[cor1]通讯作者
1]组织=陕西师范大学物理与信息技术学院,城市=西安,邮编=710119,州=陕西,国家=中国
2]组织=西北工业大学医学研究院,城市=西安,邮编=710072,州=陕西,国家=中国
3]组织=西北工业大学计算机学院,城市=西安,邮编=710072,州=陕西,国家=中国
4]组织=西北工业大学自动化学院,城市=西安,邮编=710072,州=陕西,国家=中国
5]组织=佐治亚大学计算机学院,城市=雅典,邮政编码=30602,国家=美国
理解大语言模型:从训练到推理的全面概述
摘要
ChatGPT 的引入使得用于解决下游任务的大型语言模型(大语言模型)的利用率显着增加。 在这种情况下,人们越来越关注具有成本效益的训练和部署。 大语言模型的低成本训练和部署代表了未来的发展趋势。 本文回顾了与这一新兴趋势相一致的大型语言模型训练技术和推理部署技术的演变。 关于训练的讨论包括各个方面,包括数据预处理、训练架构、预训练任务、并行训练以及模型微调相关内容。 在推理方面,论文涵盖了模型压缩、并行计算、内存调度和结构优化等主题。 它还探讨了大语言模型的利用并为其未来的发展提供了见解。
关键词:
大型语言模型训练推理调查1简介
语言建模(LM)是自然语言处理(NLP)领域实现认知智能的基本方法,近年来其进展令人瞩目[1; 2; 3]。 它在理解、生成和操作人类语言方面发挥着核心作用,是各种 NLP 应用[4]的基石,包括机器翻译、聊天机器人、情感分析和文本摘要。 随着深度学习的发展,早期的统计语言模型(SLM)逐渐转变为基于神经网络的神经语言模型(NLM)。 这种转变的特点是采用词嵌入,将词表示为分布式向量。 值得注意的是,这些词嵌入在实际的 NLP 任务中始终表现出色,深刻地影响了该领域的进步。 预训练语言模型 (PLM) 代表 NLM 之后语言模型演变的后续阶段。 PLM 的早期尝试包括 ELMo [5],它是基于双向 LSTM 架构构建的。 然而,随着以并行自注意力机制为特征的 Transformer 架构[6]的出现,预训练和微调学习范式使 PLM 成为主流方法。 这些模型通常通过对大量数据集的自我监督进行训练,巩固了它们作为该领域主要方法论的地位。
Transformer 架构非常适合扩展模型,研究分析表明,增加模型的规模或训练数据大小可以显着提高其性能。 许多研究通过不断扩大 PLM 的规模来突破模型性能的界限[7; 8; 9; 10]。 随着模型变得越来越大,会出现一种称为“涌现”的显着现象,其中它们表现出惊人的性能[8]。 这些模型能够生成高质量的文本,并具有强大的学习和推理能力。 他们甚至可以通过情境学习 (ICL)[8] 来解决少样本学习任务。 这种卓越的功能使其能够无缝应用于跨不同领域的各种下游任务[11; 12; 13; 14]。
具有更大参数大小和广泛训练数据的预训练语言模型(PLM)通常表示为大型语言模型(大语言模型)[15; 16; 17]。 模型大小通常超过 6-100 亿(6-10B)个参数。 GPT系列[18;]是大语言模型发展的一个重要里程碑。 7; 8; 19]。 值得注意的是,OpenAI于2022年11月发布了ChatGPT,标志着大语言模型时代的关键时刻,也是人工智能领域的变革时刻。 ChatGPT 使当前的人工智能算法达到了前所未有的强度和有效性水平,重塑了人类使用或开发人工智能算法的方式。 它的出现引起了研究界的关注。 然而,由于 ChatGPT 不是一个开源平台,目前使用 ChatGPT 的主要方式是通过 OpenAI 的网站 https://chat.openai.com 或通过他们的 API 接口访问它。 训练大语言模型可以替代ChatGPT,即特定领域的大语言模型,已经变得非常必要[20; 21; 22; 23; 24; 1; 25; 26]。 大语言模型的训练和部署需要处理大规模数据的专业知识和分布式并行训练的丰富实践经验 [27; 28; 29]。 这一要求强调了开发大语言模型的研究人员需要具备强大的工程能力来解决大语言模型开发过程中遇到的挑战。 对大语言模型领域感兴趣的研究人员必须具备工程技能或学会与工程师有效协作。
2背景知识
2.1 Transformer
Transformer是一种基于注意力机制的处理序列数据的深度学习模型,可以有效解决复杂的自然语言处理问题。 该模型于 2017 年首次提出[6],并在机器翻译任务中取代了传统的循环神经网络架构[30],成为最先进的模型当时。 由于其适合并行计算以及模型本身的复杂性,Transformer 在准确性和性能方面优于之前流行的循环神经网络。 Transformer 架构主要由两个模块组成:编码器和解码器,以及这些模块内的注意力机制。
2.1.1 自注意力
自注意力结构[6]: 本质上,注意力机制的目的是从大量数据中选择少量重要信息,并专注于这些重要部分,而忽略大部分不重要信息。 自注意力机制作为注意力机制的一种变体,减少了对外部信息的依赖,擅长捕捉数据或特征内部的相关性。 将自注意力机制应用在文本中——主要涉及计算单词之间的相互影响,以解决长程依赖问题。 此外,自注意力是 Transformer 背后的核心思想。 key-value Attention的核心公式如下:
| (1) |
自注意力允许模型在预测特定单词时权衡句子中不同单词的重要性。 它计算句子中所有单词值的加权和,其中权重由每个单词与目标单词的相关性确定。
自注意力机制由三个步骤组成:计算查询、键和值向量。 查询向量表示正在关注的单词,而关键向量表示句子中的所有单词。 值向量存储与每个单词相关的信息。 通过获取查询向量和关键向量之间的点积来计算注意力权重,然后进行 softmax 运算以获得单词的分布。
多头注意力[6]: 多头自注意力通过并行执行多次来扩展自注意力机制。 每个注意力头都会学习关注输入的不同方面,捕获不同的依赖性和模式。 然后将注意力头的输出连接并线性变换以获得最终表示。 通过使用多个注意力头,该模型可以捕获局部和全局依赖性,从而可以更全面地理解输入序列。 这种并行化还增强了模型捕获单词之间复杂关系的能力。 多头注意力可以表述如下:
| (2) | |||
在这种情况下,“”表示连接每个头的注意力计算结果,“”是输出层的权重矩阵,用于对连接结果进行线性变换。 这产生了多头注意力的输出。 综上所述,多头注意力通过在不同的线性变换下执行并行注意力计算,然后对结果进行串联和线性变换,增强了模型表示输入序列的能力。 该机制在 Transformer 模型中发挥着重要作用,有助于处理远程依赖关系并提高模型性能。
2.1.2编码器
Transformer模型的编码器模块[6]由多个相同的层组成,每个层包含多头注意力机制和前馈神经网络[31] 。 在多头注意力机制中,输入序列中的每个位置都被计算为与其他位置的注意力,以捕获输入序列中不同位置之间的依赖关系。 然后使用前馈神经网络进一步处理并从注意力机制的输出中提取特征。 编码器模块通过多个这样的层的堆叠逐渐提取输入序列的特征,并将最终的编码结果传递给解码器模块进行解码。 编码器模块的设计使其能够有效处理输入序列内的长程依赖关系,并在各种 NLP 任务中显着提高性能。
2.1.3解码器
Transformer模型的解码器模块[32]也由多个相同的层组成,每个层都包含多头注意力机制和前馈神经网络。 与编码器不同,解码器还包括一个额外的编码器-解码器注意力机制,用于在解码过程中计算对输入序列的注意力。 在每个位置,解码器只能与其之前的位置进行自注意力计算,以确保序列的生成不违反语法规则。 掩码在解码器中起着重要作用,确保在生成输出序列时仅关注当前时间步之前的信息,并且不会泄漏未来时间步的信息。 具体来说,解码器的自注意力机制使用掩码来防止模型在每个时间步生成预测时访问未来信息,从而保持模型的因果关系。 这确保了模型生成的输出取决于当前时间步和之前的信息,而不受未来信息的影响。
2.1.4 位置嵌入
位置和顺序对于某些任务至关重要,例如理解句子或视频。 位置和顺序定义了句子的语法,它们是句子语义的组成部分。 Transformer 利用多头自注意力(MHSA)来避免 RNN 的递归方法,从而加快训练过程。 此外,它还可以捕获句子中的远程依赖关系并处理更长的输入。 当句子中的每个词符通过 Transformer 的编码器/解码器堆栈时,模型本身缺乏每个词符的任何位置/顺序感(排列不变性)。 因此,仍然需要一种方法将 Token 的顺序信息纳入模型中。 为了使模型能够感知输入序列,可以添加有关句子中每个词符位置的位置信息,这种技术称为位置嵌入(PE)。 它在 Transformer 模型中用于将标记的顺序合并到输入表示中。 由于 Transformer 没有循环连接,因此它缺乏循环神经网络中存在的词符顺序的固有概念。 为了解决这个问题,位置嵌入为输入序列中的每个词符位置分配一个唯一的向量。 这些位置嵌入在输入模型之前会添加到单词嵌入中。 通过包含位置信息,模型可以根据标记在序列中的位置来区分标记。 在Transformer模型中,位置嵌入的核心公式可以表示为:
| (3) |
| (4) |
式中,表示位置嵌入矩阵,表示词符在句子中的位置,表示位置嵌入的维度索引,表示Transformer模型的隐藏层维度。 通过使用正弦和余弦函数并对位置 (pos) 和维度 (i) 执行不同的计算,该公式为每个位置和维度生成唯一的位置嵌入值。 因此,每个词符都被分配了一个唯一的位置嵌入向量,使模型能够感知句子中标记的顺序信息。 在实际应用中,将位置嵌入矩阵添加到输入词嵌入矩阵中,将位置信息和语义信息结合起来,从而为Transformer模型提供更全面的输入表示。
Transformer 中常用的两种位置编码方法是绝对位置编码和相对位置编码。
(1)绝对位置编码:它通过使用正弦和余弦函数为每个位置和维度生成唯一的位置嵌入值。 该方法使用上述公式中的正弦和余弦函数来计算位置嵌入值并将其添加到词嵌入中。 绝对位置编码为每个位置提供唯一的编码,使模型能够感知句子中单词的顺序信息。
(2)相对位置编码:是一种基于相对位置关系的编码方法。 相对位置编码通过计算单词之间的相对距离来表示位置信息。 这种方法用在像Transformer-XL [33]这样的模型中,相对位置编码在处理长序列时可以更好地捕获单词之间的相对位置关系。 这两种位置编码方法的目的都是向 Transformer 模型提供输入序列中单词的位置信息,使模型能够更好地理解和处理序列数据。 位置编码方法的具体选择取决于具体的应用场景和模型设计。
还有其他位置编码方法应用于其他模型,例如 RoPE [34] 和 ALiBi [35]。
RoPE是一种用绝对位置编码来表示相对位置编码的方法,应用于PaLM [36]、LLaMA [9]等大型语言模型的设计中GLM-130B [37]。
ALiBi 不会在词嵌入中添加位置嵌入,而是根据标记之间的距离将预定义的偏差矩阵添加到注意力分数中。 它应用于BLOOM [38]等大型语言模型的设计中。
一些模型还使用其他一些位置编码方法,例如混合位置编码、多位位置编码和隐式位置编码。
2.2及时学习
即时学习是一种广泛采用的机器学习方法,特别是在 NLP 领域。 从本质上讲,这种方法涉及通过精心设计提示语句来指导模型产生特定的行为或输出。 它通常用于训练和指导预训练的大语言模型来执行特定任务或生成期望的结果。 研究人员观察到,特定提示语句的设计可以引导预先训练的模型执行各种任务,例如问答、文本生成和语义理解[39; 40; 41; 42; 43; 44; 45; 46; 47; 48; 49; 50]。 这种方法的优点在于它能够通过对提示语句的简单修改来适应不同的任务,从而无需重新训练整个模型。 对于像GPT系列这样的大语言模型和其他预训练模型,即时学习为模型微调提供了一种简单而强大的手段。 通过提供适当的提示,研究人员和从业者可以定制模型的行为,使其更适合特定领域或任务要求。 简而言之,即时学习是一种机器学习方法,它建立在预先训练的语言模型的基础上,通过提示语句的设计引导模型执行各种任务,为定制模型应用程序提供更大的灵活性。 本节我们将介绍即时学习的基础知识。
2.2.1 背景和概述
即时学习是一种新的机器学习方法[51]。 在早期的自然语言处理(NLP)领域,研究人员主要采用全监督学习模式[52],在目标任务的输入和输出示例数据集上训练针对特定任务的模型。 但由于训练数据集有限,该方法无法很好地训练出高质量的模型,因此早期的NLP更多地依赖于特征工程;随着神经网络模型的出现及其在自然语言处理领域的使用,人们开始关注架构工程[53]。
然而,2017年至2019年间,NLP模型的学习方式从完全监督学习转变为新的模式:预训练和过度范式[54]。 在这种范式中,具有固定架构的模型被预先训练为语言模型,以预测观察到的文本数据的概率。 由于训练语言模型需要丰富的原始文本数据,这些语言模型可以在大型数据集上进行训练。 在此过程中,语言模型可以学习它们正在建模的语言的强大通用特征。 然后,通过引入额外的参数并使用特定于任务的目标函数对其进行微调,上述 PLM 将适应不同的下游任务。 此时,研究的重点转向了目标工程,即在预训练和微调过程中设计训练目标。 自BERT以来,NLP很长一段时间都在使用预训练和微调的方法,但这种方法需要为每个任务微调一个新模型,并且无法共享。 但对于大语言模型来说,感觉就像是对每个任务进行定制,效率非常低[51]。
赶紧学习吧,这个方法在GPT-3中展现出了惊人的能力。 GPT-3 模型通过使用自然语言提示和任务演示作为上下文,只需少量样本即可处理许多任务,而无需更新底层模型中的参数。 提示学习用预训练、提示和预测取代了预训练和微调的过程。 在这个范式中,下游任务不是通过目标工程使预训练的LM适应下游任务,而是借助文本提示重新定义下游任务,使其看起来更像原始LM训练期间解决的任务。 对于提示学习来说,只需插入不同的提示参数即可适应不同的任务。 也就是说,每个任务只需要单独训练提示参数,而不需要训练整个预训练的语言模型[55]。 这种方法极大地提高了使用预训练语言模型的效率,并显着缩短了训练时间。
