提升自己:利用自我记忆进行检索增强文本生成
摘要
通过直接访问人类书写的参考作为记忆,检索增强生成在广泛的文本生成任务中取得了很大进展。 因为更好的记忆通常会促进更好的生成(我们将其定义为原始问题)。 传统的记忆检索方法涉及选择与输入表现出最高相似度的记忆。 然而,这种方法受到检索记忆的固定语料库质量的限制。 在本文中,通过探索原始问题的二元性:更好的生成也会促进更好的记忆,我们提出了一种新颖的框架,Selfmem,它通过迭代地使用检索增强生成器来创建一个无界内存池,并使用内存选择器选择一个输出作为后续生成轮的内存。 这使得模型能够利用自己的输出(称为自记忆)来改进生成。 我们在微调小模型和少样本大语言模型这两种生成范式下,评估了 Selfmem 在三种不同文本生成任务上的有效性:神经机器翻译、抽象文本摘要和对话生成。 我们的方法在 JRC-Acquis 翻译数据集的四个方向上取得了最先进的结果,在 XSum 中达到 50.3 ROUGE-1,在 BigPatent,展示了自我记忆在增强检索增强生成模型方面的潜力。 此外,我们对 Selfmem 框架中的每个组件进行深入分析,以确定当前的系统瓶颈,并为未来的研究提供见解111Code and data available at: https://github.com/Hannibal046/SelfMemory。
1简介
近年来,检索增强文本生成在各个领域引起了越来越多的兴趣,包括神经机器翻译[28,17,2]、对话响应生成[81,6,46] 和语言建模[36,77,19]。 这种创新的生成范式最初配备了一个经过微调的小模型或一个大型语言模型(大语言模型),可以使用信息检索技术访问外部数据库(通常是训练语料库)。 随后,基于输入文本和检索到的记忆进行生成过程。
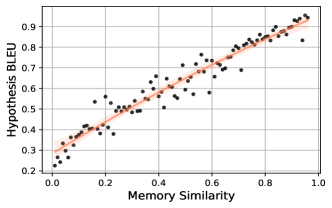
在这个范式中,记忆检索的指导原则是找到与当前输入[36,96,49]表现出最高相似度的记忆。 这与人类的直觉一致,即更相似的演示样本通常会提供更多提示。 如图1所示,对于检索增强翻译模型,仅记忆相似度就与最终翻译质量表现出很强的相关性,而不管其他可能影响翻译质量的因素(例如多义词、词法) ,以及共指)。 我们将其定义为原始问题:更好的记忆力促进更好的生成。 因此,许多研究都集中在如何检索更好的记忆上,从稀疏检索到密集检索[10, 63],从固定检索器到可学习检索器[41, 8],以及从句子级记忆到更细粒度的标记级记忆[36, 35]。
然而,之前的所有工作都存在一个根本性的限制:记忆是从固定的语料库中检索的,并且受到语料库质量的限制。 由于检索空间有限,有限内存极大地限制了内存增强生成模型的潜力[97]。 在本文中,我们探讨了原始问题的二元性,其中假设更好的生成也会促进更好的记忆。 我们提出了一种名为 Selfmem 的新颖框架,它迭代地使用检索增强生成器来创建无界内存池,并使用内存选择器选择一个输出作为后续生成轮的内存。 通过结合原始和对偶问题,检索增强生成模型可以使用自己的输出(称为自记忆)来提升自身。 Selfmem 背后的关键见解是,与推理过程中的数据分布更相似的文本不是训练数据 [87],而是模型自己的输出。
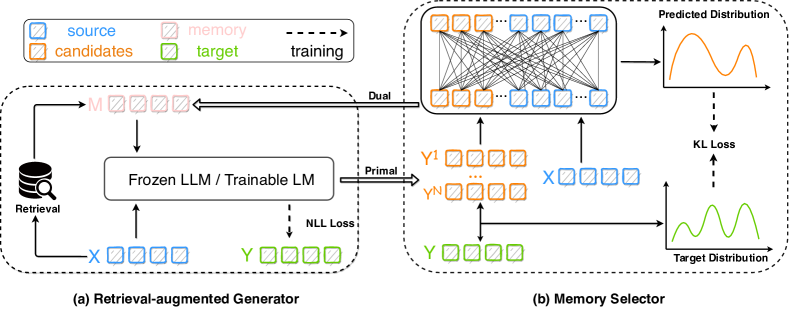
Selfmem 由两个互补的组件组成:检索增强生成器和内存选择器。 该生成器在两种不同的范式下运行:微调小模型或提示大语言模型的少样本。 对于前者,我们使用标记数据和检索到的记忆来训练生成器,而对于后者,我们采用专门用于推理的固定黑盒大语言模型以及检索到的上下文学习样本。 然后,我们使用生成器的输出来训练基于特定性能指标的内存选择器。 通过简单地用无限生成的内存替换检索到的内存,我们实现了更高质量的生成输出(原始问题),该输出随后在由内存选择器细化后用作下一轮的内存(对偶问题)。
为了评估Selfmem的功效,我们在三个不同的文本生成任务中进行了综合实验:神经机器翻译、抽象文本摘要和对话生成。 我们见证了相对于稳健基线的显着增强,在JRC-Acquis(四个方向)、XSum(50.3 ROUGE-1)和BigPatent (62.9 ROUGE-1)。 为了更深入地了解Selfmem,我们仔细研究每个关键组件并查明现有系统瓶颈以指导未来的研究工作。
2相关工作
2.1 检索增强文本生成
由于一旦收集了训练语料库,世界就不再是快照,因此我们永远不能指望一个巨大的模型能够捕获其参数中的所有内容,即使对于像 GPT-4 [62] 这样的大语言模型也是如此。 因此,为这些模型配备外部存储库来存储额外的知识或有用的演示示例以解决各种 NLP 任务[41,78,95]至关重要。
在翻译领域,早在机器翻译出现之前,本地化行业就早已采用检索技术来提高翻译人员的生产力和一致性[94]。 机器翻译的早期工作主要集中于利用内存进行统计机器翻译 (SMT) 系统[80, 50]。 对于神经机器翻译 (NMT),[28] 是第一个使用搜索引擎从训练集中检索记忆并将其与外部记忆网络合并的人。 随后的研究探索了检索增强型 NMT 的各个方面,例如记忆编码方法[92,93,31]、检索器和生成器与单语言数据的联合训练[8] 、内存粒度[35]和内存多样性[17]。 对于少样本大语言模型的生成,提出了上下文示例选择策略来提高翻译质量[2]。 此外,上下文中的机器翻译已被证明对于即时适应[79]是有效的。 对于对话响应生成任务,采用示例/模板检索作为中间步骤已被证明有利于生成信息丰富的响应[89,91,6,7]。 情境学习示例检索也有助于可控对话[46]。 其他应用包括抽象摘要[64, 14, 18, 15],代码生成[30],释义生成[34, 83],语言建模[36, 105]、反事实数据生成[24]、开放域问答[12, 33]和语义解析[99]。
2.2 神经文本重排序
通过减轻训练和推理之间的差异(即暴露偏差)并直接优化所需指标,两阶段重排序方法促进了各种文本生成任务的重大进展。 在机器翻译领域,[75]和[61]的开创性工作引入并普及了SMT的判别性重排序。 在 NMT 背景下,研究主要集中在两种主要的重新排序方法:生成式重新排序 [56, 32, 88] 和判别式重新排序 [39, 71, 23]。 对于句法解析,[21] 是第一个采用两阶段重排序方法从基本解析器中选择输出的方法,而 [11] 则引入了最大熵重排序器。 在文本摘要中,RefSum [53]提出了第二阶段摘要框架来解决训练-测试分布不匹配的问题。 SimCLS [54] 使用成对学习排序 (LTR) 来选择具有最高匹配分数的候选者。 SummaReranker [68] 采用多任务专家混合框架来利用不同的指标来捕获生成的候选者的各个方面。 BRIO [55] 重用基本模型进行第二轮微调,同时考虑交叉熵损失和候选级排名损失。 JGR [76] 采用替代训练范例来训练生成器和重新排序器。
这些重新排序方法的一个关键限制是它们仅代表一种单向过程,其中选定的候选者成为系统的最终输出。 相比之下,我们的框架创新地利用所选候选者作为检索增强生成器的后续生成轮的记忆,这可以产生具有增强记忆的更好候选者。
3方法
在本节中,我们从关于作为记忆的生成的激励实验开始(第3.1)。 然后,我们介绍Selfmem,一个由检索增强生成器(第3.2)和内存选择器组成的框架(§3.3)。 完整的框架和算法如图2和算法1所示。
