Hi-SAM:结合 Segment Anything 模型进行分层文本分割
摘要
Segment Anything Model (SAM) 是一种在大规模数据集上预训练的深度视觉基础模型,打破了一般分割的界限,并激发了各种下游应用。 本文介绍了Hi-SAM,这是一种利用 SAM 进行分层文本分割的统一模型。 Hi-SAM 擅长跨四个层次结构的文本分割,包括笔划、单词、文本行和段落 ,同时实现布局分析。 具体来说,我们首先通过参数高效的微调方法将 SAM 转变为高质量的文本笔划分割(TSS)模型。 我们使用此 TSS 模型以半自动方式迭代生成文本笔画标签,统一 HierText 数据集中四个文本层次结构的标签。 随后,有了这些完整的标签,我们推出了基于 TSS 架构和定制分层掩模解码器的端到端可训练 Hi-SAM。 在推理过程中,Hi-SAM 提供自动掩模生成(AMG)模式和提示分割模式。 就AMG模式而言,Hi-SAM首先对文本笔画前景掩模进行分割,然后对前景点进行采样以进行分层文本掩模生成,并顺便实现布局分析。 至于提示模式,Hi-SAM 通过单击即可提供单词、文本行和段落掩码。 实验结果显示了我们的 TSS 模型的最先进性能:对于文本笔划分割,Total-Text 上的 fgIOU 为 84.86%,TextSeg 上的 fgIOU 为 88.96%。 此外,与之前在 HierText 上进行联合分层检测和布局分析的专家相比,Hi-SAM 取得了显着的改进:在文本行级别上提高了 4.73% PQ 和 5.39% F1,在段落级别布局上提高了 5.49% PQ 和 7.39% F1分析,需要 更少的训练周期。 该代码可从 Hi-SAM 获取。
索引术语:
分层文本分割、统一模型、Segment Anything 模型1 简介
文本通过各种层次结构(从笔画级别到单词、文本行和段落)有效地传达丰富的高级语义。 这些层次结构在不同的应用程序中发挥着至关重要的作用。 例如,文本笔划分割(TSS)111我们将之前作品中的术语文本分割和文本笔划分割视为同一任务。 为了避免与其他文本层次结构混淆,我们在本文中始终使用文本笔划分割。 [1, 2, 3] 对于字体样式转换、场景文本删除和文本编辑很有用。 此外,单词和文本行检测对于文本实体提取和识别非常重要,而视觉文本理解[4]可能需要几何布局,例如段落分组结果[5, 6] 。 现有的工作[7,1,8,9,2,10,11,12,13]通常集中在特定的层次结构上,缺乏在统一系统内处理多粒度文本信息的综合方法。 这就提出了一个问题: 设计一个能够有效管理不同文本层次结构(包括笔划、单词、文本行和段落)的内聚分段框架是否可行? 一个主要挑战在于用所有四个文本层次结构注释的现实世界数据的可用性有限。 表 I 简要总结了现有数据集,揭示了对单词级别的主要关注。 仅 HierText [5] 提供了单词、文本行、段落的分层注释,但缺少笔画注释,并且训练集量也有限。 这表明需要所有必需的文本层次结构的数据以及分层文本分段中的数据高效训练。
| Words | Hierarchies | |||||
| Datasets | Training Images | (avg/total) | Stroke | Word | Line | Paragraph |
| MSRA-TD500 [14] | 300 | 6.9/3.5K | ✘ | ✘ | ✔ | ✘ |
| IC15 [15] | 1,000 | 4.4/6.5K | ✘ | ✔ | ✘ | ✘ |
| CTW1500 [16] | 1,000 | 6.7/10K | ✘ | ✘ | ✔ | ✘ |
| Total-Text [17] | 1,255 | 7.4/11K | ✔ | ✔ | ✘ | ✘ |
| TextSeg [1] | 2,646 | 3.9/12K | ✔ | ✔ | ✘ | ✘ |
| IC19-ArT [18] | 5,603 | 8.9/50K | ✘ | ✔ | ✘ | ✘ |
| IC19-LSVT [19] | 30,000 | 8.1/243K | ✘ | ✘ | ✔ | ✘ |
| TextOCR [20] | 21,778 | 32.1/903K | ✘ | ✔ | ✘ | ✘ |
| HierText [5] | 8,281 | 103.8/1.2M | ✘ | ✔ | ✔ | ✔ |
| HierText* (w/ SAM-TSS) | 8,281 | 103.8/1.2M | ✔ | ✔ | ✔ | ✔ |

最近,Segment Anything Model (SAM) [21] 成为通用图像分割的基础视觉模型,利用数十亿规模的与类别无关的掩模标签进行训练。 SAM 具有快速、多粒度的分割功能,可根据点、边界框或粗略掩模输入生成对象掩模。 值得注意的是,SAM 在零样本场景和跨不同领域的任务适应中表现出强大的可移植性,包括常见图像分割 [21, 22]、医学图像分析 [23, 24]、和视频处理[25, 26]。 此外,SAM 还促进了数据的可扩展性[27]。 受 SAM 卓越性能的激励,我们旨在通过利用其能力构建强大的分层文本分割模型来回答上述问题。
为此,我们提出了 Hi-SAM,一种以文本为中心的分层分割模型,它利用 SAM 的固有知识以及具有不完整文本层次注释的现有碎片训练数据。 在自动掩模生成 (AMG) 模式中,SAM 采用与类和对象无关的网格点作为分割对象的提示,范围从组到单个部分,基于跨尺度的最佳置信度。 然而,对于分层文本分割,文本必须被视为唯一的前景,并且需要显式地同时生成单词、文本行和段落掩码。 为了解决这个问题,我们建议首先对文本笔划蒙版进行分段,然后从中采样点作为随后生成单词、文本行和段落蒙版的提示。 第一步,我们惊讶地发现 SAM 可以作为具有竞争力的 TSS 模型,只需最少的定制。 与 SAM 原始掩模解码器采用基于局部点或基于框的提示进行分割不同,我们建议使用全局提示,使掩模解码器能够感知图像文本的整体上下文。 从技术上讲,我们将图像编码器特征转换为一系列标记,并将它们用作隐式提示来调整掩码解码器。 此外,我们还发现 SAM 掩码解码器用于分割具有精细细节的文本笔划的瓶颈是掩码特征尺寸较小。 因此,我们引入了一个简单而有效的模块,使掩模解码器能够以原始输入大小提供笔划特征。 我们将这个简单的基线模型称为 SAM-TSS,并证明它在各种现有数据集上超越了最先进的 (SOTA) TSS 模型。 受 SAM 的启发,我们采用迭代策略,首先使用一小组手动标记数据在 HierText [5] 上训练 SAM-TSS,然后利用训练好的 SAM-TSS 在 HierText 中注释其他笔画以最少的人工干预。
接下来,我们通过扩展 SAM-TSS 推出 Hi-SAM,这是一种用于分层文本分割的端到端可训练模型。 Hi-SAM 结合了与 SAM-TSS 的笔划掩码解码器 (S-Decoder) 并行的分层掩码解码器 (H-Decoder),可实现单词、文本行和段落级别的分段。 前景点从预测的笔画掩模中随机采样,并使用 SAM 的提示编码器转换为点提示。 对于属于特定文本的每个点提示,H-解码器使用三个输出标记来预测其分层掩码。 Hi-SAM同时支持AMG模式和交互式提示分割(IPS)模式,如图1所示。 在AMG模式下,Hi-SAM首先对笔画前景掩模进行分割,对点提示进行采样,并生成分层掩模。 在 IPS 模式下,单点单击单词会提示 Hi-SAM 生成单词掩码,以及单词所在位置的文本行和段落掩码。 此外,Hi-SAM 通过计算段落掩码的交联 (IoU) 矩阵并将其用于单词聚类,提供布局分析作为副产品。
总而言之,我们的主要贡献有三方面:
-
•
我们提出了一种简单而有效的方法,将 SAM 呈现为有竞争力的 TSS 基线模型,即,SAM-TSS。 它超越了 SOTA TSS 方法,可生成高分辨率文本笔划蒙版。 我们进一步使用它以半自动方式注释 HierText 的笔画标签,使其成为第一个具有跨四个文本层次结构的掩码注释的真实数据集。
-
•
我们引入了 Hi-SAM,它基于 SAM-TSS 构建,具有简单的附加组件,并在增强的 HierText 上进行端到端训练。 Hi-SAM是第一个分层文本分割方法,涵盖笔画、单词、文本行和段落级别,并支持AMG和IPS模式。
-
•
我们的 SAM-TSS 和 Hi-SAM 在公共和具有挑战性的数据集上提供令人信服的性能。 SAM-TSS 在 Total-Text (84.86% fgIOU ) 和 TextSeg (88.96% fgIOU) 上创造了新记录。 Hi-SAM 在 HierText 上的联合文本检测和布局分析方面大幅超越了以前的专家,同时需要的训练次数减少了 20。
2 相关工作
2.1 不同文本层次结构的专业模型
