连接点:使用图神经网络进行多元时间序列预测
摘要。
多元时间序列建模长期以来一直吸引着来自经济、金融和交通等不同领域的研究人员。 多元时间序列预测背后的一个基本假设是其变量相互依赖,但仔细观察后,可以公平地说,现有方法未能充分利用变量对之间的潜在空间依赖性。 与此同时,近年来,图神经网络(GNN)在处理关系依赖性方面表现出了强大的能力。 GNN 需要明确定义的图结构来进行信息传播,这意味着它们不能直接应用于事先未知依赖关系的多元时间序列。 在本文中,我们提出了一种专门为多元时间序列数据设计的通用图神经网络框架。 我们的方法通过图学习模块自动提取变量之间的单向关系,可以轻松地将变量属性等外部知识集成到其中。 进一步提出了一种新颖的混合跳跃传播层和扩张的初始层来捕获时间序列内的空间和时间依赖性。 图学习、图卷积和时间卷积模块在端到端框架中联合学习。 实验结果表明,我们提出的模型在 4 个基准数据集中的 3 个上优于最先进的基线方法,并在提供额外结构信息的两个流量数据集上实现了与其他方法相当的性能。
1. 介绍
现代社会受益于各种传感器来记录温度、价格、交通速度、用电量和许多其他形式数据的变化。 不同传感器记录的时间序列可以形成多元时间序列数据并且可以互连。 例如,每日气温升高可能会导致用电量增加。 为了捕捉一组动态变化变量的系统趋势,多元时间序列预测问题已经被研究了至少六十年。 它在经济、金融、生物信息学和交通领域有着巨大的应用。
多元时间序列预测方法本质上假设变量之间存在相互依赖性。 换句话说,每个变量不仅取决于其历史值,还取决于其他变量。 然而,现有的方法并没有有效地利用变量之间潜在的相互依赖性。 统计方法,例如向量自回归模型(VAR)和高斯过程模型(GP),假设变量之间存在线性相关性。 统计方法的模型复杂性随着变量数量呈二次方增长。 他们面临着大量变量过度拟合的问题。 最近开发的基于深度学习的方法,包括 LSTNet (Lai 等人,2018) 和 TPA-LSTM (Shih 等人,2019),能够有效捕获非线性图案。 LSTNet 使用一维卷积神经网络将短期局部信息编码为低维向量,并通过循环神经网络对向量进行解码。 TPA-LSTM 通过循环神经网络处理输入,并使用卷积神经网络来计算多个步骤的注意力分数。 LSTNet 和 TPA-LSTM 没有明确地对变量之间的成对依赖关系进行建模,这削弱了模型的可解释性。
图是一种特殊的数据形式,描述不同实体之间的关系。 最近,图神经网络由于其排列不变性、局部连通性和组合性而在处理图数据方面取得了巨大成功。 通过结构传播信息,图神经网络允许图中的每个节点了解其邻域上下文。 多元时间序列预测可以自然地从图形角度来看待。 多元时间序列中的变量可以被视为图中的节点,它们通过隐藏的依赖关系相互关联。 因此,使用图神经网络对多元时间序列数据进行建模可能是一种有前途的方法,可以在利用时间序列之间的相互依赖性的同时保留其时间轨迹。
最适合多元时间序列的图神经网络类型是时空图神经网络。 时空图神经网络以多元时间序列和外部图结构作为输入,旨在预测多元时间序列的未来值或标签。 与不利用结构信息的方法相比,时空图神经网络取得了显着的改进。 然而,由于以下挑战,这些方法仍然不足以建模多元时间序列:
-
•
挑战一:未知的图结构。 现有的 GNN 方法严重依赖预定义的图结构来执行时间序列预测。 在大多数情况下,多元时间序列没有明确的图形结构。 变量之间的关系必须从数据中发现,而不是作为基本事实知识提供。
-
•
挑战2:图学习和GNN学习。 尽管图结构可用,但大多数 GNN 方法仅关注消息传递(GNN 学习),而忽略了图结构不是最优的、应在训练期间更新的事实。 接下来的问题是如何在端到端框架中同时学习时间序列的图结构和 GNN。
在本文中,我们提出了一种克服这些挑战的新方法。 如图1所示,我们的框架由三个核心组件组成——图学习层、图卷积模块和时间卷积模块。 对于挑战1,我们提出了一种新颖的图学习层,它根据数据自适应地提取稀疏图邻接矩阵。 此外,我们开发了一个图卷积模块来解决变量之间的空间依赖性,给定图学习层计算的邻接矩阵。 这是专门为有向图设计的,避免了图卷积网络中经常出现的过度平滑问题。 最后,我们提出了一个时间卷积模块,通过修改的一维卷积捕获时间模式。 它既可以发现具有多个频率的时间模式,也可以处理很长的序列。
由于所有参数都可以通过梯度下降来学习,因此所提出的框架能够对多元时间序列数据进行建模,并以端到端的方式同时学习内部图结构(对于挑战2)。 为了降低解决高度非凸优化问题的难度并减少处理大图时的内存占用,我们提出了一种学习算法,该算法使用课程学习策略来寻找更好的局部最优值,并在训练期间将多元时间序列分成子组。 这里的优点是我们提出的框架通常适用于小图和大图、短时间序列和长时间序列、有或没有外部定义的图结构。 总而言之,我们的主要贡献如下:
-
•
据我们所知,这是首次使用图神经网络从基于图的角度对多元时间序列数据进行研究。
-
•
我们提出了一种新颖的图学习模块来学习变量之间隐藏的空间依赖性。 我们的方法为 GNN 模型打开了一扇新的大门,可以在没有显式图结构的情况下处理数据。
-
•
我们提出了一个用于建模多元时间序列数据和学习图结构的联合框架。 我们的框架比任何现有的时空图神经网络更通用,因为它可以处理带有或不带有预定义图结构的多元时间序列。
-
•
实验结果表明,我们的方法在 4 个基准数据集中的 3 个上优于最先进的方法,并在提供额外结构信息的两个流量数据集上实现了与其他 GNN 相当的性能。
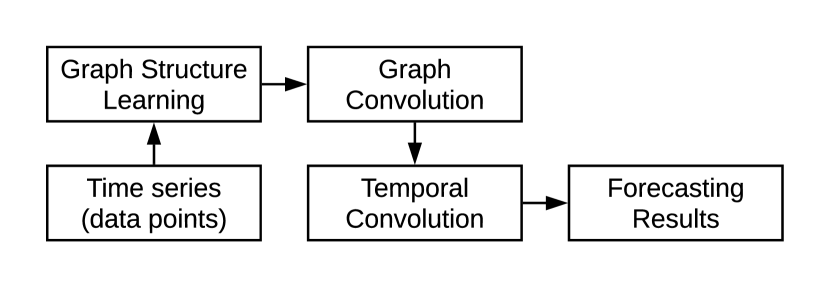
2. 背景
2.1. 多元时间序列预测
时间序列预测已经被研究了很长时间。 大多数现有方法都遵循统计方法。 自回归综合移动平均(ARIMA)(Box 等人,2015)概括了一系列线性模型,包括自回归(AR)、移动平均(MA)和自回归移动平均线(ARMA)。 向量自回归模型 (VAR) 扩展了 AR 模型以捕获多个时间序列之间的线性相互依赖性。 类似地,矢量自回归移动平均模型(VARMA)被提出作为 ARMA 模型的多元版本。 高斯过程 (GP) 作为一种贝叶斯方法,对多元变量在函数上的分布进行建模。 GP 可以自然地应用于对多元时间序列数据进行建模(Frigola,2015)。 尽管统计模型因其简单性和可解释性而被广泛用于时间序列预测,但它们对平稳过程做出了强有力的假设,并且不能很好地扩展到多元时间序列数据。 基于深度学习的方法不受平稳假设的影响,是捕获非线性的有效方法。 Lai 等人 (Lai 等人, 2018) 和 Shih 等人 (Shih 等人, 2019) 是最早针对多元时间序列设计的两个基于深度学习的模型预测。 他们使用卷积神经网络来捕获变量之间的局部依赖性,并使用循环神经网络来保留长期的时间依赖性。 卷积神经网络将变量之间的相互作用封装到全局隐藏状态中。 因此,他们无法充分利用变量对之间的潜在依赖关系。
2.2. 图神经网络
