Transformer 调查
摘要。
Transformer 在自然语言处理、计算机视觉、音频处理等许多人工智能领域取得了巨大成功。 因此,自然引起学术界和工业界研究人员的广泛兴趣。 到目前为止,Transformer 变体(又名: X-formers)已经被提出,然而,仍然缺乏对这些 Transformer 变体的系统和全面的文献综述。 在这项调查中,我们对各种 X-formers 进行了全面的回顾。 我们首先简要介绍普通 Transformer,然后提出 X-formers 的新分类法。 接下来我们从架构修改、预训练、应用三个角度介绍各种X-formers。 最后,我们概述了未来研究的一些潜在方向。
1. 介绍
Transformer (Vaswani 等人,2017)是一种著名的深度学习模型,已广泛应用于自然语言处理(NLP)、计算机视觉(CV)和语音处理等各个领域。 Transformer 最初被提出作为机器翻译的序列到序列模型(Sutskever 等人,2014)。 后来的工作表明,基于 Transformer 的预训练模型(PTM)(Qiu 等人,2020)可以在各种任务上实现最先进的性能。 因此,Transformer 已成为 NLP 领域的首选架构,尤其是 PTM。 除了语言相关的应用外,Transformer 还被应用于计算机视觉(Parmar 等人,2018;Carion 等人,2020;Dosovitskiy 等人,2020)、音频处理(Dong 等人) ,2018;Gulati 等人,2020;Chen 等人,2021) 甚至其他学科,例如化学(Schwaller 等人,2019)和生命科学(Rives 等)人,2021)。
由于成功,各种 Transformer 变体(又名: X-formers)在过去几年中已被提出。 这些 X-formers 从不同的角度改进了原版 Transformer。
-
(1)
模型效率。 应用 Transformer 的一个关键挑战是它在处理长序列时效率低下,这主要是由于自注意力模块的计算和内存复杂性造成的。 改进方法包括轻量级注意力(例如稀疏注意力变体)和分而治之方法(例如循环和分层机制)。
-
(2)
模型泛化。 由于 Transformer 是一种灵活的架构,并且对输入数据的结构偏差进行训练的假设很少,因此很难在小规模数据上进行训练。 改进方法包括引入结构偏差或正则化、对大规模无标签数据进行预训练等。
-
(3)
模型适应。 该工作线旨在使 Transformer 适应特定的下游任务和应用程序。
在本次调查中,我们的目标是对 Transformer 及其变体进行全面审查。 虽然我们可以根据上述观点来组织X-formers,但许多现有的X-formers可能会解决一个或几个问题。 例如,稀疏注意力变体不仅降低了计算复杂度,而且还在输入数据上引入了结构先验,以减轻小数据集上的过度拟合问题。 因此,对现有的各种 X-former 进行分类并主要根据它们改进 vanilla Transformer 的方式(架构修改、预训练和应用)提出新的分类法是更有条理的。 考虑到本次调查的受众可能来自不同领域,我们主要关注通用架构变体,仅简要讨论预训练和应用程序的具体变体。
2. 背景
2.1. 香草 Transformer
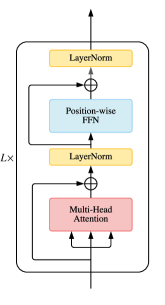
vanilla Transformer (Vaswani 等人, 2017) 是一个序列到序列模型,由编码器和解码器组成,每个编码器和解码器都是一堆 相同的块。 每个编码器块主要由多头自注意力模块和位置前馈网络(FFN)组成。 为了构建更深的模型,在每个模块周围采用残差连接(He等人,2016),然后是层归一化(Ba等人,2016)模块。 与编码器块相比,解码器块在多头自注意力模块和位置 FFN 之间额外插入交叉注意力模块。 此外,解码器中的自注意力模块适用于防止每个位置关注后续位置。 vanilla Transformer 的整体架构如图1所示。
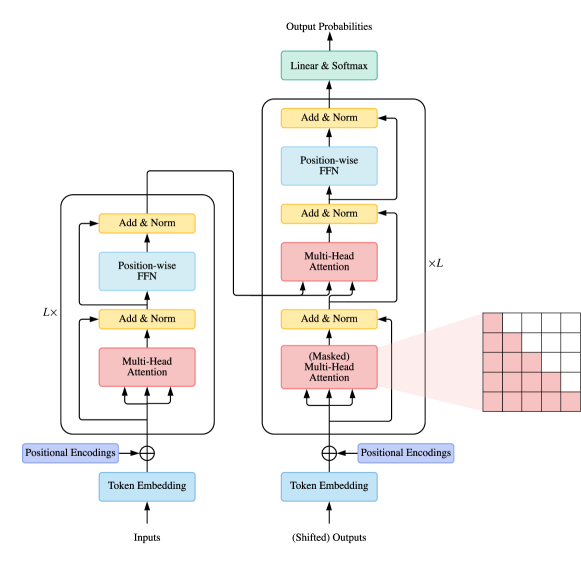
在下面的小节中,我们将介绍 vanilla Transformer 的关键模块。
2.1.1. 注意力模块
Transformer 采用 Query-Key-Value (QKV) 模型的注意力机制。 给定查询 、键 和值 的压缩矩阵表示,Transformer 使用的缩放点积注意力由下式给出111如果没有特别说明,我们在整个调查中使用行主要符号(例如, 中的第 行就是查询 ),默认情况下,所有向量都是行向量。
| (1) |
其中 和 表示查询和键(或值)的长度; 和表示键(或查询)和值的维度; 通常被称为注意力矩阵; softmax 以行方式应用。 查询和键的点积除以 以缓解 softmax 函数的梯度消失问题。
Transformer 不是简单地应用单个注意力函数,而是使用多头注意力,其中 维的原始查询、键和值被投影到 、 和 维度,分别具有 组不同的学习投影。 对于每个预测的查询、键和值以及输出,根据等式进行注意计算。 (1)。 然后,模型连接所有输出并将它们投影回 维表示。
| (2) | ||||
| (3) |
在 Transformer 中,根据查询的来源和键值对,存在三种类型的注意力:
-
•
自我关注。 在 Transformer 编码器中,我们在等式中设置。 (2),其中是上一层的输出。
-
•
掩盖自我注意。 在 Transformer 解码器中,自注意力受到限制,每个位置的查询只能关注直到并包括该位置的所有键值对。 为了启用并行训练,这通常是通过对非标准化注意力矩阵 应用掩码函数来完成的,其中通过设置 来掩码非法位置。 这种自注意力通常被称为自回归或因果注意力222这个术语似乎是从因果系统借用的,其中输出取决于过去和当前的输入,但不取决于未来的输入。.
-
•
交叉注意力。 查询是从前一(解码器)层的输出投影的,而键和值是使用编码器的输出投影的。
2.1.2. 位置方式 FFN
按位置 FFN333参数在不同位置之间共享,因此位置方向FFN也可以理解为两个内核大小为1的卷积层。 是一个完全连接的前馈模块,在每个位置上单独且相同地运行
| (4) |
其中是上一层的输出,是可训练的参数。 通常,FFN 的中间尺寸 设置为大于 。
2.1.3. 剩余连接和标准化
为了构建深度模型,Transformer 在每个模块周围采用残差连接(He 等人,2016),然后进行层归一化(Ba 等人,2016)。 例如,每个 Transformer 编码器块可以写为
| (5) | ||||
| (6) |
其中 表示自注意力模块, 表示层归一化操作。
2.1.4. 位置编码
由于 Transformer 没有引入递归或卷积,因此它不知道位置信息(特别是对于编码器)。 因此,需要额外的位置表示(第 5.1 节中详细讨论)来对标记的排序进行建模。
2.2. 型号用途
一般来说,Transformer 架构可以通过三种不同的方式使用:
-
•
编码器-解码器。 第 2 节中介绍的完整 Transformer 架构。使用2.1。 这通常用于序列到序列建模(例如神经机器翻译)。
-
•
仅限编码器。 仅使用编码器,并且编码器的输出被用作输入序列的表示。 这通常用于分类或序列标记问题。
-
•
仅解码器。 仅使用解码器,其中编码器-解码器交叉注意模块也被删除。 这通常用于序列生成,例如语言建模。
2.3. 模型分析
为了说明 Transformer 的计算时间和参数要求,我们分析了表1中 Transformer 的两个核心组件(即自注意力模块和位置 FFN)。 我们假设模型的隐藏维度为,输入序列长度为。 FFN 的中间维度设置为 ,键和值的维度设置为 ,如 Vaswani 等人 (2017) 中所示。
| Module | Complexity | #Parameters |
|---|---|---|
| self-attention | ||
| position-wise FFN |
当输入序列较短时,隐藏维度 主导自注意力和位置 FFN 的复杂性。 由此可见,Transformer 的瓶颈在于 FFN。 然而,随着输入序列变长,序列长度逐渐主导这些模块的复杂性,在这种情况下,自注意力成为Transformer的瓶颈。 此外,自注意力的计算需要存储一个注意力分布矩阵,这使得Transformer的计算不适合长序列场景(例如长文本文档和高序列的像素级建模)。分辨率图像)。 应该看到,提高 Transformer 效率的目标通常会导致 self-attention 的长序列兼容性,以及普通设置下的位置 FFN 的计算和参数效率。
2.4. Transformer 与其他网络类型的比较
2.4.1. 自注意力分析
作为 Transformer 的核心部分,自注意力机制具有灵活的机制来处理可变长度的输入。 它可以理解为一个完全连接的层,其中权重是根据输入的成对关系动态生成的。 表2比较了复杂性、顺序操作和最大路径长度444前向和后向信号从任意输入位置到任意输出位置所必须遍历的路径的最大长度。 较短的长度意味着学习远程依赖性的潜力更大。 三种常用层类型的自注意力。 我们总结self-attention的优点如下:
-
(1)
它具有与全连接层相同的最大路径长度,使其适合远程依赖关系建模。 与全连接层相比,它的参数效率更高,并且在处理可变长度输入方面更灵活。
-
(2)
由于卷积层的感受野有限,通常需要堆叠一个深层网络才能拥有全局感受野。 另一方面,恒定的最大路径长度使得自注意力能够用恒定的层数来建模远程依赖关系。
-
(3)
恒定的顺序操作和最大路径长度使自注意力机制比循环层更具有可并行性,并且更适合远程建模。
| Layer Type | Complexity | Sequential | Maximum Path Length |
|---|---|---|---|
| per Layer | Operations | ||
| Self-Attention | |||
| Fully Connected | |||
| Convolutional | |||
| Recurrent |
2.4.2. 就归纳偏置而言
Transformer 通常与卷积网络和循环网络进行比较。 众所周知,卷积网络会通过共享局部核函数施加平移不变性和局部性的归纳偏差。 类似地,循环网络通过其马尔可夫结构(Battaglia等人,2018)携带时间不变性和局部性的归纳偏差。 另一方面,Transformer 架构对数据的结构信息做出很少的假设。 这使得 Transformer 成为一种通用且灵活的架构。 副作用是,缺乏结构偏差使得 Transformer 容易对小规模数据过度拟合。
另一种密切相关的网络类型是具有消息传递的图神经网络(GNN)(Wu 等人,2021a)。 Transformer 可以被视为在完整有向图(具有自循环)上定义的 GNN,其中每个输入都是图中的一个节点。 Transformer 和 GNN 之间的主要区别在于,Transformer 没有引入有关输入数据如何构造的先验知识 - Transformer 中的消息传递过程仅取决于内容的相似性度量。
3. Transformer 的分类
迄今为止,基于vanilla Transformer,人们从架构修改类型、预训练方法和应用三个角度提出了各种各样的模型。 图 2 给出了我们对 Transformer 变体的分类的说明。
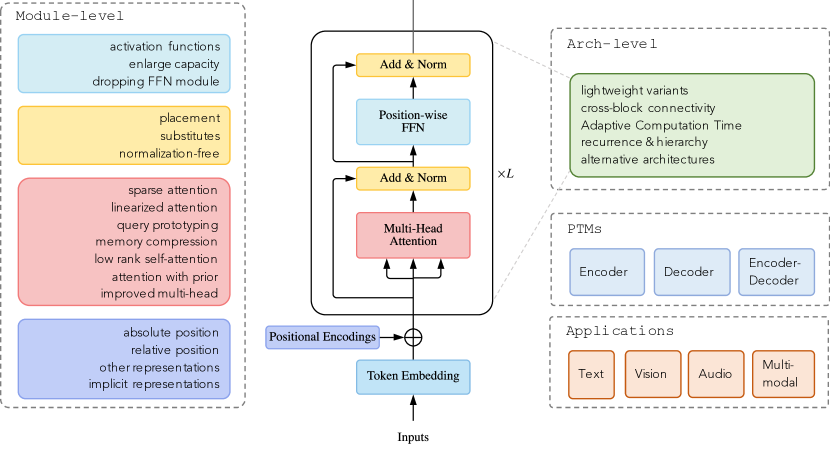
图3说明了我们的分类法和一些代表性模型。
forked edges,
for tree=
grow=east,
reversed=true,anchor=base west,
parent anchor=east,
child anchor=west,
base=left,
font=,
rectangle,
draw=hiddendraw,
rounded corners,align=left,
minimum width=2.5em,
s sep=3pt,
inner xsep=2pt,
inner ysep=1pt,
ver/.style=rotate=90, child anchor=north, parent anchor=south, anchor=center,
,
where level=1text width=2.7em,font=,,
where level=2text width=3em,font=,
where level=3text width=3em,font=,[X-formers, ver
[Module
Level
[Attention
[Sparse
[Star-Transformer(Guo
et al., 2019a), Longformer(Beltagy
et al., 2020), ETC(Ainslie et al., 2020), BigBird(Zaheer et al., 2020), Sparse Transformer(Child
et al., 2019)
BP-Transformer(Ye
et al., 2019), Image Transformer(Parmar et al., 2018), Axial Transformer(Ho et al., 2019)
,leaf,text width=21.5em]
[Routing Transformer(Roy
et al., 2020), Reformer(Kitaev
et al., 2020), SAC(Li
et al., 2020b), Sparse Sinkhorn Attention(Tay
et al., 2020b)
,leaf,text width=21.5em]
]
[Linearized
[Linear Transformer(Katharopoulos et al., 2020), Performer(Choromanski
et al., 2020a; Choromanski et al., 2020b), RFA(Peng et al., 2021), Delta Net(Schlag
et al., 2021)
,leaf,text width=18.5em]
]
[Prototype
[Clustered Attention(Vyas
et al., 2020), Informer(Zhou et al., 2021)
,leaf,text width=12em]
]
[Memory
Compress
[MCA(Liu et al., 2018), Set Transformer(Lee
et al., 2019), Linformer(Wang
et al., 2020a)
,leaf,text width=12em]
]
[Low-rank
[Low-rank Attention(Guo
et al., 2019b), CSALR(Chen
et al., 2020a), Nyströmformer (Xiong et al., 2021)
,leaf,text width=15em]
]
[Prior
Attention
[Local Transformer(Yang
et al., 2018), Gaussian Transformer(Guo
et al., 2019c)
,leaf,text width=15em]
[Predictive Attention Transformer(Wang et al., 2021), Realformer(He
et al., 2020b), Lazyformer(Ying
et al., 2021)
,leaf,text width=18.5em]
[CAMTL(Pilault
et al., 2021)
,leaf,text width=4em]
[Average Attention(Zhang
et al., 2018), Hard-Coded Gaussian Attention(You
et al., 2020), Synthesizer(Tay et al., 2020a)
,leaf]
]
[Multi-head
[Li
et al. (2018), Deshpande and
Narasimhan (2020), Talking-head Attention(Shazeer
et al., 2020)
Collaborative MHA(Cordonnier
et al., 2020)
,leaf,text width=20em]
[Adaptive Attention Span(Sukhbaatar et al., 2019a), Multi-Scale Transformer(Guo
et al., 2020)
,leaf,text width=20em]
[Dynamic Routing(Li
et al., 2019b; Gu and Feng, 2019)
,leaf,text width=6.5em]
]
]
[Position
Encoding
[Absolute
[BERT(Devlin
et al., 2019), Wang et al. ([n.d.]), FLOATER(Liu
et al., 2020b)
,leaf,text width=11em]
]
[Relative
[Shaw
et al. (2018), Music Transformer(Huang et al., 2019), T5(Raffel et al., 2020), Transformer-XL(Dai et al., 2019)
DeBERTa(He
et al., 2020a)
,leaf,text width=20em]
]
[Other Rep.
[TUPE(Ke et al., 2020), Roformer(Su
et al., 2021)
,leaf,text width=7em]
]
[Implicit Rep.
