弱监督微调预训练语言模型:
对比正则化自训练方法
抽象的
微调的预训练语言模型(LM)在许多自然语言处理(NLP)任务中取得了巨大的成功,但它们在微调阶段仍然需要过多的标记数据。 我们研究仅使用弱监督、不使用任何标记数据来微调预训练 LM 的问题。 这个问题具有挑战性,因为 LM 的高容量使得它们容易过度拟合弱监督生成的噪声标签。 为了解决这个问题,我们开发了一个对比自训练框架 COSINE,以在弱监督的情况下微调 LM。 在对比正则化和基于置信度的重新加权的支持下,我们的框架逐渐改进模型拟合,同时有效抑制误差传播。 对序列、标记和句子对分类任务的实验表明,我们的模型大幅优于最强基线,并通过完全监督的微调方法实现了有竞争力的性能。 我们的实现可在 https://github.com/yueyu1030/COSINE 上获取。
1简介
语言模型(LM)预训练和微调在各种自然语言处理任务中实现了最先进的性能Peters等人(2018); Devlin 等人 (2019);刘等人 (2019); Raffel 等人 (2019)。 这种方法将特定于任务的层堆叠在预先训练的语言模型之上, 例如、BERT Devlin 等人 (2019),然后使用特定于任务的数据微调模型。 在微调过程中,预训练语言模型中的语义和句法知识会针对目标任务进行调整。 尽管取得了成功,但微调 LM 的一个瓶颈是对标记数据的需求。 当标记数据稀缺时,微调模型往往会出现性能下降的情况,而且大量参数会导致严重的过拟合Xie et al (2019)。
为了缓解标签稀缺瓶颈,我们仅在弱监督的情况下对预训练的语言模型进行微调。 虽然收集大量干净的标记数据对于许多 NLP 任务来说成本很高,但从各种弱监督源获取弱标记数据通常很便宜,例如语义规则 Awasthi 等人 (2020) 。 例如,在情感分析中,我们可以使用规则'terrible'Negative(关键字规则)和'*不推荐*'Negative(模式规则)生成大量弱标签。
在弱监督的情况下微调语言模型并非易事。 标签噪音过大, 例如在监管薄弱的情况下,错误标签、标签覆盖范围有限是常见现象,也是不可避免的。 尽管现有的微调方法Xu等人(2020);朱等人 (2020); Jiang等人(2020)提高了LM的泛化能力,它们不是为噪声数据设计的,并且仍然容易对噪声过拟合。 此外,现有的解决标签噪声的工作存在缺陷,并且不是为微调 LM 而设计的。 例如,Ratner 等人 (2020); Varma 和 Ré (2018) 使用概率模型聚合多个弱监督来进行去噪,但它们以上下文无关的方式生成弱标签,而不使用 LM 来编码训练样本Aina 等人 (2019)。 其他作品Luo等人(2017); Wang 等人 (2019b) 专注于噪声转换,而没有明确进行实例级去噪,并且他们需要干净的训练样本。 尽管最近的一些研究Awasthi 等人 (2020); Ren等人(2020)设计了标记函数引导的神经模块来对每个样本进行去噪,它们需要弱监督的先验知识,这在实际实践中通常是不可行的。
自我训练Rosenberg 等人 (2005); Lee (2013) 是微调弱监督语言模型的合适工具。 它通过为未标记数据生成伪标签来增强训练集,从而提高模型的泛化能力。 这解决了监管薄弱、覆盖范围有限的问题。 然而,自训练的一大挑战是算法仍然会受到错误传播的影响——错误的伪标签会导致模型性能逐渐恶化。
我们提出了一种新算法 余弦111缩写对比对比SFine 自我训练ine-调整预先训练的语言模型。 仅在弱监督的情况下对预先训练的 LM 进行微调。 COSINE 利用弱标记和未标记数据,并通过对比自我训练抑制标签噪声。 弱监督学习用潜在的噪声标签丰富了数据,而我们的对比自我训练方案实现了去噪目的。 具体来说,对比自训练通过将具有相同伪标签的样本推近而将具有不同伪标签的样本拉开来规范特征空间。 这种正则化强制来自不同类别的样本的表示更加可区分,以便分类器可以做出更好的决策。 为了在对比自训练期间抑制标签噪声传播,我们提出了基于置信度的样本重新加权和正则化方法。 重新加权策略强调预测置信度高的样本,这些样本更有可能被正确分类,以减少错误预测的影响。 置信正则化鼓励模型预测的平滑性,这样任何预测都不会过度自信,从而减少错误伪标签的影响。
我们的模型很灵活,可以自然地扩展到半监督学习,其中可以使用一小组干净标签。 此外,由于我们不对弱标签的性质做出假设,因此 COSINE 可以处理各种类型的标签噪声,包括有偏差的标签和随机损坏的标签。 有偏见的标签通常是由语义规则生成的,而损坏的标签通常是通过众包生成的。
我们的主要贡献是:(1)对比正则化自训练框架,仅在弱监督的情况下对预训练的 LM 进行微调。 (2) 基于置信度的重新加权和正则化技术,减少错误传播并防止过度自信的预测。 (3)使用7个公共基准对6个NLP分类任务进行大量实验,验证了COSINE的有效性。 我们强调,与某些数据集上的完全监督模型相比,我们的模型实现了具有竞争力的性能, 例如,在 Yelp 数据集上,我们获得 (完全监督)与 (我们的)准确性比较。
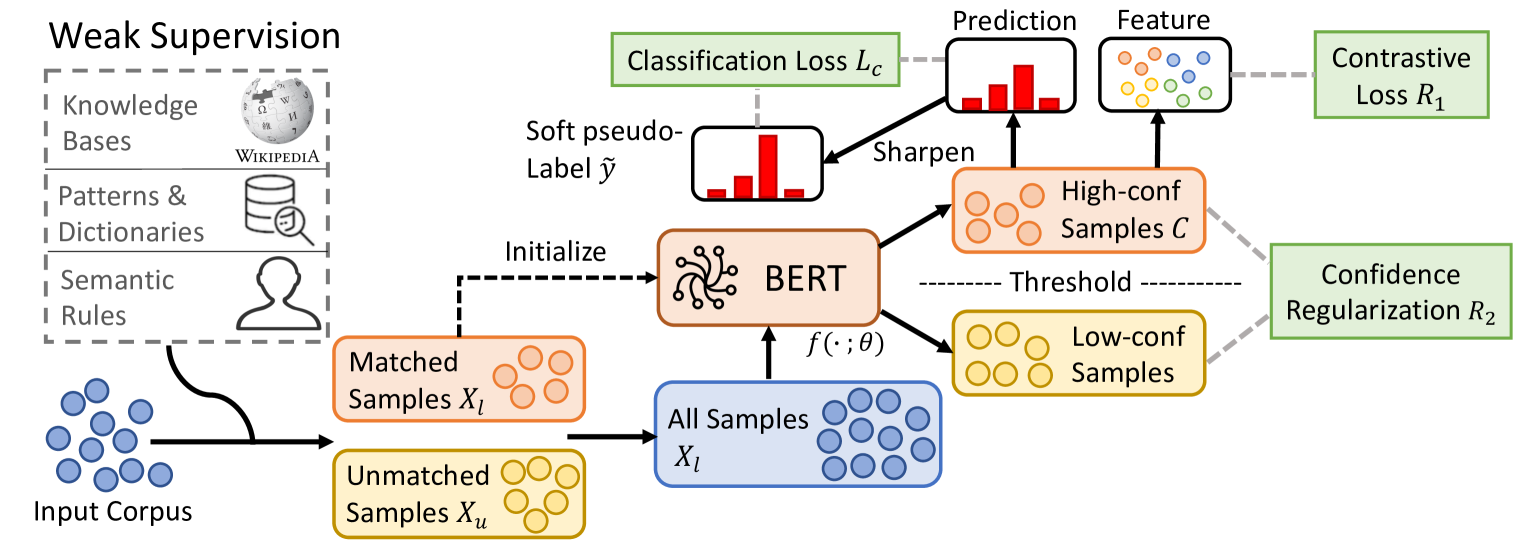
2 背景
在本节中,我们介绍弱监督和我们的问题表述。
监管薄弱。 我们不使用人工注释的数据,而是从弱监督源获取标签,包括关键字和语义规则222弱监督的示例参见附录A。. 从弱监督源,每个输入样本 被赋予标签 ,其中 对于被赋予多个标签的样本, 例如,由多个规则匹配,我们通过多数投票来确定它们的标签。
