容忍视差的无监督深度图像拼接
摘要
传统的图像拼接方法倾向于利用越来越复杂的几何特征(例如、点、线、边缘等)来提高性能。 然而,这些手工制作的特征仅适用于具有足够几何结构的特定自然场景。 相比之下,深度拼接方案通过自适应学习鲁棒的语义特征来克服不利条件,但它们无法处理大视差情况。
为了解决这些问题,我们提出了一种视差容忍无监督深度图像拼接技术(UDIS++)。 首先,我们提出了一种稳健且灵活的扭曲来模拟从全局单应性到局部薄板样条运动的图像配准。 它通过有关对齐和扭曲的联合优化,为重叠区域提供精确对齐,并为非重叠区域提供形状保留。 随后,为了提高泛化能力,我们设计了一种简单但有效的迭代策略来增强跨数据集和跨分辨率应用中的扭曲自适应。 最后,为了进一步消除视差伪影,我们建议通过缝驱动合成掩模的无监督学习来无缝合成缝合图像。 与现有方法相比,我们的解决方案具有视差容错性,并且无需针对特定场景进行复杂几何特征的繁琐设计。 大量的实验表明我们在定量和定性方面都优于 SoTA 方法。 该代码可在 https://github.com/nie-lang/UDIS2 获取。

1简介
图像拼接是一种实用技术,旨在从有限视场的不同图像构建具有宽视场(FoV)的场景。 它可用于自动驾驶、医学成像、监控视频、虚拟现实等广泛领域。
在过去的几十年里,传统的拼接方法倾向于采用越来越复杂的几何特征来实现更好的内容对齐和形状保存。 最初,SIFT [38]广泛应用于各种图像拼接算法[4, 13, 50, 5, 34, 25]中,提取判别性关键点并计算自适应扭曲。 然后,线段被证明是另一个独特的特征,可以实现更好的拼接质量并保留线性结构[31,49,32,19]。 最近,[10]中还引入了大规模边缘来保留轮廓结构。 此外,还有多种其他几何特征可用于提高拼接质量,例如深度图[33]、语义平面区域[26]等。
计算出扭曲后,通常使用切缝来消除视差伪影。 为了探索不可见的接缝,使用颜色 [22]、边缘 [35, 8]、显着图 [30] 设计了各种能量函数、深度[6]等。
从几何特征的广泛使用中,我们发现了一个明显的发展趋势:越来越复杂的特征被利用。 我们问:这些复杂的设计在实际应用中是否实用? 我们试图从两个角度来回答这个问题。 1)这些具有复杂几何特征的复杂算法很难适应没有足够几何结构的场景,例如医学图像、工业图像和其他低纹理的自然图像(图9b)、弱光或低分辨率。 2)当存在丰富的几何结构时,运行速度难以忍受(具体参见表2、3)。 这样的趋势似乎违背了“实用”的初衷。
最近,使用卷积神经网络(CNN)的深度拼接技术引起了社区的广泛关注。 他们放弃了几何特征,转而寻求高级语义特征,这些特征可以在有监督的[24,40,44,47,23]、弱监督的[46],或无监督的[41]方式。 尽管它们对各种自然或非自然条件具有鲁棒性,但它们无法处理大视差,并且在跨数据集和跨分辨率条件下表现出不令人满意的泛化能力。 大视差情况如图9a所示,其中树在参考图像中位于汽车的中间,而在目标图像中位于左侧图像。 为了处理视差,UDIS [41] 重建从特征到像素的拼接图像。 然而,视差太大,会产生不希望有的模糊效果。
在本文中,我们提出了一种视差容忍的无监督深度图像拼接技术,同时解决了传统拼接中的鲁棒性问题和深度拼接中的大视差问题。 实际上,由于有效的语义特征提取,所提出的基于深度学习的解决方案对各种场景自然具有鲁棒性。 然后,它通过两个阶段克服大视差:扭曲和合成。 在第一阶段,我们提出了一种稳健且灵活的扭曲来对图像配准进行建模。 特别是,我们同时将单应性变换和薄板样条(TPS)变换参数化为紧凑框架中的统一表示。 前者提供全局线性变换,而后者产生局部非线性变形,允许我们的扭曲以视差对齐图像。 此外,这种扭曲通过对齐和扭曲的组合优化,同时有助于内容对齐和形状保留。 在第二阶段,现有的基于重建的方法[41]将伪影消除视为从特征到像素的重建过程,导致视差区域周围不可避免地出现模糊。 为了克服这个缺点,我们将切缝的动机配合到深层合成中,并通过对接缝驱动的合成掩模的无监督学习隐式地找到“接缝”。 为此,我们设计边界和平滑度约束来限制“接缝”的端点和路线,无缝地合成拼接图像。 除了这两个阶段之外,我们还设计了一个简单的迭代策略来增强泛化能力,快速提高扭曲在不同数据集和分辨率下的配准性能。
此外,我们还对扭曲和成分进行了广泛的实验,证明了我们相对于其他 SoTA 解决方案的优越性。 贡献集中在:
-
•
我们通过将单应性和薄板样条参数化为统一表示,提出了一种鲁棒且灵活的扭曲,实现了各种场景中的无监督内容对齐和形状保存。
-
•
提出了一种新的合成方法,通过合成掩模的无监督学习来生成无缝拼接图像。 与重建[41]相比,我们的合成消除了视差伪影,而不会引入不需要的模糊。
-
•
我们设计了一个简单的迭代策略来增强不同数据集和分辨率下的扭曲适应。
2相关工作
2.1 传统图像拼接
自适应扭曲。 AutoStitch [4] 利用 SIFT [38] 提取判别性关键点来构建全局单应性变换。 此后,SIFT成为计算各种柔性扭曲不可或缺的功能,例如DHW [13]、SVA [36] APAP [50] 、ELA [28]、TFA [27] 以获得更好的对齐效果、SPHP [5]、AANAP [34],GSP [7] 以更好地保持形状。 然后,DFW[13]采用LSD[48]提取的线段与关键点一起丰富人工环境中的结构信息。 此外,线引导网格变形[49]是通过优化各种线保持项[32, 19]的能量函数来设计的。 为了保留非线性结构,GES-GSP [10]中使用边缘特征来实现局部对齐和结构保留之间的平滑过渡。 除了这些基本的几何特征(点、线和边)之外,深度图和语义平面还用于使用额外的深度一致性[33]和平面一致性来辅助特征匹配[26]。
