TimeLMs:来自 Twitter 的历时语言模型
摘要
尽管时间变量很重要,但它在 NLP 和语言模型文献中基本上被忽视了。 在本文中,我们提出了 TimeLM,这是一组专门研究历时 Twitter 数据的语言模型。 我们表明,持续学习策略有助于增强基于 Twitter 的语言模型处理未来和未分发推文的能力,同时使其与标准化和更单一的基准相比具有竞争力。 我们还进行了许多定性分析,显示他们如何应对涉及特定命名实体或概念漂移的活动的趋势和峰值。 TimeLMs 位于 https://github.com/cardiffnlp/timelms。 ††标有星号 (*) 的作者贡献相同。
1简介
神经语言模型 (LM) Devlin 等人 (2019); Radford 等人 (2019); Liu 等人 (2019) 如今是 NLP 的关键推动者。 它们促进了许多应用下游性能的普遍提升,甚至有时可以与人类判断相媲美Wang等人(2018,2019),同时还带来了通过预训练获取知识的新范式。 然而,目前从模型开发和评估的角度来看,这种范式基本上是静态的,这既影响了对未来数据的泛化能力,也影响了实验结果的可靠性,因为评估基准与训练前语料库重叠的情况并不少见Lazaridou et al. (2021)。 举个例子,BERT 和 RoBERTa 的原始版本都没有跟上当前冠状病毒大流行的情况。 这显然很麻烦,因为近年来大多数通信都受到了它的影响,但当我们谈论COVID-19或封锁<时,这些模型几乎不知道我们指的是什么。 /t1>,仅举几个例子。 历时专业化的缺乏在社交媒体等环境中尤其令人担忧,因为讨论的话题经常且快速变化Del Tredici 等人 (2019)。
在本文中,我们通过与社区共享一系列专门针对 Twitter 数据的时间特定 LM (TimeLM) 来解决此问题。 我们的举措超出了本文报告的初始发布、分析和实验结果,因为模型将定期继续训练、改进和发布。
2相关工作
在 NLP 中处理时间变量方面存在大量工作。 例如,通过专门从词嵌入模型或神经网络派生的语言表示 Hamilton 等人 (2016);西曼斯基(2017);罗森菲尔德和埃克(2018); Del Tredici 等人 (2019); Hofmann 等人 (2021)。 就 LM 的特殊情况而言,将它们暴露于新数据并相应地更新其参数(也称为持续学习)是一个有前途的方向,在机器学习中具有既定的传统Lopez-Paz 和 Ranzato (2017);刘易斯等人 (2020); Lazaridou 等人 (2021); Jang 等人 (2021). 然而,其他工作提出使用时间变量 Grootendorst (2020) 来增强基于 BERT 的主题模型。 关于领域内专业化,有许多方法通过在专业语料库上预训练通用语言模型来执行领域适应。 一个著名的案例是生物医学领域,例如 BioBERT Lee 等人 (2020)、SciBERT Beltagy 等人 (2019) 或 PubMedBERT Gu 等人 ( 2021)。 除了这些专门化语言模型的方法之外,还有与我们的论文 Agarwal 和 Nenkova (2021) 中提出的类似的时间适应分析;金等人 (2021). 特别是,这些工作表明,最近数据中的训练语言模型可能是有益的,而 Luu 等人 (2021) 在不同的环境中发现这种改进是微不足道的。 就与我们的主要目标无关的持续终身学习而言,Biesialska 等人(2020)对 NLP 文献中提出的主要技术进行了详细的调查。
另一方面,与本文更相关的是专门针对社交媒体数据(特别是 Twitter)的 LM,其中包括 BERTweet Nguyen 等人 (2020)、TweetEval Barbieri 等人 (2020)据我们所知,t1> 和 XLM-T Barbieri 等人 (2021) 是最突出的例子。 然而,上述努力几乎没有解决语言的历时性问题。 至关重要的是,它们没有解决将 LM 专门用于社交媒体和将时间变量置于框架核心的问题。 此外,希望这种时间感知模型与可用软件和可靠的基础设施一起发布。 我们的 TimeLMs 计划(详见第 3 节)旨在解决上述挑战。
3 TimeLMs:来自 Twitter 的历时语言模型
在本节中,我们将介绍不同时间段的训练语言模型的方法。
3.1Twitter 语料库
为了训练和评估语言模型,我们首先收集大量推文语料库。 下面我们解释数据收集和清理过程。
数据采集。 我们使用 Twitter 学术 API 来获取跨时间均匀分布的大量推文样本。 为了获得代表该社交平台上一般对话的样本,我们使用最常见的停用词111We use the top 10 entries from: google-10000-english.txt 的前 10 个条目,来获取时间戳间隔为 5 分钟的一组推文 -构成特定年度季度的每天的每个小时。 我们还使用 API 支持的特定标志来仅检索英文推文,并忽略转发、引用、链接、媒体帖子和广告。
