ADAPT:动作感知驾驶字幕转换器
摘要
端到端自动驾驶在交通行业具有巨大潜力。 然而,自动决策过程缺乏透明度和可解释性阻碍了其在实践中的工业采用。 早期已经有一些尝试使用注意力图或成本量来获得更好的模型可解释性,但这对普通乘客来说很难理解。 为了弥补这一差距,我们提出了一种基于端到端 Transformer 的架构 ADAPT(动作感知驾驶字幕 Transformer ),它为每个决策步骤提供用户友好自然语言叙述和推理自主车辆控制和行动。 ADAPT 通过共享视频表示联合训练驾驶字幕任务和车辆控制预测任务。 BDD-X(Berkeley DeepDrive eXplanation)数据集上的实验证明了 ADAPT 框架在自动指标和人工评估方面的最先进性能。 为了说明所提出的框架在实际应用中的可行性,我们构建了一个新颖的可部署系统,该系统以原始汽车视频作为输入并实时输出动作叙述和推理。 代码、模型和数据可在 https://github.com/jxbbb/ADAPT 获取。
我简介
自主系统的目标是获得对环境的精确感知,做出安全的实时决策,在无人参与的情况下采取可靠的行动,并为乘客提供安全舒适的乘坐体验。 自动驾驶控制器设计通常有两种范式:中介感知方法[1, 2]和端到端学习方法[3,4,5,6,7, 8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23]。 中介感知方法依赖于识别人类指定的特征,例如车辆、车道标记等,这需要严格的参数调整才能获得令人满意的性能。 相比之下,端到端方法直接将来自传感器的原始数据作为输入来生成规划路线或控制信号。
将此类自动控制系统部署到实际车辆中的关键挑战之一是自动驾驶汽车的智能决策策略往往过于复杂且难以让普通乘客理解,对他们来说,此类车辆的安全性及其可控性是重中之重。
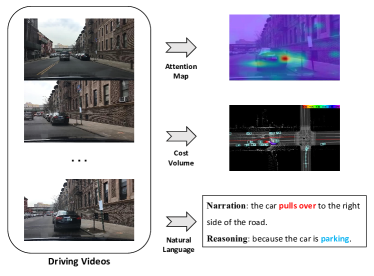
之前的一些工作探索了自主导航的解释[24,25,26,27,28,13,29,30,14]。 例如,[13]中采用成本地图,通过可视化穿越地图不同区域的难度来解释自动驾驶系统的行为。 [24]利用视觉注意力过滤掉非显着图像区域,[31]构建BEV(鸟瞰图)来可视化车辆的运动信息。 然而,如果用户不熟悉系统,这些界面很容易导致误解。
理想的解决方案是在自主控制模块的整个决策和采取行动的过程中加入自然语言叙述来指导使用,这是易于理解且用户友好的。 此外,对每个控制/动作决策的附加推理解释可以帮助用户了解车辆和周围环境的当前状态,作为自动驾驶车辆所采取动作的支持证据。 例如,“[动作叙述:]汽车停在道路右侧,[推理:]因为汽车正在停车”,如图1。 通过自然语言叙述和推理来解释车辆行为,使得整个自主系统更加透明、更容易理解。
为此,我们提出了 ADAPT,这是第一个基于动作感知 Transformer 的驾驶动作字幕架构,为乘客提供用户友好的自然语言叙述和自动驾驶车辆的推理。 为了消除字幕任务和车辆控制信号预测任务之间的差异,我们使用共享视频表示联合训练这两个任务。 通过合并文本生成头,可以将这种多任务框架构建在各种端到端自主系统上。
我们在由控制信号和视频以及动作叙述和推理组成的大规模数据集上展示了 ADAPT 方法的有效性。 基于 ADAPT,我们构建了一个新颖的可部署系统,以原始车辆导航视频作为输入,并实时生成动作叙述和推理解释。
我们的贡献可以概括为:
-
我们提出了 ADAPT,一种新的基于端到端 Transformer 的自动驾驶车辆动作叙述和推理框架。
-
我们提出了一个多任务联合训练框架,该框架可以协调驾驶动作字幕任务和控制信号预测任务。
-
我们开发了一个可部署的管道,用于在模拟器环境和现实世界中应用 ADAPT。
II 相关工作
II-A 视频字幕
视频字幕任务的主要目标是用自然语言描述给定视频的对象及其关系。 早期研究[32,33,34,35]通过在固定模板中填充识别的元素来生成具有特定句法结构的句子,这些模板不灵活且缺乏丰富性。 [36,37,38,39,40,41,42,43,44,45]利用序列学习方法生成具有灵活句法结构的自然句子。 具体来说,这些方法采用视频编码器来提取帧特征,并使用语言解码器来学习用于字幕生成的视觉文本对齐。 为了通过细粒度的对象和动作丰富字幕,[46,47,48]利用对象级表示来捕获视频中详细的对象感知交互特征。 [49]进一步开发了一种新颖的双分支卷积编码器来共同学习视频的内容和语义信息。 此外,[50]将单模态 Transformer 应用于视频字幕,并采用稀疏边界感知池来减少视频帧中的冗余。 场景理解的发展[51,52,53,54,55,56,57,58,59,60,61,62]也对字幕任务做出了很大贡献。 最近,[63]提出了一种基于端到端 Transformer 的模型 SWINBERT,它利用稀疏注意力掩模来减少连续视频帧中的冗余和不相关信息。
虽然现有的架构在一般视频字幕方面取得了有希望的结果,但它不能直接应用于动作表示,因为简单地将视频字幕转移到自动驾驶动作表示会错过一些关键信息,例如车辆速度,这在自主系统中至关重要。 如何有效地利用这些多模态信息来生成句子仍然是一个谜,这也是我们工作的重点。
