(eccv) Package eccv Warning: Package ‘hyperref’ is loaded with option ‘pagebackref’, which is *not* recommended for camera-ready version
https://coda-dataset.github.io/coda-lm/
Automated Evaluation of Large Vision-Language Models on Self-driving Corner Cases
Abstract
Large Vision-Language Models (LVLMs), due to the remarkable visual reasoning ability to understand images and videos, have received widespread attention in the autonomous driving domain, which significantly advances the development of interpretable end-to-end autonomous driving. However, current evaluations of LVLMs primarily focus on the multi-faceted capabilities in common scenarios, lacking quantifiable and automated assessment in autonomous driving contexts, let alone severe road corner cases that even the state-of-the-art autonomous driving perception systems struggle to handle. In this paper, we propose CODA-LM, a novel vision-language benchmark for self-driving, which provides the first automatic and quantitative evaluation of LVLMs for interpretable autonomous driving including general perception, regional perception, and driving suggestions. CODA-LM utilizes the texts to describe the road images, exploiting powerful text-only large language models (LLMs) without image inputs to assess the capabilities of LVLMs in autonomous driving scenarios, which reveals stronger alignment with human preferences than LVLM judges. Experiments demonstrate that even the closed-sourced commercial LVLMs like GPT-4V cannot deal with road corner cases well, suggesting that we are still far from a strong LVLM-powered intelligent driving agent, and we hope our CODA-LM can become the catalyst to promote future development.
Keywords:
LVLM Evaluation Autonomous Driving Corner Case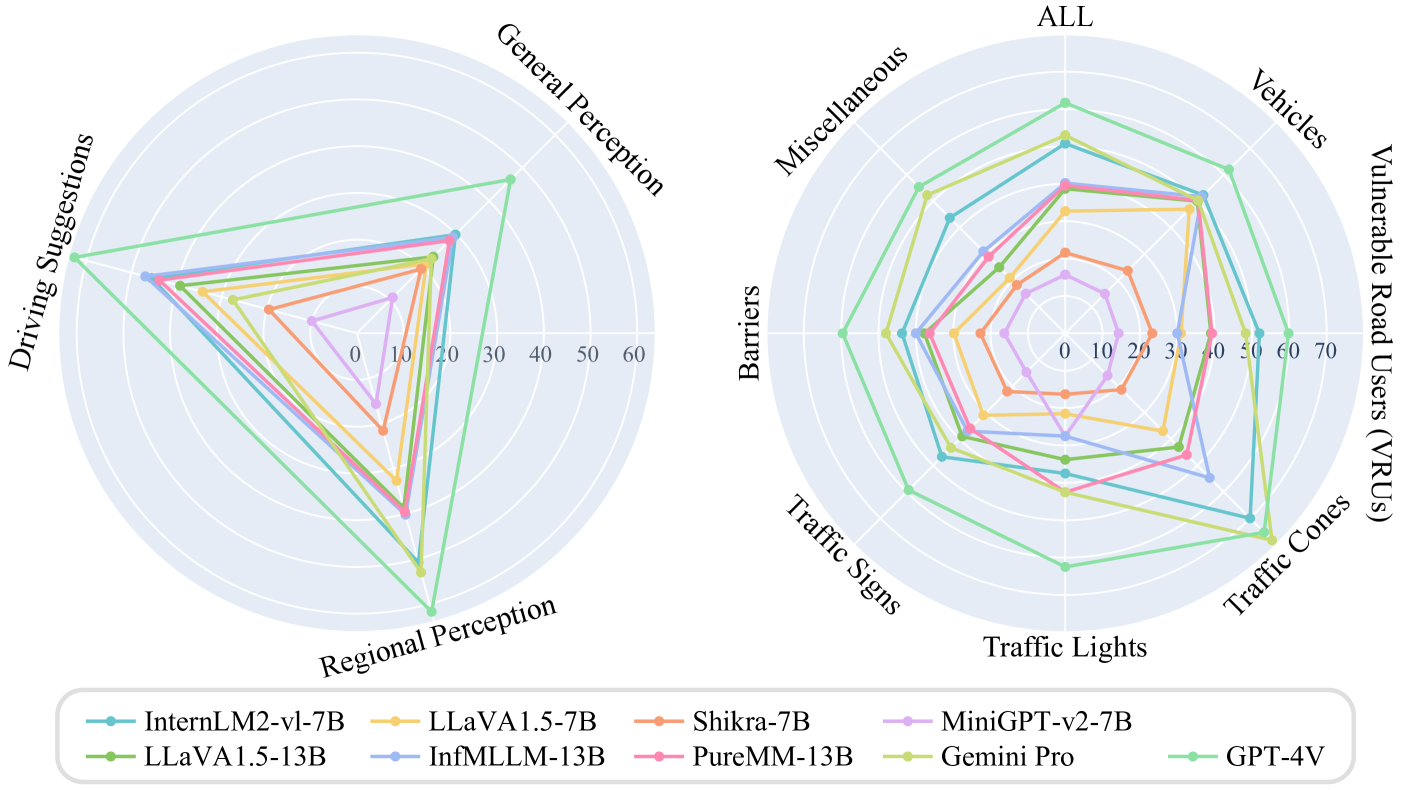
1 Introduction
Large Vision-Language Models (LVLMs) [26, 46, 16, 31] have attracted increasing attention from research communities, primarily due to their remarkable visual reasoning capabilities. Notably, under the context of autonomous driving, powerful reasoning abilities are of paramount importance [19, 35]. Since traffic scenes are inherently complicated with high variance, self-driving systems must be able to comprehend the surroundings and make decisions properly.
Traditional autonomous driving systems adopt a modular design philosophy, integrating various modules such as perception, prediction, and planning. They rely on data-driven algorithms and intricate rules to handle complex traffic scenarios. Despite that, however, they are still inadequate to generalize in the open domain, especially in addressing real-world corner cases [23]. These systems often suffer from unseen scenarios and unfamiliar objects. LVLMs, on the other hand, with their extensive world knowledge and reasoning capability, have the potential to overcome these severe challenges.
A preliminary attempt has been made in [41] to examine the ability of the powerful LVLM [31] in handling corner case scenarios. A subset of images have been selected from the CODA dataset [23] which focuses on unusual and unexpected scenarios that an autonomous vehicle might encounter. It shows that LVLMs could generalize well in out-of-distribution (OOD) road cases which are challenging for sensory perception system. However, the evaluation primarily relies on time-consuming, costly, and unscalable manual inspections. On the contrary, automated evaluation techniques are employed in general visual scenarios for the rapid development of LVLMs, including MME [13] using binary judgment and MMBench [27] with single-choice formats. However, such a simplified design is not sufficient to thoroughly evaluate LVLMs on complicated scenarios like self-driving, requiring both regional perception [17] and visual reasoning [35]. Thus, there is a necessity to develop a new benchmark for automated evaluation of LVLMs for corner cases in self-driving.
In this work, we introduce CODA-LM, a novel benchmark for systematic evaluation of LVLMs on road corner cases. First, we construct the CODA-LM dataset based on the widely used CODA [23] dataset, with three distinct tasks including general perception, regional perception, and driving suggestions. A meticulously designed pipeline is proposed for dataset construction, including pre-annotation by the LVLM, visual prompt design, and manual verification and revision. Subsequently, we demonstrate the necessity of utilizing the powerful LLM [32] as the “judge” to perform automated evaluation of LVLMs on CODA-LM, which reveals stronger consistency with human judges than the powerful LVLM [31]. We adopt the few-shot in-context learning (ICL) and meticulously designed evaluation criteria (e.g., accuracy, hallucination penalty, and consistency) to compare the responses of different LVLMs with the manually-verified reference answers. As shown in Fig. 1, we fully evaluate LVLMs’ performance regarding the three tasks and seven road categories. Experiments demonstrate that several open-sourced LVLMs [42, 26, 12, 46, 45] perform closely with the commercial LVLMs [31, 36], even GPT-4V currently cannot deal with road corner cases very well, suggesting we are still far from a strong LVLM-powered driving agent, and we hope CODA-LM can promote the future development.
