深度学习中训练不稳定性的损失曲率视角
摘要
在这项工作中,我们研究了损失 Hessian 在许多分类任务中的演变,以了解损失曲率对训练动态的影响。 虽然之前的工作重点关注不同的学习率如何影响训练期间观察到的 Hessian 损失,但我们还分析了模型初始化、架构选择和常见训练启发式(例如梯度裁剪和学习率预热)的影响。 我们的结果表明,成功的模型和超参数选择允许早期优化轨迹避免或导航出高曲率区域并进入可容忍更高学习率的平坦区域。 我们的结果提出了一个统一的观点,即针对训练不稳定性的不同缓解策略如何最终解决神经网络优化的相同潜在故障模式,即不良调节。 受调节视角的启发,我们证明学习率预热可以提高训练稳定性,就像批量归一化、层归一化、MetaInit、GradInit 和 Fixup 初始化一样。
1简介
神经网络的优化很容易失败。 虽然最近的架构进步(例如跳过连接[8]和批量归一化[11])已成功应用于生成可靠地训练的架构和超参数,即使对可训练的配置很容易导致训练出现分歧。 更一般地说,在新领域中生成一个在稳定训练和快速优化进展之间取得适当平衡的配置可能很困难,因为实践者和研究人员几乎没有可靠的启发法来指导他们完成整个过程。 因此,特定的超参数调整协议对结果[3, 28]有很大的影响,并且成功通常依赖于大量的超参数搜索[20]。 对通用架构可训练的原理性理解将使研究人员能够更可靠地驾驭这一过程,并有可能显着加速寻找更好、更具可扩展架构的研究。
这项工作的实证研究的重点是更好地理解是什么限制了使用典型小批量随机梯度下降 (SGD) 系列算法训练的深度学习模型的最大可训练学习率。 作为本次调查的一部分,我们研究了深度学习社区开发的几种方法,这些方法可以实现更高的学习率和更高的性能。 人们已经开发了许多方法来实现这一目标,特别是归一化、学习率预热、梯度裁剪[22]以及更好的模型初始化,例如Fixup[37]、MetaInit [5] 和 GradInit [38]。 虽然这些方法当然不完全相同,但它们的一个共同点是,当应用于某些模型时,它们可以以更大的学习率进行训练(例如参见图 1)。
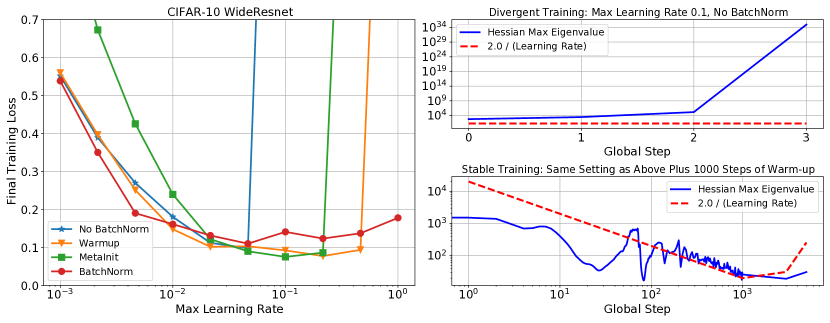
一个自然的假设是,能够以较大学习率进行训练的方法是通过降低锐度来实现的。111在整个工作中,我们将使用术语“锐度”来指代损失 Hessian 矩阵的最大特征值,表示为 。 训练期间的损失面。 事实上,这一假设已经被提出作为批量归一化[6, 26]和残差连接[17]以及损失表面的二次模型的有益效果之一预测当 [30] 时,SGD 优化不稳定。 然而,最近对二次稳定性边界与神经网络相关性的实证研究要么关注较小的模型,要么关注小学习率的全批量训练,并且不研究清晰度、模型初始化和学习率预热之间的联系 [4, 13]。
在这项工作中,我们设计了一系列大规模实验,研究当我们改变学习率、预热期、初始化和架构选择时损失锐度的演变。 我们的结果证明了 在神经网络优化中发挥的核心作用——在优化过程中保持足够小的 是在大学习率下成功训练的必要条件。 因此,减少 是适当调整许多架构和优化超参数的主要好处:包括模型初始化、标准化位置和预热计划。 具体来说,我们展示以下内容:
-
•
我们提供了大规模的经验证明,只有当优化轨迹主要位于参数空间区域中时,SGD+动量的神经网络训练才是稳定的,其中 ,其中 表示学习速度。 这证实了Wu 等人[30]的理论预测以及Jastrzebski 等人[13]和Cohen 等人[4]最近的实证观察>。
