大型语言模型自我演化综述
摘要
大型语言模型(大语言模型)在各个领域和智能代理应用中都取得了显着的进步。 然而,当前从人类或外部模型监督中学习的大语言模型成本高昂,并且随着任务复杂性和多样性的增加可能面临性能天花板。 为了解决这个问题,使大语言模型能够自主获取、完善模型本身产生的经验并从中学习的自我进化方法正在迅速发展。 这种受人类体验式学习过程启发的新训练范式提供了将大语言模型扩展到超级智能的潜力。 在这项工作中,我们对大语言模型中的自我进化方法进行了全面的调查。 我们首先提出了自我进化的概念框架,并将进化过程概述为由四个阶段组成的迭代循环:经验获取、经验细化、更新和评估。 其次,我们对大语言模型和基于LLM的智能体的进化目标进行了分类;然后,我们总结文献并为每个模块提供分类和见解。 最后,我们指出了现有的挑战并提出了改进自我进化框架的未来方向,为研究人员提供了快速发展自我进化大语言模型的关键见解。 我们相应的 GitHub 存储库位于 https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/Awesome-Self-Evolution-of-LLM。
大型语言模型自我演化综述
Zhengwei Tao††thanks: Work done while interning at Alibaba Group., Ting-En Lin, Xiancai Chen, Hangyu Li, Yuchuan Wu, Yongbin Li††thanks: Corresponding authors., Zhi Jin, Fei Huang, Dacheng Tao, Jingren Zhou Key Lab of HCST (PKU), MOE; School of Computer Science, Peking University Alibaba Group Nanyang Technological University {tttzw, xiancaich}@stu.pku.edu.cn, zhijin@pku.edu.cn {ting-en.lte, shengxiu.wyc, shuide.lyb, jingren.zhou}@alibaba-inc.com dacheng.tao@ntu.edu.sg
1简介
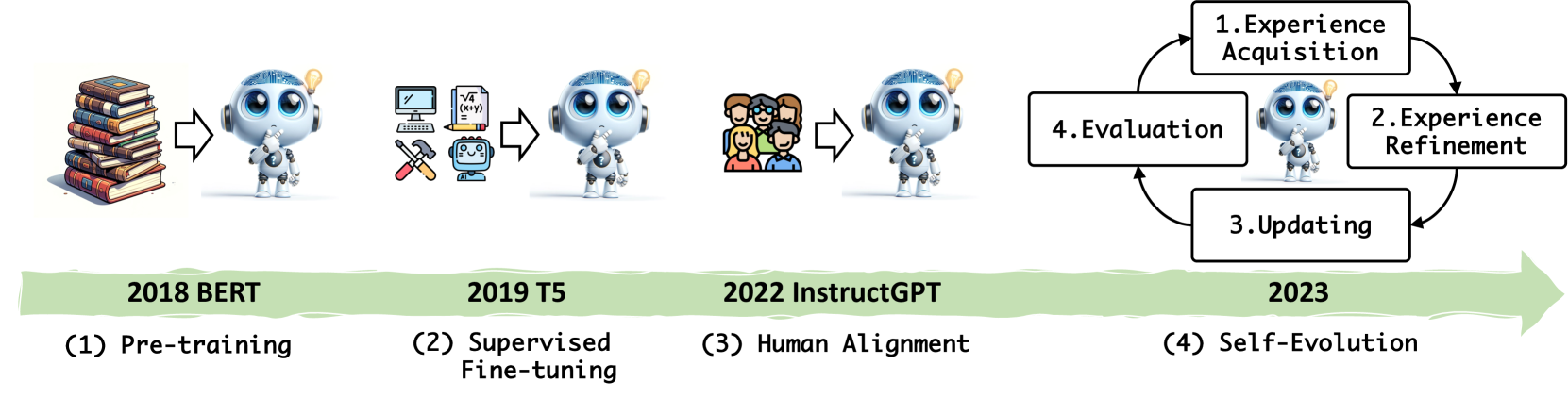
随着人工智能的快速发展,大型语言模型(大语言模型)如GPT-3.5 Ouyang 等人(2022)、GPT-4 Achiam 等人(2023) 、Gemini Team 等人 (2023)、LLaMA Touvron 等人 (2023a, b) 和 Qwen Bai 等人 (2023) 标记 a语言理解和生成的重大转变。 这些模型经历了三个发展阶段,如图1所示:对大型且多样化的语料库进行预训练,以获得对语言和世界知识的总体理解Devlin等人(2018); Brown 等人 (2020),然后通过监督微调来引出下游任务的能力 Raffel 等人 (2020);钟等人(2022)。 最后,人类偏好对齐训练使大语言模型能够像人类行为Ouyang 等人(2022)一样做出反应。 这些连续的训练范式取得了重大突破,使大语言模型能够以出色的零样本和上下文能力执行广泛的任务,例如问答Tan等人(2023)、数学推理Collins 等人 (2023)、代码生成 Liu 等人 (2024b) 以及需要与环境交互的任务解决 Liu 等人 (2023b)。
尽管取得了这些进步,人类预计新一代大语言模型可以承担更复杂的任务,例如科学发现Miret and Krishnan (2024)和未来事件预测Schoenegger等人(2024)。 然而,由于建模、标注以及与现有训练范例相关的评估等方面固有的困难,当前的大语言模型在这些复杂的任务中遇到了挑战Burns等人(2023)。 此外,最近开发的 Llama-3 模型已经在包含 15 万亿个 Token 的广泛语料库上进行了训练111https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct。 这是一个巨大的数据量,表明通过添加更多现实世界数据来显着扩展模型性能可能会造成限制。 这引起了人们对大语言模型的自我进化机制的兴趣,类似于人类智能的自然进化,并通过游戏中人工智能的发展来说明,例如从 AlphaGo Silver 等人 (2016) 到AlphaZero Silver 等人 (2017). AlphaZero 的自我对弈方法不需要标记数据,为大语言模型展示了一条超越当前限制并在无需密集人类监督的情况下实现超人性能的前进道路。
受上述范式的启发,大语言模型自我演化的研究在模型发展的不同阶段迅速增多,如自指导王等人(2023b)、自博涂等人(2024),自强黄等人(2022),自我训练Gulcehre等人(2023)。 值得注意的是,DeepMind 的 AMIE 系统Tu 等人 (2024) 在诊断准确性方面优于初级保健医生,而微软的 WizardLM-2 222https://wizardlm.github.io/WizardLM2/ 超过了 GPT-4 初始版本的性能。 这两种模型都是使用具有自主学习能力的自我进化框架开发的,代表了潜在的大语言模型训练范式转变。 然而,这些方法之间的关系仍不清楚,缺乏系统的整理和分析。
因此,我们首先全面研究大语言模型的自我演化过程,并为其发展建立概念框架。 这种自我进化的特点是经验获取、经验细化、更新和评估的迭代循环,如图2所示。 在这个周期中,大语言模型最初通过演化新任务并生成相应的解决方案来获得经验,随后完善这些经验以获得更好的监督信号。 在权重或上下文中更新模型后,将对大语言模型进行评估以衡量进展并设定新目标。
大语言模型中的自我进化概念引起了各个研究界的极大兴趣,预示着一个能够自主适应、学习和改进的模型的新时代,类似于人类响应不断变化的环境和挑战的进化。 自我进化的大语言模型不仅能够超越当前静态、数据绑定模型的局限性,而且标志着向更加动态、稳健和智能的系统的转变。 这项调查通过结构化的概念框架提供了全面的概述,加深了对自我进化大语言模型这一新兴领域的理解。 我们追溯该领域从过去到最新前沿方法和应用的演变,同时审视现有挑战并概述未来的研究方向,为开发自我进化框架和下一代模型的重大进展铺平道路。
该调查的组织如下:我们首先介绍自我进化的概述(§2),包括背景和概念框架。 我们总结了当前方法的现有进化能力和领域(§ 3)。 然后,我们对自我进化过程的不同阶段的最新进展进行了深入的分析和讨论,包括经验获取(§ 4)、经验细化(§ 5) >)、更新(§ 6)和评估(§ 7)。 最后,我们概述了未解决的问题和未来的预期方向 (§ 8)。

2概述
在本节中,我们将首先讨论自我进化的背景,然后介绍所提出的概念框架。
2.1背景
人工智能的自我进化。 人工智能代表了智能体的一种高级形式,具有与人类相似的认知能力和行为。 人工智能开发人员的愿望在于使人工智能能够利用自我进化能力,与人类发展的体验式学习过程相平行。 人工智能中自我进化的概念源自更广泛的机器学习和进化算法领域Bäck 和 Schwefel (1993)。 最初受到自然进化原理(例如选择、突变和繁殖)的影响,研究人员开发了模拟这些过程的算法,以优化复杂问题的解决方案。 Holland (1992) 的里程碑式论文引入了遗传算法,标志着人工智能自我进化能力历史上的一个基础性时刻。 神经网络和深度学习的后续发展进一步增强了这种能力,允许人工智能系统在无需人工干预的情况下修改自己的架构并提高性能Liu 等人(2021)。
人造实体可以自我进化吗? 从哲学上讲,人造实体是否能够自我进化的问题涉及自主性、意识和能动性问题。 虽然一些哲学家认为人工智能中真正的自我进化需要某种形式的意识或自我意识,但其他人则认为通过算法进行机械自我改进并不构成真正的进化Chalmers (1997)。 这场争论经常引用Dennett (1993)等思想家的著作,他们探索人类意识下的认知过程,并将其与人工系统进行对比。 最终,对人工智能自我进化能力的哲学探究仍然与“进化”的含义以及此类过程是否可以纯粹是算法或必须涉及新兴意识的解释紧密地交织在一起Searle (1986)。
2.2概念框架
在自我进化的概念框架中,我们描述了一个动态的、迭代的过程,反映了人类获取和完善技能和知识的能力。 该框架封装在图2中,强调学习和改进的循环性质。 该过程的每次迭代都专注于特定的演化目标,允许模型参与相关任务、优化其体验、更新其架构并在进入下一个周期之前评估其进度。
经验获取
在迭代中,模型确定了演化目标。 在此目标的指导下,模型开始执行新任务,生成解决方案并从环境接收反馈。 这个阶段的高潮是获得新的体验。
体验提升
获取经验后,模型会检查并完善这些经验。 这涉及丢弃不正确的数据并增强不完美的数据,从而产生精确的结果。
更新中
利用完善的经验,模型经历了更新过程,将 集成到其框架中。 这可确保模型保持最新状态并进行优化。
评估
该周期以评估阶段结束,其中通过外部环境的评估来评估模型的性能。 这一阶段的结果告知了目标,为后续的自我进化迭代奠定了基础。
概念框架概述了大语言模型的自我进化,类似于人类的获取、完善和自主学习过程。 我们在图 3 中说明了我们的分类法。
for tree= grow=east, growth parent anchor=west, parent anchor=east, child anchor=west, [Self-Evolution of LLMs, root, parent anchor=south [Evaluation (§7), node_lv1 [Qualitative, node_lv2, [Yang et al. (2023b) , LLM Explanation Zheng et al. (2024a) , ChatEval Chan et al. (2023) , node_lv3], ] [Quantitative, node_lv2, [ LLM-as-a-Judge Zheng et al. (2024a); Dubois et al. (2024) , Reward Score Ouyang et al. (2022) , node_lv3], ] ] [Updating (§6), node_lv1, [In-Context, node_lv2 [Working Memory: Reflexion Shinn et al. (2023), IML Wang et al. (2024a), EvolutionaryAgent Li et al. (2024c) , Agent-Pro Zhang et al. (2024d), ProAgent Zhang et al. (2024a) , node_lv3], [External Memory: MoT Li and Qiu (2023), MemoryBank Zhong et al. (2024b), TiM Liu et al. (2023a), IML Wang et al. (2024a), TRAN Yang et al. (2023b), MemGPT Packer et al. (2023) UA Yang et al. (2024d) , ICE Qian et al. (2024), AesopAgent Wang et al. (2024d) , node_lv3], ] [In-Weight, node_lv2 [Architecture: LoRA Hu et al. (2021), ConPET Song et al. (2023), Model Soups Wortsman et al. (2022), DAIR Yu et al. (2023a), UltraFuser Ding et al. (2024), EvoLLM Akiba et al. (2024) , node_lv3], [Regularization: InstuctGPT Ouyang et al. (2022), FuseLLM Wan et al. (2024) , Elastic Reset Noukhovitch et al. (2024), WARM Ramé et al. (2024), AMA Lin et al. (2024) , node_lv3], [Replay: RFT Yuan et al. (2023), ReST Gulcehre et al. (2023); Aksitov et al. (2023) , AMIE Tu et al. (2024), SOTOPIA- Wang et al. (2024e), LLM2LLM Lee et al. (2024), LTC Wang et al. (2023a), AT Yang et al. (2024c), SSR Huang et al. (2024a), SDFT Yang et al. (2024b) , node_lv3], ] ] [Experience Refinement (§5), node_lv1, [Correcting, node_lv2, [Critique-Free: STaR Zelikman et al. (2022), Self-Debugging Chen et al. (2023c), IterRefinement Chen et al. (2023b), Clinical SV Gero et al. (2023) , node_lv3], [Critique-Based: Self-Refine Madaan et al. (2023), CAI Bai et al. (2022), RCI Kim et al. (2023) , SELF Lu et al. (2023), CRITIC Gou et al. (2023), SelfEvolve Jiang et al. (2023), ISR-LLM Zhou et al. (2023b), Reflexion Shinn et al. (2024) , node_lv3], ] [Filtering, node_lv2, [Metric-Free: Self-Consistency Wang et al. (2022) , LMSI Huang et al. (2022), Self-Verification Weng et al. (2023) , CodeT Chen et al. (2022) , node_lv3] [Metric-Based: ReST Singh et al. (2023), AutoAct Qiao et al. (2024), Self-Talk Ulmer et al. (2024), Self-Instruct Wang et al. (2023b) , node_lv3], ] ] [Experience Acquisition (§4), node_lv1 , [Feedback (§4.3), node_lv1_5 [Environment, node_lv2, [ SelfEvolve Jiang et al. (2023), Self-Debugging Chen et al. (2023c), Reflexion Shinn et al. (2023), CRITIC Gou et al. (2023), RoboCat