UPDP:CNN 和 Vision Transformer 的统一渐进深度剪枝器
摘要
传统的通道修剪方法通过减少网络通道来有效地修剪具有深度卷积层和某些高效模块(例如流行的反向残差块)的高效 CNN 模型。 由于一些归一化层的存在,先前通过减少网络深度的深度剪枝方法不适合剪枝一些高效模型。 此外,通过直接删除激活层来微调子网会破坏原始模型权重,阻碍剪枝后的模型实现高性能。 为了解决这些问题,我们提出了一种新的有效模型深度修剪方法。 我们的方法提出了一种新颖的子网块修剪策略和渐进式训练方法。 此外,我们将剪枝方法扩展到视觉 Transformer 模型。 实验结果表明,我们的方法在各种修剪配置中始终优于现有的深度修剪方法。 我们将我们的方法应用在 ConvNeXtV1 上,获得了三个剪枝的 ConvNeXtV1 模型,它们超越了具有可比推理性能的大多数 SOTA 高效模型。 我们的方法还在视觉 Transformer 模型上实现了最先进的剪枝性能。
介绍
深度神经网络 (DNN) 在各种任务上取得了重大进展,最终在工业应用中取得了显着的成功。 在这些应用中,对模型优化的追求是一种普遍的需求,它提供了提高模型推理速度同时最大限度地减少准确性权衡的潜力。 这种追求涵盖了一系列技术,特别是模型修剪、量化和高效模型设计。 高效的模型设计包括神经架构搜索(NAS)(Cai 等人 2020; Yu 和 Huang 2019; Yu 等人 2020; Wang 等人 2021a) 和手工设计方法。
模型剪枝已成为工业应用中优化模型的流行策略。 作为主要的加速方法,模型修剪的重点是在保持准确性的同时故意删除冗余权重。 此过程通常涉及三个连续步骤:初始基线模型训练、随后对较不重要的权重或层通道进行修剪,以及对修剪后的模型进行最后的微调阶段。 值得注意的是,模型剪枝可以分为两类:非结构化剪枝和结构化剪枝。 结构化剪枝是工业应用中模型部署的首选方法,主要是由于硬件限制。 与非结构化方法相反,非结构化方法中卷积核层中不太重要的权重在每个内核通道内以稀疏方式清零,结构化剪枝包含通道剪枝和块剪枝等技术。 通道修剪侧重于消除内核内的整个通道过滤器,而块修剪则在更大范围内进行,通常针对完整块。 鉴于块剪枝通常会导致模型深度减少,因此也称为深度剪枝器。
CNN 模型设计的演变导致了更高效模型的开发。 例如,MobileNetV2 (Sandler 等人 2018) 采用大量深度卷积层并堆叠反向残差块,实现高性能,同时最大限度地减少参数和失败。 ConvNeXtV1 (Liu 等人 2022) 利用大核技巧并结合堆叠的反向残差块来实现显着的效率。 由于计算稀疏和参数较少,传统的通道剪枝方法面临深度卷积层的挑战。 此外,现在的模型平台倾向于更高程度的并行计算,如 GPU,而逐通道修剪方法将使高效模型变得更薄、更稀疏,从而导致硬件利用率较低,从而降低可实现的硬件效率。 为了解决这些问题,提出了 DepthShrinker (Fu 等人 2022) 和 Layer-Folding (Dror 等人 2021),通过重新参数化技术减少模型深度来优化 MobileNetV2 (丁等人2021a,b)。 然而,这些方法表现出一定的局限性。 (1)直接删除激活层来微调子网的机制可能会损害基线模型权重的完整性,阻碍高性能的实现。 (2) 这些方法存在使用限制,无法使用某些归一化层来修剪模型,例如 LayerNorm (Ba, Kiros, and Hinton 2016) 或 GroupNorm (Wu and He 2018) 层,因为重新参数化技术无法将不是 BatchNorm 层的归一化层合并到相邻的卷积层或全连接层中。 (3) 由于LayerNorm层的存在,这些方法无法应用于视觉Transformer模型进行优化。
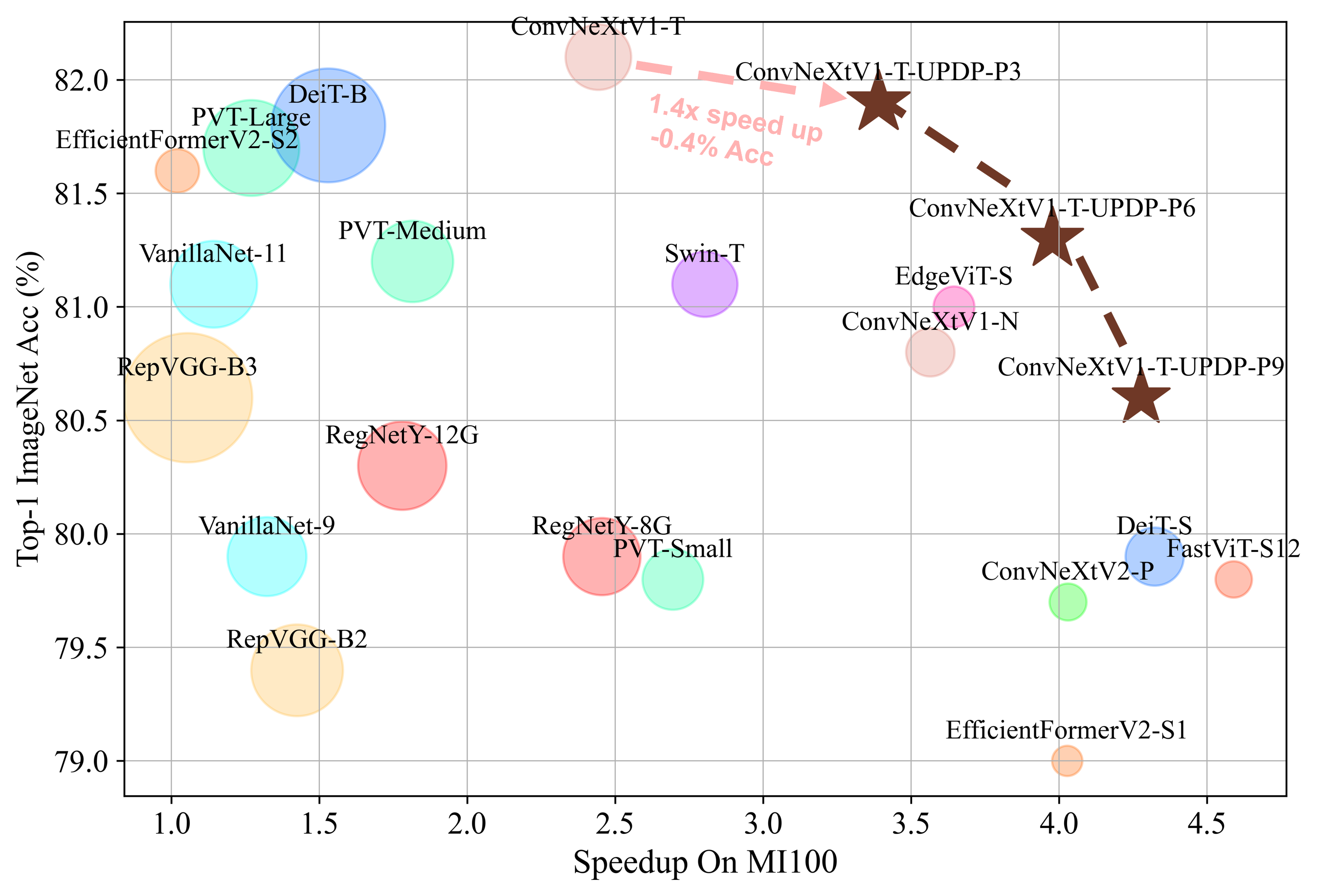
为了缓解这些问题,我们为深度修剪方法提出了一种渐进式训练策略和新颖的块修剪方法,可以修剪 CNN 和视觉 Transformer 模型。 渐进式训练策略可以将基线模型结构平滑地转移到子网结构,并且基线模型权重利用率高,从而获得更高的准确率。 我们提出的块剪枝方法可以处理现有的归一化层问题,理论上可以处理所有激活层和归一化层。 因此,我们的方法可以修剪视觉 Transformer 模型,这不适合现有的深度修剪方法。 我们的实验评估涵盖 ResNet34、MobileNetV2 和 ConvNeXtV1,展示了卓越的剪枝能力。 如图1所示,使用我们的方法剪枝的ConvNeXtV1模型超越了具有可比推理性能的大多数SOTA高效模型。 值得注意的是,我们将探索扩展到视觉 Transformer 模型,与其他视觉 Transformer 剪枝方法相比,取得了领先的剪枝结果。
我们的主要贡献可总结如下。 (1) 我们提出了一种统一且高效的深度剪枝方法来优化 CNN 和视觉 Transformer 模型。 (2) 我们提出了一种用于子网优化的渐进式训练策略,结合使用重新参数化技术的新颖的块修剪策略。 (3) 对 CNN 和视觉 Transformer 模型进行全面的实验,以展示我们的深度剪枝方法的优越剪枝性能。
