对话到行动:通过行动级别生成构建面向任务的对话系统
摘要
基于端到端生成的方法已被研究并应用于面向任务的对话系统。 然而,在工业场景中,现有方法面临可靠性(例如领域不一致的响应、重复问题等)和效率(例如计算时间长等)瓶颈。 在本文中,我们提出了一种通过动作级别生成的面向任务的对话系统。 具体来说,我们首先从大规模对话中构建对话动作,并将每个自然语言(NL)响应表示为一系列对话动作。 此外,我们训练了一个序列到序列模型,它将对话历史记录作为输入并输出一系列对话动作。 生成的对话动作被转化为口头响应。 实验结果表明,我们的轻量级方法取得了有竞争力的性能,并且具有可靠性和效率的优势。
1. 介绍
最近,直接输出适当的 NL 响应或 API 调用的基于端到端生成的方法已在面向任务的聊天机器人 中得到了深入研究(Byrne 等人,2021;Yang 等人,2021;Lin 等人, 2021; Jang 等人, 2021; Thoppilan 等人, 2022),并且已被证明对现实业务有价值,尤其是售后客户服务(Li 等人, 2017; Yan 等人, 2017;朱等人,2019;宋等人,2021;孙等人,2022)。 基于大规模预训练语言模型(Radford等人,2019;Raffel等人,2020),基于生成的方法具有更简单的架构和拟人化交互的优点。 尽管取得了重大进展,但我们发现这些 Token 级生成方法在实际场景中仍存在以下两个限制。
1. Token 级生成方法的可靠性有限,这对于面向工业任务的对话系统至关重要。 由于预训练语言模型的特性,模型可能会生成从预训练语料库中学习到的响应。 在某些情况下,此类响应毫无意义,并且在语义上与当前业务领域不相符,从而中断在线交互。 更糟糕的是,模型有时会陷入多轮生成重复响应的困境(例如,反复询问用户相同的信息)。 上述问题也被其他研究者(参见等人,2019;Fu 等人,2021)和实践者广泛观察到。111https://github.com/microsoft/DialoGPT/issues/45
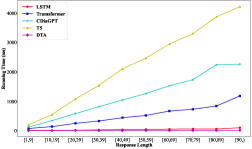
2. Token 级生成方法可能无法满足工业系统的效率要求,尤其是在解码步骤较大的情况下。 Token 级生成模型的计算时间较长,导致在线对话系统的响应延迟不可接受,尤其是当模型生成的句子长度超过阈值时(例如,30个单词的句子需要 1,544 ms 的 T5,如图所示) 3 显示)。 由于延迟问题,高峰期可能会出现大量服务请求被暂停或阻塞的情况。 此外,上述系统所需的计算资源(例如 GPU)对于小公司来说可能无法承受。
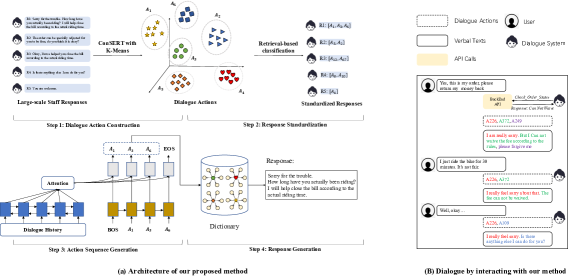
为了解决上述两个问题,本文提出了一种基于动作级生成方法的面向任务的对话系统。 受Xi等人(2022)的启发,我们用对话动作来表示响应,即可以通过聚类自动获得的一类具有唯一且相同语义的响应。 虽然 Xi 等人 (2022) 直接将整个响应视为特定的对话动作,但我们将一个响应分成多个片段 (Jin 等人, 2004) 并且每个片段可以被映射到对话动作。 通过这种方式,每个响应都被表示为一系列对话动作。 给定对话上下文,使用具有动作级循环解码器的 Seq2Seq 模型来生成对话动作序列。 此外,基于生成的对话动作序列,使用基于频率的采样方法来组成最终响应。 由于我们方法的核心组件是将对话上下文作为输入和输出动作的生成模型,因此我们的方法被命名为D ialog-To-Aactions(缩写。 DTA)。 与现有的基于 Token 级生成的系统相比,我们的 DTA 具有以下优点:1)可靠性,因为生成的自然语言响应源自预定义的对话动作; 2)效率,因为解码空间(即对话动作)和解码步骤要小得多。
2. 框架说明
2.1. 概述
我们遵循之前的端到端任务导向对话系统(Byrne等人,2021;Lin等人,2021)中采用的工作流程,其中系统将对话历史记录作为输入,并且生成一个文本字符串,该文本字符串可以用作工作人员对用户或 API 调用(例如,信息查询、操作执行等)的口头响应。 当调用API时,从API返回的信息将合并到系统的下一次响应中。 遵循此类系统交互生命周期的对话示例可以在图1(b)中找到。
我们工作的关键思想是生成对话动作,然后撰写口头回应。 为此,我们首先从大规模对话构建对话动作(步骤 1),并将每个响应表示为对话动作序列(步骤 2),如图 1 (a) 所示。 具有动作级循环解码器的 Seq2Seq 模型用于生成对话动作(步骤 3),生成的动作进一步用于组成口头响应(步骤 4)。 我们以电动自行车租赁业务的售后客服为例,用户和工作人员通过短信在线沟通。 技术细节介绍如下。
2.2. 第1步:对话行动构建