-
•
我们证明了没有归一化的架构的几种成功的初始化策略主要是通过在训练早期减少曲率来实现的,从而能够以更大的学习率进行训练。
-
•
我们表明,训练期间学习率预热逐渐降低 ,为更好的模型初始化提供类似的好处。 我们将预热运行的机制与Wu等人[30]的动态稳定性模型联系起来。
-
•
我们表明,学习率预热是研究更好的模型初始化的简单但有竞争力的基线。 我们证明了 Dauphin 和 Schoenholz [5]、Zhang 等人 [37]、Zhu 等人 [38] 在这一领域的关键进展可以通过单独学习率预热的应用来匹配。
-
•
最后,我们表明,大的损失曲率可能会导致大批量下的扩展性较差,而旨在改善损失调节的干预措施可以极大地提高模型利用数据并行性的能力。
2相关工作
理解 BatchNorm 损失 Hessian 矩阵一直是理解神经网络优化的中心研究对象。 Santurkar 等人 [26] 认为 Batch Normalization 的一个重要好处是提高了损失表面的平滑度,而 Lewkowycz 等人 [16] 指出这是改进的平滑度仅当较高的学习率与批量归一化结合使用时才会观察到。 我们的结果总体上与当前对批量归一化的理解一致,但是我们的一些实验提供了额外的细微差别,值得注意的是,我们观察到几个实例,尽管使用了批量归一化,但模型在训练早期仍遭受训练不稳定(和高损失曲率)(参见4)。
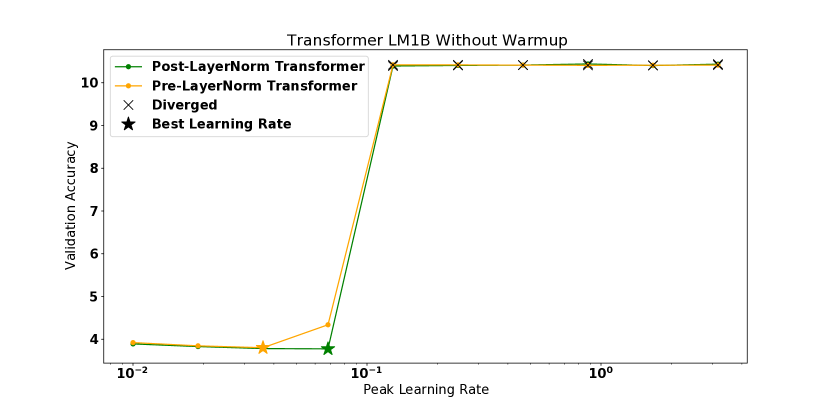
损失 Hessian 的演化 最近的研究仔细研究了清晰度和学习率之间的相互作用。 Cohen 等人[4]观察到,对于全批训练,损失曲率表现出“渐进锐化”,直到为止。 在我们的实验中,我们观察到使用 SGD 训练的模型会出现逐渐加剧的损失,但 LM1B 上的 Transformer 模型是一个明显的例外。 Lewkowycz 等人 [16] 提供了一个理论模型,预测一些在 点初始化并使用 MSE 损失进行训练的架构可能会进入“弹射器”状态,其中损失会增加早期,直到发现损失表面的较平坦区域,在 大大超过 的情况下发生发散。 我们的实验设置违反了这项工作中的许多假设,但值得注意的是,我们观察到的一些行为与弹射器动力学一致——我们观察到,即使在初始化时 ,模型也可以一致地进行训练,从而导致简短的结果初始训练不稳定,直到优化进入更平坦的区域。 然而,我们观察到一些情况,模型尽管在 点初始化,但仍存在分歧,这是该理论模型未预测到的。
Jastrzebski 等人 [13] 描述了在 SGD 中使用大学习率的几个预处理好处,即在训练期间观察到的 较小, 较大。 我们的结果为以下猜想提供了大规模的经验证据:较大的学习率会导致训练期间曲率更平坦。 此外,我们证明学习率预热和梯度裁剪利用这种机制进一步减少,因为当采用这两种技术时,一些模型可以用更大的学习率进行训练。
3实验设置
