张量程序六:
无限深度神经网络中的特征学习
摘要
通过对无限宽度神经网络进行分类并确定最佳限制,[23, 25]展示了一种通用方法,称为P,用于宽度方向超参数转移,即从窄神经网络预测宽神经网络的最佳超参数。 在这里,我们研究深度残差网络(resnet)的深度参数化的类似分类。 我们根据块乘法器和学习率的无限宽度和深度限制对深度参数化进行分类。 在每个块只有一层的 resnet 中,我们确定了一种独特的最佳参数化,称为 Depth-P,它扩展了 P,并根据经验表明它允许深度超参数传输。 我们认为特征多样性是深度网络中的关键因素,而Depth-P可以被描述为最大化特征学习和特征多样性。 利用这一点,我们发现在所有同质非线性中,绝对值可以最大化特征多样性,并且实际上根据经验可以带来更好的性能。 然而,如果每个块更深(例如现代 Transformer ),那么我们会发现此类参数化的所有可能的无限深度限制的基本限制,我们在简单网络以及在 Common Crawl 上训练的威震天 Transformer 上从理论上和经验上说明了这一点。
1简介
深度神经网络在广泛的任务中展示了卓越的性能,包括图像分类、以 AlphaGo 为代表的游戏[17],以及以 GPT-4 为代表的自然语言处理[15]. 开发这些网络的普遍趋势是增加其规模和复杂性,经验证据表明,使用相同的计算资源,具有更多参数的模型往往会表现出更好的性能。 有两种方法可以增加网络大小:宽度和深度。 宽度的属性(给定固定深度)已在文献中得到广泛研究:Yang 等人[25]最近的工作确定了最大更新参数化(P) 保证了无限宽度限制下的最大特征学习。111这里的最大特征学习指的是在无限宽度限制下特征的变化。 这应该与惰性训练体系形成对比,其中特征的变化是。 P 的另一个好处是超参数传输,可以在较小的模型上进行超参数调整;较小模型的最佳超参数选择对于较大模型(即宽度较大的模型)仍然是最佳的。 然而,尽管大规模深度模型取得了成就,并且对缩放宽度有了理论上的理解,但增加神经网络的深度仍然存在实际局限性和理论困难。 在实践中,增加深度超过一定水平通常会导致性能下降和/或最佳超参数的显着变化。 理论上,与增加宽度不同,增加深度会引入新的参数,从而显着改变训练动态。 在本文中,我们的目标是通过扩展 P 以包含深度缩放来解决这个问题。 我们将深度缩放称为Depth-P。
随着时间的推移,深度缩放问题一直持续存在。 十年前,深度神经网络经历了严重的退化问题——超过几十层会增加训练误差,而不是提高模型的性能。 这部分是由于梯度消失或爆炸问题影响了信息通过网络的有效传播。 残差网络(ResNet)[8,9,18]的引入部分解决了这个问题,允许训练更深层的网络并提高性能。 ResNet 通过分层 剩余块来构建,剩余块由一系列卷积层组成,然后与输入进行逐元素相加。 这种逐元素添加(通常称为跳过连接)是 ResNet 的一项重大创新,并且仍然是包括 Transformers [19] 在内的现代架构的重要组成部分。
具体来说,在残差架构中,第个残差块被公式化为
其中 是输入, 是输出, 是块的参数,(通常称为 residualbranch)是定义层的映射(例如 ResNet 中的卷积堆栈,或 Transformer 中的 SelfAttention 和 MLP)。 在这项工作中,我们重点关注 是具有(或不具有)激活的无偏感知器的情况。
| Branch Multiplier | Learning Rate | |
| Standard | 1 | ? (tuned) |
| Depth-P (SGD) | ||
| Depth-P (Adam) |
即使在初始化时,许多残差块的堆叠也会导致明显的问题 - 的范数随着 的增长而增长,因此最后一层特征在增加深度时没有稳定的范数。 直观上,我们可以通过使用与深度相关的常数来缩放残余分支来稳定这些特征。 然而,用任意小的常数缩放残余分支可能会导致在大深度限制下无法学习特征,因为梯度也会与缩放因子相乘。
当每个块 只有一层(一个矩阵乘法)时,我们将称为 Depth-P 的参数化确定为深度网络的最佳参数化。 它最大限度地提高了特征学习和特征多样性222我们在本文后面给出了特征学习和特征多样性的正式定义。 在块乘数和深度学习率的所有可能参数化中。 我们的框架扩展了之前在 P 上的结果,处理最佳宽度缩放[25]。 它完成了宽度缩放,因此提供了完整的宽度和深度缩放配方,保证了跨宽度和深度的最大特征学习和超参数传输。 Depth-P 包含对标准实践的以下修改:
-
1.
每个残差分支在添加到其输入之前都有一个乘数,该乘数与 的平方根成反比(其中 是深度)。 形式上,使用独立于 的常量 ,
(1) -
2.
我们设置的学习率,使得训练期间的更新与成正比。 我们基于这个原理针对不同的优化算法推导出不同的学习率方案。 对于 Adam 来说,由于其对梯度具有尺度不变性,因此 的学习率设置为 。 另一方面,SGD 的学习率被设置为常数,因为的梯度已经是 由于乘数。
在块深度 中(即 是无偏差感知器, 是单个矩阵),这种缩放导致以下属性:
-
•
在初始化时,每个残差块将贡献给主分支。 这些贡献是相互独立的,因此它们的总和大小为。
-
•
在训练过程中,由于学习率和乘数的共同作用,每个残差块的更新贡献为。 更新的贡献是高度相关的,因此它们的总和为。
这种缩放方法的更详细直观可以在部分3中找到,其中我们在一个梯度步骤之后提供了线性网络的简单分析。 我们在部分7中给出了深度参数化的完整分类。
1.1 深度最优性-P。
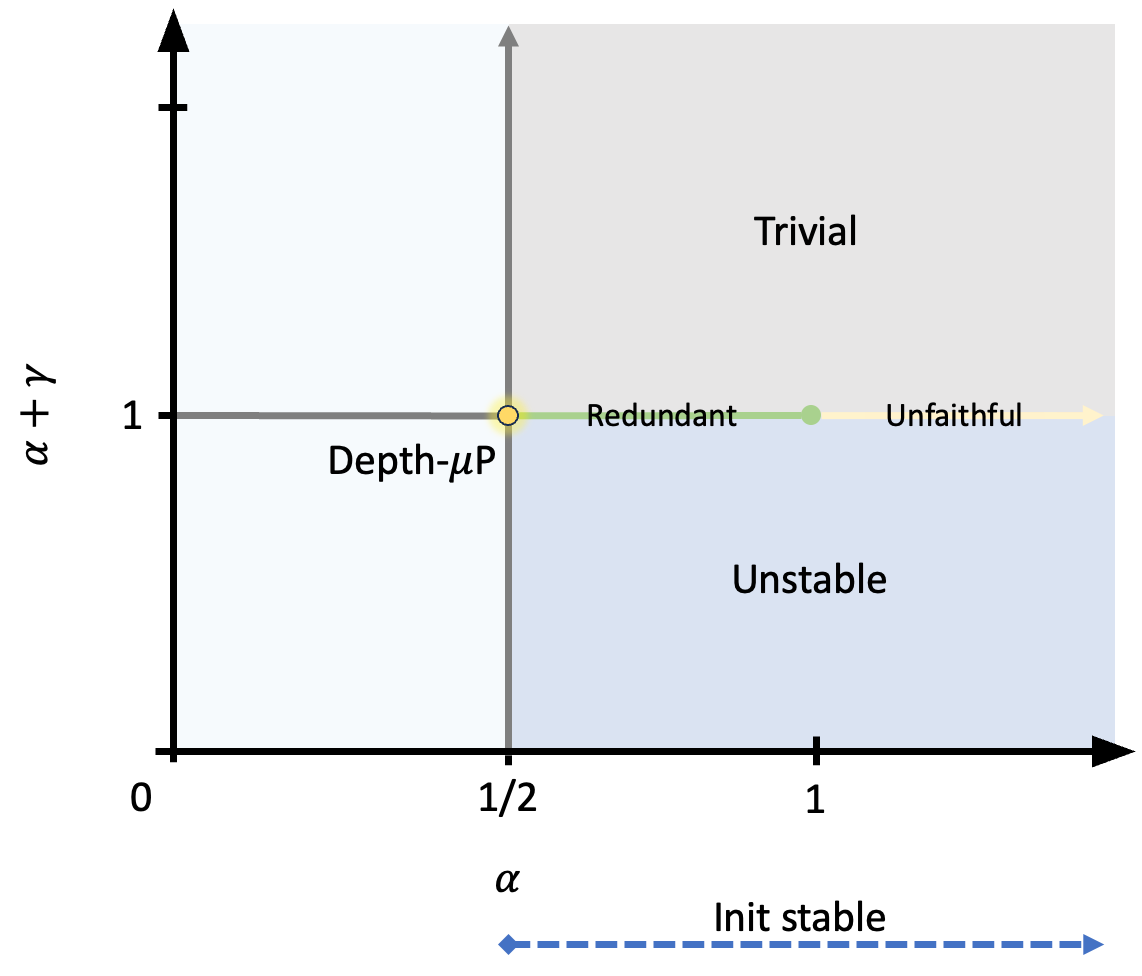
我们将 Depth-P 与其他具有分支乘数 和参数更新 的缩放策略进行了彻底比较。333这意味着如果网络稳定,Adam 的有效学习率与 成正比,SGD 的有效学习率与 成正比在初始化时。 如图图1所示,的空间被分为几个区域,每个区域在当:
-
•
初始化时需要使用 来稳定网络。 这确保了隐藏的激活和网络输出在初始化时不会爆炸;
-
•
对于任意,训练时网络不稳定。 训练期间隐藏激活或网络输出的变化随着深度的增加而爆炸;
-
•
对于任何,训练结果都是微不足道的。 随着深度的增加,网络的变化消失;
-
•
对于任何具有 的 ,网络都是不忠实的(本文稍后将提供正式定义)。 随着深度的增加,隐藏的激活在训练过程中会爆炸;
-
•
对于任何和,我们表明网络收敛到缺乏特征多样性的冗余限制,在这种情况下层具有相似的输出(以神经常微分方程的方式)。
-
•
和剩下的唯一选择是,它对应于Depth-P。
严格的定义和证明在部分7中给出。
1.2 深度超参数传递。
Depth-P 的最优性意味着(在某些假设下)网络的最优超参数也会随着深度 () 的增加而收敛。 这种收敛表明较浅网络的最佳超参数大约等于较深层网络的最佳超参数。 直接的含义是,我们可以利用这个属性从较浅的网络推断出较深层网络的超参数,从而有效地降低与超参数调整相关的成本。 通过 Depth-P,我们成功训练了包含数千个残差块的网络,同时还展示了超参数跨深度的可传递性。
1.3 块深度的不可能性结果
虽然块深度 1 的情况承认积极的结果,但我们表明块深度 的情况没有也不能(section 9)。 基本问题是,如果想保留多样性,当深度很大时,块内不同层的权重被迫以加法而不是乘法相互作用。 这会导致块深度 的性能比块深度 更差,并且最佳超参数会随着深度而变化。 我们在具有 MLP 块的 resnet 上以及在 Common Crawl 上训练的 Megatron Transformer [16] 上以教学方式演示了这一点。 这些观察结果需要重新思考当前的超参数传递方法。
2相关作品
2.1 宽度缩放和P
神经网络的无限宽度限制一直是文献中广泛研究的主题。 许多研究主要集中在检查初始化时各种统计量的行为。 有些工作已经超越了初始化阶段,探索神经网络中特征学习的动态。
懒惰的训练。
使用标准参数化,学习率为 级,444我们还通过 NTK 参数化和 学习率获得了惰性无限宽度限制。 是宽度,在无限宽度限制下产生所谓的惰性训练机制,其中特征在整个训练 [3, 25] 中保持大致恒定。 该机制也称为神经正切核 (NTK) 机制,其收敛特性已在文献[10,1,2,28]中进行了广泛研究。
特征学习和P.
