MAXIM:用于图像处理的多轴 MLP
摘要
Transformer 和多层感知器 (MLP) 模型的最新进展为计算机视觉任务提供了新的网络架构设计。 尽管这些模型被证明在图像识别等许多视觉任务中是有效的,但将它们适应低级视觉仍然存在挑战。 支持高分辨率图像的不灵活性和局部注意力的限制可能是主要瓶颈。 在这项工作中,我们提出了一种名为 MAXIM 的基于多轴 MLP 的架构,它可以作为图像处理任务的高效灵活的通用视觉主干。 MAXIM 使用 UNet 形状的层次结构,并支持由空间门控 MLP 实现的远程交互。 具体来说,MAXIM 包含两个基于 MLP 的构建模块:一个多轴门控 MLP,允许局部和全局视觉线索进行高效且可扩展的空间混合;以及一个交叉门控模块,它是交叉注意力的替代方案,它考虑了交叉注意力-功能调节。 这两个模块都完全基于 MLP,但也受益于全局和“全卷积”,这是图像处理所需的两个属性。 我们广泛的实验结果表明,所提出的 MAXIM 模型在一系列图像处理任务(包括去噪、去模糊、去雨、去雾和增强)的十多个基准测试中实现了最先进的性能,同时需要更少或相当数量的参数和 FLOPs 优于竞争模型。 源代码和经过训练的模型可在 https://github.com/google-research/maxim 上获取。
1简介
图像处理任务,例如恢复和增强,是重要的计算机视觉问题,其目的是从降级的输入中产生所需的输出。 各种类型的退化可能需要不同的图像增强处理,例如去噪、去模糊、超分辨率、去雾、低光增强等。 鉴于精选的大规模训练数据集的可用性不断增加,最近的高性能方法[110, 111, 125, 50, 20, 15, 60, 61, 17, 52, 22]基于高度设计的卷积神经网络(CNN)在许多任务上展示了最先进的(SOTA)性能。
 |
 |
 |
改进底层模型的架构设计是提高大多数计算机视觉任务(包括图像恢复)性能的关键之一。 许多研究人员发明或借用了单独的模块或构建块,并将其实施到低级视觉任务中,包括残差学习[120, 43, 95]、密集连接[121, 95],层次结构[42,41,37],多阶段框架[111,16,34,113],以及注意力机制[110 、111、66、91]。
最近对 Vision Transformers (ViT) [24,11,57] 的研究探索证明了它们作为首选 CNN 模型替代品的巨大潜力。 ViT [24] 的优雅也激发了使用更简单的全局运算符的类似模型设计,例如 MLP-Mixer [87]、gMLP [54]、GFNet [76] 和 FNet [44] 等。 尽管成功应用于许多高级任务[24,57,89,4,104,102,85],这些全局模型在低级增强方面的功效且恢复问题尚未得到广泛研究。 低级视觉 Transformers 的开创性工作 [15, 10] 直接应用了完全自注意力,仅接受固定大小的相对较小的 patch(例如 4848 )。 当使用裁剪[15]应用于较大图像时,这种策略将不可避免地导致补丁边界伪影。 基于局部注意力的 Transformer [52, 97] 改善了这个问题,但它们也受到感受野大小的限制,或者失去非局部性[93, 24],这是 Transformer 和 MLP 模型相对于分层 CNN 的一个引人注目的特性。
为了克服这些问题,我们提出了一种通用图像处理网络,称为MAXIM,用于低级视觉任务。 MAXIM 的一个关键设计元素是使用多轴方法(秒 3.2)局部和全局相互作用并行。 通过在每个分支的单轴上混合信息,这种基于 MLP 的算子变成“全卷积”并根据图像大小线性缩放,这显着提高了其灵活性用于密集的图像处理任务。 我们还定义并构建了一个纯基于 MLP 的交叉选通模块,该模块使用相同的多轴方法自适应选通 MAXIM 颈部的跳跃连接,并进一步提高性能。 受最近恢复模型的启发,我们开发了一种简单但有效的多阶段、多尺度架构,由一堆 MAXIM 主干网络组成。 MAXIM 在一系列图像处理任务上实现了强大的性能,同时需要很少的参数和 FLOP。 我们的贡献是:
-
•
一种新颖且通用的图像处理架构,称为 MAXIM,使用一堆编码器-解码器主干,由多尺度、多阶段损失进行监督。
-
•
专为低级视觉任务量身定制的多轴门控 MLP 模块,始终享有全局感受野,并且具有相对于图像大小的线性复杂度。
-
•
交叉门控块,对两个独立的特征进行交叉条件处理,也是全局且全卷积的。
-
•
大量实验表明,MAXIM 在 10 多个数据集上取得了 SOTA 结果,包括去噪、去模糊、去雨、去雾和增强。
2相关工作
修复模型。 在最近建立视觉基准的巨大努力的推动下,基于学习的模型,特别是 CNN 模型,已经开发出来,在各种图像增强任务上实现了最先进的性能[111,16,37, 50、81、17、15、52]。 这些性能提升主要归功于新颖的架构设计和/或特定于任务的模块和单元。 例如,UNet [80] 已经孵化了许多成功的编码器-解码器设计[111, 37, 20],用于图像恢复,这些设计改进了早期的单尺度特征处理模型[120, 45]。 为高级视觉任务开发的先进组件也已被引入低级视觉任务中。 残差和密集连接[120,43,95,121,95],多尺度特征学习[41,97,20],注意力机制[ 110, 111, 66, 91, 121] 和非本地网络[93, 53, 121] 就是很好的例子。 最近,多阶段网络[111,16,34,113]相对于上述单阶段模型在具有挑战性的去模糊和去雨任务[23,34,111]。 这些多阶段框架通常受到其在姿态估计 [18, 48]、动作分割 [25, 47] 和图像等更高级别问题上的成功的启发。一代[116, 117]。
低级视觉变形金刚。 Transformer 最初是针对 NLP 任务[90]提出的,其中多头自注意力和前馈 MLP 层堆叠在一起以捕获单词之间的非局部交互。 Dosovitskiy 等人.创造了术语Vision Transformer (ViT)[24],并展示了第一个用于图像识别的纯Transformer模型。 最近的几项研究探讨了 Transformer 解决低级视觉问题的问题,例如。,开创性的预训练图像处理 Transformer (IPT)[15] 。 与 ViT 类似,IPT 直接将普通 Transformer 应用于图像补丁。 [10] 的作者提出了一种时空卷积自注意力网络,该网络利用局部信息实现视频超分辨率。 最近,Swin-IR [52] 和 UFormer [97] 在一系列图像恢复任务中应用了高效的基于窗口的局部注意力模型。
MLP 视觉模型。 最近,一些作者认为,当在 ViT 中使用基于补丁的架构时,复杂的自注意力机制的必要性变得值得怀疑。 例如,MLP-Mixer [87] 采用简单的 Token 混合 MLP 来代替 ViT 中的自注意力,从而形成全 MLP 架构。 [54]的作者提出了gMLP,它将空间门控单元应用于视觉标记。 ResMLP [88] 采用仿射变换代替层标准化来实现加速。 最近的技术,例如 FNet [44] 和 GFNet [76] 证明简单的傅立叶变换可以用作自注意力或 MLP 的竞争替代方案。
3我们的方法:MAXIM
据我们所知,我们提出了第一个用于低级视觉的有效通用 MLP 架构,我们称之为 Multi-AXIs M 用于图像处理的LP (MAXIM)。 与之前的低级 Transformer [15, 10, 52, 97] 不同,MAXIM 具有几个所需的属性,使其对于图像处理任务很有吸引力。 首先,MAXIM以线性复杂度表达任意大图像上的全局感受野;其次,它直接支持任意输入分辨率,即.,是全卷积的;最后,它提供了局部(Conv)和全局(MLP)块的平衡设计,优于 SOTA 方法,无需大规模预训练[ 15]。
3.1 主干网
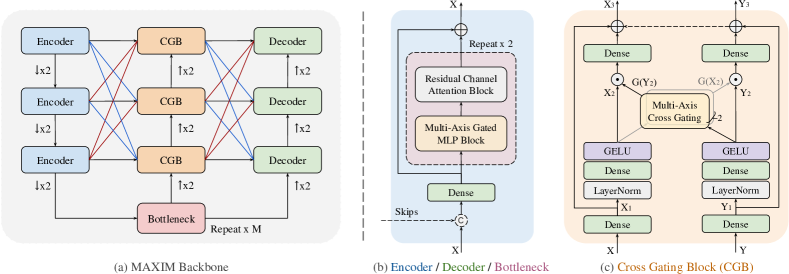
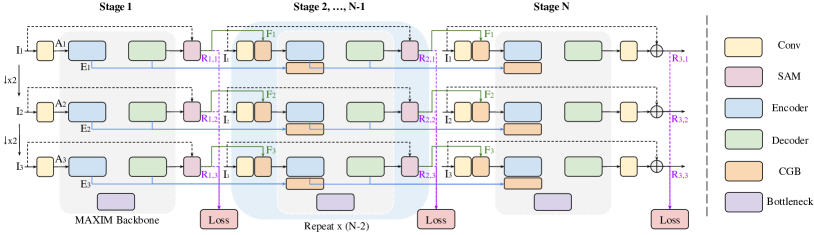
MAXIM 主干网(图 2a)遵循源自 UNet [80] 的编码器-解码器设计原则>。 我们观察到,诸如 Conv3x3 等占用空间较小的算子对于类 UNet 网络的性能至关重要。 因此,我们依赖于每个块的混合模型设计(图 2b)-本地的Conv ,以及用于远程交互的MLP——充分利用它们。
为了允许不同尺度的远程空间混合,我们将多轴门控 MLP 块 (MAB) 插入每个编码器、解码器和瓶颈中(图 2b),带有残余通道注意块 (RCAB) [100, 111] (LayerNorm-Conv-LeakyReLU-Conv-SE [31])随后堆叠。 受跳跃连接[67, 71]的门控过滤的启发,我们扩展门控MLP(gMLP)来构建交叉门控块(CGB,图) 2c),这是交叉注意力(三阶相关性)的有效二阶替代方案,用于交互或调节两个不同的特征。 我们利用瓶颈(图2a)的全局特征来门控跳跃连接,同时传播将全局功能向上细化到下一个 CGB。 多尺度特征融合[84,110,20](红色和蓝色线)用于聚合编码器中的多级信息CGB 和 CGB解码器数据流。
3.2多轴门控 MLP
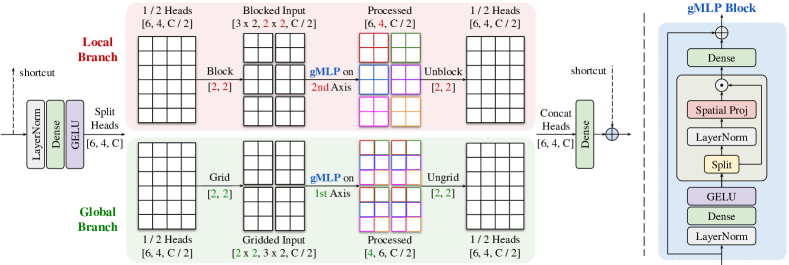
我们的工作受到[123]中提出的多轴阻塞自注意力的启发,它在多个单轴上进行注意力。 在块图像上的两个轴上执行的注意力对应于两种形式的稀疏自注意力,即区域注意力和扩张注意力。 尽管并行捕获局部和全局信息,但该模块无法适应测试图像通常具有任意大小的图像恢复或增强任务。
