我们真的取得了很大进展吗? 重新审视、基准测试和改进异构图神经网络
摘要。
11footnotetext:平等贡献。44脚注文本:通讯作者。近年来,异构图神经网络(HGNN)蓬勃发展,但每项工作使用的独特数据处理和评估设置阻碍了对其进展的充分理解。 在这项工作中,我们通过使用 12 个最新 HGNN 的官方代码、数据集、设置和超参数,系统地再现了 HGNN 的进展,揭示了有关 HGNN 进展的令人惊讶的发现。 我们发现,简单的同质 GNN,例如 GCN 和 GAT,由于设置不当而在很大程度上被低估。 具有适当输入的 GAT 通常可以在各种场景中匹配或优于所有现有的 HGNN。 为了促进稳健且可重复的 HGNN 研究,我们构建了异构图基准(HGB)111所有代码和数据均可在https://github.com/THUDM/HGB获取,HGB排行榜位于https://www.biendata.xyz/hgb。,由 11 个不同的数据集和三个任务组成。 HGB标准化了异构图数据分割、特征处理和性能评估的过程。 最后,我们引入了一个简单但非常强大的基线 Simple-HGN,它的性能显着优于 HGB 上的所有先前模型,以加速未来 HGNN 的进步。
1. 介绍
由于图神经网络(GNN)(Kipf and Welling,2017;Battaglia等人,2018)近年来已经占据了图挖掘研究的中心舞台,研究人员开始关注其潜力异构图(又名异构信息网络)(Hu 等人, 2020b; Dong 等人, 2017; Wang 等人, 2019b; Yun 等人, 2019; Fu 等人, 2020; Yang 等人, 2020b) 。 异构图由具有不同辅助信息的多种类型的节点和边组成,将新颖有效的图学习算法与嘈杂且复杂的工业场景(例如推荐)连接起来。
为了应对异构性的挑战,人们提出了各种异构 GNN(HGNN)(Wang 等人,2019b;Yun 等人,2019;Yang 等人,2020b)来解决相关任务,包括节点分类、链接预测和知识感知推荐。 以节点分类为例,HGNN 众多,如 HAN (Wang 等人, 2019b)、GTN (Yun 等人, 2019)、RSHN (Zhu 等)人, 2019), HetGNN (张 等人, 2019), MAGNN (傅 等人, 2020), HGT (胡 等人, 2020a) 和 HetSANN (Hong 等人, 2020) 是在过去两年内开发的。
尽管开发了各种新模型,但迄今为止,我们对它们实际如何取得进展的理解仍受到每个模型采用的独特数据处理和设置的限制。 为了全面展示该领域的进展,我们利用原始论文发布的代码、数据集、实验设置、超参数全面重现了 12 个最流行的 HGNN 模型的实验。 令人惊讶的是,我们发现这些最先进的 HGNN 生成的结果并不像承诺的那样令人兴奋(参见表 1),即:
-
(1)
简单同质 GNN,即 GCN (Kipf 和 Welling,2017) 和 GAT (Veličković 等人,2017) 的性能在很大程度上被低估了。 在大多数情况下,只要输入适当,即使是普通的 GAT 也可以超越现有的 HGNN。
-
(2)
部分过往作品的演出因设置不当或数据泄露而被误报。
我们的进一步调查还表明:
-
(3)
在大多数异构数据集中,元路径不是必需的。
-
(4)
HGNN 仍有很大的改进空间。
我们认为,出现上述情况很大程度上是因为每项工作的单独数据和实验设置阻碍了不同技术的公平和一致的验证,从而极大地阻碍了 HGNN 的进步。
为了促进稳健和开放的 HGNN 开发,我们构建了异构图基准 (HGB)。 HGB 目前包含 11 个异构图数据集,这些数据集在异构性(节点和边类型的数量)、任务(节点分类、链接预测和知识感知推荐)和领域(例如学术图、用户项目图和知识图谱)。 HGB 为数据加载、特征处理和评估提供了统一的接口,为比较 HGNN 模型提供了方便且一致的方法。 与 OGB (Hu 等人, 2020c) 类似,HGB 还托管一个排行榜 (https://www.biendata.xyz/hgb),用于公布可重现的状态 -最先进的 HGNN。
最后,受到表1中GAT重要性的启发,我们以GAT为骨干,设计了一个极其简单的HGNN模型——Simple-HGN。 Simple-HGN 可以被视为通过三种现有技术增强的 GAT:(1) 可学习类型嵌入以利用类型信息,(2) 残差连接以增强建模能力,以及 (3) 对输出进行 归一化嵌入。 在消融研究中,这些技术稳步提高了性能。 HGB 的实验结果表明,Simple-HGN 在 11 个数据集的三项任务上始终优于之前的 HGNN,使其成为迄今为止第一个明显优于普通 GAT 的 HGNN 模型。
综上所述,这项工作做出了以下贡献:
-
•
我们重新审视 HGNN 并找出阻碍进展的问题;
-
•
我们通过 HGB 对 HGNN 进行基准测试,以实现稳健的发展;
-
•
我们通过设计 Simple-HGN 模型来改进 HGNN。
| HAN (Wang et al., 2019b) | GTN (Yun et al., 2019) | RSHN (Zhu et al., 2019) | HetGNN (Zhang et al., 2019) | MAGNN (Fu et al., 2020) | ||||||||||
| Dataset | ACM | DBLP | ACM | IMDB | AIFB | MUTAG | BGS | MC (10%) | MC (30%) | DBLP | ||||
| Metric | Macro-F1 | Micro-F1 | Macro-F1 | Macro-F1 | Macro-F1 | Accuracy | Accuracy | Accuracy | Macro-F1 | Micro-F1 | Macro-F1 | Micro-F1 | Macro-F1 | Micro-F1 |
| model* | 91.89 | 91.85 | 94.18 | 92.68 | 60.92 | 97.22 | 82.35 | 93.10 | 97.8 | 97.9 | 98.1 | 98.2 | 93.13 | 93.61 |
| GCN* | 89.31 | 89.45 | 87.30 | 91.60 | 56.89 | - | - | - | - | - | - | - | 88.00 | 88.51 |
| GAT* | 90.55 | 90.55 | 93.71 | 92.33 | 58.14 | 91.67 | 72.06 | 66.32 | 96.2 | 96.3 | 96.5 | 96.5 | 91.05 | 91.61 |
| model | 90.94 | 90.96 | 92.95 | 92.28 | 57.532.22 | 97.22 | 82.35 | 93.10 | 97.06 | 97.11 | 97.34 | 97.37 | 92.81 | 93.36 |
| GCN | 92.25 | 92.29 | 91.48 | 92.28 | 59.111.73 | 97.22 | 79.41 | 96.55 | 91.88 | 92.04 | 95.37 | 95.57 | 88.31 | 89.37 |
| GAT | 92.08 | 92.15 | 94.18 | 92.49 | 58.861.73 | 100 | 80.88 | 100 | 98.25 | 98.30 | 98.42 | 98.50 | 94.40 | 94.78 |
2. 初步知识
2.1. 异构图
异构图(Sun and Han,2012)可以定义为,其中是节点的集合,是边的集合。 每个节点都有一个类型,每个边都有一个类型。 可能的节点类型和边类型的集合分别由和表示。 当时,图退化为普通的同质图。
2.2. 图神经网络
