为任何人制作动画:角色动画的一致且可控的图像到视频合成
摘要
角色动画旨在通过驱动信号从静止图像生成角色视频。 目前,扩散模型因其强大的生成能力已成为视觉生成研究的主流。 然而,图像到视频领域仍然存在挑战,特别是在角色动画中,暂时保持与角色详细信息的一致性仍然是一个艰巨的问题。 在本文中,我们利用扩散模型的力量,提出了一个为角色动画量身定制的新颖框架。 为了保持参考图像中复杂外观特征的一致性,我们设计了 ReferenceNet 通过空间注意力来合并细节特征。 为了确保可控性和连续性,我们引入了高效的姿势引导器来指导角色的运动,并采用有效的时间建模方法来确保视频帧之间平滑的帧间过渡。 通过扩展训练数据,我们的方法可以为任意角色设置动画,与其他图像到视频方法相比,在角色动画方面产生更好的结果。 此外,我们还根据时尚视频和人类舞蹈合成的基准评估了我们的方法,取得了最先进的结果。
![[Uncaptioned image]](x1.png)
1简介
角色动画是将源角色图像按照所需的姿势序列动画化为逼真的视频的任务,具有许多潜在的应用,例如在线零售、娱乐视频、艺术创作和虚拟角色。 从 GAN[10, 1, 20] 的出现开始,大量研究深入到图像动画和姿势迁移领域[35, 37, 31, 60, 36, 57, 54, 6]。 然而,生成的图像或视频仍然存在局部失真、细节模糊、语义不一致和时间不稳定等问题,阻碍了这些方法的广泛应用。
近年来,扩散模型[12]在生成高质量图像和视频方面展现了其优越性。 研究人员已经开始利用扩散模型的架构及其预先训练的强大生成能力来探索人类图像到视频的任务。 DreamPose[19]专注于时尚图像到视频的合成,扩展了Stable Diffusion[32]并提出了一个适配器模块来集成CLIP[29] 和 VAE[22] 图像特征。 然而,DreamPose 需要对输入样本进行微调以确保结果一致,从而导致运行效率不佳。 DisCo[45] 探索人类舞蹈的生成,类似地修改稳定扩散,通过 CLIP 集成角色特征,并通过 ControlNet[56] 合并背景特征。 然而,它在保留字符细节方面存在缺陷,并且存在帧间抖动问题。
此外,目前对角色动画的研究主要集中在特定的任务和基准上,导致泛化能力有限。 最近,受益于文本到图像研究[30,27,34,32,17,2]、视频生成(例如文本到视频、视频编辑)方面的进展[11,15,28,13,21,49,46,4,9,38,14]在视觉质量和多样性方面也取得了显着的进步。 多项研究将文本到视频的方法扩展到图像到视频[46,7,59,11]。 然而,这些方法无法从图像中捕获复杂的细节,提供更多多样性但缺乏精度,特别是当应用于角色动画时,导致角色外观的细粒度细节随时间变化。 此外,当处理大量的角色动作时,这些方法很难产生一致稳定和连续的过程。 目前,还没有观察到的同时实现通用性和一致性的角色动画方法。
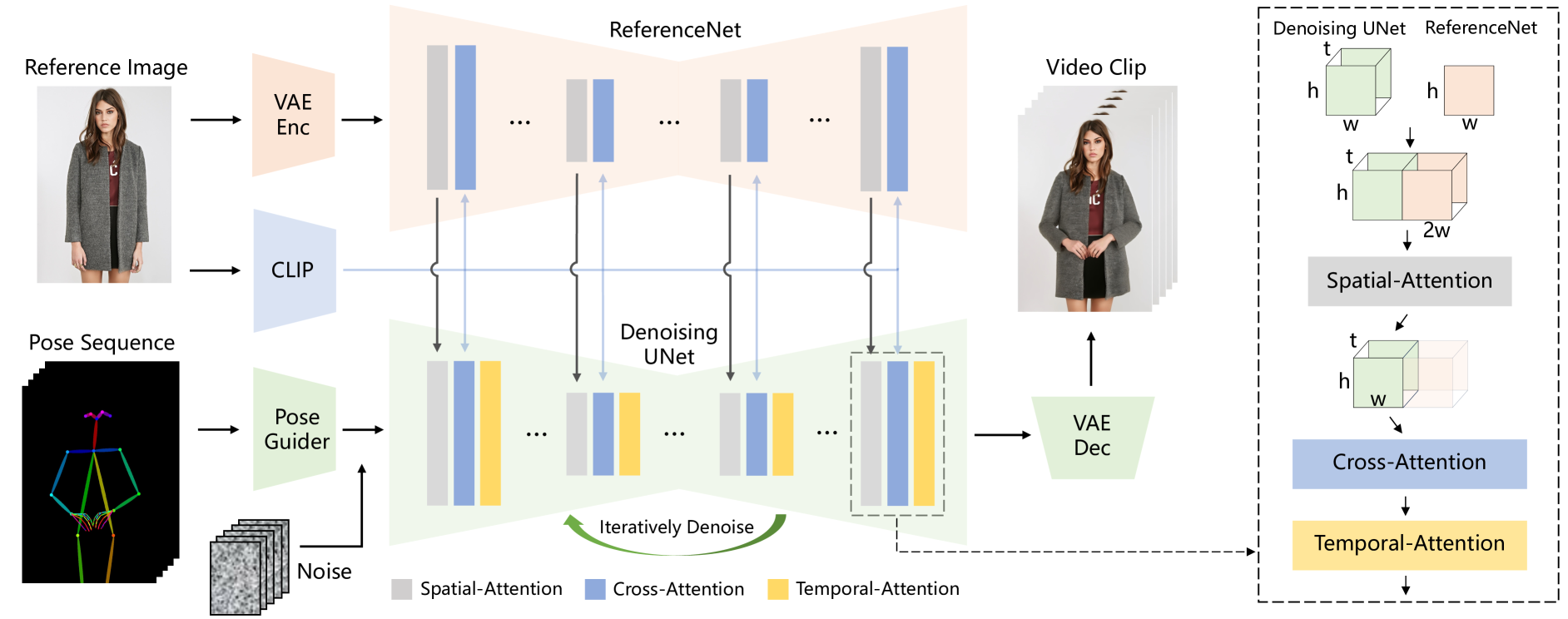
在本文中,我们提出了Animate Anybody,一种能够将角色图像转换为由所需姿势序列控制的动画视频的方法。 我们继承了稳定扩散(SD)的网络设计和预训练权重,并修改了去噪 UNet[33] 以适应多帧输入。 为了解决保持外观一致性的挑战,我们引入了 ReferenceNet,它专门设计为对称 UNet 结构,用于捕获参考图像的空间细节。 在 UNet 块的每个相应层,我们使用空间注意力[44]将 ReferenceNet 的特征集成到去噪 UNet 中。 这种架构使模型能够在一致的特征空间中全面学习与参考图像的关系,这对外观细节保留的改进做出了显着贡献。 为了确保姿态可控性,我们设计了一种轻量级姿态引导器,以有效地将姿态控制信号集成到去噪过程中。 为了实现时间稳定性,我们引入时间层来对多个帧之间的关系进行建模,从而在模拟连续且平滑的时间运动过程的同时保留视觉质量的高分辨率细节。