我们研究了在多个基准上训练的模型:用于图像分类的 CIFAR-10 [15] 和 ImageNet [25],用于语言的 LM1B [2]建模和用于神经机器翻译 (NMT) 的 WMT。 在 CIFAR-10 上,我们考虑使用或不使用批量归一化的 WideResnet [34] 和 DenseNet [10] 架构。 当没有批量归一化的训练时,我们考虑几种初始化策略,包括默认的“LeCun Normal”初始化和运行 MetaInit。 作为人为导致更差初始化的一种方法,我们还考虑了实验,其中我们按常数因子 缩放默认初始化产生的每个变量。 NMT 模型在 WMT’16 EN-DE 训练集上进行训练,在 WMT’16 EN-DE 验证集上针对超参数进行调整,并在 WMT’14 EN-DE 测试集上评估 BLEU 分数。 对于 NMT 和 LM1B 语言建模,我们训练 6 层 Transformer 模型[29]。 受Xiong等人[31]的启发,我们尝试了三种Layer Norm设置:前Layer Norm、后Layer Norm [18]以及Transformer无Layer Norm楷模。
每个模型都使用余弦衰减以不同的学习率进行训练(除非明确提及)。 对于预热实验,我们使用线性预热,它从 0 开始,在应用余弦衰减之前线性缩放到最大值 。 为了测量损失 Hessian 矩阵的最大特征值,我们使用 Lanczos 方法,其中迭代次数根据架构的需要而变化(附录中提供了详细信息)。
4 早期训练的不稳定和Hessian的损失
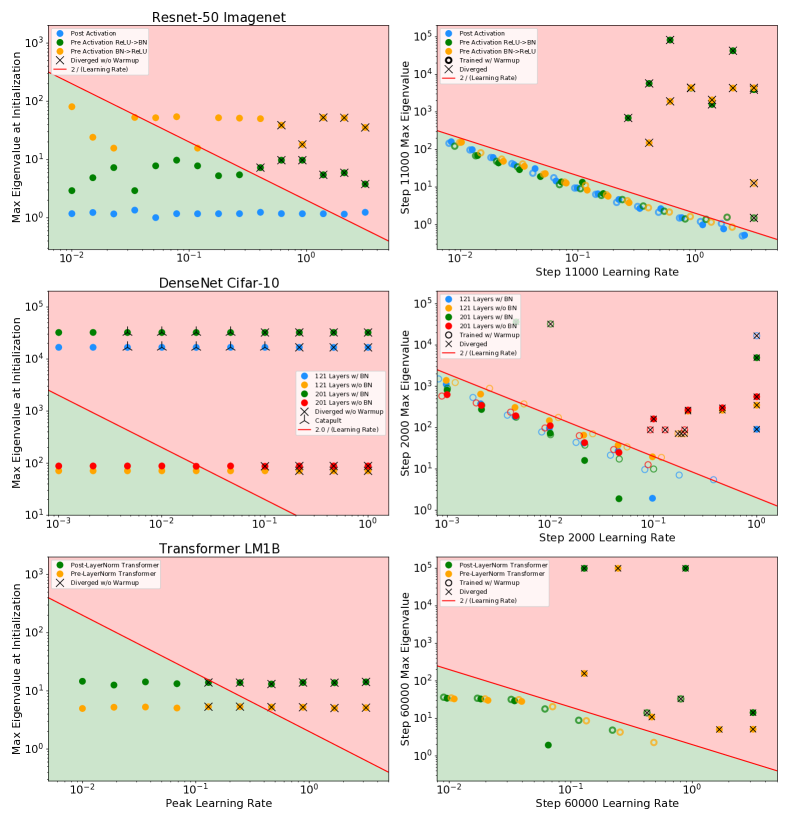
在图2中,我们绘制了在不同数据集上训练的一系列模型在初始化时和训练过程中的曲率(显示所有模型最终性能的图可以在附录中找到)。 每行表示不同的基础模型,左列绘制初始化时模型的曲率,并用“X”表示模型在没有预热的情况下训练时是否发散。 在右侧,我们绘制了训练过程中指定点的测量曲率和学习率。 我们在所有数据集中观察到,只有当优化进入 的参数空间区域时,训练才会成功,并且发散模型在发散前不久就位于该区域之外。 在初始化时,一些模型即使从不稳定区域开始也可以成功训练,并且一般来说,对于不稳定区域较深的模型更有可能出现发散。
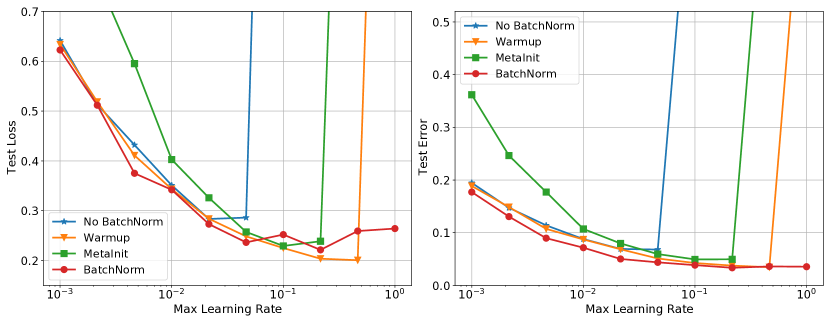
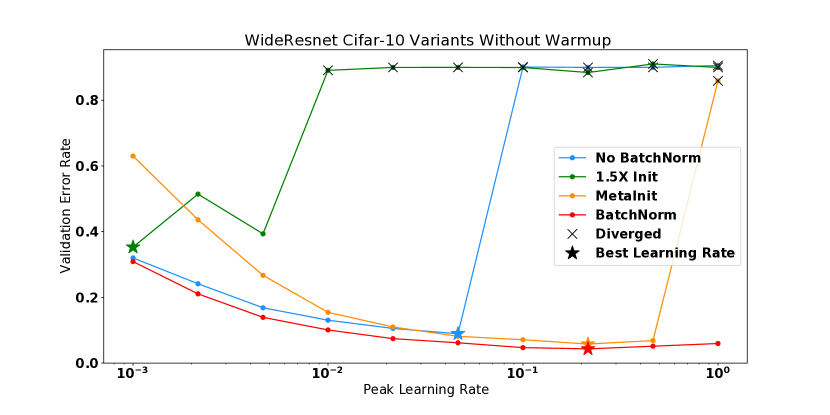
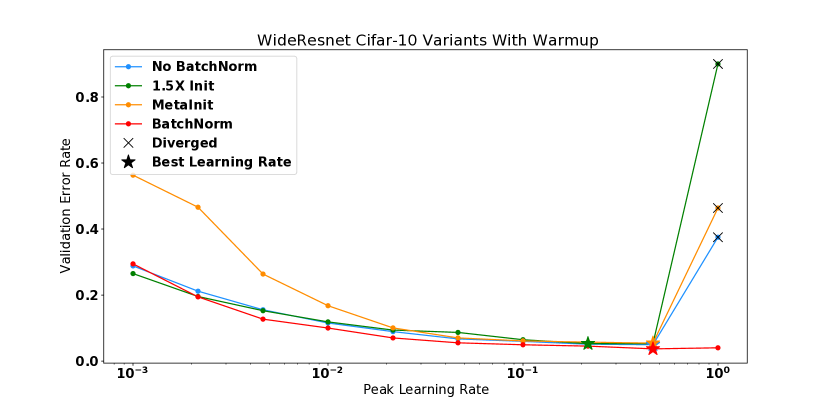
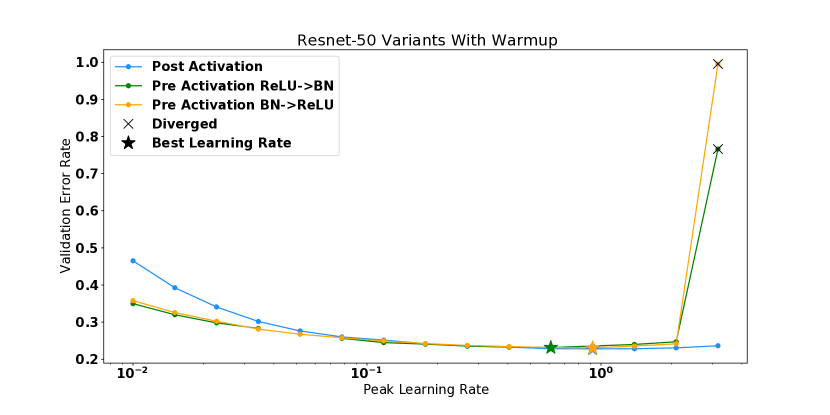
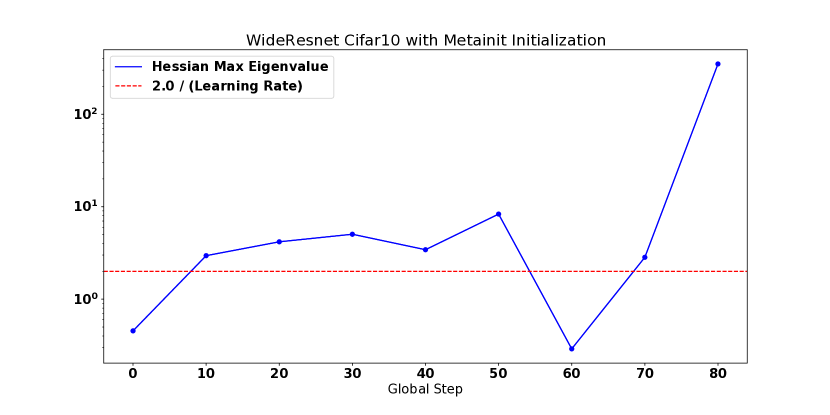
这些实验还直观地展示了不同的方法如何以更高的学习率解锁训练。 对于 CIFAR-10 WideResnet,删除批量归一化会导致模型在初始化时具有较高的曲率,并且在使用学习率 进行训练时会导致模型发散。 将 WideResnet 初始化放大 倍会加剧该问题,导致初始化时出现更高的曲率,并在 时出现发散。 MetaInit 在 非常小的点开始模型,并且允许在没有批量归一化的情况下以比默认初始化更高的学习率进行训练。 我们还观察到,当使用学习率预热来训练模型时,可以解锁更高的学习率,并且我们能够使用预热并从不良初始化开始来匹配 MetaInit 的性能。 热身对于在初始化或训练早期表现出较大 的模型特别有效。 其他模型(例如激活后 Resnet-50 和带有批量归一化的 WideResnet)并未从所考虑的学习率的预热中受益。
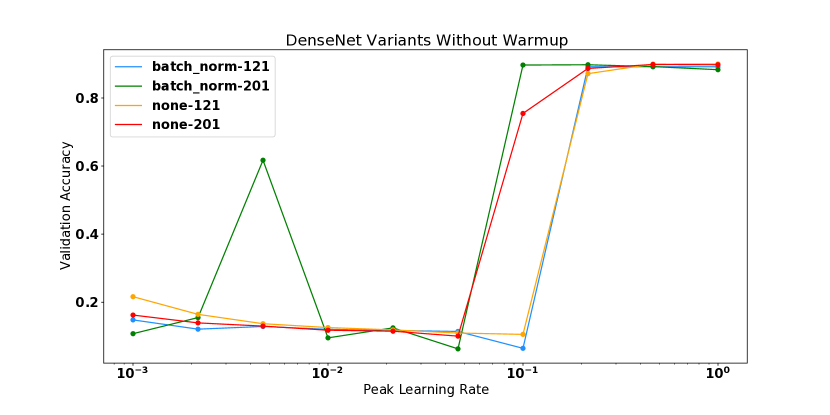
