自蒸馏弥补了语言模型微调中的分布差距
摘要
大型语言模型(大语言模型)的激增彻底改变了自然语言处理,但针对特定任务对其进行微调通常会在平衡性能和保持一般指令跟踪能力方面遇到挑战。 在本文中,我们认为任务数据集和大语言模型之间的分布差距是主要原因。 为了解决这个问题,我们引入了自蒸馏微调(SDFT),这是一种新颖的方法,通过使用模型本身生成的蒸馏数据集进行微调以匹配其原始分布来指导微调,从而弥补分布差距。 Llama-2-chat 模型在各种基准上的实验结果表明,与普通微调相比,SDFT 有效地减轻了灾难性遗忘,同时在下游任务上实现了相当或更好的性能。 此外,SDFT 展示了保持大语言模型的有用性和安全性一致性的潜力。 我们的代码可在 https://github.com/sail-sg/sdft 获取。
自蒸馏弥补了语言模型微调中的分布差距
Zhaorui Yang§, Qian Liu†, Tianyu Pang†, Han Wang§, Haozhe Feng§ Minfeng Zhu‡, Wei Chen§ §State Key Lab of CAD & CG, Zhejiang University, China †Sea AI Lab, Singapore ‡Zhejiang University, China
1简介
近年来,大型语言模型(大语言模型)的发展已成为自然语言处理(NLP)领域最具突破性的进展之一。 GPT-3 (Brown 等人, 2020) 和 PaLM (Chowdhery 等人, 2023) 等大语言模型通过利用大量文本语料库,在预训练过程中彻底改变了该领域。培训,使他们能够在广泛的任务中取得出色的少样本表现。 有监督微调(SFT)的引入(Ouyang 等人,2022b;Chung 等人,2022)进一步提升了大语言模型的能力,特别是增强了其指令跟随能力。
有趣的是,即使从相同的基础大语言模型(Touvron等人,2023;Bai等人,2023)开始,监督数据集中的微小变化也可能导致模型性能的显着差异 (周等人,2023;王等人,2023)。 因此,开源社区见证了大语言模型变体多样性的快速增长,融合了各种 SFT 数据集和技术,从而增强了它们的实用性和可访问性。
然而,SFT 通常优先考虑提高一般指令跟踪能力,这表明采用 SFT 的大语言模型可能在特定的下游任务中面临挑战。 因此,将这些模型重新用作种子语言模型(种子 LM),以便针对特定下游任务进行后续微调,已成为一种有吸引力的方法。 虽然这种方法看起来很有希望,但我们的初级知识研究揭示了通过普通微调同时增强特定任务表现和保留一般指令遵循能力的挑战,这主要是由于灾难性遗忘的问题。 与我们的发现相呼应的是,最近的研究强调,即使使用良性数据集,微调也会损害种子 LM 的安全性(Qi 等人,2024;Yang 等人,2023;Zhan 等人,2023;Pelrine 等人) ,2023)。 事实证明,旨在减轻灾难性遗忘的微调方法仍然不存在。
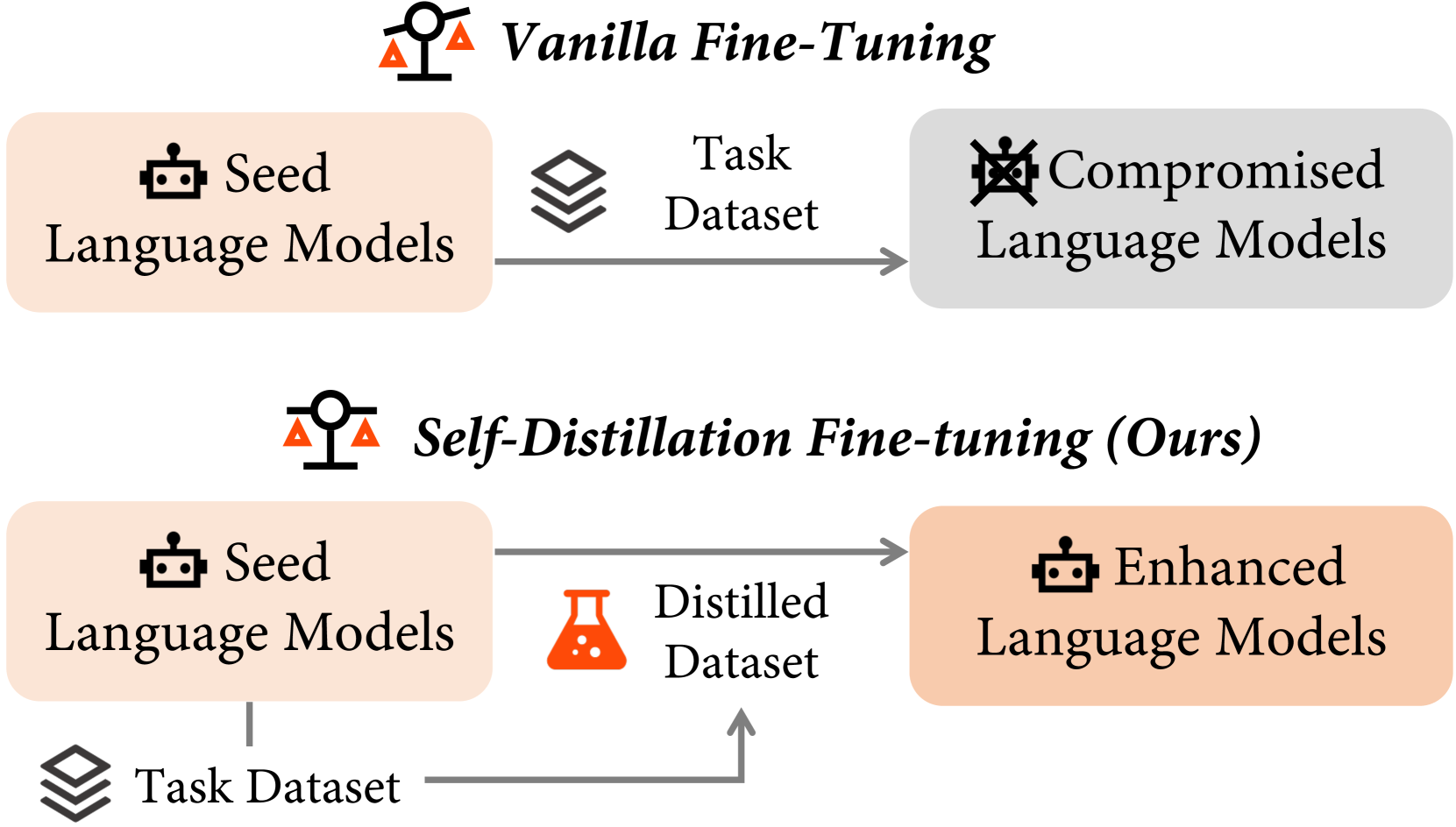
在本文中,我们提出了一种新颖的微调方法,即自蒸馏微调(SDFT),以减轻微调过程中的灾难性遗忘。 我们假设灾难性遗忘源于任务数据集和种子 LM 之间的分布差距。 为了解决这个问题,如图 1 所示,SDFT 首先提示种子 LM 生成与任务数据集中存在的原始响应保持语义等效的响应,从而生成蒸馏数据集。 图2描述了重写的代表性示例。 重写后,自生成的响应将在后续微调过程中作为代理目标。 通过该方法,SDFT 本质上保持了原始分布,避免了分布转移,从而保留了能力。
