可动画化的 3D 高斯:快速、高质量地重建多个人体头像
摘要
神经辐射场能够重建高质量的可驾驶人类化身,但其渲染成本昂贵。 为了减少消耗,我们提出了Animatable 3D Gaussian,它可以从输入图像和姿势中学习人类头像。 我们通过在规范空间中建模一组蒙皮 3D 高斯和相应的骨架,并根据输入姿势将 3D 高斯变形到姿势空间,将 3D 高斯扩展到动态人类场景。 我们引入哈希编码的形状和外观来加速训练,并提出依赖于时间的环境光遮挡,以在包含复杂运动和动态阴影的场景中实现高质量的重建。 在新颖的视图合成和新颖的姿势合成任务中,我们的方法在训练时间、渲染速度和重建质量方面都优于现有方法。 我们的方法可以轻松扩展到多人场景,并在仅 25 秒的训练内就在 10 人场景中实现了可比的新颖视图合成结果。 视频和代码请参见https://jimmyyliu.github.io/Animatable-3D-Gaussian/。
![[Uncaptioned image]](x1.png)
1简介
高质量数字人的实时渲染和快速重建在虚拟现实、游戏、体育转播、远程呈现等各个领域有着广泛的应用。 现有的方法往往需要相当长的训练时间,并且都无法在很短的训练时间内实现高质量的重建和实时渲染。
最近的方法[26,5,37]使用神经辐射场[35]隐式重建高质量的人类化身。 然而,隐式神经辐射场不可避免地会导致合成的新颖视图中出现伪影,因为它们需要对包括空白空间在内的整个空间进行建模。 由于多层感知器和每条射线的复杂点采样,其中一些方法[5, 37]需要大量内存和时间消耗。 当涉及具有动态光照和阴影的数据集时,这些方法[26,5,37]的重建质量显着下降。 这种下降归因于这些方法固有的无法适应光照和阴影的动态变化。
在本文中,我们的目标是在几秒钟内从单眼或稀疏视图视频序列中获取高保真人类头像,并以交互速率渲染高质量的新颖视图和姿势( 分辨率为 170 FPS) 。 为此,我们引入了一种针对动态人类的使用 3D 高斯 (3D-GS [28]) 的新型神经表示,称为 Animatable 3D Gaussian,克服了隐式神经辐射场中的伪影问题。 为了将 3D 高斯变形到姿势空间,我们在规范空间中建模了一组蒙皮 3D 高斯和相应的骨架。 我们使用哈希编码的形状和外观来加快收敛速度并避免过度拟合。 为了减少渲染的内存和时间消耗,我们使用 3D 高斯光栅器 [28] 来光栅化变形的 3D 高斯而不是体渲染。 为了处理动态照明和阴影,我们建议为每个时间戳对时间相关的环境光遮挡进行建模。
由于公共数据集[1]包含很少的姿势和阴影变化,我们创建一个名为GalaBasketball的新数据集,以显示我们的方法在复杂运动和动态阴影下的性能。 我们在公共数据集和我们创建的数据集上评估我们的方法,并将其与最先进的方法[26, 5]进行比较。 我们的方法能够在更短的时间内重建质量更好的人类化身。 此外,我们的方法可以扩展到多人场景并且表现良好。
总之,我们工作的主要贡献是:
-
•
我们提出了 Animatable 3D Gaussian,这是一种使用 3D Gaussian 来表示动态人体的新颖神经表示,它使 3D Gaussian 能够在动态人体场景中表现良好。
-
•
我们提出了一种新颖的人体重建流程,与最先进的方法[26, 5]相比,它可以以更低的内存和时间消耗来获取更高保真度的人体化身。
-
•
我们提出了一个与时间相关的环境光遮挡模块来重建动态阴影,这使得我们的方法能够从具有复杂运动和动态阴影的场景中获得高保真人类头像。
2相关工作
3D 人体重建。 重建3D人体一直是近年来的热门研究课题。 传统方法通过深度传感器[9, 14, 42, 19]和密集相机阵列[11, 12]实现高保真重建,但昂贵的硬件要求限制这些方法的应用。 最近的方法[1,2,18,48,20,21,47]利用参数化网格模板作为先验,例如SMPL[33]。 通过优化网格模板,这些方法能够重建不同形状的 3D 人体。 然而,它们在重建头发和织物等细节方面存在局限性。
神经辐射场[35]的出现使得神经表征在人体重建领域流行起来。 许多作品[5,26,37,3,7,6,8,10,13,15,22,23,24,25,27,29,39,40,34,32]使用神经表示在规范空间中对 3D 人体形状和外观进行建模,然后使用变形场将模型变形为姿势空间以进行渲染。 这些方法实现了高质量的重建结果,但需要大量的内存和时间消耗,因为它们通常需要复杂的隐式表示、变形算法和体渲染。 其中一项作品 InstantAvatar [26] 速度很快,但在合成图像中存在伪影。 我们的方法通过结合参数模板和隐式表达式来解决以前方法的问题,以实现快速、高质量的人体重建。
