Rainbow:结合深度强化学习的改进
摘要
深度强化学习社区对DQN算法进行了多项独立改进。 然而,尚不清楚这些扩展中哪些是互补的并且可以有效地组合。 本文研究了 DQN 算法的六种扩展,并实证研究了它们的组合。 我们的实验表明,该组合在 Atari 2600 基准测试中提供了最先进的性能,无论是在数据效率还是最终性能方面。 我们还提供了详细的消融研究的结果,显示了每个组件对整体性能的贡献。
介绍
最近在将强化学习 (RL) 扩展到复杂的顺序决策问题方面取得的许多成功都是由深度 Q 网络算法 (DQN; ? ?,?)。 它将 Q 学习与卷积神经网络和经验回放相结合,使其能够从原始像素中学习如何以人类水平的表现玩许多 Atari 游戏。 从那时起,人们提出了许多扩展来提高其速度或稳定性。
双 DQN(DDQN;? ?) 解决了 Q-learning 的高估偏差 (?),通过解耦引导操作的选择和评估。 优先体验重放 (?) 通过更频繁地重放转换来提高数据效率,从中可以学习更多内容。 决斗网络架构 (?) 通过分别表示状态值和操作优势,有助于跨操作进行泛化。 从多步引导目标中学习 (?; ?),如 A3C 中使用的 (?),改变偏差-方差权衡,并有助于将新观察到的奖励更快地传播到先前访问的状态。 分布 Q 学习 (?) 学习贴现收益的分类分布,而不是估计平均值。 噪声 DQN (?) 使用随机网络层进行探索。 当然,这个清单远非详尽无遗。
这些算法中的每一种都可以单独实现显着的性能改进。 由于它们通过解决完全不同的问题来实现这一点,并且由于它们建立在共享框架之上,因此它们可以合理地结合起来。 在某些情况下已经这样做了:优先DDQN和决斗DDQN都使用双Q学习,并且决斗DDQN还与优先经验回放相结合。 在本文中,我们建议研究一种结合了所有上述成分的药剂。 我们展示了如何整合这些不同的想法,并且它们确实在很大程度上是互补的。 事实上,它们的组合在 Arcade 学习环境中的 57 款 Atari 2600 游戏基准套件上产生了新的最先进结果 (?),无论是在数据效率还是最终性能方面。 最后,我们展示了消融研究的结果,以帮助了解不同成分的贡献。
背景
强化学习解决了代理学习在环境中行动的问题,以便最大化标量奖励信号。 没有向代理提供直接监督,例如,它永远不会直接被告知最佳行动。
代理和环境。
在每个离散时间步,环境为代理提供观察,代理通过选择操作进行响应,然后环境提供下一个奖励,折扣,并说明。 这种交互被形式化为马尔可夫决策过程,或MDP,它是一个元组,其中是一组有限的状态, 是一组有限的动作, 是(随机)转换函数, 是奖励函数, 是折扣因子。 在我们的实验中,MDP 将是 episodic,具有常数 ,除了在episode 终止时 ,但算法以一般形式表示。
在代理端,动作选择由策略 给出,该策略定义每个状态的动作概率分布。 根据时间 遇到的状态 ,我们将折扣回报 定义为代理收集的未来奖励的折扣总和,其中未来的奖励 步由该时间之前的折扣乘积 给出。 代理人的目标是通过找到好的政策来最大化预期的折扣回报。
该策略可以直接学习,也可以构建为一些其他学习量的函数。 在基于价值的强化学习中,当从给定状态、或状态动作开始遵循策略时,代理学习预期折扣回报或价值的估计对,。 从状态--行动值函数推导出新政策的常见方法是,针对行动值采取贪婪的行动。 这对应于以概率 采取具有最高值的操作(贪婪操作),否则以概率 均匀随机操作。 这种策略被用来引入一种探索形式:通过随机选择根据其当前估计是次优的行动,代理可以发现并在适当的时候修正其估计。 主要的限制是很难发现可以延续到遥远未来的替代行动方针;这激发了对更有针对性的探索形式的研究。
深度强化学习和 DQN。
较大的状态和/或动作空间使得独立学习每个状态和动作对的 Q 值估计变得困难。 在深度强化学习中,我们用深度(即多层)神经网络来表示代理的各个组件,例如策略 或值 。 这些网络的参数通过梯度下降进行训练,以最小化一些合适的损失函数。
在 DQN (?) 中,通过使用卷积神经网络来近似给定状态 的动作值(作为输入馈送到网络以原始像素帧堆栈的形式)。 在每个步骤中,基于当前状态,代理会根据操作值贪婪地选择一个操作 ,并将一个转换 () 添加到重播内存缓冲区 ( ?),保存最后一百万次转换。 使用随机梯度下降来优化神经网络的参数,以最小化损失
| (1) |
其中 是从重放内存中随机选取的时间步。 损失的梯度仅反向传播到在线网络的参数中(也用于选择动作);术语表示目标网络的参数;未直接优化的在线网络的定期副本。 使用 RMSprop (?),随机梯度下降的一种变体,基于从经验回放中均匀采样的小批量。 这意味着在上面的损失中,时间索引 将是最后一百万个转换的随机时间索引,而不是当前时间。 使用经验回放和目标网络可以实现相对稳定的 Q 值学习,并在多个 Atari 游戏上实现了超人的表现。
DQN 的扩展
DQN 是一个重要的里程碑,但现在已经知道该算法的一些局限性,并且已经提出了许多扩展。 我们建议选择六个扩展,每个扩展都解决了限制并提高了整体性能。 为了保持选择的大小易于管理,我们选择了一组解决不同问题的扩展(例如,只是众多解决探索中的一个)。
双Q学习。
由于方程 1 中的最大化步骤,传统的 Q 学习会受到高估偏差的影响,这可能会损害学习。 双 Q 学习 (?),通过在为引导目标执行的最大化中解耦从其评估中选择操作来解决这种高估问题。 可以有效地将其与 DQN (?),利用损失
这一变化被证明可以减少 DQN 中存在的有害高估,从而提高性能。
优先重播。