II-B 端到端自动驾驶
基于学习的自动驾驶是一个活跃的研究领域[64, 65]。 采用了一些基于学习的驾驶方法,例如可供性[3, 4]和强化学习[5,6,7],获得了良好的性能。 模仿方法[8,9,10,11,12,13]也被用来回归来自人类演示的控制命令。 例如,[14, 15, 16] 对车辆、骑自行车者或行人等驾驶主体的未来行为进行建模,以预测车辆路径点,而 [17, 18, 19, 20, 21 , 22, 23]直接根据传感器输入预测车辆控制信号,这与我们的控制信号预测子任务类似。
II-C 自动驾驶的可解释性
可解释性或提供全面解释的能力在人工智能的社会接受度方面发挥着重要作用[66, 67],自动驾驶也不例外。 自动驾驶汽车的大多数可解释方法都是基于视觉的[31,25,26,27,24]或基于LiDAR的[28,13,29,30,14] 。 [24] 首先利用注意力图的可视化来过滤掉不显着的图像区域,以使自动驾驶车辆合理且可解释。 然而,注意力图可能很容易包含一些不太重要的区域,从而引起乘客的误解。 [31,25,26,27]从车载摄像头构建BEV(鸟瞰图),以可视化车辆的运动信息和环境状态。 [13]以激光雷达和高清地图作为输入来预测驾驶代理的边界框,并利用成本量来解释规划者决策的原因。 此外,[14]根据分割以及驾驶代理的状态构建在线地图,以避免对高清地图的严重依赖。
尽管基于视觉或基于激光雷达的方法提供了有希望的结果,但缺乏语言解释使得它们对于像老年人这样的乘客来说过于复杂而难以理解。 [68]首先探索了自动驾驶车辆文本解释的可能性,从控制信号预测任务中离线提取视频特征,然后进行视频字幕。 不幸的是,这两个任务之间的差异使得离线提取的特征对于下游字幕任务来说不是最佳的,而下游字幕任务是我们工作的重点。
II-D 自动驾驶中的多任务学习
我们的端到端框架采用多任务学习,我们在文本生成和控制信号预测的联合目标上训练模型。 多任务学习有助于通过利用不同任务之间的归纳偏差来提取更多有用的信息[69],并在自动驾驶中显示出广阔的前景。 [70, 71]表明检测和跟踪可以一起训练。 [72]进一步将联合检测器和轨迹预测器应用到单个模型中,并获得了有希望的结果。 这个想法被[73]扩展以同时预测参与者的意图。 最近,[13]还在联合模型中包含了基于成本图的控制信号规划器。 这些工作表明,由于更好的数据利用率和共享特征,不同任务的联合训练提高了单个任务的性能,这启发了我们控制信号预测任务和文本生成任务的联合训练策略。
三方法
III-A 概述
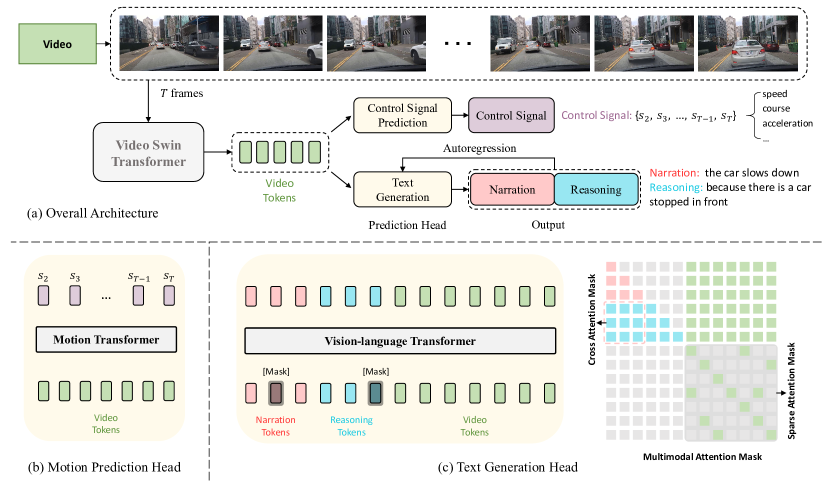
ADAPT 架构如图2所示,它解决两个任务:驱动字幕生成(DCG)和控制信号预测(CSP)。 DCG 将一系列原始视频帧作为输入,并输出两个自然语言句子:一个描述车辆的动作(例如,“汽车正在加速”),另一个解释采取此动作的原因(例如,“因为交通灯变绿”)。 CSP 将相同的视频帧作为输入,并输出一系列控制信号,例如速度、航向或加速度。
一般来说,DCG和CSP任务共享相同的视频编码器,同时采用不同的预测头来产生最终的预测结果。 对于 DCG 任务,我们采用视觉语言 Transformer 编码器通过序列到序列生成来生成两个自然语言句子。 对于 CSP 任务,我们使用运动 Transformer 编码器来预测控制信号序列。
III-B 视频编码器
遵循 Swinbert [63],我们采用 Video Swin Transformer (video swin) [74] 作为视觉编码器,将视频帧编码为视频特征标记。 给定从第一视角捕获的汽车视频,我们首先进行均匀采样以获得大小为 的 帧。 这些帧作为视频 swin 的输入传递,产生大小为 的特征 ,其中 是视频 swin 中定义的通道尺寸。 然后,视频特征被输入到不同的预测头中以执行各个任务。
III-C 预测头
文本生成头 文本生成头的目的是生成两个句子来描述车辆的动作及其背后的原因。 正如第 2 节中提到的。 III-B,视频帧被编码为大小为的视频特征。 然后,我们沿着通道维度对视频特征进行标记,产生维度为 的 标记。 对于文本输入(动作叙述和推理),我们首先对每个句子进行标记并将其填充到固定长度。 然后我们将这两个句子连接起来并用嵌入层嵌入它们。 为了识别动作叙述和推理之间的区别,我们利用分段嵌入方法(在 Bert[75] 中广泛使用)来区分它们。 我们使用可学习的 MLP 来转换视频标记的维度,以确保视频标记和文本标记之间的维度一致性。 最后,文本标记和视频标记被输入视觉语言 Transformer 编码器,它将生成一个包含动作叙述和推理的新序列。
控制信号预测头 CSP头的目标是根据视频帧预测车辆的控制信号(例如加速度)。 给定帧的视频特征,以及相应的控制信号记录,CSP头的输出是控制信号序列。 每个控制信号 或 都是一个 n 元组,其中 指的是我们利用的传感器类型。 我们首先对视频特征进行标记,然后利用另一个 Transformer(运动 Transformer)来生成这些控制信号的预测。 损失函数定义为和的均方误差:
| (1) |
请注意,我们不预测与第一帧相对应的控制信号,因为第一帧的动态信息是有限的,而其他信号可以很容易地从先前帧推断出来。
III-D 联合训练
在我们的框架中,我们假设 CSP 和 DCG 任务在视频表示的语义层面上是一致的。 直观上,动作叙述和控制信号数据是自动驾驶车辆动作的不同表达形式,而推理解释则集中于影响车辆动作的环境要素。 我们相信,在单个网络中联合训练这些任务可以通过利用不同任务之间的归纳偏差来提高性能。
训练时,CSP和DCG联合进行。 我们只需添加 和 即可得到最终的损失函数:
| (2) |
尽管两个任务是联合训练的,但每个任务的推理可以独立进行。 对于 DCG 任务,ADAPT 将视频序列作为输入,并输出包含两段的驾驶字幕。 文本生成以自回归方式执行。 具体来说,我们的模型从“[CLS]”词符开始,一次生成一个词词符,消耗之前生成的标记作为视觉语言 Transformer 编码器的输入。 生成继续,直到模型输出结尾词符“[SEP]”或达到单个句子的最大长度阈值。 将第一个句子填充到最大长度后,我们将另一个“[CLS]”连接到输入并重复上述过程。
IV 实验
在本节中,我们通过标准字幕任务的指标评估 ADAPT,包括 BLEU4 [76]、METEOR [77]、ROUGE-L [78] 和 CIDEr [79](在后面的表中缩写为 B4、M、R 和 C)。 由于字幕的定量评估仍然是一个悬而未决的问题,我们还为生成文本的主观正确性提供了详细的人工评估结果。 消融研究进一步证明了所提出的联合培训框架的有效性。
IV-A 数据集
BDD-X [68] 是一个驾驶域字幕数据集,由近 7000 个与控制信号配对的视频组成。 视频和控制信号是从 BDD100K 数据集[80]收集的。 每个视频平均时长40秒,分辨率1280×720,帧率30帧。 每个视频包含 1 到 5 个车辆行为,例如加速、右转或并道。 所有这些行为都伴随着文字标注,包括动作叙述(例如,“汽车停下来”)和推理(例如,“因为交通灯是红色的”)。 总共大约有 29000 个行为注释对。 据我们所知,BDD-X 是唯一带有汽车视频和控制信号的驾驶域字幕数据集。
| Method | Narration | Reasoning | ||||
|---|---|---|---|---|---|---|
| B4 | C | M | B4 | C | M | |
| S2VT[42] | 30.2 | 179.8 | 27.5 | 6.3 | 53.4 | 11.2 |
| S2VT++[42] | 27.1 | 157.0 | 26.4 | 5.8 | 52.7 | 10.9 |
| SAA[68] | 31.8 | 214.8 | 29.1 | 7.1 | 66.1 | 12.2 |
| WAA[68] | 32.3 | 215.8 | 29.2 | 7.3 | 69.5 | 12.2 |
| Ours | 34.6 | 247.5 | 30.6 | 11.4 | 102.6 | 15.2 |
| Method | Narration | Reasoning | Full sentence |
|---|---|---|---|
| SAA[68] | 90.8% | 62.4% | - |
| WAA[68] | 93.5% | 66.0% | - |
| Ours | 90.0% | 90.3% | 82.7% |
IV-B 实施细节
视频 swin Transformer 在 Kinetics-600 [81] 上进行预训练,而视觉语言 Transformer 和运动 Transformer 则随机初始化。 请注意,在我们的实现中,我们没有冻结视频 swin 的参数,因此 ADAPT 以完整的端到端方式进行训练。 输入视频帧的大小被调整并裁剪为 224 的空间大小。 对于叙述和推理,我们使用 WordPiece 嵌入 [75] 而不是整个单词(例如,“stops”被剪切为“stop”和“#s”)以及每个句子的最大长度是 15。 在训练期间,我们随机屏蔽 标记以进行屏蔽语言建模。 蒙面词符有机率成为“[MASK]”词符,机率成为随机单词,机率保留相同。 我们采用 AdamW 优化器,并在早期的 训练步骤中使用学习率预热,然后进行线性衰减。 40 个 epoch 的整个训练过程在 4 个 NVIDIA V100 GPU 上大约需要 13 个小时,每个 GPU 的批量大小为 4。
IV-C 主要结果
我们将 ADAPT 与 BDD-X 数据集上最先进的方法进行比较。 表I显示了标准字幕指标的比较结果。 我们观察到 ADAPT 比现有方法取得了显着的性能提升。 具体而言,在 CIDEr 指标上,ADAPT 在动作叙述方面比之前最先进的工作[68]高出 31.7,在推理方面高出 33.1。