(i) 文本笔画级别。 从背景中分割文本笔画是一项细粒度且具有挑战性的任务。 现有数据集主要针对大尺寸或中尺寸的场景文本和设计文本,例如 Total-Text [17] 和 TextSeg [1]。 为了解决训练数据有限的问题,一些方法集成了文本识别器来增强多尺度特征[8,28,9]。 此外,最近的方法[2]采用弱监督方法,将文本笔划分割与文本识别相结合。 与之前的研究相比,我们的工作展示了 SAM 知识的利用,利用 ViT 编码器的单尺度特征来实现 SOTA 性能。 (ii) 单词和文本行级别。 现有模型主要关注单词级场景文本检测,早期方法[29, 30]采用轴对齐或多向锚框进行单词定位。 为了解决任意形状的文本表示,一些方法[31,32,33,34,10,35,36]利用像素级分割掩模。 例如,DB [10] 分割文本内核区域以区分实例,执行自适应二值化过程,并采用后处理来扩展内核轮廓以获得最终结果。 或者,一些方法回归控制点 [37, 38, 12] 或预测参数化曲线 [39, 40] 以拟合文本轮廓。 然而,这些方法通常需要两组权重来进行单词和文本行检测,缺乏统一的模型。 (iii) 段落级别和布局分析。 布局分析主要关注文档场景,将视觉和语义上有凝聚力的文本块视为检测 [41] 或分段 [42] 对象。 基于语言模型的方法[43, 44]利用光学字符识别 (OCR) 标记将单词分组以进行语义解析。 最近,Long 等人. [5]引入了一种统一检测器(UD),可以解决自然和文档中的联合文本检测和布局分析问题场景。 在 UD 中,每个对象查询都经过训练以对文本行中的单词进行分段,并且布局分支会在不同对象查询之间生成亲和力矩阵,以聚类为段落。 然而,UD 在提供笔划蒙版、完整文本行和段落蒙版方面存在不足。
2.2 针对文本任务调整 Vision Foundation 模型
最近的研究[45,46,47,48]深入研究了利用 CLIP[49] 来改进场景文本检测和定位的主干表示。 具体来说,oCLIP [46] 引入了一个弱监督的预训练网络,用于对齐视觉和部分文本信息以进行场景文本检测和定位。 相比之下,TCM [47]通过视觉提示调整来调整 CLIP 模型以进行场景文本检测。 此外,为了增强场景文本识别,CLIP-OCR [50]提出了一种对称蒸馏策略,捕获 CLIP 文本编码器中的语言知识。 在我们的工作中,我们通过使用 SAM [21] 开发分层且可提示的分割框架来推进这一领域。
2.3 细分任何模型和后续行动
SAM [21]是用于通用图像分割的开创性视觉模型,通过大规模预训练展现出卓越的泛化能力。 它将其影响扩展到各种下游任务,例如图像抠图 [51]、3D 分割 [52]、视频跟踪 [25, 26] ,以及医学图像分割[24, 53]。 例如,由于域差距,SAM 在医学图像分割方面面临挑战。 一些方法[54,55,23]利用 SAM ViT 编码器上的适配器调整来更好地适应医学成像领域。 PerSAM [56] 和 Matcher [57] 引入了基于 SAM 的免训练分割框架和一次性学习。 HQ-SAM [22] 通过在大小 的融合特征上应用可学习的高质量输出词符来改善掩模细节,增强 SAM 的对象分割质量,同时保持零样本的通用性。 尽管在各个领域进行了广泛的研究,但以文本为中心的分割研究仍存在显着差距。 在这项工作中,我们介绍了第一个针对四个文本层次结构的统一分割框架。 我们确定了将 SAM 应用到掩码特征大小中的细粒度文本分割的主要限制。 我们的方法采用一种简单而有效的方法,通过提供高分辨率掩模特征来实现高质量的文本笔划分割。
3 方法论
在这项工作中,我们提出了 Hi-SAM,它擅长跨越四个层次的统一文本分割,包括笔划、单词、文本行和段落,同时实现布局分析。 在下面的小节中,我们首先简要回顾一下第 2 节中有关 SAM 的基本知识。 3.1。 然后,我们提供了构建 Hi-SAM 的详细描述。

3.1 初步
SAM [21] 由基于 ViT 的主干、提示编码器和轻量级掩码解码器组成。 主干网 (ViT-B/ViT-L/ViT-H) 提取大小为 的图像嵌入。 提示编码器将不同类型的交互式位置提示嵌入到提示标记中。 基于 Transformer 的双向掩码解码器将图像嵌入、输出标记和提示标记作为输入。 输出标记类似于 DETR [58] 中的对象查询。 掩码解码器使用多层感知器 (MLP) 根据输出标记预测动态权重,然后将动态权重应用于 空间形状中的上采样掩码特征以生成掩码结果。 尽管 SAM 显示出令人印象深刻的泛化能力,但它仍然是一个与类无关的模型。 如何利用 SAM 进行以文本为中心的分层分割是一个悬而未决的问题。
3.2 Hi-SAM概述
Hi-SAM 采用统一的分层文本分割框架,首先处理全局 TSS 任务,然后以自下而上的方式处理局部分割任务。 整体架构如图2所示。 Hi-SAM 包含五个模块:1)来自 SAM 的图像编码器,2)一个插件自提示模块,3)一个来自 SAM 掩模解码器的笔画掩模解码器(S-Decoder),4)来自 SAM 的冻结提示编码器SAM,以及5)从SAM的掩码解码器定制的分层掩码解码器(H-Decoder)。 对于TSS,我们使用自提示模块和S-Decoder来处理图像嵌入。 认识到文本笔画固有的精细细节,我们还设计了一个简单而有效的模块来生成高分辨率笔画掩模特征,从而显着提高性能。 Hi-SAM for TSS 的基本组件即.,包括图像编码器、自提示模块和 S-Decoder,称为 SAM-TSS。 它用于以半自动方式为 HierText 生成笔划标签。 SAM-TSS 的详细信息在第 2 节中介绍。 3.4。 获得文本笔划掩码后,对笔划上一定数量的前景点进行采样,作为单词、文本行和段落分割的桥梁。 利用这些前景点,提示编码器和 H-解码器用于预测其余三个文本层次结构的掩码。 该设置被称为AMG模式,而Hi-SAM还保留了SAM的IPS模式。 我们在第 2 节中介绍了 H 解码器的细节。 3.5。 给定段落掩码,Hi-SAM 能够进行布局分析,这在第 2 节中进行了描述。 3.6。 我们在第 2 节中详细介绍了 Hi-SAM 的训练和推理过程。 3.7 和秒。 3.8。
3.3 特征提取
由于SAM的图像编码器不能完全识别具有精细细节的文本,因此直接应用冻结图像编码器进行文本笔画分割并不能取得满意的结果。 为了有效增强图像编码器的适应性,我们采用适配器调整方法[54]。 SAM 图像编码器的原始参数保持冻结,同时在每个 ViT 块中插入两个可训练适配器模块。 每个适配器依次由下投影、ReLU 激活和上投影组成。 我们使用[54]中的默认设置。 接下来,我们设计了一个自提示模块,通过图像嵌入生成隐式提示标记,并将 SAM 的掩码解码器传输到具有高分辨率掩码特征的 S-解码器中。
3.4 文本笔划分割
自提示模块。 SAM 的掩码解码器将具有明确位置提示的提示标记作为输入。 为了引导 S-Decoder 分割输入图像中的所有文本笔划,我们建议使用图像嵌入本身来生成隐式提示标记。 这个想法是,文本笔画所需的提示已经存储在图像嵌入中,我们只需要将它们转换为一系列有代表性的提示标记即可。 为了实现这一点,在自我提示模块中,我们首先制定一个图像标记器函数:
| (1) |
它将图像嵌入 转换为标记 。 为词符长度,根据经验设置为。 受 TokenLearner [59] 的启发,我们使用卷积块 和后续的 函数来处理 ,生成空间注意力图:
| (2) |
其中 包含四个卷积层(内核大小 、步长 1、填充 1),第一个卷积层将维度从 减小到 . GELU 激活被插入到卷积层之间。 然后我们使用、和空间全局平均池化操作来获取 Token 。 我们重写方程。 (1) 如下:
| (3) |
其中 是逐元素乘积, 和 代表对注意力图 和图像嵌入 的重塑和广播操作。 生成的 Token 进一步发送到单个 Transformer 解码器层 以增强其表示:
| (4) |
其中 表示将输入 S-Decoder 进行文本笔划分割的最终提示标记。 将 作为查询, 作为键和值。
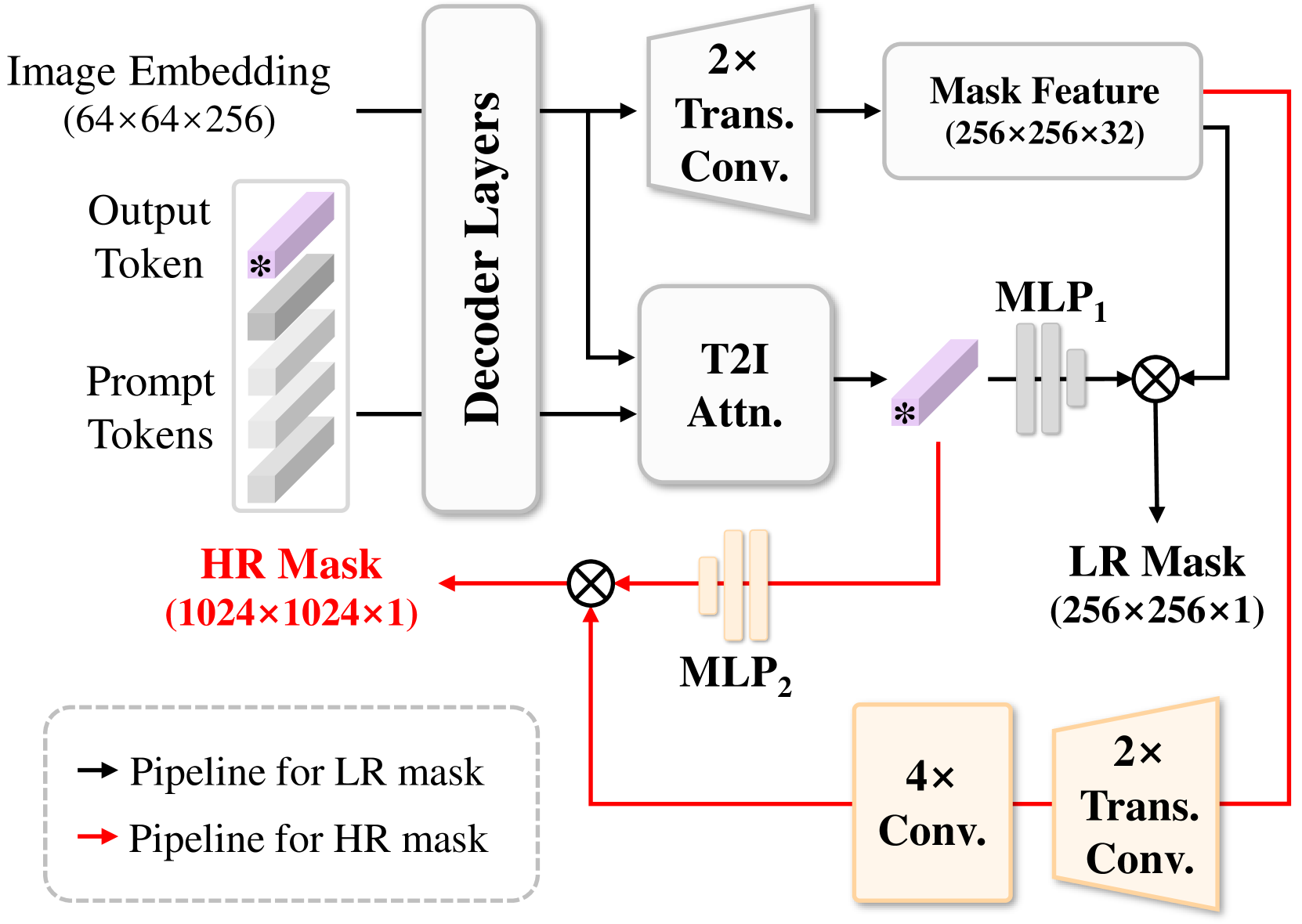
具有高分辨率掩模功能的 S 解码器。 我们观察到掩模特征分辨率主要限制文本笔画分割质量。 因此,我们设计了一种简单而有效的方法来提供高分辨率掩模特征,显着提高具有精细结构的文本笔画的性能(参见表2中的烧蚀结果)。 V)。
S-Decoder的结构如图3所示。 图3中的低分辨率掩模预测模块继承了SAM掩模解码器的参数。 让 表示继承的输出词符,它是 SAM 输出标记的第一个切片。 为了便于描述,我们在这里省略了另一个用于 IoU 预测的词符。 连接的输出和提示标记被送入S-Decoder。 经过最终的 token-to-image 注意力和转置卷积后,我们获得更新的输出词符 和上采样掩码特征 ,其中 是SAM中默认的掩模特征尺寸,是特征尺寸。 然后, 被传递到 MLP,输出与 维度匹配的向量。 文本笔划掩码 logits 通过 和 MLP 输出之间的空间逐点乘积来预测。 在推理过程中,将被插值到输入图像大小中,并使用阈值进一步处理。
对于高分辨率掩模logits,我们重用更新后的输出词符和掩模特征,同时引入一些轻量级模块。 如图3所示,我们用另外两个转置卷积层(内核大小,步长2)进一步对进行上采样,并使用四个后续的卷积层(内核大小,步幅1,填充1)用于细化特征。 在此步骤之后,我们实现了具有 空间尺寸和 维度通道的高分辨率掩模特征 。 我们初始化一个三层 MLP 并将其应用于 以生成一个新向量。 与获取类似,S-Decoder根据和更新后的结果预测大小为的最终高分辨率掩模logits向量。

