noitemsep,topsep=0pt,parsep=0pt,partopsep=0pt,leftmargin=1.5em
利用 MT-Bench 和 Chatbot Arena 评判大语言模型
。
摘要
由于基于大语言模型(LLM)的聊天助手功能广泛,且现有基准在衡量人类偏好方面存在不足,因此对其进行评估极具挑战性。 为了解决这个问题,我们探索使用强大的 LLM 作为评委,就更开放的问题对这些模型进行评估。 我们研究了大语言模型作为法官的用法和局限性,包括立场、口头禅和自我强化偏差,以及有限的推理能力,并提出了缓解其中一些问题的解决方案。 然后,我们通过引入两个基准来验证大语言模型判断与人类偏好之间的一致性:MT-bench 是一个多回合问题集;Chatbot Arena 是一个众包对战平台。 我们的研究结果表明,像 GPT-4 这样强大的大语言模型法官可以很好地匹配受控和众包的人类偏好,达到 80% 以上的一致性,与人类之间的一致性水平相同。 因此,"大语言模型即法官 "是一种可扩展、可解释的近似人类偏好的方法,否则人类偏好的获取成本将非常高昂。 此外,我们还通过评估 LLaMA 和 Vicuna 的几个变体,展示了我们的基准与传统基准的互补性。 MT-Bench 问题、3K 次专家投票和 30K 次人类偏好对话可在 https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge 上公开获取。
1导言
基于大语言模型的聊天助手(聊天机器人)层出不穷,它们利用监督指令微调和人类反馈强化学习(RLHF)来释放新的指令遵循和对话能力[31, 2, 30, 8, 52, 48, 14]。 一旦与人类对齐,这些聊天模型就会受到人类用户的强烈青睐,而不是建立在其基础上的未对齐的原始模型。 然而,用户偏好的提高并不总是与传统大语言模型基准测试得分的提高相对应--MMLU [19] 和 HELM [24] 等基准测试无法有效区分这些对齐模型与基础模型之间的差异。 这一现象表明,用户对聊天机器人有用性的看法与传统基准所采用的标准之间存在根本差异。
我们认为,造成这种差异的主要原因是,现有的评估只衡量了 LLM 在有限任务(如多选知识或检索问题)中的核心能力,而没有充分评估其在开放式任务中与人类偏好的一致性,如在多轮对话中准确遵守指令的能力。 作为演示,我们在图 1中展示了两个模型在一个MLU 问题上的对话历史。 这两个模型分别是 LLaMA-13B [39](一个未经微调的预训练基础模型)和 Vicuna-13B(我们在 LLaMA-13B 基础上对高质量对话进行微调的模型)(训练细节见 附录 E)。 尽管基本 LLaMA 模型在传统基准测试中表现出了极具竞争力的性能(表 9),但它对开放式问题的回答往往不被人类所青睐。 传统基准的这种错位凸显了本文的核心问题: 需要一种稳健且可扩展的自动方法来评估大语言模型与人类偏好的一致性。

为了研究这一点,我们引入了两个以人类评分作为主要评估指标的基准:MT-bench 和 Chatbot Arena。 MT-bench 是一系列开放式问题,用于评估聊天机器人的多轮对话和指令遵循能力--这是人类偏好的两个关键要素。 MT-bench 还经过精心设计,可根据推理和数学等核心能力对聊天机器人进行区分。 此外,我们还开发了 "聊天机器人竞技场"(Chatbot Arena),这是一个众包平台,提供真实世界场景中聊天机器人之间的匿名对战--用户同时与两个聊天机器人进行对话,并根据个人喜好对它们的回应进行评分。
虽然人工评价是评估人类偏好的黄金标准,但其过程异常缓慢且成本高昂。 为了实现评估的自动化,我们探索使用最先进的 LLM(如 GPT-4)来替代人类。 由于这些模型通常是用 RLHF 训练出来的,因此已经表现出很强的人机一致性。 我们将这种方法称为 "大语言模型即法官"。 我们在早期博文[8]和其他同期或后续工作[5中尝试过这种方法、29、14、12、52、18、33、40、7、43]。 然而,目前还没有对这种方法进行系统的研究。
在本文中,我们通过将大语言模型作为评判方法与人类评估的黄金标准进行比较,对其进行了研究。
我们研究了大语言模型即法官方法的几种潜在局限性,包括立场偏差、言语偏差、自我提升偏差和推理能力有限。
我们表明,有些偏差很小,或者可以减轻。
一旦解决了这一问题,我们从 3K 受控专家投票和 3K 野外众包人类投票中得出的结果证实,GPT-4 法官与人类评价的一致率超过 80%,达到了相同的人机一致水平(§4.2,表4)。
因此,这表明大语言模型是一种可扩展的快速评估人类偏好的方法,有望替代传统的人类评估。
本文有两方面的贡献:(1)对大语言模型作为法官的系统研究;(2)来自 MT-bench 和 Chatbot Arena 的高质量问题和多样化用户交互的人类偏好数据集。 此外,我们还主张在未来的大语言模型基准中采用混合评估框架:通过将现有的基于能力的基准和新的基于偏好的基准与大语言模型即评委相结合,人们可以迅速自动地评估模型的核心能力和人与模型之间的一致性。 我们公开发布了 80 个 MT 基准问题、3K 份专家投票以及 30K 次带有人类偏好的对话,供未来研究使用。
|
Category |
Sample Questions | |
|---|---|---|
| Writing |
1st Turn |
Compose an engaging travel blog post about a recent trip to Hawaii, highlighting cultural experiences and must-see attractions. |
|
2nd Turn |
Rewrite your previous response. Start every sentence with the letter A. |
|
| Math |
1st Turn |
Given that , find the value of . |
|
2nd Turn |
Find such that . |
|
| Knowledge |
1st Turn |
Provide insights into the correlation between economic indicators such as GDP, inflation, and unemployment rates. Explain how fiscal and monetary policies … |
|
2nd Turn |
Now, explain them again like I’m five. |
|