3.1 作为内存的生成
我们框架背后的主要动机源于这样的观察:内存(在推理过程中与数据的分布更相似)不是训练数据(38.89 BLEU,如表 1 的第一行所示) >)。 相反,它是无限生成空间内模型自身的输出(58.58 BLEU)。 一项有趣的探索涉及直接利用生成的输出作为与原始问题相关的记忆:更好的记忆促进更好的生成。
| Memory Source | Memory Quality | Hypothesis Quality |
|---|---|---|
| Retrieval | 38.89 | 58.58 |
| Beam | 58.58 | 58.43 |
| Reference | 100 | 90.43 |
| Random | 1.14 | 49.08 |
我们在 JRC-Acquis EnDe 数据集上进行实验。 表 1 中的第一行表示使用检索记忆的传统检索增强训练,并获得 58.58 BLEU 分数。 然而,直接将该训练模型的波束输出作为内存(Beam)合并回生成模型中并不会产生任何改进(第 2 行),尽管与检索到的模型相比,它与参考的相似度更高。 我们假设有两个潜在原因:(1) 由于内存分布变化(从 38.89 到 58.58),检索增强生成器在这种情况下可能无法有效泛化,(2) 与对于检索到的,即使它与参考文献有更多的重叠。
为了研究第一个假设,我们在预言和随机场景下进行实验,使用参考作为记忆(Reference),随机抽样句子作为记忆(Random)。 结果如表 1 所示,它说明了检索增强生成器(使用检索记忆进行训练)已经学会了在预言和随机场景中区分不同的记忆,而无需更新模型权重。
为了评估第二个猜想,我们首先将参考、检索记忆和束记忆的词符集分别定义为和。 重叠词符集,用表示,定义为与束存储器中的引用重叠但在检索存储器中不重叠的标记,用表示。 被认为是由波束存储器提供的附加信息。 受 NMT 模型 [58] 置信度分析的启发,我们计算集合置信度得分 ,如下所示:
| (1) |
其中 由生成模型定义。 衡量生成模型生成 Token 的置信度。 的值为0.58,而的值为0.76,说明生成器对于生成中的token比较有信心,因此不需要求助于外部存储器[38]。 集束搜索根据 对生成的候选者进行排名,其中所选内存落在生成器的置信区域内,因此不提供信息增益。 这一观察促使我们根据内存选择器中的 以外的指标来选择内存(§3.3)。
3.2 检索增强生成器
给定文本对 ,其中 是源, 是目标。 它们可以是摘要中的(文档,摘要),对话生成中的(上下文,响应)或机器翻译中的(源,目标)。 检索增强一代将首先使用 从数据存储 检索内存 。 然后由 参数化的生成器 会将 和 作为输入来生成目标句子 . 在本文中,按照标准做法,我们选择训练集为。 对于大语言模型,我们使用标准的情境学习格式给出作为演示示例。 对于可调生成器,我们只将top-1检索结果的目标端保留为内存,并且我们考虑两种常用的架构:Joint-Encoder [29,87,41]和双编码器[92,8,17]。
联合编码器
该架构是标准的基于编码器-解码器的模型[3, 84]。 输入是 和 的串联。编码器首先将输入映射到隐藏状态:
| (2) |
解码器将通过注意力机制合并 并以自回归方式生成 Token :
| (3) |
双编码器
该架构没有将 和 视为长序列,而是具有两个编码器,一个用于 ,另一个用于 。它们的输出依次由具有双重交叉注意力的解码器处理,如 [17] 所示:
| (4) | |||
| (5) |
我们使用 Transformer [84] 作为两种架构的构建块,并通过 NLL 损失优化 :
| (6) |
3.3 内存选择器
内存选择器 由 参数化,其作用是根据特定指标 从 生成的候选池 中选择一个候选 。 然后,所选择的候选将被用作的后续生成轮的存储器。 如§3.1中所述,使用作为度量将导致落入的置信区域,从而导致没有信息增益。 此外,较大的值并不一定保证提高生成质量[59]。 因此,我们将 定义为广泛用于评估生成质量的无模型指标,例如用于神经机器翻译 (NMT) 的 BLEU 和用于摘要的 ROUGE。 我们的内存选择器将源 和候选 的串联作为输入,并在 上生成多项分布 。
在本文中,我们重点关注内存选择器的作用,它由参数化。 该选择器的目标是从 生成的候选池 中,根据特定指标 选择一个候选 。
| (7) |
根据[39],的训练目标是最小化的预测与。 使用 Kullback-Leibler (KL) 散度来量化此散度。
| (8) |
是控制分布平滑度的温度。 推理时,的输出是。
3.4 组合生成器和选择器
我们为定义了两种生成模式。 第一种模式称为假设模式,为每个输入生成一个输出,用于系统评估。 第二种模式称为候选模式,为给定输入生成 N 个输出,并用于训练 以及内存选择。 通过将两种模式集成在一起,我们提出了我们提出的模型 Selfmem 的完整框架,如算法 1 所示。
4实验设置
4.1数据集
我们利用总共七个数据集评估了 Selfmem 在三代任务上的性能。 翻译。 我们在 JRC-Acquis 数据集 [82](欧盟法律平行立法文本的集合)上评估我们的框架。 它是翻译记忆增强 NMT 任务[28,92,8,17]中使用的基准数据集。 我们选择4个翻译方向,即西班牙语英语(EsEn)、德语英语(DeEn)。 总结。 我们评估 2 个摘要数据集:1) XSum [60],极端摘要,一个包含来自英国广播公司的高度抽象文章的单文档摘要数据集。 2) BigPatent [73],包含 130 万条美国专利文献记录以及人工撰写的摘要摘要。 对话。 我们在 DailyDialog [44] 上进行实验,它包含有关日常生活主题的多轮对话框,并由 [13, 4, 103] 使用。 这些数据集的详细统计数据可以在附录A中找到。
4.2实现细节
我们利用 BM25 算法 [70] 进行检索。 对于所有任务,候选生成方法包括波束宽度为 50 的波束搜索。 迭代次数由验证集的性能决定。 对于翻译,我们遵循[93,8,17]的方法,采用随机初始化的Transformer架构作为 用于可训练的小模型和用于大语言模型上下文学习的 XGLM [48]。 评估指标包括从 SacreBLEU[66] 获得的 BLEU、TER 和 chrF++。 内存选择器利用XLM-Rbase[22]作为主干,BLEU充当。 为了汇总,我们使用 BART[40] 为 BigPatent 初始化 并使用 BRIO [55] 为 XSum。 评估指标包括ROUGE (R-1/2/L)[47]。 对于对话生成,BART 充当 的骨干。 我们的对话系统使用 BLEU (B-1/2) 和 Distinct (D-1/2) 分数[43]进行评估。 对于对话和摘要任务,我们坚持[54, 26]的方法,采用RoBERTa[52]作为。 选择B-1/2的线性组合作为用于对话生成,而R-1/2/L用于摘要,遵循[76]。 如需了解更多实施细节,请参阅附录B和附录C评估指标。
| System | EsEn | EnEs | DeEn | EnDe | ||||
|---|---|---|---|---|---|---|---|---|
| Dev | Test | Dev | Test | Dev | Test | Dev | Test | |
| None Memory | ||||||||