我们改进了图像处理任务中的"多轴"概念,构建了一个(分头)多轴门控 MLP 块(MAB),如图 3所示。 我们没有在单层[123]中应用多轴注意力,而是首先将头分成两半,每个头都独立分区。 在局部分支中,大小为的特征的半头被分块为形状为的张量,表示划分为不重叠的窗口,每个窗口的大小为;在全局分支中,另一半头使用固定的网格网格化成形状,每个窗口大小为 。 为了可视化,我们在图3中设置。 为了使其完全卷积,我们仅在每个分支的单个轴上应用门控MLP(gMLP)块[54] - nd axis 用于本地分支,st axis 用于全局分支 - 同时在其他空间上共享参数轴。 直观地说,并行应用多轴 gMLP 分别对应于空间信息的局部和全局(扩张)混合。 最后,将处理后的头连接并投影以减少通道数量,并使用输入的长跳跃连接进一步组合通道数量。 值得注意的是,与处理固定大小图像补丁 [15] 的方法相比,这种方法通过避免补丁边界伪影为我们的模型提供了优势。
复杂性分析。 我们提出的多轴 gMLP 模块 (MAB) 的计算复杂度为:
| (1) |
相对于图像大小 是线性,而 ViT、Mixer 和 gMLP 等其他全局模型是二次。
3.3 交叉门控MLP模块
相对于 UNet 的一个常见改进是利用上下文特征来选择性地gate跳过连接[67, 71]中的特征传播,这通常是通过使用交叉注意力[90, 13]。 在这里,我们构建了一个有效的替代方案,即交叉门控块(CGB,图 2c),作为 MAB 的扩展(Sec. 3.2),只能处理单个特征。 CGB 可以被视为一个更通用的调节层,与多个特征[90,70,13]交互。 我们遵循与 MAB 中使用的类似设计模式。
更具体地说,令为两个输入特征,为图中第一个Dense层之后投影的特征. 2c.然后应用输入投影:
| (2) |
其中 是 激活 [30], 是层归一化 [5], 是 MLP 投影矩阵。 多轴分块门控权重分别根据 计算,但相反应用:
| (3) |
其中 表示逐元素乘法,函数 使用我们提出的多轴方法从输入中提取多轴交叉选通权重(秒)。 3.2):
| (4) |
其中 表示串联。 这里 是沿着通道维度从 分裂出来的两个独立头,其中 表示激活后的投影特征 :
| (5) |
和 是应用于具有固定窗口大小 的块/网格特征的 2nd 和 1st 轴的空间投影矩阵() 和固定网格大小 ()。 最后,我们采用来自输入的残差连接,遵循输出通道投影,保持与输入相同的通道尺寸 (),使用投影矩阵 、,表示为
| (6) |
CGB 的复杂性也受到 Eq. 1 的严格限制。
3.4多阶段多尺度框架
我们进一步采用多阶段框架,因为我们发现它比扩大模型宽度或高度更有效(参见 ablation Sec. 4.3A)。 我们认为全分辨率处理[69,77,16]是比多面片层次结构[83,111,113]更好的方法,因为后者可能会导致边界跨补丁的影响。 为了实施更强的监督,我们在每个阶段应用多尺度方法[48,18,20]来帮助网络学习。 我们利用监督注意力模块[111]沿着阶段逐步传播注意力特征。 我们利用跨门块(Sec. 3.3)进行跨阶段特征融合。 详细信息请读者参考图9。
| SIDD [2] | DND [72] | Average | ||||
|---|---|---|---|---|---|---|
| Method | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM |
| DnCNN [120] | 23.66 | 0.583 | 32.43 | 0.790 | 28.04 | 0.686 |
| MLP [7] | 24.71 | 0.641 | 34.23 | 0.833 | 29.47 | 0.737 |
| BM3D [21] | 35.65 | 0.685 | 34.51 | 0.851 | 35.08 | 0.768 |
| CBDNet* [29] | 30.78 | 0.801 | 38.06 | 0.942 | 34.42 | 0.872 |
| RIDNet* [3] | 38.71 | 0.951 | 39.26 | 0.953 | 38.99 | 0.952 |
| AINDNet* [38] | 38.95 | 0.952 | 39.37 | 0.951 | 39.16 | 0.952 |
| VDN [107] | 39.28 | 0.956 | 39.38 | 0.952 | 39.33 | 0.954 |
| SADNet* [12] | 39.46 | 0.957 | 39.59 | 0.952 | 39.53 | 0.955 |
| CycleISP* [109] | 39.52 | 0.957 | 39.56 | 0.956 | 39.54 | 0.957 |
| MIRNet [110] | 39.72 | 0.959 | 39.88 | 0.956 | 39.80 | 0.958 |
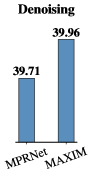
| MPRNet [111] | 39.71 | 0.958 | 39.80 | 0.954 | 39.76 | 0.956 |
| MAXIM-3S | 39.96 | 0.960 | 39.84 | 0.954 | 39.90 | 0.957 |
形式上,给定输入图像,我们首先通过缩小尺寸来提取其多尺度变体:。 MAXIM 预测 阶段中每个阶段 的多尺度恢复输出,总共产生 输出:。 尽管是多阶段的,MAXIM 仍进行端到端训练,损失在各个阶段和规模上累积:
| (7) |
其中 表示(双线性重新缩放)多尺度目标图像, 是 Charbonnier 损失 [111]:
| (8) |
我们设置的地方。 是加强高频细节的频率重建损失[35, 20]:
| (9) |
其中 表示 2D 快速傅立叶变换。 我们在所有实验中使用作为权重因子。
4实验
我们的目标是为广泛的图像处理任务构建通用主干。 因此,我们在 17 不同数据集上评估了五个不同任务上的 MAXIM:(1) 去噪、(2) 去模糊、(3) 去雨、(4) 去雾和 (5) 增强(修饰)(总结于 选项卡。 8. 更全面的结果和可视化可以在Sec.A.6中找到。
4.1 实验设置
数据集和指标。 我们测量了真实图像和预测图像之间的 PSNR 和 SSIM [96] 指标,以进行定量比较。 我们使用SIDD [2]和DND [72]进行去噪,GoPro [62],HIDE [81] 和 RealBlur [79] 用于去模糊,组合数据集 Rain13k 用于 [111] 中用于去雨。 RESIDE [46] 用于去雾,而 Five-K[8] 和 LOL [98] 用于评估增强。

|
|||||||
|---|---|---|---|---|---|---|---|
| Input | Target | VDN [107] | DANet [108] | MIRNet [110] | CycleISP [109] | MPRNet [111] | MAXIM-3S |
| GoPro [62] | HIDE [81] | Average | ||||
|---|---|---|---|---|---|---|
| Method | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM |
| DeblurGAN [40] | 28.70 | 0.858 | 24.51 | 0.871 | 26.61 | 0.865 |
| Nah et al. [62] | 29.08 | 0.914 | 25.73 | 0.874 | 27.41 | 0.894 |
| Zhang et al. [118] | 29.19 | 0.931 | - | - | - | - |
| DeblurGAN-v2 [41] | 29.55 | 0.934 | 26.61 | 0.875 | 28.08 | 0.905 |
| SRN [86] | 30.26 | 0.934 | 28.36 | 0.915 | 29.31 | 0.925 |
| Shen et al. [81] | - | - | 28.89 | 0.930 | - | - |
| Gao et al. [28] | 30.90 | 0.935 | 29.11 | 0.913 | 30.01 | 0.924 |
| DBGAN [119] | 31.10 | 0.942 | 28.94 | 0.915 | 30.02 | 0.929 |
| MT-RNN [69] | 31.15 | 0.945 | 29.15 | 0.918 | 30.15 | 0.932 |
| DMPHN [113] | 31.20 | 0.940 | 29.09 | 0.924 | 30.15 | 0.932 |
| Suin et al. [83] | 31.85 | 0.948 | 29.98 | 0.930 | 30.92 | 0.939 |
| MPRNet [111] | 32.66 | 0.959 | 30.96 | 0.939 | 31.81 | 0.949 |
| Pretrained-IPT [15] | 32.58 | - | - | - | - | - |
