PolyGen:3D 网格的自回归生成模型
摘要
多边形网格是 3D 几何的有效表示,在计算机图形、机器人和游戏开发中至关重要。 现有的基于学习的方法避免了使用 3D 网格的挑战,而是使用与神经架构和训练方法更兼容的替代对象表示。 我们提出了一种直接对网格进行建模的方法,使用基于 Transformer 的架构顺序预测网格顶点和面。 我们的模型可以以一系列输入为条件,包括对象类、体素和图像,并且由于该模型是概率性的,因此它可以生成捕获模糊场景中的不确定性的样本。 我们证明该模型能够生成高质量、可用的网格,并为网格建模任务建立对数似然基准。 我们还针对替代方法评估了表面重建指标上的条件模型,并展示了有竞争力的性能,尽管没有直接在此任务上进行训练。
1简介
多边形网格是 3D 几何的有效表示,广泛用于计算机图形学中来表示虚拟对象和场景。 自动网格生成可以更快速地创建填充游戏、电影和虚拟现实中虚拟世界的 3D 对象。 此外,网格是计算机视觉和机器人技术中的有用输出,可实现 3D 空间中的规划和交互。
现有的 3D 对象合成方法依赖于模板模型(Kalogerakis 等人,2012;Chaudhuri 等人,2011)或参数形状族(Smelik 等人,2014)的重组和变形)。 由于网格元素无序且面结构离散,因此对于深度学习架构来说,网格的使用具有挑战性。 相反,最近的深度学习方法使用对象形状的替代表示来生成 3D 对象 - 体素 (Choy 等人,2016)、点云、占用函数 (Mescheder 等人,2019)(Mescheder 等人,2019) t1> 和曲面 (Groueix 等人, 2018) - 然而网格重建被保留为后处理步骤,并且可能会产生不同质量的结果。 这与人类创建网格的方法形成鲜明对比,在人类创建网格的方法中,网格本身是中心对象,并直接使用 3D 建模软件创建。 人类创建的网格是紧凑的,并重用几何基元来有效地表示现实世界的对象。
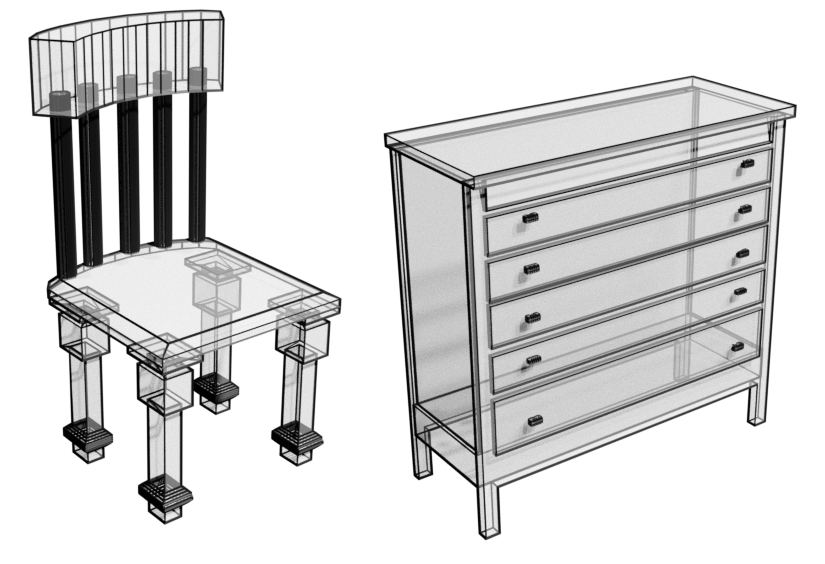
神经自回归模型已表现出对复杂、高维数据进行建模的卓越能力,包括图像(van den Oord 等人,2016c)、文本(Radford 等人,2019)和原始音频波形(van den Oord 等人,2016a)。 受这些方法的启发,我们提出了 PolyGen,一种网格的神经生成模型,它自回归估计网格顶点和面的联合分布。
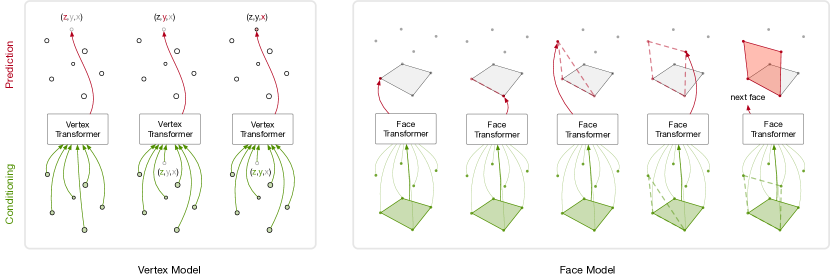
PolyGen 由两部分组成:顶点模型,无条件地对网格顶点进行建模;面模型,对输入顶点条件下的网格面进行建模。 这两个组件都利用了 Transformer 架构(Vaswani 等人,2017),该架构可以有效捕获网格数据中存在的远程依赖关系。 顶点模型使用掩码 Transformer 解码器来表达顶点序列上的分布。 对于面部模型,我们将 Transformers 与指针网络(Vinyals等人,2015)结合起来,以表达可变长度顶点序列上的分布。
我们使用对数似然和预测准确性作为指标来评估 PolyGen 的建模能力,并将生成样本的统计数据与真实数据进行比较。 我们演示了以对象类、图像和体素作为输入的条件网格生成,并与现有的网格生成方法进行比较。 总的来说,我们发现我们的模型能够创建可直接在图形应用程序中使用的多样化且逼真的几何图形。
2 PolyGen
我们的目标是估计网格 上的分布,从中我们可以生成新的示例。 网格是 3D 顶点 和多边形面 的集合,定义 3D 对象的形状。 我们将建模任务分为两部分:i) 生成网格顶点 ,ii) 生成给定顶点的网格面 。 使用链式法则我们有:
| (1) | ||||
| (2) |
我们使用单独的顶点和面模型,它们都是自回归的;将顶点和面的联合分布分解为条件分布的乘积。 为了生成网格,我们首先对顶点模型进行采样,然后将生成的顶点作为输入传递给面模型,从中我们对面进行采样(参见图 2)。 此外,我们还可以选择在上下文 上条件化顶点和面模型,例如网格类标识、输入图像或体素化形状。

2.1 边形网格
3D 网格通常由三角形集合组成,但许多网格可以使用可变大小的多边形来更紧凑地表示。 具有可变长度多边形的网格称为边形网格:
| (3) | ||||
| (4) |
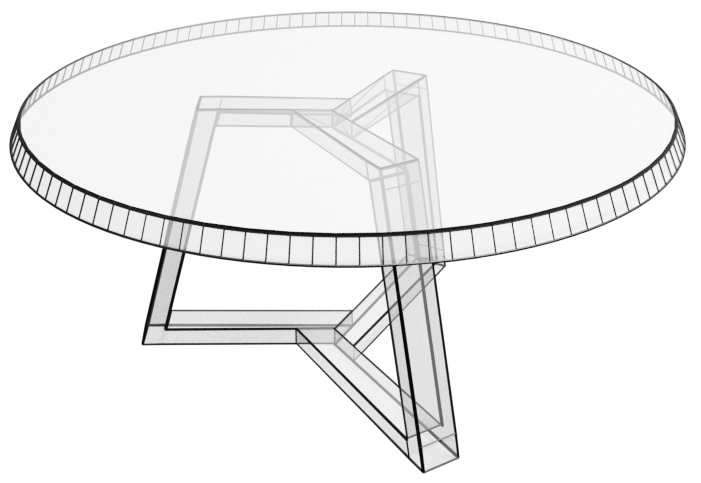
其中 是第 多边形中的面数,并且对于不同的面可能会有所不同。 这意味着大的平坦表面可以用单个多边形表示,例如图3中圆桌的顶部。 在这项工作中,我们选择使用 边形而不是三角形来表示网格。 这有两个主要优点:首先是它减小了网格的大小,因为可以用减少的面数来指定平坦表面。 其次,大多边形可以通过多种方式进行三角剖分,并且这些三角剖分在示例之间可能不一致。 通过对 边形进行建模,我们排除了这种三角测量的可变性。
此方法需要注意的是,当 大于 3 时, 边形不会唯一定义 3D 表面,除非它引用的顶点是平面的。 当渲染非平面 边形时,多边形首先通过例如将顶点投影到平面(Held,2001),如果多边形高度非平面,这可能会导致伪影。 在实践中,我们发现我们的模型生成的大多数 边形要么是平面的,要么接近平面的,因此这是一个小问题。 三角形网格是 边形网格的子集,因此如果需要,可以使用 PolyGen 对它们进行建模。
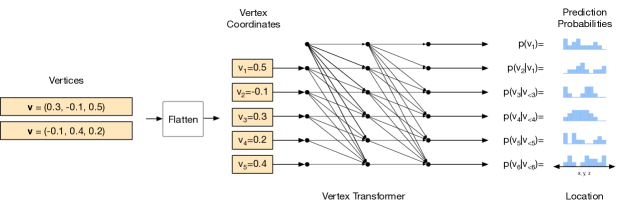
2.2 顶点模型
顶点模型的目标是表达顶点序列上的分布。 我们通过 坐标将顶点从最低到最高排序,其中 表示垂直轴。 如果存在具有相同 值的顶点,我们将按 值排序,然后按 值排序。 重新排序后,我们通过连接 坐标的元组获得展平的序列。 网格的顶点数量是可变的,因此我们使用停止词符 来指示顶点序列的结束。 我们将展平的顶点序列 及其元素表示为 。 我们将 上的联合分布分解为一系列条件顶点分布的乘积:
