0009-0008-7549-4021 0000-0003-2240-1377 0000-0001-7536-8967
af1]Department of Electrical and Computer Engineering, Tamkang University, New Taipei City, 251301, Taiwan af2]Graduate Institute of Networking and Multimedia, National Taiwan University, Taipei City, 106335, Taiwan af3]School of Nursing, National Taipei University of Nursing and Health Sciences, Taipei City, 112303, Taiwan
🖂Email: jsken.chiang@gmail.com
YOLOv9 for Fracture Detection in Pediatric Wrist Trauma X-ray Images
Abstract
The introduction of YOLOv9, the latest version of the You Only Look Once (YOLO) series, has led to its widespread adoption across various scenarios. This paper is the first to apply the YOLOv9 algorithm model to the fracture detection task as computer-assisted diagnosis (CAD) to help radiologists and surgeons to interpret X-ray images. Specifically, this paper trained the model on the GRAZPEDWRI-DX dataset and extended the training set using data augmentation techniques to improve the model performance. Experimental results demonstrate that compared to the mAP 50-95 of the current state-of-the-art (SOTA) model, the YOLOv9 model increased the value from 42.16% to 43.73%, with an improvement of 3.7%. The implementation code is publicly available at https://github.com/RuiyangJu/YOLOv9-Fracture-Detection.
1 Introduction
Computer-assisted diagnosis (CAD) helps specialists such as radiologists and surgeons to interpret medical images, including magnetic resonance imaging (MRI), computed tomography (CT), and X-ray images. The application of deep learning techniques to medical images [1, 2, 3, 4] has yielded increasingly satisfactory results, making it a popular research focus, especially in fracture detection [5, 6, 7].
You Only Look Once (YOLO) series [8, 9, 10, 11, 12, 13, 14, 15, 16] are the main neural networks for real-time object detection task, widely employed in fracture detection [17, 18, 19]. Wrist fractures in children are more common cases and the GRAZPEDWRI-DX dataset [20] provides 20,327 X-ray images of pediatric wrist trauma that can be used in fracture detection tasks. Research [21] first used the YOLOv8 [16] model for fracture detection on this dataset. Since attention mechanisms [22, 23, 24, 25] have excellent results in enhancing the performance of neural network models, Chien et al. achieved the state-of-the-art (SOTA) performance by incorporating different attention mechanisms into the YOLOv8 model.
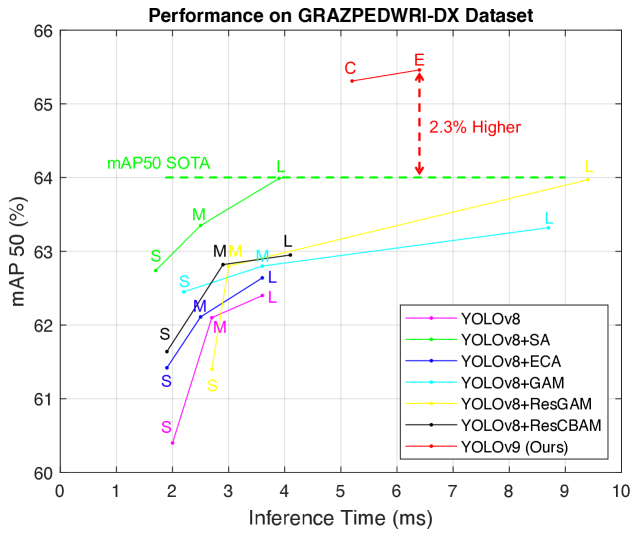
With the presentation of YOLOv9 [26], which achieved remarkable model performance on the MS COCO 2017 [27] benchmark dataset, this paper first trained the YOLOv9 model on the GRAZPEDWRI-DX dataset and obtained the SOTA performance, as shown in Fig 1.
The main contributions of this paper are as follows:
-
1.
This paper is the first to apply YOLOv9 to the fracture detection task, demonstrating that the model not only has the excellent performance in real-time object detection across real-life scenarios, but also has good results in medical image recognition.
-
2.
This paper addresses the issue of information loss in fracture detection on X-ray images by employing YOLOv9 algorithm, and aims to preserve more information during model training on low-features X-ray images, enhancing the performance of the model.
-
3.
The mAP 50-95 of YOLOv9 model trained on the GRAZPEDWRI-DX dataset is significantly improved, achieving the SOTA level.