加速神经渲染。 由于vanilla NeRF [35]的渲染速度非常慢,需要几秒钟才能获得图像,并且需要更多时间进行训练。 最近的工作[36,4,16,36,38,28,17,45,31,30,49,44,43]致力于提高神经渲染的速度。 Plenoxels [16] 提出利用稀疏体积,并结合密度和球谐系数来进行渲染。 TensoRF [4] 将体素网格分解为向量系数的聚合,旨在减小模型的大小以提高效率。 Instant-NGP [36]引入多分辨率哈希编码来完成快速渲染。 3D-GS [28] 将每个场景表示为可扩展的半透明椭球体的集合,以实现实时渲染。 这些方法主要用于静态场景的重建。 对于动态场景,FPO[45] 提出了 NeRF、PlenOctree[49] 表示、体积融合和傅里叶变换的新颖组合,以解决高效的神经建模和实时问题动态场景的渲染。 InstantAvatar [26] 在 3D 头像重建任务上应用哈希编码以实现快速渲染。 此类方法需要高内存成本并且会受到伪影的影响。 在本文中,我们将 3D-GS 从静态场景扩展到动态人体场景。
3初步
3.1 3D高斯光栅化
Kerbl 等人. [28]建议将每个场景表示为 3D 高斯函数的集合。 每个 3D 高斯 定义为:
| (1) |
其中表示3D高斯分布的几何中心,是旋转矩阵,是在三个维度上缩放高斯分布的缩放矩阵, 表示中心的不透明度, 是指一组球谐系数,用于按照标准实践 [16] 对依赖于视图的颜色分布进行建模。
3D 高斯 附近位置 的不透明度定义为:
| (2) |
其中协方差矩阵 分解为旋转矩阵 和缩放矩阵 :
| (3) |
遵循 Zwicker 等人. [51] 的方法,3D 高斯投影到 2D 图像空间,如下所示:
| (4) |
其中 是观察变换, 是投影变换的仿射近似的雅可比行列式。
随后,根据投影高斯的深度对其进行排序,并根据等式将其光栅化为相邻像素。 (2)。 每个像素都会收到一个按深度排序的颜色 和不透明度 列表。 最终像素颜色 通过混合与像素重叠的 N 个有序点来计算:
| (5) |
3.2 位姿引导变形
我们将视频序列中的每一帧定义为带有时间戳 的姿势空间,并通过线性混合蒙皮将点从规范空间变形到姿势空间。 我们使用蒙皮权重场来建模关节。 蒙皮权重字段[33]定义为:
| (6) |
其中 是骨骼数量, 是规范空间中的点。
帧 中的目标骨骼变换 可以根据输入姿势和相应的骨骼计算出来,如下所示:
| (7) |
其中指帧中各关节的旋转欧拉角(为世界旋转,其余为局部旋转),是框架中的世界平移,是规范空间中每个关节的局部位置。 详细计算过程请参见补充材料。
然后我们可以通过线性混合蒙皮将规范空间中的点 变形到姿势空间:
| (8) |
其中 指的是帧 中的点。
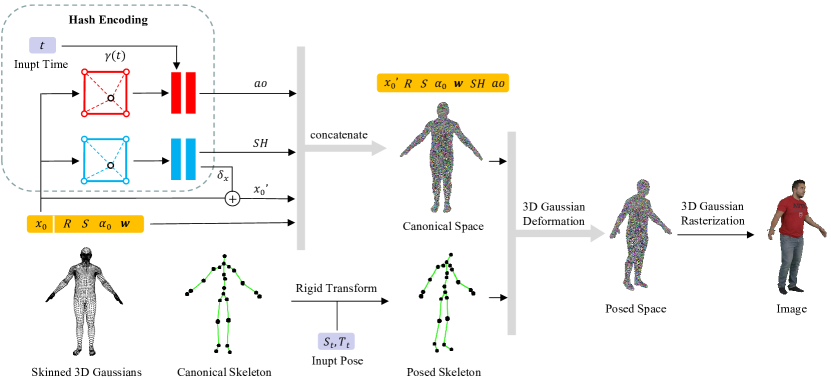
4方法
给定一个包含一个或多个移动人物及其姿势 的视频序列 ,我们可以在几秒钟内为每个人重建一个可动画的 3D 高斯表示。 对于多视图视频序列,我们重建依赖于时间的环境遮挡以实现高质量的新颖视图合成。
在本节中,我们首先在第 2 节中介绍可动画的 3D 高斯表示。 4.1。 然后我们将 3D 高斯从规范空间变形到姿势空间,如第 2 节中介绍的那样。 3.2 和秒。 4.2。 最后,我们运行 3D 高斯光栅化(第 3.1 节)来渲染特定相机参数的图像。 此外,我们建议为多视图、多人和大范围运动任务构建时间相关的环境遮挡(第4.3),这使得我们的算法能够适应遮挡引起的动态阴影。 该方法的流程如图2所示。
4.1 规范空间中的可动画 3D 高斯
具有骨架的 3D 高斯。 我们将 3D 高斯函数绑定到相应的骨架,以启用等式 1 中的线性蒙皮算法。 (8)。 所提出的可动画 3D 高斯表示由一组蒙皮 3D 高斯和方程式中提到的相应骨架 组成。 (7)。 蒙皮 3D 高斯 改编自等式 1 中的静态 3D 高斯 。 (1) 并定义如下:
| (9) |
其中 是蒙皮权重, 是顶点位移。
