![[Uncaptioned image]](ferret_icon.jpg) Ferret-v2:改进的大型语言模型引用和基础基线
Ferret-v2:改进的大型语言模型引用和基础基线
摘要
虽然 Ferret 将区域理解无缝集成到大语言模型(大语言模型)中,以促进其参考和基础能力,但它也存在一定的局限性:受到预先训练的固定视觉编码器的限制,无法在更广泛的任务上表现良好。 在这项工作中,我们推出了 Ferret-v2,它是 Ferret 的重大升级,具有三个关键设计。 (1) 任何分辨率基础和参考:一种灵活的方法,可以轻松处理更高的图像分辨率,提高模型更详细地处理和理解图像的能力。 (2) 多粒度视觉编码:通过集成额外的 DINOv2 编码器,模型可以更好地学习和多样化的底层上下文,以获取全局和细粒度的视觉信息。 (3)三阶段训练范例:除了图像标题对齐之外,还提出了在最终指令调整之前进行高分辨率密集对齐的额外阶段。 实验表明,由于其高分辨率缩放和细粒度视觉处理,Ferret-v2 比 Ferret 和其他最先进的方法有了显着的改进。 ††同等贡献。

1简介
多模态大语言模型 (MLLM) (Koh 等人, 2023; Wu 等人, 2023a; Yang 等人, 2023; Liu 等人, 2023d; Wu 等人, 2023c; Li 等人, 2023d; Ye 等人,2023;Li 等人,2023a;Gao 等人,2024;McKinzie 等人,2024)作为开发多功能通用助手的基础要素。 然而,这些方法建立在粗略的图像级对齐之上,这会受到细粒度理解(例如区域描述和推理)的影响。 为此,Peng 等人(2023);陈 等人 (2023b);你等人(2023)整合了接地能力并解锁了对话中的参照能力,即使用户能够指向物体或区域作为输入,模型响应空间边界框的坐标。 这一进步使 MLLM 能够执行需要详细视觉理解的任务,标志着该领域的重大进展。
虽然接地和参考 MLLM 表现出强大的性能,但仍有许多挑战尚未解决。 例如,上述方法使用CLIP(Jiang等人,2023)或其变体(Sun等人,2023)作为视觉编码器。 由于预先训练的图像编码器通常采用相对较低的图像分辨率(例如,224×224),这严重阻碍了 MLLM 的精细视觉理解能力。 尽管一些特定任务的 MLLM (Lv 等人,2023;Hong 等人,2023;Ye 等人,2023)已经探索了大规模处理的策略,但这些方法因其自身领域的过度复杂性而受到损害并且在传统的 MLLM 基准测试中表现不佳。 因此,该场景引发了一个关键的询问: 我们如何才能增强 MLLM 的能力,使其在详细的视觉相关任务中表现出色,同时又不影响其全局推理的熟练程度?
为了回答这个问题,我们从即、更高分辨率缩放、多粒度视觉编码和模型训练食谱三个方面来探索其潜力。 我们选择 Ferret (You 等人, 2023) 作为稳健基线,因为它有两个优点:(i) 引用和接地之间的互惠互利,以及 (ii) 更通用的引用能力(笔画、涂鸦、或复杂的多边形)。 首先,我们对更高分辨率的缩放进行了仔细的研究,评估了“直接上采样”(Wang等人,2023a;Bai等人,2023)和“任意分辨率”两种主流方法的性能” (高等人,2024;刘等人,2024),关于(i)视觉细节分析(ROC (尤等人,2023) & REC (Kazemzadeh 等人, 2014)),(ii) 分辨率关键的 OCR 任务 (TextVQA (Singh 等人, 2019)),以及 (iii) 推理 MLLM 基准 (Ferret-Bench) (你等人,2023))。 我们的分析表明,“任何分辨率”方法在利用图像细节方面优于“直接上采样”,同时保留在预训练期间获得的知识以实现有效缩放。 这将“任何分辨率”定位为需要高级视觉理解的任务的优越策略。
通过采用“任何分辨率”方法,该方法涉及将图像划分为子补丁以供 CLIP 编码器处理,我们观察到将全局上下文和高分辨率补丁合并到视觉嵌入中会带来细微的复杂性。 这是因为两种类型的图像表现出不同的特征。 为了缩小这一差距,我们建议集成 DINOv2 编码器(Oquab 等人,2023)。 DINOv2 以其擅长描绘局部物体的更精细细节而闻名,有望增强模型感知细粒度方面的能力。 此外,我们为每个视觉编码器采用单独的 MLP 投影仪,以促进对全局和细粒度视觉信息呈现的不同上下文进行更深入的探索,从而实现更全面的理解和表示。
此外,该模型分三个阶段进行战略性训练,增强分辨率处理,同时以“从粗到细”的方式保持视觉语言对齐。 最初,模型在低分辨率图像上进行训练,以实现有效的图像标题对齐。 随后,我们认识到一些下游任务需要更准确、更彻底的空间理解,而不仅仅是广泛的语义,因此我们专门设计了第二阶段,将图像的每个可能的局部对象与密集引用和检测的详细语义对齐数据。 最后,模型经过视觉指令微调,以更好地解释用户意图。
本文的贡献总结如下:(i)我们对更高分辨率的缩放进行了彻底的分析,发现“任意分辨率”方法始终优于“直接上采样”。 (ii) 基于“任意分辨率”,我们进一步提出了多粒度视觉编码,其中低分辨率图像通过CLIP进行编码,而高分辨率子补丁通过DINOv2进行编码。 这一策略促进了对全局和细粒度视觉环境的更深入理解。 (iii) Ferret-v2 在三阶段过程中进行训练,其中提出了在最终指令调整之前进行高分辨率密集对齐的附加阶段。 对各种任务(包括参考和基础、视觉问答和现代 MLLM 基准)的广泛实验证明了 Ferret-v2 相对于现有作品的优越性(见图 1)。
2 背景
粗级 MLLM。