The main contributions of this work can be summarized as follows.
-
1.
We propose CODA-LM, a novel benchmark to evaluate LVLM’s capability in addressing corner case scenarios in autonomous driving, comprising an automatic and systematic evaluation framework.
-
2.
We demonstrate that the powerful LLM can serve as a reasonable judge to evaluate LVLMs, with in-context learning and carefully designed evaluation criteria, showing a higher consistency with human judgment than the powerful LVLM.
-
3.
We comprehensively evaluate the the autonomous driving capabilities with existing LVLMs, identify their common issues, and provide suggestions for future research directions.
| Dataset | Multimodal | Corner | General Per. | Regional Per. | Suggestion |
| CODA [23] | ✗ | ✓ | ✓ | ✓ | ✗ |
| StreetHazards [18] | ✗ | ✓ | ✓ | ✓ | ✗ |
| nuScenes-QA [34] | ✓ | ✗ | ✓ | ✗ | ✗ |
| BDD-X [21] | ✓ | ✗ | ✓ | ✗ | ✗ |
| DRAMA [30] | ✓ | ✗ | ✓ | ✓ | ✓ |
| DriveLM [35] | ✓ | ✗ | ✓ | ✓ | ✓ |
| CODA-LM | ✓ | ✓ | ✓ | ✓ | ✓ |
2 Related Work
2.0.1 LVLM Evaluation.
MME [13] introduces manually designed question-answer pairs to measure both perception and cognition abilities on a total of 14 sub-tasks, converting evaluation results into binary (Yes/No) outputs for quantifiable analysis. MMBench [27] employs GPT-4 to transform free-form predictions into pre-defined multiple-choice questions and introduces the CircularEval strategy for a more robust evaluation. SEED-Bench-2 [22] adopts a similar format with MMBench but extends over 27 evaluation dimensions, evaluating LVLMs’ capabilities in image and text comprehension, interleaved image-text understanding, and generation tasks. The above evaluation method primarily relies on rigid, manually curated datasets. Auto-Bench [20] generates a vast array of question-answer-reasoning triplets by prompting LLMs [38, 10, 15], forming evaluation data. Focus on specializing capability, VisIT-Bench [5] emphasizes the instruction following capacity of the LVLMs, while TouchStone [3] highlights the lack of direct evaluation for communicative skills and visual storytelling in LVLMs, not yet to accurately evaluate performance in complex tasks like self-driving.
2.0.2 Autonomous Driving Datasets.
NuScenes-QA [34] manually constructs 460K question-answer pairs based on object attributes and the relationships between objects in scene graphs. BDD-X [21] focuses on the behavior of the ego car and provides corresponding reasons. While both datasets concentrate on general perception, DRAMA [30] and DriveLM [35] additionally pay attention to regional perception and driving suggestions. Specifically, DRAMA [30] identifies the most critical targets and offers the corresponding advice. DriveLM [35] promotes end-to-end autonomous driving understanding through the use of graph-structured question-answer pairs. However, autonomous driving systems often fail in corner cases, leading to severe accidents. StreetHazards [18] is a synthesized dataset where corner case scenes are simulated using computer graphics. CODA [23] is a real-world road corner case dataset, containing 5,000 driving scenes, spanning more than 30 object categories. As shown in Tab. 1, existing corner case datasets lack language modality, and vision-language datasets don’t cover corner case scenarios. Thus, we propose CODA-LM, the first large-scale multimodal road corner case dataset for self-driving with a hierarchical evaluation framework.
3 CODA-LM Dataset
We present the CODA-LM, a dataset constructed specifically for the autonomous driving, emphasizing the multimodal perception and planning in the corner case scenarios collected from the CODA [23] dataset. CODA-LM comprises 5,000 real-world driving scenarios with 28,000 instances of key entities textual annotations, and 10,000 corner case object texts, which addresses the notable gap in current autonomous driving multimodal datasets concerning the coverage of corner case circumstances. The critical entities affecting autonomous driving decision-making are categorized into seven distinct groups, including vehicles, vulnerable road users (VRUs), traffic signs, traffic lights, traffic cones, barriers, and miscellaneous (e.g., animals and traffic islands).
CODA-LM involves three principal tasks, including the general perception, regional perception, and driving suggestion, as illustrated in Fig. 2. The general perception task focuses on describing the existence of all salient road objects and explaining why they would affect driving behavior, while the regional perception task is dedicated to location-aware perception, where given a bounding box of a specific corner case object, LVLMs are required to describe and explain its potential effect to the ego car. The driving suggestion task, instead, aims to provide the optimal driving advices based on the previous perception results. The systematic task hierarchy requires LVLMs to deeply understand the complex driving environments, providing a comprehensive assessment of the intelligent autonomous driving agents powered by LVLMs. Next, we explain the detailed data structure of the three tasks in Sec. 3.1 to 3.3, respectively.
3.1 General Perception
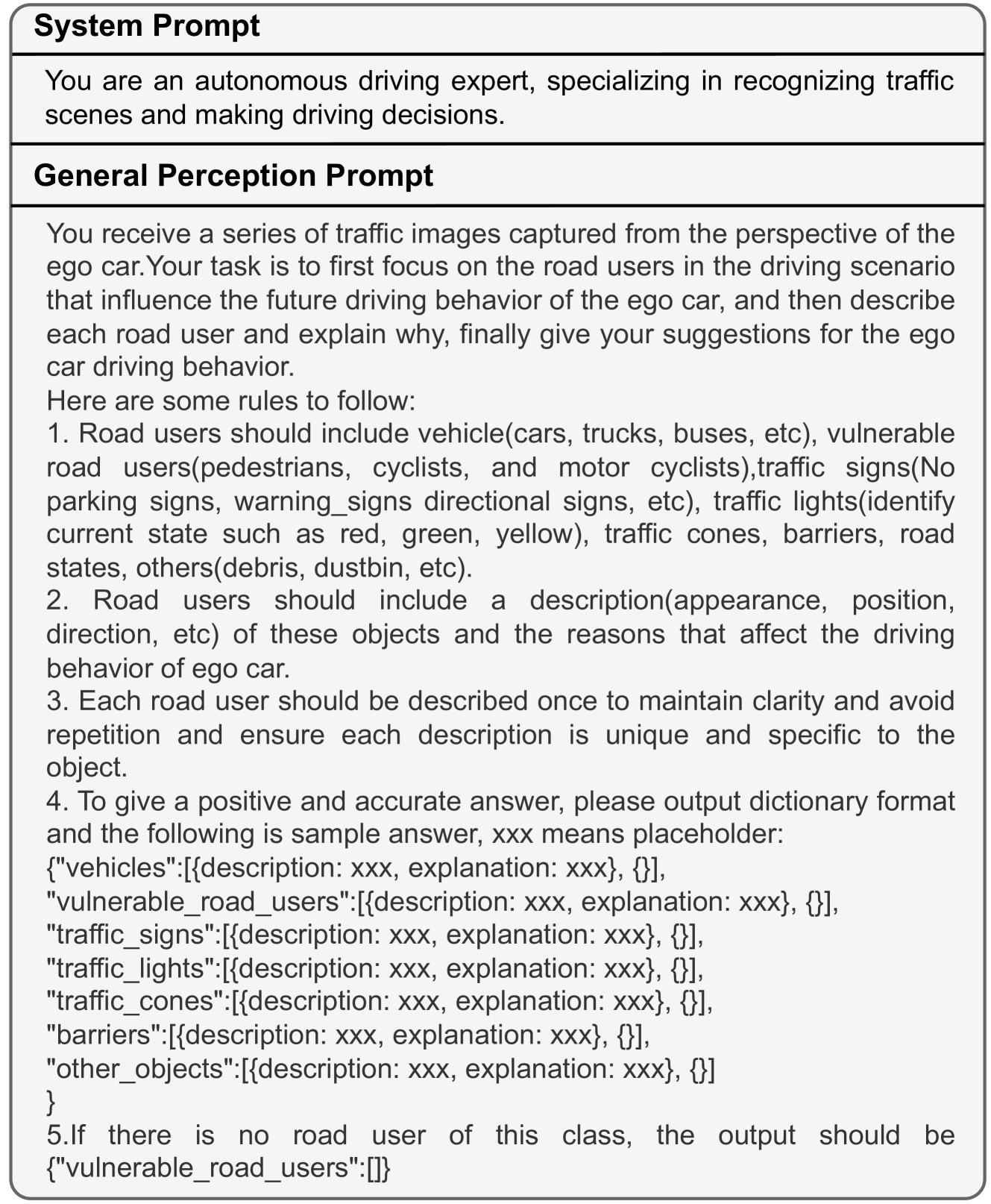
The foundational aspect of the general perception task lies in the comprehensive understanding of key entities within driving scenes, including their appearance, location, and the reasons they influence driving. This task is pivotal in evaluating the proficiency of LVLMs in interpreting complex interactive scenes, mirroring the perception process in autonomous driving. Initially, we use images from the CODA dataset [23] and query the LVLM [31] to craft detailed textual descriptions via pre-defined prompts provided in Appendix 0.A, which not only describe all the potential road obstacles in the traffic scenes but also provide explanation about why they would affect self-driving. Moreover, to comprehensively evaluate LVLMs’ performance in different environments, we classify the images based on the time and weather conditions, including night and daytime scenes for time conditions, as well as clear, cloudy, and rainy circumstances for weathers.