问题表述。 我们关注自然语言处理中的弱监督分类问题。 我们考虑三种类型的任务:序列分类、标记分类和句子对分类。 这些任务在 NLP 中具有广泛的应用范围,表1中可以找到一些示例。
形式上,弱监督分类问题定义如下:给定弱标记样本 和未标记的样本 这里表示所有样本,
| Formulation | Example Task | Input | Output | ||
| Sequence Classification |
|
||||
| Token Classification |
|
||||
| Sentence Pair Classification |
|
3方法
我们的分类器由两部分组成:BERT是预训练的语言模型,输出输入样本的隐藏表示, 在本文中,我们使用RoBERTa Liu et al (2019)作为BERT的实现。
COSINE的框架如图1所示。 首先,COSINE 使用弱标签初始化 LM。 在此步骤中,预训练的 LM 的语义和句法知识将转移到我们的模型中。 然后,它使用对比自训练来抑制标签噪声传播并继续训练。
3.1概述
COSINE的训练过程如下。
使用弱标签数据进行初始化。 我们微调 弱标记数据
| (1) |
其中 是交叉熵损失。 我们采用提前停止Dodge et al (2020)来防止模型过度拟合标签噪声。 然而,早期停止会导致拟合不足,我们通过对比自我训练来解决这个问题。
使用所有数据进行对比自我训练。 对比自训练的目标是利用所有数据(包括标记和未标记)进行微调,并减少错误标记数据的错误传播。 我们为未标记的数据生成伪标签并将其合并到训练集中。 为了减少错误传播,我们引入了对比表示学习(3.2 节)和基于置信度的样本重新加权和正则化(3.3 节)。 我们迭代地更新伪标签(用 表示)和模型。 算法1总结了这些过程。
使用当前的 更新 。 要为每个样本 生成伪标签,一种直接的方法是使用硬标签李 (2013)
| (2) |
请注意 是概率向量, 然而,这些硬伪标签只保留每个样本最可能的类别,并导致标签错误的传播。 例如,如果样本被错误地分类到错误的类,则分配 0/1 标签会使模型更新变得复杂(等式 4),因为模型会拟合错误的标签。 为了缓解这个问题,对于批次中的每个样本,我们生成软伪标签333有关硬与软的更多讨论在第 2 节中。 4.5。 谢等人(2016、2019);孟等人 (2020);梁等 (2020) 基于当前模型为
| (3) |
其中 是 非二进制软伪标签保证,即使我们的预测不准确,传播到模型更新步骤的误差也将小于使用硬伪标签。
3.2 样本对的对比学习
我们的对比自训练方法的关键要素是学习表示,鼓励同一类中的数据具有相似的表示,并将不同类中的数据分开。 具体来说,我们首先从 中选择高置信度样本(第 3.3 节)。 然后对于每对 ,我们将它们的相似度定义为
| (5) |
其中, 是 对于每个 ,我们计算其表示 ,然后我们定义对比正则化器为
| (6) |
在哪里
| (7) |
这里, 是对比损失 Chopra 等人 (20054>); Taigman 等人 (20145>)3>,444我们使用缩放欧氏距离2>
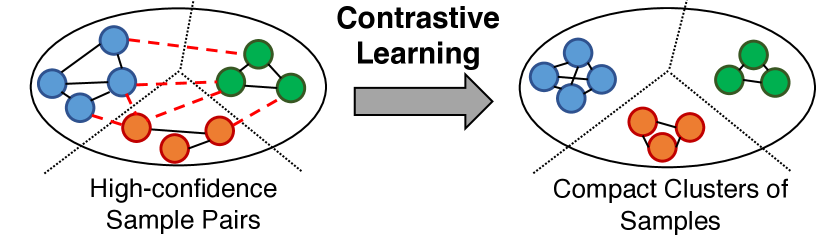
3.3 基于置信度的样本重新加权和正则化
虽然对比表示可以产生更好的决策边界,但它们需要具有高质量伪标签的样本。 在本节中,我们介绍重新加权和正则化方法来抑制错误传播并改善伪标签质量。
样本重新加权。 在分类任务中,预测置信度高的样本比置信度低的样本更有可能被正确分类。 因此,我们通过基于置信度的样本重新加权方案进一步减少标签噪声传播。 对于每个带有软伪标签 的样本 ,我们分配 权重
| (8) |
其中 是 请注意,如果预测置信度较低,则 会很大,样本权重 我们使用预定义的阈值从每个批次中选择高置信度样本,如下所示
| (9) |
然后我们将损失函数定义为
| (10) |
在哪里
| (11) |
是 Kullback-Leibler (KL) 散度。
置信度正则化 样本重新加权方法可在对比自训练过程中提升高置信度样本。 然而,这种策略依赖于错误标记的样本,其置信度较低,除非我们防止过度自信的预测,否则这可能不是真的。 为此,我们提出了一种基于置信度的正则化器,它鼓励预测的平滑性,定义为
| (12) |
其中 是 KL 散度, 该项构成了一种正则化,以防止过度自信的预测,并带来更好的泛化Pereyra 等人 (2017)。
4实验
数据集和任务。 我们使用 7 个公共基准对 6 个 NLP 分类任务进行了实验: AGNews Zhang et al (2015) 是一个主题分类任务; IMDB Maas 等人 (2011) 和 Yelp Meng 等人 (2018) t8>) 是情感分析任务; TREC Voorhees 和 Tice (19991>)0> 是一个问题分类任务; MIT-R2> Liu et al (20134>)3> 是一个 Slot Filling 任务; Chemprot5> Krallinger 等人 (20177>)6> 是一个关系分类任务; WiC8> Pilehvar 和 Camacho-Collados (20190>)9> 是一项词义消歧 (WSD) 任务。 数据集统计数据总结在表2中。 有关数据集和弱监督源的更多详细信息,请参见附录A555请注意,我们对我们的方法和所有基线使用相同的弱监督信号/规则,以进行公平比较。.