相关工作
网络修剪。 剪枝算法大致可以分为两类。 一是以为代表的非结构化剪枝算法(Han, Mao, and Dally 2015; Elsen 等人 2020; Pool and Yu 2021)。 它根据一定的标准去除权重中的冗余元素。 然而,非结构化剪枝需要专门的软件或硬件加速器来支持剪枝模型,因此其通用性不强。 与非结构化剪枝相反,结构化剪枝会剪枝整个参数结构,例如丢弃整行或整列的权重,或者卷积层中的整个滤波器。
当VGG (Simonyan and Zisserman 2014)和ResNet (He 等人 2016)兴起时,Pruning Filters (Li 等人 2016)采用L1范数选择不重要的通道并进行剪枝。 网络 FPGM (He 等人 2019) 利用卷积滤波器的几何中值来查找冗余滤波器。 随后,各种高效的 DNN 网络,例如 MobileNet 及其变体(Howard 等人 2017, 2019; Tan 等人 2019; Radosavovic 等人 2020),结合了深度卷积(Chollet 2017) 加快速度并提高准确性,从而实现在不同硬件平台上的实时部署。 MatePruning(Liu 等人 2019) 提出了 PruningNet 的概念,自动为剪枝后的模型生成权重,从而避免重新训练。 然而,虽然深度卷积在减少计算和参数方面具有优势,但它也存在一个缺点——内存占用增加,这对 GPU 和 DSP 等计算密集型硬件构成了挑战(Tan 和 Le 2021) 。 不幸的是,通道式修剪方法并没有提供直观且有效的解决方案来解决这一内存占用挑战。
与我们的工作最相关的是逐层剪枝,它可以完全删除一个块或层以减少网络深度并有效缓解内存使用问题。 Shallowing Deep Network(Chen and Zhu 2018)和 LayerPrune (Elkerdawy 等人 2020)提出了他们自己的评估卷积层重要性的策略。 ESNB (Zhou, Yen, and Yi 2021) 和 ResConv (Xu 等人 2020) 分别确定由进化搜索算法和可微参数修剪哪些层。 Layer-Folding (Dror 等人 2021) 和 DepthShinker (Fu 等人 2022) 去除块内的非线性激活函数,并使用结构将多个层合并为单个层重新参数化技术。 Layer-Folding和DepthShinker仅在少数有限模型上进行了验证,硬去除ReLU可能会对子网的准确性产生影响。
Transformer 系列模型在各种视觉任务中均表现出色(Carion 等人 2020;Strudel 等人 2021;Brown 等人 2020);然而,其高推理成本和大量内存占用阻碍了广泛采用(Pope等人2023)。 为了应对内存占用的挑战,分层修剪提供了一种有效的解决方案。 动态跳块去除一些层已成为主流的 Transformer 压缩方法(Zhang and He 2020;Dong, Cordonnier, and Loukas 2021;Michel, Levy, and Neubig 2019)。 DynamicViT (Rao 等人 2021) 动态筛选需要传递到下一层的 token 数量。 通过鼓励维度稀疏,VTP (Zhu,Tang,and Han 2021)选择具有强冗余的维度进行剪枝。
结构重新参数化。 在块内缺乏非线性激活函数的情况下,结构重新参数化技术有助于将多个卷积层合并为单个卷积层(Bhardwaj等人2022)。 这种整合有效地减少了神经网络在推理过程中的内存需求,从而加速了模型处理。 RepVGG (Ding 等人 2021b) 区分了训练和测试结构,使普通网络的性能超越了 ResNet。 此外,DBB (Ding 等人 2021a) 将多分支架构合并到单个卷积中,显着超过了传统多分支单元的速度。
神经架构搜索(NAS)。 权重共享NAS由于其训练超网、部署多个子网的灵活性和便利性,已经成为剪枝方法的主流。 Once-for-All (Cai 等人 2020) 使用渐进式训练超网。 BigNAS (Yu 等人 2020) 使用一系列简单实用的训练方法来提高训练超网的效率。 一旦超级网经过训练,就可以应用典型的搜索算法(例如遗传搜索)来为各种部署场景找到一组帕累托最优网络。
在这项工作中,我们提出了一种针对高效 CNN 和视觉 Transformer 模型的统一深度剪枝训练方法,具有渐进策略、新颖的块剪枝方法和重新参数化技术。 与 DepthShrinker 和 Layer-Folding 通过直接删除激活层来微调子网不同,我们的方法在子网训练期间逐步删除剪枝块中的激活层。 此外,我们的方法处理了归一化层问题,即 DepthShrinker 和 Layer-Folding 无法修剪块中具有 LayerNorm 或 GroupNorm 层的模型。 此外,他们无法修剪 Vision Transformer 模型。 虽然我们的工作与 VanillaNet (Chen 等人 2023) 具有类似的训练过程,而 VanillaNet 是为了设计一个全新的网络结构而提出的,但我们的方法是一个适用于 CNN 和视觉 Transformer 的通用深度剪枝框架楷模。
