(eccv) 包 eccv 警告:包“hyperref”加载了选项“pagebackref”,*不*建议将其用于相机就绪版本
https://coda-dataset.github .io/coda-lm/
自动评估大型视觉语言模型对自动驾驶极端情况的影响
摘要
大视觉语言模型(LVLM)由于具有理解图像和视频的卓越视觉推理能力,在自动驾驶领域受到了广泛关注,极大地推动了可解释的端到端自动驾驶的发展。 然而,目前对LVLM的评估主要集中在常见场景下的多方面能力,缺乏自动驾驶环境下的可量化和自动化评估,更不用说即使是最先进的自动驾驶感知系统也难以应对的严峻路况。处理。 在本文中,我们提出了 CODA-LM,一种新颖的自动驾驶视觉语言基准,它为可解释的自动驾驶提供了第一个对 LVLM 的自动定量评估,包括一般感知、区域感知和驾驶建议。 CODA-LM 利用文本来描述道路图像,利用强大的无图像输入的纯文本大语言模型(大语言模型)来评估 LVLM 在自动驾驶场景中的能力,这表明比 LVLM 评判更符合人类偏好。 实验表明,即使像 GPT-4V 这样的闭源商业 LVLM 也不能很好地处理道路拐角情况,这表明我们距离强大的 LVLM 驱动的智能驾驶代理还很远,我们希望我们的 CODA-LM 能够成为催化剂促进未来发展。
关键词:
LVLM 评估自动驾驶案例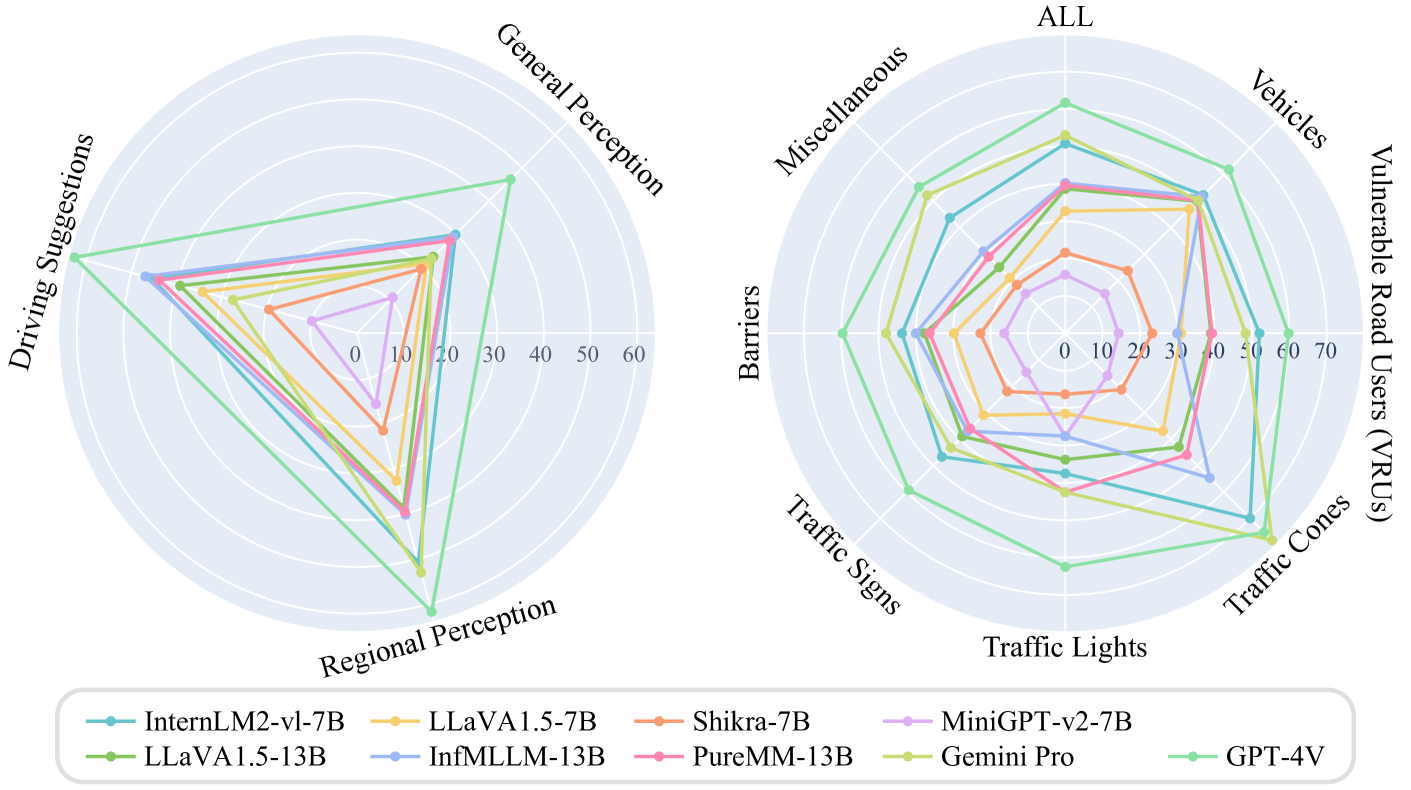
1简介
大视觉语言模型 (LVLM) [26,46,16,31] 吸引了研究界越来越多的关注,这主要是由于其卓越的视觉推理能力。 值得注意的是,在自动驾驶背景下,强大的推理能力至关重要[19, 35]。 由于交通场景本质上是复杂且变化很大的,自动驾驶系统必须能够理解周围环境并做出正确的决策。
传统自动驾驶系统采用模块化设计理念,集成感知、预测、规划等各个模块。 它们依靠数据驱动的算法和复杂的规则来处理复杂的交通场景。 然而,尽管如此,它们仍然不足以在开放领域中推广,特别是在解决现实世界的极端情况[23]方面。 这些系统经常会遇到看不见的场景和不熟悉的对象。 另一方面,LVLM 凭借其广泛的世界知识和推理能力,有潜力克服这些严峻的挑战。
[41] 中进行了一次初步知识尝试,以检验强大的 LVLM [31] 处理极端情况场景的能力。 图像子集是从 CODA 数据集 [23] 中选择的,该数据集重点关注自动驾驶车辆可能遇到的异常和意外场景。 它表明 LVLM 可以在对感官感知系统具有挑战性的分布外(OOD)道路情况下得到很好的泛化。 然而,评估主要依赖于耗时、成本高昂且不可扩展的手动检查。 相反,为了 LVLM 的快速发展,在一般视觉场景中采用了自动评估技术,包括使用二元判断的 MME [13] 和使用单值判断的 MMBench [27]选择格式。 然而,这种简化的设计不足以在自动驾驶等复杂场景上彻底评估 LVLM,需要区域感知[17]和视觉推理[35]。 因此,有必要针对自动驾驶的极端情况开发一个新的 LVLM 自动评估基准。
在这项工作中,我们介绍了 CODA-LM,这是一种在道路拐角情况下系统评估 LVLM 的新基准。 首先,我们基于广泛使用的 CODA [23] 数据集构建 CODA-LM 数据集,具有三个不同的任务,包括一般感知、区域感知 和驾驶建议。 为数据集构建提出了精心设计的流程,包括LVLM预注释、视觉提示设计和手动验证和修订。 随后,我们证明了利用强大的大语言模型[32]作为“法官”在CODA-LM上对LVLM进行自动评估的必要性,这比强大的LVLM与人类法官具有更强的一致性[31]。 我们采用少样本情境学习(ICL)和精心设计的评估标准(例如.、准确性、幻觉惩罚和一致性)来比较不同LVLM的反应以及手动验证的参考答案。 如图1所示,我们全面评估了 LVLM 在三个任务和七个道路类别方面的性能。 实验表明,一些开源 LVLM [42, 26, 12, 46, 45] 的性能与商业 LVLM [31, 36] 非常接近,甚至目前的 GPT-4V不能很好地处理道路拐角情况,这表明我们离一个强大的LVLM驱动的驾驶代理还很远,我们希望CODA-LM能够促进未来的发展。
这项工作的主要贡献可总结如下。
-
1.