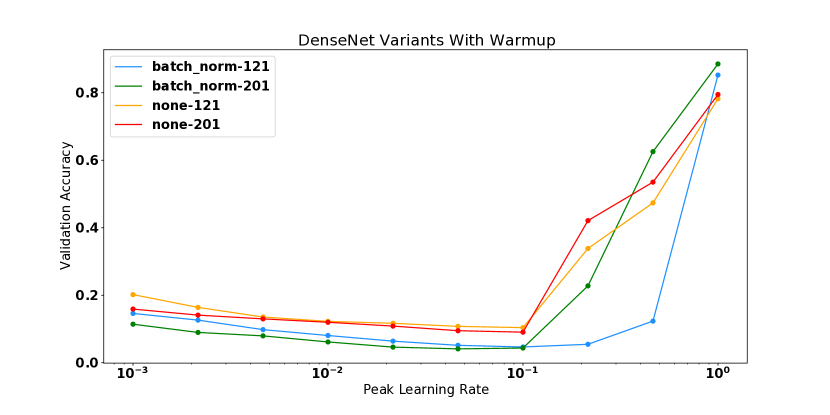
对于 DenseNet 实验,值得注意的是,具有批量归一化的模型实际上比非 BN 变体具有更高的曲率。 这与普遍接受的说法相反,即批量归一化可以提高损失表面的平滑度[6, 26],尽管并非没有先例,如Yang等人[32]所示批量归一化可能导致梯度爆炸的设置。 我们发现批量归一化模型比非 BN 变体更不稳定,因为一些模型在较小的学习率下出现分歧。 然而,当与热身相结合时,BN 模型可以在学习率 下进行训练,而这对于非 BN 变体来说并不成立,它们在这些学习率下无论有没有热身都存在差异。 这一结果表明,如果使用热身和更高的学习率进行训练,BN 仍然可以为该模型提供训练稳定性,以及更平坦的曲率中,但是在初始化时没有观察到平滑性方面的优势。
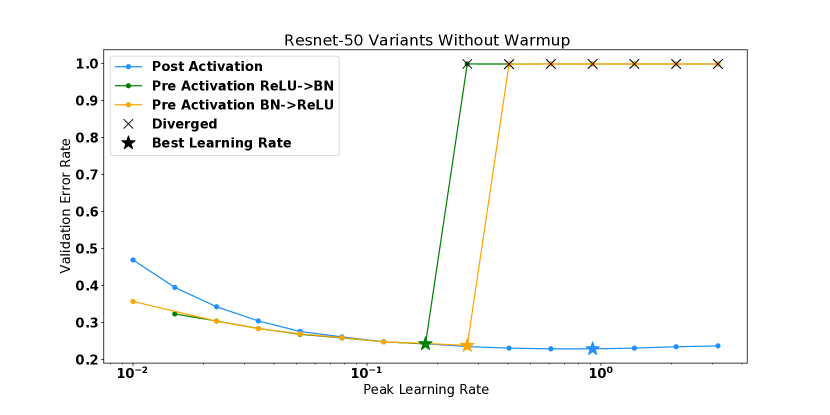
对于在 ImageNet 上训练的 Resnet-50,我们比较两个不同的残差块:预激活块 [9] 和更常用的后激活块 [8]。 对于预激活块,我们还考虑翻转 ReLU 激活和批量归一化的顺序,如 Brock 等人 [1] 中所考虑的那样。 我们发现,两个预激活模型都在相对于后激活变体具有更高曲率的区域中开始,并且这些模型在 时发散,而后激活变体可以在 。
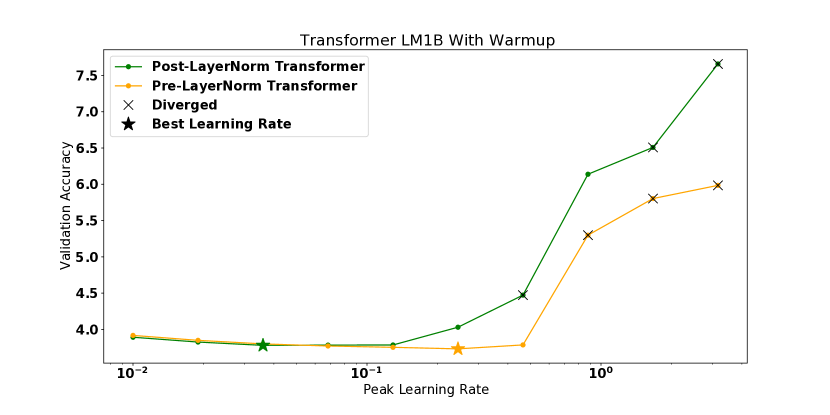
值得注意的是,我们的实验中有几个模型尽管是从 的区域开始的,但它们还是存在分歧。 对于前层规范转换器和后层规范转换器以及使用 MetaInit 初始化的 WideResnet 模型都会发生这种情况。 我们发现,对于这些发散模型,曲率在训练的初始步骤中迅速增加,这在训练中期图中部分可见,我们在其中绘制了发散之前的最终观察到的曲率。 这些模型的完整训练曲线可以在附录中找到。 这些例子值得注意,因为它表明在模型初始化时测量平滑度并不总是足以预测模型是否易于训练。 目前,一些架构创新的动机是对初始化时的梯度统计或平滑度进行分析[18]——更稳健的分析将考虑这些统计在 SGD 下的演化。
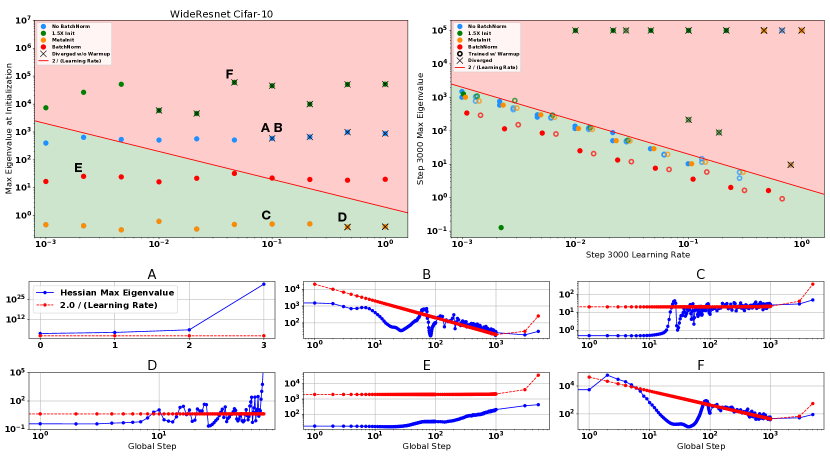
底行: 选择运行的曲率和学习率的全时演化(在顶行用字母标记)。 A:当以学习率训练时,非BN变体的分歧在3步以内。 B: 与 (A) 相同的配置,但使用热身时曲率在训练过程中逐渐减小,从而允许以 的峰值学习率成功训练。 C: MetaInit 允许通过在参数空间的平坦区域中开始优化,以学习速率 进行无需热身的训练。 尽管一开始曲率非常平坦,但我们观察到逐渐锐化,直到曲率围绕边界 波动。 D: 尽管从“稳定”区域开始,模型仍然出现分歧的示例。 曲率增长较早,最终在步长 100 之前发散。 E:以小学习率训练时渐进锐化的示例。 F: 学习率预热从更差的初始化中恢复(相同点在没有预热的情况下发散)。
5学习率预热、初始化和曲率之间的相互作用
学习率预热的成功与传统的优化智慧不一致,传统的优化智慧传统上建议根据曲率调整步长(例如,参见[19]中围绕方程2.4的讨论)。 然而,如果理解 是一个动态量,其演化与学习率计划紧密结合,那么预热期的好处就更容易理解了。 我们认为学习率预热的成功自然源于训练深度模型的两个属性:
-
1.
当学习率相对于 界限太大时,模型会出现分歧。
-
2.
