弱监督深度检测网络
摘要
目标检测的弱监督学习是图像理解中的一个重要问题,目前还没有令人满意的解决方案。 在本文中,我们通过利用在大规模图像级分类任务上预训练的深度卷积神经网络的强大功能来解决这个问题。 我们提出了一种弱监督的深度检测架构,该架构将这样的网络修改为在图像区域级别上运行,同时执行区域选择和分类。 该架构作为图像分类器进行训练,隐式学习目标检测器,这些检测器比 PASCAL VOC 数据上的其他弱监督检测系统更好。 该模型是一种简单而优雅的端到端架构,在图像级分类任务中也优于标准数据增强和微调技术。
1简介
近年来,卷积神经网络(CNN)[20]已成为图像识别领域最先进的新学习框架。 他们成功的关键是能够从大量标记数据中学习现实世界物体的复杂外观。 CNN 最引人注目的方面之一是它们能够学习泛化到许多任务的通用视觉特征。 特别是,在 ImageNet ILSVRC 等数据集上预训练的 CNN 已被证明在其他领域的识别[8]、对象检测[12]、在语义分割[13]、人体姿势估计[31]以及许多其他任务中。
在本文中,我们研究了如何在弱监督检测 (WSD) 中利用 CNN 的强大功能,这是仅使用图像级标签来学习对象检测器的问题。 从弱注释中学习的能力非常重要,原因有两个:首先,图像理解旨在学习不断增长的复杂视觉概念(例如。图像网)。 其次,CNN 训练需要大量数据。 因此,能够仅使用轻度监督来学习复杂的概念可以显着降低图像分割、图像字幕或对象检测等任务中的数据成本。
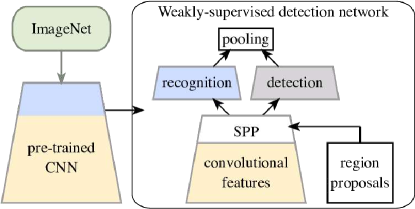
我们的研究动机是这样的假设:由于预训练的 CNN 能够很好地概括大量任务,因此它们应该包含有意义的数据表示。 例如,有证据表明,经过图像分类训练的 CNN 可以学习对象和对象部分的代理[36]。 值得注意的是,这些概念是隐式获取的,无需向网络提供有关此类结构在图像中的位置的信息。 因此,为图像分类训练的 CNN 可能已经隐含了执行对象检测所需的大部分信息。
我们并不是第一个用 CNN 解决 WSD 问题的人。 例如,Wang 等人. [34]的方法使用预训练的CNN来描述图像区域,然后学习对象类别作为相应的视觉主题。 虽然这种方法是目前弱监督目标检测领域最先进的方法,但它包含 CNN 之外的多个组件,并且需要大量调整。
在本文中,我们贡献了一种新颖的端到端方法,使用预训练的 CNN 进行弱监督目标检测,我们称之为弱监督深度检测网络(WSDDN)( 图 1)。 我们的方法(section 3)从现有网络(例如在 ImageNet 数据上预训练的 AlexNet)开始,并将其扩展为显式推理和有效地了解图像区域。为此,给定图像,第一步是通过在图像的卷积层顶部插入空间金字塔池化层来有效地提取区域级描述符。美国有线电视新闻网[14, 11]。 接下来,网络被分支以从池化的区域级特征中提取两个数据流。 第一个流将类别分数分别与每个区域相关联,执行识别。 相反,第二个流通过计算区域的概率分布来比较区域;后者代表这样一种信念:在图像中的所有候选区域中, 是包含最显着图像结构的区域,因此是检测 的代理。 对所有图像区域计算的识别和检测分数最终被聚合,以预测整个图像的类别,然后用于在学习中注入图像级监督。
将我们的方法与最常见的弱监督对象检测技术(即多实例学习(MIL)[7])进行比较是很有趣的。 MIL 在选择图像中的哪些区域看起来像感兴趣的对象和使用所选区域估计对象的外观模型之间交替。 因此,MIL 使用外观模型本身来执行区域选择。 我们的技术与 MIL 在根本上有所不同,因为区域是由网络中专用的并行检测分支选择的,该分支独立于识别分支。 通过这种方式,我们的方法有助于避免 MIL 的陷阱之一,即该方法陷入局部最优的倾向。
我们的双流 CNN 也与 Lin 等人最近的工作相关。 [21]。 他们提出了一种“双线性”架构,其中通过在相应空间位置取特征向量的外积来组合两个并行网络流的输出。 作者表示,这种结构的灵感来自人类视觉系统的腹侧和背侧流,一个侧重于识别,另一个侧重于定位。 虽然我们的架构包含两个这样的流,但相似之处只是表面的。 一个关键的区别是,在 Lin 等人. 中,两个流是完全对称的,因此没有理由相信一个应该执行分类,另一个应该执行检测;相反,在我们的方案中,检测分支被明确设计为比较区域,打破对称性。 另请注意,Lin 等人. [21] 不执行 WSD 也不评估对象检测性能。
应用修改后,网络就可以在目标数据集上进行微调,仅使用图像级标签、区域建议和反向传播。 在部分 4中,我们表明,当在 PASCAL VOC 训练集上进行微调时,该架构实现了最先进的弱对 PASCAL 数据进行监督目标检测,取得了优于当前最先进的[34]但仅使用 CNN 机器的结果。 由于该系统可以使用标准 CNN 包进行端到端训练,因此它的效率也与 Girshick 等人最近的完全监督的 Fast R-CNN 检测器一样高效。 [11],无论是在训练还是在测试中。 最后,作为我们构建的副产品,我们还获得了一个强大的图像分类器,它在目标数据上比标准微调技术表现更好。 我们的研究结果总结在部分5中。
2相关工作
大多数现有的 WSD 方法都将此任务表述为 MIL。 在这个公式中,图像被解释为一袋区域。 如果图像被标记为正,则假设其中一个区域紧密包含感兴趣的对象。 如果图像被标记为负片,则没有区域包含该对象。 学习在估计对象外观模型和使用外观模型选择正袋中对应于对象的区域之间交替进行。