GNN 的目标是根据图结构和初始节点特征 ,在 L 层变换后学习每个节点 的表示向量 。 最终表示可以服务于各种下游任务,例如节点分类、图分类(池化后)和链接预测。
图卷积网络(GCN)(Kipf and Welling,2017)是GNN模型的先驱,其中层定义为
| (1) |
其中是层之后所有节点的表示。 是可训练的权重矩阵。 是激活函数,是具有自连接的归一化邻接矩阵。
图注意力网络 (GAT) (Veličković 等人, 2017) 后来取代了来自邻居的平均聚合,即,作为加权聚合,其中每条边 的权重 来自注意力机制(为简单起见,省略了层标记 )
| (2) |
其中 和 是可学习权重, 表示节点 的邻居。多头注意力技术(Vaswani等人,2017)也被用来提高性能。
以下许多工作(Abu-El-Haija 等人,2019;Xu 等人,2018a;Ding 等人,2018;Feng 等人,2020)进一步改进了 GCN 和 GAT,重点关注同质图。 实际上, 这些同构 GNN 还可以通过简单地忽略节点和边类型来处理异构图。
2.3. 异构图中的元路径
元路径(Sun和Han,2012;Sun等人,2011)已广泛用于异构图的挖掘和学习。 元路径是具有预定义(节点或边缘)类型模式的路径,即 ,其中 和 。 研究人员认为,这些复合模式意味着不同且有用的语义。 例如,“authorpaperauthor”元路径定义“共同作者”关系,“useritemuseritem”表示第一个用户可能是最后一个项目的潜在客户。
给定一个元路径,我们可以重新连接中的节点,得到元路径邻居图 。 当且仅当 和 之间至少有一条路径遵循原始图 中的元路径 时, 才存在于 中。
3. 现有异构 GNN 的问题
我们分析了流行的异构 GNN (HGNN),这些 GNN 按其旨在解决的任务进行组织。 对于每个 HGNN,将重点分析其在使用其官方代码、与其原始论文相同的数据集、设置和超参数来重现其结果的过程中发现的缺陷,总结如下表1。
3.1. 节点分类
3.1.1. 韩(王等人,2019b)。
异构图注意力网络(HAN)是解决异构图问题的早期尝试之一。 首先,HAN 需要人类专家选择的多个元路径。 然后 HAN 使用分层注意力机制来捕获节点级和语义级重要性。 对于每个元路径,节点级注意力是通过其相应元路径邻居图上的 GAT 实现的。 给出最终表示的语义级注意力是指所有元路径邻居图的节点级结果的加权平均值。
HAN 的一个缺陷是 HAN 和 GAT 之间的比较不公平。 由于 HAN 可以被视为许多元路径邻居图上 GAT 的加权集合,因此与普通 GAT 的比较对于证明其有效性至关重要。 然而,本文中的 GCN 和 GAT 基线仅以一个元路径邻居图作为输入,丢失了原始图中的大部分信息,即使它们报告了最佳元路径的结果。路径邻居图。
为了进行公平的比较,我们通过忽略类型并仅保留目标类型节点的特征,将原始图输入 GAT。 我们发现这种简单的同质方法始终优于 HAN,这表明同质 GNN 在很大程度上被低估了(有关详细信息,请参阅表1)。
接下来的大部分工作也遵循HAN的设置来与同质GNN进行比较,遭受“同质基线中信息缺失”问题,这导致HGNN的性能进展出现积极的认知偏差。
3.1.2. GTN (云等人,2019)。
Graph Transformer 网络(GTN)能够自动发现有价值的元路径,而不是像 HAN 那样依赖于手动选择。 直觉是,可以通过将多个子图的邻接矩阵相乘来获得元路径邻居图。 因此,GTN 使用软子图选择和矩阵乘法步骤来生成元路径邻居图,然后通过 GCN 对图进行编码。
GTN 的主要缺点是它消耗大量的时间和内存。 例如,在只有 18,000 个节点的 DBLP 上训练 GTN 需要 120 GB 内存和 12 小时。 相比之下,GCN 和 GAT 仅需要 1 GB 内存和 10 秒时间。
此外,当我们使用GTN官方代码对GTN和GAT进行五次测试时,我们从表1中发现: 尽管 GTN 消耗 GAT 的 时间和 内存,但它们的平均分数没有显着差异。
3.1.3. RSHN (朱 等人, 2019)
关系结构感知异构图神经网络(RSHN)首先构建粗化线图以获得边缘特征,然后使用新颖的消息传递神经网络(MPNN)(Gilmer等人,2017)来传播节点和边缘特征。
根据官方代码,RSHN中的实验存在严重问题。 首先,它不使用验证集,只是调整测试集上的超参数。 其次,它报告了论文中测试集上准确率最高的时期的准确率。 如表1所示,我们经过精心调整的 GAT 在 AIFB 和 BGS 数据集上的这种不正确设置下甚至可以达到 100% 的准确率,这远远优于他们论文中报告的 91.67% 和 66.32% 。
3.1.4. HetGNN (张等人, 2019)
异构图神经网络 (HetGNN) 首先使用重新启动的随机游走来生成节点的邻居,然后利用 Bi-LSTM 聚合每种类型和类型之间的节点特征。
HetGNN 与 HAN 具有相同的“同质基线中信息缺失”问题:与 GAT 进行比较时,将采样图而不是原始完整图输入到 GAT。 如表1所示, 输入正确的 GAT 显然可以获得更好的性能。
3.1.5. MAGNN (Fu 等人, 2020)
元路径聚合图神经网络 (MAGNN) 是一种增强型 HAN。 其动机是,当 HAN 处理元路径邻居图时,它只考虑元路径的两个端点,而忽略中间节点。 MAGNN 提出了几种元路径编码器来对路径上的所有信息进行编码,而不仅仅是端点。
然而MAGNN的实验存在两个问题。 首先,MAGNN 继承了 HAN 的“同质基线中信息缺失”问题,并且在正确输入的情况下表现不如 GAT。
更严重的是,MAGNN 在链接预测方面存在数据泄漏问题,因为它使用批量归一化,并在训练和测试期间顺序加载正负链接。 这样,小批量中的样本要么全为正,要么全为负,批量归一化中的均值和方差将提供额外的信息。 如果我们对测试集进行洗牌,使每个小批量随机包含正样本和负样本,那么在 Last.fm 数据集上,MAGNN 的 AUC 会从 98.91 急剧下降到 71.49。
3.1.6. HGT (胡 等人, 2020a)
异构图变换器(HGT)提出了一种基于变换器的模型,用于通过异构子图采样处理大型学术异构图。 由于 HGT 主要专注于通过图采样策略处理网络规模图(Hamilton 等人,2017;Yang 等人,2020a),其论文中使用的数据集(¿ 10,000,000 个节点)对于大多数人来说是无法承受的HGNN,除非通过子图采样来调整它们。 为了消除子图采样技术对性能的影响,我们将 HGT 及其官方代码应用于论文中未使用的相对较小的数据集,与 GAT 相比,产生了混合结果(参见表 3 )。
3.1.7. HetSANN (洪 等人, 2020)
用于异构结构学习的基于注意力的图神经网络(HetSANN)使用特定于类型的图注意力层来聚合局部信息,避免手动选择元路径。 据报道,HetSANN 在论文中具有令人鼓舞的性能。
然而,数据集和预处理细节并未随官方代码一起发布,并且在提交本工作时尚未收到作者的回复。 因此,我们直接应用带有标准超参数调整的 HetSANN,在其他数据集上给出的结果并不乐观(参见表 3)。
3.2. 链接预测
3.2.1. RGCN (Schlichtkrull 等人, 2018)
关系图卷积网络(RGCN)将 GCN 扩展到关系(多边类型)图。 RGCN中的卷积可以解释为不同边类型的普通图卷积的加权和。 对于每个节点,卷积层定义如下,
| (3) |
其中 是标准化常数, 是可学习参数。
3.2.2. GATNE (Cen 等人, 2019)
通用属性多路异构网络嵌入(GATNE)利用图卷积运算来聚合来自邻居的嵌入。 它依靠Skip-gram分别学习通用嵌入、特定嵌入和属性嵌入,最后将它们全部融合。 事实上,GATNE 与其说是 GNN 风格的模型,不如说是一种网络嵌入算法。
3.3. 知识感知推荐
