CMDA:基于 LiDAR 的 3D 物体检测的跨模态和域对抗性适应
摘要
最近基于 LiDAR 的 3D 对象检测 (3DOD) 方法显示出有希望的结果,但它们通常不能很好地推广到源(或训练)数据分布之外的目标域。 为了减少此类域差距,从而使 3DOD 模型更具通用性,我们引入了一种新颖的无监督域适应 (UDA) 方法,称为 CMDA,该方法 (i) 利用图像模态(即相机图像)中的视觉语义线索作为有效的方法语义桥梁,以缩小跨模式鸟瞰图(BEV)表示中的领域差距。 此外,(ii)我们还引入了一种基于自我训练的学习策略,其中模型经过对抗性训练以生成域不变特征,这会破坏对特征实例是来自源域还是来自看不见的目标域的区分。 总体而言,我们的 CMDA 框架指导 3DOD 模型为新颖的数据分布生成信息丰富且领域自适应的特征。 在我们对 nuScenes、Waymo 和 KITTI 等大规模基准进行的广泛实验中,上述这些为 UDA 任务提供了显着的性能提升,实现了最先进的性能。
介绍
3D 物体检测 (3DOD) 是基本的计算机视觉问题之一,在自动驾驶和机器人等现实应用中发挥着至关重要的作用(Qian、Lai 和 Li 2022;Zhu 等人 2014)。 最近的研究(Shi、Wang和Li 2019;Wang等人2022;Roh等人2022)通过大规模基准测试和精确的3D视觉传感器在3DOD方面取得了重大进展。 特别是,基于 LiDAR 的方法(Liang 等人 2022;Liu 等人 2023;Yin、Zhou 和 Krahenbuhl 2021) 通过利用精确的 3D 几何信息(即,来自点云的对象位置和大小)。 然而,尽管取得了这些突破,大多数 3DOD 作品在对以前未见过的数据分布进行测试时,由于不可避免的域转移问题(例如,点密度、天气条件和地理位置的变化)而面临显着的性能下降。
为了应对这些挑战,基于激光雷达的无监督域适应(UDA)的最新方法主要集中于有效利用点云中的精确几何信息(Wang等人2021)或带有伪标签的自我训练策略(Yang等人2021)。 然而,这些方法在仅依赖几何激光雷达特征来学习与领域无关的上下文信息(例如颜色、纹理和对象外观)方面面临挑战。
为了弥补语义信息的缺失,我们引入了跨模态知识交互(CMKI),利用 RGB 图像中呈现的上下文细节来指导学习基于 LiDAR 的几何特征中丰富的语义线索。 最近关于多模态融合的研究(Zhang, Chen, and Huang 2022; Bai 等人 2022; Liu 等人 2023)表明,3D点云和2D图像的适当互补可以提高整体检测精度。 由于每个数据集的个性化多模态传感器配置,这些方法在 UDA 任务中仍然受到限制。 为了解决这些问题,我们主张利用最佳联合表示鸟瞰图 (BEV),促进深层语义线索从基于 2D 图像的特征到基于 3D LiDAR 的特征的转移。 在这里,每个图像像素的上下文细节可以作为区分语义先验,以提高 3DOD 性能。 最后,CMKI 能够通过软关联多模态线索来生成信息丰富的特征。 我们凭经验发现我们的图像辅助方法有效地克服了域转移。 据我们所知,我们是第一个在 3DOD 上采用多模态 UDA 的公司。
除了利用 2D 图像的精细细节之外,我们还专注于巧妙地扩展标准自训练方法(Yang 等人 2021),以适应以前未见过的目标数据分布。 我们提出了基于自我训练的跨域对抗网络(CDAN)学习策略,以缓解源数据和目标数据之间明显的表征差距。 为了确保跨域的明确连接,我们首先引入点云混合技术,该技术用随机方位角交换点扇区。 然后,我们进一步应用对抗性正则化来减少跨域的表示差距,引导模型学习域不变信息。 此外,我们设计了一个最小化独立 BEV 网格熵的函数,以抑制从混合输入中得出的模糊和不确定的特征。 最终,我们的领域自适应对抗性自我训练方法现在在各种跨领域场景中都很强大。
给定 3DOD、nuScenes (Caesar 等人 2020)、Waymo (Sun 等人 2020) 和 KITTI (Geiger, Lenz, and Urtasun 2012) 中的地标数据集,我们验证了我们新颖的 UDA 框架 CMDA 的通用性和有效性。 最重要的是,我们提出的框架优于基于 LiDAR 3DOD 的 UDA 现有最先进方法。 总而言之,我们的主要贡献如下:
-
•
我们提出了一种新颖的图像辅助无监督域适应方法,称为具有跨模态知识交互(CMKI)的 CMDA,通过在联合 BEV 空间中软关联多模态线索来产生高信息量特征。 据我们所知,我们是第一个介绍在基于 LiDAR 的 3DOD 上利用 2D 图像语义进行 UDA 的工作。
-
•