MIL 策略导致非凸优化问题;在实践中,求解器往往会陷入局部最优,因此解决方案的质量很大程度上取决于初始化。 多篇论文重点关注开发各种初始化策略 [18, 5, 30, 4] 以及规范优化问题 [29, 1]。 Kumar 等人. [18]提出了一种自定进度的学习策略,该策略在训练时逐步将较难的样本包含到一小组初始样本中。 Deselaers et al. [5] 根据对象性得分初始化对象位置。 Cinbis 等人. [4]提出对训练数据进行多重分割以逃避局部最优。 Song 等人。 [29]将Nesterov的平滑技术[22]应用于潜在SVM公式 [10] 针对不良初始化更加稳健。 Bilen 等人. [1]提出了 MIL 的平滑版本,它可以软性地标记对象实例,而不是选择得分最高的实例。 此外,他们的方法通过基于对称和互斥原理惩罚不太可能的配置来规范潜在对象位置。
WSD 的另一项研究[29,30,34]基于识别图像部分之间的相似性的思想。 Song 等人. [29]提出了一种基于判别图的算法,该算法选择窗口的子集,使得每个窗口都连接到其最近的窗口正面形象中的邻居。 在[30]中,同一作者扩展了此方法以发现多个同时出现的部分配置。 Wang 等人. [34]提出了一种迭代技术,通过潜在语义分析(pLSA)在正样本窗口上应用潜在语义聚类。根据分类性能对每个类进行采样并选择最具辨别力的簇。 Bilen 等人. [2]提出了一种共同学习判别模型并通过判别凸来强制选定对象区域的相似性的公式聚类算法。
最近,许多研究人员[23, 24]提出了弱监督定位原则来提高 CNN 的分类性能,而不为图像中对象的位置提供任何标注。 Oquab 等人。 [23] 采用预训练的 CNN 来计算 PASCAL VOC 图像的中级图像表示。 在后续工作中,Oquab 等人。 [24]修改了 CNN 架构以粗略定位对象预测其标签时图像中的实例。
Jaderberg 等人。 [15]提出了一种 CNN 架构,其中子网络自动预变换图像,以优化分类精度第二个子网。 这种“Transformer 网络”是通过图像级标签以端到端方式进行训练的,可以将对象与公共参考系对齐,该参考系是检测的代理。 我们的架构包含一种机制,可以预先选择可能包含对象的图像区域,也以端到端的方式进行训练;虽然这看起来可能非常不同,但这种机制也可以被认为是学习转换(将检测到的区域映射到规范参考框架的转换)。 然而,我们和他们的网络中的选择过程的性质非常不同。
3方法
在本节中,我们介绍我们的弱监督深度检测网络(WSDDN)方法。 总体思路包括三个步骤。 首先,我们获得在大规模图像分类任务上预训练的 CNN (section 3.1)。 其次,我们构建 WSDDN 作为此 CNN 的架构修改(部分 3.2)。 第三,我们再次仅使用图像级注释(section 3.3)在目标数据集上训练/微调 WSDDN。 本节的其余部分详细讨论这三个步骤。
3.1 预训练网络
我们在预训练的 CNN 上构建我们的方法,该 CNN 已经在 ImageNet ILSVRC 2012 数据 [26] 上进行了预训练,仅具有图像级监督(即。 无边界框注释)。 我们在部分4中给出了所使用的CNN架构的详细信息。
3.2弱监督深度检测网络
给定预训练的 CNN,我们通过引入三个修改将其转换为 WSDDN(另请参见图 2)。 首先,我们用实现 spatial 的层替换最后一个卷积块中紧随 ReLU 层(也分别称为 relu5 和 pool5)的最后一个池化层。金字塔池化 (SPP) [19, 14]。 这会产生一个函数,该函数将图像 和区域(边界框) 作为输入,并生成特征向量或表示 作为输出。 重要的是,该函数分解为
其中 只需对整个图像计算一次,而 对于任何给定区域 的计算速度很快。实际上,SPP 配置为与网络的第一个全连接层(即. fc6)兼容。 请注意,SPP 是作为网络层实现的,如 [11] 中所示,以允许系统端到端(并提高效率)。
给定图像,通过区域提议机制获得候选对象区域的候选列表。 在这里,我们尝试了两种方法:选择性搜索窗口 (SSW) [32] 和边缘框 (EB) [37]。 与[11]一样,我们然后修改SPP层以不将单个区域作为输入,而是将完整列表作为输入;特别是, 被定义为 沿第四维的串联(因为每个单独的 都是一个 3D 张量)。
此时,在架构中,区域级特征由两个全连接层 和 进一步处理,每个层都包含一个线性映射,后跟一个 ReLU。 根据最后一层的输出,我们分支出两个数据流,如下所述。
分类数据流。
第一个数据流通过将每个区域映射到类分数的 维向量来对各个区域执行分类,假设系统经过训练可以检测 不同的类。 这是通过评估线性映射 并生成数据矩阵 来实现的,其中包含每个区域的类预测分数。 然后将后者传递给 softmax 运算符,定义如下:
| (1) |
检测数据流。
第二个数据流通过相对于彼此对区域进行评分来执行检测。 这是通过使用第二个线性映射 在特定于类的基础上完成的,也会产生分数矩阵 。 然后它通过另一个 softmax 运算符,但这次定义如下:
| (2) |
虽然这两个流非常相似,但在分类和检测流中引入 和 非线性是一个关键区别,它允许将它们解释为执行分类和检测, 分别。 事实上,在第一种情况下,softmax 算子独立地比较每个区域的类别分数,而在第二种情况下,softmax 算子独立地比较每个类别的不同区域的分数。 因此,第一个分支预测哪个类与区域相关联,而第二个分支选择哪些区域更有可能包含信息丰富的图像片段。