| RNNsearch [3] | 55.02 | 59.34 | 50.54 | 50.48 | 50.20 | 49.74 | 44.94 | 43.98 |
| Transformer [84] | 64.08 | 64.63 | 62.02 | 61.80 | 60.18 | 60.16 | 54.65 | 55.43 |
| Retrieval Memory | ||||||||
| SEG-NMT [28] | 60.28 | 59.34 | 57.62 | 57.27 | 55.63 | 55.33 | 49.26 | 48.80 |
| NMT-pieces [101] | 63.97 | 64.30 | 61.50 | 61.56 | 60.10 | 60.26 | 55.54 | 55.14 |
| G-TFM [92] | 66.37 | 66.21 | 62.50 | 62.76 | 61.85 | 61.72 | 57.43 | 56.88 |
| MonoNMT [8] | 67.73 | 67.42 | 64.18 | 63.86 | 64.48 | 64.62 | 58.77 | 58.42 |
| CMM [17] | 67.48 | 67.76 | 63.84 | 64.04 | 64.22 | 64.33 | 58.94 | 58.69 |
| Transformer | 66.87 | 67.12 | 63.14 | 63.54 | 64.09 | 63.36 | 58.69 | 58.06 |
| Transformer | 67.74 | 67.32 | 63.93 | 64.12 | 64.50 | 64.40 | 58.16 | 58.58 |
| Self-Memory | ||||||||
| Transformer | 68.63∗ | 69.20∗ | 64.12∗ | 64.67∗ | 65.06∗ | 64.98∗ | 59.26∗ | 59.49∗ |
| Transformer | 68.26∗ | 68.80∗ | 66.07∗ | 65.94∗ | 65.32∗ | 65.65∗ | 59.88∗ | 60.11∗ |
5实验结果
5.1 机器翻译
我们选择了四个翻译方向并尝试了两种生成范式:可训练的小模型和少样本提示的大语言模型[85, 20]。 对于可训练模型,我们探索了两种架构(联合架构和双架构,详见§3.2)。 基线包括两种类型的翻译系统:一种是没有记忆增强的普通序列到序列模型[3, 84],另一种由专注于记忆编码的检索增强翻译模型组成[28, 92]、记忆构造[101]、记忆检索[8]和记忆多样性[17]。 根据实验结果222由于此范围内较高的 BLEU 分数并不一定保证卓越的翻译系统[9],我们还使用 TER 和chrF++。 结果可以在附录D中找到。 如表2所示,Selfmem显着增强了在四个翻译数据集和两种不同架构中的性能。 这是值得注意的,因为 的参数保持固定,唯一的变量是输入内存。 这一发现与原始问题一致,即改进的内存通常会带来更好的生成结果。
| Retrieval | Self | ||||
|---|---|---|---|---|---|
| memory | hypothesis | memory | hypothesis | ||
| En-De | 38.89 | 58.58 | 57.92 | 60.11 | |
| 42.56 | 64.40 | 64.32 | 65.65 | ||
| En-Es | 40.67 | 64.12 | 63.57 | 65.94 | |
| 43.05 | 67.32 | 67.78 | 68.80 | ||
表3揭示了对偶问题。 自记忆本质上代表了模型自己的输出,与地面事实表现出更大的相似性,并且可以作为生成最终输出的更有效的记忆。 这一观察结果凸显了 Selfmem 和之前的重新排名作品 [39, 68] 之间的一个关键区别。 重新排序的目的是选择比波束输出质量更高的候选,而在Selfmem中,所选候选作为检索增强生成器的记忆,不一定需要超过波束假设的质量。
| XGLM-1.7B | XGLM-4.5B | XGLM-7.5B | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Random | kNN | Self | Random | kNN | Self | Random | kNN | Self | ||
| En-De | 11.51 | 37.87 | 40.94 | 17.51 | 37.60 | 38.25 | 18.48 | 47.82 | 48.32 | |
| 27.42 | 51.00 | 51.88 | 30.62 | 48.12 | 48.36 | 33.03 | 55.65 | 55.12 | ||
| En-Es | 23.87 | 46.20 | 48.56 | 31.83 | 48.37 | 49.17 | 29.97 | 53.86 | 54.32 | |
| 25.29 | 51.55 | 53.13 | 32.16 | 48.55 | 49.22 | 35.22 | 57.25 | 57.56 | ||
表4给出了具有自记忆功能的大语言模型的结果。 我们采用 XGLM [48] 作为主干生成器,具有从 1.7B 到 7.5B 的三种不同大小。 我们使用[48]中所述的推荐提示。 考虑到 ICL [49] 中示例选择的敏感性,我们选择了三个上下文学习示例并报告了三个单独运行的平均分数。 从表中,我们首先观察到一个总体趋势,即随着模型大小的增加,少样本翻译性能会提高。 此外,我们发现更多相似的翻译演示可以显着提高所有模型大小(从随机、kNN 到 Self)的性能。 这表明情境学习中的演示示例不仅可以作为模型能力的触发因素,而且还遵循原始问题,即更好的演示示例可以带来更好的生成。 此外,通过比较表2和表4中的结果,我们可以得出结论,带有设计示例的跨语言大语言模型仍然低于本研究中的监督基线。任务。
5.2总结
在本文中,我们将可训练模型的性能与 REINA [87]、PEGASUS [100] 和 BART [40] 的性能进行比较>。 结果如表5.2所示。 最初,可以观察到内存对不同数据集有不同的影响。 BigPatent数据集中内存带来的增强明显大于XSum数据集中的增强。 这可以归因于 BigPatent 数据集的固有特征,该数据集由表现出相当相似性的官方专利文档组成。 因此,这极大地提高了原始问题的摘要质量。 此外,我们发现自记忆极大地增强了 BRIO (+1.2 R1) 和 BART (+18.5 R1) 的性能,在两个数据集上都取得了最先进的结果。 我们选择这些基线是为了公平比较,因为它们共享相同的基础生成器。 由于篇幅限制,额外的比较和SOTA模型的置信区域可以在附录E中找到。
| System | Memory | R-1 | R-2 | R-L |
|---|---|---|---|---|
| XSum | ||||
| PEGASUS | None | 47.2 | 24.6 | 39.3 |
| BRIO | None | 49.1 | 25.6 | 40.4 |
| REINA (PG) | Retrieval | 48.2 | 26.0 | 40.2 |