2 MT-Bench 和聊天机器人竞技场
2.1动机
随着大语言模型的最新进展,基于大语言模型的助手开始在各种任务中展现人工通用智能,从写作、聊天到编码[5, 30, 1, 37]. 然而,评估它们的广泛能力也变得更具挑战性。 尽管有许多语言模型的基准,但它们主要侧重于评估简短回答的封闭式问题的模型。 鉴于这些聊天助手现在可以在多轮对话中精确遵循用户指令,并以零样本方式回答开放式问题,目前的基准不足以评估这种能力。 现有的基准大多分为以下三类。
- •
- •
- •
虽然现有的大语言模型在很大程度上忽略了这一点,但在开放式、多回合的人机交互中,人类偏好可以直接衡量聊天机器人的实用性。 为了弥补这一差距,我们引入了两个专门用于评估人类偏好的新基准。 同时,这些基准旨在区分最先进模型的核心能力。
2.2 MT-Bench
我们创建了 MT-bench,这是一个由 80 个高质量多轮问题组成的基准。 MT-bench 旨在测试多轮对话和指令遵循能力,涵盖常见的使用案例,并侧重于具有挑战性的问题,以区分不同的模型。 我们确定了 8 类常见的用户提示来指导其构建:写作、角色扮演、提取、推理、数学、编码、知识 I(STEM)和知识 II(人文/社会科学)。 然后,我们针对每个类别手动设计了 10 个多轮问题。 表 1列出了几个示例问题。
2.3聊天机器人竞技场
我们的第二种方法是 "聊天机器人竞技场"(Chatbot Arena),这是一个以匿名对战为特色的众包基准平台。 在这个平台上,用户可以同时与两个匿名模特互动,向两人提出同样的问题。 他们投票决定哪种模型能提供首选答案,模型的身份在投票后公布。 在 Chatbot Arena 上运行一个月后,我们收集到了约 3 万张选票。 由于该平台不使用预先定义的问题,因此可以根据用户的不同兴趣,在野外收集各种不受限制的用例和投票。 平台截图见 Section C.2 。
3 大语言模型担任法官
虽然我们使用 MT-bench 和 Chatbot Arena 进行的初步评估依赖于人类评分,但收集人类偏好可能会耗费大量成本和精力[44, 38, 31, 2, 13]. 为了克服这一问题,我们的目标是开发一种更具可扩展性和自动化的方法。 鉴于 MT-bench 和 Chatbot Arena 中的大多数问题都是开放式的,没有参考答案,因此设计一个基于规则的程序来评估输出结果极具挑战性。 基于输出结果和参考答案之间相似度的传统评价指标(例如 ROUGE [25], BLEU [32] )对这些问题也不起作用。
随着 LLM 的不断改进,它们在许多任务[17, 20]中显示出取代人类标注员的潜力。 具体来说,我们感兴趣的是 LLM 能否有效评估聊天助手的回复,并与人类的偏好相匹配。 接下来,我们讨论大语言模型作为法官的用途和局限性。
3.1大语言法官模型的类型
我们提出了 3 种 "大语言模型即法官 "的变体。 它们可以单独实施,也可以组合实施:
这些方法各有利弊。 例如,当选手人数增加时,配对比较可能缺乏可扩展性,因为可能的配对数量呈二次曲线增长;单一答案评分可能无法辨别特定配对之间的细微差别,而且其结果可能会变得不稳定,因为如果评委模式发生变化,绝对分数的波动可能会大于相对配对结果的波动。
3.2大语言模型作为法官的优势
大语言模型即法官有两大优势:可扩展性和可解释性。 它减少了人工参与的需要,实现了可扩展的基准和快速迭代。 此外,大语言模型评委不仅提供分数,还提供解释,使其输出结果具有可解释性,如图 1所示。
3.3大语言模型作为法官的局限性
我们发现了大语言模型法官的某些偏见和局限性。 不过,我们也会在后面提出解决方案,并表明尽管存在这些限制,大语言模型法官和人类之间的一致性还是很高的。
图 10(附录)显示了位置偏差的示例。 GPT-4 的任务是评估 GPT-3.5 和 Vicuna-13B 对一个开放式问题的两种回答。 当 GPT-3.5 的答案排在前面时,GPT-4 认为 GPT-3.5 的答案更详细、更优越。 然而,在调换两个答案的位置后,GPT-4 的判断发生了翻转,倾向于 Vicuna 的答案。
为了分析位置偏差,我们在 MT-bench 中通过调用两次温度为 0.7 的 GPT-3.5 来为每个首轮问题构建两个相似的答案。 然后,我们用两种不同的提示尝试了三种 LLM:"默认 "是 图 4(附录)中的默认提示。 "重命名 "重命名我们默认提示中的助手,以查看是偏重职位还是偏重姓名。 如 Table 2,我们发现它们都表现出强烈的位置偏差。 大语言模型的评委大多倾向于第一种立场。 正如 "重命名 "提示所显示的,Claude-v1 还显示出一种名称偏好,使其偏爱 "助手 A"。 位置偏差可能非常大。 只有 GPT-4 能在 60% 以上的病例中得出一致的结果。
请注意,这项测试极具挑战性,因为答案非常相似,有时甚至连人类都无法区分。 我们将在 节 D.1中说明位置偏差在某些情况下并不那么突出。 至于这种偏差的根源,我们猜测可能源于训练数据,也可能是因果转换器从左到右架构的固有特性,但将更深入的研究作为未来工作的一部分。
| Judge | Prompt | Consistency | Biased toward first | Biased toward second | Error |
| Claude-v1 | default | 23.8% | 75.0% | 0.0% | 1.2% |
| rename | 56.2% | 11.2% | 28.7% | 3.8% | |
| GPT-3.5 | default | 46.2% | 50.0% | 1.2% | 2.5% |
| rename | 51.2% | 38.8% | 6.2% | 3.8% | |
| GPT-4 | default | 65.0% | 30.0% | 5.0% | 0.0% |
| rename | 66.2% | 28.7% | 5.0% | 0.0% |
| Judge | Claude-v1 | GPT-3.5 | GPT-4 |
| Failure rate | 91.3% | 91.3% | 8.7% |
| Default | CoT | Reference | |
| Failure rate | 14/20 | 6/20 | 3/20 |
冗长偏差是指大语言模型的评委偏爱较长的冗长回答,即使这些回答不如较短的回答清晰、高质量或准确。