我们的模型是在 5K 字符视频剪辑的内部数据集上进行训练的。 图1显示了各种角色的动画结果。 与以前的方法相比,我们的方法具有几个显着的优点。 首先,它有效地保持了视频中人物外观的空间和时间一致性。 其次,它生成的高清视频不会出现时间抖动或闪烁等问题。 第三,它能够将任何角色图像动画化为视频,不受特定领域的限制。 我们在两个特定的人类视频合成基准(UBC 时尚视频数据集[55] 和 TikTok 数据集[18])上评估我们的方法,每个基准仅使用相应的训练数据集在实验中。 我们的方法取得了最先进的结果。 我们还将我们的方法与在大规模数据上训练的一般图像到视频方法进行比较,我们的方法在角色动画方面展示了卓越的能力。 我们设想 Animate Anybody 可以作为角色视频创作的基础解决方案,激发更多创新和创意应用程序的开发。
2相关作品
2.1 图像生成的扩散模型
在文本到图像的研究中,基于扩散的方法[30,34,32,27,2,17]取得了显着优越的生成结果,成为研究的主流。 为了降低计算复杂度,潜在扩散模型[32]提出在潜在空间进行去噪,在有效性和效率之间取得平衡。 ControlNet[56] 和 T2I-Adapter[25] 通过合并额外的编码层来深入研究视觉生成的可控性,促进各种条件下的受控生成,例如姿势、掩模、边缘和深度。 一些研究进一步研究了给定图像条件下的图像生成。 IP-Adapter[53] 使扩散模型能够生成包含给定图像提示指定的内容的图像结果。 ObjectStitch[40] 和 Paint-by-Example[50] 利用 CLIP[29] 并在给定图像的情况下提出基于扩散的图像编辑方法健康)状况。 TryonDiffusion[61]将扩散模型应用于虚拟服装试穿任务,并引入Parallel-UNet结构。
2.2 视频生成的扩散模型
随着扩散模型在文本到图像应用中的成功,文本到视频的研究在模型结构方面广泛地从文本到图像模型中汲取了灵感。 许多研究[21,28,15,49,51,9,24,38,14]探索在文本到图像(T2I)模型的基础上增强帧间注意力模型来实现视频生成。 一些作品通过插入时间层将预训练的 T2I 模型转变为视频生成器。 Video LDM[4] 建议首先仅在图像上预训练模型,然后在视频上训练时间层。 AnimateDiff[11] 提出了一个在大型视频数据上训练的运动模块,可以将其注入到大多数个性化 T2I 模型中,而无需进行特定调整。 我们的方法从此类时间建模方法中汲取灵感。
一些研究将文本到视频的功能扩展到图像到视频。 VideoComposer[46] 在训练期间将图像合并到扩散输入中作为条件控制。 AnimateDiff[11] 在去噪过程中对图像潜在噪声和随机噪声进行加权混合。 VideoCrafter[7] 结合了来自 CLIP 的文本和视觉特征作为交叉注意力的输入。 然而,这些方法在实现稳定的人类视频生成方面仍然面临挑战,并且结合图像条件输入的探索仍然是需要进一步研究的领域。
2.3人体图像动画的扩散模型
图像动画[35, 37, 31, 60, 36, 57, 54, 6]旨在基于一张或多张输入图像生成图像或视频。 在最近的研究中,扩散模型提供的卓越的生成质量和稳定的可控性使其融入到人类图像动画中。 PIDM[3]提出纹理扩散块,将所需的纹理模式注入到人体姿势迁移的去噪中。 LFDM[26] 在潜在空间中合成光流序列,根据给定条件扭曲输入图像。 LEO[47]将运动表示为一系列流图,并采用扩散模型来合成运动代码序列。 DreamPose[19] 利用预训练的稳定扩散模型,并提出了一个适配器来对 CLIP 和 VAE 图像嵌入进行建模。 DisCo[45] 从 ControlNet 中汲取灵感,解耦姿态和背景的控制。 尽管结合了扩散模型来提高生成质量,这些方法仍然难以解决结果中的纹理不一致和时间不稳定等问题。 此外,没有方法可以研究和演示角色动画中更通用的功能。
3方法
我们的目标是角色动画的姿势引导图像到视频合成。 给定描述角色外观和姿势序列的参考图像,我们的模型会生成该角色的动画视频。 我们方法的流程如图2所示。 在本节中,我们首先在3.1节中对稳定扩散进行简要介绍,为我们的方法奠定了基础框架和网络结构。 然后我们在第 3.1 节中详细解释了设计细节。 最后,我们在第 3.3 节中介绍训练过程。
3.1 初步:稳定扩散