DQN 从重播缓冲区中统一采样。 理想情况下,我们希望更频繁地对那些有很多值得学习的转变进行采样。 作为学习潜力的代理,优先经验重放 (?) 以相对于上次遇到的绝对 TD 误差 的概率 进行转换采样:
其中 是确定分布形状的超参数。 新的转换以最高优先级插入到重放缓冲区中,从而提供对最近转换的偏向。 请注意,随机转变也可能受到青睐,即使几乎没有什么可以了解它们。
决斗网络。
决斗网络是一种专为基于价值的强化学习而设计的神经网络架构。 它具有两个计算流,即价值流和优势流,共享卷积编码器,并由特殊聚合器 (?) 合并。 这对应于以下动作值因式分解:
其中,、 和 分别是共享编码器 、值流 和优势流 的参数; 是它们的连接。
多步骤学习。
Q-learning 累积单个奖励,然后使用下一步的贪婪动作进行引导。 或者,可以使用前视多步目标(?)。 我们将给定状态 的截断 步返回定义为
| (2) |
然后通过最小化替代损失来定义 DQN 的多步变体,
适当调整 的多步目标通常会带来更快的学习速度 (?)。
分布式强化学习。
我们可以学习近似回报分布而不是预期回报。 最近 Bellemare、Dabney 和 Munos (2017) 提出用放置在离散支撑 上的概率质量对此类分布进行建模,其中 是一个带有 的向量原子,由为定义。 在此支持上定义时间 的近似分布 ,每个原子 上的概率质量 ,使得 。 目标是更新,使该分布与实际的回报分布紧密匹配。
要了解概率质量,关键的见解是回报分布满足贝尔曼方程的变体。 对于给定的状态 和操作 ,最优策略 下的回报分布应与通过获取下一个分布所定义的目标分布相匹配状态 和操作 ,根据折扣将其收缩为零,并通过奖励(或在随机情况下奖励的分配)将其转移。 然后,通过首先构建目标分布的新支持,然后最小化分布 和目标分布 之间的 Kullbeck-Leibler 散度,导出 Q 学习的分布变体,
| (3) |
这里 是目标分布到固定支撑 上的 L2 投影, 是相对于平均动作值 处于状态。
与非分布情况一样,我们可以使用参数 的冻结副本来构造目标分布。 参数化分布可以用神经网络表示,如 DQN 中那样,但具有 输出。 softmax 独立应用于输出的每个动作维度,以确保每个动作的分布得到适当的归一化。
噪声网络。
在《蒙特祖玛的复仇》等游戏中,使用 贪婪策略进行探索的局限性非常明显,在这些游戏中,必须执行许多操作才能收集第一个奖励。 噪声网络 (?) 提出了一个噪声线性层,它结合了确定性流和噪声流,
| (4) |
其中 和 是随机变量, 表示逐元素乘积。 然后可以使用此转换来代替标准线性 。 随着时间的推移,网络可以学会忽略噪声流,但会在状态空间的不同部分以不同的速率执行此操作,从而允许以自我退火的形式进行状态条件探索。
综合代理
在本文中,我们将所有上述组件集成到一个集成代理中,我们将其称为Rainbow。
首先,我们用多步变体替换 1 步分布损失 (3)。 我们根据累积折扣收缩 中的价值分布,并将其移动截断的 步贴现收益,从而构建目标分布。 这对应于将目标分布定义为。 由此产生的损失是
其中, 是 上的投影。
我们将多步分布损失与双Q学习结合起来,使用根据在线网络选择的中的贪婪动作作为引导动作 ,并使用目标网络评估此类操作。
在标准比例优先重放 (?) 中,绝对 TD 误差用于确定转换的优先级。 这可以在分布设置中使用平均动作值来计算。 然而,在我们的实验中,所有分布式 Rainbow 变体都根据 KL 损失优先考虑转换,因为这是算法最小化的:
作为优先级的 KL 损失对于嘈杂的随机环境可能更稳健,因为即使回报不确定,损失也可能继续减少。
该网络架构是适合与返回分布一起使用的决斗网络架构。 该网络具有共享表示 ,然后将其馈入具有 输出的价值流 以及优势流 具有 输出,其中 将表示对应于原子 和操作 的输出。 对于每个原子 ,价值流和优势流被聚合,就像在决斗 DQN 中一样,然后通过 softmax 层以获得用于估计回报分布的归一化参数分布:
其中 和 。
然后,我们将所有线性层替换为等式 (4) 中描述的噪声等效层。 在这些噪声线性层中,我们使用因式分解高斯噪声 (?) 来减少独立噪声变量的数量。
实验方法
我们现在描述用于配置和评估学习代理的方法和设置。
评估方法。
我们评估了街机学习环境中 57 个 Atari 2600 游戏的所有代理 (?)。 我们遵循?的训练和评估程序 (?) 和 van Hasselt 等人 (?)。 在训练期间,环境中每 1M 步,通过暂停学习和评估 500K 帧的最新代理来评估代理的平均分数。 剧集在 108K 帧(或 30 分钟的模拟播放)处被截断,如 van Hasselt 等人 (?)。
每场比赛的智能体得分均被标准化,因此 0% 对应于随机智能体,100% 对应于人类专家的平均得分。 标准化分数可以在所有 Atari 级别上进行汇总,以比较不同代理的表现。 跟踪所有游戏中人类标准化表现的中位数是很常见的。 我们还考虑了智能体表现高于人类表现一部分的游戏数量,以理清中位数改进的来源。 平均值人类标准化性能的信息量可能较少,因为其中主要是一些游戏(如《亚特兰蒂斯》),代理取得的分数比人类高出几个数量级。
除了跟踪作为环境步骤函数的中值性能之外,在训练结束时,我们使用两种不同的测试方案重新评估最佳代理快照。 在无操作开始训练机制中,我们在每集的开头插入随机数量(最多 30 个)的无操作操作(正如我们在 中所做的那样)。 在人类开始制度中,情节是用从人类专家轨迹的初始部分随机采样的点来初始化的(?);两种制度之间的差异表明智能体对其自身轨迹的过度拟合程度。
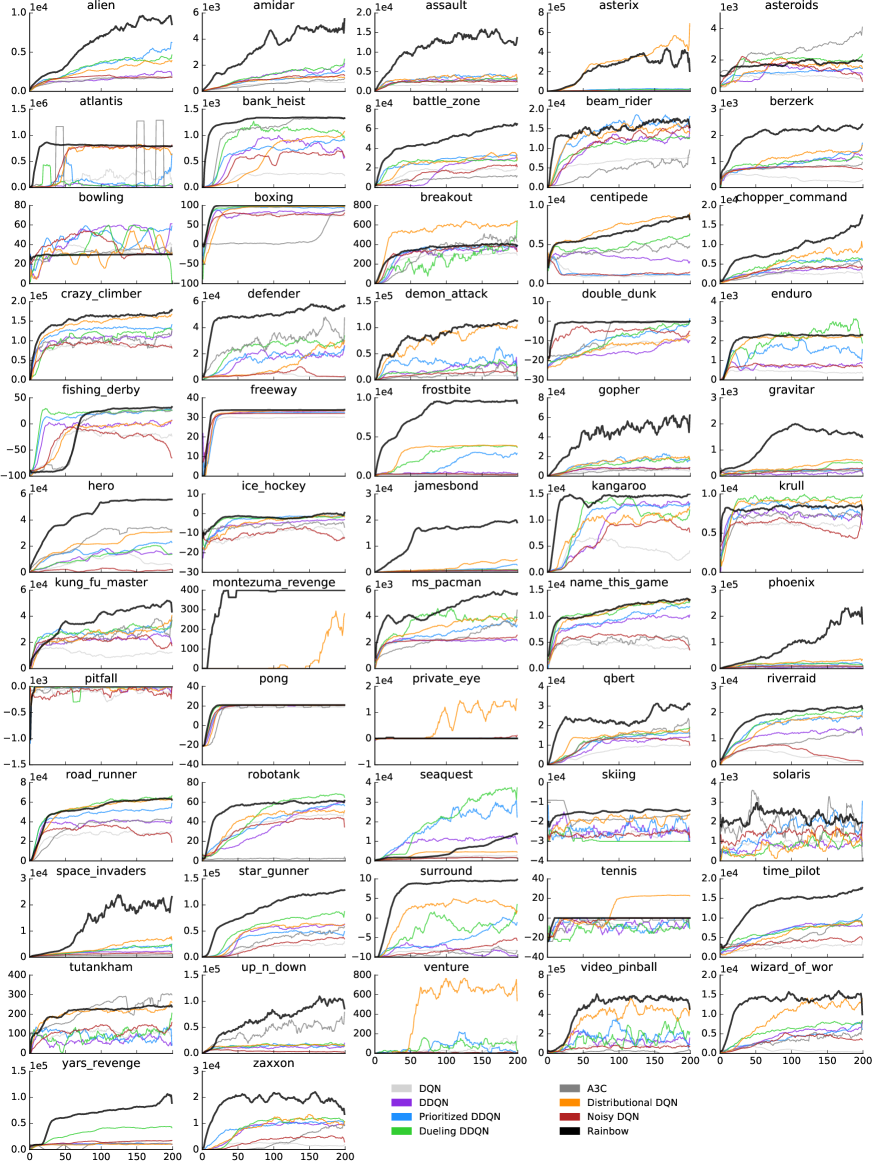