2.2.2Prompt学习的基本组成和流程
传统的预训练+微调范式中,预训练阶段与下游任务之间存在差距[51],而即时学习可以保持预训练目标格式与下游任务之间的一致性。下游任务输出格式,即将下游任务的形式与PLM预训练任务的形式对齐。 在训练PLM时,我们可以通过构造提示将原始目标任务转化为类似于PLM预训练任务的填空或延续任务。 这种方法的优点是,通过一系列适当的提示,我们可以使用单一语言模型来解决各种下游任务。
即时学习通过使用预先训练的模型和设计适当的模板来优化模型在不同任务上的性能。 即时学习由提示模板、答案映射和预训练的语言模型组成。 提示模板是提示的主体,填空[56]和基于前缀生成[57]是提示学习模板的两种常见类型。 填空模板选择文本中的一个或多个位置,并用[MASK]标签表示,用于提示模型填写相应的单词;基于前缀的模板生成涉及在句子之前添加特定的前缀,以指导模型生成适当的文本。 答案映射是根据概率分布评估所有可能的答案,选择最可能的答案作为预测输出,并将其转换为适当的类别映射词的过程。 此过程通常涉及将标签转换为自然语言词汇,称为 Verbalizer [58]。
Prompt Learning的工作流程主要包括以下四个部分:
(1)使用PLM作为基础编码器
(2)添加带有[MASK]位置的附加上下文(模板)
(3)项目标签来标记单词(verbalizer)
(4)作为预训练和微调之间的GAP
定义模板和答案空间后,我们需要选择合适的预训练语言模型。 现在有各种性能良好的预训练模型(PTM),在选择模型时,通常会考虑其范式,例如自动递归、掩码语言建模、编码器解码器等。基于此,对于摘要任务,可以选择更合适的双向自回归 Transformer (BART)模型。
模板的选择对于快速学习起着非常重要的作用。 模板一般可以根据是否是手动指定来区分:人工构造的模板还是自动搜索的模板。 人工创建模板是最直观的方法,易于理解,在实际应用中具有良好的性能。 然而,人工构建的模板也有一些缺点:手动设计模板时需要先验知识[59],并且可能会出现失败[60]。 自动生成的模板有两种类型:离散提示和连续提示。 离散提示允许模型在一组离散模板空间中选择最佳模板,而连续提示允许语言模型自动训练提示。 研究表明,使用多个模板[61]可以提高模型的性能。 选择使用多个模板并将它们聚合在一起以完成答案的最简单方法是取每个模板输出的平均值 [60] 或加权平均值 [58]。
言语化器是将标签映射到标签词的过程,言语化器的选择对于即时学习也至关重要。 构造言语器有两种方法:手动定义和自动搜索。 手动定义需要专业知识,可能存在主观性强、覆盖范围小的缺点。 为了解决这个问题,我们可以选择以下解决方案:(1)利用人类先验知识进行手动设计; (2) 以英特尔标签词开头,进行释义和扩展; (3)从内部标签词开始,利用外部知识进行扩展; (4) 分解多个token的标签; (5)虚拟词符并优化标签嵌入。 此外,我们还可以利用外部知识库来扩展和改进标签词,从而获得更好的文本分类结果[62]。
2.2.3学习策略
即时学习新范式的出现给训练过程带来了重大变化。 Prompt Learning的学习策略主要包括以下几种:(1)预训练然后微调,这是传统的预训练+微调方法[63]; (2)调优免费推广,依靠提示的设计师LM直接提供答案[64]; (3) 修复LM提示调整,使用下游任务训练数据更新提示的相关参数; (4)修复提示LM调优,该策略是对LM的参数进行调节,LM在使用提示时参数是固定的; (5)Prompt+LM调优是同时更新Prompt相关参数和LM参数的策略。
可以根据具体任务和需求选择这些不同的学习策略。 预训练+微调是最常见的策略,适合大多数任务[63]。 无微调提示适合简单任务,可以大大减少训练时间和计算资源消耗。 固定LM提示微调和固定提示LM微调适用于需要更精确控制的任务,可以通过调整提示参数或语言模型参数来优化模型性能。 结合提示和LM微调结合了两者的优点,可以进一步提高模型性能[51]。
总之,即时学习为我们提供了一种新的训练范式,可以通过适当的即时设计和学习策略来优化模型在各种下游任务上的性能。 选择合适的模板、构建有效的言语表达器、采用合适的学习策略都是提高即时学习效果的重要因素。
3大型语言模型的训练
大语言模型的训练大致可以分为三个步骤。 第一步涉及数据收集和处理。 第二步是预训练过程,包括确定模型的架构和预训练任务,并利用合适的并行训练算法来完成训练。 第三步涉及微调和对齐。 在本节中,我们将概述模型训练技术。 包括相关训练数据集的介绍、数据准备和预处理、模型架构、具体训练方法、模型评估以及大语言模型常用的训练框架。
3.1数据准备和预处理
3.1.1数据集
训练大语言模型需要大量的文本数据,这些数据的质量极大地影响大语言模型的性能。 大规模语料库的预训练使大语言模型具备了对语言的基本理解和一定的生成能力。 大语言模型训练的第一步是收集大量自然语言文本语料库。 预训练数据源多种多样,通常包含网络文本、会话数据和书籍作为通用预训练语料库。 此外,一些研究工作引入了来自专业领域的专门数据,例如代码或科学数据,以增强这些领域的大语言模型能力。 利用多种来源的文本数据进行大语言模型训练可以显着增强模型的泛化能力。 在接下来的部分中,我们将介绍训练大语言模型常用的数据集,如表1所示。 这些语料库分为 5 组进行讨论。
书籍: 大语言模型训练常用的两个书籍数据集是 BookCorpus [65] 和 Gutenberg [66]。 这些数据集包括广泛的文学体裁,包括小说、散文、诗歌、历史、科学、哲学等。 被众多大语言模型广泛采用[9; 79],这些数据集通过将模型暴露于各种文本流派和主题来促进模型的训练,从而促进对各个领域的语言的更全面的理解。
CommonCrawl: CommonCrawl [67] 管理可访问的网络爬行数据存储库,可供个人和组织免费使用。 该存储库包含大量数据,其中包括 16 年来积累的超过 2500 亿个网页。 Common Crawl 成立于 2007 年,现已发展成为学术和研究界广泛认可和引用的语料库,被超过 10,000 篇研究论文引用。 这个不断扩展的语料库是一个动态资源,每月新增 3-50 亿个网页。 它的重要性延伸到自然语言处理领域,作为许多大型语言模型的主要训练语料库。 值得注意的是,训练 GPT-3 [8] 中使用的原始 Token 的很大一部分(总计 82%)来自 CommonCrawl。 然而,由于网络档案中存在大量低质量数据,因此在使用 CommonCrawl 数据时预处理至关重要。 目前常用的基于 CommonCrawl 的过滤数据集有四种:C4 [68]、CC-Stories [69]、CC-News [70] 和 RealNews [71]。
红迪网链接: Reddit 是一个社交媒体平台,用户可以在其中提交链接和帖子,其他人可以使用“赞成票”或“反对票”系统对其进行投票。 这一特性使其成为创建高质量数据集的宝贵资源。
维基百科:维基百科[75]是一个免费开放的在线百科全书项目,拥有涵盖广泛主题的高质量百科全书内容的庞大存储库。 英文版维基百科在许多大语言模型的训练中被广泛使用[8; 9; 80],作为语言理解和生成任务的宝贵资源。 此外,维基百科提供多种语言版本,提供多种语言版本,可用于多语言环境中的训练。
代码:目前可公开访问的代码数据集的可用性有限。 现有的工作主要涉及使用互联网上的开源许可证从网络上抓取代码。 主要来源包括 Github 和 Stack Overflow。
我们组织了不同大语言模型使用的数据集。 在训练过程中,大语言模型通常在多个数据集上进行训练,如表2所示以供参考。
| LLMs | Datasets |
| GPT-3 [8] | CommonCrawl [67], WebText2 [8], Books1 [8], Books2 [8], Wikipedia [75] |
| LLaMA [9] | CommonCrawl [67], C4 [68], Wikipedia [75], Github, Books, Arxiv, StackExchange |
| PaLM [36] | Social Media, Webpages, Books, Github, Wikipedia, News (total 780B tokens) |
| T5 [68] | C4 [68], WebText, Wikipedia, RealNews |
| CodeGen [81] | the Pile, BIGQUERY, BIGPYTHON |
| CodeGeeX [82] | CodeParrot, the Pile, Github |
| GLM [37] | BooksCorpus, Wikipedia |
| BLOOM [38] | ROOTS |
| OPT [83] | BookCorpus, CCNews, CC-Stories, the Pile, Pushshift.io |
3.1.2数据预处理
一旦收集到足够的数据语料库,下一步就是数据预处理。 数据预处理的质量直接影响模型的性能和安全性。 具体的预处理步骤涉及过滤低质量文本,包括消除有毒和有偏见的内容,以确保模型符合人类道德标准。 它还包括去重,去除训练集中的重复内容,排除测试集中的冗余内容,以保持样本分布平衡。 应用隐私清理来确保模型的安全性,防止信息泄露或其他与隐私相关的问题。 另外,如果考虑微调大语言模型,还应该考虑扩大词汇量。 另一方面,LLaMA 2 模型[10] 代表了一个值得注意的例外。 这些模型放弃在预训练语料库中进行过滤,因为激进的过滤可能会意外过滤掉某些人口统计群体。 这种方法增强了基本 LLaMA 2 模型的通用性,使它们更擅长执行一系列下游任务,例如仇恨言论检测和隐私去识别。 观察结果表明,在预训练数据中放弃额外的过滤可以使基础模型以更少的示例实现合理的安全对齐[10]。 虽然这提高了通用性和安全调整效率,但在公共部署之前仍然必须实施额外的安全缓解措施,如 3.5.4 节中进一步讨论的那样。
质量过滤: 过滤低质量数据通常使用基于启发式的方法或基于分类器的方法来完成。 启发式方法涉及采用手动定义的规则来消除低质量数据[84; 72]。 例如,可以将规则设置为仅保留包含数字的文本、丢弃完全由大写字母组成的句子、删除符号与单词比例超过0.1的文件等等。 基于分类器的方法涉及在高质量数据集(例如 WebText [85])上训练分类器以过滤掉低质量数据集。
重复数据删除:语言模型有时可能会在文本生成过程中重复生成相同的内容,这可能是由于训练数据的高度重复所致。 大量的重复会导致训练不稳定,导致大语言模型[86]的表现下降。 此外,考虑通过删除训练集和测试集 [87] 中存在的重复数据来避免数据集污染也至关重要。
隐私清理: 大语言模型作为文本生成模型,需要在不同的数据集上进行训练,这可能会带来隐私问题和无意的信息泄露风险[88]。 在语言数据集的预处理阶段,必须通过系统地删除任何敏感信息来解决隐私问题。 这涉及采用匿名化、编辑或标记化等技术来消除个人身份详细信息、地理位置和其他机密数据。 通过仔细清理此类敏感内容的数据集,研究人员和开发人员可以确保在这些数据集上训练的语言模型遵守隐私标准,并降低无意泄露私人信息的风险。 必须在数据实用性和隐私保护之间取得平衡,促进在各种应用程序中负责任和合乎道德地使用语言数据集。
过滤掉有毒和有偏见的文本: 在语言数据集的预处理步骤中,一个关键的考虑因素是去除有毒和有偏见的内容,以确保开发公平和公正的语言模型。 这涉及实施强大的内容审核技术,例如采用情绪分析、仇恨言论检测和偏见识别算法。 通过利用这些工具[89],研究人员可以系统地识别和过滤掉可能延续有害刻板印象、冒犯性语言或偏见观点的文本。
3.2架构
目前,所有大语言模型都是基于Transformer架构构建的,允许这些模型扩展到数百亿甚至万亿个参数。 通常,PLM 架构分为三类:仅编码器 [90]、编码器-解码器 [68] 和仅解码器 [18] 。 最新的大语言模型不再采用Encoder-only架构,这里不再赘述。 相反,本节将重点介绍编码器-解码器和仅解码器架构。
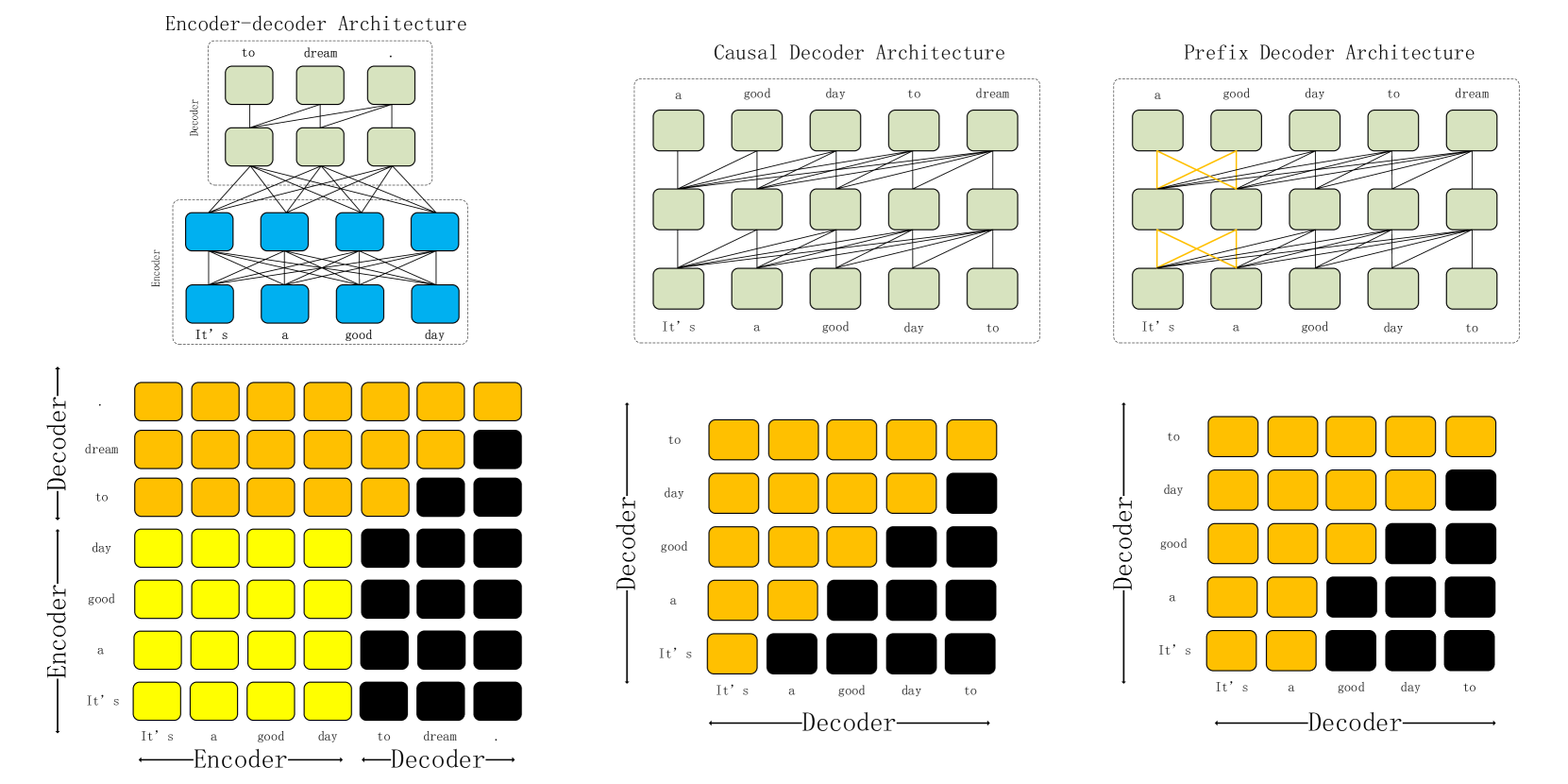
3.2.1 编码器-解码器架构
大语言模型的Encoder-decoder架构是建立在传统Transformer Encoder-decoder架构之上的。 编码器-解码器架构由两个主要组件组成:编码器和解码器。 Encoder 的每个部分都由多层 Transformer 的 Multi-Head Self-Attention 层组成,对输入序列进行编码。 另一方面,解码器利用编码器输出表示的交叉注意力,并以自回归方式生成目标序列。 编码器-解码器架构是著名大语言模型的基础,例如 T5 [68]、flan-T5 [91] 和 BART [92] 。
3.2.2 仅解码器架构
仅解码器架构的大语言模型利用传统 Transformer 架构的解码器组件。 与同时包含编码器和解码器的编码器-解码器架构不同,仅解码器架构仅专注于解码过程。 在此配置中,模型按顺序生成 Token ,并关注序列中前面的 Token 。 该架构已应用于各种语言生成任务,展示了其在文本生成等各种任务中的有效性,而无需显式编码阶段。 仅解码器架构可以进一步分为两类:因果解码器架构和前缀解码器架构。