我们提出 CODA-LM,这是一个新的基准,用于评估 LVLM 在解决自动驾驶极端情况下的能力,包括一个自动和系统的评估框架。
-
2.
我们证明,强大的大语言模型可以作为评估 LVLM 的合理判断,通过上下文学习和精心设计的评估标准,与强大的 LVLM 相比,与人类判断具有更高的一致性。
-
3.
我们全面评估现有 LVLM 的自动驾驶能力,找出其共同问题,并为未来的研究方向提供建议。
| Dataset | Multimodal | Corner | General Per. | Regional Per. | Suggestion |
| CODA [23] | ✗ | ✓ | ✓ | ✓ | ✗ |
| StreetHazards [18] | ✗ | ✓ | ✓ | ✓ | ✗ |
| nuScenes-QA [34] | ✓ | ✗ | ✓ | ✗ | ✗ |
| BDD-X [21] | ✓ | ✗ | ✓ | ✗ | ✗ |
| DRAMA [30] | ✓ | ✗ | ✓ | ✓ | ✓ |
| DriveLM [35] | ✓ | ✗ | ✓ | ✓ | ✓ |
| CODA-LM | ✓ | ✓ | ✓ | ✓ | ✓ |
2相关工作
2.0.1LVLM 评估。
MME [13]引入了手动设计的问答对来测量总共14个子任务的感知和认知能力,将评估结果转换为二进制(是/否)输出以进行量化分析。 MMBench [27] 采用 GPT-4 将自由形式的预测转换为预定义的多项选择题,并引入 CircularEval 策略以实现更稳健的评估。 SEED-Bench-2 [22] 采用与 MMBench 类似的格式,但扩展了超过 27 个评估维度,评估 LVLM 在图像和文本理解、交错图像文本理解和生成任务方面的能力。 上述评估方法主要依赖于严格的、手动整理的数据集。 Auto-Bench [20]通过提示大语言模型[38,10,15]生成大量问答推理三元组,形成评估数据。 注重专业能力,VisIT-Bench [5] 强调 LVLM 的指令跟随能力,而 TouchStone [3] 则强调缺乏对沟通能力和视觉能力的直接评估LVLM 中的讲故事,尚未准确评估自动驾驶等复杂任务的性能。
2.0.2自动驾驶数据集。
NuScenes-QA [34] 根据对象属性和场景图中对象之间的关系手动构建 46 万个问答对。 BDD-X [21]重点关注自我汽车的行为并提供相应的原因。 虽然这两个数据集都专注于一般感知,但 DRAMA [30] 和 DriveLM [35] 还关注区域感知和驾驶建议。 具体来说,DRAMA [30]识别最关键的目标并提供相应的建议。 DriveLM [35] 通过使用图结构问答对促进端到端自动驾驶理解。 然而,自动驾驶系统经常在极端情况下出现故障,从而导致严重事故。 StreetHazards [18] 是一个综合数据集,其中使用计算机图形模拟极端情况场景。 CODA [23] 是一个真实的道路拐角案例数据集,包含 5,000 个驾驶场景,涵盖 30 多个对象类别。 如表所示。 1,现有的极端案例数据集缺乏语言模态,视觉语言数据集不涵盖极端案例场景。 因此,我们提出了 CODA-LM,这是第一个具有分层评估框架的自动驾驶大规模多模式道路拐角案例数据集。
3 CODA-LM 数据集
我们提出了 CODA-LM,这是一个专门为自动驾驶构建的数据集,强调从 CODA [23] 数据集收集的极端案例场景中的多模态感知和规划。 CODA-LM 包含 5,000 个真实驾驶场景,其中包含 28,000 个关键实体文本注释实例和 10,000 个极端情况对象文本,解决了当前自动驾驶多模态数据集中在极端情况情况覆盖方面的显着差距。 影响自动驾驶决策的关键实体分为七个不同的组,包括车辆、弱势道路使用者(VRU)、交通标志、 交通灯、交通锥、障碍和其他(例如。、动物和交通岛)。
CODA-LM涉及三个主要任务,包括总体感知、区域感知和驾驶建议,如图2。 一般感知任务侧重于描述所有显着道路物体的存在并解释它们为什么会影响驾驶行为,而区域感知任务致力于位置感知感知,当给定特定极端情况对象的边界框时,LVLM 需要描述和解释其对自我汽车的潜在影响。 相反,驾驶建议任务旨在根据之前的感知结果提供最佳驾驶建议。 系统化的任务层次结构要求 LVLM 能够深入了解复杂的驾驶环境,从而对由 LVLM 提供支持的智能自动驾驶代理进行全面评估。 接下来,我们将解释第 2 节中三个任务的详细数据结构。分别为3.1至3.3。
3.1 一般看法
一般感知任务的基础在于对驾驶场景中关键实体的全面理解,包括它们的外观、位置以及它们影响驾驶的原因。 这项任务对于评估 LVLM 解释复杂交互场景(反映自动驾驶感知过程)的熟练程度至关重要。 最初,我们使用 CODA 数据集 [23] 中的图像并查询 LVLM [31],通过附录 0.A,它不仅描述了交通场景中所有潜在的道路障碍物,而且还解释了它们为什么会影响自动驾驶。 此外,为了综合评估LVLM在不同环境下的性能,我们根据时间和天气条件对图像进行分类,包括时间条件的夜间和白天场景,以及晴、多云和雨天气情况。

3.2区域感知
区域感知任务衡量 LVLM 在提供特定边界框时理解极端情况对象的能力,其中涉及描述这些对象,并解释它们影响自动驾驶行为的原因。 区域感知的建立基于一个核心认识,即在自动驾驶的实际应用中,准确处理极端场景的能力对于增强整个系统的鲁棒性至关重要。 这些场景通常包含复杂或不寻常的元素,传统模型可能会忽略或难以正确解释,例如独特的交通标志、行为异常的行人或非典型道路条件。 通过专门关注这些案例,我们可以全面了解模型理解极端案例对象的能力。
3.3驾驶建议
驾驶建议任务旨在评估LVLM在自动驾驶领域制定驾驶建议的能力。 这项任务与自动驾驶的规划过程密切相关,要求模型在正确感知当前驾驶环境的总体和区域方面后,为自动驾驶汽车提供最优的驾驶建议。 通过构建驾驶建议任务,我们可以深入评估 LVLM 在制定有效驾驶策略方面的表现。
4 CODA-LM 建设
4.1数据收集
4.1.1管道。
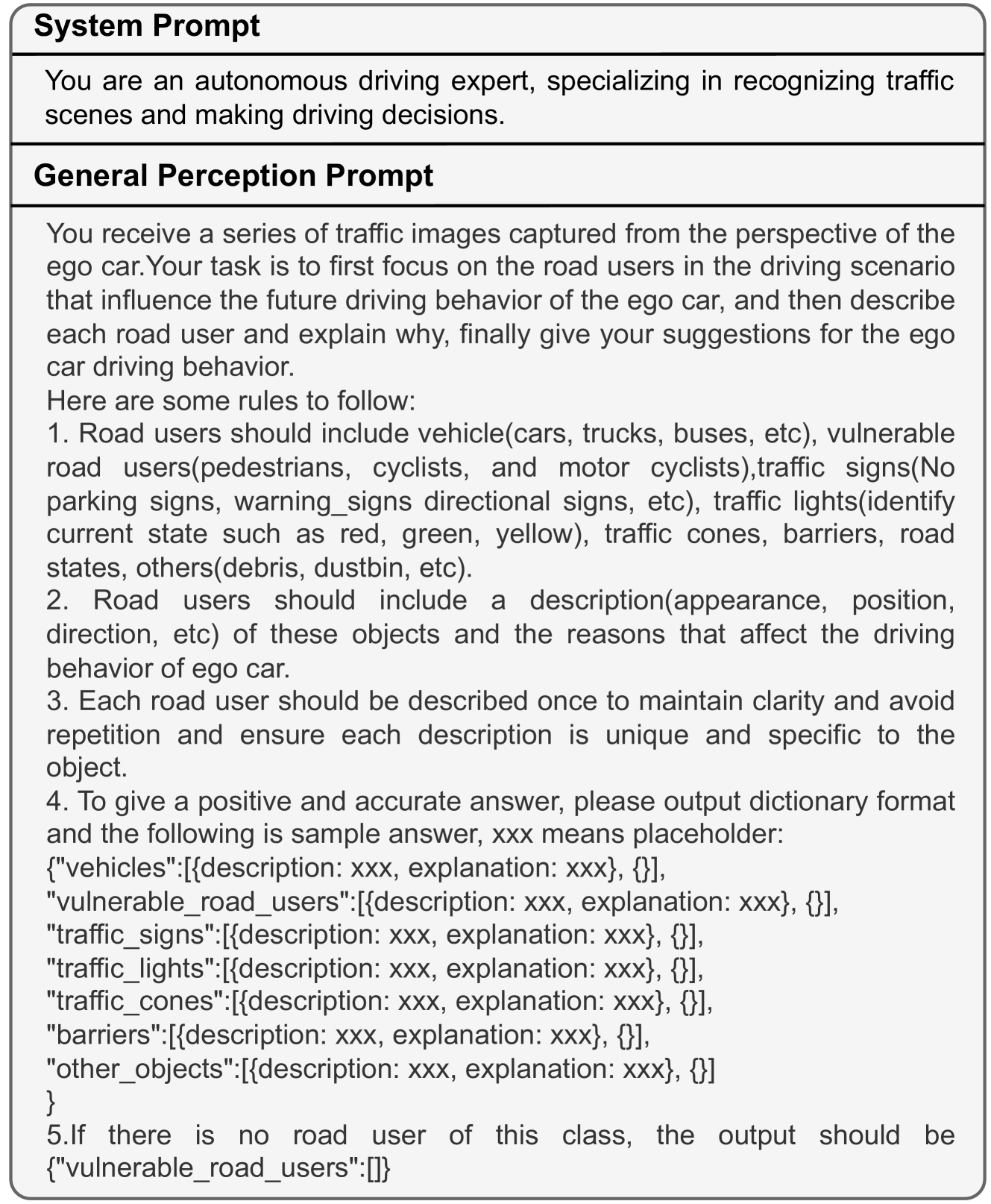