| Dataset | Task | Class | # Train | # Dev | # Test | Cover | Accuracy |
| AGNews | Topic | 4 | 96k | 12k | 12k | 56.4 | 83.1 |
| IMDB | Sentiment | 2 | 20k | 2.5k | 2.5k | 87.5 | 74.5 |
| Yelp | Sentiment | 2 | 30.4k | 3.8k | 3.8k | 82.8 | 71.5 |
| MIT-R | Slot Filling | 9 | 6.6k | 1.0k | 1.5k | 13.5 | 80.7 |
| TREC | Question | 6 | 4.8k | 0.6k | 0.6k | 95.0 | 63.8 |
| Chemprot | Relation | 10 | 12.6k | 1.6k | 1.6k | 85.9 | 46.5 |
| WiC | WSD | 2 | 5.4k | 0.6k | 1.4k | 63.4 | 58.8 |
基线。 我们将我们的模型与不同组的基线方法进行比较:
(i) 精确匹配(ExMatch):测试集直接由弱监督源标记。
(ii) 微调方法:第二组基线是 LM 的微调方法:
RoBERTa Liu 等人 (2019) 使用基于 RoBERTa 的模型和特定于任务的分类头。
自集成 (Xu等人,2020)使用自集成和蒸馏来提高性能。
FreeLB Zhu et al (2020) 采用对抗性训练来强制输出平滑。
Mixup Zhang 等人 (2018) 通过线性插值创建虚拟训练样本。
SMART Jiang et al (2020) 添加对抗性和平滑性约束来微调 LM 并实现状态-许多 NLP 任务的最先进的结果。
(iii) 弱监督模型:第三组基线是弱监督模型666除非另有说明,所有方法都使用 RoBERTa-base 作为主干。:
Snorkel Ratner 等人 (2020) 根据不同的标记函数的相关性聚合不同的标记函数。
WeSTClass Meng 等人 (2018) 使用生成的伪文档训练分类器,并使用自训练来对所有样本进行引导。
ImplyLoss Awasthi 等人 (2020) 共同训练基于规则的分类器和神经分类器以进行去噪。
去噪 Ren et al (2020)使用注意力网络来估计弱监督的可靠性,然后降低通过聚合弱标签来消除噪音。
UST Mukherjee 和 Awadallah (2020) 是最先进的自我训练,但限制有限标签。 它通过MC-dropout Gal and Ghahramani (2015)估计不确定性,然后选择不确定性较低的样本进行自训练。
评估指标。 我们使用测试集上的分类准确性作为除 MIT-R 之外的所有数据集的评估指标。 MIT-R 包含大量标记为“其他”的代币。 我们对此数据集使用其他类别的微 分数。777Chemprot数据集也包含“Others”类型,但此类实例很少,因此我们仍然使用准确率作为指标。
辅助的。 我们使用 PyTorch 实现 COSINE888https://pytorch.org/,我们使用 RoBERTa-base 作为预训练的 LM。 数据集和弱监督详细信息参见附录A。基线设置位于附录B中。 培训详细信息和设置位于附录C中。关于提前停止的讨论在附录D中。距离度量和相似性度量的比较参见附录E。
4.1 向弱标签学习
| Method | AGNews | IMDB | Yelp | MIT-R | TREC | Chemprot | WiC (dev) |
| ExMatch | |||||||
| Fully-supervised Result | |||||||
| RoBERTa-CL Liu et al. (2019) | |||||||
| Baselines | |||||||
| RoBERTa-WL Liu et al. (2019) | |||||||
| Self-ensemble Xu et al. (2020) | |||||||
| FreeLB Zhu et al. (2020) | |||||||
| Mixup Zhang et al. (2018) | |||||||
| SMART Jiang et al. (2020) | |||||||
| Snorkel Ratner et al. (2020) | --- | ||||||
| WeSTClass Meng et al. (2018) | --- | --- | |||||
| ImplyLoss Awasthi et al. (2020) | |||||||
| Denoise Ren et al. (2020) | |||||||
| UST Mukherjee and Awadallah (2020) | |||||||
| Our COSINE Framework | |||||||
| Init | |||||||
| COSINE | 87.52 | 90.54 | 95.97 | 76.61 | 82.59 | 54.36 | 67.71 |
:RoBERTa 使用干净标签进行训练。 :RoBERTa 使用弱标签进行训练。 :不公平比较。 :不适用。
我们在表 3 中总结了弱监督学习结果。 在所有数据集中,COSINE 优于所有基线模型。 一个特殊情况是 WiC 数据集,我们使用 WordNet999https://wordnet.princeton.edu/ 生成弱标签。 然而,这使得 Snorkel 能够访问开发集中的一些标记数据,从而与其他方法竞争不公平。 我们将在第二部分讨论更多关于这个数据集的信息。 4.3。
与使用弱标记数据直接微调预训练的 LM 相比,我们的模型采用了“早期停止”技术101010我们在附录D中讨论这项技术。 这样它就不会过度拟合标签噪声。 如图所示,“Init”确实实现了更好的性能,并且它为我们的框架提供了良好的初始化。 其他微调方法和弱监督模型要么无法利用预训练语言模型的力量, 例如,通气管,或依靠清洁标签, 例如,其他基线。 我们强调,尽管迄今为止最先进的方法 UST 在少数样本设置下实现了强大的性能,但他们的方法无法很好地估计噪声标签的置信度,从而导致性能较差。 我们的模型可以通过对比自训练逐渐纠正错误的伪标签并减轻错误传播。
值得注意的是,在某些数据集上, 例如、AGNews、IMDB、Yelp 和 WiC,我们的模型达到了与使用干净标签训练的模型 (RoBERTa-CL) 相同的性能水平。 这使得 COSINE 在只有弱监督的情况下具有吸引力。