我们通过在各种基准上将 SDFT 的性能与普通微调和种子 LM 的性能进行比较来系统地评估 SDFT。 这些基准包括:(1) 不同的下游任务,包括数学推理、工具使用和代码生成; (2) 一般有用性和安全性评估。 所有基准测试的结果都证明了 SDFT 相对于普通微调的优越性。 例如,对 OpenFunctions 数据集进行普通微调(Patil 等人,2023) 会导致 HumanEval 基准上的 pass@1 显着下降(Chen 等人,2021) t1>从到,构成的下降。 相比之下,SDFT 不仅减轻了这种退化,而且还略微提高了 的精度。 对我们方法的深入分析表明,增加用于微调的蒸馏数据集的比例会导致灾难性遗忘的减少,从而证实 SDFT 通过弥合分布差距来减轻灾难性遗忘。

2相关工作
微调
微调是提高模型在下游任务上的性能的普遍策略,如编码 (Roziere 等人, 2023; Luo 等人, 2024)、算术 (Luo等人,2023a)、医疗保健(Jin 等人,2023)和金融(Wu 等人,2023)。 普通微调直接最大化目标响应的对数似然。 与我们的工作类似,自玩微调(Chen等人,2024)采用相同的大语言模型作为生成器和鉴别器,引导模型更喜欢带注释的响应而不是生成的输出。 由于大语言模型的分布最终与训练数据的分布收敛,该方法并不能减少微调过程中的遗忘。
持续学习
微调使模型能够适应新的数据分布,提高其下游任务的效率。 然而,这个过程可能会导致先前获得的知识的损失,这个问题被称为灾难性遗忘(French,1999)。 一个相关领域是持续学习(Kirkpatrick 等人,2017;Lopez-Paz and Ranzato,2017),它旨在使模型能够获取新知识,同时减少这种遗忘。 传统方法往往依赖于保存历史数据进行回放(Scialom等人, 2022; Luo 等人, 2023b)、参数重要性的计算(Kirkpatrick等人, 2017; Aljundi等人,2018),或将不同的神经元分配给不同的任务(Mallya 和 Lazebnik,2018)。 然而,由于大语言模型的参数和任务空间广泛,加上原始训练数据集经常不可用,微调大语言模型特别具有挑战性,这降低了这些已建立技术的可行性(Kirkpatrick等人,2017;Lopez- Paz 和 Ranzato,2017;Scialom 等人,2022)。 尽管最近的研究(Luo等人,2023b;Scialom等人,2022)强调了持续学习对于语言模型的重要性,但大语言模型的可行解决方案还很少。 在本文中,我们对大语言模型微调过程中的灾难性遗忘问题进行了全面评估,并提出了一种专门为大语言模型设计的简单而有效的策略。
结盟
随着大语言模型能力的扩展,产生有毒内容的可能性也随之增加,从而引发重大安全问题(Perez 等人,2022;Ganguli 等人,2022)。 对此,人们提出了各种策略来使大语言模型符合人类道德标准并防止有毒内容的产生。 流行的方法包括指令调优(Ouyang 等人, 2022a; Touvron 等人, 2023)、基于人类反馈的强化学习(Ouyang 等人, 2022a; Bai 等人, 2022),以及自对准技术(Sun等人,2023)。 利用这些对齐技术,大语言模型在实用性和安全性之间取得了专门的权衡(Bianchi等人,2023;Qi等人,2024)。 虽然这些方法已证明在安全调整方面有效,但它们并没有涵盖微调带来的进一步风险。 最近的研究表明,即使使用良性数据进行微调也会导致安全性受损(Qi 等人,2024;Yang 等人,2023;Zhan 等人,2023;Pelrine 等人,2023)。 我们提出的策略可以有效缓解这种安全性下降。
3方法
在本节中,我们首先概述微调过程,然后介绍我们提出的自蒸馏微调方法及其实现细节。
3.1 微调大语言模型
虽然大语言模型在各种任务上表现出卓越的熟练程度,但在需要微调的下游任务时,它们经常遇到限制。 具体来说,我们将需要进一步微调的LM称为种子LM,表示为并由参数化。 种子 LM 通常经历一般 SFT,表明其将任务描述 上下文中的任何自然语言指令 映射到其相应输出 的能力。
