MMBench:您的多模态模型是全能型选手吗?
摘要
大型视觉语言模型最近取得了显着的进展,表现出对视觉信息的强大感知和推理能力。 然而,如何有效评估这些大型视觉语言模型仍然是阻碍未来模型发展的主要障碍。 VQAv2 或 COCO Caption 等传统基准提供了定量的性能测量,但缺乏细粒度的能力评估和不稳健的评估指标。 最近的主观基准,例如 OwlEval,通过纳入人类劳动来提供对模型能力的综合评估,但它们不可扩展并且显示出明显的偏差。 为了应对这些挑战,我们提出了 MMBench,一种新颖的多模态基准。 MMBench 有条不紊地开发了一个综合评估流程,主要由两个要素组成。 第一个元素是精心策划的数据集,在评估问题和能力的数量和种类方面超越了现有的类似基准。 第二个元素引入了一种新颖的 CircularEval 策略并结合了 ChatGPT 的使用。 此实现旨在将自由形式的预测转换为预定义的选择,从而促进对模型预测进行更稳健的评估。 MMBench 是一个系统设计的客观基准,用于稳健地评估视觉语言模型的各种能力。 我们希望 MMBench 能够帮助研究界更好地评估他们的模型,并鼓励该领域的未来进步。 项目页面:https://opencompass.org.cn/MMBench。
1简介
最近,大语言模型领域取得了显着的进展。 例如,最新的大型语言模型,如OpenAI的ChatGPT和GPT-4[31],已经表现出了卓越的推理能力,可以与人类相媲美,在某些情况下甚至超越人类的能力。 从大语言模型这些有希望的进展中汲取灵感,大型视觉语言模型(LVLM)领域经历了革命性的转变。 MiniGPT-4 [46]、Otter [23, 22] 和 LLaVA [27] 等著名作品已经展示了增强的功能在视觉语言模型领域的图像内容识别和推理方面,超越了早期模型的成就。 然而,当前大多数研究倾向于强调展示定性示例,而不是进行全面的定量实验来彻底评估其模型性能。 缺乏定量评估给比较各种模型带来了相当大的挑战。 为了解决这个问题,最近的研究探索了两种方法。 第一种方法是利用现有的公共数据集[15, 6]进行客观的定量评估。 另外,一些研究利用人力资源[40, 39]进行主观定量评估。 然而,值得注意的是,这两种方法都存在固有的局限性。
大量公共数据集,例如 VQAv2 [15]、COCO Caption [6]、GQA [20]、OK-VQA [29],长期以来一直是视觉语言模型定量评估的宝贵资源。 这些数据集提供客观指标,包括准确性、BLEU、CIDEr、等。 然而,当用于评估更先进的 LVLM 时,这些基准测试会遇到以下挑战:
-
(1)。
现有的评估指标需要预测与参考目标之间的精确匹配,从而导致潜在的局限性。 例如,在视觉问答(VQA)任务中,即使预测是“自行车”而参考答案是“自行车”,现有指标也会为当前预测分配负分,尽管其正确性。 因此,这个问题会导致大量的假阴性样本。
-
(2)。
当前的公共数据集主要侧重于评估模型在特定任务上的性能,对这些模型的细粒度功能提供的见解有限。 此外,他们对未来优化的潜在途径提供了最少的反馈。
鉴于上述挑战,最近的研究,例如 mPLUG-Owl [40] 和 LVLM-eHub [39] 提出了人类参与的主观评估策略,旨在通过在评估过程中纳入人类判断和感知来解决现有方法的局限性。 mPLUG-Owl 包含 82 个人工构建的开放式问题,与来自现有数据集的 50 张图像相关。 mPLUG-Owl 和另一个视觉语言 (VL) 模型生成预测后,人类注释者将评估这些预测的质量。 同样,受 FastChat [43] 的启发,LVLM-eHub 开发了一个在线平台,提示两个模型回答与图像相关的问题。 然后参与者比较两个模型提供的答案。 这些主观评估策略具有多种优势,包括准确匹配(人类可以准确地将预测与目标匹配,即使以不同的格式呈现)和全面评估(人类倾向于比较基于各种能力维度的两个预测,例如模型正确识别图像中的对象或理解它们之间关系的能力)。 最终得分计算为不同能力的平均分,从而可以综合评估各种模型的能力。
虽然主观评估可以更全面地评估模型的能力,但它也带来了需要解决的新挑战。 首先,人类的评价本质上是有偏见的。 因此,用不同的注释者组重现论文中呈现的结果变得具有挑战性。 此外,现有的主观评估策略还面临可扩展性问题。 每次实验后使用注释器进行模型评估是一项昂贵的工作。 此外,小规模的评估数据集可能会导致统计不稳定。 为了确保评估的稳健性,需要收集更多的数据,这反过来又需要大量的人力。
鉴于传统客观和主观基准面临的挑战,我们提出了MMBench,这是一种系统设计的客观评估基准,可以稳健地评估大型视觉语言模型的不同能力。 目前,MMBench 包含大约 3000 个单选题,涵盖 20 个不同的能力维度,例如视觉语言模型的对象定位和社会推理。 每个能力维度包括超过75个问题,能够对各种能力进行平衡、全面的评估。 能力维度不是静态的,并且会随着我们继续研究而扩展。 由于当前视觉语言模型的指令跟踪能力较弱,并且无法直接输出选择标签(A、B、C、等),因此我们无法直接将其输出与真实情况进行比较。 为了减少假阴性样本的数量,我们使用 ChatGPT 将模型的预测与多项选择题中的选项之一进行匹配,然后输出匹配选项的标签。 我们将基于 ChatGPT 的选择匹配与人类的选择匹配进行比较,发现 ChatGPT 可以完美匹配人类对 87% 模糊情况的评估,证明了其作为评估器的良好一致性和鲁棒性。 此外,为了使评估更加稳健,我们提出了一种新颖的评估策略,名为CircularEval(详细信息参见Sec. 4.1)。 我们在 MMBench 上全面评估了 14 个知名视觉语言模型,并报告了它们在不同能力维度上的表现。 此外,我们还对当代最大的多模式模型 Bard 与我们的基准开源 VLM 进行了比较评估。 性能排名提供了各种模型之间的直接比较,并为未来的优化提供了宝贵的反馈。 总而言之,我们的主要贡献有三方面:
-
系统构建的数据集:为了全面评估VLM的能力,我们精心打造了一个包含三个不同级别能力的系统框架。 在这些定义的能力级别内,我们精心策划了一个数据集,其中总共包含 2,974 个精心挑选的问题,总共涵盖了 20 种细粒度技能。
-
稳健评估:我们引入了一种新颖的循环评估策略(CircularEval)来提高评估过程的稳健性。 之后,使用ChatGPT将模型的预测与给定的选择进行匹配,即使从指令跟踪能力较差的VLM的预测中也可以成功提取选择。
2相关工作
2.1 多模态数据集
大规模视觉语言模型在复杂场景理解和视觉问答等多模态任务中表现出了巨大的潜力。 尽管迄今为止的定性结果令人鼓舞,但定量评估非常有必要系统地评估和比较不同VLM的能力。 最近的工作在许多现有的公共多模态数据集上评估了他们的模型。 COCO Caption [6]、Nocaps [2] 和 Flickr30k [41] 提供了人类生成的图像标题,相应的任务是理解图像内容并以文本形式描述。 视觉问答数据集,例如 GQA [20]、OK-VQA [29]、VQAv2 [15] 和 Vizwiz [ 16],包含与给定图像相关的问答对,用于衡量模型的视觉感知和推理能力。 一些数据集通过合并额外的任务来提供更具挑战性的问答场景。 例如,TextVQA [36] 提出有关图像中显示的文本的问题,从而将 OCR 任务纳入问答中。 ScienceQA [28]关注科学主题,要求模型将共义融入推理。 Youcook2 [45] 用视频剪辑替换图像,引入额外的时间信息。 然而,上述数据集是针对特定领域设计的,只能评估模型在一项或多项任务上的性能。 此外,跨数据集的不同数据格式和评估指标使得全面评估模型的能力变得更加困难。 Ye等人[40]构建了一个指令评估集OwlEval,它由几种与视觉相关的任务组成,但大小有限。 Fu 等人[12]构建了MME,这是一个包含多模态是/否问题的评估数据集。 然而,基于精确匹配的评估和不严格的评估设置使得更难以揭示VLM之间的真实性能差距。 与之前的工作不同,在本文中,我们提出了一种新颖的多模态基准 MMBench,它是基于测量能力而不是执行特定任务而构建的,旨在更好地一劳永逸地评估模型。
2.2多模态模型
受益于大语言模型的成功,例如 GPT [34, 4, 32]、LLaMA [38] 和 Vicuna [ 7],多模态模型最近也取得了很大的改进。 Flamingo [3]是将大语言模型引入视觉语言预训练的早期尝试之一。 为了很好地适应视觉特征,它在预训练的语言编码器层之间插入了几个门控交叉注意密集块。 OpenFlamingo [3] 提供了它的开源版本。 BLIP-2 [24] 提出了一种查询变换器(Q-former)来弥合冻结图像编码器和大型语言编码器之间的模态差距。 之后,InstructBLIP [8] 通过视觉语言指令调整扩展了 BLIP-2 [24] 并获得了更好的性能。 VisualGLM [9] 还采用 Q-former [24] 来桥接视觉模型和语言编码器 GLM [9]。 LLaVA [27] 采用仅具有语言输入的 GPT4 [31] 来生成用于视觉语言调整的指令跟踪数据。 Otter[23]还构建了一个指令调优数据集来提高OpenFlamingo的指令跟踪能力。 MiniGPT-4 [46]认为GPT4 [31]的能力来自先进的大语言模型,并建议仅采用一个项目层来使视觉表示与语言保持一致模型。 尽管它经过高计算效率的训练,但它展示了一些类似于 GPT4 [31] 的功能。 mPLUG-Owl [40] 提出了另一种学习范式,首先调整视觉编码器来总结和对齐视觉特征,然后使用 LoRA [18] 调整语言模型。 在本文中,在对所提出的 MMBench 和其他公共数据集进行彻底评估后,我们为未来的多模态研究提供了一些见解。