方法
统一渐进深度修剪器
我们的深度修剪方法旨在通过提出新颖的块修剪策略和重新参数化技术来减少模型深度,而不是直接省略块。 如图2所示,我们的块剪枝策略在块合并中将复杂且缓慢的块转换为简单且快速的块。 对于块,我们用恒等层替换激活层,用 BatchNorm (BN) 层替换 LayerNorm (LN) 或 GroupNorm (GN) 层,并在块末尾插入带有 BatchNorm 层的激活层,为块的末尾创建条件重新参数化。 然后,重新参数化技术可以合并 BatchNorm 层、相邻的卷积层或全连接层并跳过连接,如图 2 所示。
概述。 我们的方法主要包括四个主要步骤,即超网训练、子网搜索、子网训练和子网合并。 首先,我们基于基线模型构建一个超网,并进行块修改,如图2所示。 supernet训练后,使用搜索算法来搜索最佳子网。 然后,我们采用提出的渐进训练策略来优化最佳子网,并减少准确性损失。 最后,子网将通过重新参数化技术合并为更浅的模型。
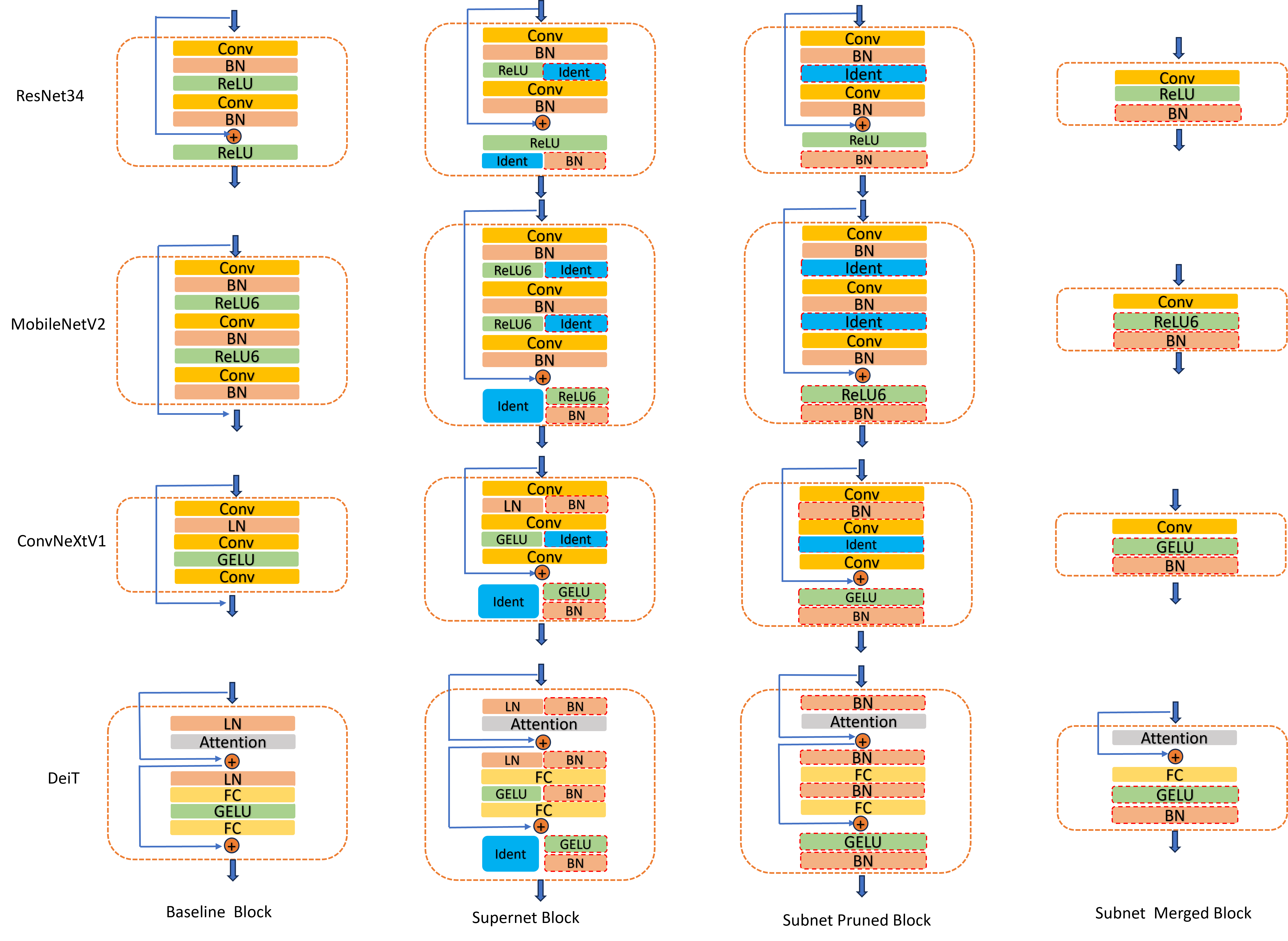
超网训练。 高效的 CNN 和视觉 Transformer 模型通常由几个基本块组成,如图2所示的一些高效模型结构。 首先,我们基于基线模型构建一个超网,然后基于三明治规则(Yu and Huang 2019)方法训练一个鲁棒的超网模型,以确保每个子网具有有意义的准确性。 我们将基线块和相应的修剪块组合成一个超网块,该超级网块同时具有基线块和修剪块流。 对于超网块来说,选择基线块流意味着不进行剪枝,选择剪枝块流意味着对块进行剪枝。 然后,子网选择是一系列选择,其中选择数等于基线模型的块数。 如果选择更多的修剪块,子网将会更快。
受 BigNAS (Yu 等人 2020) 的启发,我们采用三明治规则在每一步之前对子网络进行采样。 在每个步骤中,我们对四个连续的子网进行采样,其中第一个子网保持所有块不被剪枝,接下来的两个子网随机选择要剪枝的块,最后一个子网保持所有块被剪枝。 然后,我们用四个子网的累积梯度来优化超网。 三明治规则可以有效保证训练出来的超网的上限和下限。 还有许多方法(Wang 等人 2021b, a) 证明了三明治规则可以有效地用于训练超网,即使 epoch 的数量很少并且子网的精度分布与训练更多纪元。 这样,我们就可以降低超网的训练成本。
子网搜索。 我们的深度剪枝器的主要目标是根据指定的剪枝标准(例如要剪枝的块数量)来识别最佳子网。 如方程1所示,我们将此问题表述为最优问题。 对于所有样本及其标签,子网搜索的目标是找到精度最高的子网。 是一个二进制向量,表示子网的剪枝设置。 如果第 个块被修剪,则 设置为 。 每个子网的剪枝块数等于。遗传算法(Cai等人2020)被用来解决这个问题。
| (1) |
经过搜索过程后,我们获得了一个具有指定数量的修剪块的子网,其他块保持与基线模型相同。
子网训练。 我们需要对上一步获得的最优子网进行训练以恢复其准确性。 我们的方法不是直接训练子网,而是采用渐进式训练策略来微调从基线模型权重平滑转移的子网。 子网训练由两个阶段组成。 在第一个训练阶段,我们采用渐进式训练策略,通过控制因子逐渐从基线模型结构转移到修剪子网结构。 在第二阶段,我们继续将修剪后的子网微调到最后以获得高精度。
对于第一阶段,从0到1的逐渐过渡允许将基线块转移到修剪块的受控过程,如方程2所示,其中是基线模型的块,是子网的剪枝块,是块的输入。 这样该子网的所有剪枝块都会经历与相同的过程,顺利得到剪枝子网。
| (2) |
我们的方法在第一个训练阶段控制 从 0 到 1 的转换,然后在第二个训练阶段保持 恒定,如方程 3 所示,其中 是超参数, 是当前训练纪元, 是总训练纪元。
| (3) |
值得注意的是,为了减少后续子网合并中的误差,需要在子网训练之前修改剪枝块中相关卷积层的padding和stride。 例如,将所有不为零的填充值向前累加到块的第一个卷积层,并将剩余卷积层的填充值设置为零。 另外,将所有不等于 1 的步幅值向后累加到块的最后一个卷积层,并将其他卷积层的步幅值设置为 1。
子网合并。 在subnet训练之后,我们得到一个子网,其中一些激活层替换为Identity层,一些LayerNorm层替换为带有一些激活层的BatchNorm层,并且BatchNorm插入到修剪块的末尾。 在这个阶段,我们采用重新参数化技术使子网变浅。
-
•
在神经网络的推理阶段,可以将 BatchNorm 层的操作融合到卷积 (Conv) 层中以加速模型推理。 我们假设Conv层的参数表示为和,BN层的参数表示为。 Conv层和BN层合并后,Conv层的参数将修改如下:
| (4) |
-
•
两个相邻的全连接(FC)层可以通过融合它们的权重简单地合并为一个FC层。 假设有两个相邻的FC层,它们的权重是和,它们的偏置是和。 对于给定的输入特征 ,这两个 FC 层的输出表示为 ,可以通过权重等于 、偏置等于 的等效 FC 层获得。