直接优化随机初始化的蒙皮权重是一个重大挑战。 相反,我们将蒙皮权重视为与任何特定人体形状无关的通用人体模型的强先验。 在实践中,我们使用标准蒙皮模型初始化蒙皮权重和高斯点的位置,如第 2 节中所述。 4.4。 在优化过程中,蒙皮权重保持固定,同时优化顶点位移和骨架以准确捕捉个体的形状和运动。 在实施式(1)中基于姿势的变形之前,我们移动高斯中心。 (8):
| (10) |
哈希编码的形状和外观。 我们注意到,使用逐顶点颜色在可变形动态场景[28]中表现不佳。 由于高斯从规范空间到姿势空间的变形最初是不确定的,因此需要更多的样本和迭代才能达到收敛。 此外,基于3D高斯光栅化的渲染只能在单次迭代中将梯度反向传播到有限数量的高斯,这导致动态场景的优化过程缓慢甚至发散。 为了解决这个问题,我们建议从连续参数场中对每个顶点采样球谐系数,这能够在一次优化中影响所有相邻的高斯。 同样,使用无约束的每顶点位移很容易导致动态场景中的优化过程出现分歧。 因此,我们还对顶点位移的参数场进行建模。 对于方程中的其余参数。 (9),我们将它们存储在每个点中,以保留 3D 高斯拟合不同形状的能力。 我们定义参数字段如下:
| (11) |
由于我们的可动画 3D 高斯表示是由标准人体模型初始化的,因此 3D 高斯的中心均匀分布在人体表面附近。 我们只需要在参数字段中靠近人体表面的固定位置进行采样。 这允许对哈希编码[36]的哈希表进行显着压缩。 因此,我们选择哈希编码来建模我们的参数字段,以减少时间和存储消耗。
或者,我们提供 UV 编码的球谐系数,允许使用 UV 坐标映射快速处理自定义人体模型。 与哈希编码相比,UV 编码可能实现更高的重建质量。 球谐系数的UV映射定义如下:
| (12) |
其中 是 3D 高斯的 UV 坐标。
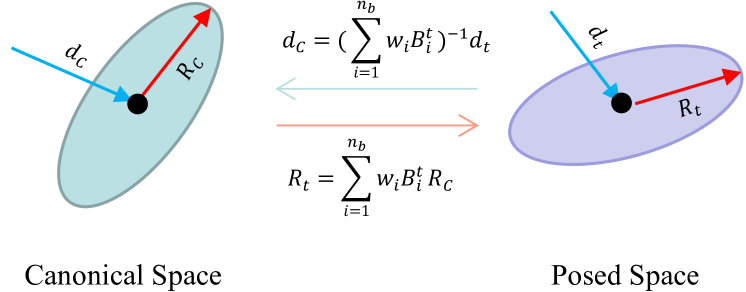
4.23D高斯变形
我们使用姿势来引导 3D 高斯的变形,如图 3 所示。 我们在第二节中引入了基于姿势的变形,它将点位置从规范空间变换到姿势空间。 3.2。 对于 3D 高斯分布,我们还需要对其方向进行变形,以在不同姿势下实现一致的各向异性高斯分布。 在不同姿势中使用相同方向会导致 3D 高斯退化为高斯球体。 与等式相同。 (8),我们将线性混合蒙皮应用于 3D 高斯的旋转 ,如下所示:
| (13) |
其中 是规范空间中的旋转, 是框架 中姿势空间中的旋转。
基于球谐函数的颜色计算的视图方向应变形到规范空间,以获得一致的各向异性颜色。 因此,我们将线性混合蒙皮的逆变换应用于视图方向:
| (14) |
其中 是规范空间中的方向, 是框架 中姿势空间中的方向。
我们通过扩展 3D 高斯光栅器 [28] 来实现上述变换,并显式导出所有参数的梯度。 这使得 3D 高斯基于姿势的变形的时间开销几乎可以忽略不计。
4.3 时间相关的环境光遮挡
我们提出了一个与时间相关的环境光遮挡模块来解决特定场景中的动态阴影问题。 我们还在等式 1 中的蒙皮 3D 高斯之上建模了环境遮挡因子 。 (9) 如下:
| (15) |
我们在考虑每个高斯的环境光遮挡后计算颜色,如下所示:
| (16) |
其中指的是球谐函数。
正如第 2 节中所讨论的。 4.1,我们还对环境光遮挡采用哈希编码,因为阴影应该在空间中连续建模。 此外,我们在哈希编码[36]的MLP模块中引入了时间的位置编码[35]的附加输入,以便捕捉随时间变化的环境光遮挡。 环境光遮挡的参数字段定义为:
| (17) |
其中函数 指的是 NeRF [35] 中使用的位置编码。
在训练开始时,我们使用固定的环境光遮挡来让模型学习与时间无关的球谐系数。 颜色稳定后我们开始优化环境光遮挡。
| male-3-casual | male-4-casual | female-3-casual | female-4-casual | |||||||||
| PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | |
| Anim-NeRF [5] (5 minutes) | 23.17 | 0.9266 | 0.0784 | 22.30 | 0.9235 | 0.0911 | 22.37 | 0.9311 | 0.0784 | 23.18 | 0.9292 | 0.0687 |