接缝切割。 接缝切割通常用作合成拼接图像的后处理操作,这引入了沿接缝的标签分配的优化问题。 为了获得合理的拼接结果,通过惩罚光度差异来定义广泛的能量项,例如欧几里得色差 [22]、梯度差 [1, 8]、运动和曝光感知差异[11]、显着差异[30]等。然后通过图割优化[22]。 除此之外,接缝切割还应用于图像对齐,以最小的接缝成本[14,51,35,29]找到最佳对齐扭曲。
这些复杂的几何特征对于具有足够几何结构的自然场景是有益的。 然而,它也有两个缺点:1)没有足够的几何结构,严格的特征要求导致拼接质量较差,甚至失败。 2)几何结构过多,计算成本急剧增加。
2.2深度图像拼接
相比之下,深度拼接方案则摆脱了无休止的几何特征设计。 他们学习在监督[24,40,44,47,23]、弱监督[46]中自动从大量数据中捕获高级语义特征,或者无监督的[41]时尚,使它们能够适应各种具有挑战性的场景。 其中,无监督的[41]由于无法获得真正的缝合标签而更受欢迎。 然而,由于基于单应性的对齐模型的限制,它无法处理大视差。 随后的重建会在视差区域周围带来不良的模糊。
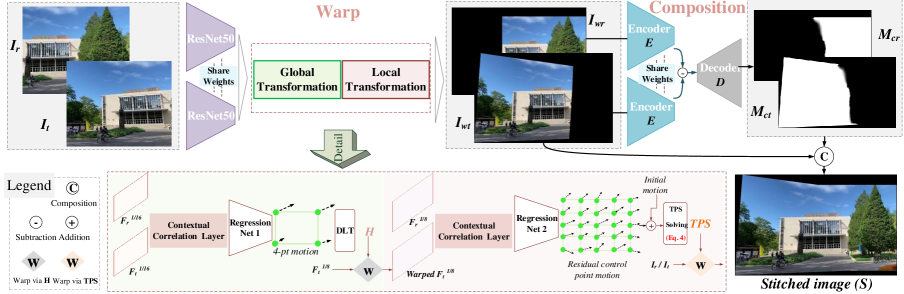
3方法论
我们的方法的概述如图2所示,其中所提出的框架由两个阶段组成:扭曲和组合。 在第一阶段,我们的方法将具有重叠区域的参考图像 () 和目标图像 () 作为输入,并回归稳健且灵活的扭曲。 然后将扭曲图像 () 输入到第二阶段以预测构图蒙版 ()。 拼接图像()可以无缝合成,如下所示:
| (1) |
3.1 无监督扭曲构造
3.1.1 扭曲参数化
单应性变换是从一个图像到另一个图像的可逆映射,具有 8 个自由度:每两个自由度用于平移、旋转、缩放和无穷远直线。 为了保证回归网络中的非奇异性[39],通常将其参数化为四个顶点[9]的运动,并将其求解为 使用 DLT [15] 矩阵。
然而,如果由不同拍摄中心的摄像机捕获非平面场景,则单应性无法实现精确对准。 为了解决这个问题,传统的拼接算法通常使用基于网格的多单应性方案[50]。 但它无法有效地并行加速,这意味着它无法用于深度学习框架[43, 42]。 具体分析请参考补充材料2.3节。 为了克服这个问题,我们建议利用TPS变换[3, 18]来实现有效的局部变形。
TPS变换是一种非线性、灵活的变换,通常用于使用薄板来近似非刚性物体的变形。 它由两组控制点确定,平面图像和扭曲图像之间一一对应。 将平面图像上的 控制点表示为 ,将扭曲图像上的对应点表示为 ()。 通过最小化由数据项和畸变项 [20] 组成的能量函数(更多详细信息,请参阅补充材料的第 2.1 节),TPS 变换可以为参数化为方程2:
| (2) |
其中 是平面图像上的任意点, 是扭曲图像上的对应点。 、 和 是转换参数。 是径向基函数,表示每个控制点对的影响。为了解决这些参数,我们根据方程2使用对控制点制定数据约束,并施加额外的维度约束[ 20]如式3所述:
| (3) |
然后,这些约束可以以矩阵计算的形式重写,参数可以如下求解:
| (4) |
其中 是一个 全一矩阵。 中的每个元素由和确定。
与单应性的 4 点参数化类似,TPS 变换也可以参数化为控制点的运动。 在这项工作中,我们定义均匀分布在目标图像上的控制点,然后预测每个控制点的运动。 为了桥接全局单应性扭曲与局部 TPS 扭曲,我们首先回归单应性变换以提供控制点的初始运动。 然后我们可以预测残余运动以进一步灵活变形。
3.1.2 扭曲管道
如图2所示,给定、,我们采用带有预训练参数的ResNet50 [17]作为主干首先提取语义特征。 它将 3 通道图像映射到高维语义特征,分辨率缩放至原始图像的 1/16。 然后,可以使用上下文相关层[43]将这些特征图(和)之间的相关性聚合成2通道特征流。 随后,使用回归网络来估计单应性扭曲的 4 点参数化。 这种全局扭曲还生成控制点的初始运动。
接下来,我们以更高分辨率()扭曲特征图,以将单应性先验嵌入到以下工作流程中。 在另一个上下文相关层和回归网络之后,控制点的残余运动被预测,从而有助于鲁棒灵活的 TPS 扭曲。
3.1.3 变形优化
为了同时实现内容对齐和形状保留,我们设计了涉及两个方面的目标函数:对齐和扭曲。
| (5) |
对于对齐,我们鼓励重叠区域在像素级别保持一致。 表示是扭曲操作,是与具有相同分辨率的全一矩阵,对齐损失可以定义如下:
| (6) | ||||
其中 和 是扭曲参数, 是用于平衡不同变换影响的超参数。
对于畸变,我们将扭曲的目标图像中的相邻控制点链接起来形成网格,并引入网格间约束和网格内约束。 前者保留非重叠区域的几何结构,而后者减少投影扭曲。 首先,我们通过 DLT 对非重叠区域中的每个网格进行类似的变换,并将 4 点投影误差作为损失。 但传统方法[16, 37]中常用的这种约束在深度学习方案中不起作用。 相反,我们从更直观的角度——网格边缘——重新探索约束。
与[42]类似,我们对超过阈值的网格边缘进行惩罚。 表示和是水平和垂直边缘的集合,我们将网格内约束描述如下:
| (7) | ||||
其中 / 是水平/垂直单位向量, 是 函数。 通过防止网格形状急剧缩放来减少投影扭曲。
通过鼓励边缘对(水平或垂直方向上的连续边缘,表示为)共线,我们将网格间约束表示为:
| (8) |
其中 是边对的数量, 是 0-1 标签,如果该边对位于非重叠区域,则设置为 1。 我们只保留非重叠区域的结构,防止对对齐产生不利影响。
3.2 无监督无缝合成
3.2.1 动机
UDIS [41]通过从特征到像素的无监督重建来合成拼接图像,但它不能处理大视差。 传统的接缝切割通过使用动态编程[2]或图形切割优化[22]寻找无缝切割路径来消除伪影,但它过度依赖光度差异。