对话动作是指具有相同语义并代表共同交际意图的一组话语或话语片段,例如提出请求或查询信息。 Xi等人(2022)将一组具有相同语义信息的话语视为对话动作,并选择与特定人员动作相对应的响应。 然而,过于简单化的设置,即将整个话语抽象为一个动作,导致表现力和可扩展性相对有限。 为了使响应更有针对性和灵活,我们根据(员工的)话语片段而不是话语来构建对话动作。 具体来说,每篇文章通过基于规则的方法分为多个片段(金等人,2004)。 此外,按照Xi等人(2022),我们利用两阶段方法对片段进行聚类。 具体来说,利用 ConSERT (Yan 等人, 2021) 生成每个单词片段的表示,然后应用 K-means 对片段进行聚类。 我们根据经验选择簇的数量 以平衡纯度和簇的数量,并将每个片段簇视为对话动作(例如 和 图1 (a))。
2.3. 第 2 步:响应标准化
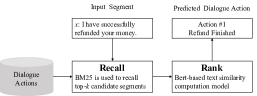
响应标准化旨在通过将每个响应映射到一系列对话动作来标准化响应(来自大规模对话)。 继Yu等人(2021)之后,我们利用基于检索的方法,检索与给定输入单词片段最相似的聚类片段,并根据相应的聚类标记输入。 如图2所示,给定输入段,我们使用BM25从所有聚类段中召回顶部段。 此外,我们还利用基于 BERT 的文本相似性计算模型 对 片段进行重新排序,并选择与 相似性最高的 片段,将其表示为:
| (1) |
其中指的是和之间的相似度。 然后用所属的对话动作来注释。
此外,我们还记录对话动作与单词片段之间的对应关系,以及对话中单词片段的频率。 具体来说,我们采用键值字典,其中键指的是对话动作,而其值是嵌套字典,其中唯一片段和以及片段的出现频率被记录。 字典 用于编写口头响应(步骤 4)。
2.4. 第三步:动作序列预测
给定一个对话作为用户()和员工()之间交换的一组话语,通过上述精心设计的步骤,每个员工话语 表示为操作序列。
在第 轮,给定对话历史 ,我们提出一个 Seq2Seq 模型来生成员工响应 。 我们首先利用Seq2Seq模型输出的动作序列,其中表示动作序列的长度,然后使用该动作序列形成口头响应(在§2.5)。
Encoder 给定对话历史,我们按顺序连接中的所有话语以及每个人员话语对应的动作序列,形成词符序列。
Bi-LSTM模型用于将词符序列编码为连续表示序列:
| (2) |
解码器考虑到效率要求和较小的解码空间,我们使用Luong注意力方法并采用LSTM作为解码器在时间步计算隐藏状态 如下:
| (3) |
其中 表示步骤 -1 处对话动作空间的概率分布, 表示该动作具有最高概率。 获得隐藏状态和上下文向量后,我们在时间步生成概率分布,如下所示:
| (4) |
其中是权重参数。 给定时间步骤 的真实标签 ,我们使用 表示步骤 的交叉熵损失其中 表示先前生成的操作。
优化目标定义为:
| (5) |
其中 表示对话集, 表示第 轮对话的对话动作序列的长度 。
2.5. 第 4 步:响应生成
3. 实验
3.1. 实验设置
3.1.1. 数据集
我们对中国的电动自行车租赁业务在线售后客服进行了实验。 在这种场景下,用户可能骑完后忘记锁车,于是要求工作人员远程锁车,降低费用。 工作人员需要通过后台API查看订单状态来判断是否可以减费。 我们从在线服务日志中收集用户与员工的对话一周。 数据统计如表1所示。 对话被随机分为训练集、开发集和测试集,比例为 8:1:1。 我们构造了 1,420 个对话动作 (§ 2.2),每个 API 调用都被视为一个对话动作。 该数据集将在线发布。
| STAT TYPE | VALUE |
|---|---|
| Dialogs | 8,363 |
| Total turns | 55,576 |
| Avg. turns per dialog | 6.65 |
| Dialogue Actions | 1,420 |
3.1.2. 基线
为了评估我们方法的有效性和效率,我们将其与以下最先进的基线进行比较:(1)LSTM,它利用了经典的基于 LSTM 的序列到序列架构(Sutskever 等人, 2014); (2) Transformer,使用 Transformer (Vaswani 等人, 2017) 作为编码器和解码器; (3)CDiaGPT,是在大规模中文会话数据集上预训练的 GPT 模型(王等人,2020); (4)T5,这是一个使用 CLUE Corpu 预训练的文本到文本传输转换器(T5)模型(Raffel 等人,2020)。
3.1.3. 评估指标
为了综合评估不同模型的有效性,我们同时进行离线评估(即在数据集上)和在线评估(即在线 A/B 测试)。
离线评估模型将特定的真实对话历史(即上下文)作为输入并生成响应。 继 Byrne 等人 (2021) 之后,我们报告了测试集中每个模型的 BLEU-4 分数。 考虑到 API 调用非常重要,我们观察每轮生成的 API 调用,并报告 API 调用的宏精度 (P)、召回率 (R) 和 F1-Score (F1)。
在线评估继Xi等人(2022)之后,我们在线部署模型并进行A/B测试。 对于每个模型,随机采样 120 个对话。 拥有领域知识的注释者需要通过将每个对话评分为“低”、“中”或“高”满意度来进行满意度评估。 222评分标准可概括如下: (i) 得分“低”表示Chatbot无法正确处理用户需求。 (ii) 得分“中”表示聊天机器人可以正确处理用户需求,但可能会生成不流畅或不完整的响应。 (iii) 得分“高”表示Chatbot能够正确处理用户需求并完美完成对话。
3.2. 主要结果