我们的方法是稳定扩散(SD)的扩展,它是从潜在扩散模型(LDM)发展而来的。 为了降低模型的计算复杂度,引入了对潜在空间中的特征分布进行建模。 SD开发了一个自动编码器[22, 43]来建立图像的隐式表示,它由编码器和解码器组成。 给定图像 ,编码器首先将其映射到潜在表示: = (),然后解码器重建它: = ()。
SD 学习将正态分布噪声 降噪为真实的潜在 。 在训练过程中,潜在图像以时间步扩散,产生潜在噪声。 训练去噪 UNet 来预测所应用的噪声。 优化过程定义为以下目标:
| (1) |
其中表示去噪UNet的函数。 表示条件信息的嵌入。 在原始 SD 中,应用 CLIP ViT-L/14[8] 文本编码器将文本提示表示为词符嵌入,以生成文本到图像。 去噪UNet由四个下采样层、一个中间层和四个上采样层组成。 层内的典型块包括三种类型的计算:2D 卷积、自注意力[44]和交叉注意力(术语为 Res-Trans 块)。 在文本嵌入和相应的网络特征之间进行交叉注意力。
推理时, 从随机高斯分布中采样,初始时间步为 ,然后通过确定性采样过程(例如 DDPM[12]、DDIM[39])逐步去噪并恢复为 。 在每次迭代中,去噪 UNet 都会预测每个时间步 对应的潜在特征上的噪声。最后,将被解码器重建以获得生成图像。
3.2网络架构
概述。 图2提供了我们方法的概述。 网络的初始输入由多帧噪声组成。 去噪UNet基于SD的设计进行配置,采用相同的框架和块单元,并继承了SD的训练权重。 此外,我们的方法还包含三个关键组成部分:1)ReferenceNet,对参考图像中的角色的外观特征进行编码; 2)Pose Guider,编码运动控制信号,实现可控的角色动作; 3)Temporal层,对时间关系进行编码,保证角色运动的连续性。
参考网。 在文本到视频的任务中,文本提示阐明了高级语义,只需要与生成的视觉内容具有语义相关性。 然而,在图像到视频的任务中,图像封装了更多低级细节特征,要求生成的结果具有精确的一致性。 在之前专注于图像驱动生成的研究中,大多数方法[53,40,50,19,45,7]采用CLIP图像编码器作为交叉注意力中文本编码器的替代品。 然而,这种设计未能解决与细节一致性相关的问题。 这种限制的一个原因是 CLIP 图像编码器的输入包含低分辨率 () 图像,导致大量细粒度细节信息的丢失。 另一个因素是CLIP被训练来匹配文本的语义特征,强调高级特征匹配,从而导致特征编码中细节特征的缺失。
因此,我们设计了一个名为ReferenceNet的参考图像特征提取网络。 我们采用与 ReferenceNet 的去噪 UNet 相同的框架,但不包括时间层。 与去噪UNet类似,ReferenceNet继承了原始SD的权重,并且每个权重更新都是独立进行的。 然后我们解释了将ReferenceNet中的特征集成到去噪UNet中的方法。 具体来说,如图2所示,我们用空间注意层替换自注意层。 给定来自去噪 UNet 的特征图 和来自 ReferenceNet 的 ,我们首先将 复制 次,并将其与 沿 维度。 然后我们执行自注意力并提取特征图的前半部分作为输出。 这种设计有两个优点:首先,ReferenceNet 可以利用原始 SD 中预先训练的图像特征建模功能,从而产生良好初始化的特征。 其次,由于ReferenceNet和去噪UNet之间本质上相同的网络结构和共享的初始化权重,去噪UNet可以选择性地从ReferenceNet中学习在同一特征空间中相关的特征。 此外,使用 CLIP 图像编码器采用交叉注意力。 利用与文本编码器的共享特征空间,它提供参考图像的语义特征,作为有益的初始化来加速整个网络训练过程。
类似的设计是 ControlNet[56],它使用零卷积将额外的控制特征引入到去噪 UNet 中。 然而,诸如深度和边缘之类的控制信息在空间上与目标图像对齐,而参考图像和目标图像在空间上相关但未对齐。 因此,ControlNet 不适合直接应用。 我们将在后续的实验4.4节中证实这一点。
虽然ReferenceNet引入了与去噪UNet相当数量的参数,但在基于扩散的视频生成中,所有视频帧都经过多次去噪,而ReferenceNet在整个过程中只需要提取一次特征。 因此,在推理过程中,不会导致计算开销的大幅增加。
