VASA-1:实时生成逼真的音频驱动说话面孔
摘要
我们介绍了 VASA,这是一个框架,可以在给定单个静态图像和语音音频剪辑的情况下生成具有吸引人的视觉情感技能 (VAS) 的逼真说话面孔。 我们的首屈一指的模型 VASA-1 不仅能够产生与音频完美同步的嘴唇运动,还能捕捉大量面部细微差别和自然头部运动,有助于感知真实性和活力。 核心创新包括基于扩散的整体面部动态和头部运动生成模型,该模型在面部潜在空间中工作,以及使用视频开发这种富有表现力和解开的面部潜在空间。 通过广泛的实验,包括对一组新指标的评估,我们表明我们的方法在各个维度上都显着优于以前的方法。 我们的方法可提供具有逼真的面部和头部动态的高视频质量,并且还支持以高达 40 FPS 的速度在线生成 512512 个视频,并且启动延迟可以忽略不计。 它为与模仿人类对话行为的逼真化身进行实时互动铺平了道路。 项目网页:https://www.microsoft.com/en-us/research/project/vasa-1/
1简介
在多媒体和通信领域,人脸不仅仅是一张面孔,而是一块动态的画布,每一个微妙的动作和表情都可以表达情感,传达无声的信息,并培养同理心。 人工智能生成的会说话的面孔的出现为未来打开了一个窗口,技术将增强人与人以及人与人工智能交互的丰富性。 这种技术有望丰富数字通信wang2021one; ma2021pixel ,提高有沟通障碍的人的可访问性johnson2018assessing ; prnewswire2024deepbrain,通过交互式人工智能辅导改变教育方式bozkurt2023speculative; kessler2018technology,并在医疗保健领域提供治疗支持和社交互动rehm2016role; leff2014头像 。
作为实现此类功能的一个步骤,我们的工作引入了 VASA-1,这是一种新方法,可以生成高度真实和生动的音频生成的说话面孔。 给定任意个人的静态面部图像,以及任何人的语音音频片段,我们的方法能够有效地生成超现实的说话面部视频。 该视频不仅具有与音频输入精确同步的嘴唇动作,而且还展示了各种自然、类人的面部动态和头部动作。
近年来,从音频创建会说话的面孔引起了人们的广泛关注,提出了多种方法zhou2020makelttalk;普拉吉瓦尔2020唇;张2021流; sun2021speech2talking ;郭2021广告; wang2021audio2head ;王2022一个; wang2023唇形器; yu2023 说话 ;张2023sadtalker ; ma2023风格谈话; he2024gaia 。 然而,现有技术还远未达到自然说话面孔的真实性。 目前的研究主要集中在唇形同步的精度上,并且获得了有希望的精度 prajwal2020lip ; wang2023lipformer . 富有表现力的面部动态的创建和逼真的面部行为的微妙差别在很大程度上仍然被忽视。 这会导致生成的面孔显得僵硬且缺乏说服力。 此外,自然的头部运动在增强现实感方面也发挥着至关重要的作用。 尽管最近的研究试图模拟真实的头部运动wang2021audio2head; yu2023 说话 ; zhang2023sadtalker,生成的动画和真实的人体运动模式之间仍然存在相当大的差距。

另一个重要因素是生成效率,它在实时通信等实时应用中发挥着关键作用。 虽然图像和视频扩散技术在说话人脸生成方面带来了显着进步du2023dae; stypulkowski2024扩散; tian2024emo 以及更广泛的视频生成领域 blattmann2023stable ; videoworldsimulators2024,大量的计算需求限制了它们在交互式系统中的实用性。 迫切需要优化算法来弥合高质量视频合成与实时应用程序的低延迟要求之间的差距。
考虑到现有方法的局限性,这项工作开发了一种高效而强大的音频调节生成模型,该模型在头部和面部运动的潜在空间中工作。 与之前的工作不同,我们在整体面部动态以及头部运动的潜在空间上训练了一个 Diffusion Transformer 模型。 我们将所有可能的面部动态——包括嘴唇运动、(非嘴唇)表情、眼睛注视和眨眼等——视为单个潜在变量,并以统一的方式对其概率分布进行建模。 相比之下,现有方法通常针对不同因素应用单独的模型,即使对它们使用交错的回归和生成公式wang2021audio2head;周2021姿势; yu2023 说话 ;王2023进步; zhang2023sadtalker . 我们的整体面部动力学建模,加上共同学习的头部运动模式,导致了各种逼真且情感丰富的谈话行为的产生。 此外,我们将一组可选的条件信号(例如主要注视方向、头部距离和情绪偏移)纳入学习过程中。 这使得复杂分布的生成建模更加容易处理,并提高了生成的可控性。
为了实现我们的目标,另一个挑战在于为上述整体面部动态构建潜在空间并收集扩散模型训练的数据。 除了面部和头部运动之外,人脸图像还包含其他因素,例如身份和外观。 在这项工作中,我们寻求使用大量的面部视频为人脸构建适当的潜在空间。 我们的目标是使面部潜在空间既具有面部动态与其他因素之间解开的完全状态,又具有高度表现力,以建模丰富的面部外观细节和动态的细微差别。 我们的方法基于 3D 辅助表示 wang2021one ; drobyshev2022megaportraits 并为其配备了一系列精心设计的损失函数。 以自监督或弱监督的方式对人脸视频进行训练,我们的编码器可以产生良好的分离因素,包括 3D 外观、身份、头部姿势和整体面部动态,而解码器可以根据给定的潜在代码生成高质量的人脸。
VASA-1 将唇音同步、面部动态和头部运动的真实性共同提升到了新的高度。 加上高图像生成质量和高效的运行速度,我们实现了逼真、栩栩如生的实时说话面孔。 通过详细的评估,我们表明我们的方法明显优于现有方法。 我们相信,VASA-1 让我们更接近未来,数字 AI 化身可以像与真人互动一样自然直观的方式与我们互动,展示有吸引力的视觉情感技能,实现更加动态和同理心的信息交换。
2相关工作
解开的人脸表示学习。