我们主要介绍卷积层之间的融合方法。 对于顺序卷积层与卷积层融合,我们采用DBB (Ding等人2021a)提出的融合方法将两层合并为等效的卷积层。 对于顺序卷积层与融合,将获得等效的卷积层,与卷积相比,具有更多参数和失败次数层。 我们提出了一种简单的方法来解决这个问题,用 Conv 层替换第一个 Conv 层,其中 Conv 的参数取自具有再训练模型的 Conv 的中心点。 然后采取DBB融合方法将两个卷积层转化为等效的卷积层。
-
•
RepVGG (Ding 等人 2021b) 提出了一种将多分支模型转换为等效单路径模型的方法。 根据卷积的可加性,对于两个具有相同核大小的卷积层,它们满足以下方程5:
| (5) |
其中表示卷积运算,和是卷积核参数,是输入数据。 RepVGG证明了恒等卷积和卷积可以等价地转化为卷积。 然后利用卷积可加性的性质,多分支卷积层可以合并为一个等效的卷积层,并且跳过连接恒等也可以合并为卷积层。
CNN 的深度修剪器
将我们的方法应用于 CNN 模型可以参考图 2 显示流程。 我们首先应该找到基本块,并参考图2中的剪枝块设计相应的剪枝块。 对于块中的激活层,我们将其替换为身份层。 对于归一化层,它不是块中的 BatchNorm 层,我们将其替换为 BatchNorm 层,否则无需执行任何操作。 最后,我们将在块末尾插入一个带有 BatchNorm 层的激活层。 如果像ResNet34块这样的位置已经存在激活层,则只需要在块末尾的激活层之后插入BatchNorm层。 剪枝完成后,回顾一下超网训练、子网搜索、子网训练和子网合并过程。 我们将获得修剪后的 CNN 模型。 对于普通 CNN 模型,我们可以定义包含两个或多个连续卷积层的块。
Vision Transformer 上的深度修剪器
实验
在本节中,我们展示深度修剪器的功效。 首先,我们阐明了实验配置,并概述了将深度剪枝器应用于 CNN 模型和视觉 Transformer 的程序。 随后,我们将我们的结果与最先进的修剪方法进行比较,以突出我们方法的优越性。 最后,我们进行了消融研究,以详细说明我们方法中子网搜索和渐进训练策略的效果。
数据集
所有实验均在ImageNet-1K(Russakovsky 等人 2015)上进行。 ImageNet-1K 数据集是广泛使用的图像分类数据集,涵盖 1000 个对象类,包含 1,281,167 个训练图像、50,000 个验证图像和 100,000 个测试图像。 我们应用传统的数据增强技术在训练期间对输入图像进行预处理,并将输入图像缩放到 ,以用于所有实验并在验证数据集上报告性能。
不同模型的实验设置
我们在一系列 CNN 模型上应用深度剪枝,包括 ResNet34 (He 等人 2016)、MobileNetV2、ConvNeXtV1 (Liu 等人 2022) 和 Vision Transformer (Touvron 等人 2021) 验证我们方法的效率。 我们利用四个 GPU 来训练我们的模型,总批量大小为 256。 在训练过程中,我们使用 10 个 epoch 来训练超网(MobileNetV2 除外)并搜索最佳子网。 然后,我们使用所提出的渐进式训练策略来训练这些子网,并完成子网合并以获得更有效的浅层模型。
ResNet34。 对于ResNet34剪枝实验,我们分别剪枝6个和10个块,并完成整个剪枝过程以获得两个剪枝的浅子网。 对于子网训练,方程3中的超参数为3,总训练周期为150。 在第 100 轮,我们将剪枝块中第一个卷积层的内核大小从 更改为 。 我们将我们的方法与 MetaPruning (Liu 等人 2019) 和通道级 NAS 方法 Universally Slimmable Networks (US) (Yu and Huang 2019) 进行比较,以验证剪枝性能。
MobileNetV2。 对于 MobileNetV2 剪枝实验,我们采用 DepthShrinker 的三种剪枝配置。 我们跳过超网训练和子网搜索阶段以获得三个相同的子网。 我们直接将这三个子网训练到底,并将最终性能与相应的子网进行比较。 我们还使用NAS方法搜索三个具有相似加速比的子网来与我们的方法进行比较。 对于子网训练,超参数训练为3,总epoch为450。
| Models | FLOPs (G) | Acc1 (%) | Speedup |
| ResNet34-Baseline | 3.67 | 73.6 | 1.00 |
| US-ResNet34-0.6 | 2.32 | 72.0 | 1.24 |
| MetaPruning-0.6 | 2.32 | 72.8 | 1.24 |
| Ours-P6 | 2.97 | 73.2 | 1.25 |
| Ours-P6* | 2.97 | 73.5 | 1.24 |
| US-ResNet34-0.5 | 1.90 | 70.8 | 1.43 |
| MetaPruning-0.5 | 1.87 | 71.6 | 1.43 |
| Ours-P10 | 2.51 | 71.8 | 1.43 |
| Ours-P10* | 2.51 | 72.4 | 1.43 |
