设置标记提示释放了 GPT-4V 中非凡的视觉基础
摘要
我们提出了一种新的视觉提示方法Set-of-Mark (SoM),以释放大型多模态模型 (LMM)(例如 GPT-4V)的视觉基础能力。 如图1(右)所示,我们采用现成的交互式分割模型(例如 SAM)将图像划分为不同粒度级别的区域,并用一组标记例如字母数字、掩码、方框。 使用标记的图像作为输入,GPT-4V 可以回答需要视觉基础的问题。 我们进行了全面的实证研究,以验证 SoM 在各种细粒度视觉和多模态任务上的有效性。 例如,我们的实验表明,在零样本设置中,带有 SoM 的 GPT-4V 优于 RefCOCOg 上最先进的完全微调参考分割模型。

1简介
在过去的几年里,我们见证了大语言模型[2,3,10,44,60,35]的显着进步。 特别是,生成式预训练 Transformer 或 GPT [2, 35] 在业界和学术界取得了多项突破。 自 GPT-4 发布以来,大型多模态模型 (LMM) 引起了研究界越来越多的兴趣。 许多工作致力于基于开源模型构建多模态 GPT-4[28,63,57,12,48,51,20]。 近日,GPT-4V(ision)发布,以其出色的多模态感知和推理能力立即受到社区关注。 其优越性和通用性在[50]中得到了体现。 尽管 GPT-4V 具有前所未有的强大视觉语言理解能力,但其细粒度的视觉接地能力却相对较弱,或者说尚待释放。 例如,GPT-4V 很难生成图像中狗的精确坐标序列111https://blog.roboflow.com/gpt-4-vision/,或一些交通灯[54]。
我们的研究动机是解决 GPT-4V 在细粒度视觉任务(例如对象引用)上的失败案例。 原则上,这些任务要求模型对视觉内容具有丰富的语义理解和准确的空间理解。 然而,正如 所指出的,促使 GPT-4V 生成包含文本描述和数字坐标的标记序列不仅会损害大语言模型的自然流畅性,而且还会忽视 LMM 使用的视觉模型中的空间理解能力。 [7]。 因此,在本研究中,我们通过提出一种新的视觉提示方法来提高视觉输入,以释放 LMM 的视觉接地能力。 人们已经针对各种视觉和多模式任务探索了视觉提示[9,19,65,46,42]。 这些作品可以分为两类。 一种是将点、框、笔划等视觉提示编码为潜在特征,然后用于提示视觉模型[65, 19]。 另一种是将视觉标记直接叠加到输入图像上。 重叠的标记可以是红色圆圈[42]、突出显示的区域[49]或带有箭头的几个圆圈[50]。 尽管这些研究证明了像素级视觉提示的前景,但它们仅限于视觉上指代一个或几个对象。 而且,所有这些标记都不容易被大语言模型“说出”,从而阻碍了GPT-4V的接地能力。
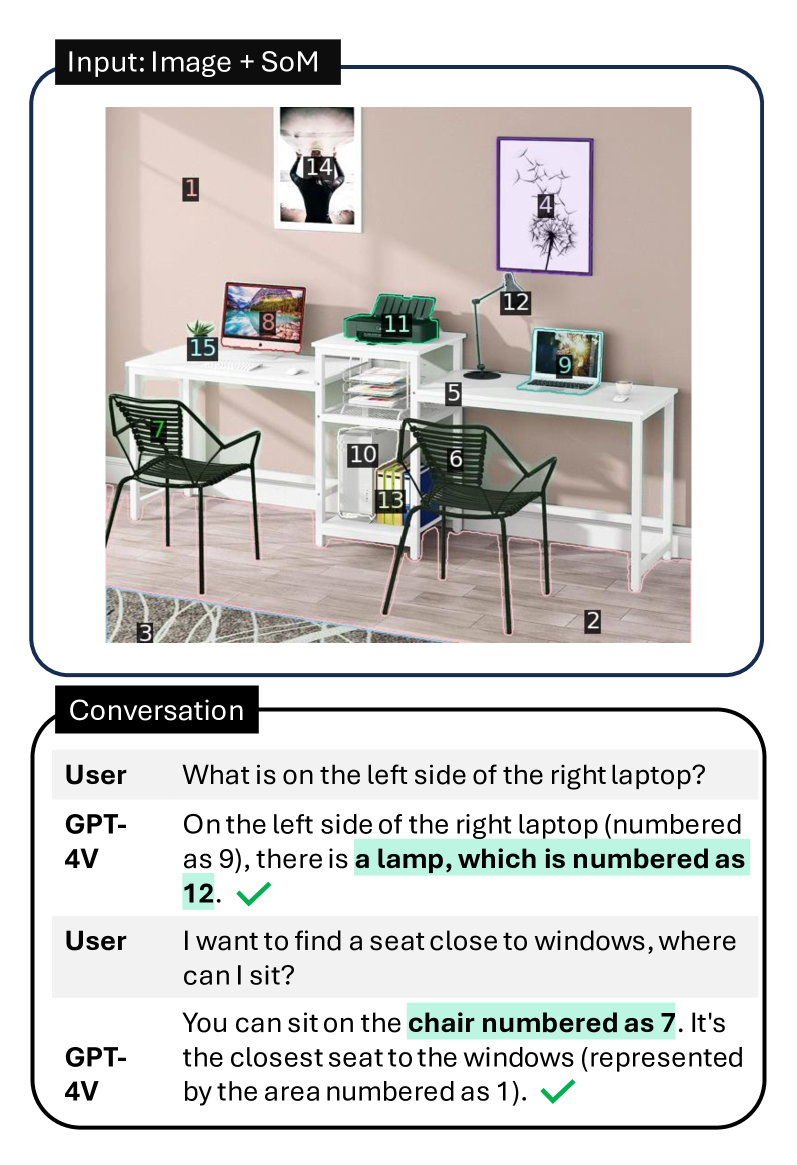
在本文中,我们提出了一种新的提示机制,称为标记集(SoM)提示,即简单地在图像区域顶部添加一组视觉标记。 我们首先将输入图像划分为一组语义上有意义的区域。 然后,我们在每个区域上覆盖各种格式的标记,例如数字、字母、掩码或框。 我们进行了一项实证研究,以验证 GPT-4V 是否可以在这些可解释和“可传播”的视觉标记的情况下更好地接地这些区域。 我们的实验表明,SoM 可以极大地释放 GPT-4V 的接地能力。 如图1所示,与标准提示相比,SoM帮助GPT-4V准确地将答案接地到相应区域,例如,正确的笔记本电脑是“9”,灯号为“12”。 同样,它也可以将左边的椅子与“7”相关联。 请注意,与 GPT-4V 的对话中没有泄漏有关标记的信息,这表明模型不仅可以理解视觉标记的语义,而且还知道如何以及何时将视觉内容与标记相关联。 据我们所知,这是第一项证明 GPT-4V 的紧急视觉接地能力可以通过视觉提示(SoM)释放的研究。 总而言之,我们的主要贡献是:
-
•
我们为 LMM 提出了一种简单而有效的视觉提示,Set-of-Mark (SoM),并根据经验表明 SoM 有效释放了 GPT-4V 的接地能力。
-
•
我们开发了一套新的评估基准来检查 GPT-4V 和其他 LMM 的接地能力。 对于数据集中的每个图像,我们采用现成的分割模型将图像分割为多个区域,并用视觉标记(例如数字)覆盖每个区域。
-
•
我们进行了定量和定性分析,以验证 SoM 在各种视觉任务上的有效性。 我们的实验表明,SoM 显着提高了 GPT-4V 在需要接地的复杂视觉任务上的性能。 例如,在零样本设置中,带有 SoM 的 GPT-4V 优于 RefCOCOg 上最先进的完全微调参考分割模型。
2 标记组提示
本节介绍标记集提示,并解释如何应用它来提示 LMM,特别是 GPT-4V。
2.1问题定义
通常,LMM 将图像 和长度为 、 的文本查询作为输入,并生成一系列长度为、的文本输出,公式为:
| (1) |
鉴于当前 LMM 中使用的大语言模型的多功能性,输入和输出文本可以由不同类型的字符(例如,字母和数字)组成,也可以是多语言的。 大量工作尝试改进输入文本的提示工程,以赋予大语言模型[47, 53]更多的推理能力。
