DemoNSF:基于多任务演示的噪声填槽任务生成框架
摘要
最近,基于提示的生成框架在序列标注任务中表现出令人印象深刻的能力。 然而,在实际对话场景中,仅仅依靠简单的模板和传统的语料库,这些方法在泛化未知输入扰动方面面临挑战。 为了弥补这一不足,我们提出了一个基于多任务演示的噪声槽填充生成框架,命名为 DemoNSF。 具体来说,我们引入了三种噪声辅助任务,即噪声恢复(NR)、随机掩码(RM)和混合辨别(HD),以在不同粒度上隐含地捕捉输入扰动的语义结构信息。 在下游主要任务中,我们为生成框架设计了一种噪声演示构建策略,该策略在训练和推理过程中明确纳入了任务特定信息和扰动分布。 在两个基准上进行的实验表明,DemoNSF 的性能优于所有基准方法,并具有很强的泛化能力。 进一步的分析为生成式框架的实际应用提供了经验指导。 我们的代码发布在 https://github.com/dongguanting/Demo-NSF 上。
1导言
目标导向对话系统中的插槽填充(SF)任务旨在识别某些领域中与任务相关的插槽类型,以理解用户的话语。 最近,传统的判别和生成模型 Liu and Lane (2015, 2016); Goo et al. (2018); Niu et al. (2019); He et al. (2020a); Yan et al. (2021a); Wang et al. (2022b); Hao et al. (2023) 在槽值填充方面表现出了卓越的能力。 尽管这些模型功能强大,但其高性能在很大程度上取决于训练集和测试集之间数据分布的一致性。 当面对人类语言表达的不确定性和多样性Wu et al. (2021)时,这些扰动会极大地影响 SF 模型的泛化能力,从而阻碍其在实际对话场景中的应用。

在实际对话系统中,模型经常会遇到各种各样的输入扰动和人为错误。 如图 1 所示,用户与对话系统的交互方式可能会偏离标准输入格式,甚至会简化查询以表达相同的意图,这都是由于人类表达习惯的多样性造成的。 此外,来自上游输入系统的错误可能会给下游模型带来干扰(如键盘输入的错别字、ASR 系统的语音错误)。 现有的槽填充模型通常是在无扰动数据集上预先训练和微调的,因此在遇到这种情况时性能会下降。
最近,已有研究Wu 等人(2021);Moradi 和 Samwald(2021a);Gui 等人(2021)探讨了稳健性问题。 然而,这些方法主要是针对特定扰动设计的,限制了对未知扰动的泛化能力。 为了捕捉噪声语义结构,PSSAT 和 CMDA 董等人(2022a);郭等人(2023)进一步引入了额外的语料库和生成模型。 不过,这种方法也存在引入额外噪声和增加计算资源消耗的风险。 虽然大型语言模型 Brown 等人 (2020); Touvron 等人 (2023); OpenAI (2023) 和基于提示的方法 Lu 等人 (2022); Xie 等人 (2022b) 在信息提取方面取得了很好的性能,但这些生成式框架在各种输入扰动方面的探索仍然是一个空白领域,阻碍了它们在现实中的应用。
为解决这一局限性,我们提出了一种基于多任务演示的生成框架,用于噪声槽填充任务,命名为 DemoNSF。 具体来说,我们设计了三种噪声辅助任务,即噪声恢复(NR)、随机掩码(RM)和混合辨别(HD),以提高在不同程度的输入扰动下的性能。 NR 旨在捕捉细粒度噪声数据和干净数据之间的映射关系。 RM 在掩码填充过程中会隐式学习扰动数据的槽实体分布。 HD 辅助生成模型在考虑全局信息的同时,还隐含地捕捉扰动数据所独有的语义特征。 在下游流程中,我们将 SF 任务表述为在有噪声的任务演示引导下从序列到序列的生成。 具体来说,DemoNSF 从噪声候选库中为每个查询选择一个语义相似的示例,将其转换为自然示范句,并通过整合噪声语义信息将示范句与输入文本一起编码。 在噪声辅助任务和演示的推动下,DemoNSF 可从显性和隐性两个层面学习扰动的语义结构。 我们的贡献有三个方面:
1)据我们所知,我们是第一个全面研究不同输入扰动对槽填充任务中生成框架的影响,并进一步验证现有基于提示的生成方法在面对不同人类表达时的脆弱性。
2)我们提出了一个简单但统一的基于多任务演示的生成框架,其中包括三个新颖的噪声辅助任务和噪声演示构建策略,以增强模型的鲁棒性和对现实世界对话场景中扰动输入的适应性。
3) 两个基准的实验表明,我们的方法优于所有基准方法,并实现了很强的泛化能力。 广泛的分析还为生成式框架的实际应用提供了经验指导。
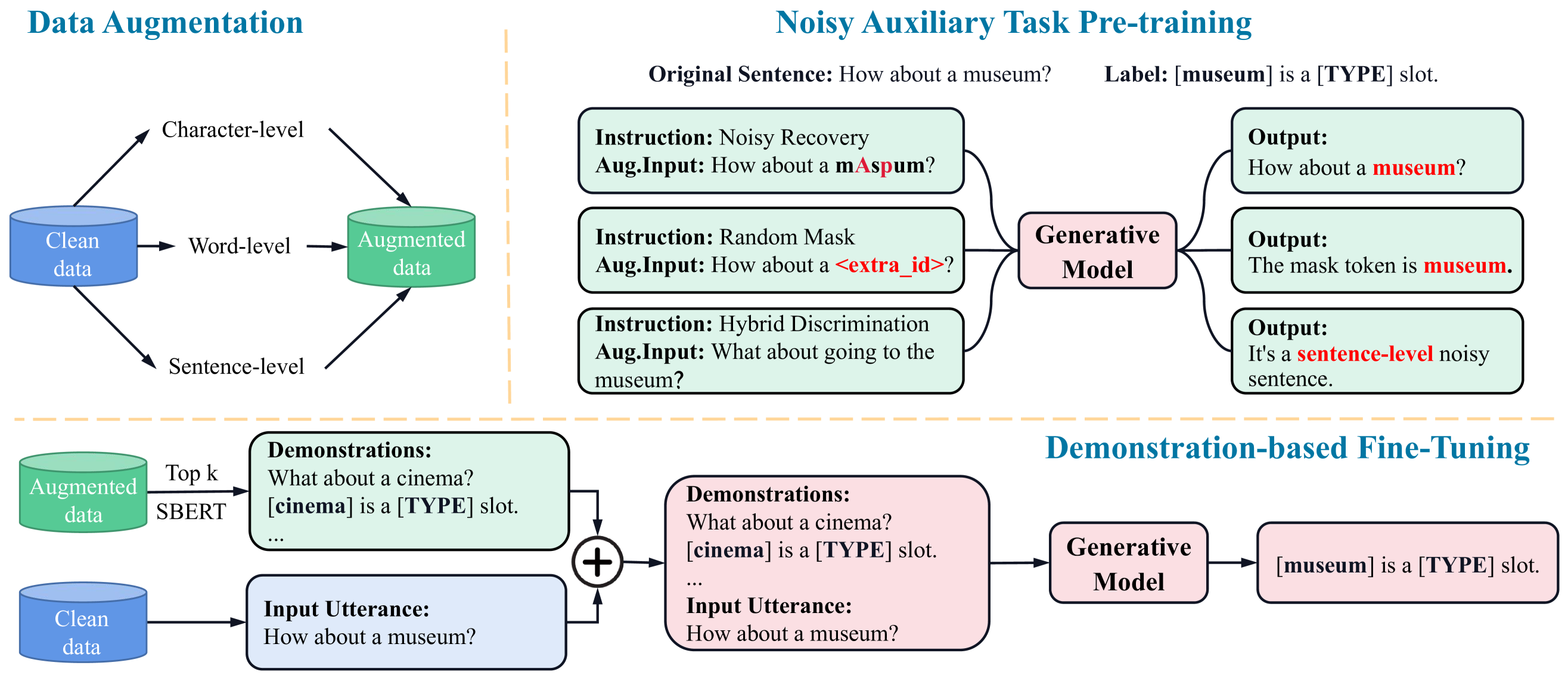
2方法
本节将介绍我们提出的 DemoNSF 的总体框架。 我们首先简要介绍了槽填充任务中针对输入扰动的问题定义。 接下来,我们针对不同的扰动提出了三种不同的噪声辅助任务。 最后,我们介绍了一种新颖的噪声演示构建策略。 我们将在以下小节中介绍这些内容111Training, and Inference can be found in Appendix。
2.1问题定义
给定输入语句 及其相应的槽类型集 ,槽填充任务旨在提取 中的所有实体。 对于噪声槽填充任务,我们将实际场景中的输入扰动过程表述为 。模型的鲁棒性在扰动测试数据集 评估,但无法访问输入扰动过程 和训练阶段的扰动数据。 在本文中、我们使用、、和 表示干净数据、增强数据和测试数据。
2.2多级数据增强
2.3噪音辅助任务
噪声槽填充任务的性能在很大程度上取决于输入扰动分布的先验知识。 在本节中,我们将介绍三种新颖的噪声辅助任务:
Noisy Recovery (NR)。 给定一个字符级增强表述 ,其中 表示字符级增强后的词符。如图 2 所示,NR 任务的目标是恢复 到其对应的干净表述 。 这项任务使模型能够捕捉到细粒度输入扰动与其干净等价物之间的映射关系,从而增强模型表示细粒度噪声数据的能力。 因此,损失函数可以表述为
| (1) |
其中 B 和 N 分别表示批大小和序列长度。
Random Mask (RM)。 受 BERT Devlin 等人 (2019) 中引入的掩码语言建模 (MLM) 概念的启发,我们提出了随机掩码填充任务。 具体地说,给定 中的一个表述,我们使用特殊的 [MASK]符号随机屏蔽一个实体,得到 。 我们的目标是恢复 [MASK] 标记的原始值。 掩码填充过程使模型能够隐式地融合扰动数据中槽位实体的语义分布。 因此,RM 任务的损失函数可定义为
| (2) |
其中表示原始词符,[MASK]表示[MASK] 词符的 logits。
Hybrid Discrimination (HD)。 为了进一步解决粗粒度输入扰动问题,我们提出了 HD 任务。 具体来说我们将 和 组合创建一个混合数据集,表示为。 我们从 随机选择表述,并根据所选表述是干净的还是有不同程度的扰动来分配不同的标签。 如图2所示,生成模型可以隐含地捕捉扰动数据的独特语义分布,同时通过区分有扰动和无扰动的输入来考虑全局信息。 损失函数 与 相同。
因此,总体损失函数 定义为:
| (3) |
其中, , 和 分别表示 NR、RM、HD 任务损失函数的权重。
| Methods | Clean | Sentence-level | Character-level | Word-level | Perturbed-Avg. | ||
|---|---|---|---|---|---|---|---|
| Verbose | Paraphrase | Simplification | Typos | Speech | |||
| GPT2 | 95.37 | 80.52 | 85.66 | 82.98 | 60.19 | 77.78 | 77.43 |
| BART | 95.28 | 77.87 | 82.72 | 82.95 | 53.90 | 73.57 | 74.20 |
| T5 | 95.49 | 81.34 | 89.13 | 83.73 | 62.43 | 81.13 | 79.55 |
| BARTNER | 94.88 | 78.00 | 88.55 | 85.04 | 65.37 | 72.65 | 77.93 |
| LightNER | 95.30 | 78.85 | 87.65 | 84.90 | 57.68 | 71.61 | 76.14 |
| InstructionNER | 95.67 | 81.57 | 88.45 | 85.29 | 65.34 | 80.13 | 80.16 |
| DemoNSF(GPT2) | 95.66(0.4) | 81.95(0.3) | 87.63(1.1) | 87.02(0.2) | 69.75(0.3) | 86.31(0.7) | 82.53(0.5) |
| DemoNSF(BART) | 95.71(1.3) | 78.83(0.7) | 88.29(0.8) | 86.01(0.7) | 65.60(0.3) | 82.48(0.4) | 80.24(1.1) |
| DemoNSF(T5) | 95.72(0.5) | 82.37(1.2) | 89.98(1.1) | 89.49(0.7) | 76.63(0.5) | 87.55(0.7) | 85.20(0.9) |
| Methods | Char+Word | Char+Sen | Word+Sent | Char+Word+Sen |
|---|---|---|---|---|
| Ent.+Sub. | Ent.+App. | App.+Sub. | Ent.+Sub.+App. | |
| BART | 58.00 | 47.27 | 50.28 | 38.36 |
| T5 | 57.44 | 56.79 | 73.47 | 47.93 |
| BARTNER | 54.83 | 49.10 | 58.92 | 42.25 |
| LightNER | 42.34 | 35.82 | 45.44 | 27.00 |
| InstructionNER | 57.87 | 58.89 | 74.45 | 50.75 |
| Ours(BART) | 61.27(0.5) | 51.26(0.9) | 68.72(0.5) | 44.27(0.9) |
| Ours(T5) | 63.59(0.3) | 63.94(1.2) | 77.69(0.7) | 55.12(0.3) |
2.4Noisy Demonstration 的构建
与以前基于demonstration Min et al. (2022) 工作不同,对于每个输入 ,我们从 而不是 选择样本 ,来融合扰乱的语义信息到模型中。 对于检索,我们采用 SBERT Reimers 和 Gurevych (2019),它可以为 和 独立生成 嵌体,并计算它们的相似度得分来对 进行排序。 随后,我们选择 top- 示例来构建噪声演示 并将它们与输入 连接,形成完整的输入 。 我们的演示模板如下所示:
"Demonstrations: [Retrieved Noisy Utterances]. [Text Span] is [Slot Type]. Input Utterance: [Original Input]."