姿势引导器。 ControlNet[56] 展示了超越文本的高度稳健的条件生成功能。 与这些方法不同的是,由于去噪 UNet 需要进行微调,我们选择不加入额外的控制网络,以防止计算复杂度显着增加。 相反,我们采用了一个轻量级的姿势引导器。 该姿势引导器使用四个卷积层( 内核, 步长,使用 16,32,64,128 个通道,类似于 [56] 中的条件编码器)以与潜在噪声相同的分辨率对齐姿态图像。 随后,将处理后的姿态图像添加到潜在噪声中,然后输入到去噪 UNet 中。 Pose Guider 使用高斯权重进行初始化,在最终的投影层中,我们采用零卷积。
时间层。 许多研究建议将补充时间层合并到文本到图像(T2I)模型中,以捕获视频帧之间的时间依赖性。 此设计有助于从基础 T2I 模型转移预训练的图像生成功能。 遵循这一原则,我们的时间层集成在 Res-Trans 块内的空间注意力和交叉注意力组件之后。 时间层的设计灵感来自 AnimateDiff[11]。 具体来说,对于一个特征图,我们首先将其重塑为,然后进行时间注意力,即沿着维度的自注意力。来自时间层的特征通过残差连接合并到原始特征中。 这种设计与我们将在下一小节中描述的两阶段训练方法相一致。 时间层专门应用于去噪 UNet 的 Res-Trans 块内。 对于ReferenceNet,它计算单个参考图像的特征,并且不参与时间建模。 由于姿势引导器实现了连续角色运动的可控性,实验表明时间层确保了外观细节的时间平滑性和连续性,从而无需复杂的运动建模。
3.3训练策略
训练过程分为两个阶段。 在第一阶段,使用单独的视频帧进行训练。 在去噪 UNet 中,我们暂时排除时间层,模型将单帧噪声作为输入。 ReferenceNet 和 Pose Guider 也在这个阶段进行训练。 参考图像是从整个视频剪辑中随机选择的。 我们根据 SD 的预训练权重初始化去噪 UNet 和 ReferenceNet 的模型。 Pose Guider 使用高斯权重进行初始化,最终投影层除外,它使用零卷积。 VAE的编码器和解码器以及CLIP图像编码器的权重都保持固定。 此阶段的优化目标是使模型在给定参考图像和目标姿态的条件下生成高质量的动画图像。 在第二阶段,我们将时间层引入到之前训练的模型中,并使用 AnimateDiff[11] 中的预训练权重对其进行初始化。 模型的输入由 24 帧视频剪辑组成。 在此阶段,我们仅训练时间层,同时固定网络其余部分的权重。
4实验
4.1实现
为了证明我们的方法在制作各种角色动画方面的适用性,我们从互联网上收集了 5K 角色视频剪辑(2-10 秒长)来训练我们的模型。 我们使用 DWPose[52] 提取视频中角色的姿势序列,包括身体和手部,将其渲染为遵循 OpenPose[5] 的姿势骨架图像。 实验在 4 个 NVIDIA A100 GPU 上进行。 在第一个训练阶段,对各个视频帧进行采样、调整大小并进行中心裁剪,使其分辨率为 。 训练进行 30,000 步,批量大小为 64。 在第二个训练阶段,我们使用 24 帧视频序列和批量大小 4 对时间层进行 10,000 个步骤的训练。 两个学习率都设置为 1e-5。 在推理过程中,我们重新调整驾驶姿势骨架的长度以近似参考图像中角色骨架的长度,并使用 DDIM 采样器进行 20 个降噪步骤。 我们采用[41]中的时间聚合方法,连接不同批次的结果来生成长视频。 为了与其他图像动画方法进行公平比较,我们还在两个特定基准(UBC 时尚视频数据集[55] 和 TikTok 数据集[18])上训练我们的模型,而不使用额外的数据,将在 4.3 节中讨论。

4.2定性结果
图3展示了我们的方法可以为任意角色制作动画,包括全身人物、半身肖像、卡通人物和类人人物。 我们的方法能够生成高清且逼真的角色细节。 即使在大量运动的情况下,它也能保持与参考图像的时间一致性,并表现出帧之间的时间连续性。 补充材料中提供了更多视频结果。
4.3比较