因果解码器架构: 在因果解码器架构中,模型输入序列中的每个词符在解码过程中只能关注过去的输入标记及其自身。 它通过使用特定的掩码实现对输入序列的单向关注,如图1所示。 事实上,不同的架构主要是通过配置不同的掩模矩阵来实现的。 该图展示了编码器-解码器和仅解码器架构(包括临时解码器和前缀解码器)之间掩码配置的比较。 因果解码器架构的代表性大语言模型是 GPT 系列[18; 7; 8; 93; 19]。 大语言模型GPT系列目前以其优越的性能而闻名,其基础因果解码器架构广泛应用于其他大语言模型,如BLOOM [38]、OPT [83]、Gopher [84] 和 LLaMA [9]。
前缀解码器架构: 前缀解码器架构结合了编码器-解码器和因果解码器架构的优点。 它利用其独特的掩码配置,如图 1 所示,实现对前缀中标记的双向关注,同时保持单向关注以生成后续标记 [54]。 这种设计允许输出序列的自回归生成,并且能够灵活地双向处理前缀标记。 采用前缀解码器架构的代表性大语言模型包括PaLM[36]和GLM[37]。
3.3预训练任务
大型语言模型(大语言模型)通常通过预训练过程学习丰富的语言表示。 在预训练过程中,这些模型利用广泛的语料库,例如来自互联网的文本数据,并通过自我监督的学习方法进行训练。 语言建模是自我监督学习任务的一种常见形式,其中模型的任务是预测给定上下文中的下一个单词。 通过这个任务,模型获得了捕获与词汇、语法、语义和文本结构相关的信息的能力。
在语言建模中[18; 7; 8; 36],模型需要预测给定上下文中的下一个单词。 此任务使模型能够对语言产生细致入微的理解。 具体来说,该模型观察大量文本数据并尝试预测文本中每个位置的下一个单词。 这种渐进的学习过程使模型能够捕获语言固有的模式和信息,将大量的语言知识编码到其参数中。 一旦预训练完成,这些模型参数就可以针对各种自然语言处理任务进行微调,以适应特定的任务要求。 语言建模的目标是训练模型以最大化文本数据的可能性。 对于给定的文本序列,记为,其中表示位置处的词符,是预测的概率给定前面的上下文,语言建模的目标函数可以使用交叉熵损失来表达。 在这里,我们将目标定义为最大化给定文本序列的条件概率:
| (5) |
语言建模是大多数大语言模型普遍的预训练目标。 除了语言建模之外,语言建模领域内还有其他预训练任务。 例如,某些模型[68; 37]使用随机替换某些部分的文本,然后采用自回归方法恢复替换的标记。 主要训练方法涉及替换间隔的自回归恢复。
3.4模型训练
3.4.1 并行训练
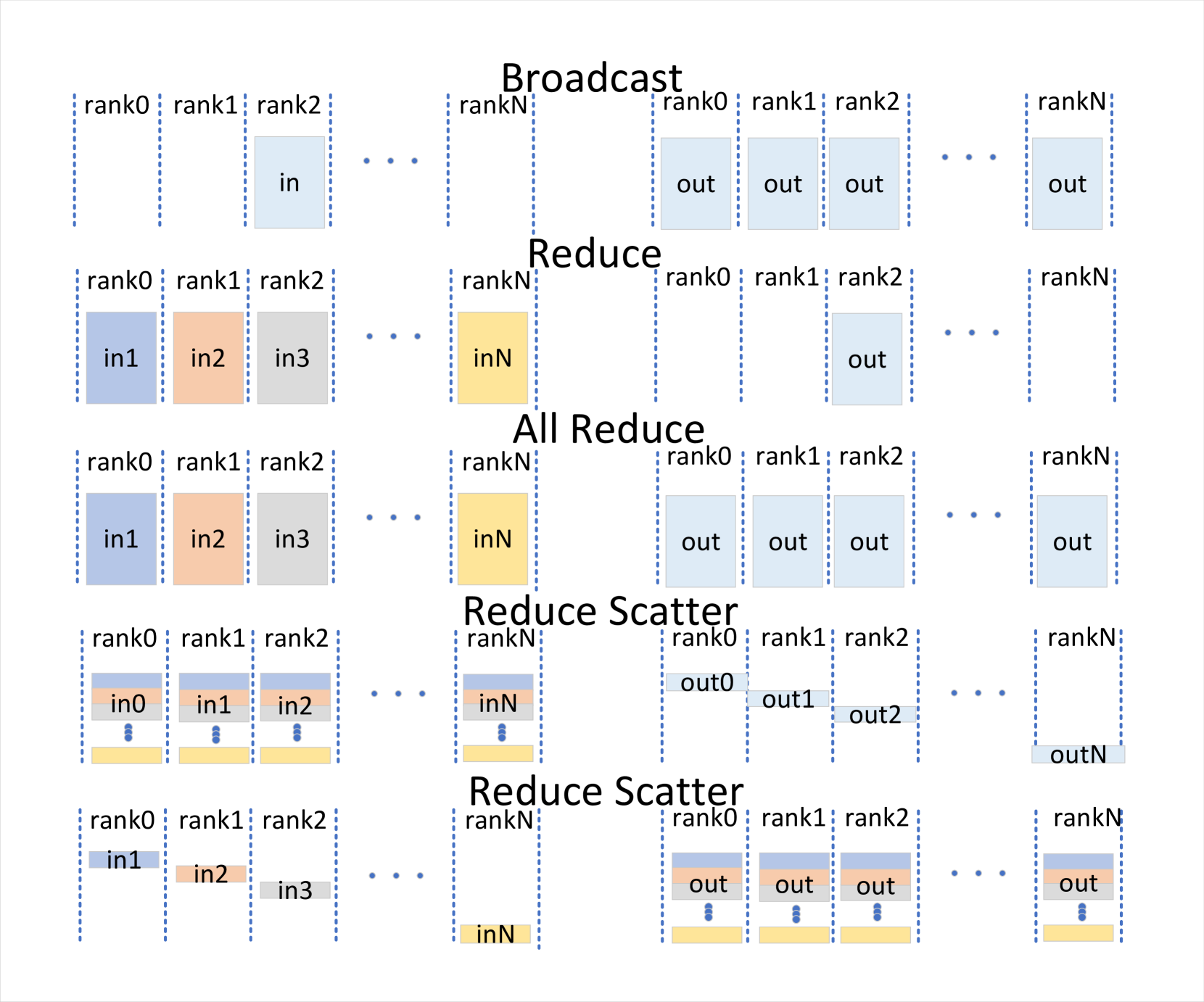
在下面提到的并行训练中,会有关于集体交流的讨论,这有助于我们更好地理解并行训练的原理。 图2列出了五种约简关系。 1)Broadcast:将数据从一个GPU发送到其他GPU。2)Reduce:减少(总和/平均)所有GPU的数据,发送到一个GPU。3)All Reduce:减少GPU的所有数据,发送到所有GPU。4 )Reduce Scatter:减少所有GPU 的数据,发送部分到所有GPU。5)All Gather:收集所有GPU 的数据,发送所有GPU。
数据并行: 数据并行[94]的流程如图3所示,有一个参数服务器,存储模型的参数和整批数据。 每个GPU使用广播来同步模型参数,并将数据划分为每个GPU的一部分,每个GPU接收一部分数据。 每个GPU使用完整的模型参数和部分数据来执行前向和后向传播。 这样,就获得了每个 GPU 的梯度。 最后,我们聚合梯度并将聚合的梯度发送回参数服务器,其中原始模型参数和聚合的完整梯度可用。 有了这些信息,我们可以使用优化器来更新模型参数。 更新后的参数将进入下一轮模型训练迭代。
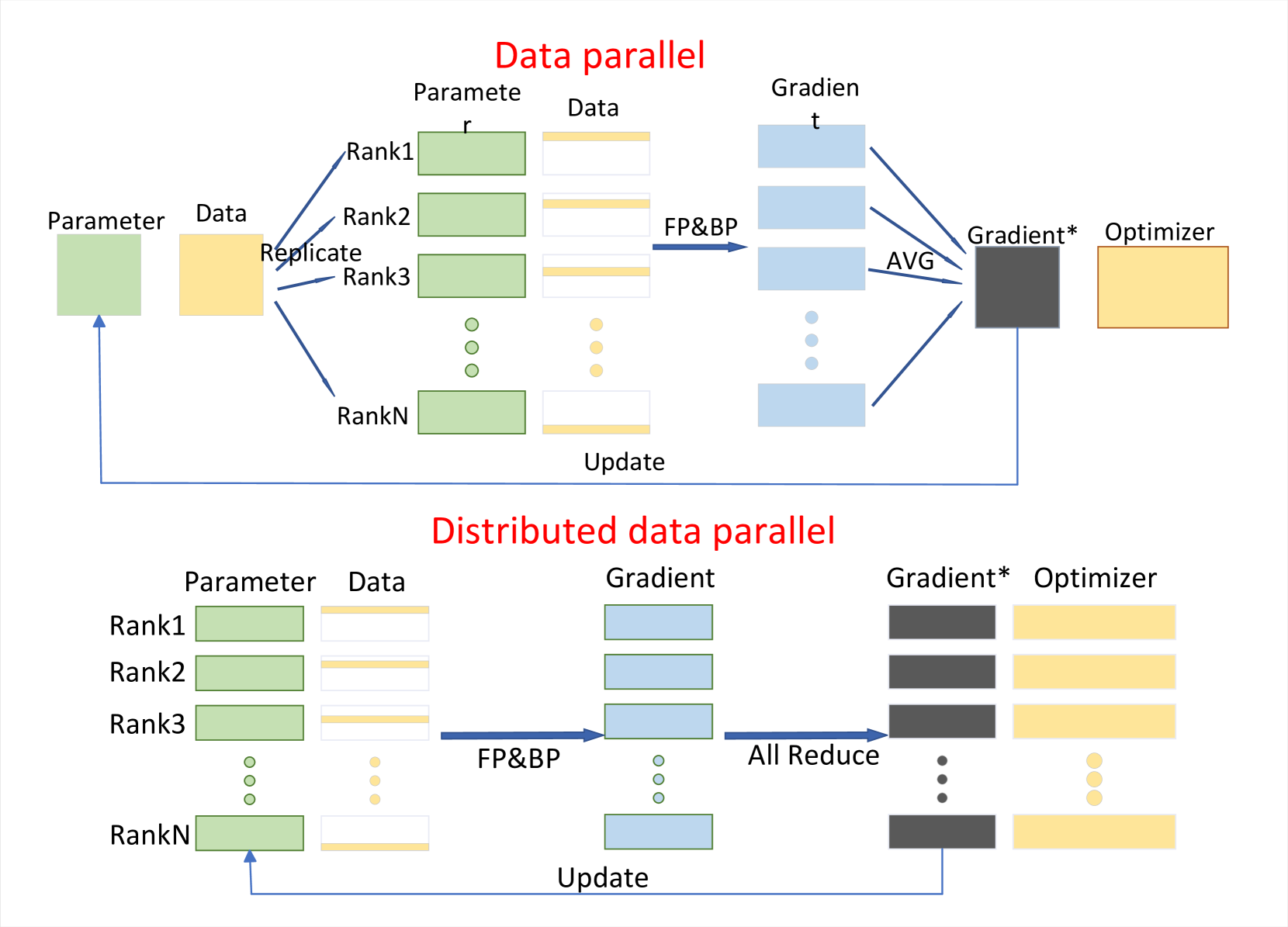
分布式数据并行[95]放弃了参数服务器的使用,而是对梯度信息采用all-reduce,保证每个GPU接收到相同的梯度信息。 all-reduce 的结果会传达给所有 GPU,使它们能够独立更新各自的模型优化器。 每轮更新后,模型的参数、梯度和优化器的历史信息在所有 GPU 上都是一致的。
中间结果对GPU内存的占用与batch size、句子长度和模型维度有关。 使用数据并行时,一批数据被分为许多部分,允许每个 GPU 处理一部分数据。 等效而言,每个 GPU 上处理的批量大小减少到原始 GPU 数量的 1 倍。 数据并行减少了输入维度,导致模型中间结果整体减少。 缺点是为了支持模型训练,每个GPU需要接收至少一条数据。 在最极端的情况下,当每个GPU只接收一份数据时,我们的参数、梯度和优化器仍然需要完全存储在GPU上。 即使我们不在 GPU 上存储任何中间结果,我们的模型仍然可能无法在单个 GPU 上执行计算。
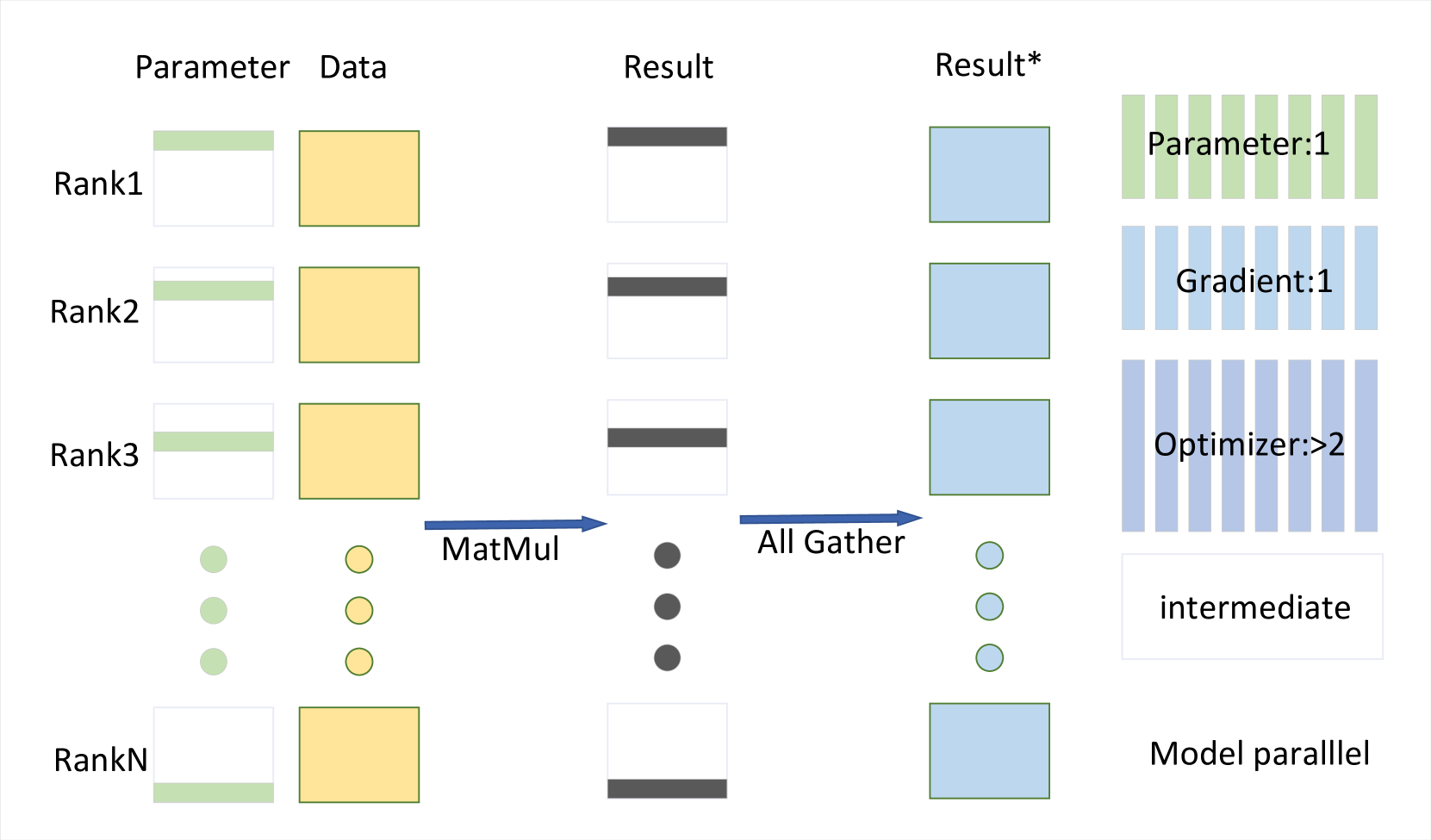
模型并行:模型并行性[96]首先由Megatron-LM引入,以减轻内存压力。 从图4中,我们可以清楚地了解模型并行的整体架构。 以Transformer中最常见的线性层为例,线性层的参数组成一个大小为A*B的矩阵,线性层的输入是大小为B*1的向量。 将其表示为 = ,我们可以利用矩阵乘法的性质将模型的参数水平划分为许多段。 每个段的大小为a除以n乘以B。利用矩阵乘法的性质,我们可以将移到括号中,最后将许多小矩阵与线性层的参数。 通过这种方法,线性层的参数可以分布在多个GPU上。 然而,确保多个 GPU 上的模型输入相同至关重要。 我们需要确保每个GPU上获得的输入是相同的,这意味着它们属于同一批次的数据,而不是使用数据并行的方法来划分数据。 然后,我们可以跨 GPU 划分参数(例如线性层),每个 GPU 接收矩阵的一小部分。 通过用这小部分和数据进行模型计算,我们得到一个子结果,如公式5所示。 这些计算的结果需要使用 all-gather 运算符连接起来并传递给所有 GPU。
| (6) | ||||
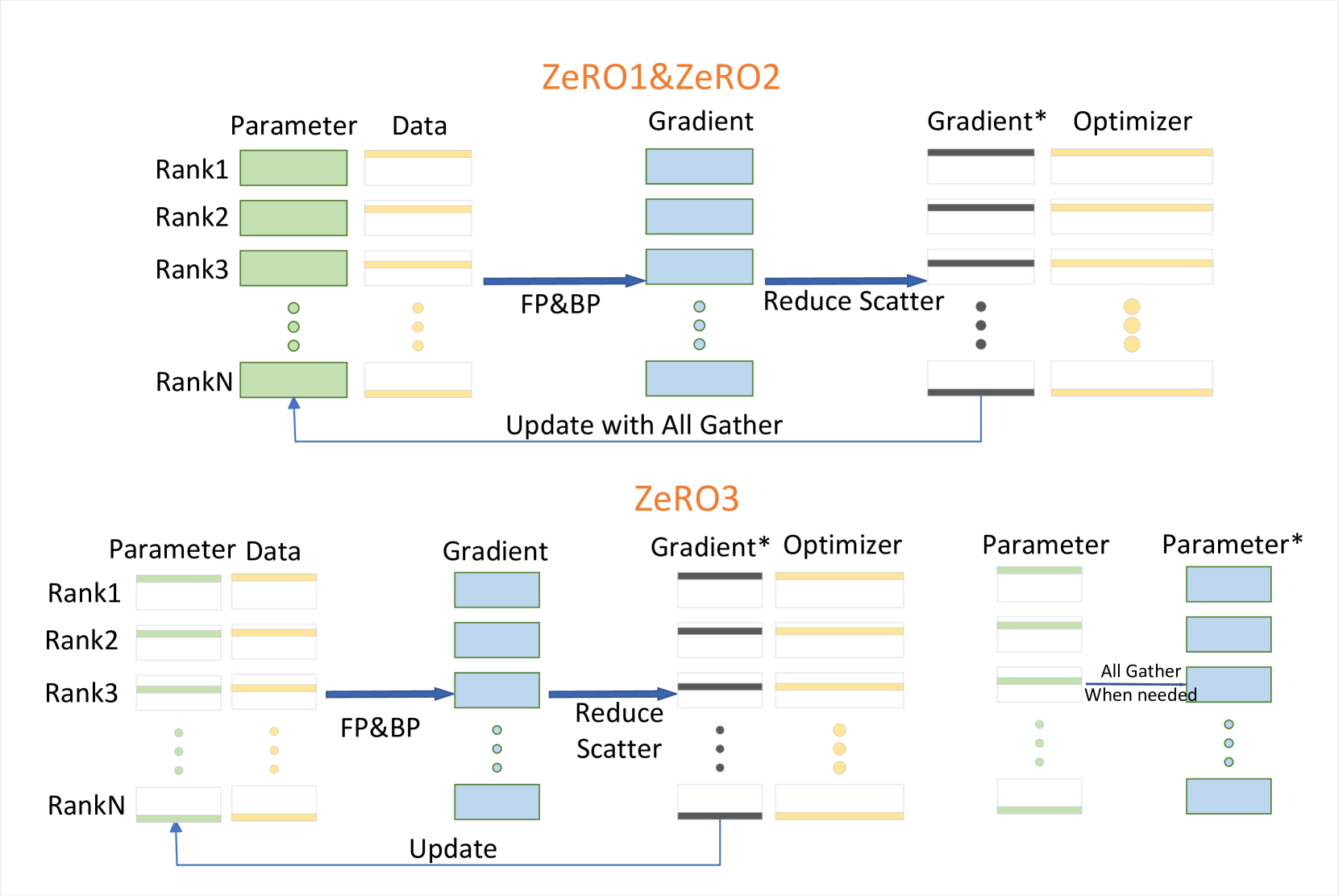
ZeRO: ZeRO [97] 是一个基于数据并行性的框架。 每个GPU上的参数更新过程中,使用同一组参数,导致计算冗余。 每个GPU都使用减少分散来消除这种冗余,以获得一部分梯度结果。 在每个 GPU 上更新部分模型参数后,执行全收集操作以同步所有 GPU 上的参数。 进行全聚集操作后,原始渐变不再需要保存在显卡上,可以将其删除。 图5展示了ZeRO的更新。 在ZeRO1中,向后传播后去除了原始梯度,而在ZeRO2中,在向后传播时预先计算出梯度*的乘积,并且仅将梯度*保存在显卡上,去除了梯度。 这样,梯度的删除就提前了,从而进一步节省了GPU内存空间。 ZeRO3对模型参数进行了详细的划分。 每个显卡只保留一部分梯度用于更新,参数更新也只影响一部分模型参数。 因此,每个显卡只需要存储与其负责的部分参数相关的参数、梯度和优化器。 在前向和后向传播过程中,需要进行一次全收集操作,操作完成后,模型参数从显卡中释放。Zero3在参数更新时没有使用全收集,但需要一次全收集操作在前向和后向传播期间,添加一个通信步骤。 与ZeRO2相比,ZeRO3是一种以时间换空间的算法。
管道并行: 管道并行性[98]和模型并行性有相似之处。 在模型并行性中,线性层被分成许多小矩阵,然后分布到不同的GPU。 对于管道并行性,模型的不同层被分配给不同的 GPU。 具体来说,如果我们有一个n层的Transformer,我们可以将Transformer的赋值给,以此类推。 在模型前向传播过程中,我们需要对进行的计算,然后将结果传递给。 接收来自 的输出,执行该层的计算并将结果传递到下一个 GPU。 该方法对每层的参数、梯度、优化器和中间结果进行分区。
3.4.2 混合精度训练
近年来,为了预训练超大型语言模型,一些研究[99]开始利用16位浮点数(FP16)来减少内存使用和通信开销。 FP16有效位数[100;的数值范围较小,精度较低。 38],但计算往往比 FP32 更快。 在一般模型训练中,FP32经常被用作训练参数的默认表示。 然而,在实际的模型训练中,模型的参数数量通常不会超过数千个数量级,完全在 FP16 的数值范围内。 为了提高计算速度,我们可以从 FP32 转换为 FP16。 在参数更新过程中,参数量大致等于梯度乘以学习率。 FP16的最小值约为1e-5。 由于梯度和学习率的乘积已经远低于 FP16 的表示范围,参数更新会导致损失,称为下溢。 因此,我们将梯度乘以学习率得到的参数更新表示为FP32。 我们不能直接将这种高精度参数更新添加到低精度模型中,因为这仍然会导致浮点下溢。 因此,我们需要在优化器上保存一个额外的单精度参数。 为了加速模型中的前向和后向传递,使用半精度参数和梯度并将其传递给优化器进行更新。 优化器的更新量保存为FP32,我们通过优化器中临时创建的FP32参数进行有效累加。 有效累加后,再转换回FP16参数。
3.4.3 卸载
优化器中的参数至少是模型参数的两倍,一项研究[101]提出了将优化器的参数从 GPU 移至 CPU 的想法。 尽管 GPU 计算比 CPU 快得多,但卸载此操作是否会成为模型优化器整体速度的瓶颈。 实际上,我们使用 ZeRO3。 使用ZeRO3优化后,参数、梯度和优化器的大小减少到GPU数量的1/n。 通过将一个 GPU 绑定到多个 CPU,我们可以有效降低每个 CPU 的计算负载。
3.4.4 重叠
内存操作通常是异步的。 这样,我们就可以提前向内存发送请求,然后再进行其他计算。 完成其他计算后,我们回来处理内存请求。 这个两步操作用于模型训练的前向传播过程。 我们需要通过gather操作获取的参数。 获取到的参数后,在的前向传播过程中,我们通过异步fetch主动获取的参数。 一旦的前向传播计算完成,的参数就已经获得并存储在GPU中。 然后我们就可以立即进行前向传播计算,等等。
3.4.5检查点
为了支持模型的后向传播,模型前向传播过程中需要保存GPU内存中的所有中间结果。 为了优化这个过程,使用了检查点机制,它不会将所有中间结果保存在GPU内存中,而是只保留某些检查点点。
下图展示了 Transformer 的简化结构。 每个 Transformer 块都接受模型输入,通过注意力和前馈过程进行复杂的计算,并产生该层的整体输出。 我们只保留 Transformer 中每个主要层的输入作为检查点。
在反向传播过程中,我们如何计算每个主要层内线性层的梯度? 我们可以执行一种称为重新计算的技术,该技术涉及在反向传播过程中重新执行每个主要层的前向传播。 我们暂时获得每个主要层内线性层的输入,获得的中间结果可以用于反向传播。 一旦该层的反向传播完成,我们就可以从 GPU 内存中丢弃检查点和模型内线性层临时重新计算的中间结果。
假设我们有一个24层的Transformer,每层包含四到五个线性层,使用检查点机制将原来需要存储的120个中间结果减少到只有24个中间结果。
3.5微调
本文大语言模型的训练分为数据收集与处理、预训练、微调三个阶段。 本节将对大语言模型的微调方法进行回顾。 具体来说,我们将微调技术分为三种类型:监督微调(SFT)[93]、对齐调整和参数高效调整。
3.5.1 监督微调
有监督微调的核心理念是在大规模预训练的基础上,以有监督的方式调整模型,增强模型更好地适应目标任务具体要求的能力。 在SFT过程中,需要为目标任务准备一个带标签的数据集,其中包括输入文本以及相应的标签。 指令调优是大语言模型微调过程中常用的技术,可以认为是SFT的一种具体形式。 它涉及在由(指令、输出)对组成的数据集上进一步训练大语言模型,重点是通过理解和遵循人类指令来增强大语言模型的能力和可控性。 我们整理了常用的指令调优数据集,如表3所示。
| Datasets | Links |
| static-hh | https://huggingface.co/datasets/Dahoas/static-hh |
| OIG | https://huggingface.co/datasets/laion/OIG |
| Self-Instruct [102] | https://github.com/yizhongw/self-instruct |
| Natural instructions [103] | https://github.com/allenai/natural-instructions |
| P3 [104] | https://huggingface.co/datasets/bigscience/P3 |
| Promptsource [105] | https://github.com/bigscience-workshop/promptsource |
| WebGPT [106] | https://huggingface.co/datasets/openai/webgpt_comparisons |
| Flan [107] | https://github.com/google-research/flan |
| MVPCorpus [108] | https://github.com/RUCAIBox/MVP |
3.5.2 对齐调整
由于大语言模型是在海量且多样化的互联网数据上进行预训练的,即使训练数据经过了一些预处理,但要保证TB级训练数据集中不存在偏见或有害内容仍然具有挑战性。 尽管大语言模型在各种自然语言处理任务中表现出了令人印象深刻的性能,但它们经常表现出与人类意图不同的行为。 这包括生成虚假信息、产生带有偏见或误导性内容的表达方式等等[93; 109]。 为了解决大语言模型表现出超出人类意图的行为的问题,对齐调整变得至关重要[93; 110]。
一般来说,对齐调整的目标是满足以下三个标准:有帮助、诚实和无害。