与大语言模型的提示工程不同,本研究的目标是开发一种新的输入图像提示方法,以释放 LMM 的视觉基础能力。 换句话说,我们努力让 LMM 具备逐个位置查看的能力。 这需要提示策略的两个基本属性:
-
•
该方法应该能够将图像划分为一组语义上有意义的区域,以与文本输出对齐,这种能力称为接地。
-
•
投射到输入图像的辅助信息应该是 LMM 可解释和可说的,以便可以在其文本输出中对其进行描述。
考虑到这一点,我们开发了标记集提示,这是一种将多个标记叠加到图像中有意义的区域的简单提示方法。 该操作将输入图像增强为标记图像,同时保持LMM的其他输入不变,如图2所示。 从数学上来说,等式(1) 变为
| (2) |
尽管将 SoM 应用于所有 LMM 很简单,但我们发现并非所有 LMM 都有能力“说出”标记。 实际上,我们发现只有 GPT-4V 在配备 SoM 时表现出紧急接地能力,并且显着优于其他 LMM。 接下来,我们将解释如何将图像划分为区域并在 SoM 中标记图像区域。
2.2 图像分区
给定输入图像,我们需要提取有意义且语义对齐的区域。 理想情况下,提取应该是自动或半自动的,以避免给用户带来额外的负担。 为了实现这一目标,我们采用了一套图像分割工具。 为了支持不同的用例,细分工具需要具备以下属性:
-
•
性能强:区域划分应足够精确,以向 GPT-4V 传达细粒度的空间布局信息。 从这个意义上说,我们选择了最先进的图像分割模型之一MaskDINO [24]。
-
•
开放词汇表:分割模型应该是开放词汇表,以便它们可以识别预定义词汇表之外的对象。 因此,我们选择 SEEM [65] 等高级模型。
-
•
丰富的粒度:最后,感兴趣的区域可能不仅是一个完整的对象,而且可能是它的一部分。 因此,我们还采用了 SAM [19] 和 Semantic-SAM [21]。
我们收集了一套图像分割模型,为用户提供了一个全面的工具箱来分割任意图像。 大多数模型都是交互式和可推广的,用户可以交互式地定制SoM提示。
基于我们的图像分割工具包,我们将大小为 的输入图像 分割为 区域 ,这些区域由 二进制掩码表示。 我们在图 3 中展示了使用我们的工具箱生成的一些 SoM 示例。

2.3 标记集生成
一旦我们获得图像分区,我们需要为每个区域生成一个对于GPT-4V接地有用的标记。 我们考虑两个因素:标记的类型和位置。
标记类型。
正如我们之前讨论的,标记类型取决于它们是否可以被 GPT-4V 解释。 在这项工作中,我们考虑字母数字,因为它不仅足够紧凑,不会占用太多图像空间,而且可以被 GPT-4V 识别(使用其 OCR 功能)。 此外,我们还考虑盒子和掩模边界作为辅助标记。 此外,我们注意到标记类型应与图像相关,以避免与原始图像内容发生任何冲突。 例如,给定充满数字的算术图像,应避免使用数字标记,而文档的屏幕截图不应使用字母字符。 我们将自动确定要使用哪些标记类型以及如何将它们组合到未来的工作中。 图 4 显示了不同的标记类型和 GPT-4V 的解释输出。
标记位置。
给定大小为 的图像,我们需要为所有 区域找到良好的标记位置。 一种直接的方法是导出第 个掩模的中心坐标 ,并在那里覆盖标记。 然而,这不可避免地会引入一些重叠或冲突,可能会混淆 GPT-4V,特别是对于具有密集对象的图像,例如,以相似位置或凹区域为中心的两个对象,如图 5 所示。



为了缓解这个问题,我们提出了一种标记分配算法,如图5右侧的算法所示。 给定一组掩码 ,我们首先计算所有掩码的面积并按升序对它们进行排序(第 6 行)。 此策略确保在大区域之前考虑较小区域。 为了进一步避免潜在的重叠,对于第 个掩码,我们排除被任何 掩码覆盖的区域(第 8 行)。 然后将生成的掩模输入距离变换算法,这有助于找到掩模内到所有边界点的最小距离最大的位置。 然而,在实践中,区域可能很小以至于标记可以覆盖(几乎)整个区域。 在这种情况下,我们将标记稍微移离该区域。 我们发现 GPT-4V 仍然可以在标记和区域之间建立良好的关联。
一旦我们确定了所有区域的标记类型和位置,我们就将标记 覆盖到区域 的位置 处。 我们确保每个标记都是唯一的,以便整套可以被大语言模型区分和朗读。
2.4 交错提示
到目前为止,我们已经获得了带有重叠标记的新图像。 此外,我们还有一组 区域标记对 。 给定 中的附加提示,我们可以使用纯文本提示或交错提示来提示 LMM:
-
•
纯文本提示。 我们可以像往常一样使用纯文本提示,而无需明确引用图像中的标记/区域。 如图1所示,即使没有任何特殊的文字提示,GPT-4V也能在相应的区域和相应的标记处自动接地。 它可以用于用户没有特定兴趣区域的广泛场景。
-
•
交错文本提示。 我们可以通过将标记直接注入文本来使用交错标记。 由于这些标记对于 LMM 是可以解释的,因此我们可以将它们无缝地融合到原始文本提示中以进行符号引用。
图6展示了这两种基于SoM的文本提示的应用示例。 请注意,对于每个问题,我们都使用新的聊天窗口来避免对话期间的上下文泄漏。 在现实场景中,上述两种文本提示策略可以结合使用,并与 GPT-4V 进行多轮对话,显着丰富人机交互。 此外,用户还可以选择自己绘制标记或修改使用工具箱生成的标记。