之前的工作已经对通过解纠缠变量表示面部图像进行了广泛的研究。 一些方法利用稀疏关键点siarohin2019first; zakharov2020fast 或 3D 脸部模型 ren2021pirenderer ;高2023高; zhang2023metaportrait 来明确表征面部动态和其他属性,但这些可能会遇到重建不准确或表达能力有限等问题。 还有许多致力于学习潜在空间中解开的表示的作品。 一种常见的方法是将人脸分为身份和非身份两部分,然后在不同的帧中重新组合,可以是二维burkov2020neural ; zhou2021pose ; liang2022expressive ; yin2022styleheat ; pang2023dpe ; wang2023progressive 或三维wang2021one ; drobyshev2022megaportraits 。 这些方法面临的主要挑战是有效地解开各种因素,同时仍然实现所有静态和动态面部属性的表达表示,这在本工作中得到解决。
音频驱动的说话面孔生成。
从音频输入生成人脸视频一直是计算机视觉和图形领域的一项长期任务。 早期的作品集中于仅合成嘴唇,通过将音频信号直接映射到嘴唇运动来实现,同时保持其他面部属性不变suwajanakorn2017synthesizing;陈2018唇;普拉吉瓦尔2020唇;阴2022风格热; heng2022videoretalking . 最近的努力扩大了范围,包括来自音频输入的更广泛的面部表情和头部运动。 例如,zhang2023sadtalker的方法将生成目标分为不同的类别,包括仅嘴唇3DMM系数、眨眼和头部姿势。 yu2023talking 提出在 zhou2021pose 潜在表达的顶部分解唇形和非唇形特征。 zhang2023sadtalker 和 yu2023talking 都直接从音频特征中回归与嘴唇相关的表示,并以概率方式对其他属性进行建模。 与这些方法相反,我们的方法从音频以及其他控制信号中生成全面的面部动态和头部姿势。 这种方法不同于进一步解开的趋势,而是寻求创造更全面和综合的产出。
视频生成。
生成模型的最新进展brown2020语言; ho2020去噪;歌曲2020评分; Song2020降噪在视频生成方面取得了重大进展。 早期的视频生成方法接近 vondrick2016generateing ;图利亚科夫2018莫科根; skorokhodov2022stylegan 采用对抗性学习 goodfellow2014generative 框架,而更新的方法 yan2021videogpt ;布拉特曼2023对齐; girdhar2023emu ; kondratyuk2023视频诗人;酒吧2024卢米埃尔; videoworldsimulators2024 利用扩散或自回归模型来捕获不同的视频分布。 近期,多部作品与我们同步tian2024emo; wei2024aniportrait 将视频扩散技术应用于音频驱动的说话脸部生成,尽管训练和推理速度较慢,但仍取得了有希望的结果。 相比之下,我们的方法可以在生成说话人脸视频时提供高效和高质量的结果。
3方法
任务定义。
如图 1 所示,我们方法的输入由任意身份的单个面部图像 和来自以下内容的语音音频剪辑 组成:再次,一个任意的人。 目标是生成输入人脸图像与给定音频以真实且连贯的方式说话的合成视频。 成功生成的视频应在几个关键方面表现出高保真度:图像帧的清晰度和真实性、音频和嘴唇运动之间的精确同步、富有表现力和情感的面部动态以及自然的头部姿势。
我们的生成过程还可以接受一组可选的控制信号来指导生成,其中包括主眼注视方向、头部到相机的距离和情绪偏移。 更多详细信息将在后面的部分中提供。
总体框架。
我们不是直接生成视频帧,而是在以音频和其他信号为条件的潜在空间中生成整体面部动态和头部运动。 给定这些运动潜在代码,我们的方法然后通过面部解码器生成视频帧,该解码器还使用面部编码器从输入图像中提取的外观和身份特征作为输入。
为了实现这一目标,我们首先构建一个人脸潜在空间并训练人脸编码器和解码器。 一个富有表现力且解开的面部潜在学习框架是在现实生活中的面部视频上精心设计和训练的。 然后,我们训练一个简单但功能强大的扩散 Transformer 来对运动分布进行建模,并在给定音频和其他条件的测试时间内生成运动潜在代码。
3.1富有表现力、解开的人脸潜在空间构建
给定一个未标记的说话人脸视频的语料库,我们的目标是为人脸构建一个具有高度解缠结和表现力的潜在空间。 这种解开可以在海量视频上对人体头部和整体面部行为进行有效的生成建模,而不管主体身份如何。 它还可以实现输出的解耦因子控制,这在许多应用中都是理想的。 现有方法缺乏表达能力 burkov2020neural ; ren2021pirenderer ; yu2023 说话 ; wang2023进步或解脱wang2021one;德罗比雪夫2022巨型肖像; zhang2023metaportrait 或两者兼而有之。 另一方面,面部外观和动态动作的表现力确保解码器可以输出具有丰富面部细节的高质量视频,并且潜在生成器能够捕获细致入微的面部动态。
为了实现这一目标,我们的模型基于 wang2021one 的 3D 辅助面部重演框架; drobyshev2022megaportraits 。 与 2D 特征图相比,3D 外观特征量可以更好地表征 3D 中的外观细节。 显式 3D 特征变形对于 3D 头部和面部运动建模也很强大。 具体来说,我们将面部图像分解为规范的 3D 外观体积 、身份代码 、3D 头部姿势 和面部动态代码 。 它们中的每一个都是通过独立的编码器从面部图像中提取的,除了 是通过首先提取姿势 3D 体积,然后通过刚性和非刚性 3D 扭曲到规范体积来构造的,如 drobyshev2022megaportraits . 单个解码器将这些潜在变量作为输入并重建面部图像,其中相反方向的类似扭曲场首先应用于以获得姿势外观体积。 读者可以参考drobyshev2022megaportraits来了解该架构的更多细节。
为了学习解纠缠的潜在空间,核心思想是通过交换视频中不同图像之间的潜在变量来构造图像重建损失。 我们的基本损失函数改编自 drobyshev2022megaportraits 。 然而,我们使用原始损失发现了面部动态和头部姿势之间的不良分离。 身份和动作之间的分离也是不完美的。 因此,我们引入了一些对于实现我们的目标至关重要的额外损失。 例如,受 pang2023dpe 的启发,我们添加了成对的头部姿势和面部动态传递损失来改善它们的解缠结。 令 和 为从主题的同一视频中随机采样的两个帧。 我们使用编码器提取它们的潜在变量,并将 的头部姿势作为 和 的面部运动转移到 上到 上作为 。 和 之间的差异损失随后被最小化。 为了加强身份和运动之间的分离,我们为跨身份姿势和面部运动转移结果添加了面部身份相似性损失。 设和为两个不同主体的视频帧,我们可以将的运动转移到上并得到。 然后,应用从和提取的深层人脸身份特征deng2019arcface之间的余弦相似度损失。