3.2 Regional Perception
The regional perception task measures LVLMs’ capability to understand corner case objects when provided with the specific bounding boxes, which involves describing these objects, and explaining the reasons why they would influence the self-driving behavior. The establishment of regional perception is based on a core realization that the ability to accurately process corner case scenarios is crucial for enhancing the overall system’s robustness in the practical application of autonomous driving. These scenarios often contain complicated or unusual elements that traditional models might overlook or struggle to interpret correctly, such as unique traffic signs, pedestrians with abnormal behavior, or atypical road conditions. By specifically focusing on these cases, we can gain a comprehensive understanding of the model’s capability to comprehend corner case objects.
3.3 Driving Suggestions
The driving suggestions task aims to evaluate LVLMs’ capability in formulating driving advices in the autonomous driving domain. This task is closely related to the planning process of autonomous driving, requiring the model to provide optimal driving suggestions for the ego car after correctly perceiving the general and regional aspects of the current driving environment. Through the construction of the driving suggestions task, we can deeply evaluate the performance of LVLMs in formulating effective driving strategies.
4 CODA-LM Construction
4.1 Data Collection
4.1.1 Pipeline.
For each sub-task in Sec. 3, we meticulously design specific prompts that guide the LVLM [31] to generate the textual pre-annotations based on the visual information. We start by constructing a comprehensive scene understanding data structure and prompt the LVLM to respond with the JSON formatted text, categorizing objects into seven classes based on the impact on driving. Each object of these categories is detailed, explaining how they affect driving. After obtaining outputs for both general and regional perception (detailed in the next paragraph), we combine these with the selected CODA image to form a composite context for the LVLM to generate driving suggestions. Finally, we ask human annotators to verify and revise the pre-annotations of all the three tasks. The overall construction pipeline is visualized in Fig. 3.

4.1.2 Visual prompts for regional perception.
For corner case objects that affect self-driving, we generate region-level objects understanding texts. In this phase, we first select images containing corner case objects from CODA [23]. Using heuristic rules, we pick objects that are ranked top two in their category by area. We filter out objects that are too crowed or have little impact on driving behavior, focusing on those significantly affecting self-driving. We provide the LVLM with bounding box inputs in two ways, one is through visual cues by marking the target with red boundary boxes on the original images, and the other is using normalized coordinates in text prompts to locate the target (marking the top-left and bottom-right points of the target, similarly with LLaVA [26]). As in Tab. 4, providing bounding boxes as visual cues proves more effective.
4.1.3 Human Verification and Revision.
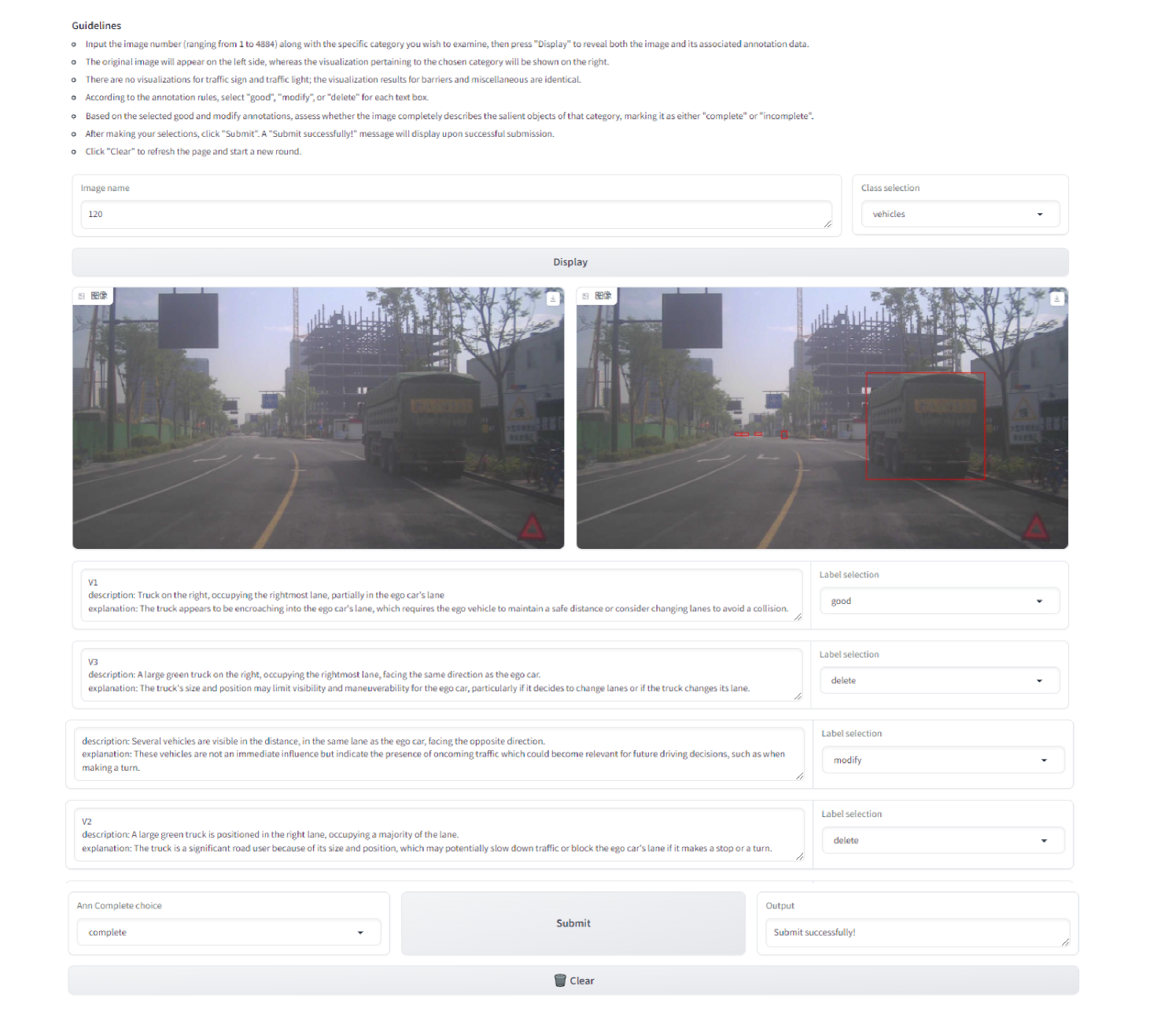
After obtaining the pre-annotations for the three sub-tasks, experienced drivers were selected to complete the annotation tasks. In addition, a labeling tool interface was developed using Gradio [1], with the interface visualized in Appendix 0.A. We provided the annotators with text output from the LVLM as the source data. The annotators were tasked with eliminating incorrectly selected objects from the source data and making final corrections to obtain the final CODA-LM.