一个直观的想法就是将切缝的动机配合到一个学习框架中。 然而,如何使我们的无监督深度缝合方法与切缝一起工作并且有效是一个主要困难。 例如,动态规划不是微分的;图割优化将绝对整数分配给标签,这会截断反向传播中的梯度。 在这个阶段,我们建议将硬标签放宽为具有浮点数的软掩模,通过特殊设计的两个约束的平衡效果,创新地监督接缝启发掩模的生成。
3.2.2 组合管道
首先,我们连接扭曲图像作为输入,并利用类似 UNet 的网络 [45] 作为我们的合成网络。 但这种模式粗略地混合了不同图像的特征。 对于这样的网络来说,感知扭曲图像之间的语义差异是具有挑战性的。
为了克服这个问题,我们使用网络的编码器通过共享权重分别从 和 中提取语义特征。 对于跳过连接,我们通过从 的特征中减去 的特征并将每个分辨率的残差传递给解码器来替换它们。 我们将最后一层的滤波器数量和激活函数设置为 1 和 来预测扭曲参考图像的 。 通过简单的后处理可以轻松获得扭曲目标图像的另一个掩模。
3.2.3构图优化
我们的无监督组合的优化目标包括边界项和平滑项,如下所示:
| (9) |
前者表示“接缝”的起点和终点,后者则约束路线。
我们期望端点是扭曲图像边界的交点。 为了实现这一点,我们利用 0-1 边界掩码 、 来指示“接缝”两侧重叠区域的边界位置。 更多详细信息请参阅补充材料的第 3.1 节。 然后,我们将边界损失表述如下:
| (10) |
此损失限制了 中与 或 重叠区域的边界像素。 然而,和共享公共交集,这会产生交集所属的歧义。 但正是这种模糊性将“接缝”的端点固定在交叉点上。
为了测量接缝的平滑度,传统的切缝方法定义了具有不同光度差异的各种能量函数。 在这项工作中,我们采用最简单的光度差作为来证明我们的有效性。 然后我们在差异图上定义平滑度如下:
| (11) | ||||
其中 是笛卡尔坐标。 为了在“接缝”两侧之间产生平滑过渡,我们还定义缝合图像的平滑度如下:
| (12) | ||||
通过添加和,我们制定了完整的平滑项。 请注意,我们的网络经过训练,可以提高提取语义差异的能力。 在推理过程中,所提出的方法不再依赖于光度差异。

3.3 迭代扭曲适应
要将预训练的模型转移到其他数据集(跨场景和跨分辨率),最常见的方法是在新数据集上进行调整。 然而,它通常需要标签来协助适应过程。 在这项工作中,我们通过设置无监督优化目标来解决此限制,如下所示:
| (13) |
与等式相比5,我们去除单应性对齐损失和扭曲损失。 因为预训练模型已经很好地学习了这些约束,所以我们所做的就是调整不同数据上的局部对齐。
此外,我们考虑一种特殊情况,即新数据集仅包含一个样本。 实验表明,我们的模型还可以稳定地优化,以迭代方式适应仅样本。 特别是,我们设置了阈值和最大迭代次数。当迭代次数达到或连续优化误差(方程13)低于时,自适应过程停止。
我们在图3中展示了一个迭代适应示例,其中随着迭代次数的增加,伪影显着减少。 完成一次迭代大约需要0.1s。
4实验
4.1 数据集和实现细节
数据集:训练为了与深度拼接方法进行直观和公平的比较,我们还在 UDIS-D [41] 数据集上建立了我们的模型。 评估在 UDIS-D 数据集和其他传统数据集[50,13,34,28,35]上进行。
详细信息: 我们使用 Adam [21] 训练扭曲和合成网络 100 和 50 个时期,学习率呈指数衰减,初始值为 。 对于扭曲阶段,和设置为10和3,并采用控制点来提供灵活的TPS转换。 对于第二阶段,我们将 和 设置为 10,000 和 1,000。 对于扭曲适应,和被分配为和50。 所有实现均基于 PyTorch,使用带有 NVIDIA RTX 3090 Ti 的单个 GPU。
| PSNR | SSIM | |||||||
| Easy | Moderate | Hard | Average | Easy | Moderate | Hard | Average | |
| 15.87 | 12.76 | 10.68 | 12.86 | 0.530 | 0.286 | 0.146 | 0.303 | |
| SIFT[38]+RANSAC[12] | 28.75 | 24.08 | 18.55 | 23.27 | 0.916 | 0.833 | 0.636 | 0.779 |
| APAP[50] | 27.96 | 24.39 | 23.79 | 0.901 | 0.837 | 0.682 | 0.794 | |
| ELA[28] | 19.19 | |||||||
| SPW[32] | 26.98 | 22.67 | 16.77 | 21.60 | 0.880 | 0.758 | 0.490 | 0.687 |
| LPC[19] | 26.94 | 22.63 | 19.31 | 22.59 | 0.878 | 0.764 | 0.610 | 0.736 |
| UDIS’s warp[41] | 25.16 | 20.96 | 18.36 | 21.17 | 0.834 | 0.669 | 0.495 | 0.648 |
| Our warp | ||||||||


| Dataset | Railtrack [50] | Fence [34] | Carpark [13] |
| Resolution | |||
| APAP [50]1 | 20.921 | 4.427 | 2.005 |
| ELA [28]1 | 18.982 | 4.739 | 2.179 |
| SPW [32]1 | 227.762 | 4.787 | 6.583 |
| LPC [19]1 | 2805.3 | 9.115 | 40.443 |
| Our warp1 | 12.073 | 5.025 | 3.486 |
| Our warp2 | 0.731 | 0.210 | 0.117 |