Bousmalis et al. (2023), SinViG Xu et al. (2024b), SOTOPIA- Wang et al. (2024e) , node_lv3_5], ] [Model, node_lv2, [ Self-Reward Yuan et al. (2024), LSX Stammer et al. (2023), DLMA Liu et al. (2024a), SIRLC Pang et al. (2023), Self-Alignment Zhang et al. (2024e), CAI Bai et al. (2022), Self-Refine Madaan et al. (2023) , node_lv3_5], ] ] [Solution (§4.2), node_lv1_5 [Negative, node_lv2, [Perturbative: RLCD Yang et al. (2023a), DLMA Liu et al. (2024a), Ditto Lu et al. (2024a) , node_lv3_5], [Contrastive: Self-Reward Yuan et al. (2024), SPIN Chen et al. (2024), GRATH Chen and Li (2024), Self-Contrast Zhang et al. (2024c), ETO Song et al. (2024), A3T Yang et al. (2024c), STE Wang et al. (2024b), COTERRORSET Tong et al. (2024) , node_lv3_5], ] [Positive, node_lv2, [Grounded: Self-Align Sun et al. (2024), SALMON Sun et al. (2023), MemoryBank Zhong et al. (2024b), TiM Liu et al. (2023a), MoT Li and Qiu (2023), IML Wang et al. (2024a), TRAN Yang et al. (2023b), MemGPT Packer et al. (2023) , node_lv3_5 ], [Self-Play: Debates Taubenfeld et al. (2024), Self-Talk Ulmer et al. (2024), Ditto Lu et al. (2024a), SOLID Askari et al. (2024), SOTOPIA- Wang et al. (2024e) , node_lv3_5], [Interactive: SelfEvolve Jiang et al. (2023), LDB Zhong et al. (2024a), ETO Song et al. (2024), AT Yang et al. (2024c), AutoAct Qiao et al. (2024), KnowAgent Zhu et al. (2024) , node_lv3_5], [Rationale-Based: LMSI Huang et al. (2022), STaR Zelikman et al. (2022), AT Yang et al. (2024c) , node_lv3_5], ] ] [Task (§4.1), node_lv1_5 [Selective, node_lv2, [ DIVERSE-EVOL Wu et al. (2023), SOFT Wang et al. (2024c), Selective Reflection-Tuning Li et al. (2024b) V-STaR Hosseini et al. (2024) , node_lv3_5], ] [Knowledge-Free, node_lv2, [ Self-Instruct Wang et al. (2023b); Honovich et al. (2022); Roziere et al. (2023), Ada-Instruct Cui and Wang (2023), Evol-Instruct Xu et al. (2024a), MetaMath Yu et al. (2023b), PromptBreeder Fernando et al. (2023), Backtranslation Li et al. (2023b), Kun Zheng et al. (2024b) , node_lv3_5], ] [Knowledge-Based, node_lv2, [Unstructured: UltraChat Ding et al. (2023), SciGLM Zhang et al. (2024b), EvIT Tao et al. (2024a), MEEL Tao et al. (2024b) , node_lv3_5], [Structured: Self-Align Sun et al. (2024), Ditto Lu et al. (2024a), SOLID Askari et al. (2024) , node_lv3_5], ] ] ] ]
3进化目标
自进化大语言模型中的进化目标作为预定义目标,自主指导其发展和完善。 就像人类根据需求和愿望设定个人目标一样,这些目标至关重要,因为它们决定了模型如何迭代地自我更新。 它们使大语言模型能够自主地从新数据中学习、优化算法并适应不断变化的环境,从反馈或自我评估中有效地“感受”其需求,并设定自己的目标来增强功能,而无需人工干预。
我们将进化目标定义为进化能力和进化方向的结合。 不断发展的能力代表着与生俱来的、细致的技能。 演化方向是演化目标旨在改进的方面。 我们将进化目标制定如下:
| (1) |
其中是进化目标,由进化能力和进化方向组成。 以“推理准确性提升”为例,“推理”是进化能力,“准确性提升”是进化方向。
3.1 不断发展的能力
在表1中,我们总结并将当前自我进化研究中的目标进化能力分为两类:大语言模型和大语言模型Agents。
3.1.1 LLM
这些是广泛下游任务的基本能力。
指令遵循:遵循指令的能力对于有效应用语言模型至关重要。 它允许这些模型满足不同任务和领域的特定用户需求,在给定的上下文 Xu 等人 (2023a) 内调整他们的响应。
推理:大语言模型可以自我进化,识别统计模式,根据信息进行逻辑联系和推论。 它们不断发展以执行更好的推理,涉及按逻辑顺序Cui and Wang (2023)系统地剖析问题。
数学:大语言模型增强解决数学问题的复杂能力,涵盖算术、数学单词、几何和自动定理证明Ahn等人(2024)走向自我进化。
编码:提高大语言模型编码能力的方法,以生成更精确和鲁棒的程序Singh 等人 (2023); Zelikman 等人 (2023)。 此外,EvoCodeBench Li 等人 (2024a) 提供了一个不断发展的基准,定期更新以防止数据泄露。
角色扮演:它涉及代理在给定上下文中理解并扮演特定角色。 这在模型必须适应社会结构或遵循与特定身份或功能相关的一组行为Lu等人(2024a)的场景中至关重要。
其他:除了上述基本进化目标外,自进化还可以实现广泛的NLP任务Stammer等人(2023); Koa 等人 (2024); Gulcehre 等人 (2023);张等人 (2024b, c).
3.1.2 基于 LLM 的代理
这里讨论的能力是用于在数字或物理世界中解决任务或模拟的高级人工智能体的特征。 这些功能反映了人类的认知功能,使这些代理能够执行复杂的任务并在动态环境中有效地交互。
规划:它涉及为未来的行动或目标制定策略和做好准备的能力。 具有此技能的智能体可以分析当前状态,预测潜在行动的结果,并创建一系列步骤来实现特定目标Qiao 等人 (2024)。
工具使用:这是使用环境中的物体或仪器来执行任务、操纵周围环境或解决问题的能力朱等人 (2024)。
体现控制:指智能体在环境中管理和协调其物理形态的能力。 这包括运动、灵巧性和物体操作Bousmalis 等人 (2023)。
沟通:传达信息并理解来自其他代理或人类的消息的技能。 具有高级沟通能力的智能体可以参与对话、与他人协作,并根据收到的通信Ulmer等人(2024)调整自己的行为。
3.2演化方向
演化方向的示例包括但不限于:
提高性能:目标是不断增强模型对各种语言和能力的理解和生成。 例如,最初训练用于回答问题和闲聊的模型可以自主扩展其熟练程度并发展诊断对话Tu等人(2024)、社交技能Wang等人(2024e)等能力。 t1>,以及角色扮演Lu等人(2024a)。
适应反馈:这涉及根据反馈改进模型响应,以更好地符合偏好或适应环境Yang 等人 (2023a);孙等人(2024)。
知识库扩展:目的是利用最新的信息和趋势不断更新模型的知识库。 例如,模型可能会自动将新的科学研究整合到其响应中 Wu 等人 (2024)。
安全、道德和减少偏差:目标是识别并减轻模型响应中的偏差,确保公平和安全。 一种有效的策略是纳入指南,例如宪法或具体规则,以识别不适当或有偏见的反应,并通过模型更新进行纠正 Bai 等人 (2022);陆等人 (2024b).
| Method | Acquisition | Refinement | Updating | Objective | ||
| Task | Solution | Feedback | ||||
| Large Language Models | ||||||
| Self-Align Sun et al. (2024) | Context-Based | Pos-G | - | Filtering | In-W | IF |
| SciGLM Zhang et al. (2024b) | Context-Based | - | - | - | In-W | Other |
| EvIT Tao et al. (2024a) | Context-Based | - | - | - | In-W | Reasoning |
| MEEL Tao et al. (2024b) | Context-Based | - | - | - | In-W | Reasoning |
| UltraChat Ding et al. (2023) | Context-Based | - | - | - | In-W | Role-Play |
| SOLID Askari et al. (2024) | Context-Based | Pos-S | - | Filtering | In-W | Role-Play |
| Ditto Lu et al. (2024a) | Context-Based | Pos-S, Neg-P | - | - | In-W | Role-Play |
| MetaMath Yu et al. (2023b) | Context-Free | Pos-R | - | - | In-W | Math |
| Self-Rewarding Yuan et al. (2024) | Context-Free | - | Model | - | In-W | IF,Reasoning,Role-Play |
| Kun Zheng et al. (2024b) | Context-Free | - | - | Filtering | In-W | IF,Reasoning |
| PromptBreeder Fernando et al. (2023) | Context-Free | - | - | - | In-C | Math, Reasoning |
| Ada-Instruct Cui and Wang (2023) | Context-Free | - | - | - | In-W | Math, Reasoning, Code |
| Backtranslation Li et al. (2023b) | Context-Free | - | - | - | In-W | IF |
| DiverseEvol Wu et al. (2023) | Selective | Pos-I | - | - | In-W | Code |
| Grath Chen and Li (2024) | Selective | Neg-C | Model | - | In-W | Reasoning |
| REST Singh et al. (2023) | Selective | - | Model | Filtering | In-W | Math, Code |
| SOFT Wang et al. (2024c) | Selective | - | - | - | In-W | IF |
| LSX Stammer et al. (2023) | - | Pos-R | Model | Correcting | In-W | Other |
| LMSI Huang et al. (2022) | - | Pos-R | - | Filtering | In-W | Math |
| TRAN Yang et al. (2023b) | - | Pos-G | - | - | In-C | Reasoning |
| MOT Li and Qiu (2023) | - | Pos-R, Pos-G | - | Filtering | In-C | Math, Reasoning |
| STaR Zelikman et al. (2022) | - | Pos-R, Neg-C | Model | Correct | In-W | Reasoning |
| COTERRORSET Tong et al. (2024) | - | Pos-R, Neg-C | - | - | In-W | Math, Reasoning |
| Self-Debugging Chen et al. (2023c) | - | Pos-I | Env | - | In-C | Code |
| SelfEvolve Jiang et al. (2023) | - | Pos-I | - | - | In-C | Code |
| Reflexion Shinn et al. (2024) | - | Pos-I, Pos-G | - | - | In-C | Code, Reasoning |
| V-STaR Hosseini et al. (2024) | - | Neg-C | Model | Filter | In-W | Math, Code |
| Self-Contrast Zhang et al. (2024e) | - | Neg-C | Model | - | In-W | Reasoning |
| SALMON Sun et al. (2023) | - | Neg-C | Model | - | In-W | IF,Reasoning,Role-Play |
| SPIN Chen et al. (2024) | - | Neg-C | - | - | In-W | IF,Reasoning,Role-Play |
| RLCD Yang et al. (2023a) | - | Neg-P | Model | - | In-W | IF |