最近的实证研究(例如[25])提供了令人信服的证据,表明特征学习在深度学习的成功中发挥着至关重要的作用。 人们普遍认为,深度神经网络取得的卓越性能可以归因于它们通过训练过程获得有意义的表示的能力。 因此,扩展网络架构成为增强此类模型性能的自然选择。
在这种背景下,[25]中引入的P(最大更新参数化)已成为一种有前景的方法,可以最大化特征学习,同时防止特征随着网络宽度的增加而爆炸。在给定固定深度的情况下增加。 值得注意的是,P 有助于跨不同网络宽度的超参数传输。 这意味着,我们可以在较小的模型上对其进行优化,并对较大的模型使用同一组超参数,而不是直接在大型模型上调整超参数。
P 的推导利用了张量程序框架[22,20,21,23,25],该框架为捕获无限中神经网络的行为提供了有价值的工具。训练过程中的宽度制度。
2.2 深度缩放
虽然增加神经网络的宽度可以提高性能,但增加网络的深度也可以带来显着的性能提升,并且大多数最先进的模型都使用深层架构。 跳跃连接的引入[8, 9]在实现深度网络方面发挥了关键作用。 然而,很明显,即使使用跳过连接和归一化层,训练深度网络仍然是一项具有挑战性的任务[12]。 此外,调整大型深度网络的超参数是一项耗时且耗时的任务。
为了解决与训练深度网络相关的挑战,一些研究提出使用深度相关的缩放器来缩放网络块,以确保初始化时或内核状态中特征和梯度的稳定性[7,4,26,13, 5、6、14、27]。 然而,这些工作缺乏对特征学习动态的洞察。 例如,有人可能会争辩说,如果学习率选择不当,特征仍然会经历爆炸性增长。 因此,有效的深度缩放方法不仅应确保初始化时的稳定性,还应为缩放学习率提供指导。
这一动机是 Depth-P 开发的基础,它为深度缩放提供了一个全面的框架。 Depth-P 包含块乘法器和学习率缩放,为训练深度网络提供完整的方案。 在多层感知器(MLP)(无跳跃连接)的情况下,Jelassi 等人[11]表明,学习率缩放保证了初始梯度后的稳定性步。 然而,目前尚不清楚在第一步之后如何调整学习率,并且这种缩放不适合具有剩余连接的架构。
3 热身:线性网络的直观解释
让我们从一个简单的例子开始,它提供了支撑我们的深度缩放策略的必要直觉。 给定深度 、宽度 ,考虑以下形式的线性残差网络
其中权重矩阵 和 是我们假设在训练期间固定的输入和输出权重矩阵。
3.1 学习率的最佳缩放
为了简化分析,我们考虑基于单个数据点的梯度更新。 第一个梯度步长由下式给出
其中 是学习率, 是具有更新方向的矩阵。 例如,对于 SGD 和 Adam,我们有以下 表达式:
-
•
SGD:,其中表示某些损失函数。555我们使用作为梯度,因为我们想与论文后面出现的深度微分方程中的区分开来。
-
•
亚当666为了简单起见,我们在本节中考虑 SignSGD,它可以看作是 Adam 的无记忆版本。 该分析对于任何提供 梯度的训练算法都有效。:。
在这两种情况下, 和 都是针对单个数据点 计算的。 最后一层特征(对于某些输入)由给出。777 为了避免任何混淆,这里我们通过 定义矩阵乘积。 我们使用下标来指代训练步骤。 在第一个梯度步骤之后,我们有以下结果
| (2) |
其中。 我们认为 的行为与 相同(在 规范中)。 这是由于 缩放因子造成的。 为了看到这一点,我们通过考虑情况 (每层单个神经元)和平方损失来进一步简化分析。 在这种情况下,术语 简化为
SGD 的缩放比例。
对于 SGD,我们有 ,其中 和 是目标输出。 因此,很容易看出
我们使用 来表示任何正整数 。
亚当的规模。
总结:通过保证参数更新为,在特征更新为时,特征保持稳定。 此 更新是由于 相关项在深度上的累积所致。
3.2 当深度达到时收敛
让我们再次看看简单情况中的,并分析它在时的行为。 本段仅旨在给出收敛的直觉。 本文稍后将提出这种收敛性的严格证明。 让我们考虑学习率为 并让 和 进行 SGD 训练的情况。 有了这个,我们有以下内容
| (3) |
WLOG,让我们假设。 那么,对于某个""的概念来说,的发生概率很高(对于某个来说,的发生概率至少为)。888这是从次指数随机变量的简单集中不等式得出的。,我们有 。 因此,我们可以看看,它简化了任务。 在高概率事件下取对数并使用泰勒展开,我们得到
对于某些。 第一项和第三项 和 分别收敛(几乎肯定)到标准高斯和 。 第二项也自然收敛,因为 在 中收敛到对数正态随机变量 ([5]),并且经过精细处理(涉及高概率界限),可以证明项 在大深度处收敛(在 范数中)。 这意味着随着深度的增加, 应该有一些弱收敛的概念。 请注意,对于一般宽度 ,相同的分析变得更加复杂。 为了避免处理高概率界限,一种方便的方法是首先将宽度设为无穷大 ,然后分析随着深度增加会发生什么。 我们将在下一节讨论这个问题。
3.3 一般情况的讨论
难以推广到非线性情况。
扩展到一般宽度场景 () 需要对术语 进行更复杂的处理,以找到最佳缩放规则,但所提出的缩放对于一般宽度仍然是最佳的。 这种基本知识分析为提出最大化特征学习的特定学习率缩放方案奠定了基础。 此外,在存在非线性的情况下证明这种扩展策略的最优性是一项艰巨的任务。 主要挑战源于训练过程中诱发的后激活之间的相关性。 克服这些挑战需要一个严格的框架,能够解决网络中关键数量的大深度限制。
为此,我们采用张量程序框架来研究基本网络量在无限宽度和深度限制下的行为。 通过利用这个框架,我们的理论研究结果表明,上述扩展策略对于具有跳跃连接的一般网络来说仍然是最佳的。 我们的框架考虑的设置是首先将宽度设为无穷大,然后是深度。 这代表了 的情况,它包含了大多数实际设置(例如大型语言模型)。
初始化的关键作用。
一种简单的深度缩放方法如下:由于权重 在训练过程中可能变得高度相关,因此必须使用 缩放块。 为了理解这一点,让我们假设块乘数为 并考虑所有权重相等的完美相关场景,即每个 都有 。 在这种情况下,最后一层特征可以表示为。 当时,特征很可能随着深度的增加而呈现爆炸性增长,而选择则保证特征稳定。
然而,在本文中,我们证明这种直觉与实际观察并不相符。 与预期相反,当时,特征并没有随着深度的增加而发生爆炸性增长。 这种现象归因于两个关键因素:随机初始化和学习率随深度的缩放。 这些因素确保权重矩阵在此过程中永远不会以这种特定方式变得高度相关。
总之,虽然基于缩放块的简单深度缩放策略可能表明需要 来稳定特征,但我们的研究结果表明,在实践中,情况并非如此。 即使选择 ,随机初始化和学习率缩放的相互作用也能有效防止特征经历爆炸性增长。
4 SGD 训练无限深线性网络动力学
本节我们继续研究Depth-P下的带有残差连接的线性神经网络。使用张量程序框架[24],我们严格推导了线性残差网络当宽度和深度依次趋于无穷大时SGD的训练动态。 我们的分析路线图包括以下三个步骤。
-
1.
我们首先通过张量程序框架[24]将网络的宽度设为无穷大。 因此,我们不是沿着训练轨迹跟踪向量和矩阵,而是跟踪与向量相对应的随机变量,即对于出现在训练计算中的向量 的坐标当时,可以被视为随机变量的独立同分布副本(称为ket)。 999的定义要求的坐标是 w.r.t。 ,如果 的坐标是 w.r.t,则 是微不足道的。 。因此,对于坐标不是 的 ,我们通过乘以 的多项式来归一化 ,因此得到的向量具有坐标 。
-
2.
由于网络是线性的,因此每个随机变量都可以通过张量程序主定理[24]写为一组零均值“基础”随机变量的线性组合。 因此,我们可以通过分析随机变量相应的线性组合的系数以及“基础”随机变量之间的协方差来跟踪随机变量。
-
3.
由于随机变量的数量和“基础”随机变量的数量与 呈线性比例,因此所有随机变量的系数都可以用六维张量表示,其中两个维度的形状为 。然后,我们将张量映射到输入域为 的一组函数。 最后,我们声称函数在时收敛,并将它们的极限确定为一组函数积分的解。
在节 10.1中,我们在线性情况下对我们的理论进行了彻底的实证验证。 实验清楚地表明了深度线性残差网络在Depth-P下的收敛性。
假设和符号
回想一下线性网络由下式给出
为了方便起见,我们假设,的SGD学习率为。 我们将 作为下标添加到任何符号中,以表示相同的对象,但在第 训练步骤中,例如,步骤 的输入是单个数据点,第层在第步的隐藏输出为,第是。令 为训练步数。 令为在时刻吸收标签的损失函数,为在时刻损失的导数,即,。 设,是的规范化版本。
张量程序分析在很大程度上取决于 w.r.t 的初始化缩放和学习率。在本文中,我们使用 P 作为缩放比例。 ,因为它在大宽度限制[23]中最大化了特征学习。 不失一般性,我们遵循[23]并假设输入和输出维度为,即, 。 为了清晰的演示,我们还假设 在本节的训练过程中被冻结,并且 的每个坐标都使用 i.i.d 初始化。 方差高斯。
4.1 P下的宽度限制
第一步,我们使用张量程序 (TP) 将网络 的宽度设为无穷大。 正如本节路线图中简要提到的,TP 框架通过 时的随机变量来表征训练过程中涉及的每个向量。 对于具有大致 iid 坐标的向量 ,我们编写 (称为 ket)来表示随机变量,使得 的条目看起来像 的 iid 副本。 那么对于任意两个具有大致 iid 坐标的向量 ,它们与 的极限内积可以写为 ,我们简洁地写为 。 使用 SGD 的深度线性网络是从向量到随机变量转换的一个简单示例。 如程序1所示,我们使用以下函数定义了一系列标量(和)和随机变量() ket 符号。 为了更好的理解,下面我们对TP进行简单的介绍。
简而言之,张量程序(TP)。
当训练神经网络时,我们可以将此过程视为从一组初始随机向量和矩阵(初始化权重)以及一些确定性量(本例中的数据集)连续创建新向量和标量的过程。 第一步,前向传播创建特征 (其中下标 表示初始化)和标量 (网络输出)。 在第一次向后传递中,计算输出导数 ,然后反向传播梯度 。 (由于 的坐标在 时消失为 0,因此 TP 会跟踪其标准化版本 。) 随着训练的进行,新的向量被创建并附加到 TP 中。 When the width goes to infinity, vectors of size in the TP (e.g., the features , and normalized gradients ) see their coordinates converge to roughly iid random variables (e.g., and in Program 1), and other scalar quantities (e.g., and ) converge to deterministic values (e.g., and in Program 1) under proper parametrization (P). 主定理[25]通过表征训练过程的无限宽度限制来捕获这些量的行为。 有关 TP 的更深入定义和详细信息,请读者参阅[25]。
现在,当我们回顾程序1时,标量和随机变量的定义应该很清楚(和除外)。 人们可以找到它们与其有限对应物之间的直接对应关系,例如:
-
•
对应,对应;
-
•
对应于,对应于。 (回想一下 是 的规范化版本。)
-
•
通过 SGD, 对应于 。
现在我们可以深入研究 和 的定义。 令 为大小为 的初始随机矩阵的集合,即 和 。 让 表示对于某些 形式为 的训练中的所有向量的集合。 然后对于每个和,我们可以将分解为和之和,其中 是一个随机变量,就像 独立于 一样, 是捕获相关部分的随机变量在 和 具体来说,让我们简单跟踪一下训练期间 发生了什么。 在第一步中,我们有 ,它具有大致高斯坐标(在大宽度限制内)。 在本例中,我们有 。 在第一次回溯后,我们会得到 ,这意味着 中的更新将包含某个向量 的 形式的项。 这意味着 将包含某个向量 的 形式的项。 当我们将宽度设为无穷大时,这项会产生一个额外的相关项。 是通过将此附加相关项与 分离来定义的。 其余项在无限宽度限制中是高斯分布,它定义了项 。 正式地,我们提出以下定义。
Definition 4.1。
我们为每个 和 定义 ,其中
-
•
是均值为零的高斯变量。 ,
如果,则、 和 是独立的。 也独立于 和 。
-
•
被定义为的线性组合。 然后我们可以将任何 归纳展开为 、 和 的线性组合,这使我们能够完全定义
4.2 随机变量的深度缩放
利用这个归纳法,我们要求在线性组合中,每个的系数为,和的系数是。 我们还声称任何 和 形式的随机变量对之间的协方差为 。
Proposition 4.2.
