(eccv) 包 eccv 警告:包“hyperref”加载了选项“pagebackref”,*不*建议将其用于相机就绪版本
11email: firstname.lastname@epfl.ch。22institutetext:Valeo.ai,法国,
33institutetext:法国索邦大学
UniTraj:可扩展车辆轨迹预测的统一框架
摘要
车辆轨迹预测越来越依赖于数据驱动的解决方案,但它们扩展到不同数据域的能力以及较大数据集大小对其泛化的影响仍有待探索。 虽然可以通过使用多个数据集来研究这些问题,但由于数据格式、地图分辨率和语义标注类型等方面的差异,这项工作极具挑战性。 为了应对这些挑战,我们引入了 UniTraj,这是一个统一各种数据集、模型和评估标准的综合框架,为车辆轨迹预测领域带来了新的机遇。 特别是,我们使用 UniTraj 进行了广泛的实验,发现当转移到其他数据集时模型性能显着下降。 然而,扩大数据规模和多样性可以显着提高性能,从而为 nuScenes 数据集带来新的最先进结果。 我们提供对数据集特征的见解来解释这些发现。 代码可以在这里找到:https://github.com/vita-epfl/UniTraj。
关键词:
车辆轨迹预测 多数据集框架 领域泛化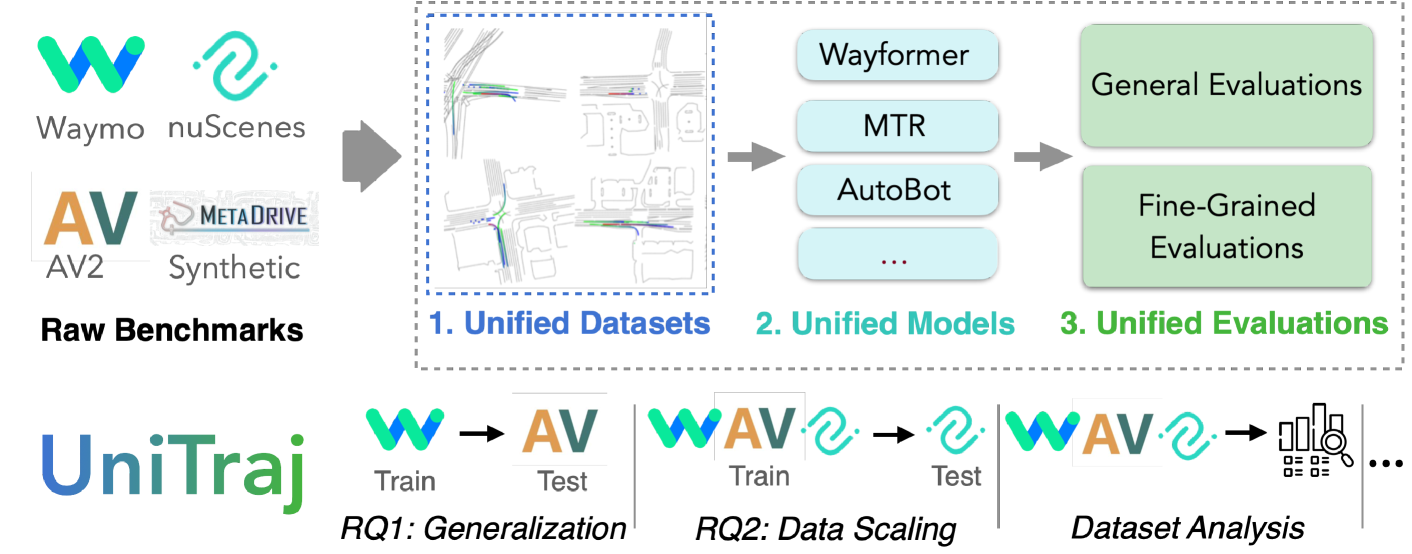
1简介
预测周围车辆的轨迹对于确保自动驾驶系统的安全和避免碰撞至关重要。 随着深度学习的出现,研究人员转向数据驱动的解决方案来解决这一预测任务。 然而,虽然这些模型可以实现高精度,但它们严重依赖于用于训练的特定数据域。
自动驾驶系统可能会遇到不同的情况,例如不同的地理位置。 这些不同的情况会引入数据域的变化,这可能会显着影响预测模型的性能。 因此,有必要研究模型在不同领域(例如数据集和城市)的性能。 然而,尽管这个问题很重要,但模型到不同领域的泛化尚未得到充分研究。 因此,我们的第一个研究问题(RQ1)是研究轨迹预测模型转移到新领域时的性能下降。
提高预测模型泛化能力的一个潜在解决方案是扩大数据集的规模以覆盖更广泛的驾驶场景。 虽然存在扩展数据集大小[10,14,8,50]的趋势,但数据集大小对轨迹预测模型性能的影响在很大程度上仍未得到探索。 我们的第二个研究问题(RQ2)是研究增加数据集大小对预测模型性能的影响。
探索这两个研究问题涉及利用多个轨迹预测数据集。 首先,这些数据集提供了不同的领域,允许对不同领域的模型泛化进行彻底检查(RQ1)。 其次,组合这些数据集会创建一个更大的数据集,从而能够探索数据扩展的渐近极限(RQ2)。 然而,在尝试利用多个数据集时存在重大挑战。 (1)每个数据集都有独特的数据格式,给研究人员利用多个数据集带来了实际困难。 (2)每个数据集都通过不同的策略进行收集和标注,包括半自动预标注和手动整理[7,14,8]。 这导致了多种差异,例如分辨率、采样率和语义注释类型的变化。 (3) 由于数据集设置(例如,预测范围)和评估指标(例如,WOMD [14] 中使用 mAP 指标,以及阿尔戈宇宙 2 [50])。 简而言之,虽然每个数据集都有助于该领域的进步,但它们是独立开发的,没有考虑与现有数据集的协调。 因此,许多轨迹预测研究使用单个数据集[13,31,2,9,46,3,37,20,22,5]来训练和评估他们的模型。
为了应对这些挑战,我们引入了“UniTraj”,一个全面的车辆轨迹预测框架。 UniTraj 无缝集成和统一多个数据源(包括 nuScenes [7]、Argoverse 2 [50] 和 Waymo Open Motion Dataset - WOMD [14])、模型(包括 AutoBot [17]、MTR [46] 和 Wayformer [35])和评估。 UniTraj 不仅作为解决我们研究问题的解决方案,还为社区提供了一个全面且灵活的平台。 首先,它旨在通过提出与各种数据集兼容的统一数据结构来轻松包含新数据集。 其次,Unitraj 通过提供与轨迹预测任务相关的大量基本数据处理和损失函数来支持并简化新方法的集成。 最后,UniTraj提供统一的评估指标,以及多样化且富有洞察力的评估方法,例如分析长尾数据实例以及不同数据样本集群的性能,以便更深入地了解模型行为。 图 1显示了框架的概述。
我们使用 UniTraj 框架进行了广泛的实验,以阐明我们的两个研究问题。 我们的研究结果表明,在数据源之间转换时,性能会大幅下降,并且不同数据集引起的泛化能力也会发生变化(RQ1)。 我们还表明,扩大数据集大小和多样性可以在不进行任何架构修改的情况下显着提高模型性能,使我们在 nuScenes 公共排行榜中排名st。 这是通过框架中所有现有数据集的训练模型来完成的。 这个统一的数据集构成了可用于训练车辆轨迹预测模型的最大公共数据,包含超过 M 个样本、 小时的数据和 不同的城市。 最后,通过对数据集进行深入分析,我们可以更全面地了解其特征。 我们的分析表明,数据集的泛化能力不仅取决于它们的大小,还取决于它们内在的多样性。 我们相信该框架为轨迹预测领域开辟了新的机遇,我们将发布该框架以促进进一步的进步。 总之,我们的贡献如下:
-
•
我们介绍 UniTraj,一个用于车辆轨迹预测的综合开源框架,集成了各种数据集、模型和评估。 它为该领域的综合研究提供了一个统一的平台。
-
•
我们研究模型在不同数据集和城市中的泛化能力,并深入了解模型获得更好泛化能力的数据集的特征。
-
•
我们利用当前可用的最大数据集来探索数据扩展对模型性能的影响,并在 nuScenes 数据集上建立一个新的最先进模型。
-
•
最后,我们对数据集进行了深入的比较分析,阐明了我们的实验结果。
2之前的工作
轨迹预测数据集。 许多学术和工业实验室通过开源现实世界驾驶数据集[38,55,6,14,7,10,19,34,8,50]为研究开发铺平了道路。 值得注意的是,Argoverse [10]是发布车道图信息的先驱之一,nuScenes [7]扩展了场景的多样性,Waymo [14] 用细粒度的信息丰富了他们的数据集,最近,Argoverse 2 [50] 发布了独特道路方面最大的数据。 虽然这些数据集有助于现场开发,但它们是孤立开发的,没有考虑与以前的数据集的协调。 因此,由于各种不兼容性,将它们组合起来存在多种挑战。 这项工作通过统一的框架解决了这些挑战。
轨迹预测基准。 多数据集基准测试已在多个领域进行了探索,例如对象检测 [57]、语义分割 [24, 45] 和动作识别 [30]. 在轨迹预测领域,此类基准主要是针对人体轨迹预测[40,1,39]而开发的。 值得注意的是,Trajnet++ [26] 通过根据交互的存在对轨迹进行分类,提供了以交互为中心的基准。 trajdata [21] 是多个人体轨迹数据集的统一接口,将场景上下文合并到输入中。 车辆轨迹规划任务的相关工作是 ScenarioNet [28],它是一个模拟器,它将多个现实世界数据集聚合成统一的格式,并提供规划开发和评估框架。 我们利用它们的数据转换来处理数据集。 据我们所知,我们是第一个提出车辆轨迹预测开源框架的人。 我们的框架不限于包含多个数据集;它还集成了多种轨迹预测模型和评估方法,从而为推进车辆轨迹预测任务的研究和开发提供了全面的资源。
轨迹预测模型的推广。 车辆轨迹预测数据集中数据格式的差异阻碍了跨数据集泛化的研究,导致该领域的研究有限。 在[53]中,将一个数据集分为不同的域来探索模型泛化。 [44]中的作者提出了一种认知不确定性估计方法并进行跨数据集评估。 在[16]中,作者研究了模型的跨数据集泛化,并显示了数据集之间的性能差距。 然而,它们对泛化差距的来源提供的见解有限。 此外,他们的代码不公开。 之前的工作还使用感知研究了轨迹预测模型在处理新场景和城市[11,27,32]、新代理类型[27]时的一些泛化方面输出而不是精选注释[49, 56, 51],并面临对抗性情况[3, 41]。 在这项工作中,我们进行了更广泛和深入的跨数据集、跨城市分析以及多数据集训练。 此外,我们还提供了对数据集特征的见解,解释了研究结果。 我们还发布了一个开源框架来促进这方面的研究。