对于我们的初始基本模型(从 2019-90M 起),我们使用了来自 API 的 2018 年至 2019 年期间均匀时间分布的语料库,并补充了来自 Archive.org 的其他推文,这些推文涵盖同一时期但分布不均匀。
数据清理。 在训练任何模型之前,我们使用本节中详细介绍的过程过滤每个模型的训练推文集。 首先假设机器人是最活跃的用户之一,我们从发布最频繁的前百分之一的用户中删除推文。 此外,根据 Lee 等人 (2021) 的建议,我们删除了重复项和近似重复项。 我们通过对小写字母和去掉标点符号后的推文文本进行哈希处理来找到近似重复的内容。 使用 MinHash (Broder,1997) 执行哈希,有 16 种排列。 最后,除经过验证的用户外,用户提及内容将替换为通用占位符 (@user)。
3.2 语言模型训练
一旦 Twitter 语料库被收集和清理,我们就开始语言模型预训练。 这包括两个阶段:(1) 训练由 2019 年底之前的数据组成的基础模型; (2) 自基础模型发布之日起,每三个月持续训练一次语言模型。
基础模型训练。 我们的基础模型使用 2019 年(含)之前的数据进行训练。 继Barbieri 等人(2020)之后,我们从原始的RoBERTa基础模型Liu 等人(2019)开始,继续在Twitter数据上训练屏蔽语言模型。 该模型使用与 Barbieri 等人 (2020) 相同的设置进行训练,即早期停止验证分割和学习率 。 这个初始的 2019-90M 基本模型在大约 15 天后在 8 个 NVIDIA V100 GPU 上收敛。
连续训练。 训练完我们的基本模型后,我们的目标是使用最新的 Twitter 语料库继续训练这个语言模型。 在撰写本文时,出于实际和后勤原因,决定每三个月训练一次每种语言模型的新版本。 训练这个更新后的语言模型的过程很简单,因为它遵循与上面解释的语言模型的初始预训练相同的训练过程。 我们的承诺是每三个月持续更新并发布一个新模型,有效地使社区能够在任何时间段使用最新的语言模型。
3.3 TimeLMs 发布摘要
在表 1 中,我们总结了截至撰写本文之日收集的 Twitter 语料库和训练的模型。 模型分为四个三个月季度(第一季度、第二季度、第三季度和第四季度)。 截至 2019 年底,我们的 2019-90M 基本模型包含 9000 万条推文。 然后,每个季度(即每三个月)添加 420 万条额外推文,并且模型会如上所述进行更新。 我们最新发布的模型是 2021-Q4 和 2021-124M(后者仅使用 2020 年和 2021 年的所有数据重新训练一次),在原始 RoBERTa 基础模型 的基础上对 1.24 亿条推文进行了训练刘等人(2019). 所有模型目前均可通过 Hugging Face 中心获取,网址为 https://huggingface.co/cardiffnlp。
| Models | Additional | Total |
|---|---|---|
| 2019-90M | - | 90.26M |
| 2020-Q1 | 4.20M | 94.46M |
| 2020-Q2 | 4.20M | 98.66M |
| 2020-Q3 | 4.20M | 102.86M |
| 2020-Q4 | 4.20M | 107.06M |
| 2021-Q1 | 4.20M | 111.26M |
| 2021-Q2 | 4.20M | 115.46M |
| 2021-Q3 | 4.20M | 119.66M |
| 2021-Q4 | 4.20M | 123.86M |
| 2021-124M | 33.60M | 123.86M |
除了这些训练语言模型的语料库之外,我们还为每个季度划分了一些推文(独立于训练集,没有重叠)。 这些集用作我们困惑度评估的测试集(参见第 4.2 节),每季度包含 30 万条推文,这些推文的采样和清理方式与原始语料库相同。
4评估
在本节中,我们的目标是评估特定时间语言模型(参见第 3 节)在特定时间任务上的有效性。 换句话说,我们的目标是测试旧模型随着时间的推移可能出现的退化,并相应地测试是否可以通过连续训练来缓解这种情况。
评估任务。 我们在两个任务中评估了发布的语言模型:(1)TweetEval Barbieri 等人(2020),它由七个下游推文分类任务组成; (2)不同时期采样的语料库的伪困惑度。 第一次评估只是为了验证基础语言模型的训练过程,而第二次评估是本文在评估方面的核心贡献,可以在不同的时间段测试不同的模型。