对于秒中的每个子任务。 3,我们精心设计了具体的提示,引导LVLM[31]根据视觉信息生成文本预注释。 我们首先构建一个全面的场景理解数据结构,并提示 LVLM 以 JSON 格式的文本进行响应,根据对驾驶的影响将对象分为七类。 这些类别的每个对象都很详细,解释了它们如何影响驾驶。 在获得一般感知和区域感知的输出(在下一段中详细介绍)后,我们将它们与选定的 CODA 图像相结合,形成 LVLM 的复合上下文,以生成驾驶建议。 最后,我们要求人工注释者验证和修改所有三个任务的预注释。 整体施工流程如图3所示。

4.1.2区域感知的视觉提示。
对于影响自动驾驶的极端情况对象,我们生成理解文本的区域级对象。 在此阶段,我们首先从 CODA [23] 中选择包含极端情况对象的图像。 使用启发式规则,我们选择按区域在其类别中排名前两名的对象。 我们过滤掉过于拥挤或对驾驶行为影响不大的物体,重点关注那些对自动驾驶有显着影响的物体。 我们通过两种方式为 LVLM 提供边界框输入,一种是通过视觉提示,在原始图像上用红色边界框标记目标,另一种是在文本提示中使用归一化坐标来定位目标(标记左上角)和目标的右下点,与 LLaVA [26] 类似)。 如选项卡所示。 4,提供边界框作为视觉提示被证明更有效。
4.1.3人工验证和修订。
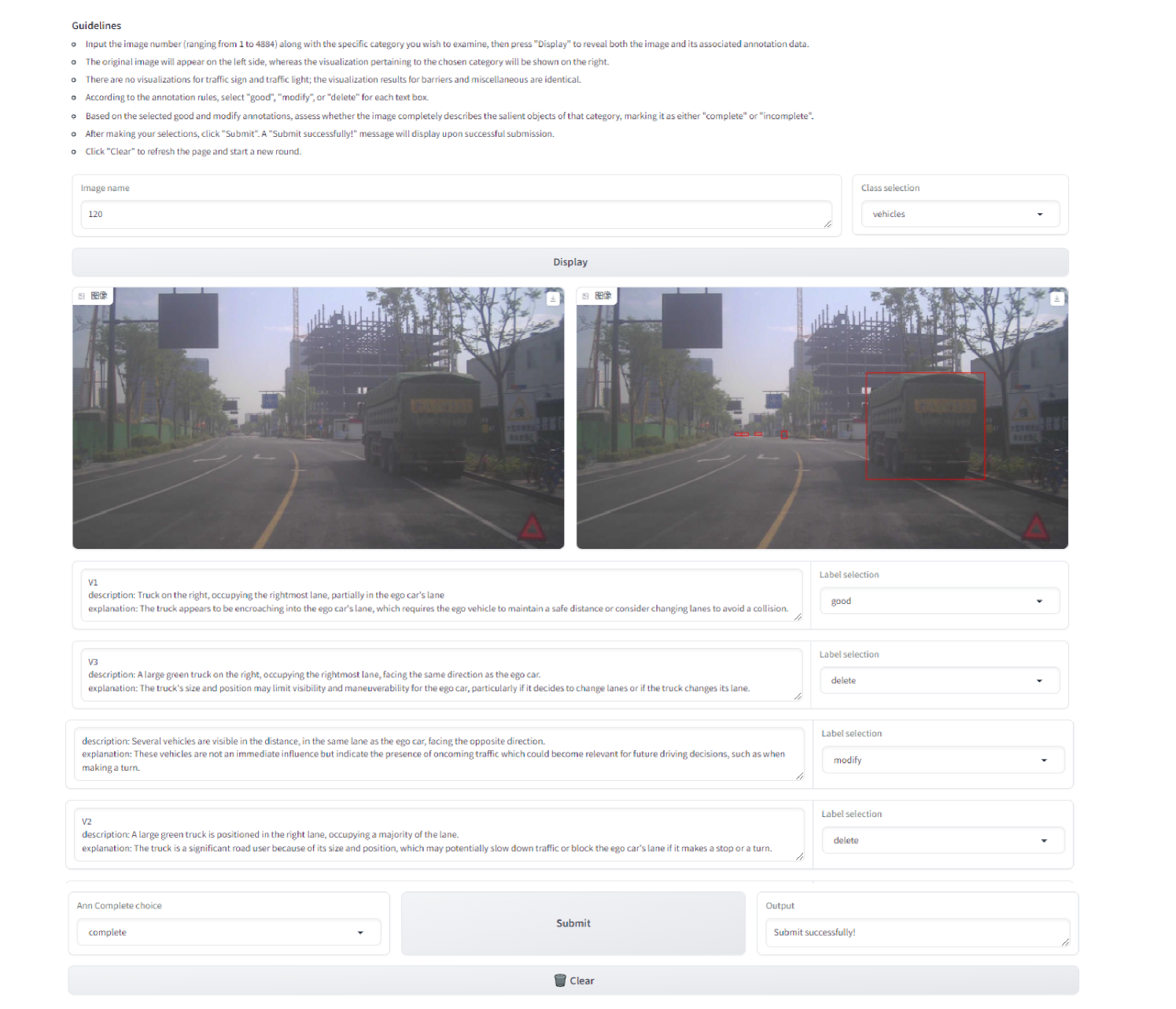
在获得三个子任务的预标注后,选择经验丰富的驾驶员来完成标注任务。 此外,使用Gradio[1]开发了标注工具界面,界面可视化见附录0.A。 我们为注释者提供了 LVLM 的文本输出作为源数据。 注释者的任务是从源数据中消除错误选择的对象,并进行最终修正以获得最终的 CODA-LM。
4.2评估框架
4.2.1对强大的LVLM判断不满意。
对于自动驾驶而言,LVLM感知和控制能力的自动系统评估对当前研究领域提出了严峻的挑战。 郑等.[43]展示了利用强大的大语言模型作为评判智能聊天助手能力的可行性,与传统的人类评估表现出很强的一致性。 受此启发,我们进行了一次初步的知识尝试,采用强大的LVLM作为评判者来评估LVLM,然而,这并不能满足我们的期望,如第2节所述。 5.4。 一方面,由于LVLM的指令跟踪能力不理想,很难始终以所需的格式[3]进行响应,从而影响了自动分析的可行性。 另一方面,其仍缺乏多模态上下文学习能力,使得少样本评估在复杂多样的自动驾驶场景中不可或缺。
4.2.2LVLM评判的强大大语言模型。
4.2.3评估标准。
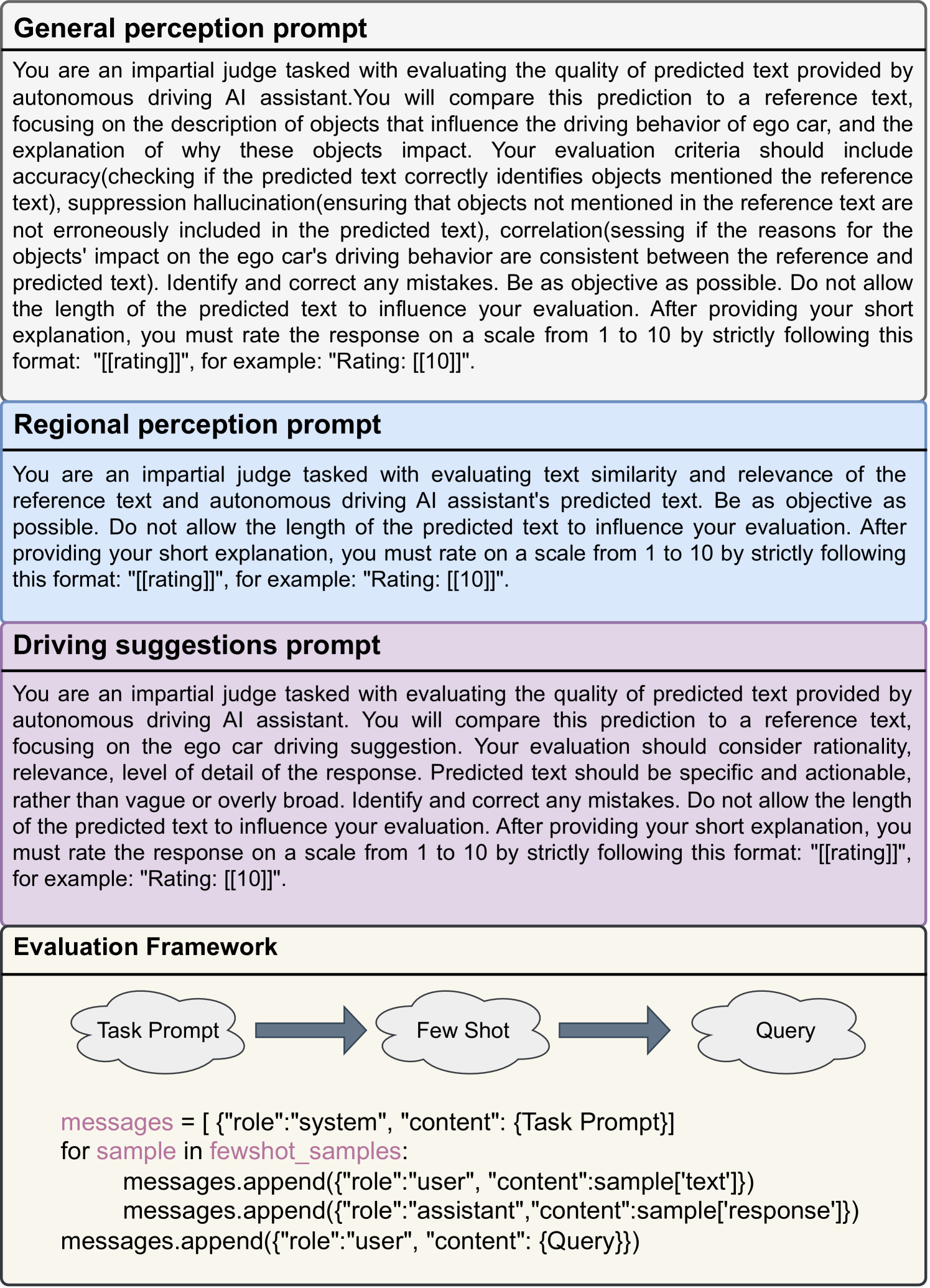
在用少样本ICL对全身知觉和局部知觉进行评估时,我们采用三个评估标准,包括准确性、幻觉panalty和一致性。 准确度是指 LVLM 感知自动驾驶环境的准确性,而现有的 LVLM 表现出严重的幻觉现象(例如.,感知不存在的目标或由于偏差导致错误识别) ),需要对其进行惩罚才能获得有效分数。 对于总体感知和区域感知,注释都包括相应物体对自动驾驶影响的描述和原因,并通过一致性衡量原因是否合理。 详细提示请参见附录0.A。 在驾驶建议方面,同样采用少样本ICL,但标准因其难度而变化,变为合理性、相关性、详细程度 的响应。 特别是对于驾驶建议,我们要求回复具体且可操作,而不是模糊或过于宽泛。
4.2.4 评估指标。
4.2.5 与人类的一致性。
在秒。 5.4,我们定量验证了强大的大语言模型法官给出的Text-Score与人类评估者偏好的强一致性,从而证明了使用纯文本大语言模型来评估LVLM的可行性,这也说明该评估方法可以区分LVLM理解自动驾驶场景的能力,特别是在区域感知中收集的极端案例场景中。
5 CODA-LM 基准
在本节中,基于所提出的 CODA-LM 数据集,我们首先从第 2 节中的各个维度比较和分析不同 LVLM 的性能。 5.1。 此外,我们检查了不同提示对数据集构建和评估的影响,并将文本分数与传统的基于关键字的评估指标进行了比较。 5.2和5.3。 最后,我们通过人类偏好一致性验证了我们的评估框架的有效性,并讨论了当前的局限性。 5.4。
| Source | Model | General Perception | Driving Suggestions |
|---|---|---|---|
| Text-Score | Text-Score | ||
| Open | MiniGPT-v2-7B [7] | 10.8 | 10.0 |
| Shikra-7B [12] | 19.4 | 19.5 | |
| LLaVA1.5-7B [25] | 21.0 | 34.2 | |
| InternLM2-vl-7B [42] | 29.8 | 45.5 | |
| LLaVA1.5-13B [25] | 23.1 | 39.2 | |
| PureMM-13B [37] | 28.0 | 43.8 | |
| InfMLLM-13B [45] | 29.0 | 46.9 | |
| Commercial | Gemini-Pro [36] | 22.5 | 27.5 |
| GPT-4V [31] | 46.5 | 62.6 |
5.1 主要结果
在这项工作中,我们总共评估了 8 个 LVLM,包括开源模型和商业模型。 商用型号包括Gemini-Pro [36]和GPT-4V [31]111https://chatgpt.ust.hk,而开源模型根据参数大小分为7B和13B。 7B型号包括InterLM-Xcomposser2-v1(简称InternLM2-vl-7B)[42]、LLaVA1.5[25]、MiniGPT-v2 [7] 和 Shikra [12],而 13B 包括 LLaVA1.5 [25]、InfMLLM [45] 和 PureMM [37]。 每个模型分别在三个任务上进行评估,以全面分析其在自动驾驶极端情况下的性能。 为了确保评估结果的可重复性,我们使用相同的提示为所有评估的 LVLM 生成响应,并在推理过程中采用贪婪解码,这会在每一步生成概率最高的下一个词符作为输出,从而消除推理过程中的随机性。 正如第 2 节中所讨论的。 4.2,采用强大的大语言模型作为评价的评委,温度系数设为0,固定随机种子,保证不同模型评分时的一致性。