、、
、、、
4.3 无限深度限制
现在我们将上面的论点形式化,并获得描述时网络动态的公式。 我们首先将线性组合的系数写为六维张量,其中。 具体来说, 表示 和 w.r.t 的导数。 和 。 这里,我们使用 表示前向传播中出现的 ket( 和 ),使用 表示前向传播中出现的 ket。向后传递( 和 )。 形式上,、、、。
然而,很难描述的极限,因为它的大小随着的增加而增加。因此,我们定义了以下一组函数:对于,
对于、
这里 被标准化为 ,因此对于不同的 , 的输入域是相同的; 乘以 ,因为 乘以 4.2;额外的 情况还可以帮助我们捕获 w.r.t 的导数。 和 。
使用和的这个定义,可以很方便地在下面的引理中写出它们的递归公式。
Lemma 4.3 (和的有限深度递归公式(引理的非正式版本 C.1)).
和 可以递归计算如下:
其中如果 则为 ,如果 则为 。
引理 4.3的证明从程序1中很简单。 在 附录 C中,我们还给出了一个正式证明,即在 是 的幂的情况下,当 增长到无穷大时, 和 收敛。 为了证明方便,限制是的幂,并且和收敛成立在一般情况下。 此外,我们根据Lemma 4.3中的和的递归推导出无限深度行为。 t2>。
Proposition 4.4 (和的无限深度限制(C.2的非正式版本) )).
在极限 内,我们有
4.4的证明来自引理4.3。 严格的证明需要首先证明满足对的积分泛函解的存在性。 该解通常是4.4中积分泛函的不动点。 证明存在性后,需要证明收敛于这一极限。 这通常需要控制有限深度和无限深度解之间的差异,并涉及获得误差传播的上限。 积分泛函在温和条件下保证存在。 我们在这里省略了存在性的完整证明,并假设泛函的行为足够良好,可以使收敛结果成立。 附录中和对于()收敛的形式证明> C 是命题正确性的展示。
这给出了分布的收敛:
Theorem 4.1.
在 限制下,kets 在分布上收敛为具有核的零均值高斯过程
因此,对于每个固定的神经元索引 ,集合 在 和 的极限中,其分布趋近于核 的零均值高斯过程。
对于熟悉随机过程的观众来说,实际上我们在 Skorohod 拓扑中整个连续深度索引过程 的收敛性很弱。
5什么原因导致超参数传递?
在一个流行的误解中,超参数传递意味着极限的存在。 例如,P 传输超参数,在这种误解中,是因为存在特征学习限制(又名 限制),即 P 随着宽度趋于无穷大。 然而,这种情况并非如此。 事实上,存在大量的无限宽度限制,例如 NTK 限制,但最优超参数的缩放方式只能有一种,因此存在并不意味着转移。 在这种误解的更强烈的版本中,迁移是由“特征学习”限制的存在所暗示的。 但同样,这是错误的,因为存在无限数量的特征学习限制(其中 限制是唯一的最大限制)。
相反,事实是,最优限制意味着最优超参数的传输。 例如,在宽度限制情况下,P 是产生最大特征学习限制的唯一参数化。 与所有其他限制相比,这显然是最佳限制。 因此P可以跨宽度传输超参数。
到目前为止,对于极限的“最优性”还没有先验定义:人们只能通过分类所有可能的极限来判断;事实证明,在限制中只能发生少量不同的行为,因此可以手动检查哪个限制是最佳的。
同样,在这项工作中,为了推导允许传输的深度缩放,我们需要分类所有可能的无限深度限制 - 以及深度-P从我们在本文后面定义的意义上来说,将被证明是最优的。101010这里有一些重要的细微差别,将在即将发表的论文中详细说明。 例如,如果超参数的空间选择不正确,那么无论以何种方式都可能出现最佳限制。 例如,如果在(宽度方向)SP 中,只考虑全局学习率的一维空间,那么所有无限宽度限制都是有缺陷的——而且实际上不存在越大的总是越好的超参数传递。 比宽度情况更有趣的是,在采用深度限制时,我们有多种特征学习模式,并且辨别哪种特征学习模式是最佳的很重要。 因此,即使通过特征学习,也不足以得出任何一个限制,并能够推断它产生 HP 转移。
在部分10中,我们提供了块缩放(又名ODE缩放)的实验,事实证明,这会导致无限深度限制的特征学习,但不是最优的。 我们的结果表明,通过这种参数化,最佳学习率发生了显着变化。
6 一般情况的预备知识
对于一般情况,我们回顾并扩展了前面部分的符号,并定义了新的符号。
符号
令为网络的深度,即残差块的数量,为网络的宽度,即所有隐藏表示的维度。 设为网络的输入,为输入层,为输出层,因此和模型输出 w.r.t. 是。 令 为吸收标签的损失函数, 为 w.r.t 的梯度。 的损失。 我们通过添加 作为下标来表示 第训练步骤的变量,例如,步骤 的输入是 111111这里,输入用于在训练步骤中执行一个梯度步骤。稍后我们将看到,我们的主张原则上应该适用于训练算法的批处理版本。,第 层在步骤 的隐藏表示为 ,步骤 的模型输出为 。令 为训练步数。
6.1 SGD、Adam 和所有 Entrywise 优化器的统一扩展
我们扩展了深度缩放的entrywise更新([24])的定义,使我们能够研究SGD、Adam和其他仅执行entrywise操作的优化算法的统一深度缩放。
Definition 6.1。
具有宽度和深度缩放的参数的基于梯度的更新由一组函数和定义。 优化时间的更新为
其中是在时间的梯度。
对于 SGD,,“真实”学习率为 。 对于亚当来说,
“真实”学习率为。
在 之前乘以梯度 的目的是确保 的输入是 w.r.t。 和 121212在Yang和Littwin [24]中被称为忠诚。;否则,当 和 变大时,更新可能会变得微不足道。 例如,如果梯度是 条目,那么,在 Adam 中,直接将梯度提供给 将始终给出 的输出,因为常量 。
在本文中,我们仅考虑,使得为。131313注意 定义 6.1中的 对参数的要求可以不同,因此可以使每个参数都满足条件。 结果,的输出一般也是。 因此,决定了更新的规模,应该是我们关注的重点。 我们将称为有效学习率。
6.2 P 和宽度缩放
最大更新参数化(P)[21]考虑了宽度扩大时网络中每个权重矩阵的初始化和学习率的变化。141414重新参数化也包含在原始P中,但对于本文的目的来说不是必需的。 它为每个权重矩阵提供了一个独特的初始化和学习率,作为宽度的函数,使得每个权重矩阵的更新最大化(达到恒定因子)。 P的好处不仅在于理论上的保证,还在于扩大宽度[23]时的超参数稳定性。
在本文中,我们假设宽度缩放遵循P。即有效学习率中的和各权重矩阵的初始化方差如下Table2。
| Input weights | Output weights | Hidden weights | |
| Init. Var. | |||
6.3 我们的设置
我们考虑一个带有无偏差感知器块的 隐藏层残差网络:
其中 指的是平均减法,对于任何 来说,由 和 给出。 的初始化和学习率遵循P。 的初始化遵循P,的学习率为。
平均减法 ()。
一般来说,如果不进行均值减法, 的均值将主导深度动态。 例如,当 为 relu 时,每一层只会将非负数添加到平均为正数的 上。 如果乘数 太大,它在深度上的积累要么导致网络输出爆炸,要么缺乏特征多样性。 正如我们将看到的,均值减法消除了这种故障模式,并实现了更强大的无限深度限制。151515请注意,使用奇数非线性也将获得类似的结果,因为它们在对称分布的输入下没有平均值,这大约是这种情况在整个训练过程中为。 这是我们之前讨论过的 = 身份的情况。 但事实证明,奇数非线性最小化了特征多样性,因此均值减法是一个更好的解决方案。
Definition 6.2。
修复一组更新函数。 上述 MLP 残差网络的深度参数化由一组数字指定,使得
-
(A)
我们独立地初始化 中 的每个条目
-
(二)
的梯度在被处理之前乘以:即,时间的更新为
(4) 其中是在时间的梯度,并且按条目应用。
各种符号。
对于向量 ,令 为其第 坐标。 对于矩阵 ,令 为其第 行。 令 为单位矩阵, 为完整的向量。 对于,令。 令 为克罗内克积。
7 深度参数化的分类
在本节中,我们全面描述深度参数化对稳定性和更新大小的影响。 为此,我们只需跟踪两个缩放:分支乘数和学习率缩放,因为初始化缩放由忠实度属性(定义如下)固定。 要求特征在初始化时不会爆炸意味着分支乘数最多必须为 。 假设更新是忠实的(即,梯度处理函数的输入是条目),则隐藏层的更新大小最多可以是,通过(雅可比)运算符 -正常的争论,但可能要少得多。 简单地说,更新大小和初始化之间可以进行权衡:如果初始化很大,那么更新可能需要很小,以免炸毁网络的其他部分;如果初始化很大,那么更新可能需要很小,以免炸毁网络的其他部分;同样,如果初始化较小,则更新大小可以较大。 但人们可能会感到惊讶,仔细的计算表明没有权衡:我们可以同时最大化初始化和更新大小。
在深入探讨细节之前,我们首先要定义训练套路、稳定、忠实和非平凡的概念。 此后,所有渐近符号如、和都应理解为极限“”。 对于随机变量,这种符号应该从弱收敛(分布收敛)的意义上来理解。 当我们对某些向量使用符号时,它应该被理解为对于所有。 最后,我们将使用粗体字符(例如 而不是 )来表示数量的“批量”版本。 这只是为了强调以下声明也适用于批量。
备注:在本节中,我们将结果表述为“声明”而不是定理。 在附录F.4中,我们提供了“启发式”证明,可以在不平凡的技术条件下进行严格证明。 我们还通过在附录D中的线性设置中严格证明它们来展示声明的正确性。我们认为这种额外的复杂性是不必要的,并且不符合本文的目的。
Definition 7.1 (训练例程).
训练例程是 、 和输入批次的包。
Definition 7.2 (稳定性)。
我们说参数化是
-
1.
初始化时稳定如果
(5) -
2.
训练期间稳定如果对于任何训练例程,任何时间、,我们有
其中符号“”指的是一个梯度步骤后的变化。
如果参数化在初始化和过程中都稳定,我们就说参数化是训练稳定。
Definition 7.3 (忠实)。
如果对于所有,我们说参数化在步骤是忠实的。 如果参数化对于所有都是忠实的,我们就说参数化是忠实的。我们还说它在初始化时是忠实的(resp。 在训练期间忠实)如果在 处为真(resp. 对于)。
注意这里的忠实指的是“忠实于”,意味着的输入是。 这与 Yang 和 Littwin [24] 中忠实度的定义不同,其中忠实度是指“忠实于 ”,这意味着 的输入是。 如部分6.1中所述,本工作中已假设“忠实于”。
Definition 7.4 (非平凡性)。
如果对于每个训练例程和任意时间 、,在" 然后 "的极限中(即函数不会在无限宽--然后--深度的极限中演化),我们说一个参数化是 三维的。 否则我们说参数化是非平凡的。
Definition 7.5 (特征学习).
我们说参数化在限制“,然后”中引入特征学习,如果存在训练例程,并且,以及任何 ,我们有 。
7.1 主要权利要求
我们现在准备公布主要结果。 下一个声明提供了参数化在初始化时稳定的充分必要条件。
Claim 7.1.
参数化在初始化时是稳定的当且仅当。
声明 7.1并不新鲜,Hayou等人[7]也报告了类似的结果。 然而,Hayou 等人[7]侧重于初始化,缺乏训练过程中类似的稳定性分析。 在下一个结果中,我们根据学习率的缩放确定了两种不同的行为。
Claim 7.2。
考虑初始化时稳定的参数化。 然后进行以下保持(彼此分开)。
-
•
训练时也很稳定,当且仅当。
-
•
这是不平凡的当且仅当。
因此,它既稳定又不平凡当且仅当。
Claim 7.3.
考虑稳定且重要的参数化。 以下保持(彼此分开)。
-
•
它在初始化时是忠实的,当且仅当。因此,是的最小选择 这保证了忠诚度。
-
•
训练期间忠实当且仅当。
因此,稳定且重要的参数化是忠实的当且仅当。
第一个主张源自众所周知的随机初始化残差网络[7]的计算。 对于第二个声明,这里的直觉是如果 和 那么 ,即更新大小随着深度而增加。 这将导致非线性输入的尺寸增大。
有人可能会说,初始化时的忠实度并不重要(例如,初始化时的特征可以收敛到零,而不会出现任何稳定性或琐碎问题),重要的是整个训练过程中的忠实度。 事实证明,初始化时的忠实度对于网络容量的优化使用起着至关重要的作用。 为了看到这一点,我们首先定义特征多样性指数的概念,它与相邻层特征的相似性有关。
Definition 7.6 (特征多样性指数)。
如果 是最大值,那么对于所有 和足够小的 ,我们说参数化具有特征多样性指数 ,并且所有时间,
其中 应解释为限制“,然后 ,然后 ”。 如果,我们就说参数化是冗余。
换句话说,特征多样性指数 是对彼此接近的层中的输出差异程度的度量。 对于,每一层的输出本质上与前一层的输出相同,因为从一层到下一层的变化率是有界的(至少是局部的),因此网络直观上是在“浪费”参数。
Claim 7.4.