文本描边蒙版的半自动标注。 我们利用获得的 SAM-TSS 模型以半自动方式为 HierText 生成笔画掩模标签。 最初,我们在文档、海报和手写场景中选择一些文本密集且细粒度的样本。 我们使用对比度调整、反转、画笔和二值化等工具在 Adobe Photoshop 中对它们进行注释。 在对 HierText 训练集中的 418 个图像进行注释后,我们将这些图像和 Total-Text 的训练图像结合起来,训练具有 ViT-L 主干的 SAM-TSS 模型,即。,SAM-TSS-L。在训练过程中,我们使用了增强功能,包括颜色抖动、随机模糊、随机旋转和大规模抖动[60]。 我们使用这个模型来标记 HierText 的剩余训练图像。 在推理过程中,我们利用滑动窗口策略来提高分割质量。 我们将窗口大小设置为 512 512,步长为 384。 手动修改假阳性和假阴性区域。 具体来说,当带注释的图像与总 HierText 训练图像之间的比率达到 1/8、1/4 和 1/2 时,我们重新训练模型并更新剩余图像的分割掩模。 随着模型的发展,我们只需要删除一些误报片段。 最后,我们使用最新的模型来标记 HierText 集中所有剩余的训练图像。 在手动检查和修改之前,我们还使用 SAM-TSS-L 来标记验证和测试图像。 图4显示了SAM-TSS-L生成的一些标注样本。
3.5 单词、文本行和段落分段
与采用隐式提示的 S-Decoder 不同,H-Decoder 从 SAM 的提示编码器接收点提示。 我们在从 SAM 掩码解码器定制的单个 H 解码器中获取单词、文本行和段落掩码。 假设我们在文本上有 前景点,提示编码器将它们处理为提示标记 ,其中 是新引入的维度。 H-decoder 将连接的输出标记和点提示标记 作为输入。 在最终的 token-to-image 注意力之后,我们对最后三个输出 token 进行切片并得到 。 在原始SAM的掩码解码器中,最后三个输出 Token 用于多掩码输出,没有具体的任务分配。 在 H-Decoder 中,对于每个点提示,我们使用三个输出标记按顺序负责单词、文本行和段落分割。 在输出标记和掩码特征之间应用逐点乘积,我们得到形状为 的掩码逻辑 ,其中包含相应的单词、文本行和段落掩码,其中点位于. 请注意,对于每个点提示,单词掩码不仅包含所选单词,还包含同一文本行中的其他单词。 这样做的目的是确保在文本密集的场景中自动生成掩码期间能够回忆单词。 UD[5]在其框架中也采用了类似的设计来确保检测召回。 此外,为了更好地分离相邻的单词实例,引导单词输出词符对单词核心区域进行分割。 在推理过程中,我们按照DB [10]中的后处理方法来获得完整的单词区域。 相反,我们不对文本行和段落标签进行处理。
此外,为了提高分词的质量,我们采用了与S-Decoder类似的方法,即.,生成更高分辨率的掩码特征。 具体来说,为了节省 GPU 内存使用,我们首先使用内核大小为 的卷积层将掩模特征的维度从 减少到 。 然后,我们直接对掩模特征进行插值以获得空间大小。 我们还使用四个内核大小为 的卷积层来细化掩模特征。 三层 MLP 用于从词级输出词符生成动态权重。 最后,使用动态权重和精细的掩码特征,我们可以获得更高分辨率的单词掩码逻辑。
3.6 布局分析
这项工作中的布局分析旨在将单词聚类到不同的块中,其中每个块中的文本在视觉上和语义上都是连贯的。 直观上,布局分析需要挖掘文本对象之间的关系。 由于H-Decoder的输出本质上呈现层次关系,因此可以顺便完成布局分析,而不需要专门设计的分支。 具体来说,在 H 解码器的预测中,每个文本行掩码都附有一个单词掩码(包含该文本行中的单词)和一个段落掩码。 如果不同文本行对应的段落掩码具有较高的IoU,我们将这些文本行及其对应的单词视为同一段落,从而实现布局分析。 具体来说,我们使用 形状的段落掩码计算 IoU 矩阵 。 然后,如果每对对象的 IoU 指标超过 ,我们将对它们进行分组。 采用[5]中使用的并查找算法将这些连接的节点合并为簇。
3.7Hi-SAM训练
在训练过程中,Hi-SAM中的可学习模块包含1)ViT编码器中的适配器,2)自我提示模块,3)S-解码器和4)H-解码器。 我们以端到端的方式优化它们。 就 S-Decoder 而言,我们同时监督低分辨率和高分辨率掩模预测。 低分辨率部分的损失函数是Focal损失[61]、Dice损失[62]和IoU均值的线性组合平方误差 (MSE) 损失的比率为 20:1:1,遵循[21]。 同样,高分辨率部分的损失函数也是Focal损失、Dice损失、MSE损失等比例的线性组合。 对于文本笔划分割,整体损失。
就 H-Decoder 而言,我们采用了对位训练策略。 对于可能包含多达数百个文本行的每个图像,我们假设某些文本行在外观上彼此相似。 我们只使用一些样本来训练 H-Decoder。 具体来说,我们在每张图像中随机采样最多 10 个文本行。 然后,我们使用这些文本行蒙版和笔划蒙版来确定每个文本行的笔划前景。 对于每个文本行,我们随机采样 2 个前景点。 最后,我们可以获得最多 20 个前景点以及真实单词、文本行和段落蒙版。 我们将前景点输入到提示编码器中,为 H 解码器生成提示标记。 如果没有前景点,则引导 H-Decoder 分割空白掩模。 总体而言,对于分词,损失函数定义为,其中和用于监督低分辨率和高分辨率的词掩码预测。 它们各自包含二元交叉熵(BCE)损失和Dice损失,比例为1:1,遵循[22]。 对于text-line,损失是BCE损失、Dice损失和IoU MSE损失以1:1:1的比例线性组合。 我们对段落 使用相同的设置。 IoU 头的预测分数可用于在自动掩模生成过程中进行掩模非极大值抑制(NMS)。 最终损失函数表述为:
| (5) |
3.8 Hi-SAM推断
自动生成掩模。 对于每个输入图像,SAM-TSS 首先生成文本笔划蒙版,其中文本笔划是唯一的前景类。 然后,我们随机采样 前景点,这些前景点通过提示编码器嵌入到提示标记中。 H-Decoder 使用它们来预测密集单词、文本行和段落掩码。 我们将文本行视为枢轴。 我们过滤掉预测 IoU 分数低于 的文本行掩码。 它们相应的单词和段落掩码也被丢弃。 接下来,我们使用剩余的文本行掩码及其 IoU 分数在 GPU 上进行矩阵 NMS [63]。 Matrix NMS 的阈值默认设置为。 NMS 之后,我们收集最终的文本行掩码及其相应的单词和段落掩码。 最后,我们根据第 2 节中所述的段落掩码完成布局分析。 3.6。 如果需要非冗余段落掩码,则可以在段落级别应用附加 NMS。 所有预测的掩模都可以插值到与输入图像相同的分辨率。 这样,我们在统一的框架中实现了跨文本笔划、单词、文本行和段落级别的分层文本分割,并顺便实现了布局分析。
交互式提示分割。 在这种模式下,推理管道仅涉及图像编码器、提示编码器和H解码器。 图像编码器首先用于提取嵌入。 对于用户点击的点,提示编码器将它们嵌入到提示标记中,并且 H-解码器为每个点生成单词、文本行和段落掩码。 由于每个单词掩码都包含一个文本行中的单词,如第 1 节中所述。 3.5,我们比较点击点和单词实例之间的接近度来确定所选单词。
4 实验
4.1 数据集和评估协议
Total-Text [17] 包括 1,255 个训练图像和 300 个测试图像。 它包含任意形状的场景文本。 Total-Text 提供文本笔划的二进制掩码标签和单词实例的多边形注释。
TextSeg [1] 包含 4,024 张图像,分为训练集、验证集和测试集,分别包含 2,646、340 和 1,038 张图像。 它重点关注场景文本和用于文本笔划分割的设计文本。
COCO_TS [64] 有来自 COCO-Text [65] 的 14,690 个图像。 COCO_TS 文本笔划蒙版标签是使用在大量合成数据上训练的弱监督分割模型从 COCO-Text 中的边界框注释自动导出的。 由于标记质量有限,我们专门使用 COCO_TS 来评估 SAM-TSS 模型的自动标记能力。
HierText [5] 由 8,281 个训练图像、1,724 个验证图像和 1,634 个测试图像组成,场景、文档、等中包含密集的文本。 它包含分层单词、文本行和段落位置注释。 单词位置用多边形注释,而文本行位置用四边形框注释。 段落位置由粗多边形表示。 HierText 具有场景、设计、印刷和手写文本。 我们在本文中提供了文本笔画级注释。
我们使用前景像素的 IOU 和 F-score 来进行文本笔划分割评估[1]。 我们按照 HierText [5] 来评估单词、文本行、段落(布局)任务,其中包括全景质量 (PQ) [66]、F 分数、精度 (P )、召回率 (R) 和紧密度 (T)。 PQ 和 F 分数是主要指标。
4.2 实现细节
基准测试和推理。 Hi-SAM 的输入图像大小为 ,与 SAM [21] 相同。 在我们的默认设置中,自提示模块为 S-Decoder 生成 12 个提示标记。 我们使用 AdamW [67] () 作为优化器。 学习率设置为。 批量大小为 8。 我们通过颜色抖动、随机旋转和尺度范围为 [0.5, 2.0] 的大规模抖动来增强输入图像。 对于 TSS,我们将 SAM-TSS 与现有的代表性 TSS 方法进行比较。 在训练过程中,对于每个数据集,我们仅按照之前的方法使用其训练集。 在 Total-Text 和 TextSeg 上,我们训练 SAM-TSS 70 个 epoch,学习率没有下降。 在 HierText 上,我们训练 SAM-TSS 80 个时期,学习率在 70 个时期除以 10。 推理时,输入图像大小也是。 对于分层文本分割,我们仅使用 HierText 的训练集。 我们训练 Hi-SAM 150 个时期,学习率在 130 个时期除以 10。 在训练过程中,我们在每张图像中随机采样最多 10 个文本行,并在每个文本行上随机采样 2 个点。 秒中的采样点数。 3.8 设置为 1,500。 在实践中,我们将这些点分成批次,默认设置为每批次 100 个点。 我们在 8 个 NVIDIA Tesla V100 (32GB) GPU 上对模型进行训练。
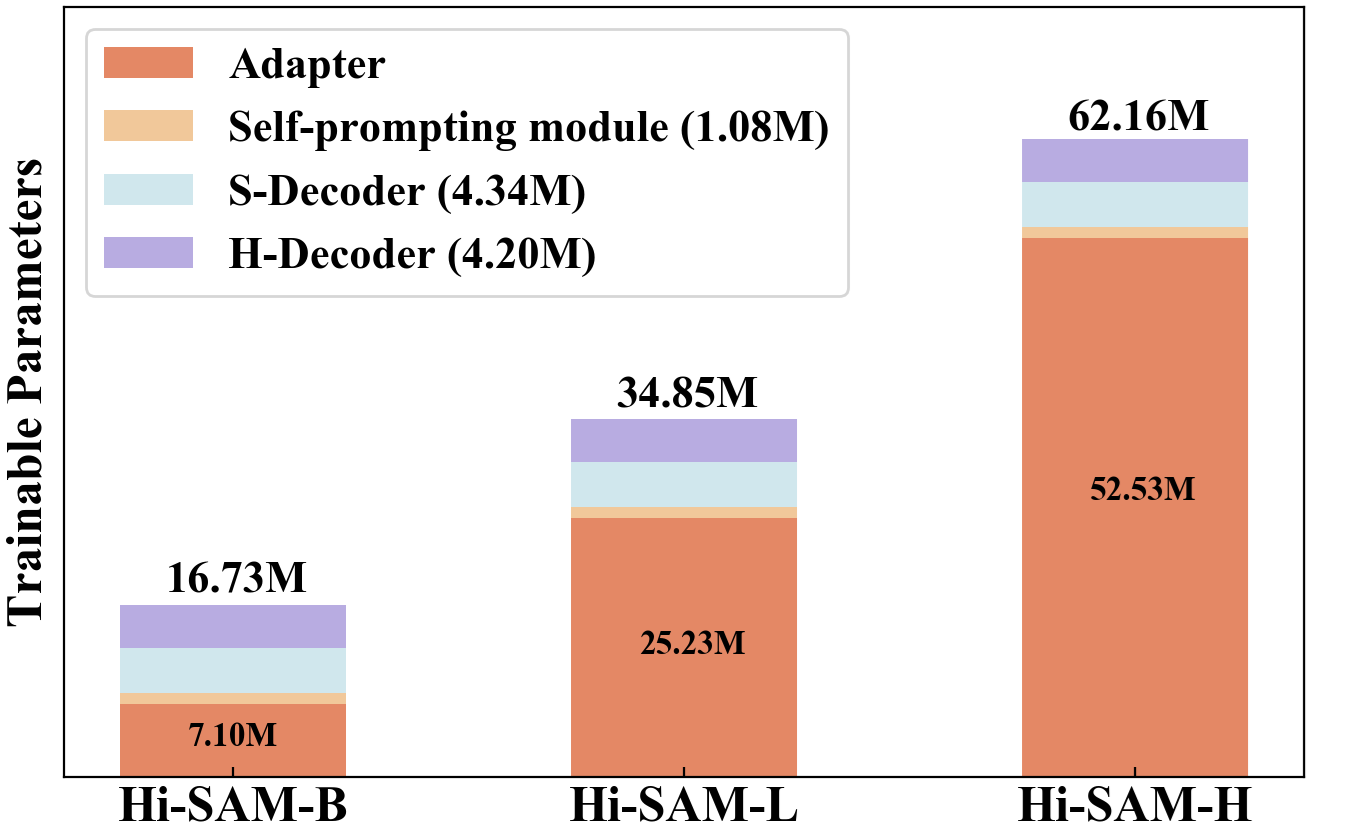