在大语言模型展示的高级推理能力的推动下(OpenAI, 2022; Chowdhery 等人, 2022; Touvron 等人, 2023a, b; Zhuang 等人, 2022b; Wei 等人, 2021),人们越来越有兴趣将这些技能扩展到视觉理解,导致多模态大语言模型的出现。 例如,Flamingo (Alayrac 等人, 2022) 利用交叉注意力机制来增强视觉上下文感知,从而实现更复杂的上下文感知视觉学习。 LLaVA (Liu 等人, 2023b, a) 和 MiniGPT-4 (Zhu 等人, 2023) 等模型侧重于在应用指令调整之前同步图像和文本特征。 此外,BLIP-2 (Li 等人, 2023d) 和 mPLUG-OWL (Ye 等人, 2023) 提供了使用视觉编码器合并图像特征的方法,即然后与大语言模型架构中的文本嵌入相结合。 然而,尽管取得了进步,这些 MLLM,包括最新的 GPT-4V (OpenAI,2023),仅限于生成文本输出,限制了它们在需要丰富区域级视觉感知的场景中的应用。
区域级 MLLM。
在最近的研究中,人们越来越关注基础模型的融合以及与密集视觉感知相关的任务。 例如,Li 等人 (2023c);邹等人 (2023); Koh 等人 (2023) 利用 CLIP 预训练基础模型来实现开放世界检测,但它们无法处理复杂的指令。 不同的是,VisionLLM (Wang 等人, 2023c) 通过利用大语言模型的指令调优,结合了一系列以视觉为中心的任务。 然而,它可能无法充分发挥大语言模型处理复杂推理任务的潜力。 在并行研究工作中,Kosmos-2 (Peng 等人,2023)、Qwen-VL (Bai 等人,2023) 利用了接地能力和开放词汇探测器。和 DetGPT (Pi 等人, 2023),实现用户引导检测。 此外,GPT4RoI (张等人, 2023b)、Shikra (陈等人, 2023b)、LLaVA-G (张等人, 2023a) 和 Ferret (You 等人, 2023) 引入空间框作为输入,并使用区域文本对训练模型,提供区域图像理解。 然而,所有上述方法都利用低分辨率图像编码器,因此限制了感知更详细分析的能力。
3方法
我们首先在第二节回顾 Ferret 的设计原则。 3.1 并在第 3 节中介绍了对更高分辨率缩放的研究。 3.2。 随后,在秒。 3.3,我们深入研究了模型架构的进步,包括在任何分辨率下的接地和引用技术,以及多粒度的视觉编码。 最后,我们介绍了一种增强的训练方法,旨在提高模型在第 2 节中对齐全局和局部元素的能力。 3.4。
3.1 重温雪貂
最近人们越来越关注模型的融合(Zhang 等人,2023b;Chen 等人,2023b;Peng 等人,2023;Lai 等人,2023;Zhao 等人,2023;You 等人, 2023)以及与视觉感知相关的任务。 Ferret (You 等人, 2023) 与其他 MLLM 的区别在于,它擅长在不同形状和细节级别的自然图像中进行空间参考和基础。
为了引用各种类型的区域,例如点、盒子或自由形状,Ferret 开发了一种混合区域表示,其中每个区域由离散坐标标记和连续区域特征以及区域名称的组合来引用如果可供使用的话。 坐标被归一化为0到999的范围,点或形状分别用[]或[]表示。 连续区域特征由空间感知视觉采样器提取,该采样器对区域特征进行采样和聚合。 最终,一个区域会以"区域名称 坐标 连续的 Fea"来表示,并输入到模型中以供参考,例如,"[100, 50, 200, 300] 连续的 Fea区域中有什么? 为了实现接地,Ferret 在文本响应中的相应区域/名词之后生成框坐标,例如,“图中有一只狗 [100, 150, 300, 200]。”
Ferret 使用预先训练的视觉编码器 (CLIP-ViT-L/14) (Radford 等人, 2021) 对图像进行编码,然后将图像特征作为附加标记与文本输入(以及混合区域表示(如果有)转换为仅解码器的语言模型(Vicuna (Zheng 等人, 2023))。 训练包含两个阶段,图像标题对齐和指令调整,并使用下一个 Token 预测损失进行更新。
虽然 Ferret 拥有灵活性和卓越的性能,但它受到预训练编码器固定分辨率的限制,这限制了其充分利用增强区域参考和定位精度优势的能力。 受此启发,我们最初深入研究确定高分辨率缩放的最有效方法。 随后,我们推出了 Ferret-v2,它是 Ferret 系列的实质性扩展,旨在研究更广泛、更具包容性的多模式学习框架。
3.2更高分辨率缩放分析
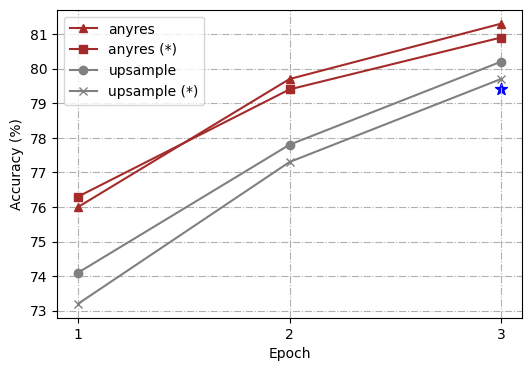
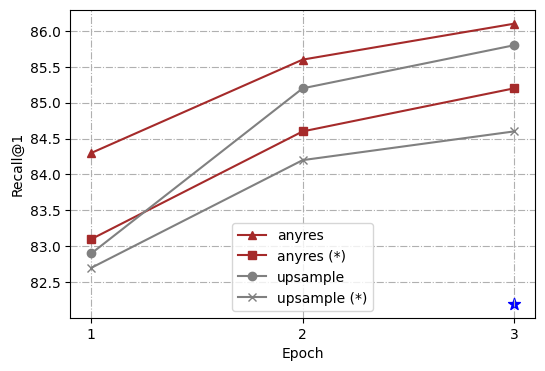
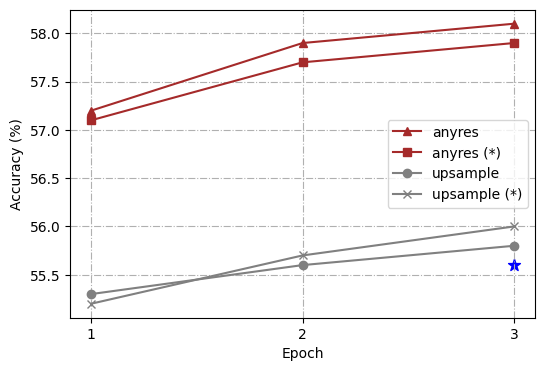
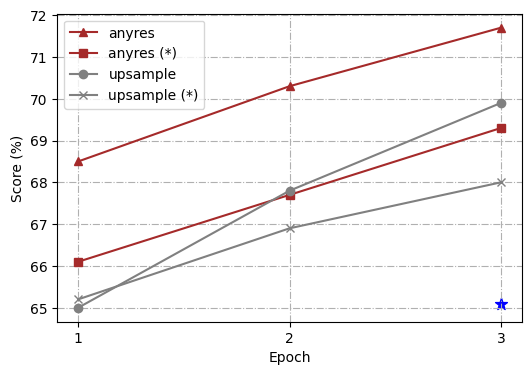
为了进一步分析,我们使用不同的高分辨率缩放方法进行了一系列对照实验,即、“直接上采样”和“任意分辨率”(Liu 等人, 2024) t1>. 整体架构和训练过程遵循 Ferret (You 等人, 2023),但从线性层到两层多层感知器 (MLP) 进行了简单修改。 此外,为了使模型能够更好地处理简短答案并在更多基准上执行,我们遵循 LLaVA 1.5 (Liu 等人, 2023b) 并为 VQA 添加额外的面向任务的数据集 ( Antol 等人, 2015) 和 OCR 到现有的 GRIT (You 等人, 2023),后者之前在 Ferret 中使用过。 为了简化我们的研究,我们选择了 4 个代表性任务:ROC(LVIS:box)、REC(RefCOCOg)、TextVQA 和 Ferret-Bench,并全面衡量训练模型的能力。
直接上采样v.s. 任何决议。
为了实验的一致性,我们将目标分辨率标准化为 448111根据不同的输入图像分辨率, Token 的数量是动态的,但 Token 的最大数量为 1280。 考虑到计算开销,我们选择了 448。,从 336 升级为两种缩放方法的视觉编码器预训练分辨率,以确保将相同的图像标记输入到大语言模型中。 在“直接上采样”的情况下,应用位置嵌入插值,并且在微调阶段将 CLIP 编码器调整到新的分辨率。 对于“任何分辨率”,我们预定义了一组分辨率以支持最多六个网格222我们使用{1x1、1x2、1x3、1x4、1x5、1x6、2x2、2x3及其转置}的网格配置。. 给定图像,我们首先通过优先考虑尽可能接近原始图像的长宽比和大小,同时最大限度地减少浪费的分辨率来选择最佳分辨率,然后将输入图像的大小调整为最佳分辨率,并将图像分割为这些网格。 所有图像块均由CLIP编码器单独编码,其特征作为图像标记输入到大语言模型中。 我们使用冻结和未冻结的编码器配置来训练模型。