[Complex Embedding(Wang et al., 2020b), R-Transformer (Wang
et al., 2019b), CPE(Chu et al., 2021)
,leaf,text width=16em]
]
]
[LayerNorm
[Placement
[post-LN(Vaswani et al., 2017; Devlin
et al., 2019; Liu
et al., 2020a), pre-LN(Vaswani et al., 2018; Klein
et al., 2017; Baevski and Auli, 2019; Child
et al., 2019; Wang
et al., 2019a)
,leaf,text width=16em]
]
[Substitutes
[AdaNorm(Xu
et al., 2019), scaled normalization(Nguyen and
Salazar, 2019), PowerNorm(Shen
et al., 2020)
,leaf,text width=16em]
]
[Norm-free
[ReZero-Transformer(Bachlechner et al., 2020)
,leaf,text width=9.5em]
]
]
[FFN
[Activ. Func.
[Swish(Ramachandran
et al., 2018), GELU(Chen et al., 2020b; Devlin
et al., 2019), GLU(Shazeer, 2020)
,leaf,text width=9.5em]
]
[Enlarge
Capacity
[Product-key Memory(Lample et al., 2019), Gshard(Lepikhin et al., 2020), Switch Transformer(Fedus
et al., 2021),
Expert Prototyping(Yang et al., 2021), Hash Layer(Roller
et al., 2021)
,leaf,text width=16em]
]
[Dropping
[All-Attention layer(Sukhbaatar et al., 2019b), Yang
et al. (2020)
,leaf,text width=11em]
]
]
]
[Arch.
Level
[Lighweight
[Lite Transformer(Wu
et al., 2020b), Funnel Transformer(Dai
et al., 2020), DeLighT(Mehta et al., 2020)
,leaf,text width=16em]
]
[Connectivity
[Realformer(He
et al., 2020b), Predictive Attention Transformer(Wang et al., 2021), Transparent Attention(Bapna
et al., 2018)
Feedback Transformer (Fan et al., 2021b)
,leaf,text width=24.5em]
]
[ACT
[UT(Dehghani et al., 2019), Conditional Computation Transformer(Bapna
et al., 2020), DeeBERT(Xin
et al., 2020), PABEE(Zhou
et al., 2020), Li
et al. (2021),
Sun et al. (2021)
,leaf,text width=24.5em]
]
[Divide &
Conquer
[Recurrence
[Transformer-XL(Dai et al., 2019), Compressive Transformer(Rae et al., 2020), Memformer(Wu
et al., 2020a)
Yoshida
et al. (2020), ERNIE-Doc(Ding et al., 2020)
,leaf,text width=20em]
]
[Hierarchy
[Miculicich et al. (2018), HIBERT(Zhang
et al., 2019), Liu and Lapata (2019), Hi-Transformer(Wu
et al., 2021b)
TENER(Yan
et al., 2019), TNT(Han
et al., 2021c)
,leaf,text width=20em]
]
]
[Alt. Arch.
[ET(So et al., 2019), Macaron Transformer(Lu
et al., 2020), Sandwich Transformer(Press
et al., 2020), MAN(Fan et al., 2021a), DARTSformer(Zhao
et al., 2021)
,leaf,text width=24.5em]
]
]
[Pre-Train
[Encoder
[BERT(Devlin
et al., 2019), RoBERTa(Liu et al., 2019a), BigBird(Zaheer et al., 2020),leaf,text width=11em]
]
[Decoder
[GPT(Radford et al., 2018), GPT-2(Radford et al., 2019), GPT-3(Brown
et al., 2020),leaf,text width=11em]
]
[Enc.Dec.
[ BART(Lewis et al., 2020), T5(Raffel et al., 2020), Switch Transformer(Fedus
et al., 2021)
,leaf,text width=11em]
]
]
[App.
[NLP
[BERT(Devlin
et al., 2019),ET(So et al., 2019), Transformer-XL(Dai et al., 2019),Compressive Transformer(Rae et al., 2020), TENER(Yan
et al., 2019)
,leaf,text width=22em]
]
[CV
[Image Transformer(Parmar et al., 2018), DETR(Carion et al., 2020), ViT(Dosovitskiy et al., 2020), Swin Transformer(Liu et al., 2021), ViViT(Arnab et al., 2021)
,leaf,text width=22em]
]
[Audio
[Speech Transformer(Dong et al., 2018), Streaming Transformer(Chen
et al., 2021), Reformer-TTS(Ihm
et al., 2020), Music Transformer(Huang et al., 2019)
,leaf,text width=25em]
]
[Multimodal
[VisualBERT(Li
et al., 2019c), VLBERT(Su
et al., 2020), VideoBERT(Sun
et al., 2019), M6(Lin et al., 2021), Chimera(Han
et al., 2021b), DALL-E(Ramesh et al., 2021), CogView(Ding et al., 2021)
,leaf,text width=25em]
]
]
]
4. 注意力
自注意力在 Transformer 中发挥着重要作用,但在实际应用中存在两个挑战。
-
(1)
复杂性。 正如第 2 节中的讨论。 2.3,self-attention的复杂度为。 因此,注意力模块在处理长序列时成为瓶颈。
-
(2)
结构优先。 自注意力不假设输入存在任何结构性偏差。 甚至订单信息也需要从训练数据中学习。 因此,Transformer(没有预训练)通常很容易在小型或中等规模的数据上过度拟合。
Attention机制的改进可以分为几个方向:
-
(1)
稀疏注意力。 这一系列工作将稀疏性偏差引入注意力机制中,从而降低了复杂性。
-
(2)
线性化注意力。 这一系列工作将注意力矩阵与内核特征图解开。 然后以相反的顺序计算注意力以实现线性复杂度。
-
(3)
原型和内存压缩。 此类方法减少查询或键值内存对的数量,以减少注意力矩阵的大小。
-
(4)
低级自注意力。 这一系列工作捕获了自注意力的低级属性。
-
(5)
注意事先。 该研究方向探索用先前的注意力分布来补充或替代标准注意力。
-
(6)
改进的多头机制。 该系列研究探索了不同的替代多头机制。
我们将在本节的其余部分详细描述这些注意力变体。
4.1. 稀疏注意力
在标准的自注意力机制中,每个词符都需要关注所有其他 Token 。 然而,据观察,对于经过训练的 Transformer,学习到的注意力矩阵 在大多数数据点 (Child 等人,2019) 上通常非常稀疏。 因此,可以通过合并结构偏差来限制每个查询涉及的查询密钥对的数量来降低计算复杂度。 在这种限制下,我们只需根据预定义的模式计算查询键对的相似度得分
| (7) |
其中 是非标准化注意力矩阵。 在实现中,项通常不存储在内存中,以减少内存占用。
从另一个角度来看,标准注意力可以被视为一个完整的二部图,其中每个查询接收来自所有内存节点的信息并更新其表示。 稀疏注意力可以被认为是一个稀疏图,其中节点之间的一些连接被删除。
根据确定稀疏连接的指标,我们将这些方法分为两类:基于位置和基于内容稀疏注意力。
4.1.1. 基于位置的稀疏注意力
在基于位置的稀疏注意力中,注意力矩阵根据一些预定义的模式受到限制。 尽管这些稀疏模式有不同的形式,但我们发现其中一些可以分解为一些原子稀疏模式。
我们首先识别一些原子稀疏模式,然后描述这些模式在一些现有工作中是如何组成的。 最后,我们介绍了一些针对特定数据类型的扩展稀疏模式。
4.1.1.1 原子稀疏注意力
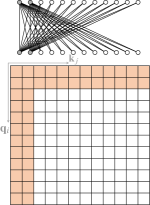
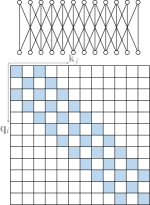
原子稀疏注意力模式主要有五种类型,如图4所示。
-
(1)
全球关注。 为了缓解稀疏注意力中远程依赖建模能力的下降,可以添加一些全局节点555实际中,这些全局节点可以从序列(内部全局节点)中选择,也可以从具有可训练参数的虚拟节点(外部全局节点)中选择。 作为节点之间信息传播的枢纽。 这些全局节点可以参与序列中的所有节点,整个序列可以参与这些全局节点,如图4(a)所示。
-
(2)
带状注意力(又名滑动窗口注意力或局部注意力)。 由于大多数数据都具有很强的局部性,因此很自然地限制每个查询只关注其邻居节点。 这种稀疏模式的一个广泛采用的类别是带状注意力,其中注意力矩阵是如图4(b)所示的带状矩阵。
-
(3)
扩张注意力。 与扩张的 CNN (van den Oord 等人,2016 年)类似,通过使用具有扩张间隙的扩张窗口 ,可以在不增加计算复杂度的情况下增加带状注意力的感受野,如图 4(c) 所示。 这可以很容易地扩展到跨步注意力,其中窗口大小不受限制,但扩张设置为一个大值。
-
(4)
随机注意力。 为了提高非局部交互的能力,为每个查询随机采样一些边,如图4(d)所示。 这是基于这样的观察:随机图(例如,Erdős-Rényi 随机图)可以与完整图具有相似的谱特性,从而导致图上随机游走的混合时间很快。
-
(5)
阻止本地注意力。 这类注意力将输入序列分割成几个不重叠的查询块,每个查询块都与一个本地内存块相关联。 查询块中的所有查询仅涉及相应内存块中的键。 图4(e)描述了一种常用的情况,其中存储器块与其对应的查询块相同。
4.1.1.2 复合稀疏注意力
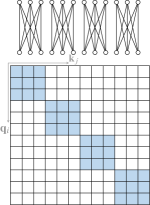
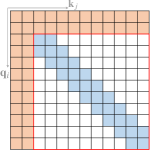
现有的稀疏注意力通常由以上原子模式中的一种以上组成。 图5说明了一些代表性的复合稀疏注意力模式。
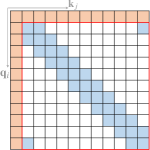
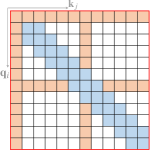
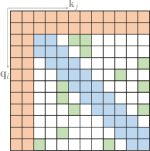
Star-Transformer (Guo 等人, 2019a) 使用带状注意力和全局注意力的组合。 具体来说,Star-Transformer仅包含一个全局节点和一个宽度为3的带状注意力,其中任意一对非相邻节点通过共享的全局节点连接,相邻节点直接相互连接。 这种稀疏模式在节点之间形成星形图。 Longformer (Beltagy 等人, 2020) 使用带状注意力和内部全局节点注意力的组合。 全局节点选择为[CLS]词符用于分类,所有问题标记用于问答任务。 他们还用扩大的窗口注意力替换了上层的一些带注意力头,以在不增加计算的情况下增加感受野。 作为 Longformer (Beltagy 等人, 2020) 的并行工作,扩展 Transformer 构造 (ETC) (Ainslie 等人, 2020) 利用带状注意力和外部全局的组合节点关注。 ETC 还包括一个掩码机制,用于处理结构化输入并采用对比预测编码 (CPC) (van den Oord 等人,2018) 进行预训练。 除了频段和全局注意力之外,BigBird (Zaheer 等人, 2020) 使用额外的随机注意力来近似完全注意力。 他们的理论分析还表明,使用稀疏编码器和稀疏解码器可以模拟任何图灵机,这解释了这些稀疏注意力模型的成功。
Sparse Transformer (Child 等人, 2019) 使用分解注意力,针对不同类型的数据设计不同的稀疏模式。 对于具有周期性结构的数据(例如图像),它使用带状注意力和跨步注意力的组合。 而对于没有周期性结构的数据(例如文本),它使用块局部注意力与全局注意力相结合的组合,其中全局节点来自输入序列中的固定位置。
4.1.1.3 扩展稀疏注意力
除了上述模式之外,一些现有研究还探索了特定数据类型的扩展稀疏模式。
对于文本数据,BP-Transformer (Ye 等人, 2019) 构造一棵二叉树,其中所有 token 都是叶节点,内部节点是包含许多 token 的跨节点。 该图中的边被构造为使得每个叶节点都连接到其邻居叶节点以及包含来自更远距离的标记的更高级别的跨度节点。 这种方法可以看作是全局注意力的扩展,其中全局节点是分层组织的,并且任何一对标记都与二叉树中的路径连接。 该方法的摘要如图6(a)所示。
还有一些针对视觉数据的扩展。 Image Transformer (Parmar 等人, 2018) 探索了两种类型的注意力:(1)按光栅扫描顺序展平图像像素,然后应用块局部稀疏注意力。 (2)2D块局部注意力,其中查询块和记忆块直接排列在2D板中,如图6(b)所示。 作为视觉数据稀疏模式的另一个例子,Axial Transformer (Ho等人,2019)在图像的每个轴上应用独立的注意力模块。 每个注意力模块混合沿一个轴的信息,同时保持沿另一轴的信息独立,如图6(c)所示。 这可以理解为按光栅扫描顺序水平和垂直地展平图像像素,然后分别对图像宽度和高度的间隙应用跨步注意力。

4.1.2. 基于内容的稀疏注意力
另一项工作是根据输入内容创建稀疏图,即稀疏连接以输入为条件。
构建基于内容的稀疏图的一种直接方法是选择那些可能与给定查询具有较大相似度分数的键。 为了有效地构建稀疏图,我们可以递归到最大内积搜索(MIPS)问题,其中尝试通过查询找到具有最大点积的键,而不计算所有点积项。 Routing Transformer (Roy 等人, 2020) 使用 k-means 聚类对查询 和键进行聚类 在同一组质心向量 上。 每个查询仅关注属于同一集群的键。 在训练期间,使用分配给它的向量的指数移动平均值除以簇计数的指数移动平均值来更新簇质心向量:
| (8) | ||||
| (9) | ||||
| (10) |
其中 表示集群 中当前向量的数量, 是超参数。
让 表示第 查询涉及的键索引集。 路由转换器中的 定义为
| (11) |
Reformer (Kitaev 等人, 2020) 使用局部敏感哈希 (LSH) 为每个查询选择键值对。 所提出的 LSH 注意力允许每个词符仅关注同一哈希桶中的标记。 基本思想是使用 LSH 函数将查询和键散列到多个桶中,相似的项以高概率落入同一个桶中。 具体来说,他们对 LSH 函数使用随机矩阵方法。 令 为存储桶的数量,给定大小为 的随机矩阵 ,LSH 函数计算如下:
| (12) |
LSH 注意力允许第 个查询仅关注带有索引的键值对
| (13) |
稀疏自适应连接 (SAC) (Li 等人, 2020b) 将输入序列视为图形,并学习使用自适应稀疏连接构建注意力边以提高特定于任务的性能。 SAC 使用 LSTM 边缘预测器来构建标记之间的边缘。 由于没有边缘的基本事实,边缘预测器通过强化学习进行训练。
稀疏 Sinkhorn Attention (Tay 等人, 2020b) 首先将查询和键拆分为多个块,并为每个查询块分配一个键块。 每个查询只允许关注分配给其相应查询块的键块中的键。 关键块的分配由排序网络控制,该网络使用 Sinkhorn 归一化生成双随机矩阵作为表示分配的排列矩阵。 他们使用这种基于内容的块稀疏注意力以及第二节中引入的块局部注意力。 4.1.1增强模型对局部性建模的能力。
4.2. 线性化注意力
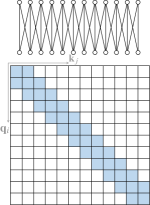
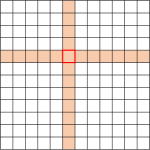
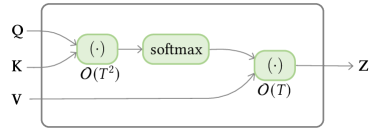
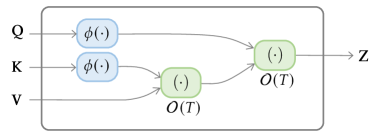
假设,计算的复杂度是二次方。 序列长度,如图7(a)所示。 如果可以分解为,我们可以以相反的顺序计算(即),从而导致复杂性。
令表示非标准化注意力矩阵,按元素应用,常规注意力可以重写为,其中; 是长度的全1列向量; 是以输入向量为对角线的对角矩阵。
线性化注意力是一类用 近似或替换非标准化注意力矩阵 的方法,其中 是按行应用的特征图方式。 因此,非归一化注意力矩阵的计算可以通过计算来线性化666类似地,分区项可以用在线性时间内计算。,如图7(b)所示。
为了进一步了解线性化注意力,我们推导了向量形式的公式。 我们考虑一种一般形式的注意力