Hi-SAM 的可训练参数统计。 我们在图5中提供了具有不同骨干网的Hi-SAM的可训练参数统计。 Hi-SAM-B、Hi-SAM-L 和 Hi-SAM-H 分别采用 ViT-B、ViT-L 和 ViT-H 主链。 具体来说,在Hi-SAM-B中,总共有16.73M可训练参数,其中适配器中有7.10M。 在三个 Hi-SAM 变体中,自提示模块只有 1.08M 可训练参数,而 S-Decoder 和 H-Decoder 分别占 4.34M 和 4.20M 可训练参数。 请注意,TSS 的 SAM-TSS-B 不需要 H 解码器,总共有 12.53M 可训练参数,而 SAM-TSS-L 和 SAM-TSS-H 分别有 30.65M 和 57.95M 可训练参数。
4.3 消融研究
4.3.1 文本笔划分割
对自提示模块中适配器和 Transformer 解码层的影响。 如表所示。 II。 我们发现直接应用 SAM 的冻结图像编码器无法产生令人满意的文本笔划分割结果,这表明原始 SAM 缺乏对精细文本细节的认识。 通过在 ViT 块中引入一些可训练参数,ViT-B 和 ViT-L 模型的性能均明显优于基线,验证了将 SAM 应用于文本图像域的重要性。 而且,使用单个 Transformer 解码器层来细化自我提示模块中的 token 可以进一步带来改进。
提示词符数的影响。 我们研究了表中提示词符数对 ViT-B 和 ViT-L 模型的影响。 III。 对于 ViT-B,使用 12 个提示 Token 可实现最佳 F 分数,并且 fgIOU 与使用 16 个提示 Token 相当,而对 ViT-L 使用 12 个提示 Token 可实现最佳性能。 为了更好地权衡复杂性和性能,我们默认采用 12 个提示标记进行文本笔划分割。
不同词符表示方法的比较。 在自我提示模块中,我们采用基于空间注意力的轻量级标记器[59]从图像嵌入中提取初始提示标记。 如表所示。 IV,我们将其与普通嵌入进行比较,后者使用初始化的嵌入作为提示标记,类似于 DETR [58] 中的对象查询。 训练后,来自普通嵌入的提示标记被固定,而来自空间注意的提示标记与图像嵌入相关。 我们观察到后一种方法表现更好,特别是当图像嵌入变得更具代表性时。 具体来说,与普通嵌入相比,ViT-B 的 fgIOU 和 F-score 分别提高了 0.15% 和 0.30%,而 ViT-L 的 fgIOU 和 F-score 分别提高了 0.67% 和 0.37%。
| Backbone | Adapter | TDecLayer | fgIOU | F-score |
| ViT-B | 68.80 | 78.31 | ||
| ✓ | 79.73 | 86.25 | ||
| ✓ | ✓ | 80.93 | 86.25 | |
| ViT-L | 69.17 | 79.86 | ||
| ✓ | 84.02 | 88.60 | ||
| ✓ | ✓ | 84.59 | 88.69 |
| Backbone | Tokens | fgIOU | F-score |
| ViT-B | 8 | 80.02 | 85.98 |
| 12 | 80.93 | 86.25 | |
| 16 | 81.04 | 86.22 | |
| ViT-L | 8 | 83.92 | 88.64 |
| 12 | 84.59 | 88.69 | |
| 16 | 83.94 | 88.44 |
| Backbone | Method | fgIOU | F-score |
| ViT-B | vanilla embedding [58] | 80.78 | 85.95 |
| spatial attention [59] | 80.93 | 86.25 | |
| ViT-L | vanilla embedding [58] | 83.92 | 88.32 |
| spatial attention [59] | 84.59 | 88.69 |
S-解码器中高分辨率掩模特征的有效性。 在选项卡中。 V,我们验证了使用高分辨率(HR)掩模特征进行文本笔划分割的有效性。 我们观察到引入 HR mask 特征显着提高了分割质量。 使用 ViT-L,fgIOU 性能在 Total-Text 上提高了 2.31%。 此外,在需要分割场景、文档和手写材料中密集文本的 HierText 上,利用 HR mask 功能可实现 14.24% 的 fgIOU 显着提升。 图6提供了一些定性结果。 使用 LR mask 功能的结果几乎丢失了所有笔划细节。 相比之下,HR mask 的预测保留了最多的细节,
| Total-Text | HierText | ||||
| Backbone | HR | fgIOU-LR | fgIOU-HR | fgIOU-LR | fgIOU-HR |
| ViT-B | 79.70 | 61.58 | |||
| ✓ | 79.91 | 80.93 (+1.23) | 61.63 | 73.39 (+11.81) | |
| ViT-L | 82.28 | 64.13 | |||
| ✓ | 83.40 | 84.59 (+2.31) | 63.75 | 78.37 (+14.24) | |

4.3.2 层次化文本切分与布局分析
在这一部分中,我们重点关注 Hi-SAM 的 H-Decoder、 和推理设置的消融研究。 我们使用 ViT-L 作为骨干在 HierText 的验证集上进行实验。
H-解码器中高分辨率掩模特征的有效性。 如第 2 节所述。 3.5,我们还引入了更高分辨率的mask特征来提高H-Decoder中的分词质量。 表1列出了不同特征分辨率之间的性能比较。 VI。 可以看出,利用H-Decoder中的高分辨率掩模功能可以更好地区分书页和文档材料上的相邻单词实例,从而为分词带来理想的改进i.e。,2.45% PQ 和 2.16% F 分数。 请注意,文本行和布局分析的指标也得到了增强,因为这些任务将单词实例视为基本单位。
不同样本策略的影响。 在训练过程中,我们在每张图像中随机采样 10 个文本行,并在每个文本行上随机采样 2 个点。 我们还研究了增加每个文本行上的点数或添加文本行样本的影响。 比较结果和相应的训练成本如表1所示。 VII。 我们可以看到,将文本行数保持在 10 并将分数增加到 5 时,单词级别的 PQ 和 F 分数提高了 0.54% 和 0.73%,文本行级别提高了 0.33% 和 0.21%,布局分析分别为 0.63% 和 0.48%。 相比之下,增加文本行样本可以在布局分析中获得更多收益。 然而,增加训练样本需要更多的训练资源。 例如,仅将每个文本行上的点数量从 2 增加到 5 会导致每个 GPU 上的训练时间增加约 1.2 并增加 6GB 内存占用。 对更多文本行进行采样也会导致更多的数据处理时间。 因此,我们使用每个图像 10 个文本行和每行 2 个点作为默认设置。
| Word | Text-Line | Layout Analysis | ||||
| Feature Size | PQ | F-score | PQ | F-score | PQ | F-score |
| 60.15 | 78.83 | 64.72 | 83.71 | 58.55 | 75.80 | |
| 62.60 | 80.99 | 65.62 | 84.04 | 58.83 | 75.84 | |
| +2.45 | +2.16 | +0.90 | +0.33 | +0.28 | +0.04 | |
| Word | Text-Line | Layout Analysis | |||||
| Strategy | PQ | F-score | PQ | F-score | PQ | F-score | Time (Mem.) |
| 10Ls 2Pts | 62.60 | 80.99 | 65.62 | 84.04 | 58.83 | 75.84 | 20.5min (16GB) |
| 10Ls 5Pts | 63.14 | 81.72 | 65.95 | 84.25 | 59.46 | 76.32 | 24.0min (22GB) |
| 25Ls 2Pts | 63.02 | 81.57 | 65.81 | 84.12 | 60.03 | 77.10 | 32.0min (22GB) |
| Word | Text-Line | Layout Analysis | ||||
| Points | PQ | F-score | PQ | F-score | PQ | F-score |
| 500 | 61.83 | 79.82 | 63.96 | 81.63 | 57.49 | 74.01 |
| 1,000 | 62.46 | 80.76 | 65.28 | 83.52 | 58.55 | 75.44 |
| 1,500 | 62.60 | 80.99 | 65.62 | 84.04 | 58.83 | 75.84 |
| 2,000 | 62.64 | 81.07 | 65.74 | 84.24 | 58.92 | 75.97 |
采样点数的影响。 正如第 2 节中提到的。 3.8,我们随机采样前景点作为提示编码器的输入。 我们在表中评估了使用不同点采样数的影响。 VIII。 采样 500 个点的性能相对较低,因为它不足以表示 HierText 中的文本,HierText 平均每个图像有 103.8 个单词实例。 当采样点加倍时,单词、文本行和布局分析的 F 值分别提高了 0.94%、1.89% 和 1.43%。 使用更多点可以进一步提高性能,但在 2,000 点时就饱和了。 为了更好地权衡性能和推理开销,我们默认将点采样数 设置为 1,500。