如图 2 所示,我们的比较分析表明,“任何分辨率”缩放方法不仅在所有任务上都比 vanilla Ferret 有了显着改进,而且还优于“直接上采样”方法。 另一个有趣的观察是,在“任何分辨率”下,更新视觉编码器总是比冻结它带来提升,而在“直接上采样”中,冻结视觉编码器有时甚至更好(如 TextVQA 结果所示)。 至于这些发现背后的原因,我们假设“直接上采样”迫使 ViT 适应更高的分辨率,这会导致词符长度偏离其预训练数据更长。 然而,微调数据的规模通常比视觉编码器的预训练数据小得多(在我们的设置中为1.3M vs. 400M),这扰乱了其预训练知识。 相反,“任何分辨率”将高分辨率图像裁剪成补丁,视觉编码器以与其预训练过程类似的词符长度处理局部补丁。 总的来说,“任何分辨率”已被证明是一种更优化的策略,可以平衡利用高分辨率图像和保留有价值的预训练知识以实现有效缩放。
3.3模型架构
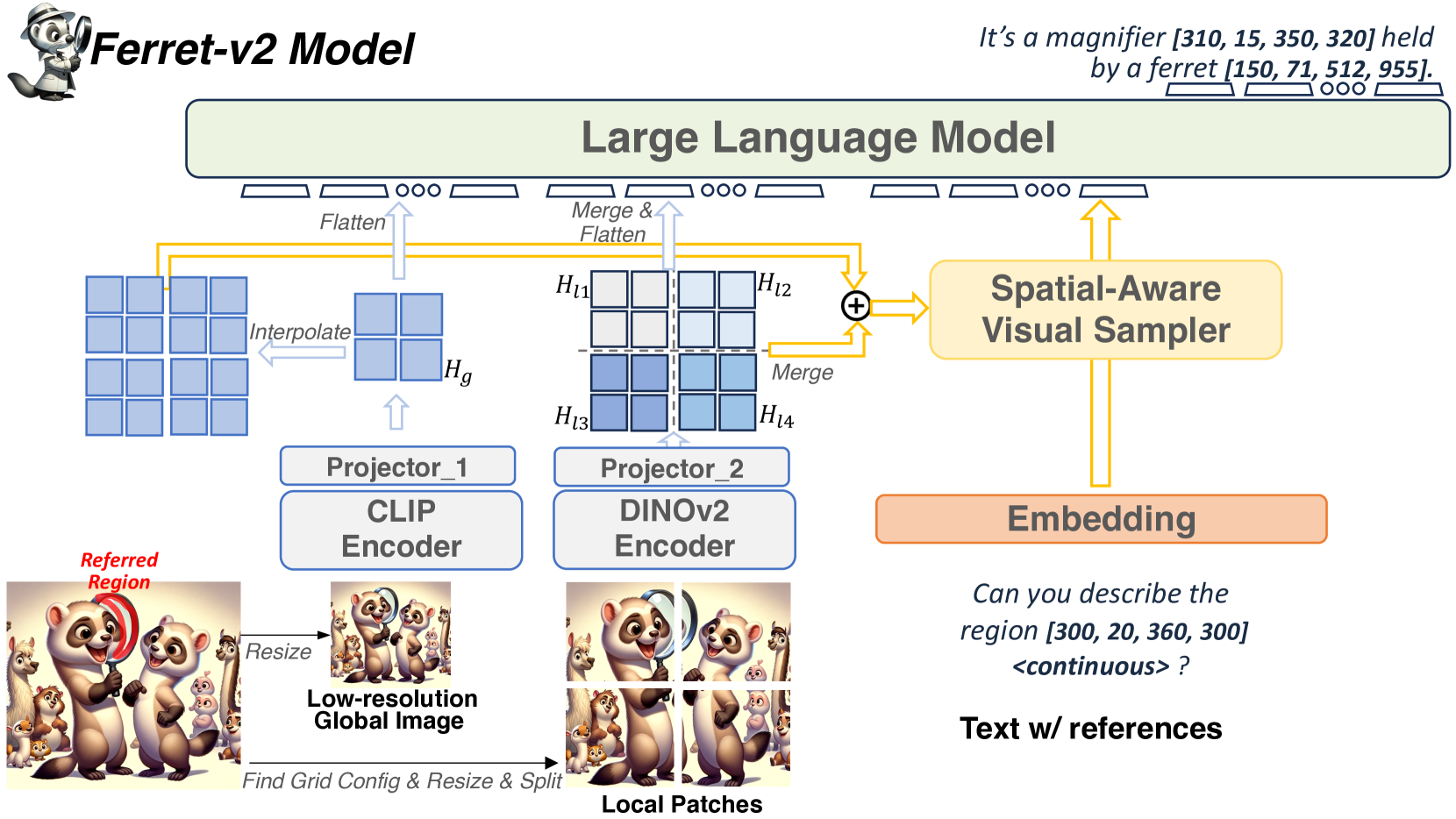
多粒度视觉编码。
在致力于“任意分辨率”缩放方法之后,另一个问题自然出现:全局低分辨率图像和局部分割图像补丁之间存在粒度差异,即全局图像可以看到整个场景,但分辨率较低,而每个局部图像只能看到场景的一部分,但具有精确的细节。
为了解决这个问题,我们探索使用不同的视觉编码器对这两种类型的图像进行编码。 具体来说,我们选择 CLIP (Radford 等人, 2021) 来编码全局图像,并选择 DINOv2 (Oquab 等人, 2023) 来编码局部分割补丁。 我们背后的动机来自于他们预训练范式的差异。 CLIP 中使用的图像文本对比目标使这些模型能够从字幕中捕获图像级语义,但由于引导字幕中的细粒度信息有限,往往会忽略丰富的像素级细节。 DINOv2经过图像级和块级自监督目标的训练,可以捕获有关局部物体的更详细的信息,例如形状或纹理,因此具有细粒度的感知能力。 此外,我们为双视觉编码器采用单独的 MLP 投影仪,旨在区分和学习全局和细粒度视觉信息的不同底层上下文:
| (1) | ||||
| (2) |
然后,局部块的特征图根据其原始排列被合并成一个大特征图,然后展平为图像特征序列。 全局图像的特征图也被展平。 两个序列被连接起来并作为视觉“标记”输入到大语言模型中。
任何分辨率参考。
Ferret 中引入的混合区域表示已被证明在处理各种类型的引用(如点、框、涂鸦等)方面是有效且通用的。其核心是连续区域特征的提取,这是由 Spatial-感知视觉采样器。 然而,直接将全局图像特征输入视觉采样器可能不足以识别高分辨率图像中的小参考对象。 受我们之前关于视觉粒度差异的发现的启发,我们进一步建议整合全局语义和局部细节的最佳部分,以实现更精确的参考。 更具体地说,在获得全局图像和局部补丁的编码特征后,我们首先将局部补丁的特征图按照其原始空间排列合并成一个大特征图,并且通过插值对全局图像特征图进行上采样,以对齐合并特征图的大小。
| (3) | |||||
| (4) |
然后,我们通过将两个处理后的特征图按通道相加来融合:,并获得具有强语义和局部感知的高分辨率特征图。 被输入到空间感知视觉采样器(You等人,2023)中以提取连续区域特征。 然后将连续特征与离散坐标组合作为混合区域表示来指代图像中的任意区域,如图3所示。
任何分辨率 接地。
通过结合全局图像和局部子补丁的视觉嵌入,我们的模型可以更有效地从高分辨率中揭示视觉细节并弥合语义。 无需具体调整,我们的框架就可以与 Ferret 的接地设计无缝对接;因此,类似地,我们通过直观的数值表示来描绘输出坐标区域,并采用大语言模型作为破译内在相关性的主要机制。
3.4训练范式
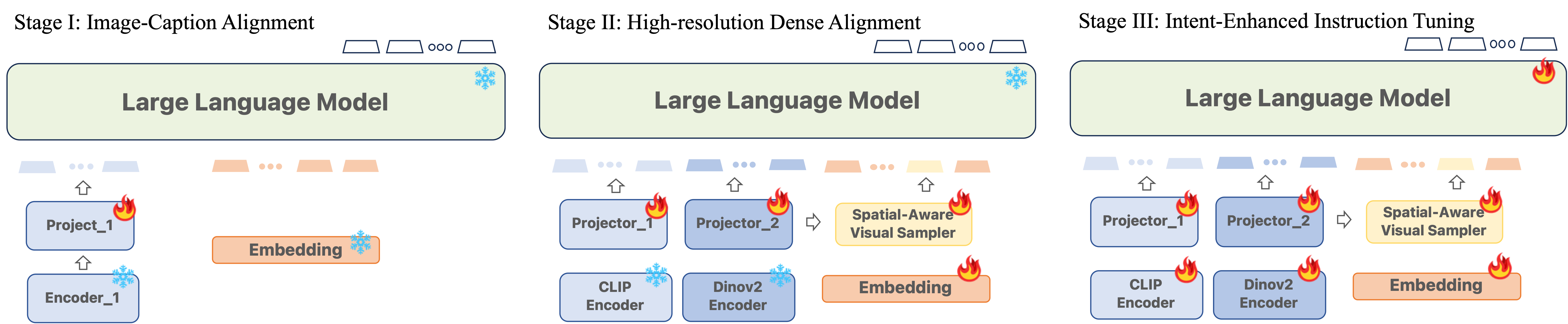
第一阶段:图像标题对齐。
微调之前的特征对齐已被广泛使用以实现更好的训练效率。 我们采用这种策略,使用 1.4M 图像文本对将预训练的 CLIP 编码器与大语言模型连接起来,并由 Chen 等人 (2023c) 转换为指令跟踪数据。 低分辨率图像编码器和大语言模型参数保持冻结,只有投影仪可训练。 如果没有这些图像-文本对的任何引用,视觉训练采样器不会参与第一阶段。
第二阶段:高分辨率密集对准。
尽管之前的图像标题对齐在粗语义上有效地连接了视觉和大语言模型,但图像标题对齐和指令调整阶段之间仍然存在严重的差距。 许多下游任务,例如引用、接地、OCR 等,需要对图像进行更精确和更全面的空间感知,而不仅仅是粗略的语义。
为了缓解上述问题,我们提出了一种针对高分辨率密集对齐的新型预训练阶段。 具体来说,此阶段不是将整个图像与全局标题对齐,而是将图像的每个可能的局部对象与详细语义对齐。 相应地,设计了两类任务和输入数据。 (1)Dense Referencing:给定图像,输入问题一一引用所有对象的区域,并询问它们的类别;模型需要相应地输出预测的类别。 一个例子是 “问题:请对以下位置的对象进行分类。 1:region_1,2:region_2,...。 答案:以下是类别:1:猫,2:狗,……”. (2) 密集检测: 给定图像,输入问题要求定位所有对象。 为了减少随机性并结合空间意识,我们伪造了按一定顺序列出对象的答案,例如光栅扫描顺序(从上到下,从左到右)。 一个例子是 “问题:请按光栅扫描顺序定位图像中的可见对象。 答案:对象为:1:cat coefficient_1,2:dog coefficient_2 ,……”. 为了确保细粒度语义的有效学习,我们从密集注释的对象数据集 - LVIS (Gupta 等人,2019)中收集数据。 平均而言,每个样本包含大约 10 个物体位置,而在指令调整阶段,参考和基础数据集大多数情况下每个样本仅提及一到两个物体位置。