| (5) |
我们使用自回归网络对该分布进行建模,该网络在每一步输出下一个顶点坐标的预测分布的参数。 该预测分布是在顶点坐标值以及停止词符 上定义的。该模型经过训练,可最大化观测数据相对于模型参数 的对数概率。
架构。 顶点模型架构的基础是 Transformer 解码器(Vaswani 等人,2017),这是一个简单而富有表现力的模型,在一系列领域中展示了显着的建模能力(Child 等人, 2019;黄等人,2019;帕尔玛等人,2018)。 网格顶点具有很强的非局部依赖性,具有对象对称性和重复部分,并且 Transformer 聚合来自输入任何部分的信息的能力使其能够捕获这些依赖性。 我们使用改进的 Transformer 变体,在残差路径内进行层归一化,如 (Child 等人, 2019; Parisotto 等人, 2019) 所示。 有关顶点模型的说明,请参阅附录中的图 12,有关 Transformer 块的完整描述,请参阅附录 C。
(c) 灯
 (d) 沙发
(d) 沙发
 (e) 钟
(e) 钟
 (f) 内阁
(f) 内阁
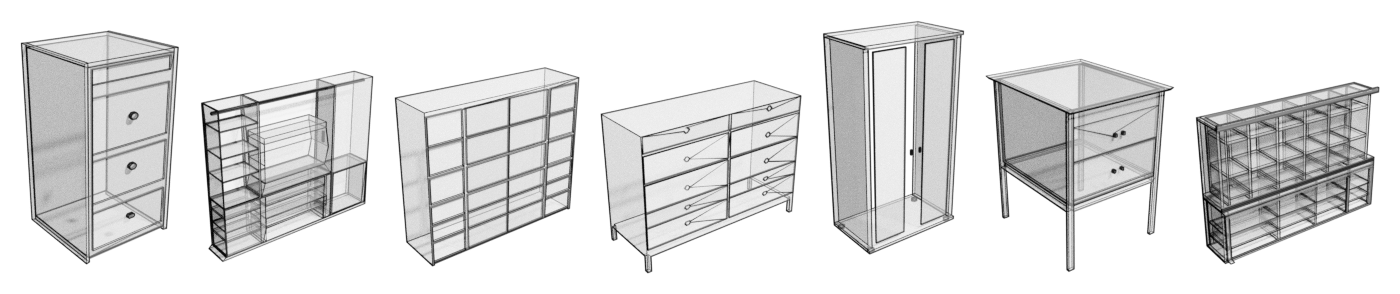 (g) 罐
(g) 罐
 (h) 长椅
(h) 长椅
 (一) 监视器
(一) 监视器
 (j) 椅子
(j) 椅子
 (k) 桌子
(k) 桌子

顶点作为离散变量。 我们对网格顶点应用 8 位均匀量化。 当落入同一容器的附近顶点被合并时,这会减小网格的大小。 我们使用分类分布对量化顶点值进行建模,并在每一步输出分布的对数。 该方法已用于对 PixelCNN (van den Oord 等人, 2016c) 和 WaveNet (van den Oord 等人, 2016a) 中的离散连续信号进行建模,并且具有能够表达不受形状限制的分布的好处。 网格顶点具有很强的对称性和复杂的依赖性,因此表达任意分布的能力非常重要。 我们发现 8 位量化是网格保真度和网格大小之间的良好权衡。 然而,应该注意的是,14 位或更高位是有损网格压缩的典型特征,在未来的工作中,我们希望将我们的方法扩展到更高分辨率的网格。
嵌入。 我们发现使用(Child等人,2019)中提出的学习位置和值嵌入方法的方法效果很好。 我们对每个输入词符使用三个嵌入: 坐标嵌入,指示输入词符是否是 、 或 坐标,位置嵌入,表示词符属于序列中的哪个顶点;值嵌入,表示词符的量化坐标值。 我们在每种情况下都使用学习到的离散嵌入。
提高效率。 使用 Transformer 对序列数据进行建模的缺点之一是,由于注意力操作的二次性质,它们会产生大量的计算成本。 当将我们的模型扩展到更大的网格时,这会带来问题。 为了解决这个问题,我们受(Salimans等人,2017)的启发,对模型进行了一些修改。 所有这些方法都通过将序列分块为顶点坐标的三元组并立即处理它们来减轻计算负担。 第一个变体使用离散物流的混合来对整个 3D 顶点进行建模。 第二个用基于 MADE 的解码器替换混合物(Germain 等人,2015)。 最后,我们提出使用 Transformer 解码器但依赖于不同顶点嵌入方案的变体。 这些修改在附录 E 中有更详细的描述。
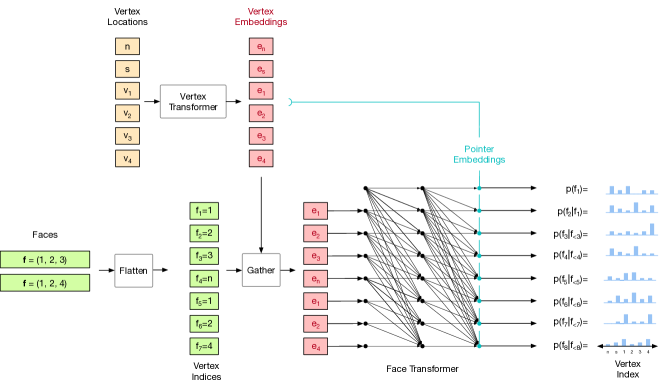
2.3人脸模型
面模型表示以网格顶点为条件的一系列网格面的分布。 我们按最低顶点索引对面进行排序,然后按下一个最低顶点索引,依此类推,其中顶点按 2.2 节中所述从最低到最高排序。 在一个面内,我们循环排列面索引,以便最低的索引位于第一个。 与顶点序列一样,我们连接面 以形成扁平序列,并带有最终的停止词符。 我们为这个扁平序列编写 ,其中包含元素 。
| (6) |
与顶点模型一样,我们在每一步输出 值的分布,并通过在训练集上最大化 的对数似然来进行训练。 分布是在 上定义的分类,其中 是输入顶点的数量,我们还为端面 和停止 标记。
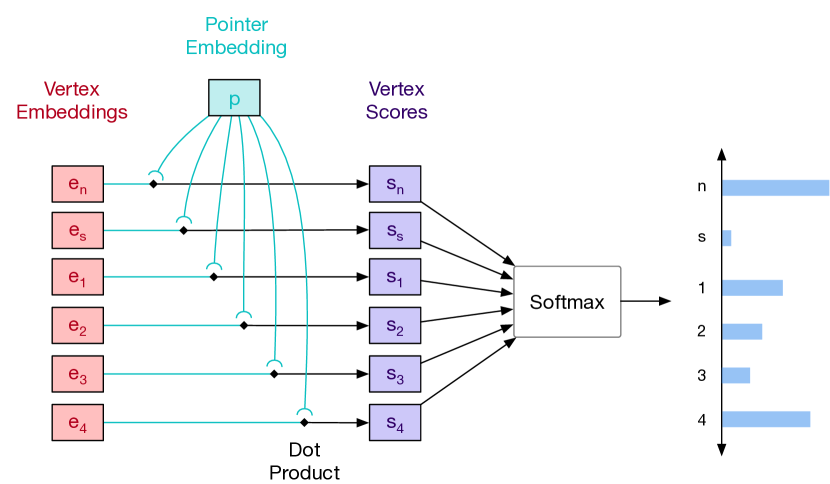
网状指针网络。 目标分布 是在输入顶点集的索引上定义的,这提出了该集的大小因示例而异的挑战。 指针网络(Vinyals等人,2015)针对这个问题提出了一个优雅的解决方案;首先使用编码器嵌入输入集,然后在每一步,自回归网络输出一个指针向量,该指针向量通过点积与输入嵌入进行比较。 然后使用 softmax 对所得分数进行归一化,以形成输入集上的有效分布。
在我们的例子中,我们使用 Transformer 编码器 获取输入顶点的上下文嵌入 。与原始指针网络使用的 LSTM 相比,这具有双向信息聚合的优势。 我们将 new-face 和 stop 标记与顶点联合嵌入,以获得总共 个输入嵌入。 Transformer 解码器 对面序列进行操作,并在每一步输出指针 。 目标分布可由下式获得
| (7) | ||||
| (8) | ||||
| (9) |
指针机构见图5,全脸模型见图13。 解码器 是一个掩码 Transformer 解码器,可对嵌入的面部标记序列进行操作。 它以两种方式对输入顶点进行调节,一种是通过下一节中解释的动态面嵌入,另一种是通过对顶点嵌入序列的交叉关注。
嵌入。 与顶点模型一样,我们使用学习的位置和值嵌入。 我们将词符的位置分解为它所属的面的索引,以及词符在面中的位置,对两者使用单独学习的嵌入。 对于值嵌入,我们遵循指针网络的方法,并通过索引到顶点编码器输出的上下文顶点嵌入来简单地嵌入顶点索引。
2.4 屏蔽无效预测