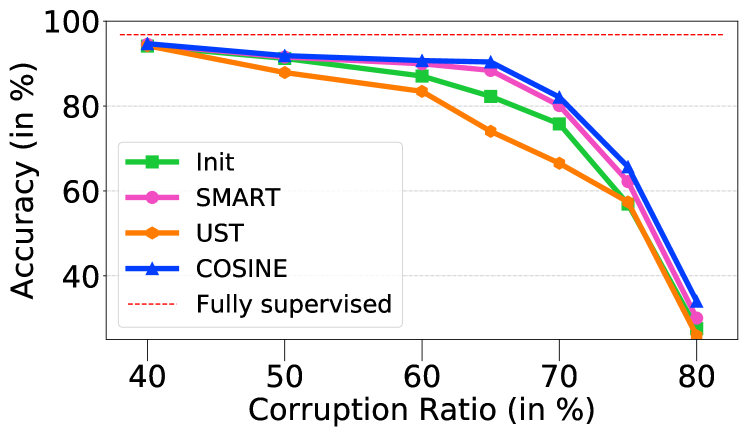
4.2 针对标签噪声的鲁棒性
我们的模型对于过度的标签噪声具有鲁棒性。 我们通过随机地将每个标签更改为另一类来破坏一定比例的标签。 这是众包中的常见场景,我们假设人类注释者以相同的概率错误地标记每个样本。 图3总结了TREC数据集上的实验结果。 与先进的微调和自训练方法相比(例如 智能和 UST)111111注意表3中的一些方法, 例如、ImplyLoss 和 Denoise 不适用于此设置,因为它们需要弱监督源,但此设置中不存在。,我们的模型始终优于基线。
| Model | Dev | Test | #Params |
| Human Baseline | 80.0 | --- | |
| BERT Devlin et al. (2019) | --- | 69.6 | 335M |
| RoBERTa (Liu et al., 2019) | 70.5 | 69.9 | 356M |
| T5 (Raffel et al., 2019) | --- | 76.9 | 11,000M |
| Semi-Supervised Learning | |||
| SenseBERT (Levine et al., 2020) | --- | 72.1 | 370M |
| RoBERTa-WL (Liu et al., 2019) | 72.3 | 70.2 | 125M |
| w/ MT (Tarvainen and Valpola, 2017) | 73.5 | 70.9 | 125M |
| w/ VAT (Miyato et al., 2018) | 74.2 | 71.2 | 125M |
| w/ COSINE | 76.0 | 73.2 | 125M |
| Transductive Learning | |||
| Snorkel (Ratner et al., 2020) | 80.5 | --- | 1M |
| RoBERTa-WL (Liu et al., 2019) | 81.3 | 76.8 | 125M |
| w/ MT (Tarvainen and Valpola, 2017) | 82.1 | 77.1 | 125M |
| w/ VAT (Miyato et al., 2018) | 84.9 | 79.5 | 125M |
| w/ COSINE | 89.5 | 85.3 | 125M |
4.3半监督学习
我们可以自然地将我们的模型扩展到半监督学习,其中部分数据可以使用干净的标签。 我们在 WiC 数据集上进行实验。 作为 SuperGLUE Wang 等人 (2019a) 基准测试的一部分,该数据集提出了一项具有挑战性的任务:模型需要确定不同句子中的相同单词是否具有相同的含义(意义)。
与之前训练集中的标签有噪声的任务不同,在这一部分中,我们利用 WiC 数据集提供的干净标签。 我们使用从词汇数据库获得的未标记句子对进一步增强 WiC 的原始训练数据(例如、WordNet、Wictionary)。 请注意,部分未标记数据可以通过规则匹配进行弱标记。 这本质上创建了一个半监督任务,其中我们有标记数据、弱标记数据和未标记数据。
由于 WiC 的弱标签是由 WordNet 生成的,并部分揭示了真实的标签信息,Snorkel (Ratner et al, 2020) 通过访问未标记的句子和验证和测试数据的弱标签。 为了与 Snorkel 进行公平比较,我们考虑转导式学习设置,通过将未标记的验证和测试数据及其弱标签集成到训练集中,我们可以访问相同的信息。 如表4所示,与Snorkel相比,采用转导学习的COSINE取得了更好的性能。 此外,与半监督基线相比(IE。 VAT 和 MT)以及使用额外资源的微调方法(IE。,SenseBERT),COSINE 在半监督和传导学习环境中都取得了更好的性能。
 (A) 的效果。
(A) 的效果。
 (二) 的效果。
(二) 的效果。
 (C) 的效果。
(C) 的效果。

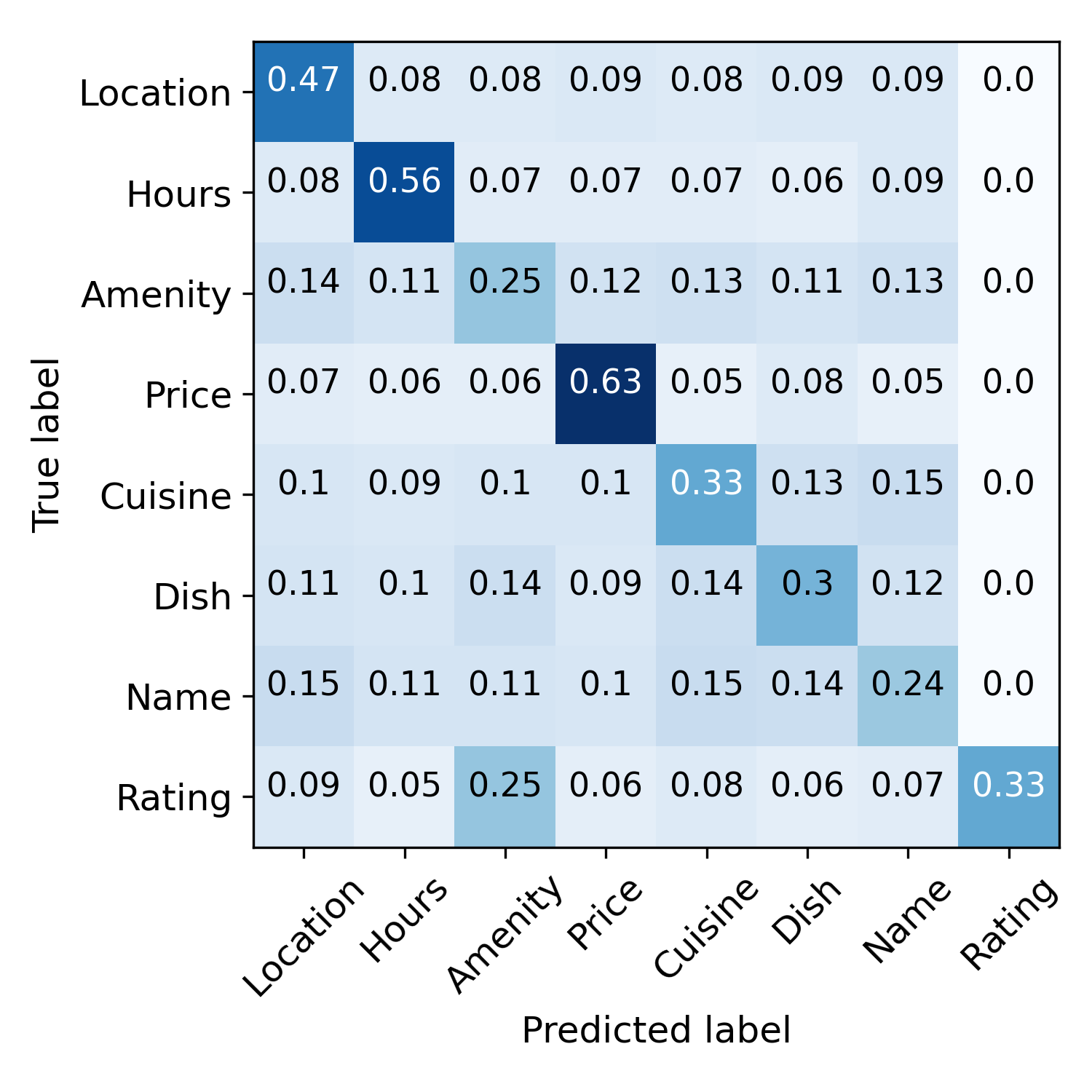
4.4案例研究
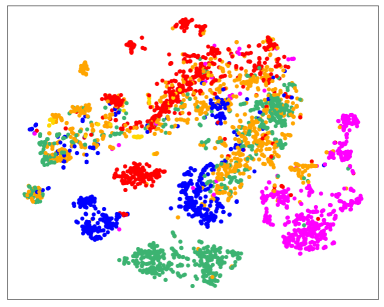
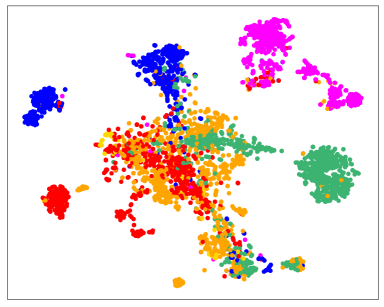
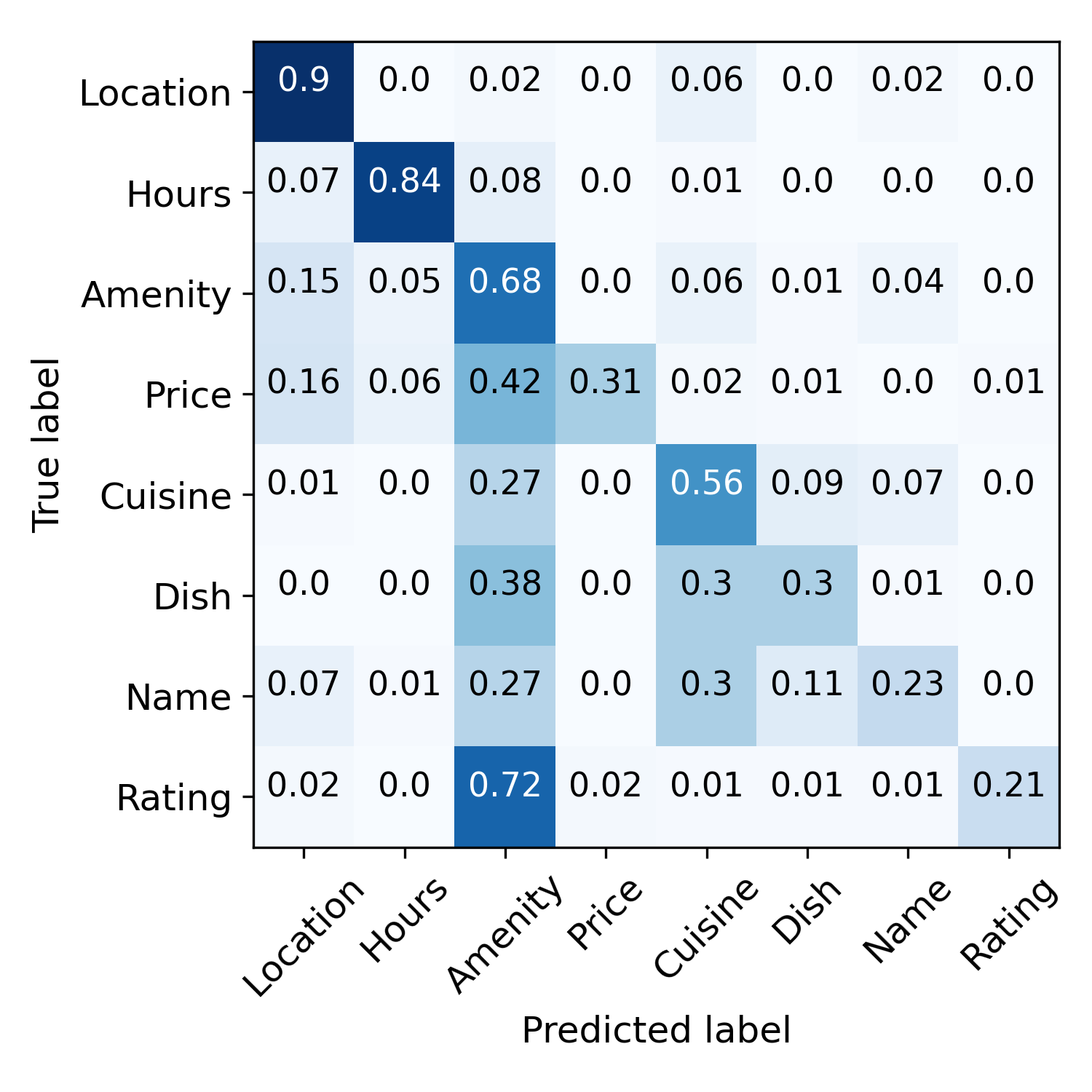
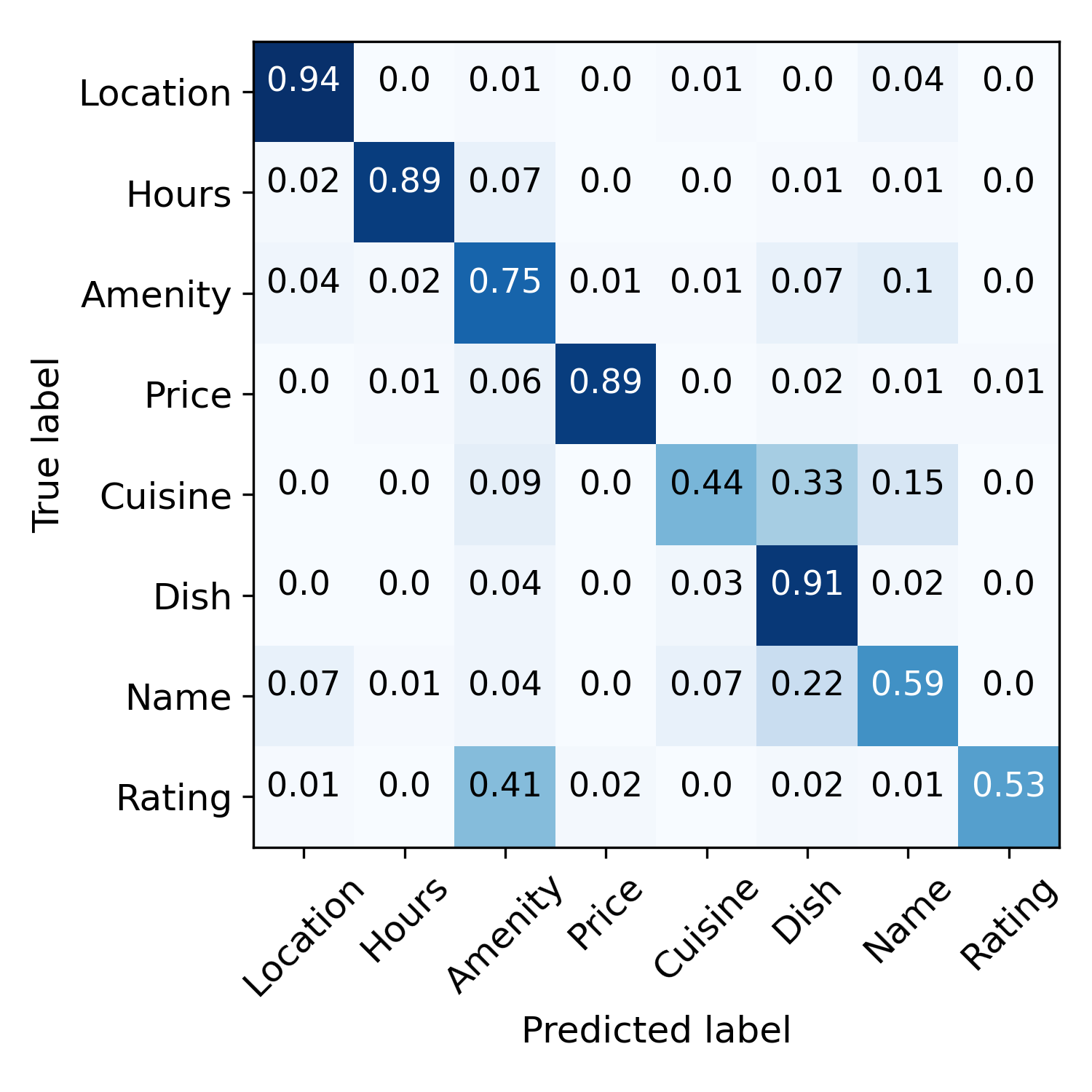
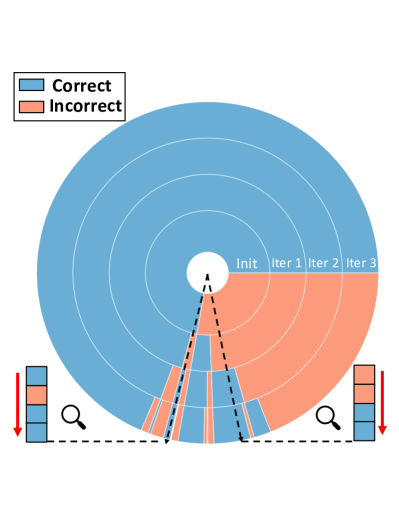
错误传播缓解和错误标签纠正。 图4直观地展示了这个过程。 在训练之前,语义规则会做出嘈杂的预测。 初始化步骤之后,模型预测的噪声更少,但偏差更大, 例如,许多样本被错误地标记为“Amenity”。 这些预测通过对比自我训练进一步完善。 最右图演示了错误标签校正。 样本用圆的半径表示,分类正确性用颜色表示, IE。,蓝色表示正确,橙色表示错误。 从内环到外环指定初始化阶段和迭代1、2、3之后的分类精度。 我们可以看到许多错误的预测在三次迭代内得到了纠正。 说明一下:右边的黑色虚线表示对应的样本在第一次迭代后被正确分类,左边的虚线表示该样本在第二次迭代后被错误分类,但在第三次迭代后被纠正。 这些结果表明我们的模型可以通过对比自我训练来纠正错误的预测。
更好的数据表示。 我们在图 7 中可视化样本嵌入。 通过结合对比正则化器 ,我们的模型可以学习同一类中数据的更紧凑的表示, 例如,绿色班级,也拉长了班级间的距离, 例如,图 7(b) 中的紫色类比图 7(a) 中的其他类更容易分离。
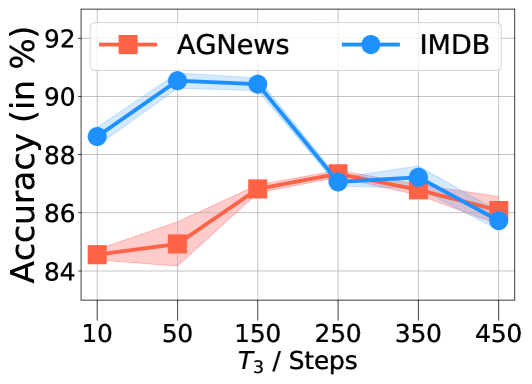
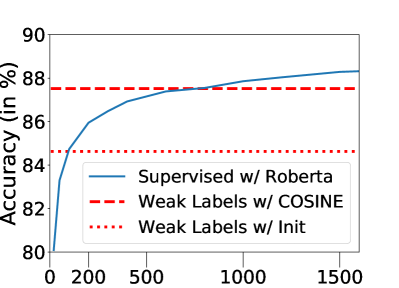
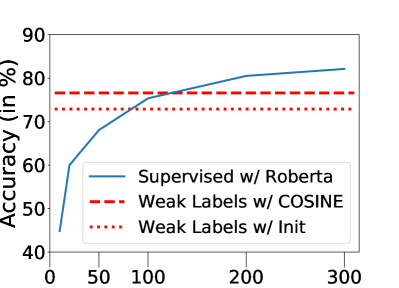
标签效率。 图8说明了监督模型超越COSINE所需的干净标签数量。 在这两个数据集上,监督模型需要大量的干净标签(Agnews 大约 750 个,MIT-R 大约 120 个)才能达到我们的性能水平,而我们的方法假设没有干净样本。
置信度越高表明准确性越高。 图6展示了IMDB上的预测置信度和预测精度之间的关系。 我们可以看到,一般来说,预测置信度越高的样本,预测精度越高。 通过我们的样本重新加权方法,我们逐渐过滤掉低置信度样本并为其他样本分配更高的权重,这有效地减轻了错误传播。