| InstantAvatar [26] (30 seconds) | 26.56 | 0.9301 | 0.1190 | 26.10 | 0.9289 | 0.1397 | 22.37 | 0.8427 | 0.2687 | 26.32 | 0.9281 | 0.1333 |
| Ours (30 seconds) | 29.06 | 0.9704 | 0.0264 | 26.16 | 0.9554 | 0.0491 | 24.59 | 0.9535 | 0.0399 | 27.26 | 0.9634 | 0.0281 |
| InstantAvatar [26] (5 seconds) | 17.30 | 0.7980 | 0.3473 | 16.44 | 0.7960 | 0.3508 | 17.22 | 0.8185 | 0.3262 | 14.91 | 0.7606 | 0.3878 |
| Ours (5 seconds) | 22.84 | 0.9395 | 0.0632 | 18.88 | 0.9103 | 0.1175 | 20.51 | 0.9301 | 0.0764 | 20.63 | 0.9246 | 0.0737 |
4.4优化详情
可动画化的 3D 高斯初始化。 3D高斯的初始化对优化结果的质量有显着影响。 不正确的初始化甚至会导致优化过程出现分歧。 对于静态3D高斯[28],使用Structure-from-Motion(SFM[41])方法来获取初始3D高斯点云,这提供了非常好的良好且密集的初始化。
然而,对于动态场景,使用SFM获取初始点云是一个巨大的挑战。 因此,我们使用标准蒙皮模型来初始化可变形 3D 高斯表示。 该标准蒙皮模型应包括一组位置和蒙皮权重,以及与输入姿势相对应的骨架。 我们建议将输入模型的顶点上采样到 100,000 个左右,以实现高重建质量。 具体来说,对于SMPL模型[33],我们在每个顶点的邻域内随机采样K个附加点(根据实验结果设置K=20)并直接复制它们的蒙皮参数以获得模型约140,000点。
损失函数。 所提出的可动画 3D 高斯表示能够准确拟合包含移动人体的动态场景,从而消除额外正则化损失的需要。 我们直接使用和D-SSIM项的组合:
| (18) |
我们使用 遵循静态 3D 高斯 [28] 的最佳实践。

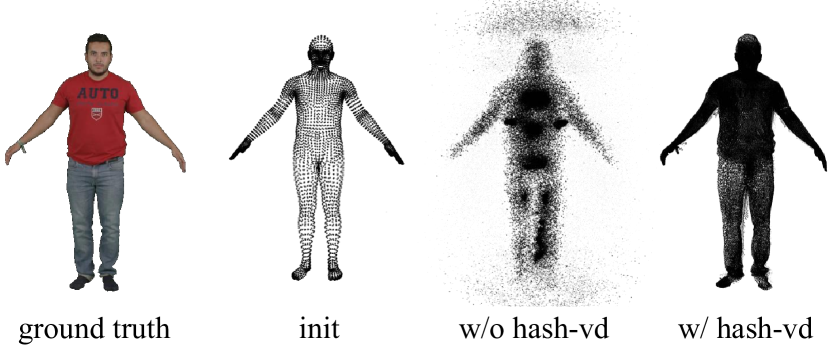
| PSNR | SSIM | LPIPS | |
|---|---|---|---|
| w/o hash-SH | 25.38 | 0.9478 | 0.0504 |
| w/o hash-vd | 22.08 | 0.8994 | 0.1678 |
| w/o J-optimize | 21.45 | 0.9311 | 0.0781 |
| ours | 26.77 | 0.9607 | 0.0359 |
5实验
我们评估了我们的方法在单目场景上的速度和质量(PSNR、SSIM [46] 和 LPIPS [50])(第 5.1 节) >)和多视图场景(第 5.2 节)。 与最先进方法的比较实验[26, 5]显示了我们方法的优越性。 此外,我们还对我们的方法进行了广泛的消融研究。 在所有实验中,我们在单个 RTX 3090 上评估我们的方法和 InstantAvatar [26],同时在 RTX 3090 上评估 Anim-NeRF。
5.1单眼场景
我们使用 PeopleSnapshot [1] 数据集来评估我们的方法在单人、单眼场景中的性能。 遵循之前的方法[26],我们将图像降采样到分辨率,并使用SMPL[33]模型进行初始化。 我们不使用任何预测的身体参数,而是使用通用模板。 由于该数据集不包含时间戳和剧烈的阴影变化,因此我们不使用时间相关的环境光遮挡模块。
比较。 我们在表中提供了定量比较。 1和图4中的视觉比较。 与InstantAvatar [26]和Anim-NeRF [5]相比,我们的方法在更短的时间(5s和30s)内实现了更高的重建质量。 如图4所示,我们的方法解决了之前方法中出现的伪影问题。 此外,我们的方法实现了最快的训练和渲染速度。 对于 分辨率图像,我们达到 50 FPS 的训练速度和 170 FPS 的渲染速度。
| idle | dribble | shot | turn | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | |
| InstantAvatar [26] (5 minutes) | 29.86 | 0.9607 | 0.0575 | 27.25 | 0.9435 | 0.0903 | 29.22 | 0.9461 | 0.0709 | 32.20 | 0.9705 | 0.0371 |
| Ours: w/o ao (50 seconds) | 37.38 | 0.9941 | 0.0042 | 36.53 | 0.9909 | 0.0059 | 37.07 | 0.9908 | 0.0067 | 36.77 | 0.9927 | 0.0062 |
| Ours: hash-SH (70 seconds) | 39.85 | 0.9957 | 0.0032 | 38.52 | 0.9934 | 0.0043 | 39.11 | 0.9933 | 0.0051 | 39.25 | 0.9951 | 0.0041 |
| Ours: uv-SH (60 seconds) | 40.75 | 0.9964 | 0.0029 | 38.53 | 0.9935 | 0.0042 | 39.44 | 0.9936 | 0.0049 | 39.74 | 0.9953 | 0.0038 |


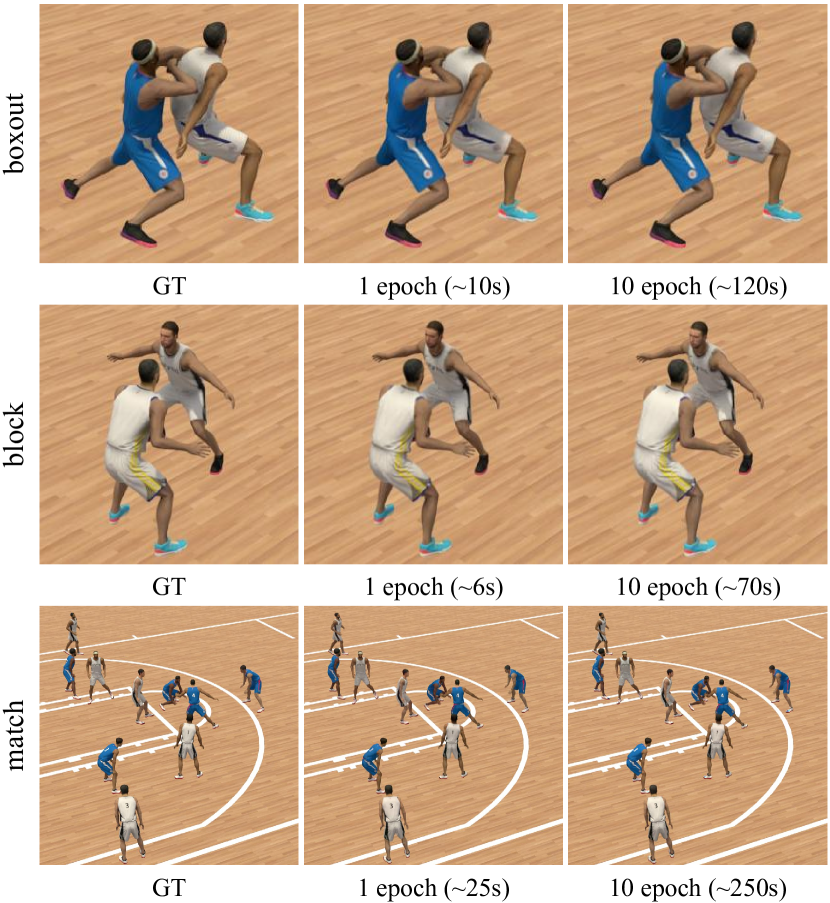
5.2 多视图场景
PeopleSnapshot [1] 数据集中几乎没有姿势和阴影变化。 为了演示所提出的方法在包含复杂运动和动态阴影的场景中的重建性能,我们创建了一个名为 GalaBasketball 的数据集,该数据集由多个具有不同形状和外观的球员模型合成。 GalaBasketball 数据集由 4 个单人场景和 3 个多人场景组成,提供 6 个均匀包围的摄像机作为训练集,1 个摄像机作为测试集。 对于单人场景,我们提供了一组额外的动作来评估新颖的姿势合成能力。 此外,我们提供了与 GalaBasketball 数据集相对应的标准蒙皮模型进行初始化,该模型在几何形状和外观方面与数据集中的任何球员都不相似。
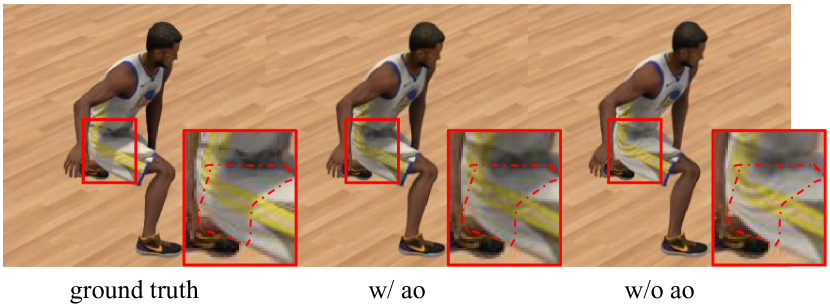
新颖的视图合成。 如表所示。 3和图6,我们评估了我们的方法在不同设置下合成GalaBasketball单人场景的新颖视图的能力。 与 InstantAvatar [26] 相比,我们的方法在任何设置下都可以在更短的训练时间内实现更高质量的新颖视图合成,并显着消除伪影。 这证明我们的可动画 3D 高斯表示可以在复杂的运动变化下进行训练并获得高质量的人体头像。 相比之下,InstantAvatar 存在伪影,并且合成质量较低,因为皮肤权重在复杂的运动变化下无法收敛到地面实况。
我们还在选项卡中提供了我们的消融研究。 3. 时间相关的环境光遮挡有助于我们的方法实现更高的新颖视图合成质量,适合时间相关的阴影变化,如图7所示。 此外,我们还为标准模型提供 UV 映射,以评估 UV 编码的球谐系数的性能。 结果表明,在允许的情况下,与哈希编码相比,使用UV编码的球谐系数可以提高速度和质量。
新颖的姿势合成。 我们使用与训练集不同的另一组动作来渲染图像,并将我们的新姿势合成结果与图 8 中的 InstantAvatar 进行比较。 由于新颖的姿势合成任务没有时间戳,因此我们不使用时间相关的环境光遮挡。 结果表明,我们重建的人体头像在新颖的姿势中实现了较高的合成质量,而 InstantAvatar 仍然存在伪影。
多人场景。 我们通过在单个 RTX 3090 上同时渲染多个人物头像来将我们的方法扩展到多人场景,而现有方法[5, 26]由于局限性而无法扩展到多人场景的执行和记忆。 图9展示了我们的方法在GalaBasketball的多人场景中的高质量新颖视图合成结果,包括两个双人场景和一个5v5场景。 我们的方法在双人场景(分辨率)上实现了 40 FPS 的训练速度和 110 FPS 的渲染速度。 在 5v5 场景( 分辨率)上,我们的方法达到了 10 FPS 的训练速度和 40 FPS 的渲染速度。 自由视点视频结果请参阅补充材料。
6结论
我们提出了一种在几秒钟内进行高质量人体重建的方法。 重建的人体头像可用于实时新颖的视图合成和新颖的姿势合成。 我们的方法由规范空间中的可动画 3D 高斯表示和基于姿势的 3D 高斯变形组成,它将 3D 高斯 [28] 扩展到可变形的人类。 我们提出的时间相关环境光遮挡在包含复杂运动和动态阴影的场景中实现了高质量的重建结果。 与最先进的方法[5, 26]相比,我们的方法需要更少的训练时间,渲染速度更快,并产生更好的重建结果。 此外,我们的方法可以轻松扩展到多人场景。