为了证明我们的方法与其他图像动画方法相比的有效性,我们在两个特定基准中评估其性能:时尚视频合成和人类舞蹈生成。 对于图像级质量的定量评估,采用了 SSIM[48]、PSNR[16] 和 LPIPS[58]。 视频级评估使用 FVD[42] 指标。

| SSIM | PSNR | LPIPS | FVD | |
|---|---|---|---|---|
| MRAA[37] | 0.749 | - | 0.212 | 253.6 |
| TPSMM[60] | 0.746 | - | 0.213 | 247.5 |
| BDMM[54] | 0.918 | 24.07 | 0.048 | 148.3 |
| DreamPose[19] | 0.885 | - | 0.068 | 238.7 |
| DreamPose* | 0.879 | 34.75 | 0.111 | 279.6 |
| Ours | 0.931 | 38.49 | 0.044 | 81.6 |
时尚视频合成。 时尚视频合成旨在使用驾驶姿势序列将时尚照片变成逼真的动画视频。 实验在 UBC 时尚视频数据集上进行,该数据集由 500 个和 100 个测试视频组成,每个视频包含大约 350 帧。 定量比较如表 1 所示。 1. 我们的结果优于其他方法,特别是在视频指标方面表现出显着的领先优势。 定性比较如图4所示。 为了公平比较,我们使用其开源代码在没有样本微调的情况下获得了 DreamPose 的结果。 在时尚视频领域,对服装细节的精细化要求非常严格。 然而,DreamPose和BDMM生成的视频未能保持服装细节的一致性,并且在颜色和精细结构元素方面表现出明显的错误。 相比之下,我们的方法产生的结果有效地保持了服装细节的一致性。

| SSIM | PSNR | LPIPS | FVD | |
|---|---|---|---|---|
| FOMM[35] | 0.648 | 29.01 | 0.335 | 405.2 |
| MRAA[37] | 0.672 | 29.39 | 0.296 | 284.8 |
| TPSMM[60] | 0.673 | 29.18 | 0.299 | 306.1 |
| Disco[45] | 0.668 | 29.03 | 0.292 | 292.8 |
| Ours | 0.718 | 29.56 | 0.285 | 171.9 |
人类舞蹈一代。 Human Dance Generation 专注于在现实世界的舞蹈场景中制作动画图像。 我们利用 TikTok 数据集,其中包括 340 个训练视频和 100 个测试单人舞蹈视频(长 10-15 秒)。 按照 DisCo 的数据集划分并利用相同的测试集(10 个 TikTok 风格的视频),我们进行了表 1 中所示的定量比较。 2,我们的方法取得了最好的结果。 为了增强泛化能力,DisCo 结合了人类属性预训练,利用大量图像对进行模型预训练。 相比之下,我们的训练完全在 TikTok 数据集上进行,产生的结果优于 DisCo。 我们在图 5 中展示了与 DisCo 的定性比较。 考虑到场景的复杂性,DisCo 的管道涉及 SAM[23] 的额外步骤来生成人体前景蒙版。 相反,我们的方法表明,即使没有明确学习人类面具,该模型也可以从主体的运动中掌握前景-背景关系,从而否定了先前的人体分割的必要性。 此外,在复杂的舞蹈序列中,我们的模型在整个动作中保持视觉连续性方面表现出色,并在处理不同角色外观方面表现出增强的鲁棒性。

一般图像到视频的方法。 目前,大量研究提出了基于大规模训练数据的具有强大生成能力的视频扩散模型。 我们选择两种最知名、最有效的图像转视频方法进行比较:AnimateDiff[11] 和 Gen-2[9]。 由于这两种方法不执行姿势控制,因此我们仅比较它们保持参考图像的外观保真度的能力。 如图6所示,当前的图像到视频方法在生成大量角色动作方面面临挑战,并且难以保持视频中的长期外观一致性,从而阻碍了对一致角色动画的有效支持。
4.4消融研究