| MIMO-UNet+ [20] | 32.45 | 0.957 | 29.99 | 0.930 | 31.22 | 0.944 |
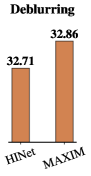
| HINet [16] | 32.71 | 0.959 | 30.32 | 0.932 | 31.52 | 0.946 |
| MAXIM-3S | 32.86 | 0.961 | 32.83 | 0.956 | 32.85 | 0.959 |
| RealBlur-R [79] | RealBlur-J [79] | Average | ||||
| Method | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM |
| Hu et al. [33] | 33.67 | 0.916 | 26.41 | 0.803 | 30.04 | 0.860 |
| Nah et al. [62] | 32.51 | 0.841 | 27.87 | 0.827 | 30.19 | 0.834 |
| DeblurGAN [40] | 33.79 | 0.903 | 27.97 | 0.834 | 30.88 | 0.869 |
| Pan et al. [68] | 34.01 | 0.916 | 27.22 | 0.790 | 30.62 | 0.853 |
| Xu et al. [103] | 34.46 | 0.937 | 27.14 | 0.830 | 30.8 | 0.884 |
| DeblurGAN-v2 [41] | 35.26 | 0.944 | 28.70 | 0.866 | 31.98 | 0.905 |
| Zhang et al. [118] | 35.48 | 0.947 | 27.80 | 0.847 | 31.64 | 0.897 |
| SRN [86] | 35.66 | 0.947 | 28.56 | 0.867 | 32.11 | 0.907 |
| DMPHN [113] | 35.70 | 0.948 | 28.42 | 0.860 | 32.06 | 0.904 |
| MPRNet [111] | 35.99 | 0.952 | 28.70 | 0.873 | 32.35 | 0.913 |
| MAXIM-3S | 35.78 | 0.947 | 28.83 | 0.875 | 32.31 | 0.911 |
| †DeblurGAN-v2 | 36.44 | 0.935 | 29.69 | 0.870 | 33.07 | 0.903 |
| †SRN [86] | 38.65 | 0.965 | 31.38 | 0.909 | 35.02 | 0.937 |
| †MPRNet [111] | 39.31 | 0.972 | 31.76 | 0.922 | 35.54 | 0.947 |
| †MIMO-UNet+ [20] | - | - | 32.05 | 0.921 | - | - |
| †MAXIM-3S | 39.45 | 0.962 | 32.84 | 0.935 | 36.15 | 0.949 |

|
|||||||
|---|---|---|---|---|---|---|---|
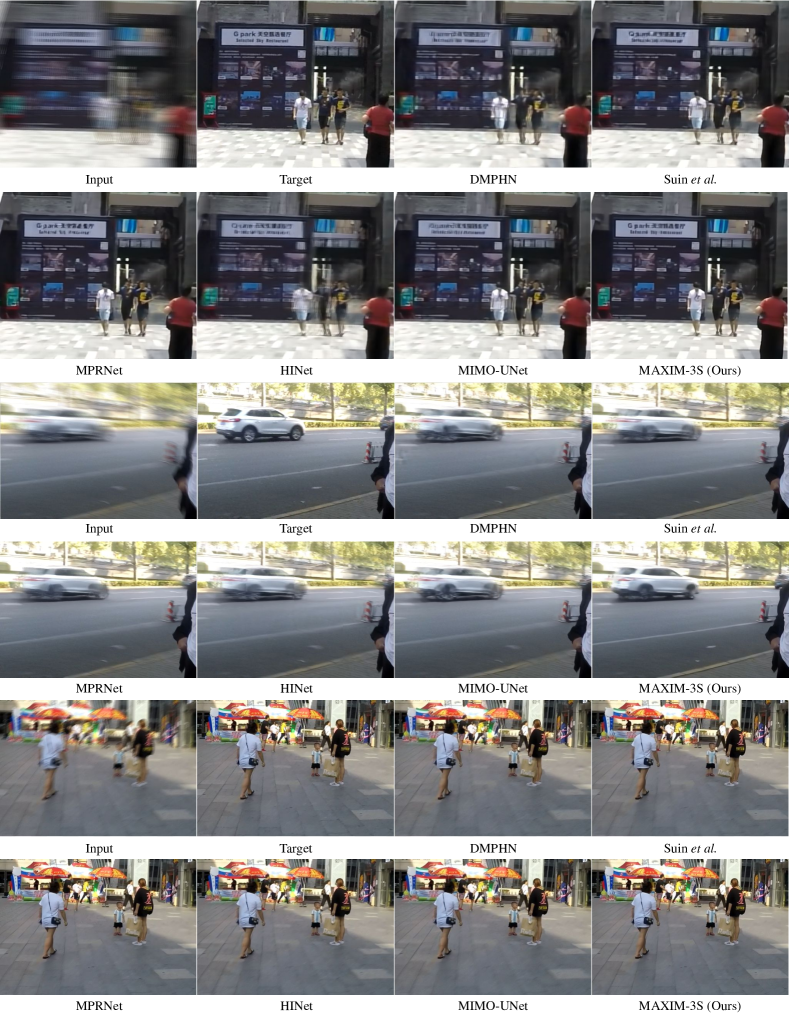
| Input | Target | DMPHN [113] | Suin et al. [83] | MPRNet [111] | HINet [16] | MIMO-UNet [20] | MAXIM-3S |
训练细节。 我们提出的 MAXIM 模型是端到端可训练的,既不需要大规模预训练,也不需要渐进训练。 网络在 随机裁剪的补丁上进行训练。 我们为每个任务训练不同的迭代。 我们使用随机水平和垂直翻转、 旋转以及概率 的 MixUp [112] 来进行数据增强。 我们使用 Adam 优化器 [39] ,初始学习率为 ,随着余弦退火衰减 [ 稳步下降到 59]。 测试时,我们使用两侧对称填充将输入图像填充为 的倍数。 经过推理,我们将填充后的图像裁剪回原始大小。 有关每项任务的更多训练详细信息,请参阅Sec.A.1。
4.2 主要结果
去噪。 我们报道 选项卡。 1 SIDD [2] 和 DND [72] 数据集上的数值比较。 可以看出,我们的方法比之前的 SOTA 技术(例如.、MIRNet [110] 性能优于 0.24 dB SIDD 上的 PSNR,同时在 DND 上获得有竞争力的 PSNR (39.84 dB)。 图 4显示了SIDD上的视觉结果。 我们的方法清楚地消除了真实的噪音,同时保留了精细的细节,与其他方法相比,产生了视觉上令人愉悦的结果。
去模糊。 选项卡。 2 显示了 MAXIM-3S 与 SOTA 去模糊方法在两个合成模糊数据集上的定量比较:GoPro [62] 和 HIDE [81]。 与之前的最佳模型 HINet [16] 相比,我们的方法在 PSNR 方面实现了 0.15 dB 增益。 值得注意的是,GoPro 训练的 MAXIM-3S 模型在 HIDE 数据集上泛化得非常好,设置了新的 SOTA PSNR 值:32.83 dB。 我们还在两种设置下对来自 RealBlur [79] 的真实世界模糊图像进行了评估:(1) 直接在 RealBlur 上应用 GoPro 训练的模型,以及 (2) 在 RealBlur 上微调模型。 在设置(1)下,MAXIM-3S在RealBlur-J子集上排名第一,同时在RealBlur-R上获得前两名的性能。 图 5显示了 GoPro [62]、HIDE [81 上评估模型的视觉比较] 和 RealBlur [79] 分别。 可以观察到,我们的模型恢复文本的效果非常好,这可能归因于在每个块中使用多轴 MLP 模块,该模块全局聚合了不同尺度的重复模式。

|
|||||||
|---|---|---|---|---|---|---|---|
| Input | Target | RESCAN [49] | PreNet [77] | MSPFN [34] | MPRNet [111] | HINet [16] | MAXIM-2S |

|
|||||||
|---|---|---|---|---|---|---|---|
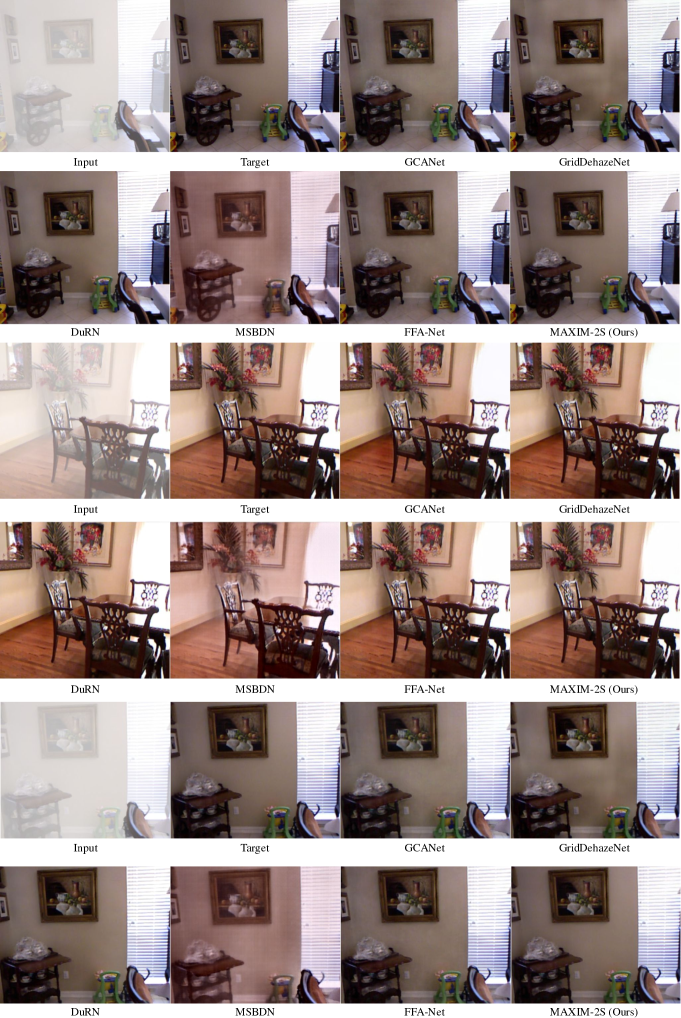
| Input | Target | GCANet [14] | GridDehaze [55] | DuRN [56] | MSBDN [23] | FFA-Net [74] | MAXIM-2S |
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

|
|||||||
| Input | Target | CycleGAN [124] | Exposure [32] | DPE [19] | EnlightenGAN | UEGAN [65] | MAXIM-2S |

|
|||||||
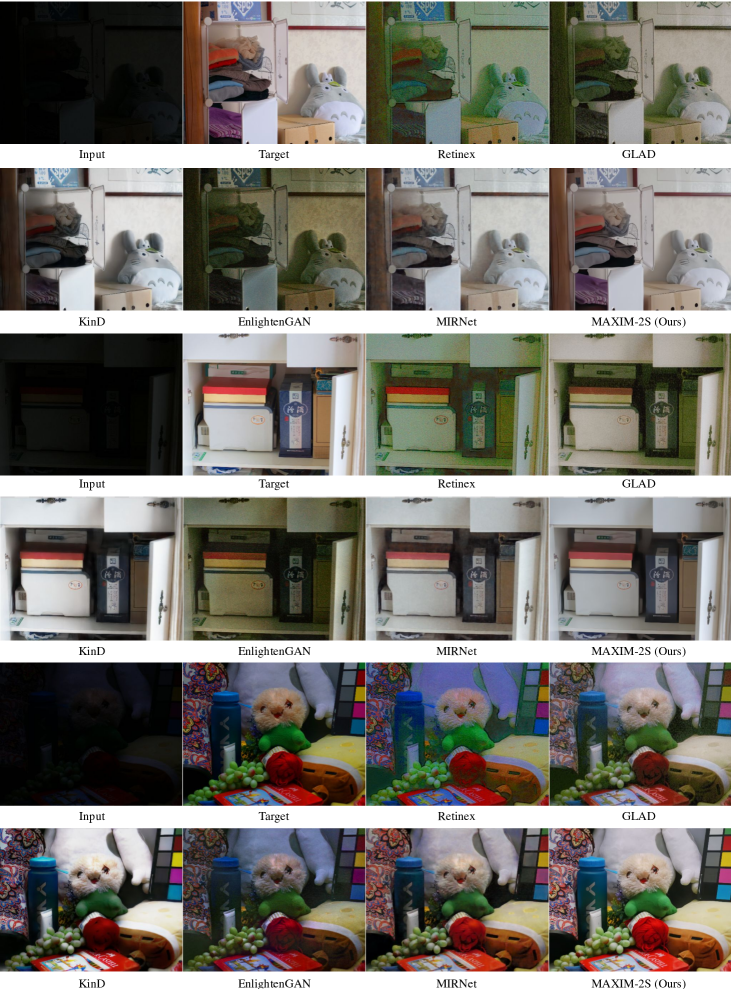
| Input | Target | Retinex [98] | GLAD [92] | KinD [122] | EnlightenGAN | MIRNet [110] | MAXIM-2S |
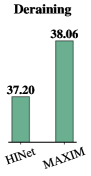
除雨。 继之前的工作[34, 111]之后,我们使用 Y 通道(在 YCbCr 颜色空间中)计算性能指标。 选项卡。 5 显示与以前的方法的定量比较。 可以看出,我们的模型在所有数据集上的 SOTA 性能都有所提高。 我们的模型相对于之前最佳模型 HINet [16] 的平均 PSNR 增益为 0.24 dB。 我们在图6中展示了一些具有挑战性的示例,这表明我们的方法始终如一地提供了忠实恢复的图像,而没有引入任何明显的视觉伪影。
去雾。 我们报告了与 SOTA 模型的比较 选项卡。 5. 我们的模型在 SOTS [46] 室内和室外设备上的 PSNR 超过了之前的最佳模型 0.94 dB 和 0.62 dB。 图 7显示我们的模型在平坦区域和纹理上恢复了更好质量的图像,同时实现了和谐的全局色调。
增强/修饰。 作为 选项卡。 6 如图所示,我们的模型分别在 FiveK [8] 和 LOL [98] 上实现了最佳 PSNR 和 SSIM 值。 正如图 8顶行所示,与其他技术相比,MAXIM 恢复了多种自然色彩。 关于底部的示例,虽然 MIRNet [110] 获得了更高的 PSNR,但我们始终观察到我们的模型获得了更好的视觉质量,细节更清晰,噪声更少。 此外,感知相关性更高的 SSIM 指数表明 MAXIM-2S 相对于 MIRNet 具有显着优势。
其他基准。 由于篇幅限制,我们在秒中详细介绍了 REDS 去模糊[63]和雨滴去除任务[73]的实验结果。 A.5。
4.3消融
我们进行了广泛的消融研究,以验证所提出的多轴门控 MLP 模块、交叉门控模块和多级多尺度架构。 评估是在 GoPro 数据集 [62] 上进行的,该数据集是在大小为 的图像块上进行 次迭代训练的。 我们使用 MAXIM-2S 模型作为 Ablation-A 和 -B 的测试平台。