3UniTraj框架
UniTraj 框架如图图1所示,由三个主要组件组成。 第一个组件统一了各种数据集的格式和特征(参见部分3.1)。 第二个组件使轨迹预测模型适应统一的数据格式,以方便其训练(参见部分3.2)。 最后一个组成部分包括对模型的全面且共享的评估过程(请参阅部分3.3)。 组件的集成允许进行多样化的实验,例如跨数据集训练、评估和数据集分析。
| Argoverse2 | WOMD | nuScenes | UniTraj | ||
|---|---|---|---|---|---|
| Coordinate frame | Scene-centric | Scene-centric | Scene-centric | Agent-centric | |
| Time length | Past | 5 sec | 1 sec | 2 sec | [0 - 8] sec |
| Future | 6 sec | 8 sec | 6 sec | [1 - 8] sec | |
| Agent features | Annotations | velocity, heading | velocity, heading | velocity, heading | velocity, heading |
| Other info | — | bounding box size | — | acceleration | |
| Coordinates | 2D | 3D | 2D | 2D | |
| Map features | Range | 200m | 200m | 500m | [0 - 500] m |
| Resolution | 0.2m2m | 0.5m | 1m | [0.2 - 2] m | |
| Coordinates | 2D | 3D | 2D | 2D |
3.1统一数据
轨迹预测数据集中存在两种类型的差异:数据格式和数据特征。 前者相当于数据结构和组织方式的差异,而后者则源于数据本身特征的差异,例如时空分辨率、范围、代理和地图分类。 在本节中,我们将提出解决这两类差异的解决方案。
3.1.1统一数据格式:
为了解决轨迹预测数据集中使用不同数据格式的问题,例如 WOMD [14] 中的 TFRecord 和 Argoverse 2 [50] 中的 Apache Parquet,我们利用 ScenarioNet [28]。 ScenarioNet 最初是为交通场景模拟和建模而设计的,但我们将其重新用于车辆轨迹预测任务。 它提供了包含高清地图和详细对象注释的统一场景描述格式,简化了不同格式数据集的解码过程。 ScenarioNet 目前支持转换 WOMD、nuScenes 和 nuPlan,并且我们将其支持扩展到 Argoverse 2 以进行我们的研究。 这减少了对多个版本的预处理代码的需求,以从原始数据集中提取信息并为预测模型的训练创建批量数据。
3.1.2统一数据特性:
尽管数据被转换为统一格式,但数据集中仍然存在显着差异,影响模型性能。
例如,Argoverse 2 中的场景长度为 秒,而 WOMD 中的场景长度为 秒;或者地图注释的精度在 nuScenes 中为 米,而在 WOMD 中为 米。
因此,我们的目标是协调这些差异并尽量减少它们对模型性能的影响。
表 1总结了差异和统一特征。
我们的数据处理方法涉及特定的协调,包括以下内容:
-
•
坐标系。 最近的轨迹预测模型主要利用矢量化、以代理为中心的数据作为输入[46,17,35,47,58]。 我们的数据处理管道旨在将场景级原始数据转换为这种格式。 它处理由多个轨迹组成的交通场景,并选择数据集中指定为训练样本的轨迹。 然后,管道将整个场景转换为这些选定代理的坐标系,并相应地标准化输入。
-
•
时间长度。 不同数据集中的轨迹具有相同的频率Hz,但持续时间在8到20秒之间。 为了标准化这方面,我们将所有轨迹截断为 8 秒的统一长度。 在此持续时间内,UniTraj 提供了灵活确定所有数据集过去和未来轨迹的统一长度的选项。
-
•
代理特点。 在这些数据集中,WOMD 提供了最详细的代理信息,包括 3D 坐标、速度、航向和边界框大小,而 nuScenes 缺乏某些数据,例如边界框大小。 我们通过使用 2D 坐标、速度和航向来标准化跨数据集的输入。 我们的数据处理还引入了补充功能,例如代理类型和轨迹时间步长的单热编码以及加速。 这些元素组合起来为模型创建丰富、统一的输入。
-
•
地图功能。 数据集的高清地图分辨率有所不同。 我们通过使用线性插值将连续点之间的距离标准化为 0.5 米来对此进行标准化,并可以选择进一步下采样来调整地图分辨率。 此外,我们还利用每个车道点的方向和单热编码车道类型来丰富数据。 我们的实验利用语义地图类别,例如中心车道、道路线、人行横道、减速带和停车标志。
我们的框架允许通过针对单一数据集研究的预定义参数来定制特定功能,同时仍然提供跨所有数据集的标准化数据格式。 数据处理模块支持各种参数,例如历史和未来轨迹的长度、每条车道的点数、地图分辨率、周围代理和线路的类型以及屏蔽属性。 由于其模块化结构,我们的数据处理管道可以轻松集成新的处理方法和模型。 该框架配备了多处理和缓存机制,可实现高效处理。 我们的框架目前包括四个大型真实数据集,包含来自 15 个城市超过 1337 小时的驾驶数据。
3.2统一模型
轨迹预测模型通常在不同的流程中实现,这使得直接比较具有挑战性并且难以确保公平性。 我们在 UniTraj 框架内集成了三个最新的轨迹预测模型。 这些模型是根据其在各种基准上的最先进结果而选择的,表明了其设计的研究价值。 我们包括:
-
•
AutoBot [17] 是一种最新的基于 Transformer 的模型,在多个现有数据集上具有具有竞争力的结果。 它基于等变特征学习来学习多头注意力块轨迹的联合分布。
-
•
MTR [46]在2022年WOMD挑战赛中排名第一。 它通过将全局意图先验与局部运动细化相结合来运作。 它使用有限数量的自适应运动查询对,允许对不同运动类型进行精确的轨迹预测和改进。
-
•
Wayformer [35] 是一种基于 Transformer 的模型,具有多轴编码器。 它采用潜在查询来促进多维输入的组合。 由于原始代码尚未发布,我们重新实现了该模型。
模型容量覆盖范围广(AutoBotM参数,MTRM参数,WayformerM参数),支持模型尺寸研究和缩放。
集成新模型:
UniTraj 数据处理管道的灵活性极大地简化了新模型的集成。
此外,我们提供标准化的输出格式,支持无缝使用 UniTraj 的评估和记录工具。
3.3统一评价
在轨迹预测中,已经提出了各种指标来评估模型,但尚未达成共识。 因此,每个数据集提供了一组不同的评估指标,这使得比较跨数据集的性能变得具有挑战性。 例如,WOMD 采用平均精度 (mAP) 指标 [14],而 Argoverse 2 使用 Brier 最小最终位移误差 (brier-minFDE) [50]。 我们的框架提供了一套统一的指标,可以对不同数据集进行全面、一致的评估。 为此,我们采用两组指标:通用评估指标和细粒度评估指标。
3.3.1 总体评价:
文献中最常见的指标是通过将输出与不同方面的真实情况进行比较来根据准确性度量提供总体分数的指标。
我们在框架中包含以下三个通用指标:
1)最小平均/最终位移误差(minADE/minFDE):它表示预测与地面实况之间的最小平均/最终位移误差。 最小值是根据输出的 模式计算的。
2) 缺失率 (MR):定义为 minFDE 超过 米的样本比例,在可接受最多 米偏差的情况下很有用。
3) Brier 最小最终位移误差 (brier-minFDE):虽然之前的指标侧重于覆盖地面实况,但它们并未考虑分配给每个预测轨迹的概率。 Brier-minFDE 指标通过向 minFDE 添加惩罚项 来解决此问题,其中 对应于与地面实况最匹配的轨迹的概率。