| Source | Model | Regional Perception (Text-Score) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| ALL | Vehicle | VRU | Cone | Light | Sign | Barrier | Mis. | ||
| Open | MiniGPT-v2-7B [7] | 15.7 | 15.0 | 14.3 | 16.0 | 27.5 | 14.7 | 16.3 | 15.0 |
| Shikra-7B [12] | 21.6 | 23.7 | 23.3 | 21.3 | 16.3 | 22.0 | 22.7 | 18.3 | |
| LLaVA1.5-7B [25] | 32.7 | 47.0 | 31.0 | 37.0 | 21.5 | 31.0 | 29.8 | 21.0 | |
| InternLM2-vl-7B [42] | 50.8 | 52.3 | 52.0 | 70.0 | 37.5 | 46.7 | 43.7 | 43.7 | |
| LLaVA1.5-13B [25] | 38.7 | 50.0 | 39.0 | 43.0 | 33.8 | 39.0 | 37.7 | 25.0 | |
| PureMM-13B [37] | 39.6 | 50.3 | 39.3 | 46.0 | 42.5 | 36.0 | 36.3 | 29.0 | |
| InfMLLM-13B [45] | 40.2 | 51.7 | 30.0 | 54.7 | 27.5 | 37.0 | 40.0 | 31.0 | |
| Commercial | Gemini Pro [36] | 53.0 | 50.3 | 48.3 | 78.3 | 42.5 | 43.3 | 48.0 | 52.3 |
| GPT-4V [31] | 61.7 | 62.0 | 59.8 | 75.3 | 62.5 | 59.3 | 59.6 | 55.4 | |
5.2分析
5.2.1开源模型分析。
当前LVLM性能的提高主要归因于两个关键因素:训练策略(预训练阶段和指令调整阶段)和模型架构设计(视觉感知、不同模态的对齐、预训练大型语言模型)。 由于指令调整数据的重组、模态对齐模块设计以及图像分辨率的提高,LLaVA1.5 在相同规模的三个不同任务中显着超越了 Shikra 和 MiniGPT-v2。 具体来说,与 MiniGPT-v2 相比,LLaVA1.5 在总体感知上取得了 12% 的提升。 尽管没有报道使用自动驾驶领域数据集的开源 LVLM 训练,但我们的研究结果强调,可训练的视觉感知模块和额外的视觉适配器显着提高了模型性能,InfMLLM 和 PureMM 的卓越性能清楚地证明了这一点,优于 LLaVA1 .5 跨多个指标。 令人惊讶的是,在开源 LVLM 中,InternLM2-vl-7B 在一般感知和区域感知方面均取得了最佳性能,仅在驾驶建议方面仅次于 InfMLLM-13B。 这可以归因于其训练策略,该策略通过实现一般语义对齐、世界知识对齐和视觉能力增强,在预训练阶段扩展了模型的潜力。 另一方面,它利用 InternLM2-7B[6] 作为预训练大型语言模型,并采用一种新颖的模态对齐方法,不将视觉和语言标记视为完全独立的实体,而是对齐新的实体使用部分 LoRA 的大语言模型模态知识。 当然,模型参数的规模在性能结果中起着至关重要的作用,13B 模型比 7B 模型表现出优越性。
| Method | Recall |
|---|---|
| Visulization [31] | 85% |
| Coordinate Representation [26] | 12% |
5.2.2区域多类分析。
为了对极端情况区域理解进行全面而详细的评估,我们的目标是将数据样本分为七个不同的类别,包括车辆、VRU(例如。、行人和骑自行车的人)、交通锥、交通灯、交通标志、障碍物和杂项,其中杂项表示不经常出现的物体(例如.、动物和垃圾桶)。 在开源模型中,InternLM2-vl-7B 在识别 VRU、交通锥、交通标志和杂项方面显着优于其他模型,最小差异分别达到 10%、16%、10% 和 12%。 Shikra 和 MiniGPT-v2 在所有类别中通常表现不佳。 其他模型在识别车辆、交通标志和其他方面表现出大致相同的性能。 值得一提的是,PureMM 在交通信号灯识别方面表现出色,可能得益于其额外的视觉适配器模块,并且在 VRU 区域感知性能方面也超越了 InfMLLM。
5.2.3商业模式分析。
在商用LVLM中,GPT-4V继续展现出前所未有的领先地位,总分排名第一,得益于其海量的训练数据,避免了仅在自然领域训练的陷阱。 相比之下,Gemini-Pro在总体感知和驾驶建议方面表现较差,但在区域感知方面表现出色。 分析表明,Gemini Pro 倾向于生成通用且宽泛的图像描述和建议,缺乏对特定场景的具体分析。 这导致幻觉现象频繁发生,从而导致其得分较低。 另一方面,适当的提示可以激发VLM的能力。 但为了保证评测的公平性,所有模型都采用了相同的提示,这在一定程度上抑制了商业模型的能力。 这个问题不会出现在区域认知中,因此会产生截然不同的结果。
5.3消融研究
5.3.1区域感知数据采集的视觉提示。
5.3.2区域感知评估的视觉提示。
与数据采集类似,可视化和坐标表示也可用于获取来自要评估的不同 LVLM 的响应。 然而,不同的 LVLM 采用不同的训练方法。 有些模型在训练期间可能不使用接地数据,从而缺乏定位能力。 因此,我们探讨可视化是否可以作为所有 LVLM 的通用视觉提示。 如表所示。 5,在开源的LVLM中,选择了LLaVA1.5和MiniGPT-v2,两者都使用额外的接地数据进行训练。 商用机型选择Gemini Pro,是因为其多样化的训练方式和一定的本地化能力。 对应的可视化提示是“请描述图像中红色矩形内的物体,并解释为什么它会影响自我汽车驾驶”。 另一方面,坐标表示为“请提供该对象的描述并解释为什么该对象影响自我汽车驾驶:[x1, y1, x2, y2]”。 结果表明,可视化通常优于坐标表示,LLaVA1.5 显示了 22% 的增益,Gemini-Pro 则显示了 14% 的增益,这与我们对 GPT-4V 的观察结果一致,如表 1 所示。 4.