A。 单独的组件。 我们通过逐步添加 (1) 级间交叉门控模块 (CGBIS)、(2) 监督注意力模块 (SAM)、(3) 跨级交叉门控模块来进行消融(CGBCS,以及(4)多尺度监督(MS-Sp)。 选项卡。 7A 表示每个相应组件的 PSNR 增益为 0.25、0.63、0.36、0.26 dB。
| FiveK [8] | LOL [98] | ||||
|---|---|---|---|---|---|
| Method | PSNR | SSIM | Method | PSNR | SSIM |
| CycleGAN [124] | 18.23 | 0.835 | Retinex [98] | 16.77 | 0.559 |
| Exposure [32] | 22.35 | 0.861 | GLAD [92] | 19.71 | 0.703 |
| EnlightenGAN | 17.74 | 0.828 | EnlightenGAN | 17.48 | 0.657 |
| DPE [19] | 24.08 | 0.922 | KinD [122] | 20.37 | 0.804 |
| UEGAN [65] | 25.00 | 0.929 | MIRNet [110] | 24.14 | 0.830 |
| MAXIM-2S | 26.15 | 0.945 | MAXIM-2S | 23.43 | 0.863 |
B. 多轴方法的效果。 我们进一步研究了我们提出的多轴方法的必要性,如图所示 选项卡。 7B. 我们在(1)基线 UNet、(2)通过添加 MAB 的本地分支(MAB)、(3)通过添加 MAB 的全局分支(MAB ),(4)添加CGB本地分支(CGB),(5)添加CGB全局分支(CGB)。 请注意,通过添加 MAB,PSNR 的巨大跳跃(+1.04 dB)很大程度上归因于输入和输出通道投影层的添加,因为我们还观察到 31.42< 的高性能/t2> dB PSNR(如果仅添加 MAB)。 总体而言,我们观察到添加 MAB 时取得了重大改进,而添加 CGB 时则获得了相对较小的改进。
C. 为什么要多级? 为了理解这一点,我们在宽度(通道)、深度(缩小步骤)和级数方面扩大了 MAXIM。 选项卡。 7C 表明,与使其更宽或更深相比,将主干打包成多级可产生最佳性能vs。复杂性权衡(32.44 dB、22.2 M、339.2 G) 。
D. 超越 gMLP:MAXIM 系列。 如Sec. 3.2中所述,我们提出的多轴方法(图 3)提供了一种在(高分辨率)图像上应用任何一维运算符的可扩展方法,具有相对于图像大小的线性复杂性,同时保持完全卷积。 我们在 SIDD [2] 上使用 MAXIM-1S 和 -2S 进行了试点研究,以探索 MAXIM 系列:MAXIM-FFT、-MLP ,-gMLP(在本文中建模),-SA,我们使用傅里叶变换滤波器 [76, 44],空间 MLP [87],gMLP [54],以及使用相同多轴方法在空间轴上的自注意力[24](图 3)。 作为 选项卡。 7D 显示,gMLP 和自注意力变体实现了最佳性能,而 FFT 和 MLP 系列的计算效率更高。 我们将更深入的探索留给未来的工作。
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5结论
我们提出了一个用于恢复或增强任务的通用网络,称为 MAXIM,受到最近流行的基于 MLP 的全局模型的启发。 我们的工作提出了一种有效且高效的方法,将 gMLP 应用于低级视觉任务,以获得全局关注,这是基本 CNN 所缺失的属性。 我们对 MAXIM 系列的 gMLP 初始化显着提高了多项具有中等复杂度的图像增强和恢复任务的最先进水平。 我们演示了一些应用程序,但还有许多超出本工作范围的可能性,使用 MAXIM 可以显着受益。 我们未来的工作包括探索用于极高分辨率图像处理的更有效模型,以及可以适应多种任务的大型模型。
更广泛的影响。 所提出的模型可以用作增强和修饰日常照片的有效工具。 然而,出于隐私考虑,去噪和去模糊等增强技术很容易被恶意使用。 根据特定数据训练的模型可能会出现偏差。 这些问题应该由研究人员负责任地解决。
6致谢
我们感谢 Junjie Ke、Mauricio Delbracio、Sungjoon Choi、Irene Zhu、Innfarn Yoo、Huiwen Chang 和 Ce Liu 的宝贵讨论和反馈。
附录A附录
A.1 数据集和训练详细信息
论文中使用的所有数据集总结在 选项卡。 8. 我们在下面描述每个数据集的训练细节。 请注意,我们将 损失用于去雾任务,同时将主论文中定义的损失用于所有其他任务。
图像去噪。 我们在 SIDD [2] 中提供的 高分辨率图像上训练我们的模型,并在 1,280 () 和 1,000 () 上进行评估t3>)图像分别由 SIDD [2] 和 DND [72] 作者提供。 DND结果通过在线服务器[1]获得。 我们将训练图像裁剪成步幅为 256 的 补丁来准备训练补丁。 我们对 MAXIM-3S 模型进行了 600k 步训练,批量大小为 256。
图像去模糊。 我们使用来自 GoPro [62] 的 2,103 个图像对训练我们的模型。 为了证明泛化能力,我们在 1,111 对 GoPro 评估集、HIDE 数据集 [81] 中的 2,025 个图像以及 RealBlur 数据集 [79]< 上评估了我们的 GoPro 训练模型。 /t1>,其中分别包含 980 个相机 JPEG 输出和 RAW 图像的配对图像。 我们将 GoPro 中的训练图像裁剪为步长为 128 的 补丁,以生成训练补丁。 我们对 MAXIM-3S 模型进行了超过 60 万步的训练,批量大小为 256。 为了评估 RealBlur 设置 (2)(请参阅主要论文),我们加载了 GoPro 预训练检查点,并分别在 RealBlur-J 和 RealBlur-R 上微调了 70k 和 15k 迭代。 此外,我们还使用来自 NTIRE 2021 图像去模糊挑战赛道 2 JPEG 工件的 REDS 数据集的 24,000 张图像来训练我们的模型[63]。 为了进行评估,我们遵循 NTIRE 2021 图像去模糊挑战赛中的设置[64],即。,我们在验证中使用了 300 张图像一组红色。 我们在 REDS [63] 上从头开始训练 10k epoch。
| Task | Dataset | #Train | #Test | Test Dubname |
|---|---|---|---|---|
| Denoising | SIDD [2] | 320 | 40 | SIDD |
| DND [72] | 0 | 50 | DND | |
| Deblurring | GoPro [62] | 2103 | 1111 | GoPro |
| HIDE [81] | 0 | 2025 | HIDE | |
| RealBlur-J [79] | 3758 | 980 | RealBlur-J | |
| RealBlur-R [79] | 3758 | 980 | RealBlur-R | |
| REDS [63] | 24000 | 300 | REDS | |
| Deraining | Rain14000 [27] | 11200 | 2800 | Test2800 |
| Rain1800 [105] | 1800 | 0 | - | |
| Rain800 [115] | 700 | 98 | Test100 | |
| Rain100H [105] | 0 | 100 | Rain100H | |
| Rain100L [105] | 0 | 100 | Rain100L | |
| Rain1200 [114] | 0 | 1200 | Test1200 | |
| Rain12 [51] | 12 | 0 | - | |
| Raindrop [73] | 861 | 58 | Raindrop-A | |
| Raindrop [73] | 0 | 239 | Raindrop-B | |
| Dehazing | RESIDE-ITS [46] | 13990 | 500 | SOTS-Indoor |
| RESIDE-OTS [46] | 313950 | 500 | SOTS-Outdoor | |
| Enhancement | MIT-Adobe FiveK [8] | 4500 | 500 | FiveK |
| (Retouching) | LOL [98] | 485 | 15 | LOL |
图像去雨。 在[111, 34]之后,我们使用了一个复合训练集,其中包含从多个数据集收集的13,712个干净的雨图像对[27, 105, 115, 105, 114, 51]。 在五个测试集上进行评估:Rain100H [105]、Rain100L [105]、Test100 [115]、Test1200 [114 ] 和 Test2800 [27]。 我们对 MAXIM-2S 模型进行了超过 50 万步的训练,批量大小为 512。 对于雨滴去除任务,我们在 Raindrop 数据集 [73] 中的 861 对训练图像上训练 MAXIM-2S,执行 80k 步骤,批量大小为 512,并在测试集 A(58 张图像)和分别是测试集 B(239 张图像)。