当学习率仅略微超过 时,优化不稳定,直到参数移动到具有较小 [30, 16] 的区域。
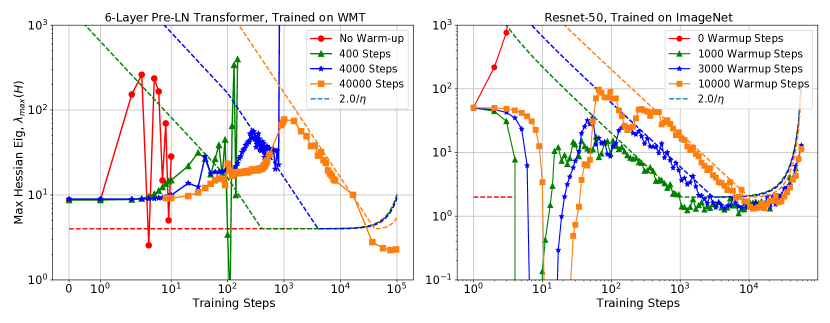
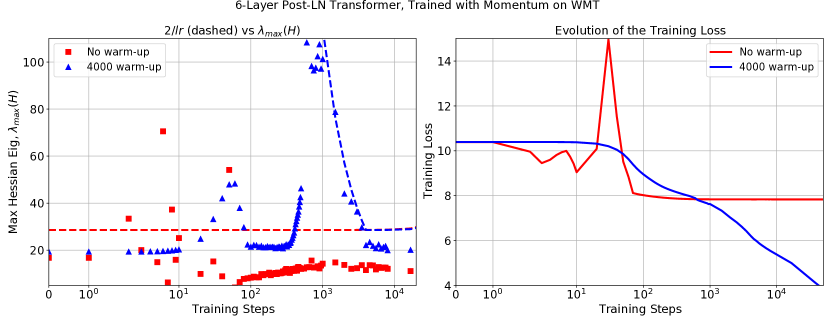
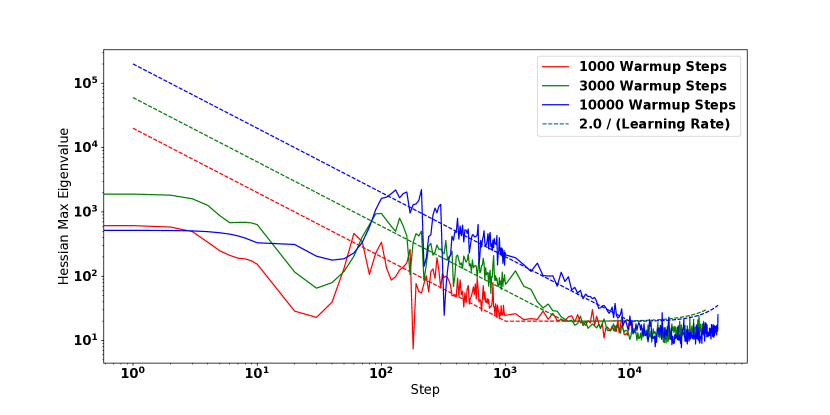
第一个标准意味着我们不能在初始化时以相对于 太大的值开始 。 第二个标准意味着逐渐增加 可以逐渐将参数“推”到优化稳定的参数空间区域(具有较低的 值)。 在图 4 中,有明显的证据表明这种“推动”,因为在预热期间,我们看到 在预热阶段的大部分时间都成立。 此外,即使我们改变预热期的长度,这种近似仍然成立。 其他示例参见附录中的图3(B 和F)以及图15。
热身并不是唯一能够在 期间减少 训练的方法,而是可以在 开始时较小的区域中初始化模型。 例如,考虑图 3 中的点 A、B 和 C。 每个点都显示了峰值学习率为 的非 BN WideResnet 的优化。 在 (A) 中,我们看到模型在没有使用默认初始化进行预热的情况下在 3 个步骤内发散。 在 (B) 中,我们看到线性预热期导致 逐渐减小,直到在步骤 1000 处达到 的峰值步长,并且不会发生发散。 最后在(C)中,我们使用MetaInit初始化相同的模型,此时在初始化时很小,并且模型可以在处进行训练而无需预热。
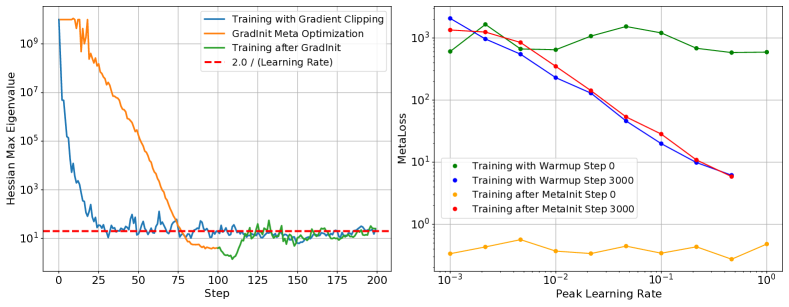
与前面提到的MetaInit类似,相关初始化策略的成功可以通过训练早期减少来解释。 在图 5(左)中,我们查看了 GradInit 元优化过程中 的演变,并将其与使用梯度裁剪简单训练相同模型进行比较222与预热类似,梯度裁剪会减小大曲率区域的步长。. 这两种方法都会导致 急剧下降,之后 徘徊在 附近。 值得注意的是,GradInit 在明显低于 界限的 处开始常规训练,但曲率在几步内迅速增加。 鉴于初始化和预热在减少 方面起着相似的作用,我们期望能够使用这两种方法实现相似的性能。 如表 1 和 2 所示,我们可以通过单独应用学习率预热来轻松匹配该领域的关键进展(有关实验详细信息,请参阅附录)。
除了控制训练中期的之外,学习率还控制着损失表面的更一般的调节措施。 例如,在图 5 中,我们观察到即使是 MetaInit gradient quotient(通过此初始化策略直接优化的条件测量)也由 mid 控制。训练。 这再次提供了进一步的证据,表明此初始化方法的主要好处是在初始化时减少 。 如图所示,通过优化更一般的梯度商获得的任何收益都必须是短暂的,因为初始化无法控制长期值。
| Model | Method | |||
|---|---|---|---|---|
| DenseNet-100 | Kaiming-Clip 1.0 | 35.43 | 93.97 | |
| DenseNet-100 | GradInit | 37.19 | 94.85 | |
| DenseNet-100 | Kaiming-Clip 6.0 | 39.0 | 94.65 |
| Model | Dataset | Method | ||
|---|---|---|---|---|
| WideResnet 28-10 (w/o BN) | CIFAR-10 | Warmup 1000 | 97.2 | |
| WideResnet 28-10 (w/o BN) | CIFAR-10 | MetaInit | 97.1 | |
| Resnet-50 (w/o BN) | ImageNet | Fixup | 76.0 | |
| Resnet-50 (w/o BN) | ImageNet | MetaInit | 76.0 | |
| Resnet-50 (w/o BN) | ImageNet | GradInit | 76.2 | |
| Resnet-50 (w/o BN) | ImageNet | Warmup 1000 | 76.2 | |
| Transformer 6L (w/o LN) | WMT | Warmup + Clip + .25x Init | 27.10 (BLEU) | |
| Transformer 6L (w/ LN) | WMT | LayerNorm | 27.01 (BLEU) |
6 曲率对批量大小缩放的影响
到目前为止,我们讨论了大的损失曲率限制了 的稳定学习率的训练范围。 在本节中,我们将重点介绍这些对可用学习率的限制如何影响模型有效利用更大批量大小的能力。 先前的研究从各种不同的角度研究了损失曲率和批量大小缩放之间的相互作用。 最值得注意的是,Shallue 等人 [27] 观察到,增加批量大小可以使训练速度持续提高,直到达到(与问题相关的)临界批量大小;将批量大小增加到超过此阈值会导致训练速度的提高逐渐减弱。 Zhang 等人[35]观察到,简单的噪声二次模型(NQM)能够捕获[27]中观察到的经验行为。 类似地,McCandlish等人[19]使用损失的二次近似来提供临界批量大小的封闭形式表达式,作为损失Hessian和随机梯度协方差的函数。 我们通过强调 在模型批量大小缩放行为中的作用来为这篇文献做出贡献。
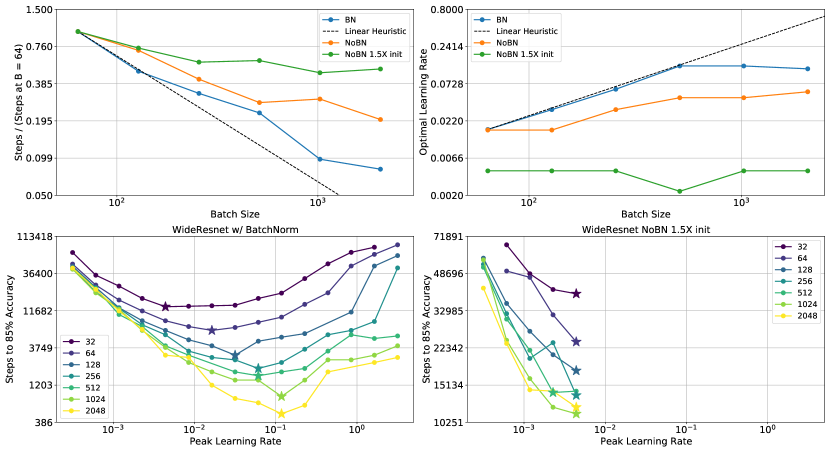
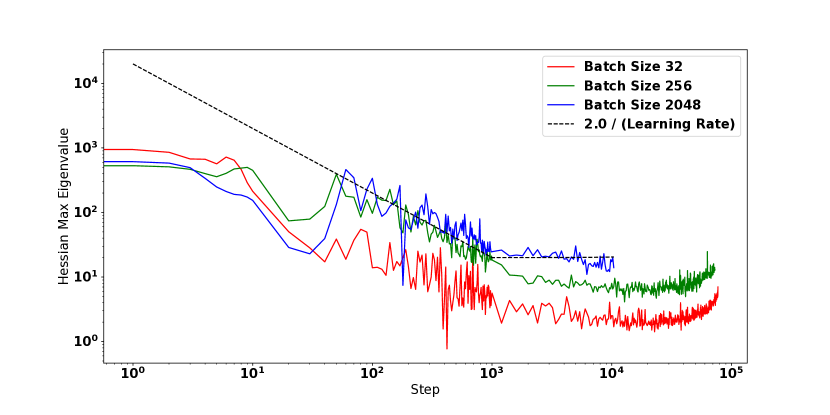