我们利用跨域对抗网络(CDAN)设计了一种实用的自我训练范例,以有效缓解跨域的表征差距。 具体来说,我们的方法敌对地限制网络学习领域不变的线索。
-
•
我们分析了我们提出的方法在多个具有挑战性的基准上的有效性,包括 nuScenes、KITTI 和 Waymo。 对各种跨域适应场景的大量实验验证了我们提出的方法在 3DOD 上实现了 UDA 的新的最先进性能。
相关工作
基于 LiDAR 的 3D 物体检测。
在早期使用点云的 3D 物体检测任务(Chen 等人 2017; Ku 等人 2018) 中,重点是通过最小化空间信息的损失将点云投影到 2D 特征空间。 最近基于 LiDAR 的 3D 物体检测工作可以分为两种不同的方法:体素网格表示和基于点的方法。 首先,基于体素的方法(Zhou and Tuzel 2018;Yan,Mao,and Li 2018;Yang,Liang,and Urtasun 2018;Lang 等人 2019;Shi 等人 2020;Deng 等人 2021) 将点云数据转换为与普通卷积神经网络(CNN)兼容的体素表示。 此外,由于点云稀疏地分布在整个图像上,因此从不同点集构建的体素表示更加有效。 尽管体素表示是通用的,并且在 3D 对象检测中显示出有竞争力的性能,但细粒度信息的损失是不可避免的。 不同的是,为了处理这个问题,基于点的方法(Yang 等人 2019; Shi, Wang, and Li 2019; Yang 等人 2020) 直接使用 3D 点云数据来利用比以前的方法。 在我们的工作中,我们采用 SECOND (Yan, Mao, and Li 2018) 和 PV-RCNN (Shi 等人 2020) 作为基线模型,它们是 3D 中的代表性网络对象检测来证明使用我们提出的方法提取域不变特征的有效性。
用于基于 LiDAR 的 3D 对象检测的无监督域适应 (UDA)。
为了将基于 LiDAR 的 3D 对象检测推广到自动驾驶,无监督域适应解决了标记源数据集和未标记目标数据集之间的性能下降问题。 在基于 LiDAR 的 3D 物体检测的早期 UDA 中,Y. Wang 等人 (Wang 等人 2020) 提出通过利用不熟悉的物体来减轻盒子尺度的归纳偏差统计标准化(SN)。 ST3D (Yang 等人 2021) 在数据管道中应用了随机对象缩放 (ROS) 和新颖的自训练框架,以展示目标场景中的效率。 转向点云分辨率领域,最近的研究提出了各种方法来补充点云的稀疏性。 SPG (Xu 等人 2021) 通过采用高效的点生成来丰富缺失的点。 3D-CoCo (Yihan 等人 2021) 利用源和目标之间的域对齐从未标记的点云中提取鲁棒特征。 LiDAR Distillation (Wei 等人 2022) 利用球坐标生成伪稀疏点集并传输源知识,有效减少域间隙。
方法
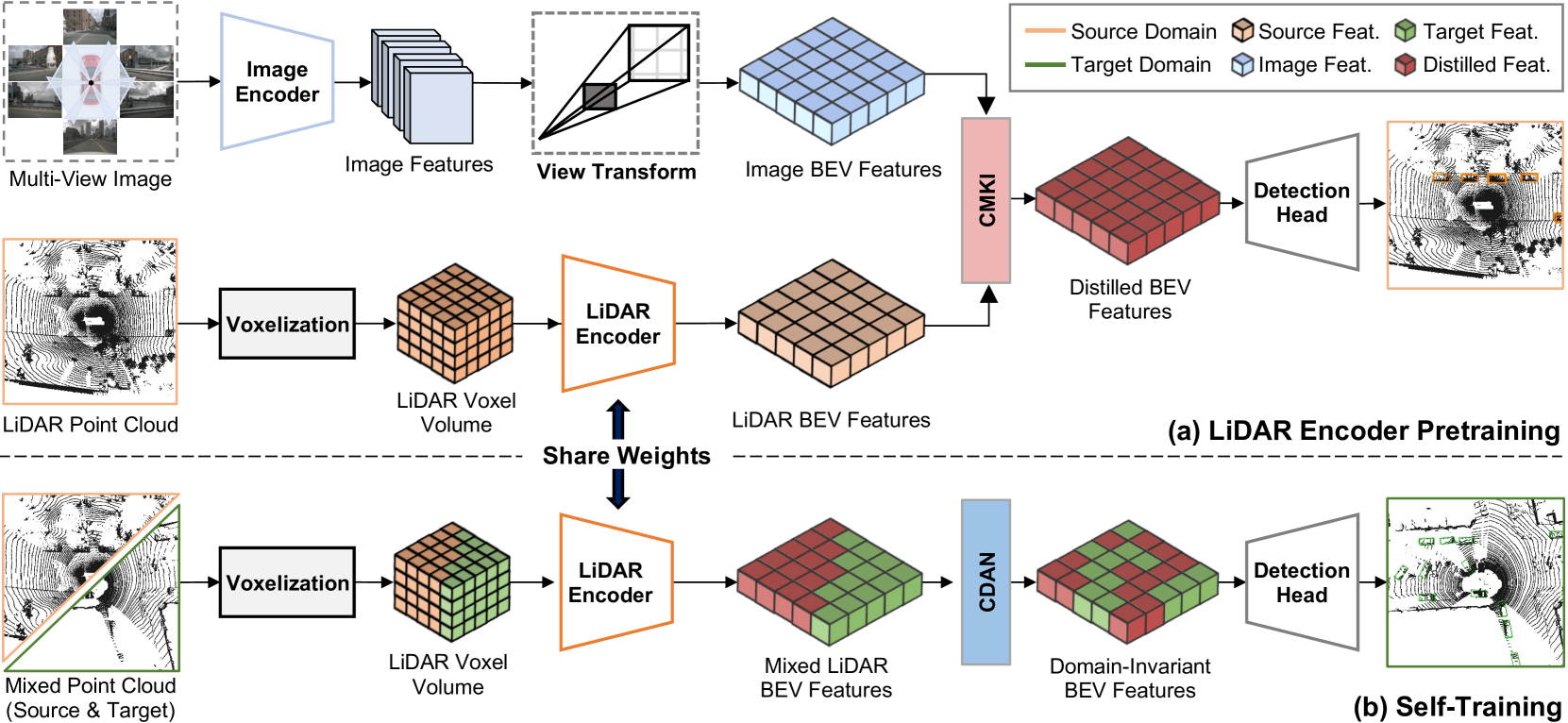
在本节中,我们提出了一种新颖的无监督域适应(UDA)框架 CMDA,用于基于 LiDAR 的 3D 对象检测(3DOD)。 我们主张在训练阶段利用多模式输入来增强跨不同领域的通用性。 具体来说,我们鼓励 LiDAR BEV 功能从相机 BEV 功能中学习丰富的语义知识,并通过跨域对抗管道明确指导这种跨模式学习,实现对不可见目标条件的广义感知。 我们首先概述我们的框架,然后介绍所提出方法的技术细节,如下:(1)跨模态知识交互(CMKI)和(2)跨域对抗网络(CDAN)。
概述
跨模态知识交互(CMKI)
最近,多模态 3DOD 机制(Zhang、Chen 和 Huang 2022;Bai 等人 2022;Vora 等人 2020) 强调了协同补充 2D 图像的几何损失与 3D 的语义损失的好处点云。 尽管有潜在的好处,但引入多模态来解决几何和语义领域差距在 3DOD 任务的 UDA 领域受到的关注有限。 在这项工作中,我们深入研究了不同模态(即、相机图像和激光雷达点云)之间交互的有效性,旨在提高 BEV 的特征质量,并改进对以前未见过的目标数据分布的检测性能。
最佳联合表示。
精确的几何对齐对于确保图像和点云特征的质量至关重要。 尽管现有的带有校准矩阵的关联技术(Chen 等人 2022; Vora 等人 2020) 采用了多模态信息,但由于非特征及其表示的同质性。 例如,相机特征以单视角或多视角编码,而LiDAR特征以BEV空间(Bai等人2022)表达。 因此,我们有动力寻找最佳的联合表示,以促进有效的跨模式知识交互,并研究其对 UDA 任务的影响。 受最近的多模态融合(Liu等人2023;Liang等人2022)的启发,我们采用BEV特征表示,旨在在它们之间传递有价值的特定于模态的线索。