图神经网络在处理网络中实体之间的空间依赖性方面取得了巨大成功。 图神经网络假设节点的状态取决于其邻居的状态。 为了捕获这种类型的空间依赖性,人们通过消息传递(Gilmer等人,2017)、信息传播(Klicpera等人,2019)开发了各种图神经网络> 和图卷积(Kipf 和 Welling,2017)。 它们共享相似的角色,本质上是通过将信息从节点的邻居传递到节点本身来捕获节点的高级表示。 最近,我们看到了一种称为时空图神经网络的图神经网络的出现。 这种形式的神经网络最初是为了解决交通预测问题而提出的(Li 等人,2018;Yu 等人,2018;Wu 等人,2019;Zheng 等人,2020;Chen 等人,2019a) 和基于骨架的动作识别(Yan 等人,2018;Shi 等人,2019)。 时空图神经网络的输入是多元时间序列,具有外部图结构,描述多元时间序列中变量之间的关系。 对于时空图神经网络,节点之间的空间依赖关系由图卷积捕获,而历史状态之间的时间依赖关系由循环神经网络保存(Seo等人,2018;Li等人,2018)或一维卷积(Yu 等人, 2018; Yan 等人, 2018)。 尽管现有的时空图神经网络与不使用图结构的方法相比取得了显着的改进,但由于缺乏预定义的图和通用框架,它们无法有效地处理纯多元时间序列数据。
3. 问题表述
在本文中,我们重点关注多元时间序列预测的任务。 让 表示维度为 的多元变量在时间步长为 t 时的值,其中 表示 变量在时间步长为 t 时的值。给定多元变量 的历史观测值 时间步长序列,我们的目标是预测 的 步长值,或未来值 的序列。 更一般地,输入信号可以与其他辅助特征相结合,例如一天中的时间、一周中的一天和季节中的一天。 将输入信号与辅助特征相串联,我们假设输入信号为,其中、为特征维度,的第一列等于,其余为辅助特征。 我们的目标是通过使用 正则化最小化绝对损失来构建从 到 的映射 。
图描述了网络中实体之间的关系。 下面我们给出与图相关的概念的正式定义。
定义 3.1(图)。
图的形式为 = ,其中 是节点集, 是边集。 我们使用 来表示图中的节点数。
定义 3.2(节点邻域)。
令 表示节点, 表示从 指向 的边。节点的邻域被定义为。
定义 3.3(邻接矩阵)。
邻接矩阵是图的数学表示,表示为 ,其中 if 和 if 。
从基于图的角度来看,我们将多元时间序列中的变量视为图中的节点。 我们使用图邻接矩阵来描述节点之间的关系。 在大多数情况下,图邻接矩阵不是由多元时间序列数据给出的,而是由我们的模型学习的。
4. MTGNN框架

4.1. 模型架构
4.2. 图学习层
图学习层自适应地学习图邻接矩阵,以捕获时间序列数据之间的隐藏关系。 为了构建图,现有研究通过距离度量来衡量节点对之间的相似性,例如点积和欧氏距离(Li等人,2018)。 这就不可避免地导致了时间复杂度和空间复杂度高的问题。 这意味着计算和内存成本随着图大小的增加呈二次方增长。 这限制了模型处理更大图的能力。 为了解决这个限制,我们采用采样方法,仅计算节点子集之间的成对关系。 这消除了每个小批量中的计算和内存瓶颈。 更多详细信息将在第 4.6 节中提供。
另一个问题是现有的距离度量通常是对称的或双向的。 在多元时间序列预测中,我们期望一个节点的状况的变化会引起另一个节点的状况(例如交通流量)的变化。 因此,学习到的关系应该是单向的。 我们提出的图学习层专门设计用于提取单向关系,如下所示:
| (1) | ||||
| (2) | ||||
| (3) | ||||
| (4) | ||||
| (5) | ||||
| (6) |
其中表示随机初始化的节点嵌入,在训练期间可以学习,是模型参数,是用于控制节点饱和率的超参数激活函数, 返回向量的前 k 个最大值的索引。 我们提出的图邻接矩阵的不对称特性是通过方程3实现的。 减法项和 ReLU 激活函数对邻接矩阵进行正则化,以便如果 为正,则其对角对应项 将为零。 方程5-6是一种使邻接矩阵稀疏同时减少后续图卷积的计算成本的策略。 对于每个节点,我们选择其前 k 个最接近的节点作为其邻居。 在保留连接节点的权重的同时,我们将非连接节点的权重设置为零。
合并外部数据。 图学习层的输入不限于节点嵌入。 在给定每个节点属性的外部知识的情况下,我们还可以设置,其中是静态节点特征矩阵。 一些作品考虑了捕获动态空间依赖性(Guo等人,2019;Shi等人,2019)。 换句话说,它们根据时间输入动态调整两个连接节点的权重。 然而,当我们需要同时学习图结构时,假设动态空间依赖使得模型极难收敛。 我们方法的优点是我们可以在训练数据集期间学习稳定且可解释的节点关系。 一旦模型在在线学习版本中进行训练,我们的图邻接矩阵也可以随着新的训练数据更新模型参数而改变。
4.3. 图卷积模块
图卷积模块旨在将节点的信息与其邻居的信息融合,以处理图中的空间依赖性。 图卷积模块由两个混合跳传播层组成,分别处理通过每个节点的流入和流出信息。 通过将两个混合跳传播层的输出相加获得净流入信息。 图4显示了图卷积模块和混合跳传播层的架构。
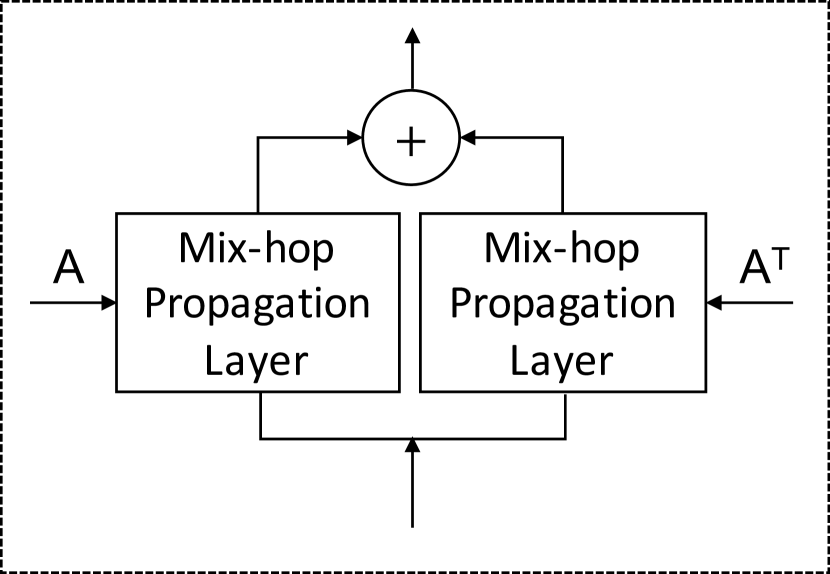
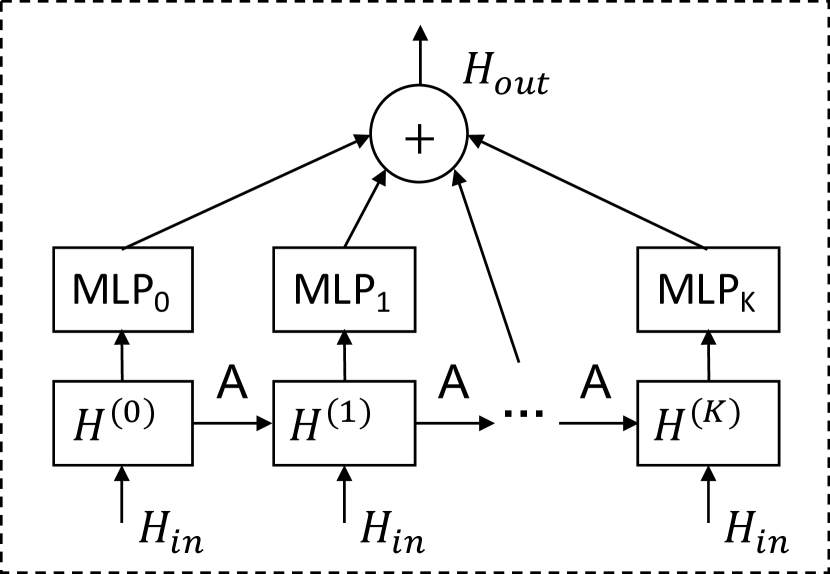
混合跳传播层。
给定图邻接矩阵,我们提出混合跳传播层来处理空间相关节点上的信息流。 所提出的混合跳传播层由两个步骤组成——信息传播步骤和信息选择步骤。 我们首先给出这两个步骤的数学形式,然后说明我们的动机。 信息传播步骤定义如下:
| (7) |
其中是一个超参数,它控制保留根节点原始状态的比例。 信息选择步骤定义如下
| (8) |
其中是传播深度,表示上一层输出的输入隐藏状态,表示当前层的输出隐藏状态,、 和 。 在图4(b)中,我们演示了所提出的混合跳传播层中的信息传播步骤和信息选择步骤。 它首先水平传播信息,垂直选择信息。
信息传播步骤递归地传播节点信息以及给定的图结构。 图卷积网络的一个严重限制是,随着图卷积层的数量趋于无穷大,节点隐藏状态会收敛到单个点。 这是因为无论初始节点状态如何,多层图卷积网络都会达到随机游走的极限分布。 为了解决这个问题,受 Klicpera 等人 (Klicpera 等人, 2019) 的启发,我们在传播过程中保留一部分节点的原始状态,以便传播的节点状态既能保留局部性,又能探索一个很深的邻里。 然而,如果我们只应用方程7,一些节点信息将会丢失。 在不存在空间依赖性的极端情况下,聚合邻域信息只会给每个节点添加无用的噪声。 因此,引入信息选择步骤来过滤掉每一跳产生的重要信息。 根据方程8,参数矩阵充当特征选择器。 当给定的图结构不存在空间依赖性时,通过将所有的调整为0,方程8仍然能够保留原始节点自身信息>。
与现有作品的连接。 mix-hop 的想法已被 (Kapoor 等人, 2019) 和 (Chen 等人, 2019b) 探索过。 Kapoor 等人 (Kapoor 等人, 2019) 连接来自不同跃点的信息。 Chen 等人 (Chen 等人, 2019b) 提出了一种注意力机制来对不同跳之间的信息进行加权。 他们都应用GCN来进行信息传播。 然而,由于 GCN 面临过度平滑的问题,来自较高跳的信息可能不会或对整体性能产生负面影响。 为了避免这种情况,我们的方法在本地信息和邻里信息之间保持平衡。 此外,Kapoor 等人 (Kapoor 等人, 2019) 表明,他们提出的具有两个混合跳层的模型能够表示两个连续跳之间的增量差异。 我们的方法只需一个混合跳传播层即可达到相同的效果。 假设 、、 和 ,则