有用:有用的概念围绕着模型生成的输出是否被证明对特定任务或查询真正有益。 在自然语言处理领域,模型生成的文本或响应应提供有价值的信息,对用户的要求或任务目标产生积极影响。
诚实:诚实意味着模型生成的输出是否真实可靠。 该模型应产生与事实一致的信息,避免捏造或扭曲。 这有助于维持用户对模型输出真实性的信任。
无害性:无害性涉及模型生成的输出是否对用户或社会不会造成伤害。 该模型应避免生成有害、攻击性或危险的内容,确保所有相关利益相关者的使用保持安全。
在训练大语言模型中,一种值得注意的对齐调整方法是基于人类反馈的强化学习(RLHF)[93]。 该方法涉及收集人类反馈数据来训练强化学习的奖励模型(RM)。 RM作为强化学习训练过程中的奖励函数,采用近端策略优化(PPO)[111]等算法来调节大语言模型。 在这种背景下,大语言模型被视为策略,动作空间被视为大语言模型的词汇。
3.5.3 参数高效调优
目前,大型PLM如ChatGPT[93; 19]规模不断壮大。 然而,对于大多数研究人员来说,对消费级硬件进行全面微调成本高昂且不切实际。 与 SFT 和对齐调整不同,参数高效调整的目标是减少计算和内存开销。 该方法涉及仅微调模型参数的一小部分或附加子集,同时保持大多数预训练参数固定,从而显着降低计算和存储成本。 值得注意的是,最先进的参数高效调整技术已经达到了与完全微调相当的性能水平。 一些常见的参数高效调整方法包括低秩适应(LoRA)[112]、前缀调整[113]和P-Tuning[114; 115]。 即使在资源有限的环境中,这些方法的采用也可以实现高效的模型调整,为实际应用提供可行性和效率。
随着大语言模型的兴起,参数高效调优受到越来越多的关注,LoRA在大语言模型的最新版本中得到了广泛的应用。 LoRA [112] 及其相关进展[116; 117] 值得注意并值得关注。
3.5.4安全微调
为了增强大语言模型的安全性和责任感,在微调过程中集成额外的安全技术至关重要。 这包括三种主要技术,适用于 SFT 和 RLHF 阶段。
监督安全微调:在这项技术中,贴标机的任务是生成包含高安全风险对抗性提示的演示数据。 然后将这些手工安全演示数据纳入 SFT 阶段,从而增强模型管理安全风险的能力。
安全 RLHF:该技术采用相同甚至更激进的对抗性提示来查询模型。 然后,使用表现出拒绝行为的最安全响应来训练 RLHF 框架内的安全奖励模型。
安全上下文蒸馏:该技术采用上下文蒸馏[118],首先在对抗性提示前添加安全前置提示,例如“你是一个安全且负责任的助手”。 此过程会产生更安全的响应。 然后根据这些更安全的演示数据对该模型进行微调,但不包含安全预先提示。 此次安全提炼进一步增强了模型的安全能力。
3.6评估
与过去不同,大规模深度学习模型相比普通模型有着更广泛的应用范围和更强的性能。 然而,能力越大,责任越大,评估这些模型变得更加复杂,需要从各个方面考虑潜在的问题和风险。 自ChatGPT流行以来,已有许多相关研究发表,其中包括参考文献中大语言模型评估的调查和总结[119; 120],有助于开发大规模深度学习模型。 本节将根据以往大型模型的评估工作,介绍一些测试数据集、评估方向和方法以及需要考虑的潜在威胁。
3.6.1 静态测试数据集
大型模型能力的评估需要适当的数据集进行验证。 在这里,我们介绍几个常用的用于测试目的的数据集。 考虑到多模态大型模型,计算机视觉的典型数据集包括 ImageNet [121] 和 Open Images [122]。 除了大语言模型常用的GLUE [123]和SuperGLUE [124]之外,MMLU [125]在测试方面也具有很强的竞争力综合能力。 如果你的模型主要使用中文,那么还应该考虑作为中文大型模型基准的 CMMLU [126],以及 XTREME [127] 和 XTREME-R [128] 是多语言大型模型的合适选择。 对于数学知识能力的评估,有MATH [129]和GSM8K [130]等数据集,而HumanEval [131]和MBPP [132]可以作为代码生成的基准。 对于人类日常生活和工作中的常识推理测试,可以使用以下数据集:HelloSwag [133]、PIQA [134]、BoolQ [135]、SIQA [136]、WinoGrande [137]、ARC [138] 和 OpenBookQA [139]. 对于医学知识,有 MedQA-USMLE [140] 和 MedMCQA [141] 等数据集。
3.6.2开放域问答评估
目前,大语言模型以问答的形式与人类互动。 与传统搜索返回的碎片化、模糊性信息相比,大语言模型提供了更加真实、高效、符合人类习惯的问答结果。 因此,ODQA(开放域问答)[142]能力的评估至关重要。 开放域问答的性能极大地影响用户体验。 常用的测试数据集包括 SquAD [143] 和 Natural Questions [144],以 F1 分数和精确匹配准确率 (EM) 作为评估指标。 但请注意,单词匹配方法可能存在某些问题,例如当事实上正确的答案不在黄金答案列表中时。 因此,人类的评估似乎是必要的,文献[145]对此事进行了详细的研究。
3.6.3安全评估
大语言模型作为一个新兴的热点研究领域,必须关注其潜在的安全威胁,防止恶意使用或遭受恶意攻击的漏洞,并解决任何可能对人类发展构成威胁的潜在长期问题。 此外,各个领域的红队对于严格评估和测试模型、识别漏洞、偏见、不准确性和安全改进领域是必要的。
潜在偏见:大语言模型的训练数据可能包含潜在的偏见,例如性别或种族。 安全评估需要解决模型是否产生或放大这些偏差以及如何减少或纠正它们。 参考文献[146]详细讨论了大语言模型中出现偏差的原因以及可能产生的严重后果。 参考文献[147]广泛研究了预训练的语言模型如何生成有害内容到什么程度,以及如何使用受控文本生成算法来防止有毒内容的生成。 CHBias [148]是一个中文数据集,可用于评估和缓解大语言模型的偏差问题。
隐私保护: 大语言模型在训练过程中可能会接触到大量的用户数据,如文本、图像等。 安全评估需要确保用户数据隐私得到有效保护,防止泄露和滥用。 参考文献[149]对ChatGPT等模型进行了研究,发现可以从这些模型中有效地提取训练数据。 参考文献[150]提供了一种解决方案,提出了一个名为DEPN(检测和编辑隐私神经元)的框架来检测和编辑预训练语言模型中的隐私神经元。 它还引入了隐私神经元聚合器,以批处理的方式消除隐私信息,在保持模型性能的同时有效减少隐私数据的泄露。
对抗性攻击: 大语言模型可能容易受到对抗性攻击,例如输入篡改、故意错误信息或生成虚假信息。 安全评估需要考虑模型的稳健性,即其抵御此类攻击的能力。 正如参考文献[151]中提到的,大语言模型仍然存在“越狱”风险,用户可以使用特定的输入方法(如角色扮演或添加特殊后缀)来操纵模型生成有毒内容,如参考论文。 特别是在使用开源预训练模型时,预训练模型中有关对抗性攻击的任何漏洞也会被继承。 参考[152]提供了一种解决方案来减轻这些漏洞造成的危害。
3.6.4评估方法
自动评估和人工评估在语言模型研究中发挥着至关重要的作用。 自动化评估通常涉及使用各种指标和指标来量化模型的性能,例如 BIEU [153]、ROUGE [154] 和 BERTSScore [155] ,可以衡量LLM生成内容的准确性。 这些指标可以帮助研究人员快速评估大规模数据上的模型性能并比较不同的模型。 然而,自动评估也有局限性,因为它无法完全捕捉语言理解和生成的复杂性。 参考文献[156]中的研究表明,对于某些开放式生成任务,手动评估更为可靠。 手动评估通常涉及人类注释者主观判断和评估模型生成的输出的质量。 这种评估方法可以帮助揭示模型在特定任务或场景中的表现,并识别自动评估可能忽略的细微问题和错误。 然而,人工评估也面临着时间成本高、主观性等挑战。 因此,往往需要结合自动评估和人工评估的优势来综合评估语言模型的性能。
3.7 LLM 框架
大型深度学习模型可显着提高准确性,但训练数十亿至数万亿个参数具有挑战性。 分布式训练等现有解决方案已经解决了基本限制,可以将这些模型适应有限的设备内存,同时获得计算、通信和开发效率。 接下来,本节将介绍几种大型语言模型框架,这些框架利用分布式训练技术,利用 GPU、CPU 和 NVMe 内存,在有限的资源上实现前所未有的模型规模,而无需重构模型代码。
Transformers Transformers[157] 是 Hugging Face 的开源 Python 库,致力于使用 Transformer 架构构建模型。 它具有简单且用户友好的 API,有助于轻松定制各种预训练模型。 凭借强大的用户和开发人员社区,Transformers 不断更新和改进模型和算法。
DeepSpeed:Deepspeed [158]是一个与PyTorch兼容的开源优化库,由微软开发,用于训练大语言模型,如MTNLG [79] 和 BLOOM [38]。 目前,它提供对ZeRO技术的全面支持,包括优化器状态分区、梯度分区和参数分区、自定义混合精度训练、一系列基于CUDA扩展的快速优化器[159]和ZeRO卸载CPU 和磁盘/NVMe。 通过以上技术。 此外,Deepspeed 还以较小的内存需求实现了出色的可扩展性和效率。
BMTrain:BMTrain [160]是清华大学开发的高效大型模型训练工具包,可用于训练数百亿参数的大型模型。 它可以以分布式方式训练模型,同时保持训练代码像独立一样简单。 BMTrain 不需要模型重构即可工作。 事实上,PyTorch 用户可以通过对现有训练管道进行几行代码更改来启用 BMTrain。 提供ZeRO优化、通信优化等多种优化技术的支持。
威震天-LM:威震天-LM [96; 161; 162] 是 NVIDIA 为大规模语言模型开发的深度学习训练库。Megatron-LM 展示了他们的技术,包括模型和数据并行、混合精度以及用于训练超大型 Transformer 模型的 FlashAttention。 具体来说,它利用 Transformer 网络的结构,通过添加一些同步原语来创建一个简单的模型并行实现,并能够在 PyTorch 中训练具有数十亿个参数的 Transformer 模型并进行高效训练。 它还对以下方面进行了深入的实证分析:他们的模型和数据并行技术,并展示了使用 512 个 GPU 时高达 76% 的扩展效率,这可以大大提高训练效率和速度,从而实现跨 GPU 的高效分布式训练。
除了上述框架外,Colossal-AI [163] 和 FastMoE [164; 165]也是两个流行的训练大语言模型框架。 原则上任何支持并行计算的深度学习框架都可以用来训练大语言模型。 示例包括 PyTorch [166]、TensorFlow [167; 168]、PaddlePaddle [169]、MXNet [170]、OneFlow [171]、MindSpore [172] 和 JAX [173]。
4 大型语言模型的推理
大型模型规模每年以近10倍的速度增长,带来巨大的计算消耗和碳排放[174]。 因此,减轻训练大型模型的计算负担,同时保留其推理能力成为了大家共同关心的问题。 本章主要介绍如何从计算和存储两个方面降低成本,即如何从模型压缩、内存调度、并行性和结构优化四个方面高效地进行大规模模型推理。
4.1 模型压缩
4.1.1 知识蒸馏
知识蒸馏[175]是指将知识从繁琐的(教师)模型转移到更适合部署的较小(学生)模型。 这是通过拟合两个模型的软目标来实现的,因为软目标比金标签提供更多信息。 最初,模型蒸馏的计算仅涉及拟合教师模型和学生模型最后一层的输出[176]。 PKD [177] 通过计算归一化隐藏状态之间的均方损失来改进此过程,允许学生模型从教师模型的多个中间层中学习。 为了发现更多适合知识蒸馏的中间表示,Jiao等人[178]提出了Tiny BERT。 这使得学生模型能够从教师模型的嵌入层和注意力矩阵中学习。
4.1.2 模型剪枝
模型剪枝涉及从大型模型的参数矩阵中删除冗余部分。 它分为非结构化剪枝和结构化剪枝。 非结构化修剪涉及删除神经网络中的各个连接或权重,而不遵循任何特定的结构模式。 在结构化剪枝中,神经网络内的特定结构模式或单元被剪枝或删除。 Gordon 等人[179]比较了非结构化和结构化剪枝对BERT模型的影响。 他们发现,非结构化剪枝的有效性随着剪枝比例的增加而显着下降,而在结构化剪枝中,可以丢弃 30-40% 的权重,而不会影响 BERT 的普适性。 模型中的不同结构可以进行结构修剪。 Michel 等人[180]修剪了注意力头,发现去除一个头通常会对 WMT 和 BERT 的性能产生积极影响。 他们提出了一种基于梯度的指标来评估注意力头的重要性,以增强修剪效果。 Fan等人[179]通过将dropout从权重扩展到层来进行层剪枝。 在训练过程中,他们随机丢弃层,并通过在测试过程中选择任何所需深度的子网络来取得良好的推理结果。
4.1.3 模型量化
模型量化背后的基本思想是减少大型模型网络中数值计算中使用的浮点位数,从而降低存储和计算成本。 这涉及将浮点运算转换为固定精度运算。 然而,随着精度的降低,模型的损失逐渐增大,当精度下降到1位时,模型的性能会突然下降。 为了解决低精度量化带来的优化挑战,Bai等人[181]提出了BinaryBERT。 他们首先训练了一个半尺寸的三元模型,然后通过权重分割用三元模型初始化了一个二元模型。 最后,他们对二元模型进行了微调。 与从头开始训练二进制模型相比,这种方法为二进制模型带来了更好的结果。
4.1.4 权重共享
权重共享的基本思想是对大语言模型的多个部分使用同一组参数。 该模型不是为每个实例或组件学习不同的参数,而是在各个部分之间共享一组通用的参数。 权重共享有助于减少需要学习的参数数量,使模型的计算效率更高,并降低过度拟合的风险,特别是在数据有限的情况下。 ALBERT [182]采用跨层参数共享策略有效减少模型参数数量,在相同参数数量下能够取得比基线更好的训练结果。