| Dataset | Railtrack [50] | Fence [34] | Carpark [13] |
| Resolution (after warping) | |||
| Seam cutting [30]1 | 46.657 | 4.058 | 0.873 |
| Reconstruction [41]1 | 304.963 | 80.837 | 10.734 |
| Our composition1 | 22.778 | 6.666 | 3.286 |
| Our composition2 | 0.532 | 0.143 | 0.071 |


4.2对比实验
为了全面证明我们的有效性,我们分别对扭曲、合成和完整的拼接框架进行了广泛的实验。
4.2.1 扭曲比较
我们将我们的扭曲与 SIFT [38]+RANSAC [12](AutoStitch [4] 的管道)、APAP [ 50]、ELA [28]、SPW [32]、LPC [19] 和 UDIS 的扭曲 [ 41]。 我们自己实现了SIFT+RANSAC,其他方法采用官方代码,默认参数如网格分辨率。 所有方法,包括我们的方法,都使用平均融合作为后处理操作。 因为这种简单的融合速度很快,并且可以更好地突出未对准的地方。
定量比较: 我们首先在具有 1,106 个评估样本的 UDIS-D 数据集 [41] 上与 UDIS [41] 相同的指标进行定量比较。 结果如表1所示,其中以单位矩阵作为“无扭曲”变换作为参考。 结果根据性能分为三部分,如[41, 43]。 由于缺乏几何特征,传统方法的程序可能会在一些具有挑战性的样本中崩溃。 当发生这种情况时,我们使用 作为评估的替代转换。
定性比较: 定性结果如图4所示,其中我们放大了不同深度表面的两个区域以突出显示视差伪影。 从图中可以看出,我们的 warp 在 UDIS-D 数据集 [41] 上大幅优于其他解决方案。
跨数据集比较: 我们使用预训练模型来评估我们在其他数据集上的性能,如图5所示。 迭代适应策略用于进一步提高对齐性能。
速度对比: 为了客观地评估速度,我们在具有三种不同分辨率的三个传统公共数据集[50,34,13]上对其进行了测试。 如表2所示,我们的warp的速度远远超过其他GPU加速的warp,而传统的warp无法通过GPU加速。 对于传统的基于网格的扭曲,运行时间不会随分辨率线性变化,并且在具有丰富几何特征的场景中(例如“railTrack”),速度变成了灾难。
4.2.2成分比较
我们将我们的组合与基于感知的切缝方法[30]和基于重建的方法[41]进行比较。 为了更直观地显示视差伪影,我们对图像进行SIFT+RANSAC变形,并给出平均融合结果以供参考。
定性比较: 传统的接缝方法通过动态规划[2]或图割优化[22]来找到接缝。 传统掩码中的值是整数,而我们的掩码中的值是浮点数。 因此,我们无法用传统的指标来定量评价我们的成分。 相反,我们在图 6 中显示了定性结果。 此外,我们承诺发布所有主观结果,包括UDIS-D中的1,106张图像以及传统数据集中的其他图像。
速度对比: 在这里,我们首先使用建议的扭曲来扭曲输入。 然后这些扭曲的图像用于不同合成方法的速度评估。 如表所示。 3,我们的组合在 GPU 加速方面比其他组合显示出显着的速度优势。
4.2.3 更多比较
在这里,我们使用其他 SoTA 方法评估完整拼接框架的性能。 结果如图9所示,其中LPC[19]和UDIS[41]采用基于感知的切缝 [30]和重建[41]用于后处理操作。 为了清楚起见,补充材料中描述了更多实验结果,包括定性比较、用户研究、具有挑战性的案例和跨数据集评估。
4.3消融研究
我们首先对不同的扭曲约束进行消融研究。 如图7(上)所示,网格间约束保留了结构,而网格内约束则减少了投影畸变。 而且,这些限制对对齐带来的不利影响很小。 定量结果在补充材料中报告。
然后我们研究平滑项对我们的构图的影响。 结果如图7(底部)所示,其中我们用矩形突出显示不连续区域。 通过对差异图和拼接图像的平滑度约束,不连续性得到显着改善。
5结论
在本文中,我们提出了一种容忍视差的无监督深度拼接解决方案。 首先,自适应地学习鲁棒灵活的扭曲,以实现内容对齐和形状保存。 我们还展示了受接缝启发的组合,以进一步减少伪影。 此外,设计了一种简单的迭代扭曲适应策略,以有效增强跨数据集和跨分辨率情况下的泛化能力。 与现有的解决方案相比,我们的方法可以解决具有挑战性的场景和大视差情况。 随着 GPU 的日益流行,我们的解决方案展现出了令人难以置信的效率。
参考
- [1] Aseem Agarwala, Mira Dontcheva, Maneesh Agrawala, Steven Drucker, Alex Colburn, Brian Curless, David Salesin, and Michael Cohen. Interactive digital photomontage. In SIGGRAPH, pages 294–302. 2004.
- [2] Shai Avidan and Ariel Shamir. Seam carving for content-aware image resizing. TOG, 26(3):10–es, 2007.
- [3] Fred L. Bookstein. Principal warps: Thin-plate splines and the decomposition of deformations. TPAMI, 11(6):567–585, 1989.
- [4] Matthew Brown and David G Lowe. Automatic panoramic image stitching using invariant features. IJCV, 74(1):59–73, 2007.