| (9) |
从这个角度来看,与串联方法相比,使用求和可以更有效地表示不同跳的所有线性交互。
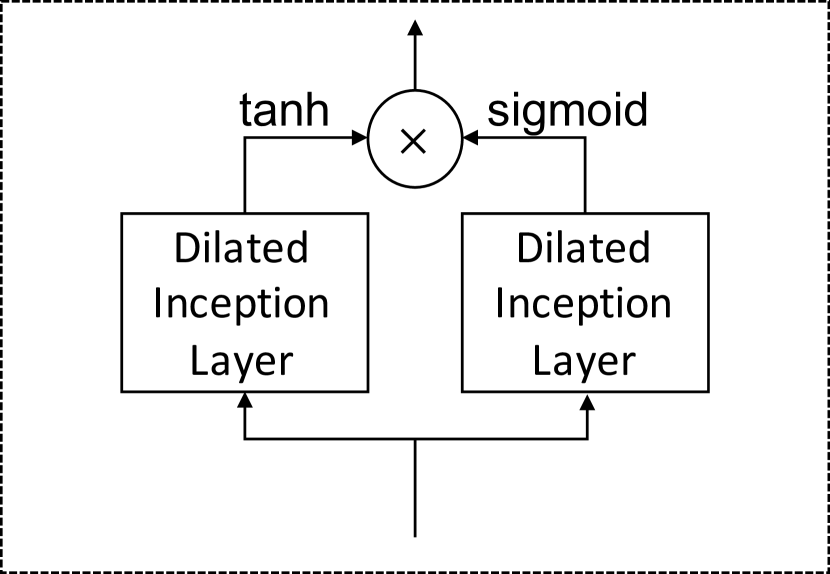
4.4. 时间卷积模块
时间卷积模块应用一组标准扩张一维卷积滤波器来提取高级时间特征。 该模块由两个扩展的初始层组成。 一个扩张的初始层后面是一个正切双曲激活函数,并充当过滤器。 另一层后面是 sigmoid 激活函数,用作控制过滤器可以传递到下一个模块的信息量的门。 图5显示了时间卷积模块和扩张初始层的架构。
扩张的初始层
时间卷积模块通过一维卷积滤波器捕获时间序列数据的顺序模式。 为了提出一个能够发现不同范围的时间模式并处理很长序列的时间卷积模块,我们提出了扩张初始层,它结合了卷积神经网络中两种广泛应用的策略,即使用多个尺寸的过滤器(Szegedy 等人, 2015) 并应用扩张卷积(Yu and Koltun, 2016)。
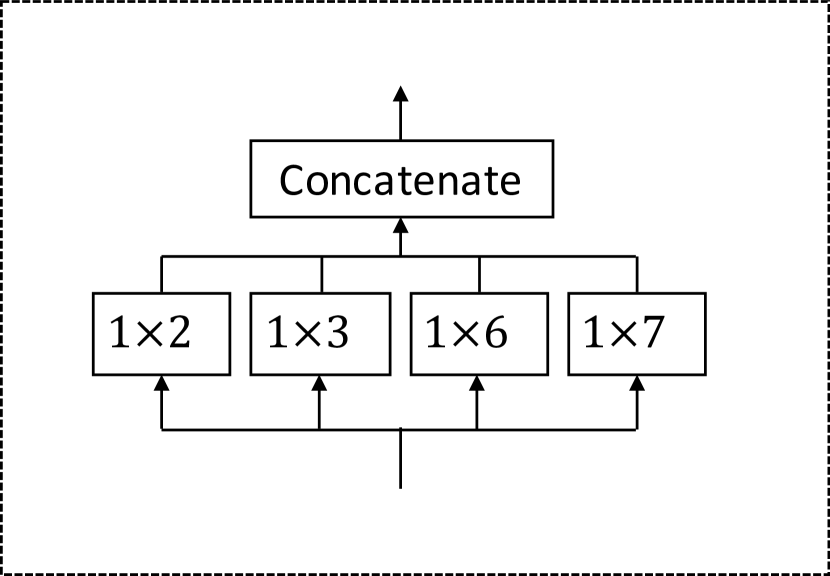
首先,选择正确的内核大小对于卷积网络来说是一个具有挑战性的问题。 滤波器尺寸可能太大而无法巧妙地表示短期信号模式,或者太小而无法充分发现长期信号模式。 在图像处理中,一种广泛采用的策略称为 inception,它将具有三种不同内核大小的 2D 卷积滤波器的输出连接起来:、 和 。 从 2D 图像到 1D 时间序列,、 和 滤波器大小的集合不适合时间信号的性质。 由于时间信号往往具有多个固有周期,例如 、、、 和 ,过滤器大小为 、 和 的初始层堆栈不能很好地涵盖这些周期。 或者,我们提出一个由四种滤波器大小组成的时间初始层,即 、、 和 。 上述周期都可以通过这些滤波器尺寸的组合来覆盖。 例如,为了表示周期 ,模型可以将输入传递到来自第一个时间起始层的 过滤器,然后通过来自第一个时间起始层的 过滤器。第二时间起始层。
其次,卷积网络的感受野大小随着网络深度和滤波器内核大小呈线性增长。 考虑一个具有 个内核大小 的卷积层的卷积网络,卷积网络的感受野大小为,
| (10) |
要处理很长的序列,需要非常深的网络或非常大的过滤器。 我们采用扩张卷积来降低模型复杂度。 扩张卷积以特定频率对下采样输入运行标准卷积滤波器。 例如,当膨胀因子为 2 时,它会对每两步采样的输入应用标准卷积。 继(Oord等人,2016)之后,我们让每层的膨胀因子以的速率呈指数增长。 假设初始扩张因子为,则核大小为的层扩张卷积网络的感受野大小为
| (11) |
这表明网络的感受野大小也随着隐藏层数量的增加而以的速度呈指数增长。 因此,使用这种扩张策略可以捕获比不使用这种扩张策略更长的序列。
形式上,结合初始和扩张,我们提出了扩张初始层,如图5(b)所示。 给定一维序列输入 和由 、、 和 组成的过滤器,我们的扩张的初始层采用以下形式,
| (12) |
其中四个滤波器的输出根据最大滤波器截断为相同长度并在通道维度上连接,表示的扩张卷积定义为
| (13) |
其中 是膨胀因子。
4.5. 跳过连接层和输出模块
跳过连接层本质上是 标准卷积,其中 是 跳过连接层输入的序列长度。 它将跳转到输出模块的信息标准化为具有相同的序列长度。 输出模块由两个标准卷积层组成,将输入的通道维度转换为所需的输出维度。 如果我们只想预测未来的某个步骤,则所需的输出维度为 。 当我们想要预测连续步骤时,所需的输出维度是。
4.6. 建议的学习算法
我们提出了一种学习算法来增强模型处理大图并稳定在更好的局部最优的能力。 图上的训练通常需要将所有节点中间状态存储到内存中。 如果图很大,就会面临内存溢出的问题。 与我们最相关的是,Chiang 等人 (Chiang 等人, 2019) 提出了一种子图训练算法来解决内存瓶颈。 他们应用图聚类算法将图划分为子图,并在划分的子图上训练图卷积网络。 在我们的问题中,基于节点的拓扑信息对节点进行聚类是不切实际的,因为我们的模型同时学习潜在的图结构。 或者,在每次迭代中,我们将节点随机分成几组,并让算法根据采样的节点学习子图结构。 这为每个节点提供了与一组中的另一个节点分配的完全可能性,以便可以计算和更新这两个节点之间的相似性得分。 另一个好处是,如果我们将节点分成 组,我们可以将图学习层的时间和空间复杂度从 降低到 每次迭代。 训练后,由于所有节点嵌入都经过良好训练,因此可以构建全局图以充分利用空间关系。 尽管计算成本较高,但可以在进行预测之前并行预先计算邻接矩阵。
我们提出的算法的第二个考虑是促进我们的模型稳定在更好的局部最优中。 在多步预测任务中,我们观察到长期预测在模型性能方面往往比短期预测取得更大的改进。 我们认为原因是我们的模型总共预测了多个步骤,长期预测比短期预测产生的损失要高得多。 因此,为了最大限度地减少总体损失,模型更加注重提高长期预测的准确性。 为了解决这个问题,我们提出了一种针对多步骤预测任务的课程学习策略。 该算法从解决最简单的问题开始,仅预测下一步。 模型找到一个好的起点是非常有利的。 随着迭代次数的增加,我们逐渐增加模型的预测长度,使模型能够逐步学习困难的任务。 涵盖所有这些,我们的算法在算法 1 中给出。 我们模型的进一步复杂性分析可以在附录A.1中找到。
5. 实验研究
我们在两项任务上验证 MTGNN - 单步预测和多步预测。 首先,我们在四个用于多元时间序列预测的基准数据集上比较 MTGNN 与其他多元时间序列模型的性能,其目的是预测单个未来步骤。 此外,为了展示 MTGNN 与其他使用预定义图结构信息的时空图神经网络相比的表现如何,我们在时空图神经网络的两个基准数据集上评估 MTGNN,其目标是预测未来的多个步骤。 进一步的参数研究结果参见附录A.4。
5.1. 实验设置
在表1中,我们总结了基准数据集的统计数据。 有关数据集的更多详细信息请参见附录A.2。 我们使用五个评估指标,包括平均绝对误差(MAE)、均方根误差(RMSE)、平均绝对百分比误差(MAPE)、相对平方根误差(RRSE)和经验相关系数(CORR)。 对于 RMSE、MAE、MAPE 和 RRSE,值越低越好。 对于 CORR,值越高越好。 其他实验设置在附录A.3中给出。
| Datasets | # Samples | # Nodes | Sample Rate | Input Length | Output Length |
| traffic | 17,544 | 862 | 1 hour | 168 | 1 |
| solar-energy | 52,560 | 137 | 10 minutes | 168 | 1 |
| electricity | 26,304 | 321 | 1 hour | 168 | 1 |
| exchange-rate | 7,588 | 8 | 1 day | 168 | 1 |