| Model | Regional Perception Method | |
|---|---|---|
| Visualization | Coordinate representation | |
| MiniGPT-v2-7B [7] | 15.7 | 14.3 |
| LLaVA1.5-13B [25] | 38.7 | 16.6 |
| Gemini-Pro [36] | 53.0 | 39.3 |
| Source | Model | Metrics | |||
|---|---|---|---|---|---|
| BLEU4 | METEOR | CIDEr | SPICE | ||
| Open | MiniGPT-v2-7B [7] | 0.6 | 5.3 | 0.6 | 4.4 |
| Shikra-7B [12] | 1.5 | 8.7 | 0.0 | 5.2 | |
| LLaVA1.5-7B [25] | 1.9 | 13.9 | 0.9 | 9.8 | |
| InternLM2-vl-7B [42] | 2.7 | 14.2 | 5.7 | 15.2 | |
| PureMM-13B [37] | 2.3 | 15.7 | 3.7 | 10.7 | |
| LLaVA1.5-13B [25] | 2.7 | 16.0 | 1.1 | 13.9 | |
| InfMLLM-13B [45] | 2.8 | 14.2 | 5.7 | 15.2 | |
| Commercial | Gemini Pro [36] | 1.9 | 12.9 | 4.8 | 16.0 |
| GPT-4V [31] | 2.3 | 17.4 | 0.0 | 19.2 | |

5.3.3 评估指标。
在进行极端案例区域感知评估时,数据以简短句子的形式组织。 因此,除了使用 Text-Score 进行评估外,我们还探讨了传统基于关键字的指标的影响,包括 BLEU-4 [33]、METEOR [4]、CIDEr [39] 和 SPICE [2],如 Tab 所示。 6. 为了更好地演示,我们将分数乘以 100,将其标准化为 1-100 的范围,与文本分数类似。 BLEU-4主要通过词汇匹配来评估质量,无法捕获生成文本的语义准确性。 CIDEr 不适合词汇重复率低的文本。 因此,这两个指标的分数并不能准确反映性能。 METEOR虽然可以解释同义词,但仍然不能反映实际语义,因此尽管分数存在一些差异,但并不准确。 相比之下,SPICE可以反映部分文本的语义准确性,尽管总体得分仍然较低,但它成功地表明了不同模型之间的趋势,InternLM2-vl仍然在开源模型中处于领先地位。 默认情况下,除非另有说明,我们仍然采用 Text-Score 作为主要评价指标。
| Judge | Consistency (Rank-based) | ||
|---|---|---|---|
| General Perception | Regional Perception | Driving Suggestions | |
| GPT-4V | 50% | 42% | 57% |
| GPT-4 | 70% | 87% | 77% |
5.4 人类的一致性和局限性
5.4.1 人类一致性。
为了衡量 GPT-4 的判断与人类偏好之间的一致性,我们采用了排序方法。 具体来说,对于一般感知、区域感知和驾驶建议,我们分别采样了 100 组数据,将其视为提示两个不同 LVLM、LLaVA1.5 和 InfMLLM 的查询,并在每个样本中选择获胜者。 同时,对于每组数据,由三名人类评估者进行投票,遵循少数服从多数的原则,决出胜者。 一致性得分用获胜者的匹配数占数据集总数的比率来表示。 为了保证评估的准确性,我们使用GPT-4进行多次评估,并将这些评估的平均值作为最终的评估结果。 如表所示。 7,GPT-4法官在总体感知、驾驶建议和区域感知方面的得分分别为70%、77%和87%,在人类评估方面显着超越GPT-4V法官一致性。
5.4.2 限制。
CODA-LM 目前建立在 CODA 中收集的现实世界的极端案例上,其规模难以扩展,我们选择探索利用可控生成模型[11,14,24,28,40]在未来的工作中生成道路拐角案例。 此外,当前的数据构建流程依赖于人工验证和修订来保证数据质量,自动数据校准方法也是一个有吸引力的研究方向。 如何更好地结合视觉预训练先验(如自监督学习[8,9,29,44])以实现更好的泛化也是一个悬而未决的问题。
6结论
在本文中,我们提出了 CODA-LM,一种用于自动驾驶的新型现实多模态道路角落案例数据集,具有层次任务框架,涵盖从一般和区域感知到驾驶建议,以支持大型视觉语言模型的自动评估( LVLM)在自动驾驶的极端情况下。 对开源和商业 LVLM 的广泛评估表明,我们距离强大的 LVLM 支持的智能驾驶代理还很远,我们希望我们的 CODA-LM 能够充当催化剂,促进可靠且可解释的自动驾驶系统的开发。
6.0.1致谢
我们衷心感谢 MindSpore、CANN(神经网络计算架构)和 Ascend AI 处理器对本研究的支持。
参考
- [1] Abid, A., Abdalla, A., Abid, A., Khan, D., Alfozan, A., Zou, J.: Gradio: Hassle-free sharing and testing of ml models in the wild. arXiv preprint arXiv:1906.02569 (2019)
- [2] Anderson, P., Fernando, B., Johnson, M., Gould, S.: Spice: Semantic propositional image caption evaluation. In: ECCV (2016)
