CodeGen2:大语言模型编程和自然语言训练课程
摘要
大型语言模型(大语言模型)在程序合成和理解任务的表示学习方面表现出了卓越的能力。 学习表示的质量似乎由神经缩放定律决定,作为模型参数和观察数量的函数,同时通过可用数据和计算量对模型性能施加上限,这是昂贵的。
在本研究中,我们尝试通过统一四个关键组件来提高用于程序综合的大语言模型的训练效率:(1)模型架构,(2)学习方法,(3)填充采样,以及(4)数据分布。 具体来说,对于模型架构,我们尝试将基于编码器和解码器的模型统一到单个前缀LM中。 对于学习方法,(i)因果语言建模,(ii)跨度损坏,(iii)填充被统一为简单的学习算法。 对于填充抽样,我们探讨了“免费午餐”假设的主张。 对于数据分布,探讨了混合分布以及编程和自然语言的多时期训练对模型性能的影响。
我们对1B大语言模型进行了一系列全面的实证实验,将这次探索的失败和成功总结为五个教训。 我们将提供训练的最终方案并发布尺寸为 1B、3.7B、7B 和 16B 参数的 CodeGen2 模型,以及开源的训练框架:https://github.com/salesforce/CodeGen 。
1简介
1.1 动机:大语言模型的成本
大型语言模型(大语言模型)在跨领域的无数任务中表现出了强大的经验表现。 在最近的工作(Chen 等人,2021b;Nijkamp 等人,2022;Fried 等人,2022;Allal 等人,2023)中,这些发现已从自然语言转移到编程语言,并取得了令人印象深刻的表现在程序综合和理解任务中。 这些模型的吸引力源于三个属性:(1)简单 - 由于依赖自注意力电路,所涉及的架构技术复杂性较低,(2)通用 - 即单个模型可以处理各种不同的任务,而不是与用于 任务的 专用模型相比,这极大地减少了资源和成本需求,并且,(3)规模 - 即神经缩放法则将模型的性能决定为以下函数:模型参数、数据的数量以幂律形式计算,也就是说,较大的模型通常会在下游任务上产生可预测的改进性能。
然而,这些优点掩盖了尚未解决的挑战:(1)虽然自注意力电路在技术上很简单,但人们必须选择一种注意力掩蔽方案来学习双向表示(编码器)或单向表示(解码器),(2 )虽然 Transformer 看起来与任务无关,但综合和理解任务尚未统一,(3)虽然通过规模提高性能很有吸引力,但即使为不同的任务训练一小组模型也会产生巨大的成本。 对于实践者来说,模型架构、学习算法和数据分布的选择并不明显。 对这些选择的探索会因计算需求而导致高昂的货币成本。
1.2 目标:通过统一和开源降低成本
为了解决货币成本和变体选择的问题,我们尝试将(1)模型架构、(2)学习目标、(3)从左到右和填充采样以及(4)数据分布统一到一个配方中,它产生了一个在广泛的综合和理解任务中具有竞争性能的单一通用模型。
为了以原则性的方式实现这些方面的统一,我们提出并评估以下假设:
-
(1)
模型架构: 编码器和解码器表示可以统一为 Prefix-LM (Raffel 等人, 2020),其中双向自注意力有利于更困难的少样本任务,而不会降低标准因果性能的性能解码器。
-
(2)
学习算法: 因果语言建模和跨度损坏的目标的混合为零样本学习(解码器)和理解任务(编码器)提供了有效的信息传输。
-
(3)
取样程序: 在“免费午餐”假设的假设下,为模型配备从左到右和填充采样,不会增加计算成本。
-
(4)
数据分布: 自然语言和编程语言的混合同时有利于两个领域的任务,而不影响单一模式的性能。
这项工作的目标是(i)分享训练经验并为这种通用模型提供统一的配方,(ii)开源训练程序的实现,以及(iii)开源一系列良好的-训练有素的模型。
1.3 调查结果:结果参差不齐
在我们试图实现这些目标的过程中,我们的方法是尝试在各个方面完全统一并收集证据来指导特征的消融。 我们试图通过对 1B 大语言模型进行大量实验的广泛研究来提供证据来拒绝或不拒绝这些假设。 我们假设的结果总结如下:
-
(1)
模型架构: 我们未能提供证据来量化 Prefix-LM 相对于我们的评估任务组中的因果解码器基线的任何优势。
-
(2)
学习算法: 我们成功地实现了目标函数的简单混合,同时保持零样本性能。
-
(3)
取样程序: 我们未能为“免费午餐”假设提供证据,即在不产生额外计算成本的情况下为模型配备填充采样。
-
(4)
数据分布: 我们展示了将自然语言和编程语言混合到单个模型中的有希望的证据。 我们为多纪元训练提供了强劲的结果。
虽然我们没有实现完全统一,但我们获得了有价值的发现,并根据许可数据训练了有竞争力的开源模型。