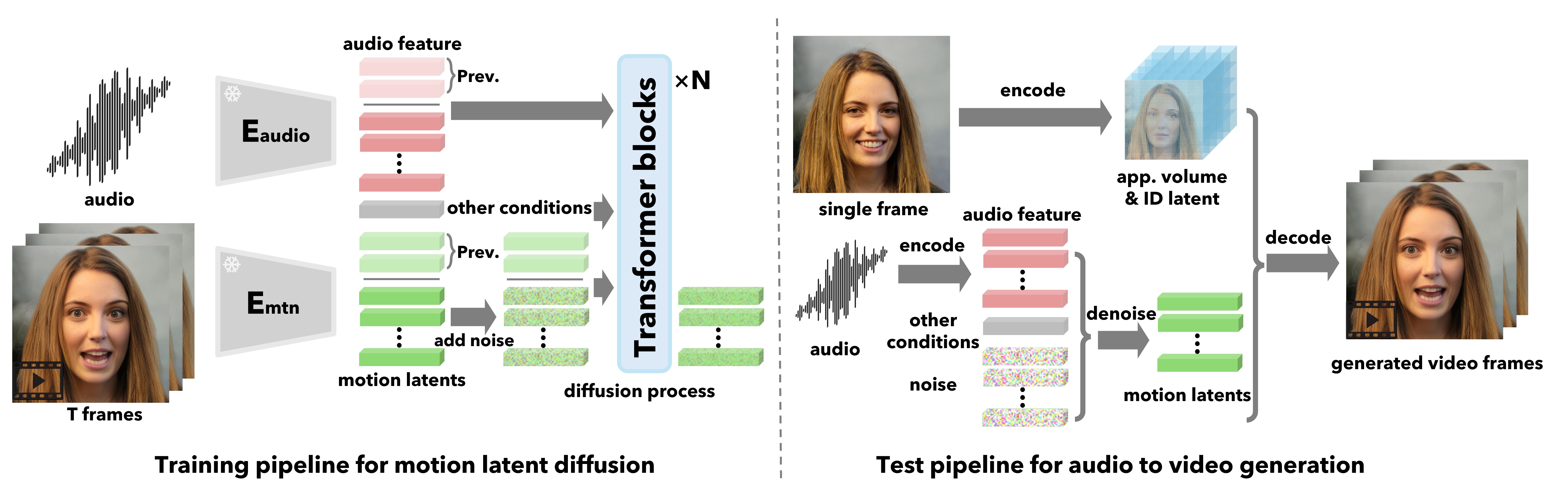
3.2使用扩散 Transformer 生成整体面部动态
给定构建的面部潜在空间和训练有素的编码器,我们可以从现实生活中说话的面部视频中提取面部动态和头部运动,并训练生成模型。 至关重要的是,我们考虑与身份无关的整体面部动态生成(HFDG),其中我们学习的潜在代码代表所有面部运动,例如嘴唇运动、(非嘴唇)表情、眼睛注视和眨眼。 这与现有方法形成鲜明对比,现有方法通过交错回归和生成公式对不同因素应用单独的模型 wang2021audio2head ;周2021姿势; yu2023 说话 ;王2023进步; zhang2023sadtalker . 此外,以前的方法通常在有限数量的身份上进行训练zhang2023sadtalker; xing2023codetalker ; fan2022faceformer 并且无法对不同人类的广泛运动模式进行建模,特别是在考虑到表达运动潜在空间的情况下。
在这项工作中,我们利用音频调节 HFDG 的扩散模型,并对来自大量身份的大量说话人脸视频进行训练。 特别是,我们应用了 Transformer 架构 vaswani2017attention ; Peebles2023可扩展; sun2023diffposetalk 用于我们的序列生成任务。 图 2 显示了我们的 HFDG 框架的概述。
正式地,从视频剪辑中提取的运动序列被定义为。 给定其随附的音频剪辑 ,我们提取同步音频特征 ,为此我们使用预训练的特征提取器 Wav2Vec2 baevski2020wav2vec 。
扩散配方。
扩散模型定义了两个马尔可夫链ho2020去噪;歌曲2020去噪; Song2020score,前向链逐步向目标数据添加高斯噪声,而反向链迭代地从噪声中恢复原始信号。 按照去噪分数匹配目标 song2020score ,我们将简化的损失函数定义为
| (1) |
其中表示时间步长,是原始运动潜在序列,是扩散前向过程生成的噪声输入. 是我们的 Transformer 网络,它预测原始信号本身而不是噪声。 是条件信号,下面将进行描述。
调理信号。
我们的音频驱动运动生成任务的主要条件信号是音频特征序列。 我们还结合了几个额外的信号,这不仅使生成模型更容易处理,而且还提高了生成的可控性。
具体来说,我们考虑主要眼睛注视方向、头到相机的距离和情绪偏移。 主要注视方向 由球坐标中的向量定义。 它指定生成的说话面孔的聚焦方向。 我们在每帧上使用 zemblys2019gazenet 提取训练视频剪辑的 ,然后使用简单的基于直方图的聚类算法。 头距是控制人脸与虚拟相机之间距离的归一化标量,它影响生成的人脸视频中的人脸比例。 我们使用 deng2019accurate 获取训练视频的比例标签。 情绪偏移调节说话脸上所描绘的情绪。 请注意,情感通常与音频有内在联系,并且很大程度上可以从音频中推断出来;因此, 仅用作添加的全局偏移,以在需要时增强或适度改变情绪。 它并非旨在在推理过程中实现总体情绪转变或产生与输入音频不一致的情绪。 在实践中,我们使用 savchenko2022hsemotion 提取的平均情感系数作为我们的情感信号。
为了实现相邻窗口之间的无缝过渡,我们将音频特征的最后 帧和前一个窗口生成的运动作为当前窗口的条件。 总而言之,我们的输入条件可以表示为
无分类器指导 (CFG) ho2022classifier 。
在训练阶段,我们随机丢弃每个输入条件。 在推理过程中,我们应用
| (2) |
其中 是条件 的 CFG 比例。 表示将条件替换为。
在训练期间,我们对每个条件使用 的掉落概率,但 和 除外,我们使用 。 这是为了确保模型能够很好地处理没有前面的音频和动作的第一个窗口(即设置为 )。 我们还随机删除 的最后几帧,以确保短于窗口长度的音频序列生成稳健的运动。
3.3 人脸视频生成
在推理时,给定任意人脸图像和音频剪辑,我们首先使用经过训练的人脸编码器提取 3D 外观体积 和身份代码 。 然后,我们提取音频特征,将它们分割成长度的片段,并使用我们训练的扩散以滑动窗口方式一一生成头部和面部运动序列 Transformer 。 随后可以使用我们经过训练的解码器生成最终视频。
4实验
实施细节。
对于面部潜在空间学习,我们使用来自 chung2018voxceleb2 的公共 VoxCeleb2 数据集,其中包含来自大约 6K 受试者的说话面部视频。 我们使用 su2020blindly 的方法对数据集进行重新处理,并丢弃多个个体和低质量的片段。 对于运动潜在生成,我们使用带有嵌入暗淡 和头号 的 8 层 Transformer 编码器作为我们的扩散网络。 该模型在 VoxCeleb2 chung2018voxceleb2 和我们收集的另一个高分辨率谈话视频数据集上进行训练,该数据集包含约 3500 个主题。 在我们的默认设置中,模型使用向前的主要注视条件、所有训练视频的平均头部距离以及空的情绪偏移条件。 CFG参数设置为和,并使用采样步长。
评估基准。
我们使用两个数据集评估我们的方法。 第一个是 VoxCeleb2 chung2018voxceleb2 的子集。 我们从 VoxCeleb2 的测试中随机选择了 46 个受试者,并为每个受试者随机采样了 10 个视频剪辑,总共 460 个剪辑。 这些视频片段长度约为515秒(80%不足10秒),内容大部分为采访和新闻报道。 为了进一步评估我们在具有更广泛声音变化的长语音生成下的方法,我们进一步收集了 17 个人的 32 个一分钟剪辑。 这些视频主要来自在线辅导课程和教育讲座,谈话风格比 VoxCeleb2 更加多样化。 我们将此数据集称为 OneMin-32。



4.1定性评估
视觉结果。
图1展示了我们的方法的一些代表性的音频驱动的说话面孔生成结果。 通过目视检查,我们的方法可以生成具有生动面部表情的高质量视频帧。 此外,它还可以产生类似人类的对话行为,包括说话和沉思时眼神的零星变化,以及自然而可变的眨眼节奏等细微差别。 我们强烈建议读者在线观看我们的视频结果,以充分了解我们方法的功能和输出质量。
发电可控性。
图3显示了我们在不同控制信号下生成的结果,包括主眼注视、头部距离和情绪偏移。 显然,我们的生成模型可以很好地解释这些信号并产生紧密遵循这些指定参数的说话面部结果。
面部潜伏的解开。
分布外一代。
我们的方法展示了处理训练分布之外的照片和音频输入的能力。 例如,如图6所示,它可以处理艺术照片、歌唱音频片段(顶部两行)和非英语语音(最后一行)。 值得注意的是,这些数据变体并不存在于训练数据集中。