3 SoM 提示视觉
我们强调,使用 SoM 提示 GPT-4V 的独特优点是它可以产生文本之外的输出。 由于每个标记都与掩码表示的图像区域专门关联,因此我们可以追溯到文本输出中任何提到的标记的掩码。 考虑图7中的示例,左侧的GPT-4V响应包含四个区域的名称和详细信息。 它可以诱导标记和文本描述之间的一对一映射,即即、。 鉴于,我们可以进一步将文本描述与所有区域的掩码相关联。 最后,我们可以桥接所有区域的三元组,即、。 生成配对文本和掩码的能力使 SoM 能够促使 GPT-4V 生成合理的视觉基础文本,更重要的是支持各种细粒度的视觉任务,这对普通的 GPT-4V 来说是一项挑战模型。
愿景任务。
我们定量地检查了 SoM 提示的 GPT-4V 的性能。 通过简单的提示工程,它可以很容易地用于但不限于广泛的视觉任务,例如
-
•
开放词汇图像分割:我们要求 GPT-4V 详尽地告诉所有标记区域的类别以及从预定池中选择的类别。
-
•
引用分割:给定一个引用表达式,GPT-4V 的任务是从我们的图像分区工具箱生成的候选区域中选择最匹配的区域。
-
•
短语基础:与指称分词略有不同,短语基础使用由多个名词短语组成的完整句子。 我们要求 GPT-4V 为所有标记的短语分配相应的区域。
-
•
视频对象分割:它以两个图像作为输入。 第一个图像是查询图像,其中包含第二个图像中需要识别的一些感兴趣的对象。 鉴于 GPT-4V 支持多个图像作为输入,我们的提示方法也可以应用于视频中跨帧的地面视觉对象。
我们在图 7 中展示了如何使用 SoM 提示 GPT-4V 来完成上述视觉任务。 值得注意的是,SoM 可以应用于更广泛的任务,如区域字幕、关键点定位和部件分割等。由于 GPT-4V 的访问权限(配额)有限,我们将重点放在上述视觉任务上,并将对其他任务的探索留待未来工作中进行。 我们将在下一节中介绍详细的实证研究。
4实验
4.1 实验设置
执行。
我们不需要为我们的方法训练任何模型。 然而,由于配额有限且缺乏 GPT-4V API,我们必须将 SoM 增强图像详尽地发送到 ChatGPT 接口。 这项工作的作者使用分而治之的策略来进行实验和评估。 对于每个实例,我们都使用一个新的聊天窗口,以便在评估过程中不会出现上下文泄漏。 从这个意义上说,我们方法的所有报告结果都是零样本。 除非另有说明,我们总是使用数字作为报告主要结果的标记。 我们的消融和定性研究显示了其他标记类型的使用。
基准。
鉴于 GPT-4V 的配额有限,目前不可能全面评估我们上面列出的每个单独视觉任务中的验证集。 因此,我们从每个数据集中选择一小部分验证数据用于我们的研究。 对于数据集中的每个图像,我们在使用图像分区工具箱提取的区域上叠加一组标记。 根据具体任务,我们利用不同的分区工具来建议区域。 在表 1 中,我们列出了每个任务的设置。
比较。
我们将我们的方法与:
-
•
GPT-4V基线预测坐标。 我们用它作为我们的基线模型。 默认情况下,GPT-4V 既不能预测框也不能生成掩模。 按照之前的实践,我们提示模型预测框坐标。 与默认的 GPT-4V 基线进行比较有助于检查我们提出的标记集提示的优点。
-
•
最先进的专业模型。 对于每个视觉任务,已经提出了多种方法。 我们选择最先进且有代表性的方法进行比较。 更具体地说,MaskDINO [24] 用于 COCO 上的通用分割,OpenSeeD [55] 用于 ADE20K 上的零样本分割,Grounding DINO [31] 和GLIPv2 [56] 用于 Flick30K 的短语基础,Grounding DINO 和 PolyFormer [29] 用于指代表达理解,PolyFormer 和 SEEM [65] 用于参考表达分割和 SegGPT [46] 用于视频对象分割。 我们试图阐明最强的通用视觉模型 GPT-4V 与经过精心设计和使用特定数据进行训练的专业模型之间的差距。
-
•
开源 LMM。 我们定量评估了最先进的开源 LMM 之一 LLaVa-1.5 [27],并与 MiniGPT-v2 [5] 进行定性比较我们的研究。 请注意,这两个模型都使用来自目标视觉任务的大量数据进行训练。 我们是第一个在视觉基准上比较封闭和开源 LMM 的人。
| Vision Task | Dataset | #Images | #Instances | Marks | Metric |
| Generic Segmentation | COCO [26] | 100 | 567 | Number & Mask | Precision |
| OV Segmentation | ADE20K [62] | 100 | 488 | Number & Mask | Precision |
| Phrase Grounding | Flickr30K [38] | 100 | 274 | Number & Box | Recall@1 |