除了自动评估措施外,我们还进行人工评估来衡量输出叙述和推理的主观正确性。 整个评价过程分为三个部分:(1)叙述,(2)推理,(3)完整句子。 在第一部分中,人类评估者判断预测的叙述是否符合车辆的动作。 在第二部分中,我们展示真实叙述和预测推理,并要求人类评估者判断推理是否正确。 然后在最后一部分,同时显示预测的叙述和预测的推理。 表II显示ADAPT在推理准确性方面优于先前的工作,同时在叙述评估上保持高精度,证明了ADAPT的有效性。
| Method | Narration | Reasoning | ||||||
|---|---|---|---|---|---|---|---|---|
| B4 | C | M | R | B4 | C | M | R | |
| Single | 33.2 | 238.9 | 29.7 | 62.0 | 8.6 | 89.7 | 14.1 | 31.4 |
| Single+ | 33.9 | 248.3 | 30.5 | 63.1 | 9.3 | 97.2 | 14.6 | 31.5 |
| Ours | 34.6 | 247.5 | 30.6 | 62.8 | 11.4 | 102.6 | 15.2 | 32.0 |
| Signals | Narration | Reasoning | |||||
|---|---|---|---|---|---|---|---|
| Speed | Course | C | M | R | C | M | R |
| ✓ | 232.0 | 29.9 | 61.5 | 88.0 | 15.1 | 31.0 | |
| ✓ | 218.2 | 29.3 | 61.2 | 88.6 | 14.1 | 30.6 | |
| ✓ | ✓ | 247.5 | 30.6 | 62.8 | 102.6 | 15.2 | 32.0 |
| Method | Narration | Reasoning | ||||
|---|---|---|---|---|---|---|
| B4 | C | M | B4 | C | M | |
| w/o cross attn | 32.7 | 234.8 | 30.0 | 10.7 | 96.6 | 15.1 |
| w/ swapped attn | 28.3 | 180.4 | 28.7 | 9.3 | 97.7 | 14.3 |
| Ours | 34.6 | 247.5 | 30.6 | 11.4 | 102.6 | 15.2 |
| Narration only | 32.9 | 240.4 | 29.6 | - | - | - |
| Reasoning only | - | - | - | 8.1 | 94.4 | 13.3 |
IV-D 消融研究
我们进行了全面的消融研究来分析 ADAPT 设计的各个方面。
动作感知联合训练的效果为了研究联合训练中动作感知对 ADAPT 的影响,我们通过删除 ADAPT 的 CSP(控制信号预测)头来训练单个字幕模型,称为“单身的”。 如表III所示,ADAPT 的表现优于单一训练,在 CIDEr 指标上,叙述提高了 15.9,推理提高了 7.2。 这表明来自其他任务的线索有助于规范共享视频表示并提高文本生成任务的性能。
另外,从图2(a)中我们可以看到,ADAPT中的字幕和控制信号数据被采用在两个流中。 一个有趣的问题是:我们是否可以简单地将控制信号传递给多模态 Transformer 来获得最终的字幕预测? 因此,我们创建了这样一个架构,它将视频标记、控制信号标记(由可学习的嵌入层生成)和屏蔽文本标记作为输入,并生成屏蔽标记的预测,这被称为“Single+”。 结果如表III第二行所示。 我们可以看到,所提出的 ADAPT 仍然取得了最好的结果,特别是对于推理部分,这证明了多任务学习相对于使用视频和控制信号作为输入的优越性,尽管后者是一种直观的设置。
| Method | Narration | Reasoning | Cost(min) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| B4 | C | M | R | B4 | C | M | R | ||
| 2 | 33.4 | 227.7 | 28.7 | 61.0 | 8.7 | 62.9 | 15.1 | 29.8 | 294 |
| 4 | 32.9 | 225.7 | 29.0 | 60.9 | 9.9 | 81.3 | 14.9 | 31.1 | 382 |
| 8 | 32.6 | 236.1 | 29.3 | 61.8 | 8.4 | 83.7 | 13.4 | 30.6 | 447 |
| 16 | 32.5 | 231.0 | 29.5 | 61.9 | 8.7 | 91.5 | 13.8 | 32.0 | 528 |
| 32 | 34.6 | 247.5 | 30.6 | 62.8 | 11.4 | 102.6 | 15.2 | 32.0 | 797 |