组合区域得分和检测。
每个区域的最终得分是通过两个评分矩阵的元素级(Hadamard)乘积获得的。 然后使用区域分数通过将对象居中的可能性对图像区域进行排名(对于每个类别独立);然后执行标准非极大值抑制(通过迭代删除与已选择区域交并 (IoU) 大于 40% 的区域)以获得图像中特定于类的检测的最终列表。
两个流分数的组合方式让人想起[21]的双线性网络,但存在三个关键区别。 第一个区别是不同的 softmax 运算符的引入显式地打破了两个流的对称性。 第二个是,我们不计算两个特征向量 的外积,而是计算元素乘积 (生成二次方更少的参数)。 第三个区别是分数 是针对特定图像区域 计算的,而不是针对网格上一组固定的图像位置计算的。 总之,这三个差异意味着我们可以将 解释为对区域进行排名的术语,而 对类别进行排名。 清楚地评估[21]中两个流的性质更加困难。
图像级分类分数。
到目前为止,WSDDN 已计算出区域级别的分数。 通过区域求和将其转换为图像级类别预测分数:
请注意, 都是 区域上 softmax 归一化分数的逐元素乘积之和,因此它在 范围内。 在此阶段不执行 Softmax,因为图像允许包含多个对象类(而区域应包含单个类)。
3.3训练 WSDDN
上一节讨论了 WSDDN 架构,这里我们解释一下模型是如何训练的。 数据是带有图像级别标签的图像的集合。我们用 表示完整的架构,将图像 映射到类别分数向量 。 模型的参数 将卷积层和全连接层中所有滤波器的系数和偏差集中在一起。 然后,使用动量随机梯度下降来优化能量函数
| (3) |
因此优化了 二进制对数损失项的总和,每个类一个。 由于在范围内,因此可以将其视为类出现在图像、即。。 当真实标签为正时,二进制日志损失变为,否则为。
3.4 空间正则化器
由于 WSDDN 针对图像级类标签进行了优化,因此它不保证任何空间平滑性,因此如果一个区域在对象类中获得高分,则具有高重叠度的相邻区域也将具有高分。 在监督检测情况下,Fast-RCNN [11] 将与地面真值框至少具有 IoU 的区域提案作为正样本,并学习将它们回归到它们的正样本中。相应的地面实况边界框。 由于我们的方法无法访问地面实况框,因此我们采用软正则化策略,在训练过程中,对第二个全连接层 fc7 中得分最高区域与至少有 IoU 的区域(即. )之间的特征图差异进行惩罚:
其中, 是类别 的正图像数, 是类别 的图像 中得分最高的区域。我们在 eq. 3 中的成本函数中添加此正则化项。
4实验
在本节中,我们对 WSDDN 及其组件在弱监督检测和图像分类方面进行了彻底的研究。
4.1基准数据。
我们在 PASCAL VOC 2007 和 2010 数据集[9]上评估我们的方法,因为它们是弱监督目标检测中最广泛使用的基准。 VOC 2007 数据集包含 2501 个训练图像、2510 个验证图像和 5011 个包含 20 个对象类别的边界框注释的测试图像,而 VOC 2010 数据集包含相同数量类别的 4998 个训练图像、5105 个验证图像和 9637 个测试图像。 我们使用建议的训练和验证拆分,并报告在 test 拆分上评估的结果。 我们报告了我们的方法在 PASCAL VOC 的对象检测和图像分类任务上的性能。
为了进行检测,我们使用两种性能指标。 第一个遵循标准 PASCAL VOC 协议,并报告检测到的框与真实框的 交集 (IoU) 处的平均精度 (AP)。 我们还报告了 CorLoc,一种常用的弱监督检测措施[6]。 CorLoc 是包含至少一个目标对象类实例的图像的百分比,其中最可信的检测到的边界框与这些实例之一至少重叠 。 与在 PASCAL 测试集上测量的 AP 不同,CorLoc 在 PASCAL 和验证子集的并集上进行评估。 对于分类,我们使用标准 PASCAL VOC 协议并报告 AP。
4.2实验设置。
我们在实验中使用三个预训练的 CNN 模型全面评估我们的方法,如[11]。 第一个网络是 VGG-CNN-F [3],它与 AlexNet [17] 类似,但减少了卷积滤波器的数量。 我们将此网络称为 S,即小型网络。 第二个是 VGG-CNN-M-1024,其深度与 S 相同,但第一个卷积层的步长较小。 我们将该网络命名为 M,表示介质。 最后一个网络是深度 VGG-VD16 模型[28],我们将此网络称为“大”网络L。 这些模型根据 ImageNet ILSVRC 2012 挑战数据 [26] 进行预训练,达到 、 和 ILSVRC 上的 top-5 准确率(使用单个中心裁剪)(重要的是在预训练期间没有提供边界框信息)。 如部分3.1中所述,我们对网络进行以下修改。 首先,我们将最后一个池化层 pool5 替换为 SPP 层 [14],该层配置为与网络的第一个全连接层兼容。 其次,我们向分类分支添加一个并行检测分支,其中包含一个全连接层,后面跟着一个 soft-max 层。 第三,我们通过元素乘积将分类和检测流结合起来,然后对各个区域的分数进行求和,并将后者输入二进制对数损失层。 请注意,该层一起评估 20 个类别的分类性能,但每个类别都被视为不同的二元分类问题;原因是 PASCAL VOC 中的类可以同时出现,因此 AlexNet 中使用的 softmax 对数损失并不合适。