对于顶点和面模型,每一步只有某些预测有效。 例如,坐标必须单调递增,停止词符只能放在坐标之后。 类似地,网格面不能有重复的索引,并且每个顶点索引必须至少由一个面引用。 在评估模型时,我们屏蔽预测的逻辑,以确保模型只能做出有效的预测。 这对模型的对数似然分数具有非负影响,因为它将无效区域中的概率质量重新分配给有效区域中的值(表 1)。 令人惊讶的是,我们发现训练过程中的掩蔽会在一定程度上降低性能,因此我们总是在不进行掩蔽的情况下进行训练。 有关所用掩码的完整说明,请参阅附录 F。





| Bits per vertex | Accuracy | |||
| Model | Vertices | Faces | Vertices | Faces |
| Uniform | 24.08 | 39.73 | 0.004 | 0.002 |
| Valid predictions | 21.41 | 25.79 | 0.009 | 0.038 |
| Draco* (Google, ) | Total: 27.68 | - | - | |
| PolyGen | 2.46 | 1.79 | 0.851 | 0.900 |
| - valid predictions | 2.47 | 1.82 | 0.851 | 0.900 |
| - discr. embed. (V) | 2.56 | - | 0.844 | - |
| - data augmentation | 3.39 | 2.52 | 0.803 | 0.868 |
| + cross attention (F) | - | 1.87 | - | 0.899 |
| Model | Bits per vertex | Accuracy | Steps per sec |
|---|---|---|---|
| Mixture | 3.01 | - | 7.19 |
| MADE decoder | 2.65 | 0.844 | 7.02 |
| Tr. decoder | 2.50 | 0.851 | 4.07 |
| + Tr. embed. | 2.48 | 0.851 | 4.60 |
| Base model | 2.46 | 0.851 | 2.98 |
2.5 条件网格生成
我们可以通过调节上下文来指导网格顶点和面的生成。 例如,我们可以输出与给定对象类一致的顶点,或者推断与输入图像关联的网格。 扩展顶点和面模型以适应上下文 是很简单的。 根据输入的领域,我们以两种方式合并上下文。 对于类身份等全局特征,我们将学习到的类嵌入投影到一个向量中,该向量被添加到每个块中自注意力层之后的中间 Transformer 表示中。 对于图像或体素等高维输入,我们联合训练一个适合领域的编码器,输出一系列上下文嵌入。 然后,Transformer 解码器对嵌入序列执行交叉注意力,就像原始机器翻译 Transformer 模型一样。
对于图像输入,我们使用由一系列下采样残差块组成的编码器。 我们使用预激活残差块 (He 等人,2016),并使用步长为 2 的卷积进行三次下采样,将大小为 的输入图像取为大小为 的特征图,其中 是模型的嵌入维度。 对于体素输入,我们使用类似的编码器,但具有 3D 卷积,将形状 的输入转换为形状 的空间嵌入。 对于这两种输入类型,我们在展平空间维度之前将坐标嵌入添加到特征图中。 有关更多架构详细信息,请参阅附录 C。
3实验
我们的主要评估指标是对数似然,我们发现它与样本质量密切相关。 我们还报告生成的网格的汇总统计数据,并将我们的模型与使用图像中的倒角距离和体素条件设置的现有方法进行比较。
3.1培训详情
我们在 ShapeNet Core V2 数据集 (Chang 等人, 2015) 上训练所有模型,将其细分为 训练、 验证和 测试分割。 训练集按照 3.2 节中的描述进行了扩充。 为了减少长序列的内存需求,我们在预处理后过滤掉具有超过 800 个顶点或超过 2800 个面索引的网格。 我们分别训练顶点和面模型的 和 权重更新,每次训练运行使用四个 V100 GPU,总批量大小为 16。 我们使用梯度裁剪范数为 1.0 的 Adam 优化器,并从最大学习率 执行余弦退火,线性预热期为 5000 步。 我们对所有模型使用 0.2 的退出率。
3.2 数据增强和渲染
一般来说,由于 ShapeNet 数据集相对较小,我们观察到明显的过度拟合,而过滤掉大网格的需要又加剧了这种情况。 为了减少这种影响,我们通过在每个轴上独立缩放顶点、为每个轴使用随机分段线性扭曲以及改变用于创建 -gon 的抽取角度来增强输入网格网格。 对于每个输入网格,我们创建 50 个增强版本,然后对其进行量化(第 2.2 节)以供训练期间使用。 我们发现增强对于获得良好的性能是必要的(表1)。 有关增强和参数设置的完整详细信息,请参阅附录 A。
渲染。 为了训练图像条件模型,我们使用 Blender (Blender 在线社区,) 创建处理后的 ShapeNet 网格的渲染。 对于每个增强网格以及每个验证和测试集网格,我们使用随机选择的照明、相机和网格材质设置以 分辨率创建渲染。 欲了解更多详情,请参阅附录 B。
3.3 无条件建模性能
我们比较在不同条件下训练的无条件模型。 作为评估指标,我们报告模型获得的负对数似然(以每个顶点的位数为单位)以及下一步预测的准确性。 对于顶点模型,这是下一个顶点坐标预测的准确性,对于面模型,这是下一个顶点索引预测的准确性。 特别是,我们比较了屏蔽无效预测(第 2.4 节)、在顶点模型中使用离散而不是连续坐标嵌入(第 5 节)、使用数据增强的效果(第 3.2 节),最后是在面部模型中使用交叉注意力。 除非另有说明,我们使用大小为 256 的嵌入、大小为 1024 的全连接层以及分别用于顶点和面模型的 18 和 12 个 Transformer 块。 由于没有直接对网格顶点和面进行建模的现有方法,因此我们报告了向整个数据域分配均匀概率的模型以及在有效预测区域上均匀的模型获得的分数。 我们还报告了由网格压缩库 Draco (Google,) 获得的压缩率。 有关 Draco 压缩设置的详细信息,请参阅附录 G。