为了检验这种偏差,我们利用 MT-bench 的模型答案设计了一种 "重复列表 "攻击。 我们首先从 MT-bench 中选择了 23 个包含编号列表的示范答案。 然后,我们要求 GPT-4 在不添加任何新信息的情况下重新表述列表,并将重新表述后的新列表插入到原始列表的开头,从而使列表变得不必要地冗长。 例如,如果原始答卷包含 5 个项目,那么新答卷将包含 10 个项目,但前 5 个项目是在原始 5 个项目的基础上重新表述的。 示例见 图 11(附录)。 我们的定义是,如果大语言模型的法官认为新的回应比旧的回应更好,那么攻击就是成功的。 表 4显示了大语言模型法官在这种攻击下的失败率,表明尽管 GPT-4 的防御能力明显优于其他模型,但所有大语言模型都可能容易出现语言偏差。 作为校准,我们发现大语言模型法官能够正确判断相同答案(即他们总是对两个相同答案返回平局),但无法通过更高级的 "重复列表 "攻击。
自我提升偏差。 我们采用社会认知文献[4]中的术语 "自我强化偏差 "来描述大语言模型评委可能偏爱自己生成的答案这一效应。
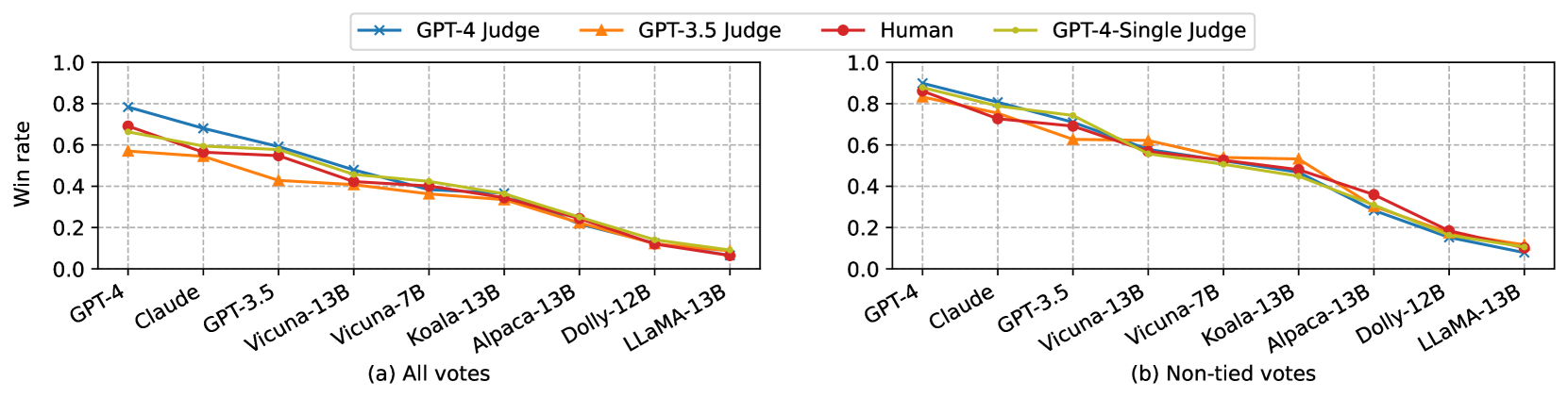
我们对这种影响进行了统计分析。 图 2(b)显示了六个模型在不同大语言模型评委和人类下的胜率(不含平局)。 与人类相比,我们确实观察到一些法官偏爱某些模式。 例如,GPT-4 对自己有利,胜率高出 10%;Claude-v1 对自己有利,胜率高出 25%。 不过,它们也偏爱其他模式,GPT-3.5 并不偏爱自己。 由于数据有限且差异较小,我们的研究无法确定模型是否表现出自我提升的偏差。 进行对照研究具有挑战性,因为我们不能轻易地在不改变质量的情况下重新表述一个回答,以适应另一种模式的风格。
3.4地址限制
我们介绍了几种解决位置偏差和数学问题评分能力有限的方法。
交换位置。 位置偏差可以通过简单的解决方案来解决。 保守的做法是通过调换两个答案的顺序两次传唤法官,只有在两个顺序都首选一个答案时才宣布获胜。 如果交换后结果不一致,我们可以称之为平局。 另一种更激进的方法是随机分配位置,如果预期正确,这种方法在大规模使用时可能会很有效。 在下面的实验中,我们采用保守的方法。
少样本法官。 我们评估了少样本能否提高位置偏差基准的一致性。 我们使用类似 MT 工作台的问题、生成答案的 GPT-3.5 和 Vicuna 以及生成判断的 GPT-4 选取了三个良好的判断示例。 示例包括三种情况:A 更好、B 更好和平局。 如 表 13(附录)所示,少样本判断可以显著提高 GPT-4 的一致性,从 65.0% 提高到 77.5%。 然而,高一致性未必意味着高准确性,我们也不确定少样本是否会带来新的偏差。 此外,较长的提示会使 API 调用 更昂贵。 我们在下面的实验中默认使用零样本提示,但在 Section D.2 中留下了额外的研究。
思维链和参照物引导法官。 在部分 3.3中,我们已经展示了大语言模型在数学和推理题评分方面的有限能力。 我们提出了两种简单的方法来缓解这一问题:思维链判断和参照物引导判断。 思维链是一种广泛使用的技术,用于提高大语言模型的推理能力[47]。 我们提出了一种类似的技术,促使大语言模型评委从独立回答问题开始,然后开始评分。 详细提示见图 6(附录)。 然而,即使有了 CoT 提示,我们发现在很多情况下,大语言模型在解决问题的过程中也会犯与给定答案完全相同的错误(见图 14 中的示例(附录),这表明大语言模型的判断仍可能受到上下文的误导。 因此,我们提出了一种参考引导法,即先独立生成大语言模型法官的答案,然后将其作为参考答案显示在法官提示中。 在表 4 中,我们看到失败率比默认提示有了显著提高(从 70% 降至 15% )。
微调法官模式。 我们尝试在竞技场数据上对 Vicuna-13B 进行微调,以充当裁判,并在附录 F中展示了一些有希望的初步结果。
3.5多回合法官
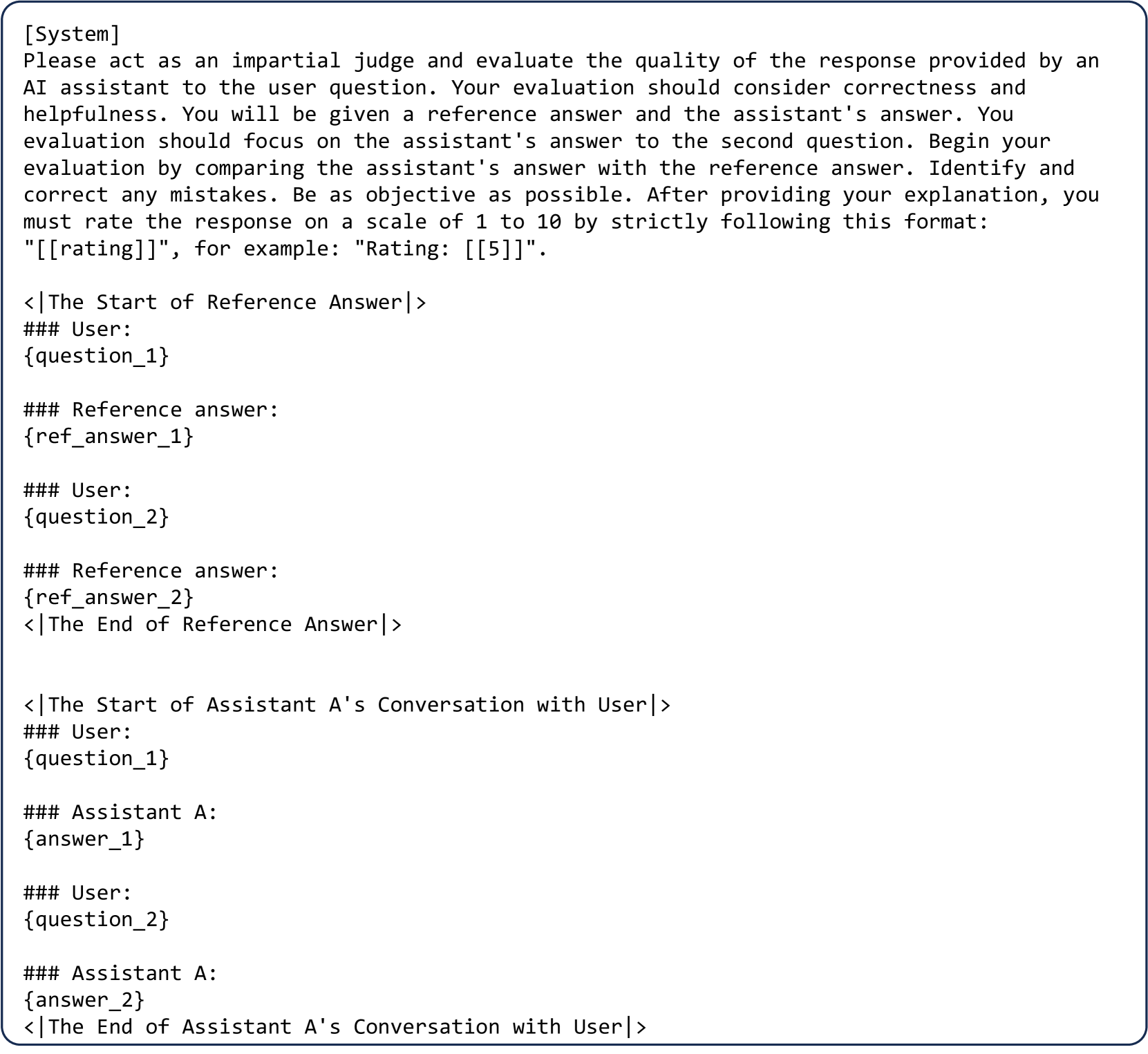
在 MT-bench 中,每个问题都涉及两轮会话能力评估。 因此,在对两个助手进行比较时,有必要提出总共两个问题和四个回答,从而使提示设计变得复杂。 我们探讨了两种可能的设计:(1) 将两个回合分成两个提示,或 (2) 在一个提示中显示完整的对话。 我们的发现是,前者会导致大语言模型法官难以准确定位助手之前的回应。 我们在图 15(附录)中举例说明了 GPT-4 由于参考错误而做出不准确判断的情况。 这说明有必要展示完整的对话,以便大语言模型法官更好地把握上下文。 然后,我们考虑了另一种设计,即在一个提示中呈现两个完整的对话,我们要求大语言模型评委关注第二个问题(图 8(附录))。 我们发现,这种方法大大缓解了上述引用问题。
4协议评估
我们在 MT-bench 和 Chatbot Arena 数据集上研究了不同大语言模型评判员与人类之间的一致性。 在 MT 工作台上,我们还研究了人类之间的一致性。 MT-bench是一项小规模研究,采用的是受控人类评估方法,而Chatbot Arena则是一项大规模研究,采用的是众包人类野外评估方法。
4.1设置
MT-bench. 我们用 6 个模型生成了所有 80 个问题的答案:GPT-4、GPT-3.5、Claude-V1、Vicuna-13B、Alpaca-13B [38] 和 LLaMA-13B [39]. 然后,我们使用两种法官:大语言模型评判员和 58 位专家级人类标签员。 贴标员大多是研究生,因此他们被认为是专家,比一般的人群工作者更熟练。 我们让大语言模型评委对所有对子进行评估,并让每个人至少评估 20 个随机多轮问题。 结果,所有问题都获得了约 3K 票。 详细的数据收集过程见附录 C。
聊天机器人竞技场 我们从 30K 竞技场数据中随机抽取了 3K 单轮投票,涵盖的模型包括 GPT-4、GPT-3.5、Claude、Vicuna-7B/13B、Koala-13B [16] 、Alpaca-13B、LLaMA-13B 和 Dolly-12B。 我们使用两种法官:大语言模型评委和收集的人群评委(2114 个唯一 IP)。
衡量标准。 我们将两类法官之间的一致定义为随机抽取的每类法官(但不完全相同)就随机抽取的问题达成一致的概率。 更多解释请参阅 Section D.3 。 平均胜率是对所有其他玩家的平均胜率。 在计算这些指标时,可以包括或不包括票数相同的票数。
4.2GPT-4与人类高度一致
我们计算了 MT 基准数据的一致性。 在表 5(b)中,采用成对比较和单一答案分级的 GPT-4 与人类专家的一致性非常高。 在设置 S2(无平局)下,GPT-4 与人类的一致性达到 85%,甚至高于人类的一致性(81%)。 这意味着 GPT-4 的判断与大多数人的判断非常一致。 我们还表明,GPT-4 的判断可能有助于人类做出更好的判断。 在数据收集过程中,当人类的选择与 GPT-4 有偏差时,我们会向人类展示 GPT-4 的判断,并询问其是否合理(详见 Section C.1)。 尽管有不同的观点,但在 75% 的情况下,人类认为 GPT-4 的判断是合理的,甚至在 34% 的情况下,人类愿意改变自己的选择。