由于空间限制,我们专注于跨游戏的汇总结果。 然而,在附录中,我们提供了所有游戏和所有代理的完整学习曲线,以及在无操作和人类开始测试制度下原始分数和标准化分数的详细比较表。
| Parameter | Value |
|---|---|
| Min history to start learning | 80K frames |
| Adam learning rate | |
| Exploration | |
| Noisy Nets | 0.5 |
| Target Network Period | 32K frames |
| Adam | |
| Prioritization type | proportional |
| Prioritization exponent | |
| Prioritization importance sampling | |
| Multi-step returns | 3 |
| Distributional atoms | |
| Distributional min/max values |
超参数调整。
Rainbow 的所有组件都有许多超参数。 超参数的组合空间对于穷举搜索来说太大,因此我们进行了有限的调整。 对于每个组件,我们从介绍该组件的论文中使用的值开始,并通过手动坐标下降调整超参数中最敏感的值。
DQN 及其变体在第一个 帧期间不执行学习更新,以确保足够的不相关更新。 我们发现,通过优先重播,可以在仅 帧之后更快地开始学习。
DQN 从探索 1 开始,对应于随机均匀行动;它将前 4M 帧的探索量退火至最终值 0.1(在后续变体中降低至 0.01)。 每当使用噪声网络时,我们都是完全贪婪的(),超参数的值为,用于初始化噪声网络中的权重溪流111噪声是在 GPU 上生成的。 GPU 上的 Tensorflow 噪声生成可能不可靠。 如果在 CPU 上产生噪音,将 降低到 0.1 可能会有所帮助。. 对于没有噪声网络的代理,我们使用 -贪婪,但比以前使用的速度更快地降低了探索率,在第一个 帧中将 退火到 0.01。
我们使用 Adam 优化器 (?),我们发现它对学习率的选择不如 RMSProp 敏感。 DQN 使用的学习率为 在 Rainbow 的所有变体中,我们使用的学习率为 (从 中选择)和值 为 Adam 的 超参数。
对于重放优先级,我们使用推荐的比例变量,优先级指数 为 ,并在整个过程中将重要性采样指数 从 0.4 线性增加到 1的训练。 优先级指数通过比较的值进行调整。 使用分布式 DQN 的 KL 损失作为优先级,我们观察到性能对于 的选择非常稳健。
多步学习中的值是Rainbow的敏感超参数。 我们比较了的值。 我们观察到 和 最初都表现良好,但总体而言 最终表现最好。
所有 57 款游戏的超参数(参见表 1)都是相同的,即 Rainbow 代理确实是一个在所有游戏中都表现良好的单一代理设置。
分析
本节我们分析主要实验结果。 首先,我们表明 Rainbow 与几个已发布的代理相比具有优势。 然后我们进行消融研究,比较该试剂的几种变体,每种变体对应于从 Rainbow 中去除单个组件。
与已发布的基线进行比较。
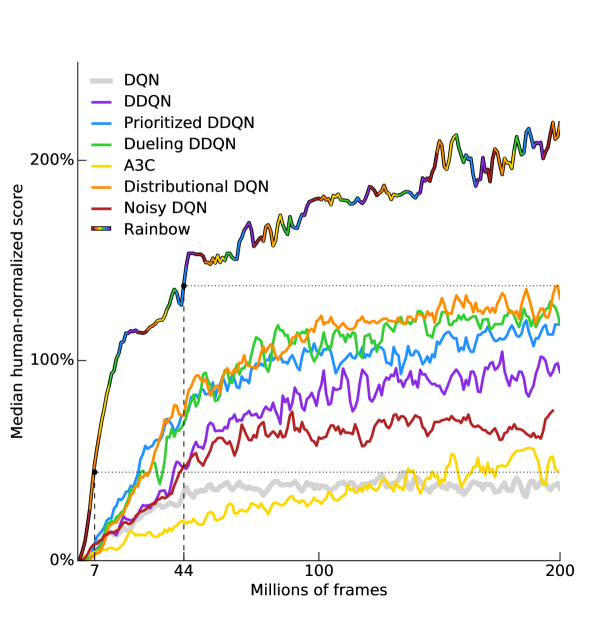
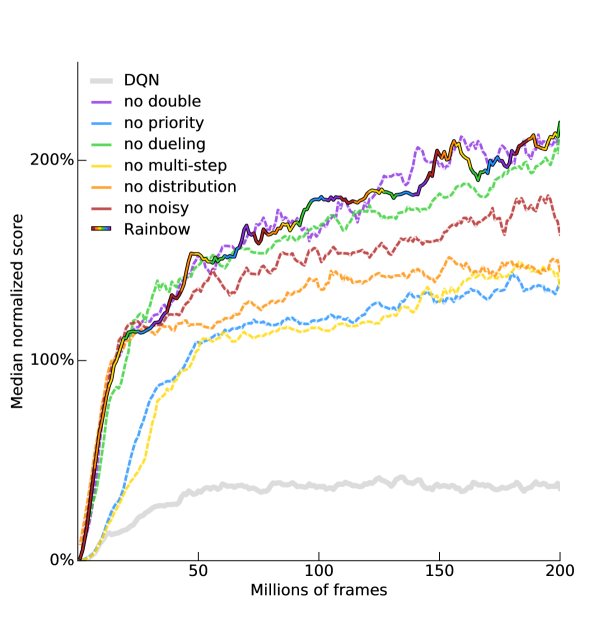
在图 1 中,我们将 Rainbow 的性能(以跨游戏的人类归一化得分中位数来衡量)与 A3C、DQN、DDQN、优先 DDQN、决斗 DDQN、分布式 DQN 和噪声的相应曲线进行了比较DQN。 我们感谢 Dueling 和 Prioritized 代理的作者提供了这些代理的学习曲线,并报告了我们自己对 DQN、A3C、DDQN、分布式 DQN 和噪声 DQN 的重新运行。 Rainbow 的性能无论是在数据效率还是最终性能方面都明显优于任何基线。 请注意,我们在 7M 帧后匹配 DQN 的最终性能,超越这些基线在 44M 帧中的最佳最终性能,并达到显着提高的最终性能。
在智能体的最终评估中,训练结束后,Rainbow 在无操作状态下的中位得分为 223%;在人类起始体系中,我们测得的中位分数为 153%。 在表2中,我们将这些分数与已发布的各个基线的中值分数进行比较。
| Agent | no-ops | human starts |
|---|---|---|
| DQN | 79% | 68% |
| DDQN (*) | 117% | 110% |
| Prioritized DDQN (*) | 140% | 128% |
| Dueling DDQN (*) | 151% | 117% |
| A3C (*) | - | 116% |
| Noisy DQN | 118% | 102% |
| Distributional DQN | 164% | 125% |
| Rainbow | 223% | 153% |
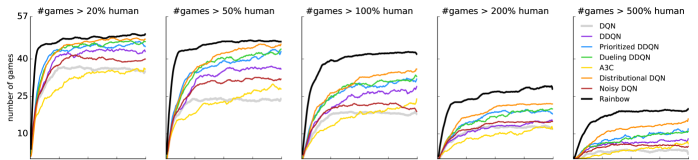
在图2(顶行)中,我们绘制了代理达到人类标准化表现的某个指定水平的游戏数量。 从左到右,子图显示了不同智能体在多少场比赛中实现了 20%、50%、100%、200% 和 500% 人类标准化表现。 这使我们能够确定性能的整体改进来自何处。 请注意,Rainbow 和其他智能体之间的性能差距在各个性能级别上都很明显:Rainbow 智能体正在提高基准智能体已经很好的游戏的分数,以及在基准智能体与人类表现仍相去甚远的游戏中的得分。
学习速度。