3实验
3.1数据集
基于 RADDLE Peng 等人 (2021) 和 SNIPS Coucke 等人 (2018),我们采用了以下提供的评估集 Dong 等人其中包括两种不同的扰动设置。 对于单一扰动设置,我们包括来自 RADDLE 的五种类型噪声表述(字符级:Typos、单词级:Speech和句子级:Simplification、Verbose和Paraphrase)。 在混合扰动设置中,我们利用 TextFlint Gui 等人 (2021) 引入字符级扰动 (EntTypos)、词级扰动 (Subword) 和句子级扰动 (AppendIrr),并将它们组合起来,得到混合扰动数据集。333由于篇幅有限,详细的实验设置(基线、数据集......)见附录 B.1。.
| Methods | Clean | Sentence-level | Character-level | Word-level | Perturbed-Avg. | ||
|---|---|---|---|---|---|---|---|
| Verbose | Paraphrase | Simplification | Typos | Speech | |||
| Text-davinci-003 | 43.09 | 34.26 | 39.34 | 38.42 | 40.12 | 37.18 | 38.54 |
| ChatGPT | 71.43 | 40.65 | 60.00 | 55.56 | 65.54 | 55.56 | 57.21 |
| ChatGPT + Clean Demos | 71.31 | 61.01 | 57.81 | 53.43 | 65.03 | 61.71 | 62.32 |
| ChatGPT + Aug Demos | 68.21 | 65.04 | 70.56 | 58.82 | 73.03 | 63.77 | 68.34 |
| ChatGPT + Mixed Demos | 76.92 | 58.73 | 68.26 | 58.61 | 74.19 | 57.78 | 65.36 |
3.2主要结果
表 1 显示了 DemoNSF 和对比基线在单一扰动设置下的主要结果。 我们得到以下观察:
(1) 当面对不同粒度的扰动时,生成模型的性能会严重下降,特别是 Typos(GPT2:35.18%| BART:41.38%| T5:33.06%)和Speech(GPT2:17.57%| BART:21.71%| T5:14.36%),这表明生成模型对细粒度扰动的鲁棒性较差。
(2) DemoNSF(T5)在不同的输入扰动下都表现出显著的优越性,同时在干净的测试数据上保持了最佳性能。 对于细粒度扰动,与 InstructionNER 相比,我们的方法在错别字和语音方面分别提高了 11.29% 和 7.42%。 DemonNSF 在粗粒度扰动方面保持了强劲的性能,尤其是在简化方面提高了 4.2%。 这些结果清楚地表明,DemonNSF 有效地捕捉到了细粒度噪声数据和干净数据之间的映射关系,同时还考虑到了对粗粒度全局语义扰动的泛化能力。
(3) DemonNSF 是一种即插即用的方法,可以在不同的骨干网上取得良好的效果。 具体来说,我们用 BART/GPT 替换了骨干网,与相应的基线相比,也取得了良好的性能。 骨干消融的结果进一步证明,我们的方法显著增强了生成模型在面对扰动时的鲁棒性。
3.3混合扰动情景
在真实对话场景中,混合扰动经常会同时出现在一个语篇中。 为了进一步验证 DemoNSF 在更现实场景中的有效性,我们进行了混合扰动实验。 如表 2 所示,DemoNSF 在所有两级扰动中的表现都明显优于其他基线,尤其是在细粒度混合扰动中取得了超过 63% 的 F1 分数。 即使在 3 个扰动的共同干扰下,DemoNSF 与基线相比仍能保持 4.37% 的改进,这进一步验证了 DemoNSF 在挑战性环境中的稳定性。
3.4不同 Demonstration 的影响
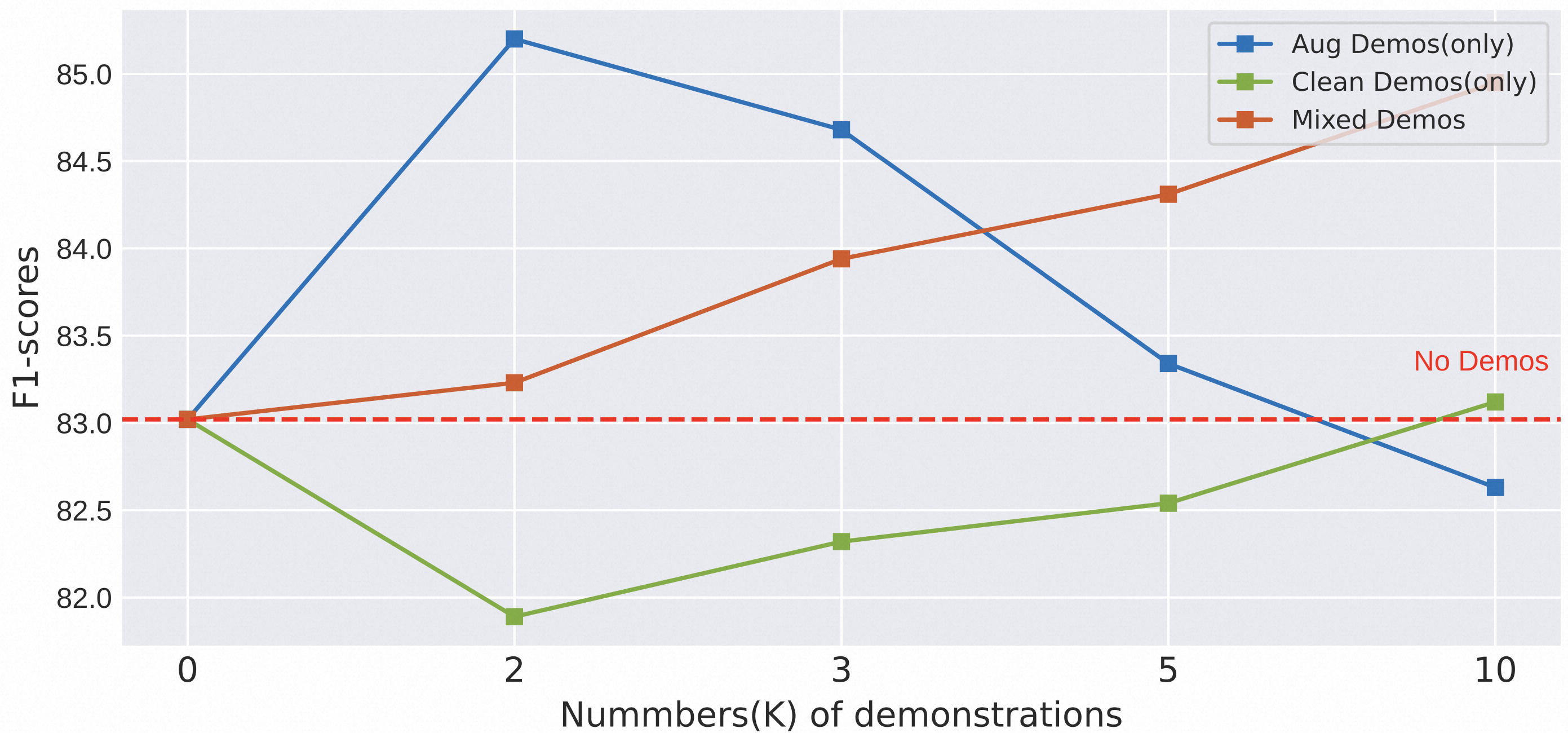
图 3 显示了单一扰动下不同类型演示数量的影响。 我们有以下发现:(1) DemoNSF 在只有两个增强样本的情况下表现出显著的性能提升,而随着样本数量的增加,其性能严重下降。 这可能是因为多样化的增强实例可以帮助模型明确地融合有噪声的语义分布Xie 等(2022a),而超过一定阈值的样本多样性甚至会带来额外的噪声。 (2) 随着数量的增加,清洁演示只能带来轻微的改善,这表明清洁样本只能为提示提供一些任务的一般信息(如实体分布、槽值映射)。 (3) 从混合数据池中检索到的演示表现出稳定的性能增益,这进一步证实了噪声语义分布与任务一般信息之间的相互促进作用,并为基于提示的生成模型的鲁棒性提供了指导。
3.5关于 ChatGPT 的 ICL 评估
为了进一步验证我们的噪声演示策略在大规模生成框架中的有效性,我们在 ChatGPT 和 Text-davinci-003 Brown等人(2020)上进行了实验。 我们直接使用它们在 RADDLE 上进行基于上下文学习(ICL)的推理Dong 等人(2022b);Brown 等人(20);Min 等人(2022),这意味着语言模型只根据条件演示示例进行预测,而不需要任何训练样本。
表 3 展示了 ChatGPT 在 5 种不同单一扰动下的总体结果。 我们得出以下结论:(1) ChatGPT 和 Text-davinci-003 在不同的输入扰动下表现不佳,远远落后于表 1 中列出的微调 SOTA 方法(DemoNSF、Instruction NER)。 可能的原因是,大型语言模型通常是在大规模的通用训练语料库上预先训练的,因此很难很好地适应零镜头环境下的特定领域扰动数据。 (2) 与基线和传统的清洁演示检索方法相比,从增强演示候选池和混合演示候选池中选择实例能显著提高整体性能。 这一发现与我们在第 3.4 节中得出的结论一致,证明了在处理输入扰动时加入噪声语义结构的有效性。 (3) 从不同扰动的角度来看,两种噪声演示策略在细粒度扰动方面都有显著改进(Typos 的改进幅度超过 8%)。 然而,在粗粒度扰动中,特别是在语音错误中,改进并不明显。 这一现象表明,噪声演示更适合拟合细粒度扰动的分布,而在严重破坏原始输入的上下文语义和插槽提法的粗粒度扰动方面,仍有很大的改进空间。 这一发现为探索大型语言模型的鲁棒性提出了进一步的挑战,这也将是我们未来研究的重点。
4结论