对于此分析,我们重点关注图 2 中考虑的三种 WideResnet 变体 - BatchNorm 模型(低曲率模型)、非 BatchNorm 模型(具有中等曲率)和非 BatchNorm 模型1.5 倍初始缩放(高曲率)。 我们训练这些模型,同时调整学习率和批量大小。 333我们在和之间的对数尺度网格上寻找最佳学习率。 对于批量大小,我们从 到 扫描 2 的幂。 然后,我们测量达到 验证精度所需的训练步骤数,以及每个批量大小的最佳学习率。 与 [27] 类似,我们通过在批量大小 下测量的值将绘制的步骤标准化为 精度。
结果如图6所示。 一些观察是有序的:随着批量大小的增加,低曲率模型显示训练速度几乎呈线性加速。 相比之下,高曲率模型在批量大小较大的情况下仅在训练速度方面表现出最小的改进。 这些缩放差异密切反映了最佳学习率 如何随批量大小变化:对于低曲率模型 随着批量大小线性增加,而对于高曲率模型 固定在 周围。 值得注意的是,对于高曲率模型 几乎总是最大的非发散值 - 这清楚地表明高损失曲率通过阻止使用更大的值来减慢训练速度。
从这些观察中可以看到一幅清晰的图景。 先前的研究表明,为了有效利用更大的批量大小,必须随着批量大小[12,7,27,19]同时提高学习率。 我们的结果表明,较大的 值对可能的最大学习率造成了严格限制,因此限制了模型有效利用数据并行性的能力。 对于高曲率模型,最佳学习率 始终接近最大的非发散学习率 - 我们相信这是一个有用的诊断,可以检测模型的训练速度是否受到 太大。 在这种情况下,我们第 5 节的结果表明,可以使用学习率预热或更好的初始化算法来改善模型相对于批量大小的缩放行为。
7 限制
我们的分析主要集中在使用 SGD 进行动量训练的模型上。 这一决定的动机是减少使用自适应预处理时出现的额外混淆。 值得注意的是,对于使用 Adam 训练的模型,尚不清楚 的类似物应该是什么。 在附录中,我们提供的证据表明,即使对于使用 Adam 训练的 Transformer 模型,损失曲率也会适应学习率,并且学习率预热会导致优化轨迹被“推”到更平坦区域的类似效果。 然而,我们会在未来的工作中对此进行更深入的分析。
最后,虽然我们的实验确实提出了关于训练更好的模型初始化对进一步加速训练的功效的疑问,但我们的测量主要集中在初始化对 mid 的(缺乏)影响上。 更好的初始化可能会对更广泛的 Hessian 特征谱产生持久影响(例如,提高较小特征值 的比率 ),而我们的分析缺少这种效果。
8结论
通过测量训练期间损失锐度演变的广泛经验实验,我们证明了初始化、学习率预热和归一化等不同方法如何通过减少 来使用更高的学习率(不会导致发散) t0> 训练期间。 值得注意的是,我们研究的两个最流行的模型(Resnet-50 和 WideResnet 28-10 的流行变体)并没有从学习率预热中受益,并且在整个训练过程中表现出较小的 值我们考虑的学习率。 因此,主要使用优化良好的架构的研究人员和从业者可能永远不会注意到使用预热的好处。 然而,即使对工作架构进行看似微不足道的修改,也很容易导致 值很大,从而在训练早期变得不稳定——对这种情况的天真的反应是大幅降低学习率,甚至更糟,一起放弃正在研究的修改。 我们希望这项工作中提出的观点可以帮助未来的研究人员更好地应对这种情况,无论是通过研究不同的初始化、应用预热和梯度裁剪,还是改变模型中归一化层的位置。
也许我们的结果最引人注目的特征是 在 和 的情况下如何一致地适应学习率。 虽然我们不是第一个观察到这种适应的人,但我们在比之前的工作限制少得多的环境下为其提供了大规模的经验证据。 对学习率的适应与传统优化智慧直接矛盾,传统优化智慧建议根据 的测量值选择步长。 展望未来,需要做更多的工作来更好地理解为什么会发生这种适应,并进一步理解它对优化器设计、步长选择和模型初始化的影响。
9社会影响
我们的结果提供了对神经网络优化的新理解,有可能通过对模型调整更有原则的理解来加速对更好模型的研究。 虽然最近提出了无归一化网络,但我们的工作从损失曲率的角度分析了这些方法,并增强了对这些网络的工作或故障模式的信心。 当部署在大规模系统中时,无归一化网络可以改善推理时的功耗。 我们还建议利用学习率预热作为计算成本高昂的初始化策略的替代方案,该策略需要自己的超参数调整。 这将简化预算限制,从而减少对环境的影响。 虽然我们的努力可能会节省计算量,但这实际上有时会导致总体使用量的增加[33]。
我们的结果需要进行大量实验才能得出有用的结论,而这些机器学习工作负载有时会导致大量碳排放[23]。 也就是说,我们使用的云计算资源以无碳电力运行,444https://www.gstatic.com/gumdrop/sustainability/24-7-explainer.pdf(虽然还不是24/7无碳,但仍然使用一些补偿)。
此外,我们的工作有助于加深对机器学习方法的理解,根据用例,这些方法有可能用于善意或有害的目的。 鉴于我们结果的基本性质,我们认为最可能的用途不会有害。
参考
- Brock et al. [2021] A. Brock, S. De, and S. L. Smith. Characterizing signal propagation to close the performance gap in unnormalized resnets. arXiv preprint arXiv:2101.08692, 2021.
- Chelba et al. [2013] C. Chelba, T. Mikolov, M. Schuster, Q. Ge, T. Brants, and P. Koehn. One billion word benchmark for measuring progress in statistical language modeling. INTERSPEECH, 2013.