与原始 DQN 设置一样,我们在单个 GPU 上运行每个代理。 匹配 DQN 最终性能所需的 7M 帧相当于不到 10 小时的挂钟时间。 完整运行 200M 帧大约需要 10 天,并且所有讨论的变体之间的差异不到 20%。 文献中包含许多替代训练设置,它们通过利用并行性来提高作为挂钟时间函数的性能,例如 ? (?), ? (?) 和 ? (?)。 在如此不同的硬件/计算资源之间正确关联性能并非易事,因此我们专门关注算法变化,以便进行同类比较。 虽然我们认为它们是重要且互补的,但我们将可扩展性和并行性问题留给了未来的工作。
消融研究。
由于 Rainbow 将几种不同的想法集成到一个代理中,因此我们进行了额外的实验,以了解各种组件在这种特定组合的背景下的贡献。
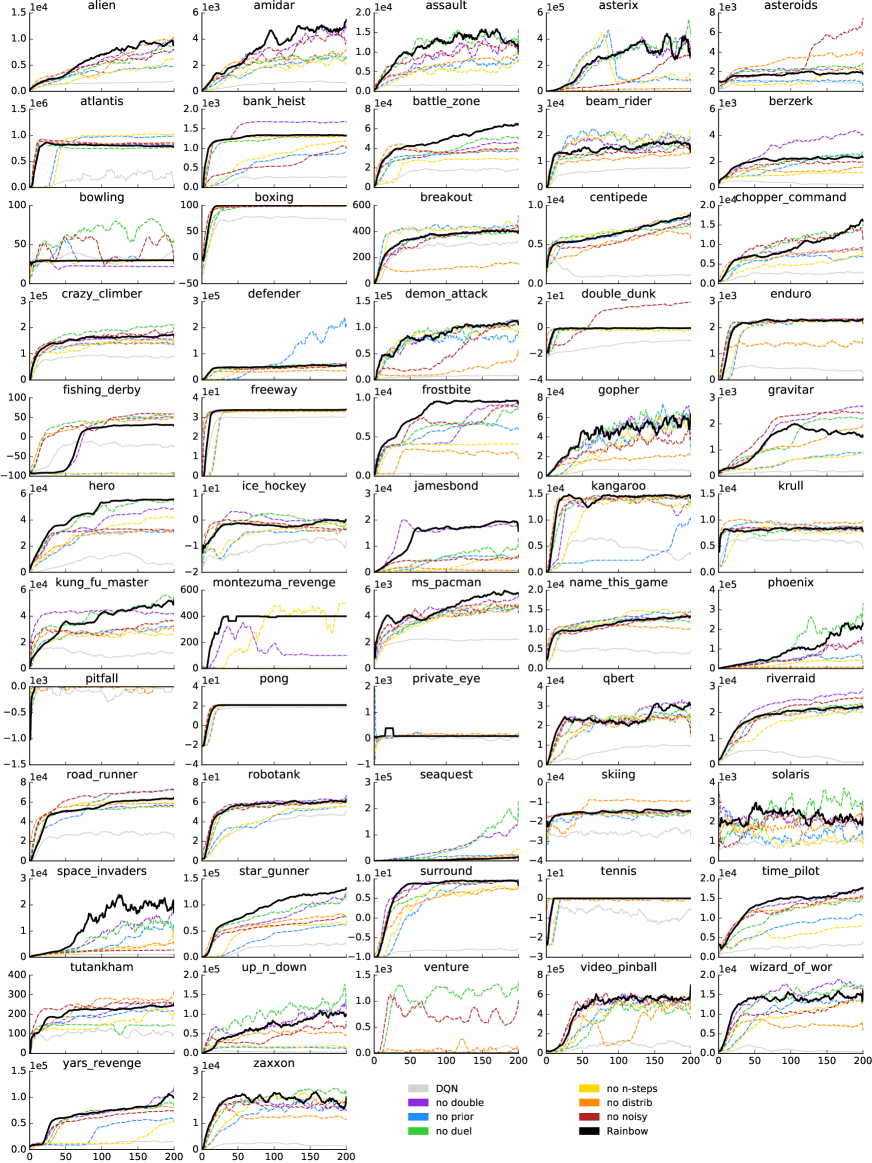
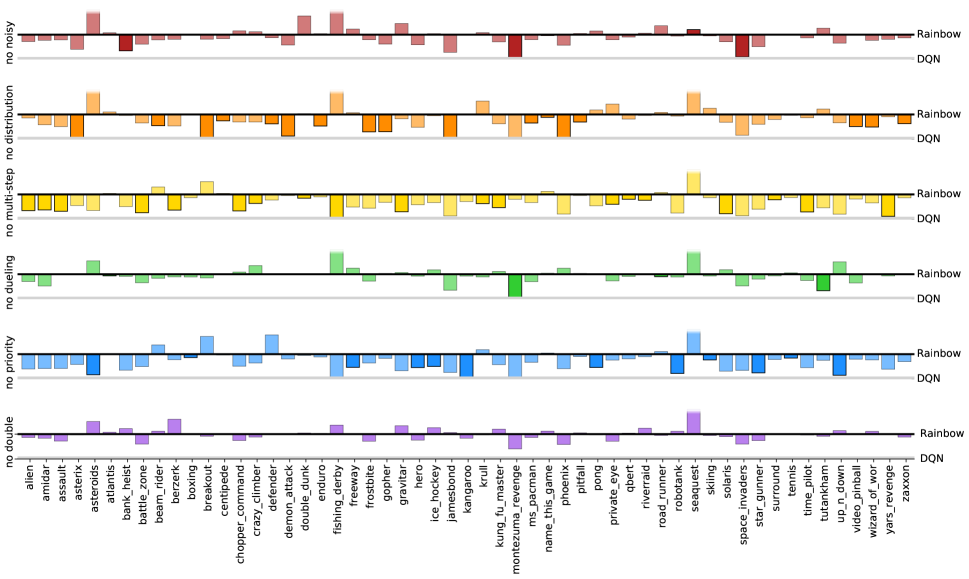
为了更好地了解每种成分对 Rainbow 剂的贡献,我们进行了消融研究。 在每次消融中,我们从完整的 Rainbow 组合中删除了一个组件。 图 3 显示了完整 Rainbow 与六个消融变体的中值归一化分数的比较。 图2(底行)显示了这些消融相对于人类标准化表现的不同阈值的表现的更详细分类,图4显示了每次消融的增益或损失对于每场比赛,在整个学习过程中取平均值。
优先重放和多步学习是 Rainbow 的两个最关键的组成部分,因为删除任何一个组件都会导致中值性能大幅下降。 毫不奇怪,删除其中任何一个都会损害早期性能。 也许更令人惊讶的是,取消多步骤学习也会损害最终的性能。 放大各个游戏(图 4),我们发现这两个组件在各个游戏中的帮助几乎一致(在 57 场游戏中,完整 Rainbow 的表现优于任一消融游戏)。
就与代理性能的相关性而言,分布式 Q 学习的排名直接低于之前的技术。 值得注意的是,在早期学习中没有明显的差异,如图 3 所示,其中对于前 4000 万帧,分布式消融的表现与完整代理一样好。 然而,如果没有分布,代理的性能就会开始落后。 当结果相对于图 2 中的人类表现分开时,我们发现分布消融似乎主要滞后于高于或接近人类水平的游戏。
就中值性能而言,当包含 Noisy Nets 时,智能体表现更好;当这些被删除并将探索委托给传统的-贪婪机制时,总体性能会更差(图3中的红线)。 虽然移除 Noisy Nets 导致一些游戏的性能大幅下降,但它也为其他游戏带来了小幅提升(图 4)。
总的来说,当从完整的 Rainbow 中删除决斗网络时,我们没有观察到显着的差异。 然而,中位数分数掩盖了决斗的影响因游戏而异的事实,如图4所示。 图 2 显示决斗可能对高于人类表现水平的游戏(# games )提供了一些改进,但对低于人类表现水平的游戏(# games )。
同样在双 Q 学习的情况下,观察到的中值性能差异(图 3)是有限的,该组件有时会损害或帮助,具体取决于游戏(图 4) >)。 为了进一步研究双 Q 学习的作用,我们将训练有素的代理的预测与根据削减的奖励计算出的实际折扣回报进行了比较。 将 Rainbow 与取消双 Q 学习的代理进行比较,我们观察到实际回报通常高于 ,因此超出了分布的支持范围,从 到。 这会导致回报被低估,而不是高估。 我们假设将值限制在这个受限范围内可以抵消 Q 学习的高估偏差。 但请注意,如果分布的支持得到扩展,双 Q 学习的重要性可能会增加。
在附录中,我们针对每款游戏展示了 Rainbow 的最终性能和学习曲线、其消融和基线。
讨论
我们已经证明,对 DQN 的多项改进可以成功集成到单个学习算法中,从而实现最先进的性能。 此外,我们已经证明,在集成算法中,除了一个组件之外的所有组件都提供了明显的性能优势。 还有更多我们无法包含的算法组件,这些组件可能是集成代理进一步实验的有希望的候选者。 在众多可能的候选者中,我们在下面讨论其中的几个。
我们在这里重点关注 Q-learning 系列中基于价值的方法。 我们还没有考虑纯粹基于策略的强化学习算法,例如信任域策略优化 (?),也不是 actor-critic 方法(?; ?)。
许多算法利用一系列数据来提高学习效率。 最优性紧缩 (?) 使用多步返回来构造额外的不等式边界,而不是用它们来替换 Q 学习中使用的 1 步目标。 资格跟踪允许对 n 步返回进行软组合 (?)。 然而,与 Rainbow 中使用的多步目标相比,顺序方法在每个梯度上都利用了更多的计算量。 此外,引入优先序列重放提出了如何存储、重放序列和确定序列优先级的问题。
情景控制 (?) 也注重数据效率,并且在某些领域被证明非常有效。 它通过使用情景记忆作为补充学习系统来改善早期学习,能够立即重新制定成功的动作序列。
除了噪声网络之外,许多其他探索方法也可能是有用的算法成分:其中包括 Bootstrapped DQN (?)、内在动机(?)和基于计数的探索(?)。 这些替代组件的集成是进一步研究的富有成效的课题。
在本文中,我们专注于核心学习更新,而不探索替代的计算架构。 从环境的并行副本进行异步学习,如 A3C 中 (?), 大猩猩 (?),或进化策略(?),可以有效地加快学习速度,至少在挂钟时间方面是这样。 但请注意,它们的数据效率可能较低。
分层强化学习也已成功应用于多种复杂的 Atari 游戏。 在 HRL 的成功应用中,我们重点介绍 h-DQN (?) 和 Feudal Networks (?)。
通过利用辅助任务,例如像素控制或特征控制(?)、监督预测 (?) 或后继特征 (?)。