在模型方面,除了用于全局图像的 CLIP 编码器之外,我们还采用预训练的 DINOv2 作为局部补丁的视觉编码器,如第 2 节中所述。 3.3。 CLIP之后的投影仪继承自图像字幕对齐阶段,并且我们在DINOv2之后进一步添加了一个单独的投影仪,其权重从CLIP的投影仪初始化以确保稳定性。 然后我们冻结两个视觉编码器和大语言模型,并且在此对齐阶段仅更新两个投影仪以及视觉采样器,并具有下一个 Token 预测损失。
第三阶段:意图增强的配置参数。
经过第二阶段的预训练后,模型获得了对图像的全面全局理解的能力,以及使用自由格式文本和灵活获得的视觉参考区域来识别和叙述感兴趣对象的能力。 我们的目标是增强模型对用户指令的遵守,同时保持其高分辨率视觉感知能力。 为了实现这一目标,我们使编码器、投影仪、区域采样器和大语言模型本身可训练。 对于训练,我们利用 GRIT 数据集 (You 等人,2023) 并合并用于 VQA (Antol 等人,2015) 和 OCR 的其他特定任务数据集(Singh 等人, 2019; Sidorov 等人, 2020) 来自 LLaVA 1.5 (Liu 等人, 2023b)。 此外,我们还确定了有助于提高性能的另外两个策略:(i)数据统一:为了促进模型从基于纯文本的全局理解无缝过渡到利用混合表示的区域理解,我们采用了开放词汇对象检测器, GLIPv2 (Zhang 等人, 2022a),在 VQA 数据集上本地化文本中的可接地名词,以及公共 OCR 模型 (Kuang 等人, 2021) 来获取文本边界OCR 数据集上的框。 (ii) 任务泛化:为了减少需要参考和接地能力的任务与不需要的任务之间的歧义,我们采用类似于 LLaVA 1.5 的方法,其中涉及附加提示,“包括每个提到的坐标”对象。”,进一步明确任务要求。
4实验
4.1 推荐和基础任务
参考。
Ferret-v2 对引用查询的增强理解体现在它能够准确解释图像中指定区域的语义。 这是通过引用对象分类 (ROC) 任务特别评估的,其中模型的任务是识别查询中提到的区域中的对象。 最初,像 Ferret 一样,我们利用 LVIS 数据集的验证分割,涵盖 1,000 多个对象类别,其中大多数是“域内”图像。 为了进一步证明 Ferret-v2 参考较小物体的能力得到提高,我们使用 SA-1B (Kirillov 等人,2023) 的部分图像和相应的人类注释编译了一个“野外”评估集来自 AS- human (Wang 等人, 2023b) 的对象,其中包含高分辨率图像、开放词汇对象和精确掩模。 我们总共使用野外对象手动验证了 700 多个高质量样本,并将其称为 SA-refer。 如表4.1所示,Ferret-v2 在 LVIS 上显着优于之前的模型,并建立了之前 Ferret 未完全实现的新基准,主要有助于高分辨率缩放。 SPHINX 还使用高分辨率输入图像;然而,在 SA-refer 更具挑战性的任务上,Ferret-v2 仍然优于它,这表明我们针对任何分辨率引用的特殊设计的优势。
接地。
视觉基础旨在将语言查询基础到对齐的图像区域。 我们使用三个著名基准测试引用表达理解(REC)的子任务:RefCOCO (Lin 等人,2014)、RefCOCO+ (Yu 等人,2016) 、RefCOCOg (Mao 等人, 2016),以及 Flickr30k 实体数据集的短语基础 (Plummer 等人, 2015)。 如表 3 所示,Ferret-v2 可以使用高分辨率输入图像,从而比 Ferret (您等人,2023) 有了显着改进。 此外,Ferret-v2 的性能优于大多数最先进的模型,包括专业模型 G-DINO-L (Liu 等人,2023c) 和其他通用模型,这些模型采用更大的输入图像尺寸。 我们的 7B 模型可以达到与 CogVLM-Grounding (Wang 等人,2023a)相当的结果,后者利用 4B 视觉模型和 6B 连接模块。 这些结果证明了 Ferret-v2 在视觉接地方面的竞争能力。
| Models | RefCOCO | RefCOCO+ | RefCOCOg | Flickr30k Entities | ||||||
| val | testA | testB | val | testA | testB | val | test | val | test | |
| MAttNet (Yu et al., 2018) | 76.40 | 80.43 | 69.28 | 64.93 | 70.26 | 56.00 | 66.67 | 67.01 | – | – |
| OFA-L (Wang et al., 2022) | 79.96 | 83.67 | 76.39 | 68.29 | 76.00 | 61.75 | 67.57 | 67.58 | – | – |
| UNITER (Chen et al., 2020) | 81.41 | 87.04 | 74.17 | 75.90 | 81.45 | 66.70 | 74.02 | 68.67 | – | – |
| VILLA (Gan et al., 2020) | 82.39 | 87.48 | 74.84 | 76.17 | 81.54 | 66.84 | 76.18 | 76.71 | – | – |
| UniTAB (Yang et al., 2022) | 86.32 | 88.84 | 80.61 | 78.70 | 83.22 | 69.48 | 79.96 | 79.97 | 78.76 | 79.58 |
| MDETR (Kamath et al., 2021) | 86.75 | 89.58 | 81.41 | 79.52 | 84.09 | 70.62 | 81.64 | 80.89 | 82.3* | 83.8* |