| DLMA Liu et al. (2024a) | - | Neg-P | Model | - | In-W | IF |
| SELF Lu et al. (2023) | - | - | Model | Correct | In-W | IF, Math |
| LLM Agents | ||||||
| AutoAct Qiao et al. (2024) | Context-Based | Pos-I | Env | Filtering | In-W | Planning, Tool |
| KnowAgent Zhu et al. (2024) | Context-Based | Pos-I, Pos-G | Env | Filtering | In-W | Embodied, Planning, Tool |
| RoboCat Bousmalis et al. (2023) | Context-Free | Pos-I | Env | - | In-W | Embodied |
| STE Wang et al. (2024b) | Context-Free | Pos-I, Neg-C | Env | Correct | In-W | Tool |
| IML Wang et al. (2024a) | - | Pos-R, Pos-G | - | - | In-C | Reasoning |
| SinViG Xu et al. (2024b) | - | Pos-I | Env | Filtering | In-W | Embodied |
| ETO Song et al. (2024) | - | Pos-I, Neg-C | Env | Correct | In-W | Tool |
| A3T Yang et al. (2024c) | - | Pos-I, Neg-C | Env | Correct | In-W | Tool |
| Debates Taubenfeld et al. (2024) | - | Pos-S | - | - | In-W | Communication |
| SOTOPIA- Wang et al. (2024e) | - | Pos-S,Pos-G | Env | - | In-W | Communication |
| Self-Talk Ulmer et al. (2024) | - | Pos-S, Pos-G | Model | Filtering | In-W | Communication |
| MemGPT Packer et al. (2023) | - | Pos-G | Env | Filtering | In-C | Communication |
| MemoryBank Zhong et al. (2024b) | - | Pos-G | Env | Filtering | In-C | Communication |
| ProAgent Zhang et al. (2024a) | - | Pos-G | Env | - | In-C | Embodied |
| Agent-Pro Zhang et al. (2024d) | - | Pos-G | Env | - | In-C | Planning |
| AesopAgent Wang et al. (2024d) | - | Pos-G | Env | - | In-C | Planning |
| ICE Qian et al. (2024) | - | Pos-G | Env | - | In-C | Planning |
| TiM Liu et al. (2023a) | - | Pos-G | - | - | In-C | Communication |
| Werewolf Xu et al. (2023b) | - | Pos-G | - | - | In-C | Planning |
4经验获取
探索和利用Gupta等人(2006)是人类和大语言模型学习的基本策略。 其中,探索涉及寻求新的经验来实现目标,类似于大语言模型自我进化的初始阶段,称为经验获取。 这个过程对于自我进化至关重要,使模型能够自主应对核心挑战,例如适应新任务、克服知识限制和增强解决方案的有效性。 此外,经验是一个整体构建,不仅包含遇到的任务Dewey (1938),还包含为解决这些任务而开发的解决方案Schön (2017),以及反馈Boud 等人 (2013) 作为任务执行结果而获得。
受此启发,我们将经验获取分为三个部分:任务演化、解决方案演化和获取反馈。 在任务演化中,大语言模型根据演化目标策划和演化新任务。 对于解决方案的演化,大语言模型开发并实施策略来完成这些任务。 最后,大语言模型可以选择收集与环境交互的反馈,以进行进一步的改进。
4.1 任务演变

为了获得新的经验,模型首先根据当前迭代中的演化目标演化出新的任务。 任务进化是引擎中启动整个进化过程的关键步骤。 正式地,我们将任务演化表示为:
| (2) |
其中是任务演化函数。 、 和 分别表示迭代 时的演化目标、模型和演化任务。 我们将有关任务演化方法 的现有研究总结归类为三组:基于知识、无知识和选择性。 我们将在以下部分详细介绍每种类型,并在图 4 中展示概念。
基于知识的
目标可以与外部知识相关联来发展,而该知识本身并不包含在当前大语言模型中。 明确地从知识中获取丰富了任务和进化目标之间的相关性。 它还确保任务中相关事实的有效性。 我们深入研究基于知识的方法,寻求在外部信息的协助下发展不断变化的目标的新任务。
第一种知识是结构化的。 结构化知识信息密集、组织良好。 Self-Align Sun 等人 (2024) 策划生成的主题引导任务,涵盖科学和法律专业知识等 20 个科学主题。 除了主题知识外,DITTO Lu 等人 (2024a) 还包括来自维基数据和维基百科的人物知识。 这些知识包括角色扮演对话的属性、个人资料和简洁的角色细节。 SOLID Askari 等人 (2024) 生成结构化实体知识作为对话开始者。
第二组由非结构化环境中演变而来的任务组成。 非结构化上下文很容易获得,但知识匮乏。 UltraChat丁等人(2023)基于30个元概念收集20种文本材料的非结构化知识来构建对话任务。 SciGLM Zhang 等人(2024b)从多元化的科学学科文本中引出问题,涵盖了丰富的科学知识。 EvIT Tao 等人 (2024a) 基于从无监督语料库中挖掘的大规模非结构化事件推导事件推理任务。 类似地,MEEL Tao 等人 (2024b) 演化了图像和文本中的多模态事件来构建 MM 事件推理的任务。
无知识
与以前需要大量人力来收集外部知识的方法不同,无知识方法使用不断发展的对象 和模型本身独立运行。 这些有效的方法可以在没有额外知识限制的情况下生成更加多样化的任务。
首先,大语言模型可以根据提示自己生成新任务。 自学 Wang 等人 (2023b); Honovich 等人 (2022); Roziere等人(2023)是一种典型的Knowledge-Free任务演化方法论。 这些方法根据进化目标自动生成各种新的任务指令。 Ada-Instruct Cui and Wang (2023)进一步提出了一种自适应任务指令生成策略,该策略对开源大语言模型进行微调,以生成用于代码补全和数学推理的冗长而复杂的任务指令。
其次,扩展和加强原有任务可以提高教学质量。 WizardLM Xu 等人 (2023a) 提出 Evol-Instruct,通过深度和广度进化来演化指令跟随任务,并在代码生成中进一步扩展它 Luo 等人 (2024). MetaMath Yu 等人 (2023b) 以多种方式重写问题,包括改写、自我验证和 FOBAR。 它发展了一个新的 MetaMathQA 数据集,用于微调大语言模型,以提高数学任务的解决能力。 Promptbreeder Fernando 等人 (2023) 通过突变提示进化种子任务。 它通过超突变提示进一步进化突变提示,以增加任务多样性。
第三,从纯文本中派生任务是另一种方法。 回译Li等人(2023b)提取未标记数据中的自包含片段并将其视为任务的答案。 同样,Kun Zheng 等人 (2024b) 提出了一种任务自进化算法,利用未标记数据中的指令进行反向翻译。
可选择的
我们可以从大规模的现有任务开始,而不是生成任务。 在每次迭代中,大语言模型可以选择与当前不断发展的目标表现出最高相关性的任务,而无需额外生成。 这种方法避免了新任务的复杂管理,简化了演化过程Zhou 等人 (2024);李等人 (2023a);陈等人(2023a)。
一种简单的任务选择方法是从任务池中随机抽取任务,例如 REST Gulcehre 等人 (2023)、REST Singh 等人 (2023),GRATH Chen 和 Li (2024) 也这样做。 DIVERSE-EVOL Wu 等人 (2023) 引入了一种数据采样技术,而不是随机选择,其中模型根据嵌入空间中的独特性选择新数据点,确保所选子集中的多样性增强。 SOFT Wang 等人训练 (2024c) 然后分割初始集合。 每次迭代都会选择分割集中的一个块作为演化任务。
Li 等人 (2024b) 提出选择性反射调优,并通过计算答案与问题相关程度的新颖指标来选择任务子集。 V-STaR Hosseini 等人 (2024) 在上一次迭代中选择正确的解决方案,并将其任务指令添加到下一次迭代的任务集中。
4.2解决方案演进
大语言模型获得进化任务后,对任务进行求解,得到相应的解。 最常见的策略是直接根据任务公式生成解决方案 Zelikman 等人 (2022); Gulcehre 等人 (2023);辛格等人 (2023);郑 等人 (2024b);袁等人 (2024). 然而,这种简单的方法可能会得到与进化目标无关的解决方案,从而导致次优进化Hare (2019)。 因此,解决方案演化使用不同的策略来解决任务并通过确保解决方案不仅生成而且具有相关性和信息性来增强大语言模型能力。 在本节中,我们将全面调查这些策略并在图5中进行说明。 我们首先将解决方案演化表述如下:
| (3) |
其中 是模型实现进化目标的策略。
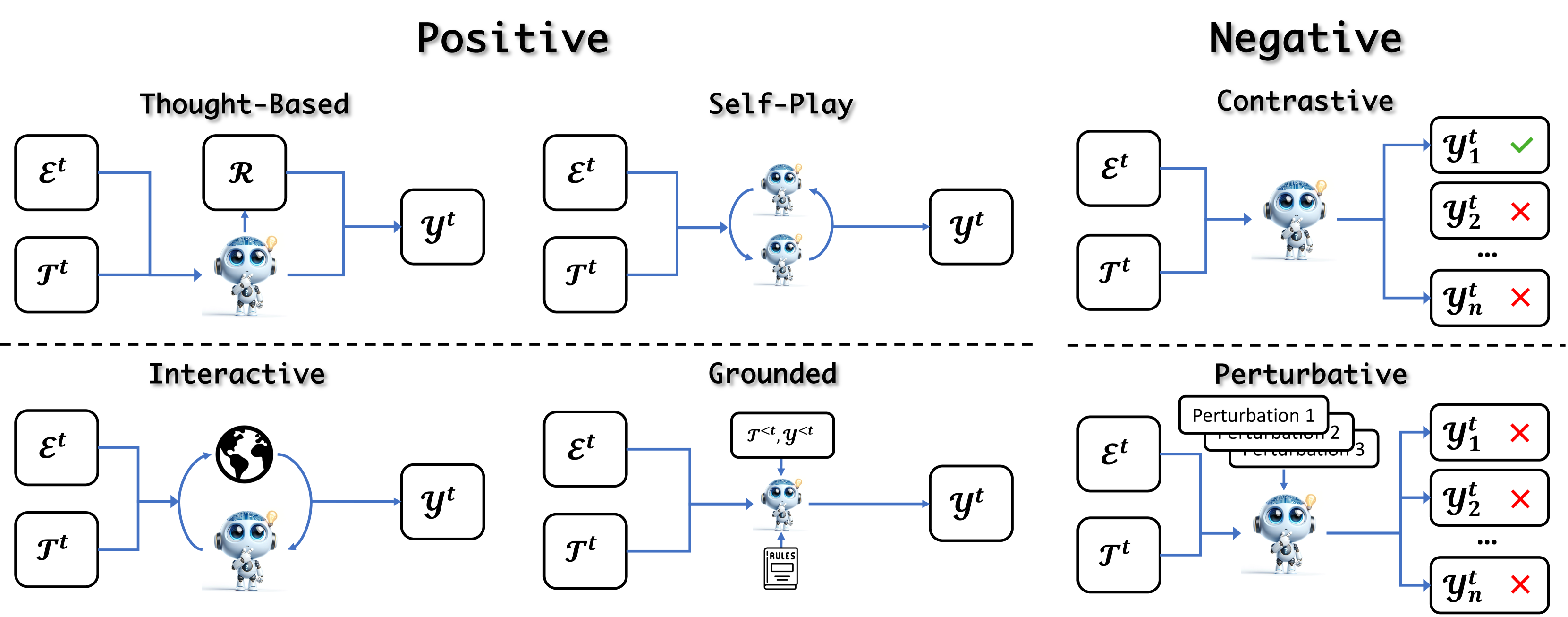
然后,我们根据解决方案的正确性将这些方法分为积极方法和消极方法。 积极方法引入了各种方法来获得正确和理想的解决方案。 相反,消极方法会引出并收集不需要的解决方案,包括不忠实或不一致的模型行为,然后将其用于偏好对齐。 我们将在以下部分中详细说明每种类型的详细信息。
4.2.1正面
当前的研究探索了超越普通推理的多种方法来寻找正解,以获得符合进化目标的正确解决方案。 我们将任务解决过程分为四种类型:基于基本原理的、交互式的、自我游戏的和扎根的。
基于基本原理的
该模型在解决任务时结合了接近不断发展的目标的基本原理解释,并且可以利用这些基本原理进行自我进化。 这些方法使模型能够明确地承认进化目标并朝该方向完成此任务 Wei 等人 (2022);姚等人 (2024); Besta 等人 (2024);姚等人 (2022).
Huang 等人 (2022) 提出了一种大语言模型使用针对未标记问题生成的“高置信度”理由增强答案进行自我进化的方法。 类似地,STAR Zelikman 等人 (2022) 在解决任务时生成基本原理。 如果答案错误,它会进一步纠正理由和答案。 然后,它使用答案和基本原理作为模型的经验。 类似地,LSX Stammer 等人 (2023) 提出了一种新颖的范例来生成答案的解释,在执行基本任务的学习者模块和评估解释质量的批评者模块之间纳入迭代循环由学习者给出。 宋等人 (2024); Yang 等人 (2024c) 在解决任务时以 ReAct Yao 等人 (2022) 风格获取基本原理。 其基本原理将在接下来的步骤中进一步训练代理。
交互的
模型可以与环境交互以增强进化过程。 这些方法可以获得对于指导自我进化方向有价值的环境反馈。
SelfEvolve 和 LDB Jiang 等人 (2023);钟等人(2024a)通过自进化提高代码生成能力。 它们允许模型生成代码并通过在解释器上运行代码来获取反馈。 作为另一个环境,宋等人(2024); Yang等人(2024c)在具体场景中互动并获取反馈。 他们学会根据自己当前的状态采取适当的行动。 对于智能体能力,AutoAct乔等人(2024)从头开始引入自我规划,关注内在的自学习过程。 在此过程中,智能体通过环境反馈的递归规划迭代来增强其能力。 继 AutoAct 之后,Zhu 等人 (2024) 通过整合自我进化和外部动作知识库,进一步增强了智能体训练。 这种方法通过环境驱动的纠正反馈循环来指导行动生成并提高规划能力。
自玩
在这种情况下,模型通过与自身的副本进行对抗来学习进化。 自我博弈是一种强大的进化方法,因为它使系统能够与自身进行通信以在闭环中获得反馈。 它在模型可以模拟角色各个方面的环境中尤其有效,例如多人游戏Silver等人(2016,2017)。 与交互方法相比,自我对战是一种在没有环境的情况下获取反馈的有效策略。
Taubenfeld 等人 (2024) 研究大语言模型模拟辩论时的系统偏差。 与辩论相反,Ulmer 等人 (2024) 按照生成的原则让大语言模型参与对话。 另一种通过角色扮演进行的对话。 Lu等人(2024a)提出了自我模拟的角色扮演对话。 该过程包括用角色概况指导大语言模型并调整其响应以保持与角色知识和风格的一致性。 同样,Askari 等人 (2024) 提出 SOLID 来生成大规模意图感知角色扮演对话。 这种自我游戏方面利用大语言模型的广泛知识来构建信息丰富的交换,从而简化对话生成过程。 Wang 等人 (2024e) 引入了一种新颖的方法,每个大语言模型遵循一个角色并相互沟通以实现其目标。
接地
为了实现不断发展的目标并减少探索空间,模型可以基于现有规则Sun等人(2024)和以前的经验,以在解决任务时提供进一步明确的指导。
大语言模型基于预先定义的规则和原则,可以更有效地生成理想的解决方案。 例如,Self-Align Sun 等人 (2024) 生成具有原则驱动约束的自我演化问题,以指导任务解决过程。 SALMON Sun 等人 (2023) 设计了一套组合原则,要求模型在解决任务时遵循。 Self-Talk Ulmer 等人 (2024) 确保大语言模型根据预设的座席角色生成符合工作流程的对话。 他们基于 GPT-4 提前生成工作流程。
除了预先定义的规则之外,基于以往的经验也可以改进解决方案。 MemoryBank Zhong 等人 (2024b) 和 TiM Liu 等人 (2023a) 通过合并以前的问答记录来回答当前问题。 MoT Li and Qiu (2023)、IML Wang 等人 (2024a) 和 TRAN Yang 等人 (2023b) 而不是以前的解决方案历史> 结合历史中的归纳规则来回答新问题。 MemGPT Packer等人(2023)结合了这些优点,检索了以前的问题、解决方案、诱发事件和用户画像知识。
4.2.2否定
除了获得积极的解决方案外,最近的研究表明,大语言模型还可以从消极的解决方案中受益,以实现自我提升Yang 等人(2023b)。 这种策略类似于人类学习技能时行为的反复试验。 本节总结了获得负解以协助自我进化的典型方法。
对比
一组广泛使用的方法是收集一个任务的多个解决方案,然后对比正面和负面的解决方案以获得改进。