- Choi et al. [2019] D. Choi, C. J. Shallue, Z. Nado, J. Lee, C. J. Maddison, and G. E. Dahl. On empirical comparisons of optimizers for deep learning. arXiv preprint arXiv:1910.05446, 2019.
- Cohen et al. [2021] J. M. Cohen, S. Kaur, Y. Li, J. Z. Kolter, and A. Talwalkar. Gradient descent on neural networks typically occurs at the edge of stability. arXiv preprint arXiv:2103.00065, 2021.
- Dauphin and Schoenholz [2019] Y. N. Dauphin and S. Schoenholz. Metainit: Initializing learning by learning to initialize. Advances in Neural Information Processing Systems, 32:12645–12657, 2019.
- Ghorbani et al. [2019] B. Ghorbani, S. Krishnan, and Y. Xiao. An investigation into neural net optimization via hessian eigenvalue density. In International Conference on Machine Learning, pages 2232–2241. PMLR, 2019.
- Goyal et al. [2017] P. Goyal, P. Dollár, R. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola, A. Tulloch, Y. Jia, and K. He. Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv preprint arXiv:1706.02677, 2017.
- He et al. [2016a] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016a.
- He et al. [2016b] K. He, X. Zhang, S. Ren, and J. Sun. Identity mappings in deep residual networks. In European conference on computer vision, pages 630–645. Springer, 2016b.
- Huang et al. [2017] G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4700–4708, 2017.
- Ioffe and Szegedy [2015] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International conference on machine learning, pages 448–456. PMLR, 2015.
- Jastrzębski et al. [2017] S. Jastrzębski, Z. Kenton, D. Arpit, N. Ballas, A. Fischer, Y. Bengio, and A. Storkey. Three factors influencing minima in sgd. arXiv preprint arXiv:1711.04623, 2017.
- Jastrzebski et al. [2020] S. Jastrzebski, M. Szymczak, S. Fort, D. Arpit, J. Tabor, K. Cho, and K. Geras. The break-even point on optimization trajectories of deep neural networks. arXiv preprint arXiv:2002.09572, 2020.
- Kingma and Ba [2014] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Krizhevsky [2009] A. Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009.
- Lewkowycz et al. [2020] A. Lewkowycz, Y. Bahri, E. Dyer, J. Sohl-Dickstein, and G. Gur-Ari. The large learning rate phase of deep learning: the catapult mechanism. arXiv preprint arXiv:2003.02218, 2020.
- Li et al. [2017] H. Li, Z. Xu, G. Taylor, C. Studer, and T. Goldstein. Visualizing the loss landscape of neural nets. arXiv preprint arXiv:1712.09913, 2017.
- Liu et al. [2020] L. Liu, X. Liu, J. Gao, W. Chen, and J. Han. Understanding the difficulty of training transformers. arXiv preprint arXiv:2004.08249, 2020.
- McCandlish et al. [2018] S. McCandlish, J. Kaplan, D. Amodei, and O. D. Team. An empirical model of large-batch training. arXiv preprint arXiv:1812.06162, 2018.
- Nado et al. [2021] Z. Nado, J. Gilmer, C. J. Shallue, R. Anil, and G. E. Dahl. A large batch optimizer reality check: Traditional, generic optimizers suffice across batch sizes. CoRR, abs/2102.06356, 2021. URL https://arxiv.org/abs/2102.06356.
- Papyan [2018] V. Papyan. The full spectrum of deepnet hessians at scale: Dynamics with sgd training and sample size. arXiv preprint arXiv:1811.07062, 2018.
- Pascanu et al. [2013] R. Pascanu, T. Mikolov, and Y. Bengio. On the difficulty of training recurrent neural networks. In International conference on machine learning, pages 1310–1318. PMLR, 2013.
- Patterson et al. [2021] D. Patterson, J. Gonzalez, Q. Le, C. Liang, L.-M. Munguia, D. Rothchild, D. So, M. Texier, and J. Dean. Carbon emissions and large neural network training. arXiv preprint arXiv:2104.10350, 2021.
- Pearlmutter [1994] B. A. Pearlmutter. Fast exact multiplication by the hessian. Neural computation, 6(1):147–160, 1994.
- Russakovsky et al. [2015] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3):211–252, 2015.
- Santurkar et al. [2018] S. Santurkar, D. Tsipras, A. Ilyas, and A. Madry. How does batch normalization help optimization? arXiv preprint arXiv:1805.11604, 2018.
- Shallue et al. [2018] C. J. Shallue, J. Lee, J. Antognini, J. Sohl-Dickstein, R. Frostig, and G. E. Dahl. Measuring the effects of data parallelism on neural network training. arXiv preprint arXiv:1811.03600, 2018.
- Sivaprasad et al. [2020] P. T. Sivaprasad, F. Mai, T. Vogels, M. Jaggi, and F. Fleuret. Optimizer benchmarking needs to account for hyperparameter tuning. In H. D. III and A. Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 9036–9045. PMLR, 13–18 Jul 2020. URL http://proceedings.mlr.press/v119/sivaprasad20a.html.
- Vaswani et al. [2017] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, volume 30, 2017. URL https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf.
- Wu et al. [2018] L. Wu, C. Ma, and W. E. How sgd selects the global minima in over-parameterized learning: A dynamical stability perspective. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, pages 8289–8298, 2018.
- Xiong et al. [2020] R. Xiong, Y. Yang, D. He, K. Zheng, S. Zheng, C. Xing, H. Zhang, Y. Lan, L. Wang, and T. Liu. On layer normalization in the transformer architecture. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 of Proceedings of Machine Learning Research, pages 10524–10533. PMLR, 2020.
- Yang et al. [2019] G. Yang, J. Pennington, V. Rao, J. Sohl-Dickstein, and S. S. Schoenholz. A mean field theory of batch normalization. arXiv preprint arXiv:1902.08129, 2019.
- York [2006] R. York. Ecological paradoxes: William stanley jevons and the paperless office. Human Ecology Review, pages 143–147, 2006.
- Zagoruyko and Komodakis [2016] S. Zagoruyko and N. Komodakis. Wide residual networks. arXiv preprint arXiv:1605.07146, 2016.
- Zhang et al. [2019a] G. Zhang, L. Li, Z. Nado, J. Martens, S. Sachdeva, G. Dahl, C. Shallue, and R. B. Grosse. Which algorithmic choices matter at which batch sizes? insights from a noisy quadratic model. Advances in neural information processing systems, 32:8196–8207, 2019a.
- Zhang et al. [2017] H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz. mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412, 2017.
- Zhang et al. [2019b] H. Zhang, Y. N. Dauphin, and T. Ma. Fixup initialization: Residual learning without normalization. arXiv preprint arXiv:1901.09321, 2019b.
- Zhu et al. [2021] C. Zhu, R. Ni, Z. Xu, K. Kong, W. R. Huang, and T. Goldstein. Gradinit: Learning to initialize neural networks for stable and efficient training. arXiv preprint arXiv:2102.08098, 2021.