| metr-la | 34272 | 207 | 5 minutes | 12 | 12 |
| pems-bay | 52116 | 325 | 5 minutes | 12 | 12 |
5.2. 比较基线方法
MTGNN 和 MTGNN+sampling 是我们要评估的模型。 MTGNN 是我们提出的模型。 MTGNN+采样是我们提出的模型,在每次迭代中对图的采样子集进行训练。 基线方法总结如下:
5.2.1. 单步预测
-
•
AR:自回归模型。
-
•
VAR-MLP:多层感知(MLP)和自回归模型(VAR)的混合模型(Zhang,2003)。
-
•
GP:高斯过程时间序列模型(Roberts等人,2013;Frigola-Alcalde,2016)。
-
•
RNN-GRU:具有完全连接的 GRU 隐藏单元的循环神经网络。
-
•
LSTNet:一种深度神经网络,结合了卷积神经网络和循环神经网络(Lai等人,2018)。
-
•
TPA-LSTM:一种注意力循环神经网络(Shih等人,2019)。
5.2.2. 多步预测
-
•
DCRNN:一种扩散卷积循环神经网络,它将扩散图卷积与循环神经网络相结合(Li等人,2018)。
-
•
STGCN:一种时空图卷积网络,它将图卷积与一维卷积结合起来(Yu等人,2018)。
-
•
Graph WaveNet:一种时空图卷积网络,它将扩散图卷积与一维扩张卷积相结合(Wu等人,2019)。
-
•
ST-MetaNet:一种序列到序列架构,采用元网络生成参数(Pan等人,2019)。
-
•
GMAN:具有空间和时间注意力的图多注意力网络(Zheng等人,2020)。
-
•
MRA-BGCN:多范围注意力双分量 GCN (Chen 等人,2019a)。
5.3. 主要结果
| Dataset | Solar-Energy | Traffic | Electricity | Exchange-Rate | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Horizon | Horizon | Horizon | Horizon | ||||||||||||||
| Methods | Metrics | 3 | 6 | 12 | 24 | 3 | 6 | 12 | 24 | 3 | 6 | 12 | 24 | 3 | 6 | 12 | 24 |
| AR | RSE | 0.2435 | 0.3790 | 0.5911 | 0.8699 | 0.5991 | 0.6218 | 0.6252 | 0.63 | 0.0995 | 0.1035 | 0.1050 | 0.1054 | 0.0228 | 0.0279 | 0.0353 | 0.0445 |
| CORR | 0.9710 | 0.9263 | 0.8107 | 0.5314 | 0.7752 | 0.7568 | 0.7544 | 0.7519 | 0.8845 | 0.8632 | 0.8591 | 0.8595 | 0.9734 | 0.9656 | 0.9526 | 0.9357 | |
| VARMLP | RSE | 0.1922 | 0.2679 | 0.4244 | 0.6841 | 0.5582 | 0.6579 | 0.6023 | 0.6146 | 0.1393 | 0.1620 | 0.1557 | 0.1274 | 0.0265 | 0.0394 | 0.0407 | 0.0578 |
| CORR | 0.9829 | 0.9655 | 0.9058 | 0.7149 | 0.8245 | 0.7695 | 0.7929 | 0.7891 | 0.8708 | 0.8389 | 0.8192 | 0.8679 | 0.8609 | 0.8725 | 0.8280 | 0.7675 | |
| GP | RSE | 0.2259 | 0.3286 | 0.5200 | 0.7973 | 0.6082 | 0.6772 | 0.6406 | 0.5995 | 0.1500 | 0.1907 | 0.1621 | 0.1273 | 0.0239 | 0.0272 | 0.0394 | 0.0580 |
| CORR | 0.9751 | 0.9448 | 0.8518 | 0.5971 | 0.7831 | 0.7406 | 0.7671 | 0.7909 | 0.8670 | 0.8334 | 0.8394 | 0.8818 | 0.8713 | 0.8193 | 0.8484 | 0.8278 | |
| RNN-GRU | RSE | 0.1932 | 0.2628 | 0.4163 | 0.4852 | 0.5358 | 0.5522 | 0.5562 | 0.5633 | 0.1102 | 0.1144 | 0.1183 | 0.1295 | 0.0192 | 0.0264 | 0.0408 | 0.0626 |
| CORR | 0.9823 | 0.9675 | 0.9150 | 0.8823 | 0.8511 | 0.8405 | 0.8345 | 0.8300 | 0.8597 | 0.8623 | 0.8472 | 0.8651 | 0.9786 | 0.9712 | 0.9531 | 0.9223 | |
| LSTNet-skip | RSE | 0.1843 | 0.2559 | 0.3254 | 0.4643 | 0.4777 | 0.4893 | 0.4950 | 0.4973 | 0.0864 | 0.0931 | 0.1007 | 0.1007 | 0.0226 | 0.0280 | 0.0356 | 0.0449 |
| CORR | 0.9843 | 0.9690 | 0.9467 | 0.8870 | 0.8721 | 0.8690 | 0.8614 | 0.8588 | 0.9283 | 0.9135 | 0.9077 | 0.9119 | 0.9735 | 0.9658 | 0.9511 | 0.9354 | |
| TPA-LSTM | RSE | 0.1803 | 0.2347 | 0.3234 | 0.4389 | 0.4487 | 0.4658 | 0.4641 | 0.4765 | 0.0823 | 0.0916 | 0.0964 | 0.1006 | 0.0174 | 0.0241 | 0.0341 | 0.0444 |
| CORR | 0.9850 | 0.9742 | 0.9487 | 0.9081 | 0.8812 | 0.8717 | 0.8717 | 0.8629 | 0.9439 | 0.9337 | 0.9250 | 0.9133 | 0.9790 | 0.9709 | 0.9564 | 0.9381 | |
| MTGNN | RSE | 0.1778 | 0.2348 | 0.3109 | 0.4270 | 0.4162 | 0.4754 | 0.4461 | 0.4535 | 0.0745 | 0.0878 | 0.0916 | 0.0953 | 0.0194 | 0.0259 | 0.0349 | 0.0456 |