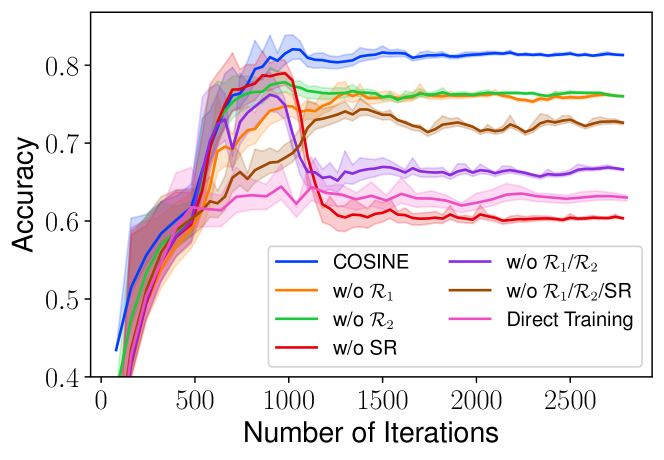
4.5消融研究
余弦的组成部分余弦。 我们检查各个组件的重要性,包括对比正则化器 、置信正则化器 ,以及样本重新加权(SR)方法和软标签。 表 5 总结了结果,图 9 直观地展示了学习曲线。 我们注意到所有组件共同对模型性能做出贡献,删除任何组件都会损害分类准确性。 例如,样本重新加权是减少误差传播的有效工具,删除它会导致模型最终过度拟合标签噪声, 例如,图9中的红色底线说明分类准确率先上升后迅速下降。 另一方面,用硬伪标签(等式2)替换软伪标签(等式3)会导致性能下降 。 这是因为硬伪标签丢失了预测置信度信息。
| Method | AGNews | IMDB | Yelp | MIT-R | TREC |
| Init | |||||
| COSINE | 87.52 | 90.54 | 95.97 | 76.61 | 82.59 |
| w/o | |||||
| w/o | |||||
| w/o SR | |||||
| w/o / | |||||
| w/o //SR | |||||
| w/o Soft Label |
5相关作品
微调预训练的语言模型。 为了提高模型在微调阶段的泛化能力,Peters 等人(2019)提出了几种方法;道奇等人 (2020);朱等人 (2020);江等人(2020);徐等人 (2020); Kong等人(2020);赵等人 (2020); Gunel 等人 (2021);张等人 (2021); Aghajanyan 等人 (20210>); Wang et al (20211>),然而,这些方法大多数都集中在完全监督的设置上,并且严重依赖大量的干净标签2>,而这些标签并不是始终可用。 为了解决这个问题,我们提出了一种对比自训练框架,该框架仅使用弱标签来微调预训练模型。 与现有的微调方法Xu等人(2020)相比;朱等人 (2020); Jiang等人(2020),我们的模型有效地降低了标签噪声,在弱监督的各种NLP任务上取得了更好的性能。
从弱监督中学习。 在弱监督学习中,训练数据通常充满噪声且不完整。 现有方法旨在通过例如聚合多个弱监督Ratner等人(2020)来对样本标签或标签函数进行去噪; Lison 等人 (2020); Ren 等人 (2020),使用干净样本 Awasthi 等人 (2020),并利用上下文信息 Mekala和尚(2020)。 然而,他们中的大多数只能对特定任务使用特定类型的弱监督, 例如、文本分类关键词Meng et al (2020); Mekala 和 Shang (2020),他们需要弱监督源的先验知识Awasthi 等人 (2020); Lison 等人 (2020); Ren 等人 (2020),这在某种程度上限制了他们的应用范围。 我们的工作与它们正交,因为我们不直接对标记函数进行去噪。 相反,我们采用对比自训练来利用预训练语言模型的力量进行去噪,这是任务无关的并且适用于各种 NLP 任务,只需最少的额外工作。
6讨论
LM 适应不同领域。 在对来自不同领域的数据进行语言模型微调时,我们可以首先继续对域内文本数据进行预训练,以更好地适应Gururangan et al (2020)。 对于一些罕见的领域,在一般领域上训练的 BERT 不是最佳的,我们可以使用在这些特定领域上预训练的 LM(例如 BioBERT Lee 等人 (2020)、SciBERT Beltagy 等人 (2019))来解决这个问题。
弱监督的可扩展性。 COSINE可以应用于具有大量类的任务。 这是因为规则可以自动生成,而无需手工制定。 例如,我们可以使用标签名称/描述作为弱监督信号Meng et al (2020)。 这种信号很容易获得,不需要手工制定规则。 一旦提供了弱监督,我们就可以创建弱标签来进一步应用COSINE。
灵活性。 COSINE 可以处理我们进行的实验之外的任务和弱监督源。 例如,除了语义规则之外,众包可以是生成伪标签的另一个弱监督源Wang et al (2013)。 此外,我们只对几个代表性任务进行实验,但我们的框架也可以应用于其他任务,例如命名实体识别(标记分类)和阅读理解(句子对分类)。
7结论
在本文中,我们提出了一种对比正则化自训练框架COSINE,用于微调弱监督的预训练语言模型。 我们的框架可以学习更好的数据表示以简化分类任务,并且还可以通过基于置信度的重新加权和正则化有效地减少标签噪声传播。 我们对各种分类任务进行了实验,包括序列分类、标记分类和句子对分类,结果证明了我们模型的有效性。
更广泛的影响
COSINE 是一个通用框架,通过将神经网络与弱监督相结合来解决标签稀缺问题。 弱监督提供了一种简单但灵活的语言来编码领域知识并捕获特征和标签之间的相关性。 当与未标记数据结合时,我们的框架可以在很大程度上解决训练 DNN 的标签稀缺瓶颈,使其能够以标签有效的方式应用于下游 NLP 分类任务。
COSINE 既不会向模型引入任何社会/道德偏见,也不会放大数据中的任何偏见。 在所有实验中,我们使用公开数据,并使用公共代码库构建算法。 我们不预见任何直接的社会后果或道德问题。
致谢
我们感谢匿名审稿人的反馈。 这项工作得到了国家科学基金会奖 III-2008334、亚马逊教师奖和谷歌教师奖的部分支持。
参考
- Aghajanyan et al. (2021) Armen Aghajanyan, Akshat Shrivastava, Anchit Gupta, Naman Goyal, Luke Zettlemoyer, and Sonal Gupta. 2021. Better fine-tuning by reducing representational collapse. In International Conference on Learning Representations.
- Aina et al. (2019) Laura Aina, Kristina Gulordava, and Gemma Boleda. 2019. Putting words in context: LSTM language models and lexical ambiguity. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3342–3348.
- Awasthi et al. (2020) Abhijeet Awasthi, Sabyasachi Ghosh, Rasna Goyal, and Sunita Sarawagi. 2020. Learning from rules generalizing labeled exemplars. In International Conference on Learning Representations.
