:
1 2010 AAAI AI4ED 研讨会
在计算机科学教育中使用大型语言模型进行学生代码引导
测试用例生成
摘要
在计算机科学教育中,测试用例是编程作业不可或缺的一部分,因为它们可以用作评估项目来测试学生的编程知识并为学生编写的代码提供个性化的反馈。 我们工作的目标是提出一种完全自动化的测试用例生成方法,可以准确地衡量学生的知识,这很重要,原因有两个。 首先,手动构建测试用例需要专业知识,并且是一个劳动密集型过程。 其次,为学生(尤其是新手程序员)开发测试用例与面向专业级软件开发人员的测试用例有显着不同。 因此,我们需要一个自动化的测试用例生成过程来评估学生的知识并提供反馈。 在这项工作中,我们提出了一种基于大型语言模型的方法来自动生成测试用例,并使用包含学生编写的 Java 代码的公开数据集来证明它们是衡量学生知识的良好方法。 我们还讨论了未来的研究方向,重点是使用测试用例来帮助学生。
关键词:
计算机科学教育;大型语言模型;测试用例生成1简介
大型语言模型(大语言模型)通过帮助教师创建测验等教育资源以及数学、编程和语言学习/理解等领域的问题(Baidoo-Anu 和 Owusu),在推进教育领域显示出巨大的前景Ansah,2023;McNichols 等人,2023;Sarsa 等人,2022;Ashok Kumar 等人,2023)。 特别是在计算机科学(CS)教育中,研究人员正在利用大语言模型自动生成编程练习,并向学生提供代码解释和个性化反馈。 (Sarsa 等人, 2022) 中的工作使用 OpenAI Codex 模型111https://openai.com/blog/openai-codex 帮助教育工作者教授课程,显着减少他们的手动工作量。 (Kazemitabaar 等人, 2023) 的研究表明,在教学中使用 Codex 有助于提高学生学习编程的能力。 他们的研究表明,从长远来看,Codex 显着提高了代码编写性能,并提高了学生在后期测试中的表现。 (Leinonen 等人, 2023)的工作利用大语言模型生成代码解释,作为示例,提高学生理解和解释代码的能力。 他们的研究表明, LLM 生成的代码解释比学生编写的解释更准确且更容易理解。 (Liffiton 等人,2023) 中的工作开发了一个基于 LLM 的系统 CodeHelp,该系统为编程学生提供按需帮助,而无需直接向他们透露解决方案。 他们的研究表明,CodeHelp 受到学生和教育工作者的好评,可以帮助学生更好地解决错误,并补充教育工作者的教学工作。 (Phung 等人, 2023b) 中的工作评估了两个大语言模型,OpenAI 的 ChatGPT 和 GPT-4 的六项任务:程序修复、提示生成、评分反馈、同伴编程、任务综合和情境化解释。 他们的研究表明,GPT-4 的表现明显优于 ChatGPT,并且在某些任务上可以与人类导师一样出色。 (Phung 等人, 2023a) 中的工作设计了一个人类导师式的编程反馈系统,该系统利用 GPT-4(“导师”)使用失败的测试用例信息生成提示并验证使用 GPT-3.5 模型(“学生”)提示质量。 他们对三个不同的基于 Python 的数据集的评估表明,他们的系统的精度接近人类导师的精度。