| (14) |
其中 是衡量输入向量之间相似性的评分函数。 在 vanilla Transformer 中,评分函数是内积 的指数。 的自然选择是核函数 ,这会导致
| (15) | ||||
| (16) |
其中 表示向量的外积。 基于这个公式,可以通过首先计算突出显示的术语 和 来线性化注意力。 这对于自回归注意力特别有益,因为可以在恒定时间内根据 和 计算累积和 和 。 这有效地使 Transformer 解码器能够像 RNN 一样运行。
方程的解释。 (16) 是模型通过聚合由(特征映射的)键和值的外积表示的关联来维护一个内存矩阵,然后通过将内存矩阵与经过适当归一化的特征映射查询相乘来检索值。 该方法有两个关键组成部分:(1)特征图,(2)聚合规则。
4.2.1. 特征图
Linear Transformer (Katharopoulos 等人, 2020) 建议使用简单的特征图。 该特征图并非旨在近似点积注意力,但经经验证明其性能与标准 Transformer 相当。
Performer (Choromanski 等人, 2020a; Choromanski 等人, 2020b) 使用近似 Transformer 评分函数的随机特征图。 随机特征图采用函数 和 。
| (17) |
其中 来自某个分布 。
Performer (Choromanski 等人,2020a)的第一个版本的灵感来自最初用于近似高斯核的随机傅里叶特征图(Rahimi and Recht,2007)。 它使用带有 的三角函数。 这种方法也被用于随机特征注意力(RFA)(Peng 等人,2021),不同之处在于设置为在应用特征图之前,查询和键被标准化。
尽管三角随机特征图导致无偏近似,但它不能保证非负注意力分数,因此可能导致不稳定的行为和异常行为。 为了缓解这个问题,Performer的第二个版本(Choromanski等人,2020b)提出了正随机特征图,它使用,从而保证点的无偏和非负近似-产品关注度。 这种方法比 Cheromanski 等人 (2020a) 更稳定,并且报告了更好的近似结果。
除了使用随机特征图来近似标准点积注意力之外,Peng 等人 (2021) 和 Choromanski 等人 (2020b) 还探索了近似 1 阶反余弦内核与。 该特征图已被证明在机器翻译和蛋白质序列建模等各种任务中有效。
Schlag 等人 (2021) 设计一个旨在促进特征空间正交性的特征图。 具体来说,给定输入 ,特征图 由偏函数定义
| (18) |
4.2.2. 聚合规则
在等式中。 (16) 关联通过简单求和聚合到内存矩阵中。 多项研究都采用了这一点(Katharopoulos 等人,2020;Choromanski 等人,2020a;Choromanski 等人,2020b)。 然而,当新关联添加到内存矩阵时,网络有选择地删除关联可能更有利。
RFA (Peng 等人, 2021) 在求和中引入了门控机制,以对序列数据中的局部依赖性进行建模。 具体来说,当向记忆矩阵 添加新关联时,在特定时间步,它们通过可学习的、依赖于输入的标量 来衡量 ,以及 的新关联(以及与 类似的机制)。 通过这种修改,历史关联呈指数衰减,并且每个时间步都倾向于最近的上下文。
Schlag等人(2021)认为简单的求和限制了存储矩阵的容量,因此提出以写入和删除的方式扩大容量。 具体来说,给定一个新的输入键值对 ,模型首先使用矩阵乘法检索当前与 关联的值 。 然后,它使用依赖于输入的门控标量 将 和 的凸组合写入内存矩阵,并删除关联 . 他们还提出了求和归一化(在更新内存矩阵之前通过其分量的总和归一化),而不是使用等式1中的分母进行归一化。 (16) 此聚合规则。
4.3. 查询原型和内存压缩
除了使用稀疏注意力或基于内核的线性化注意力之外,还可以通过减少查询或键值对的数量来降低注意力的复杂性,这会导致查询原型和 内存压缩777键值对通常称为键值内存(因此称为内存压缩)。 方法,分别。
4.3.1. 注意原型查询
在查询原型设计中,多个查询原型作为计算注意力分布的主要来源。 该模型要么将分布复制到所表示的查询的位置,要么用离散均匀分布填充这些位置。 图8(a)说明了查询原型的计算流程。
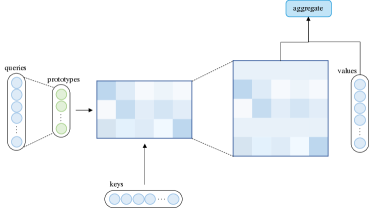
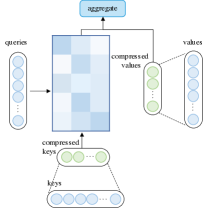
集群注意力(Vyas等人,2020)将查询分组为几个集群,然后计算集群质心的注意力分布。 集群中的所有查询共享使用相应质心计算的注意力分布。
Informer (Zhou 等人, 2021) 使用显式查询稀疏性测量从查询中选择原型,该稀疏性测量源自查询注意力分布与离散均匀分布之间的 Kullback-Leibler 散度的近似值。 然后,仅计算查询稀疏度测量下的 top- 查询的注意力分布。 其余查询分配有离散均匀分布。
4.3.2. 压缩键值内存的注意力
除了通过查询原型减少查询数量外,还可以在应用注意力机制之前通过减少键值对的数量来降低复杂度,如图8(b)所示。
Liu 等人 (2018) 提出了内存压缩注意力(MCA),它使用跨步卷积来减少键和值的数量。 这种修改被用作同一工作中提出的局部注意力的补充(如4.1节中讨论的),因为它可以捕获全局上下文。 该机制将键和值的数量减少了内核大小 的一个因子,因此在给定相同计算资源的情况下,可以比普通 Transformer 处理更长的序列。
Set Transformer (Lee 等人, 2019) 和 Luna (Ma 等人, 2021) 使用许多外部可训练的全局节点来汇总来自输入的信息,然后汇总表示充当输入参与的压缩存储器。 这将自注意力的二次复杂度降低到线性复杂度。 序列长度。
Linformer (Wang 等人, 2020a) 利用线性投影将键和值从长度 投影到更小的长度 。 这也将 self-attention 的复杂度降低为线性。 这种方法的缺点是必须假设输入序列长度,因此它不能用于自回归注意。
Poolingformer (Zhang 等人, 2021) 采用两级注意力机制,结合了滑动窗口注意力和压缩内存注意力。 滑动窗口注意力之后使用压缩记忆模块来增加感受野。 他们探索了几种不同的池化操作作为压缩操作来压缩键和值的数量,包括最大池化和动态卷积池化(Wu等人,2019)。
4.4. 低阶自注意力
一些实证和理论分析(Guo等人,2019b;Wang等人,2020a)报告自注意力矩阵通常是低秩的888的排名远远低于输入长度。. 该属性的含义是双重的:(1)低秩属性可以通过参数化显式建模; (2) 自注意力矩阵可以用低秩近似代替。
4.4.1. 低阶参数化
注意力矩阵的秩小于序列长度的事实意味着,对于输入通常较短的场景,设置 将不仅仅是过度参数化并导致过度拟合。 因此,限制 的维度以将低秩属性显式建模为归纳偏差是合理的。 Guo 等人 (2019b) 将自注意力矩阵分解为具有小 的低秩注意力模块,用于捕获远程非局部交互,以及带状注意力模块捕获本地依赖项。
4.4.2. 低阶近似
注意矩阵的低秩属性的另一个含义是可以使用低秩矩阵近似来降低自注意的复杂性。 一种密切相关的方法是核矩阵的低秩近似。 我们相信一些现有的工作是受到核近似的启发。
第 2 节中提到的一些线性化注意方法。 4.2 的灵感来自于随机特征图的核近似。 例如,Performer (Choromanski 等人, 2020a) 遵循最初提出的随机傅立叶特征图来近似高斯核。 该方法首先将注意力分布矩阵分解为,其中是高斯核矩阵,使用随机特征图来近似.
另一条工作遵循 Nyström 方法的思想。 这些基于 Nyström 的方法 (Chen 等人, 2020a; Xiong 等人, 2021) 首先通过下采样从 输入中选择 地标节点方法(例如,跨步平均池化)。 令 为选定的地标查询和键,然后在注意力计算中使用以下近似值
| (19) |
请注意等式中的。 (19) 并不总是存在。 为了缓解这个问题,CSALR (Chen 等人, 2020a) 在 中添加了一个单位矩阵,以确保逆矩阵始终存在。 Nyströmformer (Xiong 等人, 2021) 使用 的 Moore-Penrose 伪逆来代替逆,以便可以对 的情况进行近似是单一的。
4.5. 事先注意
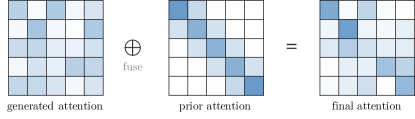
注意力机制通常将预期的注意力值输出为向量的加权和,其中权重是值上的注意力分布。 传统上,分布是根据输入生成的(例如,vanilla Transformer 中的 )。 作为一般情况,注意力分配也可以来自其他来源,我们将其称为先验。 先验注意力分布可以是对输入生成的分布的补充或替代。 我们将注意力的这种表述概括为带有先验的注意力,如图9所示。 在大多数情况下,两个注意力分布的融合可以通过在应用 softmax 之前计算与先验注意力和生成注意力相对应的分数的加权和来完成。
4.5.1. 在此之前模型局部
某些类型的数据(例如文本)可能表现出对位置的强烈偏好。 该属性可以显式编码为先验注意力。 一种简单的方法是对位置使用高斯分布。 具体来说,可以将生成的注意力分布乘以一定的高斯密度,然后重新归一化,这相当于在生成的注意力分数 上添加一个偏差项 ,其中较高的 表示第 个输入参与第 个输入的先验概率较高。
Yang 等人 (2018) 提出首先使用简单的前馈网络预测每个 的中心位置 。 高斯偏差定义为
| (20) |
其中 表示高斯的标准差,可以确定为超参数或根据输入进行预测。
高斯变换器(Guo 等人, 2019c)假设每个的中心位置为,并定义偏差为bes
| (21) |
其中是标量参数,分别控制偏差和减少中心位置的权重。
4.5.2. 低层模块优先
在 Transformer 架构中,经常观察到相邻层的注意力分布相似。 因此,很自然地提供前一层的注意力分布作为注意力计算的先验。 最终的注意力分数可以定义为
| (22) |
其中 表示第 层的注意力分数, 是应用于相邻层分数的权重,是将先前分数转换为要应用的先前分数的函数。
Predictive Attention Transformer (Wang 等人, 2021) 提出将 2D 卷积层应用于先前的注意力分数,并将最终的注意力分数计算为生成的注意力分数和卷积分数的凸组合。 这相当于等式1中将和设置为卷积层。 (22)。 他们从头开始实验训练这样的模型,并在适应预训练的 BERT 模型后进行微调,两组实验都显示出相对于基线模型的改进。
Realformer (He 等人, 2020b) 使用将之前的注意力分数直接添加到生成的注意力分数中,从而类似于注意力图上的残差跳跃连接。 相当于将式(1)中的和设置为恒等映射。 (22)。 他们对该模型进行了预训练实验。 结果表明,该模型在多个数据集中优于基线 BERT 模型,即使在预训练预算明显较低的情况下也超越了基线模型。
作为一种极端情况,Lazyformer (Ying 等人, 2021) 提出在多个相邻层之间共享注意力图。 这相当于将设置为identity并交替切换和的设置。 这种方法的好处是注意力图仅计算一次并在后续层中重复使用多次,从而降低了计算成本。 他们的预训练实验表明,所得模型仍然有效,同时计算效率更高。
4.5.3. Prior 作为多任务适配器
适配器是依赖于任务的训练模块,附加在预训练网络的特定位置,用于跨任务高效参数共享(Rebuffi等人,2017)。 Pilault 等人 (2021) 提出了一种条件自适应多任务学习 (CAMTL) 框架,该框架使用依赖于任务编码 的可训练注意先验
| (23) |
其中表示直接求和,是可训练参数,是特征明智线性调制函数(Perez等人,2018). 最大序列长度在实现中指定。 先验被公式化为块对角矩阵,并添加到预训练 Transformer 中上层的注意力分数中,以充当参数高效的多任务归纳知识转移的适配器。
4.5.4. 仅先注意
一些作品探索了使用独立于输入之间的成对交互的注意力分布。 换句话说,他们的模型仅利用先验注意力分布。
Zhang 等人 (2018) 设计了一种高效的 Transformer 解码器变体,称为平均注意力网络,它使用离散均匀分布作为注意力分布的唯一来源。 因此,这些值被聚合为所有值的累积平均值。 为了提高网络的表达能力,他们在平均注意力模块之上进一步添加了前馈门控层。 这种方法的优点是,适配的 Transformer 解码器可以像通常的 Transformer 一样以并行方式进行训练,并像 RNN 一样进行解码,从而避免了解码中的复杂性。
You 等人 (2020) 使用高斯分布作为硬编码的注意力分布来进行注意力计算。 直觉与 Yang 等人 (2018) 和 Guo 等人 (2019c) 非常相似,注意力分布应该集中在某个局部窗口上。 不同的是,他们完全放弃了生成的注意力,仅使用高斯分布进行注意力计算。 在这种方法中,均值(中心位置)和方差被设计为超参数。 实验表明,硬编码注意力仅应用于自注意力时,可以在机器翻译任务中实现与基线模型相当的性能。
合成器(Tay等人,2020a)建议将生成的注意力分数替换为:(1)可学习的、随机初始化的注意力分数,以及(2)仅由前馈网络输出的注意力分数以查询输入本身为条件。 机器翻译和语言建模的实验表明,这些变体可以实现与普通 Transformer 竞争的性能。 没有解释为什么这些变体起作用,但实证结果很有趣。
4.6. 改进的多头机构
多头注意力需要能够共同关注来自不同位置的不同表示子空间的信息。 然而,没有任何机制可以保证不同的注意力头确实捕获不同的特征。
4.6.1. 头部行为建模
使用多头注意力的基本动机是让模型共同关注来自不同位置的不同表示子空间的信息(Vaswani 等人,2017)。 然而,在 vanilla Transformer 中,没有明确的机制来保证注意力头之间的不同行为,也没有任何机制让注意力头彼此交互。 有一系列工作致力于通过引入更复杂的机制来改进多头机制,这些机制可以指导不同注意力头的行为或允许跨注意力头进行交互。
Li等人(2018)在损失函数中引入辅助分歧正则化项,以鼓励不同注意力头之间的多样性。 两个正则化项分别是为了最大化输入子空间和输出表示的余弦距离,而最后一项是通过相应注意矩阵的元素相乘来分散多个头所占据的位置。
几项探索工作表明,预先训练的 Transformer 模型表现出某些缺乏语言支持的自我关注模式。 作为代表性工作,Kovaleva 等人 (2019) 识别了 BERT 中的几种简单的注意力模式。 例如,许多注意力头只是关注特殊的 BERT 标记 [CLS] 和 [SEP]。 因此,可以引入一些约束来提高 Transformer 模型的训练。 为此,Deshpande 和 Narasimhan (2020) 提出使用辅助损失,其被定义为注意力分布图和预定义注意力模式之间的 Frobenius 范数。
Talking-head Attention (Shazeer 等人, 2020) 使用头部说话机制,将生成的注意力分数从 线性投影到 头部,应用 softmax在该空间中,然后投影到 头进行价值聚合。 动机是鼓励模型以可学习的方式在注意力头之间移动信息。
4.6.2. 跨度有限的多头
Vanilla 注意力采用完全注意力跨度假设,其中查询可以关注所有键值对。 然而,我们经常观察到,一些负责人的注意力主要集中在本地环境中,而另一些负责人则关注更广泛的环境。 因此,限制注意力的广度可能是有益的:
-
•
地点。 限制注意力广度会导致明确的局部约束。 这在局部性是重要优先事项的情况下是有利的。
-
•
效率。 如果实施得当,这样的模型可以扩展到非常长的序列,而不会引入额外的内存占用和计算时间。
限制注意力跨度可以表示为将每个注意力分布值与掩码值相乘,然后重新归一化,其中掩码可以表示为将距离映射到中的值的非增函数。 普通注意力为所有距离分配掩码值 ,如图 10(a) 所示。



Sukhbaatar 等人 (2019a) 提出使用可学习的注意力广度,如图 10(b) 所示。 掩码由可学习标量 和超参数 参数化。字符级语言建模的实验表明,自适应跨度模型的性能优于基线模型,同时 FLOPS 显着减少。 还观察到较低层通常具有较小的学习跨度,而较高层则不然。 这表明该模型可以学习特征的层次结构。
Multi-Scale Transformer (Guo 等人, 2020) 建议使用固定的注意力跨度,不同层的不同头使用不同的最大跨度。 固定注意力广度如图10(c)所示。 注意力被限制在由scale值控制的固定窗口内。他们从直观的语言学角度和 BERT 的经验观察来设计尺度,使得较高层往往具有更大的尺度(例如,大跨度),而较低层应限制较小的尺度。 他们对多项任务的实验表明,该模型可以超越基线模型,同时加速长序列的推理。
4.6.3. 多头精细聚合
在每个注意力头计算其输出表示后,普通多头注意力 (Vaswani 等人, 2017) 连接这些表示,然后对连接的表示应用线性变换以获得最终的输出表示,如下公式如下: (2)。 结合方程。 (1)(2) 和 (3),我们可以看到这个连接和项目公式相当于对 重新参数化注意力输出求和。 为此,我们首先将分为块
| (25) |
其中每个 的维度为 。 因此很容易看出多头注意力可以重新表述为
| (26) |
有人可能会说,这种简单的求和聚合范式并没有充分利用多头注意力的表达能力,并且更需要使用更复杂的聚合。
Li 等人 (2019b); Gu 和 Feng (2019) 提出使用最初为胶囊网络提出的路由方法(Sabour 等人,2017),以进一步聚合不同注意力头产生的信息。 注意力头的输出首先被转换为输入胶囊,然后在迭代路由过程后获得输出胶囊。 然后将输出胶囊连接起来作为多头注意力的最终输出。 这两篇作品都利用了两种路由机制,即动态路由(Sabour等人, 2017)和EM路由(Hinton等人, 2018)。 人们会注意到迭代路由引入了额外的参数和计算开销。 Li等人(2019b)经验表明,仅将路由机制应用于较低层可以最好地平衡翻译性能和计算效率。
4.6.4. 其他修改
已经提出了对多头机制的其他几种修改,以提高多头注意力。
Shazeer (2019) 提出多查询注意力,其中键值对在注意力头之间共享(即,对所有注意力头仅使用一个键投影和一个值投影)。 此方法的优点在于,它降低了解码所需的内存带宽要求,并生成解码速度更快的模型,同时仅导致与基线相比较小的质量下降。
Bhojanapalli 等人 (2020) 证明较小的注意力密钥大小会影响其表示任意分布的能力。 因此,他们建议将头部尺寸与头部数量 分开,这与将头部尺寸设置为 的常见做法相反。 根据经验观察,将注意力头大小设置为输入序列长度是有益的。
5. 其他模块级修改
5.1. 职位表示
定义 5.0(置换等变函数)。
令 为索引 的所有排列的集合。 函数被称为排列等变当且仅当对于任何
| (27) |