- [5] Che-Han Chang, Yoichi Sato, and Yung-Yu Chuang. Shape-preserving half-projective warps for image stitching. In CVPR, pages 3254–3261, 2014.
- [6] Xin Chen, Mei Yu, and Yang Song. Optimized seam-driven image stitching method based on scene depth information. Electronics, 11(12):1876, 2022.
- [7] Yu-Sheng Chen and Yung-Yu Chuang. Natural image stitching with the global similarity prior. In ECCV, pages 186–201, 2016.
- [8] Qinyan Dai, Faming Fang, Juncheng Li, Guixu Zhang, and Aimin Zhou. Edge-guided composition network for image stitching. PR, 118:108019, 2021.
- [9] Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Deep image homography estimation. arXiv preprint arXiv:1606.03798, 2016.
- [10] Peng Du, Jifeng Ning, Jiguang Cui, Shaoli Huang, Xinchao Wang, and Jiaxin Wang. Geometric structure preserving warp for natural image stitching. In CVPR, pages 3688–3696, 2022.
- [11] Ashley Eden, Matthew Uyttendaele, and Richard Szeliski. Seamless image stitching of scenes with large motions and exposure differences. In CVPR, pages 2498–2505, 2006.
- [12] Martin A Fischler and Robert C Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Communications of the ACM, 24(6):381–395, 1981.
- [13] Junhong Gao, Seon Joo Kim, and Michael S Brown. Constructing image panoramas using dual-homography warping. In CVPR, pages 49–56, 2011.
- [14] Junhong Gao, Yu Li, Tat-Jun Chin, and Michael S Brown. Seam-driven image stitching. In Eurographics, pages 45–48, 2013.
- [15] Richard Hartley and Andrew Zisserman. Multiple view geometry in computer vision. Cambridge university press, 2003.
- [16] Kaiming He, Huiwen Chang, and Jian Sun. Rectangling panoramic images via warping. TOG, 32(4):1–10, 2013.
- [17] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, pages 770–778, 2016.
- [18] Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. Spatial transformer networks. NIPS, 28, 2015.
- [19] Qi Jia, ZhengJun Li, Xin Fan, Haotian Zhao, Shiyu Teng, Xinchen Ye, and Longin Jan Latecki. Leveraging line-point consistence to preserve structures for wide parallax image stitching. In CVPR, pages 12186–12195, 2021.
- [20] JT Kent and KV Mardia. The link between kriging and thin-plate splines. Probability, Statistics and Optimization, pages 326–339, 1994.
- [21] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [22] Vivek Kwatra, Arno Schödl, Irfan Essa, Greg Turk, and Aaron Bobick. Graphcut textures: Image and video synthesis using graph cuts. TOG, 22(3):277–286, 2003.