离线评估和在线评估分别如表3和2所示,从中我们得到以下观察结果:(1)大规模预训练语言模型显着提高 Token 级生成模型的性能。 例如,与普通 LSTM 模型相比,T5 在 BLEU-4 分数上实现了 26.20% 的绝对提升,在 F1 上实现了 4.98% 的绝对提升。 (2)与CDiaGPT和T5模型相比,我们的轻量级DTA在离线评估中取得了有竞争力的表现,并在在线评估中获得了最高的满意度,验证了我们提出的方法的有效性。
| Model | Low | Medium | High |
|---|---|---|---|
| LSTM | 30.00 | 29.17 | 40.83 |
| Transformer | 27.50 | 28.33 | 44.17 |
| CDiaGPT | 12.50 | 13.33 | 74.17 |
| T5 | 5.83 | 15.83 | 78.33 |
| DTA | 8.33 | 12.50 | 79.17 |
| Model | BLEU-4 | P | R | F1 |
|---|---|---|---|---|
| LSTM | 20.62 | 66.16 | 78.84 | 71.72 |
| Transformer | 26.21 | 62.59 | 75.90 | 64.74 |
| CDiaGPT | 42.54 | 71.18 | 86.43 | 77.11 |
| T5 | 46.83 | 70.91 | 87.25 | 76.70 |
| DTA | 44.82 | 68.03 | 90.80 | 77.74 |
3.3. 深入分析
3.3.1. 效率问题的影响
为了研究效率问题的影响,我们收集了每个模型在相同基础设施(即 Tesla v100、32GB RAM 大小等)下处理测试样本的计算时间。 考虑到计算时间与解码步骤高度相关,我们首先根据响应长度将生成的响应分为10个子集,然后计算每个子集的平均计算时间,如图3所示。 我们可以观察到:(1)尽管性能相当,但 DTA 在计算效率方面比其他模型具有显着优势(例如,DTA 为 3.37 ms,而 DTA 为 3.37 ms)。 CDiaGPT 与 1265.56 毫秒对比 子集“[50, 59]”的 T5 为 2470.69 ms)。 (2) DTA 在较长的响应下比其他模型表现更显着。 原因是 Token 级生成模型的解码步骤与响应长度相同,而 DTA 执行动作级解码。 上述观察证明,我们的系统提供了一种有效的解决方案,可以在有限的计算资源下构建在线对话服务。
3.3.2. 可靠性问题的影响
我们通过定量检查重复问题来研究可靠性问题的影响。 具体来说,我们计算每轮和前几轮响应的 Jaccard 指数(Costa,2021)。 各模型的平均Jaccard指数如表4所示,从中我们可以看出:(1)人类反应的Jaccard指数最小,表明现有模型在方面还有改进的空间的重复问题。 (2) 我们的方法的 Jaccard 指数比 CDiaGPT 和 T5 小得多。 动作序列生成与采样策略一起可以有效缓解重复问题。
| Model | Jaccard Index |
|---|---|
| Human Response | 0.129 |
| CDiaGPT | 0.214 |
| T5 | 0.207 |
| DTA | 0.142 |
具体的在线对话如图 1 (b) 所示,其中 CDiaGPT 生成完全相同的响应。 尽管 DTA 生成类似的操作序列(例如,操作 A226、A372、A249 和 A109 的组合),但动作序列完全重复之前回合的情况要少得多。 动作顺序的微小差异可能会导致言语反应的巨大变化。 此外,采样机制保证了不同回合中的相同动作对应于不同的片段(例如三回合中的A226),这进一步使得DTA具有更好的多样性。
4. 结论
在本文中,我们提出了一种通过动作级别生成的面向任务的对话系统。 提出了一个有效的框架,以最少的手动工作从大规模对话中构建生成模型。 实验分析证明了我们的系统有能力解决现有端到端生成方法遇到的可靠性和效率问题。 未来,我们有兴趣探索一个集成系统,将 DTA 中的离散模块统一到端到端架构中。
5. 主讲人简历
主讲人:华云成。 他是美团的算法工程师,专注于对话系统的研究和构建。
6. 公司概况
美团是中国领先的本地消费产品和零售服务购物平台,包括娱乐、餐饮、送货、旅游和其他服务。
参考
- (1)