| (1) |
种子LM的微调过程可以概述如下:对于具有上下文的目标任务,每个任务示例用于更新模型参数。 此更新旨在最小化数据分布和 LM 分布之间的差异,如下所示:
| (2) |
其目的是在上下文 和输入 的情况下,最小化目标输出 与模型参数 的负对数似然。当生成的响应 与 匹配时,即微调 LM 的分布与任务数据集分布一致时, 收敛。
3.2 自蒸馏微调
随着种子 LM 的分布向任务数据集的分布收敛,它自然会提高目标任务的性能。 然而,普通的微调很容易导致灾难性的忘记一般指令跟踪功能,包括安全对齐。
为了缓解这个问题,我们提出了自蒸馏微调(SDFT),旨在更好地将任务数据集的分布与种子 LM 对齐。
如图2所示,SDFT的初始步骤涉及提示种子LM将原始响应重写为:
| (3) |
这一步标志着我们的方法和普通微调之间的主要区别,因为它涉及将原始响应映射到种子 LM 分布内的响应。 为了完成重写,我们使用了一个自蒸馏模板,它对种子 LM 提出了最低的要求,只需要它遵守我们重写响应的指令即可。 该提示的具体规格稍后详细说明。
接下来,为了确保蒸馏响应的质量,我们采用简单的启发式方法来评估蒸馏响应。 例如,在数学推理问题中,我们从提取的响应 中提取最终答案,并将其与原始响应 中的结果进行比较。 否则,我们保留原始回复。 我们将这个条件选择过程形式化为:
| (4) |
最后,用蒸馏后的响应替换原始响应进行微调,即损失变为:
| (5) |
因此,通过使用蒸馏数据集而不是任务数据集来缩小分布差距,如图2右侧所示。
3.3 蒸馏模板
在我们的工作中,蒸馏模板起着至关重要的作用。 它被设计为独立于任务,可以无缝地应用于各种任务,而无需修改。 在此框架内,模板将任务数据集中的原始响应指定为“参考答案”,并指导模型相应地生成响应。 我们大多数实验中使用的模板如图3所示。 在处理涉及数学推理的数据集时,我们稍微调整模板以更好地适应推理过程。 有关这些模板的更多详细信息,请参阅附录 B。
4实验
在本节中,我们首先介绍用于微调和评估目的的数据集。 接下来,我们对从普通微调获得的实验结果和我们提出的跨各种任务的 SDFT 方法进行比较分析,包括数学推理、代码生成和工具使用。 最后,我们评估这两种方法对安全性、常识和有用性的影响。
4.1 实验设置
我们利用 Llama-2-chat-7b 模型(Touvron 等人,2023) 作为种子 LM。
由于计算资源有限,我们在普通微调和我们提出的 SDFT 期间都使用了低秩适应(LoRA)技术(Hu等人,2022)。 LoRA 的查询矩阵和值矩阵以 的等级进行调整。 我们遵循 Llama2 的默认配置设置。 学习率从 开始,并按照余弦退火计划逐渐衰减到零。 批量大小设置为。
为了确保公平比较,我们保持两种方法几乎所有超参数的一致性。 对于包含超过 个示例的数据集,我们随机选择 个示例进行微调,以确保数据集大小的可比性。 更多详细信息请参阅附录A。
4.2 用于微调和评估的数据集
我们在各种数据集上使用 Llama-2-chat-7b 模型,包括单任务和多任务场景的数据集。 然后,我们评估种子模型和微调模型在不同任务中的性能。 用于微调和评估的数据集分类如下:
| Method | Dataset | OpenFunctions | GSM8K | HumanEval | Average |
|---|---|---|---|---|---|
| Seed LM | — | 19.6 | 29.4 | 13.4 | 20.8 |
| Vanilla FT | OpenFunctions | 34.8 | 21.5 | 9.8 | 22.0 |
| GSM8K | 17.9 | 31.9 | 12.2 | 20.7 | |
| MagiCoder | 3.6 | 23.2 | 18.9 | 15.2 | |