| REINA (B) | Retrieval | 43.2 | 21.0 | 35.5 |
| REINA (L) | Retrieval | 46.5 | 24.1 | 38.6 |
| BRIO | Retrieval | 48.6 | 26.1 | 40.6 |
| BRIO | Retrieval | 49.5 | 26.5 | 41.2 |
| BRIO | Self | 49.2 | 26.2 | 40.8 |
| BRIO | Self | 50.3 | 26.7 | 41.6 |
| System | Memory | R-1 | R-2 | R-L |
|---|---|---|---|---|
| BigPatent | ||||
| PEGASUS | None | 53.6 | 33.2 | 43.2 |
| BART | None | 44.4 | 21.3 | 31.0 |
| REINA (B) | Retrieval | 59.5 | 42.6 | 50.6 |
| REINA (L) | Retrieval | 60.7 | 43.3 | 51.3 |
| REINA (PG) | Retrieval | 44.6 | 21.5 | 33.3 |
| BART | Retrieval | 57.4 | 43.3 | 49.7 |
| BART | Retrieval | 59.6 | 43.4 | 51.0 |
| BART | Self | 61.2 | 44.6 | 52.3 |
| BART | Self | 62.9 | 48.1 | 59.6 |
5.3对话生成
如表6所示,自记忆显着增强了对话生成任务的检索增强生成器的性能。 通过使用 BLEU 作为 优化内存,自记忆在 BART 上将 B-1,2 分数比检索内存提高了 3.08 B-1 和 0.6 B-2。 有趣的是,尽管 Selfmem 在 B-1/2 方面超越了基线,但在 D-1 和 D-2 方面却落后了,这可以归因于 BLEU 分数和 Distinct 分数之间的权衡在评估对话系统时[104]。 为了解决这个问题,我们在优化时选择D-1,2作为,记为BART(四)。 表 6 中的结果突显了 Selfmem 通过直接优化内存来实现多样化和信息丰富的对话所需的属性的显着灵活性。
| System | Memory | B-1 | B-2 | D-1 | D-2 |
|---|---|---|---|---|---|
| NCM [86] | None | 33.60 | 26.80 | 3.00 | 12.80 |
| iVAE [25] | None | 30.90 | 24.90 | 2.90 | 25.00 |
| PLATO-2 [5] | None | 34.80 | 25.12 | 3.54 | 25.11 |
| DialoFlow [45] | None | 36.17 | 27.67 | 4.56 | 27.12 |
| BART | None | 20.72 | 11.36 | 3.92 | 19.44 |
| BART | Retrieval | 29.50 | 21.89 | 4.74 | 26.01 |
| BART | Retrieval | 36.72 | 31.55 | 6.13 | 35.65 |
| BART | Self | 33.43 | 22.85 | 4.66 | 26.16 |
| BART | Self | 39.80 | 32.15 | 5.84 | 32.16 |
| BART (D) | Self | 36.92 | 32.09 | 9.12 | 37.05 |

6进一步分析
为了更深入地了解 Selfmem,我们首先检查每个关键组件的影响,即 和 。 随后,我们对生成的训练输出进行详细的标记级分析,了解它们在集合中的频率。 实验在 JRC-Acquis EnDe 数据集上进行。 我们还在附录 F 和 G 中包含延迟分析和人工评估。
调整
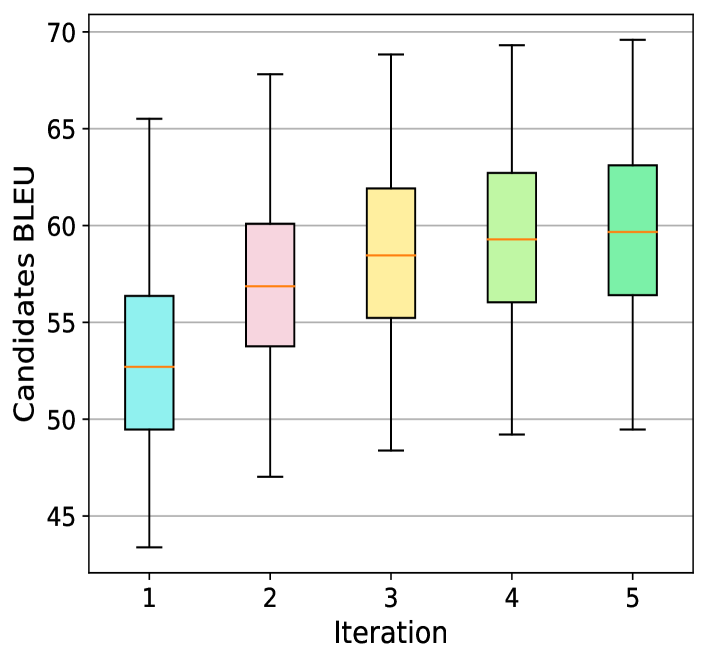
我们根据黄金排名直接从候选池中选择,探索了各种。 如图3(a)所示,两种具有增强型的架构均显着优于当前的SOTA性能(60.11 BLEU)。 此外,我们使用预言机评估了迭代过程中的候选池质量,如图3(b)所示。 此箱线图中出现了清晰的模式,揭示了 oracle、四分位数、平均和最低分数的改进候选人库。 这两个实验共同阐明了Selfmem的基本直觉:检索增强的生成器受益于优越的记忆,可以从其自己的无界输出中进行选择,随后,具有改进记忆的生成器产生更高的记忆- 下一轮选拔的优质候选人库。 因此,模型会自我提升。
调整
正如§3.1中所讨论的,我们证明了经过训练的具有固定参数的检索增强生成器具有区分“好”和“坏”记忆的能力。 这一观察结果不仅证明了我们在框架内维护固定生成器的决定是合理的,而且还意味着 不是 Selfmem 当前的瓶颈。
频率分析
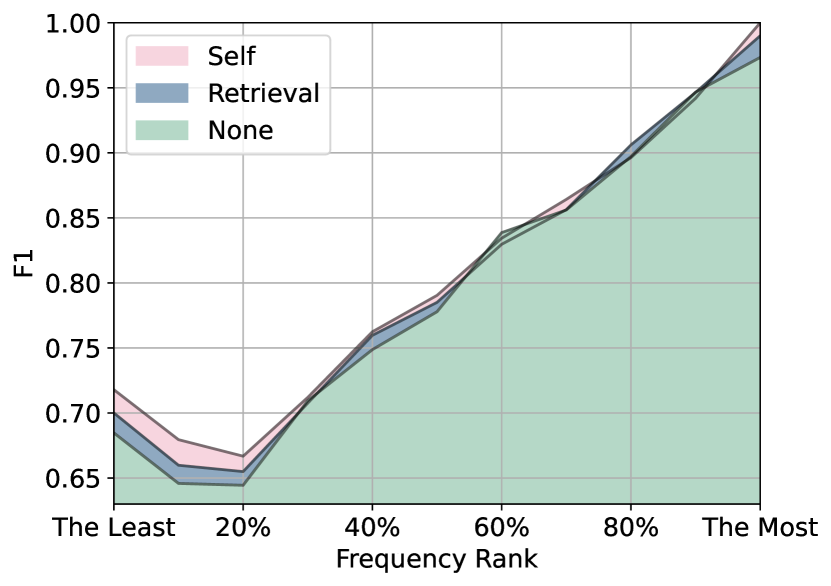
我们通过计算生成的翻译的 1-gram F1 分数并随后根据其在训练集中的频率对标记进行分类来进行全面的标记级别分析。 结果如图4所示。 出现了一个明显的模式,表明模型在训练过程中遇到词符的频率越高,生成的输出 [102] 的准确性就越高。 此外,我们的研究结果表明,检索增强模型,特别是那些结合自记忆增强的模型,在处理长尾输入方面表现出卓越的性能,这对参数模型来说是一个挑战[67, 57]。
7结论
我们首次研究了当前检索增强文献中有限记忆的根本局限性。 我们将原始和对偶问题结合在一起,提出Selfmem,这是一种通过提升生成模型及其自身输出来生成检索增强文本的通用框架。 我们对各种文本生成任务和不同的生成范式进行了全面的实验,包括可训练的小模型和少样本提示的大语言模型。 我们超越了强大的基线并提高了多个数据集中的最先进性能。 我们还仔细研究每个关键组件,并查明现有的系统瓶颈,以指导未来的研究工作。
局限性
我们讨论框架的局限性如下:
(1)虽然与其他检索增强生成模型相比,Selfmem大大提高了生成质量,但它在内存选择过程中需要更多的计算资源。 对于具有长上下文的大型数据集(例如,BigPatent),考虑到 Transformer 架构的二次时间复杂度,这将成为一个更加关键的问题。
(2)本文提出了检索增强生成的总体思路。 但我们只对生成器和内存选择器使用基于 Transformer 的架构进行实验,并且生成器和内存选择器的架构在所有文本生成任务中保持相同。 我们相信针对不同文本生成场景的模型架构、训练目标和生成方法的特定任务设计将进一步提高性能。
致谢
该工作得到了国家重点研发计划(No.2021YFC3340304)和国家自然科学基金(NSFC Grant No.62122089)的支持。 我们感谢匿名审稿人的有益评论。 赵冬岩和严睿为通讯作者。
参考
- [1] Armen Aghajanyan, Anchit Gupta, Akshat Shrivastava, Xilun Chen, Luke Zettlemoyer, and Sonal Gupta. Muppet: Massive multi-task representations with pre-finetuning. In Proc. of EMNLP, 2021.