| CORR | 0.9852 | 0.9726 | 0.9509 | 0.9031 | 0.8963 | 0.8667 | 0.8794 | 0.8810 | 0.9474 | 0.9316 | 0.9278 | 0.9234 | 0.9786 | 0.9708 | 0.9551 | 0.9372 | |
| MTGNN+sampling | RSE | 0.1875 | 0.2521 | 0.3347 | 0.4386 | 0.4170 | 0.4435 | 0.4469 | 0.4537 | 0.0762 | 0.0862 | 0.0938 | 0.0976 | 0.0212 | 0.0271 | 0.0350 | 0.0454 |
| CORR | 0.9834 | 0.9687 | 0.9440 | 0.8990 | 0.8960 | 0.8815 | 0.8793 | 0.8758 | 0.9467 | 0.9354 | 0.9261 | 0.9219 | 0.9788 | 0.9704 | 0.9574 | 0.9382 | |
表2和表3提供了MTGNN和MTGNN+采样的主要实验结果。 我们观察到 MTGNN 在大多数任务上都取得了最先进的结果,并且当它对训练的子图进行采样时,MTGNN 的性能只会出现边际下降。 下面,我们分别讨论单步和多步预测的实验结果。
5.3.1. 单步预测
在本实验中,我们将 MTGNN 与其他多元时间序列模型进行比较。 表2显示了单步预测任务的实验结果。 总的来说,我们的 MTGNN 在太阳能、交通和电力数据的几乎所有领域都取得了最先进的结果。 特别是在交通数据上,MTGNN 在 RSE 方面的改进非常显着。 MTGNN 在 3、12、24 天内根据流量数据将 RSE 分别降低了 7.24%、3.88%、4.83%。 MTGNN 明显改善交通数据结果的主要原因是交通数据的性质更适合我们关于时空依赖性的模型假设。 显然,一条道路未来的交通占用率不仅取决于其过去的交通占用率,还取决于其相连道路的占用率。 MTGNN 未能对汇率数据进行改进,可能是由于图尺寸较小和汇率数据的训练示例较少。
5.3.2. 多步预测
在本实验中,我们将 MTGNN 与其他时空图神经网络模型进行比较。 表3显示了多步预测任务的实验结果。 MTGNN 的意义在于它在不使用预定义图的情况下实现了与最先进的时空图神经网络相当的性能,而 DCRNN、STGCN 和 MRA-BGCN 完全依赖于预定义的图表。 Wavenet Graph提出了一种自适应邻接矩阵,但它需要与预定义的图结合才能达到最佳性能。 ST-MetaNet 采用注意力机制来调整预定义图的边权重。 GMAN 利用 node2vec 算法在执行注意力机制的同时保留节点结构信息。 当未定义图时,这些方法无法有效地对多元时间序列数据进行建模。
| Horizon 3 | Horizon 6 | Horizon 12 | |||||||
| MAE | RMSE | MAPE | MAE | RMSE | MAPE | MAE | RMSE | MAPE | |
| METR-LA | |||||||||
| DCRNN | 2.77 | 5.38 | 7.30% | 3.15 | 6.45 | 8.80% | 3.60 | 7.60 | 10.50% |
| STGCN | 2.88 | 5.74 | 7.62% | 3.47 | 7.24 | 9.57% | 4.59 | 9.40 | 12.70% |
| Graph WaveNet | 2.69 | 5.15 | 6.90% | 3.07 | 6.22 | 8.37% | 3.53 | 7.37 | 10.01% |
| ST-MetaNet | 2.69 | 5.17 | 6.91% | 3.10 | 6.28 | 8.57% | 3.59 | 7.52 | 10.63% |
| MRA-BGCN | 2.67 | 5.12 | 6.80% | 3.06 | 6.17 | 8.30% | 3.49 | 7.30 | 10.00% |
| GMAN | 2.77 | 5.48 | 7.25% | 3.07 | 6.34 | 8.35% | 3.40 | 7.21 | 9.72% |
| MTGNN | 2.69 | 5.18 | 6.86% | 3.05 | 6.17 | 8.19% | 3.49 | 7.23 | 9.87% |
| MTGNN+sampling | 2.76 | 5.34 | 5.18% | 3.11 | 6.32 | 8.47% | 3.54 | 7.38 | 10.05% |
| PEMS-BAY | |||||||||
| DCRNN | 1.38 | 2.95 | 2.90% | 1.74 | 3.97 | 3.90% | 2.07 | 4.74 | 4.90% |
| STGCN | 1.36 | 2.96 | 2.90% | 1.81 | 4.27 | 4.17% | 2.49 | 5.69 | 5.79% |
| Graph WaveNet | 1.30 | 2.74 | 2.73% | 1.63 | 3.70 | 3.67% | 1.95 | 4.52 | 4.63% |
| ST-MetaNet | 1.36 | 2.90 | 2.82% | 1.76 | 4.02 | 4.00% | 2.20 | 5.06 | 5.45% |
| MRA-BGCN | 1.29 | 2.72 | 2.90% | 1.61 | 3.67 | 3.80% | 1.91 | 4.46 | 4.60% |
| GMAN | 1.34 | 2.82 | 2.81% | 1.62 | 3.72 | 3.63% | 1.86 | 4.32 | 4.31% |
| MTGNN | 1.32 | 2.79 | 2.77% | 1.65 | 3.74 | 3.69% | 1.94 | 4.49 | 4.53% |
| MTGNN+sampling | 1.34 | 2.83 | 2.83% | 1.67 | 3.79 | 3.78% | 1.95 | 4.49 | 4.62% |
5.4. 消融研究
我们对 METR-LA 数据进行了消融研究,以验证有助于改善我们提出的模型结果的关键组件的有效性。 我们将没有不同组件的 MTGNN 命名为:
-
•
w/o GC:没有图卷积模块的 MTGNN。 我们用线性层替换图卷积模块。
-
•
w/o Mix-hop:在混合跳传播层中没有信息选择步骤的 MTGNN。 我们将信息传播步骤的输出直接传递到下一个模块。
-
•
w/o Inception:在扩张的初始层中没有初始的 MTGNN。 在保持相同数量的输出通道的同时,我们仅使用单个 过滤器。
-
•
w/o CL:没有课程学习的 MTGNN。 我们在不逐渐增加预测长度的情况下训练 MTGNN。