| SDFT (Ours) | OpenFunctions | 36.6 1.8 | 29.1 7.6 | 15.2 5.4 | 27.0 5.0 |
| GSM8K | 17.9 0.0 | 34.4 2.5 | 14.6 2.4 | 22.3 1.6 | |
| MagiCoder | 8.0 5.4 | 24.9 1.7 | 18.3 0.6 | 17.1 1.9 |
单任务数据集。 对于单任务数据集,我们探索在微调过程中提高 LM 的数学推理、工具使用和代码生成能力。 使用GSM8K数据集(Cobbe等人,2021)提高数学推理能力,该数据集包含8.8k个小学水平的高质量算术应用题。 通过利用函数调用数据集(例如 Gorilla Openfunctions 数据集(Patil 等人,2023))来评估工具使用熟练程度。 此外,使用 MagiCoder 数据集 (Wei 等人,2023) 提高代码生成技能,同时使用 HumanEval 数据集 (Chen 等人,2021) 进行评估。
多任务数据集。 我们使用三个高质量数据集来评估我们的方法在多任务微调场景中的有效性:Alpaca (Taori 等人, 2023)、Dolly (Conover 等人, 2023) 和 LIMA (周等人,2023)。 Alpaca 数据集涵盖各种任务,包括算术、编码和问答。 它是使用 Self-Instruct 方法 Wang 等人 (2022) 通过 text-davinci-003 模型生成的。 Dolly 数据集由七个不同的任务组成,例如开放式问答、信息提取和摘要。 LIMA 数据集涵盖广泛的主题,并由多个来源策划。
安全性评价。 我们利用 Advbench 数据集 Zou 等人 (2023) 中的有害行为指令进行评估,通过遵循 Qi 等人 (2024) 的关键字匹配来评估模型输出的安全性。 我们将安全响应的比例定义为原始安全率。 此外,我们通过在指令中附加对抗性后缀来模拟越狱尝试,如 Zou 等人 (2023) 中所示。 该条件下的安全率称为越狱安全率。
有用性评价。 我们使用 AlpacaEval Li 等人 (2023) 来评估各种模型的有用性。 该工具包括一个数据集和相关的评估指标,有助于将生成的输出与来自 Text-Davinci-003 的响应进行比较,涵盖来自多个数据集的 805 条详细指令的不同集合。 我们报告获胜率,即根据 GPT-4 判断,响应优于 Text-Davinci-003 产生的响应的实例的比例。
| Dataset for FT | Raw Safe Rate | Jailbreak Safe Rate | AlpacaEval Win Rate |
|---|---|---|---|
| Seed LM | 99.81 | 88.85 | 66.04 |
| Openfunctions | 98.27 99.23 ( 0.96) | 87.31 94.42 ( 7.11) | 35.49 67.66 ( 32.17) |
| GSM8K | 82.12 87.12 ( 5.00) | 54.81 65.58 ( 10.77) | 23.38 66.73 ( 43.35) |
| MagiCoder | 96.73 97.88 ( 1.15) | 83.65 88.65 ( 5.00) | 76.52 76.09 ( 0.43) |
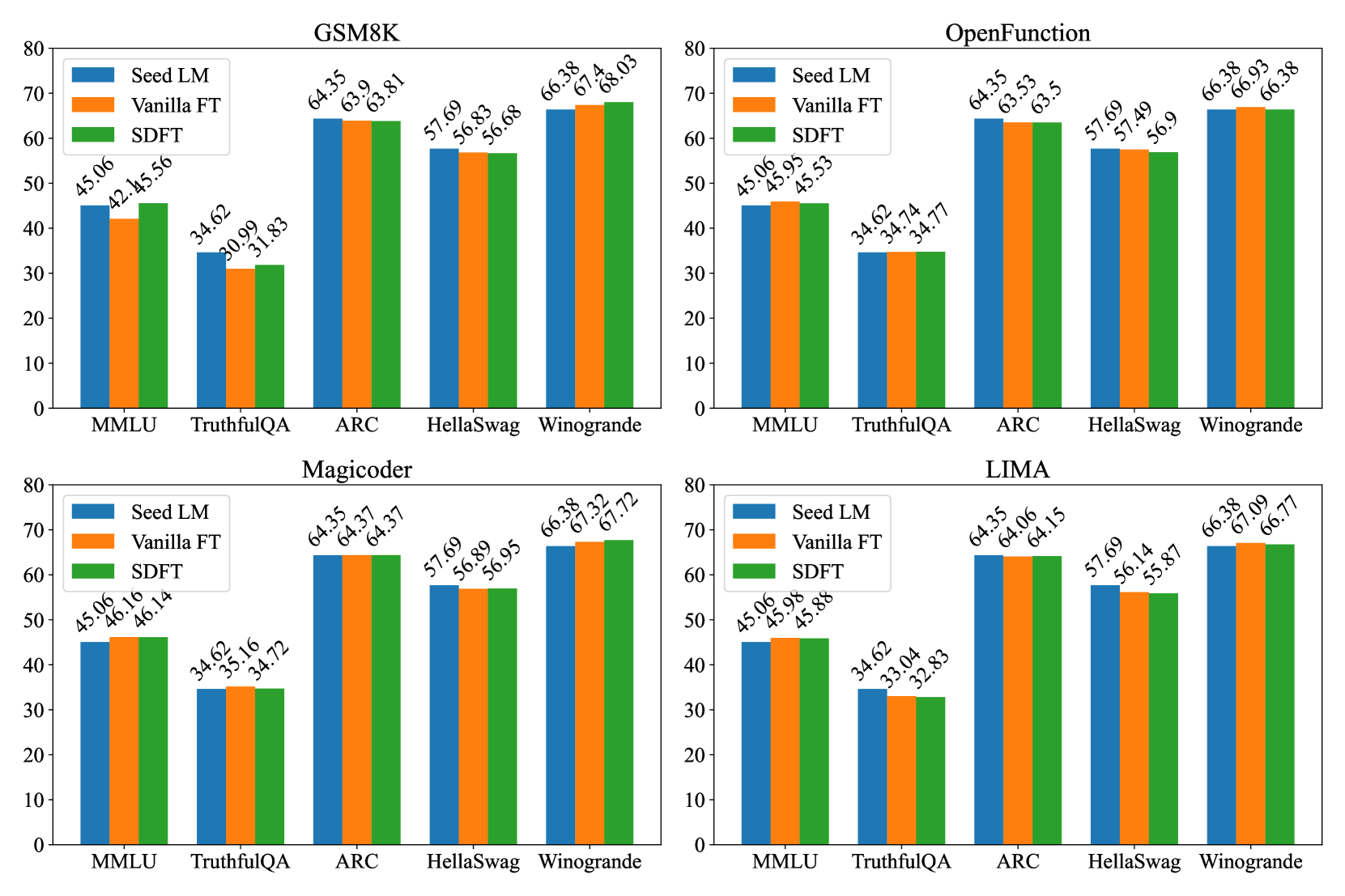
知识评价。 LM 的一般知识是通过使用 OpenLLM 排行榜的基准进行评估来评估的,特别是 MMLU Hendrycks 等人 (2021)、TruthfulQA Lin 等人 (2021)、ARC Clark 等人 (2018)、HellaSwag Zellers 等人 (2019) 和 Winogrande Sakaguchi 等人 (2021)。 这些数据集提供了跨多个领域的模型事实和常识知识的衡量标准。