尽管最近重点关注在计算机科学教育研究中使用大语言模型,但关注生成测试用例的工作相对较少。 (Agarwal 和 Karkare,2022) 中的工作提出了一种方法 LEGenT,用于生成测试用例作为入门编程课程的有针对性的反馈。 他们使用以编程语言为中心的方法来生成有针对性的测试用例,并将其用作学生的反馈。 尽管他们的方法可以推广到 11 种编程语言,但他们的工作有一个关键限制:他们在代码级别生成测试用例,即一段学生编写的代码将失败的测试用例,而没有考虑在问题级别生成测试用例,即生成一组测试用例,以根据学生为问题编写的代码来衡量他们的编程知识。 因此,他们的方法对于有针对性的反馈很有用,但忽略了测试用例作为评估的价值。 我们需要一种可扩展的方法来为学生(尤其是新手)自动生成测试用例,因为他们表现出各种各样的错误,这使得手动生成测试用例变得不切实际。
为了弥补教育环境中自动测试用例生成文献中的空白,我们提出了一种基于 LLM 的方法,用于学生针对编程问题生成代码感知测试用例。 我们的主要贡献是:
-
•
我们提出了一种基于迭代细化的全自动测试用例生成方法,该方法利用具有代表性的学生代码,同时使用大语言模型和代码编译器222The code for our paper can be found at: https://github.com/umass-ml4ed/test_case_generation。
-
•
我们在公开的 CSEDM Challenge 数据集上评估了我们的方法,并表明我们可以生成准确衡量学生知识的测试用例。
2相关工作
软件工程领域的一些著作探讨了使用大语言模型生成测试用例。 (Lemieux 等人,2023)建议使用 OpenAI Codex 来改进基于搜索的软件测试系统,方法是使用 Codex 为未涵盖的功能生成测试用例。 (Vikram 等人, 2023) 探索使用大语言模型生成基于属性的测试,以测试实现某些 Python 库(如 NumPy)功能的代码。 这些作品的动机和问题设置与我们的不同,他们的目标不是生成测试用例来衡量教育环境中学生的知识。 在教育领域,(Sarsa 等人, 2022)利用Codex进行基础知识实验,生成测试用例。 他们简单地提示模型的方法有时会生成错误的测试用例,因为与我们的方法不同,他们没有反馈机制来改进生成的测试用例。 (Agarwal 和 Karkare,2022) 提出了一种以编程语言为中心的测试用例生成方法 LEGenT。 LEGenT 将有错误的学生代码与正确的代码进行比较,以生成用于向学生提供个性化反馈的测试用例。 他们的方法在很大程度上依赖于有错误的代码和正确代码的结构相似性,并且不适用于数组、指针和递归等复杂概念。 由于我们使用基于大语言模型的系统,我们的方法更加通用,并且不太依赖于代码的结构。 此外,他们的方法只能用于生成不通过有错误代码的测试用例,而我们系统的目标是基于某些约束生成既通过又失败特定代码的测试用例。
fig:approach
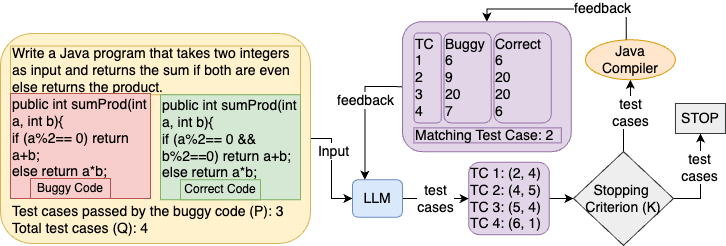
3测试用例生成方法
我们现在详细介绍测试用例生成的整体提示过程,总结在 eq:problem-definition 中。 我们的方法使用迭代细化:在每次迭代中,我们针对给定问题选择一对具有代表性的学生代码样本,以帮助大语言模型生成一组有意义且相关的测试用例。
| (1) |
代码对提示