| Referring Expression Segmentation | RefCOCO [18] | 100 | 177 | Number & Mask | mIoU |
| Referring Expression Comprehension | RefCOCO [18] | 100 | 177 | Number & Mask | ACC@0.5 |
| Video Object Segmentation | DAVIS [37] | 71 | 157 | Number & Mask | J&F |
4.2定量结果
我们在表2中展示了实验结果。
| Model | LMM | Zero-shot | OV Segmentation | RefCOCOg | Phrase Grounding | VOS | ||
| COCO | ADE20K | REC | RES | Flickr30K | DAVIS2017 | |||
| MaskDINO [23] | ✗ | ✗ | 80.7 | - | n/a | n/a | n/a | n/a |
| OpenSeeD [55] | ✗ | ✓ | - | 23.4 | n/a | n/a | n/a | n/a |
| GLIPv2 [56] | ✗ | ✗ | - | - | - | - | n/a | |
| GDINO [31] | ✗ | ✗ | n/a | n/a | n/a | 90.5 | n/a | |
| X-Decoder [64] | ✗ | ✗ | - | - | - | n/a | 62.8 | |
| PolyFormer [29] | ✗ | ✗ | n/a | n/a | 67.2 | n/a | n/a | |
| SegGPT [46] | ✗ | ✓ | n/a | n/a | n/a | n/a | n/a | 75.6 |
| SEEM [65] | ✗ | ✗ | - | - | - | - | 62.8 | |
| RedCircle [42] | ✓ | ✓ | n/a | n/a | n/a | n/a | n/a | |
| FGVP [49] | ✓ | ✓ | n/a | n/a | n/a | n/a | n/a | |
| Shikra [6] | ✓ | ✗ | n/a | n/a | n/a | 77.4 | n/a | |
| LLaVA-1.5 [27] | ✓ | ✗ | n/a | n/a | 63.3 | n/a | n/a | n/a |
| MiniGPT-v2 [5] | ✓ | ✗ | n/a | n/a | n/a | n/a | n/a | |
| Ferret [54] | ✓ | ✗ | n/a | n/a | * | n/a | 81.1 | n/a |
| GPT-4V [36] | ✓ | ✓ | n/a | n/a | 25.7 | n/a | n/a | n/a |
| GPT-4V [36] + SoM (Ours) | ✓ | ✓ | 75.7 | 63.4 | 86.4 | 75.6 | 89.2 | 78.8 |
图像分割
在图像分割任务上,我们评估了GPT-4V + SoM的分类精度,并将其与COCO Panoptic分割数据集上的强分割模型MaskDINO和ADE20K Panoptic分割数据集上的OpenSeeD进行了比较。 对于 MaskDINO 和 OpenSeeD,我们给它们 GT 框并评估输出类。 对于 GPT-4V + SoM,我们分别为 COCO 和 OpenSeeD 叠加 alpha=0.4 和 0.2 的 GT 掩模,并在每个掩模上添加 ID 号。 我们向 GPT-4V 提供数据集的词汇表,并要求它为每个区域选择一个类标签。 结果表明,GPT-4V + SoM 的零样本性能接近微调后的 MaskDINO 的性能,并且远高于 OpenSeeD 在 ADE20K 上的零样本性能。 GPT-4V 在 COCO 和 ADE20K 上的相似性能表明其对广泛的视觉和语义领域的强大泛化能力。
参考
对于参考任务,我们在 RefCOCOg 上评估 RES 和 REC。 我们使用 MaskDINO 提出掩模并将掩模和数字叠加在图像上。 我们使用 mIoU 作为评估指标,并将其与最先进的专家 PolyFormer [29] 和 SEEM [65] 进行比较。 因此,GPT-4V + SoM 的性能大幅优于 PolyFormer。 请注意,PolyFormer 的性能是在我们的数据集上评估的,以进行苹果之间的比较。 对于 REC,我们将掩码转换为我们方法的框。 当提示 GPT-4V 直接输出坐标时,我们的性能明显较差(25.7),这验证了我们之前的假设。 一旦使用 SoM 进行增强,GPT-4V 就击败了 Grounding DINO 和 Polyformer 等专家以及最近的开源 LMM(包括 Shikra、LLaVA-1.5、MiniGPT-v2 和 Ferret)。
短语基础