3 MMBench
MMBench 与现有的多模态理解基准有两个独特的特征: i) MMBench 采用各种来源的问题来评估分层分类中的多样化能力; ii) MMBench 采用基于 LLM 的稳健评估策略,可以很好地处理多模态模型的自由形式输出,并以可承受的成本产生值得信赖的评估结果。 本节我们将重点讨论 MMBench 的第一个特性,我们将后续内容组织如下:在 Sec. 3.1 中,我们介绍了MMBench的分层能力分类并讨论背后的设计理念。 在Sec. 3.2中,我们简要介绍了我们如何收集MMBench问题,并提供了MMBench的一些统计数据。
3.1 MMBench能力分层分类
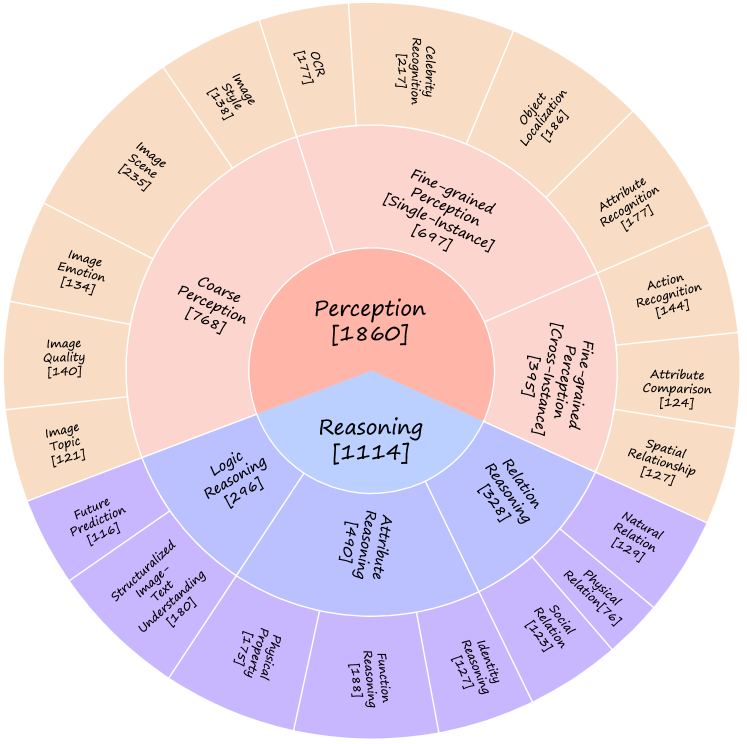
人类拥有卓越的感知和推理能力,使他们能够理解世界并与世界互动。 这些能力在人类进化中至关重要,并且是复杂认知过程的基础。 感知是指从感官输入中收集信息,而推理则是根据这些信息得出结论。 它们共同构成了现实世界中大多数任务的基础,包括识别对象、解决问题和做出决策[30, 11]。 为了追求真正的通用人工智能,视觉语言模型也有望表现出强大的感知和推理能力。 因此,我们将感知和推理作为我们能力分类中的顶级能力维度,称为L-1能力维度。 对于L-2能力,我们得出:1。 粗略感知, 2. 细粒度单实例感知,3. 细粒度跨实例感知来自L-1感知;和 1。 属性推理,2. 关系推理,3. 逻辑推理来自L-1推理。 使我们的基准尽可能细粒度,以便为开发多模态模型提供信息反馈。 我们进一步从L-2能力维度推导出L-3能力维度。
3.2数据收集与统计
在当前版本的 MMBench 中,我们针对每种 L-3 能力以多项选择问题的形式收集视觉语言 QA。 多项选择问题对应于四元组。 表示问题,表示带有()选择的集合, 对应于与问题相关的图像, 是正确答案。 在附录中,我们可视化了与每个L-3能力相对应的数据样本。 我们的数据(包括图像、选择和问题)是从多个来源收集的。 表1中提供了这些来源的全面细分。 在数据收集过程的初始或“冷启动”阶段,我们为每种 L-3 能力组装了一套 10 到 50 个多项选择问题。 这些问题作为范例,说明了与每种能力评估相关的具体问题类型。 随后,注释者利用这些范例来扩展与每种 L-3 能力相关的多项选择问题的集合。 通过参考这些范例,注释者确保收集到的问题仍然相关且适合评估目标能力。 值得注意的是,一些数据样本来源于公共数据集,例如COCO-Caption [6],它已被多个公共视觉语言模型用于预训练。 无论如何,MMBench 上的评估仍然可以被视为域外评估[8],主要原因有两个:首先,我们的数据是从这些公共数据集的验证集收集的,而不是它们的训练集。 其次,从这些公共数据集中获取的数据样本占所有 MMBench 数据样本的比例不到 10%。
数据统计。 在本研究中,我们总共收集了 2,974 个数据样本,涵盖 20 种不同的 L-3 能力。 我们在图2中描述了所有3个能力级别的问题计数。 为了确保对每种能力进行平衡和全面的评估,我们在数据收集过程中尽量保持与不同能力相关的问题的均匀分布。
数据分割。 我们遵循之前作品[29]中采用的标准做法,以4:6的比例将MMBench分为dev和test子集。 对于 dev 子集,我们公开提供所有数据样本以及所有问题的真实答案。 对于测试子集,仅发布数据样本,而真实答案仍然保密。 为了获得测试子集的评估结果,需要将预测提交到MMBench评估服务器。
| Image Source | Question Source | Choice and Answer Source |
| W3C School [1] | customize | matched code;unmatched code |
| Places [44] | customize | image-paired scene category;unpaired scene category |
| TextVQA [36] | TextVQA | ground-truth answer;unpaired answer |
| ARAS [10] | customize | image-paired action category;unpaired action category |
| CLEVR [21] | CLEVR | ground-truth answer;unpaired answer |
| PISC [25] | customize | image-paired social relation;unpaired social relation |
| KonIQ-10k [17] | customize | image-paired description;unpaired description |
| VSR [26] | customize | image-paired description;unpaired description |
| LLaVA [27] | ChatGPT generated | ChatGPT generated |
| COCO-Caption [6] | customize | image-paired description;unpaired description |
| ScienceQA [28] | ScienceQA | ground-truth answer;unpaired answer |
| Internet | customize | customize; customize |
4评估策略
在 MMBench 中,我们提出了一种新的评估策略,可以以可承受的成本产生可靠的评估结果。 在策略层面,我们采用循环评估策略,将问题多次(使用不同的提示)提供给VLM,并检查VLM是否在所有尝试中都成功解决了问题。 为了处理自由格式 VLM 的输出,我们建议使用 ChatGPT 作为选择提取的助手。 我们进行了大量的实验来研究 ChatGPT 涉及的评估程序。 结果很好地支持了 ChatGPT 作为选择提取器的有效性。 如果没有规范,我们在以下所有实验中使用 gpt-3.5-turbo-0613 作为选择提取器。

4.1 循环评估策略
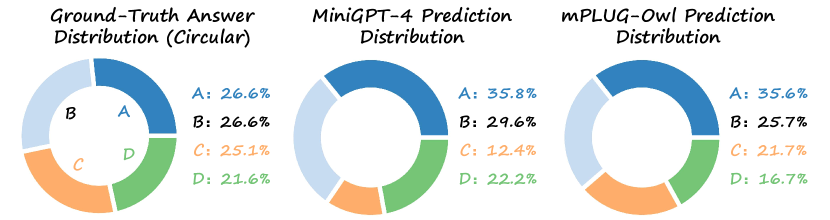
MMBench 包含了一系列旨在评估视觉语言模型 (VLM) 多方面功能的问题。 这些问题以单项选择题的形式呈现。 该公式提出了评估挑战:随机猜测可能导致 4 选择题的 Top-1 准确率达到 25%,从而有可能减少各种 VLM 之间可辨别的性能差异。 此外,我们注意到VLM可能更倾向于预测所有给定选择中的某个选择(图4),这进一步放大了评估的偏差。 为此,我们引入了一种更强大的评估策略,称为循环评估(或CircularEval)。 在此设置下,每个问题都会被馈送到 VLM 次( 等于选择数)。 每次对选择和答案应用循环移位,为 VLM 生成新的提示(图3中的示例)。 仅当 VLM 在所有旋转过程中正确预测答案时,才被视为成功解决问题。 请注意,CircularEval 不一定需要 推理成本。 根据定义,如果 VLM 在一次传递中做出了错误的预测,我们可以直接丢弃后面的传递,并说 VLM 在这道题中失败了。 CircularEval 在鲁棒性和评估成本之间实现了良好的权衡。
4.2 ChatGPT涉及的选择提取
在我们最初尝试解决 MMBench 问题时,我们发现各种 VLM 的指令跟踪能力是有限的。 尽管问题以清晰的单选题和格式良好的选项的形式呈现,但许多 VLM 仍然以自由格式文本输出答案(例如,模型的直接输出可以是正确答案是 [选择“A”内容],但不选择A)。 从自由形式的预测中提取选择对于人类来说很容易,但对于基于规则的匹配来说却很困难。 因此,我们为具有不同指令跟踪能力的所有 VLM 设计了通用评估策略:
步骤1。 匹配预测。 从 VLM 预测中提取具有精确匹配的选择。 例如,对于“C”,我们尝试匹配 “C”、“C.”、“C)”、“C”、“C).”、等。 VLM 输出中的所有单词。 匹配后,我们成功提取了模型的选择111“A”可能在句子中包含冠词。 因此,我们在匹配句子时跳过这个候选者。 .