我们将每个实验重复 10 次,每次重复 50 个周期,并在表 4 中的验证集上报告 MAE、RMSE、MAPE 的平均值以及超过 10 次运行的标准差。 图卷积模块的引入显着改善了结果,因为它使得信息能够在孤立但相互依赖的节点之间流动。 mix-hop的效果也很明显:它验证了mix-hop的使用有助于在mix-hop传播层的每个信息传播步骤中选择有用的信息。 就 RMSE 而言,启动的影响显着,但就 MAE 而言,影响较小。 这是因为,在扩张初始层的输出通道数保持不变的情况下,使用单个 滤波器的参数比使用 滤波器组合的参数多一半。 最后,我们的课程学习策略被证明是有效的。 它使我们的模型能够快速收敛到适合最简单任务的最佳值,并且随着学习难度的增加逐步调整参数。
| Methods | MTGNN | w/o GC | w/o Mix-hop | w/o Inception | w/o CL |
| MAE | 2.77150.0119 | 2.89530.0054 | 2.79750.0089 | 2.77720.0100 | 2.78280.0105 |
| RMSE | 5.80700.0512 | 6.12760.0339 | 5.85490.0474 | 5.82510.0429 | 5.82480.0366 |
| MAPE | 0.07780.0009 | 0.08310.0009 | 0.07790.0009 | 0.07780.0010 | 0.07840.0009 |
5.5. 图学习层的研究
为了验证我们提出的图学习层的有效性,我们进行了一项研究,试验了构建图邻接矩阵的不同方法。 表 5 显示了 的不同形式,以及在 METR-LA 数据验证集(平均 10 次运行)上测试的实验结果。 预定义-A由路网距离(李等人,2018)构建。 Global-A 假设邻接矩阵是参数矩阵,其中包含参数。 受(Wu等人,2019)的启发,Undirected-A和Directed-A是通过节点嵌入的相似度分数来计算的。 在(Guo等人,2019;Shi等人,2019)的推动下,Dynamic-A假设每个时间步的空间依赖性取决于其节点输入。 Uni-directed-A 是我们提出的方法。 根据表5,我们提出的单向 A 实现了最低的平均 MAE、RMSE 和 MAPE。 它比预定义-A、无向-A 和动态-A 显着改进。 我们的单向 A 在 MAE 和 MAPE 方面比无向 A 和定向 A 略有改进,但由于 RMSE 较低,因此证明更稳健。
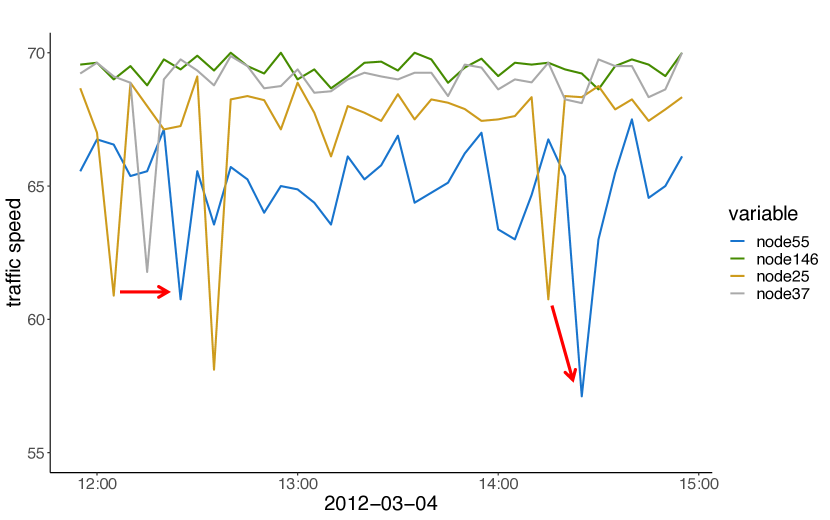
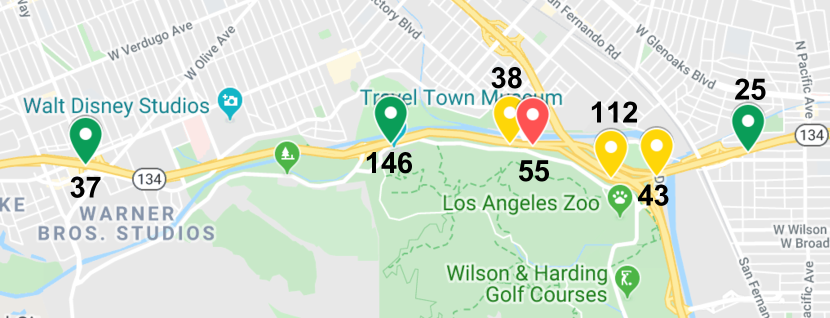
我们通过案例研究进一步研究学习到的图邻接矩阵。 在图6(a)中,我们绘制了节点 55 及其预定义的前 3 个邻居的原始时间序列。 在图 6(b) 中,我们绘制了节点 55 及其学习的前 3 个邻居的原始时间序列。 图6(c)显示了这些节点的地理位置,其中绿色节点代表中心节点学习的top-3邻居,黄色节点代表中心节点预定义的top-3邻居。 我们观察到中心节点的预定义前 3 个邻居与地图上的节点本身更接近。 因此,它们的时间序列同时相关性更强,如图6(a)中的红色圆圈所示。 相反,中心节点学习到的前 3 个邻居分布得离它更远,但仍然位于它所遵循的同一条道路上。 根据图6(b),学习到的top-3邻居的时间序列更能提前指示中心节点的极端流量状况。

| Methods | Equation | MAE | RMSE | MAPE |
|---|---|---|---|---|
| Pre-defined-A | - | 2.90170.0078 | 6.12880.0345 | 0.08360.0009 |
| Global-A | 2.84570.0107 | 5.99000.0390 | 0.08050.0009 | |
| Undirected-A | 2.77360.0185 | 5.84110.0523 | 0.07830.0012 | |
| Directed-A | 2.77580.0088 | 5.82170.0451 | 0.07830.0006 | |
| Dynamic-A | 2.81240.0102 | 5.91890.0281 | 0.07940.0008 | |
| Uni-directed-A (ours) | 2.77150.0119 | 5.80700.0512 | 0.07780.0009 |
6. 结论
在本文中,我们介绍了一种用于多元时间序列预测的新颖框架。 据我们所知,我们是第一个通过基于图的深度学习方法解决多元时间序列预测问题的人。 我们提出了一种有效的方法来利用多个时间序列之间固有的依赖关系。 我们的方法在各种多元时间序列预测任务中展示了卓越的性能,并为使用 GNN 处理各种非结构数据打开了新的大门。
致谢。
这项工作得到了澳大利亚研究委员会 (ARC) 的部分支持,资助金额为 LP160100630、LP180100654 和 DE190100626。参考
- (1)
- Box et al. (2015) George EP Box, Gwilym M Jenkins, Gregory C Reinsel, and Greta M Ljung. 2015. Time series analysis: forecasting and control. John Wiley & Sons.
- Chen et al. (2019b) Fengwen Chen, Shirui Pan, Jing Jiang, Huan Huo, and Guodong Long. 2019b. DAGCN: Dual Attention Graph Convolutional Networks. In Proc. of IJCNN.
- Chen et al. (2019a) Weiqi Chen, Ling Chen, Yu Xie, Wei Cao, Yusong Gao, and Xiaojie Feng. 2019a. Multi-Range Attentive Bicomponent Graph Convolutional Network for Traffic Forecasting. In Proc. of AAAI.
- Chiang et al. (2019) Wei-Lin Chiang, Xuanqing Liu, Si Si, Yang Li, Samy Bengio, and Cho-Jui Hsieh. 2019. Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks. In Proc. of KDD.
- Frigola (2015) Roger Frigola. 2015. Bayesian time series learning with Gaussian processes. Ph.D. Dissertation. University of Cambridge.
