 | 22.48 ± 0.55 | 10.89 ± 0.12 |
| 监督(CTA) | 64.53 ± 0.83 | 41.92 ± 1.17 | 13.64 ± 0.12 | 79.79 ± 0.59 | 54.23 ± 0.48 | 35.30 ± 0.19 | 43.05 ± 2.34 | 15.06 ± 1.02 | 7.69 ± 0.27 |
| FixMatch(RA) | 13.81 ± 3.37 | 5.07 ± 0.65 | 4.26 ± 0.05 | 48.85 ± 1.75 | 28.29 ± 0.11 | 22.60 ± 0.12 | 3.96 ± 2.17 | 2.48 ± 0.38 | 2.28 ± 0.11 |
| FixMatch(CTA) | 11.39 ± 3.35 | 5.07 ± 0.33 | 4.31 ± 0.15 | 49.95 ± 3.01 | 28.64 ± 0.24 | 23.18 ± 0.11 | 7.65 ± 7.65 | 2.64 ± 0.64 | 2.36 ± 0.19 |
C . 第4.3部分的实现详细信息
对于我们的ImageNet实验,我们使用标准的ResNet50预激活模型在32核TPU设备上以分布式方式进行训练。4 我们报告五次随机标记数据的结果。 我们为ImageNet模型使用以下超参数集:
- 批次大小。 在每个步骤中,我们的批次包含1024个带标签的示例和5120个未带标签的示例。
- 训练时间。 我们训练了300个未标记示例的模型。
- 学习率调整。 我们在前 5 个周期使用线性学习率预热,直到达到初始值 0.4。 然后,通过在第 60、120、160 和 200个周期将其乘以 0.1 来衰减学习率。
- Optimizer。 我们使用 Nesterov 动量优化器,其动量为 0.9。
- 指数移动平均线(EMA)。 我们利用衰减为 0.999 的 EMA 技术。
- 修复比赛损失。 在 FixMatch 损失中,我们使用无标签损失权重 λu = 10 和置信度阈值 τ = 0.7 。
- 权重衰减。 我们的权重衰减系数为 0.0001。 与其他数据集类似,我们通过将所有权重的L2惩罚加到模型损失中来执行权重衰减。
- 未标记图像的增强。 对于强增强,我们使用随机幅度为[10]的RandAugment。 对于弱增强,我们使用随机水平翻转。
- ImageNet预处理。 在执行增强之前,我们随机裁剪并缩放所有标记和未标记的训练图像的大小为224 × 224。 这被认为是标准的ImageNet预处理技术。
D . 数据转换清单
我们使用了RandAugment [10]和CTAugment [2]中使用的相同图像转换集。 为了完整起见,我们在表12和表13中列出了这些扩充策略的所有转换操作。
| 转换 | 描述 | 参数 | 范围 |
| 自动对比 | 通过将最暗(最亮)的像素设置为黑(白)来最大化图像对比度。 |
|
|
| 亮度 | 调整图像的亮度。 B = 0 返回黑色图像, B = 1 返回原始图像。 | B | [0.05,0.95] |
| 颜色 | 像在电视中一样调整图像的色彩平衡。 C = 0 返回黑白图像, C = 1返回原始图像。 | C | [0.05,0.95] |
| 对比 | 控制图像的对比度。 A C = 0 返回灰度图像, C = 1 返回原始图像。 | C | [0.05,0.95] |
| 均衡 | 均衡图像直方图。 |
|
|
| 身分识别 | 返回原始图像。 |
|
|
| 海报化 | 将每个像素减少到 B位。 | B | [4, 8] |
| 旋转 | 以 θ旋转图像度。 | θ | [-30,30] |
| 清晰度 | 调整图像的清晰度,其中 S = 0 返回模糊的图像,S = 1 返回原始图像。 | S | [0.05, 0.95] |
| Shear_x | 以速率 R 沿水平轴剪切图像。 | R | [-0.3,0.3] |
| 剪_y | 以速率 R 沿垂直轴剪切图像。 | R | [-0.3,0.3] |
| 日晒 | 反转阈值 T 的所有像素。 | T | [0,1] |
| Translate_x | Translates the image horizontally by (λ×image width) pixels. | λ | [-0.3, 0.3] |
| Translate_y | 以( λ ×图像高度)像素。 | λ | [-0.3, 0.3] |
| 转换 | 描述 | 参数 | 范围 |
| 自动对比 | 通过将最暗(最亮)的像素设置为黑(白)来最大化图像对比度,然后 然后以混合比 λ与原始图像混合。 | λ | [0,1] |
| 亮度 | 调整图像的亮度。 B = 0 返回黑色图像, B = 1 返回原始图像。 | B | [0,1] |
| 颜色 | 像在电视中一样调整图像的色彩平衡。 C = 0 返回黑白图像, C = 1返回原始图像。 | C | [0,1] |
| 对比 | 控制图像的对比度。 A C = 0 返回灰度图像, C = 1 返回原始图像。 | C | [0,1] |
| 剪下 | 设置边长为( L ×图像宽度)像素变为灰色。 | L | [0,0.5] |
| 均衡 | 均衡图像直方图,然后通过混合 比率 λ 与原始图像混合。 | λ | [0,1] |
| 倒置 | 反转图像的像素,然后通过混合 比率 λ 与原始图像混合。 | λ | [0,1] |
| 身分识别 | 返回原始图像。 |
|
|
| 海报化 | 将每个像素减少到 B位。 | B | [1,8] |
| 重新缩放 | 获取侧面长度为中心的裁剪( L × 图像宽度),然后重新缩放为原始使用方法 M 的图像大小。 | L | [0.5,1.0] |
|
| M | see caption |
|
| 旋转 | 将图像图像旋转 θ 度。 | θ | [-45,45] |
| 清晰度 | 调整图像的清晰度,其中 S = 0 返回模糊的图像,并且 S < / t4> = 1返回原始图像。 | S | [0,1] |
| Shear_x | 以比率 R 沿水平轴剪切图像。 | R | [-0.3,0.3] |
| Shear_y | 以速率 R 沿垂直轴剪切图像。 | R | [-0.3,0.3] |
| 光滑 | 调整图像的平滑度,其中 S = 0 返回最大平滑的图像 和< / t4> S = 1返回原始图像。 | S | [0,1] |
| 日晒 | 反转阈值 T 的所有像素。 | T | [0,1] |
| 翻译_x | 按( λ ×图像宽度)像素。 | λ | [-0.3,0.3] |
| 翻译_y | 以( λ ×图像高度)像素。 | λ | [-0.3,0.3] |