跨模式 BEV 特征图生成。
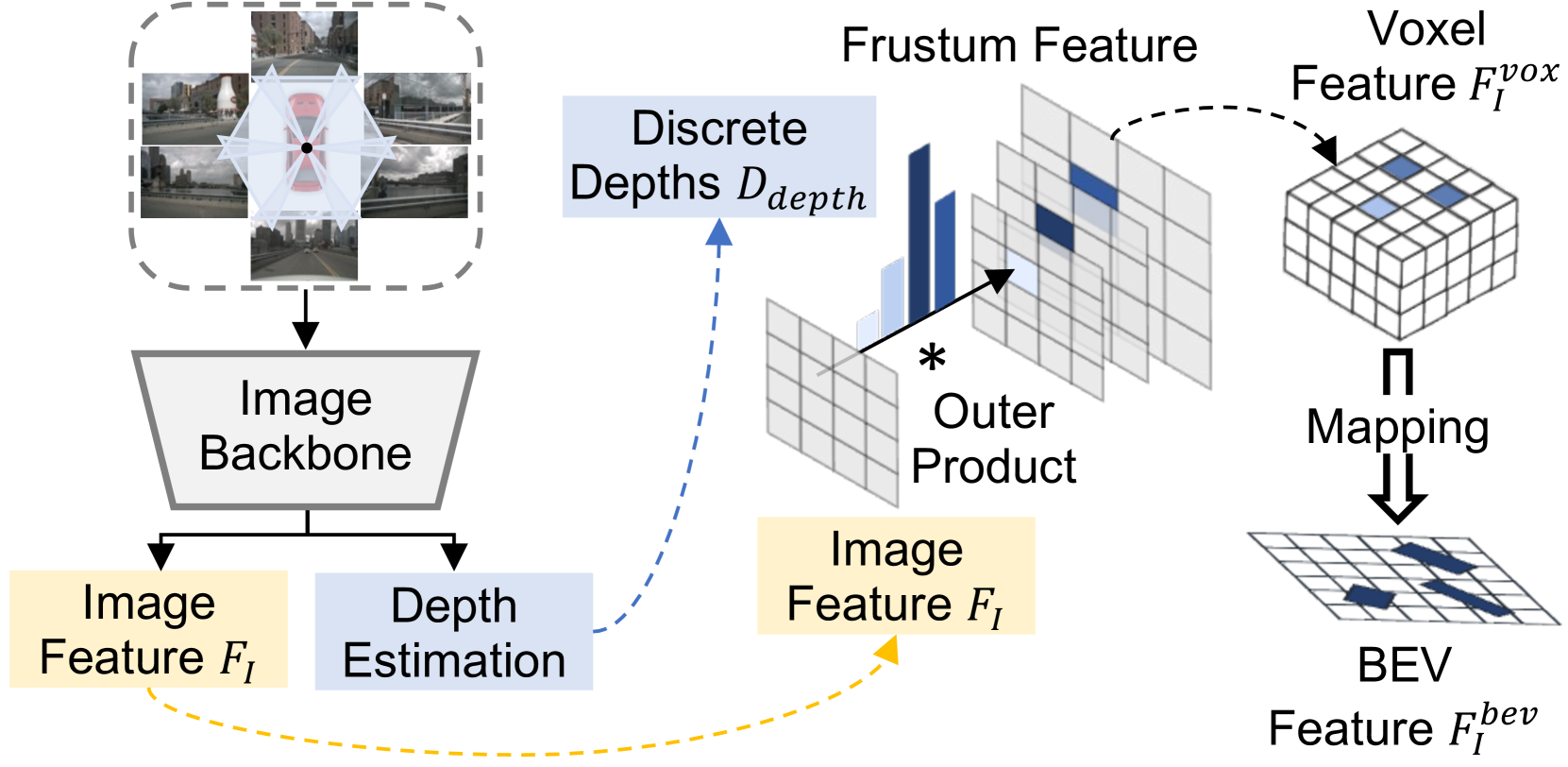
受到流行工作 Lift-Splat-Shoot (LSS) (Philion and Fidler 2020) 的启发,我们的相机流(如图 2 所示)将 RGB 图像转换为高分辨率级 BEV 表示。 首先,图像编码器从多视图图像中提取丰富语义的视觉特征。 为了构建 BEV 特征,我们应用了一个视图变换模块,将 2D 图像坐标链接到 3D 世界坐标。 对于每个像素,我们以分类方式密集预测所有可能深度 的表示,其中 表示离散深度箱。 然后,我们通过计算 和 的外积来完成上下文特征的截锥体体素。 给定相机参数,我们通过插值过程获得伪体素,将其输入体素主干以提取特征。 然后,沿高度轴压缩以产生基于图像的BEV特征图。
为了从 3D LiDAR 点云生成 BEV 特征图 ,我们遵循标准的基于体素的高度压缩方法(Zhou 和 Tuzel 2018)。
BEV 功能中的跨模式知识交互。
正如之前的研究(Wang 等人 2020; Yang 等人 2021; Xu 等人 2021; Wei 等人 2022) 所报道的,通过利用 3D 点云数据中的精确几何细节来显着增强 UDA 性能指导特征级适配。 尽管点云提供了几何信息线索,但它们在生成丰富的语义信息(例如颜色、纹理以及目标对象和背景的外观)方面受到限制。 为了弥补上下文信息的缺乏,我们有动机利用 RGB 图像的精细细节作为判别语义先验,以提高 3DOD 性能。 为此,我们专注于将丰富的语义知识从基于图像的特征转移到基于激光雷达的特征。 基于模态之间的联合 BEV 表示,我们制定了跨模态知识交互:
| (1) |
其中表示BEV特征图的宽度和长度,是范数。 通过最小化 ,我们优化了基于 3D LiDAR 的特征,以包含来自基于 2D 图像的特征的信息丰富的语义线索。 我们基于 BEV 的跨模态知识交互在输入模态之间建立了有价值的联系,并在各种跨域部署中持续产生改进,如表 1 和 2 所示。
跨域对抗网络(CDAN)
在UDA领域,带有目标伪标签的自训练策略(Xie 等人 2020; Yang 等人 2021; Yihan 等人 2021; Zou 等人 2018) 显着增强了 3DOD 的性能无监督环境下的模型。 然而,我们凭经验发现,解决源域和目标域之间的代表性差距仍然面临挑战。 具体来说,这些方法很难准确识别由不太熟悉的点样本组成的目标对象,并导致生成低质量的目标伪标签,如图5(a)所示。 为此,我们提出了一种领域自适应对抗性自训练方法,如图3所示,以增强领域不可知特征的学习并提高伪标签的准确性。
跨域混合。
为了减少自训练过程中域之间的分布变化,我们首先切换源域场景和目标域场景的点云扇区。 我们按照(Xiao等人2022)以相同的方位角切割点云扇区和相应的标签,并将它们相互交换。 请注意,每次迭代的方位角 是在特定范围内随机设置的,以避免归纳偏差。 我们的混合流程制定如下:
| (2) |
其中和表示对方位角内的点进行过滤的二进制掩码; 表示目标伪标签。 接下来,预训练的编码器将混合点云 作为输入并生成基于 LiDAR 的 BEV 特征。 我们的混合策略直接引入跨域数据实例,以促进学习域不变特征,最终提高适应性能。

域自适应判别器。
我们引入域自适应对抗鉴别器来隐式减少共享嵌入空间内源和目标之间的表示差距。 具体来说,我们通过使用梯度反转层(Ganin等人2016)的对抗性学习范式引导检测头在自训练过程中学习广义信息。 我们的跨域鉴别器尝试对来自检测头的的实例级特征的域进行分类。 每个要素实例根据其坐标标记为,以指示它属于源区域还是目标区域。 我们训练 根据以下损失函数来区分每个实例的域:
| (3) |
其中 表示对从输入数据分布 中抽取的样本 的期望。 虽然判别器 经过训练可以准确识别每个实例的域,但 3DOD 模型会生成实例级特征来欺骗判别器区分其域(即,负损失函数)。 这样,我们使用对抗性指导来鼓励 3DOD 模型学习与领域无关的特征。 此外,为了减轻随机混合域场景引起的模糊特征并增强预测置信度,我们使用 BEV 网格熵损失对网络进行正则化:
| (4) |
最后,我们推进一个简单的自训练阶段,以提高跨不同目标域的泛化性,以下损失 作为两个损失 和 的总和:
| (5) |
损失函数。
我们还利用与 3D 边界框参数回归和对象类别分类相关的传统损失项 。 将所有损失函数放在一起,我们的学习目标是:
| (6) |
其中 是从网格搜索导出的超参数,用于处理每个损失项的强度。 此外,我们使用二进制切换 来精心安排训练过程,其中 设置 为源训练, 为自身训练-训练。