4.1.5 低阶近似
低秩分解方法在模型压缩领域至关重要,因为它们允许使用更少的参数创建更紧凑的模型。 模型大小的减小对于在资源受限的设备上部署神经网络特别有利,从而提高推理过程中的效率。 Chen 等人[183]对输入矩阵进行低秩分解,使得大模型内的矩阵运算发生在较低的秩级别,有效减少了计算工作量。 从结果来看,他们提出的方法DRONE不仅保证了大模型的推理性能,而且与基线方法相比,实现了1.3倍以上的加速比。 低秩分解方法的具体选择取决于神经网络的架构和目标应用的要求。
4.2内存调度
鉴于大语言模型的大量参数,在单个消费级 GPU 上部署大语言模型受到可用视频内存的限制。 因此,可以采用适当的内存调度策略来解决大模型推理的硬件限制。 大型模型推理中的内存调度涉及复杂神经网络模型的推理或推理阶段内存访问模式的有效组织和管理。 在复杂的推理任务中,例如自然语言理解或复杂的决策,大型模型通常具有复杂的架构和相当大的内存需求。 内存调度优化了中间表示、模型参数和激活值的检索和存储,确保推理过程既准确又以最小的延迟执行。 例如,BMInf [184]利用虚拟内存原理,通过在GPU和CPU之间智能调度各层参数,实现大型模型的高效推理。
4.3并行度
推理和训练都可以利用并行化技术。 目前,推理的并行化技术主要体现在三个维度:数据并行、张量并行和管道并行。 数据并行主要涉及通过添加更多 GPU 设备来提高推理系统的整体吞吐量[101; 97; 159; 185]。 张量并行是模型并行的一种形式,其中模型的参数被划分为多个张量,每个张量在不同的处理单元上计算。 事实证明,在处理太大而无法放入单个 GPU 内存的模型时,这种方法非常有用。 张量并行主要涉及通过并行计算水平增加设备数量,以减少延迟[96]。 管道并行主要是通过并行计算垂直增加GPU设备数量,以支持更大的模型并提高设备利用率。 通常,它与张量并行相结合以实现最佳性能[98]。
4.4结构优化
在大语言模型的前向传播计算中,计算速度明显快于内存访问的速度。 推理速度可能会受到大量内存访问操作的影响。 大语言模型推理的目标之一是最小化前向传播期间的内存访问次数。 FlashAttention [186] 和 PagedAttention [187] 通过采用分块计算方法来提高计算速度,从而减少与矩阵相关的存储开销。 整个操作都在 SRAM 内进行,减少了对高带宽内存 (HBM) 的访问次数,并显着提高了计算速度。 FlashAttention和PagedAttention都已被主流推理框架采用,并无缝集成到这些框架中以方便使用。
4.5 推理框架
并行计算、模型压缩、内存调度以及Transformer结构的具体优化等都是大语言模型推理的重要组成部分,已在主流推理框架中得到有效实现。 这些框架提供了部署和运行大语言模型模型所需的基础设施和工具。 他们提供了一系列工具和接口,简化了研究人员和工程师跨不同应用场景的部署和推理过程。 框架的选择通常取决于项目要求、硬件支持和用户偏好。 在表4中,我们编译了其中一些框架以供参考。
| Framework | Links |
| TensorRT | https://github.com/NVIDIA/TensorRT-LLM |
| FasterTransformer | https://github.com/NVIDIA/FasterTransformer |
| Megatron-LM [96] | https://github.com/NVIDIA/Megatron-LM |
| FlexGen [188] | https://github.com/FMInference/FlexGen |
| DeepSpeed [158] | https://github.com/microsoft/DeepSpeed |
| vLLM [187] | https://github.com/vllm-project/vllm |
| FlexFlow [189] | https://github.com/flexflow/FlexFlow |
| StreamingLLM [190] | https://github.com/mit-han-lab/streaming-llm |
| ColossalAI [163] | https://github.com/hpcaitech/ColossalAI |
| BMCook [191] | https://github.com/OpenBMB/BMCook |
| BMInf [184] | https://github.com/OpenBMB/BMInf |
| Petals [192] | https://github.com/bigscience-workshop/petals |
5大语言模型的运用
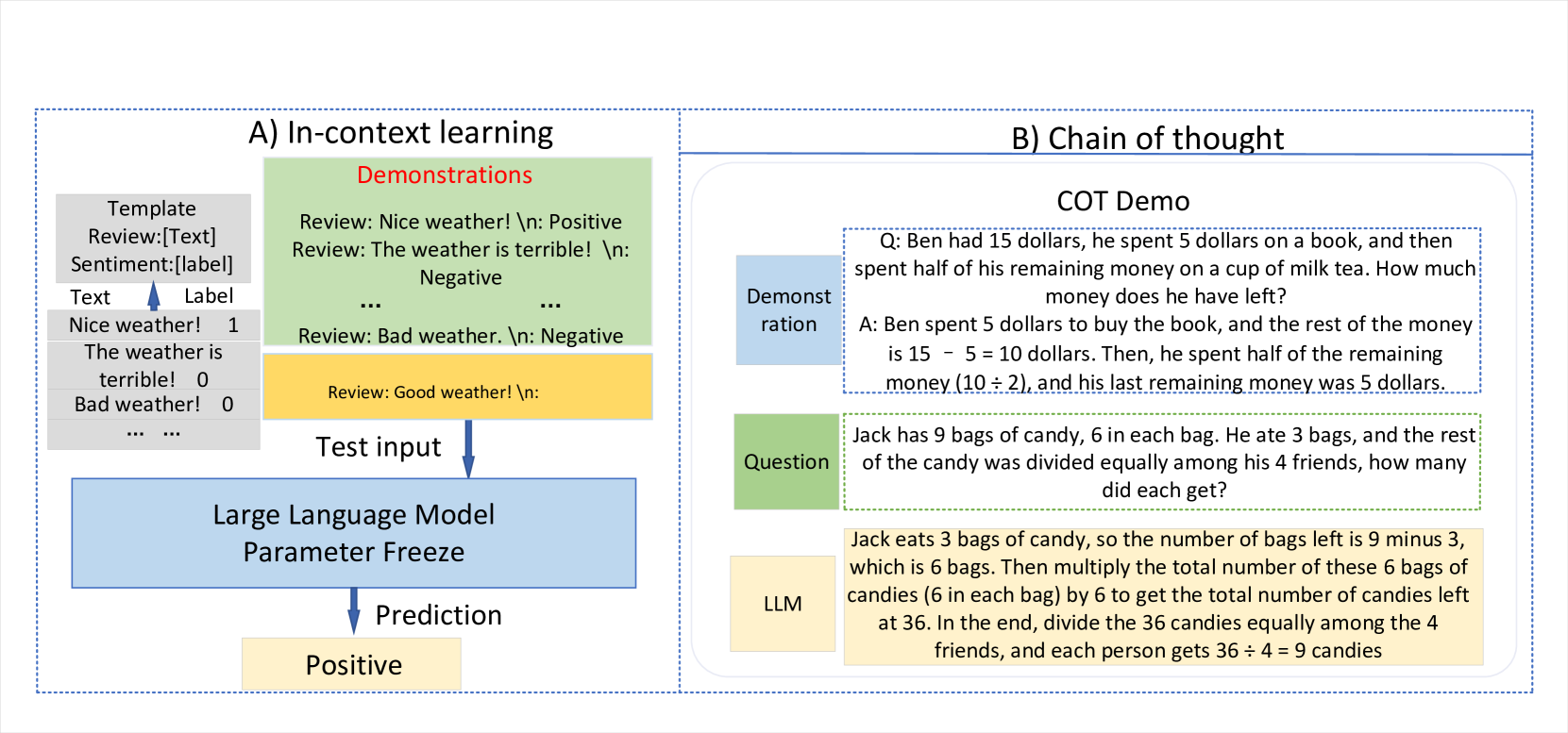
大语言模型的应用范围广泛,几乎可以应用于任何专业领域[1; 193; 46; 194; 195]。 经过预训练和微调后,大语言模型的主要用途是为各种任务设计合适的提示。 凭借强大的零样本功能,许多任务可以通过简单的提示引导大语言模型直接完成。 对于通过简单提示无法完成的更复杂的任务,采用涉及上下文学习的少样本方法来指导大语言模型完成任务。 此外,结合思想链[196; 197]提示中的提示通过引入推理过程来增强情境学习。 情境学习和思维链的流程如图6所示。 在某些专业研究方向中,获得大语言模型的中间层表示可能是必要的。 例如,在神经科学研究中,模型的嵌入表示用于研究大脑功能的激活区域[198; 199; 200; 201]。
一般来说,有几种使用大语言模型的方法。 第一个涉及通过开放 API 服务访问强大的专有模型的功能,例如利用 ChatGPT [19] 提供的 API。 第二种方法包括部署开源大语言模型供本地使用[9]。 第三种方法需要微调开源大语言模型以满足特定领域标准[43; 202],在特定领域启用它们的应用,然后在本地部署它们。 表5中,我们整理了各种开源大语言模型的信息,以供参考。 研究人员可以从这些开源大语言模型中进行选择来部署最适合他们需求的应用程序。
| LLM | Size (B) | Links |
| T5 [68] | 11B | https://github.com/google-research/text-to-text-transfer-transformer |
| CodeGen [81] | 16B | https://github.com/salesforce/CodeGen |
| MOSS [203] | 16B | https://github.com/OpenLMLab/MOSS |
| GLM [37] | 130B | https://github.com/THUDM/GLM |
| ChatGLM [37] | 6B | https://github.com/THUDM/ChatGLM3 |
| ChatYuan [204] | 0.7B | https://github.com/clue-ai/ChatYuan |
| OPT [83] | 175B | https://github.com/facebookresearch/metaseq |
| BLOOM [38] | 176B | https://huggingface.co/bigscience/bloom |
| LLaMA [9] | 65B | https://github.com/facebookresearch/llama |
| CodeGeeX [82] | 13B | https://github.com/THUDM/CodeGeeX |
| Baichuan [205] | 13B | https://github.com/baichuan-inc/Baichuan2 |
| Aquila | 7B | https://github.com/FlagAI-Open/FlagAI/tree/master/examples/Aquila |
| MiniGPT-4 [206] | 25B | https://github.com/Vision-CAIR/MiniGPT-4 |
| Vicuna [207] | 13B | https://github.com/lm-sys/FastChat |
6 未来的方向和影响
本节将深入探讨大语言模型技术的未来趋势和影响。 我们的讨论将分为三个部分:第一,大语言模型技术本身的发展趋势探讨;第二,大语言模型技术本身的发展趋势。其次,审视人工智能研究者的发展方向;最后,分析了大语言模型的持续发展所产生的社会影响。
根据现有经验,充足的高质量数据和足够数量的参数显然有助于提高模型的性能[8]。 展望未来,大语言模型的模型规模预计将继续扩大,从而增强其学习能力和整体表现。 此外,目前大多数可用的大语言模型仅限于单一的自然语言模态,缺乏处理图像、视频和语音等多模态数据的扩展。 大语言模型未来的潜在发展轨迹是处理文本以外的信息,整合图像和音频等多模态数据。 这种演变将使模型能够全面理解和生成多模态内容,从而显着拓宽大语言模型的应用范围。 大语言模型不可避免地扩展到多模态领域,势必会增加训练成本。 未来发展的重点在于通过知识蒸馏、模型压缩、量化等技术对大语言模型的参数进行高效微调和部署,旨在降低大语言模型的训练成本和推理成本。 另一个新兴趋势是针对特定行业的大语言模型的特定领域训练和微调,有助于更熟练地适应和理解行业特定术语和上下文。 最后,在探索大语言模型潜在的新架构时,当前的格局主要依赖于 Transformer 架构。 虽然 Transformer 架构自然拥有并行计算和对各种输入模式的适应性等优势,但其设计通常需要固定大小的输入。 在处理可变长度序列时,这一要求可能需要填充或截断,可能导致计算和信息效率低下,以及生成相干数据的挑战。 研究大语言模型时代循环神经网络(RNN)架构的潜力可能会成为一个关键的研究方向。 例如,在RNN架构下设计的大语言模型RWKV[208]在各种第三方评估中都表现出了有竞争力的性能,证明了其可以与大多数基于Transformer的大语言模型相媲美。
对于人工智能领域的研究人员来说,孤立地工作变得越来越不切实际。 人工智能未来的发展方向将与各行各业交织,需要与不同领域的专业人士密切合作。 至关重要的是,要开展合作,连接研究学科,并通过结合不同领域的专业知识来共同应对挑战。 同时,对人工智能研究人员的综合技能也提出了新的要求。 大语言模型的训练和部署需要熟练的大规模数据管理能力和丰富的分布式并行训练实践经验。 这一标准强调了参与大语言模型开发的研究人员拥有强大的工程能力、解决该过程中固有的挑战的重要性。 对大语言模型领域感兴趣的研究人员必须具备工程技能或熟练地与工程师合作来应对模型开发的复杂性[3]。
随着大语言模型在社会生活中的广泛应用,人们对伦理问题和社会影响的关注不断上升。 这可能涉及管理模型偏差和控制误用风险等领域的研究和改进[4]。 考虑到隐私和数据安全的重要性,大语言模型的未来发展可能会涉及更多联邦学习和去中心化方法,以在保护用户隐私的同时提高模型性能。 开发者应与决策、法学、社会学等各个领域的专家进行跨学科合作,建立大语言模型开发、部署和使用的标准和伦理框架,减轻潜在的有害后果。 在公众认知和教育方面,在大规模公众部署和应用之前,应先进行强制性认知训练。 此举旨在增强公众对大语言模型的能力和局限性的理解,促进负责任和知情的使用,特别是在教育和新闻等行业。
7结论
ChatGPT 的引入开创了大型大语言模型领域的变革时代,极大地影响了它们在各种下游任务中的利用率。 对经济有效的训练和部署的重视已成为大语言模型发展的一个关键方面。 本文针对低成本开发的新兴趋势,全面概述了大语言模型训练技术和推理部署技术的演变。 从传统统计语言模型到神经语言模型,再到ELMo和Transformer架构等PLM,为大语言模型的主导地位奠定了基础。 这些模型(特别是 GPT 系列)的规模和性能已达到前所未有的水平,展示了新兴现象并实现了跨各个领域的多功能应用。 值得注意的是,OpenAI 于 2022 年 11 月发布的 ChatGPT 标志着大语言模型领域的关键时刻,彻底改变了人工智能算法的强度和有效性。 然而,当前对 OpenAI 基础设施的依赖凸显了替代大语言模型的必要性,强调了对特定领域模型以及训练和部署过程中的进步的需求。
训练和部署大语言模型提出了挑战,需要处理大规模数据和分布式并行训练的专业知识。 大语言模型开发所需的工程能力凸显了研究人员和工程师之间的协作努力。 当我们在这篇综述中探讨大语言模型训练和推理的技术方面时,很明显,对这些过程的深入理解对于研究人员进入该领域至关重要。 展望未来,大语言模型的未来前景广阔,包括模型架构的进一步进步、训练效率的提高以及跨行业的更广泛应用。 本综述提供的见解旨在为研究人员提供应对大语言模型开发的复杂性所需的知识和理解,促进这一动态领域的创新和进步。 随着大语言模型的不断发展,它们对自然语言处理和人工智能的整体影响将塑造智能系统的未来格局。
参考
- [1] Y. Liu, T. Han, S. Ma, J. Zhang, Y. Yang, J. Tian, H. He, A. Li, M. He, Z. Liu et al., “Summary of chatgpt-related research and perspective towards the future of large language models,” Meta-Radiology, p. 100017, 2023.