ConvNeXtV1。 对于 ConvNeXtV1 剪枝实验,我们设置了三种剪枝配置,使子网在 ImageNet-1k 上获得约 81% top-1 准确率的性能。 然后,我们将这些子网与许多 SOTA 模型(包括 CNN 和视觉 Transformer 结构)进行比较,以验证我们的方法剪枝性能。 对于子网训练,超参数训练 为 4.5,总 epoch 为 450。 为了实现更好的加速,我们将剪枝块的深度卷积的内核从 7 更改为 3。
DeiT。 对于 DeiT 剪枝实验,我们进行了 6 层实验的剪枝实验,与 SOTA 视觉 Transformer 剪枝方法进行比较。 对于子网训练,超参数训练为6,总epoch为450。
与 SOTA 模型的比较
我们在单个 AMD MI100 GPU 上的类似推理速度下将深度剪枝器与最先进的剪枝方法进行比较。 继(Graham等人2021)之后,我们测量了batchsize = 128的压缩网络的平均推理加速。 在本文中,我们比较了具有可比较加速速度的不同模型的准确性。
ResNet34。 表1将我们的方法与ResNet34上的MetaPruning和NAS US方法进行了比较。 我们通过应用深度剪枝器分别剪枝 6 和 10 个块,以获得分别具有 1.25 和 1.43 加速比的两个子网。 在可比较的加速比下,我们的方法在 1.43 加速比和更长的搜索时间上超过 MetaPruing 0.8%,超过 NAS US 方法 1.6%。
| Models | FLOPs (M) | Acc1 (%) | Speedup |
| MBV2-1.4-Baseline | 630 | 76.5 | 1.00 |
| MetaPruning-0.5 | 332 | 73.2 | 1.49 |
| US-MBV2-1.4-0.6 | 384 | 73.4 | 1.56 |
| MBV2-1.4-DS-A | 519 | 74.4 | 1.75 |
| Ours-P6 | 519 | 74.8 | 1.75 |
| US-MBV2-1.4-0.4 | 286 | 72.2 | 2.04 |
| MBV2-1.4-DS-C | 492 | 73.1 | 2.16 |
| Ours-P9 | 492 | 73.8 | 2.16 |
| US-MBV2-1.4-0.3 | 213 | 68.1 | 2.40 |
| MBV2-1.4-DS-E | 474 | 72.2 | 2.50 |
| Ours-P11 | 474 | 72.5 | 2.50 |
| Models | Type | FLOPs(G) | Params(M) | Acc1(%) | Speedup |
| ConvNeXtV1-T-Baseline (Liu et al. 2022) | Conv | 4.5 | 28.6 | 82.1 | 2.4 |
| RepVGG-B1 (Ding et al. 2021b) | Conv | 11.8 | 51.8 | 78.4 | 2.1 |
| EfficientFormerV2-S1 (Li et al. 2022) | Hybrid | 0.7 | 6.1 | 79.0 | 4.0 |
| MobileOne-S4 (Vasu et al. 2023) | Conv | 3.0 | 14.8 | 79.4 | 3.9 |
| ConvNeXtV2-P (Woo et al. 2023) | Conv | 9.1 | 9.1 | 79.7 | 4.0 |
| PVT-Small (Wang et al. 2021c) | Attention | 3.8 | 24.5 | 79.8 | 2.7 |
| VanillaNet-9 (Chen et al. 2023) | Conv | 8.6 | 41.4 | 79.9 | 1.1 |
| RegNetY-12G (Radosavovic et al. 2020) | Conv | 12.1 | 51.8 | 80.3 | 1.8 |
| ConvNeXtV1-T-UPDP-P9 | Conv | 2.5 | 23.6 | 80.6 | 4.9 |
| RepVGG-B3 (Ding et al. 2021b) | Conv | 26.2 | 110.9 | 80.6 | 1.1 |
| ConvNeXtV1-N (Woo et al. 2023) | Conv | 2.5 | 15.6 | 80.8 | 3.6 |
| EdgeViT-S (Pan et al. 2022) | Hybrid | 1.9 | 11.1 | 81.0 | 3.6 |
| Swin-T (Liu et al. 2021) | Attention | 4.5 | 28.3 | 81.1 | 2.8 |
| PVT-Medium (Wang et al. 2021c) | Attention | 6.7 | 44.0 | 81.2 | 1.8 |
| ConvNeXtV1-T-UPDP-P6 | Conv | 3.1 | 27.5 | 81.3 | 4.2 |