WSDDN 通过在所有层上使用微调,在 PASCAL VOC 训练和验证数据上进行训练,这是一种广泛采用的技术,用于提高 CNN 在目标域 [3] 上的性能。 然而,在这里,微调执行学习分类和检测流的基本功能,有效地使网络学习检测对象,但仅使用弱图像级监督。 实验运行 epoch,所有层均使用前 10 个 epoch 的学习率 和后 10 个 epoch 的学习率 进行微调。 每个小批量包含来自单个图像的所有区域建议。
为了生成与我们的网络一起使用的候选区域,我们评估了两种建议方法,选择性搜索窗口(SSW)[32]使用其fast设置,以及EdgeBoxes(EB ) [37]。 除了区域建议之外,EB 还根据完全包围的轮廓数量为每个区域提供客观性分数。 我们通过 WSDDN 中的缩放层乘以与其分数成比例的特征图 来利用此附加信息,并将此设置表示为 Box Sc。 由于我们使用 SPP 层来聚合每个区域的描述符,因此不需要像原始预训练模型那样将图像大小调整为特定大小。 相反,我们保持图像的原始长宽比固定,并将其大小调整为五个不同的比例(将其最大宽度或高度分别设置为 ),如 [14] 中所示。 在训练过程中,我们对图像应用随机水平翻转,并随机选择一个比例作为抖动或数据增强的形式。 在测试时,我们对 10 个图像的输出进行平均(即。 5 个尺度及其翻转)。 我们使用公开的 CNN 工具箱 MatConvNet [33] 进行实验并共享我们的代码、模型和数据111https://github.com/hbilen/WSDDN。
当对图像进行评估时,WSDDN 会为每个目标类 和图像 生成每个区域 的分数 和每个图像的聚合分数。 对区域应用非极大值抑制(使用 % IoU 阈值),然后将评分区域和图像合并在一起以计算检测 AP 和 CorLoc。
| S | M | L | Ens. | |
|---|---|---|---|---|
| SSW | 31.1 | 30.9 | 24.3 | 33.3 |
| EB | 31.5 | 30.9 | 25.5 | 34.2 |
| EB + Box Sc. | 33.4 | 32.7 | 30.4 | 36.7 |
| EB + Box Sc. + Sp. Reg. | 34.5 | 34.9 | 34.8 | 39.3 |
| method | aero | bike | bird | boat | bottle | bus | car | cat | chair | cow | table | dog | horse | mbike | persn | plant | sheep | sofa | train | tv | mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WSDDN S | 42.9 | 56.0 | 32.0 | 17.6 | 10.2 | 61.8 | 50.2 | 29.0 | 3.8 | 36.2 | 18.5 | 31.1 | 45.8 | 54.5 | 10.2 | 15.4 | 36.3 | 45.2 | 50.1 | 43.8 | 34.5 |
| WSDDN M | 43.6 | 50.4 | 32.2 | 26.0 | 9.8 | 58.5 | 50.4 | 30.9 | 7.9 | 36.1 | 18.2 | 31.7 | 41.4 | 52.6 | 8.8 | 14.0 | 37.8 | 46.9 | 53.4 | 47.9 | 34.9 |
| WSDDN L | 39.4 | 50.1 | 31.5 | 16.3 | 12.6 | 64.5 | 42.8 | 42.6 | 10.1 | 35.7 | 24.9 | 38.2 | 34.4 | 55.6 | 9.4 | 14.7 | 30.2 | 40.7 | 54.7 | 46.9 | 34.8 |
| WSDDN Ensemble | 46.4 | 58.3 | 35.5 | 25.9 | 14.0 | 66.7 | 53.0 | 39.2 | 8.9 | 41.8 | 26.6 | 38.6 | 44.7 | 59.0 | 10.8 | 17.3 | 40.7 | 49.6 | 56.9 | 50.8 | 39.3 |
| Bilen et al. [1] | 42.2 | 43.9 | 23.1 | 9.2 | 12.5 | 44.9 | 45.1 | 24.9 | 8.3 | 24.0 | 13.9 | 18.6 | 31.6 | 43.6 | 7.6 | 20.9 | 26.6 | 20.6 | 35.9 | 29.6 | 26.4 |
| Bilen et al. [2] | 46.2 | 46.9 | 24.1 | 16.4 | 12.2 | 42.2 | 47.1 | 35.2 | 7.8 | 28.3 | 12.7 | 21.5 | 30.1 | 42.4 | 7.8 | 20.0 | 26.8 | 20.8 | 35.8 | 29.6 | 27.7 |
| Cinbis et al. [4] | 39.3 | 43.0 | 28.8 | 20.4 | 8.0 | 45.5 | 47.9 | 22.1 | 8.4 | 33.5 | 23.6 | 29.2 | 38.5 | 47.9 | 20.3 | 20.0 | 35.8 | 30.8 | 41.0 | 20.1 | 30.2 |
| Wang et al. [34] | 48.8 | 41.0 | 23.6 | 12.1 | 11.1 | 42.7 | 40.9 | 35.5 | 11.1 | 36.6 | 18.4 | 35.3 | 34.8 | 51.3 | 17.2 | 17.4 | 26.8 | 32.8 | 35.1 | 45.6 | 30.9 |