对于 Flickr30K 上的短语基础,我们使用 Grounding DINO 为每个图像生成框建议。 我们使用阈值 0.27 过滤冗余框,然后使用 SAM 预测每个框的掩码。 我们在图像上绘制方框、蒙版和数字。 我们为 GPT-4V 提供每个图像的标题和标题的名词短语,并让 GPT-4V 将每个名词短语定位到一个区域。 我们的零样本性能可与 SOTA 模型 GLIPv2 和 Grounding DINO 相媲美。
视频对象分割
我们评估 DAVIS2017 [39] 的视频分割任务。 为了获取每个视频帧的掩码建议,我们使用 MaskDINO [24]。 然后,预测的掩模将覆盖在我们的 SoM 后面带有数字标签的相应帧上。 我们遵循半监督设置,使用第一帧掩码作为参考,并对同一视频的所有其他帧进行分段。 由于GPT-4V可以接收多幅图像,因此我们提示GPT-4V使用第一帧和当前帧通过比较图像之间的相似对象来进行分割。 如表2最后一列所示,与其他通用视觉模型相比,GPT-4V 实现了最佳跟踪性能(78.8 J&F)。
4.3消融研究
标记类型。
我们研究标记类型的选择如何影响 Flickr30k 上短语基础任务的最终性能。 我们比较两种类型的标记。 第一个是数字和掩码,第二个是数字、掩码和盒子。 如表4所示,添加额外box的方案可以显着提高性能。
黄金标记位置。
从我们的工具箱中提取的区域通常可能会出现一些错误。 在本研究中,我们研究了当我们生成带有真实注释的标记时 GPT-4V 的行为方式。 具体来说,我们在 RefCOCOg 验证集中用真实的分割掩模替换了预测的分割掩模。 这意味着 GPT-4V 只需要从区域中选择一个用于注释短语。 正如预期的那样,参考分割的性能可以进一步提高,特别是当分割模型有一些遗漏区域时。 结果如表 4 所示,其中显示在我们的 SoM 中使用地面真值掩模将 RefCOCOg 性能提高了 mIoU。 我们还观察到,使用 GT 掩模时的大多数失败案例不是 GPT-4V 的问题,而是标注本身不明确或不正确。
4.4定性观察
在完成这项工作时,我们观察到了一些有趣的定性发现。

“黄金”注释并不总是黄金。
在评估 SoM 时,我们发现数据集中的一些人工注释是不正确的。 一些例子如图8(a,b,c)所示。 例如,人类用户注释了几个人,而引用表达式是“坐在沙发上的人的腿”,或者仅注释了一辆卡车以引用“卡车比赛”。 相比之下,带有 SoM 的 GPT-4V 会产生正确的答案。 这意味着视觉数据集中的“黄金”标签可能会受到一些噪音的影响,而 GPT-4V 可能是一个很好的判断,可以帮助找到不明确的注释以进一步清理。
居中标记并不总是最好的。
标记类型的动态选择。
在现实场景中,我们发现动态确定使用哪种类型的标记很重要。 例如,算术问题的图像通常包含许多数字。 在这种情况下,在 上叠加数字标记将会迷惑 GPT-4V。 同样,对于文档的屏幕截图,在图像上覆盖更多字母可能是不合理的。 因此,为了充分利用 GPT-4V 的视觉功能,用户可能需要在发送图像之前仔细设计 SoM 提示。
5相关工作
我们从提示的角度来讨论相关工作。
大语言模型与提示。
我们见证了大语言模型[2,3,10,44,60,35]的重大进展。 特别是生成式预训练 Transformer,通常称为 GPT [2, 35],它在自然语言处理领域带来了突破。 尽管大语言模型的规模在急剧扩大,但要激发推理能力,仍需要设计更复杂的查询、即、提示。 过去,许多工作试图通过快速工程化来赋予大语言模型更多的能力。 情境学习是教授大语言模型遵循特定指令的主流方式,如几个例子所示[2, 15]作为后续,一些其他技术,例如链式学习提出思想和思想树[47, 53]来增强算术、常识和符号推理任务。 与这些工作类似,我们的标记集提示可以被视为提示模型逐位置查看图像区域的一种方式。 然而,它的不同之处在于我们的方法不需要上下文中的示例。
视觉和多模式提示。
在早期的交互式图像分割[34,8,9]工作中,使用了空间提示,以便模型可以逐渐接受多个用户输入(例如,点击)完善面具。 最近,开创性工作SAM [19]及其变体[43, 11]提出了一个统一的模型来支持包括点、框和文本在内的不同类型的提示模式。 在 SEEM [65] 中,作者提出了一种新颖的视觉采样器,以扩展到跨图像的视觉提示。 同样,PerSAM [58] 和 SAM-PT [41] 微调 SAM 以支持个性化分割和点跟踪。 另一行工作直接在输入图像上生成提示。 在[1]中,图像修复被用作提示来教导模型在给定示例图像和相应输出的情况下预测密集输出(均在像素空间中)。 Painter [45] 和 SegGPT [46] 在使用蒙版图像建模来解码连续空间中的像素时有着相似的精神。 视觉提示也可以应用于多模式模型,例如 CLIP [40]。 RedCircle [42] 在图像上绘制红色圆圈,将视觉模型聚焦在封闭区域上。 在[49]中,作者通过专门分割和突出显示图像中的目标对象来增强提示。 然后,这两种方法都要求 CLIP 模型来测量提示图像和许多文本概念之间的相似度。