为了根据基线公平地评估 Rainbow,我们遵循了剪切奖励、固定动作重复和帧堆叠等常见领域修改,但这些可能会被其他学习算法改进所删除。 Pop-Art 标准化 (?) 允许删除奖励剪辑,同时保持类似的性能水平。 细粒度的动作重复(?)能够学习如何重复动作。 循环状态网络(?)可以学习时间状态表示,取代固定的观察帧堆栈。 总的来说,我们认为将真实的游戏暴露给代理是未来研究的一个有前途的方向。
参考
- [Bellemare et al. 2013] Bellemare, M. G.; Naddaf, Y.; Veness, J.; and Bowling, M. 2013. The arcade learning environment: An evaluation platform for general agents. J. Artif. Intell. Res. (JAIR) 47:253–279.
- [Bellemare et al. 2016] Bellemare, M. G.; Srinivasan, S.; Ostrovski, G.; Schaul, T.; Saxton, D.; and Munos, R. 2016. Unifying count-based exploration and intrinsic motivation. In NIPS.
- [Bellemare, Dabney, and Munos 2017] Bellemare, M. G.; Dabney, W.; and Munos, R. 2017. A distributional perspective on reinforcement learning. In ICML.
- [Blundell et al. 2016] Blundell, C.; Uria, B.; Pritzel, A.; Li, Y.; Ruderman, A.; Leibo, J. Z.; Rae, J.; Wierstra, D.; and Hassabis, D. 2016. Model-Free Episodic Control. ArXiv e-prints.
- [Dosovitskiy and Koltun 2016] Dosovitskiy, A., and Koltun, V. 2016. Learning to act by predicting the future. CoRR abs/1611.01779.
- [Fortunato et al. 2017] Fortunato, M.; Azar, M. G.; Piot, B.; Menick, J.; Osband, I.; Graves, A.; Mnih, V.; Munos, R.; Hassabis, D.; Pietquin, O.; Blundell, C.; and Legg, S. 2017. Noisy networks for exploration. CoRR abs/1706.10295.
- [Hausknecht and Stone 2015] Hausknecht, M., and Stone, P. 2015. Deep recurrent Q-learning for partially observable MDPs. arXiv preprint arXiv:1507.06527.
- [He et al. 2016] He, F. S.; Liu, Y.; Schwing, A. G.; and Peng, J. 2016. Learning to play in a day: Faster deep reinforcement learning by optimality tightening. CoRR abs/1611.01606.
- [Jaderberg et al. 2016] Jaderberg, M.; Mnih, V.; Czarnecki, W. M.; Schaul, T.; Leibo, J. Z.; Silver, D.; and Kavukcuoglu, K. 2016. Reinforcement learning with unsupervised auxiliary tasks. CoRR abs/1611.05397.
- [Kingma and Ba 2014] Kingma, D. P., and Ba, J. 2014. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR).
- [Kulkarni et al. 2016a] Kulkarni, T. D.; Narasimhan, K.; Saeedi, A.; and Tenenbaum, J. B. 2016a. Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation. CoRR abs/1604.06057.
- [Kulkarni et al. 2016b] Kulkarni, T. D.; Saeedi, A.; Gautam, S.; and Gershman, S. J. 2016b. Deep successor reinforcement learning. arXiv preprint arXiv:1606.02396.
- [Lin 1992] Lin, L.-J. 1992. Self-improving reactive agents based on reinforcement learning, planning and teaching. Machine Learning 8(3):293–321.