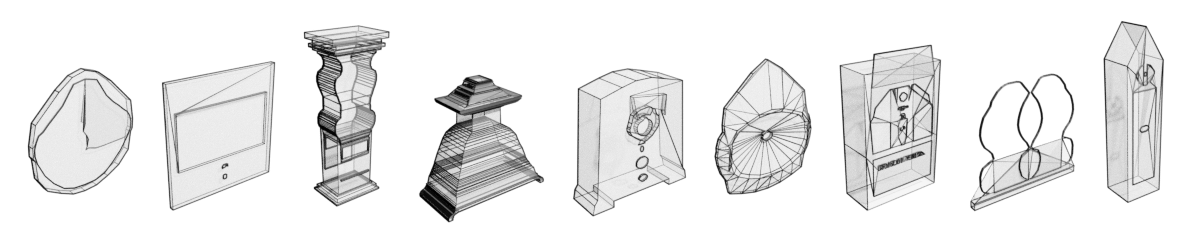
表1显示了各种模型获得的结果。 我们发现我们的模型比统一基线和 Draco 基线实现了显着更好的建模性能,这说明了学习的预测模型可以实现的收益。 我们发现,将模型预测限制在有效值范围内会导致建模性能略有改善,这表明该模型可以有效地将低概率分配给无效区域。 对顶点坐标使用离散嵌入而不是连续嵌入提供了显着的改进,将每顶点位数从 2.56 提高到 2.46。 令人惊讶的是,在人脸模型中使用交叉注意力会损害性能,我们将其归因于过度拟合。 数据增强对性能有很大影响,在没有增强的情况下训练的模型平均每个顶点损失 1.64 位。 总体而言,我们的最佳模型实现了每个顶点 4.26 位的对数似然得分,以及顶点和面模型分别的 和 预测精度。 附录中的图14显示了来自最佳性能模型的随机无条件样本。
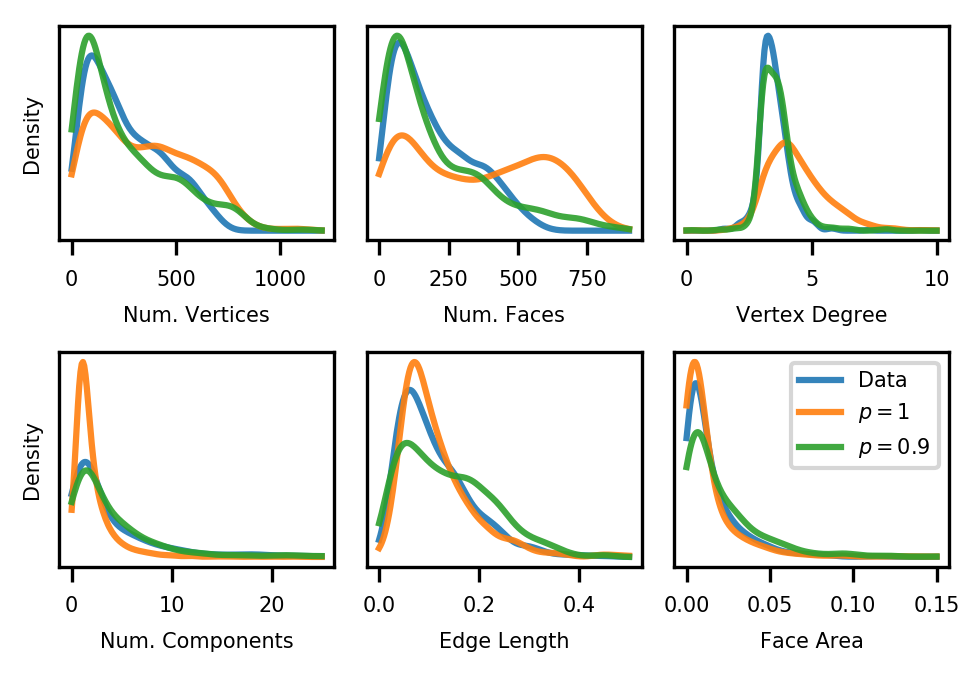
3.4无条件模型样本统计
我们将模型中样本的某些网格摘要的分布与 ShapeNet 测试集进行比较。 如果我们的模型与真实数据分布紧密匹配,那么我们期望这些摘要具有相似的分布。 我们从最好的无条件模型中抽取 1055 个样本,并丢弃在 1200 个顶点或 800 个面内不能产生停止词符的样本。 我们使用核采样(Holtzman等人,2019),我们发现它可以有效保持样本多样性,同时减少降解样本的存在。 核心采样通过从占概率质量 top- 的最小标记子集进行采样,有助于减少采样退化。
图 7 显示了来自 PolyGen 的样本的多个网格摘要的分布以及真实数据分布。 我们特别显示:采样网格和真实网格的顶点数量、面数量、节点度、平均面面积和平均边长度。 尽管这些是 3D 网格的粗略描述,但我们发现模型的样本的每个网格统计数据具有相似的分布。 我们观察到,使用 进行核采样有助于将模型分布与许多统计数据的真实数据对齐。 图 8 显示了我们的模型生成的示例 3D 网格与通过后处理占用函数 (Mescheder 等人,2019) 获得的网格进行了比较。 我们注意到,我们的网格的统计数据在很大程度上类似于人类创建的网格。
| Bits per vertex | Accuracy | ||||
|---|---|---|---|---|---|
| Context | Vertices | Faces | Total | Vertices | Faces |
| None | 2.46 | 1.79 | 4.26 | 0.851 | 0.900 |
| Class | 2.43 | 1.81 | 4.24 | 0.853 | 0.899 |
| Image | 2.30 | 1.81 | 4.11 | 0.857 | 0.900 |
| + pooling | 2.35 | 1.78 | 4.13 | 0.856 | 0.900 |
| Voxels | 2.19 | 1.82 | 4.01 | 0.859 | 0.900 |
| + pooling | 2.28 | 1.79 | 4.07 | 0.856 | 0.900 |


3.5条件建模性能
我们使用三种条件训练顶点和面部模型:类标签、图像和体素。 我们使用与最佳无条件模型相同的设置:在人脸模型中没有交叉注意的离散顶点嵌入。 与无条件模型一样,我们使用 18 层作为顶点模型,使用 12 层作为面模型。 图1和4显示了类条件示例。 图6和10分别显示了图像和体素条件模型的样本。 请注意,当我们在 ShapeNet 数据集上进行训练时,我们会显示地面实况网格和从 TurboSquid 在线对象存储库收集的精选代表性网格的输入。
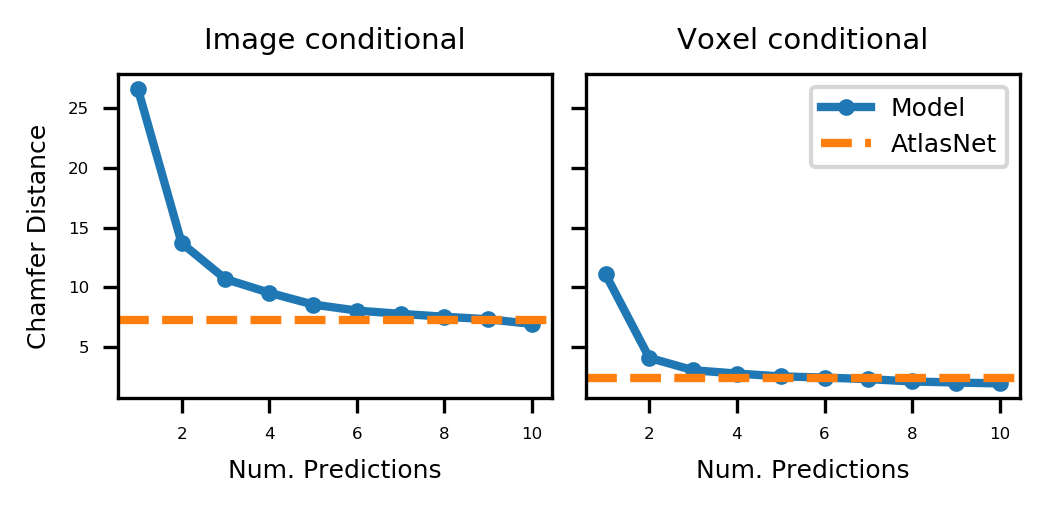





表 3 显示了调节对每顶点位数和准确性方面预测性能的影响。 我们发现,对于顶点模型,体素调节提供了最大的改进,其次是图像,然后是类标签。 这证实了我们的期望,因为体素明确地表征了粗糙形状,而图像可能会根据对象姿势和照明而变得模糊。 然而,额外的上下文并不会导致面部模型的改进,所有条件面部模型的表现都比最佳无条件模型稍差。 这可能是因为网格面在很大程度上是由输入顶点决定的,而条件上下文提供的附加信息相对较少。 在预测准确性方面,我们看到了类似的效果,顶点模型的准确性随着更丰富的上下文而提高,但面部模型却没有。 我们注意到,由于顶点和面分布的固有熵,准确度上限小于 ,因此我们预计随着模型接近此上限,增益会递减。
对于图像和体素条件模型,我们还与将全局平均池化应用于输入编码器的输出的架构进行比较。 我们观察到,以这种方式进行池化会对顶点模型的性能产生负面影响,但对面部模型的性能有很小的积极影响。
3.6网格重建
我们还评估了网格重建时的图像和体素条件模型,其中我们使用对称倒角距离作为重建度量。 对称倒角距离是两个点集 和 之间的距离度量。 它定义为:
| (10) |
对于测试集中的每个示例,我们从条件模型中抽取样本。 我们在采样网格和目标网格上均匀采样 2500 个点,并计算相应的倒角距离。 我们将我们的模型与 AtlasNet (Groueix 等人, 2018) 进行比较,AtlasNet 是一个条件模型,它使用大量使用深度网络的 Transformer 补丁来定义网格表面。 AtlasNet 输出点云,并经过训练以最小化到基于图像或点云输入的目标点云的倒角距离。 与其他方法相比,AtlasNet 实现了良好的网格重建性能,因此我们将其视为强大的基线。 我们在图像和体素条件设置中训练 AtlasNets 模型,这些模型适合使用与我们的模型相同的图像和体素编码器。 欲了解更多详情,请参阅附录 D。