1.4 贡献:课程、配方和开源
我们分享这些经过以下贡献提炼出来的发现:
-
•
五课: 结果的提炼:(1) Prefix-LM 作为一种架构,(2) 填充采样的免费午餐假设,(3) 目标函数的选择,(4) 自然语言和编程语言的数据混合,以及 (5) 多语言-纪元训练,
-
•
简单混合目标: 我们提出了一种简单、统一的未损坏和文件内跨度损坏序列与下一个 Token 预测的混合,这为从左到右和填充中间的自回归采样提供了有竞争力的性能,
-
•
开源实现: 我们将为最终配方的大语言模型训练提供精心设计和测试的参考实现,
-
•
开源模型: 一旦更大的大语言模型的训练收敛,我们将开源仅在许可数据上训练的 CodeGen2 系列可填充模型。
1.5相关工作
代码上的大语言模型
Transformer 通过注意力机制捕获序列元素之间的依赖性(Bahdanau 等人,2014),并且具有高度可扩展性,如自然语言处理(Devlin 等人,2019;Lewis 等人,2020;拉斐尔等人,2020)。 一些工作探索了这些程序综合模型(Chen 等人,2021a;Austin 等人,2021;Li 等人,2022;Fried 等人,2022;Nijkamp 等人,2022;Allal 等人,2023) 及其有效性(Vaithilingam 等人,2022)。
消融研究
Raffel 等人 (2020) 以 Prefix-LM 的形式引入非因果解码器的概念,在对下游任务进行微调后,其性能优于因果解码器。 没有评估少样本生成任务的表现。 Wang 等人 (2022) 对架构和目标进行了广泛的消融研究,得出的结论是,具有因果语言建模的纯解码器模型表现出最强的零样本泛化能力。 因此,我们将我们的研究限制在因果和非因果解码器上。 Tay 等人 (2022a) 比较编码器-解码器、仅解码器和 Prefix-LM 架构,并报告编码器-解码器模型的有益性能,但不评估零样本生成任务。 作者后来在(Tay等人, 2022b)中采用Prefix-LM代替编码器-解码器。
数据混合
LaMDA (Thoppilan 等人,2022) 接受了各种数据源的混合训练,包括对话、代码文档、问答数据、教程和维基百科。 然而,这种混合物的影响和具体来源尚不清楚。 Xie等人(2023)提出了一种基于重要性重采样的数据选择方法,允许混合不同大小的数据集,但评估仅涵盖仅编码器模型。
2方法:从统一到消融
在本节中,定义了我们目标的要求以及消融的相关组件。
2.1 要求:执行各种任务
我们的目标是通过提供学习方法和模型架构的统一,使程序综合的大语言模型训练更加高效,同时在相同的计算预算下保持(或提高)单个任务的性能。 任务集如下:
-
(1)
从左到右采样的程序综合(零样本) 作为意图规范的提示采用函数签名和文档字符串的形式。 根据从左到右自回归方式的提示,对程序进行有条件采样(或完成)。 招募 HumanEval (Chen 等人, 2021b) 来评估合成程序的质量。 具体来说,对于提示 ,我们采样 。
-
(2)
带有填充采样的程序综合(零样本) 提示包括过去和未来的标记,“中间”的标记应该被采样。 例如,提示包含函数定义的前几行和最后几行,而函数体则需要填写。 具体来说,对于提示 ,我们采样 。 招募 HumanEval-Infill (Fried 等人, 2022) 基准进行评估。
-
(3)
从示例中进行上下文学习(少样本) 任务是通过给定一组示例(或“镜头”)来定义的。 特别是,对于带有代码 和标签 的 少样本示例 ,我们对标签 进行采样。 招募 XSum 基准(Narayan 等人,2018) 进行评估。
-
(4)
使用双向表示的程序理解(张力) 因果屏蔽的解码器模型仅限于以从左到右的方式进行自回归采样。 为了理解任务,例如缺陷检测(Lu等人,2021),随着时间的推移消除这种约束,使得表示可以同时成为所有输入标记的函数似乎是可取的。 这种表示是从没有因果屏蔽的双向语言模型中获得的。 招募 CodeXGLUE (Lu 等人, 2021) 和 SuperGLUE (Wang 等人, 2019) 基准进行评估。
2.2组件:架构、目标、采样、数据
模型架构