| Task | Model | SECOND-IoU (Yan, Mao, and Li 2018) | PV-RCNN (Shi et al. 2020) | ||
| BEV AP / 3D AP | Closed Gap | BEV AP / 3D AP | Closed Gap | ||
| nuScenes Waymo | Direct Transfer | 39.18 / 20.78 | 41.30 / 25.89 | ||
| ST3D (Yang et al. 2021) | 45.35 / 27.12 | +21.62% / +19.08% | 52.50 / 36.21 | +38.63% / +31.07% | |
| ST3D++ (Yang et al. 2022) | 44.87 / 25.79 | +19.94% / +15.08% | –.– / –.– | –.–% / –.–% | |
| CMDA (Ours) | 46.79 / 29.42 | +26.66% / +26.00% | 58.57 / 45.58 | +59.57% / +59.29% | |
| Oracle | 67.72 / 54.01 | 70.29 / 59.10 | |||
| nuScenes KITTI | Direct Transfer | 51.84 / 17.92 | 68.15 / 37.17 | ||
| SN (Wang et al. 2020) | 40.03 / 21.23 | -37.55% / +05.96% | 60.48 / 49.47 | -36.82% / +27.13% | |
| ST3D (Yang et al. 2021) | 75.94 / 54.13 | +76.63% / +59.50% | 78.36 / 70.85 | +49.02% / +74.30% | |
| ST3D++ (Yang et al. 2022) | 80.52 / 62.37 | +91.19% / +80.05% | –.– / –.– | –.–% / –.–% | |
| DTS (Hu, Liu, and Hu 2023) | 81.40 / 66.60 | +93.99% / +87.66% | 83.90 / 71.80 | +75.61% / +76.40% | |
| CMDA (Ours) | 82.13 / 68.95 | +96.31% / +91.90% | 84.85 / 75.02 | +80.17% / +83.50% | |
| Oracle | 83.29 / 73.45 | 88.98 / 82.50 | |||
| Waymo nuScenes | Direct Transfer | 32.91 / 17.24 | 34.50 / 21.47 | ||
| SN (Wang et al. 2020) | 33.23 / 18.57 | +01.69% / +07.54% | 34.22 / 22.29 | -01.50% / +04.80% | |
| ST3D (Yang et al. 2021) | 35.92 / 20.19 | +15.87% / +16.73% | 36.42 / 22.99 | +10.32% / +08.89% | |
| ST3D++ (Yang et al. 2022) | 35.73 / 20.90 | +14.87% / +20.76% | –.– / –.– | –.–% / –.–% | |
| LD (Wei et al. 2022) | 40.66 / 22.86 | +40.85% / +31.88% | 43.31 / 25.63 | +47.34% / +24.34% | |
| DTS (Hu, Liu, and Hu 2023) | 41.20 / 23.00 | +43.70% / +32.67% | 44.00 / 26.20 | +51.04% / +27.68% | |
| CMDA (Ours w/ LD) | 42.81 / 24.64 | +52.19% / +41.97% | 44.44 / 26.41 | +53.41% / +28.91% | |
| Oracle | 51.88 / 34.87 | 53.11 / 38.56 | |||
实验
数据集。
我们评估了 3D 物体检测任务的地标数据集的整体性能:nuScenes (Caesar 等人 2020)、Waymo (Sun 等人 2020) 和 KITTI (Geiger) 、Lenz 和 Urtasun 2012)。 这三个数据集具有不同的点云范围和规格。 因此,我们将它们转换为统一的范围,并仅采用七个参数来在相同条件下获得一致的训练结果:中心位置,盒子大小 ,和航向角。