- [3] Bai, S., Yang, S., Bai, J., Wang, P., Zhang, X., Lin, J., Wang, X., Zhou, C., Zhou, J.: Touchstone: Evaluating vision-language models by language models. arXiv preprint arXiv:2308.16890 (2023)
- [4] Banerjee, S., Lavie, A.: Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. In: Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization (2005)
- [5] Bitton, Y., Bansal, H., Hessel, J., Shao, R., Zhu, W., Awadalla, A., Gardner, J., Taori, R., Schmidt, L.: Visit-bench: A dynamic benchmark for evaluating instruction-following vision-and-language models. In: NeurIPS (2024)
- [6] Cai, Z., Cao, M., Chen, H., Chen, K., Chen, K., Chen, X., Chen, X., Chen, Z., Chen, Z., et al.: Internlm2 technical report (2024)
- [7] Chen, J., Zhu, D., Shen, X., Li, X., Liu, Z., Zhang, P., Krishnamoorthi, R., Chandra, V., Xiong, Y., Elhoseiny, M.: Minigpt-v2: large language model as a unified interface for vision-language multi-task learning. arXiv preprint arXiv:2310.09478 (2023)
- [8] Chen, K., Hong, L., Xu, H., Li, Z., Yeung, D.Y.: Multisiam: Self-supervised multi-instance siamese representation learning for autonomous driving. In: ICCV (2021)
- [9] Chen, K., Liu, Z., Hong, L., Xu, H., Li, Z., Yeung, D.Y.: Mixed autoencoder for self-supervised visual representation learning. In: CVPR (2023)
- [10] Chen, K., Wang, C., Yang, K., Han, J., Hong, L., Mi, F., Xu, H., Liu, Z., Huang, W., Li, Z., et al.: Gaining wisdom from setbacks: Aligning large language models via mistake analysis. arXiv preprint arXiv:2310.10477 (2023)
- [11] Chen, K., Xie, E., Chen, Z., Hong, L., Li, Z., Yeung, D.Y.: Integrating geometric control into text-to-image diffusion models for high-quality detection data generation via text prompt. arXiv preprint arXiv:2306.04607 (2023)
- [12] Chen, K., Zhang, Z., Zeng, W., Zhang, R., Zhu, F., Zhao, R.: Shikra: Unleashing multimodal llm’s referential dialogue magic. arXiv preprint arXiv:2306.15195 (2023)
- [13] Fu, C., Chen, P., Shen, Y., Qin, Y., Zhang, M., Lin, X., Yang, J., Zheng, X., Li, K., Sun, X., et al.: Mme: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394 (2023)
- [14] Gao, R., Chen, K., Xie, E., Hong, L., Li, Z., Yeung, D.Y., Xu, Q.: Magicdrive: Street view generation with diverse 3d geometry control. arXiv preprint arXiv:2310.02601 (2023)
- [15] Gou, Y., Chen, K., Liu, Z., Hong, L., Xu, H., Li, Z., Yeung, D.Y., Kwok, J.T., Zhang, Y.: Eyes closed, safety on: Protecting multimodal llms via image-to-text transformation. arXiv preprint arXiv:2403.09572 (2024)
- [16] Gou, Y., Liu, Z., Chen, K., Hong, L., Xu, H., Li, A., Yeung, D.Y., Kwok, J.T., Zhang, Y.: Mixture of cluster-conditional lora experts for vision-language instruction tuning. arXiv preprint arXiv:2312.12379 (2023)