第2步。 匹配 ChatGPT 的输出。 如果步骤 1 失败,我们将尝试使用 ChatGPT 提取选择。 我们向 GPT 提供问题、选项和模型预测,然后,我们请求 ChatGPT 将预测与给定选项之一对齐,并随后生成相应选项的标签。
步骤 3. 后备:随机分配。 如果第 2 步仍然无法提取选择,我们将在所有有效选择中随机选择一个预测并标记“X”。 此外,还将添加一条注释消息来表示 ChatGPT 无法解析模型预测。 这一步是我们的预备知识可行性分析中从未遇到过的(Sec. 4.3),但为了管道完整性我们还是添加了它。
基于 ChatGPT 的选择提取。 为了利用 ChatGPT 作为选择提取器,我们使用以下模板对其进行查询,包括问题、选项和相应的 VLM 预测:
然后我们从 GPT 的响应中得到预测的选项(例如 A)。 对于大多数问题,GPT-3.5 能够返回单个字符(例如 A、B、C)作为答案。 对于每个输入,我们将模型的标签预测(在 GPT 的相似性读出之后)与实际的真实标签进行比较。 如果预测与标签匹配,则测试样本被认为是正确的。
4.3 ChatGPT作为法官:可行性分析
| Model Name | Step-1 | Step-2 |
| LLaMA-Adapter [13] | 1.0% | 100.0% |
| OpenFlamingo [3] | 98.6% | 100.0% |
| VisualGLM [9] | 14.9% | 100.0% |
| MiniGPT-4 [46] | 71.6% | 100.0% |
| LLaVA [27] | 9.9% | 100.0% |
| Otter-I [23] | 100.0% | 100.0% |
| InstructBLIP [8] | 91.2% | 100.0% |
| mPLUG-Owl [40] | 42.6% | 100.0% |
我们首先进行试点实验来研究 ChatGPT 作为判断的有效性。 为了保持设置简单,对于 MMBench ,我们对具有 1000 个样本的子集进行采样,并使用普通单遍评估策略来评估 8 个选定的 VLM。 我们还在研究中纳入了传统的 VQA 基准。
不同VLM的指令遵循能力差异很大。 ChatGPT 涉及的选择提取在 MMBench 评估中起着至关重要的作用,特别是对于指令跟踪能力较差的 VLM。 在表2中,我们展示了评估策略的步骤1和步骤2的成功率。 第 1 步的成功率(将选择与 VLM 预测进行匹配)与 VLM 的指令跟踪能力直接相关。 表2显示,不同VLM的step-1成功率相差很大,覆盖范围很广,从1.0%到100.0%。
然而,配备ChatGPT选择提取器后,所有VLM的step-2成功率接近100%,这使得MMBench上不同VLM的公平比较成为可能。 还有一点值得注意的是,指令跟随能力和整体多模态建模能力并不一定相关。 OpenFlamingo [3] 展示了所有 VLM 中最好的指令跟踪能力,同时也在 MMBench 上实现了最差的性能之一(表 5)。
人类 v.s ChatGPT:选择提取中的对齐。
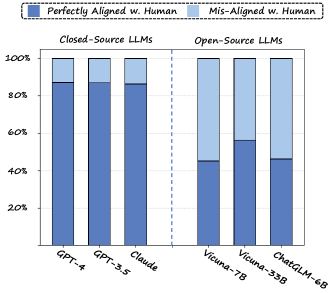
对于无法精确匹配解析的 VLM 预测,我们采用 ChatGPT 作为选择提取器。 为了验证其功效,我们对 MMBench 的子集进行了采样,其中包含 103 个问题和 824 个 () 问答对。 我们只保留评估步骤 1 无法解析的 QA 对,这会产生 376 个数据样本。 在6名志愿者的帮助下,我们对这些数据样本进行手动选择提取222人工注释将被发布。 .
在图5中,我们报告了ChatGPT和Human之间的对齐率(提取的选择完全相同)。 具体来说,ChatGPT (GPT-3.5) 实现了 87.0% 的对齐率,而更强大的 GPT-4 实现了稍好的 87.2%。 我们进一步进行了消融研究,以了解使用各种大语言模型作为选择提取器的效果。 GPT-4和ChatGPT在所有大语言模型中处于领先地位。 与 ChatGPT 相比,Claude 实现了非常接近的对齐率 (86.4%)。 现有的开源大语言模型改编自LLaMA [13]和GLM [9],在选择匹配任务上表现不佳。 进一步扩展架构(例如从 Vicuna-7B 扩展到 Vicuna-33B)只能带来有限的改进。 我们在评估中采用 ChatGPT 作为选择提取器,以实现良好的性能成本权衡。
错位案例分析。 由于新引入的伪选择“X”,有时人类和大语言模型在进行选择提取时会由于不同的匹配阈值而做出不同的决定。 例如,代理可以将预测与给定选择进行匹配,因为是与;而代理可以输出选择,因为他/她认为与任何选择都不够相似。 基于这一观察,我们将 50 个 ChatGPT 未对齐案例分为两类:

案例一。 Human 或 ChatGPT 无法将预测与给定的选择相匹配,并输出“X”。 70% 未对齐的样本属于这种情况。
案例二. Human 和 ChatGPT 成功地将预测与给定的选择匹配,但匹配结果不同。 30% 未对齐的样本属于这种情况。
在这两种情况下,I表示人类和ChatGPT的判断不太一致(可能是由于评估标准不同),而II表示人类和ChatGPT的判断完全一致不同的。 我们手动调查Case-II中的15个样本,发现: 1. 在 7 个样本中,ChatGPT 进行了正确的匹配,而人类则进行了错误的匹配; 2. 6个样本中,模型的预测不明确,且与多项选择相关; 3. 在 2 个样本中,人类进行了正确的匹配,而 ChatGPT 进行了错误的匹配。 结果表明,即使与人类注释者相比,ChatGPT 也具有强大的选择匹配能力。 我们在图6中可视化案例II样本。
针对现有多模态任务的基于 ChatGPT 的评估。 为了证明 ChatGPT 是一个通用评估器,我们还在现有的多模态任务上验证了基于 ChatGPT 的评估范例,包括 GQA [20]、OK-VQA [29]和文本-VQA [36]。 给出真实答案后,我们使用 GPT3.5 对 VLM 的预测进行评分333分数将为 [1, 2, 3, 4, 5] 中的整数。 1表示完全错误,5表示完全正确。 我们在附录中提供了用于标记的提示。 . 对于每个基准测试,我们随机选择 1000 个测试样本,并分别使用精确匹配(传统范式)和基于 GPT 的匹配进行评估,并将结果列于表 3。 基本上,与所有任务的精确匹配精度相比,基于 GPT 的评估表现出相同的趋势。 在 GQA 上,两种算法在基于 GPT 的评估下表现出非常接近的性能。 在进一步调查中,我们发现原因是 GPT 成功匹配了 MiniGPT-4 生成的略有不同的答案(与 GT 相比),而精确匹配失败(Table 7 中的示例) )。
| Dataset | GQA [20] | OK-VQA [29] | Text-VQA [36] | |||
| Model | Flamingo | MiniGPT-4 | Flamingo | MiniGPT-4 | Flamingo | MiniGPT-4 |
| Accuracy | 33.6% | 22.4% | 42.6% | 21.9% | 22.9% | 9.8% |
| Average GPT score | 2.75 | 2.74 | 2.79 | 1.97 | 1.92 | 1.54 |
5评估结果
5.1 VLM推理设置
目前,我们采用传统的零样本设置进行VLM推理,主要是由于现有VLM与少样本评估设置的兼容性有限。 然而,我们注意到大语言模型[19]中少样本评估方案的巨大潜力。 在未来的工作中,我们特别计划构建指定用于少样本评估的数据样本子集。 我们预计少样本评估将演变成一种标准评估策略,类似于大语言模型中采用的方法。
5.2 主要结果
我们选择了 14 个不同的多模态模型并在 MMBench 上对它们进行基准测试。 我们选择的模型涵盖了广泛的策略和架构,有效地说明了当前多模态理解的最新技术。 为了便于公平比较,我们主要检查所有多模态模型的“轻”版本——当存在多个变体时,参数总量低于 10B 的模型。 为了进一步参考,我们还评估了一些选定模型的较大变体(例如 13B),并报告其性能。 有关这些模型的架构和总参数的详细信息,请参阅表15。
| Eval \VLM | OpenFlamingo | LLaMA-Adapter | MiniGPT-4 | MMGPT | InstructBLIP | VisualGLM | LLaVA | mPLUG-Owl |
| VanillaEval | 34.6% | 62.6% | 50.3% | 49.1% | 61.3% | 60.4% | 56.1% | 67.3% |
| CircularEval | 4.6% | 41.2% | 24.3% | 15.3% | 36.0% | 38.1% | 38.7% | 49.4% |
| -30.0% | -21.4% | -26.0% | -33.8% | -25.3% | -22.3% | -17.4% | -17.9% | |
| Eval \VLM | OpenFlamingo v2 | -G2PT | MiniGPT-4-13B | Otter-I | InstructBLIP-13B | PandaGPT | Kosmos-2* | Shikra |
| VanillaEval | 40.0% | 61.3% | 61.3% | 68.8% | 64.4% | 55.2% | 58.2% | 69.9% |
| CircularEval | 6.6% | 43.2% | 42.3% | 51.4% | 44.0% | 33.5% | 58.2% | 58.8% |
| -33.4% | -18.1% | -19.0% | -17.4% | -20.4% | -21.7% | 0.0%* | -11.1% |
在深入研究具体的评估结果之前,我们首先将我们的 CircularEval (多次推理问题,一致性是必须的)与 VanillaEval (仅推理一次问题)进行比较。 在表 4中,我们展示了MMBench dev split上两种评估策略的结果。 对于大多数 VLM,从 VanillaEval 切换到 CircularEval 会导致模型精度显着下降。 此外,两次评价结果还可以得出不同的结论。 举个例子,InstructBLIP 在 VanillaEval 中的表现优于 LLaVA,但在 CircularEval 中我们得到了相反的结论。 在接下来的实验中,我们采用CircularEval作为我们的默认评估策略,这是一个更合理且定义明确的评估范式。
| VLM | Overall | LR | AR | RR | FP-S | FP-C | CP |
| OpenFlamingo [3] | 4.6% | 6.7% | 8.0% | 0.0% | 6.7% | 2.8% | 2.0% |
| OpenFlamingo v2 [3] | 6.6% | 4.2% | 15.4% | 0.9% | 8.1% | 1.4% | 5.0% |
| MMGPT [14] | 15.3% | 2.5% | 26.4% | 13.0% | 14.1% | 3.4% | 20.8% |
| MiniGPT-4 [46] | 24.3% | 7.5% | 31.3% | 4.3% | 30.3% | 9.0% | 35.6% |
| InstructBLIP [8] | 36.0% | 14.2% | 46.3% | 22.6% | 37.0% | 21.4% | 49.0% |
| VisualGLM [9] | 38.1% | 10.8% | 44.3% | 35.7% | 43.8% | 23.4% | 47.3% |
| LLaVA [27] | 38.7% | 16.7% | 48.3% | 30.4% | 45.5% | 32.4% | 40.6% |
| LLaMA-Adapter [42] | 41.2% | 11.7% | 35.3% | 29.6% | 47.5% | 38.6% | 56.4% |
| -G2PT | 43.2% | 13.3% | 38.8% | 40.9% | 46.5% | 38.6% | 58.1% |
| mPLUG-Owl [40] | 49.4% | 16.7% | 53.2% | 47.8% | 50.2% | 40.7% | 64.1% |
| Otter-I [23, 22] | 51.4% | 32.5% | 56.7% | 53.9% | 46.8% | 38.6% | 65.4% |
| Shikra [5] | 58.8% | 25.8% | 56.7% | 58.3% | 57.2% | 57.9% | 75.8% |
| Kosmos-2∗ [33] | 59.2% | 46.7% | 55.7% | 43.5% | 64.3% | 49.0% | 72.5% |