推荐是异构 GNN 的主要应用,但大多数相关工作(Fan 等人,2019b,a;Niu 等人,2020;Liu 等人,2020)仅关注其特定的行业数据,导致在非开放数据集和模型的可移植性有限。 知识感知推荐是一个新兴的子领域,旨在通过将项目与开放知识图中的实体链接来改进推荐。 在本文中,我们主要调查和基准测试模型。
3.3.1. KGCN (王等人, 2019d) 和 KGNN-LS (王等人, 2019c)
KGCN 通过在知识图中相应的实体邻域之间执行聚合来增强项目表示。 KGNN-LS 进一步提出了标签平滑度假设,该假设假设知识图中的相似项目可能具有相似的用户偏好。 它添加了正则化项来帮助学习这样的个性化加权知识图。
3.3.2. KGAT (王等人, 2019a)
KGAT 与 KGCN 有着大致相似的想法。 主要区别在于知识图重建的辅助损失和预训练的 BPR-MF (Rendle 等人, 2009) 特征作为输入。 尽管论文中没有详细说明,但 KGAT 的一个重要贡献是将预训练特征引入到该任务中,从而极大地提高了性能。 基于这一发现,我们成功地简化了 KGAT,并获得了相似甚至更好的性能(参见表5,表示为 KGAT)。
3.4. 概括
总之,现有 HGNN 的主要共同问题是缺乏与同质 GNN 的公平比较,而其他工作在某种程度上鼓励新模型为自己配备新颖但冗余的模块,而不是更多地关注性能的进步。 此外,还有不可忽视的部分作品存在个别问题,例如数据泄露(傅等人,2020)、测试集调优(朱等人,2019) ,并且内存和时间消耗增加了两个数量级,但效率却没有提高(Yun 等人,2019)。
4. 异构图基准
4.1. 动机和概述
当前数据集存在问题。 几种类型的数据集——学术网络(例如,ACM、DBLP)、信息网络(例如,IMDB、Reddit)和推荐图(例如,Amazon、MovieLens)——是最常用的数据集,但详细的任务设置可以在不同的论文中会有很大不同。 例如,HAN (Wang 等人, 2019b) 和 GTN (Yun 等人, 2019) 丢弃了 ACM 中的引用链接,而其他人则使用原始版本。 此外,数据集的不同分割也会导致无法比较的结果。 最后,最近的图基准测试 OGB (Hu 等人, 2020c) 主要侧重于在同构图上对图机器学习方法进行基准测试,而不是专门针对异构图。
当前管道存在问题。 为了完成任务,HGNN 之外的组件也可以发挥关键作用。 例如,MAGNN (Fu 等人, 2020) 发现并非所有类型的节点特征都有用,基于验证集的预选择可能会有所帮助(参见§ 4.3)。 RGCN (Schlichtkrull 等人, 2018) 使用 DistMult (Yang 等人, 2014) 代替点积进行链接预测训练。 我们需要控制管道中的其他组件以进行公平比较。
HGB。 鉴于这些实际问题,我们提出了用于开放、可重现的异构 GNN 研究的异构图基准(HGB)。 我们通过建立HGB管道“特征预处理HGNN编码器下游解码器”来标准化数据分割、特征处理和性能评估的过程。 对于每个模型,HGB 根据其在验证集上的性能选择最合适的特征预处理和下游解码器。
4.2. 数据集构建
HGB 从之前的作品中收集了 11 个广泛认可的中等规模数据集,其中包含预定义的元路径,使其可供各种 HGNN 使用。 统计数据总结在表2中。
4.2.1. 节点分类
节点分类遵循传导设置,其中所有边在训练期间都可用,并且节点标签按照每个数据集中的 24% 进行训练、6% 进行验证和 70% 进行测试进行分割。
-
•
DBLP222http://web.cs.ucla.edu/~yzsun/data/是一个计算机科学参考书目网站。 我们在 4 个领域使用常用的子集,其中的节点代表作者、论文、术语和地点。
-
•
IMDB333https://www.kaggle.com/karrrimba/movie-metadatacsv是一个关于电影和相关信息的网站。 使用动作、喜剧、戏剧、浪漫和惊悚类的子集。
-
•
ACM 也是一个引用网络。 我们使用 HAN (Wang 等人, 2019b) 中托管的子集,但保留所有边缘,包括论文引用和参考文献。
-
•
Freebase (Bollacker等人, 2008)是一个巨大的知识图谱。 我们按照之前的调查(Yang等人,2020c)的程序,对具有大约1,000,000条边的8种类型实体的子图进行了采样。
4.2.2. 链接预测
链接预测被表述为 HGB 中的二元分类问题。 边缘按照 81%(用于训练)、9%(用于验证)和 10%(用于测试)进行分割。 然后仅通过训练集中的边来重建图。 对于测试中的负节点对,我们首先尝试均匀采样,发现大多数模型可以轻松做出近乎完美的预测(参见附录B)。 最后,我们对负节点对的 2 跳邻居进行采样,其中负节点对与测试集中的正节点对的比例为 1:1。
-
•
亚马逊是一个在线购物平台。 我们使用 GATNE (Cen 等人, 2019) 预处理的子集,其中包含电子类别产品,它们之间具有共同查看和共同购买的链接。
-
•
LastFM 是一个在线音乐网站。 我们使用 HetRec 2011 (Cantador 等人, 2011) 发布的子集,通过过滤掉只有一个链接的用户和标签来对数据集进行预处理。
-
•
PubMed444https://pubmed.ncbi.nlm.nih.gov是一个生物医学文献库。 我们使用 HNE (Yang 等人, 2020c) 构建的子集。
4.2.3. 知识感知推荐
我们随机划分 20% 的用户-项目交互作为每个用户的测试集,并将剩下的 80% 的交互作为训练集。
-
•
Amazon-book 是 Amazon-review555http://jmcauley.ucsd.edu/data/amazon/ 与书籍相关。
-
•
LastFM是从last.fm中提取的子集,时间戳为2015年1月至2015年6月。
-
•
Yelp-2018666https://www.yelp.com/dataset 是改编自 2018 年版 Yelp 挑战赛的数据集。 餐馆和酒吧等当地企业被视为项目。
-
•
Movielens 是 Movielens-20M 的子集777https://grouplens.org/datasets/movielens/,这是一个广泛使用的推荐数据集。
为了保证数据集的质量,我们使用10核设置来过滤低频节点。 为了将项目与知识图谱实体对齐,我们采用与(Wang等人,2019d,a)相同的过程。
| Node Classification | #Nodes | #Node Types | #Edges | #Edge Types | Target | #Classes |
| DBLP | 26,128 | 4 | 239,566 | 6 | author | 4 |
| IMDB | 21,420 | 4 | 86,642 | 6 | movie | 5 |
| ACM | 10,942 | 4 | 547,872 | 8 | paper | 3 |
| Freebase | 180,098 | 8 | 1,057,688 | 36 | book | 7 |
| Link Prediction | Target | |||||
| Amazon | 10,099 | 1 | 148,659 | 2 | product-product | |
| LastFM | 20,612 | 3 | 141,521 | 3 | user-artist | |
| PubMed | 63,109 | 4 | 244,986 | 10 | disease-disease | |
| Recommendation | Amazon-book | LastFM | Movielens | Yelp-2018 | |
| #Users | 70,679 | 23,566 | 37,385 | 45,919 | |
| #Items | 24,915 | 48,123 | 6,182 | 45,538 | |