细粒度评估:
我们还提供两个细粒度的评估。
(1) 轨迹类型。
数据集通常表现出显着普遍的“直线”轨迹,导致数据集严重不平衡。 此外,我们认为罕见的轨迹类型有时可能是安全性更高的类型。
因此,专门访问罕见情况和轨迹类型的预测性能至关重要。
为了解决这个问题,UniTraj 框架可以根据轨迹类型对评估指标进行分层。 在实践中,我们采用WOMD挑战[14]中定义的轨迹分类法,将轨迹分为以下几组:“静止”、“直”、“左直”、“右直”、 “左转”、“右转”、“左掉头”、“右掉头”。
虽然这种分类法的使用提供了有价值的见解,但其范围有局限性,因为它没有考虑运动动力学的变化。
例如,它不区分直线加速和减速轨迹,两者都被归类为“直线”。
因此,我们还使用下面介绍的“卡尔曼难度”的概念。
(2)卡尔曼困难。 有些情况比其他情况更难以预测,通常是当未来不是对过去的简单推断以及背景因素发挥重要作用时。 上下文包含各种元素,例如地图数据、社交互动或来自感知的输入信号。 此外,之前的研究[33,4,48]观察到,这些复杂的场景虽然至关重要,但比更容易预测的场景出现的频率要低得多。 为了专门评估关键情况下的性能,并减少来自大量简单场景的评估噪音,[33]中的作者建议将它们过滤为与真实情况高度不匹配的场景以及卡尔曼滤波器的预测[23]。 我们遵循这个想法,因为它提供了一种简单的方法来评估情况的挑战性。 因此,UniTraj 根据卡尔曼难度对评估指标进行分层,我们将卡尔曼难度定义为地面实况轨迹与线性卡尔曼滤波器预测之间的 FDE。
4实验
UniTraj 框架为研究和实验开辟了新的机会。 本节介绍强调这些机会的实验,重点关注部分4.1中的跨域(即跨数据集和跨城市)泛化(RQ1),以及部分4.2中轨迹预测模型的数据缩放影响(RQ2)。 我们在部分4.3中提供细粒度的数据集分析和讨论。 附录中的其他实验,例如持续学习和合成到真实的迁移,进一步证明了该框架的研究效用。
实验设置: 我们从原始实现中复制模型配置和超参数。 在整个实验中,我们将训练和验证样本限制为车辆轨迹。 地图范围延伸至 m 半径,空间分辨率为 m。时间参数设置为秒的历史轨迹和秒的未来轨迹。 对于我们的多数据集训练实验,我们使用 WOMD [14]、Argoverse 2 [50] 和 nuScenes [7] 数据集。 由于 nuPlan [8] 数据集面向规划任务,缺乏用于预测任务的官方训练/验证集,由于其大量样本,我们专门将其用于跨城市泛化研究。不同的城市。 我们仅使用 brier-minFDE 指标报告结果,并将其他指标留在附录中。
4.1泛化评估
泛化到新领域是数据驱动模型的一项关键挑战,需要多样化的数据来进行综合评估。 UniTraj 框架可以探索各种数据集和城市的模型泛化。
4.1.1 跨数据集评估:
为了评估模型的泛化能力,我们在每个单独的数据集上训练模型,并评估它们在所有其他可用数据集上的性能。 结果显示在表2中。 分析表中不同列中的数据,第一个观察结果是,当在其他数据集上测试模型时,所有模型的性能都会显着下降。 这是所有三个模型架构以及所有考虑的数据集的一致趋势。 例如,MTR 下的第二列报告了在 Argoverse 2 验证集上评估的性能。 这表明 MTR 在 Argoverse 2 本身的训练集上训练时达到了峰值性能,而在 nuScenes 和 WOMD 上训练的模型表现出明显较低的性能。
通过更详细的调查,我们还可以比较不同数据集的泛化能力。 例如,考虑到同一列,在 Argoverse2 数据集上进行评估时,在 WOMD 上训练的模型优于在 nuScenes 上训练的模型。 通过对其他列进行类似的比较,我们建立了一个泛化顺序:在 WOMD 数据上训练的模型表现出最高的泛化能力,其次是在 Argoverse2 上训练的模型,然后是 nuScenes。 此顺序在所有型号中保持一致。 在 WOMD 上训练的模型的卓越泛化性可以归因于 WOMD 数据集中存在更多的数据样本和更多的多样性。 我们在4.3节中提供了更详细的解释,其中我们讨论了每个数据集的具体特征及其对模型性能和泛化的影响。
| MTR [46] | Wayformer * [35] | AutoBot [17] | ||||||||
| Evaluation | ||||||||||
| Training | #trajs | nuScenes | Argoverse 2 | WOMD | nuScenes | Argoverse 2 | WOMD | nuScenes | Argoverse 2 | WOMD |
| nuScenes | 32k | 3.06 | 4.67 | 7.53 | 3.85 | 4.93 | 7.74 | 3.36 | 4.48 | 6.89 |
| Argoverse 2 | 180k | 3.89 | 2.31 | 4.84 | 5.21 | 2.85 | 5.43 | 4.35 | 2.51 | 4.43 |
| WOMD | 1800k | 3.28 | 3.84 | 2.37 | 3.75 | 3.64 | 2.64 | 3.73 | 3.23 | 2.47 |
| All | 2012k | 2.49 | 2.22 | 2.37 | 3.34 | 2.56 | 2.61 | 3.07 | 2.54 | 2.47 |
4.1.2跨城市评价:
尽管我们致力于标准化数据格式并调整数据集之间的特征,但数据收集和标注过程可能会导致某些基本差异持续存在。 例如,标注噪音可能仍然存在于数据集中。 为了控制这种潜在的剩余差异,我们探索了当城市在单个数据集中发生变化时 AutoBot 的泛化。 与之前的实验类似,我们在每个城市训练 AutoBot,并在其余城市对其进行评估。 由于不同城市存在大量样本,我们在本实验中使用了 nuPlan [8] 数据,并从每个城市中选取了 K 个样本。 结果如表3所示。 这表明,一旦在其他城市进行评估,汽车人的表现就会下降。 例如,第一行显示在匹兹堡训练的模型在匹兹堡 (brier-minFDE ) 上表现最好,在波士顿 () 和新加坡 ()。 这表明城市之间存在明显的普遍差距,强调了不同环境之间的差异。 此外,还可以观察到,在新加坡训练的模型平均表现最差。
要点:本节的研究结果表明,在最近的大规模数据集上训练的最先进模型很难推广到新领域。 作为一项具体建议,它强调了地理多样性在数据收集和评估过程中的重要性。
| Evaluation | ||||
|---|---|---|---|---|
| Training | Pittsburgh | Boston | Singapore | Average |
| Pittsburgh | 2.4 | 2.7 | 3.5 | 2.8 |
| Boston | 4.1 | 2.2 | 3.4 | 3.2 |
| Singapore | 4.9 | 3.5 | 2.1 | 3.5 |
4.2 将数据缩放至 2M 轨迹。
UniTraj 中可用的统一数据形成了可用于训练轨迹预测模型的最大公共数据。 在本节中,我们将探讨是否可以通过简单地缩放训练数据集的大小来提高模型的性能。 因此,我们将 UniTraj 中所有现有的真实数据集组合成一个大型训练集,在该训练集上训练所考虑的模型。 此实验的结果显示在 Table 2 的底部(“全部”行),展示了相对于仅在单个数据集。 虽然不同数据集的改进并不相同,但在 nuScenes 数据集的情况下尤其显着,使得 MTR 模型在 nuScenes 排行榜中的组合数据排名 st 上进行训练(如部分4.2所示)。 例如,在“所有”数据集上训练 MTR 模型使其能够大幅优于在 nuScenes 和 Argoverse2 上训练的模型。 此外,虽然 WOMD 上的性能没有得到改善,但生成的模型比在其他数据集上用 WOMD 训练的模型表现要好得多。 这些改进归因于组合数据集与单个数据集相比相对较大的规模和多样性。 我们将在部分4.3中详细阐述这一点。