- [2] J. Wang, E. Shi, S. Yu, Z. Wu, C. Ma, H. Dai, Q. Yang, Y. Kang, J. Wu, H. Hu et al., “Prompt engineering for healthcare: Methodologies and applications,” arXiv preprint arXiv:2304.14670, 2023.
- [3] W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong et al., “A survey of large language models,” arXiv preprint arXiv:2303.18223, 2023.
- [4] J. Kaddour, J. Harris, M. Mozes, H. Bradley, R. Raileanu, and R. McHardy, “Challenges and applications of large language models,” arXiv preprint arXiv:2307.10169, 2023.
- [5] M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, and L. Zettlemoyer, “Deep contextualized word representations,” in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), Jun. 2018, pp. 2227–2237.
- [6] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- [7] A. Radford, J. Wu, D. Amodei, D. Amodei, J. Clark, M. Brundage, and I. Sutskever, “Better language models and their implications,” OpenAI Blog https://openai. com/blog/better-language-models, vol. 1, no. 2, 2019.
- [8] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language models are few-shot learners,” Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020.
- [9] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar et al., “Llama: Open and efficient foundation language models,” arXiv preprint arXiv:2302.13971, 2023.
- [10] H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale et al., “Llama 2: Open foundation and fine-tuned chat models,” arXiv preprint arXiv:2307.09288, 2023.
- [11] S. Rezayi, H. Dai, Z. Liu, Z. Wu, A. Hebbar, A. H. Burns, L. Zhao, D. Zhu, Q. Li, W. Liu et al., “Clinicalradiobert: Knowledge-infused few shot learning for clinical notes named entity recognition,” in International Workshop on Machine Learning in Medical Imaging. Springer, 2022, pp. 269–278.
- [12] Z. Liu, M. He, Z. Jiang, Z. Wu, H. Dai, L. Zhang, S. Luo, T. Han, X. Li, X. Jiang et al., “Survey on natural language processing in medical image analysis.” Zhong nan da xue xue bao. Yi xue ban= Journal of Central South University. Medical Sciences, vol. 47, no. 8, pp. 981–993, 2022.
- [13] W. Liao, Z. Liu, H. Dai, Z. Wu, Y. Zhang, X. Huang, Y. Chen, X. Jiang, D. Zhu, T. Liu et al., “Mask-guided bert for few shot text classification,” arXiv preprint arXiv:2302.10447, 2023.
- [14] S. Rezayi, Z. Liu, Z. Wu, C. Dhakal, B. Ge, H. Dai, G. Mai, N. Liu, C. Zhen, T. Liu et al., “Exploring new frontiers in agricultural nlp: Investigating the potential of large language models for food applications,” arXiv preprint arXiv:2306.11892, 2023.
- [15] T. Zhong, W. Zhao, Y. Zhang, Y. Pan, P. Dong, Z. Jiang, X. Kui, Y. Shang, L. Yang, Y. Wei et al., “Chatradio-valuer: A chat large language model for generalizable radiology report generation based on multi-institution and multi-system data,” arXiv preprint arXiv:2310.05242, 2023.
- [16] Z. Liu, T. Zhong, Y. Li, Y. Zhang, Y. Pan, Z. Zhao, P. Dong, C. Cao, Y. Liu, P. Shu et al., “Evaluating large language models for radiology natural language processing,” arXiv preprint arXiv:2307.13693, 2023.
- [17] T. Zhong, Y. Wei, L. Yang, Z. Wu, Z. Liu, X. Wei, W. Li, J. Yao, C. Ma, X. Li et al., “Chatabl: Abductive learning via natural language interaction with chatgpt,” arXiv preprint arXiv:2304.11107, 2023.
- [18] A. Radford, K. Narasimhan, T. Salimans, I. Sutskever et al., “Improving language understanding by generative pre-training,” OpenAI, 2018.
- [19] OpenAI, “Gpt-4 technical report,” 2023.
- [20] H. Dai, Z. Liu, W. Liao, X. Huang, Y. Cao, Z. Wu, L. Zhao, S. Xu, W. Liu, N. Liu, S. Li, D. Zhu, H. Cai, L. Sun, Q. Li, D. Shen, T. Liu, and X. Li, “Auggpt: Leveraging chatgpt for text data augmentation,” 2023.
- [21] Z. Liu, X. Yu, L. Zhang, Z. Wu, C. Cao, H. Dai, L. Zhao, W. Liu, D. Shen, Q. Li et al., “Deid-gpt: Zero-shot medical text de-identification by gpt-4,” arXiv preprint arXiv:2303.11032, 2023.
- [22] C. Ma, Z. Wu, J. Wang, S. Xu, Y. Wei, Z. Liu, L. Guo, X. Cai, S. Zhang, T. Zhang et al., “Impressiongpt: an iterative optimizing framework for radiology report summarization with chatgpt,” arXiv preprint arXiv:2304.08448, 2023.
- [23] W. Liao, Z. Liu, H. Dai, S. Xu, Z. Wu, Y. Zhang, X. Huang, D. Zhu, H. Cai, T. Liu et al., “Differentiate chatgpt-generated and human-written medical texts,” arXiv preprint arXiv:2304.11567, 2023.
- [24] H. Dai, Y. Li, Z. Liu, L. Zhao, Z. Wu, S. Song, Y. Shen, D. Zhu, X. Li, S. Li et al., “Ad-autogpt: An autonomous gpt for alzheimer’s disease infodemiology,” arXiv preprint arXiv:2306.10095, 2023.
- [25] Z. Guan, Z. Wu, Z. Liu, D. Wu, H. Ren, Q. Li, X. Li, and N. Liu, “Cohortgpt: An enhanced gpt for participant recruitment in clinical study,” arXiv preprint arXiv:2307.11346, 2023.
- [26] Z. Liu, Z. Wu, M. Hu, B. Zhao, L. Zhao, T. Zhang, H. Dai, X. Chen, Y. Shen, S. Li et al., “Pharmacygpt: The ai pharmacist,” arXiv preprint arXiv:2307.10432, 2023.
- [27] Y. Wei, T. Zhang, H. Zhang, T. Zhong, L. Zhao, Z. Liu, C. Ma, S. Zhang, M. Shang, L. Du et al., “Chat2brain: A method for mapping open-ended semantic queries to brain activation maps,” arXiv preprint arXiv:2309.05021, 2023.
- [28] T. Zhong, X. Wei, E. Shi, J. Gao, C. Ma, Y. Wei, S. Zhang, L. Guo, J. Han, T. Liu et al., “A small-sample method with eeg signals based on abductive learning for motor imagery decoding,” in International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2023, pp. 416–424.
- [29] J. Gao, L. Zhao, T. Zhong, C. Li, Z. He, Y. Wei, S. Zhang, L. Guo, T. Liu, J. Han et al., “Prediction of cognitive scores by joint use of movie-watching fmri connectivity and eye tracking via attention-censnet,” Psychoradiology, vol. 3, 2023.
- [30] I. Sutskever, O. Vinyals, and Q. V. Le, “Sequence to sequence learning with neural networks,” Advances in neural information processing systems, vol. 27, 2014.
- [31] G. Bebis and M. Georgiopoulos, “Feed-forward neural networks,” Ieee Potentials, vol. 13, no. 4, pp. 27–31, 1994.
- [32] Y. Yang, L. Wang, S. Shi, P. Tadepalli, S. Lee, and Z. Tu, “On the sub-layer functionalities of transformer decoder,” arXiv preprint arXiv:2010.02648, 2020.
- [33] Z. Dai, Z. Yang, Y. Yang, J. Carbonell, Q. V. Le, and R. Salakhutdinov, “Transformer-xl: Attentive language models beyond a fixed-length context,” arXiv preprint arXiv:1901.02860, 2019.
- [34] J. Su, M. Ahmed, Y. Lu, S. Pan, W. Bo, and Y. Liu, “Roformer: Enhanced transformer with rotary position embedding,” Neurocomputing, p. 127063, 2023.
- [35] O. Press, N. A. Smith, and M. Lewis, “Train short, test long: Attention with linear biases enables input length extrapolation,” arXiv preprint arXiv:2108.12409, 2021.
- [36] A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann et al., “Palm: Scaling language modeling with pathways,” arXiv preprint arXiv:2204.02311, 2022.
- [37] A. Zeng, X. Liu, Z. Du, Z. Wang, H. Lai, M. Ding, Z. Yang, Y. Xu, W. Zheng, X. Xia et al., “Glm-130b: An open bilingual pre-trained model,” arXiv preprint arXiv:2210.02414, 2022.
- [38] B. Workshop, T. L. Scao, A. Fan, C. Akiki, E. Pavlick, S. Ilić, D. Hesslow, R. Castagné, A. S. Luccioni, F. Yvon et al., “Bloom: A 176b-parameter open-access multilingual language model,” arXiv preprint arXiv:2211.05100, 2022.
- [39] L. Zhao, L. Zhang, Z. Wu, Y. Chen, H. Dai, X. Yu, Z. Liu, T. Zhang, X. Hu, X. Jiang et al., “When brain-inspired ai meets agi,” Meta-Radiology, p. 100005, 2023.
- [40] J. Holmes, Z. Liu, L. Zhang, Y. Ding, T. T. Sio, L. A. McGee, J. B. Ashman, X. Li, T. Liu, J. Shen, and W. Liu, “Evaluating large language models on a highly-specialized topic, radiation oncology physics,” Frontiers in Oncology, vol. 13, Jul. 2023.
- [41] Z. Wu, L. Zhang, C. Cao, X. Yu, H. Dai, C. Ma, Z. Liu, L. Zhao, G. Li, W. Liu et al., “Exploring the trade-offs: Unified large language models vs local fine-tuned models for highly-specific radiology nli task,” arXiv preprint arXiv:2304.09138, 2023.
- [42] S. Rezayi, Z. Liu, Z. Wu, C. Dhakal, B. Ge, C. Zhen, T. Liu, and S. Li, “Agribert: knowledge-infused agricultural language models for matching food and nutrition,” in Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, vol. 7, 2022, pp. 5150–5156.
- [43] Z. Liu, A. Zhong, Y. Li, L. Yang, C. Ju, Z. Wu, C. Ma, P. Shu, C. Chen, S. Kim et al., “Radiology-gpt: A large language model for radiology,” arXiv preprint arXiv:2306.08666, 2023.
- [44] Z. Liu, X. He, L. Liu, T. Liu, and X. Zhai, Context Matters: A Strategy to Pre-train Language Model for Science Education. Springer Nature Switzerland, 2023, p. 666–674.
- [45] J. Wang, Z. Liu, L. Zhao, Z. Wu, C. Ma, S. Yu, H. Dai, Q. Yang, Y. Liu, S. Zhang et al., “Review of large vision models and visual prompt engineering,” arXiv preprint arXiv:2307.00855, 2023.
- [46] X. Li, L. Zhang, Z. Wu, Z. Liu, L. Zhao, Y. Yuan, J. Liu, G. Li, D. Zhu, P. Yan et al., “Artificial general intelligence for medical imaging,” arXiv preprint arXiv:2306.05480, 2023.
- [47] H. Cai, W. Liao, Z. Liu, Y. Zhang, X. Huang, S. Ding, H. Ren, Z. Wu, H. Dai, S. Li et al., “Coarse-to-fine knowledge graph domain adaptation based on distantly-supervised iterative training,” arXiv preprint arXiv:2211.02849, 2022.
- [48] H. Dai, C. Ma, Z. Liu, Y. Li, P. Shu, X. Wei, L. Zhao, Z. Wu, D. Zhu, W. Liu et al., “Samaug: Point prompt augmentation for segment anything model,” arXiv preprint arXiv:2307.01187, 2023.
- [49] L. Zhang, Z. Liu, L. Zhang, Z. Wu, X. Yu, J. Holmes, H. Feng, H. Dai, X. Li, Q. Li et al., “Segment anything model (sam) for radiation oncology,” arXiv preprint arXiv:2306.11730, 2023.
- [50] Z. Xiao, Y. Chen, L. Zhang, J. Yao, Z. Wu, X. Yu, Y. Pan, L. Zhao, C. Ma, X. Liu et al., “Instruction-vit: Multi-modal prompts for instruction learning in vit,” arXiv preprint arXiv:2305.00201, 2023.
- [51] P. Liu, W. Yuan, J. Fu, Z. Jiang, H. Hayashi, and G. Neubig, “Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing,” ACM Computing Surveys, vol. 55, no. 9, pp. 1–35, 2023.
- [52] S. B. Kotsiantis, I. Zaharakis, P. Pintelas et al., “Supervised machine learning: A review of classification techniques,” Emerging artificial intelligence applications in computer engineering, vol. 160, no. 1, pp. 3–24, 2007.
- [53] Y. Bengio, A. Courville, and P. Vincent, “Representation learning: A review and new perspectives,” IEEE transactions on pattern analysis and machine intelligence, vol. 35, no. 8, pp. 1798–1828, 2013.