LMM 和提示。
在很短的时间内,大型多模态模型(LMM)已成为社区中的新研究方向。 目标是建立一个通用的多模态系统,其行为类似于大语言模型,可以使用多模态输入进行感知和推理 [28, 63, 57, 12, 59, 48, 51, 6, 20, 5, 54]. 早期的工作如 MiniGPT-4 [5] 和 LLaVa [28] 提出了一种简单而有效的方法来连接视觉和大语言模型,然后进行指令调整。 随后,类似的训练策略被应用于视频任务[33, 4]和细粒度视觉任务[6,59,20,5,54]。 请参阅[20]以获取对 LMM 的更全面的回顾。 到目前为止,学术界很少对提示 LMM 进行探索,部分原因是最近大多数开源模型的能力有限,因此无法实现这种新兴能力[47]。 最近,GPT-4V [36] 发布,随后对其进行了全面的定性研究[50]。 [50] 中的作者使用了与 RedCircle [42] 中类似的提示策略来提示 GPT-4V。 然而,它只是通过手绘圆圈或箭头展示了GPT-4V的一些参考能力,更谈不上全面的定量研究。
6讨论
GPT-4V之谜。
为什么所提议的Set-of-Mark Prompting能够与 GPT-4V 配合得如此良好仍然是个谜。 出于好奇,我们还在其他开源 LMM 上运行了一些示例,例如 LLaVa-1.5 和 MiniGPT-v2。 然而,这两种模型都很难解释这些标记并以这些标记为基础。 我们假设 GPT-4V 表现出非凡视觉接地能力的几个原因。 首先,规模很重要。 我们相信 GPT-4V 中使用的模型和训练数据的规模比上述开源 LMM 好几个数量级。 其次,数据管理策略可能是 GPT-4V 的另一个秘密武器。 GPT-4V可以自动关联图像区域和标记,而无需文本中的任何明确提示。 此类数据可能来自文献数据、图表等等,这些数据通常有明确的标签或标记[1]。 我们怀疑 GPT-4V 是否专门采用了本工作中涵盖的细粒度视觉数据。 请注意,数量极其有限,注释更多此类数据的成本很高,更不用说质量难以控制。 最后,我们注意到,上述所有怀疑都不是基于事实,而是基于我们上面进行的一些实证研究。
连接视觉与大语言模型提示。
尽管 GPT-4V 背后的未知数。 我们的工作确实迈出了连接视觉提示和大语言模型提示的第一步。 过去很多工作都研究了如何让视觉模型更加具有提示性,这些都是脱离了大语言模型的文本提示。 障碍主要是由于语言瓶颈,我们很难用语言准确地表达视觉提示。 例如,图像上随机绘制的笔画的形状/位置/颜色很难用语言描述,除非我们可以对视觉提示进行编码并微调整个模型[54]。 然而,由于细粒度的训练数据有限,开源的大视觉和语言模型较差。 我们仍然看到明显的差距。 在现阶段,我们提出的Set-of-Mark Prompting展示了一种简单但唯一可行的方法,可以继承最强LMM的所有现有功能,同时释放其强烈渴望的接地能力。 我们希望这项工作作为第一个无缝连接视觉和语言提示的工作,可以帮助为更强大的 LMM 铺平道路。
使用 GPT-4V 通过 Set-of-Mark Prompting 缩放数据。
过去,整个社区一直致力于构建细粒度、开放词汇的视觉系统,从检测[17,61,25,56,52,31]到分割[ 16, 64, 14],并进一步扩展到 3D [32, 13, 30]。 尽管取得了巨大进步,但我们一直在努力解决如何将 CLIP 中丰富的语义知识映射到细粒度领域的问题。 这主要是由于细粒度语义标注的数量极其有限,这对当前的 LMM 仍然是一个相当大的挑战。 正如我们已经看到的,细粒度空间缩放数据的可行性已经在 SAM [19] 和 Semantic-SAM [22] 中得到了证明,但是如何进一步注释这些带有语义标签的区域仍然是一个悬而未决的问题。 根据这项工作的研究,我们设想使用 GPT-4V 加上我们的标记集提示来集中扩展具有细粒度空间和详细的语言描述。
7结论
我们提出了Set-of-Mark Prompting,这是一种针对 LMM(尤其是 GPT-4V)的简单而有效的视觉提示机制。 我们证明,简单地将多个符号标记叠加在输入图像的一组区域上就可以释放 GPT-4V 的视觉基础能力。 我们对各种细粒度视觉任务进行了全面的实证研究,以证明 SoM 提示的 GPT-4V 优于完全微调的专业模型和其他开源 LMM。 此外,我们的定性结果表明,具有 SoM 的 GPT-4V 全面拥有非凡的细粒度多模态感知、认知和推理能力。 我们希望 SoM 能够激发 LMM 多模式提示的未来工作,并为多模式 AGI 铺平道路。
致谢
我们感谢朱方锐的深思熟虑的讨论。
参考
- [1] Amir Bar, Yossi Gandelsman, Trevor Darrell, Amir Globerson, and Alexei Efros. Visual prompting via image inpainting. Advances in Neural Information Processing Systems, 35:25005–25017, 2022.