4.2 Evaluation Framework
4.2.1 Unsatisfactory the powerful LVLM judge.
For autonomous driving, the automatic and systematic assessment of the perception and control capabilities of LVLMs presents severe challenges in current research areas. Zheng et al. [43] show the feasibility of using powerful LLMs as the judges to assess the capabilities of intelligent chat assistants, which demonstrates strong consistency with the traditional human assessment. Inspired by that, we conduct a preliminary attempt via adopting the powerful LVLM as judges to evaluate LVLMs, which, however, cannot fulfill our expectation, as ablated in Sec. 5.4. On one hand, due to its unsatisfactory instruction-following ability, it is difficult for the LVLM to always respond in the required format [3], adversely affecting the feasibility of conducting automatic analysis. On the other hand, it still lacks multimodal in-context learning capability, making few-shot evaluation indispensable in complex and varied autonomous driving scenarios.
4.2.2 The powerful LLM as LVLM judges.
Instead, we propose adopting the the powerful LLM as the judge to measure LVLMs in autonomous driving scenarios from multiple dimensions. Similarly with the data collection procedure discussed in Sec. 4.1, to evaluate LVLMs, we input images and the corresponding questions (i.e., general perception, regional perception and driving suggestions) to LVLMs and collect their responses. Through few-shot in-context learning (see prompts in Appendix 0.A), we query the powerful LLM to score the model responses based on the reference answers, with a single score range from 1 to 10, and the average score of the entire evaluation set serving as the final score. As we will see in Tab. 7, the LLM judge evaluates more consistently with human preference than the the LVLM judge.
4.2.3 Evaluation criteria.
Among evaluation with few-shot ICL for the general and regional perception, we adopt three evaluation criteria, including the accuracy, hallucination panalty, and consistency. Accuracy refers to LVLMs’ accuracy in perceiving the self-driving environment, while existing LVLMs exhibit severe hallucination phenomena (e.g., perceiving non-existent targets or incorrect recognition due to biases), which needs to be penalized to obtain a valid score. For both the general and regional perception, the annotations includes descriptions and reasons for the impact of corresponding objects on self-driving, with consistency measuring whether the reasons are reasonable. Check detailed prompts in Appendix 0.A. Regarding driving suggestions, the few-shot ICL is also adopted, but the criteria change due to its difficulty level, becoming rationality, relevance, and detail degree of the response. Especially for driving suggestions, we require the responses to be specific and actionable, rather than vague or overly broad.
4.2.4 Evaluation metrics.
By default, we adopt Text-Score [43] given by the powerful LLM judge as the evaluation metrics for all three tasks introduced in Sec. 3. We further explore the usage of other empirical keyword-based text generation evaluation metrics, as we will see in Tab. 6, which, however, cannot differentiate the capabilties of different LVLMs, probably to the complexity of autonomous driving perception and suggestions.
4.2.5 Consistency with Humans.
In Sec. 5.4, we quantitatively validate the strong consistency among the Text-Score given by the powerful LLM judge with human evaluators’ preferences, thereby proving the feasibility of using text-only LLMs to evaluate LVLMs, which also illustrates that this evaluation method can distinguish between the capabilities of LVLMs in understanding autonomous driving scenarios, especially in corner case scenarios collected in regional perception.
5 CODA-LM Benchmark
In this section, based on the proposed CODA-LM dataset, we first compare and analyze performance of different LVLMs from various dimensions in Sec. 5.1. Additionally, we examine the impact of different prompts on the dataset construction and evaluation, and compare the Text-Score with traditional keyword-based evaluation metrics in Sec. 5.2 and 5.3. Finally, we verify the effectiveness of our evaluation framework through human preference consistency and discuss the current limitations in Sec. 5.4.
| Source | Model | General Perception | Driving Suggestions |
|---|---|---|---|
| Text-Score | Text-Score | ||
| Open | MiniGPT-v2-7B [7] | 10.8 | 10.0 |
| Shikra-7B [12] | 19.4 | 19.5 | |
| LLaVA1.5-7B [25] | 21.0 | 34.2 | |
| InternLM2-vl-7B [42] | 29.8 | 45.5 | |
| LLaVA1.5-13B [25] | 23.1 | 39.2 | |
| PureMM-13B [37] | 28.0 | 43.8 | |
| InfMLLM-13B [45] | 29.0 | 46.9 | |
| Commercial | Gemini-Pro [36] | 22.5 | 27.5 |
| GPT-4V [31] | 46.5 | 62.6 |
5.1 Main Results
In this work, we evaluate a total of 8 LVLMs, including both open-sourced and commercial models. The commercial models consist of Gemini-Pro [36] and GPT-4V [31]111https://chatgpt.ust.hk, while the open-sourced models are categorized based on their parameter sizes into 7B and 13B. The 7B models includes InterLM-Xcomposser2-v1 (InternLM2-vl-7B, for short) [42], LLaVA1.5 [25], MiniGPT-v2 [7], and Shikra [12], while the 13B ones include the LLaVA1.5 [25], InfMLLM [45], and PureMM [37]. Each model is evaluated on the three tasks separately for a comprehensive analysis of their performance on self-driving corner cases. To ensure re-producibility of our evaluation results, we use the same prompt for generating responses for all evaluated LVLMs and employ greedy decoding during inference, which generates the next token with the highest probability at each step as output, thus eliminating randomness during inference. As discussed in Sec. 4.2, the powerful LLM is used as the judge for evaluation, with the temperature coefficient set to 0 and a fixed random seed, to ensure consistency when scoring different models.
| Source | Model | Regional Perception (Text-Score) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| ALL | Vehicle | VRU | Cone | Light | Sign | Barrier | Mis. | ||
| Open | MiniGPT-v2-7B [7] | 15.7 | 15.0 | 14.3 | 16.0 | 27.5 | 14.7 | 16.3 | 15.0 |
| Shikra-7B [12] | 21.6 | 23.7 | 23.3 | 21.3 | 16.3 | 22.0 | 22.7 | 18.3 | |
| LLaVA1.5-7B [25] | 32.7 | 47.0 | 31.0 | 37.0 | 21.5 | 31.0 | 29.8 | 21.0 | |
| InternLM2-vl-7B [42] | 50.8 | 52.3 | 52.0 | 70.0 | 37.5 | 46.7 | 43.7 | 43.7 | |
| LLaVA1.5-13B [25] | 38.7 | 50.0 | 39.0 | 43.0 | 33.8 | 39.0 | 37.7 | 25.0 | |
| PureMM-13B [37] | 39.6 | 50.3 | 39.3 | 46.0 | 42.5 | 36.0 | 36.3 | 29.0 | |
| InfMLLM-13B [45] | 40.2 | 51.7 | 30.0 | 54.7 | 27.5 | 37.0 | 40.0 | 31.0 | |
| Commercial | Gemini Pro [36] | 53.0 | 50.3 | 48.3 | 78.3 | 42.5 | 43.3 | 48.0 | 52.3 |
| GPT-4V [31] | 61.7 | 62.0 | 59.8 | 75.3 | 62.5 | 59.3 | 59.6 | 55.4 | |
The results for the general perception and driving suggestions of the different VLMs are shown in Tab. 2. The regional perception results for the different VLMs are displayed in Tab. 3. To better quantify the differences between LVLMs, we normalize original scores to a range from 1 to 100, retaining one decimal point.