很容易验证卷积网络和递归网络不是排列等变的。 然而,Transformer 中的自注意力模块和位置前馈层都是排列等变的,这在建模问题时可能是一个问题,而不是 set-input 问题,其中输入的结构是需要的。 例如,在对文本序列进行建模时,单词的顺序很重要,因此在 Transformer 架构中正确编码单词的位置至关重要。 因此,需要额外的机制将位置信息注入 Transformer 中。 常见的设计是首先使用向量表示位置信息,然后将向量作为附加输入注入到模型中。
5.1.1. 绝对位置表示
在普通 Transformer (Vaswani 等人, 2017) 中,位置信息被编码为绝对正弦位置编码。对于每个位置索引 ,编码是一个向量 ,其中每个元素都是具有预定义频率的索引的正弦 (/) 函数。
| (28) |
其中 是每个维度的手工频率。 然后将序列中每个位置的位置编码添加到词符嵌入中并馈送到 Transformer。
表示绝对位置的另一种方法是学习每个位置的一组位置嵌入(Gehring 等人,2017;Devlin 等人,2019)。 与手工制作的位置表示相比,学习嵌入更加灵活,因为位置表示可以通过反向传播来适应任务。 但是嵌入的数量仅限于训练之前确定的最大序列长度,这使得该方法不再归纳,即无法处理比训练时间中看到的序列更长的序列 (刘等人,2020b;褚等人,2021)。
Wang 等人 ([n.d.]) 建议使用正弦位置表示,但每个频率 (在方程 (28) 中)学习自数据。 这种方法保留了归纳性,但比手工制作的正弦编码更灵活。 FLOATER (Liu 等人, 2020b) 将位置表示构建为连续动态系统,并采用神经常微分方程来实现反向传播的端到端训练。 与完全可学习的方法相比,该方法具有归纳性和灵活性,同时参数效率高。
合并绝对位置表示的普通方法是将位置编码/嵌入添加到词符嵌入中。 然而,当输入信号通过各层传播时,位置信息可能会在上层中丢失。 后来的工作发现,在每个 Transformer 层的输入中添加位置表示是有益的(Al-Rfou 等人,2019;Dehghani 等人,2019;Liu 等人,2020b;Guo 等人,2019b)。
5.1.2. 相对位置表示
另一条工作重点是表示标记之间的位置关系,而不是单个标记的位置。 直觉是,在自注意力中,输入元素之间的成对位置关系(方向和距离)可能比元素的位置更有益。 遵循这一原则的方法称为相对位置表示。 Shaw 等人 (2018) 提出在注意力机制的键中添加可学习的相对位置嵌入
| (29) | ||||
| (30) | ||||
| (31) |
其中 是位置 和 之间关系的相对位置嵌入, 是决定嵌入数量的最大偏移量。 通常, 设置为可以容纳大多数输入序列的长度。 作为一个特例,InDIGO (Gu 等人, 2019) 将 设置为 ,用于其专门设计的非自回归生成框架。 作为渐进式的努力,Music Transformer (Huang 等人,2019)进一步引入了一种机制来减少这种方法的中间内存需求。 与这种方法类似,T5 Raffel 等人 (2020) 采用相对位置嵌入的简化形式,其中每个嵌入只是一个可学习的标量,它被添加到用于计算注意力权重的相应分数中。
Transformer-XL (Dai 等人, 2019) 使用正弦编码来表示位置关系,但通过重新设计注意力分数的计算来融合内容和位置信息999比例因子被省略而不失一般性。
| (32) |
其中 是可学习参数, 是正弦编码矩阵,类似于普通 Transformer 中的位置编码。 然后将 softmax 函数应用于分数 以提供注意力权重。 请注意,可学习的正弦编码(Wang 等人, [n.d.]) 也是手工制作的 的直接替代品。
DeBERTa (He 等人, 2020a) 利用像 Shaw 等人 (2018) 这样的位置嵌入,并以类似于 Transformer-XL (戴等人,2019)
| (33) |
其中 是可学习的参数, 是可学习的相对位置嵌入,如式(1)所示。 (30)。 第一项被解释为内容到内容的注意力,后两项分别被解释为(相对)内容到位置和位置到内容的注意力。
5.1.3. 其他代表
一些研究探索了使用包含绝对和相对位置信息的混合位置表示。 Transformer with Untied Position Encoding (TUPE) (Ke 等人, 2020) 将注意力分数的计算重新设计为内容到内容项、绝对位置到位置项的组合以及表示相对位置关系的偏差项
| (34) |
其中 是可学习的参数, 是位置 的位置嵌入, 是可学习的标量相对位置嵌入。
人们还可以设计一组表达绝对信息和相对信息的位置表示。 Roformer (Su 等人, 2021) 使用旋转位置嵌入 (RoPE) 通过乘以第 个输入的仿射变换嵌入来表示词符的位置 通过旋转矩阵
| (35) | ||||
| (36) |
其中表示矩阵的直和。 每个都是角度的二维顺时针旋转矩阵
| (37) |
该公式的主要优点是诱导表示是平移不变的,即 的注意力分数仅与其相对位置偏移有关
| (38) |
实际上,嵌入矩阵乘法可以通过两个元素乘法来实现,以减少内存占用。 RoPE采用绝对嵌入的形式,但可以捕获相对位置关系。 这种方法与第 2 节中的线性化注意力兼容。 4.2。
5.1.4. 没有显式编码的位置表示
Wang 等人 (2020b) 没有明确引入额外的位置编码,而是提出通过将嵌入推广到位置上的连续(复值)函数来对词嵌入中的位置信息进行编码。
R-Transformer (Wang 等人, 2019b) 使用局部 RNN 建模序列数据的局部性。 具体来说,R-Transformer 每个块的输入首先馈送到本地 RNN,然后馈送到多头自注意力模块。 RNN 结构引入排序信息并捕获局部依赖关系作为自注意力的补充。
条件位置编码 (CPE) (Chu 等人, 2021) 通过带有零填充的二维卷积在 ViT 的每一层生成条件位置编码。 这种方法背后的直觉是,卷积网络可以用零填充隐式编码绝对位置信息(Islam等人,2020)。
5.1.5. Transformer 解码器上的位置表示
值得注意的是,masked self-attention 并不是排列等变(Tsai 等人,2019)。 因此,仅利用 Transformer 解码器的模型具有在不合并显式位置表示的情况下感知位置信息的潜力。 语言建模任务的一些实证结果证实了这一点(Irie 等人,2019;Schlag 等人,2021),作者发现删除位置编码甚至可以提高性能。
5.2. 层归一化
层归一化(LN)与残差连接一起被认为是稳定深层网络训练的机制(例如,减轻不适定梯度和模型退化)。 有一些研究致力于分析和改进 LN 模块。
5.2.1. 层归一化的放置
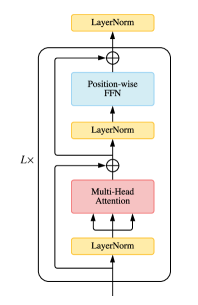
在普通 Transformer 中,LN 层位于残差块之间,称为 post-LN (Wang 等人,2019a)。 后来的 Transformer 实现(Vaswani 等人,2018;Klein 等人,2017) 将 LN 层放置在注意力或 FFN 之前的残差连接内,并在最终层之后添加一个额外的 LN 来控制注意力的大小最终输出,称为 LN 前101010据我们所知,自v1.1.7开始在Tensor2Tensor实现中采用了这种方法(Vaswani 等人,2018)。. Pre-LN 已被众多后续研究和实施所采用,例如(Baevski 和 Auli,2019;Child 等人,2019;Wang 等人,2019a)。 LN前和LN后的差异如图11所示。
Xiong等人(2020)从理论上研究了Transformers的梯度,发现post-LN Transformers在初始化时输出层附近的梯度很大,这可能是post-LN Transformers无需学习的原因速率预热(Vaswani 等人, 2017)111111学习率预热是指以极小的学习率开始优化,然后在一定次数的迭代中逐渐将其增加到预先定义的最大值。 导致训练不稳定,而 LN 之前的变形金刚不会遇到同样的问题。 因此,他们推断并凭经验验证可以安全地取消预 LN Transformer 的预热阶段。
尽管后 LN 经常导致训练不稳定和发散,但它在收敛后通常优于前 LN 变体(Liu 等人,2020a)。 与Xiong等人(2020)类似,Liu等人(2020a)进行了理论和实证分析,发现后LN编码器不会遭受梯度不平衡的影响。 因此,他们推测梯度问题并不是后 LN Transformer 训练不稳定的直接原因,并进一步确定了后 LN Transformer 中的放大效应——在初始化时,对残差分支的较重依赖导致了LN 后 Transformer 的输出偏移较大,从而导致训练不稳定。 根据这一发现,他们向后 LN Transformer 引入了额外的参数,以控制后 LN 的剩余依赖性。 这些参数根据样本数据的激活变化进行初始化,以便后 LN Transformer 的输出偏移不会被放大。 这种方法确保并促进 LN 后 Transformer 的收敛,并获得比 LN 前 Transformer 更好的性能。
5.2.2. 层标准化的替代品
Xu等人(2019)根据经验观察,LN模块中的可学习参数在大多数实验中不起作用,甚至增加了过拟合的风险。 他们从对照实验中进一步得出结论,前向归一化并不是闪电网络适用于 Transformer 的原因。 通过分析和实验,得出结论:均值和方差的导数使梯度重新居中并重新缩放,并在 LN 中发挥重要作用。 因此,他们提出了AdaNorm,一种没有可学习参数的归一化技术
| (39) | ||||
| (40) |
其中 是超参数, 表示逐元素乘法。 和 分别是输入 的平均值和标准差。
Nguyen 和 Salazar (2019) 建议用缩放归一化替换 LN 模块。 给定 维度的任何输入 ,他们的方法将其投影到学习半径 的 球体上
| (41) |
其中 是可学习的标量。 与普通 LN 相比,它的参数效率更高,并且在机器翻译数据集中尤其是在资源匮乏的环境中被证明是有效的。
Shen 等人 (2020) 讨论了为什么 Batch Normalization (BN) (Ioffe 和 Szegedy,2015) 在 Transformer 中对于文本数据表现不佳,并得出结论:BN 的性能显着下降源于与其批次统计相关的不稳定性。 因此,他们提出了 PowerNorm(PN),它对 BN 进行了三处修改:(1)它放宽了零均值归一化; (2)它使用信号的二次均值,而不是方差; (3)它使用运行统计来求二次均值,而不是使用每批次统计。 具体来说,对于第 次迭代,PN 将输出计算为
| (42) | ||||
| (43) | ||||
| (44) |
其中 是移动平均系数, 是 BN 公式中的可学习参数。
5.2.3. 无归一化 Transformer
除了 LN 之外,还有另一种机制可以构建更深层的神经网络。 ReZero (Bachlechner 等人, 2020) 用可学习的残差连接替换 LN 模块。 对于每个模块 ,ReZero 会在残差公式中重新缩放 :
| (45) |
其中 是零初始化的可学习参数。
经验证,用 ReZero 机制替换 Transformer 中的 LN 可以为输入信号带来更好的动态等距,并导致更快的收敛。
5.3. 位置方式 FFN
尽管很简单,但位置前馈网络 (FFN) 层对于 Transformer 实现良好的性能非常重要。 Dong 等人 (2021) 观察到,简单地堆叠自注意力模块会导致等级崩溃问题,从而导致 Token 均匀性归纳偏差,并且前馈层是缓解这一问题的重要组成部分之一。 各种工作都探索了对 FFN 模块的修改。
5.3.1. FFN 中的激活函数
普通 Transformer (Vaswani 等人, 2017) 采用修正线性单元 (ReLU) 激活来实现两个 FFN 层之间的非线性。 随着时间的推移,一些研究探索了 ReLU 之外的不同激活方法。
Ramachandran 等人 (2018) 尝试用 Swish 函数替换 Transformer 中的 ReLU 并观察到它在 WMT 2014 英语德语数据集上的性能持续提高。
GPT (Radford 等人, 2018) 在语言预训练上用高斯误差线性单元 (GELU) (Hendrycks and Gimpel, 2020) 替换 ReLU。 它成为许多预训练语言模型的默认做法(Devlin 等人,2019;He 等人,2020a)。
Shazeer (2020) 探索使用门控线性单元 (GLU) (Dauphin 等人,2017) 及其变体作为 FFN 中 ReLU 的直接替代品。 他们的预训练实验表明,GLU 变体通过 ReLU 激活持续改进普通 Transformer。 请注意,GLU 引入了额外的参数,并且实验是在减少 FFN 的中间维度以匹配参数计数与基线的情况下进行的。
5.3.2. 调整 FFN 以实现更大容量
有几项工作侧重于扩展 FFN,以获得更大的模型容量。 基本思想是用具有更多参数的相似结构替换 FFN。
Lample 等人 (2019) 用产品密钥存储层替换部分 FFN。 产品密钥存储器由三个组件组成:查询网络、包含两组子密钥的密钥选择模块以及值查找表。 该模型首先使用查询网络将输入投影到潜在空间,然后将生成的查询与来自键选择模块的两组子键的笛卡尔积的键进行比较,以获得 最近邻居,最后使用 最近的键在值查找表中找到相应的值,并将它们聚合以产生最终输出。 这个过程类似于注意力机制,因为生成的查询会关注大量的全局键值对。 因此,他们提出了针对关键产品存储器的多头机制,以进一步扩大该模块的容量。 大规模语言建模的实验表明,这种机制在计算开销可以忽略不计的情况下显着提高了性能。
多项研究利用专家混合 (MoE)(Shazeer 等人,2017)的理念来提高 FFN 的容量。 Gshard(Lepikhin 等人, 2020) 使用稀疏门控 MoE 层替换 Transformer 中的 FFN。 每个 MoE 层由多个 FFN(每个称为专家)组成,其结构与 vanilla Transformer 中的位置 FFN 相同。 该层的输出是 FFN 输出的加权和,使用由路由函数 计算的门值。 他们设计了一个可学习的路由函数,将 Token 分配给专家,并通过辅助损失来满足专家之间的平衡负载和长度范围内的效率,从而使专家可以分布在多个设备上。 对于 MoE 层的每次前向传递,仅激活具有 top- 门值的专家。
Switch Transformer (Fedus 等人, 2021) 建议仅使用具有最大门值的单个专家进行路由,而不是在每次前向传递中使用 专家,从而导致更小的计算足迹。 作者还设计了一个辅助损失来鼓励专家之间的负载平衡。 据报道,与非 MoE 对应物相比,它可以大幅加快预训练速度,同时具有相似的 FLOPS 数量。
Yang 等人 (2021) 建议用专家原型策略替换 top- 路由。 具体来说,所提出的策略将专家分为 不同的组,并在每个组内应用 top-1 路由。 原型组的输出被线性组合以形成MoE层的最终输出。 事实证明,该策略可以提高模型质量,同时保持恒定的计算成本。
与使用可学习的路由函数进行专家分配不同,Roller 等人 (2021) 设计了哈希层,其中 Token 被哈希到固定数量的桶中,每个桶对应于专家。 该方法不需要路由参数或任何辅助损失函数,同时显示出与现有方法(例如 Switch Transformer (Fedus 等人,2021))竞争的结果。
5.3.3. 删除 FFN 层
值得注意的是,有人可能会争辩说,在某些情况下,FFN 层可以完全删除,从而简化网络。
Sukhbaatar 等人(2019b)证明,用 Softmax 代替 ReLU 激活并去掉 FFN 中的偏置项,可以有效地将 FFN 变成一个注意力模块,在这个模块中,位置输入会关注 槽的全局键值记忆。 因此,他们建议放弃 FFN 模块,并向注意力模块添加一组全局键值对,这些键值对是与输入生成的键和值连接的可学习参数。 这种方法简化了网络结构,且不影响性能。
Yang等人(2020)的经验表明,Transformer解码器中的FFN尽管参数数量较多,但效率不高,可以安全地删除,而性能损失很小或没有。 这种方法显着提高了训练和推理速度。
6. 架构级别的变体
在本节中,我们将介绍 X-formers,它们将普通 Transformer 修改为超出模块范围。
6.1. 使Transformer变得轻量化
除了在模块级别努力减轻计算开销之外,还有一些尝试通过更高级别的修改来使 Transformer 变得轻量级。
与将注意力分解为局部约束注意力和低秩全局注意力的低秩自注意力(Guo 等人, 2019b)类似,Lite Transformer (Wu 等人, 2020b) )建议用双分支结构替换 Transformer 中的每个注意力模块,其中一个分支使用注意力来捕获远程上下文,而另一个分支使用深度卷积和线性层来捕获局部依赖关系。 该架构在模型大小和计算方面都是轻量级的,因此更适合移动设备。
Funnel Transformer (Dai 等人, 2020) 采用类似漏斗的编码器架构,其中隐藏序列的长度使用沿序列维度的池化逐渐减小,然后使用上采样恢复。 与普通 Transformer 编码器相比,该架构有效地减少了 FLOP 和内存。 当然,人们可以使用这种架构使用相同的计算资源构建更深或更广的模型。
DeLighT (Mehta 等人, 2020) 用 DeLighT 块替换了标准 Transformer 块,该块由三个子模块组成:(1)“扩展和缩减” DeLighT 转换模块以较低的计算要求学习更广泛的表示; (2)单头自注意力学习成对交互; (3) 一个轻量级的“缩减和扩展”FFN(与普通 Transformer 相反,它首先扩展隐藏表示的维度,然后将其缩减回 )。 他们还提出了一种逐块缩放策略,允许在输入附近使用更浅和更窄的块,在输出附近使用更宽和更深的块。 诱导网络比普通 Transformer 更深,但参数和操作更少。
6.2. 加强跨区块连接
在 vanilla Transformer 中,每个块将前一个块的输出作为输入,并输出一系列隐藏表示。 人们可能有兴趣创建更多输入信号可以在网络中运行的路径。 在秒。 4.5.2,我们引入了重用注意力分布的 Realformer (He 等人, 2020b) 和 Predictive Attention Transformer (Wang 等人, 2021)从前一个块引导当前块的注意力。 这可以看作是在相邻 Transformer 块之间创建一条前向路径。
在深度 Transformer 编码器-解码器模型中,解码器中的交叉注意力模块仅利用编码器的最终输出,因此误差信号必须沿着编码器的深度遍历。 这使得 Transformer 更容易受到优化问题的影响(例如梯度消失)。 透明注意力(Bapna等人,2018)使用每个交叉注意力模块中所有编码器层(包括嵌入层)的编码器表示的加权和。 对于第个解码器块,交叉注意模块被修改为关注