| G-DINO-L (Liu et al., 2023c) | 90.56* | 93.19* | 88.24* | 82.75* | 88.95* | 75.92* | 86.13* | 87.02* | – | – |
| Shikra-7B (Chen et al., 2023b) | 87.01 | 90.61 | 80.24 | 81.60 | 87.36 | 72.12 | 82.27 | 82.19 | 75.84 | 76.54 |
| MiniGPT-v2-7B (Chen et al., 2023a) | 88.06 | 91.29 | 84.30 | 79.58 | 85.52 | 73.32 | 84.19 | 84.31 | – | – |
| Qwen-VL-7B (Bai et al., 2023) | 88.55 | 92.27 | 84.51 | 82.82 | 88.59 | 76.79 | 85.96 | 86.32 | – | – |
| SPHINX-2k (Lin et al., 2023) | 91.10 | 92.88 | 87.07 | 85.51 | 90.62 | 80.45 | 88.07 | 88.65 | – | – |
| LLaVA-G (Zhang et al., 2023a) | 89.16 | – | – | 81.68 | – | – | 84.82 | – | 83.03 | 83.62 |
| VistaLLM (Pramanick et al., 2023) | 88.1 | 91.5 | 83.0 | 82.9 | 89.8 | 74.8 | 83.6 | 84.4 | – | – |
| Ferret-7B (You et al., 2023) | 87.49 | 91.35 | 82.45 | 80.78 | 87.38 | 73.14 | 83.93 | 84.76 | 80.39 | 82.21 |
| Ferret-v2-7B (Ours) | 92.79 | 94.68 | 88.69 | 87.35 | 92.75 | 79.3 | 89.42 | 89.27 | 85.52 | 85.83 |
| Shikra-13B (Chen et al., 2023b) | 87.83 | 91.11 | 81.81 | 82.89 | 87.79 | 74.41 | 82.64 | 83.16 | 77.41 | 78.44 |
| Griffon v2 (Zhan et al., 2024) | 89.6 | 91.8 | 86.5 | 81.9 | 85.5 | 76.2 | 85.9 | 86.0 | – | 84.8 |
| CogVLM-Grounding-17B (Wang et al., 2023a) | 92.76 | 94.75 | 88.99 | 88.68 | 92.91 | 83.39 | 89.75 | 90.79 | – | – |
| Ferret-13B (You et al., 2023) | 89.48 | 92.41 | 84.36 | 82.81 | 88.14 | 75.17 | 85.83 | 86.34 | 81.13 | 84.76 |
| Ferret-v2-13B (Ours) | 92.64 | 94.95 | 88.86 | 87.39 | 92.05 | 81.36 | 89.43 | 89.99 | 85.33 | 86.25 |
雪貂长凳。
Ferret-Bench (You 等人, 2023) 经过精心设计,旨在评估和基准化多模态对话模型的细粒度能力,特别是它们引用、描述和推理特定区域的能力图像,从而促进在多模态环境中对模型的参考和基础能力进行更结构化的评估。 我们使用 Ferret-Bench 将 Ferret 与之前的模型进行比较,包括 LLaVA (Liu 等人, 2023b)、Shikra (Chen 等人, 2023b)、Kosmos-2 (彭等人,2023),和鱼鹰(袁等人,2023)。 结果总结于表4.1中。 Ferret-v2在所有类型的任务中都表现出了优异的性能,表明该模型具有强大的空间理解和常识推理能力。
4.2 现代 MLLM 基准
雪貂表现出了卓越的区域推理能力;然而,它达不到通常需要面向任务的数据集的学术基准。 对于 Ferret-v2,我们特别包含伪标记的 VQA 和 OCR 数据集,并附加特殊提示,如第 2 节中所述。 3.4。 这种战略增强逐渐缩小了特定任务的区域级分析与更广泛、更通用的任务之间的差距,从而扩展了 Ferret-v2 的适用性,以涵盖细粒度和粗粒度的任务。 As presented in Table 4, we benchmark Ferret-v2 against existing MMLMs across a comprehensive suite of 10 benchmarks: VQA(Antol et al., 2015), TextVQA (aka.VQA) (Singh et al., 2019), GQA (Hudson & Manning, 2019), POPE (Li et al., 2023e), MME (Chang et al., 2023), SEED (Li et al., 2023b), LLaVA and LLaVA (Liu et al., 2023b), MM-Vet (Yu et al., 2023b), Obj-Hal (Yu et al., 2023a)). 我们的模型实现了与最新最先进模型相当的性能,特别是在 VQAv2、GQA、POPE 等任务中表现出色,这些任务需要精确的空间信息才能做出准确的响应。
| Method |
VQA |
GQA |
VQA |
POPE |
MME |
SEED |
LLaVA |
LLaVA |