局限性和未来的工作。 为了实现可选模块,我们的方法使用多个 MLP。 但在特定任务中,可以将多个MLPS合并为一个,进一步减少消耗。 由于动态场景的复杂性,我们在训练过程中没有添加或删除高斯点,这导致重建的质量受初始化点的数量影响很大,降低了高频区域的重建质量。 最后,不准确的姿势输入可能会导致我们的方法的性能下降。 通过其他正则化方法优化输入姿势可以解决这个问题,甚至可以在没有输入姿势的情况下实现人体重建。
参考
- Alldieck et al. [2018a] Thiemo Alldieck, Marcus Magnor, Weipeng Xu, Christian Theobalt, and Gerard Pons-Moll. Detailed human avatars from monocular video. In 2018 International Conference on 3D Vision (3DV), pages 98–109. IEEE, 2018a.
- Alldieck et al. [2018b] Thiemo Alldieck, Marcus Magnor, Weipeng Xu, Christian Theobalt, and Gerard Pons-Moll. Video based reconstruction of 3d people models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8387–8397, 2018b.
- Bergman et al. [2022] Alexander Bergman, Petr Kellnhofer, Wang Yifan, Eric Chan, David Lindell, and Gordon Wetzstein. Generative neural articulated radiance fields. Advances in Neural Information Processing Systems, 35:19900–19916, 2022.
- Chen et al. [2022a] Anpei Chen, Zexiang Xu, Andreas Geiger, Jingyi Yu, and Hao Su. Tensorf: Tensorial radiance fields. In European Conference on Computer Vision, pages 333–350. Springer, 2022a.
- Chen et al. [2021a] Jianchuan Chen, Ying Zhang, Di Kang, Xuefei Zhe, Linchao Bao, Xu Jia, and Huchuan Lu. Animatable neural radiance fields from monocular rgb videos. arXiv preprint arXiv:2106.13629, 2021a.
- Chen et al. [2021b] Xu Chen, Yufeng Zheng, Michael J Black, Otmar Hilliges, and Andreas Geiger. Snarf: Differentiable forward skinning for animating non-rigid neural implicit shapes. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11594–11604, 2021b.
- Chen et al. [2022b] Xu Chen, Tianjian Jiang, Jie Song, Jinlong Yang, Michael J Black, Andreas Geiger, and Otmar Hilliges. gdna: Towards generative detailed neural avatars. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20427–20437, 2022b.