该表还显示,与其他模型相比,某些模型从更大的数据量中受益更多。 具体来说,当查看 Argoverse 2 和 nuScenes 数据集上的性能时(受益于数据集大小的增加),MTR 和 Wayformer 等模型比 AutoBot 表现出更显着的改进。 这种性能增强的差异归因于模型的容量。 例如,MTR 有 M 个参数,使其具有从更大的数据集中学习的更高能力,而 AutoBot 只有 万个参数,可能无法利用附加数据。
为了说明数据大小对轨迹预测模型性能的影响,我们逐渐将组合数据集的样本数量从 % 增加到 %。 然后,我们使用所有三个数据集的平均 Brier-minFDE 指标来报告 AutoBot 模型的性能。 部分 4.2显示的曲线表明,一旦数据集大小增加,预测误差就会持续减少。 这凸显了较大数据集对模型性能的巨大好处,并为通过较大数据量提高性能提供了前景。
要点:实验结果强调了轨迹预测领域对更大、更多样化数据集的潜力和需求。 此类数据集还将突破模型当前性能的界限。
![[Uncaptioned image]](x2.png)
4.3 分析结果
4.3.1数据集分析。
我们提供数据集之间的深入比较,以帮助理解前面小节中提出的结果。 此外,这些见解有助于做出明智的决策,为特定的研究或应用需求选择最合适的数据集和设置。
基于轨迹类型的比较: 图2(a)中对 WOMD、Argoverse 2 和 nuScenes 数据集中轨迹类型的分析揭示了轨迹类型不平衡,主要表现为直线轨迹普遍存在,占所有轨迹的 54% 至 68%,掉头的情况很少。 WOMD 表现出明显多样化的轨迹组合,具有大量的左转和右转轨迹,大约是 Argoverse 2 和 nuScenes 中观察到的轨迹的两倍。 这与 Argoverse 2 和 nuScenes 形成鲜明对比,后者主要包含各种转弯动作的直线轨迹。
基于卡尔曼难度的比较: WOMD、Argoverse 2 和 nuScenes 数据集中的样本难度分布如图图2(b)所示,表现出一致的趋势,其中更简单的场景明显多于更具挑战性的场景。 WOMD 在较低到中等难度之间的分布相对均衡,约 24% 的轨迹属于最简单类别(卡尔曼难度最高为 10),在卡尔曼难度为 50.0 的情况下,轨迹的分布始终如一。 相比之下,nuScenes 和 Argoverse 2 都表现出明显偏向于较简单的难度,在最低难度范围(卡尔曼困难)中分别包含约 42% 和 46% 的样本低于 10),并且随着难度级别的增加,比例急剧下降,表明数据集主要由较简单的场景组成,这可能会限制其在更复杂情况下的训练模型中的功效。
| Traj. Type | Stationary | Straight | Straight right | Straight left | Right u-turn | Right-turn | Left u-turn | Left-turn | All |
|---|---|---|---|---|---|---|---|---|---|
| MTR (nuScenes) | 2.15 | 2.58 | 4.85 | 4.26 | 8.13 | 4.82 | 5.17 | 4.85 | 3.06 |
| MTR (All) | 2.23 | 2.31 | 3.13 | 3.06 | 2.98 | 3.53 | 2.10 | 2.82 | 2.49 |
| Evaluation | ||||
|---|---|---|---|---|
| Training | Argoverse 2 | WOMD | nuScenes | Average |
| Argoverse 2 | 2.90 | 5.07 | 4.67 | 4.21 |
| WOMD | 4.04 | 3.22 | 4.42 | 3.89 |
| nuScenes | 4.48 | 6.88 | 3.38 | 4.91 |
| All | 2.80 | 3.13 | 3.25 | 3.06 |
| Kalman | Easy | Medium | Hard |
|---|---|---|---|
| difficulty | |||
| MTR (nuScenes) | 2.93 | 4.72 | 5.01 |
| MTR (All) | 2.43 | 3.17 | 7.86 |
解释跨数据集泛化和多数据集训练实验的结果:我们在部分 4.1.1中进行的跨数据集泛化实验 表明模型在不同数据集上的推广效果并不相同。 值得注意的是,在 WOMD 上训练的模型可以更好地推广到其他数据集。 此外,在组合数据集上训练的模型表现出相当大的改进。 要理解这些现象,重要的是深入研究数据集之间的差异,重点关注两个主要方面:规模和多样性。
为了研究数据集大小的影响,我们复制了跨数据集泛化实验(Table 2),但控制了数据集大小,因为我们为每个数据集的集合选择k 个随机训练样本。 表 7显示结果。 最后一列显示了泛化层次结构,其中 WOMD 的泛化效果最好,其次是 Argoverse 2,然后是 nuScenes。 这表明更好的跨数据集泛化不仅仅归因于数据集的大小。 最后一行说明,对于多数据集训练,所有数据集都有相当大的改进,突出了在小规模数据集场景中添加更多数据的显着好处。
部分 4.3.1揭示了数据集在多样性方面有所不同。 值得注意的是,与其他数据集相比,WOMD 涵盖了最多样化的场景。 这解释了 WOMD 对其他数据集的卓越泛化性,因为多样性使模型能够更全面地学习全谱数据分布。 同样,组合数据集提供了更加多样化的轨迹集合,从而提高了模型的性能。 为了证明这一点,我们比较了在 nuScenes 和组合数据集上训练的 MTR 模型的细粒度评估。 表 5显示了两个模型的每种轨迹类型的性能,其中在完整数据上训练的模型在每种轨迹类型上都表现出色,因为完整数据包括每种轨迹类型的样本明显更多。 我们还在表7中使用卡尔曼难度度量来比较性能。 合并后的数据具有相当多的中等难度样本(如图图2(b)所示),导致中等难度的性能显着提高样品。 我们还注意到,由于数据集中挑战性场景不足,困难示例的性能下降。 这些结果凸显了数据多样性的重要性。
5结论
总之,我们的研究探讨了对于推进车辆轨迹预测领域至关重要的两个关键研究问题。 我们发现模型在跨不同领域(RQ1)进行泛化方面面临着重大挑战,在遇到新的数据集或城市时表现出相当大的性能下降。 此外,我们的研究结果证实,更大、更多样化的数据集可以显着提高模型性能和泛化能力(RQ2),强调数据丰富性的重要性。 此外,我们发布了 UniTraj 框架作为一个多功能工具,为轨迹预测的探索开辟了新的机会。 我们相信,该框架将极大地有助于推进轨迹预测领域以数据为中心的研究。
局限性:我们的框架目前仅支持矢量化输入,限制了其在基于视觉的方法中的使用。 它主要关注车辆轨迹,忽略行人动态。 未来的工作将扩展其功能,以包括原始感知数据和行人轨迹。
致谢: 作者要感谢 Mickaël Chen、Quanyi Li、Ahmad Rahimi、Yihong Xu、Olaf Dunkel 和 Ahmad Salimi 对本文的预备知识版本的有益讨论和帮助。 该项目由 Honda R&D Co., Ltd、Valeo Paris 和 ANR grant MultiTrans (ANR-21-CE23-0032) 部分资助。
参考
- [1] Javad Amirian, Bingqing Zhang, Francisco Valente Castro, Juan Jose Baldelomar, Jean-Bernard Hayet, and Julien Pettré. Opentraj: Assessing prediction complexity in human trajectories datasets. In Proceedings of the asian conference on computer vision, 2020.