在本文中,我们针对噪声槽填充任务提出了一个基于多任务演示的统一生成框架。 具体来说,我们为生成框架引入了三种新颖的噪声辅助任务和一种噪声演示构建策略,旨在从显性和隐性两个层面学习扰动的语义结构。 在两个基准上进行的实验显示了 DemoNSF 的有效性,进一步的分析为生成式框架的实际应用提供了经验指导。
局限性
为了捕捉不同粒度输入扰动的语义结构信息,我们在预训练阶段引入了三个新颖的噪声辅助任务,它们可能会比传统方法消耗更多的 GPU 内存。 这促使我们进一步提高框架的整体内存效率。 此外,我们的方法主要侧重于槽填充任务。 不过,我们相信可以将我们的工作扩展到其他场景,比如少镜头设置和零镜头设置。 我们还为今后的研究保留了这些资料。
参考资料
- Bapna et al. (2017) Ankur Bapna, Gokhan Tur, Dilek Hakkani-Tur, and Larry Heck. 2017. Towards zero-shot frame semantic parsing for domain scaling. arXiv preprint arXiv:1707.02363.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Chen et al. (2022) Xiang Chen、Lei Li、Shumin Deng、Chuanqi Tan、Changliang Xu、Fei Huang、Luo Si、Huajun Chen 和 Ningyu Zhang。 2022. Lightner: A lightweight tuning paradigm for low-resource ner via pluggable prompting.
- 陈等人(2021 年) Xiang Chen, Ningyu Zhang, Lei Li, Xin Xie, Shumin Deng, Chuanqi Tan, Fei Huang, Luo Si, and Huajun Chen. 2021. Lightner:一个轻量级生成框架,具有针对低资源用户的及时引导关注。
- 库克等人(2018) Alice Coucke、Alaa Saade、Adrien Ball、Théodore Bluche、Alexandre Caulier、David Leroy、Clément Doumouro、Thibault Gisselbrecht、Francesco Caltagirone、Thibaut Lavril、Maël Primet 和 Joseph Dureau。 2018. Snips语音平台:用于私人设计语音界面的嵌入式口语理解系统。
- 德夫林等人(2019) Jacob Devlin、Ming-Wei Chang、Kenton Lee 和 Kristina Toutanova。 2019. 伯特:预训练深度双向转换器,促进语言理解。 载于计算语言学协会北美分会2019年会议论文集:人类语言技术》第1卷(长篇论文和短篇论文),第4171-4186页。
- Dong 等人(2022a) Guanting Dong、Daichi Guo、Liwen Wang、Xuefeng Li、Zechen Wang、Chen Zeng、Keqing He、Jinzheng Zhao、Hao Lei、Xinyue Cui、Yi Huang、Junlan Feng 和 Weiran Xu。 2022a. PSSAT:用于扰动稳健槽填充的扰动语义结构感知转移方法。 第 29 届国际计算语言学会议论文集》(Proceedings of the 29th International Conference on Computational Linguistics),第 5327-5334 页,大韩民国庆州。 国际计算语言学委员会。
- Dong 等人(2023a) Guanting Dong、Zechen Wang、Liwen Wang、Daichi Guo、Dayuan Fu、Yuxiang Wu、Chen Zeng、Xuefeng Li、Tingfeng Hui、Keqing He、Xinyue Cui、Qixiang Gao 和 Weiran Xu。 2023a. 通过联合对比学习实现语义解耦的原型方法,适用于少量命名实体识别。 In ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1-5.
- Dong 等人(2023b) 董冠廷、王泽辰、赵金旭、赵刚、郭大一、傅大源、惠廷峰、曾晨、何克庆、李雪峰、王丽文、崔欣悦和徐蔚然。 2023b. 多任务语义分解框架,带针对特定任务的预训练,适用于少镜头内核。
- Dong 等人(2023c) Guanting Dong、Jinxu Zhao、Tingfeng Hui、Daichi Guo、Wenlong Wang、Boqi Feng、Yueyan Qiu、Zhuoma Gongque、Keqing He、Zechen Wang 和 Weiran Xu。 2023c. 重新审视 llms 的输入扰动问题:针对噪声槽填充任务的统一鲁棒性评估框架 在自然语言处理和中文计算中,第 682-694 页,Cham. Springer Nature Switzerland.
- Dong 等人(2022b) Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, and Zhifang Sui. 2022b. 情境学习调查 arXiv预印本arXiv:2301.00234。
- 方等人(2020) 方安杰、西蒙娜-菲丽丝、努特-利姆索帕塔姆和奥列格-罗赫连科。 2020. 利用音素表征建立预测模型,不受 asr 错误的影响。 在第 43 届信息检索研究与发展国际 ACM SIGIR 会议论文集中,第 699-708 页。
- 古等人(2018) 古志文、高光、徐云凯、霍志礼、陈宗杰、徐景伟和陈允农。 2018. 用于联合槽填充和意图预测的槽门建模。 载于计算语言学协会北美分会2018年会议论文集:人类语言技术》第 2 卷(短篇论文),第 753-757 页。
- 戈帕拉克里什南等人(2020 年) Karthik Gopalakrishnan、Behnam Hedayatnia、Longshaokan Wang、Yang Liu 和 Dilek Hakkani-Tur。 2020. 神经开放域对话系统对对话历史中的语音识别错误是否具有鲁棒性? 实证研究.