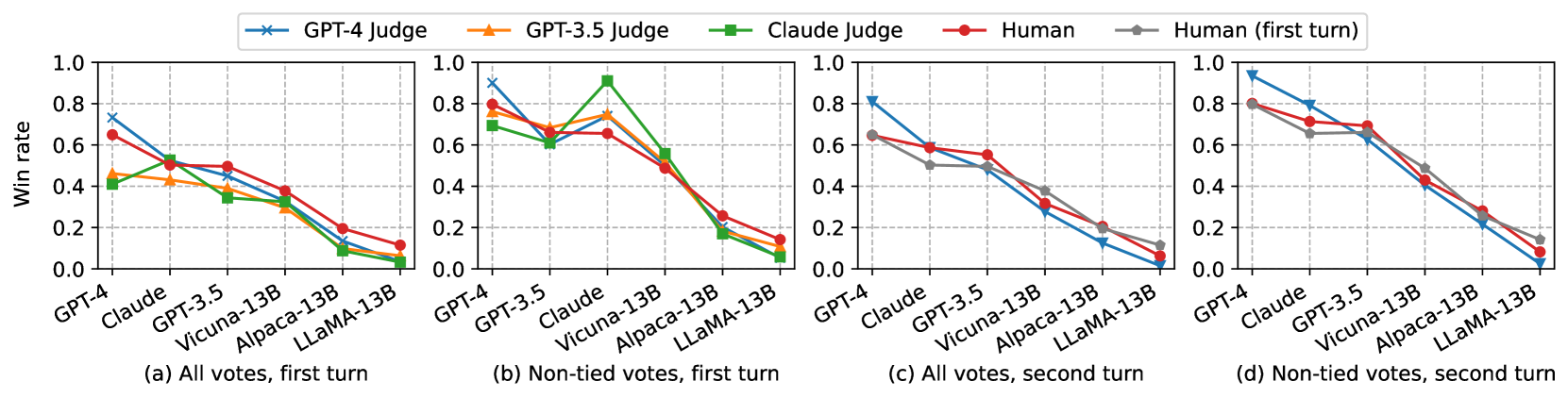
Arena 的数据也显示了类似的趋势,如 表 7 所示。 对比 GPT-4 和其他大语言模型评委,我们发现它们达到了人类之间类似的非绑定协议比率,但 GPT-4 的非绑定票数要大得多。 这说明 GPT-4 的肯定性更强,受立场偏差的影响较小,但其他模型在给出肯定答案时也有很好的表现。
在这两张表格中,采用单答案分级的 GPT-4 与成对 GPT-4 和人类偏好都非常吻合。 这说明 GPT-4 的内部评分标准相对稳定。 虽然这种方法有时可能比成对比较法的性能稍差,而且会出现更多票数相同的情况,但它是一种更具可扩展性的方法。
然后,我们通过计算不同模型对和类别的一致性进行细分分析。 我们只包括不附带条件的选票。 在表 7中,我们观察到 GPT-4 和人类的一致性随着模型对的性能差异(即胜率差异较大)而逐渐增加,从 70% 增加到接近 100%。 这表明,当模型之间存在显著性能差异时,GPT-4 与人类的吻合度更高。
| Setup | S1 (R = 33%) | S2 (R = 50%) | ||
|---|---|---|---|---|
| Judge | G4-Single | Human | G4-Single | Human |
| G4-Pair | 70% 1138 | 66% 1343 | 97% 662 | 85% 859 |
| G4-Single | - | 60% 1280 | - | 85% 739 |
| Human | - | 63% 721 | - | 81% 479 |
| Setup | S1 (R = 33%) | S2 (R = 50%) | ||
|---|---|---|---|---|
| Judge | G4-Single | Human | G4-Single | Human |
| G4-Pair | 70% 1161 | 66% 1325 | 95% 727 | 85% 864 |
| G4-Single | - | 59% 1285 | - | 84% 776 |
| Human | - | 67% 707 | - | 82% 474 |
| Setup | S1 (Random = 33%) | S2 (Random = 50%) | ||||||
|---|---|---|---|---|---|---|---|---|
| Judge | G4-S | G3.5 | C | H | G4-S | G3.5 | C | H |
| G4 | 72% 2968 | 66% 3061 | 66% 3062 | 64% 3066 | 95% 1967 | 94% 1788 | 95% 1712 | 87% 1944 |
| G4-S | - | 60% 2964 | 62% 2964 | 60% 2968 | - | 89% 1593 | 91% 1538 | 85% 1761 |
| G3.5 | - | - | 68% 3057 | 54% 3061 | - | - | 96% 1497 | 83% 1567 |
| C | - | - | - | 53% 3062 | - | - | - | 84% 1475 |
![[Uncaptioned image]](x2.png)
| Model | Writing | Roleplay | Reasoning | Math | Coding | Extraction | STEM | Humanities |
|---|---|---|---|---|---|---|---|---|
| GPT-4 | 61.2% | 67.9% | 49.3% | 66.1% | 56.3% | 66.2% | 76.6% | 72.2% |
| GPT-3.5 | 50.9% | 60.6% | 32.6% | 63.8% | 55.0% | 48.8% | 52.8% | 53.8% |
| Vicuna-13B | 39.7% | 39.2% | 20.1% | 18.0% | 36.9% | 29.2% | 47.0% | 47.5% |
| LLaMA-13B | 15.1% | 15.1% | 7.8% | 7.5% | 2.1% | 9.3% | 6.8% | 10.1% |
4.3不同法官的胜诉率
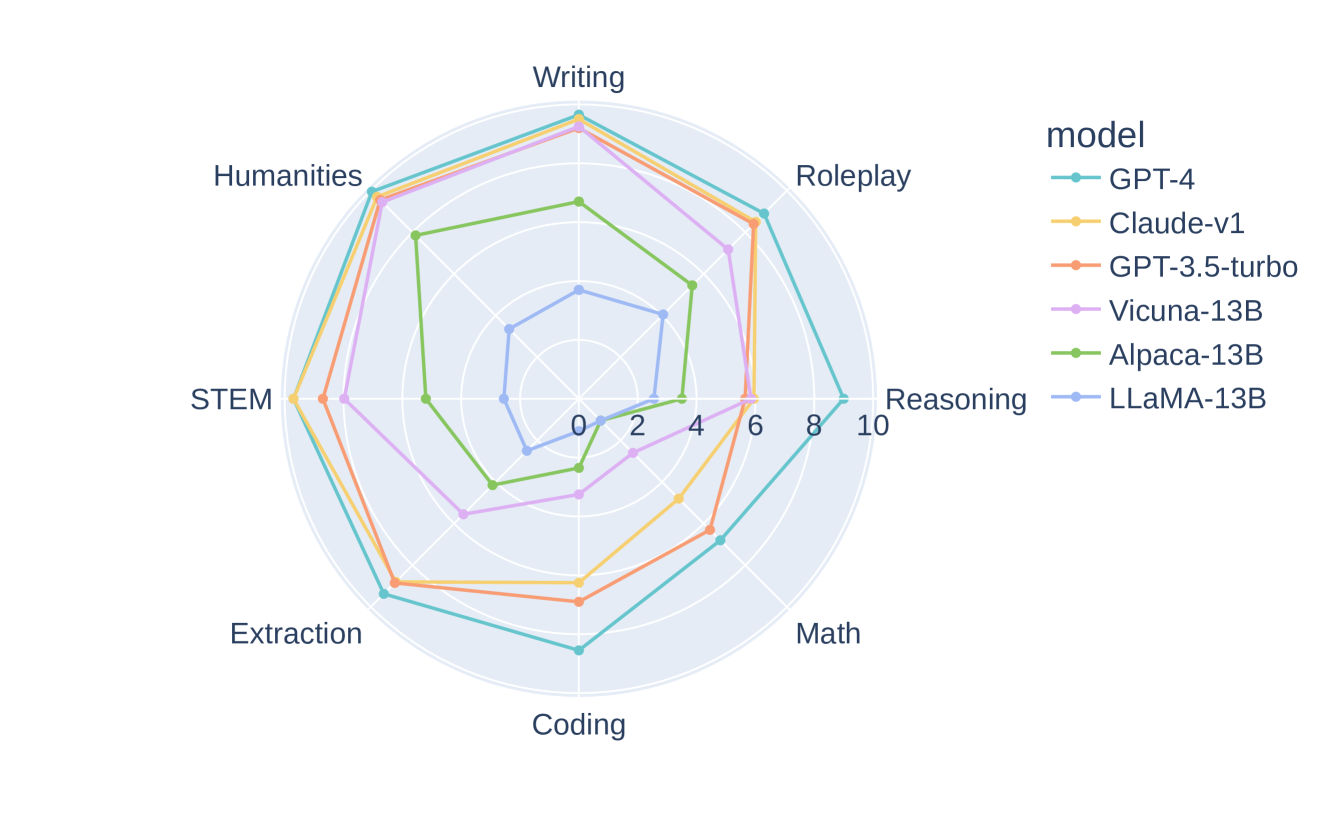
我们分别在 图 2 和 图 3 中绘制了 MT-bench 和 Chatbot Arena 上不同评委下模型的平均胜率。 大语言模型法官的胜率曲线与人类的胜率曲线非常吻合。 在 MT-bench 第二轮测试中,与第一轮测试相比,Claude 和 GPT-3.5 等专有模型更受人类青睐,这意味着多轮测试能更好地区分模型的某些高级能力。 我们还在 表 8中列出了代表机型的每类胜率,以显示 MT-bench 如何区分机型,其中我们看到 GPT-4 明显优于其他机型。 在推理、数学和编码方面,Vicuna-13B 明显不如 GPT-3.5/4。 请注意,在数学/编码类别中,GPT-3.5 和 GPT-4 的总胜率相近,因为它们都未能回答一些难题,但 GPT-4 在直接配对比较或单答案评分中仍明显优于 GPT-3。 请参阅 Section D.4 中的 MT-bench 各类得分的性能明细。
| Model | #Training Token | MMLU (5-shot) | TruthfulQA (0-shot) | MT-Bench Score (GPT-4) |
| LLaMA-7B | 1T | 35.2 | 0.22 | 2.74 |
| LLaMA-13B | 1T | 47.0 | 0.26 | 2.61 |
| Alpaca-7B | 4.4M | 40.1 | 0.26 | 4.54 |
| Alpaca-13B | 4.4M | 48.1 | 0.30 | 4.53 |
| Vicuna-7B (selected) | 4.8M | 37.3 | 0.32 | 5.95 |
| Vicuna-7B (single) | 184M | 44.1 | 0.30 | 6.04 |
| Vicuna-7B (all) | 370M | 47.1 | 0.32 | 6.00 |
| Vicuna-13B (all) | 370M | 52.1 | 0.35 | 6.39 |