评估指标。
我们遵循 KITTI 评估指标,以实现跨数据集的一致评估。 此外,除了仅提供前视图中的注释的 KITTI 数据集之外,我们还采用 360 度环绕视图配置进行评估。 我们报告了 40 个召回位置的平均精度 (AP) 以及 BEV IoU 和 3D IoU 的 0.7 IoU 阈值。 为了提供适应性能的经验下限和上限,我们提出了三个额外的参考点:直接传输 - 直接在目标域上评估源域预训练模型,Oracle - 在目标域上训练的完全监督模型,以及闭合间隙 - 表示假设的闭合间隙
| (7) |
与 SOTA 方法的性能比较。 如表所示。 1,我们将我们提出的框架与现有最先进的方法进行定量比较,其中包括统计归一化(SN)(Wang 等人 2020),ST3D (杨等人 2021)、ST3D++ (杨等人 2022)、激光雷达蒸馏 (LD) (魏等人 2022)、DTS (胡、刘和胡,2023)。 SN 应用统计归一化来减少跨域设置中框尺度的归纳偏差。 ST3D 通过数据增强提高了自训练过程的有效性,而 LD 通过生成伪点来减轻光束引起的从稠密到稀疏的密度偏移。 这些方法展示了显着的能力,但仍然依赖于 3D 传感器的几何信息,并且经常面临有效适应看不见的目标域的挑战。 为了克服这些限制,我们引入了 CMDA,其特点是跨模态知识交互(CMKI)和跨域对抗网络(CDAN)。
在选项卡中。 1,我们观察到我们的 CMDA 在所有指标上普遍优于其他五种方法,包括 BEV AP、3D AP 和 Closed Gap。 根据现有工作,我们评估了三种不同场景下的 UDA 性能:(1) nuScenes (Caesar 等人 2020) Waymo (Sun 等人 2020)、(2) nuScenes KITTI (Geiger、Lenz 和 Urtasun 2012),以及 (3) Waymo nuScenes。 CMDA 的性能增益在场景 (1) 和 (3) 中更加明显,这些场景利用多视图相机图像,因此受益于高度指导性的视觉细节。 更重要的是,在稠密到稀疏的子域转换设置中,即,Waymo nuScenes,CMDA 实现了 Closed Gap 的大幅性能提升,提升了SECOND-IoU (Yan、Mao 和 Li 2018) 为 +52.19%/+41.97%,PV-RCNN 为 +53.41%/+28.91%(Shi 等人 2020) 适用于 BEV AP / 3D AP。 这些有希望的分数表明,即使 LiDAR 传感器光束较少,我们的框架也可以有效提高无监督目标域中的 3DOD 性能。 请注意,SN 和 LD 不适合 nuScenes Waymo 任务,因此为了公平比较而被排除。
值得注意的是,我们的 CMDA 框架在使用单视图相机图像(即、nuScenes KITTI 时也获得了更高的适应分数。 在这种情况下,具有 SECOND-IoU 的 CMDA 实现了 Closed Gap 的 +96.31% / +91.90%。 总体而言,我们的 CMDA 框架有效地减少了源域和目标域之间的分布转移,从而实现了新的最先进的性能。
定性分析
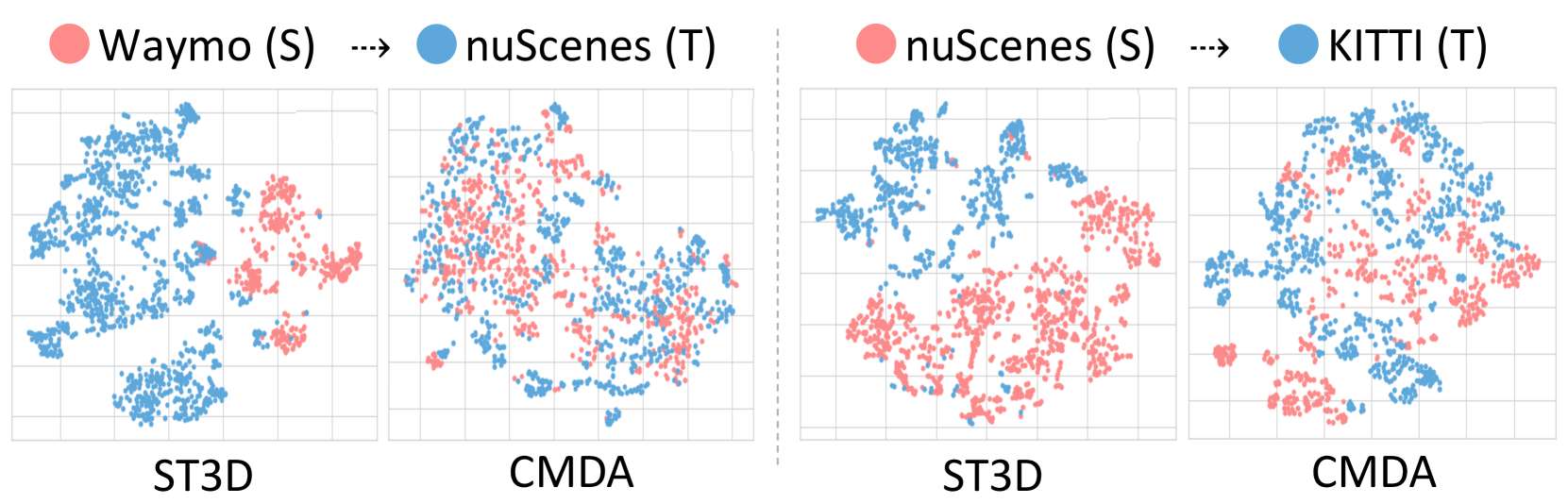
t-SNE 分析。 为了评估域差距的程度,我们提供了从源(红色)域和目标(蓝色)域学习到的特征空间的 t-SNE (van der Maaten 和 Hinton 2008) 可视化。 如图 4 所示,ST3D 在源域和目标域中表现出不同的聚类,而 CMDA 则产生包含目标域和源域的和谐分散的特征空间。 这些定性发现证实 CMDA 有效地鼓励模型学习领域不变特征。
利用视觉语义先验的影响。
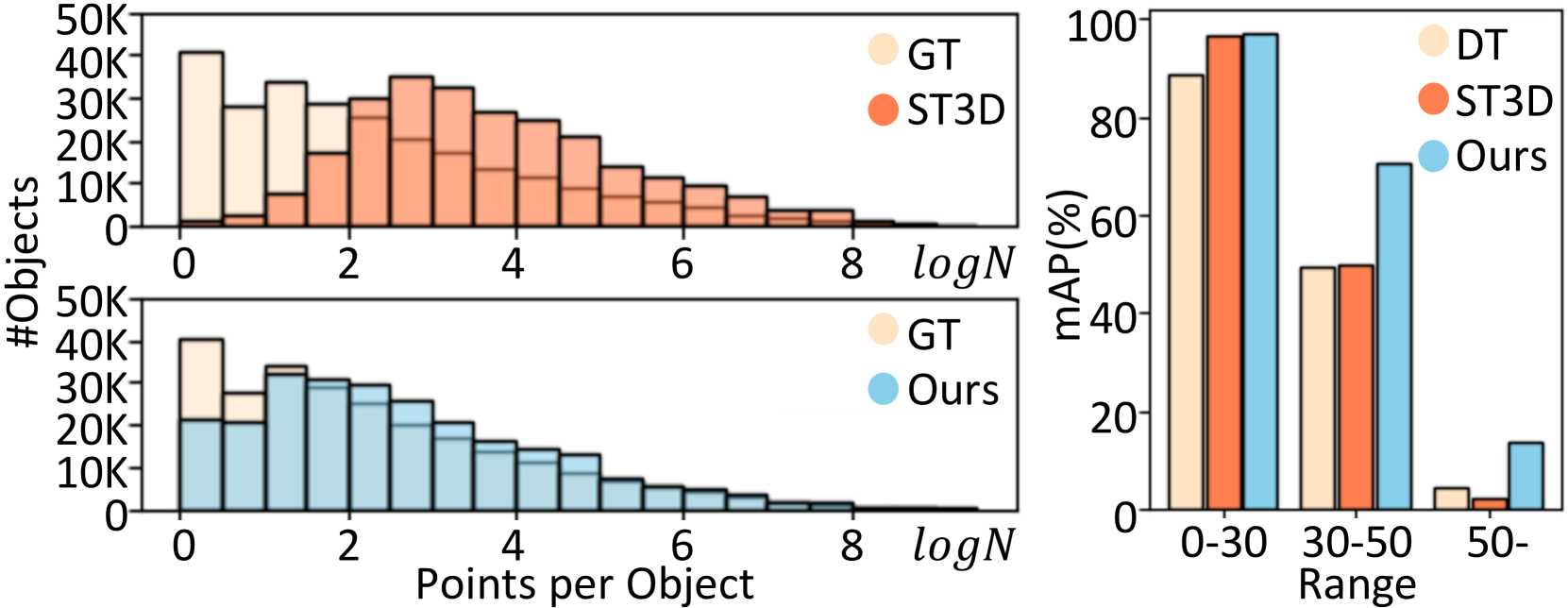
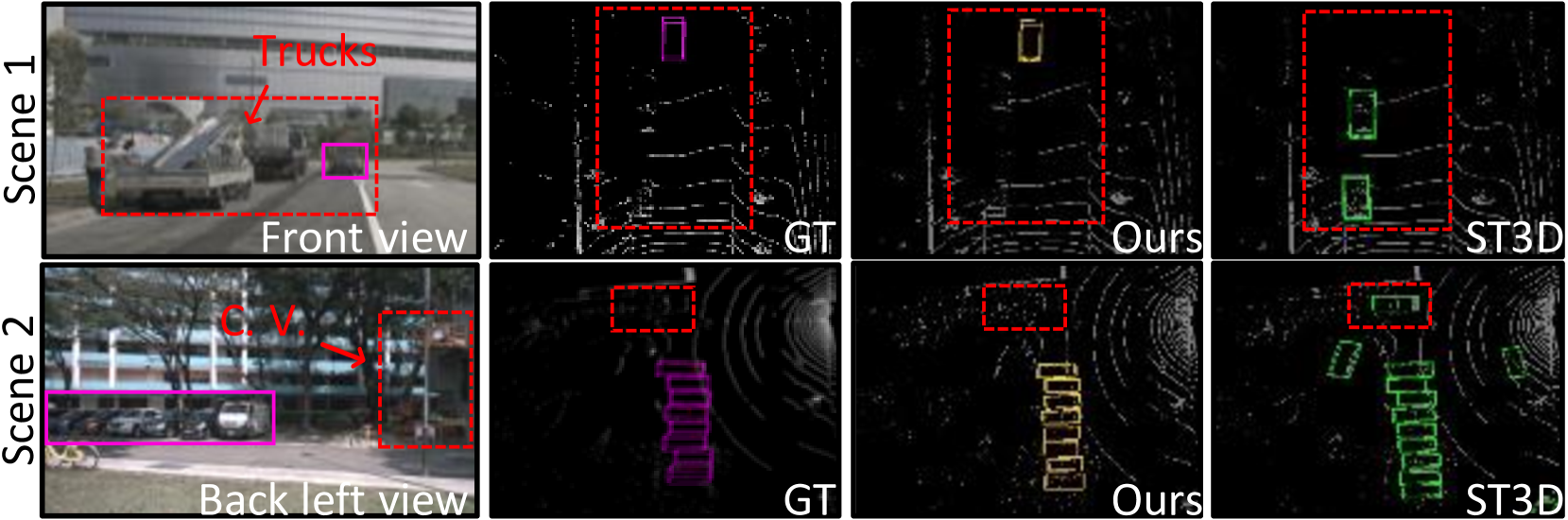
为了验证从基于图像的 BEV 特征中学习的语义先验的有效性,我们提出了额外的实验结果和定性分析。 在图5(左)中,我们根据每个对象的不同点密度对感知能力进行统计评估。 即使点相对稀疏,CMDA 也能有效检测物体。 图5(右)显示 CMDA 提高了检测精度 (mAP%),特别是对于远处的物体。
此外,图6的场景1提供了提高远距离物体检测精度的显着示例。 ST3D (Yang 等人 2021) 未能检测到相对较远的物体,而 CMDA 成功检测到它。 此外,在场景 1 和 2 中,ST3D 很难适应从统一标记(车辆)到各种标记(汽车、卡车、公共汽车、工程车辆等)的领域。 相比之下,我们的系统有效地将“汽车”与“工程车辆”和“卡车”区分开来。 这些发现证实了利用从基于图像的特征联合学习的视觉语义先验来提高整体 UDA 性能的有效性。