- [Mnih et al. 2013] Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; and Riedmiller, M. A. 2013. Playing atari with deep reinforcement learning. CoRR abs/1312.5602.
- [Mnih et al. 2015] Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A. A.; Veness, J.; Bellemare, M. G.; Graves, A.; Riedmiller, M.; Fidjeland, A. K.; Ostrovski, G.; Petersen, S.; Beattie, C.; Sadik, A.; Antonoglou, I.; King, H.; Kumaran, D.; Wierstra, D.; Legg, S.; and Hassabis, D. 2015. Human-level control through deep reinforcement learning. Nature 518(7540):529–533.
- [Mnih et al. 2016] Mnih, V.; Badia, A. P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; and Kavukcuoglu, K. 2016. Asynchronous methods for deep reinforcement learning. In International Conference on Machine Learning.
- [Nair et al. 2015] Nair, A.; Srinivasan, P.; Blackwell, S.; Alcicek, C.; Fearon, R.; De Maria, A.; Panneershelvam, V.; Suleyman, M.; Beattie, C.; Petersen, S.; Legg, S.; Mnih, V.; Kavukcuoglu, K.; and Silver, D. 2015. Massively parallel methods for deep reinforcement learning. arXiv preprint arXiv:1507.04296.
- [O’Donoghue et al. 2016] O’Donoghue, B.; Munos, R.; Kavukcuoglu, K.; and Mnih, V. 2016. Pgq: Combining policy gradient and q-learning. CoRR abs/1611.01626.
- [Osband et al. 2016] Osband, I.; Blundell, C.; Pritzel, A.; and Roy, B. V. 2016. Deep exploration via bootstrapped dqn. In NIPS.
- [Salimans et al. 2017] Salimans, T.; Ho, J.; Chen, X.; and Sutskever, I. 2017. Evolution strategies as a scalable alternative to reinforcement learning. CoRR abs/1703.03864.
- [Schaul et al. 2015] Schaul, T.; Quan, J.; Antonoglou, I.; and Silver, D. 2015. Prioritized experience replay. In Proc. of ICLR.
- [Schulman et al. 2015] Schulman, J.; Levine, S.; Moritz, P.; Jordan, M.; and Abbeel, P. 2015. Trust region policy optimization. In Proceedings of the 32Nd International Conference on International Conference on Machine Learning - Volume 37, ICML’15, 1889–1897. JMLR.org.
- [Sharma, Lakshminarayanan, and Ravindran 2017] Sharma, S.; Lakshminarayanan, A. S.; and Ravindran, B. 2017. Learning to repeat: Fine grained action repetition for deep reinforcement learning. arXiv preprint arXiv:1702.06054.
- [Stadie, Levine, and Abbeel 2015] Stadie, B. C.; Levine, S.; and Abbeel, P. 2015. Incentivizing exploration in reinforcement learning with deep predictive models. CoRR abs/1507.00814.
- [Sutton and Barto 1998] Sutton, R. S., and Barto, A. G. 1998. Reinforcement Learning: An Introduction. The MIT press, Cambridge MA.
- [Sutton 1988] Sutton, R. S. 1988. Learning to predict by the methods of temporal differences. Machine learning 3(1):9–44.
- [Tieleman and Hinton 2012] Tieleman, T., and Hinton, G. 2012. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural networks for machine learning 4(2):26–31.
- [van Hasselt et al. 2016] van Hasselt, H.; Guez, A.; Guez, A.; Hessel, M.; Mnih, V.; and Silver, D. 2016. Learning values across many orders of magnitude. In Advances in Neural Information Processing Systems 29, 4287–4295.
- [van Hasselt, Guez, and Silver 2016] van Hasselt, H.; Guez, A.; and Silver, D. 2016. Deep reinforcement learning with double Q-learning. In Proc. of AAAI, 2094–2100.
- [van Hasselt 2010] van Hasselt, H. 2010. Double Q-learning. In Advances in Neural Information Processing Systems 23, 2613–2621.
- [Vezhnevets et al. 2017] Vezhnevets, A. S.; Osindero, S.; Schaul, T.; Heess, N.; Jaderberg, M.; Silver, D.; and Kavukcuoglu, K. 2017. Feudal networks for hierarchical reinforcement learning. CoRR abs/1703.01161.
- [Wang et al. 2016] Wang, Z.; Schaul, T.; Hessel, M.; van Hasselt, H.; Lanctot, M.; and de Freitas, N. 2016. Dueling network architectures for deep reinforcement learning. In Proceedings of The 33rd International Conference on Machine Learning, 1995–2003.
附录
表3列出了DQN引入的环境框架、奖励和折扣的预处理。 表4列出了 Rainbow 从 DQN 继承的附加超参数以及本文考虑的其他基线。 Rainbow 使用非标准设置的超参数在正文中列出。 在接下来的页面中,我们列出了表格,显示了每场比赛 Rainbow 取得的分数以及无操作模式(表 6)和人工启动模式(表 5)。 在图 5 和 6 中,我们还为每个游戏绘制了 Rainbow 的学习曲线、几个基线和所有消融实验。 这些学习曲线通过 10 窗口内的移动平均值进行平滑。
| Hyper-parameter | value |
| Grey-scaling | True |
| Observation down-sampling | (84, 84) |
| Frames stacked | 4 |
| Action repetitions | 4 |
| Reward clipping | [-1, 1] |
| Terminal on loss of life | True |
| Max frames per episode | 108K |
| Hyper-parameter | value |
|---|---|
| Q network: channels | 32, 64, 64 |
| Q network: filter size | |
| Q network: stride | 4, 2, 1 |
| Q network: hidden units | 512 |
| Q network: output units | Number of actions |
| Discount factor | 0.99 |
| Memory size | 1M transitions |
| Replay period | every 4 agent steps |
| Minibatch size | 32 |