在每次迭代中,我们为 设计一个提示,其中包含 i) 编程问题和 ii) 一对代码 ,它们代表有错误的学生代码和正确的学生代码,分别如 eq:code-pair 所示。 让 表示错误代码 的分数;我们指示专门生成测试用例,以便在执行测试用例时,正确的代码通过所有测试案例和错误代码 完全通过了 测试案例。 通过这种方式,我们指示大语言模型生成测试用例,这些测试用例能够响应实际学生代码中包含的常见错误,并具有一定的正确性,这由目标分数反映出来。 为了提高的测试用例生成能力,我们提示模型以思想链(Wei等人,2022)的方式生成测试用例,通过询问它首先输出代码中错误的解释,然后生成一个测试用例,由于该错误的存在,该测试用例不会通过代码。
| (2) |
代码对选择
为了捕获学生常犯的错误,我们设计了一种策略来选择三个代码对和,因为使用所有学生代码是不切实际的。 对于,我们随机抽取一个完全正确的学生代码。 对于有错误的代码,我们首先采样一个分数等于所有学生代码中位数的代码。 然后,我们对得分最接近满分但不完美的代码进行采样。 然后,我们对代码进行采样,其得分是前两个采样代码之间得分的中位数。 这个过程确保我们选择具有代表性的学生代码,错误很少,这增加了测试用例的覆盖范围以捕获单个错误,因为很难要求大语言模型为可能有很多错误的低分代码生成测试用例或基本上是错误的。
编译器反馈和迭代细化
由于本身无法执行生成的测试用例,因此我们使用代码编译器自动执行有缺陷的代码和正确的代码 由 生成的测试用例,以获得每个代码的估计分数。 然后,我们用这些信息构造一个反馈提示 (Madaan 等人, 2023) 并重新提示 更新测试用例集(如果需要)。 这个反馈过程鼓励大语言模型使用代码编译器反馈来调整其最初生成的测试用例。 我们重复此过程 次迭代,以获得总共 个独特的测试用例。
4实验
我们现在在公开的学生代码数据集上评估我们的方法。
数据集、设置和指标
我们使用 CSEDM 挑战数据集333https://sites.google.com/ncsu.edu/csedm-dc-2021/home,其中包含 300 多名学生针对 50 个 Java 编码问题提交的带有时间戳的代码,这些问题按 5 个作业分组,每个作业需要 10-26 分代码行。 每个代码的评分在 0 到 1 之间,对应于学生代码通过的测试用例的分数。 我们使用 GPT-4 作为底层大语言模型,因为 GPT-3.5-turbo 和较小的模型不太擅长遵循提示中的说明。 我们将生成温度设置为 0,并将最大序列长度设置为 1000 个 Token 。 由于 GPT-4 擅长合并编译器反馈,因此我们总共使用 次迭代;对于较小的模型,需要更多的迭代。 我们评估我们的方法是否可以准确地对学生编写的代码进行评分; 表示使用生成的测试用例 代码 的估计分数。 这里,是一个二值函数,如果学生的问题的代码通过了测试用例,则为,否则为0。 我们考虑学生 对于同一问题 的所有代码尝试,并且为了符号简单性而没有显式索引尝试。 我们报告估计分数和真实分数之间的误差 ,如 eq:error 中所示。
| (3) |
结果与讨论
tab:results
| Assignment | Data Type | Mean |
|---|---|---|
| 439 | int and boolean | 0.1751 |
| 487 | int | 0.2700 |
| 492 | string | 0.1289 |