图像去雾。 RESIDE数据集[46]包含两个子集:室内训练集(ITS)包含由1399张干净图像生成的13,990张模糊图像,以及户外训练集(OTS)由8,970张合成的313,950张模糊图像组成无雾霾的室外场景。 我们在综合目标测试集 (SOTS) [46] 上评估了我们的模型:分别为 ITS 训练的模型提供 500 张室内图像,为 OTS 训练的模型提供 500 张室外图像。 我们使用 损失对 RESIDE-ITS 和 RESIDE-OTS 进行了 10k 和 500 epoch 的训练。
图像增强。 我们使用[65]提供的MIT-Adobe FiveK [8]数据集进行修饰评估:前4,500张图像用于训练,其余500张用于测试。 我们将训练图像裁剪为步幅为 256 的 补丁。 我们还使用了 LOL 数据集 [98],其中包含 500 对图像用于低光增强。 我们在 485 个训练图像上训练模型,并在 15 个测试图像上进行评估。 我们分别在 FiveK 和 LOL 上训练了 14k 和 180k 步。
A.2架构细节
Fig. 9中展示了我们提出的多阶段和多尺度通用框架,其中每个阶段都使用单阶段 MAXIM 主干网,这在主论文中有所说明。 我们利用多尺度输入输出方法[20]来深度监督每个阶段。 具体来说,给定输入图像,我们使用最近邻降尺度方法[20]来生成多尺度输入变体:,同时我们采用用于产生地面实况变体的双线性缩减器:。 对于每个阶段,我们使用 Conv3x3 从每个尺度的输入中提取浅层特征。 除了第一阶段之外,我们使用交叉门控块(CGB)将浅层特征与来自先前监督注意模块(SAM)[111]的注意特征融合在一起。 我们还采用跨阶段特征融合[111, 16]来帮助后面的阶段,其中来自前一阶段的中间Encoder和Decoder特征与使用CGB在当前阶段编码的特征融合(图9中的蓝线 )。
A.2.1 配置
单级 MAXIM 的 Encoder 部分的详细规格如下所示 选项卡。 9. 我们还提供每个块和层的输入和输出形状。 这里 Conv3x3_s1_w32 表示具有 3x3 内核、步幅 1 和 32 个通道的 Conv 层。 MAB和RCAB是Encoder / Decoder / Bottleneck中的两个主要组件。 请注意,在 Bottleneck 块中,我们使用 (Conv1x1) 层来替换 RCAB 中的 Conv3x3。
| Depth | Input shape | Output Shape | Layers |
|---|---|---|---|
| 1 | Conv3x3_s1_w32 | ||
| 1 | CGB* () | ||
| 1 | Conv1x1_s1_w32 | ||
| 1 | { | ||
| 1 | Conv3x3_s2_w32 | ||
| 2 | Conv3x3_s1_w64 | ||
| 2 | CGB* () | ||
| 2 | Conv1x1_s1_w64 | ||
| 2 | { | ||
| 2 | Conv3x3_s2_w64 | ||
| 3 | Conv3x3_s1_w128 | ||
| 3 | CGB* () | ||
| 3 | Conv1x1_s1_w128 | ||
| 3 | { | ||
| 3 | Conv3x3_s2_w128 | ||
| 4 | Conv1x1_s1_w256 | ||
| 4 | { | ||
| 4 | Conv1x1_s1_w256 | ||
| 4 | { |
MAXIM 的 Decoder 部分关于以下对称: 选项卡。 9,并且具有相同的配置。 对于CGB琴颈,我们对深度1和2使用,而对深度3采用。 基本上,我们将高分辨率阶段的块和网格大小设置为 (即。特征大小) 用于低分辨率阶段(即。特征尺寸)。 因此,输入图像的两个维度都需要能被 64 整除,因此需要在推理过程中用 64 的乘数来填充图像。
A.2.2与其他 MLP 的比较
A.3JAX 实现
这里我们提供了 MAXIM 关键组件的 JAX [6] 实现,即 算法 中的多轴门控 MLP 模块 (MAB) 1。
A.4 性能与。 复杂
我们展示了性能与。复杂性权衡 选项卡。 11 与所有任务的其他竞争方法相比。 可以看出,我们的模型以非常适中的复杂度获得了最先进的性能。 例如,在去噪方面,MAXIM-3S 只有 FLOPs 和 MIRNet [110] 的 参数;在去模糊方面,我们的 MAXIM-3S 模型仅需要先前最佳模型 HINet [16] 参数数量的 参数数量,并且仅需要 参数数量Transformer 模型 IPT [15] 的参数数量。 还值得注意的是,与 IPT 不同,我们的模型不需要大规模预训练即可获得领先的性能,这使其对于数据集通常规模有限的低级任务具有吸引力。
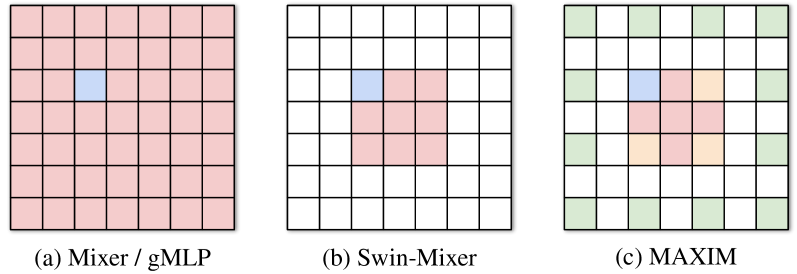
| Model | Complexity | Fully-conv | Global |
|---|---|---|---|
| MLP-Mixer [87] | ✗ | ✓ | |
| gMLP [54] | ✗ | ✓ | |
| Swin-Mixer [57] | ✓ | ✗ | |
| MAXIM (ours) | ✓ | ✓ |
A.5额外实验
由于主论文篇幅有限,我们还展示了去模糊和雨滴去除的实验结果。
REDS 去模糊 [63]。 选项卡。 12 显示了 MAXIM-3S 与获胜解决方案 HINet [16] 以及领先模型 MPRNet [111] 在 NTIRE 2021 图像去模糊挑战赛 REDS 数据集上的定量比较轨道 2 JPEG 伪影[63]。 这些指标是根据 300 个验证图像计算并取平均值的。 我们的 MAXIM-3S 模型的 PSNR 超过 HINet 0.1 dB。
| Task | Dataset | Model | PSNR | Params | FLOPs |
|---|---|---|---|---|---|
| Denoise | SIDD [2] | MPRNet [111] | 39.71 | 15.7M | 1176G |
| MIRNet [110] | 39.72 | 31.7M | 1572G | ||
| MAXIM-3S | 39.96 | 22.2M | 339G | ||
| Deblur | GoPro [62] | MPRNet [111] | 32.66 | 20.1M | 1554G |
| HINet [16] | 32.71 | 88.7M | 341G | ||
| IPT [15] | 32.58 | 114M | 1188G | ||
| MAXIM-3S | 32.86 | 22.2M | 339G | ||
| Derain | Rain13k (Average) | MSPFN [34] | 30.75 | 21.7M | - |
| MPRNet [111] | 32.73 | 3.64M | 297G | ||
| MAXIM-2S | 33.24 | 14.1M | 216G | ||
| Dehaze | Indoor [46] | MSBDN [23] | 33.79 | 31.3M | 83G |
| FFA-Net [74] | 36.36 | 4.5M | 576G | ||
| MAXIM-2S | 39.72 | 14.1M | 216G | ||
| Enhance | LOL [98] | MIRNet [110] | 24.14 | 31.7M | 1572G |
| MAXIM-2S | 23.43 | 14.1M | 216G |
| REDS [63] | ||
|---|---|---|
| Method | PSNR | SSIM |
| MPRNet [111] | 28.79 | 0.911 |
| HINet [16] | 28.83 | 0.862 |
| MAXIM-3S | 28.93 | 0.865 |
| Raindrop-A [73] | Raindrop-B [73] | |||
|---|---|---|---|---|
| Method | PSNR | SSIM | PSNR | SSIM |
| AGAN [73] | 31.62 | 0.921 | 25.05 | 0.811 |
| DuRN [56] | 31.24 | 0.926 | 25.32 | 0.817 |
| Quan [75] | 31.36 | 0.928 | - | - |
| MAXIM-2S | 31.87 | 0.935 | 25.74 | 0.827 |
去除雨滴 [73]。 除了主论文中报告的雨条纹去除任务之外,我们还评估了雨滴去除任务上的 MAXIM 模型。 可以看出 选项卡。 13,我们的模型在 Raindrop 测试集 A 和 B 上实现了最佳性能:31.87 dB 和 25.74 dB PSNR。
A.6 更多视觉比较
去噪。 图 12显示了我们的模型与SIDD上的SOTA模型的去噪结果[2]。 我们的模型恢复了更多细节,产生视觉上令人愉悦的输出。
去模糊。 GoPro [62]、HIDE [81]、RealBlur-J [79] 和 REDS [63] 上的视觉结果如图图13、图14、图1>152>0>、图4>16<分别为 /t15>3>。 我们的模型在合成和现实世界的去模糊基准上都优于其他竞争方法。
去雾。 我们在图23和中提供了SOTS [46]室内和室外设备的去雾比较。 图24。