4.1 推文评估
TweetEval Barbieri 等人 (2020) 是一个统一的 Twitter 基准测试,由七个异构推文分类任务组成。 它通常用于评估 Twitter 数据上语言模型(或更普遍的任务无关模型)的性能。 通过此评估,我们的目标只是展示随我们的包发布的模型的总体竞争力,无论其时间段如何。
评估任务。 TweetEval 中的 7 个推文分类任务分别是表情符号预测 Barbieri 等人 (2018)、情感识别 Mohammad 等人 (2018)、仇恨语音检测 Basile 等人 ( 2019)、反讽检测Van Hee 等人(2018)、攻击性语言识别Zampieri 等人(2019)、情感分析Rosenthal 等人( 2017) 和姿态检测 Mohammad 等人 (2016)。
实验设置。 与 TweetEval 原始基线类似,仅进行了适度的参数搜索。 唯一微调的超参数是学习率(、、)。 每个模型训练的时期数是可变的,因为我们使用提前停止来监控验证损失。 验证损失还用于在每个任务中选择最佳模型。
比较系统。 比较系统(SVM、FastText、BLSTM、RoBERTa-base 和 TweetEval)取自原始 TweetEval 论文以及最先进的 BERTweet 模型 Nguyen 等人 (2020),经过超过 9 亿条推文(2013 年至 2019 年发布)的训练。 所有比较的语言模型都基于 RoBERTa-base 架构。
| Emoji | Emotion | Hate | Irony | Offensive | Sentiment | Stance | ALL | |
| SVM | 29.3 | 64.7 | 36.7 | 61.7 | 52.3 | 62.9 | 67.3 | 53.5 |
| FastText | 25.8 | 65.2 | 50.6 | 63.1 | 73.4 | 62.9 | 65.4 | 58.1 |
| BLSTM | 24.7 | 66.0 | 52.6 | 62.8 | 71.7 | 58.3 | 59.4 | 56.5 |
| RoBERTa-Base | 30.8 | 76.6 | 44.9 | 55.2 | 78.7 | 72.0 | 70.9 | 61.3 |
| TweetEval | 31.6 | 79.8 | 55.5 | 62.5 | 81.6 | 72.9 | 72.6 | 65.2 |
| BERTweet | 33.4 | 79.3 | 56.4 | 82.1 | 79.5 | 73.4 | 71.2 | 67.9 |
| TimeLM-19 | 33.4 | 81.0 | 58.1 | 48.0 | 82.4 | 73.2 | 70.7 | 63.8 |
| TimeLM-21 | 34.0 | 80.2 | 55.1 | 64.5 | 82.2 | 73.7 | 72.9 | 66.2 |
| Metric | M-F1 | M-F1 | M-F1 | F(i) | M-F1 | M-Rec | AVG (F1) | TE |
结果。 TweetEval 结果总结在表 2 中。 BERTweet 接受了更多数据的训练,获得了最好的平均结果。 然而,在查看单个任务时,BERTweet 在讽刺检测任务上优于我们最新发布的模型,即 TimeLM-19 和 TimeLM-21222我们注意到讽刺数据集是使用 #irony 标签通过远程监督创建的,并且可能存在“标签”泄漏,因为 BERTweet 是唯一训练的模型讽刺数据集的时间段(2014/15)的推文。 仅有的。 还需要强调的是,TweetEval 任务最迟包括截至 2018 年的推文(大多数任务要早得多)。 这表明我们最新发布的模型(即 TimeLM-21)即使训练到 2021 条推文,即使在过去的推文上也普遍具有竞争力。 事实上,在大多数任务中,TimeLM-21 优于最相似的 TweetEval 模型,该模型是按照类似策略进行训练的(在本例中,直到 2019 年,训练的推文数量较少)。
4.2时间感知语言模型评估
一旦基础模型和后续模型的有效性在下游任务中得到测试,我们的目标是衡量发布的各种模型对时间感知评估的敏感程度。 为此,我们依靠伪困惑度测量 Salazar 等人 (2020)。
评估指标:伪困惑度(PPPL)。 Salazar 等人 (2020) 引入的伪对数似然(PLL)分数是通过用掩码迭代替换序列中的每个词符,并对相应的条件对数概率求和来计算的。 这种方法特别适合屏蔽语言模型,而不是传统的从左到右模型。 伪困惑度 (PPPL) 类似地遵循标准困惑度公式,使用 PLL 计算条件概率。