4.2定量评价
评估指标。
我们使用以下指标对生成的嘴唇运动、头部姿势和整体视频质量进行定量评估,包括以类似于 CLIP radford2021learning 的方式训练的新数据驱动音频姿势同步指标:
-
•
音频口型同步。 我们使用预训练的音频唇形同步网络,即 SyncNet chung2017out 来评估输入音频与视频中生成的唇形运动的对齐情况。 具体来说,我们将置信度得分和特征距离分别计算为 和 。 较高的 和较低的 表示总体上音频唇形同步质量较好。
-
•
音频姿势对齐。 测量生成的头部姿势和输入音频之间的对齐情况并非易事,并且没有完善的指标。 最近的一些研究zhang2023sadtalker; sun2023diffposetalk 使用节拍对齐分数 siyao2022bailando 来评估音频姿势对齐。 然而,这个指标并不是最佳的,因为在自然语音和人类头部运动的背景下,“节拍”的概念是不明确的。 在这项工作中,我们引入了一种新的数据驱动训练指标,称为对比音频和姿势预(CAPP)分数。 受 CLIP radford2021learning 的启发,我们联合训练姿势序列编码器和音频序列编码器,并预测输入姿势序列和音频是否配对。 音频编码器从预训练的 Wav2Vec2 网络 baevski2020wav2vec 初始化,姿势编码器是随机初始化的 6 层 Transformer 网络。 输入窗口大小为3秒。 我们的 CAPP 模型经过 2K 小时的现实音频和姿势序列训练,并展示了评估音频输入和生成姿势之间的同步程度的强大能力(参见第 4.3 节)。
-
•
姿势变化强度。 我们进一步定义姿势变化强度分数,它是相邻帧之间姿势角度差异的平均值。 对所有生成视频的所有帧进行平均后, 提供了方法生成的整体头部运动强度的指示。
-
•
视频质量。 继之前的视频生成作品 yan2021videogpt ; skorokhodov2022stylegan ,我们使用 Fréchet Video Distance (FVD) unterthiner2019fvd 来评估生成的视频质量。 我们使用 25 个连续帧的序列来计算 FVD 度量。
比较方法。
我们将我们的方法与现有的音频驱动的说话面孔生成方法进行比较:MakeItTalk zhou2020makelttalk 、 Audio2Head wang2021audio2head ; zhang2023sadtalker 和 SadTalker zhang2023sadtalker 。 MakeItTalk zhou2020makelttalk 采用 LSTM 将音频转换为动态面部标志,然后使用这些标志通过图像变形或基于神经网络的图像转换将源图像动画化为视频序列。 Audio2Head wang2021audio2head 使用运动感知循环网络将音频转换为头部姿势,该姿势与原始音频一起用于生成密集的运动场。 运动场进一步应用于图像特征,然后由神经网络生成最终输出。 SadTalker zhang2023sadtalker 使用 VAE 网络从音频生成姿势偏移,并使用回归网络从音频特征预测仅唇形系数。 随机变量用于眨眼生成。 该方法可以从相同的音频输入生成不同的姿势和眨眼,但只能回归其他运动(例如眉毛、凝视和面部表情)的确定性模式。
主要结果。
对于每个音频输入,我们为确定性方法生成单个视频,即 MakeItTalk 和 Audio2Head。 对于 SadTalker zhang2023sadtalker 和我们的方法,我们对每个音频采样三个视频并对计算的指标进行平均。 由于这些方法使用不同的姿势表示,我们从生成的帧中重新提取头部姿势以计算姿势相关的度量(即 CAPP 和 )。 对于 FVD 指标,我们使用真实视频和生成视频的 2K 25 帧视频剪辑。 作为参考,我们还报告了真实视频的评估指标。
表 1 和表 2 显示了 VoxCeleb2 和 OneMin-32 基准测试的结果。 请注意,我们没有评估 VoxCeleb2 上的 FVD,因为它的视频质量各不相同且通常较低。 在这两个基准测试中,我们的方法在所有评估指标的所有方法中都取得了最佳结果。 就音频唇形同步分数( 和 )而言,我们的方法大大优于所有其他方法。 请注意,我们的方法比真实视频产生更好的分数,这是由于音频 CFG 的影响(参见第 4.3 节)。 我们生成的姿势与音频更好地一致,尤其是在 OneMin-32 基准上,如 CAPP 分数所反映的那样。 根据,头部运动也表现出最高强度,尽管与真实视频的强度仍有差距。 我们的 FVD 分数明显低于其他分数,这表明我们的结果具有更高的视频质量和真实感。
| CAPP | P | |||
| MakeItTalk zhou2020makelttalk | 4.176 | 15.513 | -0.051 | 0.210 |
| Audio2Head wang2021audio2head | 6.172 | 8.470 | 0.246 | 0.260 |
| SadTalker zhang2023sadtalker | 5.843 | 8.813 | 0.441 | 0.275 |
| Ours | ||||
| Real video | 7.640 | 7.189 | 0.588 | 0.505 |
| CAPP | P | ||||
| MakeItTalk zhou2020makelttalk | -0.123 | 14.340 | 0.002 | 0.190 | 304.833 |
| Audio2Head wang2021audio2head | 5.992 | 8.211 | 0.205 | 0.239 | 209.772 |
| SadTalker zhang2023sadtalker | 5.501 | 8.850 | 0.383 | 0.252 | 214.507 |
| Ours | |||||
| Real video | 7.192 | 7.254 | 0.559 | 0.405 | 29.245 |
4.3分析和消融研究
CAPP 指标。
我们分析了我们提出的 CAPP 指标在测量音频和头部姿势之间的对齐方面的有效性。
| 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 0.608 | 0.462 | 0.206 | 0.069 | 0.082 |