修饰。 图 25 显示了我们的模型与提供的 5-K 数据集 [8] 上的竞争方法的其他比较通过 [65] 修饰结果。
低光增强。 图 26展示了LOL [98]测试集上低光增强的评估。
A.7 权重可视化
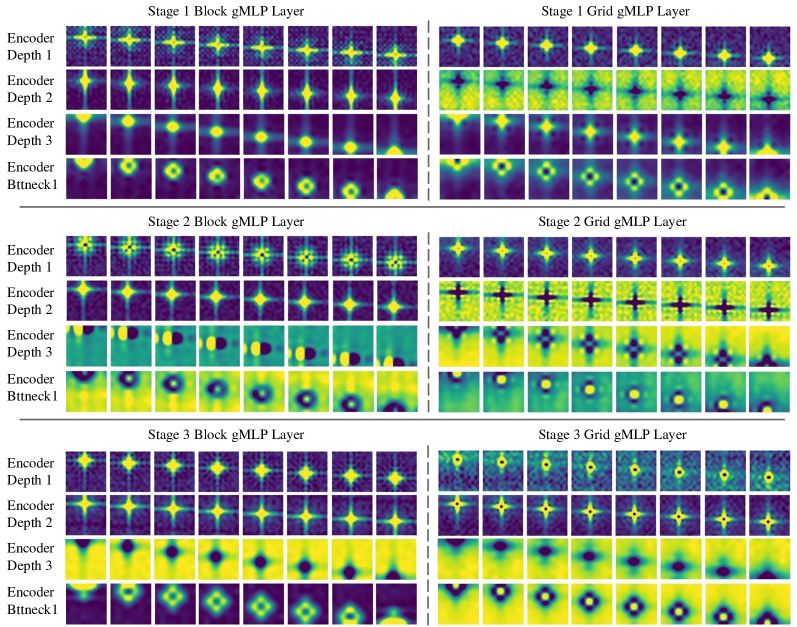
图 11可视化在 GoPro 上训练的 MAXIM-3S 每个阶段的块 gMLP 和网格 gMLP 层的空间投影矩阵 [62]。 与[54]类似,我们也观察到学习后的权重表现出局部性和空间不变性。 令人惊讶的是,全局网格 gMLP 层还学习执行“局部”操作(但在统一扩张网格上)。 同一层中的块gMLP和网格gMLP的空间权重通常表现出相似或耦合的形状,这可能归因于多轴gMLP块中的平行分支设计。 然而,我们还没有观察到这些过滤器在不同阶段如何变化的明显趋势。
A.8限制和讨论
我们的模型与现有 SOTA 共有的一个潜在限制是对现实世界示例的泛化相对不充分。 这也许可以归因于现有合成图像恢复基准提供的训练示例。 通过数据生成方案创建更真实的大规模数据集[82, 94]可以改善这一缺点。 此外,我们观察到我们的模型倾向于稍微过度拟合某些基准,因为我们在训练期间没有应用强正则化(例如。,dropout)。 尽管我们发现正则化可能会导致我们的模型在我们评估的这些基准上的性能略有下降,但未来值得探索以有效提高我们的恢复模型的泛化能力。
值得一提的是,我们的模型能够生成高质量的清晰图像,在视觉上可与最先进的生成模型[123, 36]相媲美。 值得注意的是,我们的模型产生了更保守的结果,而不会产生许多不存在的细节的幻觉,从而提供比生成模型更可靠的结果。












参考
- [1] Darmstadt noise dataset. https://noise.visinf.tu-darmstadt.de/benchmark, 2017. Accessed: 2021-10-30.
- [2] Abdelrahman Abdelhamed, Stephen Lin, and Michael S Brown. A high-quality denoising dataset for smartphone cameras. In CVPR, pages 1692–1700, 2018.
- [3] Saeed Anwar and Nick Barnes. Real image denoising with feature attention. In CVPR, pages 3155–3164, 2019.
- [4] Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, and Cordelia Schmid. Vivit: A video vision transformer. arXiv preprint arXiv:2103.15691, 2021.
- [5] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- [6] James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018.
- [7] Harold C Burger, Christian J Schuler, and Stefan Harmeling. Image denoising: Can plain neural networks compete with bm3d? In CVPR, pages 2392–2399. IEEE, 2012.
- [8] Vladimir Bychkovsky, Sylvain Paris, Eric Chan, and Frédo Durand. Learning photographic global tonal adjustment with a database of input/output image pairs. In CVPR, pages 97–104. IEEE, 2011.
- [9] Bolun Cai, Xiangmin Xu, Kui Jia, Chunmei Qing, and Dacheng Tao. Dehazenet: An end-to-end system for single image haze removal. IEEE TIP, 25(11):5187–5198, 2016.
- [10] Jiezhang Cao, Yawei Li, Kai Zhang, and Luc Van Gool. Video super-resolution transformer. arXiv preprint arXiv:2106.06847, 2021.
- [11] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In ECCV, pages 213–229. Springer, 2020.
- [12] Meng Chang, Qi Li, Huajun Feng, and Zhihai Xu. Spatial-adaptive network for single image denoising. In ECCV, pages 171–187. Springer, 2020.
- [13] Chun-Fu Chen, Quanfu Fan, and Rameswar Panda. Crossvit: Cross-attention multi-scale vision transformer for image classification. arXiv preprint arXiv:2103.14899, 2021.
- [14] Dongdong Chen, Mingming He, Qingnan Fan, Jing Liao, Liheng Zhang, Dongdong Hou, Lu Yuan, and Gang Hua. Gated context aggregation network for image dehazing and deraining. In 2019 IEEE winter conference on applications of computer vision (WACV), pages 1375–1383. IEEE, 2019.
- [15] Hanting Chen, Yunhe Wang, Tianyu Guo, Chang Xu, Yiping Deng, Zhenhua Liu, Siwei Ma, Chunjing Xu, Chao Xu, and Wen Gao. Pre-trained image processing transformer. In CVPR, pages 12299–12310, 2021.
- [16] Liangyu Chen, Xin Lu, Jie Zhang, Xiaojie Chu, and Chengpeng Chen. Hinet: Half instance normalization network for image restoration. In CVPRW, pages 182–192, 2021.
- [17] Li-Heng Chen, Christos G Bampis, Zhi Li, Andrey Norkin, and Alan C Bovik. Proxiqa: A proxy approach to perceptual optimization of learned image compression. IEEE TIP, 30:360–373, 2020.
- [18] Yilun Chen, Zhicheng Wang, Yuxiang Peng, Zhiqiang Zhang, Gang Yu, and Jian Sun. Cascaded pyramid network for multi-person pose estimation. In CVPR, pages 7103–7112, 2018.
- [19] Yu-Sheng Chen, Yu-Ching Wang, Man-Hsin Kao, and Yung-Yu Chuang. Deep photo enhancer: Unpaired learning for image enhancement from photographs with gans. In CVPR, pages 6306–6314, 2018.
- [20] Sung-Jin Cho, Seo-Won Ji, Jun-Pyo Hong, Seung-Won Jung, and Sung-Jea Ko. Rethinking coarse-to-fine approach in single image deblurring. In ICCV, pages 4641–4650, 2021.
- [21] Kostadin Dabov, Alessandro Foi, Vladimir Katkovnik, and Karen Egiazarian. Image denoising by sparse 3-d transform-domain collaborative filtering. IEEE TIP, 16(8):2080–2095, 2007.