| PandaGPT [37] | 33.5% | 10.0% | 38.8% | 23.5% | 27.9% | 35.2% | 48.3% |
| MiniGPT-4-13B [46] | 42.3% | 20.8% | 50.7% | 30.4% | 49.5% | 26.2% | 50.7% |
| InstructBLIP-13B [8] | 44.0% | 19.1% | 54.2% | 34.8% | 47.8% | 24.8% | 56.4% |
| VLM | Overall | LR | AR | RR | FP-S | FP-C | CP |
| OpenFlamingo [3] | 4.3% | 9.1% | 11.4% | 3.3% | 2.5% | 1.6% | 1.5% |
| OpenFlamingo v2 [3] | 5.7% | 11.4% | 12.8% | 1.4% | 5.5% | 0.8% | 4.0% |
| MMGPT [14] | 16.0% | 1.1% | 23.9% | 20.7% | 18.3% | 5.2% | 18.2% |
| MiniGPT-4 [46] | 23.0% | 13.6% | 32.9% | 8.9% | 28.7% | 11.2% | 28.3% |
| VisualGLM [9] | 33.5% | 11.4% | 48.8% | 27.7% | 35.8% | 17.6% | 41.5% |
| InstructBLIP [8] | 33.9% | 21.6% | 47.4% | 22.5% | 33.0% | 24.4% | 41.1% |
| LLaVA [27] | 36.2% | 15.9% | 53.6% | 28.6% | 41.8% | 20.0% | 40.4% |
| LLaMA-Adapter [42] | 39.5% | 13.1% | 47.4% | 23.0% | 45.0% | 33.2% | 50.6% |
| -G2PT | 39.8% | 14.8% | 46.7% | 31.5% | 41.8% | 34.4% | 49.8% |
| mPLUG-Owl [40] | 46.6% | 19.9% | 56.1% | 39.0% | 53.0% | 26.8% | 59.4% |
| Otter-I [23, 22] | 48.3% | 22.2% | 63.3% | 39.4% | 46.8% | 36.4% | 60.6% |
| Kosmos-2∗ [33] | 58.2% | 48.6% | 59.9% | 34.7% | 65.6% | 47.9% | 70.4% |
| Shikra [5] | 60.2% | 33.5% | 69.6% | 53.1% | 61.8% | 50.4% | 71.7% |
| PandaGPT [37] | 30.6% | 15.3% | 41.5% | 22.0% | 20.3% | 20.4% | 47.9% |
| MiniGPT-4-13B [46] | 42.3% | 17.0% | 62.6% | 30.0% | 49.8% | 19.6% | 50.6% |
| InstructBLIP-13B [8] | 43.1% | 17.0% | 59.5% | 36.2% | 45.8% | 24.0% | 53.8% |
我们在 MMBench 现有的 20 个叶子能力上详尽地评估了 8 个模型。 在 Table 5 和 Table 6 中,我们报告模型的整体性能以及六种L-2能力的性能,即逻辑推理(LR)、属性推理(AR)、关系推理(RR)、细粒度感知(跨实例) (FP-C)、细粒度感知(单实例)(FP-S) 和粗粒度感知 (CP)。 这些结果为了解每个模型在多模态理解的不同方面的各自优势和局限性提供了宝贵的见解。
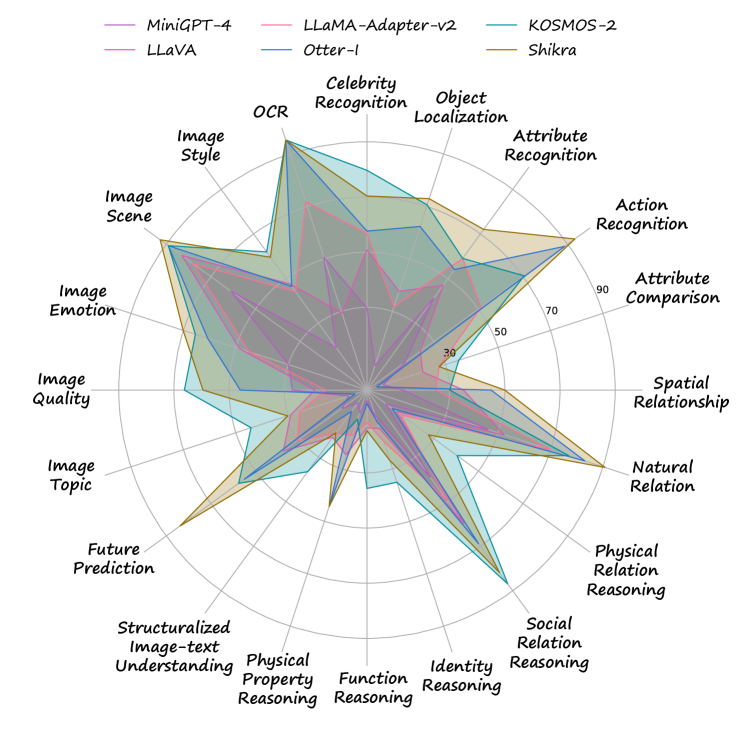
如Table6和Table5所示、Shikra 和 Kosmos-2 产生了优异的结果,在几乎所有 L-2 能力上都显着优于其他模型。 其次是 mPLUG-Owl、Otter-I 和 LLaMA-Adapter 这两个型号444根据提交评估结果的作者介绍,评估的模型是使用 LAION400M [35] for Visual-Language 训练的 LLaMA-Adapter预训练和 LLaVA–I [27] 用于指令调整。 也都表现出了可圈可点的表现,并且彼此具有可比性。 之后,四个模型(Otter-I、InstructBLIP、VisualGLM、LLaVA)总体性能大致处于同一水平,但在 L2 能力方面各有优势。 在所有 14 个模型中,OpenFlamingo、MMGPT 和 MiniGPT-4 (7B) 与其他模型相比表现出较低的整体性能。 此外,很明显,模型扩展可以增强性能指标。 这一点很明显,MiniGPT-4-13B 比 MiniGPT-4 的性能高出了令人印象深刻的 19.3%,而 InstructBLIP-13B 比其前身 InstructBLIP 的性能高出 9.2%。
MMBench 的评估表明,每个多模态模型在不同的能力水平上都表现出独特的优势和劣势。 这一观察结果强调了根据给定任务的具体要求和目标仔细选择和微调多模态模型的重要性。 此外,某些能力的局限性表明了多模态人工智能系统进一步研究和开发的潜在方向。
为了更深入的了解,我们在Table8中对L3能力进行了全面的分析,让读者可以一探究竟MMBench 并更深入地了解评估模型之间的性能差异。
5.3分析
通过综合评估,我们观察到一些有趣的事实,有望为未来的优化提供见解。
现有的 VLM 的指令跟踪能力有限。 为了有效评估,我们引导每个模型仅输出每个选项的标签,例如 A、B、C 或 D。然而,我们观察到这些模型通常会生成与一个选项或一个选项相对应的完整句子。句子在语义上类似于选项之一。 这种趋势是使用 ChatGPT 进行选择提取的主要原因。 为了提高多模态模型的可用性以赋能多样化的应用,追求更强的指令跟踪能力可能是一个重要的方向。
现有 VLM 的整体性能仍然有限。 严格的CircularEval策略表明现有VLM的整体性能并不令人满意。 在实验中,除了 Kosmos-2 和 Shikra 之外,所有 VLM 在 MMBench test 上对于最多 4 个选项的多项选择题都未能达到 50% Top-1 准确率。 可能的原因有两个:1. 当前的 VLM 不够强大,无法在提示略有不同的情况下生成相同的预测(CircularEval 下的性能比 VanillaEval 下的性能差得多,请参阅表 4)。 2. 当前 VLM 的功能仍然相当有限,还可以进一步改进。 我们希望MMBench和我们的评估策略能够成为未来VLM开发、迭代和优化的重要资源。
跨实例理解和逻辑推理是极其困难的。 对我们评估结果的检查表明,跨实例理解——特别是关系推理(RR)和跨实例细粒度感知(FP-C)——对现有的视觉语言模型(VLM)提出了重大挑战。 所有模型的跨实例细粒度感知在 dev 和 test 分割上的平均准确率分别为 27.7% 和 23.4%,显着低于单实例细粒度感知(FP-S)。 关系推理 (RR) 和属性推理 (AR) 之间也存在类似的差异,如 表 6 和 5. 此外,与其他L-2能力相比,现有模型的逻辑推理(LR)能力显得非常弱,平均准确率仅为17.8%。 结果表明,提高 VLM 的跨实例理解和逻辑推理能力可能是一个重要且有前途的方向。
对象定位数据的引入预计将提高模型性能。 在各种模型中,Kosmos-2 和 Shikra 的表现尤其出色,几乎所有 L-2 功能都得到了显着改进,特别是在逻辑推理和跨实例细粒度感知方面。 与其他模型相比,Kosmos-2 和 Shikra 都在其训练数据集中纳入了对象定位。 定位数据的集成将更详细的特定于对象的信息注入模型中,使模型能够更有效地理解对象的动态状态。 此外,它有助于阐明不同对象之间的关系和交互。 该策略对模型逻辑推理和跨实例细粒度感知能力的增强做出了实质性贡献。
6结论
传统基准(VQAv2、COCO Caption 等等)和主观基准(mPLUG-Owl、等)的固有局限性,强调了对创新评估范式的需求。视觉语言理解。 为了解决这个问题,我们引入了 MMBench,这是一个多模态基准,提出了一个涵盖 20 个能力维度的 2,974 个多项选择题的客观评估管道。 为了产生稳健可靠的评估结果,我们引入了一种名为CircularEval的新评估策略。 该策略比普通的 1-pass 评估严格得多,并且可以以可承受的成本产生可靠的评估结果。 此外,我们利用 ChatGPT 将模型预测与目标选择进行比较,从而能够在具有不同指令跟踪能力级别的 VLM 之间进行公平比较。 对MMBench和公共基准的综合研究表明使用ChatGPT作为判断的可行性。 我们希望 MMBench 能够帮助研究界优化模型并激发未来的进步。
7致谢
我们对社区贡献者的贡献表示衷心感谢。 微软亚洲研究院的董力和彭志良在MMBench上提供了Kosmos-2的推理结果。 此外,感谢上海人工智能实验室的高鹏和徐鹏提供-G2PT和LLaMA-Adapter的推理结果。 我们也感谢商汤科技的张昭和陈克勤提供的 Shikra 推理结果。 此外,我们还要感谢上海人工智能实验室的葛嘉业,感谢他精心安排了数据收集过程并确保了数据集的及时交付。 Yixiao Fang 在 MMBench 上推断 MMGPT 方面的帮助也值得我们赞赏。 最后,我们要感谢上海人工智能实验室的徐军和杜晓勤,他们的支持对MMBench网页和排行榜的建设起到了重要作用。
附录A基于GPT的VQA评估
用于基于 GPT 的 GQA [20] 评估的提示:
用于基于 GPT 的 OK-VQA [29] 和 Text-VQA [36] 评估的提示:
许多MiniGPT-4 GQA答案无法进行精确匹配,但可以通过基于GPT的评估进行匹配。 这里我们提供一些例子:
| Question | GroundTruth | MiniGPT-4 Answer | GPT Score |
| On which side of the picture is the leather bag? | right | leather bag is on right side | 5 |
| Who is wearing a shirt? | girl | woman is wearing shirt | 5 |
| What is the pen made of? | plastic | pen is made of plastic## | 5 |
| What does the male person ride on? | bike | bicycle | 4 |
| Is the microwave silver and rectangular? | Yes | microwave is silver and rectangular | 5 |
| How does the silver lamp appear to be, on or off? | off | silver lamp appears to be off ## | 5 |
附录BL-3粒度的评估结果
在表、8、9、10、11、12和13中,我们介绍了 VLM 在所有 20 种 L-3 能力上的表现。 我们注意到L-3能力的排名更加多样化。 除了领先的 VLM Shikra 和 Kosmos-2 之外,其他 VLM,包括 mPKUG-Owl、InstructBLIP-13B、MiniGPT-4-13B、Otter-I 也在 dev 上的一个/多个子任务中获得第一名 / 测试 OmniMMBench 的拆分。
| Split | VLM | CP |
|
|
|
|
|
||||||||||
| DEV | OpenFlamingo | 2.0% | 0.0% | 1.9% | 0.0% | 1.9% | 8.3% | ||||||||||
| OpenFlamingo v2 | 5.0% | 3.8% | 3.8% | 4.0% | 3.7% | 13.9% | |||||||||||
| MMGPT | 20.8% | 3.8% | 21.0% | 56.0% | 13.0% | 8.3% | |||||||||||
| MiniGPT-4 | 35.6% | 15.1% | 53.3% | 32.0% | 20.4% | 41.7% | |||||||||||
| LLaVA | 40.6% | 30.2% | 43.8% | 70.0% | 22.2% | 33.3% | |||||||||||
| VisualGLM | 47.3% | 37.7% | 73.3% | 50.0% | 0.0% | 52.8% | |||||||||||