在使用 Transformer 进行表示学习时(Devlin 等人,2019;Lewis 等人,2020;Raffel 等人,2020),普遍存在两种建模方案,它们在隐藏向量上下文化的注意力掩码方面有所不同。 对于向量的序列,我们有所不同:(1)基于双向编码器的表示,其中每个词符向量可以参与所有其他词符向量标记,(2)基于单向解码器的表示,其中每个词符向量只能参与先前的标记。 虽然每个隐藏向量可以与所有其他向量进行上下文关联的基于编码器的表示对于理解任务可能是理想的,但语言建模需要具有时间因果掩码的基于解码器的表示,其中联合密度被分解为条件随时间的乘积脚步。 为了统一这两种方案,我们采用基于前缀的语言建模(Prefix-LM)的概念(Raffel等人,2020)。 对于前缀,我们将输入序列 分解为前缀 和上下文 。对于前缀(其中),每个词符可以参与前缀中的所有其他标记,这相当于双向表示。 对于上下文,每个词符只能关注之前的标记,这相当于单向解码器表示。 这将前缀上的双向注意力与因果屏蔽的要求统一起来,以随时间分解联合密度。 希望能够实现综合任务的竞争性自回归采样,同时学习强大的双向表示以理解任务。
学习算法
基于编码器或解码器的模型架构的选择通常指导语言建模学习算法的选择。 基于编码器的模型可以通过去噪跨度损坏形式的掩码语言建模任务进行训练(Devlin 等人,2019;Raffel 等人,2020)。 基于解码器的模型可以以下一个 Token 预测任务(Radford等人,2018)的形式被训练为密度语言模型。 对于基于编码器的模型,流行的算法是词符重建或去噪任务的变体,其中标记的范围会受到损坏或扰动。 对于 标记的序列 ,扰动 将标记的范围替换为特殊掩码标记 。 学习任务是从扰动中恢复原始序列。 基于去噪的学习目标已被证明对于语言理解任务非常有效。 对于基于解码器的模型,流行的算法是基于最大似然的因果语言建模学习,其形式为下一个词符预测任务(Radford等人,2018)。 对于标记的序列,任务是在给定先前标记的情况下预测词符。 在这项工作中,我们探索了一种混合了因果语言建模目标和跨度损坏的学习算法。 我们假设对于这种混合,应尽量减少特定于任务的先验信息,以避免过度拟合特定任务。 也就是说,理想情况下,任务混合比、前缀长度和跨度长度的分布是均匀的。
抽样程序
从语言模型中进行自回归采样的形式的程序合成已被确立为主要方法。 虽然从左到右采样只能考虑以前的标记,但通常在编辑现有代码文件时,需要根据文件中当前位置之前和之后的上下文来调节采样。 多个变体 (Du 等人, 2022; Fried 等人, 2022; Bavarian 等人, 2022) 将序列 重新排列为 ,使得给定 的填充 可以通过因果屏蔽解码器中的标准下一个标记预测目标来学习。 Bavarian 等人 (2022) 在“免费午餐”假设下声称,经过这种修改的训练观察的训练大语言模型不会在零样本生成任务中产生任何额外的计算成本或性能下降。
数据分布
在最大似然学习中,通过最小化数据和模型分布之间的某些偏差度量来学习模型。 令人惊讶的是,当增加观测数量和模型参数时,从拟合密度中采样时出现了少样本能力(Brown等人,2020;Wei等人,2022)。 对于程序综合,Nijkamp 等人 (2022) 演示了多轮对话方案中的采样可执行代码,类似于 (Ouyang 等人, 2022),但没有明确的指令微调。 假设这些能力源于数据的弱监督。 程序通常包含带有英文说明的函数。 我们尝试增加自然语言的数量,以进一步提高这种能力,并显式地创建自然语言和编程语言的混合。 此外,生成的模型可能在两个领域的下游任务上都具有竞争力。
3 结果:教训和秘诀
在本节中,我们提出统一和消融研究尝试的实证结果和结论,这些结果被提炼为以下五个教训。
3.1 第1课:Prefix-LM的好处值得怀疑
正如所讨论的,Prefix-LM 充当具有双向注意力的编码器,以及具有因果掩码的自回归解码器。 然而,尚不清楚这种架构的统一是否会带来两端的竞争性能。 我们从三个角度评估这个问题:数据、表征和客观。 下面,我们将双向注意力覆盖的序列的前半部分称为非因果部分,将序列的其余部分称为因果部分。
3.1.1数据
背景和假设
当使用下一个词符预测训练 Prefix-LM 时,非因果部分的损失被掩盖,因为预测是由编码时使用的未来标记告知的。 根据每个序列中非因果部分的长度,这意味着负责梯度更新的有效标记数量的减少,这就提出了前缀掩码是否会对 Prefix-LM 的学习产生负面影响的问题。 具体来说,我们假设由于通过 NTP 的信息传输速率较慢,非因果部分缺乏梯度会导致代码生成任务结果更差。
结果和发现