| Method | Venue | fgIOU | F-score |
| DeepLabV3+ [69] | ECCV’18 | 74.44 | 82.40 |
| HRNetV2-W48 [70] | TPAMI’20 | 75.29 | 82.50 |
| HRNetV2-W48 + OCR [70] | TPAMI’20 | 76.23 | 83.20 |
| TexRNet + DeeplabV3+ [1] | CVPR’21 | 76.53 | 84.40 |
| TexRNet + HRNetV2-W48 [1] | CVPR’21 | 78.47 | 84.80 |
| SegFormer [71] | NeurIPS’21 | 73.31 | 84.60 |
| PGTSNet [9] | CVPR’22 | 79.10 | 84.70 |
| TFT [68] | ACM MM’23 | 82.10 | 90.20 |
| SAM-TSS-B | 80.93 | 86.25 | |
| SAM-TSS-L | 84.59 | 88.69 | |
| SAM-TSS-H | 84.86 | 89.68 |
| Method | Venue | fgIOU | F-score |
| DeepLabV3+ [69] | ECCV’18 | 84.07 | 91.40 |
| HRNetV2-W48 [70] | TPAMI’20 | 85.03 | 91.40 |
| HRNetV2-W48 + OCR [70] | TPAMI’20 | 85.98 | 91.80 |
| TexRNet + DeeplabV3+ [1] | CVPR’21 | 86.06 | 92.10 |
| TexRNet + HRNetV2-W48 [1] | CVPR’21 | 86.84 | 92.40 |
| SegFormer [71] | NeurIPS’21 | 84.59 | 91.60 |
| TFT [68] | ACM MM’23 | 87.11 | 93.10 |
| SAM-TSS-B | 87.15 | 92.81 | |
| SAM-TSS-L | 88.77 | 93.79 | |
| SAM-TSS-H | 88.96 | 93.87 |
| Method | Venue | fgIOU | F-score |
| TexRNet + HRNetV2-W48 [1] (S: 1024) | CVPR’21 | 55.50 | 65.64 |
| TexRNet + HRNetV2-W48 [1] (S: 1536) | CVPR’21 | 65.72 | 75.19 |
| TexRNet + HRNetV2-W48 [1] (S: 2048) | CVPR’21 | 70.77 | 80.32 |
| SAM-TSS-B | 73.39 | 81.34 | |
| SAM-TSS-L | 78.37 | 84.99 | |
| SAM-TSS-H | 79.27 | 85.63 | |
| SAM-TSS-B † | 85.80 | 92.21 | |
| SAM-TSS-L † | 89.04 | 94.26 | |
| SAM-TSS-H † | 88.59 | 93.79 |
4.4 与最先进方法的比较
4.4.1 文本笔划分割
全文本基准。 与其他方法相比,我们的方法首次利用视觉基础模型[21]并实现高分辨率文本笔划分割。 尽管以前的方法诉诸利用额外的文本识别器来增强语义特征[9],或额外的文本检测器和注释[68],但SAM-TSS仍然优于它们并实现了Total-Text 上最好的 fgIOU 性能。 如表所示。 IX,与 TFT [68] 相比,SAM-TSS-L 实现了 2.49% fgIOU 的增益,SAM-TSS-H 呈现最先进的 84.86 %fgIOU。 与 PGTSNet [9] 相比,SAM-TSS-L 明显优于 PGTSNet 5.49% fgIOU。
TextSeg 基准。 如表所示。 X,我们的方法在 TextSeg 上提供了值得称赞的性能。 SAM-TSS-B 实现了 87.15% fgIOU,SAM-TSS-L 将 fgIOU 性能进一步提高了 1.62%。 此外,SAM-TSS-H 达到 88.96% fgIOU。 Total-Text 和 TextSeg 的一些可视化示例如图7所示。
| COCO_TS Total-Text | COCO_TS TextSeg | COCO_TS HierText | ||||||||||
| Model for Auto-labeling | fgIOU | F-score | fgIOU | F-score | fgIOU | F-score | ||||||
| Original [64] | 65.45 | 75.84 | 58.54 | 84.48 | 53.83 | 66.21 | ||||||
| SAM-TSS-L trained on Total-Text | 80.02 | +14.57 | 87.33 | +11.49 | 56.93 | -1.61 | 84.13 | -0.35 | 63.64 | +9.81 | 71.63 | +5.42 |
| SAM-TSS-L trained on TextSeg | 76.09 | +10.64 | 84.10 | +8.26 | 81.12 | +22.58 | 91.51 | +7.03 | 54.75 | +0.92 | 61.26 | -4.95 |
| SAM-TSS-L trained on HierText | 76.23 | +10.78 | 86.33 | +10.49 | 71.23 | +12.69 | 86.87 | +2.39 | 69.95 | +16.12 | 79.67 | +13.46 |

HierText 基准。 HierText 在自然场景和文档场景中分割具有精细细节的文本时提出了重大挑战。 我们在 HierText 上评估 TextRNet [1] 与 HRNetV2-W48 [70] 主干网进行比较。 如表中所示。 XI,TextRNet只实现了55.50%的fgIOU,尽管它使用了更大的输入尺寸,即,输入图像的短边设置为1,024。 我们的具有 ViT-L 主干的模型达到了 78.37% 的 fgIOU。 此外,应用滑动窗口策略进一步将fgIOU性能提高了10.67%。 我们在图8中提供了使用和不使用滑动窗口策略的一些定性比较。 使用滑动窗口策略可以显着提高极小文本的分割质量。
COCO_TS 上的自动标记。 我们进一步比较 SAM-TSS-L 生成的标签与 COCO_TS 上的原始标签的质量。 我们在 Total-Text、TextSeg 和 HierText 上训练了三个 SAM-TSS-L 模型,使用滑动窗口策略(窗口大小:512 512,步长:384)自动标记 COCO_TS 中的图像。 然后,我们在 COCO_TS 上使用这些不同的标签训练 SAM-TTS 40 个周期,并在其他数据集上评估它们,无需微调。 跨不同数据集概括性能的能力可以作为标签质量的可靠指标。 请注意,COCO_TS 的原始标签包含很多不确定区域,我们按照之前的方法[64, 1]将它们用于训练基线模型。
结果报告在表中。 XII。 可以看出,使用我们生成的标签训练的模型总体上表现出明显更好的泛化性能,这表明我们的模型具有出色的自动标记能力。 请注意,使用从 Total-Text 上训练的模型获得的标签不会提高 TextSeg 的性能。 这可能是因为 TextSeg 包含场景和设计文本,而 Total-Text 主要强调场景文本。

| Method | Stroke | Word | TL | WG in TL | Para. | Layout (WG in Para.) | Promptable | Training on HierText |
| Unified Detector [5] | ✘ | ✔ | ✘ | ✔ | ✘ | ✔ | ✘ | 128 TPUv3 cores, 3091 epochs |
| Hi-SAM (Ours) | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | 8 V100 GPUs, 150epochs |
| Stroke | Word | Text-Line | Layout Analysis | ||||||||||||||
| Method | fgIOU | F-score | PQ | F-score | P | R | T | PQ | F-score | P | R | T | PQ | F-score | P | R | T |
| Unified Detector [5] | 48.21 | 61.51 | 67.54 | 56.47 | 78.38 | 62.23 | 79.91 | 79.64 | 80.19 | 77.87 | 53.60 | 68.58 | 76.04 | 62.45 | 78.17 | ||
| Hi-SAM-B | 70.94 | 79.78 | 59.74 | 78.34 | 83.97 | 73.41 | 76.25 | 63.34 | 82.15 | 89.17 | 76.16 | 77.10 | 54.46 | 71.15 | 78.53 | 65.03 | 76.54 |