| Wang et al. [34]+context | 48.9 | 42.3 | 26.1 | 11.3 | 11.9 | 41.3 | 40.9 | 34.7 | 10.8 | 34.7 | 18.8 | 34.4 | 35.4 | 52.7 | 19.1 | 17.4 | 35.9 | 33.3 | 34.8 | 46.5 | 31.6 |
| method | aero | bike | bird | boat | bottle | bus | car | cat | chair | cow | table | dog | horse | mbike | persn | plant | sheep | sofa | train | tv | mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WSDDN S | 68.5 | 67.5 | 56.7 | 34.3 | 32.8 | 69.9 | 75.0 | 45.7 | 17.1 | 68.1 | 30.5 | 40.6 | 67.2 | 82.9 | 28.8 | 43.7 | 71.9 | 62.0 | 62.8 | 58.2 | 54.2 |
| WSDDN M | 65.1 | 63.4 | 59.7 | 45.9 | 38.5 | 69.4 | 77.0 | 50.7 | 30.1 | 68.8 | 34.0 | 37.3 | 61.0 | 82.9 | 25.1 | 42.9 | 79.2 | 59.4 | 68.2 | 64.1 | 56.1 |
| WSDDN L | 65.1 | 58.8 | 58.5 | 33.1 | 39.8 | 68.3 | 60.2 | 59.6 | 34.8 | 64.5 | 30.5 | 43.0 | 56.8 | 82.4 | 25.5 | 41.6 | 61.5 | 55.9 | 65.9 | 63.7 | 53.5 |
| WSDDN Ensemble | 68.9 | 68.7 | 65.2 | 42.5 | 40.6 | 72.6 | 75.2 | 53.7 | 29.7 | 68.1 | 33.5 | 45.6 | 65.9 | 86.1 | 27.5 | 44.9 | 76.0 | 62.4 | 66.3 | 66.8 | 58.0 |
| Bilen et al. [2] | 66.4 | 59.3 | 42.7 | 20.4 | 21.3 | 63.4 | 74.3 | 59.6 | 21.1 | 58.2 | 14.0 | 38.5 | 49.5 | 60.0 | 19.8 | 39.2 | 41.7 | 30.1 | 50.2 | 44.1 | 43.7 |
| Cinbis et al. [4] | 65.3 | 55.0 | 52.4 | 48.3 | 18.2 | 66.4 | 77.8 | 35.6 | 26.5 | 67.0 | 46.9 | 48.4 | 70.5 | 69.1 | 35.2 | 35.2 | 69.6 | 43.4 | 64.6 | 43.7 | 52.0 |
| Wang et al. [34] | 80.1 | 63.9 | 51.5 | 14.9 | 21.0 | 55.7 | 74.2 | 43.5 | 26.2 | 53.4 | 16.3 | 56.7 | 58.3 | 69.5 | 14.1 | 38.3 | 58.8 | 47.2 | 49.1 | 60.9 | 48.5 |
| method | aero | bike | bird | boat | bottle | bus | car | cat | chair | cow | table | dog | horse | mbike | persn | plant | sheep | sofa | train | tv | mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WSDDN S | 92.5 | 89.9 | 89.5 | 88.3 | 66.5 | 83.6 | 92.1 | 90.3 | 73.0 | 85.7 | 72.6 | 91.4 | 90.1 | 89.0 | 94.4 | 78.1 | 86.0 | 76.1 | 91.1 | 85.5 | 85.3 |
| WSDDN M | 93.9 | 91.0 | 90.4 | 89.3 | 72.7 | 86.4 | 91.9 | 91.5 | 73.8 | 85.6 | 74.9 | 91.9 | 91.5 | 89.9 | 94.5 | 78.6 | 85.0 | 78.6 | 91.5 | 85.7 | 86.4 |
| WSDDN L | 93.3 | 93.9 | 91.6 | 90.8 | 82.5 | 91.4 | 92.9 | 93.0 | 78.1 | 90.5 | 82.3 | 95.4 | 92.7 | 92.4 | 95.1 | 83.4 | 90.5 | 80.1 | 94.5 | 89.6 | 89.7 |