结果。 表3显示了所有测试集中的伪困惑结果。 作为主要结论,该表显示了在大多数测试集(尤其是同时代的测试集)中评估旧数据时,最新模型的表现往往优于训练后的模型。 这可以通过简单地观察表3的列中的递减值来理解。 然而,也有一些有趣的例外。 例如,2020 年第一季度和 2020 年第二季度测试集对应于冠状病毒大流行的全球开始,通常更适合在此期间训练的模型。 尽管如此,根据更现代的数据训练的模型似乎收敛到了最佳结果。
| Models | 2020-Q1 | 2020-Q2 | 2020-Q3 | 2020-Q4 | 2021-Q1 | 2021-Q2 | 2021-Q3 | 2021-Q4 | Change |
|---|---|---|---|---|---|---|---|---|---|
| Barbieri et al.,2020 | 9.420 | 9.602 | 9.631 | 9.651 | 9.832 | 9.924 | 10.073 | 10.247 | N/A |
| 2019-90M | 4.823 | 4.936 | 4.936 | 4.928 | 5.093 | 5.179 | 5.273 | 5.362 | N/A |
| 2020-Q1 | 4.521 | 4.625 | 4.699 | 4.692 | 4.862 | 4.952 | 5.043 | 5.140 | - |
| 2020-Q2 | 4.441 | 4.439 | 4.548 | 4.554 | 4.716 | 4.801 | 4.902 | 5.005 | -4.01% |
| 2020-Q3 | 4.534 | 4.525 | 4.450 | 4.487 | 4.652 | 4.738 | 4.831 | 4.945 | -2.15% |
| 2020-Q4 | 4.533 | 4.524 | 4.429 | 4.361 | 4.571 | 4.672 | 4.763 | 4.859 | -2.81% |
| 2021-Q1 | 4.509 | 4.499 | 4.399 | 4.334 | 4.439 | 4.574 | 4.668 | 4.767 | -2.89% |
| 2021-Q2 | 4.499 | 4.481 | 4.376 | 4.319 | 4.411 | 4.445 | 4.570 | 4.675 | -2.83% |
| 2021-Q3 | 4.471 | 4.455 | 4.335 | 4.280 | 4.366 | 4.394 | 4.422 | 4.565 | -3.26% |
| 2021-Q4 | 4.467 | 4.455 | 4.330 | 4.263 | 4.351 | 4.381 | 4.402 | 4.463 | -2.24% |
| 2021-124M | 4.319 | 4.297 | 4.279 | 4.219 | 4.322 | 4.361 | 4.404 | 4.489 | N/A |
随着时间的推移而退化。 一个模型需要多长时间才会过时? 总体而言,一年后 PPPL 分数往往会增加近 10%。 总体而言,PPPL 似乎在每个季度更新时都持续下降。 这一结果强化了对更新语言模型的需求,即使是在短期内,例如三个月的季度。 在大多数情况下,未来数据的降级通常比旧数据的降级更大。 这个结果并不完全出乎意料,因为新模型还接受了更多时间段内更多数据的训练。 在第 6.1 节中,我们对此进行了扩展,包括一个详细说明语言模型随时间的相对性能下降的表格。
5Python 接口
在本节中,我们将介绍一个集成的 Python 接口,该接口与本文中介绍的数据和语言模型一起发布。 正如 3.3 节中提到的,所有语言模型都可以从 Hugging Face 中心获得,并且我们的代码旨在与该平台一起使用。
我们的界面基于 Transformers 包 Wolf 等人 (2020),专注于提供对针对特定时期和相关用例训练的语言模型的简单单行访问。 我们的界面使用的语言模型的选择是使用四种操作模式之一来确定的:(1)“最新”:使用我们最近训练的 Twitter 模型; (2)“对应”:使用仅在每条推文日期(即其特定季度)之前训练的模型; (3) 自定义:提供首选日期或季度(例如“2021-Q3”); (4)“季度”:使用每季度训练一次的所有可用模型。 指定了首选语言模型后,代码中存在三个主要功能,即:(1)计算伪困惑度分数,(2)评估我们发布或定制的测试集中的语言模型,以及(3)获得屏蔽预测。