| Hi-SAM-L | 75.22 | 82.90 | 63.10 | 81.83 | 87.22 | 77.06 | 77.11 | 66.17 | 84.85 | 90.66 | 79.74 | 77.99 | 57.61 | 74.49 | 80.43 | 69.37 | 77.34 |
| Hi-SAM-H | 75.73 | 83.36 | 64.30 | 82.86 | 87.66 | 78.56 | 77.60 | 66.96 | 85.30 | 91.09 | 80.20 | 78.50 | 59.09 | 75.97 | 81.52 | 71.13 | 77.79 |
| Stroke | Word | Text-Line | Layout Analysis | ||||||||||||||
| Method | fgIOU | F-score | PQ | F-score | P | R | T | PQ | F-score | P | R | T | PQ | F-score | P | R | T |
| Unified Detector [5] | 48.47 | 61.65 | 67.18 | 56.96 | 78.47 | 61.29 | 78.66 | 78.98 | 78.34 | 77.92 | 52.86 | 67.73 | 76.17 | 60.98 | 78.04 | ||
| Hi-SAM-B | 70.35 | 79.65 | 59.20 | 77.48 | 83.51 | 72.26 | 76.41 | 62.89 | 81.44 | 88.89 | 75.13 | 77.22 | 55.66 | 72.64 | 80.06 | 66.48 | 76.63 |
| Hi-SAM-L | 74.86 | 82.87 | 62.60 | 80.99 | 86.48 | 76.16 | 77.29 | 65.62 | 84.04 | 90.29 | 78.59 | 78.08 | 58.83 | 75.84 | 81.72 | 70.75 | 77.57 |
| Hi-SAM-H | 75.45 | 83.21 | 63.83 | 82.08 | 87.02 | 77.67 | 77.76 | 66.70 | 84.82 | 90.97 | 79.45 | 78.64 | 60.34 | 77.22 | 83.47 | 71.84 | 78.14 |
| Hi-SAM-B † | 70.35 | 79.65 | 61.17 | 80.55 | 84.35 | 77.08 | 75.93 | 67.32 | 88.17 | 91.21 | 85.32 | 76.35 | 57.85 | 75.88 | 81.43 | 71.03 | 76.24 |
| Hi-SAM-L † | 74.86 | 82.87 | 64.63 | 84.08 | 87.79 | 80.68 | 76.87 | 69.58 | 90.06 | 92.28 | 87.94 | 77.27 | 60.42 | 78.16 | 82.35 | 74.37 | 77.30 |
| Hi-SAM-H † | 75.45 | 83.21 | 65.73 | 85.06 | 88.18 | 82.15 | 77.28 | 70.61 | 90.81 | 92.85 | 88.85 | 77.76 | 61.81 | 79.40 | 83.86 | 75.38 | 77.85 |
4.4.2 层次化文本切分与布局分析
我们评估了 Hi-SAM 在 HierText 上的分层文本分割和布局分析性能。 我们首先比较 SOTA 统一检测器 (UD) [5] 和我们的 Hi-SAM 之间的功能和训练成本。
与UD的比较。 UD 使用 MaX-DeepLab-S 主干网络[72],其可训练参数量与 Hi-SAM-H 类似。 UD 的输入图像大小与我们的 Hi-SAM 相同。 UD 中的每个对象查询都经过训练,可以对一个文本行中的单词(而不是单个单词)进行分段。 因此,如表所示。 XIII,UD可以自然地在文本行级别进行单词分组,并且还可以通过后处理进行单词实例分割。 UD利用布局分支将对象查询聚类到不同的组中,从而实现布局分析(段落级别的单词分组)。 但是,UD 不具有提示性,无法分割文本笔划蒙版并实现完整的文本行和段落蒙版。 此外,UD 在 128 个 TPUv3 核心上进行训练,批量大小为 256,步长为 100K(约 3,091 epoch)。 相比之下,Hi-SAM 是第一个以文本为中心的模型,可以执行上述所有任务,并且是快速的。 此外,Hi-SAM 需要 更少的训练周期,并在八个 NVIDIA V100 GPU 上进行训练。
测试集的结果。 如表所示。 XIV,与UD相比,我们的方法在词级、文本行级和布局分析的PQ和F-score方面取得了显着的改进。 例如,Hi-SAM-H 在单词级别优于 UD 16.09% PQ 和 21.35% F 得分,在文本行级别单词分组方面优于 UD 4.73% PQ 和 5.39% F 得分,5.49% PQ 和 7.39% F 得分段落级布局分析。 我们注意到 UD 在单词级别表现不佳,可能是因为 UD 在密集文本场景中无法更好地分离相邻实例。 然而,这不会影响文本行和段落级别的性能。 请注意,UD 利用每个图像中的所有样本进行训练,并通过计算对象查询之间的亲和力分数来执行布局分析。 相比之下,我们设计了完全不同的训练和推理管道,其中我们仅对每个图像中的几个样本进行采样并实现布局分析,而无需额外的布局分支。 即使训练次数减少了 20,我们的方法仍然取得了明显更好的性能。 比较不同的 Hi-SAM 变体,我们观察到 Hi-SAM-L 明显优于 Hi-SAM-B,即。,实现了 3.36% PQ 和 3.49 的改进单词级别的 F 分数增加了 %,文本行级别的 PQ 增加了 2.83%,F 分数增加了 2.70%,段落级别的 PQ 增加了 3.15%,F 分数增加了 3.34%。 与 Hi-SAM-L 相比,主要改进在于布局分析结果,因为具有更好的图像嵌入。


验证集的结果。 我们还报告了 HierText 验证集的结果,如选项卡所示。 XV。 UD结果采集自官方GitHub仓库222https://github.com/google-research-datasets/hiertext。 可以看出,与 UD 相比,我们的方法也实现了与测试集类似的性能改进。 Hi-SAM-H 在单词级别优于 UD 15.36% PQ 和 20.43% F 得分,在文本行级别单词分组方面优于 UD 5.41% PQ 和 6.16% F 得分,在段落级别优于 UD 7.48% PQ 和 9.49% F 得分布局分析。 此外,我们利用清晰单词的多边形标注来计算质心点,并在推理过程中采用这些点作为生成分层掩码的提示。 我们观察到,使用这些质心点作为提示主要可以提高召回率(R)分数,尤其是在文本行级别。 例如,对于 Hi-SAM-B,单词级别、文本行级别和布局分析的召回分数分别提高了 4.82%、10.19% 和 4.55%。 对于 Hi-SAM-H,单词级别、文本行级别和布局分析的召回率指标分别提高了 4.49%、9.40% 和 3.54%。 这表明仍有开发更好采样策略的空间。 也许利用简单的计数模块来提供文本中心热图可能会有所帮助。 此外,由于我们对文本行掩码应用 NMS 并丢弃相应的字级掩码,因此剩余的字级掩码可能无法实现最佳分割。
5 限制与讨论
虽然 Hi-SAM 已表现出令人鼓舞的性能,但仍有进一步改进的潜力。 首先,由于主干网较重,现有的 Hi-SAM 模型无法达到实时推理速度。 由于SAM[73,74,75]的一些后续在开发轻量级SAM模型方面取得了很大进展,因此有望通过探索更轻量级的结构来开发高效的Hi-SAM模型。 其次,由于我们冻结了 SAM 图像编码器的预训练训练权重,并且仅使用 HierText 来处理 Hi-SAM,因此 Hi-SAM 对未知领域的适应性会受到限制。 第三,Hi-SAM 需要跨越四个文本层次结构的标签,这在实际数据集中是稀缺的。 值得尝试探索合成数据或基于扩散的[76]方法来生成具有复杂布局和准确文本内容的大规模分层文本数据。 第四,我们观察Tab中Hi-SAM的文本笔划分割结果。 XIV 低于 Tab 中的值。 XI。 如何在训练和推理过程中更好地协同不同的文本层次结构也是一个悬而未决的问题。
6 结论
在本研究中,我们演示了通过最少的定制将 SAM 转变为尖端的文本笔划分割模型 SAM-TSS。 它能够半自动生成高质量的文本笔画标签,帮助统一 HierText 中四个文本层次结构的注释。 基于这些进步,我们推出了 Hi-SAM——一种用于分层文本分割的开创性统一模型。 它可以跨多个级别无缝运行,从笔画到段落,同时无需任何专用模块即可进行布局分析。 它在自动掩模生成和交互式提示分割模式方面都表现出了出色的性能。 广泛的实验结果明确强调了我们提出的方法与现有代表性方法相比的优越性能。 我们希望这项工作能够为现实世界文本图像中实用的分层文本分割铺平道路,并激发该领域的进一步探索。
参考
- [1] X. Xu, Z. Zhang, Z. Wang, B. Price, Z. Wang, and H. Shi, “Rethinking text segmentation: A novel dataset and a text-specific refinement approach,” in CVPR, 2021, pp. 12 045–12 055.