| 494 | int array | 0.1475 |
| 502 | int array | 0.1008 |
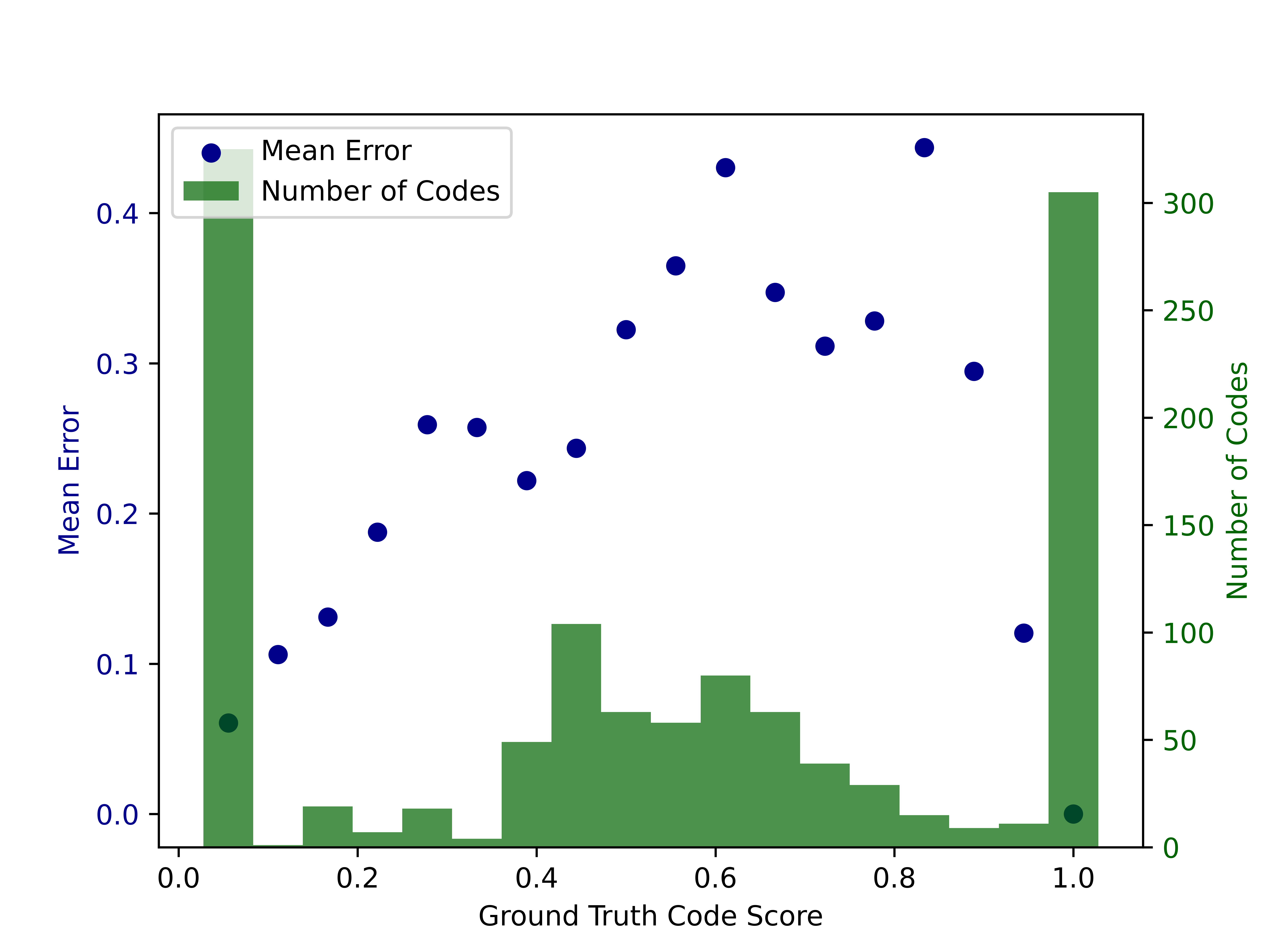
fig:494-46
tab:results 显示输入数据类型以及每个作业下所有问题的错误平均值。 一般来说,我们观察到,与输入数据类型“int”和“boolean”的赋值相比,输入数据类型“string”和“int array”的赋值具有较低的平均误差。 这种差异是由于前一种情况涉及更复杂的概念,因此学生编写的代码表现出类似的误解和错误。 因此,我们的方法产生了一组非常适合这些任务的通用测试用例。 相反,涉及“int”和“boolean”等更简单概念的作业会导致学生编写的代码存在各种各样的错误,需要大量的测试用例来捕获它们。 因此,一组有限的 测试用例并不能很好地概括所有学生和问题。 我们还注意到,类别“int”和“boolean”的代码提交数量是类别“string”和“int array”的代码提交数量的两倍。 我们的代码对选择策略仅选择三个代码对来表示特定作业,这对于“int”和“boolean”等类别可能无效,因为由于许多学生提交,它们代表了各种各样的错误。 将来,我们可以根据该分配的代码提交数量按比例对不同的代码对进行采样,以确保较低的平均误差。
分析
图:494-46 显示了作业 494 中问题 46 的代码错误和频率,按实际得分排序。 问题是检查给定值是否存在于给定数组中的至少一对相邻对中。 每个蓝点代表具有特定地面真实分数的代码的平均误差。 每个绿色条代表与地面实况代码分数的特定范围相对应的代码总数。 分别具有最低分数和最高分数的(几乎)完全正确和不正确的代码数量远高于具有中间分数的部分正确代码的数量。 最常见的完全错误的学生代码反映了编程概念上的误解,包括在没有处理整个数组的情况下从方法中提前返回“true”或“false”,或者不正确地使用“continue”和“break”等控制语句。 具有中间分数的部分正确的学生代码更加微妙,并且通常不会描述概念上的误解。 这些错误主要是关于对问题的误解,包括不正确的数组索引,例如“i+2”而不是“i+1”,或者不正确的条件,例如“==”代替“!=”。
我们观察到,生成的测试用例集在得分最低或最高的代码上获得了最小的错误。 这一观察结果表明,大多数生成的测试用例要么通过了所有正确的代码,要么在得分最差的代码上失败。 此外,由于此类代码的数量(具有最高或最低的地面真实代码分数)较高,因此平均误差非常低。 相反,具有中等真实分数的代码出现频率较低且错误较高。 这一观察结果表明,生成的测试用例仍然不能总是捕捉到有一些问题的部分正确代码和完全正确代码之间的细微差别,这证明了我们的代码对选择方法是正确的,即选择分数高于中位数的有错误的代码并询问大语言模型为他们生成测试用例。
定性示例
清单 1 和 2 分别显示了作业 502 中问题 45 的一对有错误和正确的代码,tab:case-study 显示了问题陈述和生成的测试案例。 有问题的代码中的错误是它只检查 6 之后紧邻的下一个索引中的 7,而不检查 6 之后的任何位置。 因此,有错误的代码和正确的代码对于测试用例 2 和 3 具有不同的输出,而对于测试用例 1 和 4 具有相同的输出。 这个例子表明,通过显式引用有错误的代码,我们的大语言模型提示方法使其能够生成反映学生错误的测试用例。