自我奖励,SPIN Yuan 等人 (2024); Chen等人(2024)通过比较高分和低分的答案来更新模型。 同样,GRATH Chen and Li (2024) 生成正确和错误答案。 然后它通过比较这两个答案来训练模型。 自我对比张等人(2024c)对比了这些差异,并将这些差异总结成一个清单,可以用来重新检查和消除差异。 在 ETO Song 等人 (2024) 中,模型与实体环境交互来完成任务并从故障解决方案中进行优化。 A3T Yang 等人 (2024c) 通过在解决任务的每个操作后添加基本原理来改进 ETO。 STE Wang 等人 (2024b) 实施反复试验,模型使用不熟悉的工具解决任务。 它通过分析失败的尝试来学习,以改进未来任务中的问题解决策略。 最近,COTERRORSET Tong 等人 (2024) 获得了 PALM-2 生成的错误解,并提出了错误调整,这要求模型避免犯错误。
扰乱的
与对比相比,扰动方法试图有意添加扰动以获得负解。 模型稍后可以学会避免生成这些否定答案。 添加扰动以获得负解比对比方法更可控。
有些方法添加扰动以产生有害的解决方案Yang等人(2023a);刘等人(2024a)。 给定一项任务,RLCD Yang 等人 (2023a) 策划正向和负向指令,并生成正向和反向解决方案。 DLMA Liu 等人 (2024a) 收集正负指导提示,并随后产生相应的正负解决方案。
另一种方式是融入负面背景,而不是有害的扰动。 同上 Lu 等人 (2024a) 添加负面人物角色以生成不正确的对话。 然后,该模型从负面对话中学习,以发展角色对话能力。
4.3反馈
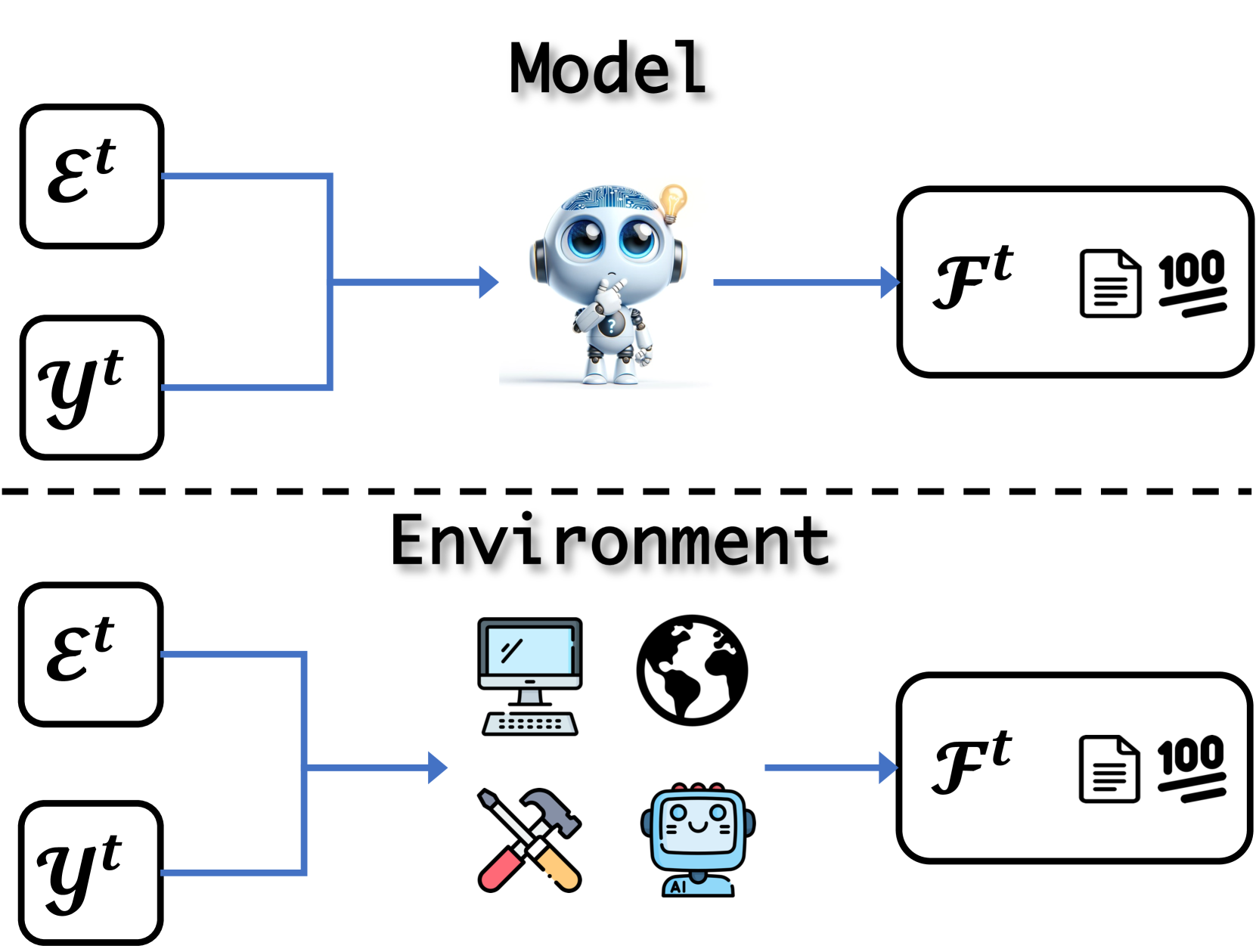
当人类学习技能时,反馈在证明解决方案的正确性方面发挥着至关重要的作用。 这些关键信息使人类能够反思并更新他们的技能。 与这个过程类似,大语言模型应该在自我进化的循环中,在任务解决期间或之后获得反馈。 我们将流程正式化如下:
| (4) |
其中是获取反馈的方法。
在这一部分中,我们总结了两种类型的反馈。 模型反馈是指收集大语言模型本身的评价或评分。 此外,环境表示直接从外部环境收到的反馈。 我们在图 6 中说明了这些概念。
4.3.1模型
目前的研究表明,大语言模型可以很好地扮演批评家Zheng 等人(2024a)。 在自我进化的循环中,模型不断自我判断,获取解的反馈。
反馈的一种类型是指示正确性的分数。 自我奖励 Yuan 等人 (2024)、LSX Stammer 等人 (2023) 和 DLMA Liu 等人 (2024a) 评价自己解决方案并通过LLM-as-a-Judge提示输出分数。 与此类似,SIRLC Pang 等人(2023)利用大语言模型的自我评价结果作为进一步强化学习的奖励。 自对准Zhang 等人 (2024e) 利用大语言模型的自我评估能力来生成其输出的事实准确性的置信度分数。
另一种类型提供文字描述,提供多维信息。 为了通过监督学习改变响应的分布,CAI Bai 等人 (2022) 要求模型根据宪法中的原则批评其响应。 与监督学习和强化学习方法相比,Self-Refine Madaan 等人 (2023) 允许模型以少样本的方式对其自身输出生成自然语言反馈。
4.3.2环境
另一种形式的反馈来自环境,常见于可以直接评估解决方案的任务中。 这种反馈是精确而详尽的,可以为模型更新提供足够的信息。 它们可能源自代码解释器 Jiang 等人 (2023);陈 等人 (2023c); Shinn 等人 (2024),工具执行 Qiao 等人 (2024); Gou 等人 (2023),体现环境 Bousmalis 等人 (2023);徐等人 (2024b); Zhou 等人 (2023b),以及其他大语言模型或代理人 Wang 等人 (2024e); Taubenfeld 等人 (2024); Ulmer 等人 (2024)。
对于代码生成,Self-Debugging Chen 等人 (2023c) 利用测试用例的执行结果作为反馈的一部分,而 SelfEvolve Jiang 等人 (2023) 则接收来自口译员。 类似地,Reflexion Shinn 等人 (2023) 也从代码解释器获取运行时反馈。 然后进一步反思以产生思想。 该运行时反馈包含回溯信息,可以指出改进代码生成的关键信息。
最近,方法赋予大语言模型和智能体使用工具的能力。 执行工具带来反馈 Gou 等人 (2023);乔等人 (2024);宋等人 (2024);杨等人 (2024c);王等人(2024b)。
RoboCat Bousmalis 等人 (2023) 和 SinViG Xu 等人 (2024b) 在机器人实体环境中行动。 这种反馈是精确而有力的,可以指导自我进化。
在基于 LLM 的多智能体系统中,通信反馈是常见且有效的。 代理人可以互相纠正和支持,实现共同评价 Wang 等人 (2024e); Taubenfeld 等人 (2024); Ulmer 等人 (2024)。
5 体验精炼
在经验获取之后、自我进化更新之前,大语言模型可以通过经验精炼来提高输出的质量和可靠性。 它帮助大语言模型在不依赖外部资源的情况下适应新的信息和环境,从而在动态环境中提供更可靠、更有效的帮助。 该过程表述如下:
| (5) |
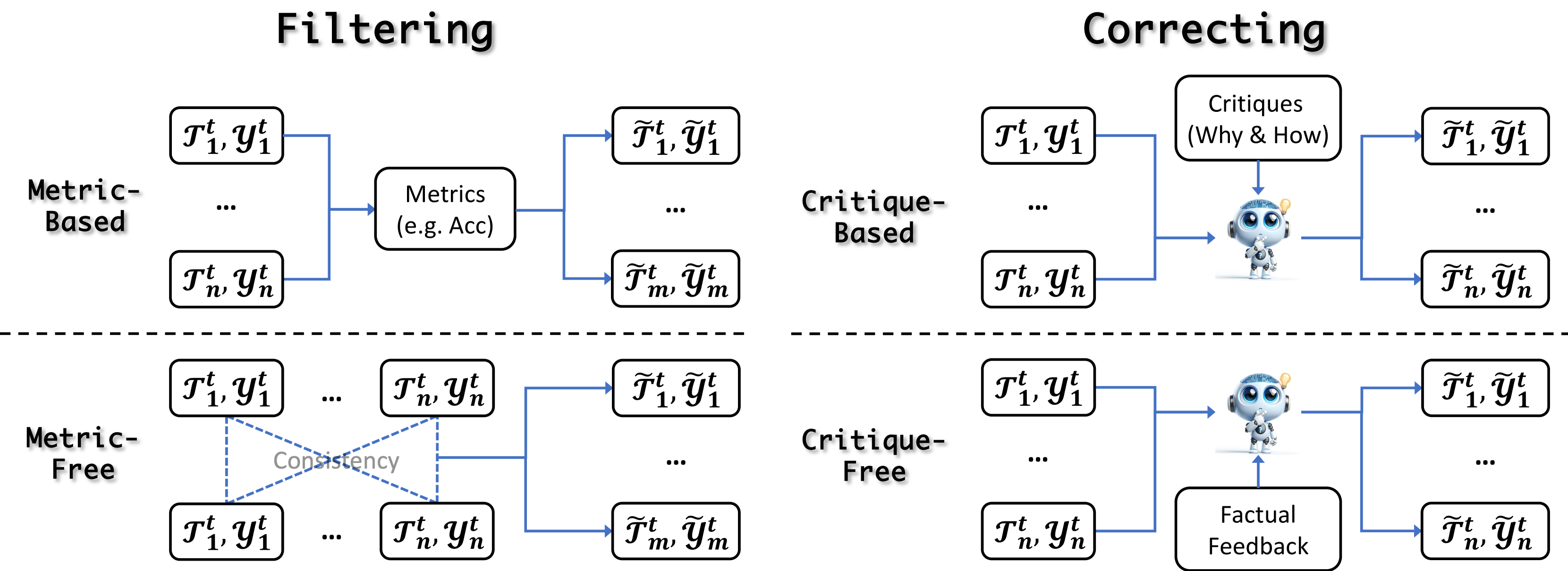
其中是体验细化的方法,是细化的任务和解决方案。 我们将这些方法分为两类:过滤和校正。
5.1过滤
自我进化的细化涉及两种主要的过滤策略:基于度量和无度量。 前者使用外部指标来评估和过滤输出,而后者不依赖这些指标。 这确保了只有最可靠和高质量的数据才能用于进一步更新。
5.1.1 基于指标
通过依赖反馈和预定义的标准,基于度量的过滤提高了输出的质量 Singh 等人 (2023);乔等人 (2024); Ulmer 等人 (2024); Wang等人(2023b),保证大语言模型能力在每次迭代的细化中逐步增强。
例如,ReST Singh 等人 (2023) 结合了奖励函数来过滤从当前策略中采样的数据集。 该函数根据生成样本的正确性提供二元奖励,而不是根据 ReST Gulcehre 等人 (2023) 中根据人类偏好训练的学习奖励模型。 AutoAct Qiao 等人 (2024) 利用 F1 分数和准确性作为合成轨迹的奖励,并收集具有完全正确答案的轨迹以进行进一步的训练。 Self-Talk Ulmer 等人 (2024) 测量已完成的子目标数量来过滤生成的对话,确保只使用高质量的数据进行训练。 为了鼓励源指令的多样性,Self-Instruct Wang 等人 (2023b) 在将低质量或重复的指令添加到任务池之前,会使用 ROUGE-L 相似性和启发式自动过滤它们。
过滤标准或指标对于维持生成输出的质量和可靠性至关重要,从而确保模型能力的持续改进。
5.1.2 无公制
有些方法寻求外部指标之外的过滤策略,使过程更加灵活和适应性强。 无度量过滤通常涉及对输出进行采样,并根据内部一致性度量或其他模型固有标准对其进行评估Huang 等人 (2022);翁等人 (2023);陈等人(2022)。 自我一致性Wang等人(2022)中的过滤是基于多个生成的推理路径中最终答案的一致性,一致性越高表明可靠性越高。 LMSI Huang 等人 (2022) 利用 CoT 提示和自我一致性来生成高置信度的自我训练数据。
设计准确反映输出质量的内部一致性措施可能具有挑战性。 自我验证 Weng 等人 (2023) 允许模型选择具有最高可解释验证分数的候选答案,通过评估预测值和原始条件值之间的一致性来计算。 对于代码生成任务,CodeT Chen 等人 (2022) 既考虑了输出与生成的测试用例的一致性,也考虑了输出与其他代码样本的一致性。
这些方法强调了语言模型根据内部协议进行自我评估和过滤其输出的能力,展示了在无需外部指标直接干预的情况下自我进化的重大进步。
5.2修正
自我进化的最新进展凸显了迭代自我修正的重要性,它使模型能够完善其经验。 本节将所采用的方法分为两类:基于批评和无批评纠正。 批评通常作为强烈的暗示,包括感知错误或次优输出背后的基本原理,指导模型改进迭代。
5.2.1 基于批评
这些方法依赖于额外的评判过程来得出对经验的批评。 然后,根据批评完善经验。 通过利用自行生成的 Madaan 等人 (2023); Bai 等人 (2022); Shinn 等人 (2023); Lu 等人 (2023) 或环境交互产生的批评 Gou 等人 (2023);江等人 (2023); Zhou等人(2023b),该模型受益于细致入微的修正的详细反馈。
大语言模型已经证明了他们识别输出中的错误的能力。 Self-Refine Madaan 等人 (2023) 引入了一个迭代过程,其中模型根据可操作的自我反馈来完善其初始输出,而无需额外的训练。 为了从修正中发展,CAI Bai 等人 (2022) 在监督学习阶段对其输出进行批评和修订,显着改进了初始模型。 应用于自动化计算机任务的代理时,RCI Kim 等人 (2023) 基于对输出中发现错误的批评改进了其先前的输出。
由于较弱的模型可能会在自我批评过程中遇到很大困难,因此有几种方法使模型能够使用外部工具提供的批评来纠正输出。 CRITIC Gou 等人 (2023) 允许大语言模型根据与一般领域的工具交互时获得的批评来修改输出。 SelfEvolve Jiang 等人 (2023) 提示大语言模型根据解释器抛出的错误信息细化答案代码。 ISR-LLM Zhou 等人 (2023b) 通过在迭代自我完善过程中使用验证器,帮助大语言模型规划者找到修改后的行动计划。
这种方法的主要优点在于它能够处理详细的反馈并做出反应,从而可能导致更有针对性和细致入微的纠正。
5.2.2 无批评
与基于批评的方法相反,无批评的方法直接利用客观信息来纠正经验Zelikman 等人 (2022); Chen 等人 (2023c, b); Gero 等人 (2023). 这些方法的优点是独立于批评提供的细致入微的反馈,允许严格遵守事实准确性或具体指导方针进行纠正,而不会因批评而引入潜在的偏见。
一组无批判方法修改了关于任务是否正确解决的信号的经验。 自学推理机 (STaR) Zelikman 等人 (2022) 提出了一种迭代生成原理来回答问题的技术。 如果答案不正确,系统会再次提示模型提供正确答案,以生成更明智的理由。 自调试 Chen 等人 (2023c) 使模型能够通过调查单元测试的执行结果并自行解释代码来执行调试步骤。
与依赖任务解决信号不同,可以利用解决过程中产生的其他信息。 IterRefinement Chen 等人 (2023b) 依赖于一系列精致的提示,鼓励模型在没有任何直接批评的情况下重新考虑和改进其先前的输出。 对于信息提取任务,Clinical SV Gero 等人 (2023) 将输入中的每个元素作为证据,并使用提供的证据修剪不准确的元素。
这些无批评的方法简化了纠正机制,从而更容易实施和更快的调整。

6正在更新
经验细化后,我们进入关键的更新阶段,利用细化的经验来提高模型性能。 我们制定更新如下:
| (6) |
其中是更新函数。 这些更新方法通过适应新的经验并在不断变化的环境和迭代训练过程中不断提高性能来保持模型的有效性。
我们将这些方法分为权重学习(涉及模型权重的更新)和上下文学习(涉及外部或工作记忆的更新)。
6.1体重
更新大语言模型重量的经典训练范式包括连续预训练 Brown 等人 (2020); Roziere 等人 (2023),监督微调 Longpre 等人 (2023),以及偏好对齐 Ouyang 等人 (2022); Touvron 等人 (2023a)。 然而,在自我进化的迭代训练过程中,核心挑战在于实现整体提升和防止灾难性遗忘,这需要在保留原有技能的同时提炼或获得新的能力。 这一挑战的解决方案可以分为三种主要策略:基于重放、基于正则化和基于合并的方法。
6.1.1 基于重播
基于重播的方法重新引入以前的数据以保留旧知识。 一是经验回放,将原训练数据与新训练数据混合更新大语言模型Roziere等人(2023);杨等人 (2024c);郑 等人 (2023); Lee 等人 (2024);王等人(2023a)。 例如,拒绝采样微调(RFT)Yuan 等人(2023)和强化自我训练(ReST)Gulcehre 等人(2023); Aksitov 等人 (2023) 方法通过将种子训练数据与模型本身生成的过滤后的新输出混合来迭代更新大型语言模型。 AMIE Tu 等人 (2024) 利用自对弈模拟学习环境进行迭代改进,并通过内部和外部自对弈循环将生成的对话与监督微调数据混合。 SOTOPIA- Wang 等人 (2024e) 利用专家模型的行为克隆和自我生成的社交互动轨迹来强化积极行为。
另一种是生成重放,它采用自我生成的合成数据作为知识来减轻灾难性遗忘。 例如,自合成排练 (SSR) Huang 等人 (2024a) 生成用于排练的合成训练实例,使模型能够保留其能力,而不依赖于先前训练阶段的真实数据。 自蒸馏微调(SDFT)Yang 等人 (2024b) 从模型本身生成蒸馏数据集,以弥合任务数据集和大语言模型原始分布之间的分布差距,从而减轻灾难性遗忘。
6.1.2 基于正则化
基于正则化的方法限制模型的更新,以防止与原始行为的重大偏差,例如基于函数和权重的正则化。 基于函数的正则化侧重于修改模型在 Zhong 等人 (2023) 期间优化的损失训练函数;彭等人(2023)。 例如,InstuctGPT 欧阳等人(2022)在更新后的策略模型上采用了来自初始策略模型输出概率的每词符 KL-发散惩罚。 FuseLLM Wan 等人 (2024) 采用类似于知识蒸馏 Hinton 等人 (2015) 的技术,利用源大语言模型生成的概率分布来转移集体知识到目标大语言模型。
基于权重的正则化 Kirkpatrick 等人 (2017) 直接针对训练期间模型的权重。 Elastic Reset Noukhovitch 等人 (2024) 等技术通过定期将在线模型重置为其先前状态的指数移动平均值来对抗 RLHF 中的对齐漂移。 此外,Ramé 等人 (2024) 引入了 WARM,它通过权重平均结合了多种奖励模型,以解决奖励黑客和错位问题。 此外,AMA Lin 等人 (2024) 自适应地平均模型权重,以优化奖励最大化和遗忘缓解之间的权衡。
6.1.3 基于架构
基于体系结构的方法明确利用额外的参数或模型进行更新,包括基于分解和合并的方法。 基于分解的方法将大型神经网络参数分为一般组件和特定于任务的组件,并且仅更新特定于任务的参数以减轻遗忘。 LoRA Hu 等人 (2021); Dettmers 等人 (2024) 注入可训练的低秩矩阵,以显着减少可训练参数的数量,同时保持或提高跨各种任务的模型性能。 此范式后来被 GPT4tools Yang 等人 (2024a)、OpenAGI Ge 等人 (2024) 和 Dromedary Sun 等人 (2024) 采用。 Dynamic ConPET Song 等人 (2023) 将预选和预测与特定任务的 LoRA 模块相结合以防止遗忘,确保大语言模型可扩展且有效地适应新任务。
另一方面,基于合并的方法涉及组合多个模型或层以实现总体改进,包括但不限于将多个通用和专用模型权重合并为单个模型 Wortsman 等人 (2022); Ilharco 等人 (2022);于等人 (2023a); Yadav 等人 (2024),通过专家混合方法 Ding 等人 (2024) 甚至分层合并和升级,例如 EvoLLM Akiba 等人(2024)。