- [2] Sweta Agrawal, Chunting Zhou, Mike Lewis, Luke Zettlemoyer, and Marjan Ghazvininejad. In-context examples selection for machine translation. CoRR, 2022.
- [3] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. In Proc. of ICLR, 2015.
- [4] Siqi Bao, Huang He, Fan Wang, Hua Wu, and Haifeng Wang. PLATO: pre-trained dialogue generation model with discrete latent variable. In Proc. of ACL, 2020.
- [5] Siqi Bao, Huang He, Fan Wang, Hua Wu, Haifeng Wang, Wenquan Wu, Zhen Guo, Zhibin Liu, and Xinchao Xu. PLATO-2: Towards building an open-domain chatbot via curriculum learning. In Proc. of ACL Findings, 2021.
- [6] Deng Cai, Yan Wang, Wei Bi, Zhaopeng Tu, Xiaojiang Liu, Wai Lam, and Shuming Shi. Skeleton-to-response: Dialogue generation guided by retrieval memory. In Proc. of NAACL, 2019.
- [7] Deng Cai, Yan Wang, Wei Bi, Zhaopeng Tu, Xiaojiang Liu, and Shuming Shi. Retrieval-guided dialogue response generation via a matching-to-generation framework. In Proc. of EMNLP, 2019.
- [8] Deng Cai, Yan Wang, Huayang Li, Wai Lam, and Lemao Liu. Neural machine translation with monolingual translation memory. In Proc. of ACL, 2021.
- [9] Chris Callison-Burch, Miles Osborne, and Philipp Koehn. Re-evaluating the role of Bleu in machine translation research. In Proc. of EACL, 2006.
- [10] Qian Cao and Deyi Xiong. Encoding gated translation memory into neural machine translation. In Proc. of EMNLP, 2018.
- [11] Eugene Charniak and Mark Johnson. Coarse-to-fine n-best parsing and maxent discriminative reranking. In Proc. of ACL, 2005.
- [12] Danqi Chen, Adam Fisch, Jason Weston, and Antoine Bordes. Reading wikipedia to answer open-domain questions. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1870–1879, 2017.
- [13] Wei Chen, Yeyun Gong, Song Wang, Bolun Yao, Weizhen Qi, Zhongyu Wei, Xiaowu Hu, Bartuer Zhou, Yi Mao, Weizhu Chen, Biao Cheng, and Nan Duan. Dialogved: A pre-trained latent variable encoder-decoder model for dialog response generation. In Proc. of ACL, 2022.
- [14] Xiuying Chen, Hind Alamro, Mingzhe Li, Shen Gao, Rui Yan, Xin Gao, and Xiangliang Zhang. Target-aware abstractive related work generation with contrastive learning. In Proc. of SIGIR, 2022.
- [15] Xiuying Chen, Mingzhe Li, Shen Gao, Xin Cheng, Qiang Yang, Qishen Zhang, Xin Gao, and Xiangliang Zhang. A topic-aware summarization framework with different modal side information. Proc. of SIGIR, 2023.
- [16] Xiuying Chen, Mingzhe Li, Xin Gao, and Xiangliang Zhang. Towards improving faithfulness in abstractive summarization. In Proc. of NeurIPS, 2022.
- [17] Xin Cheng, Shen Gao, Lemao Liu, Dongyan Zhao, and Rui Yan. Neural machine translation with contrastive translation memories. In Proc. of EMNLP, 2022.
- [18] Xin Cheng, Shen Gao, Yuchi Zhang, Yongliang Wang, Xiuying Chen, Mingzhe Li, Dongyan Zhao, and Rui Yan. Towards personalized review summarization by modeling historical reviews from customer and product separately. arXiv preprint arXiv:2301.11682, 2023.
- [19] Xin Cheng, Yankai Lin, Xiuying Chen, Dongyan Zhao, and Rui Yan. Decouple knowledge from paramters for plug-and-play language modeling. In Findings of the Association for Computational Linguistics: ACL 2023, pages 14288–14308, Toronto, Canada, July 2023. Association for Computational Linguistics.
- [20] Xin Cheng, Xun Wang, Tao Ge, Si-Qing Chen, Furu Wei, Dongyan Zhao, and Rui Yan. Scale: Synergized collaboration of asymmetric language translation engines, 2023.
- [21] Michael Collins and Terry Koo. Discriminative reranking for natural language parsing. Comput. Linguistics, 2005.
- [22] Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. Unsupervised cross-lingual representation learning at scale. In Proc. of ACL, 2020.
- [23] Yuntian Deng, Anton Bakhtin, Myle Ott, Arthur Szlam, and Marc’Aurelio Ranzato. Residual energy-based models for text generation. In Proc. of ICLR, 2020.
- [24] Tanay Dixit, Bhargavi Paranjape, Hannaneh Hajishirzi, and Luke Zettlemoyer. CORE: A retrieve-then-edit framework for counterfactual data generation. In Proc. of EMNLP Findings, 2022.
- [25] Le Fang, Chunyuan Li, Jianfeng Gao, Wen Dong, and Changyou Chen. Implicit deep latent variable models for text generation. In Proc. of EMNLP, 2019.
- [26] Jiazhan Feng, Chongyang Tao, Zhen Li, Chang Liu, Tao Shen, and Dongyan Zhao. Reciprocal learning of knowledge retriever and response ranker for knowledge-grounded conversations. In Proc. of COLING, 2022.
- [27] Tingchen Fu, Xueliang Zhao, Chongyang Tao, Ji-Rong Wen, and Rui Yan. There are a thousand hamlets in a thousand people’s eyes: Enhancing knowledge-grounded dialogue with personal memory. In Proc. of ACL, 2022.
- [28] Jiatao Gu, Yong Wang, Kyunghyun Cho, and Victor O. K. Li. Search engine guided neural machine translation. In Proc. of AAAI, 2018.
- [29] Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. Retrieval augmented language model pre-training. In Proc. of ICML, 2020.
- [30] Tatsunori B. Hashimoto, Kelvin Guu, Yonatan Oren, and Percy Liang. A retrieve-and-edit framework for predicting structured outputs. In Proc. of NeurIPS, 2018.
- [31] Qiuxiang He, Guoping Huang, Qu Cui, Li Li, and Lemao Liu. Fast and accurate neural machine translation with translation memory. In Proc. of ACL, 2021.
- [32] Kenji Imamura and Eiichiro Sumita. Ensemble and reranking: Using multiple models in the NICT-2 neural machine translation system at WAT2017. In Proceedings of the 4th Workshop on Asian Translation, WAT@IJCNLP 2017, Taipei, Taiwan, November 27- December 1, 2017, 2017.
- [33] Gautier Izacard and Edouard Grave. Leveraging passage retrieval with generative models for open domain question answering. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 874–880, Online, April 2021. Association for Computational Linguistics.