首先,我们通过手动将帧偏移引入地面真实音频姿势对来研究其对时间移位的敏感性。 我们从 VoxCeleb2 测试片段中提取 3 秒的剪辑片段,产生大约 2.1K 个音频姿势对。 这些对的平均 CAPP 分数为 ,如表 3 所示。 手动帧移位会导致 CAPP 分数快速下降,对于大于两帧的移位接近于零。 这表明 CAPP 分数和音频头部姿势对齐之间存在很强的相关性。
| 0.2 | 0.5 | 1.0 | 1.5 | 3.0 |
|---|---|---|---|---|
| 0.368 | 0.584 | 0.608 | 0.587 | 0.505 |
我们通过使用各种因素手动缩放连续帧之间的姿势差异,进一步研究头部运动强度对 CAPP 的影响。 表 4 显示改变运动强度会对 CAPP 分数产生负面影响,这表明 CAPP 可以根据强度评估音频和姿势的对齐情况。 然而,这种对强度的敏感性似乎不如对时间错位的敏感性那么明显。
CFG 尺度。
扩散模型的CFG策略ho2022classifier可以在样本质量和多样性之间取得权衡。 在这里,我们评估模型中音频和主要凝视条件(即方程 2 中的 和 )的 CFG 尺度的选择。
如表5所示,随着值的增加,注视控制的准确性提高。 将音频 CFG 比例增加到 可显着增强唇音对齐( 和 )、姿势音频对齐 (CAPP) 和姿势的性能变化强度 ()。 使用正音频 CFG,唇音对齐分数甚至超过了在真实视频上评估的分数(没有音频 CFG 的结果,即 ,比它们稍差或相当)。 此外,FVD 分数略有下降,表明视频质量稍好。
| CAPP | P | ||||||
|---|---|---|---|---|---|---|---|
| 7.087 | 7.391 | 0.414 | 0.291 | 117.425 | 5.730 | 0.004 | |
| 7.134 | 7.345 | 0.421 | 0.290 | 116.547 | 5.329 | 0.004 | |
| 7.108 | 7.386 | 0.414 | 0.298 | 117.784 | 5.064 | 0.005 | |
| 7.957 | 6.635 | 0.465 | 0.316 | 105.884 | 5.253 | 0.005 | |
| 8.218 | 6.437 | 0.474 | 0.342 | 104.886 | 5.333 | 0.005 | |
| 8.295 | 6.397 | 0.455 | 0.395 | 104.293 | 5.531 | 0.005 | |
| (steps) | 8.293 | 6.363 | 0.523 | 0.243 | 117.060 | 5.469 | 0.006 |
| Real video | 7.192 | 7.254 | 0.559 | 0.405 | 29.244 | – | – |
进一步增加 会略微改善唇音同步并减少 ,但代价是稍微降低音频姿势同步和凝视可控性。 此外,对生成视频的观察表明,较高的 会显着放大强声音的嘴部运动,并在快速讲话时导致头部姿势抖动。 为了平衡性能和整体发电质量,我们将 和 设置为标准配置。
我们还评估了采样步骤对性能的影响。 表 5 说明,减少从 到 的步长可改善音频唇形和音频姿势对齐,同时会影响姿势变化强度和整体视频质量。 对于这个潜在运动生成模块来说,减少步骤可以将推理过程加速 5 倍。
5结论
总之,我们的工作提出了 VASA-1,这是一种音频驱动的说话脸部生成模型,该模型因其从单个图像和音频输入中高效生成逼真的唇形同步、生动的面部表情和自然的头部运动而脱颖而出。 它在提供视频质量和性能效率方面显着优于现有方法,在生成的面部视频中展示了有前途的视觉情感技能。 技术基石是创新的整体面部动态和头部运动生成模型,该模型在富有表现力和解开的面部潜在空间中工作。
VASA-1 取得的进步有可能重塑通信、教育和医疗保健等各个领域的人与人以及人与人工智能的互动。 可控调节信号的集成进一步增强了模型对个性化用户体验的适应性。
局限性和未来的工作。
我们的方法仍然存在一些局限性。 目前,它仅处理直到躯干的人体区域。 延伸到整个上半身可以提供额外的功能。 在利用 3D 潜在表示时,缺乏更明确的 3D 人脸模型,例如 wu2022anifacegan ; wu2023aniportraitgan 可能会因神经渲染而导致纹理粘连等伪影。 此外,我们的方法没有考虑头发和衣服等非刚性元素,这可以通过更强大的视频先验来解决。 未来,我们还计划融入更多元的说话风格和情绪,以提高表达力和控制力。
6 社会影响和负责任的人工智能考虑因素
我们的研究重点是为虚拟人工智能化身生成音频驱动的视觉情感技能,旨在实现积极的应用。 无意创建用于误导或欺骗的内容。 然而,与其他相关内容生成技术一样,它仍然可能被滥用于模仿人类。 我们反对任何创造真实人物的误导性或有害内容的行为,并且有兴趣应用我们的技术来推进伪造检测。 目前,该方法生成的视频仍然包含可识别的伪影,数值研究表明,距离真实视频的真实性仍有差距。
在承认滥用的可能性的同时,必须认识到我们的技术的巨大积极潜力。 这些好处——从增强教育公平、改善有沟通障碍的个人的可及性,以及为有需要的人提供陪伴或治疗支持——强调了我们的研究和其他相关探索的重要性。 我们致力于负责任地开发人工智能,以促进人类福祉为目标。
贡献声明
徐思成、陈国军、郭玉晓是各算法模块的实现、训练、实验以及数据处理和管理的核心贡献者。 杨蛟龙提出了项目构想,主导了项目,设计了总体框架,并为每个组件提供了详细的技术建议。 李崇、臧正宇和张益中为提高系统质量、进行评估和展示结果做出了贡献。 童欣在整个项目过程中提供了技术建议并帮助进行项目协调。 郭百宁提供战略研究方向指导、科学建议和其他项目支持。 论文由杨蛟龙和徐思成撰写。
致谢
我们要感谢我们的同事张政、吴志荣、刘树杰、陈东、谭旭等人为我们的项目提供的宝贵讨论和富有洞察力的建议。
参考
- (1) https://www.prnewswire.com/news-releases/deepbrain-ai-delivers-ai-avatar-to-empower-people-with-disabilities-302026965.html, 2024. [Online; accessed 8-Apr-2024].
- (2) Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in Neural Information Processing Systems, 33:12449–12460, 2020.