为了证明 ReferenceNet 设计的有效性,我们探索了替代设计,包括(1)仅使用 CLIP 图像编码器来表示参考图像特征,而不集成 ReferenceNet,(2)最初对 SD 进行微调,然后使用参考图像对 ControlNet 进行微调。 (3)整合以上两种设计。 实验在 UBC 时尚视频数据集上进行。 如图7所示,可视化结果表明ReferenceNet优于其他三种设计。 单纯依靠CLIP特征作为参考图像特征可以保留图像相似性,但无法充分传递细节。 ControlNet 不会增强结果,因为它的特征缺乏空间对应性,使其不适用。 定量结果也显示在表中。 3,展示了我们设计的优越性。

| SSIM | PSNR | LPIPS | FVD | |
|---|---|---|---|---|
| CLIP | 0.897 | 36.09 | 0.089 | 208.5 |
| ControlNet | 0.892 | 35.89 | 0.105 | 213.9 |
| CLIP+ControlNet | 0.898 | 36.03 | 0.086 | 205.4 |
| Ours | 0.931 | 38.49 | 0.044 | 81.6 |
5 限制
我们的方法的局限性可以概括为三个方面:首先,与许多视觉生成模型类似,我们的模型可能难以为手部运动生成高度稳定的结果,有时会导致扭曲和运动模糊。 其次,由于图像仅从一个角度提供信息,因此在角色运动过程中生成看不见的部分是一个不适定问题,会遇到潜在的不稳定。 第三,由于使用了 DDPM,与基于非扩散模型的方法相比,我们的模型表现出较低的运行效率。
6结论
在本文中,我们提出了 Animate Anybody,这是一个角色动画框架,能够将角色照片转换为由所需姿势序列控制的动画视频,同时确保一致的外观和时间稳定性。 我们提出了 ReferenceNet,它真正保留了复杂的角色外观,并且我们还实现了高效的姿势可控性和时间连续性。 我们的方法不仅适用于一般角色动画,而且在特定基准测试中优于现有方法。 Animate Anybody 作为一种基础方法,具有未来扩展到各种图像到视频应用程序的潜力。
参考
- Arjovsky et al. [2017] Martin Arjovsky, Soumith Chintala, and Léon Bottou. Wasserstein generative adversarial networks. In International conference on machine learning, pages 214–223. PMLR, 2017.
- Balaji et al. [2022] Yogesh Balaji, Seungjun Nah, Xun Huang, Arash Vahdat, Jiaming Song, Karsten Kreis, Miika Aittala, Timo Aila, Samuli Laine, Bryan Catanzaro, et al. ediffi: Text-to-image diffusion models with an ensemble of expert denoisers. arXiv preprint arXiv:2211.01324, 2022.
- Bhunia et al. [2023] Ankan Kumar Bhunia, Salman Khan, Hisham Cholakkal, Rao Muhammad Anwer, Jorma Laaksonen, Mubarak Shah, and Fahad Shahbaz Khan. Person image synthesis via denoising diffusion model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5968–5976, 2023.
- Blattmann et al. [2023] Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22563–22575, 2023.
- Cao et al. [2017] Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7291–7299, 2017.