| (46) |
其中每个 是一个可训练参数。 这有效地缩短了编码器中每一层到误差信号的路径,从而简化了更深层次 Transformer 模型的优化。
与普通 Transformer 相关的另一个问题是每个位置只能处理较低层的历史表示。 Feedback Transformer (Fan 等人, 2021b) 提出在 Transformer 解码器中添加反馈机制,其中每个位置关注所有层的历史表示的加权和
| (47) |
6.3. 自适应计算时间
Vanilla Transformer 与大多数神经模型一样,利用固定的(学习的)计算过程来处理每个输入。 一个有趣且有希望的修改是使计算时间以输入为条件,即将自适应计算时间(ACT)(Graves,2016)引入到 Transformer 模型中。 此类修改可能会带来以下优点:
-
•
针对困难示例的特征细化。 对于难以处理的数据,浅层表示可能不足以完成手头的任务。 更理想的是应用更多的计算来获得更深入、更精细的表示。
-
•
简单示例的效率。 在处理简单的示例时,浅层表示可能足以完成任务。 在这种情况下,如果网络能够学习使用减少的计算时间来提取特征,那将是有益的。

Universal Transformer (UT) (Dehghani 等人, 2019) 采用了深度递归机制,该机制使用在深度上共享的模块迭代地细化所有符号的表示,如图 12(a)。 它还添加了按位置动态停止机制,计算每个时间步每个符号的停止概率。 如果符号的停止概率大于预定义的阈值,则符号的表示将在后续时间步中保持不变。 当所有符号停止或达到预定义的最大步长时,循环停止。
Conditional Computation Transformer (CCT) (Bapna 等人, 2020) 在每个自注意力层和前馈层添加门控模块来决定是否跳过当前层,如图12(b)。 作者还引入了一种辅助损失,鼓励模型调整门控模块,以使实际计算成本与可用计算预算相匹配。
与 UT 中使用的动态停止机制类似,有一行工作专门用于调整每个输入的层数,以实现良好的速度与精度权衡,这称为提前退出 机制,如图12(c)所示。 一种常用的技术是在每一层添加一个内部分类器并联合训练所有分类器。 这些方法的核心是每一层用来决定是否退出的标准。 DeeBERT (Xin 等人, 2020) 利用当前层的输出概率分布的熵来判断是否退出。 PABEE (Zhou 等人, 2020) 统计预测保持不变的次数来决定是否退出。 Li等人(2021)设计了一种基于窗口的不确定性准则,以实现序列标记任务的token级部分退出。 Sun等人(2021)提出了一种基于投票的退出策略,该策略在每一层考虑所有过去内部分类器的预测,以推断正确的标签并决定是否退出。
6.4. 具有分而治之策略的变形金刚
自注意力对序列长度的二次复杂度会显着限制某些下游任务的性能。 例如,语言建模通常需要远程上下文。 除了第 2 节中介绍的技术之外。 4,处理长序列的另一种有效方法是使用分而治之策略,即将输入序列分解为更精细的片段,以便可以有效地处理 Transformer 或 Transformer 模块。 我们确定了两个代表性的方法类,循环和分层转换器,如图13所示。 这些技术可以理解为 Transformer 模型的包装,其中 Transformer 充当基本组件,被重用来处理不同的输入段。
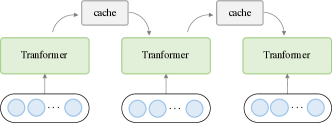
6.4.1. 循环 Transformer
在循环 Transformer 中,维护高速缓存以合并历史信息。 在处理一段文本时,网络从缓存中读取作为附加输入。 处理完成后,网络通过简单地复制隐藏状态或使用更复杂的机制来写入内存。 摘要流程如图13(a)所示。
Transformer-XL (Dai 等人, 2019) 通过缓存前一段的表示来解决固定长度上下文的限制,并在模型处理当前段时将其重新用作扩展上下文。 对于第 层和第 段,输入表示 与前一段的表示 连接起来生成键和值
| (48) | ||||
| (49) |
其中定义为词嵌入序列,表示停止梯度操作,表示沿时间维度连接两个向量序列。 此方法将最大上下文长度扩展了 ,其中 是层数, 是缓存内存序列的长度。
Compressive Transformer (Rae 等人, 2020) 通过将缓存扩展为两级内存,进一步扩展了这一想法。 在 Transformer-XL 中,前一个段的激活被缓存为内存,用于增强当前段,而旧段的激活将被丢弃。 另一方面,压缩 Transformer 对较旧的激活应用压缩操作(例如,卷积、池化等)并将它们存储在压缩内存中。 为了避免训练压缩子网络中具有损失梯度的昂贵的反向传播时间(BPTT),他们建议使用局部损失函数,其中原始记忆是从压缩记忆构建的。 该方法进一步将理论最大历史上下文长度从 Transformer-XL 的 扩展到 ,其中 是压缩率, 是压缩内存的长度。
Memformer (Wu 等人, 2020a) 将递归机制从仅解码器架构扩展到编码器-解码器架构。 他们向编码器引入了类似于普通 Transformer 中的交叉注意力的内存交叉注意力,以允许 Transformer 编码器关注内存。 他们还在编码器输出的顶部引入了内存槽注意,以显式地写入下一段的内存。 为了避免长时间步长范围内的 BPTT,他们提出了内存重播反向传播(MRBP)算法,该算法在每个时间步长重播内存,以完成长时间展开的梯度反向传播。
Yoshida 等人 (2020) 提出了一种简单的微调机制,将递归添加到预训练的语言模型中(例如 GPT-2 (Radford 等人, 2019) )。 他们首先使用每层 池表示的加权平均值,将第 段生成的表示压缩为一个向量表示。
| (50) |
其中表示第段的序列长度,是根据可学习参数进行softmax归一化的权重。 然后,将此压缩表示馈送到前馈网络,以生成第 段的内存状态 ,然后将其添加到特定的键值输入之前注意力层。 这种方法有效地扩展了预训练语言模型的上下文长度,而无需对原始模型的架构进行重大改变。
ERNIE-Doc (Ding 等人, 2020) 在 Transformer-XL 中使用的递归机制的基础上提出了一种增强的递归机制,通过用 中的历史表示替换内存第-层。
| (51) |
与使用等式中第 层的表示相反。 (48)。 这种修改本质上导致了更大的有效上下文长度。
6.4.2. 分层 Transformer
分层 Transformer 将输入分层分解为更细粒度的元素。 低级特征首先被输入到 Transformer 编码器,产生输出表示,然后将其聚合(使用池化或其他操作)以形成高级特征,然后由高级 Transformer 进行处理。 这类方法可以理解为一个层次抽象的过程。 该方法的概述如图13(b)所示。 这种方法的优点有两个:(1)分层建模允许模型用有限的资源处理长输入; (2)它有潜力生成有利于任务的更丰富的表示。
6.5.2.1 长序列输入的分层
对于本质上具有较长输入长度的任务,可以使用分层 Transformer 对远程依赖关系进行有效建模。 对于文档级机器翻译任务,Miculicich 等人 (2018) 在翻译句子时从源端和目标端引入对先前句子的依赖。 他们使用注意力机制作为聚合操作来总结低级信息。 对于文档摘要,HIBERT (Zhang 等人, 2019) 通过首先学习所有句子的句子表示来对文本文档进行编码,然后使用这些句子表示来编码文档级表示,然后用于生成摘要。 该模型使用最后一个隐藏表示(对应于EOS词符)作为每个句子的表示。 Liu 和 Lapata (2019) 提出了一种用于多文档摘要的类似分层 Transformer,其中使用具有全局可训练查询节点和低级表示作为源的关注层来聚合提取的低级表示键值对。 Hi-Transformer (Wu 等人, 2021b) 首先利用句子 Transformer 和文档 Transformer 来分层学习文档上下文感知句子表示。 然后,将文档上下文感知的句子表示馈送到另一个句子 Transformer,以进一步改进句子上下文建模。
6.5.2.2 分层以获得更丰富的表示
人们可能还对使用分层模型来获取对当前任务有益的更丰富的表示感兴趣。 例如,TENER (Yan 等人, 2019) 使用低级 Transformer 编码器对字符特征进行编码,然后将其与词嵌入连接作为高级 Transformer 编码器的输入。 这包含了更多功能并缓解了数据稀疏和词汇表外(OOV)的问题。 最近新兴的 Vision Transformer (Dosovitskiy 等人, 2020) 将输入图像划分为多个图块,作为 Transformer 的基本输入元素,这可能会丢失图块内的固有像素级信息。 为了解决这个问题,Transformer in Transformer (TNT) (Han 等人, 2021c) 在每一层使用一个内部 Transformer 块来转换像素表示,以及一个外部 Transformer 块,该块采用块表示的融合向量和像素表示作为输入。
6.5. 探索替代架构
尽管 Transformer 架构取得了成功,但人们可能会质疑当前的 Transformer 架构是否最优。 有趣的是,一些研究已经探索了 Transformer 的替代架构。
Lu 等人 (2020) 将 Transformer 解释为多粒子动态系统中对流扩散方程的数值常微分方程 (ODE) 求解器,并设计了 Macaron Transformer,它将每个 Transformer 块替换为FFN-attention-FFN 变体。
Sandwich Transformer (Press 等人,2020)探索重组注意力模块和 FFN 模块,使注意力模块主要位于下层,FFN 模块位于上层。 诱导模型改善了多种语言建模基准的困惑度,而无需增加参数、内存或训练时间。
Mask Attention Network (MAN) (Fan 等人, 2021a) 在每个 Transformer 块中的自注意力模块前面添加一个动态 mask 注意模块。 掩码以词符表示为条件,即标记和头索引之间的相对距离。 所提出的动态掩模注意力被证明可以有效地对文本数据中的局部性进行建模,并且归纳模型在机器翻译和抽象摘要方面始终优于基线模型。
值得注意的是,有一系列工作使用神经架构搜索(NAS)来搜索替代的 Transformer 架构。 Evolved Transformer (ET) (So 等人, 2019) 采用基于进化的架构搜索,并使用标准 Transformer 架构播种初始群体。 搜索到的模型在多种语言任务上表现出相对于 Transformer 的一致改进。 作为另一项代表作品,DARTSformer(Zhao 等人, 2021) 应用可微架构搜索(DARTS)(Liu 等人, 2019b),并结合多分裂可逆网络以及用于提高内存效率的反向传播重建算法。 生成的模型始终优于标准 Transformer,并且与较大的 ET 模型相比具有优势,并且搜索成本显着降低。
7. 预训练的 Transformer
与卷积网络和循环网络本质上包含局部性归纳偏差的一个关键区别是,Transformer 不对数据的结构做出任何假设。 一方面,这有效地使 Transformer 成为一个非常通用的架构,具有捕获不同范围的依赖关系的潜力。 另一方面,这使得 Transformer 在数据有限时容易出现过拟合。 缓解此问题的一种方法是在模型中引入归纳偏差。
最近的研究表明,在大型语料库上预训练的 Transformer 模型可以学习有利于下游任务的通用语言表示(Qiu 等人,2020)。 这些模型是使用各种自我监督目标进行预训练的,例如,根据上下文预测屏蔽词。 预训练模型后,我们可以简单地在下游数据集上对其进行调整,而不是从头开始训练模型。 为了说明在预训练中使用 Transformer 的典型方法,我们确定了一些预训练的 Transformer 并将它们分类如下。
-
•
仅限编码器。 一系列工作使用 Transformer 编码器作为其骨干架构。 BERT (Devlin 等人, 2019) 是典型的 PTM,通常用于自然语言理解任务。 它利用掩码语言模型(MLM)和下一句预测(NSP)作为自我监督的训练目标。 RoBERTa (Liu 等人, 2019a) 进一步调整了 BERT 的训练,并删除了 NSP 目标,因为它被发现会损害下游任务的性能。
-
•
仅解码器。 一些研究重点关注语言建模方面的 Transformer 解码器的预训练。 例如,生成式预训练 Transformer (GPT)系列(即GPT (Radford 等人, 2018)、GPT-2 (Radford 等人, 2019),和 GPT-3 (Brown 等人, 2020)) 致力于扩展预训练的 Transformer 解码器,最近表明,大规模 PTM 可以通过输入任务和示例实现令人印象深刻的少样本性能作为构造提示(Brown 等人, 2020) 到模型中。
-
•
编码器-解码器。 也有采用 Transformer 编码器-解码器作为整体架构的 PTM。 BART (Lewis 等人, 2020) 将 BERT 的去噪目标扩展到编码器-解码器架构。 使用编码器-解码器架构的好处是诱导模型具备执行自然语言理解和生成的能力。 T5 (Raffel 等人, 2020) 采用类似的架构,是最早在下游任务中使用任务特定文本前缀的研究之一。
8. Transformer 的应用
Transformer 最初是为机器翻译而设计的,但由于其灵活的架构,已广泛应用于 NLP 之外的各个领域,包括 CV 和音频处理。
(1)自然语言处理。 Transformer 及其变体在 NLP 任务中得到了广泛的探索和应用,例如机器翻译 (Vaswani 等人, 2017; Mehta 等人, 2020; Raffel 等人, 2020; So 等人, 2019; Fan 等人, 2021a)、语言建模(Dai 等人, 2019; Shoeybi 等人, 2020; Roy 等人, 2020; Rae 等人, 2020) 和命名实体识别 (Yan等人,2019;李等人,2020c)。 我们投入了大量精力在大规模文本语料库上预训练 Transformer 模型,我们认为这是 Transformer 在 NLP 中广泛应用的主要原因之一。
(2)计算机视觉。 Transformer 还适用于各种视觉任务,例如图像分类 (Chen 等人, 2020b; Dosovitskiy 等人, 2020; Liu 等人, 2021)、物体检测 (Carion 等人) ,2020;郑等人,2020a;刘等人,2021),图像生成(Parmar 等人,2018;Jiang 等人,2021)处理(Shao等人,2021;Arnab等人,2021)。 Han 等人 (2021a) 和 Khan 等人 (2021) 提供了对视觉变形金刚现有作品的评论。 我们鼓励读者参考这些调查,以进一步了解目前 Transformers 在 CV 中的研究进展。
(3)音频应用。 Transformer 还可以扩展到音频相关的应用,例如语音识别(Dong 等人, 2018; Pham 等人, 2019; Chen 等人, 2021; Gulati 等人, 2020)、语音合成(Li 等人,2019a;Zheng 等人,2020b;Ihm 等人,2020),语音增强(Kim 等人,2020;Yu 等人,2021) 和音乐一代(黄等人,2019)。
(4)多模式应用。 由于其灵活的架构,Transformer 也被应用于各种多模态场景,例如视觉问答(Li 等人, 2019c; Hu 等人, 2020; Su 等人, 2020; Li 等人, 2020a)、视觉常识推理(Li 等人, 2019c; Su 等人, 2020)、字幕生成(Sun 等人, 2019; Cornia 等人, 2020; Lin 等人, 2021)、语音到文本翻译(Han 等人, 2021b)和文本到图像生成(Ramesh 等人, 2021; Lin 等人, 2021;丁等人,2021)。
9. 结论和未来方向
在这项调查中,我们对 X-formers 进行了全面的概述,并提出了一个新的分类法。 现有的大部分工作从效率、泛化和应用等不同角度改进了 Transformer。 改进包括结合结构先验、设计轻量级架构、预训练等。
尽管 X-formers 已经证明了他们执行各种任务的能力,但挑战仍然存在。 除了目前关注的问题(例如效率和泛化性)之外,Transformer 的进一步改进可能在于以下几个方向:
(1)理论分析。 Transformer 的架构已被证明能够支持具有足够参数的大规模训练数据集。 许多研究表明,Transformer 的容量比 CNN 和 RNN 更大,因此有能力处理大量的训练数据。 当 Transformer 在足够的数据上进行训练时,它通常比 CNN 或 RNN 具有更好的性能。 直观的解释是,Transformer 对数据结构的先验假设很少,因此比 CNN 和 RNN 更灵活。 然而,理论原因尚不清楚,我们需要对 Transformer 能力进行一些理论分析。
(2)超越注意力的更好的全局交互机制。 Transformer 的一个主要优点是使用注意力机制来对输入数据中节点之间的全局依赖关系进行建模。 然而,许多研究表明,对于大多数节点来说,充分的关注是不必要的。 在某种程度上,无法区分地计算所有节点的注意力是低效的。 因此,在有效建模全球交互方面仍有很大的改进空间。 一方面,自注意力模块可以被视为具有动态连接权重的全连接神经网络,它通过动态路由聚合非局部信息。 因此,其他动态路由机制是值得探索的替代方法。 另一方面,全局交互也可以通过其他类型的神经网络来建模,例如记忆增强模型。
(3)多模态数据统一框架。 在许多应用场景中,集成多模态数据对于提高任务性能是有用且必要的。 此外,通用人工智能还需要能够捕获不同模态之间的语义关系。 由于 Transformer 在文本、图像、视频和音频方面取得了巨大成功,我们有机会构建统一的框架并更好地捕捉多模态数据之间的内在联系。 然而,模内和跨模态注意力的设计仍有待改进。
最后,我们希望本次调查能够成为一个实际参考,帮助读者更好地了解当前 Transformer 的研究进展,并帮助读者进一步改进 Transformer 的各种应用。
参考
- (1)
- Ainslie et al. (2020) Joshua Ainslie, Santiago Ontanon, Chris Alberti, Vaclav Cvicek, Zachary Fisher, Philip Pham, Anirudh Ravula, Sumit Sanghai, Qifan Wang, and Li Yang. 2020. ETC: Encoding Long and Structured Inputs in Transformers. In Proceedings of EMNLP. Online, 268–284. https://doi.org/10.18653/v1/2020.emnlp-main.19