- Frigola-Alcalde (2016) Roger Frigola-Alcalde. 2016. Bayesian time series learning with Gaussian processes. Ph.D. Dissertation. University of Cambridge.
- Gilmer et al. (2017) Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. 2017. Neural message passing for quantum chemistry. In Proc. of ICML. 1263–1272.
- Guo et al. (2019) Shengnan Guo, Youfang Lin, Ning Feng, Chao Song, and Huaiyu Wan. 2019. Attention based spatial-temporal graph convolutional networks for traffic flow forecasting. In Proc. of AAAI, Vol. 33. 922–929.
- Kapoor et al. (2019) Amol Kapoor, Aram Galstyan, Bryan Perozzi, Greg Ver Steeg, Hrayr Harutyunyan, Kristina Lerman, Nazanin Alipourfard, and Sami Abu-El-Haija. 2019. MixHop: Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing. In Proc. of ICML.
- Kipf and Welling (2017) Thomas N Kipf and Max Welling. 2017. Semi-supervised classification with graph convolutional networks. In Proc. of ICLR.
- Klicpera et al. (2019) Johannes Klicpera, Aleksandar Bojchevski, and Stephan Günnemann. 2019. Predict then propagate: Graph neural networks meet personalized pagerank. In Proc. of ICLR.
- Lai et al. (2018) Guokun Lai, Wei-Cheng Chang, Yiming Yang, and Hanxiao Liu. 2018. Modeling long-and short-term temporal patterns with deep neural networks. In Proc. of SIGIR. ACM, 95–104.
- Li et al. (2018) Yaguang Li, Rose Yu, Cyrus Shahabi, and Yan Liu. 2018. Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. In Proc. of ICLR.
- Oord et al. (2016) Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. 2016. Wavenet: A generative model for raw audio. arXiv:1609.03499 (2016).
- Pan et al. (2019) Zheyi Pan, Yuxuan Liang, Weifeng Wang, Yong Yu, Yu Zheng, and Junbo Zhang. 2019. Urban Traffic Prediction from Spatio-Temporal Data Using Deep Meta Learning. In KDD. ACM, 1720–1730.
- Roberts et al. (2013) Stephen Roberts, Michael Osborne, Mark Ebden, Steven Reece, Neale Gibson, and Suzanne Aigrain. 2013. Gaussian processes for time-series modelling. Philos. Trans. R. Soc. A 371, 1984 (2013), 20110550.
- Seo et al. (2018) Youngjoo Seo, Michaël Defferrard, Pierre Vandergheynst, and Xavier Bresson. 2018. Structured sequence modeling with graph convolutional recurrent networks. In Proc. of NIPS. Springer, 362–373.
- Shi et al. (2019) Lei Shi, Yifan Zhang, Jian Cheng, and Hanqing Lu. 2019. Two-Stream Adaptive Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proc. of CVPR. 12026–12035.
- Shih et al. (2019) Shun-Yao Shih, Fan-Keng Sun, and Hung-yi Lee. 2019. Temporal pattern attention for multivariate time series forecasting. Machine Learning 108, 8-9 (2019), 1421–1441.
- Szegedy et al. (2015) Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. 2015. Going deeper with convolutions. In Proc. of CVPR. 1–9.
- Wu et al. (2019) Zonghan Wu, Shirui Pan, Guodong Long, Jing Jiang, and Chengqi Zhang. 2019. Graph WaveNet for Deep Spatial-Temporal Graph Modeling. In Proc. of IJCAI.
- Yan et al. (2018) Sijie Yan, Yuanjun Xiong, and Dahua Lin. 2018. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proc. of AAAI. 3482–3489.
- Yu et al. (2018) Bing Yu, Haoteng Yin, and Zhanxing Zhu. 2018. Spatio-Temporal Graph Convolutional Networks: A Deep Learning Framework for Traffic Forecasting. In Proc. of IJCAI. 3634–3640.