- Chan et al. [2019] Caroline Chan, Shiry Ginosar, Tinghui Zhou, and Alexei A Efros. Everybody dance now. In Proceedings of the IEEE/CVF international conference on computer vision, pages 5933–5942, 2019.
- Chen et al. [2023] Haoxin Chen, Menghan Xia, Yingqing He, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Jinbo Xing, Yaofang Liu, Qifeng Chen, Xintao Wang, et al. Videocrafter1: Open diffusion models for high-quality video generation. arXiv preprint arXiv:2310.19512, 2023.
- Dosovitskiy et al. [2021] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021.
- Esser et al. [2023] Patrick Esser, Johnathan Chiu, Parmida Atighehchian, Jonathan Granskog, and Anastasis Germanidis. Structure and content-guided video synthesis with diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7346–7356, 2023.
- Goodfellow et al. [2014] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. Advances in neural information processing systems, 27, 2014.
- Guo et al. [2023] Yuwei Guo, Ceyuan Yang, Anyi Rao, Yaohui Wang, Yu Qiao, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv preprint arXiv:2307.04725, 2023.
- Ho et al. [2020] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020.
- Ho et al. [2022a] Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303, 2022a.
- Ho et al. [2022b] Jonathan Ho, Tim Salimans, Alexey A. Gritsenko, William Chan, Mohammad Norouzi, and David J. Fleet. Video diffusion models. In NeurIPS, 2022b.
- Hong et al. [2023] Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023.
- Hore and Ziou [2010] Alain Hore and Djemel Ziou. Image quality metrics: Psnr vs. ssim. In 2010 20th international conference on pattern recognition, pages 2366–2369. IEEE, 2010.
- Huang et al. [2023] Lianghua Huang, Di Chen, Yu Liu, Yujun Shen, Deli Zhao, and Jingren Zhou. Composer: Creative and controllable image synthesis with composable conditions. In International Conference on Machine Learning, 2023.
- Jafarian and Park [2021] Yasamin Jafarian and Hyun Soo Park. Learning high fidelity depths of dressed humans by watching social media dance videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12753–12762, 2021.
- Karras et al. [2023] Johanna Karras, Aleksander Holynski, Ting-Chun Wang, and Ira Kemelmacher-Shlizerman. Dreampose: Fashion video synthesis with stable diffusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 22680–22690, 2023.
- Karras et al. [2019] Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019.
- Khachatryan et al. [2023] Levon Khachatryan, Andranik Movsisyan, Vahram Tadevosyan, Roberto Henschel, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Text2video-zero: Text-to-image diffusion models are zero-shot video generators. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 15954–15964, 2023.
- Kingma and Welling [2014] Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. In 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Proceedings, 2014.
- Kirillov et al. [2023] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4015–4026, 2023.
- Ma et al. [2023] Yue Ma, Yingqing He, Xiaodong Cun, Xintao Wang, Ying Shan, Xiu Li, and Qifeng Chen. Follow your pose: Pose-guided text-to-video generation using pose-free videos. arXiv preprint arXiv:2304.01186, 2023.
- Mou et al. [2023] Chong Mou, Xintao Wang, Liangbin Xie, Jian Zhang, Zhongang Qi, Ying Shan, and Xiaohu Qie. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. arXiv preprint arXiv:2302.08453, 2023.
- Ni et al. [2023] Haomiao Ni, Changhao Shi, Kai Li, Sharon X Huang, and Martin Renqiang Min. Conditional image-to-video generation with latent flow diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18444–18455, 2023.
- Nichol et al. [2021] Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. In International Conference on Machine Learning, 2021.
- QI et al. [2023] Chenyang QI, Xiaodong Cun, Yong Zhang, Chenyang Lei, Xintao Wang, Ying Shan, and Qifeng Chen. Fatezero: Fusing attentions for zero-shot text-based video editing. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 15932–15942, 2023.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Ramesh et al. [2022] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 1(2):3, 2022.
- Ren et al. [2020] Yurui Ren, Ge Li, Shan Liu, and Thomas H Li. Deep spatial transformation for pose-guided person image generation and animation. IEEE Transactions on Image Processing, 29:8622–8635, 2020.
- Rombach et al. [2022] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022.
- Ronneberger et al. [2015] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, pages 234–241. Springer, 2015.
- Saharia et al. [2022] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. Advances in Neural Information Processing Systems, 35:36479–36494, 2022.
- Siarohin et al. [2019a] Aliaksandr Siarohin, Stéphane Lathuilière, Sergey Tulyakov, Elisa Ricci, and Nicu Sebe. First order motion model for image animation. Advances in neural information processing systems, 32, 2019a.