为了评估这个假设,我们首先使用因果语言建模在 BigPython (Nijkamp 等人,2022) 上训练 Prefix-LM,并将 HumanEval 上的模型性能与经过相同数量的训练的因果解码器基线进行比较脚步。 非因果部分的长度设置为,其中和是序列长度。 令人惊讶的是,除了前 100,000 个步骤之外,我们观察到 Prefix-LM 的 HumanEval 分数在大多数预训练中与因果解码器持平,没有表现出学习速度较慢的趋势。 此外,相对于 InCoder (Fried 等人,2022),结合因果语言模型和跨度损坏进行训练的 Prefix-LM 产生了有竞争力的填充能力。
接下来,我们在 Stack (Kocetkov 等人, 2022) 上重复相同的实验,Python 占数据集中所有 token 的 9.4%。 我们参考表 2 了解 HumanEval 和 HumanEval-Infill 结果。 然而,与上面令人鼓舞的结果相反,我们在整个预训练中观察到严格较差的 pass@,导致比因果解码器基线差 2 个点。
基于这些相互矛盾的观察结果,我们推测 Prefix-LM 中存在由于目标语言(例如 Python)缺乏足够的梯度更新而产生的负面影响,由于专门训练,该影响并未更早出现在 Python 上执行大量步骤。 至于这种效应是在某个阈值时还是逐渐显现,仍然是一个问题。
3.1.2表示
背景和假设
Prefix-LM 由于双向注意力而很有吸引力,它允许模型将隐藏状态与过去和未来的标记联系起来。 仅受注意力掩码的存在控制,如果生成的模型具有竞争力,则可以轻松切换编码器或解码器的角色,从而实现简单的统一。
基于 Prefix-LM (Tay 等人, 2022b) 最近的成功,我们假设经过训练的 Prefix-LM 产生了一种有竞争力的编码器表示,可用于一系列判别任务,同时保留作为解码器的生成能力。
为了测试这个假设,我们使用因果语言建模和跨度损坏的混合来训练 Prefix-LM,假设去噪产生了强表示(Raffel 等人,2020;Tay 等人,2022a)。 为了扩大任务覆盖范围,我们在编程和自然语言上训练模型,并在 CodeXGLUE (Lu 等人,2021) 的缺陷检测任务和 SuperGLUE 的 4 个任务上评估每个模型(王等人,2019),分别。 我们在某个时间步(第一个或最后一个词符)在隐藏状态之上附加一个分类头以适应每个任务。 除了基于微调的判别任务之外,我们还检查双向注意力是否可以增强上下文学习能力。 我们遵循 UL2 并评估 XSum 上自然语言训练的模型作为少样本生成任务。 我们通过增加作为上下文输入模型的示例数量来检查性能变化。
结果和发现
在表2中,Prefix-LM 通常比在 SuperGLUE 任务上以相同目标训练的因果解码器取得更好的结果,这部分回答了我们的问题,即双向注意力可能会产生信息丰富的表示。 然而,我们的 1B 参数模型无法与更小的仅编码器预训练模型(例如 CodeXGLUE 上的 CodeBERT 或 SuperGLUE 上的 RoBERTa-large)竞争,这使我们得出结论,这些表示的信息量不足以证明替换较小规模的合理性具有一个 Prefix-LM 的仅编码器预训练模型。 对于少样本 XSum,无论非因果部分的样本数量有多少,我们都没有观察到两个模型之间存在有意义的差异。
| Model | Size | HumanEval | HumanEval-Infill | |
|---|---|---|---|---|
| SingleLine | MultiLine | |||
| Incoder | 1.3B | 9.79 | 52.56 | 23.85 |
| 6.7B | 15.20 | 66.69 | 34.62 | |
| CodeGen2.0 | 1B | 10.27 | 53.41 | 23.41 |
| 3.7B | 14.88 | 65.72 | 33.45 | |
| 7B | 19.09 | 68.74 | 38.88 | |
| 16B | 20.46 | - | - | |
3.1.3目标
背景和假设
正如所讨论的,Prefix-LM 在使用 UL2 (Tay 等人,2022a) 进行训练时似乎很有效,UL2 提出将因果语言模型 (CLM) 和去噪与 6 个不同的超参数结合起来。 该目标在不同模型规模下的一系列任务上比 CLM 和 T5 式的跨度损坏取得了显着的进步。 为了在编程语言领域取得类似的竞争结果,我们使用 UL2 目标(包括任务标记)训练 Prefix-LM,但发现训练后的模型在 HumanEval 上比 pass@1 上明显差 9 分CLM 基线。 我们假设这种意外的表现不佳的结果是由于 UL2 目标之一(S 降噪器)使用的未损坏序列比例较小,平均将 75% 的序列视为前缀。
结果和发现