- [2] Mohammadhossein Bahari, Ismail Nejjar, and Alexandre Alahi. Injecting knowledge in data-driven vehicle trajectory predictors. Transportation research part C: emerging technologies, 128:103010, 2021.
- [3] Mohammadhossein Bahari, Saeed Saadatnejad, Ahmad Rahimi, Mohammad Shaverdikondori, Amir Hossein Shahidzadeh, Seyed-Mohsen Moosavi-Dezfooli, and Alexandre Alahi. Vehicle trajectory prediction works, but not everywhere. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17123–17133, 2022.
- [4] Hedi Ben-Younes, Éloi Zablocki, Mickaël Chen, Patrick Pérez, and Matthieu Cord. Raising context awareness in motion forecasting. In CVPRW, pages 4408–4417. IEEE, 2022.
- [5] Prarthana Bhattacharyya, Chengjie Huang, and Krzysztof Czarnecki. Ssl-lanes: Self-supervised learning for motion forecasting in autonomous driving. In Conference on Robot Learning, pages 1793–1805. PMLR, 2023.
- [6] Julian Bock, Robert Krajewski, Tobias Moers, Steffen Runde, Lennart Vater, and Lutz Eckstein. The ind dataset: A drone dataset of naturalistic road user trajectories at german intersections. In 2020 IEEE Intelligent Vehicles Symposium (IV), pages 1929–1934. IEEE, 2020.
- [7] Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020.
- [8] Holger Caesar, Juraj Kabzan, Kok Seang Tan, Whye Kit Fong, Eric Wolff, Alex Lang, Luke Fletcher, Oscar Beijbom, and Sammy Omari. nuplan: A closed-loop ml-based planning benchmark for autonomous vehicles. arXiv preprint arXiv:2106.11810, 2021.
- [9] Yulong Cao, Chaowei Xiao, Anima Anandkumar, Danfei Xu, and Marco Pavone. Advdo: Realistic adversarial attacks for trajectory prediction. In European Conference on Computer Vision, pages 36–52. Springer, 2022.
- [10] Ming-Fang Chang, John Lambert, Patsorn Sangkloy, Jagjeet Singh, Slawomir Bak, Andrew Hartnett, De Wang, Peter Carr, Simon Lucey, Deva Ramanan, et al. Argoverse: 3d tracking and forecasting with rich maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [11] Guangyi Chen, Junlong Li, Jiwen Lu, and Jie Zhou. Human trajectory prediction via counterfactual analysis. In ICCV, pages 9804–9813. IEEE, 2021.
- [12] Jiuyu Chen, Zhongli Wang, Jian Wang, and Baigen Cai. Q-eanet: Implicit social modeling for trajectory prediction via experience-anchored queries. IET Intelligent Transport Systems, 2023.
- [13] Pasquale Coscia, Francesco Castaldo, Francesco AN Palmieri, Alexandre Alahi, Silvio Savarese, and Lamberto Ballan. Long-term path prediction in urban scenarios using circular distributions. Journal on Image and Vision Computing, 69:81–91, 2018.
- [14] Scott Ettinger, Shuyang Cheng, Benjamin Caine, Chenxi Liu, Hang Zhao, Sabeek Pradhan, Yuning Chai, Ben Sapp, Charles R Qi, Yin Zhou, et al. Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9710–9719, 2021.
- [15] William Falcon and The PyTorch Lightning team. PyTorch Lightning, Mar. 2019.
- [16] Thomas Gilles, Stefano Sabatini, Dzmitry Tsishkou, Bogdan Stanciulescu, and Fabien Moutarde. Uncertainty estimation for cross-dataset performance in trajectory prediction. IEEE Int. Conf. on Robotics and Automation Workshop on Fresh Perspectives on the Future of Autonomous Driving, 2022.
- [17] Roger Girgis, Florian Golemo, Felipe Codevilla, Martin Weiss, Jim Aldon D’Souza, Samira Ebrahimi Kahou, Felix Heide, and Christopher Pal. Latent variable sequential set transformers for joint multi-agent motion prediction. In International Conference on Learning Representations, 2022.