- Siarohin et al. [2019b] Aliaksandr Siarohin, Stéphane Lathuilière, Sergey Tulyakov, Elisa Ricci, and Nicu Sebe. Animating arbitrary objects via deep motion transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2377–2386, 2019b.
- Siarohin et al. [2021] Aliaksandr Siarohin, Oliver J Woodford, Jian Ren, Menglei Chai, and Sergey Tulyakov. Motion representations for articulated animation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13653–13662, 2021.
- Singer et al. [2023] Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, Devi Parikh, Sonal Gupta, and Yaniv Taigman. Make-a-video: Text-to-video generation without text-video data. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023.
- Song et al. [2021] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021.
- Song et al. [2023] Yizhi Song, Zhifei Zhang, Zhe Lin, Scott Cohen, Brian Price, Jianming Zhang, Soo Ye Kim, and Daniel Aliaga. Objectstitch: Object compositing with diffusion model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18310–18319, 2023.
- Tseng et al. [2023] Jonathan Tseng, Rodrigo Castellon, and Karen Liu. Edge: Editable dance generation from music. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 448–458, 2023.
- Unterthiner et al. [2018] Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717, 2018.
- Van Den Oord et al. [2017] Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning. Advances in neural information processing systems, 30, 2017.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Wang et al. [2023a] Tan Wang, Linjie Li, Kevin Lin, Chung-Ching Lin, Zhengyuan Yang, Hanwang Zhang, Zicheng Liu, and Lijuan Wang. Disco: Disentangled control for referring human dance generation in real world. arXiv preprint arXiv:2307.00040, 2023a.
- Wang et al. [2023b] Xiang Wang, Hangjie Yuan, Shiwei Zhang, Dayou Chen, Jiuniu Wang, Yingya Zhang, Yujun Shen, Deli Zhao, and Jingren Zhou. Videocomposer: Compositional video synthesis with motion controllability. In Thirty-seventh Conference on Neural Information Processing Systems, 2023b.
- Wang et al. [2023c] Yaohui Wang, Xin Ma, Xinyuan Chen, Antitza Dantcheva, Bo Dai, and Yu Qiao. Leo: Generative latent image animator for human video synthesis. arXiv preprint arXiv:2305.03989, 2023c.
- Wang et al. [2004] Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 13(4):600–612, 2004.
- Wu et al. [2023] Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Stan Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7623–7633, 2023.
- Yang et al. [2023a] Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, and Fang Wen. Paint by example: Exemplar-based image editing with diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18381–18391, 2023a.
- Yang et al. [2023b] Shuai Yang, Yifan Zhou, Ziwei Liu, and Chen Change Loy. Rerender a video: Zero-shot text-guided video-to-video translation. arXiv preprint arXiv:2306.07954, 2023b.
- Yang et al. [2023c] Zhendong Yang, Ailing Zeng, Chun Yuan, and Yu Li. Effective whole-body pose estimation with two-stages distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4210–4220, 2023c.
- Ye et al. [2023] Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models. arXiv preprint arXiv:2308.06721, 2023.
- Yu et al. [2023] Wing-Yin Yu, Lai-Man Po, Ray CC Cheung, Yuzhi Zhao, Yu Xue, and Kun Li. Bidirectionally deformable motion modulation for video-based human pose transfer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7502–7512, 2023.
- Zablotskaia et al. [2019] Polina Zablotskaia, Aliaksandr Siarohin, Bo Zhao, and Leonid Sigal. Dwnet: Dense warp-based network for pose-guided human video generation. arXiv preprint arXiv:1910.09139, 2019.
- Zhang et al. [2023a] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3836–3847, 2023a.
- Zhang et al. [2022] Pengze Zhang, Lingxiao Yang, Jian-Huang Lai, and Xiaohua Xie. Exploring dual-task correlation for pose guided person image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7713–7722, 2022.
- Zhang et al. [2018] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018.
- Zhang et al. [2023b] Shiwei Zhang, Jiayu Wang, Yingya Zhang, Kang Zhao, Hangjie Yuan, Zhiwu Qin, Xiang Wang, Deli Zhao, and Jingren Zhou. I2vgen-xl: High-quality image-to-video synthesis via cascaded diffusion models. arXiv preprint arXiv:2311.04145, 2023b.
- Zhao and Zhang [2022] Jian Zhao and Hui Zhang. Thin-plate spline motion model for image animation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3657–3666, 2022.
- Zhu et al. [2023] Luyang Zhu, Dawei Yang, Tyler Zhu, Fitsum Reda, William Chan, Chitwan Saharia, Mohammad Norouzi, and Ira Kemelmacher-Shlizerman. Tryondiffusion: A tale of two unets. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4606–4615, 2023.