- [2] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners, 2020.
- [3] Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
- [4] Guo Chen, Yin-Dong Zheng, Jiahao Wang, Jilan Xu, Yifei Huang, Junting Pan, Yi Wang, Yali Wang, Yu Qiao, Tong Lu, and Limin Wang. Videollm: Modeling video sequence with large language models, 2023.
- [5] Jun Chen, Deyao Zhu, Xiaoqian Shen, Xiang Li, Zechu Liu, Pengchuan Zhang, Raghuraman Krishnamoorthi, Vikas Chandra, Yunyang Xiong, and Mohamed Elhoseiny. Minigpt-v2: Large language model as a unified interface for vision-language multi-task learning. github, 2023.
- [6] Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multimodal llm’s referential dialogue magic, 2023.
- [7] Ting Chen, Saurabh Saxena, Lala Li, David J. Fleet, and Geoffrey Hinton. Pix2seq: A language modeling framework for object detection, 2022.
- [8] Xi Chen, Zhiyan Zhao, Feiwu Yu, Yilei Zhang, and Manni Duan. Conditional diffusion for interactive segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7345–7354, 2021.
- [9] Xi Chen, Zhiyan Zhao, Yilei Zhang, Manni Duan, Donglian Qi, and Hengshuang Zhao. Focalclick: Towards practical interactive image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1300–1309, 2022.
- [10] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- [11] Haixing Dai, Chong Ma, Zhengliang Liu, Yiwei Li, Peng Shu, Xiaozheng Wei, Lin Zhao, Zihao Wu, Dajiang Zhu, Wei Liu, et al. Samaug: Point prompt augmentation for segment anything model. arXiv preprint arXiv:2307.01187, 2023.
- [12] Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning, 2023.
- [13] Runyu Ding, Jihan Yang, Chuhui Xue, Wenqing Zhang, Song Bai, and Xiaojuan Qi. Pla: Language-driven open-vocabulary 3d scene understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7010–7019, 2023.
- [14] Zheng Ding, Jieke Wang, and Zhuowen Tu. Open-vocabulary panoptic segmentation with maskclip. arXiv preprint arXiv:2208.08984, 2022.
- [15] Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, and Zhifang Sui. A survey for in-context learning. arXiv preprint arXiv:2301.00234, 2022.
- [16] Golnaz Ghiasi, Xiuye Gu, Yin Cui, and Tsung-Yi Lin. Scaling open-vocabulary image segmentation with image-level labels. In European Conference on Computer Vision, pages 540–557. Springer, 2022.
- [17] Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, and Yin Cui. Open-vocabulary object detection via vision and language knowledge distillation. arXiv preprint arXiv:2104.13921, 2021.
- [18] Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. Referitgame: Referring to objects in photographs of natural scenes. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 787–798, 2014.
- [19] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. Segment anything, 2023.
- [20] Chunyuan Li, Zhe Gan, Zhengyuan Yang, Jianwei Yang, Linjie Li, Lijuan Wang, and Jianfeng Gao. Multimodal foundation models: From specialists to general-purpose assistants. arXiv preprint arXiv:2309.10020, 2023.
- [21] Feng Li, Hao Zhang, Peize Sun, Xueyan Zou, Shilong Liu, Jianwei Yang, Chunyuan Li, Lei Zhang, and Jianfeng Gao. Semantic-sam: Segment and recognize anything at any granularity, 2023.
- [22] Feng Li, Hao Zhang, Peize Sun, Xueyan Zou, Shilong Liu, Jianwei Yang, Chunyuan Li, Lei Zhang, and Jianfeng Gao. Semantic-sam: Segment and recognize anything at any granularity. arXiv preprint arXiv:2307.04767, 2023.
- [23] Feng Li, Hao Zhang, Huaizhe xu, Shilong Liu, Lei Zhang, Lionel M. Ni, and Heung-Yeung Shum. Mask dino: Towards a unified transformer-based framework for object detection and segmentation, 2022.
- [24] Feng Li, Hao Zhang, Huaizhe Xu, Shilong Liu, Lei Zhang, Lionel M Ni, and Heung-Yeung Shum. Mask dino: Towards a unified transformer-based framework for object detection and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3041–3050, 2023.
- [25] Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. Grounded language-image pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10965–10975, 2022.
- [26] Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft coco: Common objects in context, 2015.
- [27] Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning, 2023.
- [28] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023.
- [29] Jiang Liu, Hui Ding, Zhaowei Cai, Yuting Zhang, Ravi Kumar Satzoda, Vijay Mahadevan, and R. Manmatha. Polyformer: Referring image segmentation as sequential polygon generation, 2023.
- [30] Kunhao Liu, Fangneng Zhan, Jiahui Zhang, Muyu Xu, Yingchen Yu, Abdulmotaleb El Saddik, Christian Theobalt, Eric Xing, and Shijian Lu. 3d open-vocabulary segmentation with foundation models. arXiv preprint arXiv:2305.14093, 2023.
- [31] Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding dino: Marrying dino with grounded pre-training for open-set object detection, 2023.
- [32] Yuheng Lu, Chenfeng Xu, Xiaobao Wei, Xiaodong Xie, Masayoshi Tomizuka, Kurt Keutzer, and Shanghang Zhang. Open-vocabulary 3d detection via image-level class and debiased cross-modal contrastive learning. arXiv preprint arXiv:2207.01987, 2022.
- [33] Chenyang Lyu, Minghao Wu, Longyue Wang, Xinting Huang, Bingshuai Liu, Zefeng Du, Shuming Shi, and Zhaopeng Tu. Macaw-llm: Multi-modal language modeling with image, audio, video, and text integration, 2023.