不同控制信号类型的影响在我们的实现中,我们利用控制信号(例如课程)作为 CSP 任务的监督。 在此分析中,我们研究了 ADAPT 不同监督信号类型的影响。 我们实验中的基本信号是速度和航向。 我们首先去掉其中一个进行实验,结果如表IV前两行所示。 然后在第三排同时使用速度和航向,这与之前的实验相同。 我们观察到删除每个信号都会导致性能下降。 例如,在没有速度输入的情况下,CIDEr 指标在叙述时下降 29.3,在推理时下降 14.0。 这是可以理解的,因为了解速度和路线可以帮助网络学习为叙述和推理提供信息的表示,而缺乏任何一个都可能导致视频表示的偏差。
| Method | Course | Speed | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE(degree) | RMSE(m/s) | |||||||||||
| Single | 6.3 | 8.3 | 84.7 | 90.5 | 97.2 | 98.7 | 3.4 | 5.0 | 25.5 | 37.8 | 86.8 | 98.7 |
| Ours | 6.4 | 62.2 | 85.5 | 89.9 | 97.2 | 98.8 | 2.5 | 11.1 | 28.1 | 45.3 | 94.3 | 99.5 |
叙述与推理的交互 与一般字幕任务相比,驾驶字幕任务生成两个句子:动作叙述和推理。 在本节中,我们通过控制注意力掩模或两个句子的顺序来探索这两个片段如何相互作用。
具体来说,如图2(c)右侧所示,我们对每个句子使用因果自注意力掩码,其中单词词符只能关注现有的输出标记,并采用稀疏注意[63]视频 Token 。 推理部分对叙述部分有充分的关注,称为交叉注意力,它定义了推理对叙述的依赖性。 在本节中,我们首先进行没有交叉注意或交换交叉注意(通过交换叙述和推理的顺序)的实验。 结果报告于表V中。与默认设置(表示为“我们的”)相比,没有交叉注意的结果在两个句子中的性能都较低,这表明在叙述片段上调节推理片段有利于训练。 而且交叉注意力交换后的表现也会下降,尤其是叙述部分,这进一步证明了推理对叙述的依赖,而不是相反。
此外,我们只用一个句子进行实验,称为“仅叙述”和“仅推理”。 表V显示,两个句子的训练都提高了性能,尤其是推理部分,表明叙述和推理之间的交互促进了完整字幕任务的每个组成部分。
不同采样率的影响在之前的实验中,我们从给定视频中均匀采样帧以及相同时间戳的控制信号数据。 在本研究中,我们通过改变采样帧的数量来研究采样率的影响。 具体来说,我们从可变长度视频中统一采样帧,如表VI所示。 随着采样数量的增加,ADAPT 的性能稳步提高,因为更多的帧会导致更少的视觉内容丢失。 这表明可以通过密集采样的帧和控制信号来增强字幕结果。 表VI中还提供了训练时间成本。 我们希望这种消融能够为机器人从业者提供有关驾驶字幕的准确性与效率权衡的见解。

IV-E 控制信号预测分析
虽然驱动字幕任务的主要目标是生成句子,但我们也研究了控制信号预测任务的性能。 我们使用均方根误差(RMSE)和容错精度()来衡量最终性能。 容错精度意味着我们首先使用两个阈值来确定控制信号偏差的范围并将其截断。 例如,我们将预测航向的截断值定义为:
| (3) |
其中是真实路线,是容忍阈值。 那么当然代表的是以百分比形式记录的的准确度,速度的的定义也类似。 结果在表VII中提供。 我们观察到我们的联合训练框架可以进一步提高控制信号预测的性能,表明联合训练的好处。
IV-F 在自治系统中的部署
我们进一步开发了在模拟器环境(例如 Carla [82])和现实世界中部署 ADAPT 的管道。 该系统以原始车辆视频作为输入,实时生成动作叙述和推理解释。 具体来说,我们首先记录相机从前视图拍摄的帧。 然后将最后几秒的帧作为输入传递给 ADAPT,以生成当前步骤的动作叙述和推理。 此外,我们还进一步利用文本转语音技术,将生成的句子转换为语音叙述,使普通乘客更方便、更具互动性(尤其对视力障碍乘客有帮助)。
V 结论
基于语言的可解释性对于社会接受自动驾驶车辆至关重要。 我们提出了 Adapt(动作感知驾驶字幕转换器),这是一种基于端到端转换器的新框架,用于为自动驾驶车辆生成动作叙述和推理。 ADAPT利用多任务联合训练来减少驾驶动作字幕任务和控制信号预测任务之间的差异。 在 BDD-X 数据集上对标准字幕指标以及人工评估进行的实验证明了 ADAPT 相对于最先进方法的有效性。 我们进一步开发了一个可部署的管道,用于 ADAPT 在模拟器环境和现实世界中的应用。
参考
- [1] S. Behere and M. Törngren, “A functional architecture for autonomous driving,” in Proceedings of the First International Workshop on Automotive Software Architecture, 2015, pp. 3–10.
- [2] E. Yurtsever, J. Lambert, A. Carballo, and K. Takeda, “A survey of autonomous driving: Common practices and emerging technologies,” IEEE access, vol. 8, pp. 58 443–58 469, 2020.