6.2上下文
除了直接更新模型参数之外,另一种方法是利用大语言模型的上下文功能从经验中学习,从而无需昂贵的训练成本即可实现快速自适应更新。 这些方法可分为更新外部记忆和工作记忆。
| Method | Content | Operation |
| MoT Li and Qiu (2023) | Experience | Insert |
| TRAN Yang et al. (2023b) | Rationale | Insert, Reflect |
| MemoryBank Zhong et al. (2024b) | Experience, Rationale | Insert, Reflect, Forget |
| MemGPT Packer et al. (2023) | Experience | Insert, Forget |
| TiM Liu et al. (2023a) | Rationale | Insert |
| IML Wang et al. (2024a) | Rationale | Insert, Reflect |
| ICE Qian et al. (2024) | Rationale | Insert, Reflect |
| AesopAgent Wang et al. (2024d) | Experience, Rationale | Insert, Reflect |
外部存储器
这种方法利用外部模块来收集、更新和检索过去的经验和知识,使模型能够访问丰富的见解并在不更新模型参数的情况下获得更好的结果。 外部记忆机制在AI Agent系统中很常见 Xu 等人 (2023b);钱 等人 (2024);王等人 (2024d). 本节详细概述了更新外部存储器的最新方法,重点介绍了存储器内容和更新操作方面,并总结在表2中>。
内容:外部记忆主要存储两种类型的内容:过去的经验和反映的基本原理,每种内容都有不同的用途。 例如,过去的经验提供了宝贵的历史背景,可以作为实现改善成果的指导力量。 MoT Li and Qiu (2023) 归档过滤后的问答对,以构建有益的记忆库。 此外,MemGPT Packer 等人 (2023) 中的 FIFO 队列机制维护消息的滚动历史记录,封装代理和用户之间的交互、系统通知以及函数调用的输入和输出。
另一方面,反映的基本原理提供了支持决策的简洁解释,例如规则。 例如,TRAN Yang 等人 (2023b) 将从经验中推断出的规则与错误信息一起归档,以减少未来的错误。 相应地,TiM Liu 等人 (2023a) 保留了归纳推理,定义为阐明实体之间关系的文本。 此外,IML Wang 等人 (2024a) 和 ICE Qian 等人 (2024) 存储了从一系列轨迹得出的全面注释和规则,展示了广泛的内容类型内存系统可以容纳的。
MemoryBank钟等人(2024b)和AesopAgent王等人(2024d)建立了经验知识库和反思知识库,这是两种记忆的整合。
更新操作: 我们把对内存的操作分为Insert、Reflect和Forget。 最常见的操作是插入,方法将文本内容插入到内存中进行存储Li and Qiu (2023);杨等人 (2023b);钟 等人 (2024b); Packer 等人 (2023);刘等人 (2023a);王等人(2024a)。 另一种操作是反思,即思考和总结以前的经验,以概念化规则和知识以供将来使用Yang等人(2023b);钟 等人 (2024b);王等人 (2024a);钱等人 (2024). 最后,由于记忆存储空间有限,忘记内容对于保持记忆有效和内容有效至关重要。 MemGPT Packer等人(2023)采用先进先出队列来忘记内容。 MemoryBank Zhong 等人 (2024b) 在每个项目的插入时间上建立了一条遗忘曲线。
工作记忆
这些方法利用过去的经验,通过更新内部记忆流、状态或信念(称为工作记忆)来发展智能体的能力,通常以言语提示的形式出现。 Reflexion Shinn 等人 (2023) 引入了言语强化学习,无需传统模型更新即可改进决策。 同样,IML Wang 等人 (2024a) 使基于 LLM 的代理能够通过直接在工作记忆中根据过去的经验总结、提炼和更新知识来自主学习和适应环境。
EvolutionaryAgent Li 等人 (2024c) 通过进化和选择原则,使智能体与动态变化的社会规范保持一致,利用环境反馈进行自我进化。 Agent-Pro Zhang 等人 (2024d) 采用策略级反思和优化,允许代理根据过去的结果在交互场景中调整自己的行为和信念。 最后,ProAgent Zhang 等人 (2024a) 通过动态解释队友的意图和适应行为来增强多智能体系统中的合作。
这些集体作品证明了将过去的经验和知识整合到智能体的记忆流中的重要性,以完善他们的状态或信念,从而提高跨各种任务和环境的性能和适应性。
7评估
就像人类的学习过程一样,必须通过评估来确定当前的能力水平是否足够,是否满足应用要求。 此外,正是从这些评估中,人们可以确定未来学习的方向。 然而,如何准确评估进化模型的性能并为未来的改进提供方向是一个至关重要但尚未充分探索的研究领域。 对于给定的进化模型,我们将评估过程概念化如下:
| (7) |
其中 表示评估函数,用于衡量当前模型的性能得分 () 并为下一次迭代提供不断发展的目标 ()。 评估函数可以分为定量和定性方法,每种方法都提供有关模型性能和需要改进的领域的宝贵见解。
7.1定量评价
该方法侧重于提供可测量的指标来可靠地评估大语言模型的性能,例如自动 Papineni 等人 (2002); Lin (2004) 和人类评估。 然而,传统的自动指标难以准确评估日益复杂的任务,而人工评估并不是自主自我进化的理想选择。 最近的趋势是使用大语言模型作为自动评估器的人工代理,为评估提供经济高效且可扩展的解决方案。
例如,奖励模型分数已被广泛用于衡量模型或任务性能Shinn等人(2024)并选择最佳检查点Ouyang等人(2022)。 LLM 法官郑等人(2024a)使用大语言模型评估大语言模型,采用配对比较、单一答案评分、参考指导评分等方法。 这表明大语言模型可以紧密匹配人类的判断,从而实现高效的大规模评估。
7.2定性评估
定性评估涉及案例研究和分析来得出见解,为后续迭代提供不断发展的指导。 LLM-as-a-judge Zheng 等人 (2024a) 等举措提供了其评估背后的推理; ChatEval Chan 等人 (2023) 通过辩论机制探讨模型输出的优缺点。 此外,TRAN Yang 等人 (2023b) 利用过去的错误来制定增强未来大语言模型性能的规则。 尽管如此,与实例层面的批评或反思相比,任务或模型层面的定性评估仍然需要全面的研究。
8 未解决的问题
8.1 目标:多样性和层次结构
3 部分总结了现有的演进目标及其覆盖范围。 尽管如此,这些突出的目标只能满足人类巨大需求的一小部分。 大语言模型在各种任务和行业中的广泛应用凸显了在为不断发展的目标建立自我进化框架方面尚未解决的挑战,这些框架可以全面解决更广泛的现实世界任务Eloundou等人(2023)。
此外,不断发展的目标的概念需要潜在的等级结构;例如,UltraTool Huang 等人(2024b)和T-Eval Chen 等人(2023d)将工具使用能力分为各个子维度。 将进化目标探索为可管理的子目标并单独追求它们成为一种可行的策略。
总体而言,显然迫切需要开发能够有效解决多样化和分层目标的自我进化框架。
8.2自治程度:从低到高
大型模型中的自我进化正在兴起,但其自主级别缺乏明确的定义。 我们将自我进化分为三层:低、中、高级自主
低级
在此级别中,用户预定义了演化对象并且它保持不变。 用户需要自行设计不断发展的管道,即所有模块。 然后,模型基于设计的框架完成自我进化过程。 我们用以下公式表示这种自我进化水平:
| (8) |
其中表示要演化的模型。 是不断变化的输出。 是环境。 目前的大部分作品都处于这个水平。
中级
在该级别中,用户仅设置演化对象并保持不变。 用户无需设计框架中的具体模块。 模型可以独立构造各个模块进行自进化。 该级别表示如下:
| (9) |
高水平
在最后一级,模型诊断其缺陷并构建自我进化方法来改进自身。 这就是自我进化的最终目的。 用户模型根据评估输出设置自己的演化对象。 不断发展的目标会在迭代过程中发生变化。 此外,模型还设计了框架中的具体模块。 我们将该级别表示为:
| (10) |
正如之前的开放问题(§ 8.1)中所讨论的,还有大量未实现的目标。 然而,现有的自进化框架大多处于底层,需要专门设计的模块 Yuan 等人 (2024);卢等人 (2024a);乔等人 (2024). 这些框架是依赖于目标的,并且依赖于大量的人类努力来开发。 穷尽所有目标并不具有部署效率,因此迫切需要开发中高层自我演化框架。 在中等水平上,不需要专家的努力来设计特定的模块。 大语言模型可以根据目标进行自我进化。 那么在高层次上,大语言模型可以调查他们目前的不足,并有针对性地进行演进。 总而言之,开发高度自主的自我进化框架仍然是一个悬而未决的问题。
8.3经验的获取和提炼:从经验到理论
假设我们已经解决了前两个挑战,开发出了有前途的自我进化框架,那么自我进化大语言模型的探索缺乏坚实的理论基础。 这个想法假设大语言模型可以在有或没有环境反馈的情况下自我改进或纠正其输出。 然而,其背后的机制仍不清楚。 研究结果喜忧参半:Huang 等人 (2023) 在超过 220 亿个参数的模型中观察到自我纠正行为,而 Ganguli 等人 (2023) 发现大语言模型陷入困境无需外部反馈即可自我纠正推理错误。
一个相关的挑战是使用自行生成的数据进行学习。 批评者认为这种方法可能会减少语言多样性 Guo 等人 (2023) 并导致“模型崩溃”,即模型无法捕获复杂的长尾数据分布 Shumailov 等人 (2023) 。 此外,Alemohammad 等人 (2023) 揭示,根据合成输出训练的生成模型会逐渐失去输出质量和多样性。 Fu 等人 (2024) 通过理论上分析自消耗训练循环对模型性能的影响来扩展这一点,强调平衡合成数据和真实数据以减少误差积累的重要性。
近期研究Yang 等人 (2024c); Singh 等人 (2023) 还表明,当前的方法在经过三轮以上的自我进化后很难改进。 一个假设的原因是大语言模型的自我批评并未与不断发展的目标共同进化,但仍需要更多的实验和理论支持。 这些发现凸显了对自我进化大语言模型进行更多理论探索的迫切需要。 解决这些问题对于推动该领域发展并确保模型能够随着时间的推移有效学习和改进至关重要。
8.4 更新:稳定性-塑性困境
稳定性-可塑性困境代表了一个至关重要但尚未解决的挑战,这对于迭代自我进化至关重要。 这种困境反映了平衡保留先前学到的信息(稳定性)和适应新数据或任务(可塑性)的难度。 现有的大语言模型要么忽视这个问题,要么采用可能无效的传统方法。 虽然从头开始训练模型可以缓解灾难性遗忘的问题,但它的效率非常低,特别是当模型参数呈指数级增长且自主学习能力不断提高时。 在获取新技能和保留现有知识之间找到平衡对于实现有效和高效的自我进化,从而实现整体进步至关重要。
8.5评估:系统性和演进性
为了有效评估大语言模型,动态、全面的基准至关重要。 随着我们向通用人工智能(AGI)迈进,这一点变得更加关键。 由于大语言模型不断发展的性质以及通过与搜索引擎等环境交互而可能访问测试数据,从而破坏了其可靠性,传统的静态基准面临着被淘汰的风险。 动态基准,如 Sotopia Zhou 等人 (2023a),提出了一种解决方案,即创建一个基于 LLM 的环境,专门用于评估大语言模型的社交智能,从而避免了静态基准带来的限制。
8.6 安全和超级对准
大语言模型的进步为人工智能系统在支持性决策和自主决策方面达到甚至超越专家级能力提供了可能性。 为了安全起见,确保这些大语言模型符合人类价值观和偏好至关重要,特别是为了减少可能影响政治辩论等领域的固有偏见,正如 Taubenfeld 等人 (2024) 所强调的那样。 OpenAI 的倡议 Superalignment Leike 和 Sutskever (2023) 旨在通过开发可扩展的训练方法、验证对齐模型以及通过可扩展的监督对对齐过程进行压力测试来对齐超级智能 Saunders 等人(2022)、稳健性Perez 等人 (2022)、自动可解释性 Bills 等人 (2023) 以及对抗性测试。 尽管挑战依然存在,但 Superalignment 标志着开发自我进化的大语言模型的初步尝试,该模型以可扩展的方式与人类道德和价值观紧密结合。
9结论
大语言模型向自我进化范式的进化代表了人工智能类似于人类学习过程的变革性转变。 它有望克服当前严重依赖人类标注和教师模型的模型的局限性。 这项调查提出了一个理解和开发自我进化大语言模型的综合框架,围绕经验获取、完善、更新和评估的迭代周期构建。 通过详细介绍该框架内的进展并对进化目标进行分类,我们对当前方法进行了全面概述,并强调了大语言模型自主适应、学习和改进的潜力。 我们还确定了现有的挑战并提出了未来的研究方向,旨在加速向更加动态、智能和高效的模型迈进。 这项工作加深了对自我进化大语言模型的理解。 它为人工智能的重大进步铺平了道路,标志着朝着实现能够在复杂的现实世界任务中超越人类表现的超级智能系统迈出了一步。
致谢
这项工作得到了阿里巴巴集团通过阿里巴巴研究院实习生计划的支持。
参考
- Achiam et al. (2023) Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774.
- Ahn et al. (2024) Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, and Wenpeng Yin. 2024. Large language models for mathematical reasoning: Progresses and challenges. arXiv preprint arXiv:2402.00157.
- Akiba et al. (2024) Takuya Akiba, Makoto Shing, Yujin Tang, Qi Sun, and David Ha. 2024. Evolutionary optimization of model merging recipes. arXiv preprint arXiv:2403.13187.
- Aksitov et al. (2023) Renat Aksitov, Sobhan Miryoosefi, Zonglin Li, Daliang Li, Sheila Babayan, Kavya Kopparapu, Zachary Fisher, Ruiqi Guo, Sushant Prakash, Pranesh Srinivasan, et al. 2023. Rest meets react: Self-improvement for multi-step reasoning llm agent. arXiv preprint arXiv:2312.10003.