- Acharya et al. (2021) Anish Acharya, Suranjit Adhikari, Sanchit Agarwal, Vincent Auvray, Nehal Belgamwar, Arijit Biswas, Shubhra Chandra, Tagyoung Chung, Maryam Fazel-Zarandi, Raefer Gabriel, Shuyang Gao, Rahul Goel, Dilek Hakkani-Tur, Jan Jezabek, Abhay Jha, Jiun-Yu Kao, Prakash Krishnan, Peter Ku, Anuj Goyal, Chien-Wei Lin, Qing Liu, Arindam Mandal, Angeliki Metallinou, Vishal Naik, Yi Pan, Shachi Paul, Vittorio Perera, Abhishek Sethi, Minmin Shen, Nikko Strom, and Eddie Wang. 2021. Alexa Conversations: An Extensible Data-driven Approach for Building Task-oriented Dialogue Systems. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Demonstrations. Association for Computational Linguistics, Online, 125–132. https://doi.org/10.18653/v1/2021.naacl-demos.15
- Byrne et al. (2021) Bill Byrne, Karthik Krishnamoorthi, Saravanan Ganesh, and Mihir Kale. 2021. TicketTalk: Toward human-level performance with end-to-end, transaction-based dialog systems. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, Online, 671–680. https://doi.org/10.18653/v1/2021.acl-long.55
- Costa (2021) Luciano da F Costa. 2021. Further generalizations of the Jaccard index. arXiv preprint arXiv:2110.09619 (2021).
- Fu et al. (2021) Zihao Fu, Wai Lam, Anthony Man-Cho So, and Bei Shi. 2021. A theoretical analysis of the repetition problem in text generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 12848–12856.
- Jang et al. (2021) Youngsoo Jang, Jongmin Lee, and Kee-Eung Kim. 2021. GPT-Critic: Offline Reinforcement Learning for End-to-End Task-Oriented Dialogue Systems. In International Conference on Learning Representations.
- Jin et al. (2004) Meixun Jin, Mi-Young Kim, Dongil Kim, and Jong-Hyeok Lee. 2004. Segmentation of Chinese long sentences using commas. In Proceedings of the Third SIGHAN Workshop on Chinese Language Processing. 1–8.
- Lee et al. (2019) Sungjin Lee, Qi Zhu, Ryuichi Takanobu, Zheng Zhang, Yaoqin Zhang, Xiang Li, Jinchao Li, Baolin Peng, Xiujun Li, Minlie Huang, and Jianfeng Gao. 2019. ConvLab: Multi-Domain End-to-End Dialog System Platform. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations. Association for Computational Linguistics, Florence, Italy, 64–69. https://doi.org/10.18653/v1/P19-3011
- Li et al. (2017) Feng-Lin Li, Minghui Qiu, Haiqing Chen, Xiongwei Wang, Xing Gao, Jun Huang, Juwei Ren, Zhongzhou Zhao, Weipeng Zhao, Lei Wang, et al. 2017. Alime assist: An intelligent assistant for creating an innovative e-commerce experience. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. 2495–2498.