- [2] X. Zu, H. Yu, B. Li, and X. Xue, “Weakly-supervised text instance segmentation,” in ACM MM, 2023, pp. 1915–1923.
- [3] D. Peng, Z. Yang, J. Zhang, C. Liu, Y. Shi, K. Ding, F. Guo, and L. Jin, “Upocr: Towards unified pixel-level ocr interface,” arXiv preprint arXiv:2312.02694, 2023.
- [4] S. Appalaraju, B. Jasani, B. U. Kota, Y. Xie, and R. Manmatha, “Docformer: End-to-end transformer for document understanding,” in ICCV, 2021, pp. 993–1003.
- [5] S. Long, S. Qin, D. Panteleev, A. Bissacco, Y. Fujii, and M. Raptis, “Towards end-to-end unified scene text detection and layout analysis,” in CVPR, 2022, pp. 1049–1059.
- [6] S. Long, S. Qin, Y. Fujii, A. Bissacco, and M. Raptis, “Hierarchical text spotter for joint text spotting and layout analysis,” in WACV, 2024, pp. 903–913.
- [7] J. Liu, Z. Chen, B. Du, and D. Tao, “Asts: A unified framework for arbitrary shape text spotting,” IEEE TIP, vol. 29, pp. 5924–5936, 2020.
- [8] Y. Ren, J. Zhang, B. Chen, X. Zhang, and L. Jin, “Looking from a higher-level perspective: Attention and recognition enhanced multi-scale scene text segmentation,” in ACCV, 2022, pp. 3138–3154.
- [9] X. Xu, Z. Qi, J. Ma, H. Zhang, Y. Shan, and X. Qie, “Bts: a bi-lingual benchmark for text segmentation in the wild,” in CVPR, 2022, pp. 19 152–19 162.
- [10] M. Liao, Z. Wan, C. Yao, K. Chen, and X. Bai, “Real-time scene text detection with differentiable binarization,” in AAAI, vol. 34, no. 07, 2020, pp. 11 474–11 481.
- [11] S.-X. Zhang, C. Yang, X. Zhu, and X.-C. Yin, “Arbitrary shape text detection via boundary transformer,” IEEE TMM, 2023.
- [12] M. Ye, J. Zhang, S. Zhao, J. Liu, B. Du, and D. Tao, “Dptext-detr: Towards better scene text detection with dynamic points in transformer,” in AAAI, vol. 37, no. 3, 2023, pp. 3241–3249.
- [13] M. Ye, J. Zhang, S. Zhao, J. Liu, T. Liu, B. Du, and D. Tao, “Deepsolo: Let transformer decoder with explicit points solo for text spotting,” in CVPR, 2023, pp. 19 348–19 357.
- [14] C. Yao, X. Bai, W. Liu, Y. Ma, and Z. Tu, “Detecting texts of arbitrary orientations in natural images,” in CVPR, 2012, pp. 1083–1090.
- [15] D. Karatzas, L. Gomez-Bigorda, A. Nicolaou, S. Ghosh, A. Bagdanov, M. Iwamura, J. Matas, L. Neumann, V. R. Chandrasekhar, S. Lu et al., “Icdar 2015 competition on robust reading,” in ICDAR, 2015, pp. 1156–1160.
- [16] Y. Liu, L. Jin, S. Zhang, C. Luo, and S. Zhang, “Curved scene text detection via transverse and longitudinal sequence connection,” PR, vol. 90, pp. 337–345, 2019.
- [17] C. K. Ch’ng and C. S. Chan, “Total-text: A comprehensive dataset for scene text detection and recognition,” in ICDAR, vol. 1, 2017, pp. 935–942.
- [18] C. K. Chng, Y. Liu, Y. Sun, C. C. Ng, C. Luo, Z. Ni, C. Fang, S. Zhang, J. Han, E. Ding et al., “Icdar2019 robust reading challenge on arbitrary-shaped text-rrc-art,” in ICDAR, 2019, pp. 1571–1576.
- [19] Y. Sun, Z. Ni, C.-K. Chng, Y. Liu, C. Luo, C. C. Ng, J. Han, E. Ding, J. Liu, D. Karatzas et al., “Icdar 2019 competition on large-scale street view text with partial labeling-rrc-lsvt,” in ICDAR, 2019, pp. 1557–1562.
- [20] A. Singh, G. Pang, M. Toh, J. Huang, W. Galuba, and T. Hassner, “Textocr: Towards large-scale end-to-end reasoning for arbitrary-shaped scene text,” in CVPR, 2021, pp. 8802–8812.
- [21] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo et al., “Segment anything,” in ICCV, 2023, pp. 4015–4026.
- [22] L. Ke, M. Ye, M. Danelljan, Y. Liu, Y.-W. Tai, C.-K. Tang, and F. Yu, “Segment anything in high quality,” in NeurIPS, 2023.
- [23] J. Cheng, J. Ye, Z. Deng, J. Chen, T. Li, H. Wang, Y. Su, Z. Huang, J. Chen, L. Jiang et al., “Sam-med2d,” arXiv:2308.16184, 2023.
- [24] W. Yue, J. Zhang, K. Hu, Y. Xia, J. Luo, and Z. Wang, “Surgicalsam: Efficient class promptable surgical instrument segmentation,” in AAAI, 2023.
- [25] Y. Cheng, L. Li, Y. Xu, X. Li, Z. Yang, W. Wang, and Y. Yang, “Segment and track anything,” arXiv:2305.06558, 2023.
- [26] J. Yang, M. Gao, Z. Li, S. Gao, F. Wang, and F. Zheng, “Track anything: Segment anything meets videos,” arXiv:2304.11968, 2023.