为了使用伪困惑度对语言模型进行更广泛的评估,我们提供了 2020 年和 2021 年测试数据的随机子集。333仅限 50K 条推文,这是 Twitter 允许的最大值。 所有测试推文的 ID 都可以在存储库中找到。 为了评估 Transformers 包中的其他模型,我们提供了“eval_model”方法 (tlms.eval_model()) 来计算任何给定的推文或文本集(例如,我们提供的子集)的伪困惑度)使用 Transformers 包支持的其他语言模型。 两种评分方法不仅提供特定于每个模型的伪困惑度分数(取决于指定的模型名称或 TimeLM 指定的模式),还提供不同模型分配给每条推文的 PLL 分数。
最后,可以轻松获得对任何给定推文或文本的屏蔽标记的预测,如代码 2 所示。
请注意,虽然本文中包含的示例与特定日期相关(即 created_at 字段),但这些仅是“相应”模式所必需的。
6分析
为了补充上一节的评估,我们在三个重要方面进行了更详细的分析:(1)对语言模型随时间的退化进行定量分析; (2) 时间与大小的关系(6.2); (3) 定性分析,我们展示时间对特定示例的语言模型的影响(6.3 节)。
6.1降解分析
表4显示了TimeLM语言模型相对于测试集的相对性能下降(或改进),测试集的时间段是最近训练的时间段(表中的对角线)。 该表显示了模型在较新的数据集中如何表现得更差,在最新的 2021 年第 4 季度模型上,性能下降了 2020 年第 1 季度早期模型的 13.68%(数据比语言的最新数据晚了近两年)模型经过训练)。
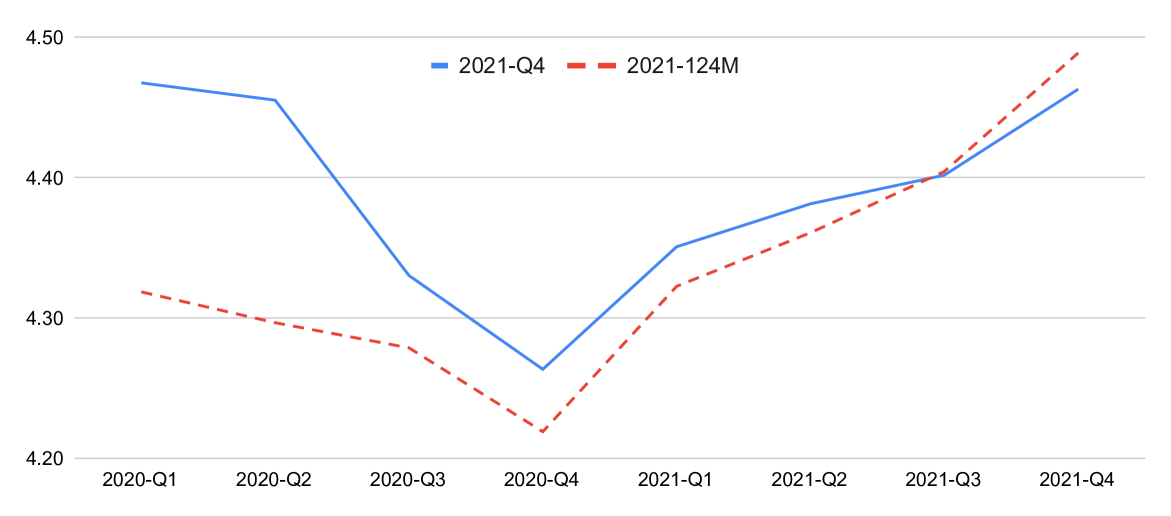
为了比较连续训练与单次训练的效果,图1显示了2021-124M(同时使用2020-2021年所有数据进行训练)和2021-Q4(更新2021 年第三季度)型号。 请注意 2021-124M 训练总体上显示出性能的提高,其中最大的差异出现在 2020 年前两个季度,但最近几个季度的情况却并非如此,连续的效果似乎稍好一些。 虽然需要更多的分析,但这一结果表明,单次训练对于早期是有益的,而季度训练似乎更适合最新的数据。 然而,在每季度更新的模型中似乎没有任何有意义的灾难性遗忘,因为差异相对较小。
| Models | 2020-Q1 | 2020-Q2 | 2020-Q3 | 2020-Q4 | 2021-Q1 | 2021-Q2 | 2021-Q3 | 2021-Q4 |
|---|---|---|---|---|---|---|---|---|
| 2020-Q1 | 0.00% | 2.29% | 3.94% | 3.78% | 7.52% | 9.52% | 11.53% | 13.68% |
| 2020-Q2 | 0.04% | 0.00% | 2.46% | 2.59% | 6.24% | 8.16% | 10.42% | 12.75% |
| 2020-Q3 | 1.87% | 1.67% | 0.00% | 0.82% | 4.53% | 6.47% | 8.54% | 11.10% |
| 2020-Q4 | 3.95% | 3.74% | 1.57% | 0.00% | 4.82% | 7.14% | 9.22% | 11.43% |
| 2021-Q1 | 1.58% | 1.37% | -0.89% | -2.36% | 0.00% | 3.05% | 5.16% | 7.39% |
| 2021-Q2 | 1.21% | 0.82% | -1.55% | -2.83% | -0.77% | 0.00% | 2.83% | 5.19% |
| 2021-Q3 | 1.12% | 0.75% | -1.95% | -3.20% | -1.26% | -0.61% | 0.00% | 3.25% |
| 2021-Q4 | 0.10% | -0.17% | -2.97% | -4.47% | -2.51% | -1.83% | -1.37% | 0.00% |
6.2时间和大小控制实验
鉴于前面提出的结果,人们自然会想知道这种改进是否是由于训练规模的增加或附加数据的新近性所致。 虽然这个问题不容易回答(可能答案介于这两个原因之间),但我们进行了一个简单的控制实验作为初步尝试。 为此,我们使用 2021 年第三季度 (2021-Q3) 两倍的训练数据训练了一个额外的语言模型。 这样,训练推文的总数就与 2021 年第四季度(2021-Q4)之前训练的模型完全相同。
| Models | 2021-Q2 | 2021-Q3 | 2021-Q4 |
|---|---|---|---|
| 2021-Q2 | 4.445 | 4.570 | 4.675 |
| 2021-Q3 | 4.394 | 4.422 | 4.565 |
| 2021-Q3-2x | 4.380 | 4.380 | 4.534 |
| 2021-Q4 | 4.381 | 4.402 | 4.463 |