图9显示了网格重建结果。 我们发现,在进行单个预测时,我们的模型的表现比 AtlasNet 差。 这并不意外,因为 AtlasNet 直接优化评估指标,而我们的模型则不然。 当允许进行 10 次预测时,我们的模型取得了比 AtlasNet 稍好的性能。 总的来说,我们发现虽然我们的模型并不总是产生良好的网格重建,但它通常在 10 个样本内产生非常好的重建,这对于许多实际应用来说可能足够了。
4相关工作
3D 对象的生成模型存在多种形式,包括有序(Nash & Williams,2017)和无序(Li 等人,2019;Yang 等人,2019)点云、体素(Choy 等人, 2016; Wu 等人, 2016; Tatarchenko 等人, 2017; Rezende 等人, 2016)。 最近,函数表示的使用取得了重大进展,例如带符号距离函数 (Park 等人,2019) 和其他隐式函数 (Mescheder 等人,2019)。 显式生成 3D 网格的方法示例相对较少。 此类作品主要使用参数化的可变形网格(Groueix等人,2018),或者通过网格面片的集合形成网格。 我们的方法的独特之处在于我们直接对人们创建的网格数据进行建模,而不是替代表示或参数化。 此外,我们的模型是概率性的,这意味着我们可以产生不同的输出,并以有原则的方式响应模糊的输入。
PolyGen 的顶点模型类似于 PointGrow (Sun 等人, 2020),它使用自回归分解来建模 3D 点云,使用基于自注意力的架构输出离散坐标分布。 PointGrow 在固定长度的点云而不是可变的顶点序列上运行,并使用定制的自注意力架构,与其他领域的现代自回归模型相比,该架构相对较浅。 相比之下,我们使用最先进的深度架构以及顶点和面模型,使我们能够生成高质量的 3D 网格。
这项工作借鉴了为自然语言处理中的序列建模而开发的架构。 其中包括序列到序列训练范式(Sutskever 等人,2014)、Transformer 架构(Vaswani 等人,2017;Child 等人,2019;Parisotto 等人,2019) 和指针网络(Vinyals 等人,2015)。 此外,我们的工作受到原始数据顺序模型的启发,例如 WaveNet (van den Oord 等人, 2016a) PixelRNN 及其变体 (van den Oord 等人, 2016b; Menick & Kalchbrenner ,2019),以及音乐变形金刚(黄等人,2019)。
我们的工作还与 Polygon-RNN (Castrejón 等人, 2017; Acuna 等人, 2018) 相关,这是一种使用多边形在计算机视觉中进行高效分割的方法。 Polygon-RNN 获取输入图像并自回归输出一系列隐式定义分割区域的 坐标。 相比之下,PolyGen 在 3D 空间中运行,并明确定义了多个多边形的连接性。
最后,我们的工作与图结构化数据的生成模型相关,例如 GraphRNN (You 等人, 2018) 和 GRAN (Liao 等人, 2019),因为网格可以被认为是属性图。 这些工作重点是对图连接性进行建模,而不是对图属性进行建模,而我们对节点属性(顶点位置)进行建模,并将这些属性合并到我们的连接性模型中。
5结论
在这项工作中,我们展示了 PolyGen,一种 3D 网格的深度生成模型。 我们将网格生成问题提出为自回归序列建模,并结合 Transformer 和指针网络的优点,以便灵活地对可变长度网格序列进行建模。 PolyGen 能够生成连贯且多样化的网格样本,我们相信它将开启计算机视觉、机器人和 3D 内容创建领域的一系列应用。
致谢
作者感谢 Dan Rosenbaum、Sander Dieleman、Yujia Li 和 Craig Donner 进行了有益的讨论·
参考
- Acuna et al. (2018) Acuna, D., Ling, H., Kar, A., and Fidler, S. Efficient interactive annotation of segmentation datasets with polygon-rnn++. In CVPR, pp. 859–868. IEEE Computer Society, 2018.
- (2) Blender Online Community. Blender - a 3d modelling and rendering package. URL http://www.blender.org.
- Castrejón et al. (2017) Castrejón, L., Kundu, K., Urtasun, R., and Fidler, S. Annotating object instances with a polygon-rnn. In CVPR, pp. 4485–4493. IEEE Computer Society, 2017.
- Chang et al. (2015) Chang, A. X., Funkhouser, T., Guibas, L., Hanrahan, P., Huang, Q., Li, Z., Savarese, S., Savva, M., Song, S., Su, H., Xiao, J., Yi, L., and Yu, F. ShapeNet: An Information-Rich 3D Model Repository. Technical Report arXiv:1512.03012 [cs.GR], Stanford University — Princeton University — Toyota Technological Institute at Chicago, 2015.