MM-Vet |
Obj-Hal |
|---|---|---|---|---|---|---|---|---|---|---|
| BLIP-2-13B |
41.0 |
41 |
42.5 |
85.3 |
1293.8 |
46.4 |
– |
38.1 |
22.4 |
– |
| InstructBLIP-7B |
– |
49.2 |
50.1 |
– |
– |
53.4 |
– |
60.9 |
26.2 |
– |
| IDEFICS-9B |
50.9 |
38.4 |
25.9 |
– |
– |
– |
– |
– |
– |
– |
| Qwen-VL-7B |
78.8 |
59.3 |
63.8 |
– |
– |
56.3 |
– |
– |
– |
– |
| Qwen-VL-Chat-7B |
78.2 |
57.5 |
61.5 |
– |
1487.5 |
58.2 |
– |
– |
– |
43.8/23.0 |
| LLaVA-1.5-7B |
78.5 |
62.0 |
58.2 |
85.9 |
1510.7 |
58.6 |
82.7 |
63.4 |
30.5 |
46.3/22.6 |
| Ferret-v2-7B (Ours) | 81.5 | 64.7 | 61.7 | 87.8 | 1510.3 | 58.7 | 89.1 | 67.7 | 34.9 | 23.8/14.7 |
| InstructBLIP-13B |
– |
49.5 |
50.7 |
78.9 |
1212.8 |
– |
– |
58.2 |
25.6 |
– |
| Shikra-13B |
77.4 |
– |
– |
– |
– |
– |
– |
– |
– |
– |
| IDEFICS-80B |
60.0 |
45.2 |
30.9 |
– |
– |
– |
– |
– |
– |
– |
| LLaVA-1.5-13B |
80.0 |
63.3 |
61.3 |
85.9 |
1531.3 |
61.6 |
83.4 |
70.7 |
35.4 |
– |
| LLaVA-1.5-13B-HD | 81.8 |
64.7 |
62.5 |
86.3 |
1500.1 |
62.6 |
– |
72.0 | 39.4 |
– |
| Ferret-v2-13B (Ours) | 81.8 | 64.8 |
62.2 |
88.1 | 1521.4 |
61.7 |
90.7 |
69.9 |
35.7 |
34.7/16.8 |
5消融研究
在下面的所有消融研究中,我们遵循第 2 节。 3.2,我们的评估主要集中在不同模型在参考、基础、OCR 和推理等维度上的表现。
任何分辨率接地和参考。
我们对任何决议的基础和参考进行消融研究。 如表 5 所示,适应任何分辨率都会显着提高任务性能,因此需要全面了解更高分辨率的细节。 通过集成全局语义和局部细节的优点,可以更精确地提高跨 LVIS 和 SA 数据集的引用任务的精度。 此外,这种集成适度增强了接地能力,这表明接地和推荐可以在我们提出的框架内获得互惠互利。
多粒度视觉编码和第二阶段预训练。
我们最初的消融研究重点是合并一个额外的 DINOv2 编码器来编码高分辨率补丁。 我们利用 CLIP 第一阶段的投影权重进行初始化,然后在第三阶段进行微调。 如表5所示,单独使用视觉粒度编码显着增强了参考和基础性能。 此外,在预训练过程中引入中间阶段 II 可以提高所有评估指标。
6 结论
我们推出 Ferret-v2,它是原版 Ferret 模型的重大升级。 它具有处理任何分辨率参考和基础训练、多粒度视觉编码和新颖的三级管道的先进功能。 这些改进使 Ferret-v2 能够以更高分辨率和更精细的细节处理和理解图像。 与大多数 MLLM 一样,Ferret-v2 可能会产生有害的反事实反应。
致谢
作者衷心感谢张一哲、李阳浩、宋良辰和尤基恩提供的宝贵指导、建议和反馈。 另外感谢胡家明、高明飞对大规模训练的支持。 我们实验中使用的基线模型基于GitHub存储库中发布的开源代码;我们感谢所有公开代码的作者,这极大地加快了我们的项目进度。
参考
- Alayrac et al. (2022) Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. NeurIPS, 2022.
- Antol et al. (2015) Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. In CVPR, pp. 2425–2433, 2015.
- Bai et al. (2023) Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv:2308.12966, 2023.
- Chang et al. (2023) Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. A survey on evaluation of large language models. ACM Transactions on Intelligent Systems and Technology, 2023.
- Chen et al. (2023a) Jun Chen, Deyao Zhu, Xiaoqian Shen, Xiang Li, Zechu Liu, Pengchuan Zhang, Raghuraman Krishnamoorthi, Vikas Chandra, Yunyang Xiong, and Mohamed Elhoseiny. Minigpt-v2: large language model as a unified interface for vision-language multi-task learning. arXiv:2310.09478, 2023a.