| VanillaNet-11 (Chen et al. 2023) | Conv | 10.3 | 50.0 | 81.1 | 1.1 |
| EfficientFormerV2-S2 (Li et al. 2022) | Hybrid | 1.3 | 12.6 | 81.6 | 1.0 |
| PVT-Large (Wang et al. 2021c) | Attention | 9.8 | 61.0 | 81.7 | 1.3 |
| DeiT-B (Touvron et al. 2021) | Attention | 17.5 | 86.0 | 81.8 | 1.5 |
| ConvNeXtV1-T-UPDP-P3 | Conv | 3.8 | 28.3 | 81.9 | 3.3 |
MobileNetV2。 表2显示了MobileNetV2-1.4上的实验结果。 我们采用与 DepthShrinker 相同的子网,但子网训练过程与我们的渐进式训练策略不同。 我们在 2.16 加速比下实现了比 MBV2-1.4-DS-C 高 0.7% 的精度,并且在其他加速比下与 DepthShrinker 相比也有一些改进。 我们还比较了MetaPruning,与ResNet34类似,我们重现了MetaPruning-0.35,其推理速度与MBV2-1.4-DS-C相当,而我们的深度剪枝以更高的加速比实现了2.1%的准确率提高。
| Models | FLOPs (G) | Params (M) | Acc1 (%) | Speedup |
| DeiT-Tiny | 1.3 | 5.4 | 72.2 | 1.00 |
| SCOP* | 0.8 | - | 68.9 | - |
| HVT* | 0.7 | - | 69.7 | - |
| SViTE | 1.0 | 4.2 | 70.1 | 1.12 |
| WD-Pruning | 0.7 | 3.5 | 70.3 | 1.20 |
| XPruner | 0.6 | - | 71.1 | - |
| Ours-P6 | 0.9 | 3.8 | 70.3 | 1.26 |
ConvNeXtV1。 表3将我们的准确性与一些常见的高效模型进行了比较,因为ConvNeXtV1没有压缩方法。 我们以表中最慢的网络EfficientFormerV2-S2为基准,测试了AMD平台上所有网络的加速比。 我们按精度将模型划分为多个级别,我们的深度剪枝方法在不同级别下以相当的速度实现了更高的精度。
DeiT。 如表4所示,我们的方法在精度和加速比方面都优于其他最先进的方法。 我们提出的深度剪枝器实现了 1.26 加速比,而 top-1 精度仅下降 1.9%。 通过替换可合并模块并应用重新参数化技术,我们提出的方法可以缩小网络并带来真正的推理加速。
消融研究
在本节中,我们分析子网搜索和渐进训练策略的有效性。
| Models | Before FT(%) | After FT(%) |
| ResNet34-P10-A | 57.8 | 71.8 |
| ResNet34-P10-B | 55.9 | 71.2 |
子网搜索的有效性。 在基于 ResNet34 的子网微调 (FT) 之前,我们通过比较两个具有不同精度的剪枝 10 层子网的性能来验证 ResNet34 子网搜索的有效性。 表5显示ResNet34-P10-A在子网微调之前具有较高的精度,可以达到较高的微调精度,这证明了超网训练和子网搜索最优子网的有效性,并具有最终的高性能。
| Models | Direct (%) | Progressive (%) |
| ResNet34-P10 | 71.3 | 71.8 |
| MBV2-1.4-P9 | 73.1 | 73.8 |
| ConvNeXtV1-T-P3 | 81.6 | 81.9 |
| DeiT-Tiny-P6 | 69.5 | 70.3 |
渐进式训练策略的有效性。 与硬去除非线性激活函数相比,我们的渐进式训练在每个子网络的准确性上都有显着的提高。 如表6所示,对于各种子网络,我们观察到渐进训练比直接训练方法提高了 0.3%-0.8% 的准确率。
结论
在本文中,我们为高效的 CNN 和视觉 Transformer 模型提出了一种统一的深度剪枝器,以在深度维度上剪枝模型。 我们的深度剪枝包括四个步骤,分别是超网训练、子网搜索、子网训练和子网合并。 我们提出了一种新颖的块修剪方法和渐进式训练策略,以更好地利用基线模型权重。 在子网合并过程中,我们使用重新参数化技术使子网变得更浅、更快。 我们将我们的方法应用于几个 CNN 模型和 Transformer 模型。 SOTA 剪枝性能证明了我们方法的优越性。 未来,我们将在更多 Transformer 模型和任务上探索我们的方法。
参考
- Ba, Kiros, and Hinton (2016) Ba, J. L.; Kiros, J. R.; and Hinton, G. E. 2016. Layer normalization. arXiv preprint arXiv:1607.06450.