- [27] D. Wang, J. Zhang, B. Du, M. Xu, L. Liu, D. Tao, and L. Zhang, “SAMRS: Scaling-up remote sensing segmentation dataset with segment anything model,” in NeurIPS Datasets and Benchmarks Track, 2023. [Online]. Available: https://openreview.net/forum?id=jHrgq55ftl
- [28] X. Wang, C. Wu, H. Yu, B. Li, and X. Xue, “Textformer: Component-aware text segmentation with transformer,” in ICME, 2023, pp. 1877–1882.
- [29] M. Liao, B. Shi, X. Bai, X. Wang, and W. Liu, “Textboxes: A fast text detector with a single deep neural network,” in AAAI, vol. 31, no. 1, 2017.
- [30] M. Liao, B. Shi, and X. Bai, “Textboxes++: A single-shot oriented scene text detector,” IEEE TIP, vol. 27, no. 8, pp. 3676–3690, 2018.
- [31] Y. Baek, B. Lee, D. Han, S. Yun, and H. Lee, “Character region awareness for text detection,” in CVPR, 2019, pp. 9365–9374.
- [32] W. Wang, E. Xie, X. Li, W. Hou, T. Lu, G. Yu, and S. Shao, “Shape robust text detection with progressive scale expansion network,” in CVPR, 2019, pp. 9336–9345.
- [33] W. Wang, E. Xie, X. Song, Y. Zang, W. Wang, T. Lu, G. Yu, and C. Shen, “Efficient and accurate arbitrary-shaped text detection with pixel aggregation network,” in ICCV, 2019, pp. 8440–8449.
- [34] J. Ye, Z. Chen, J. Liu, and B. Du, “Textfusenet: Scene text detection with richer fused features.” in IJCAI, vol. 20, 2020, pp. 516–522.
- [35] S.-X. Zhang, X. Zhu, C. Yang, H. Wang, and X.-C. Yin, “Adaptive boundary proposal network for arbitrary shape text detection,” in CVPR, 2021, pp. 1305–1314.
- [36] Q. Bu, S. Park, M. Khang, and Y. Cheng, “Srformer: Empowering regression-based text detection transformer with segmentation,” in AAAI, 2023.
- [37] P. Dai, S. Zhang, H. Zhang, and X. Cao, “Progressive contour regression for arbitrary-shape scene text detection,” in CVPR, 2021, pp. 7393–7402.
- [38] X. Zhang, Y. Su, S. Tripathi, and Z. Tu, “Text spotting transformers,” in CVPR, 2022, pp. 9519–9528.
- [39] Y. Liu, H. Chen, C. Shen, T. He, L. Jin, and L. Wang, “Abcnet: Real-time scene text spotting with adaptive bezier-curve network,” in CVPR, 2020, pp. 9809–9818.
- [40] Y. Zhu, J. Chen, L. Liang, Z. Kuang, L. Jin, and W. Zhang, “Fourier contour embedding for arbitrary-shaped text detection,” in CVPR, 2021, pp. 3123–3131.
- [41] S. Schreiber, S. Agne, I. Wolf, A. Dengel, and S. Ahmed, “Deepdesrt: Deep learning for detection and structure recognition of tables in document images,” in ICDAR, vol. 1, 2017, pp. 1162–1167.
- [42] J. Lee, H. Hayashi, W. Ohyama, and S. Uchida, “Page segmentation using a convolutional neural network with trainable co-occurrence features,” in ICDAR, 2019, pp. 1023–1028.
- [43] Y. Huang, T. Lv, L. Cui, Y. Lu, and F. Wei, “Layoutlmv3: Pre-training for document ai with unified text and image masking,” in ACM MM, 2022, pp. 4083–4091.
- [44] C. Li, B. Bi, M. Yan, W. Wang, S. Huang, F. Huang, and L. Si, “Structurallm: Structural pre-training for form understanding,” arXiv:2105.11210, 2021.
- [45] S. Song, J. Wan, Z. Yang, J. Tang, W. Cheng, X. Bai, and C. Yao, “Vision-language pre-training for boosting scene text detectors,” in CVPR, 2022, pp. 15 681–15 691.
- [46] C. Xue, W. Zhang, Y. Hao, S. Lu, P. H. Torr, and S. Bai, “Language matters: A weakly supervised vision-language pre-training approach for scene text detection and spotting,” in ECCV, 2022, pp. 284–302.
- [47] W. Yu, Y. Liu, W. Hua, D. Jiang, B. Ren, and X. Bai, “Turning a clip model into a scene text detector,” in CVPR, 2023, pp. 6978–6988.
- [48] W. Yu, Y. Liu, X. Zhu, H. Cao, X. Sun, and X. Bai, “Turning a clip model into a scene text spotter,” arXiv:2308.10408, 2023.
- [49] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in ICML, 2021, pp. 8748–8763.
- [50] Z. Wang, H. Xie, Y. Wang, J. Xu, B. Zhang, and Y. Zhang, “Symmetrical linguistic feature distillation with clip for scene text recognition,” in ACM MM, 2023, pp. 509–518.
- [51] J. Yao, X. Wang, L. Ye, and W. Liu, “Matte anything: Interactive natural image matting with segment anything models,” arXiv:2306.04121, 2023.
- [52] J. Cen, Z. Zhou, J. Fang, C. Yang, W. Shen, L. Xie, X. Zhang, and Q. Tian, “Segment anything in 3d with nerfs,” in NeurIPS, 2023.
- [53] W. Yue, J. Zhang, K. Hu, Q. Wu, Z. Ge, Y. Xia, J. Luo, and Z. Wang, “Part to whole: Collaborative prompting for surgical instrument segmentation,” arXiv:2312.14481, 2023.
- [54] J. Wu, R. Fu, H. Fang, Y. Liu, Z. Wang, Y. Xu, Y. Jin, and T. Arbel, “Medical sam adapter: Adapting segment anything model for medical image segmentation,” arXiv:2304.12620, 2023.
- [55] K. Zhang and D. Liu, “Customized segment anything model for medical image segmentation,” arXiv:2304.13785, 2023.
- [56] R. Zhang, Z. Jiang, Z. Guo, S. Yan, J. Pan, H. Dong, P. Gao, and H. Li, “Personalize segment anything model with one shot,” arXiv:2305.03048, 2023.
- [57] Y. Liu, M. Zhu, H. Li, H. Chen, X. Wang, and C. Shen, “Matcher: Segment anything with one shot using all-purpose feature matching,” arXiv:2305.13310, 2023.
- [58] N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in ECCV, 2020, pp. 213–229.
- [59] M. Ryoo, A. Piergiovanni, A. Arnab, M. Dehghani, and A. Angelova, “Tokenlearner: Adaptive space-time tokenization for videos,” in NeurIPS, vol. 34, 2021, pp. 12 786–12 797.
- [60] G. Ghiasi, Y. Cui, A. Srinivas, R. Qian, T.-Y. Lin, E. D. Cubuk, Q. V. Le, and B. Zoph, “Simple copy-paste is a strong data augmentation method for instance segmentation,” in CVPR, 2021, pp. 2918–2928.
- [61] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár, “Focal loss for dense object detection,” in ICCV, 2017.
- [62] F. Milletari, N. Navab, and S.-A. Ahmadi, “V-net: Fully convolutional neural networks for volumetric medical image segmentation,” in 3DV, 2016.
- [63] X. Wang, R. Zhang, T. Kong, L. Li, and C. Shen, “Solov2: Dynamic and fast instance segmentation,” in NeurIPS, 2020.
- [64] S. Bonechi, P. Andreini, M. Bianchini, and F. Scarselli, “Coco_ts dataset: pixel–level annotations based on weak supervision for scene text segmentation,” in ICANN, 2019, pp. 238–250.
- [65] A. Veit, T. Matera, L. Neumann, J. Matas, and S. Belongie, “Coco-text: Dataset and benchmark for text detection and recognition in natural images,” arXiv:1601.07140, 2016.
- [66] A. Kirillov, K. He, R. Girshick, C. Rother, and P. Dollár, “Panoptic segmentation,” in CVPR, 2019, pp. 9404–9413.
- [67] I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” in ICLR, 2019.
- [68] H. Yu, X. Wang, K. Niu, B. Li, and X. Xue, “Scene text segmentation with text-focused transformers,” in ACM MM, 2023, pp. 2898–2907.
- [69] L.-C. Chen, Y. Zhu, G. Papandreou, F. Schroff, and H. Adam, “Encoder-decoder with atrous separable convolution for semantic image segmentation,” in ECCV, 2018, pp. 801–818.
- [70] J. Wang, K. Sun, T. Cheng, B. Jiang, C. Deng, Y. Zhao, D. Liu, Y. Mu, M. Tan, X. Wang et al., “Deep high-resolution representation learning for visual recognition,” IEEE TPAMI, vol. 43, no. 10, pp. 3349–3364, 2020.
- [71] E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Alvarez, and P. Luo, “Segformer: Simple and efficient design for semantic segmentation with transformers,” NeurIPS, vol. 34, pp. 12 077–12 090, 2021.
- [72] H. Wang, Y. Zhu, H. Adam, A. Yuille, and L.-C. Chen, “Max-deeplab: End-to-end panoptic segmentation with mask transformers,” in CVPR, 2021, pp. 5463–5474.
- [73] X. Zhao, W. Ding, Y. An, Y. Du, T. Yu, M. Li, M. Tang, and J. Wang, “Fast segment anything,” arXiv:2306.12156, 2023.
- [74] C. Zhang, D. Han, Y. Qiao, J. U. Kim, S.-H. Bae, S. Lee, and C. S. Hong, “Faster segment anything: Towards lightweight sam for mobile applications,” arXiv:2306.14289, 2023.
- [75] C. Zhou, X. Li, C. C. Loy, and B. Dai, “Edgesam: Prompt-in-the-loop distillation for on-device deployment of sam,” arXiv:2312.06660, 2023.
- [76] J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” in NeurIPS, vol. 33, 2020, pp. 6840–6851.