我们通过简化 UL2 的降噪器超参数来验证前缀长度的影响,以便 (1) S 降噪器的百分比更高(14% 到 50%),并且 (2) S 降噪器的平均前缀长度更短(75 % 到 50%),并观察 HumanEval 相对于原始 UL2 超参数的持续改进。 一般来说,我们得出的结论是,对未损坏序列的因果语言建模与 HumanEval 中的零样本生成任务一致,这需要在前缀末尾进行采样,因此我们最大化序列中用于梯度更新的标记数量学习竞争模型。
3.2 第二课:Infill 不是免费的午餐
背景和假设
编写代码的过程涉及编辑文件内的标记,而不仅仅是在末尾。 在尝试为模型配备这种填充能力的几项工作中,Bavarian 等人 (2022) 声称通过仔细排列,实现了上下文末尾从左到右采样不降级的填充。训练数据中的一部分序列,“免费”获得填充能力。另一方面,并发工作报告填充是“廉价的”,即如果模型在填充目标上进行训练,则 HumanEval 中从左到右的采样会出现一致的性能下降(阿拉等人,2023)。 虽然报告的结果相互矛盾,但我们假设,如果按照 Bavarian 等人 (2022) 的方法进行训练,填充确实是免费的,并尝试用我们的模型重现填充学习。
结果和发现
为了验证免费午餐假设,我们按照 Bavarian 等人 (2022) 中的实验设置,训练一个混合了 CLM 和 PSM(前缀、后缀、中间序列重新排序)填充目标的因果解码器。 然而,与仅使用因果语言模型训练的因果解码器基线相比,我们观察到 HumanEval 性能的 pass@1 下降了约 1 个百分点。 因此,我们的观察遵循(Allal等人,2023)的观点,即填充不是免费的,并且我们留下仔细的重新实现以重现“免费填充”未来的作品。
| Model | HumanEval | Infill-Single | Infill-Multi | XSum | SuperGLUE | CodeXGLUE |
|---|---|---|---|---|---|---|
| pass@1 | pass@1 | pass@1 | R-L | BoolQ (Acc) | Defect (Acc) | |
| Decoder | 7.99 | 43.37 | 17.40 | 10.28 | 0.774 | 0.635 |
| Prefix-LM | 6.71 | 39.11 | 17.25 | 9.78 | 0.806 | 0.640 |
3.3 第3课:目标可以很简单,但需要谨慎选择
背景和假设
到目前为止,我们从上面的教训中了解到(1)Prefix-LM 不是一个理想的架构,因为多语言性能较差且表示实用性低于标准,(2)填充不是免费的,但 HumanEval 性能接近于此的非填充模型。
为了训练我们的因果解码器模型具有竞争性的从左到右和填充采样能力,我们对齐序列格式(例如,没有任务标记),消除复杂性,并假设任务混合和跨度长度的均匀分布,以避免相对于 (Tay 等人, 2022a)。 我们选择跨度损坏作为 InCoder (Fried 等人, 2022) 的基本填充目标。 然而,我们在选择损坏范围时采取了不同的方法:(1)我们首先对序列与掩码的动态比率进行采样,(2)然后我们对范围长度和掩码位置进行采样,以使 Token 总数匹配先前确定的原始序列的比率。 此外,我们还介绍了以下两项更改:
-
•
混合目标。 虽然 InCoder 学习预测跨度损坏序列中出现的子序列中的下一个标记,但我们为序列的一部分合并了专用的因果语言建模目标。 对于每个样本,跨度损坏或因果语言建模目标的选择由决定。 我们没有按照 UL2 的建议在序列中添加任务词符作为前缀,因为在任务标记的存在下没有观察到显着的差异。
-
•
文件级损坏。 跨度损坏可能会意外地掩盖文档边界,从而导致格式错误的上下文,从而使模型感到困惑。 为了避免这种情况,我们在文件级别应用跨度损坏,即,如果一个序列由于文档边界而可以分为两个子序列,则对每个子序列应用跨度损坏,并将它们连接在一起。 这导致某些序列具有多对去噪实例。
结果和发现
我们检查四种模型大小的配方:1B、3.7B、7B 和 16B,并将它们称为 CodeGen2。111截至提交时,16B参数模型仍在训练中。 一旦训练收敛,我们将修改手稿并开源模型。 对于训练,使用 Stack v1.1 (Kocetkov 等人, 2022) 的子集,并使用更强的许可指南进行过滤。 这些模型在 HumanEval (Chen 等人, 2021a) 和 HumanEval-Infill (Fried 等人, 2022; Bavarian 等人, 2022) 上进行评估,我们跟踪它们的截断策略。 不过,我们注意到 InCoder 的实验结果与原论文存在差异,因为我们只使用了掩码末端词符 (<eom>) 而不是启发式方法来确定填充序列的末端,以衡量填充和停止的行识别能力。