- Alemohammad et al. (2023) Sina Alemohammad, Josue Casco-Rodriguez, Lorenzo Luzi, Ahmed Imtiaz Humayun, Hossein Babaei, Daniel LeJeune, Ali Siahkoohi, and Richard Baraniuk. 2023. Self-consuming generative models go mad. In The Twelfth International Conference on Learning Representations.
- Askari et al. (2024) Arian Askari, Roxana Petcu, Chuan Meng, Mohammad Aliannejadi, Amin Abolghasemi, Evangelos Kanoulas, and Suzan Verberne. 2024. Self-seeding and multi-intent self-instructing llms for generating intent-aware information-seeking dialogs. arXiv preprint arXiv:2402.11633.
- Bäck and Schwefel (1993) Thomas Bäck and Hans-Paul Schwefel. 1993. An overview of evolutionary algorithms for parameter optimization. Evolutionary computation, 1(1):1–23.
- Bai et al. (2023) Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report. arXiv preprint arXiv:2309.16609.
- Bai et al. (2022) Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. 2022. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073.
- Besta et al. (2024) Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. 2024. Graph of thoughts: Solving elaborate problems with large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 17682–17690.
- Bills et al. (2023) Steven Bills, Nick Cammarata, Dan Mossing, Henk Tillman, Leo Gao, Gabriel Goh, Ilya Sutskever, Jan Leike, Jeff Wu, and William Saunders. 2023. Language models can explain neurons in language models. URL https://openaipublic. blob. core. windows. net/neuron-explainer/paper/index. html.(Date accessed: 14.05. 2023).
- Boud et al. (2013) David Boud, Rosemary Keogh, and David Walker. 2013. Reflection: Turning experience into learning. Routledge.
- Bousmalis et al. (2023) Konstantinos Bousmalis, Giulia Vezzani, Dushyant Rao, Coline Manon Devin, Alex X Lee, Maria Bauza Villalonga, Todor Davchev, Yuxiang Zhou, Agrim Gupta, Akhil Raju, et al. 2023. Robocat: A self-improving generalist agent for robotic manipulation. Transactions on Machine Learning Research.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Burns et al. (2023) Collin Burns, Pavel Izmailov, Jan Hendrik Kirchner, Bowen Baker, Leo Gao, Leopold Aschenbrenner, Yining Chen, Adrien Ecoffet, Manas Joglekar, Jan Leike, et al. 2023. Weak-to-strong generalization: Eliciting strong capabilities with weak supervision. arXiv preprint arXiv:2312.09390.
- Chalmers (1997) David J Chalmers. 1997. The conscious mind: In search of a fundamental theory. Oxford Paperbacks.
- Chan et al. (2023) Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. 2023. Chateval: Towards better llm-based evaluators through multi-agent debate. In The Twelfth International Conference on Learning Representations.
- Chen et al. (2022) Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and Weizhu Chen. 2022. Codet: Code generation with generated tests. arXiv preprint arXiv:2207.10397.
- Chen et al. (2023a) Lichang Chen, Shiyang Li, Jun Yan, Hai Wang, Kalpa Gunaratna, Vikas Yadav, Zheng Tang, Vijay Srinivasan, Tianyi Zhou, Heng Huang, et al. 2023a. Alpagasus: Training a better alpaca with fewer data. arXiv preprint arXiv:2307.08701.
- Chen et al. (2023b) Pinzhen Chen, Zhicheng Guo, Barry Haddow, and Kenneth Heafield. 2023b. Iterative translation refinement with large language models. arXiv preprint arXiv:2306.03856.
- Chen and Li (2024) Weixin Chen and Bo Li. 2024. Grath: Gradual self-truthifying for large language models. arXiv preprint arXiv:2401.12292.
- Chen et al. (2023c) Xinyun Chen, Maxwell Lin, Nathanael Schaerli, and Denny Zhou. 2023c. Teaching large language models to self-debug. In The 61st Annual Meeting Of The Association For Computational Linguistics.
- Chen et al. (2023d) Zehui Chen, Weihua Du, Wenwei Zhang, Kuikun Liu, Jiangning Liu, Miao Zheng, Jingming Zhuo, Songyang Zhang, Dahua Lin, Kai Chen, et al. 2023d. T-eval: Evaluating the tool utilization capability step by step. arXiv preprint arXiv:2312.14033.
- Chen et al. (2024) Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. 2024. Self-play fine-tuning converts weak language models to strong language models. arXiv preprint arXiv:2401.01335.
- Chung et al. (2022) Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. 2022. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416.
- Collins et al. (2023) Katherine M Collins, Albert Q Jiang, Simon Frieder, Lionel Wong, Miri Zilka, Umang Bhatt, Thomas Lukasiewicz, Yuhuai Wu, Joshua B Tenenbaum, William Hart, et al. 2023. Evaluating language models for mathematics through interactions. arXiv preprint arXiv:2306.01694.
- Cui and Wang (2023) Wanyun Cui and Qianle Wang. 2023. Ada-instruct: Adapting instruction generators for complex reasoning. arXiv preprint arXiv:2310.04484.
- Dennett (1993) Daniel C Dennett. 1993. Consciousness explained. Penguin uk.
- Dettmers et al. (2024) Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2024. Qlora: Efficient finetuning of quantized llms. Advances in Neural Information Processing Systems, 36.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Dewey (1938) John Dewey. 1938. Experience and education: Kappa delta pi. International Honor Society in Education.
- Ding et al. (2024) Ning Ding, Yulin Chen, Ganqu Cui, Xingtai Lv, Ruobing Xie, Bowen Zhou, Zhiyuan Liu, and Maosong Sun. 2024. Mastering text, code and math simultaneously via fusing highly specialized language models. arXiv preprint arXiv:2403.08281.
- Ding et al. (2023) Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. 2023. Enhancing chat language models by scaling high-quality instructional conversations. arXiv preprint arXiv:2305.14233.
- Dubois et al. (2024) Yann Dubois, Chen Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy S Liang, and Tatsunori B Hashimoto. 2024. Alpacafarm: A simulation framework for methods that learn from human feedback. Advances in Neural Information Processing Systems, 36.
- Eloundou et al. (2023) Tyna Eloundou, Sam Manning, Pamela Mishkin, and Daniel Rock. 2023. Gpts are gpts: An early look at the labor market impact potential of large language models. arXiv preprint arXiv:2303.10130.
- Fernando et al. (2023) Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rocktäschel. 2023. Promptbreeder: Self-referential self-improvement via prompt evolution. arXiv preprint arXiv:2309.16797.
- Fu et al. (2024) Shi Fu, Sen Zhang, Yingjie Wang, Xinmei Tian, and Dacheng Tao. 2024. Towards theoretical understandings of self-consuming generative models. arXiv preprint arXiv:2402.11778.
- Ganguli et al. (2023) Deep Ganguli, Amanda Askell, Nicholas Schiefer, Thomas I Liao, Kamilė Lukošiūtė, Anna Chen, Anna Goldie, Azalia Mirhoseini, Catherine Olsson, Danny Hernandez, et al. 2023. The capacity for moral self-correction in large language models. arXiv preprint arXiv:2302.07459.