- Al-Rfou et al. (2019) Rami Al-Rfou, Dokook Choe, Noah Constant, Mandy Guo, and Llion Jones. 2019. Character-Level Language Modeling with Deeper Self-Attention. In Proceedings of AAAI. 3159–3166. https://doi.org/10.1609/aaai.v33i01.33013159
- Arnab et al. (2021) Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, and Cordelia Schmid. 2021. ViViT: A Video Vision Transformer. arXiv:2103.15691 [cs.CV]
- Ba et al. (2016) Lei Jimmy Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. 2016. Layer Normalization. CoRR abs/1607.06450 (2016). arXiv:1607.06450
- Bachlechner et al. (2020) Thomas Bachlechner, Bodhisattwa Prasad Majumder, Huanru Henry Mao, Garrison W. Cottrell, and Julian J. McAuley. 2020. ReZero is All You Need: Fast Convergence at Large Depth. CoRR abs/2003.04887 (2020). arXiv:2003.04887
- Baevski and Auli (2019) Alexei Baevski and Michael Auli. 2019. Adaptive Input Representations for Neural Language Modeling. In Proceedings of ICLR. https://openreview.net/forum?id=ByxZX20qFQ
- Bapna et al. (2020) Ankur Bapna, Naveen Arivazhagan, and Orhan Firat. 2020. Controlling Computation versus Quality for Neural Sequence Models. arXiv:2002.07106 [cs.LG]
- Bapna et al. (2018) Ankur Bapna, Mia Chen, Orhan Firat, Yuan Cao, and Yonghui Wu. 2018. Training Deeper Neural Machine Translation Models with Transparent Attention. In Proceedings of EMNLP. Brussels, Belgium, 3028–3033. https://doi.org/10.18653/v1/D18-1338
- Battaglia et al. (2018) Peter W. Battaglia, Jessica B. Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez, Vinicius Zambaldi, Mateusz Malinowski, Andrea Tacchetti, David Raposo, Adam Santoro, Ryan Faulkner, Caglar Gulcehre, Francis Song, Andrew Ballard, Justin Gilmer, George Dahl, Ashish Vaswani, Kelsey Allen, Charles Nash, Victoria Langston, Chris Dyer, Nicolas Heess, Daan Wierstra, Pushmeet Kohli, Matt Botvinick, Oriol Vinyals, Yujia Li, and Razvan Pascanu. 2018. Relational inductive biases, deep learning, and graph networks. arXiv:1806.01261 [cs.LG]
- Beltagy et al. (2020) Iz Beltagy, Matthew E. Peters, and Arman Cohan. 2020. Longformer: The Long-Document Transformer. arXiv:2004.05150 [cs.CL]
- Bhojanapalli et al. (2020) Srinadh Bhojanapalli, Chulhee Yun, Ankit Singh Rawat, Sashank J. Reddi, and Sanjiv Kumar. 2020. Low-Rank Bottleneck in Multi-head Attention Models. In Proceedings of ICML. 864–873. http://proceedings.mlr.press/v119/bhojanapalli20a.html
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language Models are Few-Shot Learners. In Proceedings of NeurIPS. 1877–1901. https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf
- Carion et al. (2020) Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. 2020. End-to-End Object Detection with Transformers. In Proceedings of ECCV. 213–229. https://doi.org/10.1007/978-3-030-58452-8_13
- Chen et al. (2020b) Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, and Ilya Sutskever. 2020b. Generative Pretraining From Pixels. In Proceedings of ICML. 1691–1703. http://proceedings.mlr.press/v119/chen20s.html
- Chen et al. (2021) Xie Chen, Yu Wu, Zhenghao Wang, Shujie Liu, and Jinyu Li. 2021. Developing Real-time Streaming Transformer Transducer for Speech Recognition on Large-scale Dataset. arXiv:2010.11395 [cs.CL]
- Chen et al. (2020a) Ziye Chen, Mingming Gong, Lingjuan Ge, and Bo Du. 2020a. Compressed Self-Attention for Deep Metric Learning with Low-Rank Approximation. In Proceedings of IJCAI. 2058–2064. https://doi.org/10.24963/ijcai.2020/285
- Child et al. (2019) Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. 2019. Generating Long Sequences with Sparse Transformers. arXiv:1904.10509 [cs.LG]
- Choromanski et al. (2020a) Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, David Belanger, Lucy Colwell, and Adrian Weller. 2020a. Masked Language Modeling for Proteins via Linearly Scalable Long-Context Transformers. arXiv:2006.03555 [cs.LG]
- Choromanski et al. (2020b) Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, David Belanger, Lucy Colwell, and Adrian Weller. 2020b. Rethinking Attention with Performers. arXiv:2009.14794 [cs.LG]
- Chu et al. (2021) Xiangxiang Chu, Zhi Tian, Bo Zhang, Xinlong Wang, Xiaolin Wei, Huaxia Xia, and Chunhua Shen. 2021. Conditional Positional Encodings for Vision Transformers. arXiv:2102.10882 [cs.CV]
- Cordonnier et al. (2020) Jean-Baptiste Cordonnier, Andreas Loukas, and Martin Jaggi. 2020. Multi-Head Attention: Collaborate Instead of Concatenate. CoRR abs/2006.16362 (2020). arXiv:2006.16362
- Cornia et al. (2020) Marcella Cornia, Matteo Stefanini, Lorenzo Baraldi, and Rita Cucchiara. 2020. Meshed-Memory Transformer for Image Captioning. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020. IEEE, 10575–10584. https://doi.org/10.1109/CVPR42600.2020.01059
- Dai et al. (2020) Zihang Dai, Guokun Lai, Yiming Yang, and Quoc Le. 2020. Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing. In Proceedings of NeurIPS. https://proceedings.neurips.cc/paper/2020/hash/2cd2915e69546904e4e5d4a2ac9e1652-Abstract.html
- Dai et al. (2019) Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc Le, and Ruslan Salakhutdinov. 2019. Transformer-XL: Attentive Language Models beyond a Fixed-Length Context. In Proceedings of ACL. Florence, Italy, 2978–2988. https://doi.org/10.18653/v1/P19-1285
- Dauphin et al. (2017) Yann N. Dauphin, Angela Fan, Michael Auli, and David Grangier. 2017. Language Modeling with Gated Convolutional Networks. In Proceedings of ICML. 933–941. http://proceedings.mlr.press/v70/dauphin17a.html
- Dehghani et al. (2019) Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Lukasz Kaiser. 2019. Universal Transformers. In Proceedings of ICLR. https://openreview.net/forum?id=HyzdRiR9Y7
- Deshpande and Narasimhan (2020) Ameet Deshpande and Karthik Narasimhan. 2020. Guiding Attention for Self-Supervised Learning with Transformers. In Findings of the Association for Computational Linguistics: EMNLP 2020. Online, 4676–4686. https://doi.org/10.18653/v1/2020.findings-emnlp.419
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of HLT-NAACL. Minneapolis, Minnesota, 4171–4186. https://doi.org/10.18653/v1/N19-1423
- Ding et al. (2021) Ming Ding, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin, Xu Zou, Zhou Shao, Hongxia Yang, and Jie Tang. 2021. CogView: Mastering Text-to-Image Generation via Transformers. arXiv:2105.13290 [cs.CV]
- Ding et al. (2020) Siyu Ding, Junyuan Shang, Shuohuan Wang, Yu Sun, Hao Tian, Hua Wu, and Haifeng Wang. 2020. ERNIE-DOC: The Retrospective Long-Document Modeling Transformer. (2020). arXiv:2012.15688 [cs.CL]
- Dong et al. (2018) Linhao Dong, Shuang Xu, and Bo Xu. 2018. Speech-Transformer: A No-Recurrence Sequence-to-Sequence Model for Speech Recognition. In Proceedings of ICASSP. 5884–5888. https://doi.org/10.1109/ICASSP.2018.8462506
- Dong et al. (2021) Yihe Dong, Jean-Baptiste Cordonnier, and Andreas Loukas. 2021. Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth. CoRR abs/2103.03404 (2021). arXiv:2103.03404
- Dosovitskiy et al. (2020) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2020. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv:2010.11929 [cs.CV]
- Fan et al. (2021b) Angela Fan, Thibaut Lavril, Edouard Grave, Armand Joulin, and Sainbayar Sukhbaatar. 2021b. Addressing Some Limitations of Transformers with Feedback Memory. https://openreview.net/forum?id=OCm0rwa1lx1
- Fan et al. (2021a) Zhihao Fan, Yeyun Gong, Dayiheng Liu, Zhongyu Wei, Siyuan Wang, Jian Jiao, Nan Duan, Ruofei Zhang, and Xuanjing Huang. 2021a. Mask Attention Networks: Rethinking and Strengthen Transformer. In Proceedings of NAACL. 1692–1701. https://www.aclweb.org/anthology/2021.naacl-main.135
- Fedus et al. (2021) William Fedus, Barret Zoph, and Noam Shazeer. 2021. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. CoRR abs/2101.03961 (2021). arXiv:2101.03961
- Gehring et al. (2017) Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin. 2017. Convolutional Sequence to Sequence Learning. In Proceedings of ICML. 1243–1252.