 (a) LAMBADA(准确度)
(a) LAMBADA(准确度)
 (b) PIQA(准确度)
(b) PIQA(准确度)
 (c) 兰巴达(困惑)
(c) 兰巴达(困惑)
 (d) HumanEval(通过@1)
(d) HumanEval(通过@1)
3.4 第4课:多模态数据混合
背景和假设
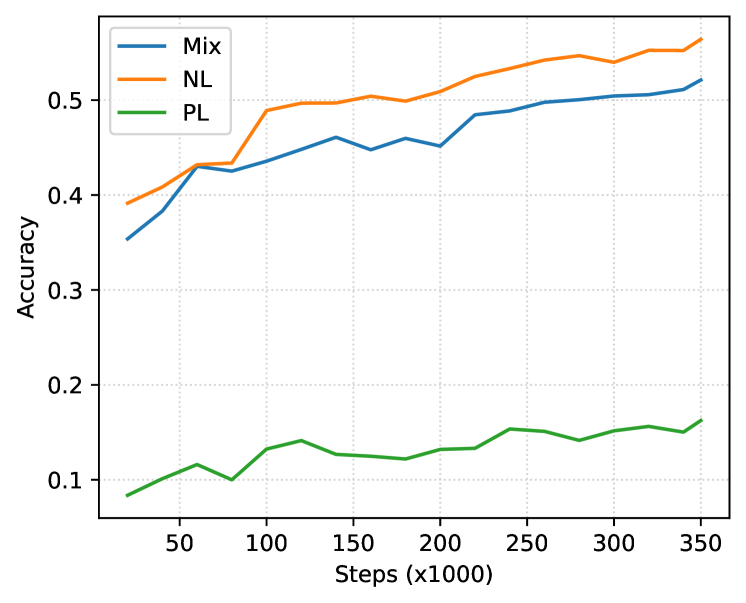
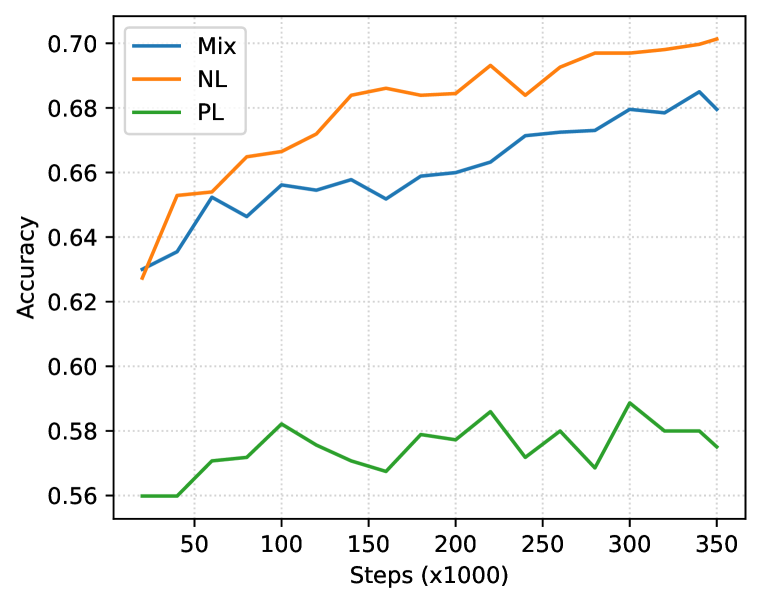
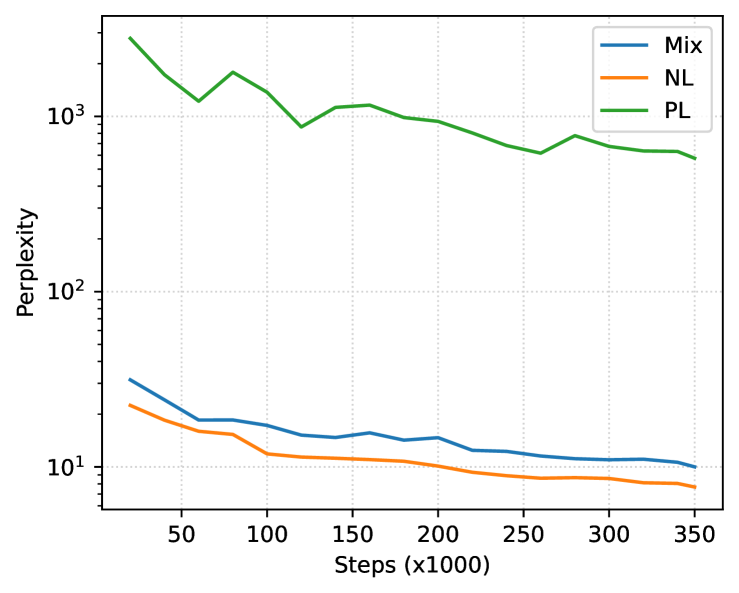
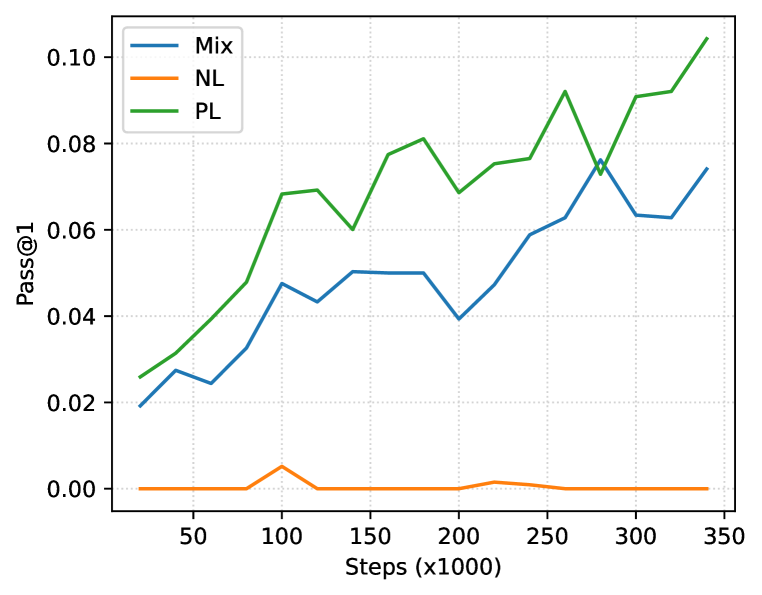
由于代码感知会话大语言模型的兴起,人们对自然语言和编程语言之间的跨模式应用越来越感兴趣,因此需要针对混合文本模式进行测试的训练方法。 在某种程度上,以评论和文档形式存在于编程语言数据中,以及以在线问答论坛的代码片段形式存在于自然语言数据中,这对于大规模大语言来说是一个足够的监督学习信号。代码模型,展示从文本生成代码的能力(Nijkamp 等人,2022)。 然而,我们的基础知识实验表明,尽管存在隐式混合,但这种代码大语言模型在自然语言任务上表现不佳。 我们的假设是,可以通过自然语言分布中的足够学习信号来缓解较差的表现。 我们通过在自然语言和编程语言的混合(Mix)上使用组合的因果语言建模和跨度损坏目标来训练因果解码器来测试假设。 批次中的示例是从 Pile (Gao 等人, 2020) 和 Stack 数据中抽取的概率相同。
结果和发现
该模型在训练步骤中以零样本的方式对编程和自然语言下游任务进行评估,以评估数据混合对每种模态的影响;具体来说,我们报告了 HumanEval 的 pass@1、LAMBADA (Paperno 等人,2016) 的准确性和困惑度以及 PIQA (Bisk 等人,2020) 的准确性。 为了进行比较,我们将训练数据更改为(1)仅 Pile (Gao 等人, 2020) (NL) 或 (2) 仅 Stack ( Kocetkov 等人, 2022) (PL),并接受相同步数的训练。 图 1 描述了这些任务的结果。 在训练步骤中,我们一致地观察到:
-
•
在给定相同计算预算的情况下,Mix 的评估任务的性能并不优于其他基准。 由于在 Mix 下对每个域的暴露减少了 50%,因此该模型的性能合理地比域匹配的对应模型差(例如、PL人类评估)。
-
•
Mix 的表现与领域匹配模型非常接近。 从训练的早期开始,Mix 显着提高了域不匹配基线的性能(例如,LAMBADA 的 PL),这表明人们应该如果 (a) 计算预算受到限制并且 (b) 生成的模型用于两个领域,则混合自然语言和编程语言。
尽管如此,我们发现该方法很有希望,即使是简单的训练数据混合也可以在两个领域进行高效学习,这可能表明使用 Mix 进行稍长的训练可以为这两个领域产生一个有竞争力的模型。
3.5 第5课:多纪元训练
背景和假设
由于野外数据是有限的,模型大小规模的增加仅限于某一点。 这是由于通常的做法是只对模型进行一个历元的预训练,即,模型在训练过程中对每个序列只观察一次。 然而,我们假设该模型有能力从重复观察中吸收信息。 此外,跨度损坏可以被解释为数据增强的一种手段。 也就是说,原始观察的扰动可能会在重复的情况下传输信息。 最后,在词符预算增加的情况下扩展的学习率衰减函数允许在更长的时间内在更高的学习率下进行学习。
为了测试这个假设,我们在重复的 StarCoderData (Li 等人, 2023)(一种包含提交和问题的多语言编程语言数据)上训练了一个具有 CodeGen2 目标的 7B 参数模型,总共 1.4 万亿个 Token ,总共 5 个 epoch。 相应地设置学习率计划,以便在总步长上进行衰减。 我们参考这个模型CodeGen2.5。
结果和发现
结果如表3所示。 与针对 400B Token 训练的基线 CodeGen2-7B 模型相比,我们观察到 pass@ 方面有显着的增益,这表明多轮训练继续提高程序综合能力,尽管没有280B后暴露新数据。 然而,以下每个因素如何促进改进仍有待回答:(1) 更多数量的 Token ,(2) 将腐败作为数据增强的一种形式,(3) 更长时间内更高的学习率。 为了获得更全面的理解,进行额外的消融至关重要,我们将其留作未来的工作。