| GPT-3.5 | - | 70.0 | - | 7.94 |
| GPT-4 | - | 86.4 | - | 8.99 |
5人类偏好基准和标准化基准
MT-bench 和 Chatbot Arena 等人类偏好基准是对当前标准化大语言模型基准的宝贵补充。 它们侧重于模型的不同方面,建议的方法是用这两种基准对模型进行全面评估。
我们在 MMLU [19]、Truthful QA [26] (MC1) 和 MT-bench (GPT-4 judge) 上对从 LLaMA 派生的几个模型变体进行了评估。 训练详情见附录E。由于我们在节 4.2中证明了 GPT-4 单答题分级也有很好的表现,因此我们在 MT-bench 中使用 GPT-4 单答题分级,因为它具有可扩展性和简单性。 我们要求 GPT-4 使用我们的提示模板(图 5、图 9),并报告平均得分 个回合。 表 9显示了结果。 我们发现,在高质量的对话数据集(即 ShareGPT)上进行微调可以持续提高模型在 MMLU 上的性能,而且这种提高会随着微调数据规模的扩大而扩大。 另一方面,高质量的小型对话数据集可以快速教会模型一种 GPT-4(或近似人类)偏好的风格,但却无法显著提高 MMLU,如仅用 4.8M 词符或 3K 对话训练的 Vicuna-7B(选中)所示。 在表 9中,没有任何一个基准可以确定模型的质量,这意味着需要进行综合评估。 我们的研究结果表明,使用大语言模型作为判断器来近似人类偏好是非常可行的,并可能成为未来基准的新标准。 我们还将定期更新排行榜,提供更多模型 111https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard。 值得注意的是,致力于动态数据收集和基准测试的研究平台 DynaBench [21] 与我们的精神不谋而合。 DynaBench 通过强调人在回路中的动态数据,解决了静态标准化基准带来的饱和与过度拟合等挑战。 我们的 "大语言模型即法官 "方法可以实现此类平台的自动化和规模化。
6讨论
局限性。 本文强调了 "有用性",但在很大程度上忽视了 "安全性"。 诚实和无害对于聊天助手来说也至关重要 [2]。 我们预计,通过修改默认提示,类似的方法也可用于评估这些指标。 此外,在 "有用性 "中还包含多个维度,如准确性、相关性和创造性,但在本研究中,这些维度都被合并为一个指标。 通过对这些维度进行分析和分离,可以得出更全面的评估结果。 我们在节 3.4中提出了解决大语言模型即法官的局限性和偏差的初步方案,但我们预计可以开发出更先进的方法。
数据收集和发布。 附录 C详细描述了数据收集和发布过程,其中包括我们给用户的说明、数据收集界面截图、参与用户信息以及发布的数据内容。
社会影响。 这项研究的社会影响是多方面的。 我们的评估方法有助于提高聊天机器人的质量和用户体验。 然而,解决这些方法中的偏差问题至关重要。 我们的数据集有助于更好地研究人类偏好和模型行为。 先进的聊天助手可能会取代人类的某些任务,从而导致工作岗位的更换和新的机遇。
未来发展方向。 1) 利用更广泛的类别集为聊天机器人制定大规模基准 2)与人类偏好一致的开源大语言模型判断 3)增强开放模型的数学/推理能力。
7结论
在本文中,我们提出了用于聊天机器人评估的大语言模型,并利用来自 MT-bench 上 58 位专家以及 Chatbot Arena 上数千名大众用户的人类偏好数据,系统地检验了其功效。 我们的研究结果表明,强语言模型可以达到 80% 以上的一致率,与人类专家之间的一致水平相当,从而为基于大语言模型的评估框架奠定了基础。
鸣谢
本项目的部分支持来自 Anyscale、Astronomer、谷歌、IBM、英特尔、Lacework、微软、MBZUAI、三星 SDS、Uber 和 VMware 的捐赠。 Lianmin Zheng 由 Meta 博士奖学金资助。 我们感谢耿新阳、刘浩、Eric Wallace、李学成、张天一、何启荣和林凯文在讨论中提出的真知灼见。
参考资料
- [1] Rohan Anil, Andrew M Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, et al. Palm 2 technical report. arXiv preprint arXiv:2305.10403, 2023.
- [2] Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862, 2022.
- [3] Niels J Blunch. Position bias in multiple-choice questions. Journal of Marketing Research, 21(2):216–220, 1984.
- [4] Jonathon D Brown. Evaluations of self and others: Self-enhancement biases in social judgments. Social cognition, 4(4):353–376, 1986.
- [5] Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
- [6] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- [7] Cheng-Han Chiang and Hung-yi Lee. Can large language models be an alternative to human evaluations? arXiv preprint arXiv:2305.01937, 2023.
- [8] Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023.
- [9] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018.
- [10] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- [11] Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35:16344–16359, 2022.
- [12] Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. arXiv preprint arXiv:2305.14314, 2023.