- Chibane et al. [2020] Julian Chibane, Thiemo Alldieck, and Gerard Pons-Moll. Implicit functions in feature space for 3d shape reconstruction and completion. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6970–6981, 2020.
- Collet et al. [2015] Alvaro Collet, Ming Chuang, Pat Sweeney, Don Gillett, Dennis Evseev, David Calabrese, Hugues Hoppe, Adam Kirk, and Steve Sullivan. High-quality streamable free-viewpoint video. ACM Transactions on Graphics (ToG), 34(4):1–13, 2015.
- Corona et al. [2021] Enric Corona, Albert Pumarola, Guillem Alenya, Gerard Pons-Moll, and Francesc Moreno-Noguer. Smplicit: Topology-aware generative model for clothed people. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11875–11885, 2021.
- Debevec et al. [2000] Paul Debevec, Tim Hawkins, Chris Tchou, Haarm-Pieter Duiker, Westley Sarokin, and Mark Sagar. Acquiring the reflectance field of a human face. In Proceedings of the 27th annual conference on Computer graphics and interactive techniques, pages 145–156, 2000.
- Debevec et al. [2023] Paul E Debevec, Camillo J Taylor, and Jitendra Malik. Modeling and rendering architecture from photographs: A hybrid geometry-and image-based approach. In Seminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 465–474. 2023.
- Dong et al. [2022] Zijian Dong, Chen Guo, Jie Song, Xu Chen, Andreas Geiger, and Otmar Hilliges. Pina: Learning a personalized implicit neural avatar from a single rgb-d video sequence. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20470–20480, 2022.
- Dou et al. [2016] Mingsong Dou, Sameh Khamis, Yury Degtyarev, Philip Davidson, Sean Ryan Fanello, Adarsh Kowdle, Sergio Orts Escolano, Christoph Rhemann, David Kim, Jonathan Taylor, et al. Fusion4d: Real-time performance capture of challenging scenes. ACM Transactions on Graphics (ToG), 35(4):1–13, 2016.
- Feng et al. [2022] Yao Feng, Jinlong Yang, Marc Pollefeys, Michael J Black, and Timo Bolkart. Capturing and animation of body and clothing from monocular video. In SIGGRAPH Asia 2022 Conference Papers, pages 1–9, 2022.
- Fridovich-Keil et al. [2022] Sara Fridovich-Keil, Alex Yu, Matthew Tancik, Qinhong Chen, Benjamin Recht, and Angjoo Kanazawa. Plenoxels: Radiance fields without neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5501–5510, 2022.
- Garbin et al. [2021] Stephan J Garbin, Marek Kowalski, Matthew Johnson, Jamie Shotton, and Julien Valentin. Fastnerf: High-fidelity neural rendering at 200fps. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14346–14355, 2021.
- Guo et al. [2021] Chen Guo, Xu Chen, Jie Song, and Otmar Hilliges. Human performance capture from monocular video in the wild. In 2021 International Conference on 3D Vision (3DV), pages 889–898. IEEE, 2021.
- Guo et al. [2019] Kaiwen Guo, Peter Lincoln, Philip Davidson, Jay Busch, Xueming Yu, Matt Whalen, Geoff Harvey, Sergio Orts-Escolano, Rohit Pandey, Jason Dourgarian, et al. The relightables: Volumetric performance capture of humans with realistic relighting. ACM Transactions on Graphics (ToG), 38(6):1–19, 2019.
- Habermann et al. [2019] Marc Habermann, Weipeng Xu, Michael Zollhoefer, Gerard Pons-Moll, and Christian Theobalt. Livecap: Real-time human performance capture from monocular video. ACM Transactions On Graphics (TOG), 38(2):1–17, 2019.
- Habermann et al. [2020] Marc Habermann, Weipeng Xu, Michael Zollhofer, Gerard Pons-Moll, and Christian Theobalt. Deepcap: Monocular human performance capture using weak supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5052–5063, 2020.
- He et al. [2020] Tong He, John Collomosse, Hailin Jin, and Stefano Soatto. Geo-pifu: Geometry and pixel aligned implicit functions for single-view human reconstruction. Advances in Neural Information Processing Systems, 33:9276–9287, 2020.
- He et al. [2021] Tong He, Yuanlu Xu, Shunsuke Saito, Stefano Soatto, and Tony Tung. Arch++: Animation-ready clothed human reconstruction revisited. In Proceedings of the IEEE/CVF international conference on computer vision, pages 11046–11056, 2021.
- Huang et al. [2020] Zeng Huang, Yuanlu Xu, Christoph Lassner, Hao Li, and Tony Tung. Arch: Animatable reconstruction of clothed humans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3093–3102, 2020.
- Jiang et al. [2022a] Boyi Jiang, Yang Hong, Hujun Bao, and Juyong Zhang. Selfrecon: Self reconstruction your digital avatar from monocular video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5605–5615, 2022a.
- Jiang et al. [2023] Tianjian Jiang, Xu Chen, Jie Song, and Otmar Hilliges. Instantavatar: Learning avatars from monocular video in 60 seconds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16922–16932, 2023.
- Jiang et al. [2022b] Wei Jiang, Kwang Moo Yi, Golnoosh Samei, Oncel Tuzel, and Anurag Ranjan. Neuman: Neural human radiance field from a single video. In European Conference on Computer Vision, pages 402–418. Springer, 2022b.