- [23] Hyeokjun Kweon, Hyeonseong Kim, Yoonsu Kang, Youngho Yoon, Wooseong Jeong, and Kuk-Jin Yoon. Pixel-wise deep image stitching. arXiv preprint arXiv:2112.06171, 2021.
- [24] Wei-Sheng Lai, Orazio Gallo, Jinwei Gu, Deqing Sun, Ming-Hsuan Yang, and Jan Kautz. Video stitching for linear camera arrays. arXiv preprint arXiv:1907.13622, 2019.
- [25] Kyu-Yul Lee and Jae-Young Sim. Warping residual based image stitching for large parallax. In CVPR, pages 8198–8206, 2020.
- [26] Aocheng Li, Jie Guo, and Yanwen Guo. Image stitching based on semantic planar region consensus. TIP, 30:5545–5558, 2021.
- [27] Jing Li, Baosong Deng, Rongfu Tang, Zhengming Wang, and Ye Yan. Local-adaptive image alignment based on triangular facet approximation. TIP, 29:2356–2369, 2019.
- [28] Jing Li, Zhengming Wang, Shiming Lai, Yongping Zhai, and Maojun Zhang. Parallax-tolerant image stitching based on robust elastic warping. TMM, 20(7):1672–1687, 2017.
- [29] Jiaxue Li and Yicong Zhou. Automatic color image stitching using quaternion rank-1 alignment. In CVPR, pages 19720–19729, 2022.
- [30] Nan Li, Tianli Liao, and Chao Wang. Perception-based seam cutting for image stitching. Signal, Image and Video Processing, 12(5):967–974, 2018.
- [31] Shiwei Li, Lu Yuan, Jian Sun, and Long Quan. Dual-feature warping-based motion model estimation. In ICCV, pages 4283–4291, 2015.
- [32] Tianli Liao and Nan Li. Single-perspective warps in natural image stitching. TIP, 29:724–735, 2019.
- [33] Tianli Liao and Nan Li. Natural image stitching using depth maps. arXiv preprint arXiv:2202.06276, 2022.
- [34] Chung-Ching Lin, Sharathchandra U Pankanti, Karthikeyan Natesan Ramamurthy, and Aleksandr Y Aravkin. Adaptive as-natural-as-possible image stitching. In CVPR, pages 1155–1163, 2015.
- [35] Kaimo Lin, Nianjuan Jiang, Loong-Fah Cheong, Minh Do, and Jiangbo Lu. Seagull: Seam-guided local alignment for parallax-tolerant image stitching. In ECCV, pages 370–385, 2016.
- [36] Wen-Yan Lin, Siying Liu, Yasuyuki Matsushita, Tian-Tsong Ng, and Loong-Fah Cheong. Smoothly varying affine stitching. In CVPR, pages 345–352, 2011.
- [37] Feng Liu, Michael Gleicher, Hailin Jin, and Aseem Agarwala. Content-preserving warps for 3d video stabilization. TOG, 28(3):1–9, 2009.
- [38] David G Lowe. Distinctive image features from scale-invariant keypoints. IJCV, 60(2):91–110, 2004.
- [39] Ty Nguyen, Steven W Chen, Shreyas S Shivakumar, Camillo Jose Taylor, and Vijay Kumar. Unsupervised deep homography: A fast and robust homography estimation model. IEEE Robotics and Automation Letters, 3(3):2346–2353, 2018.
- [40] Lang Nie, Chunyu Lin, Kang Liao, Meiqin Liu, and Yao Zhao. A view-free image stitching network based on global homography. Journal of Visual Communication and Image Representation, 73:102950, 2020.
- [41] Lang Nie, Chunyu Lin, Kang Liao, Shuaicheng Liu, and Yao Zhao. Unsupervised deep image stitching: Reconstructing stitched features to images. TIP, 30:6184–6197, 2021.
- [42] Lang Nie, Chunyu Lin, Kang Liao, Shuaicheng Liu, and Yao Zhao. Deep rectangling for image stitching: A learning baseline. In CVPR, pages 5740–5748, 2022.
- [43] Lang Nie, Chunyu Lin, Kang Liao, Shuaicheng Liu, and Yao Zhao. Depth-aware multi-grid deep homography estimation with contextual correlation. CSVT, 32(7):4460–4472, 2022.
- [44] Lang Nie, Chunyu Lin, Kang Liao, and Yao Zhao. Learning edge-preserved image stitching from multi-scale deep homography. Neurocomputing, 491:533–543, 2022.
- [45] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015.
- [46] Dae-Young Song, Geonsoo Lee, HeeKyung Lee, Gi-Mun Um, and Donghyeon Cho. Weakly-supervised stitching network for real-world panoramic image generation. arXiv preprint arXiv:2209.05968, 2022.
- [47] Dae-Young Song, Gi-Mun Um, Hee Kyung Lee, and Donghyeon Cho. End-to-end image stitching network via multi-homography estimation. SPL, 28:763–767, 2021.
- [48] Rafael Grompone Von Gioi, Jeremie Jakubowicz, Jean-Michel Morel, and Gregory Randall. Lsd: A fast line segment detector with a false detection control. TPAMI, 32(4):722–732, 2008.
- [49] Tian-Zhu Xiang, Gui-Song Xia, Xiang Bai, and Liangpei Zhang. Image stitching by line-guided local warping with global similarity constraint. PR, 83:481–497, 2018.
- [50] Julio Zaragoza, Tat-Jun Chin, Michael S Brown, and David Suter. As-projective-as-possible image stitching with moving dlt. In CVPR, pages 2339–2346, 2013.