- Graves (2016) Alex Graves. 2016. Adaptive Computation Time for Recurrent Neural Networks. CoRR abs/1603.08983 (2016). arXiv:1603.08983
- Gu et al. (2019) Jiatao Gu, Qi Liu, and Kyunghyun Cho. 2019. Insertion-based Decoding with Automatically Inferred Generation Order. Trans. Assoc. Comput. Linguistics 7 (2019), 661–676. https://transacl.org/ojs/index.php/tacl/article/view/1732
- Gu and Feng (2019) Shuhao Gu and Yang Feng. 2019. Improving Multi-head Attention with Capsule Networks. In Proceedings of NLPCC. 314–326. https://doi.org/10.1007/978-3-030-32233-5_25
- Gulati et al. (2020) Anmol Gulati, James Qin, Chung-Cheng Chiu, Niki Parmar, Yu Zhang, Jiahui Yu, Wei Han, Shibo Wang, Zhengdong Zhang, Yonghui Wu, and Ruoming Pang. 2020. Conformer: Convolution-augmented Transformer for Speech Recognition. In Proceedings of Interspeech. 5036–5040. https://doi.org/10.21437/Interspeech.2020-3015
- Guo et al. (2019c) Maosheng Guo, Yu Zhang, and Ting Liu. 2019c. Gaussian Transformer: A Lightweight Approach for Natural Language Inference. In Proceedings of AAAI. 6489–6496. https://doi.org/10.1609/aaai.v33i01.33016489
- Guo et al. (2019a) Qipeng Guo, Xipeng Qiu, Pengfei Liu, Yunfan Shao, Xiangyang Xue, and Zheng Zhang. 2019a. Star-Transformer. In Proceedings of HLT-NAACL. 1315–1325. https://www.aclweb.org/anthology/N19-1133
- Guo et al. (2020) Qipeng Guo, Xipeng Qiu, Pengfei Liu, Xiangyang Xue, and Zheng Zhang. 2020. Multi-Scale Self-Attention for Text Classification. In Proceedings of AAAI. 7847–7854. https://aaai.org/ojs/index.php/AAAI/article/view/6290
- Guo et al. (2019b) Qipeng Guo, Xipeng Qiu, Xiangyang Xue, and Zheng Zhang. 2019b. Low-Rank and Locality Constrained Self-Attention for Sequence Modeling. IEEE/ACM Trans. Audio, Speech and Lang. Proc. 27, 12 (2019), 2213–2222. https://doi.org/10.1109/TASLP.2019.2944078
- Han et al. (2021b) Chi Han, Mingxuan Wang, Heng Ji, and Lei Li. 2021b. Learning Shared Semantic Space for Speech-to-Text Translation. arXiv:2105.03095 [cs.CL]
- Han et al. (2021a) Kai Han, Yunhe Wang, Hanting Chen, Xinghao Chen, Jianyuan Guo, Zhenhua Liu, Yehui Tang, An Xiao, Chunjing Xu, Yixing Xu, Zhaohui Yang, Yiman Zhang, and Dacheng Tao. 2021a. A Survey on Visual Transformer. arXiv:2012.12556 [cs.CV]
- Han et al. (2021c) Kai Han, An Xiao, Enhua Wu, Jianyuan Guo, Chunjing Xu, and Yunhe Wang. 2021c. Transformer in Transformer. arXiv:2103.00112 [cs.CV]
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Residual Learning for Image Recognition. In Proceedings CVPR. 770–778. https://doi.org/10.1109/CVPR.2016.90
- He et al. (2020a) Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. 2020a. DeBERTa: Decoding-enhanced BERT with Disentangled Attention. arXiv:2006.03654
- He et al. (2020b) Ruining He, Anirudh Ravula, Bhargav Kanagal, and Joshua Ainslie. 2020b. RealFormer: Transformer Likes Residual Attention. arXiv:2012.11747 [cs.LG]
- Hendrycks and Gimpel (2020) Dan Hendrycks and Kevin Gimpel. 2020. Gaussian Error Linear Units (GELUs). arXiv:1606.08415 [cs.LG]
- Hinton et al. (2018) Geoffrey E. Hinton, Sara Sabour, and Nicholas Frosst. 2018. Matrix capsules with EM routing. In Proceedings of ICLR. https://openreview.net/forum?id=HJWLfGWRb
- Ho et al. (2019) Jonathan Ho, Nal Kalchbrenner, Dirk Weissenborn, and Tim Salimans. 2019. Axial Attention in Multidimensional Transformers. CoRR abs/1912.12180 (2019). arXiv:1912.12180
- Hu et al. (2020) Ronghang Hu, Amanpreet Singh, Trevor Darrell, and Marcus Rohrbach. 2020. Iterative Answer Prediction With Pointer-Augmented Multimodal Transformers for TextVQA. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020. 9989–9999. https://doi.org/10.1109/CVPR42600.2020.01001
- Huang et al. (2019) Cheng-Zhi Anna Huang, Ashish Vaswani, Jakob Uszkoreit, Ian Simon, Curtis Hawthorne, Noam Shazeer, Andrew M. Dai, Matthew D. Hoffman, Monica Dinculescu, and Douglas Eck. 2019. Music Transformer. In Proceedings of ICLR. https://openreview.net/forum?id=rJe4ShAcF7
- Ihm et al. (2020) Hyeong Rae Ihm, Joun Yeop Lee, Byoung Jin Choi, Sung Jun Cheon, and Nam Soo Kim. 2020. Reformer-TTS: Neural Speech Synthesis with Reformer Network. In Proceedings of Interspeech, Helen Meng, Bo Xu, and Thomas Fang Zheng (Eds.). 2012–2016. https://doi.org/10.21437/Interspeech.2020-2189
- Ioffe and Szegedy (2015) Sergey Ioffe and Christian Szegedy. 2015. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of ICML. 448–456. http://proceedings.mlr.press/v37/ioffe15.html
- Irie et al. (2019) Kazuki Irie, Albert Zeyer, Ralf Schlüter, and Hermann Ney. 2019. Language Modeling with Deep Transformers. In Proceedings of Interspeech. 3905–3909. https://doi.org/10.21437/Interspeech.2019-2225
- Islam et al. (2020) Md. Amirul Islam, Sen Jia, and Neil D. B. Bruce. 2020. How much Position Information Do Convolutional Neural Networks Encode?. In Proceedings of ICLR. https://openreview.net/forum?id=rJeB36NKvB
- Jiang et al. (2021) Yifan Jiang, Shiyu Chang, and Zhangyang Wang. 2021. TransGAN: Two Transformers Can Make One Strong GAN. arXiv:2102.07074 [cs.CV]
- Katharopoulos et al. (2020) Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. 2020. Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention. In Proceedings of ICML. 5156–5165. http://proceedings.mlr.press/v119/katharopoulos20a.html
- Ke et al. (2020) Guolin Ke, Di He, and Tie-Yan Liu. 2020. Rethinking Positional Encoding in Language Pre-training. arXiv:2006.15595 [cs.CL]
- Khan et al. (2021) Salman Khan, Muzammal Naseer, Munawar Hayat, Syed Waqas Zamir, Fahad Shahbaz Khan, and Mubarak Shah. 2021. Transformers in Vision: A Survey. arXiv:2101.01169 [cs.CV]
- Kim et al. (2020) Jaeyoung Kim, Mostafa El-Khamy, and Jungwon Lee. 2020. T-GSA: Transformer with Gaussian-Weighted Self-Attention for Speech Enhancement. In 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2020, Barcelona, Spain, May 4-8, 2020. IEEE, 6649–6653. https://doi.org/10.1109/ICASSP40776.2020.9053591
- Kitaev et al. (2020) Nikita Kitaev, Lukasz Kaiser, and Anselm Levskaya. 2020. Reformer: The Efficient Transformer. In Proceedings of ICLR. https://openreview.net/forum?id=rkgNKkHtvB
- Klein et al. (2017) Guillaume Klein, Yoon Kim, Yuntian Deng, Jean Senellart, and Alexander Rush. 2017. OpenNMT: Open-Source Toolkit for Neural Machine Translation. In Proceedings of ACL. 67–72. https://www.aclweb.org/anthology/P17-4012
- Kovaleva et al. (2019) Olga Kovaleva, Alexey Romanov, Anna Rogers, and Anna Rumshisky. 2019. Revealing the Dark Secrets of BERT. In Proceedings of EMNLP-IJCNLP. 4364–4373. https://doi.org/10.18653/v1/D19-1445
- Lample et al. (2019) Guillaume Lample, Alexandre Sablayrolles, Marc’Aurelio Ranzato, Ludovic Denoyer, and Hervé Jégou. 2019. Large Memory Layers with Product Keys. In Proceedings of NeurIPS. 8546–8557. https://proceedings.neurips.cc/paper/2019/hash/9d8df73a3cfbf3c5b47bc9b50f214aff-Abstract.html
- Lee et al. (2019) Juho Lee, Yoonho Lee, Jungtaek Kim, Adam R. Kosiorek, Seungjin Choi, and Yee Whye Teh. 2019. Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks. In Proceedings of ICML. 3744–3753. http://proceedings.mlr.press/v97/lee19d.html
- Lepikhin et al. (2020) Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2020. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding. CoRR abs/2006.16668 (2020). arXiv:2006.16668
- Lewis et al. (2020) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of ACL. 7871–7880. https://doi.org/10.18653/v1/2020.acl-main.703
- Li et al. (2018) Jian Li, Zhaopeng Tu, Baosong Yang, Michael R. Lyu, and Tong Zhang. 2018. Multi-Head Attention with Disagreement Regularization. In Proceedings of EMNLP. Brussels, Belgium, 2897–2903. https://doi.org/10.18653/v1/D18-1317
- Li et al. (2019b) Jian Li, Baosong Yang, Zi-Yi Dou, Xing Wang, Michael R. Lyu, and Zhaopeng Tu. 2019b. Information Aggregation for Multi-Head Attention with Routing-by-Agreement. In Proceedings of HLT-NAACL. 3566–3575. https://doi.org/10.18653/v1/N19-1359
- Li et al. (2019c) Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, and Kai-Wei Chang. 2019c. VisualBERT: A Simple and Performant Baseline for Vision and Language. arXiv:1908.03557 [cs.CV]
- Li et al. (2019a) Naihan Li, Shujie Liu, Yanqing Liu, Sheng Zhao, and Ming Liu. 2019a. Neural Speech Synthesis with Transformer Network. In Proceedings of AAAI. 6706–6713. https://doi.org/10.1609/aaai.v33i01.33016706
- Li et al. (2020a) Wei Li, Can Gao, Guocheng Niu, Xinyan Xiao, Hao Liu, Jiachen Liu, Hua Wu, and Haifeng Wang. 2020a. UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning. arXiv preprint arXiv:2012.15409 (2020).
- Li et al. (2020b) Xiaoya Li, Yuxian Meng, Mingxin Zhou, Qinghong Han, Fei Wu, and Jiwei Li. 2020b. SAC: Accelerating and Structuring Self-Attention via Sparse Adaptive Connection. In Proceedings of NeurIPS. https://proceedings.neurips.cc/paper/2020/hash/c5c1bda1194f9423d744e0ef67df94ee-Abstract.html
- Li et al. (2021) Xiaonan Li, Yunfan Shao, Tianxiang Sun, Hang Yan, Xipeng Qiu, and Xuanjing Huang. 2021. Accelerating BERT Inference for Sequence Labeling via Early-Exit. arXiv:2105.13878 [cs.CL]
- Li et al. (2020c) Xiaonan Li, Hang Yan, Xipeng Qiu, and Xuanjing Huang. 2020c. FLAT: Chinese NER Using Flat-Lattice Transformer. In Proceedings of ACL. 6836–6842. https://doi.org/10.18653/v1/2020.acl-main.611
- Lin et al. (2021) Junyang Lin, Rui Men, An Yang, Chang Zhou, Ming Ding, Yichang Zhang, Peng Wang, Ang Wang, Le Jiang, Xianyan Jia, Jie Zhang, Jianwei Zhang, Xu Zou, Zhikang Li, Xiaodong Deng, Jie Liu, Jinbao Xue, Huiling Zhou, Jianxin Ma, Jin Yu, Yong Li, Wei Lin, Jingren Zhou, Jie Tang, and Hongxia Yang. 2021. M6: A Chinese Multimodal Pretrainer. arXiv:2103.00823 [cs.CL]
- Liu et al. (2019b) Hanxiao Liu, Karen Simonyan, and Yiming Yang. 2019b. DARTS: Differentiable Architecture Search. In Proceedings of ICLR. https://openreview.net/forum?id=S1eYHoC5FX
- Liu et al. (2020a) Liyuan Liu, Xiaodong Liu, Jianfeng Gao, Weizhu Chen, and Jiawei Han. 2020a. Understanding the Difficulty of Training Transformers. In Proceedings of EMNLP. 5747–5763. https://doi.org/10.18653/v1/2020.emnlp-main.463
- Liu et al. (2018) Peter J. Liu, Mohammad Saleh, Etienne Pot, Ben Goodrich, Ryan Sepassi, Lukasz Kaiser, and Noam Shazeer. 2018. Generating Wikipedia by Summarizing Long Sequences. In Proceedings of ICLR. https://openreview.net/forum?id=Hyg0vbWC-
- Liu et al. (2020b) Xuanqing Liu, Hsiang-Fu Yu, Inderjit S. Dhillon, and Cho-Jui Hsieh. 2020b. Learning to Encode Position for Transformer with Continuous Dynamical Model. In Proceedings of ICML. 6327–6335. http://proceedings.mlr.press/v119/liu20n.html
- Liu and Lapata (2019) Yang Liu and Mirella Lapata. 2019. Hierarchical Transformers for Multi-Document Summarization. In Proceedings of ACL. Florence, Italy, 5070–5081. https://doi.org/10.18653/v1/P19-1500
- Liu et al. (2019a) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019a. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv:1907.11692 [cs.CL]
- Liu et al. (2021) Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. 2021. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv:2103.14030 [cs.CV]
- Lu et al. (2020) Yiping Lu, Zhuohan Li, Di He, Zhiqing Sun, Bin Dong, Tao Qin, Liwei Wang, and Tie-Yan Liu. 2020. Understanding and Improving Transformer From a Multi-Particle Dynamic System Point of View. https://openreview.net/forum?id=SJl1o2NFwS
- Ma et al. (2021) Xuezhe Ma, Xiang Kong, Sinong Wang, Chunting Zhou, Jonathan May, Hao Ma, and Luke Zettlemoyer. 2021. Luna: Linear Unified Nested Attention. arXiv:2106.01540 [cs.LG]
- Mehta et al. (2020) Sachin Mehta, Marjan Ghazvininejad, Srinivasan Iyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2020. DeLighT: Very Deep and Light-weight Transformer. arXiv:2008.00623 [cs.LG]
- Miculicich et al. (2018) Lesly Miculicich, Dhananjay Ram, Nikolaos Pappas, and James Henderson. 2018. Document-Level Neural Machine Translation with Hierarchical Attention Networks. In Proceedings of EMNLP. Brussels, Belgium, 2947–2954. https://doi.org/10.18653/v1/D18-1325
- Nguyen and Salazar (2019) Toan Q. Nguyen and Julian Salazar. 2019. Transformers without Tears: Improving the Normalization of Self-Attention. CoRR abs/1910.05895 (2019). arXiv:1910.05895
- Parmar et al. (2018) Niki Parmar, Ashish Vaswani, Jakob Uszkoreit, Lukasz Kaiser, Noam Shazeer, Alexander Ku, and Dustin Tran. 2018. Image Transformer. In Proceedings of ICML. 4052–4061. http://proceedings.mlr.press/v80/parmar18a.html
- Peng et al. (2021) Hao Peng, Nikolaos Pappas, Dani Yogatama, Roy Schwartz, Noah Smith, and Lingpeng Kong. 2021. Random Feature Attention. In Proceedings of ICLR. https://openreview.net/forum?id=QtTKTdVrFBB
- Perez et al. (2018) Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron C. Courville. 2018. FiLM: Visual Reasoning with a General Conditioning Layer. In Proceedings of AAAI. 3942–3951. https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/view/16528
- Pham et al. (2019) Ngoc-Quan Pham, Thai-Son Nguyen, Jan Niehues, Markus Müller, and Alex Waibel. 2019. Very Deep Self-Attention Networks for End-to-End Speech Recognition. In Proceedings of Interspeech. 66–70. https://doi.org/10.21437/Interspeech.2019-2702
- Pilault et al. (2021) Jonathan Pilault, Amine El hattami, and Christopher Pal. 2021. Conditionally Adaptive Multi-Task Learning: Improving Transfer Learning in NLP Using Fewer Parameters & Less Data. In Proceedings of ICLR. https://openreview.net/forum?id=de11dbHzAMF
- Press et al. (2020) Ofir Press, Noah A. Smith, and Omer Levy. 2020. Improving Transformer Models by Reordering their Sublayers. In Proceedings of ACL. Online, 2996–3005. https://doi.org/10.18653/v1/2020.acl-main.270
- Qiu et al. (2020) Xipeng Qiu, TianXiang Sun, Yige Xu, Yunfan Shao, Ning Dai, and Xuanjing Huang. 2020. Pre-trained Models for Natural Language Processing: A Survey. SCIENCE CHINA Technological Sciences 63, 10 (2020), 1872–1897. https://doi.org/10.1007/s11431-020-1647-3
- Radford et al. (2018) Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding by generative pre-training. (2018).
- Radford et al. (2019) Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language Models are Unsupervised Multitask Learners. (2019).