- Chen et al. (2023b) Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multimodal llm’s referential dialogue magic. arXiv:2306.15195, 2023b.
- Chen et al. (2023c) Lin Chen, Jisong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. Sharegpt4v: Improving large multi-modal models with better captions. arXiv preprint arXiv:2311.12793, 2023c.
- Chen et al. (2020) Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu. Uniter: Universal image-text representation learning. In ECCV, pp. 104–120. Springer, 2020.
- Chowdhery et al. (2022) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- Gan et al. (2020) Zhe Gan, Yen-Chun Chen, Linjie Li, Chen Zhu, Yu Cheng, and Jingjing Liu. Large-scale adversarial training for vision-and-language representation learning. In NeurIPS, volume 33, pp. 6616–6628, 2020.
- Gao et al. (2024) Peng Gao, Renrui Zhang, Chris Liu, Longtian Qiu, Siyuan Huang, Weifeng Lin, Shitian Zhao, Shijie Geng, Ziyi Lin, Peng Jin, et al. Sphinx-x: Scaling data and parameters for a family of multi-modal large language models. arXiv preprint arXiv:2402.05935, 2024.
- Gupta et al. (2019) Agrim Gupta, Piotr Dollar, and Ross Girshick. Lvis: A dataset for large vocabulary instance segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 5356–5364, 2019.
- Hong et al. (2023) Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. Cogagent: A visual language model for gui agents. arXiv preprint arXiv:2312.08914, 2023.
- Hudson & Manning (2019) Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In CVPR, pp. 6700–6709, 2019.
- Jiang et al. (2023) Dongsheng Jiang, Yuchen Liu, Songlin Liu, Xiaopeng Zhang, Jin Li, Hongkai Xiong, and Qi Tian. From clip to dino: Visual encoders shout in multi-modal large language models. arXiv preprint arXiv:2310.08825, 2023.
- Kamath et al. (2021) Aishwarya Kamath, Mannat Singh, Yann LeCun, Gabriel Synnaeve, Ishan Misra, and Nicolas Carion. Mdetr-modulated detection for end-to-end multi-modal understanding. In ICCV, pp. 1780–1790, 2021.
- Kazemzadeh et al. (2014) Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. Referitgame: Referring to objects in photographs of natural scenes. In EMNLP, 2014.
- Kirillov et al. (2023) Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. arXiv:2304.02643, 2023.
- Koh et al. (2023) Jing Yu Koh, Ruslan Salakhutdinov, and Daniel Fried. Grounding language models to images for multimodal inputs and outputs. In ICML, 2023.
- Kuang et al. (2021) Zhanghui Kuang, Hongbin Sun, Zhizhong Li, Xiaoyu Yue, Tsui Hin Lin, Jianyong Chen, Huaqiang Wei, Yiqin Zhu, Tong Gao, Wenwei Zhang, Kai Chen, Wayne Zhang, and Dahua Lin. Mmocr: A comprehensive toolbox for text detection, recognition and understanding. arXiv preprint arXiv:2108.06543, 2021.
- Lai et al. (2023) Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmentation via large language model. arXiv preprint arXiv:2308.00692, 2023.
- Li et al. (2023a) Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Jingkang Yang, and Ziwei Liu. Otter: A multi-modal model with in-context instruction tuning. arXiv:2305.03726, 2023a.
- Li et al. (2023b) Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. Seed-bench: Benchmarking multimodal llms with generative comprehension. arXiv preprint arXiv:2307.16125, 2023b.
- Li et al. (2023c) Feng Li, Hao Zhang, Peize Sun, Xueyan Zou, Shilong Liu, Jianwei Yang, Chunyuan Li, Lei Zhang, and Jianfeng Gao. Semantic-sam: Segment and recognize anything at any granularity. arXiv:2307.04767, 2023c.
- Li et al. (2023d) Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv:2301.12597, 2023d.
- Li et al. (2023e) Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. arXiv preprint arXiv:2305.10355, 2023e.
- Lin et al. (2014) Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014.
- Lin et al. (2023) Ziyi Lin, Chris Liu, Renrui Zhang, Peng Gao, Longtian Qiu, Han Xiao, Han Qiu, Chen Lin, Wenqi Shao, Keqin Chen, et al. Sphinx: The joint mixing of weights, tasks, and visual embeddings for multi-modal large language models. arXiv preprint arXiv:2311.07575, 2023.
- Liu et al. (2023a) Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. arXiv preprint, 2023a.
- Liu et al. (2023b) Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In NeurIPS, 2023b.
- Liu et al. (2024) Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, January 2024. URL https://llava-vl.github.io/blog/2024-01-30-llava-next/.
- Liu et al. (2023c) Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499, 2023c.
- Liu et al. (2023d) Zhaoyang Liu, Yinan He, Wenhai Wang, Weiyun Wang, Yi Wang, Shoufa Chen, Qinglong Zhang, Yang Yang, Qingyun Li, Jiashuo Yu, et al. Internchat: Solving vision-centric tasks by interacting with chatbots beyond language. arXiv:2305.05662, 2023d.
- Lv et al. (2023) Tengchao Lv, Yupan Huang, Jingye Chen, Lei Cui, Shuming Ma, Yaoyao Chang, Shaohan Huang, Wenhui Wang, Li Dong, Weiyao Luo, et al. Kosmos-2.5: A multimodal literate model. arXiv preprint arXiv:2309.11419, 2023.
- Mao et al. (2016) Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan L Yuille, and Kevin Murphy. Generation and comprehension of unambiguous object descriptions. In CVPR, 2016.
- McKinzie et al. (2024) Brandon McKinzie, Zhe Gan, Jean-Philippe Fauconnier, Sam Dodge, Bowen Zhang, Philipp Dufter, Dhruti Shah, Xianzhi Du, Futang Peng, Floris Weers, et al. Mm1: Methods, analysis & insights from multimodal llm pre-training. arXiv preprint arXiv:2403.09611, 2024.
- OpenAI (2023) OpenAI. GPT-4 technical report. arXiv:2303.08774, 2023.
- OpenAI (2022) TB OpenAI. Chatgpt: Optimizing language models for dialogue. openai, 2022.
- Oquab et al. (2023) Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023.
- Peng et al. (2023) Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding multimodal large language models to the world. arXiv:2306.14824, 2023.
- Pi et al. (2023) Renjie Pi, Jiahui Gao, Shizhe Diao, Rui Pan, Hanze Dong, Jipeng Zhang, Lewei Yao, Jianhua Han, Hang Xu, Lingpeng Kong, and Tong Zhang. Detgpt: Detect what you need via reasoning. arXiv:2305.14167, 2023.
- Plummer et al. (2015) Bryan A Plummer, Liwei Wang, Chris M Cervantes, Juan C Caicedo, Julia Hockenmaier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In CVPR, pp. 2641–2649, 2015.