考虑一个稳定且重要的参数化,该参数化在训练期间(但不一定在初始化时)更加忠实。 那么如果是多余的。
要理解 Claim 7.4 背后的直觉,让我们看看 时会发生什么。 在这种情况下,随着深度的增加,初始化权重的随机性不会对训练轨迹产生影响。 要看到这一点,请考虑一些图层索引。 这些块被 划分,该值大于累积随机性的大小(顺序为 )。 这基本上破坏了初始化的所有随机性,因此学习特征中的随机性将仅包含来自 和 (输入和输出矩阵)的随机性。 当深度趋于无穷大时,两个相邻层中随机性的贡献变得不那么重要,最终相邻层变得非常相似,因为这些层的梯度高度相关。
相反,我们得到以下结果,它定义了 Depth-P。
Claim 7.5 (深度 -P)。
是独特的参数化,它是稳定的、重要的、忠实的、诱导特征学习,并通过实现最大的特征多样性。
就特征多样性而言,当时发生相变现象。 更准确地说,对于 Depth-P,我们可以证明 而对于所有 来说,相同的数量是 ,这表明Depth-P 生成 的粗略路径。 这允许特征从一层到下一层发生显着变化,从而有效地使用参数。 对于熟悉粗糙路径理论的读者来说,连续性指数是路径中布朗增量的结果。161616读者可能会问我们能否得到小于的指数。 这确实是可能的,但需要使用相关权重。 我们把这个问题留给未来的工作。
此外,对于,存在特征崩溃的现象,即特征将包含在由输入层和输出层生成的代数中,但不包含随机性来自隐藏层(参见部分 F.2)。 直观上, 的情况类似于宽度情况,其中深度平均场塌陷为单个神经元(所有神经元变得本质上相同)。 对于深度而言,特征(层)仍然相对不同,但冗余不允许这些特征发生显着变化。
7.2 Sublety:分层(局部)线性化,但不是全局线性化
Definition 7.7。
我们说参数化引起分层线性化当且仅当当(即)时每层都可以在不改变网络输出的情况下进行线性化,
Claim 7.6。
稳定且重要的参数化会导致分层线性化 iff 。
但是,请注意,这并不意味着整个网络是线性化的(w.r.t. 神经正切核意义上的所有参数)。 在我们的设置中,输入和输出层以恒定比例初始化(w.r.t. ),实际上不可能有内核限制。 即使在 Section 4 中的线性情况下,我们也可以看到学习的模型不是线性的。
如果输出层的初始化比我们的设置大倍(假设,因此宽度缩放仍然遵循P),它可能会引起参数化可以使整个网络线性化。 在这种情况下,学习率必须小于Depth-P的倍才能获得训练过程中的稳定性,因此参数的变化也是倍小,这可以导致整个网络的线性化。 由于我们专注于最大特征学习,因此严格的论证超出了本文的范围。
8功能多样性
在本节中,我们表明非线性的选择和非线性的放置可以极大地影响特征多样性。
8.1梯度多样性
梯度多样性是特征多样性的重要因素。 观察 处的梯度 在极限 内的 中是连续的。 在线性模型(或前非线性模型,其中非线性被置于权重之前)中,这会导致相邻块之间的 非常相似。 结果(因为权重 接收与 成比例的更新),在下一个前向传递中,相邻块对主分支 的贡献非常相似。 这导致模型容量的浪费。
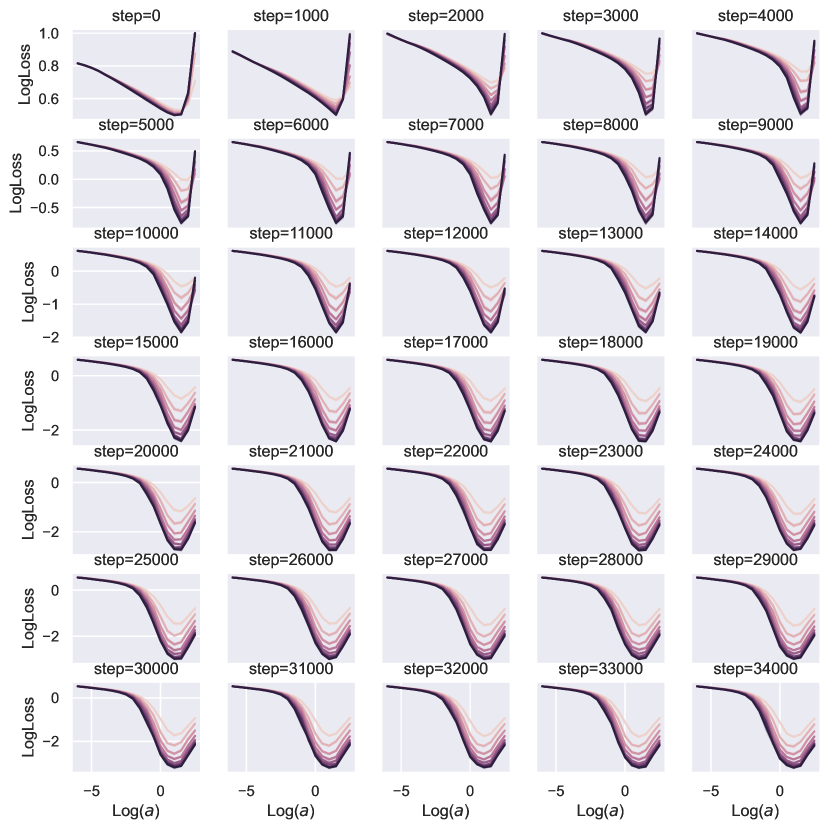
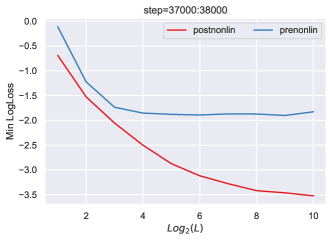
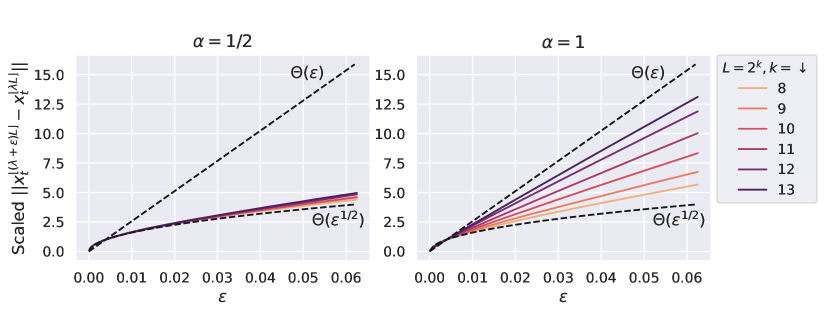
8.2 Pre-Nonlin 导致性能不佳
例如,在 图 2中,对于一个 relu 前非线性重网(即图块由 而不是 给出),我们可以看到,虽然深度-P 确实转移了超参数(正如我们的理论所预测的那样),但其性能却大大低于 图 10 中的后非线性重构网络,并且深度超过 8 层后性能没有任何提升。 具体来说,这是因为类似于线性情况,而在相邻块之间也相似。 因此,权重 的梯度与 成比例,与附近的块相比几乎没有多样性。
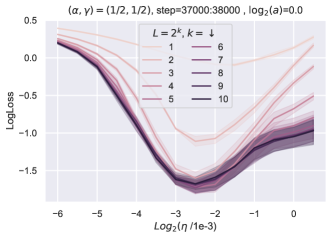
8.3 利用绝对值非线性最大化特征多样性
在非线性模型中,我们有。 由于 几乎独立于 Depth-P 限制中的所有其他 ,因此 可以用于解相关 ,取决于 是什么。 例如,如果 是 relu,则 是阶跃函数。 近似为深度 P 限制内的零均值高斯分布,因此 近似为 0 或 1,各有一半概率。 这比线性情况更好地解相关 。 但当然,这种推理自然会得出这样的结论: 将是 的最佳解相关器,并且是特征多样性的最大化(其中 正 1-齐次函数的类) - 那么 和 对于 是完全去相关的。
事实上,如图图 3所示,将绝对值替换为可以极大地提高深度(块)的训练性能深度1)resnets。
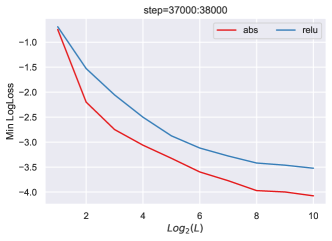
一般来说,任何非线性都可以代替绝对值。
8.4 特征多样性与分层线性化处于紧张状态
能够解相关 的原因与分层线性化有很大关系。 回想一下,在 Depth-P 中, 可以分解为大小为 的零均值高斯部分 和修正项 大小为 (对应于分解 )。 对于 , 独立于 ,但 可以与所有其他 非常强地相关。 因此,可以去相关,正是因为支配,这也正是我们进行分层线性化的原因。
在缩放时,与同阶,不会发生分层线性化,但 无法再有效地解相关 。
我们再次提醒读者,这种情况下的分层线性化并不是有害的(在块深度为 1 的情况下),因为 实际上累积了所有先前块的学习特征的贡献,因此强烈依赖于学习轨迹(与(横向)NTK 情况相反,其中 在初始化时已确定)。
9 块深度2及以上
符号备注: 在这里和下一节中,所有大 O 表示法仅在 中;假设宽度缩放在P 中。
在这项工作的大部分内容中,我们考虑了 eq. 1 中 的深度 1 MLP,很简单导出并分类每个块中较大深度的无限宽度然后无限深度的限制。 特别是,以下 缩放在具有块深度 的更一般设置中仍然有意义,并导致明确定义的限制:
| (6) |
这就是我们在块深度为 1 的情况下所说的 Depth-P,但我们不会在一般块深度的情况下使用这个名称,因为此参数化不再是最佳的。171717最佳的确切含义将在下面解释。
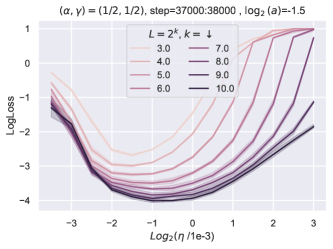
9.1 块深度有缺陷
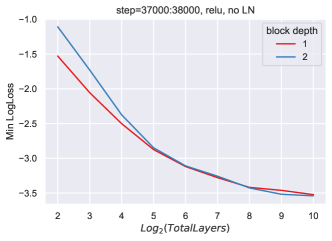
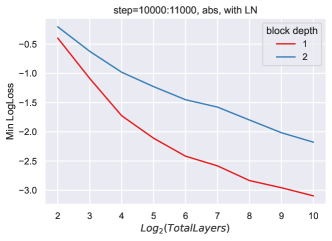
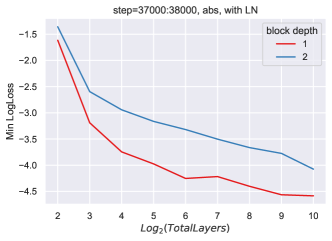
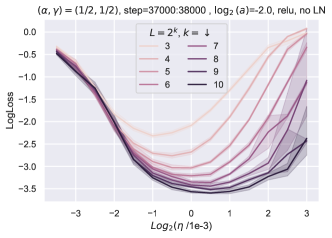
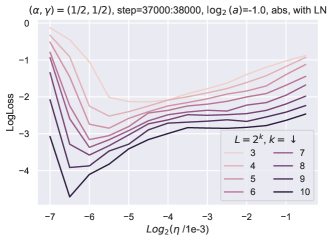
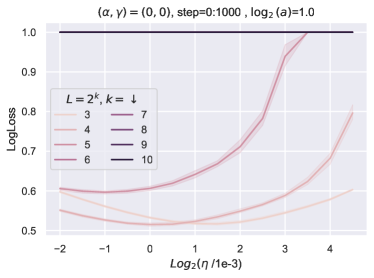
同时,随着块总数的增加,我们看到超参数发生了不平凡甚至显着的变化(图 6)。
9.2 块深度2缩放的缺陷
在块深度 情况下 缩放不再精细的原因是块中各层之间的乘法交互的线性化。 事实上,就像块深度为 1 的情况一样, 缩放会强制每个权重矩阵的权重更新 小于初始化 。 因此,在块内,深度较大时的训练动态处于内核状态,其中对块输出的贡献仅是求和,而不是每层权重更新的单独贡献的产品。
当在所有 块上聚合时,结果是块之间仅存在 的乘法交互,而层内则没有。 换句话说,网络输出由 形式的贡献主导,例如在线性情况下,其中每个 可以是 之一或 ,但不是 。 所有其他贡献(都涉及块内交互,如 )都是副标题。 在一般非线性情况下,替换块
与线性化版本
将实现与深度 相同的性能,其中 和 。
当块深度(我们在这项工作中的主要研究对象)时,所有交互都被包括在内,但当时,情况不再如此。
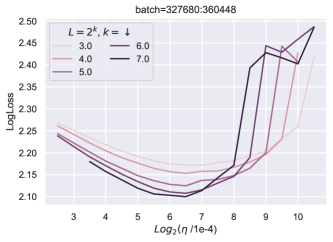
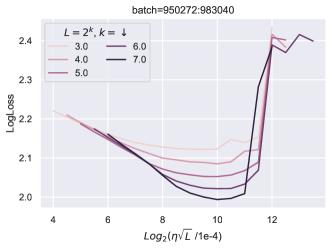
在图 7中,损失热图作为块乘数和学习率的函数,生动地证明了块深度2的这一点。
深度小
当块数为时,(学习率,块乘数)的最佳子级别集具有斜率。 换句话说,在最佳值附近,将学习率加倍同时将块乘数除以 4 具有类似的性能。 这是因为和以乘法方式交互,因此它们的大小加倍会导致它们对块输出的贡献增加四倍。 块乘数同时减少 4,则大致保持其贡献大小不变。
大深度
另一方面,当深度为 时,最佳子级别集具有斜率 :将学习率加倍,同时将块乘数减半具有类似的性能。 这反映了 和 现在相加地交互这一事实。
中间深度插入了这种现象,如深度 图中所示。
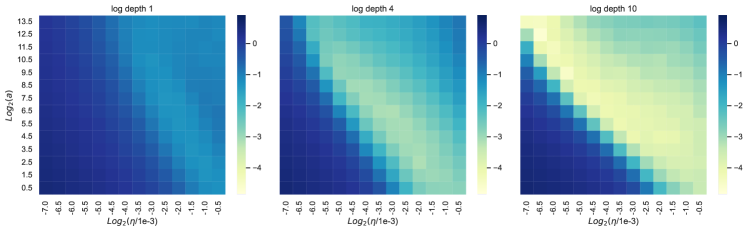
在相同的热图中,我们可以看到随着深度从 变化,最优(学习率、块乘数)(在 参数化中)从网格中部移动到左上角> 到 ,证明缺乏超参数传输。
这种斜率的变化在 ReLU 网络中也可以看到,无论有没有层范数。
最后,我们注意到, 缩放仍然会产生 限制,其中网络仍然学习整体特征,即使在每个块中这不再是正确的。 因此,这再次提醒我们,单纯的“特征学习”并不意味着“超参数迁移”!