- Chaudhuri et al. (2011) Chaudhuri, S., Kalogerakis, E., Guibas, L. J., and Koltun, V. Probabilistic reasoning for assembly-based 3d modeling. ACM Trans. Graph., 30(4):35, 2011.
- Child et al. (2019) Child, R., Gray, S., Radford, A., and Sutskever, I. Generating long sequences with sparse transformers. CoRR, abs/1904.10509, 2019.
- Choy et al. (2016) Choy, C. B., Xu, D., Gwak, J., Chen, K., and Savarese, S. 3d-r2n2: A unified approach for single and multi-view 3d object reconstruction. In ECCV (8), volume 9912 of Lecture Notes in Computer Science, pp. 628–644. Springer, 2016.
- Germain et al. (2015) Germain, M., Gregor, K., Murray, I., and Larochelle, H. Made: Masked autoencoder for distribution estimation. In ICML, 2015.
- (9) Google. Draco compression library. https://github.com/google/draco. Accessed: 2020-02-04.
- Groueix et al. (2018) Groueix, T., Fisher, M., Kim, V. G., Russell, B. C., and Aubry, M. A papier-mâché approach to learning 3d surface generation. In CVPR, pp. 216–224. IEEE Computer Society, 2018.
- He et al. (2016) He, K., Zhang, X., Ren, S., and Sun, J. Identity mappings in deep residual networks. In ECCV (4), volume 9908 of Lecture Notes in Computer Science, pp. 630–645. Springer, 2016.
- Held (2001) Held, M. FIST: fast industrial-strength triangulation of polygons. Algorithmica, 30(4):563–596, 2001.
- Holtzman et al. (2019) Holtzman, A., Buys, J., Forbes, M., and Choi, Y. The curious case of neural text degeneration. CoRR, abs/1904.09751, 2019.
- Huang et al. (2019) Huang, C. A., Vaswani, A., Uszkoreit, J., Simon, I., Hawthorne, C., Shazeer, N., Dai, A. M., Hoffman, M. D., Dinculescu, M., and Eck, D. Music transformer: Generating music with long-term structure. In ICLR (Poster). OpenReview.net, 2019.
- Kalogerakis et al. (2012) Kalogerakis, E., Chaudhuri, S., Koller, D., and Koltun, V. A probabilistic model for component-based shape synthesis. ACM Trans. Graph., 31(4):55:1–55:11, 2012.
- Li et al. (2019) Li, C., Zaheer, M., Zhang, Y., Póczos, B., and Salakhutdinov, R. Point cloud GAN. In DGS@ICLR. OpenReview.net, 2019.
- Liao et al. (2019) Liao, R., Li, Y., Song, Y., Wang, S., Nash, C., Hamilton, W. L., Duvenaud, D., Urtasun, R., and Zemel, R. S. Efficient graph generation with graph recurrent attention networks. CoRR, abs/1910.00760, 2019.