4.3 SDFT在下游任务上取得更好的结果
表1展示了三个下游任务的微调结果。 结果表明,虽然普通微调可以提高模型在目标任务上的效率,但它也会导致其他任务的性能显着下降。 例如,如表第一行所示,使用 Openfunctions 数据集进行微调会导致模型的编码能力下降,从 降低到 。 数学推理能力也出现了类似的下降,GSM8K 数据集的准确性从 下降到 。
此外,所提出的 SDFT 可以有效缓解这种性能下降。 在引用的实例中,模型保留了其数学推理能力,达到了 的准确度,与种子模型的性能 () 密切相关。 对于在 HumanEval 上评估的编码性能,有边际改进,性能从种子模型的 上升到 。当专注于目标任务时,SDFT 也优于普通的fine-调整,与 相比,提供 的准确度。
4.4 SDFT 保持对齐
正如表 2 中的结果所强调的那样,对大多数数据集的微调已被证明会导致安全性一致性和一般有用性显着下降。 例如,在GSM8K数据集上进行微调后,安全率从下降到,越狱安全率从下降到,AlpacaEval 的胜率从 减少到 。 相比之下,我们提出的 SDFT 方法有效地缓解了这种下降,将原始安全率和越狱安全率分别提高了 和 。 值得注意的是,与种子模型相比,获胜率略有提高,得分为 与 。
表3展示了对包含多个任务的指令遵循数据集进行微调后的评估结果。 由于这些数据集的目标任务未指定,因此我们将评估重点放在微调后的安全性和一般帮助上。 根据表 2 中指出的模式,对这些数据集的微调通常会导致安全性和有用性指标显着降低。 我们观察到所有三个指标均显着下降,每个指标下降幅度约为 。 相比之下,我们提出的 SDFT 方法有效地缓解了这种减少,将减少限制在 以下。
| Method | Dataset | Raw Safe Rate | Jailbreak Safe Rate | Win Rate |
| Seed LM | — | 99.81 | 88.85 | 66.04 |
| Vanilla FT | Alpaca | 86.54 | 52.69 | 27.62 |
| Dolly | 81.73 | 26.54 | 22.09 | |
| LIMA | 81.35 | 58.08 | 41.34 | |
| SDFT (Ours) | Alpaca | 96.15 9.6 | 86.15 33.5 | 65.07 37.5 |
| Dolly | 96.35 14.6 | 72.69 46.2 | 61.60 39.5 | |
| LIMA | 94.42 13.1 | 78.08 20.0 | 59.38 18.0 |
4.5一般知识保持不变
图4展示了一般知识的结果。 尽管普通的微调会损害下游性能和一致性,但模型的一般知识能力相对不受影响。 例如,在 OpenFunctions 数据集上进行微调后,微调后的模型与种子 LM 之间的性能差异小于 。 在使用 SDFT 进行微调后也观察到了这一点。
5分析
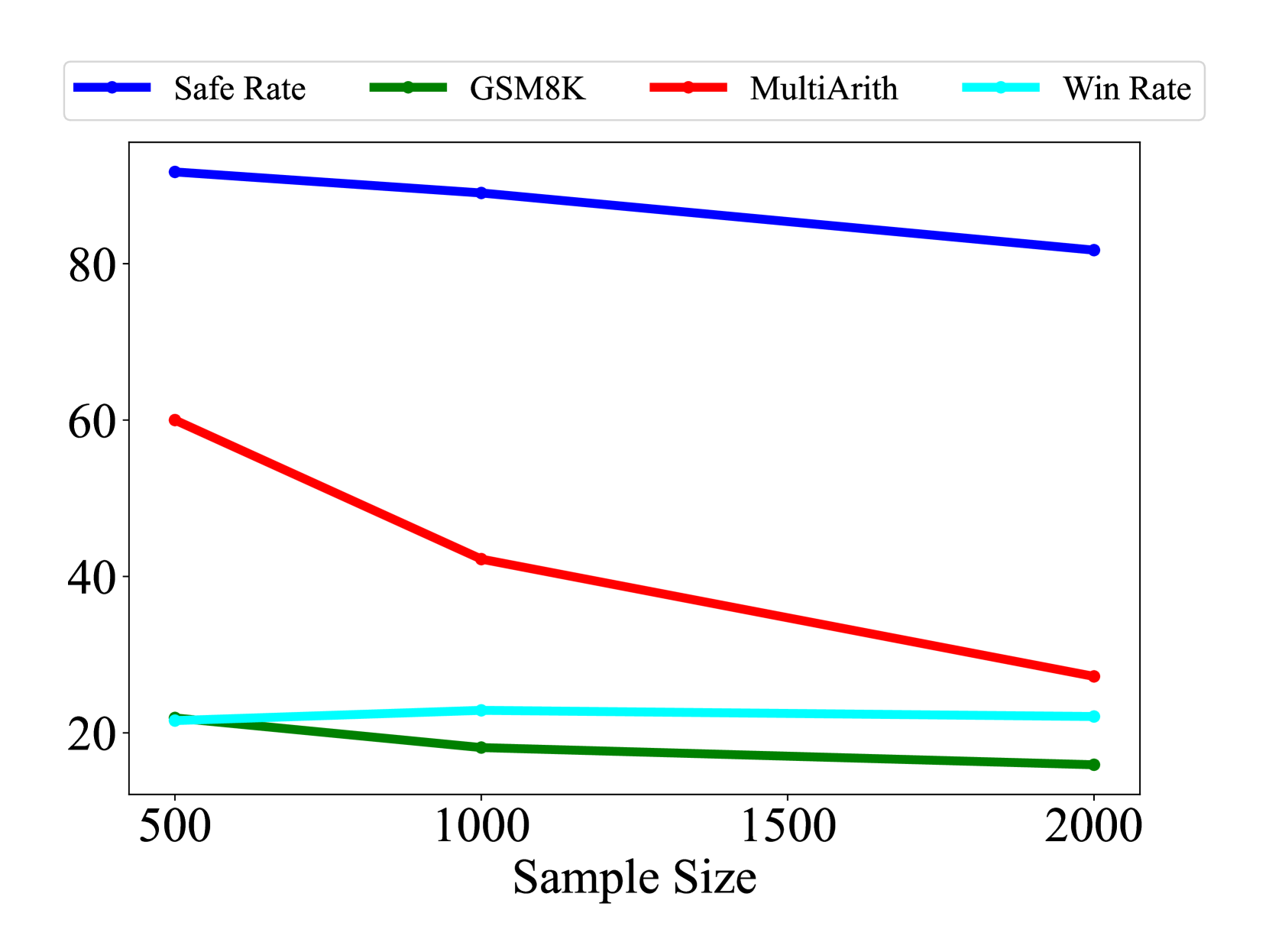
在本节中,我们进行详细分析,以了解分布转移对灾难性遗忘的影响。 除了4节中概述的评估指标外,我们还采用了四个补充指标来评估分布变化的程度。 我们利用种子模型和微调模型在 Advbench Zou 等人 (2023) 数据集上生成响应,并对这些响应进行比较分析。
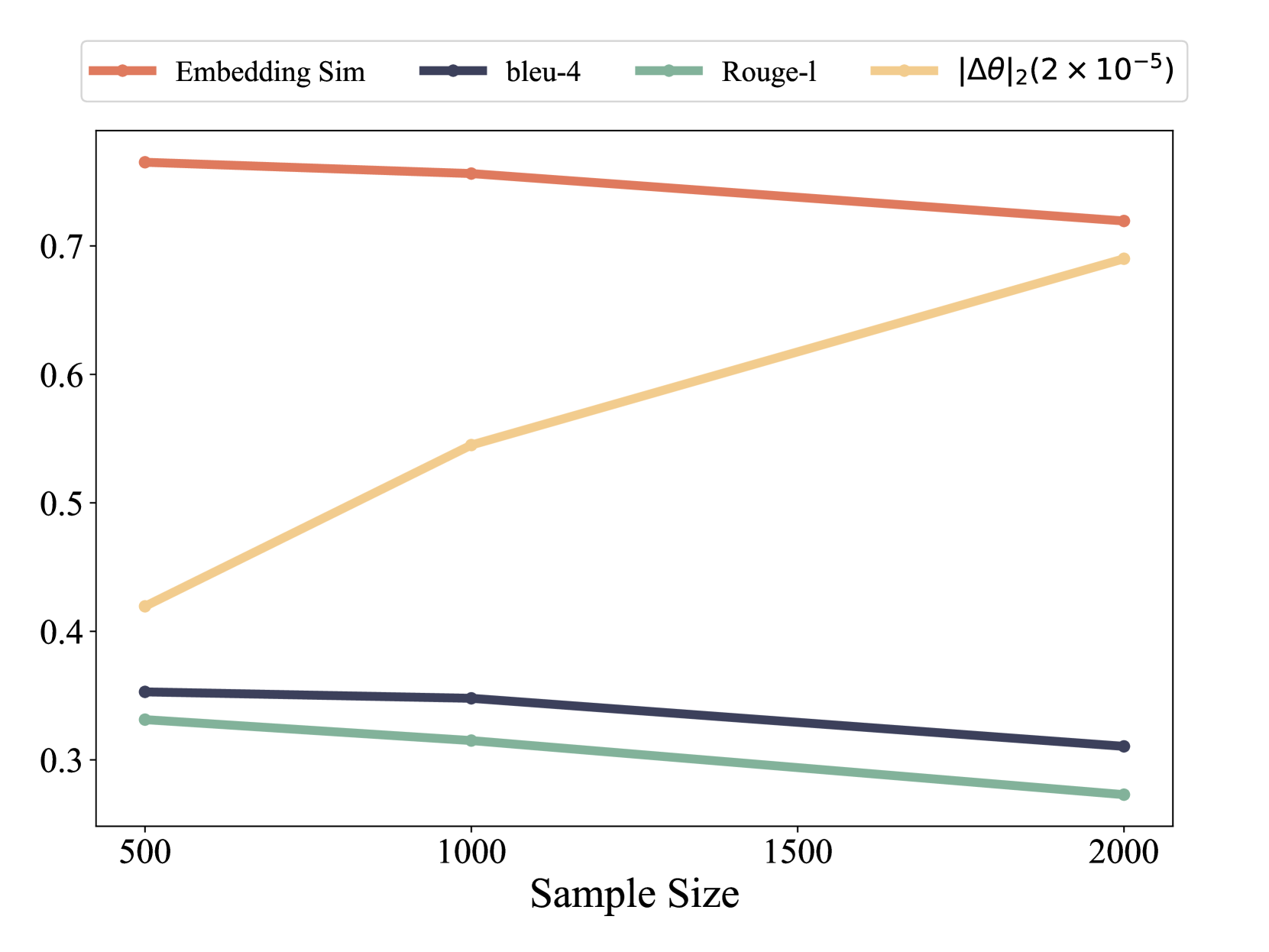