9.3 参数化的分类
这些热图已经证明,没有参数化(全局学习率181818meaning, the learning tied across all layers in a block中,块乘法器)可以稳健地传输超参数,因为任何此类参数化只能移动热图,但不能拉伸它们,所以无法将一个斜坡的子标高组“转移”到另一斜坡的子标高组中。
但是,即使我们允许块中各层之间的学习率有所不同,也没有稳定、忠实、重要的参数化可以避免上述线性化问题。
为了简单起见,固定正齐次非线性和块深度 2。191919but our arguments generalize trivially to arbitrary block depth 我们考虑由块中每一层的学习率以及块乘数(每个块一个)组成的超参数空间; WLOG 所有权重均已初始化。202020This is WLOG because the nonlinearities are homogeneous 这会产生一个维度为
事实上,要发生这种情况,对于某些,权重更新必须至少为(初始化大小)。 但这会给块输出 带来一个与噪声项一样大的漂移项。 这意味着参数化不稳定(如果块乘数 为 )或缺乏特征多样性(如果块乘数 为 )。
例如,在线性模型中,
在 (噪声项)上是独立且零均值的,而 在 (漂移项)上是相关的。 始终是 ,因为 是。 如果是,则也是如此,使得漂移项与噪声项一样大。 如果是,那么,导致是。212121我们还可以观察到,如果,那么通过对称性,后向传播也会遇到同样的问题。 但对于一般的块深度,这个论点没有说明任何关于中间层的事情,而上面提出的论点意味着对于任何来说不能是。
相同的论点可以直接适用于非线性 MLP(均值减法)和任意块深度 ,以及不一定是正齐次的一般非线性,超参数空间扩大以包括初始化。
9.4 那么什么是最佳参数化?
所有上述考虑因素都表明,在增加每个块的复杂性时,我们在考虑中缺少关键的超参数。 我们现在的研究类似于对 SP 中全局学习率的一维超参数空间的简单研究。 发现这些缺失的超参数将是未来工作的一个重要问题。
10实验
10.1 在线性情况下验证理论
在部分4中,我们展示了线性网络训练动态的完整描述可以用来表示> 和。在本节中,我们提供了支持我们的理论发现的实证结果。 我们首先验证 Lemma 中 的有限深度递归公式 4.3 是当宽度达到时的正确限制无穷大,然后继续证明无限深度极限是正确的。
无限宽度限制。
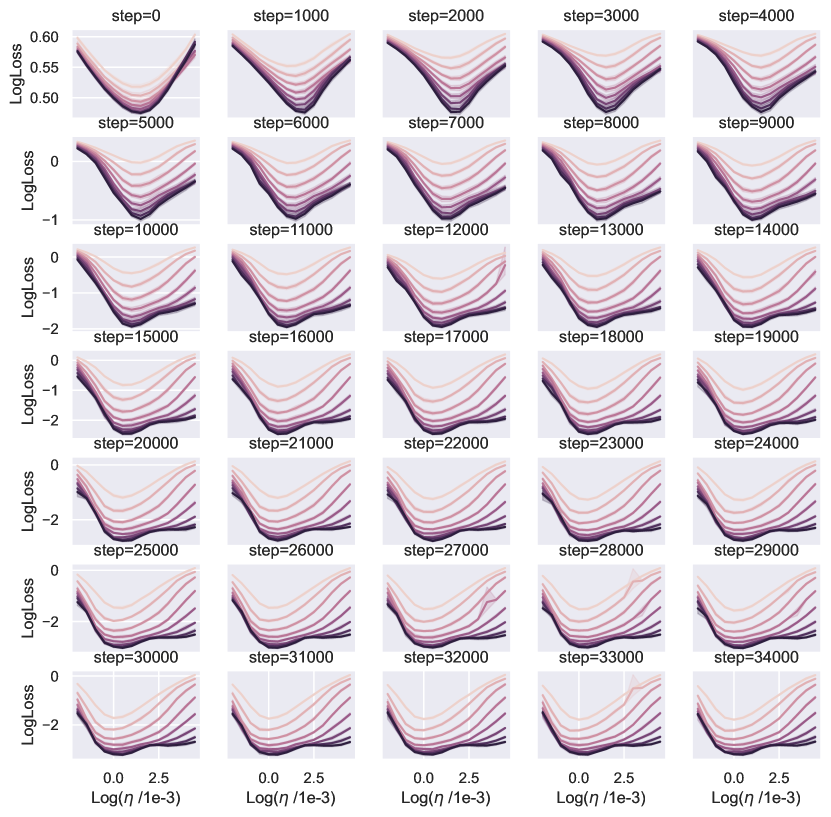
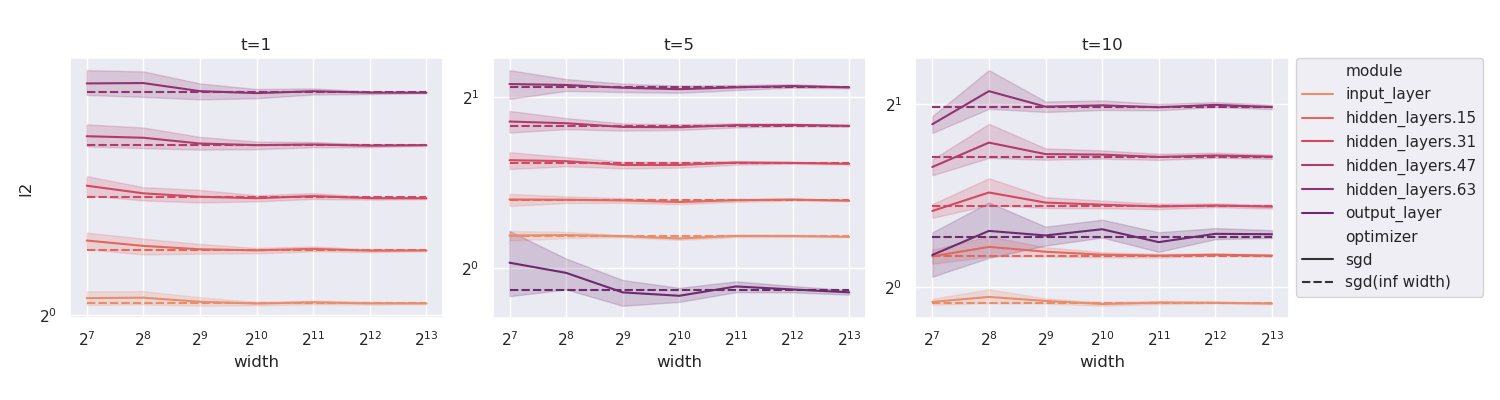
在图 8中,我们训练了一系列宽度为的层线性网络在 MNIST 上使用 步骤,并绘制均方根222222向量的均方根为,在中表示为“l2” 图8和9。 使用实线的层输出。 我们还使用 的递归公式计算相应统计量的无限宽度限制,并将它们绘制为水平虚线。 为了使图形清晰,我们仅绘制索引 16、32、48 和 64 的输入层、输出层和隐藏层的统计数据。 很明显,随着宽度的增加,实线在整个训练台阶上一致地汇聚到虚线。 这表明我们对无限宽度限制的计算是正确的。
无限深度限制。
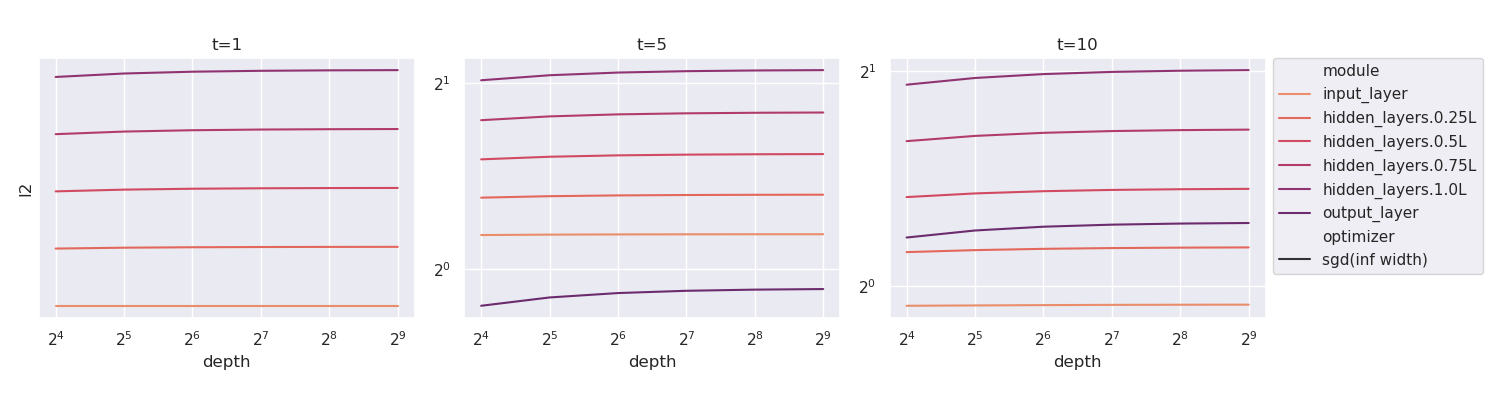
我们验证当深度增长时,上面的无限宽度限制收敛。 我们考虑相同架构的线性网络,但深度从 到 不同。 我们再次使用的递归公式计算层输出的均方根值,并将它们绘制在图 9中t1>,深度为轴。 为了使图更清晰,我们只绘制了输入层、输出层和隐藏层的统计数据,其索引分别为 、、 和 。我们可以观察到,当深度从 增长到 时,层输出的统计量迅速收敛,这验证了我们的收敛结果。
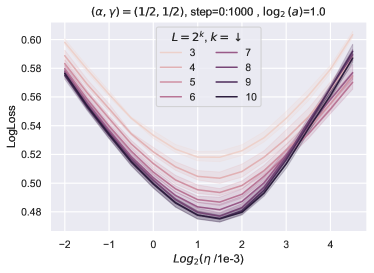
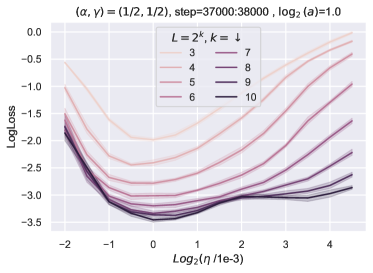
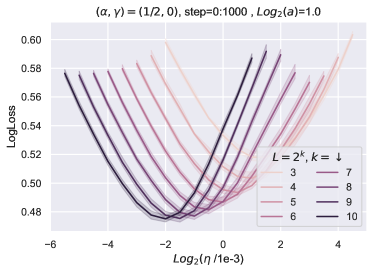
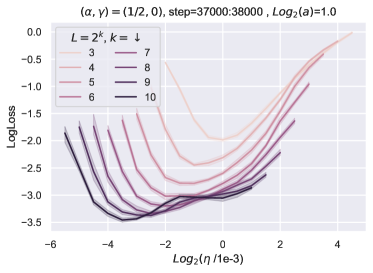
10.2 超参数传输
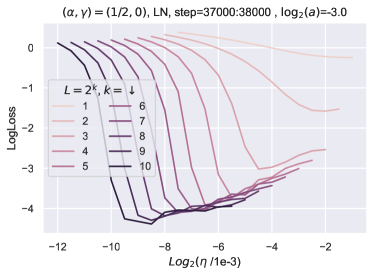
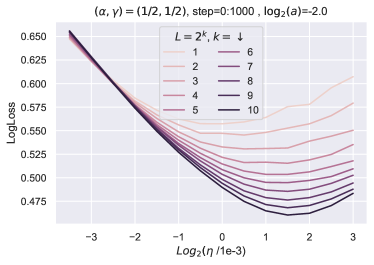
在本节中,我们提供经验证据来证明 Depth-P 缩放的最优性以及某些量在深度上的可转移性。 我们使用 Adam 优化器在 CIFAR-10 数据集上训练块深度为 1(每个残差块中有 1 个 MLP 层)的普通残差网络,批量大小为 ,对于 epoch(输入和输出层数是固定的)。 网络参数化如下
权重按照规则进行训练
其中学习率和块乘数是超参数。232323注意,这里的是常数,有效学习率由给出。 的值取决于选择的参数化。 对于 Depth-P,我们有 ,对于标准参数化,我们有 。242424在标准参数化中,通常没有随深度缩放学习率的规则,并且通常通过网格搜索找到最佳学习率。 在这里,我们假设在标准参数化中,学习率按 缩放以保持忠实度。 在我们的实验中,我们假设基础深度 ,这意味着我们在上面的参数化中将 替换为 。
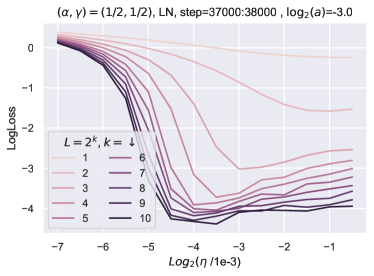
学习率迁移 ()。
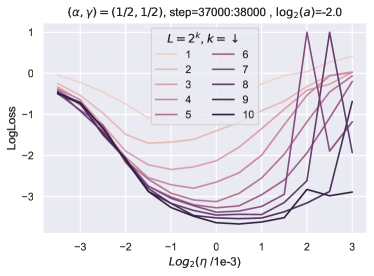
特征学习足以进行 HP 迁移吗?
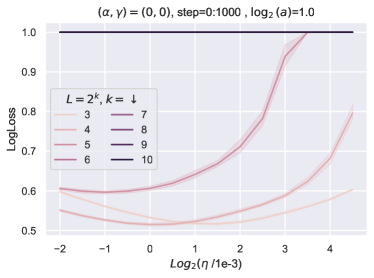
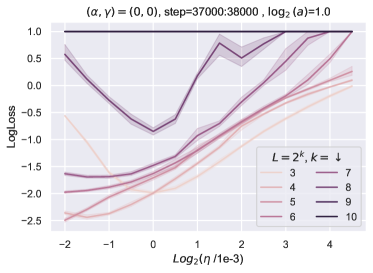
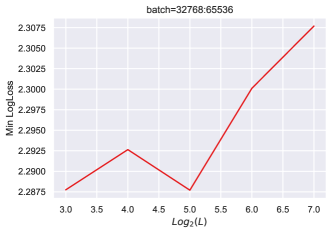
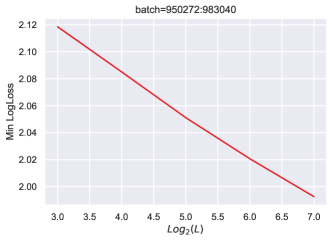