| Model | Size | Tokens | HumanEval | ||
|---|---|---|---|---|---|
| pass@1 | pass@10 | pass@100 | |||
| CodeGen2.0 | 7B | 400B | 18.83 | 31.78 | 50.41 |
| CodeGen2.0 | 16B | 400B | 20.46 | 36.50 | 56.71 |
| CodeGen2.5 | 7B | 1.4T | 28.36 | 47.46 | 75.15 |
4 结论:经验教训和开源
大语言模型的训练成本高昂,并且涉及无数的设计选择。 我们的目标是通过统一架构、目标、采样程序和数据分布来应对这一挑战。 我们对每个方面都提出了假设,并将积极和消极的发现提炼成五个教训。 虽然我们没有实现令人满意的统一,但这次探索的结果和我们最终的训练方案可能对实践者有价值。
总之,对于我们的假设,我们相信 (1) Prefix-LM 架构不会对我们的任务集产生任何可测量的改进,(2) 训练具有填充采样的模型不是免费的午餐,(3) 简单的混合因果语言建模和仅限于文件内跨度的跨度损坏就足够了,(4)编程和自然语言的混合分布看起来很有希望,(5)有强有力的证据表明多纪元训练的有效性用CodeGen2.5演示。
为了促进未来的研究,我们将向社区开源训练实现以及由此产生的 CodeGen2 模型系列,参数大小为 1B、3.7B、7B 和 16B。
参考
- Allal et al. (2023) Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, et al. Santacoder: don’t reach for the stars! arXiv preprint arXiv:2301.03988, 2023.
- Austin et al. (2021) Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021.
- Bahdanau et al. (2014) Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, 2014.
- Bavarian et al. (2022) Mohammad Bavarian, Heewoo Jun, Nikolas Tezak, John Schulman, Christine McLeavey, Jerry Tworek, and Mark Chen. Efficient training of language models to fill in the middle. arXiv preprint arXiv:2207.14255, 2022.
- Bisk et al. (2020) Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language. In Thirty-Fourth AAAI Conference on Artificial Intelligence, 2020.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Chen et al. (2021a) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021a.
- Chen et al. (2021b) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021b.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4171–4186, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-1423. URL https://aclanthology.org/N19-1423.
- Du et al. (2022) Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. Glm: General language model pretraining with autoregressive blank infilling. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 320–335, 2022.