- Pramanick et al. (2023) Shraman Pramanick, Guangxing Han, Rui Hou, Sayan Nag, Ser-Nam Lim, Nicolas Ballas, Qifan Wang, Rama Chellappa, and Amjad Almahairi. Jack of all tasks, master of many: Designing general-purpose coarse-to-fine vision-language model. arXiv preprint arXiv:2312.12423, 2023.
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pp. 8748–8763. PMLR, 2021.
- Sidorov et al. (2020) Oleksii Sidorov, Ronghang Hu, Marcus Rohrbach, and Amanpreet Singh. Textcaps: a dataset for image captioning with reading comprehension. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16, pp. 742–758. Springer, 2020.
- Singh et al. (2019) Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. In CVPR, pp. 8317–8326, 2019.
- Sun et al. (2023) Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. Eva-clip: Improved training techniques for clip at scale. arXiv preprint arXiv:2303.15389, 2023.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023a.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023b.
- Wang et al. (2022) Peng Wang, An Yang, Rui Men, Junyang Lin, Shuai Bai, Zhikang Li, Jianxin Ma, Chang Zhou, Jingren Zhou, and Hongxia Yang. Ofa: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework. In International Conference on Machine Learning, pp. 23318–23340. PMLR, 2022.
- Wang et al. (2023a) Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, et al. Cogvlm: Visual expert for pretrained language models. arXiv preprint arXiv:2311.03079, 2023a.
- Wang et al. (2023b) Weiyun Wang, Min Shi, Qingyun Li, Wenhai Wang, Zhenhang Huang, Linjie Xing, Zhe Chen, Hao Li, Xizhou Zhu, Zhiguo Cao, et al. The all-seeing project: Towards panoptic visual recognition and understanding of the open world. arXiv preprint arXiv:2308.01907, 2023b.
- Wang et al. (2023c) Wenhai Wang, Zhe Chen, Xiaokang Chen, Jiannan Wu, Xizhou Zhu, Gang Zeng, Ping Luo, Tong Lu, Jie Zhou, Yu Qiao, et al. Visionllm: Large language model is also an open-ended decoder for vision-centric tasks. arXiv:2305.11175, 2023c.
- Wei et al. (2021) Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners. In ICLR, 2021.
- Wu et al. (2023a) Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, and Nan Duan. Visual chatgpt: Talking, drawing and editing with visual foundation models. arXiv:2303.04671, 2023a.
- Wu et al. (2023b) Tsung-Han Wu, Giscard Biamby, David Chan, Lisa Dunlap, Ritwik Gupta, Xudong Wang, Joseph E. Gonzalez, and Trevor Darrell. See, say, and segment: Teaching lmms to overcome false premises. arXiv:2312.08366, 2023b.
- Wu et al. (2023c) Xiaoyang Wu, Zhuotao Tian, Xin Wen, Bohao Peng, Xihui Liu, Kaicheng Yu, and Hengshuang Zhao. Towards large-scale 3d representation learning with multi-dataset point prompt training. arXiv:2308.09718, 2023c.
- Yang et al. (2022) Zhengyuan Yang, Zhe Gan, Jianfeng Wang, Xiaowei Hu, Faisal Ahmed, Zicheng Liu, Yumao Lu, and Lijuan Wang. Unitab: Unifying text and box outputs for grounded vision-language modeling. In ECCV, pp. 521–539. Springer, 2022.
- Yang et al. (2023) Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. Mm-react: Prompting chatgpt for multimodal reasoning and action. arXiv:2303.11381, 2023.
- Ye et al. (2023) Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, et al. mplug-owl: Modularization empowers large language models with multimodality. arXiv:2304.14178, 2023.
- You et al. (2023) Haoxuan You, Haotian Zhang, Zhe Gan, Xianzhi Du, Bowen Zhang, Zirui Wang, Liangliang Cao, Shih-Fu Chang, and Yinfei Yang. Ferret: Refer and ground anything anywhere at any granularity. arXiv:2310.07704, 2023.
- Yu et al. (2016) Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling context in referring expressions. In ECCV. Springer, 2016.
- Yu et al. (2018) Licheng Yu, Zhe Lin, Xiaohui Shen, Jimei Yang, Xin Lu, Mohit Bansal, and Tamara L Berg. Mattnet: Modular attention network for referring expression comprehension. In CVPR, pp. 1307–1315, 2018.
- Yu et al. (2023a) Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, et al. Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback. arXiv preprint arXiv:2312.00849, 2023a.
- Yu et al. (2023b) Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities. arXiv preprint arXiv:2308.02490, 2023b.
- Yuan et al. (2023) Yuqian Yuan, Wentong Li, Jian Liu, Dongqi Tang, Xinjie Luo, Chi Qin, Lei Zhang, and Jianke Zhu. Osprey: Pixel understanding with visual instruction tuning. arXiv preprint arXiv:2312.10032, 2023.
- Zhan et al. (2024) Yufei Zhan, Yousong Zhu, Hongyin Zhao, Fan Yang, Ming Tang, and Jinqiao Wang. Griffon v2: Advancing multimodal perception with high-resolution scaling and visual-language co-referring. arXiv preprint arXiv:2403.09333, 2024.
- Zhang et al. (2023a) Hao Zhang, Hongyang Li, Feng Li, Tianhe Ren, Xueyan Zou, Shilong Liu, Shijia Huang, Jianfeng Gao, Lei Zhang, Chunyuan Li, et al. Llava-grounding: Grounded visual chat with large multimodal models. arXiv preprint arXiv:2312.02949, 2023a.
- Zhang et al. (2022a) Haotian Zhang, Pengchuan Zhang, Xiaowei Hu, Yen-Chun Chen, Liunian Li, Xiyang Dai, Lijuan Wang, Lu Yuan, Jenq-Neng Hwang, and Jianfeng Gao. Glipv2: Unifying localization and vision-language understanding. Advances in Neural Information Processing Systems, 35:36067–36080, 2022a.
- Zhang et al. (2023b) Shilong Zhang, Peize Sun, Shoufa Chen, Min Xiao, Wenqi Shao, Wenwei Zhang, Kai Chen, and Ping Luo. Gpt4roi: Instruction tuning large language model on region-of-interest. arXiv:2307.03601, 2023b.
- Zhang et al. (2022b) Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022b.
- Zhao et al. (2023) Yang Zhao, Zhijie Lin, Daquan Zhou, Zilong Huang, Jiashi Feng, and Bingyi Kang. Bubogpt: Enabling visual grounding in multi-modal llms. arXiv preprint arXiv:2307.08581, 2023.
- Zheng et al. (2023) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric. P Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023.
- Zhu et al. (2023) Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv:2304.10592, 2023.
- Zou et al. (2023) Xueyan Zou, Jianwei Yang, Hao Zhang, Feng Li, Linjie Li, Jianfeng Gao, and Yong Jae Lee. Segment everything everywhere all at once. arXiv:2304.06718, 2023.