- Ge et al. (2024) Yingqiang Ge, Wenyue Hua, Kai Mei, Juntao Tan, Shuyuan Xu, Zelong Li, Yongfeng Zhang, et al. 2024. Openagi: When llm meets domain experts. Advances in Neural Information Processing Systems, 36.
- Gero et al. (2023) Zelalem Gero, Chandan Singh, Hao Cheng, Tristan Naumann, Michel Galley, Jianfeng Gao, and Hoifung Poon. 2023. Self-verification improves few-shot clinical information extraction. arXiv preprint arXiv:2306.00024.
- Gou et al. (2023) Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. 2023. Critic: Large language models can self-correct with tool-interactive critiquing. arXiv preprint arXiv:2305.11738.
- Gulcehre et al. (2023) Caglar Gulcehre, Tom Le Paine, Srivatsan Srinivasan, Ksenia Konyushkova, Lotte Weerts, Abhishek Sharma, Aditya Siddhant, Alex Ahern, Miaosen Wang, Chenjie Gu, et al. 2023. Reinforced self-training (rest) for language modeling. arXiv preprint arXiv:2308.08998.
- Guo et al. (2023) Yanzhu Guo, Guokan Shang, Michalis Vazirgiannis, and Chloé Clavel. 2023. The curious decline of linguistic diversity: Training language models on synthetic text. arXiv preprint arXiv:2311.09807.
- Gupta et al. (2006) Anil K Gupta, Ken G Smith, and Christina E Shalley. 2006. The interplay between exploration and exploitation. Academy of management journal, 49(4):693–706.
- Hare (2019) Joshua Hare. 2019. Dealing with sparse rewards in reinforcement learning. arXiv preprint arXiv:1910.09281.
- Hinton et al. (2015) Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531.
- Holland (1992) John H Holland. 1992. Adaptation in natural and artificial systems: an introductory analysis with applications to biology, control, and artificial intelligence. MIT press.
- Honovich et al. (2022) Or Honovich, Thomas Scialom, Omer Levy, and Timo Schick. 2022. Unnatural instructions: Tuning language models with (almost) no human labor. arXiv preprint arXiv:2212.09689.
- Hosseini et al. (2024) Arian Hosseini, Xingdi Yuan, Nikolay Malkin, Aaron Courville, Alessandro Sordoni, and Rishabh Agarwal. 2024. V-star: Training verifiers for self-taught reasoners. arXiv preprint arXiv:2402.06457.
- Hu et al. (2021) Edward J Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. 2021. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations.
- Huang et al. (2024a) Jianheng Huang, Leyang Cui, Ante Wang, Chengyi Yang, Xinting Liao, Linfeng Song, Junfeng Yao, and Jinsong Su. 2024a. Mitigating catastrophic forgetting in large language models with self-synthesized rehearsal. arXiv preprint arXiv:2403.01244.
- Huang et al. (2022) Jiaxin Huang, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, and Jiawei Han. 2022. Large language models can self-improve. arXiv preprint arXiv:2210.11610.
- Huang et al. (2023) Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. 2023. Large language models cannot self-correct reasoning yet. In The Twelfth International Conference on Learning Representations.
- Huang et al. (2024b) Shijue Huang, Wanjun Zhong, Jianqiao Lu, Qi Zhu, Jiahui Gao, Weiwen Liu, Yutai Hou, Xingshan Zeng, Yasheng Wang, Lifeng Shang, et al. 2024b. Planning, creation, usage: Benchmarking llms for comprehensive tool utilization in real-world complex scenarios. arXiv preprint arXiv:2401.17167.
- Ilharco et al. (2022) Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. 2022. Editing models with task arithmetic. In The Eleventh International Conference on Learning Representations.
- Jiang et al. (2023) Shuyang Jiang, Yuhao Wang, and Yu Wang. 2023. Selfevolve: A code evolution framework via large language models. arXiv preprint arXiv:2306.02907.
- Kim et al. (2023) Geunwoo Kim, Pierre Baldi, and Stephen McAleer. 2023. Language models can solve computer tasks. arXiv preprint arXiv:2303.17491.
- Kirkpatrick et al. (2017) James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. 2017. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, 114(13):3521–3526.
- Koa et al. (2024) Kelvin JL Koa, Yunshan Ma, Ritchie Ng, and Tat-Seng Chua. 2024. Learning to generate explainable stock predictions using self-reflective large language models. arXiv preprint arXiv:2402.03659.
- Lee et al. (2024) Nicholas Lee, Thanakul Wattanawong, Sehoon Kim, Karttikeya Mangalam, Sheng Shen, Gopala Anumanchipali, Michael W Mahoney, Kurt Keutzer, and Amir Gholami. 2024. Llm2llm: Boosting llms with novel iterative data enhancement. arXiv preprint arXiv:2403.15042.
- Leike and Sutskever (2023) Jan Leike and Ilya Sutskever. 2023. Introducing superalignment. Accessed: 2024-04-01.
- Li et al. (2024a) Jia Li, Ge Li, Xuanming Zhang, Yihong Dong, and Zhi Jin. 2024a. Evocodebench: An evolving code generation benchmark aligned with real-world code repositories. arXiv preprint arXiv:2404.00599.
- Li et al. (2024b) Ming Li, Lichang Chen, Jiuhai Chen, Shwai He, Jiuxiang Gu, and Tianyi Zhou. 2024b. Selective reflection-tuning: Student-selected data recycling for llm instruction-tuning. arXiv preprint arXiv:2402.10110.
- Li et al. (2023a) Ming Li, Yong Zhang, Zhitao Li, Jiuhai Chen, Lichang Chen, Ning Cheng, Jianzong Wang, Tianyi Zhou, and Jing Xiao. 2023a. From quantity to quality: Boosting llm performance with self-guided data selection for instruction tuning. arXiv preprint arXiv:2308.12032.
- Li et al. (2024c) Shimin Li, Tianxiang Sun, and Xipeng Qiu. 2024c. Agent alignment in evolving social norms. arXiv preprint arXiv:2401.04620.
- Li et al. (2023b) Xian Li, Ping Yu, Chunting Zhou, Timo Schick, Luke Zettlemoyer, Omer Levy, Jason Weston, and Mike Lewis. 2023b. Self-alignment with instruction backtranslation. arXiv preprint arXiv:2308.06259.
- Li and Qiu (2023) Xiaonan Li and Xipeng Qiu. 2023. Mot: Memory-of-thought enables chatgpt to self-improve. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6354–6374.
- Lin (2004) Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pages 74–81.
- Lin et al. (2024) Yong Lin, Hangyu Lin, Wei Xiong, Shizhe Diao, Jianmeng Liu, Jipeng Zhang, Rui Pan, Haoxiang Wang, Wenbin Hu, Hanning Zhang, Hanze Dong, Renjie Pi, Han Zhao, Nan Jiang, Heng Ji, Yuan Yao, and Tong Zhang. 2024. Mitigating the alignment tax of rlhf. In arXiv.
- Liu et al. (2024a) Aiwei Liu, Haoping Bai, Zhiyun Lu, Xiang Kong, Simon Wang, Jiulong Shan, Meng Cao, and Lijie Wen. 2024a. Direct large language model alignment through self-rewarding contrastive prompt distillation. arXiv preprint arXiv:2402.11907.
- Liu et al. (2024b) Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2024b. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. Advances in Neural Information Processing Systems, 36.
- Liu et al. (2023a) Lei Liu, Xiaoyan Yang, Yue Shen, Binbin Hu, Zhiqiang Zhang, Jinjie Gu, and Guannan Zhang. 2023a. Think-in-memory: Recalling and post-thinking enable llms with long-term memory. arXiv preprint arXiv:2311.08719.
- Liu et al. (2023b) Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. 2023b. Agentbench: Evaluating llms as agents. arXiv preprint arXiv:2308.03688.
- Liu et al. (2021) Yuqiao Liu, Yanan Sun, Bing Xue, Mengjie Zhang, Gary G Yen, and Kay Chen Tan. 2021. A survey on evolutionary neural architecture search. IEEE transactions on neural networks and learning systems, 34(2):550–570.
- Longpre et al. (2023) Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, et al. 2023. The flan collection: Designing data and methods for effective instruction tuning. In International Conference on Machine Learning, pages 22631–22648. PMLR.
- Lu et al. (2023) Jianqiao Lu, Wanjun Zhong, Wenyong Huang, Yufei Wang, Fei Mi, Baojun Wang, Weichao Wang, Lifeng Shang, and Qun Liu. 2023. Self: Language-driven self-evolution for large language model. arXiv preprint arXiv:2310.00533.
- Lu et al. (2024a) Keming Lu, Bowen Yu, Chang Zhou, and Jingren Zhou. 2024a. Large language models are superpositions of all characters: Attaining arbitrary role-play via self-alignment. arXiv preprint arXiv:2401.12474.
- Lu et al. (2024b) Xinyu Lu, Bowen Yu, Yaojie Lu, Hongyu Lin, Haiyang Yu, Le Sun, Xianpei Han, and Yongbin Li. 2024b. Sofa: Shielded on-the-fly alignment via priority rule following. arXiv preprint arXiv:2402.17358.
- Luo et al. (2024) Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. 2024. Wizardcoder: Empowering code large language models with evol-instruct. In The Twelfth International Conference on Learning Representations.
- Madaan et al. (2023) Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. 2023. Self-refine: Iterative refinement with self-feedback. arXiv preprint arXiv:2303.17651.
- Miret and Krishnan (2024) Santiago Miret and NM Krishnan. 2024. Are llms ready for real-world materials discovery? arXiv preprint arXiv:2402.05200.
- Noukhovitch et al. (2024) Michael Noukhovitch, Samuel Lavoie, Florian Strub, and Aaron C Courville. 2024. Language model alignment with elastic reset. Advances in Neural Information Processing Systems, 36.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744.
- Packer et al. (2023) Charles Packer, Vivian Fang, Shishir G Patil, Kevin Lin, Sarah Wooders, and Joseph E Gonzalez. 2023. Memgpt: Towards llms as operating systems. arXiv preprint arXiv:2310.08560.
- Pang et al. (2023) Jing-Cheng Pang, Pengyuan Wang, Kaiyuan Li, Xiong-Hui Chen, Jiacheng Xu, Zongzhang Zhang, and Yang Yu. 2023. Language model self-improvement by reinforcement learning contemplation. arXiv preprint arXiv:2305.14483.
- Papineni et al. (2002) Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318.
- Peng et al. (2023) Keqin Peng, Liang Ding, Qihuang Zhong, Yuanxin Ouyang, Wenge Rong, Zhang Xiong, and Dacheng Tao. 2023. Token-level self-evolution training for sequence-to-sequence learning. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 841–850.
- Perez et al. (2022) Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. 2022. Red teaming language models with language models. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3419–3448.
- Qian et al. (2024) Cheng Qian, Shihao Liang, Yujia Qin, Yining Ye, Xin Cong, Yankai Lin, Yesai Wu, Zhiyuan Liu, and Maosong Sun. 2024. Investigate-consolidate-exploit: A general strategy for inter-task agent self-evolution. arXiv preprint arXiv:2401.13996.
- Qiao et al. (2024) Shuofei Qiao, Ningyu Zhang, Runnan Fang, Yujie Luo, Wangchunshu Zhou, Yuchen Eleanor Jiang, Chengfei Lv, and Huajun Chen. 2024. Autoact: Automatic agent learning from scratch via self-planning. arXiv preprint arXiv:2401.05268.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67.
- Ramé et al. (2024) Alexandre Ramé, Nino Vieillard, Léonard Hussenot, Robert Dadashi, Geoffrey Cideron, Olivier Bachem, and Johan Ferret. 2024. Warm: On the benefits of weight averaged reward models. arXiv preprint arXiv:2401.12187.
- Roziere et al. (2023) Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al. 2023. Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950.
- Saunders et al. (2022) William Saunders, Catherine Yeh, Jeff Wu, Steven Bills, Long Ouyang, Jonathan Ward, and Jan Leike. 2022. Self-critiquing models for assisting human evaluators. arXiv preprint arXiv:2206.05802.
- Schoenegger et al. (2024) Philipp Schoenegger, Peter S Park, Ezra Karger, and Philip E Tetlock. 2024. Ai-augmented predictions: Llm assistants improve human forecasting accuracy. arXiv preprint arXiv:2402.07862.
- Schön (2017) Donald A Schön. 2017. The reflective practitioner: How professionals think in action. Routledge.
- Searle (1986) John R Searle. 1986. Minds, brains and science. Harvard university press.
- Shinn et al. (2024) Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2024. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems, 36.
- Shinn et al. (2023) Noah Shinn, Beck Labash, and Ashwin Gopinath. 2023. Reflexion: an autonomous agent with dynamic memory and self-reflection. arXiv preprint arXiv:2303.11366.
- Shumailov et al. (2023) Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, and Ross Anderson. 2023. The curse of recursion: Training on generated data makes models forget. arXiv preprint arXiv:2305.17493.
- Silver et al. (2016) David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. 2016. Mastering the game of go with deep neural networks and tree search. nature, 529(7587):484–489.
- Silver et al. (2017) David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, et al. 2017. Mastering chess and shogi by self-play with a general reinforcement learning algorithm. arXiv preprint arXiv:1712.01815.
- Singh et al. (2023) Avi Singh, John D Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Peter J Liu, James Harrison, Jaehoon Lee, Kelvin Xu, Aaron Parisi, et al. 2023. Beyond human data: Scaling self-training for problem-solving with language models. arXiv preprint arXiv:2312.06585.
- Song et al. (2023) Chenyang Song, Xu Han, Zheni Zeng, Kuai Li, Chen Chen, Zhiyuan Liu, Maosong Sun, and Tao Yang. 2023. Conpet: Continual parameter-efficient tuning for large language models. arXiv preprint arXiv:2309.14763.
- Song et al. (2024) Yifan Song, Da Yin, Xiang Yue, Jie Huang, Sujian Li, and Bill Yuchen Lin. 2024. Trial and error: Exploration-based trajectory optimization for llm agents. arXiv preprint arXiv:2403.02502.
- Stammer et al. (2023) Wolfgang Stammer, Felix Friedrich, David Steinmann, Hikaru Shindo, and Kristian Kersting. 2023. Learning by self-explaining.