考虑表5上的结果,我们发现在所有测试季度中,使用第三季度两倍数据训练的模型优于使用默认第三季度数据训练的模型。 这证实了这样的假设:增加训练数据可以提高语言模型的性能。 与 2021-Q4 之前训练的模型相比,结果显示这个 2021-Q3-2x 模型在 2021-Q2 和 2021-Q3 测试集中仅稍好一些。 然而,正如我们所预期的那样,在更新的数据(即 2021 年第四季度之前)中训练的模型在更新的测试集(即 2021 年第四季度)上获得了最佳的总体结果。
6.3定性分析
| Model | So glad I’m <mask> vaccinated. | I keep forgetting to bring a <mask>. | Looking forward to watching <mask> Game tonight! |
| 2020-Q1 | not | bag | the |
| getting | purse | The | |
| self | charger | this | |
| 2020-Q2 | not | mask | The |
| getting | bag | the | |
| fully | purse | End | |
| 2020-Q3 | not | mask | the |
| getting | bag | The | |
| fully | purse | End | |
| 2020-Q4 | not | bag | the |
| getting | purse | The | |
| fully | charger | End | |
| 2021-Q1 | getting | purse | the |
| not | charger | The | |
| fully | bag | End | |
| 2021-Q2 | fully | bag | the |
| getting | charger | The | |
| not | lighter | this | |
| 2021-Q3 | fully | charger | the |
| getting | bag | The | |
| not | purse | This | |
| 2021-Q4 | fully | bag | Squid |
| getting | lighter | the | |
| not | charger | The |
在本节中,我们在实践中说明在不同方面训练的模型如何感知特定的推文。 首先,我们使用他们的掩码语言建模头来预测上下文中的<掩码>词符。 表 6 显示了我们每个季度模型的三条推文和相关预测。 属于最相关季度的模型展示了更符合该时期趋势的背景知识。 在两个与新冠病毒相关的示例中,我们观察到人们对完全接种疫苗这一一般概念的认识不断增强(而不是未接种疫苗,这是 2020 年第一季度模型的最高预测)在前者中,以及在后者中,忘记口罩比忘记与特定时期不太相关的其他服装(例如充电器)的可能性更大, 打火机或钱包。 最后,请注意,在最后一个例子 "期待今晚观看<面具>游戏!"中,只有到 2021 年第四季度,预测才会发生重大变化,因为此时模型已经接触到 "乌贼游戏 "节目的反应,与该节目的全球发布在时间上重叠。
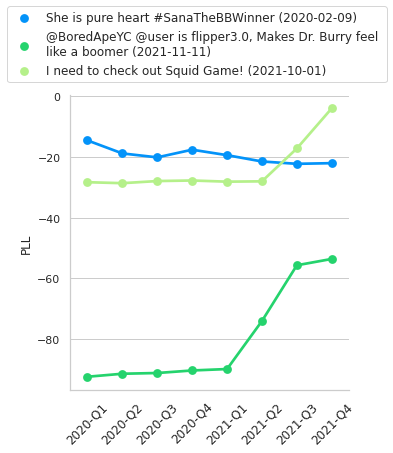
我们的第二项分析涉及推文的伪对数似然 (PLL) 分数的可视化,需要了解与特定时期相关的趋势或事件(图 2)。 事实上,最近的模型更擅长预测涉及流行事件的推文,例如 NFT 或节目“Squid Game”。 相反,我们观察到有关旧真人秀选手的推文的 PLL 分数停滞(甚至下降)。
7结论
在本文中,我们提出了 TimeLM,这是在不同时间段在 Twitter 上训练的语言模型。 该计划还包括未来每三个月训练一次语言模型,从而为 NLP 从业者提供免费使用的最新语言模型。 这些语言模型与简单的 Python 界面一起发布,该界面有助于加载和使用这些模型,包括时间感知评估。 在本文的评估中,我们不仅从理论角度,而且从实践角度展示了时间感知训练的相关性,因为结果表明,当模型用于未来数据时,性能会明显下降,这是实践中最常见的设置之一。
作为未来的工作,我们计划在语言模型中明确集成时间跨度变量,即引入字符串前缀,如 Dhingra 等人 (2022) 和 Rosin 等人 ( 2022)。
参考
- Agarwal and Nenkova (2021) Oshin Agarwal and Ani Nenkova. 2021. Temporal effects on pre-trained models for language processing tasks. arXiv preprint arXiv:2111.12790.