消融研究
| Task | Method | SECOND-IoU | PV-RCNN | ||
| ST3D | CMKI | CDAN | BEV AP / 3D AP | BEV AP / 3D AP | |
| nuScenes Waymo | - | - | - | 39.18 / 20.78 | 41.30 / 25.89 |
| - | - | 44.41 / 22.26 | 47.28 / 28.57 | ||
| - | - | 45.35 / 27.12 | 52.50 / 36.21 | ||
| - | 45.43 / 28.63 | 53.04 / 42.75 | |||
| 46.79 / 29.42 | 58.57 / 45.58 | ||||
| nuScenes KITTI | - | - | - | 51.84 / 17.92 | 68.15 / 37.17 |
| - | - | 63.86 / 37.22 | 72.12 / 40.17 | ||
| - | - | 75.94 / 54.13 | 78.36 / 70.85 | ||
| - | 78.52 / 60.04 | 82.43 / 72.20 | |||
| 82.13 / 68.95 | 84.85 / 75.02 | ||||
CDAN 和 CMKI 的作用。 在选项卡中。 2,我们在 SECOND-IoU (Yan, Mao, and Li 2018) 和 PV-RCNN (Shi 等人 2020) 上评估各种适应配置中的 CMKI 和 CDAN )。 ST3D (Yang 等人 2021) 表示基线自我训练方法,每个设置中的第一行表示 Direct Transfer。 为了研究每种方法的单独效果,我们故意不使用任何增强策略(例如、LD (Wei 等人 2022)、SN (Wang 等人2020))。 标签。 2 表明,CMKI 和 CDAN 的添加提高了所有实验的自适应能力。 值得注意的是,CMKI 强调丰富的语义知识对于实现广义识别的重要性,与Direct Transfer相比,BEV AP 的差距缩小了 12.02%,3D AP 的差距缩小了 19.30%。 CDAN 通过对抗性判别器学习与领域无关的 BEV 特征,进一步增强了泛化能力,与直接传输相比,BEV AP 提高了 30.29%,3D AP 提高了 51.03%。 这些结果证明了我们的 CMDA 框架在大幅提高 3DOD UDA 质量方面的强大功能。
| Task | Method | SECOND-IoU | PV-RCNN | ||
| ST3D | CL | CDAN | BEV AP / 3D AP | BEV AP / 3D AP | |
| nuScenes KITTI | - | - | - | 51.84 / 17.92 | 68.15 / 37.17 |
| - | - | 75.94 / 54.13 | 78.36 / 70.85 | ||
| - | 79.20 / 58.20 | 80.99 / 71.51 | |||
| - | 80.13 / 63.67 | 83.27 / 73.05 | |||
CDAN 与对比学习 (CL)。 为了验证CDAN的有效性,在表中。 3,我们提供了与 3D-CoCo (Yihan 等人 2021) 后基于对比学习 (CL) 的适应方法的比较。 为了公平比较,我们采用相同的源预训练权重,并在自训练期间将每种学习策略应用于来自检测头的实例。 虽然基于 CL 的方法具有良好匹配的正/负对,增强了基线自训练方法 (ST3D),但由于样本差异或精度误差等隐性问题,与 CDAN 相比,它的改进有限。 与基于 CL 的方法不同,CDAN 显着受益于对抗机制,并成功应对这些挑战,产生稳定的适应效果;与直接传输相比,BEV AP 高达 +28.29% / 3D AP 高达 +45.75%。
结论
在这项工作中,我们引入了一种新颖的无监督域适应方法,称为 CMDA,以提高现有基于 LiDAR 的 3D 对象检测模型的泛化能力。 为了缩小源域和目标域(在训练期间无法访问其标签)之间的差距,我们提出了两个主要步骤:(i)跨模态 LiDAR 编码器预训练和(ii)跨域 LiDAR 仅自训练。 在 (i) 中,一对基于图像和基于 LiDAR 的 BEV 特征进行对齐,以学习模态不可知(因此更具有域不变)特征。 此外,在(ii)中,我们应用对抗性正则化来减少源域和目标域之间的表示差距。 我们对大规模数据集进行的广泛实验证明了我们提出的方法在各种跨域适应场景中的有效性,实现了最先进的 UDA 性能。