| PandaGPT | 48.3% | 30.2% | 69.5% | 62.0% | 1.9% | 63.9% | |||||||||||
| InstructBLIP | 49.0% | 49.1% | 65.7% | 50.0% | 5.6% | 63.9% | |||||||||||
| MiniGPT-4-13B | 50.7% | 64.2% | 61.9% | 56.0% | 3.7% | 61.1% | |||||||||||
| InstructBLIP-13B | 56.4% | 73.6% | 73.3% | 58.0% | 11.1% | 47.2% | |||||||||||
| LLaMA-Adapter | 56.4% | 45.3% | 75.2% | 76.0% | 3.7% | 69.4% | |||||||||||
| -G2PT | 58.1% | 47.2% | 80.0% | 60.0% | 20.4% | 63.9% | |||||||||||
| mPLUG-Owl | 64.1% | 73.6% | 72.4% | 84.0% | 16.7% | 69.4% | |||||||||||
| Otter-I | 65.4% | 64.2% | 84.8% | 70.0% | 16.7% | 77.8% | |||||||||||
| Kosmos-2 | 72.5% | 69.8% | 82.9% | 82.0% | 40.7% | 80.6% | |||||||||||
| Shikra | 75.8% | 62.3% | 96.2% | 86.0% | 37.0% | 80.6% | |||||||||||
| TEST | OpenFlamingo | 1.5% | 0.0% | 4.6% | 0.0% | 1.2% | 0.0% | ||||||||||
| OpenFlamingo v2 | 4.0% | 1.2% | 5.4% | 3.6% | 2.3% | 7.1% | |||||||||||
| MMGPT | 18.3% | 3.5% | 30.0% | 35.7% | 7.0% | 9.4% | |||||||||||
| MiniGPT-4 | 28.3% | 9.4% | 46.2% | 19.0% | 7.0% | 50.6% | |||||||||||
| LLaVA | 40.4% | 37.6% | 52.3% | 47.6% | 29.1% | 29.4% | |||||||||||
| InstructBLIP | 41.1% | 34.1% | 61.5% | 35.7% | 0.0% | 63.5% | |||||||||||
| VisualGLM | 41.5% | 30.6% | 68.5% | 41.7% | 0.0% | 52.9% | |||||||||||
| PandaGPT | 47.9% | 38.8% | 66.2% | 38.1% | 17.4% | 69.4% | |||||||||||
| -G2PT | 49.8% | 41.2% | 75.4% | 38.1% | 20.9% | 60.0% | |||||||||||
| LLaMA-Adapter | 50.6% | 31.8% | 70.0% | 44.0% | 25.6% | 71.8% | |||||||||||
| MiniGPT-4-13B | 50.6% | 62.4% | 75.4% | 38.1% | 4.7% | 60.0% | |||||||||||
| InstructBLIP-13B | 53.8% | 61.2% | 71.5% | 41.7% | 5.8% | 80.0% | |||||||||||
| mPLUG-Owl | 59.4% | 71.8% | 75.4% | 54.8% | 17.4% | 69.4% | |||||||||||
| Otter-I | 60.6% | 62.4% | 83.1% | 46.4% | 4.7% | 95.3% | |||||||||||
| Kosmos-2 | 70.4% | 70.6% | 76.9% | 61.9% | 44.2% | 95.3% | |||||||||||
| Shikra | 71.7% | 72.9% | 90.8% | 59.5% | 30.2% | 95.3% |
| Split | VLM | FP-S |
|
|
|
OCR | ||||||
| DEV | OpenFlamingo | 6.7% | 2.5% | 10.4% | 4.0% | 15.0% | ||||||
| OpenFlamingo v2 | 8.1% | 1.2% | 14.3% | 10.1% | 5.0% | |||||||
| MMGPT | 14.1% | 1.2% | 10.4% | 27.3% | 15.0% | |||||||
| PandaGPT | 27.9% | 14.8% | 50.6% | 23.2% | 22.5% | |||||||
| MiniGPT-4 | 30.3% | 7.4% | 50.6% | 35.4% | 25.0% | |||||||
| InstructBLIP | 37.0% | 6.2% | 51.9% | 47.5% | 45.0% | |||||||
| VisualGLM | 43.8% | 19.8% | 41.6% | 67.7% | 37.5% | |||||||
| LLaVA | 45.5% | 8.6% | 64.9% | 59.6% | 47.5% | |||||||
| -G2PT | 46.5% | 11.1% | 71.4% | 63.6% | 27.5% | |||||||
| Otter-I | 46.8% | 16.0% | 61.0% | 58.6% | 52.5% | |||||||
| LLaMA-Adapter | 47.5% | 17.3% | 68.8% | 59.6% | 37.5% | |||||||
| InstructBLIP-13B | 47.8% | 14.8% | 55.8% | 69.7% | 45.0% | |||||||
| MiniGPT-4-13B | 49.5% | 28.4% | 54.5% | 68.7% | 35.0% | |||||||
| mPLUG-Owl | 50.2% | 18.5% | 63.6% | 70.7% | 37.5% | |||||||
| Shikra | 57.2% | 32.1% | 75.3% | 63.6% | 57.5% | |||||||
| Kosmos-2 | 64.3% | 38.3% | 71.4% | 80.8% | 62.5% | |||||||
| TEST | OpenFlamingo | 2.5% | 2.9% | 3.0% | 1.7% | 2.6% | ||||||
| OpenFlamingo v2 | 5.5% | 2.9% | 7.0% | 8.5% | 2.6% | |||||||
| MMGPT | 18.2% | 3.8% | 23.0% | 28.0% | 16.9% | |||||||
| PandaGPT | 20.2% | 7.6% | 37.0% | 19.5% | 16.9% | |||||||
| MiniGPT-4 | 28.7% | 8.6% | 41.0% | 29.7% | 39.0% | |||||||
| InstructBLIP | 33.0% | 2.9% | 41.0% | 40.7% | 51.9% | |||||||
| VisualGLM | 35.8% | 8.6% | 40.0% | 52.5% | 41.6% | |||||||
| -G2PT | 41.8% | 17.1% | 56.0% | 59.3% | 29.9% | |||||||
| LLaVA | 41.8% | 13.3% | 47.0% | 50.8% | 59.7% | |||||||
| LLaMA-Adapter | 45.0% | 15.2% | 59.0% | 56.8% | 49.4% | |||||||
| InstructBLIP-13B | 45.8% | 5.7% | 45.0% | 65.3% | 71.4% | |||||||
| Otter-I | 46.8% | 11.4% | 54.0% | 57.6% | 68.8% | |||||||
| MiniGPT-4-13B | 49.8% | 21.0% | 64.0% | 55.9% | 61.0% | |||||||
| mPLUG-Owl | 53.0% | 16.2% | 63.0% | 78.0% | 51.9% | |||||||
| Shikra | 61.8% | 27.6% | 72.0% | 70.3% | 81.8% | |||||||
| Kosmos-2 | 65.6% | 40.4% | 59.0% | 79.7% | 86.8% |
| Split | VLM | FP-C |
|
|
|
||||||
| DEV | OpenFlamingo v2 | 1.4% | 2.2% | 2.3% | 0.0% | ||||||
| OpenFlamingo | 2.8% | 2.2% | 0.0% | 5.4% | |||||||
| MMGPT | 3.4% | 2.2% | 2.3% | 5.4% | |||||||
| MiniGPT-4 | 9.0% | 0.0% | 11.4% | 14.3% | |||||||
| InstructBLIP | 21.4% | 6.7% | 11.4% | 41.1% | |||||||
| VisualGLM | 23.4% | 0.0% | 31.8% | 35.7% | |||||||
| InstructBLIP-13B | 24.8% | 6.7% | 36.4% | 30.4% | |||||||
| MiniGPT-4-13B | 26.2% | 20.0% | 20.5% | 35.7% | |||||||
| LLaVA | 32.4% | 6.7% | 38.6% | 48.2% | |||||||
| PandaGPT | 35.2% | 11.1% | 25.0% | 62.5% | |||||||
| LLaMA-Adapter | 38.6% | 11.1% | 47.7% | 53.6% | |||||||
| Otter-I | 38.6% | 15.6% | 4.5% | 83.9% | |||||||
| -G2PT | 38.6% | 6.7% | 45.5% | 58.9% | |||||||
| mPLUG-Owl | 40.7% | 13.3% | 27.3% | 73.2% | |||||||
| Kosmos-2 | 49.0% | 31.1% | 56.8% | 57.1% | |||||||
| Shikra | 57.9% | 33.3% | 45.5% | 87.5% | |||||||
| TEST | OpenFlamingo v2 | 0.8% | 0.0% | 0.0% | 2.3% | ||||||
| OpenFlamingo | 1.6% | 1.2% | 3.8% | 0.0% | |||||||
| MMGPT | 5.2% | 3.7% | 3.8% | 8.0% | |||||||
| MiniGPT-4 | 11.2% | 9.8% | 6.2% | 17.0% | |||||||
| VisualGLM | 17.6% | 7.3% | 8.8% | 35.2% | |||||||
| MiniGPT-4-13B | 19.6% | 17.1% | 8.8% | 31.8% | |||||||
| LLaVA | 20.0% | 14.6% | 21.2% | 23.9% | |||||||
| PandaGPT | 20.4% | 12.2% | 15.0% | 33.0% | |||||||
| InstructBLIP-13B | 24.0% | 9.8% | 17.5% | 43.2% | |||||||
| InstructBLIP | 24.4% | 9.8% | 2.5% | 58.0% | |||||||
| mPLUG-Owl | 26.8% | 18.3% | 22.5% | 38.6% | |||||||
| LLaMA-Adapter | 33.2% | 19.5% | 27.5% | 51.1% | |||||||
| -G2PT | 34.4% | 19.5% | 33.8% | 48.9% | |||||||
| Otter-I | 36.4% | 12.2% | 3.8% | 88.6% | |||||||