- [13] Shizhe Diao, Rui Pan, Hanze Dong, Ka Shun Shum, Jipeng Zhang, Wei Xiong, and Tong Zhang. Lmflow: An extensible toolkit for finetuning and inference of large foundation models. arXiv preprint arXiv:2306.12420, 2023.
- [14] Yann Dubois, Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. Alpacafarm: A simulation framework for methods that learn from human feedback. arXiv preprint arXiv:2305.14387, 2023.
- [15] Jiazhan Feng, Qingfeng Sun, Can Xu, Pu Zhao, Yaming Yang, Chongyang Tao, Dongyan Zhao, and Qingwei Lin. Mmdialog: A large-scale multi-turn dialogue dataset towards multi-modal open-domain conversation. arXiv preprint arXiv:2211.05719, 2022.
- [16] Xinyang Geng, Arnav Gudibande, Hao Liu, Eric Wallace, Pieter Abbeel, Sergey Levine, and Dawn Song. Koala: A dialogue model for academic research. Blog post, April 2023.
- [17] Fabrizio Gilardi, Meysam Alizadeh, and Maël Kubli. Chatgpt outperforms crowd-workers for text-annotation tasks. arXiv preprint arXiv:2303.15056, 2023.
- [18] Arnav Gudibande, Eric Wallace, Charlie Snell, Xinyang Geng, Hao Liu, Pieter Abbeel, Sergey Levine, and Dawn Song. The false promise of imitating proprietary llms. arXiv preprint arXiv:2305.15717, 2023.
- [19] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
- [20] Fan Huang, Haewoon Kwak, and Jisun An. Is chatgpt better than human annotators? potential and limitations of chatgpt in explaining implicit hate speech. arXiv preprint arXiv:2302.07736, 2023.
- [21] Douwe Kiela, Max Bartolo, Yixin Nie, Divyansh Kaushik, Atticus Geiger, Zhengxuan Wu, Bertie Vidgen, Grusha Prasad, Amanpreet Singh, Pratik Ringshia, et al. Dynabench: Rethinking benchmarking in nlp. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4110–4124, 2021.
- [22] Miyoung Ko, Jinhyuk Lee, Hyunjae Kim, Gangwoo Kim, and Jaewoo Kang. Look at the first sentence: Position bias in question answering. arXiv preprint arXiv:2004.14602, 2020.
- [23] Andreas Köpf, Yannic Kilcher, Dimitri von Rütte, Sotiris Anagnostidis, Zhi-Rui Tam, Keith Stevens, Abdullah Barhoum, Nguyen Minh Duc, Oliver Stanley, Richárd Nagyfi, et al. Openassistant conversations–democratizing large language model alignment. arXiv preprint arXiv:2304.07327, 2023.
- [24] Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. Holistic evaluation of language models. arXiv preprint arXiv:2211.09110, 2022.
- [25] Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pages 74–81, 2004.
- [26] Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958, 2021.
- [27] Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, et al. The flan collection: Designing data and methods for effective instruction tuning. arXiv preprint arXiv:2301.13688, 2023.
- [28] Swaroop Mishra, Daniel Khashabi, Chitta Baral, and Hannaneh Hajishirzi. Cross-task generalization via natural language crowdsourcing instructions. In ACL, 2022.
- [29] OpenAI. Evals is a framework for evaluating llms and llm systems, and an open-source registry of benchmarks. https://github.com/openai/evals.
- [30] OpenAI. Gpt-4 technical report, 2023.
- [31] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- [32] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002.
- [33] Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. Instruction tuning with gpt-4. arXiv preprint arXiv:2304.03277, 2023.
- [34] Priya Raghubir and Ana Valenzuela. Center-of-inattention: Position biases in decision-making. Organizational Behavior and Human Decision Processes, 99(1):66–80, 2006.
- [35] Siva Reddy, Danqi Chen, and Christopher D Manning. Coqa: A conversational question answering challenge. Transactions of the Association for Computational Linguistics, 7:249–266, 2019.
- [36] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106, 2021.
- [37] Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. arXiv preprint arXiv:2206.04615, 2022.
- [38] Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023.
- [39] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- [40] Peiyi Wang, Lei Li, Liang Chen, Dawei Zhu, Binghuai Lin, Yunbo Cao, Qi Liu, Tianyu Liu, and Zhifang Sui. Large language models are not fair evaluators. arXiv preprint arXiv:2305.17926, 2023.
- [41] Xuanhui Wang, Nadav Golbandi, Michael Bendersky, Donald Metzler, and Marc Najork. Position bias estimation for unbiased learning to rank in personal search. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, pages 610–618, 2018.
- [42] Yidong Wang, Zhuohao Yu, Zhengran Zeng, Linyi Yang, Cunxiang Wang, Hao Chen, Chaoya Jiang, Rui Xie, Jindong Wang, Xing Xie, Wei Ye, Shikun Zhang, and Yue Zhang. Pandalm: An automatic evaluation benchmark for llm instruction tuning optimization, 2023.
- [43] Yizhong Wang, Hamish Ivison, Pradeep Dasigi, Jack Hessel, Tushar Khot, Khyathi Raghavi Chandu, David Wadden, Kelsey MacMillan, Noah A Smith, Iz Beltagy, et al. How far can camels go? exploring the state of instruction tuning on open resources. arXiv preprint arXiv:2306.04751, 2023.
- [44] Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language model with self generated instructions, 2022.
- [45] Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Anjana Arunkumar, Arjun Ashok, Arut Selvan Dhanasekaran, Atharva Naik, David Stap, et al. Super-naturalinstructions:generalization via declarative instructions on 1600+ tasks. In EMNLP, 2022.
- [46] Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652, 2021.
- [47] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903, 2022.
- [48] Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244, 2023.
- [49] Zongheng Yang, Zhanghao Wu, Michael Luo, Wei-Lin Chiang, Romil Bhardwaj, Woosuk Kwon, Siyuan Zhuang, Frank Sifei Luan, Gautam Mittal, Scott Shenker, and Ion Stoica. SkyPilot: An intercloud broker for sky computing. In 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), pages 437–455, Boston, MA, April 2023. USENIX Association.
- [50] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830, 2019.
- [51] Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan. Agieval: A human-centric benchmark for evaluating foundation models. arXiv preprint arXiv:2304.06364, 2023.
- [52] Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. Lima: Less is more for alignment. arXiv preprint arXiv:2305.11206, 2023.