- Kerbl et al. [2023] Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics (ToG), 42(4):1–14, 2023.
- Li et al. [2022] Ruilong Li, Julian Tanke, Minh Vo, Michael Zollhöfer, Jürgen Gall, Angjoo Kanazawa, and Christoph Lassner. Tava: Template-free animatable volumetric actors. In European Conference on Computer Vision, pages 419–436. Springer, 2022.
- Lindell et al. [2021] David B Lindell, Julien NP Martel, and Gordon Wetzstein. Autoint: Automatic integration for fast neural volume rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14556–14565, 2021.
- Liu et al. [2020] Lingjie Liu, Jiatao Gu, Kyaw Zaw Lin, Tat-Seng Chua, and Christian Theobalt. Neural sparse voxel fields. Advances in Neural Information Processing Systems, 33:15651–15663, 2020.
- Liu et al. [2021] Lingjie Liu, Marc Habermann, Viktor Rudnev, Kripasindhu Sarkar, Jiatao Gu, and Christian Theobalt. Neural actor: Neural free-view synthesis of human actors with pose control. ACM transactions on graphics (TOG), 40(6):1–16, 2021.
- Loper et al. [2023] Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi-person linear model. In Seminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 851–866. 2023.
- Mihajlovic et al. [2021] Marko Mihajlovic, Yan Zhang, Michael J Black, and Siyu Tang. Leap: Learning articulated occupancy of people. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10461–10471, 2021.
- Mildenhall et al. [2021] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021.
- Müller et al. [2022] Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding. ACM Transactions on Graphics (ToG), 41(4):1–15, 2022.
- Peng et al. [2021] Sida Peng, Yuanqing Zhang, Yinghao Xu, Qianqian Wang, Qing Shuai, Hujun Bao, and Xiaowei Zhou. Neural body: Implicit neural representations with structured latent codes for novel view synthesis of dynamic humans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9054–9063, 2021.
- Reiser et al. [2021] Christian Reiser, Songyou Peng, Yiyi Liao, and Andreas Geiger. Kilonerf: Speeding up neural radiance fields with thousands of tiny mlps. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14335–14345, 2021.
- Saito et al. [2019] Shunsuke Saito, Zeng Huang, Ryota Natsume, Shigeo Morishima, Angjoo Kanazawa, and Hao Li. Pifu: Pixel-aligned implicit function for high-resolution clothed human digitization. In Proceedings of the IEEE/CVF international conference on computer vision, pages 2304–2314, 2019.
- Saito et al. [2020] Shunsuke Saito, Tomas Simon, Jason Saragih, and Hanbyul Joo. Pifuhd: Multi-level pixel-aligned implicit function for high-resolution 3d human digitization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 84–93, 2020.
- Schonberger and Frahm [2016] Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4104–4113, 2016.
- Su et al. [2020] Zhuo Su, Lan Xu, Zerong Zheng, Tao Yu, Yebin Liu, and Lu Fang. Robustfusion: Human volumetric capture with data-driven visual cues using a rgbd camera. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part IV 16, pages 246–264. Springer, 2020.
- Sun et al. [2022] Cheng Sun, Min Sun, and Hwann-Tzong Chen. Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5459–5469, 2022.
- Wang et al. [2022a] Angtian Wang, Peng Wang, Jian Sun, Adam Kortylewski, and Alan Yuille. Voge: a differentiable volume renderer using gaussian ellipsoids for analysis-by-synthesis. In The Eleventh International Conference on Learning Representations, 2022a.
- Wang et al. [2022b] Liao Wang, Jiakai Zhang, Xinhang Liu, Fuqiang Zhao, Yanshun Zhang, Yingliang Zhang, Minye Wu, Jingyi Yu, and Lan Xu. Fourier plenoctrees for dynamic radiance field rendering in real-time. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13524–13534, 2022b.
- Wang et al. [2004] Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 13(4):600–612, 2004.
- Xiang et al. [2020] Donglai Xiang, Fabian Prada, Chenglei Wu, and Jessica Hodgins. Monoclothcap: Towards temporally coherent clothing capture from monocular rgb video. In 2020 International Conference on 3D Vision (3DV), pages 322–332. IEEE, 2020.
- Xu et al. [2018] Weipeng Xu, Avishek Chatterjee, Michael Zollhöfer, Helge Rhodin, Dushyant Mehta, Hans-Peter Seidel, and Christian Theobalt. Monoperfcap: Human performance capture from monocular video. ACM Transactions on Graphics (ToG), 37(2):1–15, 2018.
- Yu et al. [2021] Alex Yu, Ruilong Li, Matthew Tancik, Hao Li, Ren Ng, and Angjoo Kanazawa. Plenoctrees for real-time rendering of neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5752–5761, 2021.
- Zhang et al. [2018] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018.
- Zwicker et al. [2001] Matthias Zwicker, Hanspeter Pfister, Jeroen Van Baar, and Markus Gross. Ewa volume splatting. In Proceedings Visualization, 2001. VIS’01., pages 29–538. IEEE, 2001.