tab:case-study
| Programming Question | Test Case | Buggy | Correct |
|---|---|---|---|
| Given an int array, return the sum of the numbers in the array, except ignore sections of numbers starting with a 6 and extending to the next 7 (every 6 will be followed by at least one 7). Return 0 for no numbers. | 6 | 6 | |
| 17 | 0 | ||
| 13 | 3 | ||
| 15 | 15 |
5 结论和未来的工作
在这项工作中,我们提出了一种基于全自动迭代细化的方法,用于使用大型语言模型生成学生代码引导的测试用例。 我们精心设计了一系列提示,其中包括用于自动生成测试用例的选定代表性学生代码,并使用编译器反馈来完善它们。 我们在现实世界的学生编码数据集上评估我们的方法,并表明我们可以生成(有时)准确捕获学生表现的测试用例。 未来的工作有很多途径。 我们可以通过开发多样化的学生代码选择策略来改进我们的方法,该策略捕获更广泛的错误,以进一步提高生成的测试用例的多样性。 我们还计划进行人工评估,以评估我们生成的测试用例的有效性,并将其与计算机科学教育专家生成的测试用例进行比较。 沿着另一个方向,我们可以研究测试用例是否可以作为形成性评估工具来衡量学生的编程知识。 然后,我们可以在自适应测试环境中使用它们,其目标是为学生选择和/或生成相关测试用例,以便有效地评估他们的知识。 最后,我们还可以使用这些测试用例来设计模块,为学生编写的代码提供个性化反馈,帮助他们理解错误并纠正错误。
6致谢
作者感谢 NSF 通过拨款 DUE-2215193 提供的支持。
附录A迭代提示工程
在我们的工作中,我们提出了一种全自动生成测试用例的方法,其中涉及使用代码编译器(Java 编译器)的反馈来提示大语言模型。 为了实现自动反馈过程,我们必须确保一些工程细节。 我们确保大语言模型提示是字典或JSON可序列化对象的形式,以便我们可以轻松提取测试用例。 我们的反馈提示被构造为包含有关生成的每个测试用例的表格信息(表示为文本)以及错误的输出和正确的代码。 这种表示反馈的明确方式通过向大语言模型提供逐点测试用例反馈来减少大语言模型中的幻觉。 关于针对有错误的学生代码自动执行生成的测试用例,我们观察到一些测试用例触发了运行时错误,包括无限循环,从而导致执行永远不会结束。 我们使用一些工程技术(例如多线程和计时)来限制每个学生代码上单个测试用例的执行。 如果出现运行时错误,我们会终止测试用例的执行,并将运行时错误反馈给大语言模型,以便其纠正测试用例。
参考
- Agarwal and Karkare (2022) Nimisha Agarwal and Amey Karkare. Legent: Localizing errors and generating testcases for cs1. In Proceedings of the Ninth ACM Conference on Learning@ Scale, pages 102–112, 2022.