- Rae et al. (2020) Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, Chloe Hillier, and Timothy P. Lillicrap. 2020. Compressive Transformers for Long-Range Sequence Modelling. In Proceedings of ICLR. https://openreview.net/forum?id=SylKikSYDH
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv:1910.10683 [cs.LG]
- Rahimi and Recht (2007) Ali Rahimi and Benjamin Recht. 2007. Random Features for Large-Scale Kernel Machines. In Proceedings of NeurIPS. 1177–1184. https://proceedings.neurips.cc/paper/2007/hash/013a006f03dbc5392effeb8f18fda755-Abstract.html
- Ramachandran et al. (2018) Prajit Ramachandran, Barret Zoph, and Quoc V. Le. 2018. Searching for Activation Functions. In Proceedings of ICLR. https://openreview.net/forum?id=Hkuq2EkPf
- Ramesh et al. (2021) Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. 2021. Zero-Shot Text-to-Image Generation. arXiv:2102.12092 [cs.CV]
- Rebuffi et al. (2017) Sylvestre-Alvise Rebuffi, Hakan Bilen, and Andrea Vedaldi. 2017. Learning multiple visual domains with residual adapters. In Proceedings of NeurIPS. 506–516. https://proceedings.neurips.cc/paper/2017/hash/e7b24b112a44fdd9ee93bdf998c6ca0e-Abstract.html
- Rives et al. (2021) Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott, C. Lawrence Zitnick, Jerry Ma, and Rob Fergus. 2021. Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences. Proceedings of the National Academy of Sciences 118, 15 (2021). https://doi.org/10.1073/pnas.2016239118
- Roller et al. (2021) Stephen Roller, Sainbayar Sukhbaatar, Arthur Szlam, and Jason Weston. 2021. Hash Layers For Large Sparse Models. arXiv:2106.04426 [cs.LG]
- Roy et al. (2020) Aurko Roy, Mohammad Saffar, Ashish Vaswani, and David Grangier. 2020. Efficient Content-Based Sparse Attention with Routing Transformers. arXiv:2003.05997 [cs.LG]
- Sabour et al. (2017) Sara Sabour, Nicholas Frosst, and Geoffrey E. Hinton. 2017. Dynamic Routing Between Capsules. In Proceedings of NeurIPS. 3856–3866. https://proceedings.neurips.cc/paper/2017/hash/2cad8fa47bbef282badbb8de5374b894-Abstract.html
- Schlag et al. (2021) Imanol Schlag, Kazuki Irie, and Jürgen Schmidhuber. 2021. Linear Transformers Are Secretly Fast Weight Memory Systems. CoRR abs/2102.11174 (2021). arXiv:2102.11174
- Schwaller et al. (2019) Philippe Schwaller, Teodoro Laino, Théophile Gaudin, Peter Bolgar, Christopher A. Hunter, Costas Bekas, and Alpha A. Lee. 2019. Molecular Transformer: A Model for Uncertainty-Calibrated Chemical Reaction Prediction. ACS Central Science 5, 9 (2019), 1572–1583. https://doi.org/10.1021/acscentsci.9b00576
- Shao et al. (2021) Jie Shao, Xin Wen, Bingchen Zhao, and Xiangyang Xue. 2021. Temporal Context Aggregation for Video Retrieval With Contrastive Learning. In Proceedings of WACV. 3268–3278.
- Shaw et al. (2018) Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. 2018. Self-Attention with Relative Position Representations. In Proceedings of HLT-NAACL. New Orleans, Louisiana, 464–468. https://doi.org/10.18653/v1/N18-2074
- Shazeer (2019) Noam Shazeer. 2019. Fast Transformer Decoding: One Write-Head is All You Need. CoRR abs/1911.02150 (2019). arXiv:1911.02150
- Shazeer (2020) Noam Shazeer. 2020. GLU Variants Improve Transformer. arXiv:2002.05202 [cs.LG]
- Shazeer et al. (2020) Noam Shazeer, Zhenzhong Lan, Youlong Cheng, Nan Ding, and Le Hou. 2020. Talking-Heads Attention. CoRR abs/2003.02436 (2020). arXiv:2003.02436
- Shazeer et al. (2017) Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V. Le, Geoffrey E. Hinton, and Jeff Dean. 2017. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. In Proceedings of ICLR. https://openreview.net/forum?id=B1ckMDqlg
- Shen et al. (2020) Sheng Shen, Zhewei Yao, Amir Gholami, Michael W. Mahoney, and Kurt Keutzer. 2020. PowerNorm: Rethinking Batch Normalization in Transformers. In Proceedings of ICML. 8741–8751. http://proceedings.mlr.press/v119/shen20e.html
- Shoeybi et al. (2020) Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2020. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. arXiv:1909.08053 [cs.CL]
- So et al. (2019) David R. So, Quoc V. Le, and Chen Liang. 2019. The Evolved Transformer. In Proceedings of ICML. 5877–5886. http://proceedings.mlr.press/v97/so19a.html
- Su et al. (2021) Jianlin Su, Yu Lu, Shengfeng Pan, Bo Wen, and Yunfeng Liu. 2021. RoFormer: Enhanced Transformer with Rotary Position Embedding. arXiv:2104.09864
- Su et al. (2020) Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, and Jifeng Dai. 2020. VL-BERT: Pre-training of Generic Visual-Linguistic Representations. In Proceedings of ICLR. https://openreview.net/forum?id=SygXPaEYvH
- Sukhbaatar et al. (2019a) Sainbayar Sukhbaatar, Edouard Grave, Piotr Bojanowski, and Armand Joulin. 2019a. Adaptive Attention Span in Transformers. In Proceedings of ACL. Florence, Italy, 331–335. https://doi.org/10.18653/v1/P19-1032
- Sukhbaatar et al. (2019b) Sainbayar Sukhbaatar, Edouard Grave, Guillaume Lample, Herve Jegou, and Armand Joulin. 2019b. Augmenting Self-attention with Persistent Memory. arXiv:1907.01470 [cs.LG]
- Sun et al. (2019) Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, and Cordelia Schmid. 2019. VideoBERT: A Joint Model for Video and Language Representation Learning. In Proceedings of ICCV. 7463–7472. https://doi.org/10.1109/ICCV.2019.00756
- Sun et al. (2021) Tianxiang Sun, Yunhua Zhou, Xiangyang Liu, Xinyu Zhang, Hao Jiang, Zhao Cao, Xuanjing Huang, and Xipeng Qiu. 2021. Early Exiting with Ensemble Internal Classifiers. arXiv:2105.13792 [cs.CL]
- Sutskever et al. (2014) Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. 2014. Sequence to Sequence Learning with Neural Networks. In Proceedings of NeurIPS. 3104–3112. https://proceedings.neurips.cc/paper/2014/hash/a14ac55a4f27472c5d894ec1c3c743d2-Abstract.html
- Tay et al. (2020a) Yi Tay, Dara Bahri, Donald Metzler, Da-Cheng Juan, Zhe Zhao, and Che Zheng. 2020a. Synthesizer: Rethinking Self-Attention in Transformer Models. CoRR abs/2005.00743 (2020). arXiv:2005.00743
- Tay et al. (2020b) Yi Tay, Dara Bahri, Liu Yang, Donald Metzler, and Da-Cheng Juan. 2020b. Sparse Sinkhorn Attention. In Proceedings of ICML. 9438–9447. http://proceedings.mlr.press/v119/tay20a.html
- Tsai et al. (2019) Yao-Hung Hubert Tsai, Shaojie Bai, Makoto Yamada, Louis-Philippe Morency, and Ruslan Salakhutdinov. 2019. Transformer Dissection: An Unified Understanding for Transformer’s Attention via the Lens of Kernel. In Proceedings of EMNLP-IJCNLP. Hong Kong, China, 4344–4353. https://doi.org/10.18653/v1/D19-1443
- van den Oord et al. (2016) Aäron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew W. Senior, and Koray Kavukcuoglu. 2016. WaveNet: A Generative Model for Raw Audio. In Proceedings of ISCA. 125. http://www.isca-speech.org/archive/SSW_2016/abstracts/ssw9_DS-4_van_den_Oord.html
- van den Oord et al. (2018) Aäron van den Oord, Yazhe Li, and Oriol Vinyals. 2018. Representation Learning with Contrastive Predictive Coding. CoRR abs/1807.03748 (2018). arXiv:1807.03748
- Vaswani et al. (2018) Ashish Vaswani, Samy Bengio, Eugene Brevdo, Francois Chollet, Aidan Gomez, Stephan Gouws, Llion Jones, Łukasz Kaiser, Nal Kalchbrenner, Niki Parmar, Ryan Sepassi, Noam Shazeer, and Jakob Uszkoreit. 2018. Tensor2Tensor for Neural Machine Translation. In Proceedings of AMTA. 193–199. https://www.aclweb.org/anthology/W18-1819
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. In Proceedings of NeurIPS. 5998–6008. https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
- Vyas et al. (2020) Apoorv Vyas, Angelos Katharopoulos, and François Fleuret. 2020. Fast Transformers with Clustered Attention. arXiv:2007.04825 [cs.LG]
- Wang et al. ([n.d.]) Benyou Wang, Lifeng Shang, Christina Lioma, Xin Jiang, Hao Yang, Qun Liu, and Jakob Grue Simonsen. [n.d.]. On Position Embeddings in BERT, url = https://openreview.net/forum?id=onxoVA9FxMw, year = 2021. In Proceedings of ICLR.
- Wang et al. (2020b) Benyou Wang, Donghao Zhao, Christina Lioma, Qiuchi Li, Peng Zhang, and Jakob Grue Simonsen. 2020b. Encoding word order in complex embeddings. In Proceedings of ICLR. https://openreview.net/forum?id=Hke-WTVtwr
- Wang et al. (2019a) Qiang Wang, Bei Li, Tong Xiao, Jingbo Zhu, Changliang Li, Derek F. Wong, and Lidia S. Chao. 2019a. Learning Deep Transformer Models for Machine Translation. In Proceedings of ACL. 1810–1822. https://doi.org/10.18653/v1/p19-1176
- Wang et al. (2020a) Sinong Wang, Belinda Z. Li, Madian Khabsa, Han Fang, and Hao Ma. 2020a. Linformer: Self-Attention with Linear Complexity. arXiv:2006.04768 [cs.LG]
- Wang et al. (2021) Yujing Wang, Yaming Yang, Jiangang Bai, Mingliang Zhang, Jing Bai, Jing Yu, Ce Zhang, and Yunhai Tong. 2021. Predictive Attention Transformer: Improving Transformer with Attention Map Prediction. https://openreview.net/forum?id=YQVjbJPnPc9
- Wang et al. (2019b) Zhiwei Wang, Yao Ma, Zitao Liu, and Jiliang Tang. 2019b. R-Transformer: Recurrent Neural Network Enhanced Transformer. CoRR abs/1907.05572 (2019). arXiv:1907.05572
- Wu et al. (2021b) Chuhan Wu, Fangzhao Wu, Tao Qi, and Yongfeng Huang. 2021b. Hi-Transformer: Hierarchical Interactive Transformer for Efficient and Effective Long Document Modeling. arXiv:2106.01040 [cs.CL]
- Wu et al. (2019) Felix Wu, Angela Fan, Alexei Baevski, Yann N. Dauphin, and Michael Auli. 2019. Pay Less Attention with Lightweight and Dynamic Convolutions. In Proceedings of ICLR. https://openreview.net/forum?id=SkVhlh09tX
- Wu et al. (2020a) Qingyang Wu, Zhenzhong Lan, Jing Gu, and Zhou Yu. 2020a. Memformer: The Memory-Augmented Transformer. arXiv:2010.06891 [cs.CL]
- Wu et al. (2020b) Zhanghao Wu, Zhijian Liu, Ji Lin, Yujun Lin, and Song Han. 2020b. Lite Transformer with Long-Short Range Attention. In Proceedings of ICLR. https://openreview.net/forum?id=ByeMPlHKPH
- Wu et al. (2021a) Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and Philip S. Yu. 2021a. A Comprehensive Survey on Graph Neural Networks. IEEE Trans. Neural Networks Learn. Syst. 32, 1 (2021), 4–24. https://doi.org/10.1109/TNNLS.2020.2978386
- Xin et al. (2020) Ji Xin, Raphael Tang, Jaejun Lee, Yaoliang Yu, and Jimmy Lin. 2020. DeeBERT: Dynamic Early Exiting for Accelerating BERT Inference. In Proceedings of ACL. 2246–2251. https://doi.org/10.18653/v1/2020.acl-main.204
- Xiong et al. (2020) Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tie-Yan Liu. 2020. On Layer Normalization in the Transformer Architecture. In Proceedings of ICML. 10524–10533. http://proceedings.mlr.press/v119/xiong20b.html
- Xiong et al. (2021) Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, and Vikas Singh. 2021. Nyströmformer: A Nyström-based Algorithm for Approximating Self-Attention. (2021).
- Xu et al. (2019) Jingjing Xu, Xu Sun, Zhiyuan Zhang, Guangxiang Zhao, and Junyang Lin. 2019. Understanding and Improving Layer Normalization. In Proceedings of NeurIPS. 4383–4393. https://proceedings.neurips.cc/paper/2019/hash/2f4fe03d77724a7217006e5d16728874-Abstract.html
- Yan et al. (2019) Hang Yan, Bocao Deng, Xiaonan Li, and Xipeng Qiu. 2019. TENER: Adapting transformer encoder for named entity recognition. arXiv preprint arXiv:1911.04474 (2019).
- Yang et al. (2021) An Yang, Junyang Lin, Rui Men, Chang Zhou, Le Jiang, Xianyan Jia, Ang Wang, Jie Zhang, Jiamang Wang, Yong Li, Di Zhang, Wei Lin, Lin Qu, Jingren Zhou, and Hongxia Yang. 2021. Exploring Sparse Expert Models and Beyond. arXiv:2105.15082 [cs.LG]
- Yang et al. (2018) Baosong Yang, Zhaopeng Tu, Derek F. Wong, Fandong Meng, Lidia S. Chao, and Tong Zhang. 2018. Modeling Localness for Self-Attention Networks. In Proceedings of EMNLP. Brussels, Belgium, 4449–4458. https://doi.org/10.18653/v1/D18-1475
- Yang et al. (2020) Yilin Yang, Longyue Wang, Shuming Shi, Prasad Tadepalli, Stefan Lee, and Zhaopeng Tu. 2020. On the Sub-layer Functionalities of Transformer Decoder. In Findings of EMNLP. Online, 4799–4811. https://doi.org/10.18653/v1/2020.findings-emnlp.432
- Ye et al. (2019) Zihao Ye, Qipeng Guo, Quan Gan, Xipeng Qiu, and Zheng Zhang. 2019. BP-Transformer: Modelling Long-Range Context via Binary Partitioning. arXiv:1911.04070 [cs.CL]
- Ying et al. (2021) Chengxuan Ying, Guolin Ke, Di He, and Tie-Yan Liu. 2021. LazyFormer: Self Attention with Lazy Update. CoRR abs/2102.12702 (2021). arXiv:2102.12702
- Yoshida et al. (2020) Davis Yoshida, Allyson Ettinger, and Kevin Gimpel. 2020. Adding Recurrence to Pretrained Transformers for Improved Efficiency and Context Size. CoRR abs/2008.07027 (2020). arXiv:2008.07027
- You et al. (2020) Weiqiu You, Simeng Sun, and Mohit Iyyer. 2020. Hard-Coded Gaussian Attention for Neural Machine Translation. In Proceedings of ACL. Online, 7689–7700. https://doi.org/10.18653/v1/2020.acl-main.687
- Yu et al. (2021) Weiwei Yu, Jian Zhou, HuaBin Wang, and Liang Tao. 2021. SETransformer: Speech Enhancement Transformer. Cognitive Computation (02 2021). https://doi.org/10.1007/s12559-020-09817-2
- Zaheer et al. (2020) Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. 2020. Big Bird: Transformers for Longer Sequences. arXiv:2007.14062 [cs.LG]
- Zhang et al. (2018) Biao Zhang, Deyi Xiong, and Jinsong Su. 2018. Accelerating Neural Transformer via an Average Attention Network. In Proceedings of ACL. Melbourne, Australia, 1789–1798. https://doi.org/10.18653/v1/P18-1166
- Zhang et al. (2021) Hang Zhang, Yeyun Gong, Yelong Shen, Weisheng Li, Jiancheng Lv, Nan Duan, and Weizhu Chen. 2021. Poolingformer: Long Document Modeling with Pooling Attention. arXiv:2105.04371
- Zhang et al. (2019) Xingxing Zhang, Furu Wei, and Ming Zhou. 2019. HIBERT: Document Level Pre-training of Hierarchical Bidirectional Transformers for Document Summarization. In Proceedings of ACL. Florence, Italy, 5059–5069. https://doi.org/10.18653/v1/P19-1499
- Zhao et al. (2021) Yuekai Zhao, Li Dong, Yelong Shen, Zhihua Zhang, Furu Wei, and Weizhu Chen. 2021. Memory-Efficient Differentiable Transformer Architecture Search. arXiv:2105.14669 [cs.LG]
- Zheng et al. (2020a) Minghang Zheng, Peng Gao, Xiaogang Wang, Hongsheng Li, and Hao Dong. 2020a. End-to-End Object Detection with Adaptive Clustering Transformer. CoRR abs/2011.09315 (2020). arXiv:2011.09315
- Zheng et al. (2020b) Yibin Zheng, Xinhui Li, Fenglong Xie, and Li Lu. 2020b. Improving End-to-End Speech Synthesis with Local Recurrent Neural Network Enhanced Transformer. In Proceedings of ICASSP. 6734–6738. https://doi.org/10.1109/ICASSP40776.2020.9054148
- Zhou et al. (2021) Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. 2021. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. In Proceedings of AAAI.
- Zhou et al. (2020) Wangchunshu Zhou, Canwen Xu, Tao Ge, Julian McAuley, Ke Xu, and Furu Wei. 2020. BERT Loses Patience: Fast and Robust Inference with Early Exit. arXiv:2006.04152
- Zhu et al. (2020) Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. 2020. Deformable DETR: Deformable Transformers for End-to-End Object Detection. CoRR abs/2010.04159 (2020). arXiv:2010.04159