| Kosmos-2 | 47.9% | 35.1% | 35.0% | 70.5% | |||||||
| Shikra | 50.4% | 26.8% | 27.5% | 93.2% |
| Split | VLM | AR |
|
|
|
||||||
| DEV | OpenFlamingo | 8.0% | 10.7% | 8.6% | 2.2% | ||||||
| OpenFlamingo v2 | 15.4% | 14.7% | 8.6% | 28.9% | |||||||
| MMGPT | 26.4% | 24.0% | 9.9% | 60.0% | |||||||
| MiniGPT-4 | 31.3% | 14.7% | 19.8% | 80.0% | |||||||
| LLaMA-Adapter | 35.3% | 16.0% | 32.1% | 73.3% | |||||||
| -G2PT | 38.8% | 20.0% | 38.3% | 71.1% | |||||||
| PandaGPT | 38.8% | 16.0% | 46.9% | 62.2% | |||||||
| VisualGLM | 44.3% | 18.7% | 50.6% | 75.6% | |||||||
| InstructBLIP | 46.3% | 17.3% | 51.9% | 84.4% | |||||||
| LLaVA | 48.3% | 25.3% | 53.1% | 77.8% | |||||||
| MiniGPT-4-13B | 50.7% | 30.7% | 49.4% | 86.7% | |||||||
| mPLUG-Owl | 53.2% | 18.7% | 66.7% | 86.7% | |||||||
| InstructBLIP-13B | 54.2% | 30.7% | 56.8% | 88.9% | |||||||
| Kosmos-2 | 55.7% | 33.3% | 56.8% | 91.1% | |||||||
| Otter-I | 56.7% | 29.3% | 61.7% | 93.3% | |||||||
| Shikra | 56.7% | 30.7% | 63.0% | 88.9% | |||||||
| TEST | OpenFlamingo | 11.4% | 14.0% | 9.3% | 11.0% | ||||||
| OpenFlamingo v2 | 12.8% | 9.0% | 7.5% | 24.4% | |||||||
| MMGPT | 23.9% | 13.0% | 12.1% | 52.4% | |||||||
| MiniGPT-4 | 32.9% | 13.0% | 29.9% | 61.0% | |||||||
| PandaGPT | 41.5% | 15.0% | 42.1% | 73.2% | |||||||
| -G2PT | 46.7% | 31.0% | 38.3% | 76.8% | |||||||
| LLaMA-Adapter | 47.4% | 25.0% | 44.9% | 78.0% | |||||||
| InstructBLIP | 47.4% | 17.0% | 52.3% | 78.0% | |||||||
| VisualGLM | 48.8% | 26.0% | 44.9% | 81.7% | |||||||
| LLaVA | 53.6% | 35.0% | 48.6% | 82.9% | |||||||
| mPLUG-Owl | 56.1% | 23.0% | 59.8% | 91.5% | |||||||
| InstructBLIP-13B | 59.5% | 24.0% | 67.3% | 92.7% | |||||||
| Kosmos-2 | 59.9% | 30.0% | 65.4% | 89.0% | |||||||
| MiniGPT-4-13B | 62.6% | 35.0% | 67.3% | 90.2% | |||||||
| Otter-I | 63.3% | 45.0% | 60.7% | 89.0% | |||||||
| Shikra | 69.6% | 50.0% | 70.1% | 92.7% |
| Split | VLM | LR |
|
|
|||
| DEV | MMGPT | 2.5% | 2.6% | 2.4% | |||
| OpenFlamingo v2 | 4.2% | 5.1% | 2.4% | ||||
| OpenFlamingo | 6.7% | 9.0% | 2.4% | ||||
| MiniGPT-4 | 7.5% | 5.1% | 11.9% | ||||
| PandaGPT | 10.0% | 10.3% | 9.5% | ||||
| VisualGLM | 10.8% | 12.8% | 7.1% | ||||
| LLaMA-Adapter | 11.7% | 7.7% | 19.0% | ||||
| -G2PT | 13.3% | 10.3% | 19.0% | ||||
| InstructBLIP | 14.2% | 14.1% | 14.3% | ||||
| mPLUG-Owl | 16.7% | 10.3% | 28.6% | ||||
| LLaVA | 16.7% | 17.9% | 14.3% | ||||
| InstructBLIP-13B | 19.2% | 19.2% | 19.0% | ||||
| MiniGPT-4-13B | 20.8% | 20.5% | 21.4% | ||||
| Shikra | 25.8% | 16.7% | 42.9% | ||||
| Otter-I | 32.5% | 20.5% | 54.8% | ||||
| Kosmos-2 | 46.7% | 43.6% | 52.4% | ||||
| TEST | MMGPT | 1.1% | 0.0% | 2.7% | |||
| OpenFlamingo | 9.1% | 1.0% | 20.3% | ||||
| VisualGLM | 11.4% | 3.9% | 21.6% | ||||
| OpenFlamingo v2 | 11.4% | 2.9% | 23.0% | ||||
| LLaMA-Adapter | 13.1% | 11.8% | 14.9% | ||||
| MiniGPT-4 | 13.6% | 3.9% | 27.0% | ||||
| -G2PT | 14.8% | 6.9% | 25.7% | ||||
| PandaGPT | 15.3% | 6.9% | 27.0% | ||||
| LLaVA | 15.9% | 13.7% | 18.9% | ||||
| InstructBLIP-13B | 17.0% | 5.9% | 32.4% | ||||
| MiniGPT-4-13B | 17.0% | 6.9% | 31.1% | ||||
| mPLUG-Owl | 19.9% | 5.9% | 39.2% | ||||
| InstructBLIP | 21.6% | 4.9% | 44.6% | ||||
| Otter-I | 22.2% | 4.9% | 45.9% | ||||
| Shikra | 33.5% | 14.7% | 59.5% | ||||
| Kosmos-2 | 48.6% | 35.6% | 66.2% |
| Split | VLM | RR |
|
|
|
|||
| DEV | OpenFlamingo | 0.0% | 0.0% | 0.0% | 0.0% | |||
| OpenFlamingo v2 | 0.9% | 0.0% | 0.0% | 2.1% | ||||
| MiniGPT-4 | 4.3% | 2.3% | 8.3% | 4.2% | ||||
| MMGPT | 13.0% | 14.0% | 0.0% | 18.8% | ||||
| InstructBLIP | 22.6% | 34.9% | 8.3% | 18.8% | ||||
| PandaGPT | 23.5% | 20.9% | 8.3% | 33.3% | ||||
| LLaMA-Adapter | 29.6% | 37.2% | 16.7% | 29.2% | ||||
| MiniGPT-4-13B | 30.4% | 53.5% | 8.3% | 20.8% | ||||
| LLaVA | 30.4% | 37.2% | 12.5% | 33.3% | ||||
| InstructBLIP-13B | 34.8% | 55.8% | 8.3% | 29.2% | ||||
| VisualGLM | 35.7% | 62.8% | 8.3% | 25.0% | ||||
| -G2PT | 40.9% | 60.5% | 16.7% | 35.4% | ||||
| Kosmos-2 | 43.5% | 76.7% | 29.2% | 20.8% | ||||
| mPLUG-Owl | 47.8% | 69.8% | 8.3% | 47.9% | ||||
| Otter-I | 53.9% | 76.7% | 20.8% | 50.0% | ||||
| Shikra | 58.3% | 93.0% | 20.8% | 45.8% | ||||
| TEST | OpenFlamingo v2 | 1.4% | 1.2% | 3.8% | 0.0% | |||
| OpenFlamingo | 3.3% | 0.0% | 11.5% | 1.2% | ||||
| MiniGPT-4 | 8.9% | 11.2% | 5.8% | 8.6% | ||||
| MMGPT | 20.7% | 27.5% | 3.8% | 24.7% | ||||
| PandaGPT | 22.1% | 27.5% | 9.6% | 24.7% | ||||
| InstructBLIP | 22.5% | 27.5% | 11.5% | 24.7% | ||||
| LLaMA-Adapter | 23.0% | 31.2% | 19.2% | 17.3% | ||||
| VisualGLM | 27.7% | 46.2% | 3.8% | 24.7% | ||||
| LLaVA | 28.6% | 37.5% | 21.2% | 24.7% | ||||
| MiniGPT-4-13B | 30.0% | 43.8% | 21.2% | 22.2% | ||||
| -G2PT | 31.5% | 57.5% | 15.4% | 16.0% | ||||
| Kosmos-2 | 34.7% | 57.5% | 36.5% | 11.1% | ||||
| InstructBLIP-13B | 36.2% | 47.5% | 25.0% | 32.1% | ||||
| mPLUG-Owl | 39.0% | 61.3% | 15.4% | 32.1% | ||||
| Otter-I | 39.4% | 55.0% | 9.6% | 43.2% | ||||
| Shikra | 53.1% | 83.8% | 19.2% | 44.4% |
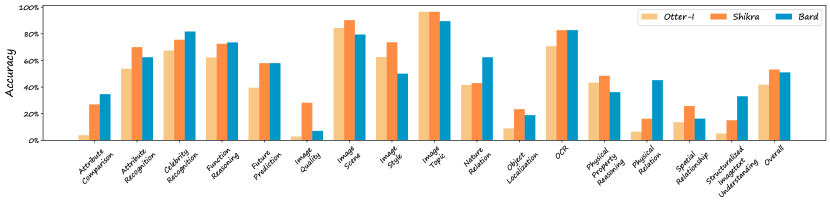
附录 C Google Bard 与开源 VLM:定量比较
2023 年 3 月,Google 推出了 Bard,这是基于 Transformer 的 LaMDA 的轻量级优化版本。 与 ChatGPT 类似,Bard 是闭源模型,通过 Web UI 向用户提供服务。 2023年7月,谷歌宣布了Bard的最新更新,能够处理图像输入。 为了概述 Bard 的多模态能力,我们在 MMBench 的测试拆分上对其进行了如下评估,并将其与其他最先进的 VLM 进行了比较。
MMBench 的测试部分包括 1798 个问题。 在测试过程中,我们发现巴德拒绝处理包含人脸的图像。 为了公平比较,我们在测试中删除了巴德拒绝回答的问题,并丢弃了评估四种人类相关能力(图像情感、身份推理、社会关系和动作识别)的问题。 过滤后,我们构建了 1226 个样本和 16 个叶子能力维度的子集。
我们将 Bard 与在 MMBench 上表现良好的两种最先进的 VLM(Shikra 和 Otter-I)进行比较。 结果如 Figure 7 所示。 Bard 的整体准确率高达 51%,令人印象深刻,跻身迄今为止提出的顶级 VLM 之列。 值得注意的是,巴德擅长回答涉及常识推理的问题。 它在自然关系问题上达到了 62.3% 的准确率,在物理关系问题上达到了 45.2% 的准确率,远远超过了例如 Otter-I 和 Shikra 等同类产品。 同时,分析表明,Bard 在空间关系和物体定位等需要空间感知的任务中表现相对较低。 考虑到 Shikra 将视觉基础任务纳入其训练数据中以增强其定位能力,这一观察结果与预期相符,而这一方面可能未集成到 Bard 的训练过程中。