- [34] Amirhossein Kazemnejad, Mohammadreza Salehi, and Mahdieh Soleymani Baghshah. Paraphrase generation by learning how to edit from samples. In Proc. of ACL, 2020.
- [35] Urvashi Khandelwal, Angela Fan, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis. Nearest neighbor machine translation. In Proc. of ICLR, 2021.
- [36] Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis. Generalization through memorization: Nearest neighbor language models. In Proc. of ICLR, 2020.
- [37] Philipp Koehn. Statistical significance tests for machine translation evaluation. In Proc. of EMNLP, 2004.
- [38] Ankit Kumar, Ozan Irsoy, Peter Ondruska, Mohit Iyyer, James Bradbury, Ishaan Gulrajani, Victor Zhong, Romain Paulus, and Richard Socher. Ask me anything: Dynamic memory networks for natural language processing. In Proc. of ICML, 2016.
- [39] Ann Lee, Michael Auli, and Marc’Aurelio Ranzato. Discriminative reranking for neural machine translation. In Proc. of ACL, 2021.
- [40] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proc. of ACL, 2020.
- [41] Patrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Proc. of NeurIPS, 2020.
- [42] Jinpeng Li, Yingce Xia, Rui Yan, Hongda Sun, Dongyan Zhao, and Tie-Yan Liu. Stylized dialogue generation with multi-pass dual learning. In Proc. of NeurIPS, 2021.
- [43] Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and Bill Dolan. A diversity-promoting objective function for neural conversation models. In Proc. of NAACL, 2016.
- [44] Yanran Li, Hui Su, Xiaoyu Shen, Wenjie Li, Ziqiang Cao, and Shuzi Niu. Dailydialog: A manually labelled multi-turn dialogue dataset. In Proceedings of the Eighth International Joint Conference on Natural Language Processing, IJCNLP 2017, Taipei, Taiwan, November 27 - December 1, 2017 - Volume 1: Long Papers, 2017.
- [45] Zekang Li, Jinchao Zhang, Zhengcong Fei, Yang Feng, and Jie Zhou. Conversations are not flat: Modeling the dynamic information flow across dialogue utterances. In Proc. of ACL, 2021.
- [46] Zekun Li, Wenhu Chen, Shiyang Li, Hong Wang, Jing Qian, and Xifeng Yan. Controllable dialogue simulation with in-context learning. In Proc. of EMNLP Findings, 2022.
- [47] Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, 2004.
- [48] Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O’Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona T. Diab, Veselin Stoyanov, and Xian Li. Few-shot learning with multilingual generative language models. In Proc. of EMNLP, 2022.
- [49] Jiachang Liu, Dinghan Shen, Yizhe Zhang, Bill Dolan, Lawrence Carin, and Weizhu Chen. What makes good in-context examples for gpt-3? In Proceedings of Deep Learning Inside Out: The 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, DeeLIO@ACL 2022, Dublin, Ireland and Online, May 27, 2022, 2022.
- [50] Lemao Liu, Hailong Cao, Taro Watanabe, Tiejun Zhao, Mo Yu, and Conghui Zhu. Locally training the log-linear model for SMT. In Proc. of EMNLP, 2012.
- [51] Yang Liu and Mirella Lapata. Text summarization with pretrained encoders. In Proc. of EMNLP, 2019.
- [52] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized BERT pretraining approach. CoRR, 2019.
- [53] Yixin Liu, Zi-Yi Dou, and Pengfei Liu. Refsum: Refactoring neural summarization. In Proc. of NAACL, 2021.
- [54] Yixin Liu and Pengfei Liu. Simcls: A simple framework for contrastive learning of abstractive summarization. In Proc. of ACL, 2021.
- [55] Yixin Liu, Pengfei Liu, Dragomir R. Radev, and Graham Neubig. BRIO: bringing order to abstractive summarization. In Proc. of ACL, 2022.
- [56] Yuchen Liu, Long Zhou, Yining Wang, Yang Zhao, Jiajun Zhang, and Chengqing Zong. A comparable study on model averaging, ensembling and reranking in NMT. In Proc. of NLPCC, 2018.
- [57] Alexander Long, Wei Yin, Thalaiyasingam Ajanthan, Vu Nguyen, Pulak Purkait, Ravi Garg, Alan Blair, Chunhua Shen, and Anton van den Hengel. Retrieval augmented classification for long-tail visual recognition. In Proc. of CVPR, 2022.
- [58] Yu Lu, Jiali Zeng, Jiajun Zhang, Shuangzhi Wu, and Mu Li. Learning confidence for transformer-based neural machine translation. In Proc. of ACL, 2022.
- [59] Clara Meister, Ryan Cotterell, and Tim Vieira. If beam search is the answer, what was the question? In Proc. of EMNLP, 2020.
- [60] Shashi Narayan, Shay B. Cohen, and Mirella Lapata. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. In Proc. of EMNLP, 2018.
- [61] Franz Josef Och, Daniel Gildea, Sanjeev Khudanpur, Anoop Sarkar, Kenji Yamada, Alexander M. Fraser, Shankar Kumar, Libin Shen, David Smith, Katherine Eng, Viren Jain, Zhen Jin, and Dragomir R. Radev. A smorgasbord of features for statistical machine translation. In Proc. of NAACL, 2004.
- [62] OpenAI. GPT-4 technical report. CoRR, 2023.
- [63] Md. Rizwan Parvez, Wasi Uddin Ahmad, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang. Retrieval augmented code generation and summarization. In Proc. of EMNLP Findings, 2021.
- [64] Hao Peng, Ankur P. Parikh, Manaal Faruqui, Bhuwan Dhingra, and Dipanjan Das. Text generation with exemplar-based adaptive decoding. In Proc. of NAACL, 2019.
- [65] Jonathan Pilault, Raymond Li, Sandeep Subramanian, and Chris Pal. On extractive and abstractive neural document summarization with transformer language models. In Proc. of EMNLP, 2020.
- [66] Matt Post. A call for clarity in reporting BLEU scores. In Proceedings of the Third Conference on Machine Translation: Research Papers, WMT 2018, Belgium, Brussels, October 31 - November 1, 2018, 2018.
- [67] Vikas Raunak, Siddharth Dalmia, Vivek Gupta, and Florian Metze. On long-tailed phenomena in neural machine translation. In Proc. of EMNLP Findings, 2020.
- [68] Mathieu Ravaut, Shafiq R. Joty, and Nancy F. Chen. Summareranker: A multi-task mixture-of-experts re-ranking framework for abstractive summarization. In Proc. of ACL, 2022.
- [69] Mathieu Ravaut, Shafiq R. Joty, and Nancy F. Chen. Towards summary candidates fusion. CoRR, 2022.
- [70] Stephen E. Robertson and Hugo Zaragoza. The probabilistic relevance framework: BM25 and beyond. Found. Trends Inf. Retr., 2009.
- [71] Julian Salazar, Davis Liang, Toan Q. Nguyen, and Katrin Kirchhoff. Masked language model scoring. In Proc. of ACL, 2020.
- [72] Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words with subword units. In Proc. of ACL, 2016.
- [73] Eva Sharma, Chen Li, and Lu Wang. BIGPATENT: A large-scale dataset for abstractive and coherent summarization. In Proc. of ACL, 2019.
- [74] Noam Shazeer and Mitchell Stern. Adafactor: Adaptive learning rates with sublinear memory cost. In Proc. of ICML, 2018.
- [75] Libin Shen, Anoop Sarkar, and Franz Josef Och. Discriminative reranking for machine translation. In Proc. of NAACL, 2004.