- [17] Han, J., Liang, X., Xu, H., Chen, K., Hong, L., Ye, C., Zhang, W., Li, Z., Liang, X., Xu, C.: Soda10m: Towards large-scale object detection benchmark for autonomous driving. arXiv preprint arXiv:2106.11118 (2021)
- [18] Hendrycks, D., Basart, S., Mazeika, M., Mostajabi, M., Steinhardt, J., Song, D.: A benchmark for anomaly segmentation. arXiv preprint arXiv:1911.11132 (2019)
- [19] Hu, Y., Yang, J., Chen, L., Li, K., Sima, C., Zhu, X., Chai, S., Du, S., Lin, T., Wang, W., et al.: Planning-oriented autonomous driving. In: CVPR (2023)
- [20] Ji, Y., Ge, C., Kong, W., Xie, E., Liu, Z., Li, Z., Luo, P.: Large language models as automated aligners for benchmarking vision-language models. arXiv preprint arXiv:2311.14580 (2023)
- [21] Kim, J., Rohrbach, A., Darrell, T., Canny, J., Akata, Z.: Textual explanations for self-driving vehicles. In: ECCV (2018)
- [22] Li, B., Ge, Y., Ge, Y., Wang, G., Wang, R., Zhang, R., Shan, Y.: Seed-bench-2: Benchmarking multimodal large language models. arXiv preprint arXiv:2311.17092 (2023)
- [23] Li, K., Chen, K., Wang, H., Hong, L., Ye, C., Han, J., Chen, Y., Zhang, W., Xu, C., Yeung, D.Y., et al.: Coda: A real-world road corner case dataset for object detection in autonomous driving. arXiv preprint arXiv:2203.07724 (2022)
- [24] Li, P., Liu, Z., Chen, K., Hong, L., Zhuge, Y., Yeung, D.Y., Lu, H., Jia, X.: Trackdiffusion: Multi-object tracking data generation via diffusion models. arXiv preprint arXiv:2312.00651 (2023)
- [25] Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tuning. arXiv preprint arXiv:2310.03744 (2023)
- [26] Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. arxiv preprint arxiv:2304.08485 (2023)
- [27] Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., et al.: Mmbench: Is your multi-modal model an all-around player? arXiv preprint arXiv:2307.06281 (2023)
- [28] Liu, Z., Chen, K., Zhang, Y., Han, J., Hong, L., Xu, H., Li, Z., Yeung, D.Y., Kwok, J.: Geom-erasing: Geometry-driven removal of implicit concept in diffusion models. arXiv preprint arXiv:2310.05873 (2023)
- [29] Liu, Z., Han, J., Chen, K., Hong, L., Xu, H., Xu, C., Li, Z.: Task-customized self-supervised pre-training with scalable dynamic routing. In: AAAI (2022)
- [30] Malla, S., Choi, C., Dwivedi, I., Choi, J.H., Li, J.: Drama: Joint risk localization and captioning in driving. In: WACV (2023)
- [31] OpenAI: ChatGPT (2023), https://openai.com/research/gpt-4v-system-card
- [32] OpenAI: ChatGPT (2023), https://chat.openai.com
- [33] Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: Bleu: a method for automatic evaluation of machine translation. In: ACL (2002)