特别是,我们使用种子模型的输出作为评估分布偏移程度的参考,计算微调模型的 BLEU-4 和 ROUGE-L 分数。 我们还利用 Sentence-BERT Reimers and Gurevych (2019) 来导出句子嵌入,并按照 Zhang 等人 (2023) 使用这些嵌入之间的余弦相似度。 最后,我们通过将更新的参数与种子模型的参数进行比较来量化参数偏移的程度,将它们的距离视为参数偏移幅度的度量。 BLEU-4、ROUGE-L 和嵌入相似度分数越低,分布偏移就越大。 相反,参数变化与参数变化的范数成正比。
| Dataset for FT | Template | Openfunctions | HumanEval | GSM8K | Raw Safe | Jailbreak Safe | Win Rate |
|---|---|---|---|---|---|---|---|
| Openfunction | Vanilla FT | 34.82 | 9.76 | 21.53 | 98.27 | 87.31 | 35.49 |
| Refer | 35.71 | 13.41 | 27.37 | 98.85 | 89.81 | 68.45 | |
| Using | 36.61 | 15.24 | 29.11 | 99.23 | 94.42 | 67.66 | |
| Dolly | Vanilla FT | 8.04 | 17.07 | 15.92 | 81.73 | 26.54 | 22.09 |
| Refer | 17.86 | 14.02 | 24.26 | 96.35 | 69.62 | 61.60 | |
| Using | 16.07 | 14.63 | 26.31 | 97.31 | 72.69 | 57.52 |
5.1 分布变化与灾难性遗忘相关
我们引入不同程度的分布偏移,并通过两种方法研究其影响:(1)通过采样不同数量的示例进行微调,其中用于微调的数据点数量的增加对应于更大的分布偏移。 (2) 将香草微调与 SDFT 混合,其中涉及用原始样本替换蒸馏样本。 我们定义混合比来表示所使用的蒸馏样品的比例。 混合比 表示独家使用我们的 SDFT, 表示普通微调。
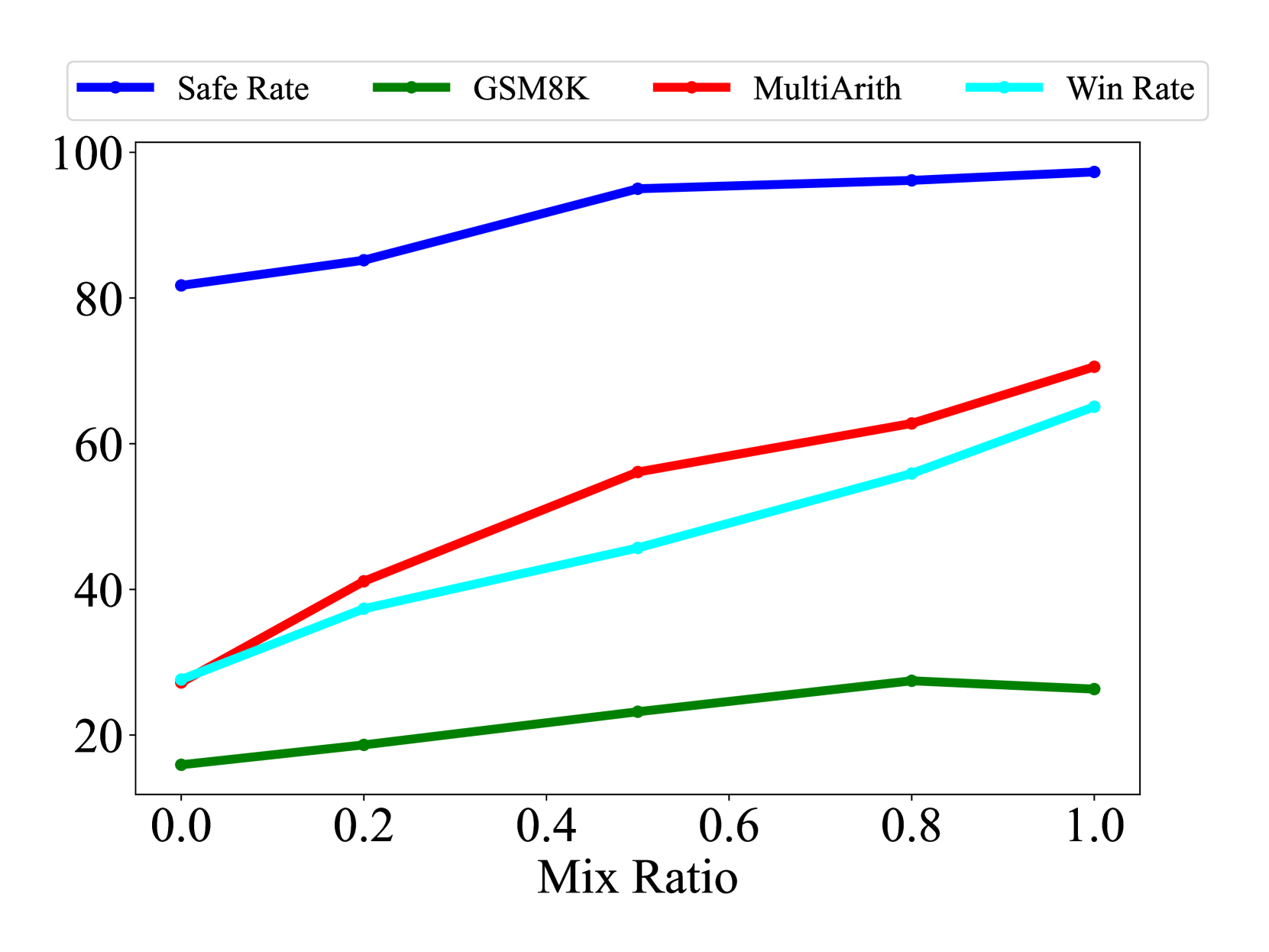
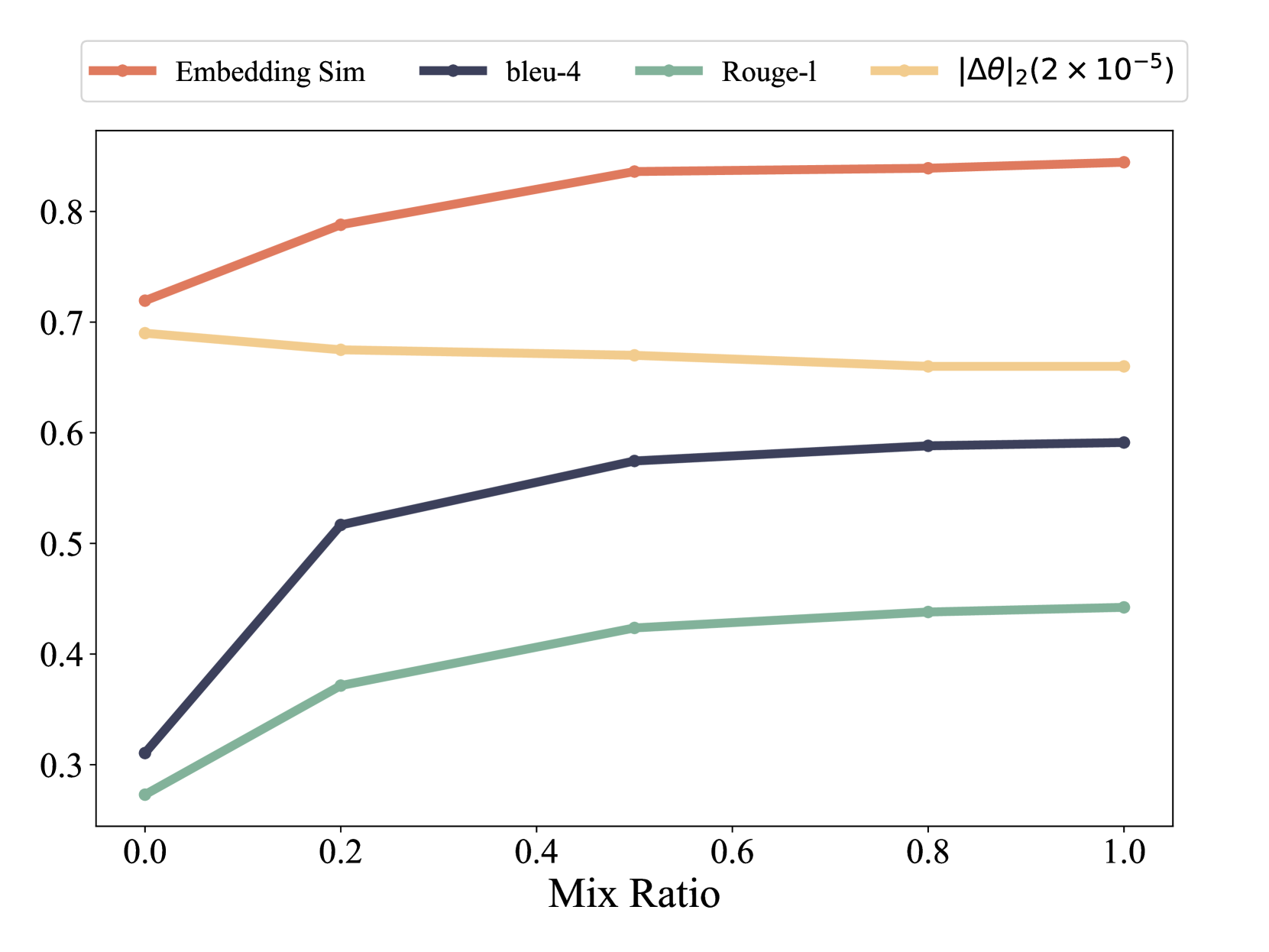
图 6 和 6 说明了不同样本量的结果。 随着样本量的增加,我们观察到 BLEU-4、ROUGE-L 和嵌入相似性得分显着下降,同时参数偏移幅度也随之升高。 这一趋势意味着分布转移的程度加大。 因此,在 GSM8K、MultiArith、Advbench 和 AlpacaEval 等基准测试中模型性能明显下降,表明灾难性遗忘加剧。
同样,图 8 和 8 显示了与上升的混合比相对应的结果。 随着该比率的增加,BLEU-4、ROUGE-L 和嵌入相似性得分呈上升趋势,而参数偏移的规模减小,表明分布偏移有所缓解。 因此,基准测试表现全面改善,表明灾难性遗忘的严重程度有所降低。
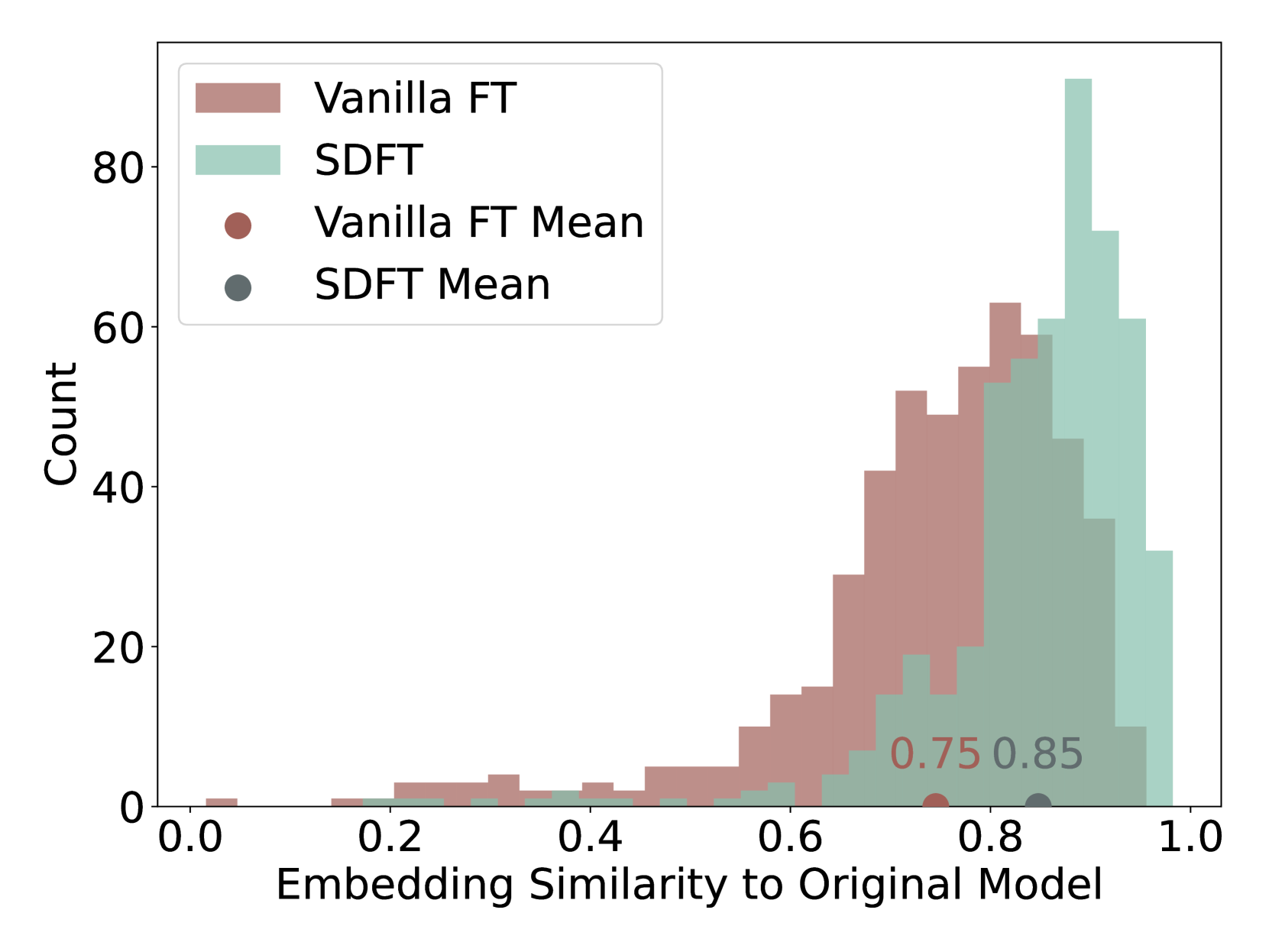
图 9 说明了通过普通微调和我们的 SDFT 获得的相似度分布。 值得注意的是,SDFT 模型在微调模型和种子模型之间具有更高的相似性,这意味着分布偏移减少。
5.2 蒸馏模板的稳健性
6 结论和局限性
在本文中,我们对下游任务的语言模型微调过程中的灾难性遗忘进行了系统评估。 我们的研究结果表明,微调过程中的分布变化可能会导致一般任务能力的性能下降,以及模型的安全性和有用性。 为了提高目标任务的性能,同时保持 LM 的广泛功能,我们提出了一种即插即用策略 SDFT,以减少分布转移并减轻灾难性遗忘。 大量实验表明,SDFT 可以有效减少遗忘,并提供与针对目标任务的普通微调相当或更好的性能。
我们的研究存在一定的局限性。 由于计算资源的限制,我们的实验基于采用 LoRA 技术的 Llama-2-7b-chat 模型。 涉及更大模型和全参数调整的研究仍有待探索。 此外,我们的安全评估仅限于 Advbench 数据集和固定的对抗性后缀,将针对其他越狱策略的鲁棒性留到未来。