- Beltagy et al. (2019) Iz Beltagy, Kyle Lo, and Arman Cohan. 2019. SciBERT: A pretrained language model for scientific text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3615–3620.
- Chopra et al. (2005) Sumit Chopra, Raia Hadsell, and Yann LeCun. 2005. Learning a similarity metric discriminatively, with application to face verification. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR’05), volume 1, pages 539–546.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186.
- Dodge et al. (2020) Jesse Dodge, Gabriel Ilharco, Roy Schwartz, Ali Farhadi, Hannaneh Hajishirzi, and Noah A. Smith. 2020. Fine-tuning pretrained language models: Weight initializations, data orders, and early stopping. CoRR, abs/2002.06305.
- Gal and Ghahramani (2015) Yarin Gal and Zoubin Ghahramani. 2015. Bayesian convolutional neural networks with bernoulli approximate variational inference. CoRR, abs/1506.02158.
- Gunel et al. (2021) Beliz Gunel, Jingfei Du, Alexis Conneau, and Veselin Stoyanov. 2021. Supervised contrastive learning for pre-trained language model fine-tuning. In International Conference on Learning Representations.
- Gururangan et al. (2020) Suchin Gururangan, Ana Marasović, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A. Smith. 2020. Don’t stop pretraining: Adapt language models to domains and tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8342–8360.
- Jiang et al. (2020) Haoming Jiang, Pengcheng He, Weizhu Chen, Xiaodong Liu, Jianfeng Gao, and Tuo Zhao. 2020. SMART: Robust and efficient fine-tuning for pre-trained natural language models through principled regularized optimization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2177–2190.
- Kong et al. (2020) Lingkai Kong, Haoming Jiang, Yuchen Zhuang, Jie Lyu, Tuo Zhao, and Chao Zhang. 2020. Calibrated language model fine-tuning for in- and out-of-distribution data. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1326–1340.
- Krallinger et al. (2017) Martin Krallinger, Obdulia Rabal, Saber A Akhondi, et al. 2017. Overview of the biocreative VI chemical-protein interaction track. In Proceedings of the sixth BioCreative challenge evaluation workshop, volume 1, pages 141–146.
- Lee (2013) Dong-Hyun Lee. 2013. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Workshop on challenges in representation learning, ICML, volume 3, page 2.
- Lee et al. (2020) Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. 2020. Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4):1234–1240.
- Levine et al. (2020) Yoav Levine, Barak Lenz, Or Dagan, Ori Ram, Dan Padnos, Or Sharir, Shai Shalev-Shwartz, Amnon Shashua, and Yoav Shoham. 2020. SenseBERT: Driving some sense into BERT. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4656–4667.