5.2 Analysis
5.2.1 Open-source model analysis.
The improvements in current LVLMs’ performance are primarily attributed to two pivotal factors: training strategies(pre-training stage and instruction tuning stage), and model architecture design(visual perception, the alignment of different modalities, pre-training large language models). Thanks to the reorganization of instruction tuning data, modality alignment module designs, and increased image resolution, LLaVA1.5 has notably surpassed both Shikra and MiniGPT-v2 across three distinct tasks at the same scale. Specifically, LLaVA1.5 achieved a 12% improvement in general perception compared to MiniGPT-v2. Although none of the reported open-source LVLMs train using datasets of the autonomous driving domain, our findings emphasize that trainable visual perception module and additional visual adapters significantly enhance model performance, which is clearly demonstrated by the remarkble performance of InfMLLM and PureMM, outperforming LLaVA1.5 across mutliple metrics. Surprisingly, among the open-source LVLMs, InternLM2-vl-7B achieves the best performance in both general and regional perception, only ranking second to InfMLLM-13B for driving suggestions. This can be attributed to its training strategy, which expands the model’s potential during the pre-training phase by achieving general semantic alignment, world knowledge alignment, and vision capability enhancement. On the other hand, it leverages InternLM2-7B[6] as pre-training large language model and adopts a novel approach to modality alignment by not treating visual and language tokens as entirely separate entities but instead aligning new modal knowledge with LLMs using partial LoRA. Certainly, the scale of model parameters plays a crucial role in performance outcomes, with 13B models demonstrating superiority over 7B models.
| Method | Recall |
|---|---|
| Visulization [31] | 85% |
| Coordinate Representation [26] | 12% |
5.2.2 Regional multi-class analysis.
For a comprehensive and detailed evaluation of corner case regional understanding, we aim at categorizing data samples into seven different categories, including vehicle, VRU (e.g., pedestrians and cyclists), traffic cone, traffic light, traffic sign, barrier, and miscellaneous, with miscellaneous denoting infrequently appearing objects (e.g., animals and trash bins). Among open-sourced models, InternLM2-vl-7B significantly outperforms other models in recognizing VRUs, traffic cones, traffic signs, and miscellaneous, with the smallest differences reaching 10%, 16%, 10%, and 12% respectively. Shikra and MiniGPT-v2 generally perform poorly across all categories. Other models show roughly equivalent performance in recognizing vehicles, traffic signs, and miscellaneous. It’s worth mentioning that PureMM excels notably in the traffic light recognition, likely benefiting from its additional visual adapter module, and also surpasses the InfMLLM in the VRU regional perception performance.
5.2.3 Commercial model analysis.
Among the commercial LVLMs, GPT-4V continues to demonstrate an unprecedented leadership position, ranking first in total score, benefiting from its massive training data and avoiding the pitfalls of training solely in the natural domain. In contrast, Gemini-Pro showes weaker performance in general perception and driving suggestions but excels in the regional perception. The analysis indicates that Gemini Pro tends to generate generic and broad image descriptions and suggestions, lacking specific analysis of particular scenes. This leads to a frequent occurrence of hallucinatory phenomena, which contributes to its lower scoring. On the other hand, suitable prompts can stimulate the capabilities of VLMs. However, to ensure the fairness of evaluation, all models utilized the same prompts, which to some extent suppressed the capabilities of commercial models. This issue don’t arise in regional perception, thus producing a starkly different outcome.
5.3 Ablation Study
5.3.1 Visual prompts for regional perception data acquisition.
Regional perception data aims to analyze the fine-grained corner case objects given specific bounding boxes. We conduct an ablation study to evaluate the impact of different visual prompts on the pre-annotation generated by the powerful LVLM, including visualization, which refers to visualize the target object within the original image with a red boundary box as shown in Fig. 3 (middle), and coordinate representation, which utilizes normalized coordinates to identify the target, typically represented by the top-left and bottom-right points following LLaVA [26]. We adopt 100 images for ablation, and a recall-based evaluation (i.e., the proportion of images where the corresponding quality met the requirements). As shown in Tab. 4, visualization achieves a score of 85%, significantly surpassing coordinate representation with only 12%.
5.3.2 Visual prompts for Regional Perception Evaluation.
Similar to data acquisition, both visualization and and coordinate representation can also be used to obtain responses from different LVLMs to be evaluated. However, various LVLMs employ different training approaches. Some models may not utilize grounding data during training, thereby lacking localization capabilities. Thus, we explore whether visualization could serve as a universal visual prompt for all LVLMs. As shown in Tab. 5, among open-sourced LVLMs, LLaVA1.5 and MiniGPT-v2 are selected, both of which are trained with additional grounding data. For commercial models, Gemini Pro is chosen due to its diversified training methods and certain localization capabilities. The corresponding prompt for visualization is “Please describe the object inside the red rectangle in the image and explain why it affects ego car driving”. The coordinate representation, on the other hand, is “Please provide a description for this object and explain why this object affects ego car driving: [x1, y1, x2, y2]”. The results indicated that visualization generally outperforms coordinate representations, with LLaVA1.5 showing a 22% gain and Gemini-Pro with a 14% gain, consistently with our observation for GPT-4V as demonstrated in Tab. 4.
| Model | Regional Perception Method | |
|---|---|---|
| Visualization | Coordinate representation | |
| MiniGPT-v2-7B [7] | 15.7 | 14.3 |
| LLaVA1.5-13B [25] | 38.7 | 16.6 |
| Gemini-Pro [36] | 53.0 | 39.3 |
| Source | Model | Metrics | |||
|---|---|---|---|---|---|
| BLEU4 | METEOR | CIDEr | SPICE | ||
| Open | MiniGPT-v2-7B [7] | 0.6 | 5.3 | 0.6 | 4.4 |
| Shikra-7B [12] | 1.5 | 8.7 | 0.0 | 5.2 | |
| LLaVA1.5-7B [25] | 1.9 | 13.9 | 0.9 | 9.8 | |
| InternLM2-vl-7B [42] | 2.7 | 14.2 | 5.7 | 15.2 | |
| PureMM-13B [37] | 2.3 | 15.7 | 3.7 | 10.7 | |
| LLaVA1.5-13B [25] | 2.7 | 16.0 | 1.1 | 13.9 | |
| InfMLLM-13B [45] | 2.8 | 14.2 | 5.7 | 15.2 | |
| Commercial | Gemini Pro [36] | 1.9 | 12.9 | 4.8 | 16.0 |
| GPT-4V [31] | 2.3 | 17.4 | 0.0 | 19.2 | |

5.3.3 Evaluation metrics.
When conducting a corner case regional perception evaluation, the data is organized in the form of brief sentences. Therefore, in addition to using the Text-Score for evaluation, we also explore the impact of traditional keyword-based metrics, including BLEU-4 [33], METEOR [4], CIDEr [39], and SPICE [2], as shown in Tab. 6. For better demonstration, we multiplie the scores by 100, normalizing them to a range of 1-100, similarly with the Text-Score. BLEU-4 primarily evaluates quality through lexical matching and cannot capture the semantic accuracy of the generated text. CIDEr is not suitable for texts with low lexical repetition. Hence, the scores from these two metrics do not reflect performance accurately. Although METEOR can account for synonyms, it still does not reflect the actual semantics, so despite some differences in scores, they are not accurate. In contrast, SPICE can reflect semantic accuracy to some text, and even though the overall scores are still low, it successfully indicates the trend among different models, with InternLM2-vl still leading among open-source models. By default, we still adopt the Text-Score as the primary evaluation metrics, unless otherwise specified.
| Judge | Consistency (Rank-based) | ||
|---|---|---|---|
| General Perception | Regional Perception | Driving Suggestions | |
| GPT-4V | 50% | 42% | 57% |
| GPT-4 | 70% | 87% | 77% |
5.4 Human Consistency and Limitations
5.4.1 Human consistency.
To measure the consistency between GPT-4’s judgment and human preferences, we employ a ranking method. Specifically, for general perception, regional perception, and driving suggestions, we sample 100 sets of data respectively, which are considered as queries to prompt two different LVLM, LLaVA1.5 and InfMLLM, and select the winner in each sample. Concurrently, for each set of data, three human evaluators utilize to vote, adhering to the principle where the minority conforms to the majority, to determine the winner. The consistency score is represented by the ratio of the number of matches in winners to the total number of data sets. To ensure the accuracy of the evaluation, We use GPT-4 to perform multiple evaluations and use the average of these evaluation as the final evaluation result. As shown in Tab. 7, the GPT-4 judge achieves scores of 70%, 77%, and 87% for general perception, driving suggestions and regional perception, respectively, significantly surpassing the GPT-4V judge with respect to human evaluation consistency.