- (3) Omer Bar-Tal, Hila Chefer, Omer Tov, Charles Herrmann, Roni Paiss, Shiran Zada, Ariel Ephrat, Junhwa Hur, Yuanzhen Li, Tomer Michaeli, et al. Lumiere: A space-time diffusion model for video generation. arXiv preprint arXiv:2401.12945, 2024.
- (4) James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions. https://cdn. openai. com/papers/dall-e-3.pdf, 2(3):8, 2023.
- (5) Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127, 2023.
- (6) Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22563–22575, 2023.
- (7) Aras Bozkurt, Xiao Junhong, Sarah Lambert, Angelica Pazurek, Helen Crompton, Suzan Koseoglu, Robert Farrow, Melissa Bond, Chrissi Nerantzi, Sarah Honeychurch, et al. Speculative futures on chatgpt and generative artificial intelligence (ai): A collective reflection from the educational landscape. Asian Journal of Distance Education, 18(1):53–130, 2023.
- (8) Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators. 2024.
- (9) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, 33:1877–1901, 2020.
- (10) Egor Burkov, Igor Pasechnik, Artur Grigorev, and Victor Lempitsky. Neural head reenactment with latent pose descriptors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13786–13795, 2020.
- (11) Lele Chen, Zhiheng Li, Ross K Maddox, Zhiyao Duan, and Chenliang Xu. Lip movements generation at a glance. In European Conference on Computer Vision, pages 520–535, 2018.
- (12) Kun Cheng, Xiaodong Cun, Yong Zhang, Menghan Xia, Fei Yin, Mingrui Zhu, Xuan Wang, Jue Wang, and Nannan Wang. Videoretalking: Audio-based lip synchronization for talking head video editing in the wild. In SIGGRAPH Asia 2022, pages 1–9, 2022.
- (13) Joon Son Chung, Arsha Nagrani, and Andrew Zisserman. Voxceleb2: Deep speaker recognition. arXiv preprint arXiv:1806.05622, 2018.
- (14) Joon Son Chung and Andrew Zisserman. Out of time: automated lip sync in the wild. In Asian Conference on Computer Vision Workshops, pages 251–263. Springer, 2017.
- (15) Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4690–4699, 2019.
- (16) Yu Deng, Jiaolong Yang, Sicheng Xu, Dong Chen, Yunde Jia, and Xin Tong. Accurate 3d face reconstruction with weakly-supervised learning: From single image to image set. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 0–0, 2019.
- (17) Nikita Drobyshev, Jenya Chelishev, Taras Khakhulin, Aleksei Ivakhnenko, Victor Lempitsky, and Egor Zakharov. Megaportraits: One-shot megapixel neural head avatars. In Proceedings of the 30th ACM International Conference on Multimedia, pages 2663–2671, 2022.
- (18) Chenpeng Du, Qi Chen, Tianyu He, Xu Tan, Xie Chen, Kai Yu, Sheng Zhao, and Jiang Bian. Dae-talker: High fidelity speech-driven talking face generation with diffusion autoencoder. In Proceedings of the ACM International Conference on Multimedia, pages 4281–4289, 2023.