- [18] Chengcheng Guo, Bo Zhao, and Yanbing Bai. Deepcore: A comprehensive library for coreset selection in deep learning. In International Conference on Database and Expert Systems Applications, pages 181–195. Springer, 2022.
- [19] John Houston, Guido Zuidhof, Luca Bergamini, Yawei Ye, Long Chen, Ashesh Jain, Sammy Omari, Vladimir Iglovikov, and Peter Ondruska. One thousand and one hours: Self-driving motion prediction dataset. In Conference on Robot Learning, pages 409–418. PMLR, 2021.
- [20] Kai-Chieh Hsu, Karen Leung, Yuxiao Chen, Jaime Fernàndez Fisac, and Marco Pavone. Interpretable trajectory prediction for autonomous vehicles viacounterfactual responsibility. In IEEE/RSJ Int. Conf. on Intelligent Robots & Systems, 2023.
- [21] Boris Ivanovic, Guanyu Song, Igor Gilitschenski, and Marco Pavone. trajdata: A unified interface to multiple human trajectory datasets. In Proceedings of the Neural Information Processing Systems (NeurIPS) Track on Datasets and Benchmarks, New Orleans, USA, Dec. 2023.
- [22] Chiyu Jiang, Andre Cornman, Cheolho Park, Benjamin Sapp, Yin Zhou, Dragomir Anguelov, et al. Motiondiffuser: Controllable multi-agent motion prediction using diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9644–9653, 2023.
- [23] Rudolph Emil Kalman. A new approach to linear filtering and prediction problems. 1960.
- [24] Dongwan Kim, Yi-Hsuan Tsai, Yumin Suh, Masoud Faraki, Sparsh Garg, Manmohan Chandraker, and Bohyung Han. Learning semantic segmentation from multiple datasets with label shifts. In European Conference on Computer Vision, pages 20–36. Springer, 2022.
- [25] James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, 114(13):3521–3526, 2017.
- [26] Parth Kothari, Sven Kreiss, and Alexandre Alahi. Human trajectory forecasting in crowds: A deep learning perspective. IEEE Transactions on Intelligent Transportation Systems, 2021.
- [27] Parth Kothari, Danya Li, Yuejiang Liu, and Alexandre Alahi. Motion style transfer: Modular low-rank adaptation for deep motion forecasting. In CoRL, volume 205 of Proceedings of Machine Learning Research, pages 774–784. PMLR, 2022.
- [28] Quanyi Li, Zhenghao Peng, Lan Feng, Zhizheng Liu, Chenda Duan, Wenjie Mo, and Bolei Zhou. Scenarionet: Open-source platform for large-scale traffic scenario simulation and modeling. Advances in Neural Information Processing Systems, 2023.
- [29] Quanyi Li, Zhenghao Peng, Lan Feng, Qihang Zhang, Zhenghai Xue, and Bolei Zhou. Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning. IEEE transactions on pattern analysis and machine intelligence, 45(3):3461–3475, 2022.
- [30] Junwei Liang, Enwei Zhang, Jun Zhang, and Chunhua Shen. Multi-dataset training of transformers for robust action recognition. Advances in Neural Information Processing Systems, 35:14475–14488, 2022.
- [31] Ming Liang, Bin Yang, Rui Hu, Yun Chen, Renjie Liao, Song Feng, and Raquel Urtasun. Learning lane graph representations for motion forecasting. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16, pages 541–556. Springer, 2020.
- [32] Yuejiang Liu, Riccardo Cadei, Jonas Schweizer, Sherwin Bahmani, and Alexandre Alahi. Towards robust and adaptive motion forecasting: A causal representation perspective. In CVPR, pages 17060–17071. IEEE, 2022.
- [33] Osama Makansi, Özgün Çiçek, Yassine Marrakchi, and Thomas Brox. On exposing the challenging long tail in future prediction of traffic actors. In ICCV, pages 13127–13137. IEEE, 2021.
- [34] Andrey Malinin, Neil Band, German Chesnokov, Yarin Gal, Mark JF Gales, Alexey Noskov, Andrey Ploskonosov, Liudmila Prokhorenkova, Ivan Provilkov, Vatsal Raina, et al. Shifts: A dataset of real distributional shift across multiple large-scale tasks. arXiv preprint arXiv:2107.07455, 2021.
- [35] Nigamaa Nayakanti, Rami Al-Rfou, Aurick Zhou, Kratarth Goel, Khaled S Refaat, and Benjamin Sapp. Wayformer: Motion forecasting via simple & efficient attention networks. In IEEE International Conference on Robotics and Automation (ICRA), pages 2980–2987. IEEE, 2023.
- [36] Jonah Philion, Xue Bin Peng, and Sanja Fidler. Trajeglish: Learning the language of driving scenarios. arXiv preprint arXiv:2312.04535, 2023.
- [37] Mozhgan Pourkeshavarz, Changhe Chen, and Amir Rasouli. Learn tarot with mentor: A meta-learned self-supervised approach for trajectory prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8384–8393, 2023.
- [38] Alexandre Robicquet, Amir Sadeghian, Alexandre Alahi, and Silvio Savarese. Learning social etiquette: Human trajectory prediction in crowded scenes. In European Conference on Computer Vision (ECCV), volume 2, page 5, 2016.
- [39] Andrey Rudenko, Luigi Palmieri, Wanting Huang, Achim J Lilienthal, and Kai O Arras. The atlas benchmark: an automated evaluation framework for human motion prediction. In 2022 31st IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), pages 636–643. IEEE, 2022.
- [40] Amir Sadeghian, Vineet Kosaraju, Agrim Gupta, Silvio Savarese, and Alexandre Alahi. Trajnet: Towards a benchmark for human trajectory prediction. arXiv preprint, 2018.
- [41] Jay Sarva, Jingkang Wang, James Tu, Yuwen Xiong, Sivabalan Manivasagam, and Raquel Urtasun. Adv3d: Generating safety-critical 3d objects through closed-loop simulation. CoRR, abs/2311.01446, 2023.
- [42] Maximilian Schäfer, Kun Zhao, and Anton Kummert. Caspnet++: Joint multi-agent motion prediction, 2023.
- [43] Ari Seff, Brian Cera, Dian Chen, Mason Ng, Aurick Zhou, Nigamaa Nayakanti, Khaled S Refaat, Rami Al-Rfou, and Benjamin Sapp. Motionlm: Multi-agent motion forecasting as language modeling. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8579–8590, 2023.
- [44] Wenbo Shao, Yanchao Xu, Jun Li, Chen Lv, Weida Wang, and Hong Wang. How does traffic environment quantitatively affect the autonomous driving prediction? IEEE Transactions on Intelligent Transportation Systems, 2023.
- [45] Bowen Shi, Xiaopeng Zhang, Haohang Xu, Wenrui Dai, Junni Zou, Hongkai Xiong, and Qi Tian. Multi-dataset pretraining: A unified model for semantic segmentation. arXiv preprint arXiv:2106.04121, 2021.
- [46] Shaoshuai Shi, Li Jiang, Dengxin Dai, and Bernt Schiele. Motion transformer with global intention localization and local movement refinement. Advances in Neural Information Processing Systems, 35:6531–6543, 2022.
- [47] Balakrishnan Varadarajan, Ahmed Hefny, Avikalp Srivastava, Khaled S Refaat, Nigamaa Nayakanti, Andre Cornman, Kan Chen, Bertrand Douillard, Chi Pang Lam, Dragomir Anguelov, et al. Multipath++: Efficient information fusion and trajectory aggregation for behavior prediction. In 2022 International Conference on Robotics and Automation (ICRA), pages 7814–7821. IEEE, 2022.