- [51] Fan Zhang and Feng Liu. Parallax-tolerant image stitching. In CVPR, pages 3262–3269, 2014.
附录 A 补充材料
关于网络架构,我们没有提供层、通道等具体细节,因为我们希望读者更多地关注我们解决问题的方法背后的动机。 具体细节,我们承诺发布代码供参考。
附录B变形的更多细节
B.1 TPS 的物理性
薄板样条(TPS)方法可以通过使用可变形薄板来模拟任意2D变形,这比使用单应性更通用。 当所有控制点都正确匹配时,我们的目标是使用曲率最小的薄板。 然后,我们制定一个涉及对齐和扭曲的能量优化问题,如[3]中所述:
| (14) |
其中是控制扭曲平滑度的平衡因子。 取向能和畸变能定义如下:
| (15) | ||||
其中 是扭曲函数。 当时,允许控制点稍微错位,以产生失真较小的扭曲。 然而,在我们的实现中,我们设置 来强烈约束控制点的运动。 这意味着我们的网络预测控制点的运动,并强制实际运动 () 等于预测运动。 通过最小化方程。 14,我们能够确定扭曲函数,其推导如下(参见手稿中的方程2):
| (16) |
B.2 对准和扭曲的讨论
在上一节中,我们解释了对齐所有控制点会导致扭曲函数失真。 为了缓解这个问题,我们避免增加等式中的。 14 并假设控制点均匀分布在目标图像中,并且它们的运动是平滑的。 我们通过连接控制点形成网格,并引入网格内约束(手稿的等式7)和网格间约束(手稿的等式8) )用于内容保存。
总而言之,所提出的扭曲产生了两项改进。 (1)我们的TPS网络架构有利于重叠区域的对齐。 (2)畸变损失(手稿的方程7,8)有利于非重叠区域的畸变消除。
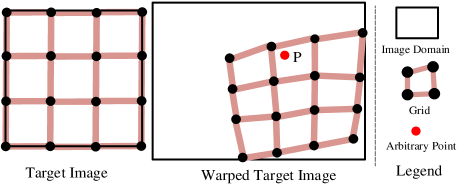
B.3 多重单应性与 TPS
TPS 扭曲比传统的基于网格的多单应性扭曲 [50] 更适合深度拼接。 在这里,我们详细讨论一下原因。
多单应拼接方法通过网格变形将目标图像扭曲成扭曲的目标图像,如图8所示。 在实现中,通常利用向后插值来避免无效像素,例如孔洞。 在后向插值中,对于扭曲的目标图像中的任意点,我们需要计算目标图像中的相应位置。 然后利用双线性插值得到的像素值。因此,如何计算对应的位置是关键问题。 为此,首先要确定多单应性扭曲中属于哪个网格剂量。 在图8的情况下,似乎很容易发现属于第二个网格,因此我们可以通过该网格的四对顶点计算相应的单应性。 然而,如何以高效并行的方式确定扭曲目标图像中所有点的归属是一个很大的困难。 由于翘曲网格具有不规则的形状,甚至可能产生非凸网格。 这个过程很难并行加速,尤其是在 GPU 中,导致训练时间难以忍受。 (根据经验,训练过程可能需要数百万次迭代。)
相比之下,TPS 变换的优点是所有像素共享相同的扭曲函数(方程16),从而无需确定每个像素属于特定网格。 在多单应性方案中,像素的扭曲仅由四对顶点决定,而在TPS中,它受到所有控制点对的影响(我们论文中的)。 因此,对于 TPS,可以以并行方式有效地实现扭曲目标图像中所有像素的后向插值,从而使训练过程比多重单应性更快。
B.4 与使用 TPS 的拼接方法的差异
现有的利用TPS的拼接方法都是传统的基于特征的解决方案。 例如,ELA [28] 使用匹配的关键点(例如 SIFT)计算 TPS 变换。 然后处理这种转换以减少计算成本和失真。
相比之下,所提出的方法是第一个利用 TPS 变换的基于深度学习的拼接方案。 此扭曲的计算不再依赖于匹配的关键点。 相反,我们最初定义均匀分布在目标图像中的控制点,然后使用无监督网络预测这些点的运动。 通过初始控制点和预测运动,我们获得两组一一对应的控制点。 然后,我们使用网格内和网格间约束作为附加损失函数来制定扭曲并消除投影和结构扭曲。 与 ELA 相比,我们提出的方法实现了出色的对齐(手稿的表 1)、更少的扭曲(手稿的图 5)和更高的效率(表 2 手稿)。
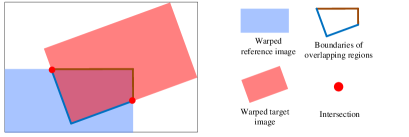



附录C成分的更多详细信息
C.1 边界项
C.2 与接缝切割的区别
传统的接缝方法通过动态规划找到不可见的接缝,或者通过图切割优化来分配组合标签。 这些方法中用于融合的掩码仅包含 0 或 1 值。
然而,对于学习系统来说,具有严格整数的预测掩模将阻止梯度反向传播。 此外,具有严格整数的掩码很容易在合成结果中产生不连续的内容。 因此,我们将掩模的值定义为浮动,并对拼接图像提出平滑度约束(手稿的等式12),以鼓励该“接缝”两侧的平滑过渡。 图 10 显示了接缝切割 [30] 和我们的掩模,其中我们的“接缝”明显更宽。 这就是为什么我们无法用传统指标定量评估我们的构成。

附录D分析
D.1 鲁棒性分析
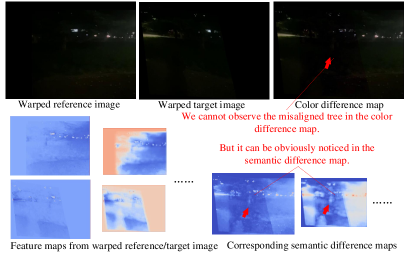