| Game | DQN | A3C | DDQN | Prior. DDQN | Duel. DDQN | Distrib. DQN | Noisy DQN | Rainbow |
|---|---|---|---|---|---|---|---|---|
| alien | 634.0 | 518.4 | 1033.4 | 900.5 | 1,486.5 | 1,997.5 | 533.3 | 6,022.9 |
| amidar | 178.4 | 263.9 | 169.1 | 218.4 | 172.7 | 237.7 | 148.0 | 202.8 |
| assault | 3489.3 | 5474.9 | 6060.8 | 7,748.5 | 3,994.8 | 5,101.3 | 5,124.3 | 14,491.7 |
| asterix | 3170.5 | 22140.5 | 16837.0 | 31,907.5 | 15,840.0 | 395,599.5 | 8,277.3 | 280,114.0 |
| asteroids | 1458.7 | 4474.5 | 1193.2 | 1,654.0 | 2,035.4 | 2,071.7 | 4,078.1 | 2,249.4 |
| atlantis | 292491.0 | 911,091.0 | 319688.0 | 593,642.0 | 445,360.0 | 289,803.0 | 303,666.5 | 814,684.0 |
| bank_heist | 312.7 | 970.1 | 886.0 | 816.8 | 1,129.3 | 835.6 | 955.0 | 826.0 |
| battle_zone | 23750.0 | 12950.0 | 24740.0 | 29,100.0 | 31,320.0 | 32,250.0 | 26,985.0 | 52,040.0 |
| beam_rider | 9743.2 | 22707.9 | 17417.2 | 26,172.7 | 14,591.3 | 15,002.4 | 15,241.5 | 21,768.5 |
| berzerk | 493.4 | 817.9 | 1011.1 | 1,165.6 | 910.6 | 1,000.0 | 670.8 | 1,793.4 |
| bowling | 56.5 | 35.1 | 69.6 | 65.8 | 65.7 | 76.8 | 79.3 | 39.4 |
| boxing | 70.3 | 59.8 | 73.5 | 68.6 | 77.3 | 62.1 | 66.3 | 54.9 |
| breakout | 354.5 | 681.9 | 368.9 | 371.6 | 411.6 | 548.7 | 423.3 | 379.5 |
| centipede | 3973.9 | 3755.8 | 3853.5 | 3,421.9 | 4,881.0 | 7,476.9 | 4,214.4 | 7,160.9 |
| chopper_command | 5017.0 | 7021.0 | 3495.0 | 6,604.0 | 3,784.0 | 9,600.5 | 8,778.5 | 10,916.0 |
| crazy_climber | 98128.0 | 112646.0 | 113782.0 | 131,086.0 | 124,566.0 | 154,416.5 | 98,576.5 | 143,962.0 |
| defender | 15917.5 | 56533.0 | 27510.0 | 21,093.5 | 33,996.0 | 32,246.0 | 18,037.5 | 47,671.3 |
| demon_attack | 12550.7 | 113,308.4 | 69803.4 | 73,185.8 | 56,322.8 | 109,856.6 | 25,207.8 | 109,670.7 |
| double_dunk | -6.0 | -0.1 | -0.3 | 2.7 | -0.8 | -3.7 | -1.0 | -0.6 |
| enduro | 626.7 | -82.5 | 1216.6 | 1,884.4 | 2,077.4 | 2,133.4 | 1,021.5 | 2,061.1 |
| fishing_derby | -1.6 | 18.8 | 3.2 | 9.2 | -4.1 | -4.9 | -3.7 | 22.6 |
| freeway | 26.9 | 0.1 | 28.8 | 27.9 | 0.2 | 28.8 | 27.1 | 29.1 |
| frostbite | 496.1 | 190.5 | 1448.1 | 2,930.2 | 2,332.4 | 2,813.9 | 418.8 | 4,141.1 |
| gopher | 8190.4 | 10022.8 | 15253.0 | 57,783.8 | 20,051.4 | 27,778.3 | 13,131.0 | 72,595.7 |
| gravitar | 298.0 | 303.5 | 200.5 | 218.0 | 297.0 | 422.0 | 250.5 | 567.5 |
| hero | 14992.9 | 32464.1 | 14892.5 | 20,506.4 | 15,207.9 | 28,554.2 | 2,454.2 | 50,496.8 |
| ice_hockey | -1.6 | -2.8 | -2.5 | -1.0 | -1.3 | -0.1 | -2.4 | -0.7 |
| kangaroo | 4496.0 | 94.0 | 11204.0 | 10,241.0 | 10,334.0 | 9,555.5 | 7,465.0 | 10,841.0 |
| krull | 6206.0 | 5560.0 | 6796.1 | 7,406.5 | 8,051.6 | 6,757.8 | 6,833.5 | 6,715.5 |
| kung_fu_master | 20882.0 | 28819.0 | 30207.0 | 31,244.0 | 24,288.0 | 33,890.0 | 27,921.0 | 28,999.8 |
| montezuma_revenge | 47.0 | 67.0 | 42.0 | 13.0 | 22.0 | 130.0 | 55.0 | 154.0 |
| ms_pacman | 1092.3 | 653.7 | 1241.3 | 1,824.6 | 2,250.6 | 2,064.1 | 1,012.1 | 2,570.2 |
| name_this_game | 6738.8 | 10476.1 | 8960.3 | 11,836.1 | 11,185.1 | 11,382.3 | 7,186.4 | 11,686.5 |
| phoenix | 7484.8 | 52894.1 | 12366.5 | 27,430.1 | 20,410.5 | 31,358.3 | 15,505.0 | 103,061.6 |
| pitfall | -113.2 | -78.5 | -186.7 | -14.8 | -46.9 | -342.8 | -154.4 | -37.6 |
| pong | 18.0 | 5.6 | 19.1 | 18.9 | 18.8 | 18.9 | 18.0 | 19.0 |
| private_eye | 207.9 | 206.9 | -575.5 | 179.0 | 292.6 | 5,717.5 | 5,955.4 | 1,704.4 |
| qbert | 9271.5 | 15148.8 | 11020.8 | 11,277.0 | 14,175.8 | 15,035.9 | 9,176.6 | 18,397.6 |
| road_runner | 35215.0 | 34216.0 | 43156.0 | 56,990.0 | 58,549.0 | 56,086.0 | 35,376.5 | 54,261.0 |
| robotank | 58.7 | 32.8 | 59.1 | 55.4 | 62.0 | 49.8 | 50.9 | 55.2 |
| seaquest | 4216.7 | 2355.4 | 14498.0 | 39,096.7 | 37,361.6 | 3,275.4 | 2,353.1 | 19,176.0 |
| skiing | -12142.1 | -10911.1 | -11490.4 | -10,852.8 | -11,928.0 | -13,247.7 | -13,905.9 | -11,685.8 |
| solaris | 1295.4 | 1956.0 | 810.0 | 2,238.2 | 1,768.4 | 2,530.2 | 2,608.2 | 2,860.7 |
| space_invaders | 1293.8 | 15,730.5 | 2628.7 | 9,063.0 | 5,993.1 | 6,368.6 | 1,697.2 | 12,629.0 |
| star_gunner | 52970.0 | 138218.0 | 58365.0 | 51,959.0 | 90,804.0 | 67,054.5 | 31,864.5 | 123,853.0 |
| surround | -6.0 | -9.7 | 1.9 | -0.9 | 4.0 | 4.5 | -3.1 | 7.0 |
| tennis | 11.1 | -6.3 | -7.8 | -2.0 | 4.4 | 22.6 | -2.1 | -2.2 |
| time_pilot | 4786.0 | 12,679.0 | 6608.0 | 7,448.0 | 6,601.0 | 7,684.5 | 5,311.0 | 11,190.5 |
| tutankham | 45.6 | 156.3 | 92.2 | 33.6 | 48.0 | 124.3 | 123.3 | 126.9 |
| venture | 136.0 | 23.0 | 21.0 | 244.0 | 200.0 | 462.0 | 10.5 | 45.0 |
| video_pinball | 154414.1 | 331628.1 | 367823.7 | 374,886.9 | 110,976.2 | 455,052.7 | 241,851.7 | 506,817.2 |
| wizard_of_wor | 1609.0 | 17,244.0 | 6201.0 | 7,451.0 | 7,054.0 | 11,824.5 | 4,796.5 | 14,631.5 |