- [3] A. Sauer, N. Savinov, and A. Geiger, “Conditional affordance learning for driving in urban environments,” in Conference on Robot Learning. PMLR, 2018, pp. 237–252.
- [4] Y. Xiao, F. Codevilla, C. Pal, and A. M. López, “Action-based representation learning for autonomous driving,” arXiv preprint arXiv:2008.09417, 2020.
- [5] D. Chen, V. Koltun, and P. Krähenbühl, “Learning to drive from a world on rails,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15 590–15 599.
- [6] M. Toromanoff, E. Wirbel, and F. Moutarde, “End-to-end model-free reinforcement learning for urban driving using implicit affordances,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 7153–7162.
- [7] J. Wang, Y. Wang, D. Zhang, Y. Yang, and R. Xiong, “Learning hierarchical behavior and motion planning for autonomous driving,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 2235–2242.
- [8] M. Bojarski, D. Del Testa, D. Dworakowski, B. Firner, B. Flepp, P. Goyal, L. D. Jackel, M. Monfort, U. Muller, J. Zhang et al., “End to end learning for self-driving cars,” arXiv preprint arXiv:1604.07316, 2016.
- [9] F. Codevilla, M. Müller, A. López, V. Koltun, and A. Dosovitskiy, “End-to-end driving via conditional imitation learning,” in 2018 IEEE international conference on robotics and automation (ICRA). IEEE, 2018, pp. 4693–4700.
- [10] M. Müller, A. Dosovitskiy, B. Ghanem, and V. Koltun, “Driving policy transfer via modularity and abstraction,” arXiv preprint arXiv:1804.09364, 2018.
- [11] D. A. Pomerleau, “Alvinn: An autonomous land vehicle in a neural network,” Advances in neural information processing systems, vol. 1, 1988.
- [12] B. Wei, M. Ren, W. Zeng, M. Liang, B. Yang, and R. Urtasun, “Perceive, attend, and drive: Learning spatial attention for safe self-driving,” in 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 4875–4881.
- [13] W. Zeng, W. Luo, S. Suo, A. Sadat, B. Yang, S. Casas, and R. Urtasun, “End-to-end interpretable neural motion planner,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 8660–8669.
- [14] S. Casas, A. Sadat, and R. Urtasun, “Mp3: A unified model to map, perceive, predict and plan,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 14 403–14 412.
- [15] D. Chen, B. Zhou, V. Koltun, and P. Krähenbühl, “Learning by cheating,” in Conference on Robot Learning. PMLR, 2020, pp. 66–75.
- [16] A. Filos, P. Tigkas, R. McAllister, N. Rhinehart, S. Levine, and Y. Gal, “Can autonomous vehicles identify, recover from, and adapt to distribution shifts?” in International Conference on Machine Learning. PMLR, 2020, pp. 3145–3153.
- [17] A. Behl, K. Chitta, A. Prakash, E. Ohn-Bar, and A. Geiger, “Label efficient visual abstractions for autonomous driving,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 2338–2345.
- [18] A. Bühler, A. Gaidon, A. Cramariuc, R. Ambrus, G. Rosman, and W. Burgard, “Driving through ghosts: Behavioral cloning with false positives,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 5431–5437.
- [19] F. Codevilla, E. Santana, A. M. López, and A. Gaidon, “Exploring the limitations of behavior cloning for autonomous driving,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 9329–9338.
- [20] Z. Huang, C. Lv, Y. Xing, and J. Wu, “Multi-modal sensor fusion-based deep neural network for end-to-end autonomous driving with scene understanding,” IEEE Sensors Journal, vol. 21, no. 10, pp. 11 781–11 790, 2020.
- [21] E. Ohn-Bar, A. Prakash, A. Behl, K. Chitta, and A. Geiger, “Learning situational driving,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 296–11 305.
- [22] A. Prakash, A. Behl, E. Ohn-Bar, K. Chitta, and A. Geiger, “Exploring data aggregation in policy learning for vision-based urban autonomous driving,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 763–11 773.
- [23] Y. Xiao, F. Codevilla, A. Gurram, O. Urfalioglu, and A. M. López, “Multimodal end-to-end autonomous driving,” IEEE Transactions on Intelligent Transportation Systems, 2020.
- [24] J. Kim and J. Canny, “Interpretable learning for self-driving cars by visualizing causal attention,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2942–2950.
- [25] A. Hu, Z. Murez, N. Mohan, S. Dudas, J. Hawke, V. Badrinarayanan, R. Cipolla, and A. Kendall, “Fiery: Future instance prediction in bird’s-eye view from surround monocular cameras,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15 273–15 282.
- [26] J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,” in European Conference on Computer Vision. Springer, 2020, pp. 194–210.
- [27] H. Wang, P. Cai, Y. Sun, L. Wang, and M. Liu, “Learning interpretable end-to-end vision-based motion planning for autonomous driving with optical flow distillation,” in 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 13 731–13 737.
- [28] A. Cui, S. Casas, A. Sadat, R. Liao, and R. Urtasun, “Lookout: Diverse multi-future prediction and planning for self-driving,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 16 107–16 116.
- [29] W. Zeng, S. Wang, R. Liao, Y. Chen, B. Yang, and R. Urtasun, “Dsdnet: Deep structured self-driving network,” in European conference on computer vision. Springer, 2020, pp. 156–172.