- Barbieri et al. (2021) Francesco Barbieri, Luis Espinosa Anke, and Jose Camacho-Collados. 2021. XLM-T: A multilingual language model toolkit for twitter. arXiv preprint arXiv:2104.12250.
- Barbieri et al. (2020) Francesco Barbieri, Jose Camacho-Collados, Luis Espinosa Anke, and Leonardo Neves. 2020. TweetEval: Unified benchmark and comparative evaluation for tweet classification. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1644–1650, Online. Association for Computational Linguistics.
- Barbieri et al. (2018) Francesco Barbieri, Jose Camacho-Collados, Francesco Ronzano, Luis Espinosa-Anke, Miguel Ballesteros, Valerio Basile, Viviana Patti, and Horacio Saggion. 2018. SemEval 2018 task 2: Multilingual emoji prediction. In Proceedings of The 12th International Workshop on Semantic Evaluation, pages 24–33, New Orleans, Louisiana. Association for Computational Linguistics.
- Basile et al. (2019) Valerio Basile, Cristina Bosco, Elisabetta Fersini, Debora Nozza, Viviana Patti, Francisco Manuel Rangel Pardo, Paolo Rosso, and Manuela Sanguinetti. 2019. SemEval-2019 task 5: Multilingual detection of hate speech against immigrants and women in Twitter. In Proceedings of the 13th International Workshop on Semantic Evaluation, pages 54–63, Minneapolis, Minnesota, USA. Association for Computational Linguistics.
- Beltagy et al. (2019) Iz Beltagy, Kyle Lo, and Arman Cohan. 2019. SciBERT: A pretrained language model for scientific text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3615–3620, Hong Kong, China. Association for Computational Linguistics.
- Biesialska et al. (2020) Magdalena Biesialska, Katarzyna Biesialska, and Marta R Costa-jussà. 2020. Continual lifelong learning in natural language processing: A survey. In Proceedings of the 28th International Conference on Computational Linguistics, pages 6523–6541.
- Broder (1997) A.Z. Broder. 1997. On the resemblance and containment of documents. In Proceedings. Compression and Complexity of SEQUENCES 1997 (Cat. No.97TB100171), pages 21–29.
- Del Tredici et al. (2019) Marco Del Tredici, Raquel Fernández, and Gemma Boleda. 2019. Short-term meaning shift: A distributional exploration. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2069–2075, Minneapolis, Minnesota. Association for Computational Linguistics.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- Dhingra et al. (2022) Bhuwan Dhingra, Jeremy R. Cole, Julian Martin Eisenschlos, Daniel Gillick, Jacob Eisenstein, and William W. Cohen. 2022. Time-Aware Language Models as Temporal Knowledge Bases. Transactions of the Association for Computational Linguistics, 10:257–273.
- Grootendorst (2020) Maarten Grootendorst. 2020. BERTopic: Leveraging BERT and c-TF-IDF to create easily interpretable topics.
- Gu et al. (2021) Yu Gu, Robert Tinn, Hao Cheng, Michael Lucas, Naoto Usuyama, Xiaodong Liu, Tristan Naumann, Jianfeng Gao, and Hoifung Poon. 2021. Domain-specific language model pretraining for biomedical natural language processing. ACM Transactions on Computing for Healthcare (HEALTH), 3(1):1–23.
- Hamilton et al. (2016) William L. Hamilton, Jure Leskovec, and Dan Jurafsky. 2016. Diachronic word embeddings reveal statistical laws of semantic change. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1489–1501, Berlin, Germany. Association for Computational Linguistics.
- Hofmann et al. (2021) Valentin Hofmann, Janet Pierrehumbert, and Hinrich Schütze. 2021. Dynamic contextualized word embeddings. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 6970–6984, Online. Association for Computational Linguistics.
- Jang et al. (2021) Joel Jang, Seonghyeon Ye, Sohee Yang, Joongbo Shin, Janghoon Han, Gyeonghun Kim, Stanley Jungkyu Choi, and Minjoon Seo. 2021. Towards continual knowledge learning of language models. arXiv preprint arXiv:2110.03215.