| yars_revenge | 4577.5 | 7157.5 | 6270.6 | 5,965.1 | 25,976.5 | 8,267.7 | 5,487.3 | 93,007.9 |
| zaxxon | 4412.0 | 24,622.0 | 8593.0 | 9,501.0 | 10,164.0 | 15,130.0 | 7,650.5 | 19,658.0 |
| Game | DQN | DDQN | Prior. DDQN | Duel. DDQN | Distrib. DQN | Noisy DQN | Rainbow |
|---|---|---|---|---|---|---|---|
| alien | 1620.0 | 3747.7 | 6,648.6 | 4,461.4 | 4,055.8 | 2,394.9 | 9,491.7 |
| amidar | 978.0 | 1793.3 | 2,051.8 | 2,354.5 | 1,267.9 | 1,608.0 | 5,131.2 |
| assault | 4280.0 | 5393.2 | 7,965.7 | 4,621.0 | 5,909.0 | 5,198.6 | 14,198.5 |
| asterix | 4359.0 | 17356.5 | 41,268.0 | 28,188.0 | 400,529.5 | 12,403.8 | 428,200.3 |
| asteroids | 1364.5 | 734.7 | 1,699.3 | 2,837.7 | 2,354.7 | 4,814.1 | 2,712.8 |
| atlantis | 279987.0 | 106056.0 | 427,658.0 | 382,572.0 | 273,895.0 | 329,010.0 | 826,659.5 |
| bank_heist | 455.0 | 1030.6 | 1,126.8 | 1,611.9 | 1,056.7 | 1,323.0 | 1,358.0 |
| battle_zone | 29900.0 | 31700.0 | 38,130.0 | 37,150.0 | 41,145.0 | 32,050.0 | 62,010.0 |
| beam_rider | 8627.5 | 13772.8 | 22,430.7 | 12,164.0 | 13,213.4 | 12,534.0 | 16,850.2 |
| berzerk | 585.6 | 1225.4 | 1,614.2 | 1,472.6 | 1,421.8 | 837.3 | 2,545.6 |
| bowling | 50.4 | 68.1 | 62.6 | 65.5 | 74.1 | 77.3 | 30.0 |
| boxing | 88.0 | 91.6 | 98.8 | 99.4 | 98.1 | 83.3 | 99.6 |
| breakout | 385.5 | 418.5 | 381.5 | 345.3 | 612.5 | 459.1 | 417.5 |
| centipede | 4657.7 | 5409.4 | 5,175.4 | 7,561.4 | 9,015.5 | 4,355.8 | 8,167.3 |
| chopper_command | 6126.0 | 5809.0 | 5,135.0 | 11,215.0 | 13,136.0 | 9,519.0 | 16,654.0 |
| crazy_climber | 110763.0 | 117282.0 | 183,137.0 | 143,570.0 | 178,355.0 | 118,768.0 | 168,788.5 |
| defender | 23633.0 | 35338.5 | 24,162.5 | 42,214.0 | 37,896.8 | 23,083.0 | 55,105.0 |
| demon_attack | 12149.4 | 58044.2 | 70,171.8 | 60,813.3 | 110,626.5 | 24,950.1 | 111,185.2 |
| double_dunk | -6.6 | -5.5 | 4.8 | 0.1 | -3.8 | -1.8 | -0.3 |
| enduro | 729.0 | 1211.8 | 2,155.0 | 2,258.2 | 2,259.3 | 1,129.2 | 2,125.9 |
| fishing_derby | -4.9 | 15.5 | 30.2 | 46.4 | 9.1 | 7.7 | 31.3 |
| freeway | 30.8 | 33.3 | 32.9 | 0.0 | 33.6 | 32.0 | 34.0 |
| frostbite | 797.4 | 1683.3 | 3,421.6 | 4,672.8 | 3,938.2 | 583.6 | 9,590.5 |
| gopher | 8777.4 | 14840.8 | 49,097.4 | 15,718.4 | 28,841.0 | 15,107.9 | 70,354.6 |
| gravitar | 473.0 | 412.0 | 330.5 | 588.0 | 681.0 | 443.5 | 1,419.3 |
| hero | 20437.8 | 20130.2 | 27,153.9 | 20,818.2 | 33,860.9 | 5,053.1 | 55,887.4 |
| ice_hockey | -1.9 | -2.7 | 0.3 | 0.5 | 1.3 | -2.1 | 1.1 |
| kangaroo | 7259.0 | 12992.0 | 14,492.0 | 14,854.0 | 12,909.0 | 12,117.0 | 14,637.5 |
| krull | 8422.3 | 7920.5 | 10,263.1 | 11,451.9 | 9,885.9 | 9,061.9 | 8,741.5 |
| kung_fu_master | 26059.0 | 29710.0 | 43,470.0 | 34,294.0 | 43,009.0 | 34,099.0 | 52,181.0 |
| montezuma_revenge | 0.0 | 0.0 | 0.0 | 0.0 | 367.0 | 0.0 | 384.0 |
| ms_pacman | 3085.6 | 2711.4 | 4,751.2 | 6,283.5 | 3,769.2 | 2,501.6 | 5,380.4 |
| name_this_game | 8207.8 | 10616.0 | 13,439.4 | 11,971.1 | 12,983.6 | 8,332.4 | 13,136.0 |
| phoenix | 8485.2 | 12252.5 | 32,808.3 | 23,092.2 | 34,775.0 | 16,974.3 | 108,528.6 |
| pitfall | -286.1 | -29.9 | 0.0 | 0.0 | -2.1 | -18.2 | 0.0 |
| pong | 19.5 | 20.9 | 20.7 | 21.0 | 20.8 | 21.0 | 20.9 |
| private_eye | 146.7 | 129.7 | 200.0 | 103.0 | 15,172.9 | 3,966.0 | 4,234.0 |
| qbert | 13117.3 | 15088.5 | 18,802.8 | 19,220.3 | 16,956.0 | 15,276.3 | 33,817.5 |
| road_runner | 39544.0 | 44127.0 | 62,785.0 | 69,524.0 | 63,366.0 | 41,681.0 | 62,041.0 |
| robotank | 63.9 | 65.1 | 58.6 | 65.3 | 54.2 | 53.5 | 61.4 |
| seaquest | 5860.6 | 16452.7 | 44,417.4 | 50,254.2 | 4,754.4 | 2,495.4 | 15,898.9 |
| skiing | -13062.3 | -9021.8 | -9,900.5 | -8,857.4 | -14,959.8 | -16,307.3 | -12,957.8 |
| solaris | 3482.8 | 3067.8 | 1,710.8 | 2,250.8 | 5,643.1 | 3,204.5 | 3,560.3 |
| space_invaders | 1692.3 | 2525.5 | 7,696.9 | 6,427.3 | 6,869.1 | 2,145.5 | 18,789.0 |
| star_gunner | 54282.0 | 60142.0 | 56,641.0 | 89,238.0 | 69,306.5 | 34,504.5 | 127,029.0 |
| surround | -5.6 | -2.9 | 2.1 | 4.4 | 6.2 | -3.3 | 9.7 |
| tennis | 12.2 | -22.8 | 0.0 | 5.1 | 23.6 | 0.0 | -0.0 |
| time_pilot | 4870.0 | 8339.0 | 11,448.0 | 11,666.0 | 7,875.0 | 6,157.0 | 12,926.0 |
| tutankham | 68.1 | 218.4 | 87.2 | 211.4 | 249.4 | 231.6 | 241.0 |
| venture | 163.0 | 98.0 | 863.0 | 497.0 | 1,107.0 | 0.0 | 5.5 |
| video_pinball | 196760.4 | 309941.9 | 406,420.4 | 98,209.5 | 478,646.7 | 270,444.6 | 533,936.5 |
| wizard_of_wor | 2704.0 | 7492.0 | 10,373.0 | 7,855.0 | 15,994.5 | 5,432.0 | 17,862.5 |
| yars_revenge | 18089.9 | 11712.6 | 16,451.7 | 49,622.1 | 16,608.6 | 9,570.1 | 102,557.0 |
| zaxxon | 5363.0 | 10163.0 | 13,490.0 | 12,944.0 | 18,347.5 | 9,390.0 | 22,209.5 |