- Mistletoe et al (2021) 桂涛、王晓、张琦、刘琴、邹一成、周昕、郑蕊、张冲、吴钦卓、叶家成、庞泽雄、张永新、李正艳、马若天、费子楚、蔡瑞建、赵俊、胡兴武严志恒、谭一丁、胡媛、边启元、刘志华、朱博林、秦珊、邢晓宇、傅金兰、张悦、彭敏龙、郑晓青、周雅倩、魏中玉、邱西鹏和黄璇菁。 2021. Textflint:用于自然语言处理的统一多语言鲁棒性评估工具包。
- Guo 等人(2023 年) Daichi Guo、Guanting Dong、Dayuan Fu、Yuxiang Wu、Chen Zeng、Tingfeng Hui、Liwen Wang、Xuefeng Li、Zechen Wang、Keqing He、Xinyue Cui 和 Weiran Xu。 2023. 重新审视词汇外问题以填补空白:具有多级数据增强功能的统一对比框架词。 ArXiv, abs/2302.13584.
- 郝等人(2023 年) Xia Hao、Lu Wang、Hongmei Zhu 和 Xuchao Guo。 2023. 基于增强型异构关注机制的联合农业意图检测和插槽填充。 Computers and Electronics in Agriculture,207:107756。
- He et al (2020a) Keqing He, Yuanmeng Yan, and Weiran Xu. 2020a. 通过整合上下文表征和背景知识学习标记 oov 标记。 计算语言学协会第 58 届年会论文集,第 619-624 页。
- He et al (2020b) 何克清、张金超、闫远梦、徐蔚然、牛成和周洁。 2020b. 针对对抗性攻击的跨域时隙填充的对比零点学习。 第 28 届计算语言学国际会议论文集》,第 1461-1467 页,西班牙巴塞罗那(在线)。 国际计算语言学委员会。
- He et al (2020c) 何克清、张金超、闫远梦、徐蔚然、牛成和周洁。 2020c. 对抗性攻击下的跨域时隙填充对比零点学习。 第 28 届计算语言学国际会议论文集》(Proceedings of the 28th International Conference on Computational Linguistics),第 1461-1467 页。
- 黄和陈(2020) Chao-Wei Huang 和 Yun-Nung Chen. 2020. 为口语理解学习稳健的上下文嵌入。
- 李等人(2021 年) Dong-Ho Lee、Mahak Agarwal、Akshen Kadakia、Jay Pujara 和 Xiang Ren。 2021. 好例子让学习者学得更快为资源匮乏的学生提供基于示范的简单学习。 arXiv预印本arXiv:2110.08454。
- 李和贾(2019) Sungjin Lee 和 Rahul Jha. 2019. 用于会话语言理解的零点自适应转移。 在AAAI 人工智能会议论文集中,第 33 卷,第 6642-6649 页。
- 刘易斯等人(2019) Mike Lewis、Yinhan Liu、Naman Goyal、Marjan Ghazvininejad、Abdelrahman Mohamed、Omer Levy、Ves Stoyanov 和 Luke Zettlemoyer。 2019. 巴特:用于自然语言生成、翻译和理解的去噪序列到序列预训练。
- 李等人(2020a) 李明达、刘欣悦、阮伟彤、卢卡-索尔达尼、瓦尔-哈姆扎和苏成伟。 2020a. 通过将 n-best 假设与分层注意力相结合,实现口语理解的多任务学习。 In Proceedings of the 28th International Conference on Computational Linguistics: Industry Track, pages 113–123.
- 李等人(2020b) 李明达、阮伟彤、刘欣悦、卢卡-索尔达尼、瓦尔-哈姆扎和苏成伟。 2020b. 利用 asr n 最佳假设提高口语理解能力。
- 梁等人(2022 年) 梁小传、张宁玉、程思源、毕振、张振如、谭传琪、黄松芳、黄飞和陈华军。 2022. 预训练语言模型的对比演示调整。 arXiv预印本arXiv:2204.04392。
- Liu 和 Lane(2015 年) 刘兵和伊恩-莱恩 2015. 用于口语理解的递归神经网络结构化输出预测。 在 Proc. NIPS 口语理解与交互机器学习研讨会.
- 刘和连恩(2016) Bing Liu 和 Ian R. Lane。 2016. 基于注意力的递归神经网络模型,用于联合意图检测和插槽填充。 在 InterSPEECH 中。
- Liu et al (2023) Jiachi Liu, Liwen Wang, Guanting Dong, Xiaoshuai Song, Zechen Wang, Zhengyang Wang, Shanglin Lei, Jinzheng Zhao, Keqing He, Bo Xiao, et al.2023. 实现稳健和可推广的训练:针对输入扰动的噪声槽填充实证研究。 arXiv预印本arXiv:2310.03518。
- Liu et al (2020a) 刘杰希、高信隆一、温家鑫、万大珍、李红光、聂蔚然、李成、彭伟和黄敏烈。 2020a. 任务导向对话中语言理解的稳健性测试。 arXiv预印本arXiv:2012.15262。
- Liu et al (2020b) Zihan Liu, Genta Indra Winata, Peng Xu, and Pascale Fung. 2020b. 教练:从粗到细的跨域槽填充方法 arXiv preprint arXiv:2004.11727.
- Lu 等人(2022 年) 吕耀杰、刘青、戴岱、肖新艳、林红玉、韩先培、孙乐、吴华。 2022. 用于通用信息提取的统一结构生成。 In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5755-5772, Dublin, Ireland. 计算语言学协会。
- 马(2019) 爱德华-马 2019. Nlp 增加。 https://github.com/makcedward/nlpaug。
- Ma 等人(2022 年) Tingting Ma, Huiqiang Jiang, Qianhui Wu, Tiejun Zhao, and Chin-Yew Lin. 2022. 用于少量命名实体识别的分解元学习。 arXiv预印本arXiv:2204.05751。
- Min 等人(2021 年) Sewon Min、Mike Lewis、Hannaneh Hajishirzi 和 Luke Zettlemoyer。 2021. 用于少量文本分类的噪声信道语言模型提示。 arXiv预印本arXiv:2108.04106。
- Min 等人(2022 年) Sewon Min、Xinxi Lyu、Ari Holtzman、Mikel Artetxe、Mike Lewis、Hannaneh Hajishirzi 和 Luke Zettlemoyer。 2022. 重新思考演示的作用:是什么让情境学习行之有效?