为了补充Figure 8中的定量分析,我们还提供了一些巴德的定性示例。 Figure 8展示了一些好的案例。 在左边的例子中,巴德熟练地处理复杂的场景,提炼关键信息,并得出合理的结论。 值得注意的是,经过我们测试的大多数 VLM 都无法对这个特定问题做出正确的回答。 在右边的例子中,巴德从卡通中识别出正确的概念,避免了蛇和老鼠之间和谐互动所产生的任何潜在混乱。 这凸显了巴德非凡的常识推理能力。

在Figure 9 中,我们提供了说明性示例,突出了 Bard 的性能缺陷。 这些实例源自图像样式和图像质量任务。 前者需要模型来辨别图像类别,而后者则涉及评估一对图像的视觉属性,例如亮度。 这些任务之间的一个共同特征是图像内容对于任务目标来说无关紧要。 Bard 在这两项任务上表现不佳,每项任务的准确率分别为 50% 和 7%。 这些案例中的附表直观地表明了巴德过度关注语义概念以及所提供的文本和图像中所描绘的对象的倾向,使其难以有效地解决有关整体风格和属性的查询。
最后但并非最不重要的一点是,在上述所有示例中,巴德始终如一地提供结构良好的答复,经常使用要点列表和表格来提高清晰度。 此外,在大多数问题中,巴德都遵循一致的回答格式:首先提出预测的选项,随后提供全面的理由,最后列举替代选择不正确的原因。 从聊天机器人的角度来看,巴德无疑是最出色的多模式聊天机器人之一。
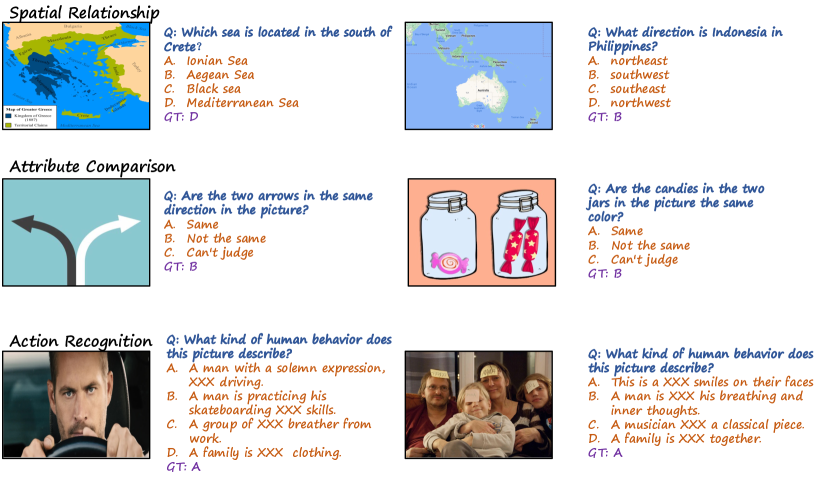
附录 DMMBench 中的示例





附录E每种能力的定义
在表14中,我们介绍了各个能力的定义。
| Name | Ability |
| Image Style | Determine which type of image it belongs to, such as photos, paintings, CT scans, etc. |
| Image Scene | Determine which environment is shown in the image, such as indoors, outdoors, forest, city, mountains, waterfront, sunny day, rainy day, etc. |
| Image Emotion | Determine which subjective emotion is conveyed by the overall image, such as cold, cheerful, sad, or oppressive. |
| Image Quality | Determine the objective quality of the image, such as whether it is blurry, bright or dark, contrast, etc. |
| Image Topic | Determine what the subject of the image is, such as scenery, portrait, close-up of an object, text, etc. |
| Object Localization | For a single object, determine its position in the image (such as top, bottom, etc.), its absolute coordinates in the image, count the number of objects, and the orientation of the object |
| Attribute Recognition | Recognition of texture, shape, appearance characteristics, emotions, category, celebrities, famous places and objects, optical characters |
| Celebrity Recognition | Recognition of celebrities, landmarks, and common items. |
| OCR | Recognition of text, formula, and sheet in the image. |
| Spatial Relationship | Determine the relative position between objects in image. |
| Attribute Comparison | Compare attributes of different objects in image, such as shape, color, etc. |
| Action Recognition | Recognizing human actions, including pose motion, human-object interaction, and human-human interaction. |
| Structuralized Image-Text Understanding | Structured understanding of images and text, including parsing the content of charts (such as the trends of multiple bars in a bar chart), understanding the code in an image, etc. |
| Physical Property Reasoning | Predict the physical property of an object. Examples: the physical property of concentrated sulfuric acid is that it is volatile, the physical property of water is its fluidity, etc. |
| Function Reasoning | Predict the function of an object. Examples: the function of a broom is to sweep the floor, the function of a spatula is to cook, the function of a pen is to write, etc. |
| Identity Reasoning | Predict the identity of a person. Example: by observing a person’s clothing and appearance, one may infer his / her occupation and social status |
| Social Relation | Relations in human society or relations defined from the human perspective. Examples: Inter-person relations, such as father and son, husband and wife, friend, hostile, etc. |
| Physical Relation | All relationships that exist in the physical world, 3D spatial relationships and the connections between objects are. |
| Nature Relation | Other abstract relationships that exist in nature. Examples: predation, symbiosis, coexistence, etc. |
| Future Prediction | Predict what will happen in the future. Examples: if it is thundering in the sky now, it can be predicted that it will rain soon (physical phenomenon); if someone raises their fist, it means they are going to hit someone (event occurrence); if someone’s face becomes serious, it means they are going to get angry (emotional change). |
附录F评估模型的详细信息
| VLM | Language Backbone | Vision Backbone | Overall Parameters | Trainable Parameters |
| OpenFlamingo | LLaMA 7B | CLIP ViT-L/14 | 9B | 1.3B |
| OpenFlamingov2 | MPT 7B | CLIP ViT-L/14 | 9B | 1.3B |
| MMGPT | LLaMA 7B | CLIP ViT-L/14 | 9B | 22.5M |
| MiniGPT-4 | Vicuna 7B | EVA-G | 8B | 11.9M |
| MiniGPT-4-13B | Vicuna 13B | EVA-G | 14B | 11.9M |
| PandaGPT | Vicuna 13B | ImageBind ViT-H/14 | 14B | 28.8M |
| VisualGLM | ChatGLM 6B | EVA-CLIP | 8B | 0.2B |
| InstructBLIP | Vicuna 7B | EVA-G | 8B | 0.2B |
| InstructBLIP-13B | Vicuna 13B | EVA-G | 14B | 0.2B |
| Otter-I | LLaMA 7B | CLIP ViT-L/14 | 9B | 1.3B |
| LLaVA | LLaMA 7B | CLIP ViT-L/14 | 7.2B | 7B |
| LLaMA-Adapter | LLaMA 7B | CLIP ViT-L/14 | 7.2B | 1.2M |
| mPLUG-Owl | LLaMA 7B | CLIP ViT-L/14 | 7.2B | 0.4B |
| KOSMOS-2 | Decoder Only 1.3B | CLIP ViT-L/14 | 1.6B | 1.6B |
| Shikra | LLaMA 7B | CLIP ViT-L/14 | 7.2B | 6.7B |
| -G2PT | LLaMA 7B | ViT-G | 7B | 8B |
参考
- [1] W3c school. In https://www.w3schools.com/, 2023.
- [2] Harsh Agrawal, Karan Desai, Yufei Wang, Xinlei Chen, Rishabh Jain, Mark Johnson, Dhruv Batra, Devi Parikh, Stefan Lee, and Peter Anderson. Nocaps: Novel object captioning at scale. In Proceedings of the IEEE/CVF international conference on computer vision, pages 8948–8957, 2019.
- [3] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing Systems, 35:23716–23736, 2022.
- [4] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- [5] Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multimodal llm’s referential dialogue magic. arXiv preprint arXiv:2306.15195, 2023.