- [76] Weizhou Shen, Yeyun Gong, Yelong Shen, Song Wang, Xiaojun Quan, Nan Duan, and Weizhu Chen. Joint generator-ranker learning for natural language generation. CoRR, 2022.
- [77] Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Rich James, Mike Lewis, Luke Zettlemoyer, and Wen tau Yih. Replug: Retrieval-augmented black-box language models, 2023.
- [78] Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Rich James, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. REPLUG: retrieval-augmented black-box language models. CoRR, 2023.
- [79] Suzanna Sia and Kevin Duh. In-context learning as maintaining coherency: A study of on-the-fly machine translation using large language models. CoRR, 2023.
- [80] Michel Simard and Pierre Isabelle. Phrase-based machine translation in a computer-assisted translation environment. In Proceedings of Machine Translation Summit XII: Papers, MTSummit 2009, Ottawa, Canada, August 26-30, 2009, 2009.
- [81] Yiping Song, Rui Yan, Xiang Li, Dongyan Zhao, and Ming Zhang. Two are better than one: An ensemble of retrieval- and generation-based dialog systems. CoRR, 2016.
- [82] Ralf Steinberger, Bruno Pouliquen, Anna Widiger, Camelia Ignat, Tomaz Erjavec, Dan Tufis, and Dániel Varga. The jrc-acquis: A multilingual aligned parallel corpus with 20+ languages. In Proc. of LREC, 2006.
- [83] Yixuan Su, David Vandyke, Simon Baker, Yan Wang, and Nigel Collier. Keep the primary, rewrite the secondary: A two-stage approach for paraphrase generation. In Proc. of ACL Findings, 2021.
- [84] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Proc. of NeurIPS, 2017.
- [85] David Vilar, Markus Freitag, Colin Cherry, Jiaming Luo, Viresh Ratnakar, and George Foster. Prompting palm for translation: Assessing strategies and performance, 2023.
- [86] Oriol Vinyals and Quoc V. Le. A neural conversational model. CoRR, 2015.
- [87] Shuohang Wang, Yichong Xu, Yuwei Fang, Yang Liu, Siqi Sun, Ruochen Xu, Chenguang Zhu, and Michael Zeng. Training data is more valuable than you think: A simple and effective method by retrieving from training data. In Proc. of ACL, 2022.
- [88] Yuguang Wang, Shanbo Cheng, Liyang Jiang, Jiajun Yang, Wei Chen, Muze Li, Lin Shi, Yanfeng Wang, and Hongtao Yang. Sogou neural machine translation systems for WMT17. In Proceedings of the Second Conference on Machine Translation, WMT 2017, Copenhagen, Denmark, September 7-8, 2017, 2017.
- [89] Jason Weston, Emily Dinan, and Alexander H. Miller. Retrieve and refine: Improved sequence generation models for dialogue. In Proceedings of the 2nd International Workshop on Search-Oriented Conversational AI, SCAI@EMNLP 2018, Brussels, Belgium, October 31, 2018, 2018.
- [90] Wenhao Wu, Wei Li, Xinyan Xiao, Jiachen Liu, Ziqiang Cao, Sujian Li, Hua Wu, and Haifeng Wang. BASS: boosting abstractive summarization with unified semantic graph. In Proc. of ACL, 2021.
- [91] Yu Wu, Furu Wei, Shaohan Huang, Yunli Wang, Zhoujun Li, and Ming Zhou. Response generation by context-aware prototype editing. In Proc. of AAAI, 2019.
- [92] Mengzhou Xia, Guoping Huang, Lemao Liu, and Shuming Shi. Graph based translation memory for neural machine translation. In Proc. of AAAI, 2019.
- [93] Jitao Xu, Josep Maria Crego, and Jean Senellart. Boosting neural machine translation with similar translations. In Proc. of ACL, 2020.
- [94] Masaru Yamada. The effect of translation memory databases on productivity. Translation research projects, 2011.
- [95] Michihiro Yasunaga, Armen Aghajanyan, Weijia Shi, Rich James, Jure Leskovec, Percy Liang, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih. Retrieval-augmented multimodal language modeling. CoRR, 2022.
- [96] Dani Yogatama, Cyprien de Masson d’Autume, and Lingpeng Kong. Adaptive semiparametric language models. Trans. Assoc. Comput. Linguistics, 2021.
- [97] Wenhao Yu, Dan Iter, Shuohang Wang, Yichong Xu, Mingxuan Ju, Soumya Sanyal, Chenguang Zhu, Michael Zeng, and Meng Jiang. Generate rather than retrieve: Large language models are strong context generators, 2023.
- [98] Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. Big bird: Transformers for longer sequences. In Proc. of NeurIPS, 2020.
- [99] Yury Zemlyanskiy, Michiel de Jong, Joshua Ainslie, Panupong Pasupat, Peter Shaw, Linlu Qiu, Sumit Sanghai, and Fei Sha. Generate-and-retrieve: Use your predictions to improve retrieval for semantic parsing. In Proceedings of the 29th International Conference on Computational Linguistics, pages 4946–4951, Gyeongju, Republic of Korea, October 2022. International Committee on Computational Linguistics.
- [100] Jingqing Zhang, Yao Zhao, Mohammad Saleh, and Peter J. Liu. PEGASUS: pre-training with extracted gap-sentences for abstractive summarization. In Proc. of ICML, 2020.
- [101] Jingyi Zhang, Masao Utiyama, Eiichiro Sumita, Graham Neubig, and Satoshi Nakamura. Guiding neural machine translation with retrieved translation pieces. In Proc. of NAACL, 2018.
- [102] Tong Zhang, Wei Ye, Baosong Yang, Long Zhang, Xingzhang Ren, Dayiheng Liu, Jinan Sun, Shikun Zhang, Haibo Zhang, and Wen Zhao. Frequency-aware contrastive learning for neural machine translation. In Proc. of AAAI, 2022.
- [103] Xueliang Zhao, Lemao Liu, Tingchen Fu, Shuming Shi, Dongyan Zhao, and Rui Yan. Towards efficient dialogue pre-training with transferable and interpretable latent structure. CoRR, 2022.
- [104] Yinhe Zheng, Zikai Chen, Rongsheng Zhang, Shilei Huang, Xiaoxi Mao, and Minlie Huang. Stylized dialogue response generation using stylized unpaired texts. In Proc. of AAAI, 2021.
- [105] Zexuan Zhong, Tao Lei, and Danqi Chen. Training language models with memory augmentation. CoRR, 2022.