- (19) Yingruo Fan, Zhaojiang Lin, Jun Saito, Wenping Wang, and Taku Komura. Faceformer: Speech-driven 3d facial animation with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18770–18780, 2022.
- (20) Yue Gao, Yuan Zhou, Jinglu Wang, Xiao Li, Xiang Ming, and Yan Lu. High-fidelity and freely controllable talking head video generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5609–5619, 2023.
- (21) Rohit Girdhar, Mannat Singh, Andrew Brown, Quentin Duval, Samaneh Azadi, Sai Saketh Rambhatla, Akbar Shah, Xi Yin, Devi Parikh, and Ishan Misra. Emu video: Factorizing text-to-video generation by explicit image conditioning. arXiv preprint arXiv:2311.10709, 2023.
- (22) Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. Advances in Neural Information Processing Systems, 27, 2014.
- (23) Yudong Guo, Keyu Chen, Sen Liang, Yong-Jin Liu, Hujun Bao, and Juyong Zhang. Ad-nerf: Audio driven neural radiance fields for talking head synthesis. In IEEE/CVF International Conference on Computer Vision, pages 5784–5794, 2021.
- (24) Tianyu He, Junliang Guo, Runyi Yu, Yuchi Wang, Jialiang Zhu, Kaikai An, Leyi Li, Xu Tan, Chunyu Wang, Han Hu, et al. Gaia: Zero-shot talking avatar generation. In International Conference on Learning Representations, 2024.
- (25) Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020.
- (26) Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022.
- (27) Esperanza Johnson, Ramón Hervás, Carlos Gutiérrez López de la Franca, Tania Mondéjar, Sergio F Ochoa, and Jesús Favela. Assessing empathy and managing emotions through interactions with an affective avatar. Health informatics journal, 24(2):182–193, 2018.
- (28) Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8110–8119, 2020.
- (29) Greg Kessler. Technology and the future of language teaching. Foreign Language Annals, 51(1):205–218, 2018.
- (30) Dan Kondratyuk, Lijun Yu, Xiuye Gu, José Lezama, Jonathan Huang, Rachel Hornung, Hartwig Adam, Hassan Akbari, Yair Alon, Vighnesh Birodkar, et al. Videopoet: A large language model for zero-shot video generation. arXiv preprint arXiv:2312.14125, 2023.
- (31) Julian Leff, Geoffrey Williams, Mark Huckvale, Maurice Arbuthnot, and Alex P Leff. Avatar therapy for persecutory auditory hallucinations: What is it and how does it work? Psychosis, 6(2):166–176, 2014.
- (32) Borong Liang, Yan Pan, Zhizhi Guo, Hang Zhou, Zhibin Hong, Xiaoguang Han, Junyu Han, Jingtuo Liu, Errui Ding, and Jingdong Wang. Expressive talking head generation with granular audio-visual control. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3387–3396, 2022.
- (33) Shugao Ma, Tomas Simon, Jason Saragih, Dawei Wang, Yuecheng Li, Fernando De La Torre, and Yaser Sheikh. Pixel codec avatars. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 64–73, 2021.
- (34) Yifeng Ma, Suzhen Wang, Zhipeng Hu, Changjie Fan, Tangjie Lv, Yu Ding, Zhidong Deng, and Xin Yu. Styletalk: One-shot talking head generation with controllable speaking styles. In AAAI Conference on Artificial Intelligence, pages arXiv–2301, 2023.
- (35) Youxin Pang, Yong Zhang, Weize Quan, Yanbo Fan, Xiaodong Cun, Ying Shan, and Dong-ming Yan. Dpe: Disentanglement of pose and expression for general video portrait editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 427–436, 2023.
- (36) William Peebles and Saining Xie. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205, 2023.
- (37) KR Prajwal, Rudrabha Mukhopadhyay, Vinay P Namboodiri, and CV Jawahar. A lip sync expert is all you need for speech to lip generation in the wild. In ACM International Conference on Multimedia, pages 484–492, 2020.
- (38) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763. PMLR, 2021.
- (39) Imogen C Rehm, Emily Foenander, Klaire Wallace, Jo-Anne M Abbott, Michael Kyrios, and Neil Thomas. What role can avatars play in e-mental health interventions? exploring new models of client–therapist interaction. Frontiers in Psychiatry, 7:186, 2016.
- (40) Yurui Ren, Ge Li, Yuanqi Chen, Thomas H Li, and Shan Liu. PIRenderer: Controllable portrait image generation via semantic neural rendering. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 13759–13768, 2021.
- (41) Andrey V Savchenko. Hsemotion: High-speed emotion recognition library. Software Impacts, 14:100433, 2022.
- (42) Aliaksandr Siarohin, Stéphane Lathuilière, Sergey Tulyakov, Elisa Ricci, and Nicu Sebe. First order motion model for image animation. In Advances in Neural Information Processing Systems, 2019.
- (43) Li Siyao, Weijiang Yu, Tianpei Gu, Chunze Lin, Quan Wang, Chen Qian, Chen Change Loy, and Ziwei Liu. Bailando: 3d dance generation by actor-critic gpt with choreographic memory. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11050–11059, 2022.
- (44) Ivan Skorokhodov, Sergey Tulyakov, and Mohamed Elhoseiny. Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3626–3636, 2022.
- (45) Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020.
- (46) Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456, 2020.
- (47) Michał Stypułkowski, Konstantinos Vougioukas, Sen He, Maciej Zięba, Stavros Petridis, and Maja Pantic. Diffused heads: Diffusion models beat gans on talking-face generation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 5091–5100, 2024.
- (48) Shaolin Su, Qingsen Yan, Yu Zhu, Cheng Zhang, Xin Ge, Jinqiu Sun, and Yanning Zhang. Blindly assess image quality in the wild guided by a self-adaptive hyper network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3667–3676, 2020.
- (49) Yasheng Sun, Hang Zhou, Ziwei Liu, and Hideki Koike. Speech2talking-face: Inferring and driving a face with synchronized audio-visual representation. In International Joint Conference on Artificial Intelligence, volume 2, page 4, 2021.