- Sun et al. (2023) Zhiqing Sun, Yikang Shen, Hongxin Zhang, Qinhong Zhou, Zhenfang Chen, David Cox, Yiming Yang, and Chuang Gan. 2023. Salmon: Self-alignment with principle-following reward models. arXiv preprint arXiv:2310.05910.
- Sun et al. (2024) Zhiqing Sun, Yikang Shen, Qinhong Zhou, Hongxin Zhang, Zhenfang Chen, David Cox, Yiming Yang, and Chuang Gan. 2024. Principle-driven self-alignment of language models from scratch with minimal human supervision. Advances in Neural Information Processing Systems, 36.
- Tan et al. (2023) Yiming Tan, Dehai Min, Yu Li, Wenbo Li, Nan Hu, Yongrui Chen, and Guilin Qi. 2023. Evaluation of chatgpt as a question answering system for answering complex questions. arXiv preprint arXiv:2303.07992.
- Tao et al. (2024a) Zhengwei Tao, Xiancai Chen, Zhi Jin, Xiaoying Bai, Haiyan Zhao, and Yiwei Lou. 2024a. Evit: Event-oriented instruction tuning for event reasoning.
- Tao et al. (2024b) Zhengwei Tao, Zhi Jin, Junqiang Huang, Xiancai Chen, Xiaoying Bai, Haiyan Zhao, Yifan Zhang, and Chongyang Tao. 2024b. Meel: Multi-modal event evolution learning.
- Taubenfeld et al. (2024) Amir Taubenfeld, Yaniv Dover, Roi Reichart, and Ariel Goldstein. 2024. Systematic biases in llm simulations of debates. arXiv preprint arXiv:2402.04049.
- Team et al. (2023) Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. 2023. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805.
- Tong et al. (2024) Yongqi Tong, Dawei Li, Sizhe Wang, Yujia Wang, Fei Teng, and Jingbo Shang. 2024. Can llms learn from previous mistakes? investigating llms’ errors to boost for reasoning. arXiv preprint arXiv:2403.20046.
- Touvron et al. (2023a) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023a. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023b. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Tu et al. (2024) Tao Tu, Anil Palepu, Mike Schaekermann, Khaled Saab, Jan Freyberg, Ryutaro Tanno, Amy Wang, Brenna Li, Mohamed Amin, Nenad Tomasev, et al. 2024. Towards conversational diagnostic ai. arXiv preprint arXiv:2401.05654.
- Ulmer et al. (2024) Dennis Ulmer, Elman Mansimov, Kaixiang Lin, Justin Sun, Xibin Gao, and Yi Zhang. 2024. Bootstrapping llm-based task-oriented dialogue agents via self-talk. arXiv preprint arXiv:2401.05033.
- Wan et al. (2024) Fanqi Wan, Xinting Huang, Deng Cai, Xiaojun Quan, Wei Bi, and Shuming Shi. 2024. Knowledge fusion of large language models. In The Twelfth International Conference on Learning Representations.
- Wang et al. (2024a) Bo Wang, Tianxiang Sun, Hang Yan, Siyin Wang, Qingyuan Cheng, and Xipeng Qiu. 2024a. In-memory learning: A declarative learning framework for large language models. arXiv preprint arXiv:2403.02757.
- Wang et al. (2024b) Boshi Wang, Hao Fang, Jason Eisner, Benjamin Van Durme, and Yu Su. 2024b. Llms in the imaginarium: Tool learning through simulated trial and error. arXiv preprint arXiv:2403.04746.
- Wang et al. (2024c) Haoyu Wang, Guozheng Ma, Ziqiao Meng, Zeyu Qin, Li Shen, Zhong Zhang, Bingzhe Wu, Liu Liu, Yatao Bian, Tingyang Xu, et al. 2024c. Step-on-feet tuning: Scaling self-alignment of llms via bootstrapping. arXiv preprint arXiv:2402.07610.
- Wang et al. (2024d) Jiuniu Wang, Zehua Du, Yuyuan Zhao, Bo Yuan, Kexiang Wang, Jian Liang, Yaxi Zhao, Yihen Lu, Gengliang Li, Junlong Gao, et al. 2024d. Aesopagent: Agent-driven evolutionary system on story-to-video production. arXiv preprint arXiv:2403.07952.
- Wang et al. (2023a) Kuan Wang, Yadong Lu, Michael Santacroce, Yeyun Gong, Chao Zhang, and Yelong Shen. 2023a. Adapting llm agents through communication. arXiv preprint arXiv:2310.01444.
- Wang et al. (2024e) Ruiyi Wang, Haofei Yu, Wenxin Zhang, Zhengyang Qi, Maarten Sap, Graham Neubig, Yonatan Bisk, and Hao Zhu. 2024e. Sotopia-: Interactive learning of socially intelligent language agents. arXiv preprint arXiv:2403.08715.
- Wang et al. (2022) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171.
- Wang et al. (2023b) Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2023b. Self-instruct: Aligning language models with self-generated instructions. In The 61st Annual Meeting Of The Association For Computational Linguistics.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837.
- Weng et al. (2023) Yixuan Weng, Minjun Zhu, Fei Xia, Bin Li, Shizhu He, Shengping Liu, Bin Sun, Kang Liu, and Jun Zhao. 2023. Large language models are better reasoners with self-verification. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 2550–2575.
- Wortsman et al. (2022) Mitchell Wortsman, Gabriel Ilharco, Samir Ya Gadre, Rebecca Roelofs, Raphael Gontijo-Lopes, Ari S Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, et al. 2022. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In International conference on machine learning, pages 23965–23998. PMLR.
- Wu et al. (2023) Shengguang Wu, Keming Lu, Benfeng Xu, Junyang Lin, Qi Su, and Chang Zhou. 2023. Self-evolved diverse data sampling for efficient instruction tuning. arXiv preprint arXiv:2311.08182.
- Wu et al. (2024) Tongtong Wu, Linhao Luo, Yuan-Fang Li, Shirui Pan, Thuy-Trang Vu, and Gholamreza Haffari. 2024. Continual learning for large language models: A survey. arXiv preprint arXiv:2402.01364.
- Xu et al. (2023a) Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. 2023a. Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244.
- Xu et al. (2024a) Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, Qingwei Lin, and Daxin Jiang. 2024a. WizardLM: Empowering large pre-trained language models to follow complex instructions. In The Twelfth International Conference on Learning Representations.
- Xu et al. (2024b) Jie Xu, Hanbo Zhang, Xinghang Li, Huaping Liu, Xuguang Lan, and Tao Kong. 2024b. Sinvig: A self-evolving interactive visual agent for human-robot interaction. arXiv preprint arXiv:2402.11792.
- Xu et al. (2023b) Yuzhuang Xu, Shuo Wang, Peng Li, Fuwen Luo, Xiaolong Wang, Weidong Liu, and Yang Liu. 2023b. Exploring large language models for communication games: An empirical study on werewolf. arXiv preprint arXiv:2309.04658.
- Yadav et al. (2024) Prateek Yadav, Derek Tam, Leshem Choshen, Colin A Raffel, and Mohit Bansal. 2024. Ties-merging: Resolving interference when merging models. Advances in Neural Information Processing Systems, 36.
- Yang et al. (2023a) Kevin Yang, Dan Klein, Asli Celikyilmaz, Nanyun Peng, and Yuandong Tian. 2023a. Rlcd: Reinforcement learning from contrastive distillation for lm alignment. In The Twelfth International Conference on Learning Representations.
- Yang et al. (2024a) Rui Yang, Lin Song, Yanwei Li, Sijie Zhao, Yixiao Ge, Xiu Li, and Ying Shan. 2024a. Gpt4tools: Teaching large language model to use tools via self-instruction. Advances in Neural Information Processing Systems, 36.
- Yang et al. (2023b) Zeyuan Yang, Peng Li, and Yang Liu. 2023b. Failures pave the way: Enhancing large language models through tuning-free rule accumulation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 1751–1777.
- Yang et al. (2024b) Zhaorui Yang, Qian Liu, Tianyu Pang, Han Wang, Haozhe Feng, Minfeng Zhu, and Wei Chen. 2024b. Self-distillation bridges distribution gap in language model fine-tuning. arXiv preprint arXiv:2402.13669.
- Yang et al. (2024c) Zonghan Yang, Peng Li, Ming Yan, Ji Zhang, Fei Huang, and Yang Liu. 2024c. React meets actre: Autonomous annotations of agent trajectories for contrastive self-training. arXiv preprint arXiv:2403.14589.
- Yang et al. (2024d) Zonghan Yang, An Liu, Zijun Liu, Kaiming Liu, Fangzhou Xiong, Yile Wang, Zeyuan Yang, Qingyuan Hu, Xinrui Chen, Zhenhe Zhang, et al. 2024d. Towards unified alignment between agents, humans, and environment. arXiv preprint arXiv:2402.07744.
- Yao et al. (2024) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2024. Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 36.
- Yao et al. (2022) Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629.
- Yu et al. (2023a) Le Yu, Bowen Yu, Haiyang Yu, Fei Huang, and Yongbin Li. 2023a. Language models are super mario: Absorbing abilities from homologous models as a free lunch. arXiv preprint arXiv:2311.03099.
- Yu et al. (2023b) Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. 2023b. Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284.
- Yuan et al. (2024) Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. 2024. Self-rewarding language models. arXiv preprint arXiv:2401.10020.
- Yuan et al. (2023) Zheng Yuan, Hongyi Yuan, Chengpeng Li, Guanting Dong, Chuanqi Tan, and Chang Zhou. 2023. Scaling relationship on learning mathematical reasoning with large language models. arXiv preprint arXiv:2308.01825.
- Zelikman et al. (2023) Eric Zelikman, Eliana Lorch, Lester Mackey, and Adam Tauman Kalai. 2023. Self-taught optimizer (stop): Recursively self-improving code generation. arXiv preprint arXiv:2310.02304.
- Zelikman et al. (2022) Eric Zelikman, Jesse Mu, Noah D Goodman, and Yuhuai Tony Wu. 2022. Star: Self-taught reasoner bootstrapping reasoning with reasoning. Advances in Neural Information Processing Systems (NeurIPS).
- Zhang et al. (2024a) Ceyao Zhang, Kaijie Yang, Siyi Hu, Zihao Wang, Guanghe Li, Yihang Sun, Cheng Zhang, Zhaowei Zhang, Anji Liu, Song-Chun Zhu, et al. 2024a. Proagent: building proactive cooperative agents with large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 17591–17599.
- Zhang et al. (2024b) Dan Zhang, Ziniu Hu, Sining Zhoubian, Zhengxiao Du, Kaiyu Yang, Zihan Wang, Yisong Yue, Yuxiao Dong, and Jie Tang. 2024b. Sciglm: Training scientific language models with self-reflective instruction annotation and tuning. arXiv preprint arXiv:2401.07950.
- Zhang et al. (2024c) Wenqi Zhang, Yongliang Shen, Linjuan Wu, Qiuying Peng, Jun Wang, Yueting Zhuang, and Weiming Lu. 2024c. Self-contrast: Better reflection through inconsistent solving perspectives.
- Zhang et al. (2024d) Wenqi Zhang, Ke Tang, Hai Wu, Mengna Wang, Yongliang Shen, Guiyang Hou, Zeqi Tan, Peng Li, Yueting Zhuang, and Weiming Lu. 2024d. Agent-pro: Learning to evolve via policy-level reflection and optimization. arXiv preprint arXiv:2402.17574.
- Zhang et al. (2024e) Xiaoying Zhang, Baolin Peng, Ye Tian, Jingyan Zhou, Lifeng Jin, Linfeng Song, Haitao Mi, and Helen Meng. 2024e. Self-alignment for factuality: Mitigating hallucinations in llms via self-evaluation. arXiv preprint arXiv:2402.09267.
- Zheng et al. (2023) Haoqi Zheng, Qihuang Zhong, Liang Ding, Zhiliang Tian, Xin Niu, Changjian Wang, Dongsheng Li, and Dacheng Tao. 2023. Self-evolution learning for mixup: Enhance data augmentation on few-shot text classification tasks. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 8964–8974.
- Zheng et al. (2024a) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2024a. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems, 36.
- Zheng et al. (2024b) Tianyu Zheng, Shuyue Guo, Xingwei Qu, Jiawei Guo, Weixu Zhang, Xinrun Du, Chenghua Lin, Wenhao Huang, Wenhu Chen, Jie Fu, et al. 2024b. Kun: Answer polishment for chinese self-alignment with instruction back-translation. arXiv preprint arXiv:2401.06477.
- Zhong et al. (2024a) Li Zhong, Zilong Wang, and Jingbo Shang. 2024a. Ldb: A large language model debugger via verifying runtime execution step-by-step. arXiv preprint arXiv:2402.16906.
- Zhong et al. (2023) Qihuang Zhong, Liang Ding, Juhua Liu, Bo Du, and Dacheng Tao. 2023. Self-evolution learning for discriminative language model pretraining. In Findings of the Association for Computational Linguistics: ACL 2023, pages 4130–4145.
- Zhong et al. (2024b) Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. 2024b. Memorybank: Enhancing large language models with long-term memory. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19724–19731.
- Zhou et al. (2024) Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. 2024. Lima: Less is more for alignment. Advances in Neural Information Processing Systems, 36.
- Zhou et al. (2023a) Xuhui Zhou, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Yu, Zhengyang Qi, Louis-Philippe Morency, Yonatan Bisk, Daniel Fried, Graham Neubig, et al. 2023a. Sotopia: Interactive evaluation for social intelligence in language agents. In The Twelfth International Conference on Learning Representations.
- Zhou et al. (2023b) Zhehua Zhou, Jiayang Song, Kunpeng Yao, Zhan Shu, and Lei Ma. 2023b. Isr-llm: Iterative self-refined large language model for long-horizon sequential task planning. arXiv preprint arXiv:2308.13724.
- Zhu et al. (2024) Yuqi Zhu, Shuofei Qiao, Yixin Ou, Shumin Deng, Ningyu Zhang, Shiwei Lyu, Yue Shen, Lei Liang, Jinjie Gu, and Huajun Chen. 2024. Knowagent: Knowledge-augmented planning for llm-based agents. arXiv preprint arXiv:2403.03101.