- [48] Yuning Wang, Pu Zhang, Lei Bai, and Jianru Xue. FEND: A future enhanced distribution-aware contrastive learning framework for long-tail trajectory prediction. In CVPR, pages 1400–1409. IEEE, 2023.
- [49] Xinshuo Weng, Boris Ivanovic, Kris Kitani, and Marco Pavone. Whose track is it anyway? improving robustness to tracking errors with affinity-based trajectory prediction. In CVPR, pages 6563–6572. IEEE, 2022.
- [50] Benjamin Wilson, William Qi, Tanmay Agarwal, John Lambert, Jagjeet Singh, Siddhesh Khandelwal, Bowen Pan, Ratnesh Kumar, Andrew Hartnett, Jhony Kaesemodel Pontes, et al. Argoverse 2: Next generation datasets for self-driving perception and forecasting. arXiv preprint arXiv:2301.00493, 2023.
- [51] Yihong Xu, Loïck Chambon, Éloi Zablocki, Mickaël Chen, Alexandre Alahi, Matthieu Cord, and Patrick Pérez. Towards motion forecasting with real-world perception inputs: Are end-to-end approaches competitive? In ICRA, 2024.
- [52] Zhen Yao, Xin Li, Bo Lang, and Mooi Choo Chuah. Goal-lbp: Goal-based local behavior guided trajectory prediction for autonomous driving. IEEE Transactions on Intelligent Transportation Systems, pages 1–10, 2023.
- [53] Luyao Ye, Zikang Zhou, and Jianping Wang. Improving the generalizability of trajectory prediction models with frenet-based domain normalization. IEEE International Conference on Robotics and Automation (ICRA), 2023.
- [54] Ruonan Yu, Songhua Liu, and Xinchao Wang. Dataset distillation: A comprehensive review. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.
- [55] Wei Zhan, Liting Sun, Di Wang, Haojie Shi, Aubrey Clausse, Maximilian Naumann, Julius Kummerle, Hendrik Konigshof, Christoph Stiller, Arnaud de La Fortelle, et al. Interaction dataset: An international, adversarial and cooperative motion dataset in interactive driving scenarios with semantic maps. arXiv preprint arXiv:1910.03088, 2019.
- [56] Pu Zhang, Lei Bai, Jianru Xue, Jianwu Fang, Nanning Zheng, and Wanli Ouyang. Trajectory forecasting from detection with uncertainty-aware motion encoding. CoRR, abs/2202.01478, 2022.
- [57] Xingyi Zhou, Vladlen Koltun, and Philipp Krähenbühl. Simple multi-dataset detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7571–7580, 2022.
- [58] Zikang Zhou, Jianping Wang, Yung-Hui Li, and Yu-Kai Huang. Query-centric trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17863–17873, 2023.
6附录
在本附录中,我们提供了额外的内容来补充我们的主要论文。 这包括一组实验,进一步向研究界阐明 UniTraj 框架的功能(参见部分6.1),其他结果包括交叉-检查模型的性能并报告其他指标(请参阅部分6.2),以及有关UniTraj框架的更多详细信息(请参阅节 6.3)。
6.1 使用 UniTraj 进行进一步实验
UniTraj 是一种灵活且全面的工具,可以提供各种研究机会。 虽然我们在主论文中展示了其中的一些内容,但我们在这里展示了该框架的其他机会和功能。
6.1.1 在多个数据集上持续学习
在不删除先验知识的情况下使轨迹预测模型适应新数据集(称为灾难性遗忘[25])对于自动驾驶模型至关重要。 我们在表 8中的结果说明了这一挑战,其中我们在 k 个 WOMD 样本(resp. Argoverse 2)数据集,然后在 Argoverse 2(分别)上进行微调。 WOMD)。 使用 Argoverse 2 数据微调 WOMD 训练模型可适度提高 Argoverse 2 的性能(提高 +0.92),但会显着损害其 WOMD 性能(-0.52)。 同样,使用 WOMD 数据微调 Argoverse 2 训练模型可显着提高 WOMD 性能 (+2.06),但会严重影响 Argoverse 2 性能 (-0.98)。 这是由于 WOMD 和 Argoverse 2 之间存在相当大的领域差距,如我们的跨数据集泛化实验所示。 这一结果体现了灾难性遗忘的问题,凸显了在不影响之前学习的数据集性能的情况下平衡对新数据集的适应的挑战。
| Training | Finetuning | Improvement | Forgetting | |
|---|---|---|---|---|
| domain | domain | (finetun. dom.) | (train. dom.) | |
| WOMD | Argoverse 2 | + 0.92 | - 0.52 | |
| Argoverse 2 | WOMD | + 2.06 | - 0.98 |
| Training | minADE6 () | brier-minFDE () |
|---|---|---|
| PG | 8.36 | 14.35 |
| nuScenes | 1.28 | 3.55 |
| nuscenes and PG | 1.30 | 3.56 |
6.1.2 合成数据
合成数据是一种经济高效且多功能的方法,特别是在自动驾驶领域,因为它易于生成,并且能够在训练期间模拟各种甚至罕见的驾驶场景。 在我们的方法中,我们利用通过程序生成(PG)创建的大型合成数据集来预训练我们的模型。 PG 是 MetaDrive 模拟器[29]中使用的一项技术,有助于根据预定义规则创建各种交通场景和地图。 在我们的实验中,我们使用MetaDrive模拟器的相同设置;交通密度为每 100 米 15 辆汽车,并在每个场景中包含 2 个路障。 这导致创建了 30,000 个独特的场景。
我们使用合成 PG 数据集训练 AutoBot,然后在 nuScenes 数据集上对其进行调节。 预训练阶段有助于在模型中注入基本行为,例如车道跟踪和避免碰撞。 表 9显示了我们的实验结果。 表的第一行和第二行之间的比较揭示了数据集之间存在显着的域差距。 具体来说,在 PG 数据集上训练的模型在 nuScenes 数据集上的表现明显不佳。 此外,与未经过预训练的模型相比,该模型在微调后并没有表现出任何实质性的性能改进。 这一结果表明,虽然合成数据可能作为训练和将模型引入一系列条件的有用起点,但其在提高现实世界性能方面的有效性可能有限。 这种限制归因于真实数据和合成数据之间的领域差距,以及合成数据的简单性和有限的多样性。 我们相信,更真实、更多样化的合成数据集可能有助于作为预训练源。
| Traj. Type | Stationary | Straight | Straight right | Straight left | Right u-turn | Right-turn | Left u-turn | Left-turn | All |