| #Interactions | 846,434 | 3,034,763 | 539,300 | 1,183,610 | |
| #Entities | 113,487 | 106,389 | 24,536 | 136,499 | |
| #Relations | 39 | 9 | 20 | 42 | |
| #Triplets | 2,557,746 | 464,567 | 237,155 | 1,853,704 |
4.3. 特征预处理
正如§4.1中指出的,输入特征的预处理对性能有很大影响。 我们的预处理方法如下。
线性变换。 由于不同类型节点的输入特征可能在维度上有所不同,因此我们使用每个节点类型带有偏差的线性层将所有节点特征映射到共享特征空间。 这些线性层中的参数将与后续的 HGNN 一起进行优化。
有用的类型选择。 在许多数据集中,只有部分类型的特征对任务有用。 我们可以选择节点类型的子集来保留其特征,并将其他类型节点的特征替换为one-hot向量。 结合线性变换,替换相当于为未选择类型的每个节点学习一个单独的嵌入。 理想情况下,我们应该枚举所有类型的子集,并根据验证集的性能报告最好的一个,但由于训练模型次的消耗很高,我们决定只枚举三种选择,即使用所有给定的节点特征,仅使用目标节点类型的特征,或将所有节点特征替换为独热向量。
4.4. 下游解码器和损失函数
4.4.1. 节点分类
将 HGNN 的最终维度设置为与类数相同后,我们采用最常见的损失函数。 对于单标签分类,我们使用 softmax 和交叉熵损失。 对于多标签数据集,即 HGB 中的 IMDB,我们使用 sigmoid 激活和二元交叉熵损失。
4.4.2. 链接预测
正如 RGCN (Battaglia 等人, 2018) 所表明的那样,DistMult (Yang 等人, 2014) 的性能优于直接点积,因为具有多种类型的边,即对于节点对 和目标边缘类型 ,
| (4) |
其中 是类型 的可学习方阵(有时用对角矩阵进行正则化)。 我们发现,即使只有单一类型的边需要预测,DistMult 有时也优于点积。 我们尝试了点积和 DistMult 解码器,并报告了最佳结果。 损失函数是二元交叉熵。
4.4.3. 知识感知推荐
推荐与链接预测类似,但数据分布不同,更注重排名。 我们基于点积定义节点之间的相似度函数。 正如第 3.3.2 节中提到的,预训练的 BPR-MF 嵌入至关重要。 我们通过 中的偏置项合并 BPR-MF 嵌入 以避免修改其他模型的输入或架构,即
| (5) |
继KGAT (Wang 等人, 2019a)之后,我们选择BPR (Rendle 等人, 2009)损失进行训练。
| (6) |
其中是正对,是随机采样的负对。
4.5. 评估设置
我们通过使用不同的随机种子运行 5 次来评估所有数据集的所有方法,并报告平均分数和标准差。
4.5.1. 节点分类
我们使用 Macro-F1 和 Micro-F1 指标评估多类(DBLP、ACM、Freebase)和多标签(IMDB)数据集的节点分类。 实现基于sklearn888https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html。
4.5.2. 链接预测
我们使用 ROC-AUC(ROC 曲线下面积)和 MRR(平均倒数排名)指标来评估链接预测。 由于我们通常需要确定一个阈值,何时将一对对解码器给出的分数分类为正,ROC-AUC 可以在整个范围内评估差异阈值下的性能。 MRR可以评估不同方法的排名性能。 按照(Yang 等人, 2020c),我们计算测试集中由头对组成的MRR分数,并返回它们的平均值作为MRR性能。
4.5.3. 知识感知推荐
推荐任务更注重排序而不是分类。 因此,我们采用recall@20和ndcg@20作为我们的评估指标。 测试集中所有用户的平均指标被报告为基准性能。
5. 一个简单的异构 GNN
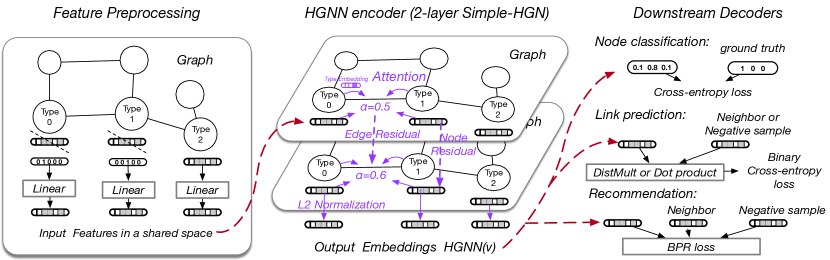
受到简单 GAT 相对于先进专用异构 GNN 的优势的启发,我们提出了 Simple-HGN,一种简单有效的异构图建模方法。 Simple-HGN 采用 GAT 作为骨干,并通过重新设计三种众所周知的技术进行了增强:可学习的边缘类型嵌入、残差连接和输出嵌入的 归一化。 图 1 展示了 Simple-HGN 的完整流程。
5.1. 可学习的边缘类型嵌入
尽管 GAT 在建模同质图方面具有强大的能力,但由于忽略了节点或边类型,它对于异构图可能不是最佳的。 为了解决这个问题,我们通过将边类型信息纳入注意计算来扩展原始图注意机制。 具体来说,在每一层,我们为每个边类型分配一个维度嵌入,并使用边类型嵌入和节点嵌入来计算注意力得分如下999为了简洁起见,我们在该等式中省略了上标。:
| (7) |
其中 表示节点 和节点 之间的边的类型, 是用于转换类型嵌入的可学习矩阵。
| DBLP | IMDB | ACM | Freebase | |||||
| Macro-F1 | Micro-F1 | Macro-F1 | Micro-F1 | Macro-F1 | Micro-F1 | Macro-F1 | Micro-F1 | |
| RGCN | 91.520.50 | 92.070.50 | 58.850.26 | 62.050.15 | 91.550.74 | 91.410.75 | 46.780.77 | 58.331.57 |
| HAN | 91.670.49 | 92.050.62 | 57.740.96 | 64.630.58 | 90.890.43 | 90.790.43 | 21.311.68 | 54.771.40 |
| GTN | 93.520.55 | 93.970.54 | 60.470.98 | 65.140.45 | 91.310.70 | 91.200.71 | - | - |
| RSHN | 93.340.58 | 93.810.55 | 59.853.21 | 64.221.03 | 90.501.51 | 90.321.54 | - | - |
| HetGNN | 91.760.43 | 92.330.41 | 48.250.67 | 51.160.65 | 85.910.25 | 86.050.25 | - | - |
| MAGNN | 93.280.51 | 93.760.45 | 56.493.20 | 64.671.67 | 90.880.64 | 90.770.65 | - | - |
| HetSANN | 78.552.42 | 80.561.50 | 49.471.21 | 57.680.44 | 90.020.35 | 89.910.37 | - | - |
| HGT | 93.010.23 | 93.490.25 | 63.001.19 | 67.200.57 | 91.120.76 | 91.000.76 | 29.282.52 | 60.511.16 |
| GCN | 90.840.32 | 91.470.34 | 57.881.18 | 64.820.64 | 92.170.24 | 92.120.23 | 27.843.13 | 60.230.92 |
| GAT | 93.830.27 | 93.390.30 | 58.941.35 | 64.860.43 | 92.260.94 | 92.190.93 | 40.742.58 | 65.260.80 |
| Simple-HGN | 94.010.24 | 94.460.22 | 63.531.36 | 67.360.57 | 93.420.44 | 93.350.45 | 47.721.48 | 66.290.45 |
| Amazon | LastFM | PubMed | ||||
| ROC-AUC | MRR | ROC-AUC | MRR | ROC-AUC | MRR | |