- [22] Mauricio Delbracio, Hossein Talebi, and Peyman Milanfar. Projected distribution loss for image enhancement. ICCP, 2021.
- [23] Hang Dong, Jinshan Pan, Lei Xiang, Zhe Hu, Xinyi Zhang, Fei Wang, and Ming-Hsuan Yang. Multi-scale boosted dehazing network with dense feature fusion. In CVPR, pages 2157–2167, 2020.
- [24] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021.
- [25] Yazan Abu Farha and Jurgen Gall. Ms-tcn: Multi-stage temporal convolutional network for action segmentation. In CVPR, pages 3575–3584, 2019.
- [26] Xueyang Fu, Jiabin Huang, Xinghao Ding, Yinghao Liao, and John Paisley. Clearing the skies: A deep network architecture for single-image rain removal. IEEE TIP, 26(6):2944–2956, 2017.
- [27] Xueyang Fu, Jiabin Huang, Delu Zeng, Yue Huang, Xinghao Ding, and John Paisley. Removing rain from single images via a deep detail network. In CVPR, pages 3855–3863, 2017.
- [28] Hongyun Gao, Xin Tao, Xiaoyong Shen, and Jiaya Jia. Dynamic scene deblurring with parameter selective sharing and nested skip connections. In CVPR, pages 3848–3856, 2019.
- [29] Shi Guo, Zifei Yan, Kai Zhang, Wangmeng Zuo, and Lei Zhang. Toward convolutional blind denoising of real photographs. In CVPR, pages 1712–1722, 2019.
- [30] Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016.
- [31] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7132–7141, 2018.
- [32] Yuanming Hu, Hao He, Chenxi Xu, Baoyuan Wang, and Stephen Lin. Exposure: A white-box photo post-processing framework. ACM TOG, 37(2):1–17, 2018.
- [33] Zhe Hu, Sunghyun Cho, Jue Wang, and Ming-Hsuan Yang. Deblurring low-light images with light streaks. In CVPR, pages 3382–3389, 2014.
- [34] Kui Jiang, Zhongyuan Wang, Peng Yi, Chen Chen, Baojin Huang, Yimin Luo, Jiayi Ma, and Junjun Jiang. Multi-scale progressive fusion network for single image deraining. In CVPR, pages 8346–8355, 2020.
- [35] Liming Jiang, Bo Dai, Wayne Wu, and Chen Change Loy. Focal frequency loss for image reconstruction and synthesis. In ICCV, pages 13919–13929, 2021.
- [36] Yifan Jiang, Shiyu Chang, and Zhangyang Wang. Transgan: Two transformers can make one strong gan. arXiv preprint arXiv:2102.07074, 1(3), 2021.
- [37] Yifan Jiang, Xinyu Gong, Ding Liu, Yu Cheng, Chen Fang, Xiaohui Shen, Jianchao Yang, Pan Zhou, and Zhangyang Wang. Enlightengan: Deep light enhancement without paired supervision. IEEE TIP, 30:2340–2349, 2021.
- [38] Yoonsik Kim, Jae Woong Soh, Gu Yong Park, and Nam Ik Cho. Transfer learning from synthetic to real-noise denoising with adaptive instance normalization. In CVPR, pages 3482–3492, 2020.
- [39] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [40] Orest Kupyn, Volodymyr Budzan, Mykola Mykhailych, Dmytro Mishkin, and Jiří Matas. Deblurgan: Blind motion deblurring using conditional adversarial networks. In CVPR, pages 8183–8192, 2018.
- [41] Orest Kupyn, Tetiana Martyniuk, Junru Wu, and Zhangyang Wang. Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better. In ICCV, pages 8878–8887, 2019.
- [42] Wei-Sheng Lai, Jia-Bin Huang, Narendra Ahuja, and Ming-Hsuan Yang. Deep laplacian pyramid networks for fast and accurate super-resolution. In CVPR, pages 624–632, 2017.
- [43] Christian Ledig, Lucas Theis, Ferenc Huszár, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, et al. Photo-realistic single image super-resolution using a generative adversarial network. In CVPR, pages 4681–4690, 2017.
- [44] James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, and Santiago Ontanon. Fnet: Mixing tokens with fourier transforms. arXiv preprint arXiv:2105.03824, 2021.
- [45] Boyi Li, Xiulian Peng, Zhangyang Wang, Jizheng Xu, and Dan Feng. Aod-net: All-in-one dehazing network. In ICCV, pages 4770–4778, 2017.
- [46] Boyi Li, Wenqi Ren, Dengpan Fu, Dacheng Tao, Dan Feng, Wenjun Zeng, and Zhangyang Wang. Benchmarking single-image dehazing and beyond. IEEE TIP, 28(1):492–505, 2019.
- [47] Shi-Jie Li, Yazan AbuFarha, Yun Liu, Ming-Ming Cheng, and Juergen Gall. Ms-tcn++: Multi-stage temporal convolutional network for action segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–1, 2020.
- [48] Wenbo Li, Zhicheng Wang, Binyi Yin, Qixiang Peng, Yuming Du, Tianzi Xiao, Gang Yu, Hongtao Lu, Yichen Wei, and Jian Sun. Rethinking on multi-stage networks for human pose estimation. arXiv preprint arXiv:1901.00148, 2019.
- [49] Xia Li, Jianlong Wu, Zhouchen Lin, Hong Liu, and Hongbin Zha. Recurrent squeeze-and-excitation context aggregation net for single image deraining. In ECCV, pages 254–269, 2018.
- [50] Yinxiao Li, Pengchong Jin, Feng Yang, Ce Liu, Ming-Hsuan Yang, and Peyman Milanfar. Comisr: Compression-informed video super-resolution. In ICCV, 2021.
- [51] Yu Li, Robby T Tan, Xiaojie Guo, Jiangbo Lu, and Michael S Brown. Rain streak removal using layer priors. In CVPR, pages 2736–2744, 2016.
- [52] Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration using swin transformer. In IEEE Int. Conf. Comput. Vis. Worksh., 2021.
- [53] Ding Liu, Bihan Wen, Yuchen Fan, Chen Change Loy, and Thomas S Huang. Non-local recurrent network for image restoration. arXiv preprint arXiv:1806.02919, 2018.
- [54] Hanxiao Liu, Zihang Dai, David R So, and Quoc V Le. Pay attention to mlps. arXiv preprint arXiv:2105.08050, 2021.
- [55] Xiaohong Liu, Yongrui Ma, Zhihao Shi, and Jun Chen. Griddehazenet: Attention-based multi-scale network for image dehazing. In ICCV, pages 7314–7323, 2019.
- [56] Xing Liu, Masanori Suganuma, Zhun Sun, and Takayuki Okatani. Dual residual networks leveraging the potential of paired operations for image restoration. In CVPR, pages 7007–7016, 2019.
- [57] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. ICCV, 2021.
- [58] Zheng Liu, Botao Xiao, Muhammad Alrabeiah, Keyan Wang, and Jun Chen. Single image dehazing with a generic model-agnostic convolutional neural network. IEEE Signal Processing Letters, 26(6):833–837, 2019.
- [59] Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983, 2016.
- [60] Erik Matlin and Peyman Milanfar. Removal of haze and noise from a single image. In Computational Imaging X, volume 8296, page 82960T. International Society for Optics and Photonics, 2012.
- [61] Zibo Meng, Runsheng Xu, and Chiu Man Ho. Gia-net: Global information aware network for low-light imaging. In European Conference on Computer Vision, pages 327–342. Springer, 2020.
- [62] Seungjun Nah, Tae Hyun Kim, and Kyoung Mu Lee. Deep multi-scale convolutional neural network for dynamic scene deblurring. In CVPR, pages 3883–3891, 2017.
- [63] Seungjun Nah, Sanghyun Son, Suyoung Lee, Radu Timofte, and Kyoung Mu Lee. Ntire 2021 challenge on image deblurring. In CVPR Workshops, pages 149–165, June 2021.
- [64] Seungjun Nah, Sanghyun Son, Suyoung Lee, Radu Timofte, and Kyoung Mu Lee. Ntire 2021 challenge on image deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 149–165, 2021.
- [65] Zhangkai Ni, Wenhan Yang, Shiqi Wang, Lin Ma, and Sam Kwong. Towards unsupervised deep image enhancement with generative adversarial network. IEEE TIP, 29:9140–9151, 2020.
- [66] Ben Niu, Weilei Wen, Wenqi Ren, Xiangde Zhang, Lianping Yang, Shuzhen Wang, Kaihao Zhang, Xiaochun Cao, and Haifeng Shen. Single image super-resolution via a holistic attention network. In ECCV, pages 191–207. Springer, 2020.
- [67] Ozan Oktay, Jo Schlemper, Loic Le Folgoc, Matthew Lee, Mattias Heinrich, Kazunari Misawa, Kensaku Mori, Steven McDonagh, Nils Y Hammerla, Bernhard Kainz, et al. Attention u-net: Learning where to look for the pancreas. arXiv preprint arXiv:1804.03999, 2018.
- [68] Jinshan Pan, Deqing Sun, Hanspeter Pfister, and Ming-Hsuan Yang. Blind image deblurring using dark channel prior. In CVPR, pages 1628–1636, 2016.
- [69] Dongwon Park, Dong Un Kang, Jisoo Kim, and Se Young Chun. Multi-temporal recurrent neural networks for progressive non-uniform single image deblurring with incremental temporal training. In ECCV, pages 327–343. Springer, 2020.
- [70] Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. In AAAI, volume 32, 2018.
- [71] Olivier Petit, Nicolas Thome, Clement Rambour, Loic Themyr, Toby Collins, and Luc Soler. U-net transformer: self and cross attention for medical image segmentation. In International Workshop on Machine Learning in Medical Imaging, pages 267–276. Springer, 2021.
- [72] Tobias Plotz and Stefan Roth. Benchmarking denoising algorithms with real photographs. In CVPR, pages 1586–1595, 2017.