- Ashok Kumar et al. (2023) Nischal Ashok Kumar, Nigel Fernandez, Zichao Wang, and Andrew Lan. Improving reading comprehension question generation with data augmentation and overgenerate-and-rank. In Ekaterina Kochmar, Jill Burstein, Andrea Horbach, Ronja Laarmann-Quante, Nitin Madnani, Anaïs Tack, Victoria Yaneva, Zheng Yuan, and Torsten Zesch, editors, Proceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023), pages 247–259, Toronto, Canada, July 2023. Association for Computational Linguistics. 10.18653/v1/2023.bea-1.22. URL https://aclanthology.org/2023.bea-1.22.
- Baidoo-Anu and Owusu Ansah (2023) David Baidoo-Anu and Leticia Owusu Ansah. Education in the era of generative artificial intelligence (ai): Understanding the potential benefits of chatgpt in promoting teaching and learning. Available at SSRN 4337484, 2023.
- Kazemitabaar et al. (2023) Majeed Kazemitabaar, Justin Chow, Carl Ka To Ma, Barbara J. Ericson, David Weintrop, and Tovi Grossman. Studying the effect of ai code generators on supporting novice learners in introductory programming. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, CHI ’23, New York, NY, USA, 2023. Association for Computing Machinery. ISBN 9781450394215. 10.1145/3544548.3580919. URL https://doi.org/10.1145/3544548.3580919.
- Leinonen et al. (2023) Juho Leinonen, Paul Denny, Stephen MacNeil, Sami Sarsa, Seth Bernstein, Joanne Kim, Andrew Tran, and Arto Hellas. Comparing code explanations created by students and large language models. In Proceedings of the 2023 Conference on Innovation and Technology in Computer Science Education V. 1, ITiCSE 2023, page 124–130, New York, NY, USA, 2023. Association for Computing Machinery. ISBN 9798400701382. 10.1145/3587102.3588785. URL https://doi.org/10.1145/3587102.3588785.
- Lemieux et al. (2023) Caroline Lemieux, Jeevana Priya Inala, Shuvendu K. Lahiri, and Siddhartha Sen. Codamosa: Escaping coverage plateaus in test generation with pre-trained large language models. In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), pages 919–931, 2023. 10.1109/ICSE48619.2023.00085.
- Liffiton et al. (2023) Mark Liffiton, Brad Sheese, Jaromir Savelka, and Paul Denny. Codehelp: Using large language models with guardrails for scalable support in programming classes. arXiv preprint arXiv:2308.06921, 2023.
- Madaan et al. (2023) Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback. arXiv preprint arXiv:2303.17651, 2023.
- McNichols et al. (2023) Hunter McNichols, Wanyong Feng, Jaewook Lee, Alexander Scarlatos, Digory Smith, Simon Woodhead, and Andrew Lan. Exploring automated distractor and feedback generation for math multiple-choice questions via in-context learning. arXiv preprint arXiv:2308.03234, 2023.
- Phung et al. (2023a) Tung Phung, Victor-Alexandru Pădurean, Anjali Singh, Christopher Brooks, José Cambronero, Sumit Gulwani, Adish Singla, and Gustavo Soares. Automating human tutor-style programming feedback: Leveraging gpt-4 tutor model for hint generation and gpt-3.5 student model for hint validation. arXiv preprint arXiv:2310.03780, 2023a.
- Phung et al. (2023b) Tung Phung, Victor-Alexandru Pădurean, José Cambronero, Sumit Gulwani, Tobias Kohn, Rupak Majumdar, Adish Singla, and Gustavo Soares. Generative ai for programming education: Benchmarking chatgpt, gpt-4, and human tutors. In Proceedings of the 2023 ACM Conference on International Computing Education Research - Volume 2, ICER ’23, page 41–42, New York, NY, USA, 2023b. Association for Computing Machinery. ISBN 9781450399753. 10.1145/3568812.3603476. URL https://doi.org/10.1145/3568812.3603476.
- Sarsa et al. (2022) Sami Sarsa, Paul Denny, Arto Hellas, and Juho Leinonen. Automatic generation of programming exercises and code explanations using large language models. In Proceedings of the 2022 ACM Conference on International Computing Education Research-Volume 1, pages 27–43, 2022.
- Vikram et al. (2023) Vasudev Vikram, Caroline Lemieux, and Rohan Padhye. Can large language models write good property-based tests? arXiv preprint arXiv:2307.04346, 2023.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837, 2022.