- [34] Kevin McGuinness and Noel E O’connor. A comparative evaluation of interactive segmentation algorithms. Pattern Recognition, 43(2):434–444, 2010.
- [35] OpenAI. Gpt-4 technical report, 2023.
- [36] OpenAI. Gpt-4v(ision) system card, 2023.
- [37] Federico Perazzi, Jordi Pont-Tuset, Brian McWilliams, Luc Van Gool, Markus Gross, and Alexander Sorkine-Hornung. A benchmark dataset and evaluation methodology for video object segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 724–732, 2016.
- [38] Bryan A. Plummer, Liwei Wang, Chris M. Cervantes, Juan C. Caicedo, Julia Hockenmaier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models, 2016.
- [39] Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Arbeláez, Alex Sorkine-Hornung, and Luc Van Gool. The 2017 davis challenge on video object segmentation. arXiv preprint arXiv:1704.00675, 2017.
- [40] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021.
- [41] Frano Rajič, Lei Ke, Yu-Wing Tai, Chi-Keung Tang, Martin Danelljan, and Fisher Yu. Segment anything meets point tracking. arXiv preprint arXiv:2307.01197, 2023.
- [42] Aleksandar Shtedritski, Christian Rupprecht, and Andrea Vedaldi. What does clip know about a red circle? visual prompt engineering for vlms, 2023.
- [43] Lv Tang, Haoke Xiao, and Bo Li. Can sam segment anything? when sam meets camouflaged object detection. arXiv preprint arXiv:2304.04709, 2023.
- [44] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- [45] Xinlong Wang, Wen Wang, Yue Cao, Chunhua Shen, and Tiejun Huang. Images speak in images: A generalist painter for in-context visual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6830–6839, 2023.
- [46] Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, and Tiejun Huang. Seggpt: Segmenting everything in context, 2023.
- [47] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837, 2022.
- [48] Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, and Nan Duan. Visual chatgpt: Talking, drawing and editing with visual foundation models. arXiv preprint arXiv:2303.04671, 2023.
- [49] Lingfeng Yang, Yueze Wang, Xiang Li, Xinlong Wang, and Jian Yang. Fine-grained visual prompting, 2023.
- [50] Zhengyuan Yang, Linjie Li, Kevin Lin, Jianfeng Wang, Chung-Ching Lin, Zicheng Liu, and Lijuan Wang. The dawn of lmms: Preliminary explorations with gpt-4v(ision), 2023.
- [51] Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. Mm-react: Prompting chatgpt for multimodal reasoning and action. arXiv preprint arXiv:2303.11381, 2023.
- [52] Lewei Yao, Jianhua Han, Youpeng Wen, Xiaodan Liang, Dan Xu, Wei Zhang, Zhenguo Li, Chunjing Xu, and Hang Xu. Detclip: Dictionary-enriched visual-concept paralleled pre-training for open-world detection. Advances in Neural Information Processing Systems, 35:9125–9138, 2022.
- [53] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. arXiv preprint arXiv:2305.10601, 2023.
- [54] Haoxuan You, Haotian Zhang, Zhe Gan, Xianzhi Du, Bowen Zhang, Zirui Wang, Liangliang Cao, Shih-Fu Chang, and Yinfei Yang. Ferret: Refer and ground anything anywhere at any granularity, 2023.
- [55] Hao Zhang, Feng Li, Xueyan Zou, Shilong Liu, Chunyuan Li, Jianfeng Gao, Jianwei Yang, and Lei Zhang. A simple framework for open-vocabulary segmentation and detection, 2023.
- [56] Haotian Zhang, Pengchuan Zhang, Xiaowei Hu, Yen-Chun Chen, Liunian Harold Li, Xiyang Dai, Lijuan Wang, Lu Yuan, Jenq-Neng Hwang, and Jianfeng Gao. Glipv2: Unifying localization and vision-language understanding, 2022.
- [57] Renrui Zhang, Jiaming Han, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, Peng Gao, and Yu Qiao. Llama-adapter: Efficient fine-tuning of language models with zero-init attention. arXiv preprint arXiv:2303.16199, 2023.
- [58] Renrui Zhang, Zhengkai Jiang, Ziyu Guo, Shilin Yan, Junting Pan, Hao Dong, Peng Gao, and Hongsheng Li. Personalize segment anything model with one shot. arXiv preprint arXiv:2305.03048, 2023.
- [59] Shilong Zhang, Peize Sun, Shoufa Chen, Min Xiao, Wenqi Shao, Wenwei Zhang, Yu Liu, Kai Chen, and Ping Luo. Gpt4roi: Instruction tuning large language model on region-of-interest, 2023.
- [60] Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
- [61] Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chunyuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, et al. Regionclip: Region-based language-image pretraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16793–16803, 2022.
- [62] Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017.
- [63] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023.
- [64] Xueyan Zou, Zi-Yi Dou, Jianwei Yang, Zhe Gan, Linjie Li, Chunyuan Li, Xiyang Dai, Harkirat Behl, Jianfeng Wang, Lu Yuan, Nanyun Peng, Lijuan Wang, Yong Jae Lee, and Jianfeng Gao. Generalized decoding for pixel, image, and language, 2022.
- [65] Xueyan Zou, Jianwei Yang, Hao Zhang, Feng Li, Linjie Li, Jianfeng Gao, and Yong Jae Lee. Segment everything everywhere all at once. arXiv preprint arXiv:2304.06718, 2023.
附录 A用例
将 GPT-4V 与建议的 SoM 提示相结合,我们运行了许多实际用例,以检查其与原始 GPT-4V 相比的通用性和优点。