道德声明
我们提出的方法 SDFT 有效地缓解了语言模型微调过程中的灾难性遗忘问题,包括安全对齐的退化。 因此,这个过程不会带来额外的风险。
我们利用各种开源英语数据集进行训练,包括 Alpaca (Taori 等人, 2023)、Dolly (Conover 等人, 2023)、LIMA (周等人, 2023)、GSM8K (Cobbe 等人, 2021)、OpenFunctions (Patil 等人, 2023) 和 MagiCoder (魏等人,2023)。 Llama-2-chat 模型 (Touvron 等人, 2023) 作为我们训练的种子模型。 我们承认这些数据集和模型中可能存在固有偏差。
参考
- Aljundi et al. (2018) Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny, Marcus Rohrbach, and Tinne Tuytelaars. 2018. Memory aware synapses: Learning what (not) to forget. In European Conference on Computer Vision, pages 139–154.
- Bai et al. (2023) Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu. 2023. Qwen technical report. arXiv preprint arXiv:2309.16609.
- Bai et al. (2022) Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862.
- Bianchi et al. (2023) Federico Bianchi, Mirac Suzgun, Giuseppe Attanasio, Paul Röttger, Dan Jurafsky, Tatsunori Hashimoto, and James Zou. 2023. Safety-tuned llamas: Lessons from improving the safety of large language models that follow instructions. arXiv preprint arXiv:2309.07875.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374.
- Chen et al. (2024) Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. 2024. Self-play fine-tuning converts weak language models to strong language models. CoRR, abs/2401.01335.
- Chowdhery et al. (2023) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel. 2023. Palm: Scaling language modeling with pathways. J. Mach. Learn. Res., 24:240:1–240:113.
- Chung et al. (2022) Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. 2022. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416.