- [30] A. Sadat, S. Casas, M. Ren, X. Wu, P. Dhawan, and R. Urtasun, “Perceive, predict, and plan: Safe motion planning through interpretable semantic representations,” in European Conference on Computer Vision. Springer, 2020, pp. 414–430.
- [31] A. Saha, O. Mendez, C. Russell, and R. Bowden, “Translating images into maps,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 9200–9206.
- [32] S. Guadarrama, N. Krishnamoorthy, G. Malkarnenkar, S. Venugopalan, R. Mooney, T. Darrell, and K. Saenko, “Youtube2text: Recognizing and describing arbitrary activities using semantic hierarchies and zero-shot recognition,” in Proceedings of the IEEE international conference on computer vision, 2013, pp. 2712–2719.
- [33] P. Hanckmann, K. Schutte, and G. J. Burghouts, “Automated textual descriptions for a wide range of video events with 48 human actions,” in European Conference on Computer Vision. Springer, 2012, pp. 372–380.
- [34] A. Kojima, T. Tamura, and K. Fukunaga, “Natural language description of human activities from video images based on concept hierarchy of actions,” International Journal of Computer Vision, vol. 50, no. 2, pp. 171–184, 2002.
- [35] M. Rohrbach, W. Qiu, I. Titov, S. Thater, M. Pinkal, and B. Schiele, “Translating video content to natural language descriptions,” in Proceedings of the IEEE international conference on computer vision, 2013, pp. 433–440.
- [36] S. Chen, J. Chen, Q. Jin, and A. Hauptmann, “Video captioning with guidance of multimodal latent topics,” in Proceedings of the 25th ACM international conference on Multimedia, 2017, pp. 1838–1846.
- [37] L. Gao, Y. Lei, P. Zeng, J. Song, M. Wang, and H. T. Shen, “Hierarchical representation network with auxiliary tasks for video captioning and video question answering,” IEEE Transactions on Image Processing, 2022.
- [38] W. Ji and R. Wang, “A multi-instance multi-label dual learning approach for video captioning,” ACM Transactions on Multimidia Computing Communications and Applications, vol. 17, no. 2s, pp. 1–18, 2021.
- [39] Y. Pan, T. Mei, T. Yao, H. Li, and Y. Rui, “Jointly modeling embedding and translation to bridge video and language,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 4594–4602.
- [40] Y. Pan, T. Yao, H. Li, and T. Mei, “Video captioning with transferred semantic attributes,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 6504–6512.
- [41] R. Pasunuru and M. Bansal, “Multi-task video captioning with video and entailment generation,” arXiv preprint arXiv:1704.07489, 2017.
- [42] S. Venugopalan, M. Rohrbach, J. Donahue, R. Mooney, T. Darrell, and K. Saenko, “Sequence to sequence-video to text,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 4534–4542.
- [43] S. Venugopalan, H. Xu, J. Donahue, M. Rohrbach, R. Mooney, and K. Saenko, “Translating videos to natural language using deep recurrent neural networks,” arXiv preprint arXiv:1412.4729, 2014.
- [44] L. Yao, A. Torabi, K. Cho, N. Ballas, C. Pal, H. Larochelle, and A. Courville, “Describing videos by exploiting temporal structure,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 4507–4515.
- [45] H. Yu, J. Wang, Z. Huang, Y. Yang, and W. Xu, “Video paragraph captioning using hierarchical recurrent neural networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 4584–4593.
- [46] B. Zhao, X. Li, X. Lu et al., “Video captioning with tube features.” in IJCAI, 2018, pp. 1177–1183.
- [47] B. Pan, H. Cai, D.-A. Huang, K.-H. Lee, A. Gaidon, E. Adeli, and J. C. Niebles, “Spatio-temporal graph for video captioning with knowledge distillation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 10 870–10 879.
- [48] Z. Zhang, Y. Shi, C. Yuan, B. Li, P. Wang, W. Hu, and Z.-J. Zha, “Object relational graph with teacher-recommended learning for video captioning,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 13 278–13 288.
- [49] S. Liu, Z. Ren, and J. Yuan, “Sibnet: Sibling convolutional encoder for video captioning,” in Proceedings of the 26th ACM international conference on Multimedia, 2018, pp. 1425–1434.
- [50] T. Jin, S. Huang, M. Chen, Y. Li, and Z. Zhang, “Sbat: Video captioning with sparse boundary-aware transformer,” arXiv preprint arXiv:2007.11888, 2020.
- [51] W. Wang, H. Bao, L. Dong, J. Bjorck, Z. Peng, Q. Liu, K. Aggarwal, O. K. Mohammed, S. Singhal, S. Som et al., “Image as a foreign language: Beit pretraining for all vision and vision-language tasks,” arXiv preprint arXiv:2208.10442, 2022.
- [52] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick, “Masked autoencoders are scalable vision learners,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 000–16 009.
- [53] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 012–10 022.
- [54] T. Zhang, X. Chen, Y. Wang, Y. Wang, and H. Zhao, “Mutr3d: A multi-camera tracking framework via 3d-to-2d queries,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 4537–4546.
- [55] M. Han, Z. Zhang, Z. Jiao, X. Xie, Y. Zhu, S.-C. Zhu, and H. Liu, “Scene reconstruction with functional objects for robot autonomy,” International Journal of Computer Vision, vol. 130, no. 12, pp. 2940–2961, 2022.