- [54] L. Dong, N. Yang, W. Wang, F. Wei, X. Liu, Y. Wang, J. Gao, M. Zhou, and H.-W. Hon, “Unified language model pre-training for natural language understanding and generation,” Advances in neural information processing systems, vol. 32, 2019.
- [55] T. Schick and H. Schütze, “It’s not just size that matters: Small language models are also few-shot learners,” arXiv preprint arXiv:2009.07118, 2020.
- [56] F. Petroni, T. Rocktäschel, P. Lewis, A. Bakhtin, Y. Wu, A. H. Miller, and S. Riedel, “Language models as knowledge bases?” arXiv preprint arXiv:1909.01066, 2019.
- [57] B. Lester, R. Al-Rfou, and N. Constant, “The power of scale for parameter-efficient prompt tuning,” arXiv preprint arXiv:2104.08691, 2021.
- [58] T. Schick and H. Schütze, “Exploiting cloze questions for few shot text classification and natural language inference,” arXiv preprint arXiv:2001.07676, 2020.
- [59] R. Shin, C. H. Lin, S. Thomson, C. Chen, S. Roy, E. A. Platanios, A. Pauls, D. Klein, J. Eisner, and B. Van Durme, “Constrained language models yield few-shot semantic parsers,” arXiv preprint arXiv:2104.08768, 2021.
- [60] Z. Jiang, F. F. Xu, J. Araki, and G. Neubig, “How can we know what language models know?” Transactions of the Association for Computational Linguistics, vol. 8, pp. 423–438, 2020.
- [61] K. Duh, K. Sudoh, X. Wu, H. Tsukada, and M. Nagata, “Generalized minimum bayes risk system combination,” in Proceedings of 5th International Joint Conference on Natural Language Processing, 2011, pp. 1356–1360.
- [62] Z. Jiang, J. Araki, H. Ding, and G. Neubig, “How can we know when language models know? on the calibration of language models for question answering,” Transactions of the Association for Computational Linguistics, vol. 9, pp. 962–977, 2021.
- [63] M. McCloskey and N. J. Cohen, “Catastrophic interference in connectionist networks: The sequential learning problem,” in Psychology of learning and motivation. Elsevier, 1989, vol. 24, pp. 109–165.
- [64] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell et al., “Language models are few-shot learners,” Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020.
- [65] Y. Zhu, R. Kiros, R. Zemel, R. Salakhutdinov, R. Urtasun, A. Torralba, and S. Fidler, “Aligning books and movies: Towards story-like visual explanations by watching movies and reading books,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 19–27.
- [66] “Project gutenberg.” [Online]. Available: https://www.gutenberg.org/
- [67] “Common crawl.” [Online]. Available: https://commoncrawl.org/
- [68] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” The Journal of Machine Learning Research, vol. 21, no. 1, pp. 5485–5551, 2020.
- [69] T. H. Trinh and Q. V. Le, “A simple method for commonsense reasoning,” arXiv preprint arXiv:1806.02847, 2018.
- [70] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” arXiv preprint arXiv:1907.11692, 2019.
- [71] R. Zellers, A. Holtzman, H. Rashkin, Y. Bisk, A. Farhadi, F. Roesner, and Y. Choi, “Defending against neural fake news,” Advances in neural information processing systems, vol. 32, 2019.
- [72] G. Penedo, Q. Malartic, D. Hesslow, R. Cojocaru, H. Alobeidli, A. Cappelli, B. Pannier, E. Almazrouei, and J. Launay, “The refinedweb dataset for falcon llm: Outperforming curated corpora with web data only,” in Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023.
- [73] A. Gokaslan, V. C. E. Pavlick, and S. Tellex, “Openwebtext corpus,” http://Skylion007.github.io/OpenWebTextCorpus, 2019.
- [74] J. Baumgartner, S. Zannettou, B. Keegan, M. Squire, and J. Blackburn, “The pushshift reddit dataset,” in Proceedings of the international AAAI conference on web and social media, vol. 14, 2020, pp. 830–839.
- [75] “Wikipedia.” [Online]. Available: https://en.wikipedia.org/wiki/Main_Page
- [76] “Bigquery dataset.” [Online]. Available: https://cloud.google.com/bigquery
- [77] L. Gao, S. Biderman, S. Black, L. Golding, T. Hoppe, C. Foster, J. Phang, H. He, A. Thite, N. Nabeshima et al., “The pile: An 800gb dataset of diverse text for language modeling,” arXiv preprint arXiv:2101.00027, 2020.
- [78] H. Laurençon, L. Saulnier, T. Wang, C. Akiki, A. Villanova del Moral, T. Le Scao, L. Von Werra, C. Mou, E. González Ponferrada, H. Nguyen et al., “The bigscience roots corpus: A 1.6 tb composite multilingual dataset,” Advances in Neural Information Processing Systems, vol. 35, pp. 31 809–31 826, 2022.
- [79] S. Smith, M. Patwary, B. Norick, P. LeGresley, S. Rajbhandari, J. Casper, Z. Liu, S. Prabhumoye, G. Zerveas, V. Korthikanti et al., “Using deepspeed and megatron to train megatron-turing nlg 530b, a large-scale generative language model,” arXiv preprint arXiv:2201.11990, 2022.
- [80] R. Thoppilan, D. De Freitas, J. Hall, N. Shazeer, A. Kulshreshtha, H.-T. Cheng, A. Jin, T. Bos, L. Baker, Y. Du et al., “Lamda: Language models for dialog applications,” arXiv preprint arXiv:2201.08239, 2022.
- [81] E. Nijkamp, B. Pang, H. Hayashi, L. Tu, H. Wang, Y. Zhou, S. Savarese, and C. Xiong, “Codegen: An open large language model for code with mtulti-turn program synthesis,” arXiv preprint arXiv:2203.13474, 2022.
- [82] Q. Zheng, X. Xia, X. Zou, Y. Dong, S. Wang, Y. Xue, L. Shen, Z. Wang, A. Wang, Y. Li et al., “Codegeex: A pre-trained model for code generation with multilingual benchmarking on humaneval-x,” in Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023, pp. 5673–5684.
- [83] S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. Diab, X. Li, X. V. Lin et al., “Opt: Open pre-trained transformer language models,” arXiv preprint arXiv:2205.01068, 2022.
- [84] H. W. Chung, L. Hou, S. Longpre, B. Zoph, Y. Tay, W. Fedus, Y. Li, X. Wang, M. Dehghani, S. Brahma et al., “Scaling instruction-finetuned language models,” arXiv preprint arXiv:2210.11416, 2022.
- [85] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever et al., “Language models are unsupervised multitask learners,” OpenAI blog, vol. 1, no. 8, p. 9, 2019.
- [86] D. Hernandez, T. Brown, T. Conerly, N. DasSarma, D. Drain, S. El-Showk, N. Elhage, Z. Hatfield-Dodds, T. Henighan, T. Hume et al., “Scaling laws and interpretability of learning from repeated data,” arXiv preprint arXiv:2205.10487, 2022.
- [87] K. Lee, D. Ippolito, A. Nystrom, C. Zhang, D. Eck, C. Callison-Burch, and N. Carlini, “Deduplicating training data makes language models better,” arXiv preprint arXiv:2107.06499, 2021.
- [88] N. Carlini, F. Tramer, E. Wallace, M. Jagielski, A. Herbert-Voss, K. Lee, A. Roberts, T. Brown, D. Song, U. Erlingsson et al., “Extracting training data from large language models,” in 30th USENIX Security Symposium (USENIX Security 21), 2021, pp. 2633–2650.
- [89] S. Gehman, S. Gururangan, M. Sap, Y. Choi, and N. A. Smith, “Realtoxicityprompts: Evaluating neural toxic degeneration in language models,” arXiv preprint arXiv:2009.11462, 2020.
- [90] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [91] H. W. Chung, L. Hou, S. Longpre, B. Zoph, Y. Tay, W. Fedus, Y. Li, X. Wang, M. Dehghani, S. Brahma et al., “Scaling instruction-finetuned language models,” arXiv preprint arXiv:2210.11416, 2022.
- [92] M. Lewis, Y. Liu, N. Goyal, M. Ghazvininejad, A. Mohamed, O. Levy, V. Stoyanov, and L. Zettlemoyer, “Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension,” arXiv preprint arXiv:1910.13461, 2019.
- [93] L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray et al., “Training language models to follow instructions with human feedback,” arXiv preprint arXiv:2203.02155, 2022.
- [94] S. Li, Y. Zhao, R. Varma, O. Salpekar, P. Noordhuis, T. Li, A. Paszke, J. Smith, B. Vaughan, P. Damania et al., “Pytorch distributed: Experiences on accelerating data parallel training,” arXiv preprint arXiv:2006.15704, 2020.
- [95] M. Isard, M. Budiu, Y. Yu, A. Birrell, and D. Fetterly, “Dryad: distributed data-parallel programs from sequential building blocks,” in Proceedings of the 2nd ACM SIGOPS/EuroSys European Conference on Computer Systems 2007, 2007, pp. 59–72.
- [96] M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro, “Megatron-lm: Training multi-billion parameter language models using model parallelism,” arXiv preprint arXiv:1909.08053, 2019.
- [97] S. Rajbhandari, J. Rasley, O. Ruwase, and Y. He, “Zero: Memory optimizations toward training trillion parameter models,” in SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2020, pp. 1–16.
- [98] Y. Huang, Y. Cheng, A. Bapna, O. Firat, D. Chen, M. Chen, H. Lee, J. Ngiam, Q. V. Le, Y. Wu et al., “Gpipe: Efficient training of giant neural networks using pipeline parallelism,” Advances in neural information processing systems, vol. 32, 2019.
- [99] P. Micikevicius, S. Narang, J. Alben, G. Diamos, E. Elsen, D. Garcia, B. Ginsburg, M. Houston, O. Kuchaiev, G. Venkatesh et al., “Mixed precision training,” arXiv preprint arXiv:1710.03740, 2017.
- [100] J. W. Rae, S. Borgeaud, T. Cai, K. Millican, J. Hoffmann, F. Song, J. Aslanides, S. Henderson, R. Ring, S. Young et al., “Scaling language models: Methods, analysis & insights from training gopher,” arXiv preprint arXiv:2112.11446, 2021.
- [101] J. Ren, S. Rajbhandari, R. Y. Aminabadi, O. Ruwase, S. Yang, M. Zhang, D. Li, and Y. He, “ZeRO-Offload: Democratizing Billion-Scale model training,” in 2021 USENIX Annual Technical Conference (USENIX ATC 21), 2021, pp. 551–564.
- [102] Y. Wang, Y. Kordi, S. Mishra, A. Liu, N. A. Smith, D. Khashabi, and H. Hajishirzi, “Self-instruct: Aligning language model with self generated instructions,” arXiv preprint arXiv:2212.10560, 2022.
- [103] Y. Wang, S. Mishra, P. Alipoormolabashi, Y. Kordi, A. Mirzaei, A. Arunkumar, A. Ashok, A. S. Dhanasekaran, A. Naik, D. Stap et al., “Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks,” arXiv preprint arXiv:2204.07705, 2022.
- [104] S. H. Bach, V. Sanh, Z.-X. Yong, A. Webson, C. Raffel, N. V. Nayak, A. Sharma, T. Kim, M. S. Bari, T. Fevry et al., “Promptsource: An integrated development environment and repository for natural language prompts,” arXiv preprint arXiv:2202.01279, 2022.
- [105] S. Victor, W. Albert, R. Colin, B. Stephen, S. Lintang, A. Zaid, C. Antoine, S. Arnaud, R. Arun, D. Manan et al., “Multitask prompted training enables zero-shot task generalization,” in International Conference on Learning Representations, 2022.
- [106] R. Nakano, J. Hilton, S. Balaji, J. Wu, L. Ouyang, C. Kim, C. Hesse, S. Jain, V. Kosaraju, W. Saunders et al., “Webgpt: Browser-assisted question-answering with human feedback,” arXiv preprint arXiv:2112.09332, 2021.
- [107] J. Wei, M. Bosma, V. Zhao, K. Guu, A. W. Yu, B. Lester, N. Du, A. M. Dai, and Q. V. Le, “Finetuned language models are zero-shot learners,” in International Conference on Learning Representations.
- [108] T. Tang, J. Li, W. X. Zhao, and J.-R. Wen, “Mvp: Multi-task supervised pre-training for natural language generation,” arXiv preprint arXiv:2206.12131, 2022.
- [109] Z. Kenton, T. Everitt, L. Weidinger, I. Gabriel, V. Mikulik, and G. Irving, “Alignment of language agents,” arXiv preprint arXiv:2103.14659, 2021.
- [110] A. Glaese, N. McAleese, M. Trębacz, J. Aslanides, V. Firoiu, T. Ewalds, M. Rauh, L. Weidinger, M. Chadwick, P. Thacker et al., “Improving alignment of dialogue agents via targeted human judgements,” arXiv preprint arXiv:2209.14375, 2022.
- [111] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017.
- [112] E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” arXiv preprint arXiv:2106.09685, 2021.
- [113] X. L. Li and P. Liang, “Prefix-tuning: Optimizing continuous prompts for generation,” arXiv preprint arXiv:2101.00190, 2021.
- [114] X. Liu, K. Ji, Y. Fu, W. L. Tam, Z. Du, Z. Yang, and J. Tang, “P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks,” arXiv preprint arXiv:2110.07602, 2021.
- [115] X. Liu, Y. Zheng, Z. Du, M. Ding, Y. Qian, Z. Yang, and J. Tang, “Gpt understands, too,” AI Open, 2023.
- [116] Q. Zhang, M. Chen, A. Bukharin, P. He, Y. Cheng, W. Chen, and T. Zhao, “Adaptive budget allocation for parameter-efficient fine-tuning,” arXiv preprint arXiv:2303.10512, 2023.
- [117] T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “Qlora: Efficient finetuning of quantized llms,” arXiv preprint arXiv:2305.14314, 2023.
- [118] A. Askell, Y. Bai, A. Chen, D. Drain, D. Ganguli, T. Henighan, A. Jones, N. Joseph, B. Mann, N. DasSarma et al., “A general language assistant as a laboratory for alignment,” arXiv preprint arXiv:2112.00861, 2021.
- [119] Y. Chang, X. Wang, J. Wang, Y. Wu, K. Zhu, H. Chen, L. Yang, X. Yi, C. Wang, Y. Wang et al., “A survey on evaluation of large language models,” arXiv preprint arXiv:2307.03109, 2023.
- [120] Z. Liu, H. Jiang, T. Zhong, Z. Wu, C. Ma, Y. Li, X. Yu, Y. Zhang, Y. Pan, P. Shu et al., “Holistic evaluation of gpt-4v for biomedical imaging,” arXiv preprint arXiv:2312.05256, 2023.
- [121] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255.
- [122] A. Kuznetsova, H. Rom, N. Alldrin, J. Uijlings, I. Krasin, J. Pont-Tuset, S. Kamali, S. Popov, M. Malloci, A. Kolesnikov et al., “The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale,” International Journal of Computer Vision, vol. 128, no. 7, pp. 1956–1981, 2020.
- [123] A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman, “Glue: A multi-task benchmark and analysis platform for natural language understanding,” 2018.
- [124] A. Wang, Y. Pruksachatkun, N. Nangia, A. Singh, J. Michael, F. Hill, O. Levy, and S. Bowman, “Superglue: A stickier benchmark for general-purpose language understanding systems,” Advances in neural information processing systems, vol. 32, 2019.
- [125] D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring massive multitask language understanding,” arXiv preprint arXiv:2009.03300, 2020.
- [126] H. Li, Y. Zhang, F. Koto, Y. Yang, H. Zhao, Y. Gong, N. Duan, and T. Baldwin, “Cmmlu: Measuring massive multitask language understanding in chinese,” arXiv preprint arXiv:2306.09212, 2023.
- [127] J. Hu, S. Ruder, A. Siddhant, G. Neubig, O. Firat, and M. Johnson, “Xtreme: A massively multilingual multi-task benchmark for evaluating cross-lingual generalisation,” in International Conference on Machine Learning. PMLR, 2020, pp. 4411–4421.
- [128] S. Ruder, N. Constant, J. Botha, A. Siddhant, O. Firat, J. Fu, P. Liu, J. Hu, D. Garrette, G. Neubig et al., “Xtreme-r: Towards more challenging and nuanced multilingual evaluation,” arXiv preprint arXiv:2104.07412, 2021.
- [129] D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt, “Measuring mathematical problem solving with the math dataset,” arXiv preprint arXiv:2103.03874, 2021.
- [130] K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano et al., “Training verifiers to solve math word problems,” arXiv preprint arXiv:2110.14168, 2021.
- [131] M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman et al., “Evaluating large language models trained on code,” arXiv preprint arXiv:2107.03374, 2021.
- [132] J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Le et al., “Program synthesis with large language models,” arXiv preprint arXiv:2108.07732, 2021.