5.4.2 Limitations.
CODA-LM is currently built on real-world corner cases collected in CODA, whose size is difficult to scale, and we opt to explore utilizing controllable generative models [11, 14, 24, 28, 40] to generate road corner cases in the future work. Moreover, the current data construction pipeline relies on human verification and revision to ensure the quality of data annotation, and an automatic data calibration approach is also an appealing research direction. How to better incorporate vision pre-trained prior like self-supervised learning [8, 9, 29, 44] for better generalization is also an open question.
6 Conclusion
In this paper, we propose CODA-LM, a novel real-world multimodality road corner case dataset for autonomous driving with a hierarchy task framework, spanning from general and regional perception to driving suggestions, to support automated evaluation of Large Vision-language Models (LVLMs) on self-driving corner cases. Extensive evaluation on both open-sourced and commercial LVLMs demonstrates that we are still far from a strong LVLM-powered intelligent driving agent and we hope our CODA-LM can serve as the catalyst to promote the development of reliable and interpretable autonomous driving systems.
6.0.1 Acknowledgement
We gratefully acknowledge support of MindSpore, CANN (Compute Architecture for Neural Networks) and Ascend AI Processor used for this research.
References
- [1] Abid, A., Abdalla, A., Abid, A., Khan, D., Alfozan, A., Zou, J.: Gradio: Hassle-free sharing and testing of ml models in the wild. arXiv preprint arXiv:1906.02569 (2019)
- [2] Anderson, P., Fernando, B., Johnson, M., Gould, S.: Spice: Semantic propositional image caption evaluation. In: ECCV (2016)
- [3] Bai, S., Yang, S., Bai, J., Wang, P., Zhang, X., Lin, J., Wang, X., Zhou, C., Zhou, J.: Touchstone: Evaluating vision-language models by language models. arXiv preprint arXiv:2308.16890 (2023)
- [4] Banerjee, S., Lavie, A.: Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. In: Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization (2005)
- [5] Bitton, Y., Bansal, H., Hessel, J., Shao, R., Zhu, W., Awadalla, A., Gardner, J., Taori, R., Schmidt, L.: Visit-bench: A dynamic benchmark for evaluating instruction-following vision-and-language models. In: NeurIPS (2024)
- [6] Cai, Z., Cao, M., Chen, H., Chen, K., Chen, K., Chen, X., Chen, X., Chen, Z., Chen, Z., et al.: Internlm2 technical report (2024)
- [7] Chen, J., Zhu, D., Shen, X., Li, X., Liu, Z., Zhang, P., Krishnamoorthi, R., Chandra, V., Xiong, Y., Elhoseiny, M.: Minigpt-v2: large language model as a unified interface for vision-language multi-task learning. arXiv preprint arXiv:2310.09478 (2023)
- [8] Chen, K., Hong, L., Xu, H., Li, Z., Yeung, D.Y.: Multisiam: Self-supervised multi-instance siamese representation learning for autonomous driving. In: ICCV (2021)
- [9] Chen, K., Liu, Z., Hong, L., Xu, H., Li, Z., Yeung, D.Y.: Mixed autoencoder for self-supervised visual representation learning. In: CVPR (2023)
- [10] Chen, K., Wang, C., Yang, K., Han, J., Hong, L., Mi, F., Xu, H., Liu, Z., Huang, W., Li, Z., et al.: Gaining wisdom from setbacks: Aligning large language models via mistake analysis. arXiv preprint arXiv:2310.10477 (2023)
- [11] Chen, K., Xie, E., Chen, Z., Hong, L., Li, Z., Yeung, D.Y.: Integrating geometric control into text-to-image diffusion models for high-quality detection data generation via text prompt. arXiv preprint arXiv:2306.04607 (2023)
- [12] Chen, K., Zhang, Z., Zeng, W., Zhang, R., Zhu, F., Zhao, R.: Shikra: Unleashing multimodal llm’s referential dialogue magic. arXiv preprint arXiv:2306.15195 (2023)