附录 A 提示模板
我们列出了大语言法官的提示模板。 请参阅我们的 github 代码库 222https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge 了解更多详情。





附录 B 案例研究
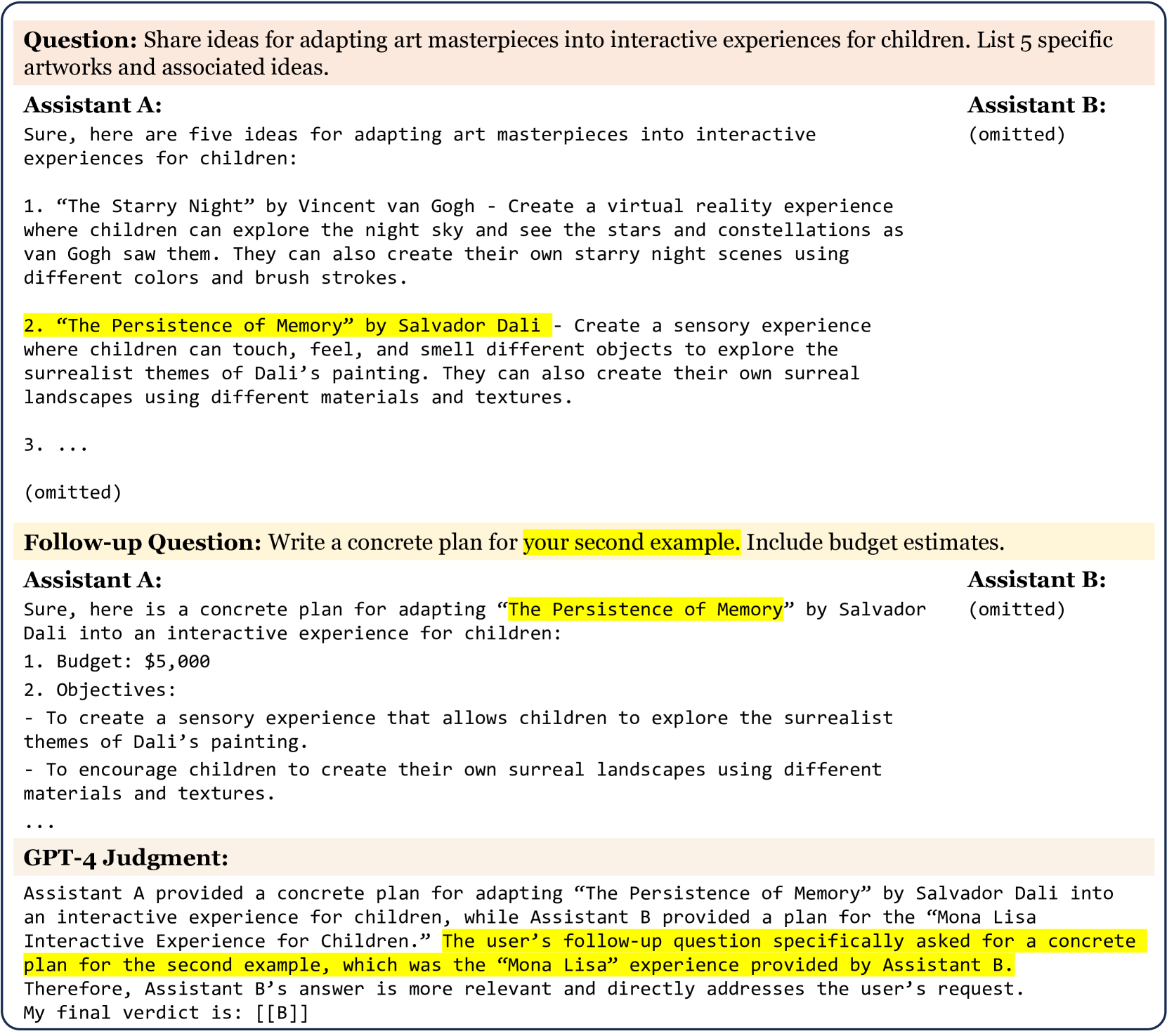
我们列举了几个案例研究。 示例由 gpt-4-0314 生成。 未来的 GPT-4 版本可能无法完全复制它们。





附录 C数据收集
我们将介绍 MT-bench 和 Chatbot Arena 的数据收集过程。
C.1MT-本人体评估


为了邀请参与者,我们让他们签署了一份申请表,征得了他们的同意。 我们为他们评判 20 个问题支付 20 美元,相当于每小时 35 美元左右。 参与者大多是来自十多所大学的研究生。
C.2聊天机器人竞技场
图 18显示了聊天机器人竞技场的截图。 用户必须接受使用条款,这些条款会征得用户的同意,并赋予我们发布对话数据的权利。 操作说明显示在界面顶部。 这是一个免费网站。 我们不向用户支付任何费用,任何用户无需注册即可使用本平台。 更多介绍和分析,请访问https://lmsys.org/blog/2023-05-03-arena/。
C.3数据发布
我们将清理个人身份信息 (PII),并使用 OpenAI 节制 API 标记有毒对话,以便发布数据集。
附录 D其他实验结果
我们将介绍一些额外的实验结果。
D.1位置偏差
我们还测试了另外两个提示,并在 表 10 中展示了全部结果。"分数 "更改了默认提示,让模型输出两个绝对分数,而不是哪个更好。 "简短 "是我们默认提示的简化版本,删除了 "避免任何立场偏差......"、"开始评估......并提供简短解释 "等指示。 我们可以发现,不同的提示对不同的模型有不同的影响。 例如,"评分 "提示可以提高 GPT-3.5 的一致性,但会降低 Claude-v1 和 GPT-4 的一致性。
| Judge | Prompt | Consistency | Biased toward first | Biased toward second | Error |
|---|---|---|---|---|---|
| claude-v1 | default | 23.8% | 75.0% | 0.0% | 1.2% |
| rename | 56.2% | 11.2% | 28.7% | 3.8% | |
| score | 20.0% | 80.0% | 0.0% | 0.0% | |
| short | 22.5% | 75.0% | 2.5% | 0.0% | |
| gpt-3.5-turbo | default | 46.2% | 50.0% | 1.2% | 2.5% |
| rename | 51.2% | 38.8% | 6.2% | 3.8% | |
| score | 55.0% | 33.8% | 11.2% | 0.0% | |
| short | 38.8% | 57.5% | 3.8% | 0.0% | |
| gpt-4 | default | 65.0% | 30.0% | 5.0% | 0.0% |
| rename | 66.2% | 28.7% | 5.0% | 0.0% | |
| score | 51.2% | 46.2% | 2.5% | 0.0% | |
| short | 62.5% | 35.0% | 2.5% | 0.0% |
如表11所示,立场偏差在写作和干/人文知识等开放性问题上更为明显。 正如我们在 Section 3.3 中展示的那样,在数学和编码问题上,大语言模型评委更有信心,尽管他们的判断经常会出错。 最后,我们使用 GPT-4 和默认提示来判断三个不同的模型对,从而研究模型对如何影响位置偏差。 如 表 12所示,位置偏差在性能接近的模型中更为明显,当两个模型的性能相差很大时,位置偏差几乎可以消失。
| Category | Consistent | Biased toward first | Biased toward second |
|---|---|---|---|
| writing | 42.0% | 46.0% | 12.0% |
| roleplay | 68.0% | 30.0% | 2.0% |
| reasoning | 76.0% | 20.0% | 4.0% |
| math | 86.0% | 4.0% | 10.0% |
| coding | 86.0% | 14.0% | 0.0% |
| extraction | 78.0% | 12.0% | 10.0% |
| stem | 44.0% | 54.0% | 2.0% |
| humanities | 36.0% | 60.0% | 4.0% |
| Pair | Consistent | Biased toward first | Biased toward second |
|---|---|---|---|
| GPT-3.5 vs Claude-V1 | 67.5% | 23.8% | 8.8% |
| GPT-3.5 vs Vicuna-13B | 73.8% | 23.8% | 2.5% |
| GPT-3.5 vs LLaMA-13B | 98.8% | 1.2% | 0.0% |
D.2少样本法官
我们研究了少样本如何改进大语言模型的判断。 如表13所示,它们显著提高了三个大语言模型评委的一致性。 它几乎缓解了 GPT-4 的位置偏差,但将 GPT-3.5 的位置偏差从第一位置移到了第二位置。 然后,我们在 MT-bench 上测量了少样本 GPT-4 配对比较与人类的一致性,但发现其表现与零样本 GPT-4 配对比较类似。
| Model | Prompt | Consistency | Biased toward first | Biased toward second | Error |
|---|---|---|---|---|---|
| Claude-v1 | zero-shot | 23.8% | 75.0% | 0.0% | 1.2% |
| few-shot | 63.7% | 21.2% | 11.2% | 3.8% | |
| GPT-3.5 | zero-shot | 46.2% | 50.0% | 1.2% | 2.5% |
| few-shot | 55.0% | 16.2% | 28.7% | 0.0% | |
| GPT-4 | zero-shot | 65.0% | 30.0% | 5.0% | 0.0% |
| few-shot | 77.5% | 10.0% | 12.5% | 0.0% |
D.3协议评估
协议计算。 我们将两类法官之间的一致定义为随机抽取的每类法官(但不完全相同)就随机抽取的问题达成一致的概率。 例如,如果我们比较的是 GPT-4 和克劳德,那么同意度就是 GPT-4 和克劳德在随机选择的一个问题的投票上达成一致的概率。 如果我们比较的是 GPT-4 和人类,那么一致度就是 GPT-4 和随机抽取的人类就随机抽取的问题达成投票一致的概率。 人与人之间的一致是指两个随机抽取但不完全相同的人就随机抽取的问题达成投票一致的概率。
请注意,与 GPT4 和人类的一致性相比,人类之间的一致性可能是较低的估计值。 假设有三个人对一个问题分别投了 "A"、"A "和 "B "票。 它们之间的一致性只有 ,因为有三对"(A,A)"、"(A,B)"和"(A,B)"。 但是,如果 GPT4 投 "第一票",则 GPT4 与这三人之间的协议为 ,否则为 。
因此,为了更全面地了解所发生的情况,我们引入了一种新的法官类型,称为 "人类多数"(human-majority),它考虑了每个问题中人类投票的多数。 然后计算 GPT4 与人类多数票之间的一致性,即 GPT4 在随机选择的问题上与人类多数票一致的概率。 GPT-4 与人类的一致性上限是人类-多数与人类的一致性。 当对某一问题的表决没有多数票时,则按偶数票计算。 例如,如果某个问题的 "A "和 "B "人类票数相等,而 GPT4 投了 "A "票,那么在这个问题上,同意的票数计为 。
更多结果 表 14(b)显示了 MT-bench 的更多一致性结果。 除了专家标注者(以 "Human "表示),我们还包括作者投票(以 "Author "表示)。