在部分5中,我们解释了超参数传输发生的时间和原因。 准确地说,为了获得 HP 传递,需要对所有特征学习限制进行分类并选择最佳的一个。 我们引入了特征多样性的概念,并表明 Depth-P 在最大化特征多样性的意义上是最优的。 为了表明 HP 传输需要最优性,我们训练了一个带有 的 resnet,这也是一个特征学习限制。 图 11显示,在这种情况下,学习率随深度呈现显着变化。 有趣的是,在这种情况下,常数 似乎随着深度的增加而增加,这表明网络正在尝试突破 ODE 限制,这是次优的。 请注意,在 Figure 10 中,与 Figure 11 中的 ODE 参数化相比,使用深度-P 可以获得更好的训练损失。
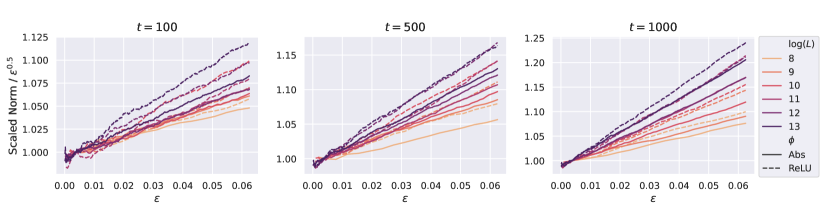
我们还有与 LayerNorm (LN) 的传输吗?
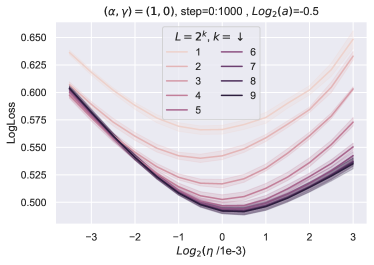
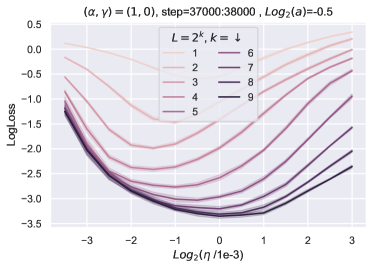
我们的理论仅考虑均值减法(MS),图10显示了MS的结果。为了查看 LN 是否影响 HP 传输,我们使用与图 10相同的设置来训练 resnet,其中绝对值非线性和 LN 应用于 在与 进行矩阵乘法之前(preLN)。 我们在非线性之后保留 MS,尽管它可以被删除,因为 LN 在下一层中应用。 图12中报告的结果表明,Depth-P 也保证了 LN 的学习率迁移。
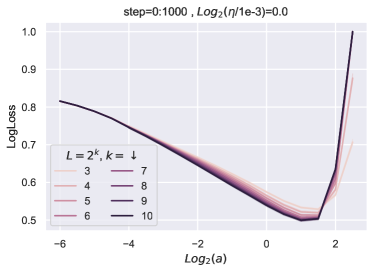
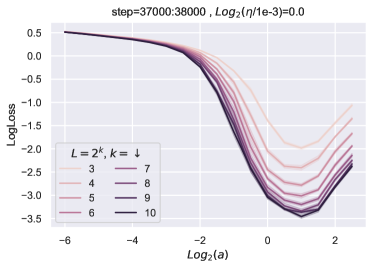
块乘数传输 ()。
10.3 Transformer 中会发生什么?

因为 Transformer 的块深度为 2,如部分 9中讨论的,我们有足够的理由怀疑(学习率,块multiplier)将能够在 Transformer 的深度上稳健地传输超参数。
在这里,我们使用受过 Common Crawl 训练的威震天进行了大规模实验,并对我们的观察结果进行了分类。252525我们使用余弦衰减计划和 500 个预热步骤对模型进行 3900 个步骤的训练。 我们使用的序列长度为 4096,批量大小为 256,导致每次训练运行大约 4B 个 Token 。 总之,在我们的特定设置(应该接近大多数大型语言模型预训练)中,我们看到 缩放似乎在 (LABEL:{fig :megatron-scaling-shifts}(右))。 然而,我们也看到 1) 深度在初始训练中表现更差 (LABEL:{fig:megatron-deeper-worse}(左)),以及 2) 最佳超参数规模如 训练中间(图 16(左))。 结合 Section 9 的理论见解,这使我们得出结论,虽然 缩放实际上可能是可行的它在 Transformer 训练中很有用,但它可能对架构和算法的变化,甚至像训练时间这样的简单事情很脆弱。
事实上,我们观察到 Transformer 对块乘数 不敏感(图 14),因此唯一的相关的超参数实际上只是学习率。 因此,如现代大规模预训练中所做的那样,凭经验测量最佳学习率的缩放趋势实际上可能是一种更稳健的传输超参数的方法。
这里是Transformer层的数量,每个层由一个注意力层和一个MLP层组成(每个层的深度为2)。
10.4功能多样性
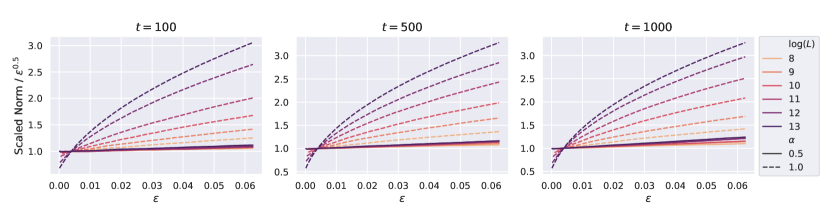
在本节中,我们将根据经验验证我们关于特征多样性指数的主张(Claims 7.4 和 7.5)。 我们使用与上一节相同的设置,即,我们使用 Adam 和批量大小 在 CIFAR-10 数据集上训练宽度 的深度残差网络。 在图17中,我们比较了两个参数化,Depth-P ()和ODE 参数化。 我们在 处测量 的两个参数化和变化的深度。 对于每个参数化和深度,我们通过乘以常数来重新调整函数,使得,然后绘制重新调整后的函数 干净的演示。 我们可以清楚地观察到,对于任何 ,Depth-P 的特征多样性指数(几乎),而当 增长时,ODE 参数化的曲线会从 变为 。 这完全符合我们的理论,即 Depth-P 最大化特征多样性,而其他参数化(即使使用特征学习)具有较小的特征多样性指数,应该在无限深度中达到 限制。
与和一起增长。
在 图 18中,我们在 处测量 ,并通过 除法 附加 和常数 使 对其进行重新缩放、然后绘制重新缩放的函数 以对 和 进行简洁的比较。 我们观察到,对于 Depth-P 和 ODE 参数化,曲线的斜率随着 和 一起增长。沿的增长可以通过层之间的累积相关性来解释。 ODE 参数化沿 的增长是因为当 增长时,附近层之间的独立分量减少。 我们对 Depth-P 沿 的增长没有清晰的理解,我们将其留作未来的工作。
绝对值激活增加了特征多样性。
在图19中,我们绘制了与图18相同的曲线> 但比较 Depth-P 下的 ReLU 激活和绝对值激活。我们观察到绝对值激活的曲线斜率小于 ReLU 激活。 它符合我们的理论,即绝对值激活会增加特征多样性。
致谢
我们感谢张辉帅、杰里米·伯恩斯坦、爱德华·胡、迈克尔·桑塔克罗斯、卢卡斯·刘的有益评论和讨论。 D. Yu 得到了 NSF 和 ONR 的支持。 部分工作是D. Yu在微软实习期间完成的。
作者贡献
GY在探索阶段的早期开发了核心理论并进行了实验,大部分实验都在最终草案中进行。 DY 研究并证明了线性 resnet 的关键主张(包括极限方程、收敛性和参数化分类),起草了论文的第一个版本,并进行了实验验证理论主张(包括线性情况的收敛性和特征多样性)分离)。 CZ在探索阶段的后期进行了实验。 与一般块深度情况相比,他们揭示了 Depth-P 在块深度 1 情况下的可行性。 CZ 还在论文的最终版本中进行了威震天实验。 SH 从项目一开始就致力于头脑风暴,编写了线性网络的热身部分,形式化了特征多样性指数的概念,并帮助将实验结果转化为图表和可视化。
参考
- Allen-Zhu et al. [2019] Z. Allen-Zhu, Y. Li, and Z. Song. A convergence theory for deep learning via over-parameterization, 2019.