- [73] Rui Qian, Robby T Tan, Wenhan Yang, Jiajun Su, and Jiaying Liu. Attentive generative adversarial network for raindrop removal from a single image. In CVPR, pages 2482–2491, 2018.
- [74] Xu Qin, Zhilin Wang, Yuanchao Bai, Xiaodong Xie, and Huizhu Jia. Ffa-net: Feature fusion attention network for single image dehazing. In AAAI, volume 34, pages 11908–11915, 2020.
- [75] Yuhui Quan, Shijie Deng, Yixin Chen, and Hui Ji. Deep learning for seeing through window with raindrops. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2463–2471, 2019.
- [76] Yongming Rao, Wenliang Zhao, Zheng Zhu, Jiwen Lu, and Jie Zhou. Global filter networks for image classification. arXiv preprint arXiv:2107.00645, 2021.
- [77] Dongwei Ren, Wangmeng Zuo, Qinghua Hu, Pengfei Zhu, and Deyu Meng. Progressive image deraining networks: A better and simpler baseline. In CVPR, pages 3937–3946, 2019.
- [78] Wenqi Ren, Lin Ma, Jiawei Zhang, Jinshan Pan, Xiaochun Cao, Wei Liu, and Ming-Hsuan Yang. Gated fusion network for single image dehazing. In CVPR, 2018.
- [79] Jaesung Rim, Haeyun Lee, Jucheol Won, and Sunghyun Cho. Real-world blur dataset for learning and benchmarking deblurring algorithms. In ECCV, pages 184–201. Springer, 2020.
- [80] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015.
- [81] Ziyi Shen, Wenguan Wang, Xiankai Lu, Jianbing Shen, Haibin Ling, Tingfa Xu, and Ling Shao. Human-aware motion deblurring. In ICCV, pages 5572–5581, 2019.
- [82] Sanghyun Son, Jaeha Kim, Wei-Sheng Lai, Ming-Hsuan Yang, and Kyoung Mu Lee. Toward real-world super-resolution via adaptive downsampling models. IEEE transactions on pattern analysis and machine intelligence, 2021.
- [83] Maitreya Suin, Kuldeep Purohit, and AN Rajagopalan. Spatially-attentive patch-hierarchical network for adaptive motion deblurring. In CVPR, pages 3606–3615, 2020.
- [84] Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deep high-resolution representation learning for human pose estimation. In CVPR, pages 5693–5703, 2019.
- [85] Peize Sun, Yi Jiang, Rufeng Zhang, Enze Xie, Jinkun Cao, Xinting Hu, Tao Kong, Zehuan Yuan, Changhu Wang, and Ping Luo. Transtrack: Multiple-object tracking with transformer. arXiv preprint arXiv:2012.15460, 2020.
- [86] Xin Tao, Hongyun Gao, Xiaoyong Shen, Jue Wang, and Jiaya Jia. Scale-recurrent network for deep image deblurring. In CVPR, pages 8174–8182, 2018.
- [87] Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, et al. Mlp-mixer: An all-mlp architecture for vision. arXiv preprint arXiv:2105.01601, 2021.
- [88] Hugo Touvron, Piotr Bojanowski, Mathilde Caron, Matthieu Cord, Alaaeldin El-Nouby, Edouard Grave, Gautier Izacard, Armand Joulin, Gabriel Synnaeve, Jakob Verbeek, et al. Resmlp: Feedforward networks for image classification with data-efficient training. arXiv preprint arXiv:2105.03404, 2021.
- [89] Ashish Vaswani, Prajit Ramachandran, Aravind Srinivas, Niki Parmar, Blake Hechtman, and Jonathon Shlens. Scaling local self-attention for parameter efficient visual backbones. In CVPR, pages 12894–12904, 2021.
- [90] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS, pages 5998–6008, 2017.
- [91] Tianyu Wang, Xin Yang, Ke Xu, Shaozhe Chen, Qiang Zhang, and Rynson WH Lau. Spatial attentive single-image deraining with a high quality real rain dataset. In CVPR, pages 12270–12279, 2019.
- [92] Wenjing Wang, Chen Wei, Wenhan Yang, and Jiaying Liu. Gladnet: Low-light enhancement network with global awareness. In 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), pages 751–755. IEEE, 2018.
- [93] Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. In CVPR, pages 7794–7803, 2018.
- [94] Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1905–1914, 2021.
- [95] Xintao Wang, Ke Yu, Shixiang Wu, Jinjin Gu, Yihao Liu, Chao Dong, Yu Qiao, and Chen Change Loy. Esrgan: Enhanced super-resolution generative adversarial networks. In IEEE Eur. Conf. Comput. Vis. Worksh., pages 0–0, 2018.
- [96] Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE TIP, 13:600–612, 2004.
- [97] Zhendong Wang, Xiaodong Cun, Jianmin Bao, and Jianzhuang Liu. Uformer: A general u-shaped transformer for image restoration. arXiv preprint arXiv:2106.03106, 2021.
- [98] Chen Wei, Wenjing Wang, Wenhan Yang, and Jiaying Liu. Deep retinex decomposition for low-light enhancement. arXiv preprint arXiv:1808.04560, 2018.
- [99] Wei Wei, Deyu Meng, Qian Zhao, Zongben Xu, and Ying Wu. Semi-supervised transfer learning for image rain removal. In CVPR, pages 3877–3886, 2019.
- [100] Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon. Cbam: Convolutional block attention module. In ECCV, pages 3–19, 2018.
- [101] Haiyan Wu, Yanyun Qu, Shaohui Lin, Jian Zhou, Ruizhi Qiao, Zhizhong Zhang, Yuan Xie, and Lizhuang Ma. Contrastive learning for compact single image dehazing. In CVPR, pages 10551–10560, 2021.
- [102] Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. Segformer: Simple and efficient design for semantic segmentation with transformers. arXiv preprint arXiv:2105.15203, 2021.
- [103] Li Xu, Shicheng Zheng, and Jiaya Jia. Unnatural l0 sparse representation for natural image deblurring. In CVPR, pages 1107–1114, 2013.
- [104] Runsheng Xu, Hao Xiang, Zhengzhong Tu, Xin Xia, Ming-Hsuan Yang, and Jiaqi Ma. V2x-vit: Vehicle-to-everything cooperative perception with vision transformer. arXiv preprint arXiv:2203.10638, 2022.
- [105] Wenhan Yang, Robby T Tan, Jiashi Feng, Jiaying Liu, Zongming Guo, and Shuicheng Yan. Deep joint rain detection and removal from a single image. In CVPR, pages 1357–1366, 2017.
- [106] Rajeev Yasarla and Vishal M Patel. Uncertainty guided multi-scale residual learning-using a cycle spinning cnn for single image de-raining. In CVPR, pages 8405–8414, 2019.
- [107] Zongsheng Yue, Hongwei Yong, Qian Zhao, Lei Zhang, and Deyu Meng. Variational denoising network: Toward blind noise modeling and removal. arXiv preprint arXiv:1908.11314, 2019.
- [108] Zongsheng Yue, Qian Zhao, Lei Zhang, and Deyu Meng. Dual adversarial network: Toward real-world noise removal and noise generation. In ECCV, pages 41–58. Springer, 2020.
- [109] Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming-Hsuan Yang, and Ling Shao. Cycleisp: Real image restoration via improved data synthesis. In CVPR, pages 2696–2705, 2020.
- [110] Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming-Hsuan Yang, and Ling Shao. Learning enriched features for real image restoration and enhancement. In ECCV, pages 492–511. Springer, 2020.
- [111] Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming-Hsuan Yang, and Ling Shao. Multi-stage progressive image restoration. In CVPR, pages 14821–14831, 2021.
- [112] Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412, 2017.
- [113] Hongguang Zhang, Yuchao Dai, Hongdong Li, and Piotr Koniusz. Deep stacked hierarchical multi-patch network for image deblurring. In CVPR, pages 5978–5986, 2019.
- [114] He Zhang and Vishal M Patel. Density-aware single image de-raining using a multi-stream dense network. In CVPR, pages 695–704, 2018.
- [115] He Zhang, Vishwanath Sindagi, and Vishal M Patel. Image de-raining using a conditional generative adversarial network. IEEE TCSVT, 30(11):3943–3956, 2019.
- [116] Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, and Dimitris N Metaxas. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In ICCV, pages 5907–5915, 2017.
- [117] Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, and Dimitris N Metaxas. Stackgan++: Realistic image synthesis with stacked generative adversarial networks. IEEE TPAMI, 41(8):1947–1962, 2018.
- [118] Jiawei Zhang, Jinshan Pan, Jimmy Ren, Yibing Song, Linchao Bao, Rynson WH Lau, and Ming-Hsuan Yang. Dynamic scene deblurring using spatially variant recurrent neural networks. In CVPR, pages 2521–2529, 2018.
- [119] Kaihao Zhang, Wenhan Luo, Yiran Zhong, Lin Ma, Bjorn Stenger, Wei Liu, and Hongdong Li. Deblurring by realistic blurring. In CVPR, pages 2737–2746, 2020.
- [120] Kai Zhang, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE TIP, 26(7):3142–3155, 2017.
- [121] Yulun Zhang, Yapeng Tian, Yu Kong, Bineng Zhong, and Yun Fu. Residual dense network for image super-resolution. In CVPR, pages 2472–2481, 2018.
- [122] Yonghua Zhang, Jiawan Zhang, and Xiaojie Guo. Kindling the darkness: A practical low-light image enhancer. In ACM MM, pages 1632–1640, 2019.
- [123] Long Zhao, Zizhao Zhang, Ting Chen, Dimitris N Metaxas, and Han Zhang. Improved transformer for high-resolution gans. arXiv preprint arXiv:2106.07631, 2021.
- [124] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. In ICCV, pages 2223–2232, 2017.
- [125] Xiang Zhu, Filip Šroubek, and Peyman Milanfar. Deconvolving psfs for a better motion deblurring using multiple images. In European Conference on Computer Vision, pages 636–647. Springer, 2012.