致谢
这项工作主要得到了三星高级技术学院 (SAIT) (85%) 和韩国政府 (MSIT) 资助的信息与通信技术规划与评估研究所 (IITP) 赠款的支持(编号:2017)。 2019-0-00079,人工智能研究生院项目(高丽大学),15%)。
参考
- Bai et al. (2022) Bai, X.; Hu, Z.; Zhu, X.; Huang, Q.; Chen, Y.; Fu, H.; and Tai, C.-L. 2022. Transfusion: Robust lidar-camera fusion for 3d object detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 1090–1099.
- Caesar et al. (2020) Caesar, H.; Bankiti, V.; Lang, A. H.; Vora, S.; Liong, V. E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; and Beijbom, O. 2020. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 11621–11631.
- Chen et al. (2017) Chen, X.; Ma, H.; Wan, J.; Li, B.; and Xia, T. 2017. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 1907–1915.
- Chen et al. (2022) Chen, Y.; Li, Y.; Zhang, X.; Sun, J.; and Jia, J. 2022. Focal Sparse Convolutional Networks for 3D Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
- Deng et al. (2021) Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; and Li, H. 2021. Voxel r-cnn: Towards high performance voxel-based 3d object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, 1201–1209.
- Ganin et al. (2016) Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; and Lempitsky, V. 2016. Domain-adversarial training of neural networks. The journal of machine learning research, 17(1): 2096–2030.
- Geiger, Lenz, and Urtasun (2012) Geiger, A.; Lenz, P.; and Urtasun, R. 2012. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Conference on Computer Vision and Pattern Recognition (CVPR).
- Hu, Liu, and Hu (2023) Hu, Q.; Liu, D.; and Hu, W. 2023. Density-Insensitive Unsupervised Domain Adaption on 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 17556–17566.
- Ku et al. (2018) Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; and Waslander, S. L. 2018. Joint 3d proposal generation and object detection from view aggregation. In 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 1–8. IEEE.