- Lin et al. (2021) Zhaojiang Lin, Andrea Madotto, Genta Indra Winata, Peng Xu, Feijun Jiang, Yuxiang Hu, Chen Shi, and Pascale Fung. 2021. Bitod: A bilingual multi-domain dataset for task-oriented dialogue modeling. arXiv preprint arXiv:2106.02787 (2021).
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog 1, 8 (2019), 9.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J Liu, et al. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 21, 140 (2020), 1–67.
- See et al. (2019) Abigail See, Stephen Roller, Douwe Kiela, and Jason Weston. 2019. What makes a good conversation? how controllable attributes affect human judgments. arXiv preprint arXiv:1902.08654 (2019).
- Song et al. (2021) Shuangyong Song, Chao Wang, Haiqing Chen, and Huan Chen. 2021. An Emotional Comfort Framework for Improving User Satisfaction in E-Commerce Customer Service Chatbots. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Industry Papers. Association for Computational Linguistics, Online, 130–137. https://doi.org/10.18653/v1/2021.naacl-industry.17
- Sun et al. (2021) Kai Sun, Seungwhan Moon, Paul Crook, Stephen Roller, Becka Silvert, Bing Liu, Zhiguang Wang, Honglei Liu, Eunjoon Cho, and Claire Cardie. 2021. Adding Chit-Chat to Enhance Task-Oriented Dialogues. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, Online, 1570–1583. https://doi.org/10.18653/v1/2021.naacl-main.124
- Sutskever et al. (2014) Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014. Sequence to sequence learning with neural networks. Advances in neural information processing systems 27 (2014).
- Thoppilan et al. (2022) Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, et al. 2022. Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239 (2022).
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems 30 (2017).
- Wang et al. (2020) Yida Wang, Pei Ke, Yinhe Zheng, Kaili Huang, Yong Jiang, Xiaoyan Zhu, and Minlie Huang. 2020. A Large-Scale Chinese Short-Text Conversation Dataset. In NLPCC. https://arxiv.org/abs/2008.03946
- Xi et al. (2022) Xiangyu Xi, Chenxu Lv, Yuncheng Hua, Wei Ye, Chaobo Sun, Shuaipeng Liu, Fan Yang, and Guanglu Wan. 2022. A Low-Cost, Controllable and Interpretable Task-Oriented Chatbot: With Real-World After-Sale Services as Example. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (Madrid, Spain) (SIGIR ’22). Association for Computing Machinery, New York, NY, USA, 3398–3402. https://doi.org/10.1145/3477495.3536331
- Yan et al. (2021) Yuanmeng Yan, Rumei Li, Sirui Wang, Fuzheng Zhang, Wei Wu, and Weiran Xu. 2021. ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, Online, 5065–5075. https://doi.org/10.18653/v1/2021.acl-long.393
- Yan et al. (2017) Zhao Yan, Nan Duan, Peng Chen, Ming Zhou, Jianshe Zhou, and Zhoujun Li. 2017. Building task-oriented dialogue systems for online shopping. In Thirty-First AAAI Conference on Artificial Intelligence.
- Yang et al. (2021) Yunyi Yang, Yunhao Li, and Xiaojun Quan. 2021. Ubar: Towards fully end-to-end task-oriented dialog system with gpt-2. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 14230–14238.
- Yu et al. (2021) Dian Yu, Luheng He, Yuan Zhang, Xinya Du, Panupong Pasupat, and Qi Li. 2021. Few-shot Intent Classification and Slot Filling with Retrieved Examples. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, Online, 734–749. https://doi.org/10.18653/v1/2021.naacl-main.59
- Zhu et al. (2020) Qi Zhu, Zheng Zhang, Yan Fang, Xiang Li, Ryuichi Takanobu, Jinchao Li, Baolin Peng, Jianfeng Gao, Xiaoyan Zhu, and Minlie Huang. 2020. ConvLab-2: An Open-Source Toolkit for Building, Evaluating, and Diagnosing Dialogue Systems. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations. Association for Computational Linguistics, Online, 142–149. https://doi.org/10.18653/v1/2020.acl-demos.19
- Zhu (2019) Xiaoming Zhu. 2019. Case ii (part a): Jimi’s growth path: Artificial intelligence has redefined the customer service of jd. com. In Emerging Champions in the Digital Economy. Springer, 91–103.