- 莫拉迪和萨姆瓦尔德(2021a) Milad Moradi 和 Matthias Samwald。 2021a. 评估神经语言模型对输入扰动的稳健性。 arXiv预印本arXiv:2108.12237。
- 莫拉迪和萨姆瓦尔德(2021b) Milad Moradi 和 Matthias Samwald。 2021b. 评估神经语言模型对输入扰动的稳健性。 2021年自然语言处理经验方法会议论文集。
- 纳米斯尔等人(2020 年) Marcin Namysl、Sven Behnke 和 Joachim Köhler. 2020. Nat:鲁棒性神经序列标注的噪声感知训练。 arXiv预印本arXiv:2005.07162。
- 纳米斯尔等人(2021 年) Marcin Namysl、Sven Behnke 和 Joachim Köhler. 2021. 经验误差建模提高了噪声神经序列标注的鲁棒性。 计算语言学协会论文集:ACL-IJCNLP 2021。
- Niu et al (2019) Peiqing Niu, Zhongfu Chen, Meina Song, et al. 用于联合意图检测和插槽填充的新型双向关联模型。 arXiv预印本arXiv:1907.00390。
- 开放人工智能(2023 年) OpenAI。 2023. Gpt-4技术报告。
- Peng et al (2020) 彭宝林、李春元、张竹、朱晨光、李金超和高剑锋。 2020. Raddle:鲁棒性任务导向对话系统的评估基准和分析平台。 arXiv预印本arXiv:2012.14666。
- Peng 等人(2021 年) 彭宝林、李春元、张竹、朱晨光、李金超和高剑锋。 2021. RADDLE:面向任务的鲁棒对话系统的评估基准和分析平台。 在第 59 届计算语言学协会年会暨第 11 届自然语言处理国际联合会议论文集(第 1 卷:长篇论文)中,第 4418-4429 页,在线阅读。 计算语言学协会。
- 拉德福德等人(2019) Alec Radford、Jeffrey Wu、Rewon Child、David Luan、Dario Amodei、Ilya Sutskever 等,2019 年。 Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- 拉斐尔等人(2020 年) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer.
- 雷默斯和古雷维奇(2019) 尼尔斯-莱默斯和伊丽娜-古列维奇。 2019. 句子-伯特:使用连体伯特网络的句子嵌入。
- 阮等人(2020 年) 阮炜彤、雅罗斯拉夫-涅恰耶夫、陈洛欣、苏成伟和伊姆雷-基斯。 2020. 实现 ASR 错误鲁棒性口语理解系统。 在 INTERSPEECH 中,第 901-905 页。
- 沙阿等人(2019) Darsh J Shah、Raghav Gupta、Amir A Fayazi 和 Dilek Hakkani-Tur。 2019. 稳健的零点跨域插槽填充示例值。 arXiv预印本arXiv:1906.06870。
- Touvron 等人(2023 年) Hugo Touvron、Thibaut Lavril、Gautier Izacard、Xavier Martinet、Marie-Anne Lachaux、Timothée Lacroix、Baptiste Rozière、Naman Goyal、Eric Hambro、Faisal Azhar、Aurelien Rodriguez、Armand Joulin、Edouard Grave 和 Guillaume Lample。 2023. Llama:开放、高效的基础语言模型。
- Wang 等人(2022a) Jianing Wang, Chenggyu Wang, Chuanqi Tan, Minghui Qiu, Songfang Huang, Jun Huang, and Ming Gao. 2022a. SpanProto:用于少量命名实体识别的基于跨度的两阶段原型网络。 In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3466–3476, Abu Dhabi, United Arab Emirates. 计算语言学协会。
- Wang 等人(2022b) 王丽文、李汝梅、闫阳、闫元萌、王思睿、吴伟和徐蔚然。 2022b. Instructionner:基于指令的多任务生成框架,适用于少发 ner。
- 王等人(2021 年) 王立文、李雪峰、刘家驰、何克庆、严元萌和徐蔚然。 2021. 通过原型对比学习和标签混淆桥接目标域:重新探索用于插槽填充的零点学习。 自然语言处理经验方法 2021 年会议论文集,第 9474-9480 页,多米尼加共和国在线和蓬塔卡纳。 计算语言学协会。
- 魏等人(2022 年) Jason Wei、Xuezhi Wang、Dale Schuurmans、Maarten Bosma、Ed Chi、Quoc Le 和 Denny Zhou。 2022. 思维链提示激发大型语言模型中的推理。 arXiv预印本arXiv:2201.11903。
- Wu 等人(2021 年) Di Wu, Yiren Chen, Liang Ding, and Dacheng Tao. 2021. 弥合纯数据训练与真实世界推理之间的差距,促进口语理解。 arXiv预印本arXiv:2104.06393。
- Xie 等人(2022a) Sang Michael Xie、Aditi Raghunathan、Percy Liang 和 Tengyu Ma。 2022a. 作为隐式贝叶斯推理的语境中学习的解释。
- Xie 等人(2022b) Tianbao Xie, Chen Henry Wu, Peng Shi, Ruiqi Zhong, Torsten Scholak, Michihiro Yasunaga, Chien-Sheng Wu, Ming Zhong, Pengcheng Yin, Sida I. Wang, Victor Zhong, Bailin Wang, Chengzu Li, Connor Boyle, Ansong Ni, Ziyu Yao, Dragomir Radev, Caiming Xiong, Lingpeng Kong, Rui Zhang, Noah A. Smith, Luke Zettlemoyer, and Tao Yu. 2022b. UnifiedSKG:利用文本到文本语言模型统一和多任务结构化知识基础。 在 2022 自然语言处理经验方法会议论文集 中,第 602-631 页,阿拉伯联合酋长国阿布扎比。 计算语言学协会。
- Yan 等人(2021a) Hang Yan, Tao Gui, Junqi Dai, Qipeng Guo, Zheng Zhang, and Xipeng Qiu. 2021a. 适用于各种 NER 子任务的统一生成框架。 在第 59 届计算语言学协会年会暨第 11 届自然语言处理国际联合会议论文集(第 1 卷:长篇论文)中,第 5808-5822 页,在线阅读。 计算语言学协会。
- Yan 等人(2021b) Hang Yan, Tao Gui, Junqi Dai, Qipeng Guo, Zheng Zhang, and Xipeng Qiu. 2021b. 各种 ner 子任务的统一生成框架。
- 赵等人(2021) 赵子豪、埃里克-华莱士、石峰、丹-克莱因和萨米尔-辛格。 2021. 使用前进行校准:提高语言模型的少拍性能。 在国际机器学习会议上,第 12697-12706 页。 PMLR.
附录 A方法详情
A.1训练和推理
对于多级数据增强,我们利用 NLPAug Ma (2019) 从不同级别的干净数据池中构建一个噪声候选数据池。 在上游预训练阶段,我们采用多任务训练策略,总体损失函数表示为 (13)。
在下游的基于演示的微调阶段,我们直接输入基于演示的输入 进入模型进行预测。 在推理过程中、我们还使用 SBERT Reimers 和 Gurevych (2019) 检索测试数据的任务演示,这些数据来自、确保训练和推理阶段的一致性。
附录 B实验细节
B.1更多数据集详情
Based on RADDLE Peng et al. (2020) and SNIPS Coucke et al. (2018), we adhere to the evaluation set provided by PSSAT Dong et al. (2022a), which includes two settings: single perturbation and mixed perturbation.