附录 A数据集详细信息
| Task | Dataset | #Train | #Dev | #Test |
| Translation | JRC () | 663,487 | 2,454 | 2,483 |
| JRC () | 653,127 | 2,533 | 2,596 | |
| Summarization | BigPatent | 1,207,222 | 67,068 | 67,072 |
| XSum | 204,045 | 11,332 | 11,334 | |
| Dialogue | DailyDialog | 87,170 | 8,069 | 7,740 |
附录B自我记忆详细信息
对于机器翻译任务,按照[93,8,17]我们使用随机初始化Transformer架构[84]为。 我们使用联合bpe算法[72]并在双编码器架构的内存编码器和源编码器之间共享参数。 超参数设置遵循[17],dropout 0.1,标签平滑0.1,梯度裁剪1.0,Adafactor [74],预热步骤4000,最大学习率4.4 e-2 和训练 epoch 总共 30 个。 评估指标是来自 SacreBLEU [66] 的 BLEU、TER 和 chrF++。 内存选择器的主干是XLM-Rbase[22],BLEU为。 的超参数设置遵循 [39], 0.5,候选排名的最小最大归一化,最大学习率 5e-5 的 Adam 优化器和多项式衰减调度器和分类器 dropout 0.2。
对于摘要,我们使用 BART [40] 为 BigPatent 初始化 ,遵循 [87] 和状态 -用于 XSum 的最先进的 BRIO [55]。 优化基于Adafactor,最大学习率为5e-3,预热步骤10000,梯度裁剪值1.0。 XSum 的最大输入长度为 512,BigPatent 的最大输入长度为 1024。 评估指标为 Rouge (R-1/2/L) [47]。
对于对话生成,我们使用 BART 作为 DailyDialog 上 的骨干。 我们根据学习率 {5e-3,1e-3,4e-4} 调整超参数,并为 DailyDialog 设置 dropout 0.1、批量大小 64、标签平滑因子 0.1、最大输入长度 120。 在[4, 13]之后,我们使用 BLEU (B-1/2) 和 Distinct (D-1,2) [43] 评估我们的对话系统。 对于摘要和对话生成任务,我们遵循 [54, 26] 并采用 RoBERTa [52] 作为 我们选择B-1/2的线性组合作为对话生成的和遵循[76]的R-1/2/L作为摘要。 我们从{0.08,0.2,0.5,0.8}调整超参数,从{5e-5,7e-5,2e-4}调整学习率。 的最大输入长度是 512,我们从源和候选的较长输入中截断标记。
附录C评估详细信息
机器翻译
我们使用 SacreBLEU333https://github.com/mjpost/sacrebleu.git[66]。 BLEU、TER 和 chrF++ 的签名如表8所示。
| Signature |
|---|
| nrefs:1|case:mixed|eff:no|tok:13a|smooth:exp|version:2.0.0 |
| nrefs:1|case:lc|tok:tercom|norm:no|punct:yes|asian:no|version:2.0.0 |
| nrefs:1|case:mixed|eff:yes|nc:6|nw:2|space:no|version:2.0.0 |
总结
我们使用标准 ROUGE [47] Perl 包444https://github.com/summanlp/evaluation/tree/master/ROUGE-RELEASE-1.5.5进行评估。 在[55]之后,我们使用PTB tokenizer555https://nlp.stanford.edu/nlp/javadoc/javanlp/edu/stanford/nlp/process/PTBTokenizer.html 用于标记化。 ROUGE 的参数为“-c 95 -r 1000 -n 2 -m”。
对话生成
在[27]之后,我们使用NLTK BLEU 666https://www.nltk.org/_modules/nltk/translate/bleu_score.html 使用空格作为标记器和平滑方法1。 区分得分来自 [42]。
附录 D 有关翻译任务的更多结果
| System | Memory | BLEU | chrF++ | TER |
|---|---|---|---|---|
| Transformer | None | 55.43 | 70.31 | 36.35 |
| Transformer | Retrieval | 58.06 | 71.58 | 35.41 |
| Transformer | Retrieval | 58.58 | 72.22 | 34.39 |
| Transformer | Self | 59.49 | 72.62 | 34.04 |
| Transformer | Self | 60.11 | 73.25 | 32.62 |
附录 E更多总结基线
| System | R-1 | R-2 | R-L |
|---|---|---|---|
| XSum | |||
| [51] | 38.8 | 16.5 | 31.3 |
| [40] | 45.1 | 22.3 | 37.3 |
| [100] | 47.2 | 24.6 | 39.3 |
| [54] | 47.6 | 24.6 | 39.4 |
| [55] | 49.1 | 25.6 | 40.4 |
| [87](PG) | 48.2 | 26.0 | 40.2 |
| [87](B) | 43.1 | 21.0 | 35.5 |
| [87](L) | 46.5 | 24.1 | 38.6 |
| [68] | 48.1 | 25.0 | 40.0 |
| [69] | 47.1 | 24.1 | 38.8 |
| [16] | 47.8 | 25.0 | 39.7 |
| Selfmem | 50.3 | 26.7 | 41.6 |
| System | R-1 | R-2 | R-L |
|---|---|---|---|
| BigPatent | |||
| [100] | 53.6 | 33.1 | 42.3 |
| [40] | 44.4 | 21.3 | 31.0 |
| [98] | 60.6 | 42.5 | 50.0 |
| [65] | 38.7 | 12.3 | 34.1 |
| [90] | 45.0 | 20.3 | 39.2 |
| [1] | 52.3 | 33.5 | 42.8 |
| [87] (B) | 59.5 | 42.6 | 50.6 |
| [87] (L) | 60.7 | 43.3 | 51.3 |
| [87] (PG) | 44.6 | 21.5 | 33.3 |
| Selfmem | 62.9 | 48.1 | 59.6 |
| System | ROUGE-1/2/L | 95%-conf.int |
|---|---|---|
| XSum | ||
| BRIO | 50.3 | 0.49986 - 0.50602 |
| 26.7 | 0.26300 - 0.26989 | |
| 41.6 | 0.41231 - 0.41900 | |
| BigPatent | ||
| BART | 62.9 | 0.62664 - 0.63080 |
| 48.1 | 0.47783 - 0.48333 | |
| 59.6 | 0.59401 - 0.59847 | |
附录F延迟的实证分析
在表12中,我们展示了Selfmem延迟的经验结果(以秒为单位)。 我们将 Selfmem 与跨各种数据集和计算平台(包括 CPU 和 CUDA)的检索增强基线模型进行比较。 Selfmem 的迭代次数设置为 1。 所有实验均在同一台设备上进行,配备 1 个 NVIDIA A100 GPU 和 1 个 AMD EPYC 7V13 64 核处理器。
| NMT | XSum | BigPatent | DailyDialog | ||
| Average Input Length | 87 | 512 | 1024 | 71 | |
| Average Output Length | 44 | 75 | 127 | 16 | |
| CPU | |||||
| Retrieval-augmented Baseline | 0.97 | 1.79 | 3.16 | 0.32 | |
| Selfmem | Candidate Generation | 3.20 | 7.50 | 15.00 | 1.02 |
| Memory Selection | 0.50 | 0.52 | 0.95 | 0.14 | |
| Hypothesis Generation | 0.97 | 1.79 | 3.00 | 0.32 | |
| 4.80 | 5.47 | 6.04 | 4.63 | ||
| CUDA | |||||
| Retrieval-augmented Baseline | 0.29 | 0.44 | 0.75 | 0.10 | |
| Selfmem | Candidate Generation | 0.51 | 1.00 | 1.72 | 0.18 |
| Memory Selection | 0.01 | 0.01 | 0.01 | 0.01 | |
| Hypothesis Generation | 0.29 | 0.44 | 0.75 | 0.10 | |
| 2.76 | 2.99 | 3.35 | 2.91 | ||
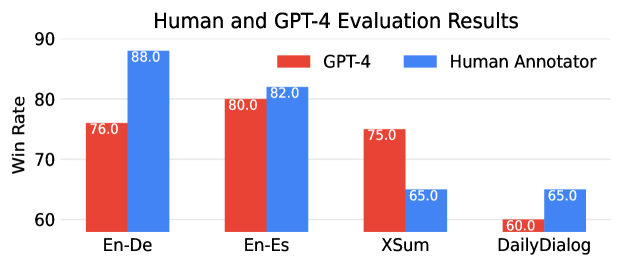
附录 G人类和 GPT-4 评估
我们使用人类注释者和 GPT-4 (gpt-4-0314) 注释者对 Selfmem 和基线系统生成的输出进行成对排序。 对于 GPT-4 注释器,我们利用 Alpaca Eval 777https://github.com/tatsu-lab/alpaca_eval/blob/main/src/alpaca_eval/evaluators_configs/alpaca_eval_gpt4/alpaca_eval.txt。 我们随机选择 50 个样本用于翻译任务,20 个样本用于摘要和对话任务。 Selfmem 与检索增强基线的胜率如图 1 所示。