- Menick & Kalchbrenner (2019) Menick, J. and Kalchbrenner, N. Generating high fidelity images with subscale pixel networks and multidimensional upscaling. In ICLR. OpenReview.net, 2019.
- Mescheder et al. (2019) Mescheder, L. M., Oechsle, M., Niemeyer, M., Nowozin, S., and Geiger, A. Occupancy networks: Learning 3d reconstruction in function space. In CVPR, pp. 4460–4470. Computer Vision Foundation / IEEE, 2019.
- Nash & Williams (2017) Nash, C. and Williams, C. K. I. The shape variational autoencoder: A deep generative model of part-segmented 3d objects. Comput. Graph. Forum, 36(5):1–12, 2017.
- Parisotto et al. (2019) Parisotto, E., Song, H. F., Rae, J. W., Pascanu, R., Gülçehre, Ç., Jayakumar, S. M., Jaderberg, M., Kaufman, R. L., Clark, A., Noury, S., Botvinick, M. M., Heess, N., and Hadsell, R. Stabilizing transformers for reinforcement learning. CoRR, abs/1910.06764, 2019.
- Park et al. (2019) Park, J. J., Florence, P., Straub, J., Newcombe, R. A., and Lovegrove, S. Deepsdf: Learning continuous signed distance functions for shape representation. In CVPR, pp. 165–174. Computer Vision Foundation / IEEE, 2019.
- Parmar et al. (2018) Parmar, N., Vaswani, A., Uszkoreit, J., Kaiser, L., Shazeer, N., Ku, A., and Tran, D. Image transformer. In ICML, volume 80 of Proceedings of Machine Learning Research, pp. 4052–4061. PMLR, 2018.
- Radford et al. (2019) Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog, 1(8):9, 2019. URL https://openai.com/blog/better-language-models/.
- Rezende et al. (2016) Rezende, D. J., Eslami, S. M. A., Mohamed, S., Battaglia, P. W., Jaderberg, M., and Heess, N. Unsupervised learning of 3d structure from images. In NIPS, pp. 4997–5005, 2016.
- Salimans et al. (2017) Salimans, T., Karpathy, A., Chen, X., and Kingma, D. P. Pixelcnn++: Improving the pixelcnn with discretized logistic mixture likelihood and other modifications. arXiv preprint arXiv:1701.05517, 2017.
- Smelik et al. (2014) Smelik, R. M., Tutenel, T., Bidarra, R., and Benes, B. A survey on procedural modelling for virtual worlds. Comput. Graph. Forum, 33(6):31–50, 2014.
- Sun et al. (2020) Sun, Y., Wang, Y., Liu, Z., Siegel, J. E., and Sarma, S. E. Pointgrow: Autoregressively learned point cloud generation with self-attention. In Winter Conference on Applications of Computer Vision, 2020.
- Sutskever et al. (2014) Sutskever, I., Vinyals, O., and Le, Q. V. Sequence to sequence learning with neural networks. In NIPS, pp. 3104–3112, 2014.
- Tatarchenko et al. (2017) Tatarchenko, M., Dosovitskiy, A., and Brox, T. Octree generating networks: Efficient convolutional architectures for high-resolution 3d outputs. In ICCV, pp. 2107–2115. IEEE Computer Society, 2017.
- (31) TurboSquid. TurboSquid. https://www.turbosquid.com/.
- van den Oord et al. (2016a) van den Oord, A., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., Kalchbrenner, N., Senior, A. W., and Kavukcuoglu, K. Wavenet: A generative model for raw audio. In SSW, pp. 125. ISCA, 2016a.
- van den Oord et al. (2016b) van den Oord, A., Kalchbrenner, N., Espeholt, L., Kavukcuoglu, K., Vinyals, O., and Graves, A. Conditional image generation with pixelcnn decoders. In NIPS, pp. 4790–4798, 2016b.
- van den Oord et al. (2016c) van den Oord, A., Kalchbrenner, N., and Kavukcuoglu, K. Pixel recurrent neural networks. In ICML, volume 48 of JMLR Workshop and Conference Proceedings, pp. 1747–1756. JMLR.org, 2016c.
- Vaswani et al. (2017) Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I. Attention is all you need. In NIPS, pp. 5998–6008, 2017.
- Vinyals et al. (2015) Vinyals, O., Fortunato, M., and Jaitly, N. Pointer networks. In NIPS, pp. 2692–2700, 2015.
- Wu et al. (2016) Wu, J., Zhang, C., Xue, T., Freeman, B., and Tenenbaum, J. Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling. In NIPS, pp. 82–90, 2016.
- Yang et al. (2019) Yang, G., Huang, X., Hao, Z., Liu, M., Belongie, S. J., and Hariharan, B. Pointflow: 3d point cloud generation with continuous normalizing flows. CoRR, abs/1906.12320, 2019.
- You et al. (2018) You, J., Ying, R., Ren, X., Hamilton, W. L., and Leskovec, J. Graphrnn: Generating realistic graphs with deep auto-regressive models. In ICML, volume 80 of Proceedings of Machine Learning Research, pp. 5694–5703. PMLR, 2018.