- [6] Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco captions: Data collection and evaluation server. arXiv preprint arXiv:1504.00325, 2015.
- [7] Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023), 2023.
- [8] Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. arXiv preprint arXiv:2305.06500, 2023.
- [9] Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. Glm: General language model pretraining with autoregressive blank infilling. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 320–335, 2022.
- [10] Haodong Duan, Yue Zhao, Kai Chen, Yuanjun Xiong, and Dahua Lin. Mitigating representation bias in action recognition: Algorithms and benchmarks, 2022.
- [11] Jerry A Fodor. The modularity of mind. MIT press, 1983.
- [12] Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Zhenyu Qiu, Wei Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, and Rongrong Ji. Mme: A comprehensive evaluation benchmark for multimodal large language models. ArXiv, abs/2306.13394, 2023.
- [13] Peng Gao, Jiaming Han, Renrui Zhang, Ziyi Lin, Shijie Geng, Aojun Zhou, Wei Zhang, Pan Lu, Conghui He, Xiangyu Yue, et al. Llama-adapter v2: Parameter-efficient visual instruction model. arXiv preprint arXiv:2304.15010, 2023.
- [14] Tao Gong, Chengqi Lyu, Shilong Zhang, Yudong Wang, Miao Zheng, Qian Zhao, Kuikun Liu, Wenwei Zhang, Ping Luo, and Kai Chen. Multimodal-gpt: A vision and language model for dialogue with humans, 2023.
- [15] Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017.
- [16] Danna Gurari, Qing Li, Abigale J Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P Bigham. Vizwiz grand challenge: Answering visual questions from blind people. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3608–3617, 2018.
- [17] V. Hosu, H. Lin, T. Sziranyi, and D. Saupe. Koniq-10k: An ecologically valid database for deep learning of blind image quality assessment. IEEE Transactions on Image Processing, 29:4041–4056, 2020.
- [18] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- [19] Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Jiayi Lei, et al. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models. arXiv preprint arXiv:2305.08322, 2023.
- [20] Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709, 2019.
- [21] Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2901–2910, 2017.
- [22] Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Fanyi Pu, Jingkang Yang, Chunyuan Li, and Ziwei Liu. Mimic-it: Multi-modal in-context instruction tuning. 2023.
- [23] Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Jingkang Yang, and Ziwei Liu. Otter: A multi-modal model with in-context instruction tuning. arXiv preprint arXiv:2305.03726, 2023.
- [24] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023.
- [25] Junnan Li, Yongkang Wong, Qi Zhao, and Mohan S Kankanhalli. Dual-glance model for deciphering social relationships. In Proceedings of the IEEE international conference on computer vision, pages 2650–2659, 2017.
- [26] Fangyu Liu, Guy Edward Toh Emerson, and Nigel Collier. Visual spatial reasoning. Transactions of the Association for Computational Linguistics, 2023.
- [27] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023.
- [28] Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. Advances in Neural Information Processing Systems, 35:2507–2521, 2022.
- [29] Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. Ok-vqa: A visual question answering benchmark requiring external knowledge. In Proceedings of the IEEE/cvf conference on computer vision and pattern recognition, pages 3195–3204, 2019.
- [30] Mike Oaksford and Nick Chater. Bayesian rationality: The probabilistic approach to human reasoning. Oxford University Press, 2007.
- [31] OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023.
- [32] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- [33] Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding multimodal large language models to the world. arXiv preprint arXiv:2306.14824, 2023.
- [34] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- [35] Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv preprint arXiv:2111.02114, 2021.
- [36] Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317–8326, 2019.
- [37] Yixuan Su, Tian Lan, Huayang Li, Jialu Xu, Yan Wang, and Deng Cai. Pandagpt: One model to instruction-follow them all. arXiv preprint arXiv:2305.16355, 2023.
- [38] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- [39] Peng Xu, Wenqi Shao, Kaipeng Zhang, Peng Gao, Shuo Liu, Meng Lei, Fanqing Meng, Siyuan Huang, Yu Jiao Qiao, and Ping Luo. Lvlm-ehub: A comprehensive evaluation benchmark for large vision-language models. 2023.
- [40] Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, et al. mplug-owl: Modularization empowers large language models with multimodality. arXiv preprint arXiv:2304.14178, 2023.
- [41] Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics, 2:67–78, 2014.
- [42] Renrui Zhang, Jiaming Han, Chris Liu, Peng Gao, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, and Yu Qiao. Llama-adapter: Efficient fine-tuning of language models with zero-init attention, 2023.
- [43] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric. P Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023.
- [44] Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017.
- [45] Luowei Zhou, Chenliang Xu, and Jason Corso. Towards automatic learning of procedures from web instructional videos. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018.
- [46] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023.