| WSDDN Ensemble | 95.0 | 92.6 | 91.2 | 90.4 | 79.0 | 89.2 | 92.8 | 92.4 | 78.5 | 90.5 | 80.4 | 95.1 | 91.6 | 92.5 | 94.7 | 82.2 | 89.9 | 80.3 | 93.1 | 89.1 | 89.0 |
| Oquab et al. [23] | 88.5 | 81.5 | 87.9 | 82.0 | 47.5 | 75.5 | 90.1 | 87.2 | 61.6 | 75.7 | 67.3 | 85.5 | 83.5 | 80.0 | 95.6 | 60.8 | 76.8 | 58.0 | 90.4 | 77.9 | 77.7 |
| SPP [14] | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | 82.4 |
| VGG-F [3] | 88.7 | 83.9 | 87.0 | 84.7 | 46.9 | 77.5 | 86.3 | 85.4 | 58.6 | 71.0 | 72.6 | 82.0 | 87.9 | 80.7 | 91.8 | 58.5 | 77.4 | 66.3 | 89.1 | 71.3 | 77.4 |
| VGG-M-1024 [3] | 91.4 | 86.9 | 89.3 | 85.8 | 53.3 | 79.8 | 87.8 | 88.6 | 59.0 | 77.2 | 73.1 | 85.9 | 88.3 | 83.5 | 91.8 | 59.9 | 81.4 | 68.3 | 93.0 | 74.1 | 79.9 |
| VGG-S [3] | 95.3 | 90.4 | 92.5 | 89.6 | 54.4 | 81.9 | 91.5 | 91.9 | 64.1 | 76.3 | 74.9 | 89.7 | 92.2 | 86.9 | 95.2 | 60.7 | 82.9 | 68.0 | 95.5 | 74.4 | 82.4 |
| VGG-VD16 [28] | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | – | 89.3 |
| method | aero | bike | bird | boat | bottle | bus | car | cat | chair | cow | table | dog | horse | mbike | persn | plant | sheep | sofa | train | tv | mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WSDDN Ensemble | 57.4 | 51.8 | 41.2 | 16.4 | 22.8 | 57.3 | 41.8 | 34.8 | 13.1 | 37.6 | 10.8 | 37.0 | 45.2 | 64.9 | 14.1 | 22.3 | 33.8 | 27.6 | 49.1 | 44.8 | 36.2 |
| Cinbis et al. [4] | 44.6 | 42.3 | 25.5 | 14.1 | 11.0 | 44.1 | 36.3 | 23.2 | 12.2 | 26.1 | 14.0 | 29.2 | 36.0 | 54.3 | 20.7 | 12.4 | 26.5 | 20.3 | 31.2 | 23.7 | 27.4 |
| method | aero | bike | bird | boat | bottle | bus | car | cat | chair | cow | table | dog | horse | mbike | persn | plant | sheep | sofa | train | tv | mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WSDDN Ensemble | 77.4 | 73.2 | 61.9 | 39.6 | 50.8 | 84.4 | 67.5 | 49.6 | 38.6 | 73.4 | 30.4 | 53.2 | 72.9 | 84.1 | 30.3 | 53.1 | 76.6 | 48.5 | 61.6 | 66.7 | 59.7 |
| Cinbis et al. [4] | 61.1 | 65.0 | 59.2 | 44.3 | 28.3 | 80.6 | 69.7 | 31.2 | 42.8 | 73.3 | 38.3 | 50.2 | 74.9 | 70.9 | 37.3 | 37.1 | 65.3 | 55.3 | 61.7 | 58.2 | 55.2 |
4.3检测结果
基线方法。
首先,我们设计一个单流分类检测网络作为 WSDDN 的替代基线。 部分构建与 WSDDN 类似,我们用 SPP 替换 VGG-CNN-F 模型的 pool5 层。 但是,我们不会分支两个流,而是简单地将以下损失层附加到最后一个全连接层()
术语)是最大运算符的软近似,并且发现比使用最大评分区域产生更好的性能。 [1] 中也报告了这一观察结果。 请注意,非线性是必要的,否则聚合基于区域的分数将会对大多数无信息区域的分数进行求和。 损失函数再次是 二元铰链损失的总和,每个类别一个。 该基线在 PASCAL VOC 测试集上获得 mAP 检测分数,远低于当前最佳水平([34] 中的 >)。
预训练的 CNN 架构。
对象提案。