| RGCN | 86.340.28 | 93.920.16 | 57.210.09 | 77.680.17 | 78.290.18 | 90.260.24 |
| GATNE | 77.390.50 | 92.040.36 | 66.870.16 | 85.930.63 | 63.390.65 | 80.050.22 |
| HetGNN | 77.740.24 | 91.790.03 | 62.090.01 | 83.560.14 | 73.630.01 | 84.000.04 |
| MAGNN | - | - | 56.810.05 | 72.930.59 | - | - |
| HGT | 88.262.06 | 93.870.65 | 54.990.28 | 74.961.46 | 80.120.93 | 90.850.33 |
| GCN | 92.840.34 | 97.050.12 | 59.170.31 | 79.380.65 | 80.480.81 | 90.990.56 |
| GAT | 91.650.80 | 96.580.26 | 58.560.66 | 77.042.11 | 78.051.77 | 90.020.53 |
| Simple-HGN | 93.400.62 | 96.940.29 | 67.590.23 | 90.810.32 | 83.390.39 | 92.070.26 |
| Amazon-Book | LastFM | Yelp-2018 | MovieLens | |||||
| recall@20 | ndcg@20 | recall@20 | ndcg@20 | recall@20 | ndcg@20 | recall@20 | ndcg@20 | |
| KGCN | 0.14640.0002 | 0.07690.0002 | 0.08190.0002 | 0.07050.0002 | 0.06830.0003 | 0.04310.0003 | 0.42370.0008 | 0.27530.0005 |
| KGNN-LS | 0.14480.0003 | 0.07590.0001 | 0.08060.0003 | 0.06950.0002 | 0.06710.0003 | 0.04220.0002 | 0.42180.0008 | 0.27410.0005 |
| KGAT | 0.15070.0003 | 0.08020.0004 | 0.08770.0003 | 0.07490.0003 | 0.06970.0002 | 0.04500.0001 | 0.45320.0004 | 0.30070.0008 |
| KGAT | 0.14860.0003 | 0.07900.0002 | 0.08900.0002 | 0.07620.0002 | 0.07150.0001 | 0.04600.0001 | 0.45530.0003 | 0.30310.0006 |
| Simple-HGN | 0.15870.0011 | 0.08540.0005 | 0.09170.0006 | 0.07970.0003 | 0.07320.0003 | 0.04660.0003 | 0.46180.0007 | 0.30900.0007 |
5.2. 剩余连接
由于过度平滑和梯度消失问题,GNN 很难变得很深(Li 等人,2018;Xu 等人,2018b)。 计算机视觉中缓解这一问题的一个著名解决方案是残差连接(He等人,2016)。 然而,最初的 GCN 论文(Kipf 和 Welling,2017) 显示了图卷积上残差连接的负面结果。 最近的研究(Li等人,2020)发现,精心设计的预激活实现可以使GNN中的残差连接再次变得出色。
节点残差。 我们为跨层的节点表示添加预激活残差连接。 层的聚合可以表示为
| (8) |
其中 是边 的注意力权重, 是激活函数 (ELU (Clevert 等人, 2015)默认)。 当第层维度发生变化时,需要额外的可学习线性变换,即
| (9) |
边缘残差。 最近,Realformer (He 等人, 2020) 揭示了注意力分数上的残余连接也有帮助。 通过等式获得原始注意力分数后。 (7),我们向它们添加剩余连接,
| (10) |
其中超参数 是缩放因子。
多头注意力。 与GAT类似,我们采用多头注意力来增强模型的表达能力。 具体来说,我们根据方程(8)执行独立注意机制,并将它们的结果连接起来作为最终表示。 对应的更新规则为:
| (11) |
| (12) |
| (13) |
其中 表示串联操作, 是由 线性变换 根据方程 (9)。
通常输出尺寸不能精确地除以头数。 在 GAT 之后,我们不再使用串联,而是对最终 () 层的表示采用平均,即
| (14) |
链路预测的适应。 我们稍微修改了模型架构,以获得更好的链路预测性能。 边缘残差被移除,最终的嵌入是所有层嵌入的串联。 此改编版本与 JKNet (Xu 等人, 2018b) 类似。
| Task | Node Classification | Link Prediction | Recommendation | |||
| Dataset | IMDB | Last.fm | Movielens-20M | |||
| Metric | Macro-F1 | Micro-F1 | ROC-AUC | MRR | recall@20 | ndcg@20 |
| Simple-HGN | 63.531.36 | 67.360.57 | 67.590.23 | 90.810.32 | 0.46260.0006 | 0.35320.0005 |
| w.o. type embedding | 63.041.00 | 67.060.40 | 67.610.13 | 90.520.13 | 0.46320.0005 | 0.35370.0007 |
| w.o. L2 normalization | 58.061.62 | 65.330.69 | 61.070.96 | 82.511.56 | 0.38370.0187 | 0.28160.0173 |
| w.o. residual connections | 61.612.34 | 66.281.11 | 63.330.78 | 84.130.62 | 0.42610.0004 | 0.31920.0006 |
5.3. 标准化
输出嵌入的归一化对于基于检索的任务非常常见,因为归一化后的点积将相当于余弦相似度。 但我们也发现了它对分类任务的改进,这在计算机视觉中也观察到了(Ranjan等人,2017)。 此外,它建议将缩放参数乘以输出嵌入(Ranjan等人,2017)。 我们发现调整适当的 确实可以提高性能,但在不同的数据集中它差异很大。 因此,我们保留方程的形式。 (15) 为简单起见。
6. 实验
我们对 1) 3 节中讨论的所有 HGNN、2) GCN 和 GAT 以及 3) HGB 上的 Simple-HGN 的结果进行了基准测试。 所有实验均报告五次运行的平均值和标准方差。
6.1. 基准
表 3、4 和 5 分别报告节点分类、链路预测和知识感知推荐的结果。 结果表明,在公平比较下,1)简单同质 GAT 在大多数情况下可以匹配最好的 HGNN,2)继承自 GAT,Simple-HGN 在四个数据集上的节点分类、三个数据集上的链接预测方面始终优于所有先进的 HGNN 方法。数据集,以及三个数据集的知识感知推荐。
所有以前的 HGNN 的实现都是基于其官方代码,以避免重新实现引入的错误。 如有必要,唯一的修改发生在其数据加载接口和下游解码器上,以使它们的代码适应 HGB 管道。
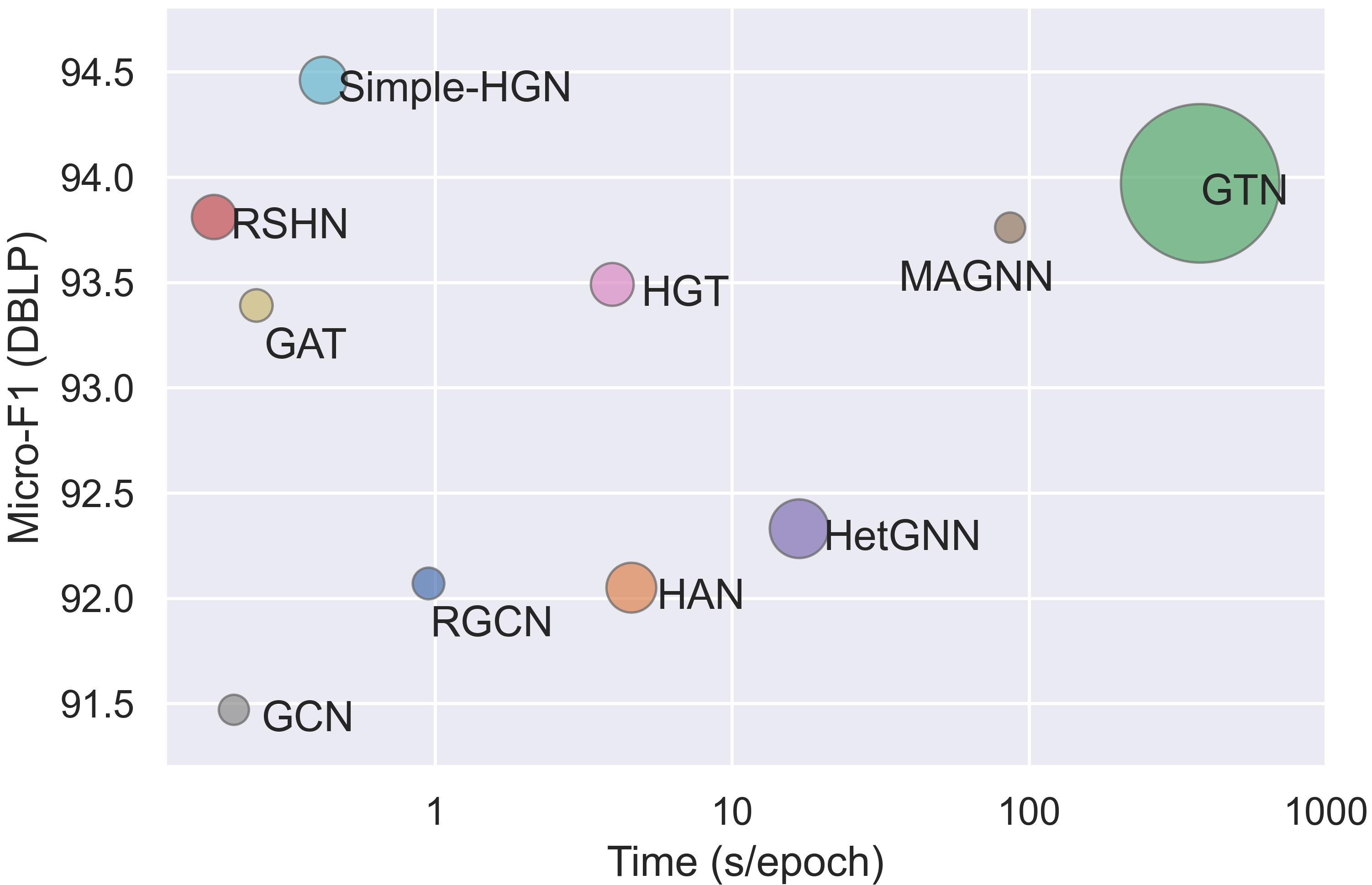
6.2. 时间和内存消耗