- Lang et al. (2019) Lang, A. H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; and Beijbom, O. 2019. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 12697–12705.
- Liang et al. (2022) Liang, T.; Xie, H.; Yu, K.; Xia, Z.; Lin, Z.; Wang, Y.; Tang, T.; Wang, B.; and Tang, Z. 2022. Bevfusion: A simple and robust lidar-camera fusion framework. Advances in Neural Information Processing Systems, 35: 10421–10434.
- Liu et al. (2023) Liu, Z.; Tang, H.; Amini, A.; Yang, X.; Mao, H.; Rus, D. L.; and Han, S. 2023. Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation. In 2023 IEEE International Conference on Robotics and Automation (ICRA), 2774–2781. IEEE.
- Philion and Fidler (2020) Philion, J.; and Fidler, S. 2020. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIV 16, 194–210. Springer.
- Qian, Lai, and Li (2022) Qian, R.; Lai, X.; and Li, X. 2022. 3D object detection for autonomous driving: A survey. Pattern Recognition, 130: 108796.
- Roh et al. (2022) Roh, W.; Chang, G.; Moon, S.; Nam, G.; Kim, C.; Kim, Y.; Kim, S.; and Kim, J. 2022. Ora3d: Overlap region aware multi-view 3d object detection. arXiv preprint arXiv:2207.00865.
- Shi et al. (2020) Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; and Li, H. 2020. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10529–10538.
- Shi, Wang, and Li (2019) Shi, S.; Wang, X.; and Li, H. 2019. Pointrcnn: 3d object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 770–779.
- Sun et al. (2020) Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. 2020. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2446–2454.
- van der Maaten and Hinton (2008) van der Maaten, L.; and Hinton, G. 2008. Visualizing High-Dimensional Data Using t-629 SNE. Journal of Machine Learning Research, 9(2579-2605): 630.
- Vora et al. (2020) Vora, S.; Lang, A. H.; Helou, B.; and Beijbom, O. 2020. Pointpainting: Sequential fusion for 3d object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 4604–4612.
- Wang et al. (2021) Wang, C.; Ma, C.; Zhu, M.; and Yang, X. 2021. Pointaugmenting: Cross-modal augmentation for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11794–11803.
- Wang et al. (2020) Wang, Y.; Chen, X.; You, Y.; Li, L. E.; Hariharan, B.; Campbell, M.; Weinberger, K. Q.; and Chao, W.-L. 2020. Train in germany, test in the usa: Making 3d object detectors generalize. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11713–11723.
- Wang et al. (2022) Wang, Y.; Guizilini, V. C.; Zhang, T.; Wang, Y.; Zhao, H.; and Solomon, J. 2022. Detr3d: 3d object detection from multi-view images via 3d-to-2d queries. In Conference on Robot Learning, 180–191. PMLR.
- Wei et al. (2022) Wei, Y.; Wei, Z.; Rao, Y.; Li, J.; Zhou, J.; and Lu, J. 2022. Lidar distillation: Bridging the beam-induced domain gap for 3d object detection. arXiv preprint arXiv:2203.14956.
- Xiao et al. (2022) Xiao, A.; Huang, J.; Guan, D.; Cui, K.; Lu, S.; and Shao, L. 2022. PolarMix: A General Data Augmentation Technique for LiDAR Point Clouds. arXiv preprint arXiv:2208.00223.
- Xie et al. (2020) Xie, Q.; Luong, M.-T.; Hovy, E.; and Le, Q. V. 2020. Self-training with noisy student improves imagenet classification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 10687–10698.
- Xu et al. (2021) Xu, Q.; Zhou, Y.; Wang, W.; Qi, C. R.; and Anguelov, D. 2021. Spg: Unsupervised domain adaptation for 3d object detection via semantic point generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 15446–15456.
- Yan, Mao, and Li (2018) Yan, Y.; Mao, Y.; and Li, B. 2018. Second: Sparsely embedded convolutional detection. Sensors, 18(10): 3337.
- Yang, Liang, and Urtasun (2018) Yang, B.; Liang, M.; and Urtasun, R. 2018. Hdnet: Exploiting hd maps for 3d object detection. In Conference on Robot Learning, 146–155. PMLR.
- Yang et al. (2021) Yang, J.; Shi, S.; Wang, Z.; Li, H.; and Qi, X. 2021. St3d: Self-training for unsupervised domain adaptation on 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10368–10378.
- Yang et al. (2022) Yang, J.; Shi, S.; Wang, Z.; Li, H.; and Qi, X. 2022. ST3D++: Denoised Self-Training for Unsupervised Domain Adaptation on 3D Object Detection. IEEE transactions on pattern analysis and machine intelligence, 45(5): 6354–6371.
- Yang et al. (2020) Yang, Z.; Sun, Y.; Liu, S.; and Jia, J. 2020. 3dssd: Point-based 3d single stage object detector. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 11040–11048.
- Yang et al. (2019) Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; and Jia, J. 2019. Std: Sparse-to-dense 3d object detector for point cloud. In Proceedings of the IEEE/CVF international conference on computer vision, 1951–1960.
- Yihan et al. (2021) Yihan, Z.; Wang, C.; Wang, Y.; Xu, H.; Ye, C.; Yang, Z.; and Ma, C. 2021. Learning transferable features for point cloud detection via 3d contrastive co-training. Advances in Neural Information Processing Systems, 34: 21493–21504.
- Yin, Zhou, and Krahenbuhl (2021) Yin, T.; Zhou, X.; and Krahenbuhl, P. 2021. Center-based 3d object detection and tracking. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 11784–11793.
- Zhang, Chen, and Huang (2022) Zhang, Y.; Chen, J.; and Huang, D. 2022. CAT-Det: Contrastively Augmented Transformer for Multi-modal 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 908–917.
- Zhou and Tuzel (2018) Zhou, Y.; and Tuzel, O. 2018. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, 4490–4499.
- Zhu et al. (2014) Zhu, M.; Derpanis, K. G.; Yang, Y.; Brahmbhatt, S.; Zhang, M.; Phillips, C.; Lecce, M.; and Daniilidis, K. 2014. Single image 3D object detection and pose estimation for grasping. In 2014 IEEE International Conference on Robotics and Automation (ICRA), 3936–3943. IEEE.
- Zou et al. (2018) Zou, Y.; Yu, Z.; Kumar, B.; and Wang, J. 2018. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training. In Proceedings of the European conference on computer vision (ECCV), 289–305.