接下来,我们比较了两种流行的对象提议方法 SSW [32] 和 EB [37] 的检测性能。 虽然两种区域建议都提供了质量相当的区域建议,但使用 EB 的箱体得分(在 表 1 中表示为 Box Sc)会使模型 S 和 M 的检测性能得到 的改善,并提高模型 L 的检测性能。
空间正则化器。
我们表示使用附加空间正则化项训练 WSDDN 的设置(表示为 Sp.Reg. 在表1中)。 最后,正则化的引入提高了模型S、M的检测性能、和 mAP点分别为和L。 这些改进表明,较大的网络从高置信区域周围引入空间不变性中受益更多。
与现有技术的比较。
评估设计决策后,我们遵循最佳设置(table 1 中的最后一行)并以弱方式将 WSDDN 与现有技术进行比较table 2 和 table 3 中的监督检测文献> 对于 VOC 2007 数据集以及 table0> 51> 和 table3> 64>2> VOC 2010 数据集。 结果表明,我们的方法已经取得了比这些单一模型和集成模型的替代方案更好的总体性能,并且集成模型进一步提高了性能。 之前的大部分工作[29,30,1,35,2]使用Caffe参考CNN模型[16],该模型与模型S 在本文中,作为一个黑盒来提取 SSW 提案的特征。 除了 CNN 特征之外,Cinbis et al. [4] 使用 Fisher Vectors [25] 和 EB objectness Zitnick 和 Dollar [37] 的衡量标准。 与之前的工作不同,WSDDN 基于对原始 CNN 架构的简单修改,并使用反向传播对目标数据进行微调。
接下来,我们更详细地研究结果。 虽然我们的方法在大多数类别中显着优于替代方法,但在椅子、人物和盆栽植物类别中并不那么强大。 失败和成功案例见 fig. 3。 可以指出的是,到目前为止,我们系统最重要的故障模式是对象部分(例如人脸)被检测为整个对象。 这可以通过以下事实来解释:“面部”等部分通常比对象的其他部分更具辨别力并且外观变化较小。 请注意,这种失败模式的根本原因是,我们和许多其他作者一样,将对象定义为对给定对象类最具预测性的图像区域,而这些区域可能不包括整个对象。 因此,解决这个问题需要在模型中加入额外的提示来尝试学习“整个对象”。
我们模型的输出也可以用作现有弱监督检测方法之一的输入,该方法使用 CNN 作为特征提取的黑盒。 研究这个选项留待未来的工作。

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|
4.4分类结果
虽然 WSDDN 主要是为弱监督目标检测而设计的,但最终它被训练来执行图像分类。 因此,评估其在这项任务上的表现也很有趣。 为此,我们使用 PASCAL VOC 2007 基准,并将其与经常与 CNN 结合使用的标准微调技术进行对比,并在表 6中显示结果t2>。 [3,14,23] 对这些技术进行了彻底的研究。 Chatfield 等人。 [3]特别分析了 PASCAL VOC 上的许多微调变体,包括广泛的数据增强。 他们尝试了三种架构:VGG-F、VGG-M 和 VGG-S。 虽然 VGG-F 是最快的模型,但其他两个网络速度较慢但更准确。 如4.2中所述,我们分别用预训练的VGG-F和VGG-M-1024初始化WSDDN S和M,因此它们应被视为正确的基线。 WSDDN S 和 M 分别比 VGG-F 和 VGG-M-1024 提高了 和 点。
我们还将 WSDDN 与 SPP-net [14] 进行比较,后者使用 Overfeat-7 [27] 和 4 级空间金字塔池化层 用于监督对象检测。 虽然它们不执行微调,但它们包含空间池层。 应用于图像分类时,它们在 PASCAL VOC 2007 上的最佳性能是。 最后,我们将 WSDDN L 与竞争产品 VGG-VD16 [28] 进行比较。 有趣的是,该方法还通过聚合多个位置和尺度上最后一个全连接层的激活来利用粗略的局部信息。 WSDDN L 的性能优于这一极具竞争力的基线,优势为 点。
5结论
在本文中,我们提出了 WSDDN,这是对用于图像分类的预训练 CNN 的简单修改,使其能够执行弱监督检测。 它在弱监督检测方面比现有方法取得了明显更好的性能,同时只需要使用反向传播、区域建议和图像级标签对目标数据集进行微调。 由于它在 SPP 层之上工作,因此在训练和测试时也非常高效。 WSDDN 还被证明比传统的微调技术表现更好,可以提高预训练 CNN 在图像分类问题上的性能。
我们已经将对象部分的检测确定为该方法的失败模式,损害了其在选定对象类别中的性能,并将其归咎于用于识别对象的主要标准,即高度独特的图像区域的选择。 我们目前正在探索有利于检测完整物体的补充线索。
致谢: 这项工作感谢 EPSRC EP/L024683/1、EPSRC Seebibyte EP/M013774/1 和 ERC 起始拨款 IDIU 的支持。
参考
- [1] H. Bilen, M. Pedersoli, and T. Tuytelaars. Weakly supervised object detection with posterior regularization. In Proc. BMVC., 2014.
- [2] H. Bilen, M. Pedersoli, and T. Tuytelaars. Weakly supervised object detection with convex clustering. In Proc. CVPR, 2015.