- Liang et al. (2020) Chen Liang, Yue Yu, Haoming Jiang, Siawpeng Er, Ruijia Wang, Tuo Zhao, and Chao Zhang. 2020. Bond: Bert-assisted open-domain named entity recognition with distant supervision. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, page 1054–1064.
- Lison et al. (2020) Pierre Lison, Jeremy Barnes, Aliaksandr Hubin, and Samia Touileb. 2020. Named entity recognition without labelled data: A weak supervision approach. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1518–1533.
- Liu et al. (2013) Jingjing Liu, Panupong Pasupat, Yining Wang, Scott Cyphers, and James R. Glass. 2013. Query understanding enhanced by hierarchical parsing structures. In 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, pages 72–77. IEEE.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized BERT pretraining approach. CoRR, abs/1907.11692.
- Loshchilov and Hutter (2019) Ilya Loshchilov and Frank Hutter. 2019. Decoupled weight decay regularization. In International Conference on Learning Representations.
- Luo et al. (2017) Bingfeng Luo, Yansong Feng, Zheng Wang, Zhanxing Zhu, Songfang Huang, Rui Yan, and Dongyan Zhao. 2017. Learning with noise: Enhance distantly supervised relation extraction with dynamic transition matrix. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 430–439.
- Maas et al. (2011) Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. 2011. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 142–150.
- Maaten and Hinton (2008) Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-sne. Journal of machine learning research, 9(Nov):2579–2605.
- Mekala and Shang (2020) Dheeraj Mekala and Jingbo Shang. 2020. Contextualized weak supervision for text classification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 323–333.
- Meng et al. (2018) Yu Meng, Jiaming Shen, Chao Zhang, and Jiawei Han. 2018. Weakly-supervised neural text classification. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, page 983–992.
- Meng et al. (2020) Yu Meng, Yunyi Zhang, Jiaxin Huang, Chenyan Xiong, Heng Ji, Chao Zhang, and Jiawei Han. 2020. Text classification using label names only: A language model self-training approach. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9006–9017.
- Miyato et al. (2018) Takeru Miyato, Shin-ichi Maeda, Masanori Koyama, and Shin Ishii. 2018. Virtual adversarial training: a regularization method for supervised and semi-supervised learning. IEEE transactions on pattern analysis and machine intelligence, 41(8):1979–1993.
- Mukherjee and Awadallah (2020) Subhabrata Mukherjee and Ahmed Hassan Awadallah. 2020. Uncertainty-aware self-training for text classification with few labels. CoRR, abs/2006.15315.
- Pereyra et al. (2017) Gabriel Pereyra, George Tucker, Jan Chorowski, Lukasz Kaiser, and Geoffrey E. Hinton. 2017. Regularizing neural networks by penalizing confident output distributions. CoRR, abs/1701.06548.
- Peters et al. (2018) Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 2227–2237.
- Peters et al. (2019) Matthew E. Peters, Sebastian Ruder, and Noah A. Smith. 2019. To tune or not to tune? adapting pretrained representations to diverse tasks. In Proceedings of the 4th Workshop on Representation Learning for NLP (RepL4NLP-2019), pages 7–14.
- Pilehvar and Camacho-Collados (2019) Mohammad Taher Pilehvar and Jose Camacho-Collados. 2019. WiC: the word-in-context dataset for evaluating context-sensitive meaning representations. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 1267–1273.
- Raffel et al. (2019) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2019. Exploring the limits of transfer learning with a unified text-to-text transformer. CoRR, abs/1910.10683.
- Ratner et al. (2020) Alexander Ratner, Stephen H. Bach, Henry R. Ehrenberg, Jason A. Fries, Sen Wu, and Christopher Ré. 2020. Snorkel: rapid training data creation with weak supervision. VLDB Journal, 29(2):709–730.
- Ren et al. (2020) Wendi Ren, Yinghao Li, Hanting Su, David Kartchner, Cassie Mitchell, and Chao Zhang. 2020. Denoising multi-source weak supervision for neural text classification. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3739–3754.
- Rosenberg et al. (2005) Chuck Rosenberg, Martial Hebert, and Henry Schneiderman. 2005. Semi-supervised self-training of object detection models. WACV/MOTION, 2.
- Taigman et al. (2014) Yaniv Taigman, Ming Yang, Marc’Aurelio Ranzato, and Lior Wolf. 2014. Deepface: Closing the gap to human-level performance in face verification. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Tarvainen and Valpola (2017) Antti Tarvainen and Harri Valpola. 2017. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Advances in Neural Information Processing Systems, pages 1195–1204.
- Varma and Ré (2018) Paroma Varma and Christopher Ré. 2018. Snuba: Automating weak supervision to label training data. Proc. VLDB Endowment, 12(3):223–236.
- Voorhees and Tice (1999) Ellen M. Voorhees and Dawn M. Tice. 1999. The TREC-8 question answering track evaluation. In Proceedings of The Eighth Text REtrieval Conference, volume 500-246.
- Wang et al. (2019a) Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2019a. Superglue: A stickier benchmark for general-purpose language understanding systems. In Advances in Neural Information Processing Systems, pages 3261–3275.
- Wang et al. (2013) Aobo Wang, Cong Duy Vu Hoang, and Min-Yen Kan. 2013. Perspectives on crowdsourcing annotations for natural language processing. Language resources and evaluation, 47(1):9–31.
- Wang et al. (2021) Boxin Wang, Shuohang Wang, Yu Cheng, Zhe Gan, Ruoxi Jia, Bo Li, and Jingjing Liu. 2021. InfoBERT: Improving robustness of language models from an information theoretic perspective. In International Conference on Learning Representations.
- Wang et al. (2019b) Hao Wang, Bing Liu, Chaozhuo Li, Yan Yang, and Tianrui Li. 2019b. Learning with noisy labels for sentence-level sentiment classification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 6286–6292.
- Xie et al. (2016) Junyuan Xie, Ross Girshick, and Ali Farhadi. 2016. Unsupervised deep embedding for clustering analysis. In Proceedings of The 33rd International Conference on Machine Learning, pages 478–487.
- Xie et al. (2019) Qizhe Xie, Zihang Dai, Eduard H. Hovy, Minh-Thang Luong, and Quoc V. Le. 2019. Unsupervised data augmentation for consistency training. CoRR, abs/1904.12848.
- Xu et al. (2020) Yige Xu, Xipeng Qiu, Ligao Zhou, and Xuanjing Huang. 2020. Improving BERT fine-tuning via self-ensemble and self-distillation. CoRR, abs/2002.10345.
- Zhang et al. (2018) Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin, and David Lopez-Paz. 2018. mixup: Beyond empirical risk minimization. In International Conference on Learning Representations.
- Zhang et al. (2021) Tianyi Zhang, Felix Wu, Arzoo Katiyar, Kilian Q Weinberger, and Yoav Artzi. 2021. Revisiting few-sample BERT fine-tuning. In International Conference on Learning Representations.
- Zhang et al. (2015) Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015. Character-level convolutional networks for text classification. In Advances in Neural Information Processing Systems 28, pages 649–657.
- Zhao et al. (2020) Mengjie Zhao, Tao Lin, Fei Mi, Martin Jaggi, and Hinrich Schütze. 2020. Masking as an efficient alternative to finetuning for pretrained language models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2226–2241.
- Zhou et al. (2020) Wenxuan Zhou, Hongtao Lin, Bill Yuchen Lin, Ziqi Wang, Junyi Du, Leonardo Neves, and Xiang Ren. 2020. NERO: A neural rule grounding framework for label-efficient relation extraction. In Proceedings of The Web Conference 2020, page 2166–2176.
- Zhu et al. (2020) Chen Zhu, Yu Cheng, Zhe Gan, Siqi Sun, Tom Goldstein, and Jingjing Liu. 2020. Freelb: Enhanced adversarial training for natural language understanding. In International Conference on Learning Representations.