我们测试了 DBLP 数据集上用于节点分类的所有可用 HGNN 的时间和内存消耗。 结果如图2所示。 值得注意的是,我们只测量每个模型一个 epoch 的时间消耗,但收敛所需的 epoch 数量可能多种多样且难以准确定义。 由于我们未能获得合理的 Micro-F1 分数,HetSANN 被省略。
6.3. 消融研究
7. 讨论与结论
在这项工作中,我们确定了异构 GNN 中被忽视的问题,设置了异构图基准(HGB),并引入了一个简单而强大的基准 Simple-HGN。 这项工作的目标是通过促进可重复和稳健的研究来理解和推进异构 GNN 的发展。
尽管取得了广泛且有希望的结果,但异构 GNN 和广泛的异构图表示学习仍然存在悬而未决的问题。
显式类型信息有用吗? 表 6 中的消融研究表明,类型嵌入仅带来了微小的改进。 我们假设主要原因是节点特征的异质性已经暗示了不同的节点和边类型。 另一种可能是当前的图注意力机制(Veličković等人,2017)太弱,无法将类型信息与特征信息融合。 我们把这个问题留到以后研究。
元路径或变体在 GNN 中仍然有用吗? 元路径(Sun and Han,2012)被提出来将不同的语义与人类先验分开。 然而,(图)神经网络的前提是通过提取数据背后隐含的有用特征来避免特征工程过程。 前面几节的结果还表明,基于元路径的 GNN 不会产生优于同构 GAT 的性能。 是否有比现有尝试更好的方法来利用异构 GNN 中的元路径? 未来异构 GNN 仍然需要元路径吗?替代品是什么?
致谢。
该工作得到国家自然科学基金杰出青年基金(61825602)和国家自然科学基金(61836013)的支持。 作者衷心感谢 UIUC 的王浩南和阿里巴巴的杨红霞的友好反馈。参考
- (1)
- Abu-El-Haija et al. (2019) Sami Abu-El-Haija, Bryan Perozzi, Amol Kapoor, Nazanin Alipourfard, Kristina Lerman, Hrayr Harutyunyan, Greg Ver Steeg, and Aram Galstyan. 2019. Mixhop: Higher-order graph convolutional architectures via sparsified neighborhood mixing. In ICML’19. PMLR, 21–29.
- Battaglia et al. (2018) Peter W Battaglia, Jessica B Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez, Vinicius Zambaldi, Mateusz Malinowski, Andrea Tacchetti, David Raposo, Adam Santoro, Ryan Faulkner, et al. 2018. Relational inductive biases, deep learning, and graph networks. arXiv preprint arXiv:1806.01261 (2018).
- Bollacker et al. (2008) Kurt Bollacker, Colin Evans, Praveen Paritosh, Tim Sturge, and Jamie Taylor. 2008. Freebase: a collaboratively created graph database for structuring human knowledge. In SIGMOD’08. 1247–1250.
- Cantador et al. (2011) Iván Cantador, Peter Brusilovsky, and Tsvi Kuflik. 2011. Second workshop on information heterogeneity and fusion in recommender systems (HetRec2011). In RecSys’11. 387–388.
- Cen et al. (2019) Yukuo Cen, Xu Zou, Jianwei Zhang, Hongxia Yang, Jingren Zhou, and Jie Tang. 2019. Representation learning for attributed multiplex heterogeneous network. In KDD’19. 1358–1368.
- Clevert et al. (2015) Djork-Arné Clevert, Thomas Unterthiner, and Sepp Hochreiter. 2015. Fast and accurate deep network learning by exponential linear units (elus). arXiv preprint arXiv:1511.07289 (2015).
- Ding et al. (2018) Ming Ding, Jie Tang, and Jie Zhang. 2018. Semi-supervised learning on graphs with generative adversarial nets. In CIKM’18. 913–922.
- Dong et al. (2017) Yuxiao Dong, Nitesh V Chawla, and Ananthram Swami. 2017. metapath2vec: Scalable Representation Learning for Heterogeneous Networks. In KDD ’17. ACM, 135–144.
- Fan et al. (2019b) Shaohua Fan, Junxiong Zhu, Xiaotian Han, Chuan Shi, Linmei Hu, Biyu Ma, and Yongliang Li. 2019b. Metapath-guided heterogeneous graph neural network for intent recommendation. In KDD’19. 2478–2486.
- Fan et al. (2019a) Wenqi Fan, Yao Ma, Qing Li, Yuan He, Eric Zhao, Jiliang Tang, and Dawei Yin. 2019a. Graph neural networks for social recommendation. In WWW’19. 417–426.
- Feng et al. (2020) Wenzheng Feng, Jie Zhang, Yuxiao Dong, Yu Han, Huanbo Luan, Qian Xu, Qiang Yang, Evgeny Kharlamov, and Jie Tang. 2020. Graph Random Neural Networks for Semi-Supervised Learning on Graphs. NeurIPS 33 (2020).
- Fu et al. (2020) Xinyu Fu, Jiani Zhang, Ziqiao Meng, and Irwin King. 2020. MAGNN: metapath aggregated graph neural network for heterogeneous graph embedding. In WWW’20.
- Gilmer et al. (2017) Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. 2017. Neural message passing for quantum chemistry. In ICML’17. PMLR, 1263–1272.