- [3] K. Chatfield, K. Simonyan, A. Vedaldi, and A. Zisserman. Return of the devil in the details: Delving deep into convolutional nets. In Proc. BMVC., 2014.
- [4] R. G. Cinbis, J. Verbeek, and C. Schmid. Weakly supervised object localization with multi-fold multiple instance learning. arXiv preprint arXiv:1503.00949, 2015.
- [5] T. Deselaers, B. Alexe, and V. Ferrari. Localizing objects while learning their appearance. In Proc. ECCV, pages 452–466, 2010.
- [6] T. Deselaers, B. Alexe, and V. Ferrari. Weakly supervised localization and learning with generic knowledge. IJCV, 100(3):275–293, 2012.
- [7] T. G. Dietterich, R. H. Lathrop, and T. Lozano-Perez. Solving the multiple instance problem with axis-parallel rectangles. Artificial Intelligence, 89(1-2):31–71, 1997.
- [8] J. Donahue, Y. Jia, O. Vinyals, J. Hoffman, N. Zhang, E. Tzeng, and T. Darrell. Decaf: A deep convolutional activation feature for generic visual recognition. CoRR, abs/1310.1531, 2013.
- [9] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The PASCAL Visual Object Classes (VOC) challenge. IJCV, 88(2):303–338, 2010.
- [10] P. F. Felzenszwalb, R. B. Grishick, D. McAllester, and D. Ramanan. Object detection with discriminatively trained part based models. IEEE PAMI, 2010.
- [11] R. Girshick. Fast r-cnn. In Proc. ICCV, 2015.
- [12] R. B. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proc. CVPR, 2014.
- [13] B. Hariharan, P. Arbeláez, R. Girshick, and J. Malik. Simultaneous detection and segmentation. In Proc. ECCV, pages 297–312, 2014.
- [14] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In Proc. ECCV, pages 346–361, 2014.
- [15] M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu. Spatial transformer networks. 2015.
- [16] Y. Jia. Caffe: An open source convolutional architecture for fast feature embedding. http://caffe.berkeleyvision.org/, 2013.
- [17] A. Krizhevsky, I. Sutskever, and G. E. Hinton. ImageNet classification with deep convolutional neural networks. In NIPS, pages 1106–1114, 2012.
- [18] M. P. Kumar, B. Packer, and D. Koller. Self-paced learning for latent variable models. In NIPS, pages 1189–1197, 2010.
- [19] S. Lazebnik, C. Schmid, and J. Ponce. Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories. In Proc. CVPR, 2006.
- [20] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1(4):541–551, 1989.
- [21] T. J. Lin, A. RoyChowdhury, and S. Maji. Bilinear cnn models for fine-grained visual recognition. In Proc. ICCV, 2015.
- [22] Y. Nesterov. Smooth minimization of non-smooth functions. Mathematical programming, 103(1):127–152, 2005.
- [23] M. Oquab, L. Bottou, I. Laptev, and J. Sivic. Learning and Transferring Mid-Level Image Representations using Convolutional Neural Networks. In Proc. CVPR, 2014.
- [24] M. Oquab, L. Bottou, I. Laptev, and J. Sivic. Is object localization for free?–weakly-supervised learning with convolutional neural networks. In CVPR, pages 685–694, 2015.
- [25] F. Perronnin, J. Sánchez, and T. Mensink. Improving the Fisher kernel for large-scale image classification. In Proc. ECCV, 2010.
- [26] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, S. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. Berg, and F. Li. Imagenet large scale visual recognition challenge. IJCV, 2015.
- [27] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv preprint arXiv:1312.6229, 2013.
- [28] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In International Conference on Learning Representations, 2015.
- [29] H. O. Song, R. Girshick, S. Jegelka, J. Mairal, Z. Harchaoui, and T. Darrell. On learning to localize objects with minimal supervision. In Proc. ICML, pages 1611–1619, 2014.
- [30] H. O. Song, Y. J. Lee, S. Jegelka, and T. Darrell. Weakly-supervised discovery of visual pattern configurations. In NIPS, pages 1637–1645, 2014.
- [31] A. Toshev and C. Szegedy. DeepPose: Human pose estimation via deep neural networks. arXiv preprint arXiv:1312.4659, 2013.
- [32] K. van de Sande, J. Uijlings, T. Gevers, and A. Smeulders. Segmentation as selective search for object recognition. In Proc. ICCV, 2011.
- [33] A. Vedaldi and K. Lenc. Matconvnet – convolutional neural networks for matlab. In Proceeding of the ACM Int. Conf. on Multimedia, 2015.
- [34] C. Wang, W. Ren, K. H., and T. Tan. Weakly supervised object localization with latent category learning. In Proc. ECCV, volume 8694, pages 431–445, 2014.
- [35] J. Wang, Y. Song, T. Leung, C. Rosenberg, J. Wang, J. Philbin, B. Chen, and Y. Wu. Learning fine-grained image similarity with deep ranking. In Proc. CVPR, 2014.
- [36] B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba. Object detectors emerge in deep scene CNNs. In ICLR, 2015.
- [37] C. L. Zitnick and P. Dollár. Edge boxes: Locating object proposals from edges. In Proc. ECCV, pages 391–405, 2014.