Warp:我们认为所提出的方法比传统解决方案更稳健,尤其是在具有挑战性的情况下。 为了说明这一点,我们将我们的方法与代表传统解决方案的 APAP [50] 进行比较。 在图11a中,我们展示了一个具有极低光照的具有挑战性的案例。 APAP 提取 SIFT 关键点,这些关键点使用红色或绿色圆圈标记。 然后使用 RANSAC 去除异常值(红色圆圈),绿线表示匹配的关键点。 如图11a所示,关键点非常稀疏,有些关键点甚至不匹配,很容易导致拼接失败。 相比之下,我们的解决方案提取语义特征图,随着网络层数的增加,语义特征图变得越来越明显,从而有助于我们的鲁棒性。
合成:关于合成,现有的切缝方法主要依赖于色差或其他像素级能量图。 然而,这些地图在具有挑战性的情况下通常会丢失一些重要内容,例如弱光。 图 11b 显示了色差图中缺少树(以红色箭头突出显示)的示例。 所提出的深度合成方法通过提取语义差异图克服了这个问题,即使它是用色差进行训练的。 通过大量样本(简单案例和挑战性案例)的训练,即使在弱光场景中,合成网络也能够感知语义差异。 我们在图11b中说明了合成网络提取的特征图和语义残差,其中在语义差异图中可以明显注意到树。

D.2 投影畸变分析
与其他扭曲相比,我们的扭曲产生的投影扭曲更少。 我们从两个角度来分析这个现象:
i) 传统方法根据匹配特征估计扭曲。 然而,这些特征通常分布在一些纹理丰富的局部区域,因此扭曲与这些区域很好地对齐,并忽略了其他重叠区域。 与它们相比,我们的目标是对齐重叠区域中的所有像素(手稿的等式6)。 因此,我们的扭曲产生的投影扭曲较少。
ii)为了进一步消除投影扭曲,我们设计了一个网格内约束(手稿的方程7)以防止变形网格急剧缩放。

附录 E更多结果


E.1 变形结果
E.2 合成结果
这里,我们在图20中展示更多大视差构图的对比结果。 为了直观地突出视差伪影,我们使用 SIFT+RANSAC 来对齐输入图像并将结果与平均融合混合以供参考。 然后我们将我们的结果与 UDIS-D [41] 中的 SoTA 组合方法(基于感知的切缝 [30] 和重建 [41])进行比较t2> 和其他大视差数据集[35]。
E.3完整解决方案的结果
然后,我们将我们的完整框架与其他 SoTA 解决方案(LPC [19] 和 UDIS [41])进行比较,以切缝或重建作为后处理操作。 定性结果如图21所示。
此外,我们严格遵循 UDIS 中的实验设置并进行用户研究来测试视觉偏好。 参与者包括 10 名具有计算机视觉背景的志愿者和 10 名社区外志愿者。 具体来说,我们将我们的方法与LPC [19]和UDIS [41]一一进行比较。 每次,四个图像都会显示在一个屏幕上:输入、拼接结果以及 LPC/UDIS 的结果。 我们的方法和其他方法的结果每次都以随机顺序示出。 用户可以放大图像,并需要回答首选哪种结果。 在“无偏好”的情况下,用户需要回答两个结果是“都好”还是“都不好”。 这些研究是在 UDIS-D [41] 的测试集中进行的,这意味着每个用户都必须在 1,106 张图像中将每种方法与我们的方法进行比较。 结果如图13所示。
此外,我们在图22中的传统数据集[28,35,50,13,51]中展示了更多结果。 我们的解决方案可以在不同分辨率和视差的不同场景中生成自然、无缝的结果。 此外,我们承诺发布所有主观结果,包括 UDIS-D 中的 1,106 张图像和传统数据集中的其他图像。
E.4 具有挑战性的场景的结果
| Loss | PSNR | SSIM | |
| 1 | w/o + | 25.54 | 0.841 |
| 2 | w/o | 25.53 | 0.840 |
| 3 | w/o | 25.48 | 0.839 |
| 4 | Our warp | 25.43 | 0.838 |
| Architecture | PSNR | SSIM | |
| 1 | Homography + Homography | 24.46 | 0.802 |
| 2 | TPS + TPS | 25.31 | 0.836 |
| 3 | Homography + TPS | 25.43 | 0.838 |
E.5消融研究
如手稿的图 7 所示,扭曲约束有效地保留了形状。 而且,它对对齐产生的负面影响很小。 定量结果如表4所示,其中当我们采用这些保形约束时,SSIM 仅降低了 0.03。
此外,我们在表5中证明了TPS与单应性相结合的优越性。 与仅单应性相比,这种组合可以显着提高对齐性能。 与仅 TPS 相比,该组合以更少的计算成本实现了稍微更好的性能。

E.6 多图像拼接
大多数拼接方法(例如,LPC[19]、UDIS[41])专注于拼接两个图像,我们的也是如此。 然而,拼接多个图像可以通过执行多个成对拼接来推广。 这里,我们在图16中展示了拼接4幅图像的情况。