- Hamilton et al. (2017) William L Hamilton, Rex Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs. arXiv preprint arXiv:1706.02216 (2017).
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In CVPR’16.
- He et al. (2020) Ruining He, Anirudh Ravula, Bhargav Kanagal, and Joshua Ainslie. 2020. RealFormer: Transformer Likes Residual Attention. arXiv preprint arXiv:2012.11747 (2020).
- Hong et al. (2020) Huiting Hong, Hantao Guo, Yucheng Lin, Xiaoqing Yang, Zang Li, and Jieping Ye. 2020. An attention-based graph neural network for heterogeneous structural learning. In AAAI’20, Vol. 34. 4132–4139.
- Hu et al. (2020c) Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. 2020c. Open graph benchmark: Datasets for machine learning on graphs. arXiv preprint arXiv:2005.00687 (2020).
- Hu et al. (2020b) Ziniu Hu, Yuxiao Dong, Kuansan Wang, Kai-Wei Chang, and Yizhou Sun. 2020b. GPT-GNN: Generative Pre-Training of Graph Neural Networks. In KDD.
- Hu et al. (2020a) Ziniu Hu, Yuxiao Dong, Kuansan Wang, and Yizhou Sun. 2020a. Heterogeneous graph transformer. In WWW’20. 2704–2710.
- Kipf and Welling (2017) Thomas N Kipf and Max Welling. 2017. Semi-supervised classification with graph convolutional networks. In ICLR’17.
- Li et al. (2020) Guohao Li, Chenxin Xiong, Ali Thabet, and Bernard Ghanem. 2020. Deepergcn: All you need to train deeper gcns. arXiv preprint arXiv:2006.07739 (2020).
- Li et al. (2018) Qimai Li, Zhichao Han, and Xiao-Ming Wu. 2018. Deeper insights into graph convolutional networks for semi-supervised learning. In AAAI’18, Vol. 32.
- Liu et al. (2020) Danyang Liu, Jianxun Lian, Shiyin Wang, Ying Qiao, Jiun-Hung Chen, Guangzhong Sun, and Xing Xie. 2020. KRED: Knowledge-Aware Document Representation for News Recommendations. In RecSys’20. 200–209.
- Niu et al. (2020) Xichuan Niu, Bofang Li, Chenliang Li, Rong Xiao, Haochuan Sun, Hongbo Deng, and Zhenzhong Chen. 2020. A Dual Heterogeneous Graph Attention Network to Improve Long-Tail Performance for Shop Search in E-Commerce. In KDD’20. 3405–3415.
- Ranjan et al. (2017) Rajeev Ranjan, Carlos D Castillo, and Rama Chellappa. 2017. L2-constrained softmax loss for discriminative face verification. arXiv preprint arXiv:1703.09507 (2017).
- Rendle et al. (2009) Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. 2009. BPR: Bayesian personalized ranking from implicit feedback. In UAI’09. 452–461.
- Schlichtkrull et al. (2018) Michael Schlichtkrull, Thomas N Kipf, Peter Bloem, Rianne Van Den Berg, Ivan Titov, and Max Welling. 2018. Modeling relational data with graph convolutional networks. In ESWC’18. Springer, 593–607.
- Sun and Han (2012) Yizhou Sun and Jiawei Han. 2012. Mining Heterogeneous Information Networks: Principles and Methodologies. Morgan and Claypool Publishers.
- Sun et al. (2011) Yizhou Sun, Jiawei Han, Xifeng Yan, Philip S Yu, and Tianyi Wu. 2011. Pathsim: Meta path-based top-k similarity search in heterogeneous information networks. PVLDB 4, 11 (2011), 992–1003.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. NeurIPS 30 (2017), 5998–6008.
- Veličković et al. (2017) Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. 2017. Graph attention networks. arXiv preprint arXiv:1710.10903 (2017).
- Wang et al. (2019c) Hongwei Wang, Fuzheng Zhang, Mengdi Zhang, Jure Leskovec, Miao Zhao, Wenjie Li, and Zhongyuan Wang. 2019c. Knowledge-aware graph neural networks with label smoothness regularization for recommender systems. In KDD’19. 968–977.
- Wang et al. (2019d) Hongwei Wang, Miao Zhao, Xing Xie, Wenjie Li, and Minyi Guo. 2019d. Knowledge graph convolutional networks for recommender systems. In WWW’19. 3307–3313.
- Wang et al. (2019a) Xiang Wang, Xiangnan He, Yixin Cao, Meng Liu, and Tat-Seng Chua. 2019a. Kgat: Knowledge graph attention network for recommendation. In KDD’19. 950–958.
- Wang et al. (2019b) Xiao Wang, Houye Ji, Chuan Shi, Bai Wang, Yanfang Ye, Peng Cui, and Philip S Yu. 2019b. Heterogeneous graph attention network. In WWW’19.
- Xu et al. (2018a) Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. 2018a. How Powerful are Graph Neural Networks?. In ICLR’18.
- Xu et al. (2018b) Keyulu Xu, Chengtao Li, Yonglong Tian, Tomohiro Sonobe, Ken-ichi Kawarabayashi, and Stefanie Jegelka. 2018b. Representation Learning on Graphs with Jumping Knowledge Networks. ICML (2018), 5449–5458.
- Yang et al. (2014) Bishan Yang, Wen-tau Yih, Xiaodong He, Jianfeng Gao, and Li Deng. 2014. Embedding entities and relations for learning and inference in knowledge bases. arXiv preprint arXiv:1412.6575 (2014).
- Yang et al. (2020b) Carl Yang, Aditya Pal, Andrew Zhai, Nikil Pancha, Jiawei Han, Charles Rosenberg, and Jure Leskovec. 2020b. MultiSage: Empowering GCN with Contextualized Multi-Embeddings on Web-Scale Multipartite Networks. In KDD’20. 2434–2443.
- Yang et al. (2020c) Carl Yang, Yuxin Xiao, Yu Zhang, Yizhou Sun, and Jiawei Han. 2020c. Heterogeneous Network Representation Learning: A Unified Framework with Survey and Benchmark. TKDE (2020).
- Yang et al. (2020a) Zhen Yang, Ming Ding, Chang Zhou, Hongxia Yang, Jingren Zhou, and Jie Tang. 2020a. Understanding negative sampling in graph representation learning. In KDD’20. 1666–1676.
- Yun et al. (2019) Seongjun Yun, Minbyul Jeong, Raehyun Kim, Jaewoo Kang, and Hyunwoo J Kim. 2019. Graph Transformer Networks. In NeurIPS’19.
- Zhang et al. (2019) Chuxu Zhang, Dongjin Song, Chao Huang, Ananthram Swami, and Nitesh V Chawla. 2019. Heterogeneous graph neural network. In KDD’19. 793–803.
- Zhu et al. (2019) Shichao Zhu, Chuan Zhou, Shirui Pan, Xingquan Zhu, and Bin Wang. 2019. Relation structure-aware heterogeneous graph neural network. In ICDM’19.