- [13] Fu, C., Chen, P., Shen, Y., Qin, Y., Zhang, M., Lin, X., Yang, J., Zheng, X., Li, K., Sun, X., et al.: Mme: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394 (2023)
- [14] Gao, R., Chen, K., Xie, E., Hong, L., Li, Z., Yeung, D.Y., Xu, Q.: Magicdrive: Street view generation with diverse 3d geometry control. arXiv preprint arXiv:2310.02601 (2023)
- [15] Gou, Y., Chen, K., Liu, Z., Hong, L., Xu, H., Li, Z., Yeung, D.Y., Kwok, J.T., Zhang, Y.: Eyes closed, safety on: Protecting multimodal llms via image-to-text transformation. arXiv preprint arXiv:2403.09572 (2024)
- [16] Gou, Y., Liu, Z., Chen, K., Hong, L., Xu, H., Li, A., Yeung, D.Y., Kwok, J.T., Zhang, Y.: Mixture of cluster-conditional lora experts for vision-language instruction tuning. arXiv preprint arXiv:2312.12379 (2023)
- [17] Han, J., Liang, X., Xu, H., Chen, K., Hong, L., Ye, C., Zhang, W., Li, Z., Liang, X., Xu, C.: Soda10m: Towards large-scale object detection benchmark for autonomous driving. arXiv preprint arXiv:2106.11118 (2021)
- [18] Hendrycks, D., Basart, S., Mazeika, M., Mostajabi, M., Steinhardt, J., Song, D.: A benchmark for anomaly segmentation. arXiv preprint arXiv:1911.11132 (2019)
- [19] Hu, Y., Yang, J., Chen, L., Li, K., Sima, C., Zhu, X., Chai, S., Du, S., Lin, T., Wang, W., et al.: Planning-oriented autonomous driving. In: CVPR (2023)
- [20] Ji, Y., Ge, C., Kong, W., Xie, E., Liu, Z., Li, Z., Luo, P.: Large language models as automated aligners for benchmarking vision-language models. arXiv preprint arXiv:2311.14580 (2023)
- [21] Kim, J., Rohrbach, A., Darrell, T., Canny, J., Akata, Z.: Textual explanations for self-driving vehicles. In: ECCV (2018)
- [22] Li, B., Ge, Y., Ge, Y., Wang, G., Wang, R., Zhang, R., Shan, Y.: Seed-bench-2: Benchmarking multimodal large language models. arXiv preprint arXiv:2311.17092 (2023)
- [23] Li, K., Chen, K., Wang, H., Hong, L., Ye, C., Han, J., Chen, Y., Zhang, W., Xu, C., Yeung, D.Y., et al.: Coda: A real-world road corner case dataset for object detection in autonomous driving. arXiv preprint arXiv:2203.07724 (2022)
- [24] Li, P., Liu, Z., Chen, K., Hong, L., Zhuge, Y., Yeung, D.Y., Lu, H., Jia, X.: Trackdiffusion: Multi-object tracking data generation via diffusion models. arXiv preprint arXiv:2312.00651 (2023)
- [25] Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tuning. arXiv preprint arXiv:2310.03744 (2023)
- [26] Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. arxiv preprint arxiv:2304.08485 (2023)
- [27] Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., et al.: Mmbench: Is your multi-modal model an all-around player? arXiv preprint arXiv:2307.06281 (2023)
- [28] Liu, Z., Chen, K., Zhang, Y., Han, J., Hong, L., Xu, H., Li, Z., Yeung, D.Y., Kwok, J.: Geom-erasing: Geometry-driven removal of implicit concept in diffusion models. arXiv preprint arXiv:2310.05873 (2023)
- [29] Liu, Z., Han, J., Chen, K., Hong, L., Xu, H., Xu, C., Li, Z.: Task-customized self-supervised pre-training with scalable dynamic routing. In: AAAI (2022)
- [30] Malla, S., Choi, C., Dwivedi, I., Choi, J.H., Li, J.: Drama: Joint risk localization and captioning in driving. In: WACV (2023)
- [31] OpenAI: ChatGPT (2023), https://openai.com/research/gpt-4v-system-card
- [32] OpenAI: ChatGPT (2023), https://chat.openai.com
- [33] Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: Bleu: a method for automatic evaluation of machine translation. In: ACL (2002)