在单一扰动设置下,RADDLE 可作为一个众包诊断评估数据集,涵盖对话系统的各种真实世界噪声文本。 PSSATDong et al. (2022a)从 RADDLE 中提取各种类型的噪声语料(错别字、语音、简化、口头禅和转述),以建立测试数据池。 具体来说,Typos是由于非标准缩写或键盘错误造成的,而Speech则是由于 ASR 系统产生的识别和合成错误造成的。 简化指用户使用简洁的词语表达自己的意图,而冗长指用户使用多余的词语来表达相同的意图。 转述在用户中也很普遍,他们会根据自己的语言习惯使用不同的词语或重新表述文本。
在多重扰动设置中,我们利用 TextFlint Gui 等人 (2021) 工具包引入字符级噪声 (EntTypos)、单词级噪声 (Subword) 和句子级噪声 (AppendIrr)。 然后,我们结合不同类型的噪声数据,构建一个多扰动评估集。 有关这些扰动的详细介绍,请参阅 TextFlint 的 GitHub 代码库 444https://www.textflint.io/textflint 。
| Methods | Clean | Sentence-level | Character-level | Word-level | Perturbed-Avg. | ||
|---|---|---|---|---|---|---|---|
| Verbose | Paraphrase | Simplification | Typos | Speech | |||
| DemoNSF(Backbone) | 95.49 | 81.34 | 89.13 | 83.73 | 62.43 | 81.13 | 79.55 |
| 95.17 | 81.13 | 88.96 | 87.98 | 67.22 | 82.61 | 81.58 | |
| 95.30 | 81.04 | 89.88 | 86.78 | 62.31 | 85.84 | 81.17 | |
| 95.39 | 81.37 | 90.36 | 87.20 | 64.61 | 82.66 | 81.24 | |
| 95.82 | 80.79 | 89.28 | 86.89 | 73.74 | 84.40 | 83.02 | |
| 95.37 | 80.28 | 88.91 | 85.94 | 69.00 | 84.62 | 81.75 | |
| 95.90 | 80.04 | 90.71 | 87.19 | 71.23 | 82.60 | 82.35 | |
| 95.08 | 80.04 | 90.34 | 85.39 | 76.41 | 85.14 | 83.46 | |
| DemoNSF(Full) | 95.72 | 82.37 | 89.98 | 89.49 | 76.63 | 87.55 | 85.20 |
B.2基线
在本文中,我们将重点比较 DemoNSF 和多个使用生成式框架的最先进基线,如下所示:
GPT2 Radford等人(2019)是OpenAI开发的纯解码器框架模型 555https://openai.com/。 它旨在通过预测给定序列中的下一个单词来生成类人文本。 GPT-2 能在不同领域生成连贯且与上下文相关的文本,因此广受欢迎,并被用于文本补全、翻译和创意写作等任务。
BART 是由 Lewis 等人(2019) 引入的序列到序列模型架构。 它在训练过程中结合了自回归和去噪目标,以学习输入序列的稳健表示。
T5 是 Raffel 等人 (2020) 提出的预训练模型。 它利用转换器架构,将各种自然语言处理任务转换为文本到文本的传输任务。
BARTNER Yan等人(2021b)是一种基于指针的序列到序列架构,专为NER任务而设计。 它通过预测输入句子中的实体及其相应的类型索引,将 NER 子任务转换为统一的序列生成任务。
LightNER 陈等人(2022)是一个基于指针的序列到序列模型,它建立在 BARTNER 的基础上。 它引入了一种及时调整技术,在注意力机制中加入了额外的参数。
InstructionNER Wang等人(2022b)是一个基于指令的多任务生成框架,专门设计用于处理少量 NER 任务。 它将 NER 任务重新定义为自然语言生成问题,并引入了描述性说明和可选机制,使模型能够理解不同的任务并限制输出空间。
B.3实施细节
在上游预训练阶段,我们将批量大小设置为 32,预训练过程一般需要 1 小时左右,共 5 个历元。 在本文中,我们在不进行任何超参数搜索的情况下进行了所有实验。 在多任务训练策略中,我们为三个噪声辅助任务分配了相同的权重,即设置 、、and to. 相应的学习率设置为 1e-5。 对于基于演示的微调阶段,我们也将批量大小设为 32,5 个历元的平均训练时间为 2 小时,学习率设为 5e-5。 在选择示范时,我们从噪声候选库中调用相似度得分最高的前 2 个实例。
在所有实验中,我们使用 NVIDIA RTX A6000 GPU 训练和测试各种方法。 为了选出最佳模型,我们每 400 个训练步骤使用 F1 指标评估验证集上的性能。 表2和表1中的实验使用了 T5 和 BART 的基础版本,表5中我们还采用了单扰动设置下的大版本模型。 我们检索从、从 和从 用于烧蚀研究和研究演示次数影响的实验。 我们将在盲审之后发布我们的代码。
| Methods | Clean | Sentence-level | Character-level | Word-level | Perturbed-Avg. | ||
|---|---|---|---|---|---|---|---|
| Verbose | Paraphrase | Simplification | Typos | Speech | |||
| BART | 95.21 | 79.23 | 87.20 | 83.81 | 57.79 | 75.65 | 76.74 |
| T5 | 95.58 | 82.12 | 88.36 | 85.98 | 68.25 | 81.31 | 81.20 |
| BARTNER | 95.30 | 79.96 | 90.44 | 87.24 | 75.32 | 76.22 | 81.84 |
| LightNER | 96.02 | 80.32 | 90.40 | 87.97 | 67.28 | 75.57 | 80.31 |
| InstructionNER | 95.05 | 82.01 | 87.82 | 85.25 | 69.75 | 80.09 | 80.98 |
| DemoNSF(BART) | 95.77(1.4) | 81.25(0.7) | 90.56(0.1) | 88.12(0.5) | 74.20(0.7) | 84.58(0.3) | 83.74(0.4) |
| DemoNSF(T5) | 95.81(0.7) | 83.77(0.4) | 91.58(0.6) | 89.78(0.2) | 77.70(1.3) | 87.96(0.9) | 86.16(0.5) |
附录 C更多详细实验
C.1消融研究
我们进行了一项烧蚀研究,以调查 DemoNSF 中主要成分的特征。 如表 4 所示,我们得出以下结论:1) 添加任何组件后,模型的性能都会提高,这说明我们设计的每个部分都是必要的。 2) 对于三种不同粒度的扰动,我们观察到专门为每种扰动设计的辅助任务都有显著改进。 具体来说,NR 任务可以学习字符级扰动与干净数据之间的映射关系,从而将错字率提高 4.79%。 而 RM 任务则是在掩码填充过程中隐含地捕捉槽实体的语义信息。 它在单词级扰动(语音)下取得了约 4.71% 的改进。 至于 HD 任务,它能够捕捉扰动数据的独特分布信息,并在保持泛化的同时显著提高模型在粗粒度扰动下的性能,尤其是在简化(3.47%)方面。 3) 采取联合预训练任务()与增加其中一个相比,效果明显改善、这表明联合预训练目标具有相互促进的作用(结果 3.47%)。 4) 我们探索了三种演示检索策略的消融研究。 , , and represent retrieve demonstrations from , and , respectively. 至于,我们确保同时包含干净和噪音演示。 我们发现,在扰动测试数据上,串联演示确实能产生令人兴奋的结果。 具体来说当 能够吸收更多样化的数据分布,并且在干净数据和扰动数据上都表现良好、的侧重于引入扰动数据的分布信息、这样,生成模型就能最大限度地学习扰动句子和槽实体的分布信息,使其更加稳健。