- Jin et al. (2021) Xisen Jin, Dejiao Zhang, Henghui Zhu, Wei Xiao, Shang-Wen Li, Xiaokai Wei, Andrew Arnold, and Xiang Ren. 2021. Lifelong pretraining: Continually adapting language models to emerging corpora. arXiv preprint arXiv:2110.08534.
- Lazaridou et al. (2021) Angeliki Lazaridou, Adhiguna Kuncoro, Elena Gribovskaya, Devang Agrawal, Adam Liska, et al. 2021. Pitfalls of static language modelling. arXiv preprint arXiv:2102.01951.
- Lee et al. (2020) Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. 2020. Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4):1234–1240.
- Lee et al. (2021) Katherine Lee, Daphne Ippolito, Andrew Nystrom, Chiyuan Zhang, Douglas Eck, Chris Callison-Burch, and Nicholas Carlini. 2021. Deduplicating training data makes language models better. arXiv preprint arXiv:2107.06499.
- Lewis et al. (2020) Patrick Lewis, Pontus Stenetorp, and Sebastian Riedel. 2020. Question and answer test-train overlap in open-domain question answering datasets. arXiv preprint arXiv:2008.02637.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
- Lopez-Paz and Ranzato (2017) David Lopez-Paz and Marc' Aurelio Ranzato. 2017. Gradient episodic memory for continual learning. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc.
- Luu et al. (2021) Kelvin Luu, Daniel Khashabi, Suchin Gururangan, Karishma Mandyam, and Noah A Smith. 2021. Time waits for no one! analysis and challenges of temporal misalignment. arXiv preprint arXiv:2111.07408.
- Mohammad et al. (2018) Saif Mohammad, Felipe Bravo-Marquez, Mohammad Salameh, and Svetlana Kiritchenko. 2018. SemEval-2018 task 1: Affect in tweets. In Proceedings of The 12th International Workshop on Semantic Evaluation, pages 1–17, New Orleans, Louisiana. Association for Computational Linguistics.
- Mohammad et al. (2016) Saif Mohammad, Svetlana Kiritchenko, Parinaz Sobhani, Xiaodan Zhu, and Colin Cherry. 2016. SemEval-2016 task 6: Detecting stance in tweets. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), pages 31–41, San Diego, California. Association for Computational Linguistics.
- Nguyen et al. (2020) Dat Quoc Nguyen, Thanh Vu, and Anh Tuan Nguyen. 2020. BERTweet: A pre-trained language model for English tweets. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 9–14, Online. Association for Computational Linguistics.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Rosenfeld and Erk (2018) Alex Rosenfeld and Katrin Erk. 2018. Deep neural models of semantic shift. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 474–484, New Orleans, Louisiana. Association for Computational Linguistics.
- Rosenthal et al. (2017) Sara Rosenthal, Noura Farra, and Preslav Nakov. 2017. SemEval-2017 task 4: Sentiment analysis in Twitter. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), pages 502–518, Vancouver, Canada. Association for Computational Linguistics.
- Rosin et al. (2022) Guy D. Rosin, Ido Guy, and Kira Radinsky. 2022. Time masking for temporal language models. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, WSDM ’22, page 833–841, New York, NY, USA. Association for Computing Machinery.
- Salazar et al. (2020) Julian Salazar, Davis Liang, Toan Q. Nguyen, and Katrin Kirchhoff. 2020. Masked language model scoring. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2699–2712, Online. Association for Computational Linguistics.
- Szymanski (2017) Terrence Szymanski. 2017. Temporal word analogies: Identifying lexical replacement with diachronic word embeddings. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 448–453, Vancouver, Canada. Association for Computational Linguistics.
- Van Hee et al. (2018) Cynthia Van Hee, Els Lefever, and Véronique Hoste. 2018. SemEval-2018 task 3: Irony detection in English tweets. In Proceedings of The 12th International Workshop on Semantic Evaluation, pages 39–50, New Orleans, Louisiana. Association for Computational Linguistics.
- Wang et al. (2019) Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. 2019. Superglue: A stickier benchmark for general-purpose language understanding systems. arXiv preprint arXiv:1905.00537.
- Wang et al. (2018) Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. 2018. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
- Zampieri et al. (2019) Marcos Zampieri, Shervin Malmasi, Preslav Nakov, Sara Rosenthal, Noura Farra, and Ritesh Kumar. 2019. SemEval-2019 task 6: Identifying and categorizing offensive language in social media (OffensEval). In Proceedings of the 13th International Workshop on Semantic Evaluation, pages 75–86, Minneapolis, Minnesota, USA. Association for Computational Linguistics.