- Yu and Koltun (2016) Fisher Yu and Vladlen Koltun. 2016. Multi-scale context aggregation by dilated convolutions. In ICLR.
- Zhang (2003) G Peter Zhang. 2003. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 50 (2003), 159–175.
- Zheng et al. (2020) Chuanpan Zheng, Xiaoliang Fan, Cheng Wang, and Jianzhong Qi. 2020. GMAN: A Graph Multi-Attention Network for Traffic Prediction. In Proc. of AAAI.
附录 A 附录:再现性
在本节中,我们提供了实现可重复性的详细信息。 我们的源代码111https://github.com/nnzhan/MTGNN 是公开的。
A.1。 复杂性分析
我们分析了所提出的模型 MTGNN 主要组件的时间复杂度,总结在表6中。 图学习层的时间复杂度为,其中表示节点数量,表示节点输入特征向量的维度,表示节点隐藏特征向量的维度。 将和视为常量,图学习层的时间复杂度变为。 这归因于节点隐藏特征向量的成对计算。 图卷积模块的时间复杂度为,其中为传播深度,为节点数,表示节点状态的输入维度,表示节点状态的输出维度。 将、和视为常数,图卷积模块的时间复杂度变为。 这个结果来自于这样的事实:在信息传播步骤中,每个节点从其邻居接收信息,并且每个节点的邻居数量之和恰好等于边的数量。 时间卷积模块的时间复杂度等于,其中是输入序列长度,是输入通道数,是输出通道数,是膨胀因子。 时间卷积模块的时间复杂度主要取决于,即输入特征图的大小。
| Components | Time Complexity |
|---|---|
| Graph Learning Layer | |
| Graph Convolution Module | |
| Temporal Convolution Module |
A.2。 数据
在表1中,我们总结了基准数据集的统计数据。 下面介绍这些数据集的详细信息。
A.2.1。 单步预测
-
•
交通:来自加州交通部的交通数据集包含 2015 年和 2016 年旧金山湾区高速公路 862 个传感器测量的道路占用率。
-
•
太阳能:来自国家可再生能源实验室的太阳能数据集包含 2007 年从阿拉巴马州 137 个光伏电站收集的太阳能输出。
-
•
电力:UCI 机器学习存储库中的电力数据集包含 2012 年至 2014 年 321 个客户的用电量。
-
•
汇率:汇率数据集包含澳大利亚、英国、加拿大、瑞士、中国、日本、新西兰、新加坡等8个国家1990年至2016年的每日汇率。
继(Lai 等人, 2018)之后,我们按时间顺序将这四个数据集分为训练集(60%)、验证集(20%)和测试集(20%)。 输入序列长度为168,输出序列长度为1。 模型经过独立训练以预测目标未来步骤(地平线)3、6、12 和 24。
A.2.2。 多步预测
-
•
METR-LA:来自洛杉矶大都会交通局的 METR-LA 数据集包含 2012 年 3 月至 2012 年 6 月期间洛杉矶县高速公路上 207 个环路检测器测量的平均交通速度。
-
•
PEMS-BAY:来自加州交通局 (CalTrans) 的 PEMS-BAY 数据集包含 2017 年 1 月至 2017 年 5 月期间湾区 325 个传感器测量的平均交通速度。
遵循(Li 等人, 2018),我们按时间顺序将这两个数据集分为训练集(70%)、验证集(20%)和测试集(10%)。 输入序列长度为12,目标序列包含接下来的12个未来步骤。 一天中的时间用作输入的辅助功能。 对于选定的基线方法,成对道路网络距离用作预定义的图形结构。
A.3。 实验装置
我们重复实验 10 次并报告评估指标的平均值。 该模型由 Adam 优化器使用梯度剪辑 5 进行训练。 学习率为0.001。 l2 正则化惩罚为 0.0001。 在每个时间卷积模块之后应用 0.3 的 Dropout。 Layernorm 在每个图卷积模块之后应用。 混合跳传播层的深度设置为2。 来自混合跳传播层的保留率设置为。 图学习层激活函数的饱和率设置为。 节点嵌入的维度为 40。 其他超参数根据不同的任务报告。
A.3.1。 单步预测
我们使用 5 个图卷积模块和 5 个时间卷积模块,膨胀指数因子为 2。 起始卷积有1个输入通道和16个输出通道。 图卷积模块和时间卷积模块都有 16 个输出通道。 跳过连接层都有 32 个输出通道。 第一层输出模块有64个输出通道,第二层输出模块有1个输出通道。 训练epoch数为30。 对于交通、太阳能和电力,每个节点的邻居数量为 20。 对于 Exchange-Rate,每个节点的邻居数量为 8。 批量大小设置为 4。 对于 MTGNN+采样模型,我们将图的节点随机分为三个分区,批量大小为 16。 继(Lai等人,2018)之后,我们使用RSE和CORR作为评估指标。
A.3.2。 多步预测
我们使用 3 个图卷积模块和 3 个时间卷积模块,膨胀指数因子为 1。 起始卷积有2个输入通道和32个输出通道。 图卷积模块和时间卷积模块都有32个输出通道。 跳过连接层都有 64 个输出通道。 输出模块的第一层有128个输出通道,第二层有12个输出通道。 每个节点的邻居数量为 20。 训练epoch数为100。 批量大小设置为 64。 继(Li等人,2018)之后,我们使用MAE、RMSE和MAPE作为评估指标。
A.4。 参数研究
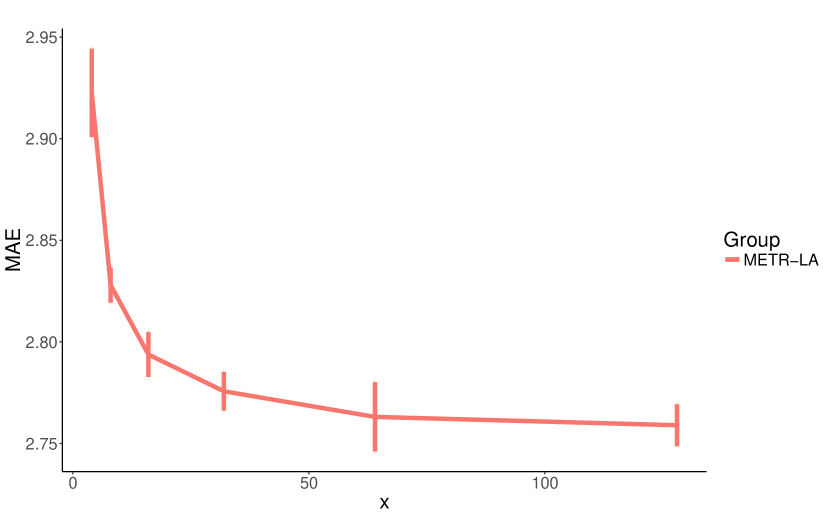
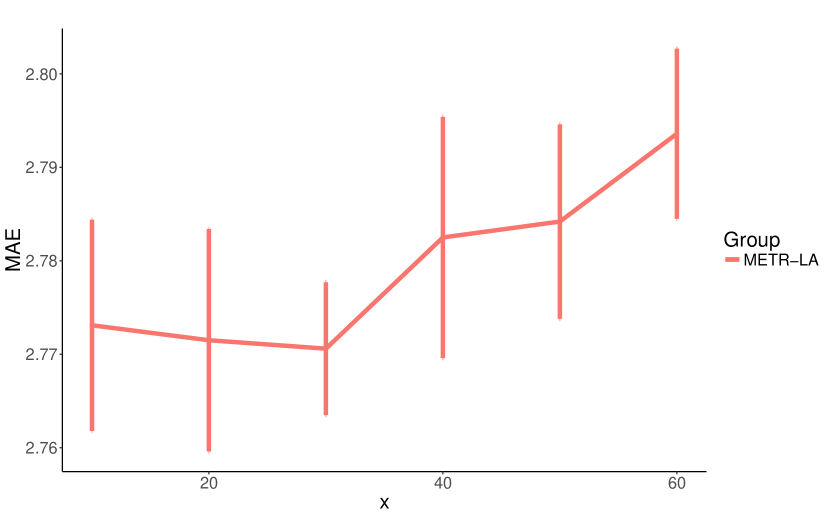
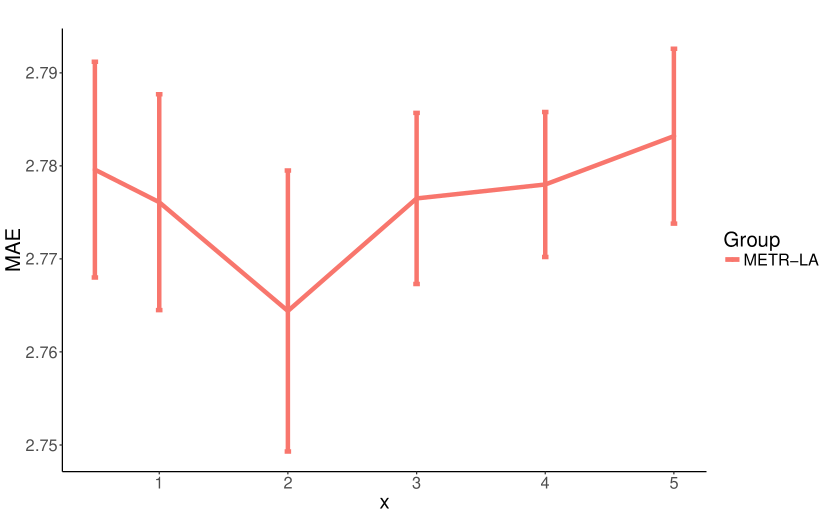
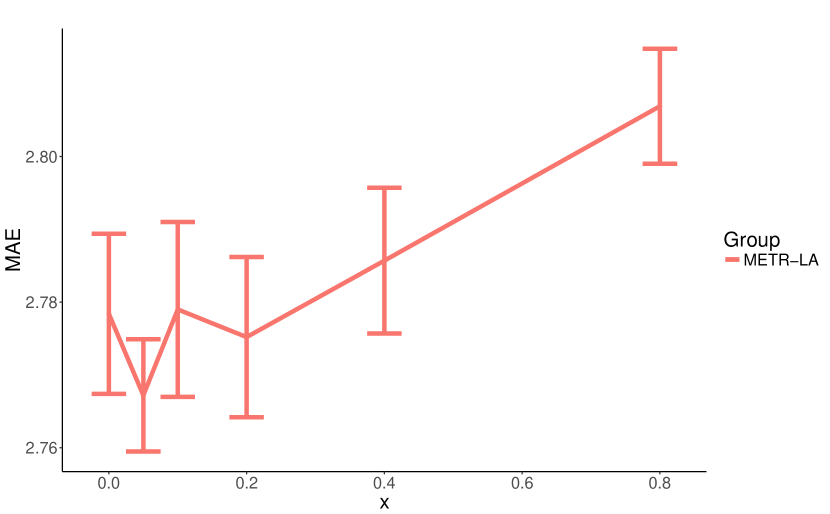
我们对影响 MTGNN 模型复杂度的八个核心超参数进行了参数研究。 我们将这些超参数列出如下:层数,时间卷积模块的数量,范围从 1 到 6。 滤波器数量,即时间卷积模块和图卷积模块的输出通道数,范围为 4 到 128。 邻居数量,即公式5中的参数,范围为10到60。 饱和率,即公式1、2和3中的参数,范围为0.5至5。 混合跳传播层的保留率,即公式7中的参数,范围为0到0.8。 混合跳传播层的深度,即公式8中的参数,范围为1到6。
我们将每个实验重复 10 次,每次 50 个 epoch,并报告验证集上 10 次运行的 MAE 平均值和标准差。 我们在每个实验中更改正在研究的参数并固定其他参数。 图7显示了我们参数研究的实验结果。 如图7(a)和图7(b)所示,增加层数和滤波器数量增强了模型的表达能力,同时减少了MAE损失。 图7(c)显示少量邻居可以提供更好的结果。 这可能是因为一个节点可能只依赖于有限数量的其他节点,而增加其邻域只会给模型带来噪音。 模型性能对饱和率不敏感,如图7(d)所示。 然而,大的饱和率可能会将图学习层方法生成的邻接矩阵的值强加为 0 或 1。 如图7(e)所示,高保留率会显着降低模型性能。 我们认为这是因为默认情况下混合跳传播层的传播深度设置为,因此,保留高比例的根信息会限制节点探索其邻域。 图7(f)表明,用2或3步传播节点信息就足够了。 随着传播深度的增加,所提出的混合跳传播层不会遇到信息聚合引起的过度平滑问题。 当传播深度等于6时,其平均MAE最低,但变化较大。