附录A其他数字
附录B图2模型的性能
在本节中,我们绘制了正文图 2 中所示的所有模型的性能与学习率。 这些如图9、10、11和12所示。 对于发散的模型,我们绘制了发散之前实现的最佳测试性能。 在所有设置中,高曲率通过限制较高学习率的使用来影响最终性能。
我们还注意到图 2 中的几个模型尽管训练是在参数空间的稳定区域中开始的,但还是出现了分歧。 在图 13 中,我们绘制了训练期间损失锐度的演变,表明它很快进入 的区域,然后在第 90 步附近发散。
附录 C 通过 Lanczos 计算 Hessian 特征谱的详细信息
我们使用 Lanczos 迭代来估计 Hessian 矩阵的顶部特征值。 Lanczos 算法仅需要 Hessian 向量积,可以通过 Pearlmutter 的技巧 [24] 有效计算。 先前的研究表明,这种方法提供了一个强大且可扩展的框架来检查大型神经网络 [6, 21] 的 Hessian 特征值。
对于我们的 WMT / LM1B 实验,我们运行 步骤的算法,而对于图像模型,我们使用 步骤。 当监控顶部特征值作为 Lanczos 步数函数的演化时,在除一种情况外的所有情况下,我们观察到算法收敛。 对于具有 ReLUBN 排序的 Resnet 的情况,由于顶部特征值和体之间的特征间隙非常小,收敛速度明显较慢。 在这种情况下,我们使用 Lanczos 步骤来缓解该问题。
众所周知,Lanczos 算法可能会受到有限精度算术导致的数值不稳定的影响。 为了缓解这些问题,Lanczos 向量以 float64 精度存储,并且我们在算法的每一步都执行重新正交化。
附录 D表 1 和表 2 的培训详细信息
D.1 神经机器翻译
神经机器翻译实验基于 Transformer 模型[29]。 我们在编码器和解码器上使用单独的嵌入,以及大小为 32000 的通用词块词汇表。 对于深度,我们在编码器和解码器上都使用 6 层。 对于宽度,我们尝试了两种模型,即 Transformer-Base 和 Transformer-Wide。 对于 Transformer-Base,我们使用 512 个维度、8 个头和 2048 个前馈维度的词嵌入。 对于 Transformer-Wide,我们使用 1024 个维度、16 个头和 4096 个前馈维度的词嵌入。 图 3 和图 5 中报告的实验使用 Transformer-Base。 表 2 中报告的实验使用由 Adam [14] 训练的 Transformer-Wide 模型。 我们全面考虑了预热、学习率、梯度裁剪和 init_scaling,并优化了验证损失,以评估表 2 中报告的测试集 BLEU 的性能。 所有模型都训练了 60 个 epoch,Transformer-Base 模型的批量大小为 1024,Transformer-Big 模型的批量大小为 512。 对于所有这些模型,我们使用 0.1 的 dropout、0.1 的标签平滑并且没有权重衰减。
D.2 DenseNet
在表 2 中,ResNet-50(无 BN)架构以批量大小 512 训练了 100 个周期,l2 正则化为 5e-5,dropout 为 0.3。 它使用 SGD 进行训练,nesterov 动量为 0.9,学习率为 0.2。 我们在全局 l2 范数为 5 时应用梯度裁剪,并使用线性学习率预热,预热周期为 1000 步。
对于表 1,DenseNet-100 模型使用 Gradinit 代码库 555https://github.com/zhuchen03/gradinit 通过修改提供的 DenseNet 脚本以应用范数 6 的梯度裁剪并使用默认初始化而不是 GradInit。
附录 E图 2 的培训详细信息
WideResnet-28-10 模型以 1024 的批量大小进行了 300 个 epoch 的训练。 我们应用了 MixUp 增强[36]。 对于学习率预热,我们使用 1000 个线性预热步骤,直到达到峰值学习率,此时学习率根据余弦时间表衰减。
DenseNet 模型使用 SGD 优化器进行训练,批量大小为 512,动量为 0.9,权重衰减为 5e-4,L2 正则化为 1e-4,预热步骤为 1000 步(对于使用预热的模型),然后进行余弦衰减。 这些模型接受了 200 个 epoch 的训练。 对于 DenseNet 架构,我们使用的 Growth_rate 为 32,Reduction 为 0.5。
Resnet-50 模型使用 Nesterov 动量为 0.9 的 SGD 优化器以批量大小 2048 进行训练。 学习率计划与 WideResnet 情况相同,先进行 1000 步的线性预热,然后进行余弦衰减。 我们应用了 0.1 的标签平滑,并使用标准翻转加裁剪来进行数据增强。
LM1B 上的 Transformer 模型使用 SGD 以批量大小 1024 进行训练,nesterov 动量为 0.9。 我们使用 512 的嵌入维度、8 个头的 6 层和 1024 的 MLP 隐藏维度。 注意力流失率为0.1。 学习率计划遵循与 Resnet 案例相同的方法。
附录 F使用 Adam 优化器进行曲率自适应
正文中的讨论主要集中在使用 SGD 和动量训练的模型上。 在本附录中,我们简要检查类似的结论是否适用于使用预处理的 Adam 等优化器。 对于应用预处理的优化器,是否应该对学习率进行曲率自适应,目前尚不清楚。 然而,考虑到 Adam 是应用于非对角 Hessian 矩阵的对角预处理器,可能会观察到一些类似的效果。
考虑一个简单的二次损失
其中优化是通过具有固定对角预处理矩阵 的预处理梯度下降来执行的:
因此,这个简单的模型表明以下矩阵的最大特征值可能与 Adam 训练的模型的训练不稳定性有关
| (1) |
虽然 (1) 没有考虑自适应预处理或动量的影响,但我们发现一些经验证据表明这种近似可以帮助理解优化的稳定性。
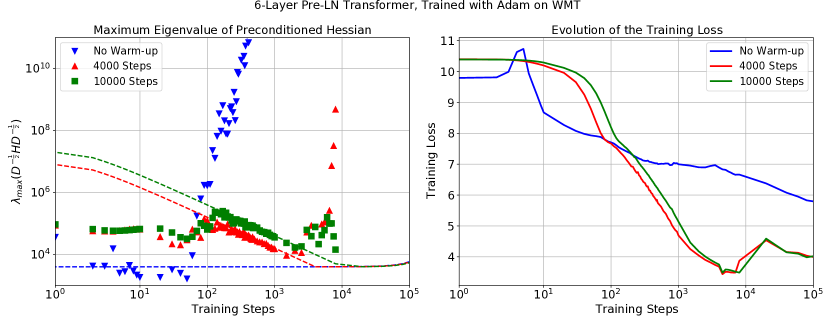
下面的图 14 检查了使用 Adam 和不同预热长度训练的三个 Transformer 模型的 的演变。 这里,是一个带有的对角矩阵。 我们观察到,与使用动量训练的模型类似,最大(预处理)Hessian 特征值适应热身计划(绿色和红色标记)。 我们注意到,也许由于动量或自适应预处理的影响,阈值 似乎与数据不太一致。 相反,根据经验校正的阈值 似乎更适合数据。 我们观察到模型训练中的不稳定性与跨越经验校正阈值的 完全一致。
这些观察结果表明,正文中讨论的一些见解似乎适用于自适应优化器的情况。 我们将对这种更复杂的环境的进一步探索留给未来的工作。
附录 G使用的计算资源
几乎所有实验都使用带有 v2 云 TPU 的 Google Cloud Platform,但以下实验除外:图 2 Resnet-50 和 Densenet 实验使用 v3 云 TPU,而 GradInit 代码在具有单个 V100 GPU 的云计算机上运行。 图 2 的实验是在几天内同时使用多达 50 个 v2 TPU 并行完成的。 此外,所有机器翻译模型均在 v3 云 TPU 上进行训练。