- Chizat and Bach [2018] L. Chizat and F. Bach. On the global convergence of gradient descent for over-parameterized models using optimal transport, 2018.
- Chizat et al. [2020] L. Chizat, E. Oyallon, and F. Bach. On lazy training in differentiable programming, 2020.
- Hanin and Rolnick [2018] B. Hanin and D. Rolnick. How to start training: The effect of initialization and architecture, 2018.
- Hayou [2023] S. Hayou. On the infinite-depth limit of finite-width neural networks. Transactions on Machine Learning Research, 2023.
- Hayou and Yang [2023] S. Hayou and G. Yang. Width and depth limits commute in residual networks. In A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 12700–12723. PMLR, 23–29 Jul 2023. URL https://proceedings.mlr.press/v202/hayou23a.html.
- Hayou et al. [2021] S. Hayou, E. Clerico, B. He, G. Deligiannidis, A. Doucet, and J. Rousseau. Stable resnet. In A. Banerjee and K. Fukumizu, editors, Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, volume 130 of Proceedings of Machine Learning Research, pages 1324–1332. PMLR, 13–15 Apr 2021. URL https://proceedings.mlr.press/v130/hayou21a.html.
- He et al. [2016a] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016a.
- He et al. [2016b] K. He, X. Zhang, S. Ren, and J. Sun. Identity mappings in deep residual networks. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part IV 14, pages 630–645. Springer, 2016b.
- Jacot et al. [2020] A. Jacot, F. Gabriel, and C. Hongler. Neural tangent kernel: Convergence and generalization in neural networks, 2020.
- Jelassi et al. [2023] S. Jelassi, B. Hanin, Z. Ji, S. J. Reddi, S. Bhojanapalli, and S. Kumar. Depth dependence of p learning rates in relu mlps, 2023.
- Liu et al. [2020] L. Liu, X. Liu, J. Gao, W. Chen, and J. Han. Understanding the difficulty of training transformers. arXiv preprint arXiv:2004.08249, 2020.
- Noci et al. [2022] L. Noci, S. Anagnostidis, L. Biggio, A. Orvieto, S. P. Singh, and A. Lucchi. Signal propagation in transformers: Theoretical perspectives and the role of rank collapse, 2022.
- Noci et al. [2023] L. Noci, C. Li, M. B. Li, B. He, T. Hofmann, C. Maddison, and D. M. Roy. The shaped transformer: Attention models in the infinite depth-and-width limit, 2023.
- OpenAI [2023] OpenAI. Gpt-4 technical report, 2023.
- Shoeybi et al. [2019] M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053, 2019.
- Silver et al. [2016] D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. van den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, S. Dieleman, D. Grewe, J. Nham, N. Kalchbrenner, I. Sutskever, T. P. Lillicrap, M. Leach, K. Kavukcuoglu, T. Graepel, and D. Hassabis. Mastering the game of go with deep neural networks and tree search. Nature, 529:484–489, 2016.
- Srivastava et al. [2015] R. K. Srivastava, K. Greff, and J. Schmidhuber. Highway networks, 2015.
- Vaswani et al. [2017] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need, 2017.
- Yang [2020a] G. Yang. Scaling limits of wide neural networks with weight sharing: Gaussian process behavior, gradient independence, and neural tangent kernel derivation, 2020a.
- Yang [2020b] G. Yang. Tensor programs ii: Neural tangent kernel for any architecture, 2020b.
- Yang [2021] G. Yang. Tensor programs i: Wide feedforward or recurrent neural networks of any architecture are gaussian processes, 2021.
- Yang and Hu [2021] G. Yang and E. J. Hu. Tensor programs iv: Feature learning in infinite-width neural networks. In International Conference on Machine Learning, pages 11727–11737. PMLR, 2021.
- Yang and Littwin [2023] G. Yang and E. Littwin. Tensor programs ivb: Adaptive optimization in the infinite-width limit, 2023.
- Yang et al. [2022] G. Yang, E. J. Hu, I. Babuschkin, S. Sidor, X. Liu, D. Farhi, N. Ryder, J. Pachocki, W. Chen, and J. Gao. Tensor programs v: Tuning large neural networks via zero-shot hyperparameter transfer. arXiv preprint arXiv:2203.03466, 2022.
- Zhang et al. [2019] H. Zhang, Y. N. Dauphin, and T. Ma. Fixup initialization: Residual learning without normalization, 2019.
- Zhang et al. [2023] H. Zhang, D. Yu, M. Yi, W. Chen, and T.-Y. Liu. Stabilize deep resnet with a sharp scaling factor , 2023.
- Zou et al. [2018] D. Zou, Y. Cao, D. Zhou, and Q. Gu. Stochastic gradient descent optimizes over-parameterized deep relu networks, 2018.
附录A符号
本节介绍 [24] 中的新 TP 表示法。 在本文中我们只需要内积和外积的定义。
平均
当时,我们总是使用希腊下标来索引其条目。 那么表示其平均条目。 此表示法仅用于对 维度进行平均,但不适用于恒定维度。
A.1 张量程序 Ansatz:通过随机变量表示向量
从张量程序框架[25]中,我们知道随着宽度变大,(预)激活向量的条目及其梯度将在初始化和训练时变得大致独立同分布。 因此,任何此类向量的行为都可以通过反映其条目分布的随机变量来跟踪。 虽然我们称之为“张量程序 Ansatz”,但它是一种完全严格的微积分。
A.1.1 Ket 表示法
具体来说,如果 是这样一个向量,那么我们为这样一个随机变量写 (称为 ket),这样 的条目看起来像来自 的 iid 样本。对于任何两个这样的向量 ,每个 的 将看起来像iid 从随机向量 中采样,例如 ,我们将其简洁地写为 这里 被称为 bra,被解释为一种对 的“转置”。 在我们的约定中, 始终是独立于 的随机变量, 始终具有 典型条目大小。262626i.e., as 。
该表示法可以推广到 的情况。 在这种情况下,我们可以将 视为由 给出的 矩阵。
因为我们经常需要将 ket 与对角矩阵相乘,所以我们引入一个简写:
| (7) |
如果 是 并且 是 维向量。
A.1.2 外积
同样,如果 和 都具有形状 ,则表达式
更正式地说, 被定义为一个运算符,它接受 ket 并返回 ket
即,它返回随机向量 乘以右侧的确定性矩阵 。 这对应于的限制。 同样, 通过以下方式作用于胸罩 :
对应于的限制。 的这个定义使得表达式
明确(因为任何对操作进行排序的方式都会给出相同的答案)。
Remark A.1 (潜在混乱)。
人们不应该不将解释为标量随机变量,它会作用于ket 以产生,这是确定性的。 另一方面, 始终是 的线性组合,通常是非确定性随机变量。 特别是,和之间的任何相关性并不直接在它们的外积中发挥作用:我们总是有,其中 是独立于 的 的 iid 副本。
对角插入的外积
A.1.3 非线性外积
如果 是两个向量 和 的(线性)外积,则 是非线性 到 ,是一种非线性外积。传递到 ket 表示法,一般我们将 定义为运算符作用于 ket 为
其中 是独立于 的 的 iid 副本,并且期望仅针对前者。 这就像在有限的 情况下,
此外,如果,那么
其中 表示向量的外积,并且期望涵盖所有内容。
更一般地,如果 ,则 是一个将 kets 带到 kets 的运算符,定义为
Remark A.2 (潜在混乱)。
注意,并不是算子连续函数演算中算子在下的镜像,而是 例如,如果 ,则 不是 ,后者通常是“对运算符求平方”的含义,但是而是。
A.1.4 与之前的表示法的比较
对于熟悉张量程序论文的读者来说,这种新的“bra-ket”表示法(又名狄拉克表示法)与旧的表示法相关
新符号的期望内积的简洁性应该已经很明显了。 此外,旧的表示法与多向量不太兼容,而 清楚地表明 表示恒定维度边。 因此,(非线性)外积很难用它来表达,特别是当它与随机变量的收缩需要显式期望符号 时。
附录 B 带 Bra-ket 表示法的无限宽度限制
和之前一样,当程序的宽度 趋于无穷大时,我们可以通过随机变量的演算来推断程序的行为。 下面我们通过新的 ket 表示法而不是之前的 表示法来定义它们。
凯特建筑。
我们为程序中的每个向量 和每个标量 递归定义随机变量 (称为 ket)和确定性数 。 对于程序中的向量,我们还定义了随机变量和(称为hat-ket和分别为 dot-ket),使得 。 这些与旧 TP 表示法 [25] 中的 和 相同,并且满足
-
帽子
所有帽子都是具有零均值和协方差的联合高斯分布272727在eq. 8中,为当且仅当 和 是相同的矩阵(如程序中的符号)时,确定性数字为 1,否则为 0。 不应解释为当 和 取相同值时恰好为 1 的随机变量。
(8) -
点
每个 dot-ket 都是之前 ket 的线性组合,由以下等式表示
(9)
eq. 9 与 [25, Zdot] 中的方程相同,但在胸罩中的表述更加简洁-ket 表示法:
Yang 和 Littwin [24] 中的 有一个替代概念,即
由于我们引入了操作符视图,这样写起来就更方便了。
我们可以将 ket 视为运算符对 ket 执行操作的结果。
Definition B.1.
令 为张量程序中的初始矩阵。 我们将 定义为 ket 上的线性运算符 282828 为了严格起见,我们需要指定ket的“希尔伯特空间”。 这有点迂腐,对本文的要点并不重要,但希尔伯特空间可以构造如下:令 为由 kets 生成的 代数程序。 令 为 在扩展 的所有程序 上的并集(更准确地说,直接限制)。 那么所讨论的希尔伯特空间就是我们程序的 上的随机变量的 空间。 其行为由
任何等于的线性运算符 对于某些初始矩阵称为初始运算符。
我们还定义了运算符之间的伴随关系:
参数更新
在SGD情况下,的参数更新很简单。 利用运算符符号和外积符号,我们可以写出
在这项工作中,表示一步的变化,即
表示总变化,即
我们简洁地写成。 (与Yang和Littwin[24]相比,和分别由和改变因为我们想使用 进行渐变,而不是 ,后者现在用于深度微分)。
注意一般情况下,
在哪里
所以
| (10) |
为了方便起见,在本文的其余部分中,我们编写 。 eq. 10 的推广遵循 Yang 和 Littwin [24]。
附录C线性情况的详细信息
C.1 4.2
这里我们提供了4.2的证明草图,形式证明是由无限深度限制中和的存在来暗示的。
证明草图。
这些声明可以通过对 和 进行归纳来推理。让我们以为例,因为与对称。 通过扩展的定义,我们有
通过归纳法注意到,和,所以
然后通过展开 并注意通过归纳,、、、、,我们有
同样通过展开,,
C.2 和的形式化递归公式
以同样的方式对和进行展开,我们正式推导出下面和的递归公式。
Lemma C.1 (和的有限深度递归公式)。
可以递归计算如下:
对于,
-
•
,
-
•
对于 、、、、、0>
-
•
,
-
•
,
-
•
,
-
•
对于 、、、、、0>
程序 1 的证明很简单。 和 的递归性质产生以下无限深度行为。
Proposition C.2 (和的无限深度限制)。
在极限中,我们有:
C.3 当时和收敛
在本节中,我们证明当时和将收敛。 为了方便起见,我们只考虑为某个整数时的情况。为了区分不同对应的和,我们添加深度作为上标,即和.
Theorem C.3.