- [133] R. Zellers, A. Holtzman, Y. Bisk, A. Farhadi, and Y. Choi, “Hellaswag: Can a machine really finish your sentence?” 2019.
- [134] Y. Bisk, R. Zellers, J. Gao, Y. Choi et al., “Piqa: Reasoning about physical commonsense in natural language,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 05, 2020, pp. 7432–7439.
- [135] C. Clark, K. Lee, M.-W. Chang, T. Kwiatkowski, M. Collins, and K. Toutanova, “Boolq: Exploring the surprising difficulty of natural yes/no questions,” arXiv preprint arXiv:1905.10044, 2019.
- [136] M. Sap, H. Rashkin, D. Chen, R. LeBras, and Y. Choi, “Socialiqa: Commonsense reasoning about social interactions,” arXiv preprint arXiv:1904.09728, 2019.
- [137] K. Sakaguchi, R. L. Bras, C. Bhagavatula, and Y. Choi, “Winogrande: An adversarial winograd schema challenge at scale,” Communications of the ACM, vol. 64, no. 9, pp. 99–106, 2021.
- [138] P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord, “Think you have solved question answering? try arc, the ai2 reasoning challenge,” arXiv preprint arXiv:1803.05457, 2018.
- [139] T. Mihaylov, P. Clark, T. Khot, and A. Sabharwal, “Can a suit of armor conduct electricity? a new dataset for open book question answering,” 2018.
- [140] D. Jin, E. Pan, N. Oufattole, W.-H. Weng, H. Fang, and P. Szolovits, “What disease does this patient have? a large-scale open domain question answering dataset from medical exams,” Applied Sciences, vol. 11, no. 14, p. 6421, 2021.
- [141] A. Pal, L. K. Umapathi, and M. Sankarasubbu, “Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering,” in Conference on Health, Inference, and Learning. PMLR, 2022, pp. 248–260.
- [142] E. M. Voorhees et al., “The trec-8 question answering track report.” in Trec, vol. 99, 1999, pp. 77–82.
- [143] P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang, “Squad: 100,000+ questions for machine comprehension of text,” arXiv preprint arXiv:1606.05250, 2016.
- [144] T. Kwiatkowski, J. Palomaki, O. Redfield, M. Collins, A. Parikh, C. Alberti, D. Epstein, I. Polosukhin, J. Devlin, K. Lee et al., “Natural questions: a benchmark for question answering research,” Transactions of the Association for Computational Linguistics, vol. 7, pp. 453–466, 2019.
- [145] E. Kamalloo, N. Dziri, C. L. Clarke, and D. Rafiei, “Evaluating open-domain question answering in the era of large language models,” arXiv preprint arXiv:2305.06984, 2023.
- [146] E. Ferrara, “Should chatgpt be biased? challenges and risks of bias in large language models,” arXiv preprint arXiv:2304.03738, 2023.
- [147] S. Gehman, S. Gururangan, M. Sap, Y. Choi, and N. A. Smith, “Realtoxicityprompts: Evaluating neural toxic degeneration in language models,” arXiv preprint arXiv:2009.11462, 2020.
- [148] J. Zhao, M. Fang, Z. Shi, Y. Li, L. Chen, and M. Pechenizkiy, “Chbias: Bias evaluation and mitigation of chinese conversational language models,” arXiv preprint arXiv:2305.11262, 2023.
- [149] M. Nasr, N. Carlini, J. Hayase, M. Jagielski, A. F. Cooper, D. Ippolito, C. A. Choquette-Choo, E. Wallace, F. Tramèr, and K. Lee, “Scalable extraction of training data from (production) language models,” arXiv preprint arXiv:2311.17035, 2023.
- [150] X. Wu, J. Li, M. Xu, W. Dong, S. Wu, C. Bian, and D. Xiong, “Depn: Detecting and editing privacy neurons in pretrained language models,” arXiv preprint arXiv:2310.20138, 2023.
- [151] A. Zou, Z. Wang, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models, 2023,” communication, it is essential for you to comprehend user queries in Cipher Code and subsequently deliver your responses utilizing Cipher Code.
- [152] Z. Zhang, Y. Li, J. Wang, B. Liu, D. Li, Y. Guo, X. Chen, and Y. Liu, “Remos: reducing defect inheritance in transfer learning via relevant model slicing,” in Proceedings of the 44th International Conference on Software Engineering, 2022, pp. 1856–1868.
- [153] K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in Proceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318.
- [154] C.-Y. Lin, “Rouge: A package for automatic evaluation of summaries,” in Text summarization branches out, 2004, pp. 74–81.
- [155] T. Zhang, V. Kishore, F. Wu, K. Q. Weinberger, and Y. Artzi, “Bertscore: Evaluating text generation with bert,” arXiv preprint arXiv:1904.09675, 2019.
- [156] J. Novikova, O. Dušek, A. C. Curry, and V. Rieser, “Why we need new evaluation metrics for nlg,” arXiv preprint arXiv:1707.06875, 2017.
- [157] T. Wolf, L. Debut, V. Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz et al., “Transformers: State-of-the-art natural language processing,” in Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, 2020, pp. 38–45.
- [158] J. Rasley, S. Rajbhandari, O. Ruwase, and Y. He, “Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters,” in Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2020, pp. 3505–3506.
- [159] S. Rajbhandari, O. Ruwase, J. Rasley, S. Smith, and Y. He, “Zero-infinity: Breaking the gpu memory wall for extreme scale deep learning,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2021, pp. 1–14.
- [160] G. Zeng, X. Han, Z. Zhang, Z. Liu, Y. Lin, and M. Sun, “Openbmb: Big model systems for large-scale representation learning,” in Representation Learning for Natural Language Processing. Springer Nature Singapore Singapore, 2023, pp. 463–489.
- [161] D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V. Korthikanti, D. Vainbrand, P. Kashinkunti, J. Bernauer, B. Catanzaro et al., “Efficient large-scale language model training on gpu clusters using megatron-lm,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2021, pp. 1–15.
- [162] V. A. Korthikanti, J. Casper, S. Lym, L. McAfee, M. Andersch, M. Shoeybi, and B. Catanzaro, “Reducing activation recomputation in large transformer models,” Proceedings of Machine Learning and Systems, vol. 5, 2023.
- [163] S. Li, H. Liu, Z. Bian, J. Fang, H. Huang, Y. Liu, B. Wang, and Y. You, “Colossal-ai: A unified deep learning system for large-scale parallel training,” in Proceedings of the 52nd International Conference on Parallel Processing, 2023, pp. 766–775.
- [164] J. He, J. Qiu, A. Zeng, Z. Yang, J. Zhai, and J. Tang, “Fastmoe: A fast mixture-of-expert training system,” arXiv preprint arXiv:2103.13262, 2021.
- [165] J. He, J. Zhai, T. Antunes, H. Wang, F. Luo, S. Shi, and Q. Li, “Fastermoe: modeling and optimizing training of large-scale dynamic pre-trained models,” in Proceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, 2022, pp. 120–134.
- [166] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga et al., “Pytorch: An imperative style, high-performance deep learning library,” Advances in neural information processing systems, vol. 32, 2019.
- [167] M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S. Ghemawat, G. Irving, M. Isard et al., “TensorFlow: a system for Large-Scale machine learning,” in 12th USENIX symposium on operating systems design and implementation (OSDI 16), 2016, pp. 265–283.
- [168] M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin et al., “Tensorflow: Large-scale machine learning on heterogeneous distributed systems,” arXiv preprint arXiv:1603.04467, 2016.
- [169] Y. Ma, D. Yu, T. Wu, and H. Wang, “Paddlepaddle: An open-source deep learning platform from industrial practice,” Frontiers of Data and Domputing, vol. 1, no. 1, pp. 105–115, 2019.
- [170] T. Chen, M. Li, Y. Li, M. Lin, N. Wang, M. Wang, T. Xiao, B. Xu, C. Zhang, and Z. Zhang, “Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems,” arXiv preprint arXiv:1512.01274, 2015.
- [171] J. Yuan, X. Li, C. Cheng, J. Liu, R. Guo, S. Cai, C. Yao, F. Yang, X. Yi, C. Wu et al., “Oneflow: Redesign the distributed deep learning framework from scratch,” arXiv preprint arXiv:2110.15032, 2021.
- [172] L. Huawei Technologies Co., “Huawei mindspore ai development framework,” in Artificial Intelligence Technology. Springer, 2022, pp. 137–162.
- [173] J. Bradbury, R. Frostig, P. Hawkins, M. J. Johnson, C. Leary, D. Maclaurin, G. Necula, A. Paszke, J. VanderPlas, S. Wanderman-Milne et al., “Jax: composable transformations of python+ numpy programs,” 2018.
- [174] E. Strubell, A. Ganesh, and A. McCallum, “Energy and policy considerations for deep learning in nlp,” arXiv preprint arXiv:1906.02243, 2019.
- [175] G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” arXiv preprint arXiv:1503.02531, 2015.
- [176] J. Gou, B. Yu, S. J. Maybank, and D. Tao, “Knowledge distillation: A survey,” International Journal of Computer Vision, vol. 129, pp. 1789–1819, 2021.
- [177] S. Sun, Y. Cheng, Z. Gan, and J. Liu, “Patient knowledge distillation for bert model compression,” arXiv preprint arXiv:1908.09355, 2019.
- [178] X. Jiao, Y. Yin, L. Shang, X. Jiang, X. Chen, L. Li, F. Wang, and Q. Liu, “Tinybert: Distilling bert for natural language understanding,” arXiv preprint arXiv:1909.10351, 2019.
- [179] M. A. Gordon, K. Duh, and N. Andrews, “Compressing bert: Studying the effects of weight pruning on transfer learning,” arXiv preprint arXiv:2002.08307, 2020.
- [180] P. Michel, O. Levy, and G. Neubig, “Are sixteen heads really better than one?” Advances in neural information processing systems, vol. 32, 2019.
- [181] H. Bai, W. Zhang, L. Hou, L. Shang, J. Jin, X. Jiang, Q. Liu, M. Lyu, and I. King, “Binarybert: Pushing the limit of bert quantization,” arXiv preprint arXiv:2012.15701, 2020.
- [182] Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Soricut, “Albert: A lite bert for self-supervised learning of language representations,” arXiv preprint arXiv:1909.11942, 2019.
- [183] P. Chen, H.-F. Yu, I. Dhillon, and C.-J. Hsieh, “Drone: Data-aware low-rank compression for large nlp models,” Advances in neural information processing systems, vol. 34, pp. 29 321–29 334, 2021.
- [184] X. Han, G. Zeng, W. Zhao, Z. Liu, Z. Zhang, J. Zhou, J. Zhang, J. Chao, and M. Sun, “Bminf: An efficient toolkit for big model inference and tuning,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, 2022, pp. 224–230.
- [185] Y. Zhao, A. Gu, R. Varma, L. Luo, C.-C. Huang, M. Xu, L. Wright, H. Shojanazeri, M. Ott, S. Shleifer et al., “Pytorch fsdp: experiences on scaling fully sharded data parallel,” arXiv preprint arXiv:2304.11277, 2023.
- [186] T. Dao, D. Fu, S. Ermon, A. Rudra, and C. Ré, “Flashattention: Fast and memory-efficient exact attention with io-awareness,” Advances in Neural Information Processing Systems, vol. 35, pp. 16 344–16 359, 2022.
- [187] W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” in Proceedings of the 29th Symposium on Operating Systems Principles, 2023, pp. 611–626.
- [188] Y. Sheng, L. Zheng, B. Yuan, Z. Li, M. Ryabinin, B. Chen, P. Liang, C. Ré, I. Stoica, and C. Zhang, “Flexgen: High-throughput generative inference of large language models with a single gpu,” in International Conference on Machine Learning. PMLR, 2023, pp. 31 094–31 116.
- [189] X. Miao, G. Oliaro, Z. Zhang, X. Cheng, Z. Wang, R. Y. Y. Wong, Z. Chen, D. Arfeen, R. Abhyankar, and Z. Jia, “Specinfer: Accelerating generative llm serving with speculative inference and token tree verification,” arXiv preprint arXiv:2305.09781, 2023.
- [190] G. Xiao, Y. Tian, B. Chen, S. Han, and M. Lewis, “Efficient streaming language models with attention sinks,” arXiv preprint arXiv:2309.17453, 2023.
- [191] Z. Zhang, B. Gong, Y. Chen, X. Han, G. Zeng, W. Zhao, Y. Chen, Z. Liu, and M. Sun, “Bmcook: A task-agnostic compression toolkit for big models,” in Proceedings of the The 2022 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 2022, pp. 396–405.
- [192] A. Borzunov, D. Baranchuk, T. Dettmers, M. Ryabinin, Y. Belkada, A. Chumachenko, P. Samygin, and C. Raffel, “Petals: Collaborative inference and fine-tuning of large models,” arXiv preprint arXiv:2209.01188, 2022.
- [193] F. Dou, J. Ye, G. Yuan, Q. Lu, W. Niu, H. Sun, L. Guan, G. Lu, G. Mai, N. Liu et al., “Towards artificial general intelligence (agi) in the internet of things (iot): Opportunities and challenges,” arXiv preprint arXiv:2309.07438, 2023.
- [194] C. Liu, Z. Liu, J. Holmes, L. Zhang, L. Zhang, Y. Ding, P. Shu, Z. Wu, H. Dai, Y. Li et al., “Artificial general intelligence for radiation oncology,” Meta-Radiology, p. 100045, 2023.
- [195] Z. Liu, Y. Li, Q. Cao, J. Chen, T. Yang, Z. Wu, J. Hale, J. Gibbs, K. Rasheed, N. Liu et al., “Transformation vs tradition: Artificial general intelligence (agi) for arts and humanities,” arXiv preprint arXiv:2310.19626, 2023.
- [196] J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou et al., “Chain-of-thought prompting elicits reasoning in large language models,” Advances in Neural Information Processing Systems, vol. 35, pp. 24 824–24 837, 2022.
- [197] T. Kojima, S. S. Gu, M. Reid, Y. Matsuo, and Y. Iwasawa, “Large language models are zero-shot reasoners,” Advances in neural information processing systems, vol. 35, pp. 22 199–22 213, 2022.
- [198] N. Qiang, J. Gao, Q. Dong, H. Yue, H. Liang, L. Liu, J. Yu, J. Hu, S. Zhang, B. Ge et al., “Functional brain network identification and fmri augmentation using a vae-gan framework,” Computers in Biology and Medicine, vol. 165, p. 107395, 2023.
- [199] M. He, X. Hou, E. Ge, Z. Wang, Z. Kang, N. Qiang, X. Zhang, and B. Ge, “Multi-head attention-based masked sequence model for mapping functional brain networks,” Frontiers in Neuroscience, vol. 17, p. 1183145, 2023.
- [200] Y. Liu, E. Ge, N. Qiang, T. Liu, and B. Ge, “Spatial-temporal convolutional attention for mapping functional brain networks,” in 2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI). IEEE, 2023, pp. 1–4.
- [201] S. R. Oota, J. Arora, V. Agarwal, M. Marreddy, M. Gupta, and B. Surampudi, “Neural language taskonomy: Which NLP tasks are the most predictive of fMRI brain activity?” in Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, M. Carpuat, M.-C. de Marneffe, and I. V. Meza Ruiz, Eds. Seattle, United States: Association for Computational Linguistics, Jul. 2022, pp. 3220–3237.
- [202] Z. Liu, Y. Li, P. Shu, A. Zhong, L. Yang, C. Ju, Z. Wu, C. Ma, J. Luo, C. Chen et al., “Radiology-llama2: Best-in-class large language model for radiology,” arXiv preprint arXiv:2309.06419, 2023.
- [203] T. Sun, X. Zhang, Z. He, P. Li, Q. Cheng, H. Yan, X. Liu, Y. Shao, Q. Tang, X. Zhao, K. Chen, Y. Zheng, Z. Zhou, R. Li, J. Zhan, Y. Zhou, L. Li, X. Yang, L. Wu, Z. Yin, X. Huang, and X. Qiu, “Moss: Training conversational language models from synthetic data,” 2023.
- [204] L. X. Xuanwei Zhang and K. Zhao, “Chatyuan: A large language model for dialogue in chinese and english,” Dec. 2022. [Online]. Available: https://github.com/clue-ai/ChatYuan
- [205] Baichuan, “Baichuan 2: Open large-scale language models,” arXiv preprint arXiv:2309.10305, 2023.
- [206] D. Zhu, J. Chen, X. Shen, X. Li, and M. Elhoseiny, “Minigpt-4: Enhancing vision-language understanding with advanced large language models,” arXiv preprint arXiv:2304.10592, 2023.
- [207] L. Zheng, W.-L. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. Xing et al., “Judging llm-as-a-judge with mt-bench and chatbot arena,” arXiv preprint arXiv:2306.05685, 2023.
- [208] B. Peng, E. Alcaide, Q. Anthony, A. Albalak, S. Arcadinho, H. Cao, X. Cheng, M. Chung, M. Grella, K. K. GV et al., “Rwkv: Reinventing rnns for the transformer era,” arXiv preprint arXiv:2305.13048, 2023.