| Methods | Clean | Sent | Word | Char | Char+Word | Char+Sent | Word+Sent | Char+Word+Sent |
|---|---|---|---|---|---|---|---|---|
| App. | Sub. | Ent. | Ent.+Sub. | Ent.+App. | App.+Sub. | Ent.+Sub.+App. | ||
| BART | 79.43 | 65.95 | 71.20 | 57.84 | 58.00 | 47.27 | 50.28 | 38.36 |
| T5 | 94.12 | 83.97 | 85.13 | 65.90 | 57.44 | 56.79 | 73.47 | 47.93 |
| BARTNER | 86.34 | 69.33 | 77.22 | 62.28 | 54.83 | 49.10 | 58.92 | 42.25 |
| LightNER | 81.39 | 60.63 | 70.18 | 52.59 | 42.34 | 35.82 | 45.44 | 27.00 |
| InstructionNER | 94.69 | 84.32 | 84.78 | 66.93 | 57.87 | 58.89 | 74.45 | 50.75 |
| DemoNSF (BART) | 87.16(0.7) | 76.05(1.2) | 79.56(1.3) | 67.31(0.2) | 61.27(0.5) | 51.26(0.9) | 68.72(0.5) | 44.27(0.9) |
| DemoNSF (T5) | 94.75(1.7) | 86.83(0.5) | 86.81(0.2) | 72.79(0.4) | 63.59(0.3) | 63.94(1.2) | 77.69(0.7) | 55.12(0.3) |
C.2大版本模型的结果
我们比较了 DemoNSF 和其他基线在大版本模型(即 T5-large 和 BART-large)上的性能。 尽管使用了参数规模更大的模型,生成模型在面对扰动输入,尤其是细粒度扰动时,性能仍会显著下降。 如表 5 所示,我们可以发现,在错别字方面,BART 和 T5 的模型性能分别下降了 37.42% 和 27.33%;在语音方面,BART 和 T5 的模型性能分别下降了 19.56% 和 14.27%。 我们的方法还在细粒度和粗粒度扰动方面取得了令人印象深刻的改进。 具体来说,与基于 T5 的 InstructionNER 相比,DemoNSF 在所有扰动输入的平均性能上提高了 5.18% F1;与基于 BART 的 BARTNER 相比,提高了 1.63%。
C.3混合扰动的细节
对于 SNIPS 上的混合扰动实验,我们还研究了 DemoNSF 在单一扰动(AppendIrr、Sub 和 EntTypos)上的性能。 如表 6 所示,我们得到了类似的结论。 具体而言,我们的方法显著改善了细粒度扰动(例如,在 EntTypos 上改善了 5.86%)。 而我们的方法在粗粒度扰动上也保持了令人振奋的性能(例如,在 AppendIrr 上提高了 2.51%)。
附录 D相关工作
D.1插槽填充
Sequence Labeling Paradigm. 最初,填槽任务通常被定义为序列标注问题。 以往的方法可分为两类:一阶段方法和两阶段方法。 具体来说,单阶段方法Bapna 等人(2017);Shah 等人(2019);Lee 和 Jha(2019)对每种插槽类型单独进行插槽填充。 它首先生成词级表示,然后根据每个槽类型的串联特征进行预测。 然而,这些方法只能学习实体之间的表面映射,存在多重预测问题。 To address these limitations, a branch of two-stage methods Liu et al. (2020b); He et al. (2020b); Wang et al. (2021); Ma et al. (2022); Dong et al. (2023a); Wang et al. (2022a); Dong et al. (2023b) are proposed. 首先,使用粗粒度二进制序列标注模型来识别语篇中的所有槽实体。 随后,实体值被映射到语义空间中相应插槽标签的表示形式,以便对插槽类型进行有效分类。
Generative Framework. 最近,一些工作Wang 等(2022b)开始将 NER 和槽填充任务重新表述为序列到序列(seq2seq)任务,并整合了生成方法。 BARTNERHe 等人 (20c) 提出了一种基于指针的 seq2seq 架构,它将 NER 任务转换为统一的序列生成任务,并从输入句子和相应的类型索引中预测实体 LightNERChen 等人 (2021) 在 BARTNER 的注意机制中引入了 prompt-tuning 机制,在低资源场景下取得了可喜的改进。 此外,一些基于提示的生成方法Lu 等人(2022);Xie 等人(2022b)在信息提取方面也取得了很好的效果。 然而,他们对各种输入扰动的生成框架的探索仍是一个空白领域,阻碍了他们在面向任务的现实对话系统中的应用。
D.2输入扰动问题
最近,人们对增强 NLP 系统对输入扰动的适应能力越来越感兴趣。 Moradi和Samwald(2021b)介绍了各种NLP系统在合成生成的基准上对输入扰动的鲁棒性的经验评估。 Namysl等人(2020, 2021)重点研究了NER模型对光学字符识别(OCR)噪声和拼写错误的鲁棒性。 与其他 NLP 系统相比,对话系统与用户的交互更为频繁,因此会面临更多不同的输入噪声。 Fang et al. (2020); Gopalakrishnan et al. (2020) investigate the robustness of dialogue systems on ASR noise, and Ruan et al. (2020); Li et al. (2020b); Huang and Chen (2020); Li et al. (2020a) mainly focus on the ASR-noise-robustness SLU models in dialogue systems.
以前研究鲁棒性问题的大多数研究(Moradi 和 Samwald,2021a;Wu 等人,2021;Liu 等人,2020a)主要集中在基于规则的合成数据集上,而这些数据集确实存在一定的局限性。 同时,现实世界中的对话系统由于与用户的频繁互动,会遇到更多的干扰。 为了进一步探索这一方向,RADDLE Peng等人(2020)为对话系统提供了一个众包鲁棒性评估基准,其中包括真实对话场景中存在的各种噪声语料。 Liu 等人(2020a)介绍了语言理解增强,这是一种结合四种数据增强技术来模拟自然扰动的方法。 为了应对更复杂的噪声场景,董等人(2022a);刘等人(2023)研究了判别神经模型的输入扰动问题。 本文主要关注生成式框架在输入扰动问题上的表现。
D.3示范式学习
GPT 系列 Radford 等人(2019);Brown 等人(2020) 首先进行了演示,从训练数据中抽取了一些示例,并用模板将其转换为适当填充的提示。 Based on the task reformulation and whether the parameters are updated, the existing demonstration-based learning research can be broadly divided into three categories: In-context Learning Brown et al. (2020); Zhao et al. (2021); Min et al. (2021); Wei et al. (2022), Prompt-based Fine-tuning Liang et al. (2022); Dong et al. (2023c), Classifier-based Fine-tuning Lee et al. (2021). 然而,这些方法在微调时主要采用示范学习,无法充分发挥示范学习的效果。