附录

A. 数据增强
对于 ShapeNet 数据集中的每个输入网格,我们创建 50 个在训练期间使用的增强版本(图 11)。 我们首先对网格进行归一化,使网格边界框的长对角线长度等于 1。 然后,我们应用以下增强,在每次增强之后执行相同的边界框标准化。 所有增强和网格渲染都在顶点量化之前执行。
轴缩放。 我们独立地缩放每个轴,在间隔 内均匀采样缩放因子 、 和 。
分段线性扭曲。 我们通过将区间 分为 5 个偶数子区间,从方差为 0.5 的对数正态分布中对每个子区间采样梯度 来定义连续的分段线性扭曲函数,并组成片段。 对于和坐标,我们通过在上反映具有大约0.5的三个子间隔的扭曲函数来确保扭曲函数关于零对称。 这保留了这些轴经常出现的数据的对称性。
平面网格抽取。 我们使用 Blender 的平面抽取修改器 (https://docs.blender.org/manual/en/latest/modeling/modifiers/generate/decimate.html) 来创建 - gon 网格。 这会合并曲面之间的角度大于特定公差的相邻面。 由于不同的抽取级别,不同的容差会导致不同尺寸的网格具有不同的连通性。 我们使用此属性进行数据增强,并从区间 中均匀采样容差度。
B、渲染
我们使用 Blender 创建 3D 网格的渲染图像,以便训练图像条件模型(图 11)。 我们使用 Blender 的 Cycles (https://docs.blender.org/manual/en/latest/render/cycles/index.html) 路径跟踪渲染器,并随机化光照、相机和网格材料。 在所有场景中,我们将输入网格放置在原点,并进行缩放以使边界框在长对角线上为 1m。
照明。 我们使用位于原点上方 1.5m 处的 20W 区域光,矩形大小为 2.5m,并从 范围内均匀采样多个 15W 点光源。 我们独立选择每个点光源的位置,在间隔内均匀采样和坐标,并对采样在区间内统一坐标。
相机。 我们将摄像机定位在距离网格中心 的位置,其中 是在 之间均匀采样的,在 之间采样的仰角位置,在 之间均匀采样的旋转位置。 我们在 中对相机的焦距进行采样。 我们还在 中采样了滤镜大小 (https://docs.blender.org/manual/en/latest/render/cycles/render_settings/film.html),其中添加少量的模糊。
物体材料。 我们发现使用 Blender 时,ShapeNet 材质和纹理在不同示例中的应用不一致,并且在许多情况下根本没有加载纹理。 我们没有使用不一致的纹理,而是随机生成 3D 网格的材质,以产生一定程度的视觉变化。 对于网格中的每个纹理组,我们采样了一种新材质。 材质是通过链接 Blender 节点构建的 (https://docs.blender.org/manual/en/latest/render/shader_nodes/introduction.html#textures)。 特别是,我们使用细节 = 16、比例 的噪声着色器,并从间隔 进行比例绘制。 噪声着色器用作颜色渐变节点的输入,该节点在输入颜色和白色之间进行插值。 然后,颜色渐变节点设置漫反射 BSDF 材质的颜色 https://docs.blender.org/manual/en/latest/render/shader_nodes/shader/diffuse.html,该颜色应用于纹理组中的面。
C. Transformer 块
我们使用改进的 Transformer 变体,将层归一化移至残差路径内,如 (Child 等人, 2019; Parisotto 等人, 2019) 所示。 特别是,我们按如下方式组成 Transformer 块:
| (11) | ||||
| (12) | ||||
| (13) | ||||
| (14) |
其中和是第块中的残差和中间表示,下标FC和MMH表示全连接和屏蔽多路输出分别是头部自注意力层。 我们在 ReLU 激活后立即应用 dropout,因为这在初始实验中表现良好。
D.AtlasNet
我们使用与条件 PolyGen 模型相同的图像和体素编码器(表 4)。 为了与原始方法保持一致,我们将最终的特征图投影到 1024 维,然后应用全局平均池化以获得向量形状表示。 与原始方法一样,解码器是一个 MLP,具有 4 个大小分别为 1024、512、256、128 的全连接层,前三层具有 ReLU 非线性,最终输出层具有 tanh。 解码器采用形状表示以及 2D 点作为输入,并输出 3D 向量。 我们使用 25 个补丁,并使用与 PolyGen 相同的优化设置(第 3 节)进行训练,但针对的是 步骤。
倒角距离。 为了评估 AtlasNet 模型的倒角距离,我们首先通过将 2D 三角网格传递到每个 AtlasNet 补丁模型来生成网格,如 (Groueix 等人,2018) 中所述。 然后我们对生成的 3D 网格上的点进行采样。
E. 替代顶点模型
在本节中,我们将提供有关第 5 节中提到的更高效顶点模型变体的更多详细信息。
在第一个变体中,我们不是按顺序处理 、 和 坐标,而是将它们的嵌入连接在一起并将它们传递给线性投影。 这形成了 层 Transformer 的输入序列,我们称之为 躯干。 在(Salimans等人,2017)之后,我们输出描述完整3D顶点的联合分布的离散物流的混合参数。 该模型的主要好处是现在对短 倍的序列执行自注意力。 这体现在训练时间大大缩短(参见2)。 不幸的是,速度的提高是以性能显着降低为代价的。 这可能是因为底层连续分量不太适合峰值和多模态顶点分布。
在第二个变体中,我们提出了参数分布假设,并使用 MADE 风格的屏蔽 MLP (Germain 等人, 2015) 和 残差块来解码 层躯干转化为三个条件离散分布的序列:
| (19) |
正如预期的那样,此更改提高了测试数据的可能性,同时增加了计算成本。 我们注意到,与基本模型不同,MADE 解码器只能直接访问单个顶点内的坐标分量,并且必须依赖躯干的输出来了解先前生成的顶点的分量。
我们让解码器直接在模型的第三个替代版本中处理所有生成的坐标。 我们用 层 Transformer 替换 MADE 解码器,该 Transformer 以 为条件(这次由 层躯干产生)并在扁平化的模型上运行顶点组件的序列(类似于基本模型)。 调节是通过将 添加到 、 和 的嵌入来完成的。 虽然比 MADE 版本慢,但生成的网络在性能上明显更接近基本模型。
最后,我们使用 层 Transformer 而不是简单的串联来嵌入每个顶点坐标三元组,从而使模型变得更加强大。 具体来说,我们对每个顶点内该 Transformer 的输出进行求和池化。 在此变体中,我们将躯干的深度减少到 层。 这导致测试可能性类似于基本模型的测试可能性。
F. 掩盖无效预测
正如 2.2 节中提到的,我们在评估模型时掩盖了无效的预测。 我们识别数据中存在的许多硬约束,并掩盖违反这些约束的模型预测。 掩蔽概率质量均匀分布在剩余的有效值中。 我们使用以下面具:
顶点模型。
-
•
停止词符只能出现在 坐标之后:
(20) -
•
- 坐标不减:
(21) -
•
如果关联的 坐标相等,则 坐标不递减:
(22) -
•
- 如果关联的 和 - 坐标相等,则坐标会增加:
(23)
脸部模型。
-
•
新的面部标记不能重复:
(24) -
•
新面的第一个顶点索引不小于前一个面的第一个顶点索引:
(25) -
•
面内的顶点索引大于该面中的第一个索引:
(26) -
•
面内的顶点索引是唯一的:
(27) -
•
新面的第一个索引不大于最低的未引用顶点索引:
(28)
G.Draco 压缩设置
我们将表 1 中的模型与 Draco (Google, )(Google 创建的高性能 3D 网格压缩库)进行比较。 我们使用最高的压缩设置,将位置量化为 8 位,并且不进行量化,以便与我们的模型运行的 8 位网格表示进行比较。 请注意,Draco 执行的量化与我们的统一量化不同,因此报告的分数不能直接比较。 相反,它们充当对现有方法获得的压缩程度的大致估计。
H. 无条件样本
图 14 显示了使用 PolyGen 和细胞核采样 ant top- 生成的一批随机无条件样本。 图中亮点。 首先,模型学习主要输出与形状类别一致的对象。 其次,样本中包含很大比例的某些对象类别,包括桌子、椅子和沙发。 这反映了 ShapeNet 数据集的严重类别不平衡,许多类别的代表性不足。 最后,该集合中存在某些故障模式。 其中包括具有断开连接的组件的网格、过早生成停止词符的网格、生成不完整的对象的网格以及不具有可识别为形状类之一的独特形式的网格。
| layer name | output size | layer parameters |
| conv1 | 12812864 | 77, 64, stride 2 |
| conv2_x | 646464 | 33 max pool, stride 2 |
| 1 | ||
| conv3_x | 3232128 | 2 |
| conv4_x | 1616256 | 2 |
| 256256 | spatial flatten (or) | |
| 1256 | average pool |
| layer name | output size | layer parameters |
| embed | 2828288 | embed, 8 |
| conv1 | 14141464 | 777, 64, stride 2 |
| conv2_x | 14141464 | 1 |
| conv3_x | 777256 | 2 |
| 343256 | spatial flatten (or) | |
| 1256 | average pool |