- Bhardwaj et al. (2022) Bhardwaj, K.; Milosavljevic, M.; O’Neil, L.; Gope, D.; Matas, R.; Chalfin, A.; Suda, N.; Meng, L.; and Loh, D. 2022. Collapsible linear blocks for super-efficient super resolution. MLSys, 4: 529–547.
- Brown et al. (2020) Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J. D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. 2020. Language models are few-shot learners. NeurIPS, 33: 1877–1901.
- Cai et al. (2020) Cai, H.; Gan, C.; Wang, T.; Zhang, Z.; and Han, S. 2020. Once for All: Train One Network and Specialize it for Efficient Deployment. In ICLR.
- Carion et al. (2020) Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; and Zagoruyko, S. 2020. End-to-end object detection with transformers. In ECCV, 213–229. Springer.
- Chen et al. (2023) Chen, H.; Wang, Y.; Guo, J.; and Tao, D. 2023. VanillaNet: the Power of Minimalism in Deep Learning. arXiv preprint arXiv:2305.12972.
- Chen and Zhao (2018) Chen, S.; and Zhao, Q. 2018. Shallowing deep networks: Layer-wise pruning based on feature representations. TPAMI, 41(12): 3048–3056.
- Chollet (2017) Chollet, F. 2017. Xception: Deep learning with depthwise separable convolutions. In CVPR, 1251–1258.
- Ding et al. (2021a) Ding, X.; Zhang, X.; Han, J.; and Ding, G. 2021a. Diverse branch block: Building a convolution as an inception-like unit. In CVPR, 10886–10895.
- Ding et al. (2021b) Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; and Sun, J. 2021b. Repvgg: Making vgg-style convnets great again. In CVPR, 13733–13742.
- Dong, Cordonnier, and Loukas (2021) Dong, Y.; Cordonnier, J.-B.; and Loukas, A. 2021. Attention is not all you need: Pure attention loses rank doubly exponentially with depth. In ICML, 2793–2803. PMLR.
- Dror et al. (2021) Dror, A. B.; Zehngut, N.; Raviv, A.; Artyomov, E.; Vitek, R.; and Jevnisek, R. 2021. Layer folding: Neural network depth reduction using activation linearization. arXiv preprint arXiv:2106.09309.
- Elkerdawy et al. (2020) Elkerdawy, S.; Elhoushi, M.; Singh, A.; Zhang, H.; and Ray, N. 2020. To filter prune, or to layer prune, that is the question. In ACCV.
- Elsen et al. (2020) Elsen, E.; Dukhan, M.; Gale, T.; and Simonyan, K. 2020. Fast sparse convnets. In CVPR, 14629–14638.
- Fu et al. (2022) Fu, Y.; Yang, H.; Yuan, J.; Li, M.; Wan, C.; Krishnamoorthi, R.; Chandra, V.; and Lin, Y. 2022. DepthShrinker: a new compression paradigm towards boosting real-hardware efficiency of compact neural networks. In ICML, 6849–6862. PMLR.
- Graham et al. (2021) Graham, B.; El-Nouby, A.; Touvron, H.; Stock, P.; Joulin, A.; Jégou, H.; and Douze, M. 2021. Levit: a vision transformer in convnet’s clothing for faster inference. In ICCV, 12259–12269.
- Han, Mao, and Dally (2015) Han, S.; Mao, H.; and Dally, W. J. 2015. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149.
- He et al. (2016) He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual learning for image recognition. In CVPR, 770–778.
- He et al. (2019) He, Y.; Liu, P.; Wang, Z.; Hu, Z.; and Yang, Y. 2019. Filter pruning via geometric median for deep convolutional neural networks acceleration. In CVPR, 4340–4349.
- Howard et al. (2019) Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. 2019. Searching for mobilenetv3. In ICCV, 1314–1324.
- Howard et al. (2017) Howard, A. G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; and Adam, H. 2017. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861.
- Li et al. (2016) Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; and Graf, H. P. 2016. Pruning filters for efficient convnets. arXiv preprint arXiv:1608.08710.
- Li et al. (2022) Li, Y.; Hu, J.; Wen, Y.; Evangelidis, G.; Salahi, K.; Wang, Y.; Tulyakov, S.; and Ren, J. 2022. Rethinking vision transformers for mobilenet size and speed. arXiv preprint arXiv:2212.08059.
- Liu et al. (2021) Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; and Guo, B. 2021. Swin transformer: Hierarchical vision transformer using shifted windows. In ICCV, 10012–10022.
- Liu et al. (2022) Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; and Xie, S. 2022. A ConvNet for the 2020s. CVPR.
- Liu et al. (2019) Liu, Z.; Mu, H.; Zhang, X.; Guo, Z.; Yang, X.; Cheng, K.-T.; and Sun, J. 2019. Metapruning: Meta learning for automatic neural network channel pruning. In ICCV, 3296–3305.