- Fried et al. (2022) Daniel Fried, Armen Aghajanyan, Jessy Lin, Sida Wang, Eric Wallace, Freda Shi, Ruiqi Zhong, Wen-tau Yih, Luke Zettlemoyer, and Mike Lewis. Incoder: A generative model for code infilling and synthesis. arXiv preprint arXiv:2204.05999, 2022.
- Gao et al. (2020) Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027, 2020.
- Kocetkov et al. (2022) Denis Kocetkov, Raymond Li, Loubna Ben Allal, Jia Li, Chenghao Mou, Carlos Muñoz Ferrandis, Yacine Jernite, Margaret Mitchell, Sean Hughes, Thomas Wolf, et al. The stack: 3 tb of permissively licensed source code. arXiv preprint arXiv:2211.15533, 2022.
- Lewis et al. (2020) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 7871–7880, 2020.
- Li et al. (2023) Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, Qian Liu, Evgenii Zheltonozhskii, Terry Yue Zhuo, Thomas Wang, Olivier Dehaene, Mishig Davaadorj, Joel Lamy-Poirier, João Monteiro, Oleh Shliazhko, Nicolas Gontier, Nicholas Meade, Armel Zebaze, Ming-Ho Yee, Logesh Kumar Umapathi, Jian Zhu, Benjamin Lipkin, Muhtasham Oblokulov, Zhiruo Wang, Rudra Murthy, Jason Stillerman, Siva Sankalp Patel, Dmitry Abulkhanov, Marco Zocca, Manan Dey, Zhihan Zhang, Nour Fahmy, Urvashi Bhattacharyya, Wenhao Yu, Swayam Singh, Sasha Luccioni, Paulo Villegas, Maxim Kunakov, Fedor Zhdanov, Manuel Romero, Tony Lee, Nadav Timor, Jennifer Ding, Claire Schlesinger, Hailey Schoelkopf, Jan Ebert, Tri Dao, Mayank Mishra, Alex Gu, Jennifer Robinson, Carolyn Jane Anderson, Brendan Dolan-Gavitt, Danish Contractor, Siva Reddy, Daniel Fried, Dzmitry Bahdanau, Yacine Jernite, Carlos Muñoz Ferrandis, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries. Starcoder: may the source be with you! 2023.
- Li et al. (2022) Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel Mankowitz, Esme Sutherland Robson, Pushmeet Kohli, Nando de Freitas, Koray Kavukcuoglu, and Oriol Vinyals. Competition-level code generation with alphacode, Feb 2022.
- Lu et al. (2021) Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, Ambrosio Blanco, Colin Clement, Dawn Drain, Daxin Jiang, Duyu Tang, et al. Codexglue: A machine learning benchmark dataset for code understanding and generation. arXiv preprint arXiv:2102.04664, 2021.
- Narayan et al. (2018) Shashi Narayan, Shay B Cohen, and Mirella Lapata. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. arXiv preprint arXiv:1808.08745, 2018.
- Nijkamp et al. (2022) Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. Codegen: An open large language model for code with multi-turn program synthesis. arXiv preprint arXiv:2203.13474, 2022.
- Ouyang et al. (2022) Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155, 2022.
- Paperno et al. (2016) Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Ngoc Quan Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. The LAMBADA dataset: Word prediction requiring a broad discourse context. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 1525–1534, Berlin, Germany, August 2016. Association for Computational Linguistics. doi: 10.18653/v1/P16-1144. URL https://aclanthology.org/P16-1144.
- Radford et al. (2018) Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training. 2018.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J Liu, et al. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21(140):1–67, 2020.
- Tay et al. (2022a) Yi Tay, Mostafa Dehghani, Vinh Q Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, and Donald Metzler. Unifying language learning paradigms. arXiv preprint arXiv:2205.05131, 2022a.
- Tay et al. (2022b) Yi Tay, Jason Wei, Hyung Won Chung, Vinh Q Tran, David R So, Siamak Shakeri, Xavier Garcia, Huaixiu Steven Zheng, Jinfeng Rao, Aakanksha Chowdhery, et al. Transcending scaling laws with 0.1% extra compute. arXiv preprint arXiv:2210.11399, 2022b.
- Thoppilan et al. (2022) Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, et al. Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239, 2022.
- Vaithilingam et al. (2022) Priyan Vaithilingam, Tianyi Zhang, and Elena L Glassman. Expectation vs. experience: Evaluating the usability of code generation tools powered by large language models. In CHI Conference on Human Factors in Computing Systems Extended Abstracts, pp. 1–7, 2022.
- Wang et al. (2019) Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. Superglue: A stickier benchmark for general-purpose language understanding systems. Advances in neural information processing systems, 32, 2019.
- Wang et al. (2022) Thomas Wang, Adam Roberts, Daniel Hesslow, Teven Le Scao, Hyung Won Chung, Iz Beltagy, Julien Launay, and Colin Raffel. What language model architecture and pretraining objective works best for zero-shot generalization? In International Conference on Machine Learning, pp. 22964–22984. PMLR, 2022.
- Wei et al. (2022) Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. Emergent abilities of large language models. arXiv preprint arXiv:2206.07682, 2022.
- Xie et al. (2023) Sang Michael Xie, Shibani Santurkar, Tengyu Ma, and Percy Liang. Data selection for language models via importance resampling. arXiv preprint arXiv:2302.03169, 2023.