- [34] Qian, T., Chen, J., Zhuo, L., Jiao, Y., Jiang, Y.G.: Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario. arXiv preprint arXiv:2305.14836 (2023)
- [35] Sima, C., Renz, K., Chitta, K., Chen, L., Zhang, H., Xie, C., Luo, P., Geiger, A., Li, H.: Drivelm: Driving with graph visual question answering. arXiv preprint arXiv:2312.14150 (2023)
- [36] Team, G., Anil, R., Borgeaud, S., Wu, Y., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
- [37] Team, P.: PureMM (2023), https://github.com/Q-MM/PureMM
- [38] Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023)
- [39] Vedantam, R., Lawrence Zitnick, C., Parikh, D.: Cider: Consensus-based image description evaluation. In: CVPR (2015)
- [40] Wang, Y., Gao, R., Chen, K., Zhou, K., Cai, Y., Hong, L., Li, Z., Jiang, L., Yeung, D.Y., Xu, Q., Zhang, K.: Detdiffusion: Synergizing generative and perceptive models for enhanced data generation and perception. arXiv preprint arXiv:2403.13304 (2024)
- [41] Wen, L., Yang, X., Fu, D., Wang, X., Cai, P., Li, X., Ma, T., Li, Y., Xu, L., Shang, D., et al.: On the road with gpt-4v (ision): Early explorations of visual-language model on autonomous driving. arXiv preprint arXiv:2311.05332 (2023)
- [42] Zhang, P., Wang, X.D.B., Cao, Y., Xu, C., Ouyang, L., Zhao, Z., Ding, S., Zhang, S., Duan, H., Yan, H., et al.: Internlm-xcomposer: A vision-language large model for advanced text-image comprehension and composition. arXiv preprint arXiv:2309.15112 (2023)
- [43] Zheng, L., Chiang, W.L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E., et al.: Judging llm-as-a-judge with mt-bench and chatbot arena. In: NeruIPS (2023)
- [44] Zhili, L., Chen, K., Han, J., Lanqing, H., Xu, H., Li, Z., Kwok, J.: Task-customized masked autoencoder via mixture of cluster-conditional experts. In: ICLR (2023)
- [45] Zhou, Q., Wang, Z., Chu, W., Xu, Y., Li, H., Qi, Y.: Infmllm: A unified framework for visual-language tasks. arXiv preprint arXiv:2311.06791 (2023)
- [46] Zhu, D., Chen, J., Shen, X., Li, X., Elhoseiny, M.: Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arxiv:2304.10592 (2023)
Supplementary Material
Appendix 0.A More on Dataset Construction
0.A.0.1 Gradio labeling tool graphical user interface (GUI).
Fig. 5 shows a screenshot of our labeling tool in the general perception task. We utilize Gradio and aim to assist human annotators to refine general perception pre-annotations deriving from the powerful LVLM. The annotator refines following the principles of merging, modifying, and deleting step by step.
0.A.0.2 Prompts for pre-annotation.

0.A.0.3 Prompts for evaluation.
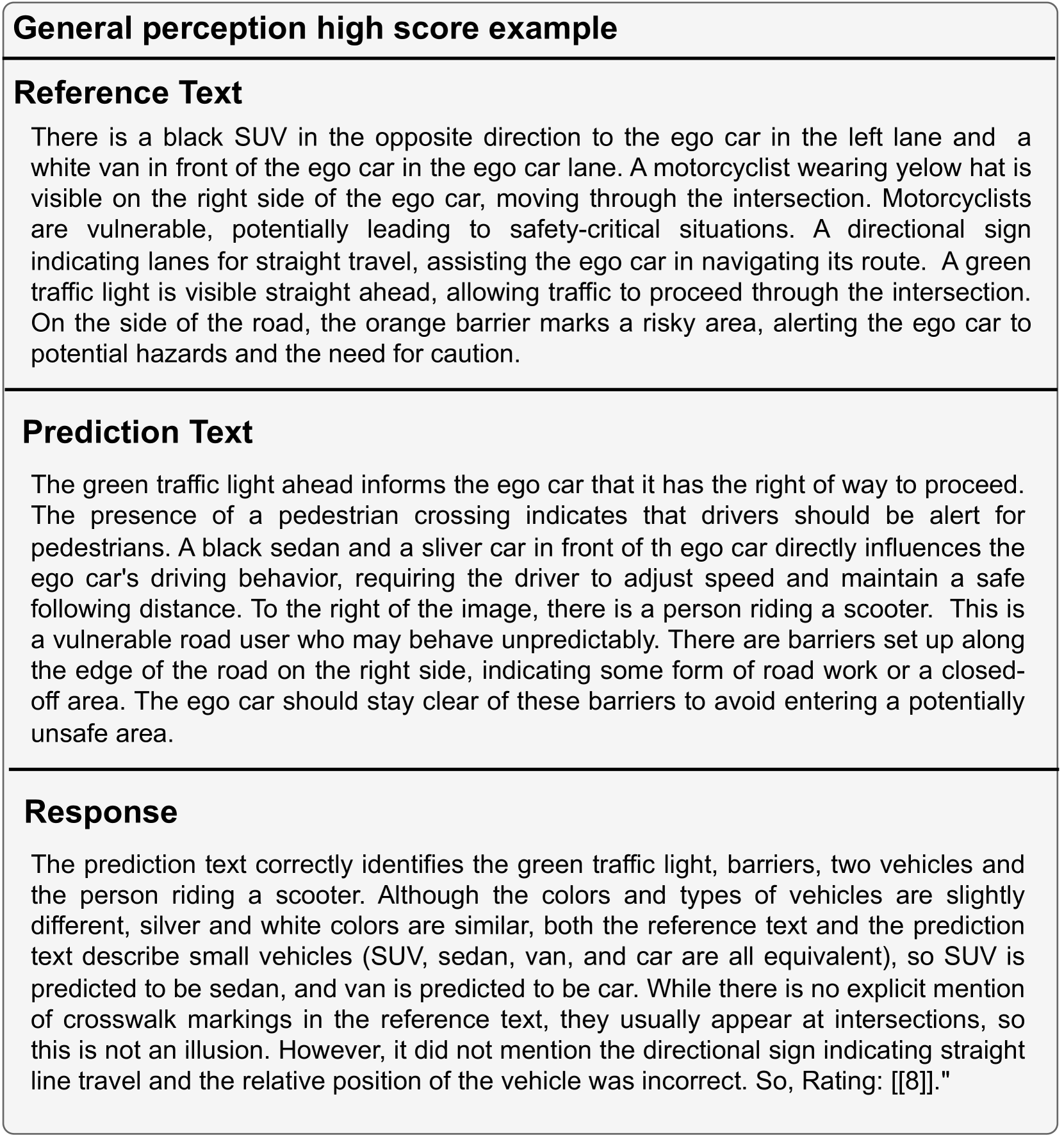
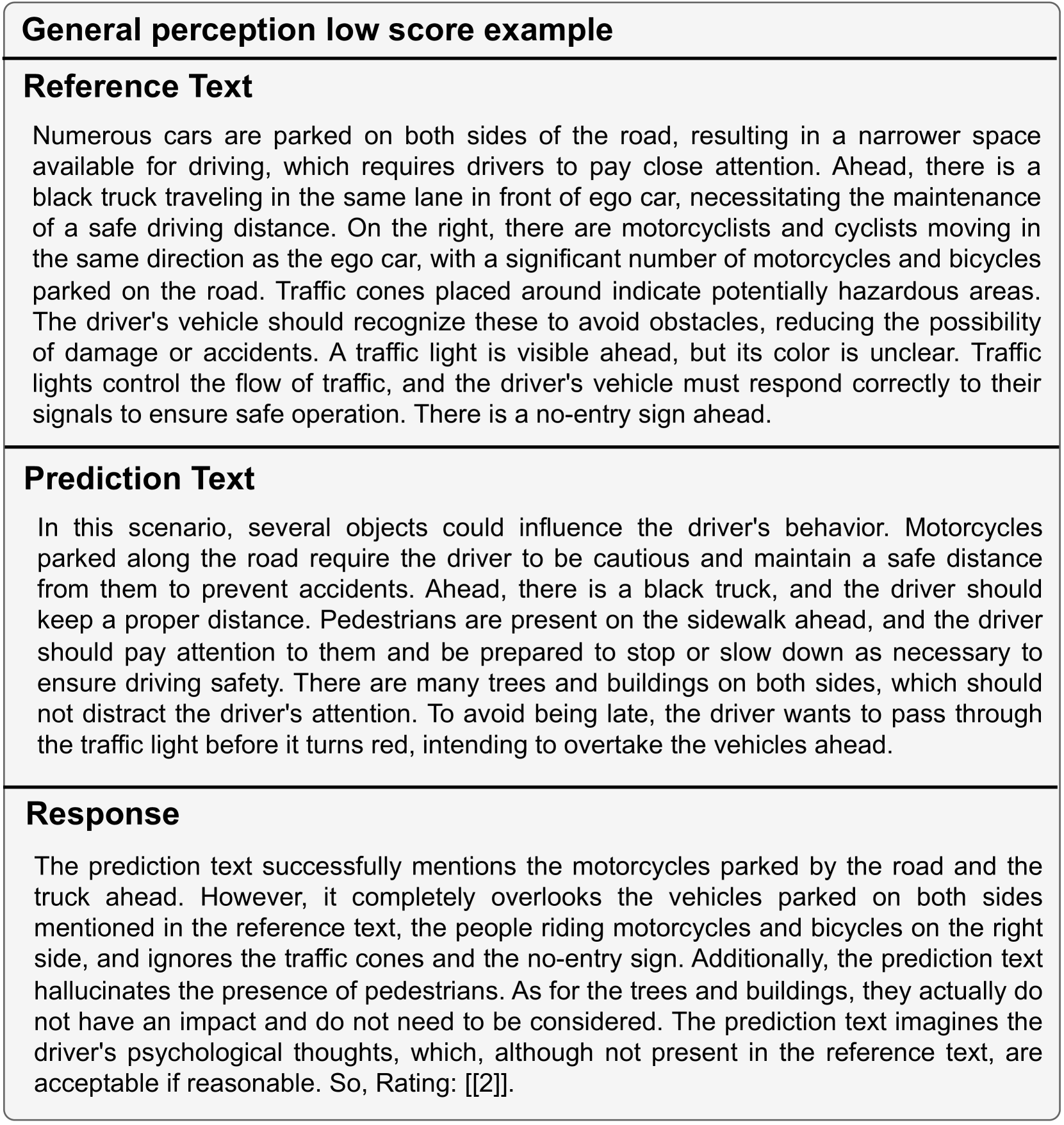
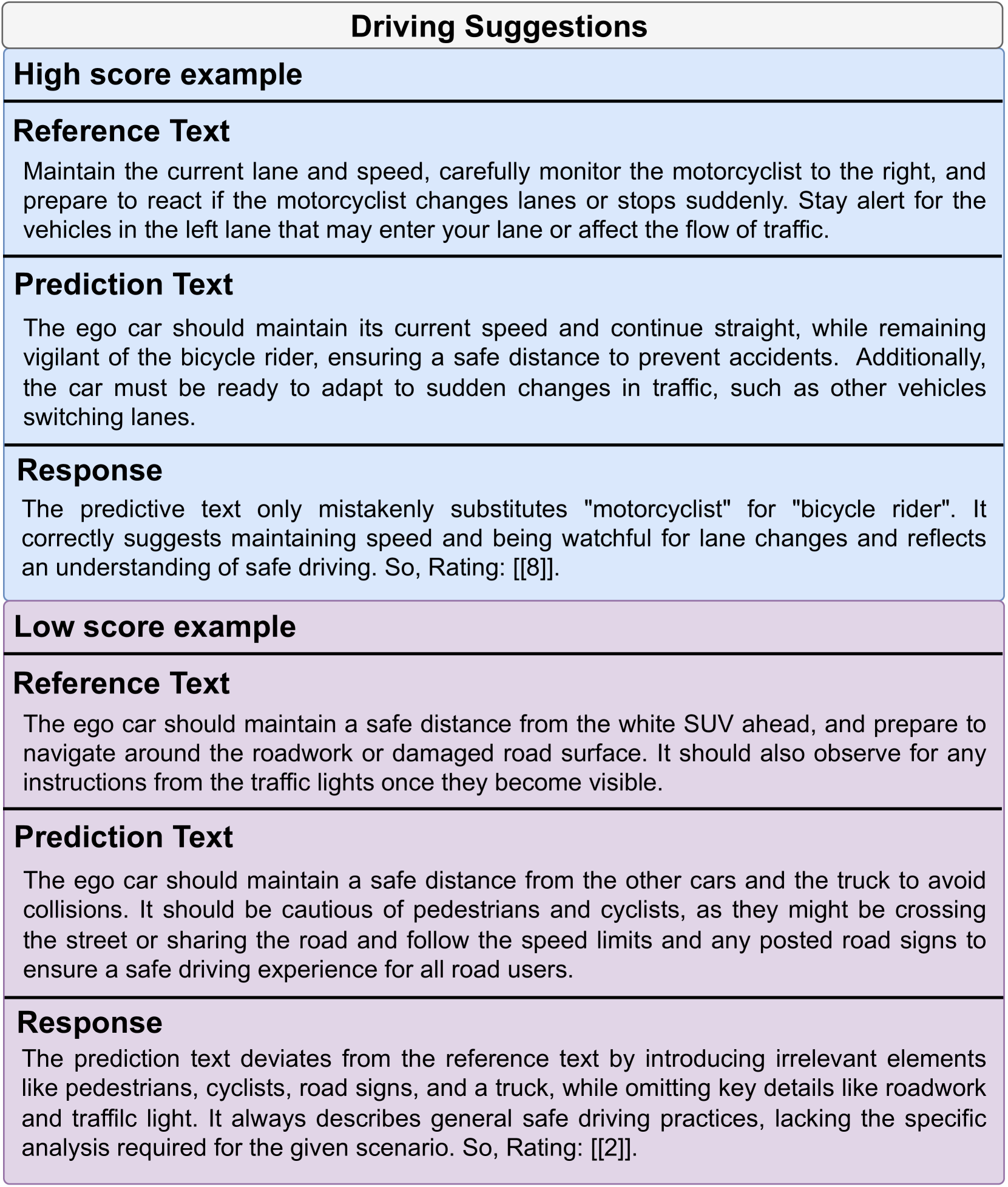
To comprehensively and accurately assess the performance of different VLMs, we design distinct evaluation prompts for each task, as shown in Fig. 8. Meanfile, we use few-shot in-context learning method to improve accuracy for general perception and driving suggestions. Specifically, we design in-context examples with different scores to assitant judge. Please see few-shot in-context-learning examples for general perception in Fig. 9 and Fig. 10 for details. Additionally, few-shot in-context-learning examples for driving suggestions see in Fig. 11.

Appendix 0.B Qualitative comparison
In this section, we present three data examples from CODA-LM, as illustrated in Figures 12 to 14. For additional data, please visit our anonymous project website at https://coda-lm.github.io/. Building on CODA-LM, we subsequently analyze the responses from different LVLMs across three tasks, as shown in Figures 15 to 20.