附录A监管薄弱细节
COSINE在训练过程中不需要任何人工标注的例子,只需要关键词、语义规则等弱监督源。 根据现有著作Awasthi等人(2020)的一些研究; Zhou等人(2020),这种弱监督的获得成本低廉,而且比收集清洁标签效率更高。 通过这种方式,我们可以使用这些弱监督源获得比人工更多的标记示例。
我们将两种类型的语义规则用作弱监督:
-
关键字规则:HAS(x, L) C。如果与列表中的单词之一匹配,我们将其标记为
-
模式规则:MATCH(x, R) C。如果与正则表达式匹配,我们将其标记为
除了关键词规则和模式规则之外,我们还可以利用第三方工具来获取弱标签。 这些工具(例如 文本块121212https://textblob.readthedocs.io/en/dev/index.html。)可以在网上获得,并且可以很便宜地获得,但是它们的预测不够准确(当直接使用该工具来预测所有训练样本的标签时,在 Yelp 数据集上的准确率约为 60%)。
我们现在介绍每个数据集上的语义规则:
| Rule | Example |
| HAS (x, [amino acid,mutant, mutat, replace] ) part_of |
A major part of this processing requires endoproteolytic cleavage at specific pairs of basic [CHEMICAL]amino acid[CHEMICAL] residues, an event necessary for the maturation of a variety of important biologically active proteins, such as insulin and [GENE]nerve growth factor[GENE]. |
| HAS (x, [bind, interact, affinit] ) regulator |
The interaction of [CHEMICAL]naloxone estrone azine[CHEMICAL] (N-EH) with various [GENE]opioid receptor[GENE] types was studied in vitro. |
| HAS (x, [activat, increas, induc, stimulat, upregulat] ) upregulator/activator |
The results of this study suggest that [CHEMICAL]noradrenaline[CHEMICAL] predominantly, but not exclusively, mediates contraction of rat aorta through the activation of an [GENE]alphalD-adrenoceptor[GENE]. |
| HAS (x, [downregulat, inhibit, reduc, decreas] ) downregulator/inhibitor |
These results suggest that [CHEMICAL]prostacyclin[CHEMICAL] may play a role in downregulating [GENE]tissue factor[GENE] expression in monocytes, at least in part via elevation of intracellular levels of cyclic AMP. |
|
HAS (x, [ agoni, tagoni]* ) agonist * (note the leading whitespace in both cases) |
Alprenolol and BAAM also caused surmountable antagonism of [CHEMICAL]isoprenaline[CHEMICAL] responses, and this [GENE]beta 1-adrenoceptor[GENE] antagonism was slowly reversible. |
| HAS (x, [antagon] ) antagonist |
It is concluded that [CHEMICAL]labetalol[CHEMICAL] and dilevalol are [GENE]beta 1-adrenoceptor[GENE] selective antagonists. |
| HAS (x, [modulat, allosteric] ) modulator |
[CHEMICAL]Hydrogen sulfide[CHEMICAL] as an allosteric modulator of [GENE]ATP-sensitive potassium channels[GENE] in colonic inflammation. |
| HAS (x, [cofactor] ) cofactor |
The activation appears to be due to an increase of [GENE]GAD[GENE] affinity for its cofactor, [CHEMICAL]pyridoxal phosphate[CHEMICAL] (PLP). |
| HAS (x, [substrate, catalyz, transport, produc, conver] ) substrate/product |
Kinetic constants of the mutant [GENE]CrAT[GENE] showed modification in favor of longer [CHEMICAL]acyl-CoAs[CHEMICAL] as substrates. |
| HAS (x, [not] ) not |
[CHEMICAL]Nicotine[CHEMICAL] does not account for the CSE stimulation of [GENE]VEGF[GENE] in HFL-1. |
附录 B基线设置
我们基于他们的原始论文实现了 Self-ensemble、FreeLB、Mixup 和 UST。
对于其他基线,我们使用他们的官方版本:
WeSTClass Meng et al (2018):https:// /github.com/yumeng5/WeSTClass。
RoBERTa 刘等人 (2019):https://github.com/huggingface/transformers.
SMART Jiang 等人 (2020):https://github.com/namisan/mt-dnn 。
浮潜Ratner等人(2020):https://www.snorkel.org/。
ImplyLoss Awasthi 等人 (2020):https://github.com/awasthiabhijeet/Learning-From -规则。
去噪Ren等人(2020):https://github.com/weakrules/Denoise-multi -弱源。
附录 C实验设置详细信息
C.1 计算基础设施
系统:Ubuntu 18.04.3 LTS; Python 3.7;火炬 1.2。 CPU:Intel(R) Core(TM) i7-5930K CPU @ 3.50GHz。 GPU:GeForce GTX TITAN X。
C.2 超参数
我们使用 AdamW Loshchilov 和 Hutter (2019) 作为优化器,学习率选自 0>
超参数如表7所示。 我们使用网格搜索来找到每个任务的最佳设置。 具体来说,我们搜索从到, 所有结果均报告为三轮运行的平均值。
| Hyper-parameter | AGNews | IMDB | Yelp | MIT-R | TREC | Chemprot | WiC |
| Dropout Ratio | 0.1 | ||||||
| Maximum Tokens | 128 | 256 | 512 | 64 | 64 | 400 | 256 |
| Batch Size | 32 | 16 | 16 | 64 | 16 | 24 | 32 |
| Weight Decay | |||||||
| Learning Rate | |||||||
| 160 | 160 | 200 | 150 | 500 | 400 | 1700 | |
| 3000 | 2500 | 2500 | 1000 | 2500 | 1000 | 3000 | |
| 250 | 50 | 100 | 15 | 30 | 15 | 80 | |
| 0.6 | 0.7 | 0.7 | 0.2 | 0.3 | 0.7 | 0.7 | |
| 0.1 | 0.05 | 0.05 | 0.1 | 0.05 | 0.05 | 0.05 | |
C.3 参数数量
COSINE 和大多数基线(RoBERTa-WL / RoBERTa-CL / SMART / WeSTClass / Self-Ensemble / FreeLB / Mixup / UST)都是建立在 RoBERTa-base 模型上,具有约 125M 参数。 Snorkel 是一个只有几个参数的生成模型。 ImplyLoss和Denoise冻结了嵌入并且参数少于1M。 然而,这些模型在我们的实验中无法取得令人满意的性能。
| Distance | Euclidean | Cos | ||||
| Similarity | Hard | KL-based | L2-based | Hard | KL-based | L2-based |
| AGNews | 87.52 | 86.44 | 86.72 | 87.34 | 86.98 | 86.55 |
| MIT-R | 76.61 | 76.68 | 76.49 | 76.55 | 76.76 | 76.58 |
附录D提前停止和提前停止
我们的模型在初始化阶段采用提前停止策略。 这里我们使用“早期停止”来区别“早期停止”,这是微调算法中的标准。 早期停止是指当评估分数下降时我们停止训练的技术。 提前停止是不言自明的,也就是说,我们甚至在评估分数开始下降之前,仅用几个步骤对预先训练的 LM 进行微调。 该技术可以有效防止模型过拟合。 例如,如图 5(b) 所示,在 IMDB 数据集上,我们的模型在使用弱标签进行 240 次初始化迭代后出现过拟合。 相比之下,在使用干净标签时,即使经过 400 次迭代微调,该模型仍能获得良好的性能。 这验证了提前停车的必要性。
附录E对比学习中距离测量的比较
对比正则化器 与两个设计相关:样本距离度量 在我们的实现中,我们使用缩放的欧几里得距离作为 和等式。 5 作为 131313为了加速对比学习,我们采用双随机采样近似来降低计算成本。 具体来说,每批 中的高置信度样本 产生 个样本对,我们对 . 在这里我们讨论其他设计。
E.1 样本距离度量
给定编码的矢量化表示 和 对于样本
缩放欧氏距离(Euclidean):我们计算 和 作为
| (13) |
余弦距离 (Cos)141414我们使用 Cos 来区别我们的模型名称COSINE。:除了缩放欧氏距离之外,余弦距离是另一种广泛使用的距离度量:
| (14) |
E.2 相似性度量示例
给定软伪标签 和 样本 在所有情况下, 缩放到范围 (我们在方程 7
硬相似度:两个样本之间的硬相似度计算如下
| (15) |
这被称为“硬”相似性,因为我们获得了一个二元标签, IE。,如果两个样本对应的硬伪标签相同,我们就说它们相似,否则我们就说它们不相似。
基于软KL的相似度:我们基于KL距离计算相似度,如下所示。
| (16) |
其中是缩放因子,我们默认设置 。
基于 L2 的软相似度:我们基于 L2 距离计算相似度,如下所示。
| (17) |
不同和下的E.3余弦。
我们在表 8 中展示了 COSINE 在 Agnews 和 MIT-R 上不同选择 和 的性能。 我们可以看到 COSINE 对于这些选择是稳健的。 在我们的实验中,我们默认使用缩放的欧氏距离和硬相似度。