- (50) Zhiyao Sun, Tian Lv, Sheng Ye, Matthieu Gaetan Lin, Jenny Sheng, Yu-Hui Wen, Minjing Yu, and Yong-jin Liu. Diffposetalk: Speech-driven stylistic 3d facial animation and head pose generation via diffusion models. arXiv preprint arXiv:2310.00434, 2023.
- (51) Supasorn Suwajanakorn, Steven M Seitz, and Ira Kemelmacher-Shlizerman. Synthesizing obama: learning lip sync from audio. ACM Transactions on Graphics, 36(4):1–13, 2017.
- (52) Linrui Tian, Qi Wang, Bang Zhang, and Liefeng Bo. Emo: Emote portrait alive-generating expressive portrait videos with audio2video diffusion model under weak conditions. arXiv preprint arXiv:2402.17485, 2024.
- (53) Sergey Tulyakov, Ming-Yu Liu, Xiaodong Yang, and Jan Kautz. Mocogan: Decomposing motion and content for video generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1526–1535, 2018.
- (54) Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphaël Marinier, Marcin Michalski, and Sylvain Gelly. Fvd: A new metric for video generation. 2019.
- (55) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in Neural Information Processing Systems, 30, 2017.
- (56) Carl Vondrick, Hamed Pirsiavash, and Antonio Torralba. Generating videos with scene dynamics. Advances in Neural Information Processing Systems, 29, 2016.
- (57) Duomin Wang, Yu Deng, Zixin Yin, Heung-Yeung Shum, and Baoyuan Wang. Progressive disentangled representation learning for fine-grained controllable talking head synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17979–17989, 2023.
- (58) Jiayu Wang, Kang Zhao, Shiwei Zhang, Yingya Zhang, Yujun Shen, Deli Zhao, and Jingren Zhou. Lipformer: High-fidelity and generalizable talking face generation with a pre-learned facial codebook. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13844–13853, 2023.
- (59) Suzhen Wang, Lincheng Li, Yu Ding, Changjie Fan, and Xin Yu. Audio2head: Audio-driven one-shot talking-head generation with natural head motion. In International Joint Conference on Artificial Intelligence, 2021.
- (60) Suzhen Wang, Lincheng Li, Yu Ding, and Xin Yu. One-shot talking face generation from single-speaker audio-visual correlation learning. In AAAI Conference on Artificial Intelligence, volume 36, pages 2531–2539, 2022.
- (61) Ting-Chun Wang, Arun Mallya, and Ming-Yu Liu. One-shot free-view neural talking-head synthesis for video conferencing. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10039–10049, 2021.
- (62) Huawei Wei, Zejun Yang, and Zhisheng Wang. Aniportrait: Audio-driven synthesis of photorealistic portrait animation. arXiv preprint arXiv:2403.17694, 2024.
- (63) Yue Wu, Yu Deng, Jiaolong Yang, Fangyun Wei, Qifeng Chen, and Xin Tong. Anifacegan: Animatable 3d-aware face image generation for video avatars. Advances in Neural Information Processing Systems, 35:36188–36201, 2022.
- (64) Yue Wu, Sicheng Xu, Jianfeng Xiang, Fangyun Wei, Qifeng Chen, Jiaolong Yang, and Xin Tong. Aniportraitgan: Animatable 3d portrait generation from 2d image collections. In SIGGRAPH Asia 2023, pages 1–9, 2023.
- (65) Jinbo Xing, Menghan Xia, Yuechen Zhang, Xiaodong Cun, Jue Wang, and Tien-Tsin Wong. Codetalker: Speech-driven 3d facial animation with discrete motion prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12780–12790, 2023.
- (66) Wilson Yan, Yunzhi Zhang, Pieter Abbeel, and Aravind Srinivas. Videogpt: Video generation using vq-vae and transformers. arXiv preprint arXiv:2104.10157, 2021.
- (67) Fei Yin, Yong Zhang, Xiaodong Cun, Mingdeng Cao, Yanbo Fan, Xuan Wang, Qingyan Bai, Baoyuan Wu, Jue Wang, and Yujiu Yang. Styleheat: One-shot high-resolution editable talking face generation via pre-trained stylegan. In European Conference on Computer Vision, pages 85–101, 2022.
- (68) Zhentao Yu, Zixin Yin, Deyu Zhou, Duomin Wang, Finn Wong, and Baoyuan Wang. Talking head generation with probabilistic audio-to-visual diffusion priors. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7645–7655, 2023.
- (69) Egor Zakharov, Aleksei Ivakhnenko, Aliaksandra Shysheya, and Victor Lempitsky. Fast bi-layer neural synthesis of one-shot realistic head avatars. In European Conference on Computer Vision, pages 524–540, 2020.
- (70) Raimondas Zemblys, Diederick C Niehorster, and Kenneth Holmqvist. gazenet: End-to-end eye-movement event detection with deep neural networks. Behavior research methods, 51:840–864, 2019.
- (71) Bowen Zhang, Chenyang Qi, Pan Zhang, Bo Zhang, HsiangTao Wu, Dong Chen, Qifeng Chen, Yong Wang, and Fang Wen. Metaportrait: Identity-preserving talking head generation with fast personalized adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22096–22105, 2023.
- (72) Wenxuan Zhang, Xiaodong Cun, Xuan Wang, Yong Zhang, Xi Shen, Yu Guo, Ying Shan, and Fei Wang. Sadtalker: Learning realistic 3d motion coefficients for stylized audio-driven single image talking face animation. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8652–8661, 2023.
- (73) Zhimeng Zhang, Lincheng Li, Yu Ding, and Changjie Fan. Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3661–3670, 2021.
- (74) Hang Zhou, Yasheng Sun, Wayne Wu, Chen Change Loy, Xiaogang Wang, and Ziwei Liu. Pose-controllable talking face generation by implicitly modularized audio-visual representation. In Proceedings of the IEEE/CVF Conference on computer Vision and Pattern Recognition, pages 4176–4186, 2021.
- (75) Yang Zhou, Xintong Han, Eli Shechtman, Jose Echevarria, Evangelos Kalogerakis, and Dingzeyu Li. Makelttalk: speaker-aware talking-head animation. ACM Transactions On Graphics (TOG), 39(6):1–15, 2020.