- [34] Qian, T., Chen, J., Zhuo, L., Jiao, Y., Jiang, Y.G.: Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario. arXiv preprint arXiv:2305.14836 (2023)
- [35] Sima, C., Renz, K., Chitta, K., Chen, L., Zhang, H., Xie, C., Luo, P., Geiger, A., Li, H.: Drivelm: Driving with graph visual question answering. arXiv preprint arXiv:2312.14150 (2023)
- [36] Team, G., Anil, R., Borgeaud, S., Wu, Y., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
- [37] Team, P.: PureMM (2023), https://github.com/Q-MM/PureMM
- [38] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023)
- [39] Vedantam, R., Lawrence Zitnick, C., Parikh, D.: Cider: Consensus-based image description evaluation. In: CVPR (2015)
- [40] Wang, Y., Gao, R., Chen, K., Zhou, K., Cai, Y., Hong, L., Li, Z., Jiang, L., Yeung, D.Y., Xu, Q., Zhang, K.: Detdiffusion: Synergizing generative and perceptive models for enhanced data generation and perception. arXiv preprint arXiv:2403.13304 (2024)
- [41] Wen, L., Yang, X., Fu, D., Wang, X., Cai, P., Li, X., Ma, T., Li, Y., Xu, L., Shang, D., et al.: On the road with gpt-4v (ision): Early explorations of visual-language model on autonomous driving. arXiv preprint arXiv:2311.05332 (2023)
- [42] Zhang, P., Wang, X.D.B., Cao, Y., Xu, C., Ouyang, L., Zhao, Z., Ding, S., Zhang, S., Duan, H., Yan, H., et al.: Internlm-xcomposer: A vision-language large model for advanced text-image comprehension and composition. arXiv preprint arXiv:2309.15112 (2023)
- [43] Zheng, L., Chiang, W.L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E., et al.: Judging llm-as-a-judge with mt-bench and chatbot arena. In: NeruIPS (2023)
- [44] Zhili, L., Chen, K., Han, J., Lanqing, H., Xu, H., Li, Z., Kwok, J.: Task-customized masked autoencoder via mixture of cluster-conditional experts. In: ICLR (2023)
- [45] Zhou, Q., Wang, Z., Chu, W., Xu, Y., Li, H., Qi, Y.: Infmllm: A unified framework for visual-language tasks. arXiv preprint arXiv:2311.06791 (2023)
- [46] Zhu, D., Chen, J., Shen, X., Li, X., Elhoseiny, M.: Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arxiv:2304.10592 (2023)
补充材料
附录 0.A 有关数据集构建的更多信息
0.A.0.1 渐变标注工具图形用户界面(GUI)。
图5显示了我们的标记工具在一般感知任务中的屏幕截图。 我们利用 Gradio 旨在帮助人类注释者完善源自强大 LVLM 的一般感知预注释。 标注者按照逐步合并、修改、删除的原则进行细化。
0.A.0.2 提示进行预注释。

0.A.0.3 提示评估。
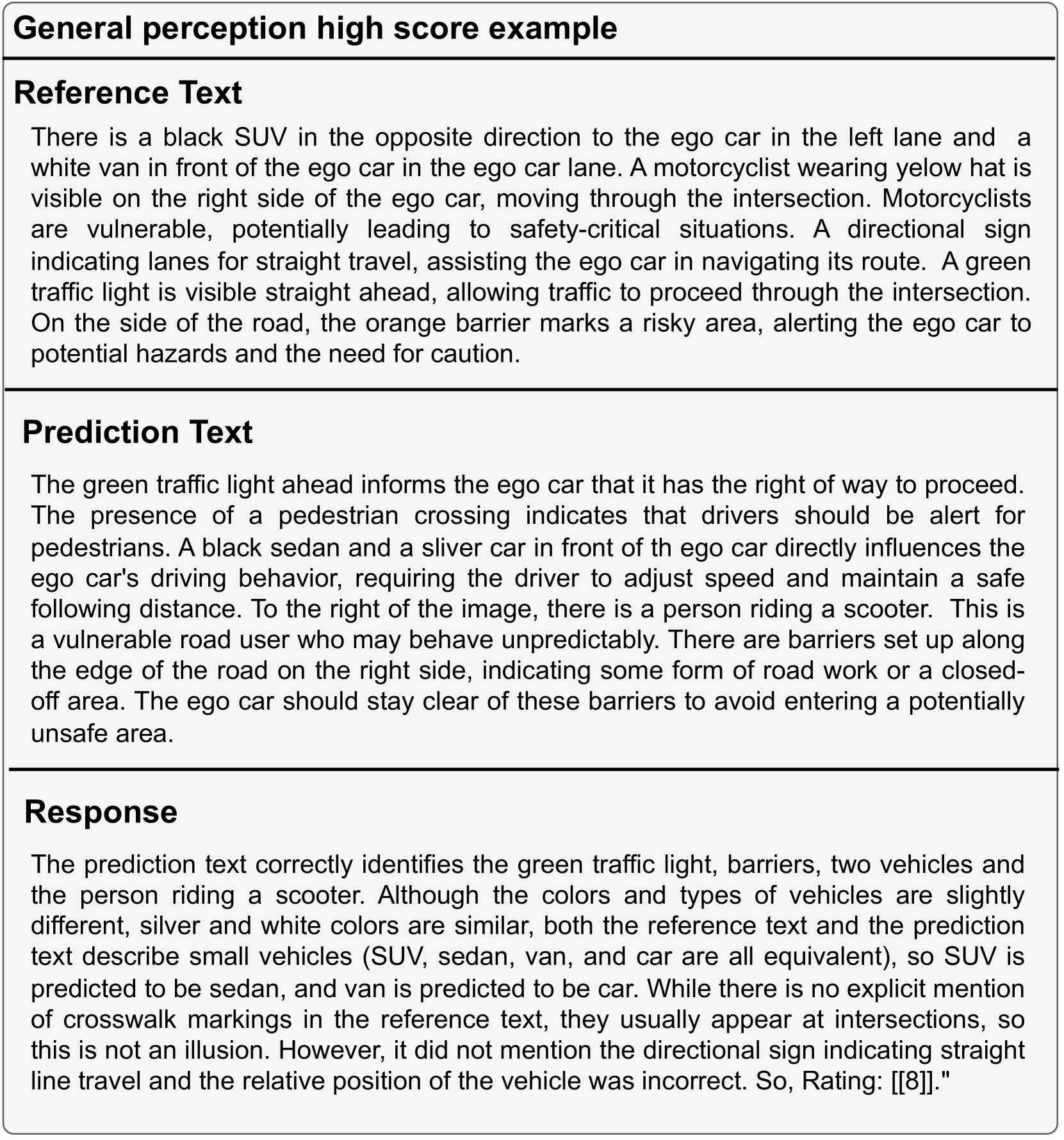
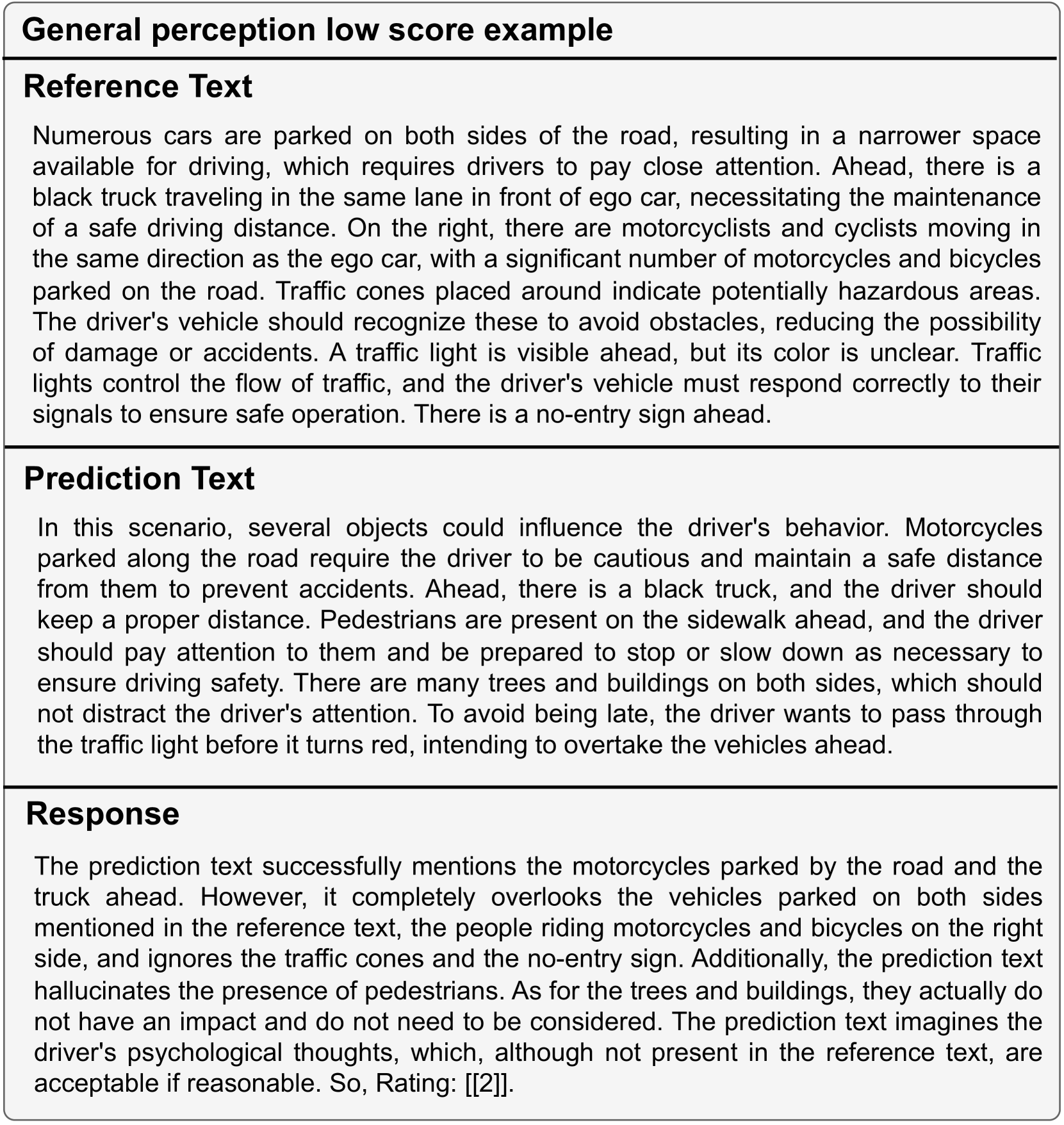
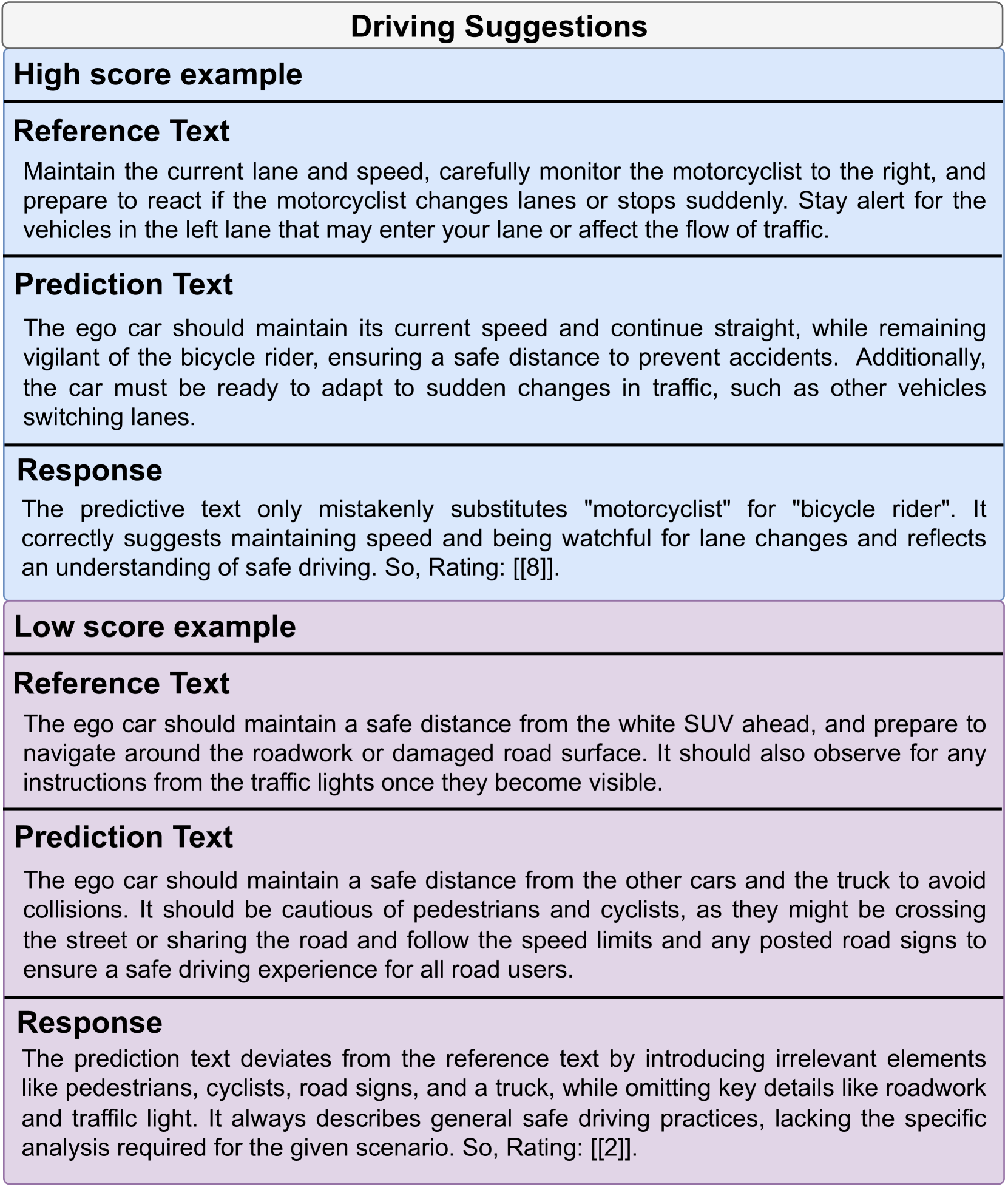
为了全面、准确地评估不同VLM的性能,我们为每个任务设计了不同的评估提示,如图8所示。 Meanfile,我们使用少样本上下文学习方法来提高一般感知和驾驶建议的准确性。 具体来说,我们设计了具有不同分数的上下文示例来辅助判断。 详情请参阅图9及图10中一般认知的少样本情境学习范例。 此外,用于驾驶建议的上下文学习示例样本如图11所示。
附录0.B定性比较
在本节中,我们将介绍来自 CODA-LM 的三个数据示例,如图 12 至 14 所示。 如需更多数据,请访问我们的匿名项目网站:https://coda-lm.github.io/。 在 CODA-LM 的基础上,我们随后分析了三个任务中不同 LVLM 的响应,如图 15 至 20 所示。