|---|---|---|---|---|---|---|---|---|---|
| AutoBot | 1.50 | 2.21 | 2.77 | 2.69 | 8.06 | 2.99 | 4.32 | 2.69 | 2.47 |
| MTR | 1.09 | 2.13 | 2.86 | 2.90 | 5.96 | 2.83 | 4.58 | 2.64 | 2.37 |
6.1.3 使用细粒度评估来比较不同模型的性能:
我们在主论文的表 2 中比较了多种轨迹预测模型的性能。 该表提供了不同模型之间的比较。 具体来说,它显示了 AutoBot 和 MTR 在 WOMD 数据集上的性能,其中 MTR 实现了较低的错误率 ,优于 AutoBot 的 。 然而,这是一个过程比较,没有任何关于每个模型的优缺点的详细信息。 得益于 UniTraj 中提供的细粒度评估方法,我们在表10和11 第一个表比较了不同轨迹类型的性能。 虽然 MTR 总体上优于 AutoBot,但它在特定轨迹(例如右直、左直和左掉头)方面落后。 第二个表还显示,汽车人在中等难度的场景中超过了 MTR。 这些见解提供了更彻底的比较,并有助于查明模型中的特定薄弱环节。
6.1.4 其他潜在的未来方向
UniTraj 框架为构建轨迹预测基础模型铺平了道路。 基础模型通常是在大量数据集上进行训练的,而到目前为止,这些数据集在轨迹预测领域中还不容易获得。 一种有效的解决方法是利用广泛的合成数据进行初始模型训练,然后对现实数据集进行微调。 UniTraj 通过集成各种合成数据集以及该领域当前可用的最大真实数据的集合来促进这种方法。 这一研究方向已经受到关注,最近一些轨迹预测研究采用了基础模型概念,对动作空间进行标记,并专注于预测后续的词符[43, 36]。
该框架还为其他研究提供了机会,例如核心集选择和数据集蒸馏[18, 54]。 这涉及创建轨迹数据的紧凑子集,其中封装了组合数据集中的大部分信息。
6.2补充结果
在本节中,我们提出了补充主要论文中的结果的其他结果。 我们首先提供集成到框架中的预测模型的性能与其官方报告的性能进行比较,以验证我们的集成是否正确。 然后,我们报告了超出 brie-minFDE 的指标,以获得我们在论文中提出的结果。
6.2.1 交叉检查基线与原始论文的性能
对于 MTR,我们在 WOMD 上报告数字。 我们在 WOMD 上训练 MTR,设置与官方设置相同,例如 1 秒的过去轨迹和 8 秒的未来轨迹。 然后,我们在官方 WOMD 验证集上评估模型,使用官方评估工具报告数字。 表12中的结果表明,与原始实现相比,集成MTR可以实现相似的性能。
| mAP | minADE | minFDE | MissRate | |
|---|---|---|---|---|
| Vehicle | 0.44 | 0.78 | 1.55 | 0.16 |
| Pedestrian | 0.43 | 0.35 | 0.73 | 0.07 |
| Cyclist | 0.36 | 0.72 | 1.45 | 0.19 |
| Avg (ours) | 0.41 | 0.62 | 1.24 | 0.14 |
| Avg-original | 0.42 | 0.60 | 1.23 | 0.14 |
同样,对于 Wayformer,我们在 WOMD 上报告数据,数据设置与官方设置相同。 由于原始论文没有报告验证集上的数字,我们将我们的性能与 MTR 进行比较。 表13中的结果表明,我们内部实施的 Wayformer 在 minADE 和 minFDE 指标方面优于 MTR。 然而,由于 Wayformer 非公开实施中缺乏某些细节,mAP 指标性能仍然存在差异。
| mAP | minADE | minFDE | MissRate | |
|---|---|---|---|---|
| Vehicle | 0.28 | 0.67 | 1.39 | 0.14 |
| Pedestrian | 0.25 | 0.32 | 0.67 | 0.09 |
| Cyclist | 0.24 | 0.68 | 1.40 | 0.21 |
| Avg (ours) | 0.26 | 0.56 | 1.15 | 0.15 |
对于汽车人,请参阅我们在主论文表 4 中 nuScenes 排行榜上的结果。
6.2.2 报告其他指标
我们通过提供额外的评估指标来扩展对模型泛化能力的检查,先前在主论文中使用brierFDE指标(表2)报告了这一点:minFDE in Table 14,表15中的minADE和表16<中的MR /t8>。 我们报告相同实验的指标;分别在每个数据集上训练模型,并评估它们在所有其他数据集上的表现。
我们的扩展分析证实了在不熟悉的数据集上观察到的模型性能下降的趋势,这是在所考虑的模型架构和数据集上一致的结果。 它还强化了主论文中得出的结论,说明了 WOMD 训练的模型优于其他模型的泛化层次结构,其次是 Argoverse 2 和 nuScenes。
我们进一步确认了训练模型在组合数据集上的好处,这与主要论文的见解一致,显示出显着的性能改进,尤其是对于 nuScenes。
| MTR [46] | Wayformer * [35] | AutoBot [17] | ||||||||
| Evaluation | ||||||||||
| Training | #trajs | nuScenes | Argoverse 2 | WOMD | nuScenes | Argoverse 2 | WOMD | nuScenes | Argoverse 2 | WOMD |
| nuScenes | 32k | 2.33 | 3.89 | 6.72 | 2.83 | 3.87 | 6.75 | 2.62 | 3.70 | 5.85 |
| Argoverse 2 | 180k | 3.10 | 1.68 | 4.04 | 4.21 | 1.92 | 4.44 | 3.52 | 1.70 | 3.59 |
| WOMD | 1800k | 2.52 | 3.14 | 1.78 | 2.76 | 2.65 | 1.65 | 2.90 | 2.41 | 1.65 |
| All | 2012k | 1.81 | 1.61 | 1.78 | 2.35 | 1.57 | 1.62 | 2.24 | 1.73 | 1.66 |
| MTR [46] | Wayformer * [35] | AutoBot [17] | ||||||||
| Evaluation | ||||||||||
| Training | #trajs | nuScenes | Argoverse 2 | WOMD | nuScenes | Argoverse 2 | WOMD | nuScenes | Argoverse 2 | WOMD |
| nuScenes | 32k | 1.06 | 1.85 | 2.85 | 1.33 | 1.70 | 2.62 | 1.21 | 1.62 | 2.35 |
| Argoverse 2 | 180k | 1.42 | 0.85 | 1.73 | 1.70 | 0.95 | 1.83 | 1.59 | 0.85 | 1.43 |
| WOMD | 1800k | 1.17 | 1.50 | 0.78 | 1.33 | 1.25 | 0.73 | 1.42 | 1.15 | 0.73 |
| All | 2012k | 0.85 | 0.82 | 0.78 | 1.13 | 0.80 | 0.72 | 1.12 | 0.86 | 0.74 |
| MTR [46] | Wayformer * [35] | AutoBot [17] | ||||||||
| Evaluation | ||||||||||
| Training | #trajs | nuScenes | Argoverse 2 | WOMD | nuScenes | Argoverse 2 | WOMD | nuScenes | Argoverse 2 | WOMD |
| nuScenes | 32k | 0.41 | 0.58 | 0.71 | 0.48 | 0.61 | 0.74 | 0.40 | 0.52 | 0.65 |
| Argoverse 2 | 180k | 0.47 | 0.30 | 0.59 | 0.53 | 0.32 | 0.63 | 0.49 | 0.27 | 0.55 |
| WOMD | 1800k | 0.44 | 0.49 | 0.33 | 0.44 | 0.45 | 0.25 | 0.42 | 0.40 | 0.25 |
| All | 2012k | 0.32 | 0.28 | 0.33 | 0.33 | 0.23 | 0.24 | 0.36 | 0.27 | 0.25 |
6.3 有关 UniTraj 框架的更多详细信息
6.3.1 训练管道
UniTraj 内的训练管道以 PyTorch Lightning [15] 为基础。 PyTorch Lightning 是一个复杂的深度学习框架,可以满足人工智能研究人员和机器学习从业者的需求。 在我们的实现中,我们在分布式数据并行 (DDP) 模式下利用 PyTorch Lightning 的训练模块,实现高效的多 GPU 加速,从而提高训练速度和有效性。
6.3.2 训练设置
在我们的实验中,我们使用 8 个 A100 GPU 来训练所有模型。 MTR、Wayformer 和 Autobot 的批量大小分别为 256、256 和 128。 MTR、Wayformer 和 Autobot 的训练时间分别约为 1 小时、15 分钟和 5 分钟。 我们根据验证集上的最佳 min-brierFDE 选择检查点。