- [56] S. Huang, Z. Wang, P. Li, B. Jia, T. Liu, Y. Zhu, W. Liang, and S.-C. Zhu, “Diffusion-based generation, optimization, and planning in 3d scenes,” arXiv preprint arXiv:2301.06015, 2023.
- [57] Y. Li, Y. Tu, X. Chen, H. Zhao, and G. Zhou, “Distance-aware occlusion detection with focused attention,” IEEE Transactions on Image Processing, vol. 31, pp. 5661–5676, 2022.
- [58] B. Jin, B. Tian, H. Zhao, and G. Zhou, “Language-guided semantic style transfer of 3d indoor scenes,” in Proceedings of the 1st Workshop on Photorealistic Image and Environment Synthesis for Multimedia Experiments, 2022, pp. 11–17.
- [59] P. Li, B. Tian, Y. Shi, X. Chen, H. Zhao, G. Zhou, and Y.-Q. Zhang, “Toist: Task oriented instance segmentation transformer with noun-pronoun distillation,” arXiv preprint arXiv:2210.10775, 2022.
- [60] X. Chen, H. Zhao, G. Zhou, and Y.-Q. Zhang, “Pq-transformer: Jointly parsing 3d objects and layouts from point clouds,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 2519–2526, 2022.
- [61] H. Zhao, M. Lu, A. Yao, Y. Chen, and L. Zhang, “Learning to draw sight lines,” International Journal of Computer Vision, vol. 128, pp. 1076–1100, 2020.
- [62] H. Zhao, M. Lu, A. Yao, Y. Guo, Y. Chen, and L. Zhang, “Physics inspired optimization on semantic transfer features: An alternative method for room layout estimation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 10–18.
- [63] K. Lin, L. Li, C.-C. Lin, F. Ahmed, Z. Gan, Z. Liu, Y. Lu, and L. Wang, “Swinbert: End-to-end transformers with sparse attention for video captioning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 17 949–17 958.
- [64] J. Janai, F. Güney, A. Behl, A. Geiger et al., “Computer vision for autonomous vehicles: Problems, datasets and state of the art,” Foundations and Trends® in Computer Graphics and Vision, vol. 12, no. 1–3, pp. 1–308, 2020.
- [65] A. Tampuu, T. Matiisen, M. Semikin, D. Fishman, and N. Muhammad, “A survey of end-to-end driving: Architectures and training methods,” IEEE Transactions on Neural Networks and Learning Systems, 2020.
- [66] L. Yuan, X. Gao, Z. Zheng, M. Edmonds, Y. N. Wu, F. Rossano, H. Lu, Y. Zhu, and S.-C. Zhu, “In situ bidirectional human-robot value alignment,” Science robotics, vol. 7, no. 68, p. eabm4183, 2022.
- [67] M. Edmonds, F. Gao, H. Liu, X. Xie, S. Qi, B. Rothrock, Y. Zhu, Y. N. Wu, H. Lu, and S.-C. Zhu, “A tale of two explanations: Enhancing human trust by explaining robot behavior,” Science Robotics, vol. 4, no. 37, p. eaay4663, 2019.
- [68] J. Kim, A. Rohrbach, T. Darrell, J. Canny, and Z. Akata, “Textual explanations for self-driving vehicles,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 563–578.
- [69] X. Chen, T. Liu, H. Zhao, G. Zhou, and Y.-Q. Zhang, “Cerberus transformer: Joint semantic, affordance and attribute parsing,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 19 649–19 658.
- [70] C. Feichtenhofer, A. Pinz, and A. Zisserman, “Detect to track and track to detect,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 3038–3046.
- [71] D. Frossard, E. Kee, and R. Urtasun, “Deepsignals: Predicting intent of drivers through visual signals,” in 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 9697–9703.
- [72] W. Luo, B. Yang, and R. Urtasun, “Fast and furious: Real time end-to-end 3d detection, tracking and motion forecasting with a single convolutional net,” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2018, pp. 3569–3577.
- [73] S. Casas, W. Luo, and R. Urtasun, “Intentnet: Learning to predict intention from raw sensor data,” in Conference on Robot Learning. PMLR, 2018, pp. 947–956.
- [74] Z. Liu, J. Ning, Y. Cao, Y. Wei, Z. Zhang, S. Lin, and H. Hu, “Video swin transformer,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 3202–3211.
- [75] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [76] K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in Proceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318.
- [77] S. Banerjee and A. Lavie, “Meteor: An automatic metric for mt evaluation with improved correlation with human judgments,” in Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, 2005, pp. 65–72.
- [78] C.-Y. Lin and F. J. Och, “Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics,” in Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics (ACL-04), 2004, pp. 605–612.
- [79] R. Vedantam, C. Lawrence Zitnick, and D. Parikh, “Cider: Consensus-based image description evaluation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 4566–4575.
- [80] F. Yu, H. Chen, X. Wang, W. Xian, Y. Chen, F. Liu, V. Madhavan, and T. Darrell, “Bdd100k: A diverse driving dataset for heterogeneous multitask learning,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 2636–2645.
- [81] J. Carreira, E. Noland, A. Banki-Horvath, C. Hillier, and A. Zisserman, “A short note about kinetics-600,” arXiv preprint arXiv:1808.01340, 2018.
- [82] A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun, “Carla: An open urban driving simulator,” in Conference on robot learning. PMLR, 2017, pp. 1–16.