、、
-
•
是柯西序列,
-
•
是柯西序列。
证明是通过 归纳得出的。如果任何 都得到满足,我们将在 上证明以下声明 (A) (B) (C) (D)。对于,(A) (B) (C) (D) 是微不足道的。
关于的假设
假设 使得 和 对于 、、,
-
(A)
,
-
(二)
,。
-
(C)
是 -Lipschitz w.r.t。 , 是 -Lipschitz w.r.t。 。
-
(四)
,。
评论
(A) 表明 和 收敛。 我们只关心 ,因为 永远不会被使用,并且 是已知的:对于 ,
第 步的证明(前向传播)
在下面的小节中,我们将归纳证明所有 和 的升序,以及 的升序 ,
-
(D0)
;
-
(C0)
对于,;
-
(B0)
;
-
(A0)
;
-
(C1)
;
-
(B1)
;
-
(A1)
其中、、、、。
第 步的证明(向后传递)
通过对 的降序进行归纳,类似的界限也适用于 和 。
结论
结合时间 时的后向传递和前向传递,可以看出 (A)(B)(C)(D) 在 时也成立,且 更大(但恒定)。因此,通过对训练步数的归纳,(A)(B)(C)(D) 对任何常数 都成立。
前向传递中的 C.3.1 (D0、C0、B0、A0 的证明)
我们首先考虑
(D0) 和 之间的差异
假设(是微不足道的),让,注意自以来,所以对于,
如。
(C0) 利普希茨 w.r.t.
对于,
(B0) 有界
再次假设 ( 是微不足道的,因为 ),因为 ,我们可以绑定 :
只要。
(A0) 和 之间的差异有界
当 时,这是微不足道的。 当 时,Lipschitz w.r.t 也是微不足道的。 ,结果
当时,由于
我们将其与基于前两个步骤扩展的 进行比较
为了桥接上述两者,即匹配 和 的输入,我们需要一个中间项
现在我们可以分别绑定和,它们加起来就是的绑定。
和
总而言之,如,
前向传播中的 C.3.2 (C1、B1、A1 的证明)
现在考虑。 通过扩展
我们将有
(C1) 利普希茨
由于 和 有界且 Lipschitz,
(B1) 有界
从开始,我们将绑定为:
只要。
(A1) 和 之间的差异有界
很容易看出对于,
我们将证明对于,
然后通过(C1),对于,
假设,我们比较和。 直观上来说,两者都是,他们的区别是。 具体来说,两者都可以写成四个部分:
和 ,其中 的定义方式与 相同,但使用 和 而不是 和 。 接下来我们一一绑定:
-
1.
中唯一难以绑定的部分是
通过与(A0)几乎相同的证明,
然后我们有
-
2.
边界 与 类似,我们首先在其中绑定
然后我们有
-
3.
对于,我们首先简化
和
我们再次引入一个中间术语
然后我们就可以绑定了
-
4.
对于 ,我们使用
用于。 最后,
总共,
因此,从开始,
附录D线性情况下深度参数化的分类
我们讨论了带有 SGD 训练的线性残差网络的分类结果,并在这个简化的设置中给出了严格的证明。 回想一下线性残差网络:
其中,的有效学习率为。 不失一般性,我们假设。
D.1初始化
在初始化时,我们有
在哪里
由于 独立于 ,因此我们有
使用这个递归,我们可以写
因此, 当且仅当,否则 会与较大的 一起爆炸。
类似的论点代表 和 。 因此,我们证明了Claim 7.1。
类似地,我们可以得到第一个反向传递的稳定性,即对于。 给定,我们还可以确定的大小
这意味着
D.2 第一步梯度更新后
现在我们看第二个前向传递,假设输入相同,即 ,我们有
其中 和 是 的规范化版本,它恰好等于 。 通过和的定义,我们得到与Depth-P情况类似的公式:
现在我们写和,然后
通过扩展 ,我们有
| (11) |
请注意,eq. 11 中的四项是相互独立的。
训练过程中稳定且不平凡。
最后,我们可以对 进行推理(注意 ,因此 ),它表明参数化在第一步中是否稳定292929我们需要和来保持稳定性,但它们与类似。,以及第一步的参数化是否重要:
因此,我们证明了 Claim 7.2 参数化在训练过程中是稳定的 iff ,并且是非平凡的 iff 。
忠诚。
虽然线性情况下没有激活,但我们仍然证明 Claim 7.3 来启发一般情况的证明。
在初始化时,和具有相同的大小,因此,忠实性相当于稳定性,这意味着当且仅当时才会发生。
特征多样性指数。
分层线性化。
声明 7.6 在这种简化的设置中是微不足道的,因为分层线性化对于线性网络始终成立。 为了启发一般情况的证明,我们回顾一下,当时它比小得多。 如果有激活函数,线性化会在中带来的误差,这意味着到的误差。
D.3 超越一步
上面的论点一般是跟踪导数和协方差,换句话说,深度-P 情况下的 和。
然后可以通过跟踪 和 的顺序来推理所有声明。
使用 和 区分参数化。
和 的参数化都是重要的、稳定的和忠实的。 然而,(Depth-P)与在跟踪的难度和。对于,我们可以看到的、和。 在这种情况下,我们可以通过用 忽略 来简化递归:
其中如果 则为 ,如果 则为 。 注意 被简化为仅依赖于 的函数,因为固定 时 是常数。
这种简化意味着任何 中的随机性不会对无限深度限制中的动力学产生影响 - 4.4 中 的复杂函数积分为当 时简化为 ODE。 这种 ODE 动态还直接意味着 的特征多样性指数为 0。
附录 E 非线性深度 -P 限制
当非线性 并非微不足道时,由于 和 的复杂构成,最终表示 的分布可能高度非高斯,这一点可以从已知的大宽度极限实例中推测出来。 对于有限深度 确实是这种情况。但事实上,当时,又变成了高斯过程!
限制 GP 的核可以用与线性情况类似的方式计算:
Definition E.1。
递归地定义 和
这里
其中。
然后
Claim E.1。
对于足够平滑的非线性 ,在 极限内,kets 在分布上收敛为具有核的零均值高斯过程
如定义E.1中所定义。 因此,对于每个固定的神经元索引 ,集合 在 和 的极限中,其分布趋近于核 的零均值高斯过程。
我们将其视为一个主张,因为我们不想详细了解“足够平滑的非线性”在这里的含义,也不想给出证明。 相反,我们给出了直观的理由。
声明 E.1的启发式论证。
首先,在Depth-P中,我们可以对每个块进行泰勒展开
因此,在考虑了块乘数之后,余项贡献了。 对深度 求和,根据 Gronwall 引理,所有层的余数总和为 ,因此我们可以忽略它们。 从这里开始,我们研究线性化块。
现在关键的观察是 或 中的每一个始终等于 因子,与 的线性组合,其中该线性组合中的每个系数都是 且是确定性的。 我们将这样的线性组合称为良好的线性组合。 我们可以通过 上的归纳论证看出这一点。事实上,在初始化时,这个说法是非常正确的。 假设此声明对于 成立,那么很容易看出对于向后传递 kets 它在 处仍然成立。 唯一重要的部分是显示 的前向传播。 通过上面的泰勒展开,我们只需要证明 是通过良好的线性组合“很好地近似”的。 通过归纳, 和 都是良好线性组合与某些 的 形式项之间的乘积。 因此 的形式是 乘以良好的线性组合。 但仅与该线性组合中的单个分量相关,并且与所有其他分量无关。 因此,在深度求和时,不相关的分量会经历大数定律,可以将 替换为其期望值;相关分量只是每个大小为 的 个元素的总和,因此总共为 。 这样就完成了归纳。
这样推理,好的线性组合的系数就对应于DefinitionE.1中的,填入归纳的细节产生了定义E.1中的递归公式。
最后,由于良好的线性组合是独立项的大和,因此中心极限定理告诉我们分布收敛于高斯过程。 ∎
声明 E.1对于理论家来说是个好消息,我们有一个如此简单的基本架构形式。 同时,人们可能会担心这种高斯形式缺乏表现力。 但事实上,一些常见的架构或算法选择会使极限变得非高斯分布。 例如,使用 Adam 或 SignSGD 等自适应优化器。 或者在矩阵乘法之前添加非线性,即“prenonlin”(除了后面的“postnonlin”)。
一般来说,我们可以得到一个带有 McKean-Vlasov 元素的随机微分方程,描述 随着深度和时间的演变。 然而,所涉及的随机积分不是通常的伊藤或斯特拉托诺维奇积分,因为深度演化需要对布朗运动的非适应过程进行积分。 相反,我们需要使用 Skorohod 积分,并且 SDE 仅在 Malliavin 微积分意义上定义。 这不仅仅是数学上的挑剔;相反,假设伊藤微积分(相当于假设某些量之间不正确的独立性)将导致错误的预测和计算。 Malliavin 微积分与张量程序密切相关,我们将在未来的工作中发展它们的关系以及一般无限深度极限的理论。
附录F一般情况下证明的启发式
本节中的符号主要在附录A中定义。 完整的符号在[24]中定义。
F.1 深度-P
让 位于 处,其中 处。 回想一下网络的定义和归一化梯度
其中 坐标、 坐标和 坐标。
我们还滥用了 符号,并将其用作 ket 上的运算符:。
向前。
与线性情况类似,可以证明在技术条件下(主要是在激活函数上)TP 的无限深度极限遵循动态
其中 指分数图层索引( 表示图层索引 为 ), 指到训练步骤, 矩阵运算符(在附录 B中定义),波浪线符号指的是对象的“标准化”版本,即乘以ket 与 对于某些 ,使得乘法(归一化 ket)为 w.r.t。 ,对于规范化运算符也是如此。 如果 已经位于更宽的波浪号符号下,我们还将其简化为 。 第一项代表高斯噪声。
在线性情况下,我们有
笔记
使用多向量符号,我们写
落后。
与前向传播类似,我们获得无限深度 TP 的以下动态
这里 术语被删除了。 各个术语可以简化如下
产品规则中的其他条款被删除,因为
F.2 分支
F.2.1转发:
其中等式如下,因为 包含 的 代数,因此 。 从开始,,期望值实际上刚刚超过。
F.2.2 向后
这里 和 被丢弃,因为前者是零均值且独立于 ,后者被丢弃是因为 是包含 的 代数。
F.3 分支,
F.3.1转发
因为和上面的理由是一样的。
F.3.2 向后
这里,
F.4索赔的理由
声称7.2。 当很简单时训练期间的稳定性(需要一些激活函数的技术条件)。 这是因为权重更新的阶数为 ,而特征更新涉及的大小不超过 项,大小为 (加上不有助于大深度限制中的更新)。 当时,最多个阶项之和的贡献将减小到零,网络输出在这种情况下将收敛到 ,产生一个微不足道的极限。 然而,当 时,更新在无限深度限制中仍然很重要,从而产生了一个不平凡的限制。
声称7.3。 考虑稳定且重要的参数化(即 )。 仅当 时才能实现初始化的忠实性。 这在 [7] 中通过更通用的设置得到了证明。 只要,就可以确保训练期间的忠实度,因为功能更新始终是深度。 在这种情况下,对于 、 和权重更新,随着深度的增加而爆炸,这会产生 的爆炸行为。
声明7.4当时,我们在时获得平滑的极限动力学,如部分所示t6> F.3。 这个限制过程是一个平滑的过程(没有布朗跳跃),满足所需的冗余定义。
声称7.5。 仍有待证明Depth-P是非冗余的。 这是本例中动态限制的结果 (Section F.1)。 使用 Depth-P,隐藏层初始化的随机性在整个训练过程中始终存在,从而产生一个打破冗余的类布朗项。
附录 G其他实验
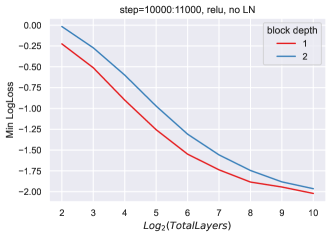
G.1 大深度标准参数化失败
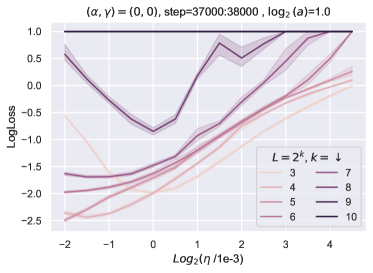
G.2 块深度为 2 的实验
目前,我们的理论涵盖了块深度为 1 的 resnet,并且我们的实验证实了理论结果。 我们对时钟深度 2(即残差块由 2 个全连接层组成)进行了类似的实验,看看学习率是否随 Depth-P 变化。结果报告于图21中。 结果显示学习率发生显着变化,这可能表明随着块深度的增加,需要进行调整以稳定超参数随深度的变化。
G.3其他实验