- Michel, Levy, and Neubig (2019) Michel, P.; Levy, O.; and Neubig, G. 2019. Are sixteen heads really better than one? NeurIPS, 32.
- Pan et al. (2022) Pan, J.; Bulat, A.; Tan, F.; Zhu, X.; Dudziak, L.; Li, H.; Tzimiropoulos, G.; and Martinez, B. 2022. Edgevits: Competing light-weight cnns on mobile devices with vision transformers. In ECCV, 294–311. Springer.
- Pan et al. (2021) Pan, Z.; Zhuang, B.; Liu, J.; He, H.; and Cai, J. 2021. Scalable vision transformers with hierarchical pooling. In ICCV, 377–386.
- Pool and Yu (2021) Pool, J.; and Yu, C. 2021. Channel permutations for N: M sparsity. NeurIPS, 34: 13316–13327.
- Pope et al. (2023) Pope, R.; Douglas, S.; Chowdhery, A.; Devlin, J.; Bradbury, J.; Heek, J.; Xiao, K.; Agrawal, S.; and Dean, J. 2023. Efficiently scaling transformer inference. MLSys, 5.
- Radosavovic et al. (2020) Radosavovic, I.; Kosaraju, R. P.; Girshick, R.; He, K.; and Dollár, P. 2020. Designing network design spaces. In CVPR, 10428–10436.
- Rao et al. (2021) Rao, Y.; Zhao, W.; Liu, B.; Lu, J.; Zhou, J.; and Hsieh, C.-J. 2021. Dynamicvit: Efficient vision transformers with dynamic token sparsification. NeurIPS, 34: 13937–13949.
- Russakovsky et al. (2015) Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. 2015. Imagenet large scale visual recognition challenge. Int J Comput Vis, 115: 211–252.
- Sandler et al. (2018) Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; and Chen, L.-C. 2018. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition, 4510–4520.
- Simonyan and Zisserman (2014) Simonyan, K.; and Zisserman, A. 2014. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
- Strudel et al. (2021) Strudel, R.; Garcia, R.; Laptev, I.; and Schmid, C. 2021. Segmenter: Transformer for semantic segmentation. In ICCV, 7262–7272.
- Tan et al. (2019) Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; and Le, Q. V. 2019. Mnasnet: Platform-aware neural architecture search for mobile. In CVPR, 2820–2828.
- Tan and Le (2021) Tan, M.; and Le, Q. 2021. Efficientnetv2: Smaller models and faster training. In ICML, 10096–10106. PMLR.
- Tang et al. (2022) Tang, Y.; Han, K.; Wang, Y.; Xu, C.; Guo, J.; Xu, C.; and Tao, D. 2022. Patch slimming for efficient vision transformers. In CVPR, 12165–12174.
- Tang et al. (2020) Tang, Y.; Wang, Y.; Xu, Y.; Tao, D.; XU, C.; Xu, C.; and Xu, C. 2020. SCOP: Scientific Control for Reliable Neural Network Pruning. In Larochelle, H.; Ranzato, M.; Hadsell, R.; Balcan, M.; and Lin, H., eds., NeurIPS, volume 33, 10936–10947. Curran Associates, Inc.
- Touvron et al. (2021) Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; and Jegou, H. 2021. Training data-efficient image transformers & distillation through attention. In ICML, volume 139, 10347–10357.
- Vasu et al. (2023) Vasu, P. K. A.; Gabriel, J.; Zhu, J.; Tuzel, O.; and Ranjan, A. 2023. MobileOne: An Improved One Millisecond Mobile Backbone. In CVPR, 7907–7917.
- Wang et al. (2021a) Wang, D.; Gong, C.; Li, M.; Liu, Q.; and Chandra, V. 2021a. Alphanet: Improved training of supernets with alpha-divergence. In ICML, 10760–10771. PMLR.
- Wang et al. (2021b) Wang, D.; Li, M.; Gong, C.; and Chandra, V. 2021b. Attentivenas: Improving neural architecture search via attentive sampling. In CVPR, 6418–6427.
- Wang et al. (2021c) Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; and Shao, L. 2021c. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In ICCV, 568–578.
- Woo et al. (2023) Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Kweon, I. S.; and Xie, S. 2023. Convnext v2: Co-designing and scaling convnets with masked autoencoders. In CVPR, 16133–16142.
- Wu and He (2018) Wu, Y.; and He, K. 2018. Group normalization. In ECCV, 3–19.
- Xu et al. (2020) Xu, P.; Cao, J.; Shang, F.; Sun, W.; and Li, P. 2020. Layer pruning via fusible residual convolutional block for deep neural networks. arXiv preprint arXiv:2011.14356.
- Yu et al. (2022) Yu, F.; Huang, K.; Wang, M.; Cheng, Y.; Chu, W.; and Cui, L. 2022. Width & Depth Pruning for Vision Transformers. AAAI, 36(3): 3143–3151.
- Yu and Huang (2019) Yu, J.; and Huang, T. S. 2019. Universally slimmable networks and improved training techniques. In ICCV, 1803–1811.
- Yu et al. (2020) Yu, J.; Jin, P.; Liu, H.; Bender, G.; Kindermans, P.-J.; Tan, M.; Huang, T.; Song, X.; Pang, R.; and Le, Q. 2020. Bignas: Scaling up neural architecture search with big single-stage models. In ECCV, 702–717. Springer.
- Yu and Xiang (2023) Yu, L.; and Xiang, W. 2023. X-Pruner: eXplainable Pruning for Vision Transformers. ArXiv, abs/2303.04935.
- Zhang and He (2020) Zhang, M.; and He, Y. 2020. Accelerating training of transformer-based language models with progressive layer dropping. NeurIPS, 33: 14011–14023.
- Zhou, Yen, and Yi (2021) Zhou, Y.; Yen, G. G.; and Yi, Z. 2021. Evolutionary shallowing deep neural networks at block levels. TNNLS, 33(9): 4635–4647.
- Zhu, Tang, and Han (2021) Zhu, M.; Tang, Y.; and Han, K. 2021. Vision transformer pruning. arXiv preprint arXiv:2104.08500.