附录A时间和内存消耗
附录 B随机阴性
链路预测任务中测试集负样本的分布对性能得分有很大影响。 我们的基准测试中随机阴性测试的结果如表7所示。 我们可以看到,分数大大高于表4中的分数。 大多数作品(Cen等人,2019;Fu等人,2020;Zhang等人,2019)使用随机采样的负对来评估链接预测,对于大多数方法来说,负对很容易与正对区分开来。 然而,在现实场景中,由于广泛使用的“检索然后重新排序”工业管道,我们通常需要区分具有相似特征的正负节点对,而不是随机节点对。 因此,我们选择使用采样的 2 跳邻居作为基准测试中的负测试集。
| Amazon | Last.fm | PubMed | ||||
| ROC-AUC | MRR | ROC-AUC | MRR | ROC-AUC | MRR | |
| RGCN | 89.760.33 | 95.760.22 | 81.900.29 | 96.680.14 | 88.320.08 | 96.890.20 |
| GATNE | 96.670.08 | 98.680.06 | 87.420.22 | 96.350.24 | 78.360.92 | 90.640.49 |
| HetGNN | 95.510.39 | 97.910.08 | 87.350.02 | 96.150.18 | 84.140.01 | 91.000.03 |
| MAGNN | - | - | 76.500.21 | 85.680.04 | - | - |
| HGT | 91.702.31 | 96.070.68 | 80.490.78 | 95.480.38 | 90.290.68 | 97.310.09 |
| GCN | 98.570.21 | 99.770.02 | 84.710.1 | 96.600.12 | 86.061.23 | 98.800.56 |
| GAT | 98.450.11 | 99.610.22 | 83.552.11 | 91.455.66 | 87.571.23 | 98.380.11 |
| Simple-HGN | 98.740.25 | 99.520.08 | 91.040.22 | 99.210.15 | 91.400.30 | 96.040.25 |
附录C超参数
在所有情况下,我们都在 内搜索学习率,并在 内搜索权重衰减率。 我们在推荐中设置dropout率为0.1,在节点分类和链接预测中默认设置为0.5。 对于批量大小,我们会尝试,除非作者的代码有特殊要求。 对于训练纪元,我们将使用基于验证集评估的提前停止机制来保证完全训练。
为了简洁起见,我们将表示一些变量。 假设图层嵌入的维度为,边嵌入的维度为,注意力向量的维度(如果存在)为,图层的数量为,注意力头数量为,LeakyReLU的负斜率为。
对于输入特征类型,我们使用 表示使用所有给定特征, 表示仅使用目标节点特征, 表示所有具有 1 的节点- 热门功能。
C.1。 简单HGN
C.1.1。 节点分类
我们为所有数据集设置、、。 对于 DBLP、ACM 和 Freebase 数据集,我们设置 、。 对于 IMDB 数据集,我们设置 、。 我们为 IMDB 设置 ,为 ACM 设置 ,为 DBLP 和 Freebase 设置 。
C.1.2。 链接预测
我们为所有数据集设置、、、、。 对于Amazon和PubMed,我们使用DistMult作为解码器,并设置。 对于LastFM,我们使用点积作为解码器,并设置。 我们对所有数据集使用 。
C.1.3。 推荐
对于所有数据集,我们按照 (Wang 等,2019a) 中的建议设置了 、、、、。
C.2。 韩
C.2.1。 节点分类
我们为所有数据集设置 、、 和 。 对于输入要素类型,我们在 Freebase 中使用 ,在其他数据集中使用 。 我们也尝试过更大的,但是性能的变化变得非常大。 因此,我们按照HAN代码中的建议保留。
C.3。 GTN
C.3.1。 节点分类
我们对所有数据集使用他们论文中建议的自适应学习率。 我们设置,GTN通道数为2。 对于 DBLP 和 ACM,我们设置 。 对于 IMDB 数据集,我们设置 。
此外,正如 GTN 论文中所建议的,我们将关键字节点信息聚合为邻居的属性,并使用左子图进行节点分类。 我们还尝试将整个图用于 GTN。 不幸的是,它在这种情况下崩溃了,这表明 GTN 对图结构很敏感。
C.4。 RSHN
对于 IMDB 和 DBLP,我们设置 和 。 对于 ACM,我们 和 。 我们分别使用 表示 ACM、IMDB 和 DBLP。
C.5。 神经网络
C.5.1。 节点分类
我们将所有数据集的 、 和批量大小设置为 200。 对于随机游走,我们将游走长度设置为 30,窗口大小设置为 5。
C.5.2。 链接预测
我们将所有数据集的 、 和批量大小设置为 200。 对于随机游走,我们将游走长度设置为 30,窗口大小设置为 5。
C.6。 磁力神经网络
我们在所有情况下都设置 、 和 。
C.6.1。 节点分类
我们在所有情况下都使用 。 对于 DBLP 和 ACM 数据集,我们将批量大小设置为 8,邻居样本数设置为 100。 对于 IMDB 数据集,我们使用完整的批量训练。
C.6.2。 链接预测
我们将 LastFM 的批量大小设置为 8,将相邻样本数设置为 100。 对于其他数据集,我们未能使 MAGNN 代码适应它们,因为存在太多硬编码。
C.7。 海特桑恩
C.7.1。 节点分类
对于 ACM,我们设置 、、 和 。 对于 IMDB,我们设置 、、 和 。 对于 DBLP,我们设置 、、 和 。
C.8。 肝移植
C.8.1。 节点分类
我们在每一层中使用层归一化,并为所有数据集设置,。 对于 ACM、DBLP、Freebase 和 IMDB, 分别设置为 2、3、3、5。 对于输入特征类型,我们在 Freebase 中使用 ,在 IMDB 和 DBLP 中使用 ,在 ACM 中使用 。
C.8.2。 链接预测
对于所有数据集,我们在每一层中使用层归一化,并将、、和DistMult设置为解码器。
C.9。 GCN
C.9.1。 节点分类
我们为所有数据集设置。 我们为 DBLP、ACM 和 Freebase 设置 ,为 IMDB 设置 。 我们对 DBLP 和 Freebase 使用 ,对 ACM 和 IMDB 使用 。
C.9.2。 链接预测
我们为所有数据集设置 、 和 。
C.10。 盖特
C.10.1。 节点分类
我们为所有数据集设置、。 对于 DBLP、ACM 和 Freebase,我们设置 和 。 对于 IMDB,我们设置 和 。 我们对 DBLP 和 Freebase 使用 ,对 ACM 使用 ,对 IMDB 使用 。
C.10.2。 链接预测
我们为所有数据集设置 、、 和 。
C.11。 RGCN
C.11.1。 节点分类
我们为所有数据集设置。 对于ACM,我们设置,。 对于 DBLP 和 Freebase,我们设置 、。 对于 IMDB,我们设置 、。
C.11.2。 链接预测
我们为所有数据集设置 、 和 。
C.12。 盖特内
C.12.1。 链接预测
我们为所有数据集设置、、、。
对于随机游走,我们将游走长度设置为 30,窗口大小设置为 5。 对于邻居采样,我们将用于优化的负样本设置为 5,将用于聚合的邻居样本设置为 10。
C.13。 KGCN 和 KGNN-LS
C.13.1。 推荐
对于所有数据集,我们设置 和 。 我们还尝试堆叠更多的图层,但这样做时性能会下降,这在(Wang 等人, 2019d; Wang 等人, 2019c) 实验中也发现了。 我们使用求和聚合器,因为它具有(Wang等人,2019d)中报告的最佳整体性能。
C.14。 凯格特
C.14.1。 推荐
我们为所有数据集设置、、。 对于注意力机制,我们根据其官方代码保留双向交互聚合器。
附录 D 元路径
基准实验中使用的元路径如表8所示。 我们尝试遵循先前的工作来选择元路径。 例如,DBLP、IMDB 和 LastFM 中的元路径来自(Fu 等人, 2020)。 ACM数据集中的元路径基于(Wang等人, 2019b),我们还添加了一些与引文和参考关系相关的元路径,这些元路径在(Wang等人, 2019b)中没有使用。人,2019b)。 对于Freebase数据集,我们首先统计长度从2到4的最常见的元路径,然后根据验证集的性能手动选择其中的7个。
| Dataset | Meta-path | Meaning | |||||||||||||||
| DBLP |
|
|
|||||||||||||||
| IMDB |
|
|
|||||||||||||||
| ACM |
|
|
|||||||||||||||
| Freebase |
|
|
|||||||||||||||
| LastFM |
|
|