- Clark et al. (2018) Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv:1803.05457v1.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Conover et al. (2023) Mike Conover, Matt Hayes, Ankit Mathur, Jianwei Xie, Jun Wan, Sam Shah, Ali Ghodsi, Patrick Wendell, Matei Zaharia, and Reynold Xin. 2023. Free dolly: Introducing the world’s first truly open instruction-tuned llm.
- French (1999) Robert M French. 1999. Catastrophic forgetting in connectionist networks. Trends in cognitive sciences, 3(4):128–135.
- Ganguli et al. (2022) Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, et al. 2022. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned. arXiv preprint arXiv:2209.07858.
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring massive multitask language understanding. In International Conference on Learning Representations.
- Hu et al. (2022) Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. Lora: Low-rank adaptation of large language models. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net.
- Jin et al. (2023) Qiao Jin, Yifan Yang, Qingyu Chen, and Zhiyong Lu. 2023. Genegpt: Augmenting large language models with domain tools for improved access to biomedical information. ArXiv.
- Kirkpatrick et al. (2017) James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. 2017. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, 114(13):3521–3526.
- Li et al. (2023) Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Alpacaeval: An automatic evaluator of instruction-following models. https://github.com/tatsu-lab/alpaca_eval.
- Lin et al. (2021) Stephanie Lin, Jacob Hilton, and Owain Evans. 2021. Truthfulqa: Measuring how models mimic human falsehoods.
- Lopez-Paz and Ranzato (2017) David Lopez-Paz and Marc’Aurelio Ranzato. 2017. Gradient episodic memory for continual learning. In Advances in Neural Information Processing Systems, volume 30.
- Luo et al. (2023a) Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Jianguang Lou, Chongyang Tao, Xiubo Geng, Qingwei Lin, Shifeng Chen, and Dongmei Zhang. 2023a. Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct. arXiv preprint arXiv:2308.09583.
- Luo et al. (2023b) Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. 2023b. An empirical study of catastrophic forgetting in large language models during continual fine-tuning. arXiv preprint arXiv:2308.08747.
- Luo et al. (2024) Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. 2024. Wizardcoder: Empowering code large language models with evol-instruct. In International Conference on Learning Representations.
- Mallya and Lazebnik (2018) Arun Mallya and Svetlana Lazebnik. 2018. Packnet: Adding multiple tasks to a single network by iterative pruning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7765–7773.
- Ouyang et al. (2022a) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022a. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems.
- Ouyang et al. (2022b) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. 2022b. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022.
- Patil et al. (2023) Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. 2023. Gorilla: Large language model connected with massive apis. In arXiv preprint arXiv:2305.15334.
- Pelrine et al. (2023) Kellin Pelrine, Mohammad Taufeeque, Michal Zajac, Euan McLean, and Adam Gleave. 2023. Exploiting novel gpt-4 apis. arXiv preprint arXiv:2312.14302.
- Perez et al. (2022) Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. 2022. Red teaming language models with language models. arXiv preprint arXiv:2202.03286.
- Qi et al. (2024) Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. 2024. Fine-tuning aligned language models compromises safety, even when users do not intend to! In International Conference on Learning Representations.
- Reimers and Gurevych (2019) Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992, Hong Kong, China. Association for Computational Linguistics.
- Roziere et al. (2023) Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al. 2023. Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950.
- Sakaguchi et al. (2021) Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2021. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106.
- Scialom et al. (2022) Thomas Scialom, Tuhin Chakrabarty, and Smaranda Muresan. 2022. Fine-tuned language models are continual learners. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 6107–6122.
- Sun et al. (2023) Zhiqing Sun, Yikang Shen, Qinhong Zhou, Hongxin Zhang, Zhenfang Chen, David Cox, Yiming Yang, and Chuang Gan. 2023. Principle-driven self-alignment of language models from scratch with minimal human supervision. In Advances in Neural Information Processing Systems.
- Taori et al. (2023) Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, abs/2307.09288.
- Wang et al. (2023) Yizhong Wang, Hamish Ivison, Pradeep Dasigi, Jack Hessel, Tushar Khot, Khyathi Raghavi Chandu, David Wadden, Kelsey MacMillan, Noah A. Smith, Iz Beltagy, and Hannaneh Hajishirzi. 2023. How far can camels go? exploring the state of instruction tuning on open resources. CoRR, abs/2306.04751.
- Wang et al. (2022) Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2022. Self-instruct: Aligning language model with self generated instructions. arXiv preprint arXiv:2212.10560.
- Wei et al. (2023) Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang. 2023. Magicoder: Source code is all you need. arXiv preprint arXiv:2312.02120.
- Wu et al. (2023) Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. 2023. Bloomberggpt: A large language model for finance. arXiv preprint arXiv:2303.17564.
- Yang et al. (2023) Xianjun Yang, Xiao Wang, Qi Zhang, Linda Petzold, William Yang Wang, Xun Zhao, and Dahua Lin. 2023. Shadow alignment: The ease of subverting safely-aligned language models. arXiv preprint arXiv:2310.02949.
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics.
- Zhan et al. (2023) Qiusi Zhan, Richard Fang, Rohan Bindu, Akul Gupta, Tatsunori Hashimoto, and Daniel Kang. 2023. Removing rlhf protections in gpt-4 via fine-tuning. arXiv preprint arXiv:2311.05553.
- Zhang et al. (2023) Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. 2023. Automatic chain of thought prompting in large language models. In International Conference on Learning Representations.
- Zhou et al. (2023) Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. 2023. Lima: Less is more for alignment. arXiv preprint arXiv:2305.11206.
- Zou et al. (2023) Andy Zou, Zifan Wang, J Zico Kolter, and Matt Fredrikson. 2023. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043.
附录A实验细节
在所有实验中,我们使用低秩适应 (LoRA) 技术(Hu 等人) 对 Llama-2-chat-7b 模型 (Touvron 等人, 2023) 进行微调,2022)。 LoRA 的查询矩阵和值矩阵以 的等级进行调整。 我们遵循 Llama2 的默认配置设置。 学习率从 开始,并按照余弦退火计划逐渐衰减到零。 批量大小设置为。
我们随机抽取了 2,000 个示例的子集,并对 Alpaca Taori 等人 (2023)、Dolly Conover 等人 (2023) 和 MagiCoder 进行了 2 个 epoch 的微调Wei 等人 (2023) 数据集。 与 LIMA Zhou 等人 (2023)。 GSM8K Cobbe 等人 (2021) 和 OpenFunction Patil 等人 (2023) 数据集,我们对整个训练集进行了训练。 我们训练 LIMA 2 个时期,另外两个数据集训练 5 个时期。
为了评估模型的一般有用性,我们采用 AlpacaEval 框架 111https://github.com/tatsu-lab/alpaca_eval,GPT-4 作为评估器。 OpenLLM 排行榜中基准的评估是通过 lm-evaluation-harness 222https://github.com/EleutherAI/lm-evaluation-harness。 此外,我们使用 HumanEval 数据集 Chen 等人 (2021) 评估编码能力,并利用 bigcode-evaluation-harness 项目333https://github.com/bigcode-project/bigcode-evaluation-harness。
附录 B模板和示例
本节提供了我们实验中使用的模板以及每个数据集上蒸馏的一些说明性示例。
在我们的大多数实验中,我们使用标准的 alpaca Taori 等人 (2023) 模板进行微调和预测,如图 10 所示。
为了使数学推理数据集更容易提取最终答案,我们在评估过程中指定了最终答案的格式。 用于评估的模板如图13所示。