| Setup | S1 (R = 33%) | S2 (R = 50%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Judge | G4-S | C | Author | Human | Human-M | G4-S | C | Author | Human | Human-M |
| G4-P | 70% 1138 | 63% 1198 | 69% 345 | 66% 1343 | 67% 821 | 97% 662 | 94% 582 | 92% 201 | 85% 859 | 85% 546 |
| G4-S | - | 66% 1136 | 67% 324 | 60% 1280 | 60% 781 | - | 90% 563 | 94% 175 | 85% 739 | 85% 473 |
| C | - | - | 58% 343 | 54% 1341 | 55% 820 | - | - | 89% 141 | 85% 648 | 86% 414 |
| Author | - | - | 69% 49 | 65% 428 | 55% 93 | - | - | 87% 31 | 83% 262 | 76% 46 |
| Human | - | - | - | 63% 721 | 81% 892 | - | - | - | 81% 479 | 90% 631 |
| Setup | S1 (R = 33%) | S2 (R = 50%) | ||||||
|---|---|---|---|---|---|---|---|---|
| Judge | G4-S | Author | Human | Human-M | G4-S | Author | Human | Human-M |
| G4-P | 70% 1161 | 66% 341 | 66% 1325 | 68% 812 | 95% 727 | 88% 205 | 85% 864 | 85% 557 |
| G4-S | - | 65% 331 | 59% 1285 | 61% 783 | - | 89% 193 | 84% 776 | 85% 506 |
| Author | - | 67% 49 | 68% 413 | 63% 87 | - | 87% 31 | 86% 273 | 84% 54 |
| Human | - | - | 67% 707 | 83% 877 | - | - | 82% 474 | 91% 629 |
D.4按类别打分,单项答案评分
我们在 MT-bench 上使用单答题分级对 6 个模型进行了评估,并在 图 19中绘制了分类得分图。
附录 E 维库纳模型的训练细节
Vicuna 是利用 ShareGPT.com 的公共 API 收集到的用户共享对话,通过微调 LLaMA 基础模型创建的。 ShareGPT 是一个用户可以分享其 ChatGPT 会话的网站。 为确保数据质量,我们将 HTML 转换回 markdown,并过滤掉一些不合适或低质量的样本,这样数据清理后就有 125K 个对话。333在这项研究中,我们使用的数据(125K)比我们之前博文中的版本(70K)更多。 然后,我们将冗长的对话分割成符合模型最大上下文长度的较小片段。
我们利用经过清理的 ShareGPT 数据集构建了三个不同规模的训练数据集。 其统计数据见 表 9,我们还将其与 Alpaca [38] 数据集进行了比较。 "全部 "是完整的数据集。 "单次 "只包括每次对话的第一轮。 "精选 "是一个由 3K 个序列组成的小型高质量数据集。 为了构建 "精选 "数据集,我们选取了由 GPT-4 生成的至少包含 3 轮对话的序列,并运行聚类算法将其分为 3K 个聚类,然后选取每个聚类的中心点。
所有模型(Vicuna-7B/13B)都使用相同的超参数进行训练:全局批量大小=128,学习=2e-5,epochs=3,seq length=2048。 除 "选定 "外,我们对其进行了 5 个历元的训练。 训练代码建立在 Alpaca 代码之上,但还能处理多轮对话。 训练由 8x A100 GPU 完成。 最长的单次训练约需 2 天。 我们利用 SkyPilot [49] 管理点实例来节省训练成本,并利用 FlashAttention [11] 来优化内存。 训练代码见 https://github.com/lm-sys/FastChat。
| Dataset Name | Alpaca | Selected | Single | All |
| #Token | 4.4M | 4.8M | 184M | 370M |
| #Sequence | 52K | 3K | 257K | 257K |
| Avg. turns of conversation | 1.0 | 4.0 | 1.0 | 2.9 |
| Avg. response length (token) | 65 | 343 | 473 | 373 |
附录 F探索作为法官的维库纳
在本文中,我们主要评估的是 GPT-4 等近源模型作为人类评价的替代物的能力。 然而,随着评估次数的增加,GPT-4 等模型服务也会变得昂贵。 另一方面,流行的开源 LLM(如 Vicuna-13B)显示出很强的语言理解能力,而且价格比近源 LLM 便宜得多。 在本节中,我们将进一步探讨使用 Vicuna-13B 作为成本更低的替代品的可能性。
F.1零样本维库纳
在使用原样(零样本)时,Vicuna-13B 明显受到我们讨论的限制,例如位置偏差。 如表 16所示,Vicuna-13B 在不同提示模板中的一致性从 11.2% 到 16.2%,远低于所有闭源模型。 此外,由于其遵循指令的能力较弱,错误率较高(从 22.5% 到 78.8%)。 在许多情况下,Vicuna-13B 都会提供诸如 "答案 A 比答案 B 好 "之类的回复,而不会遵循预先定义的模板。 这些回复以自然语言的形式呈现,难以自动解析,因此模型在可扩展的自动评估管道中的作用较小。
F.2阿雷纳微调维库纳
训练
由于零样本的 Vicuna-13B 模型无法胜任,我们利用 Chatbot Arena 的人类投票对模型进行了进一步的微调。 具体来说,我们从竞技场中随机抽取了 22K 张单轮投票,涵盖了本文提交时支持的所有模型(GPT-4、GPT-3.5、Claude-v1、Vicuna-13b、Vicuna-7b、Koala-13B、Alpaca-13B、LLaMA-13B、Dolly-12B、FastChat-T5、RWKV-4-Raven、MPT-Chat、OpenAssistant、ChatGLM 和 StableLM),以便在更广泛的聊天机器人输出和人类偏好范围内展示模型。 我们使用 20K 张选票进行训练,使用 2K 张选票进行验证。 为了解决上述弱指令遵循问题,我们将该问题表述为一个 3 向序列分类问题。 因此,模型只需预测聊天机器人输出中哪一个更好(或平局),而无需完全按照提供的答案模板。 具体来说,我们使用默认提示和两个模型答案来构建输入。 标签为 A、B 和平局(包括两票相差和两票相等)。 我们使用余弦学习率调度器和 2e-5 最大学习率进行 3 个历元的训练。 我们使用 2K 验证数据集来选择超参数,并在论文主体中使用相同的 3K 数据集进行测试。
位置偏差结果
位置偏差结果见 表 16。 一致性从 16.2% 显著提高到 65.0%。 由于采用了分类方法,每个输出结果都是可识别的(错误率为 0%)。 此外,我们还测量了测试数据集的分类准确率。
协议结果
当包括所有三个标签时,它的得分率为 56.8%;当不包括平局预测和标签时,它的得分率为 85.5%,分别大幅超过随机猜测的 33% 和 50%,并显示出与 GPT-4 匹配的积极信号(分别为 66% 和 87%)。 总之,经过进一步微调的 Vicuna-13B 模型显示出巨大的潜力,可以作为廉价的开源 LLM 替代昂贵的闭源 LLM。 同时发表的一篇论文[42]也得出了类似的结论。
| Judge | Prompt | Consistency | Biased toward first | Biased toward second | Error |
|---|---|---|---|---|---|
| Vicuna-13B-Zero-Shot | default | 15.0% | 53.8% | 8.8% | 22.5% |
| rename | 16.2% | 12.5% | 40.0% | 31.2% | |
| score | 11.2% | 10.0% | 0.0% | 78.8% | |
| Vicuna-13B-Fine-Tune | default | 65.0% | 27.5% | 7.5% | 0.0% |