2 Related Works
In the field of object detection task, detectors typically employ either one-stage or two-stage algorithms. Compared to two-stage object detectors, the models of YOLO series offer a more balanced combination of accuracy and inference speed, making them suitable for deployment on mobile computing platforms for medical image recognition. Son et al. [28] utilized YOLOv4 [9] and U-Net [29] as auxiliary diagnostic tools to assist dentists in identifying mandibular fractures without resorting to cone beam computed tomography (CBCT). Jeon et al. [30] employed YOLOv4 [9] to aid surgeons in diagnosing trauma by detecting the fracture and mapping it onto a 3D reconstructed bone image, providing a clear display of the fracture region through the red mask overlaid on the 3D bone image. Hržić et al. [18] employed the YOLOv4 [9] model for fracture detection on the GRAZPEDWRI-DX dataset [20], which was the first to demonstrate that the models of YOLO series can assist radiologists in more accurately predicting wrist injuries in children on X-ray images. Ahmed et al. [31] demonstrated the potential of one-stage algorithm models in enhancing the accuracy of diagnosis on pediatric wrist X-ray images by employing YOLOv5 [12], YOLOv6 [13], YOLOv7 [15], and YOLOv8 [16] models for wrist anomaly detection, respectively. Warin et al. [32] utilized the YOLOv5 [12] model to detect mandibular fractures in panoramic X-ray images, demonstrating the ability of the YOLOv5 model to recognize mandibular fractures at an expert level. Gaikwad et al. [33] applied the YOLOv5 [12] model to detect major and minor fractures of the C1 to C7 vertebrae, achieving an accuracy rate of 89%. Zou et al. [34] investigated various fracture morphologies throughout the body, including angle fractures, normal fractures, line fractures, and disoriented angle fractures. They integrated the YOLOv7 [15] model with the attention mechanism [35], achieving the superior performance on the FracAtlas [36] dataset. Samothai et al. [17] demonstrated that the YOLOX [10] model exhibits faster convergence speed and higher accuracy than YOLOR [11] by detecting the fracture region through the methods such as detector head decoupling, anchor-free, and augmentation strategies. They also showed that YOLOX can locate fractures even in low-featured X-ray images. Moon et al. [37] proposed a computer-aided facial bone fracture diagnosis (CA-FBFD) system based on the YOLOX model, effectively reducing the workload of doctors in diagnosing facial fractures in facial CT scans. While the application of the models of YOLO series to medical image recognition is a hot research topic, to date, no one has utilized YOLOv9 [26] for fracture detection.
| Model |
|
|
|
|
|
|
||||||||||||
| YOLOv8[16] | 43.61 | 164.9 | 59 | 62.44 | 40.32 | 3.6 | ||||||||||||
| YOLOv8+SA[22] | 43.64 | 165.4 | 62 | 63.99 | 41.49 | 3.9 | ||||||||||||
| YOLOv8+ECA[23] | 43.64 | 165.5 | 61 | 62.64 | 40.21 | 3.6 | ||||||||||||
| YOLOv8+GAM[24] | 49.29 | 183.5 | 60 | 63.32 | 40.74 | 8.7 | ||||||||||||
| YOLOv8+ResGAM[38] | 49.29 | 183.5 | 62 | 63.97 | 41.18 | 9.4 | ||||||||||||
| YOLOv8+ResCBAM[25] | 53.87 | 196.2 | 62 | 62.95 | 40.10 | 4.1 | ||||||||||||
| YOLOv9-C (Ours) | 51.02 | 239.0 | 64 | 65.31 | 42.66 | 5.2 | ||||||||||||
| YOLOv9-E (Ours) | 69.42 | 244.9 | 64 | 65.46 | 43.32 | 6.4 |
Note: The model size of all YOLOv8 and its variants listed in the table is large. [t1n1]Speed is the total time for preprocessing, inference, and post-processing.
3 Method
3.1 YOLOv9
Neural networks often have the challenge of information loss since the input data undergoes multiple layers of feature extraction and spatial transformation, resulting in the loss of the original information. This issue is particularly pronounced in X-ray images, where the low-features present significant difficult in fracture detection tasks. Specifically, models trained on such low-featured images tend to perform poorly, and addressing the problem of information loss could substantially enhance the accuracy of model predictions. To address this, we utilizing the YOLOv9 algorithm, which leverages the Programmable Gradient Information (PGI) and the Generalized Efficient Layer Aggregation Network (GELAN) to more effectively extract key features.
3.1.1 Programmable Gradient Information
Programmable Gradient Information (PGI) is an auxiliary supervision framework designed to manage the propagation of gradient information across various semantic levels, to improve the detection capability of the model. PGI comprises three main components: main branch, auxiliary reversible branch, and multi-level auxiliary information. During the inference process, it exclusively employs the main branch, which handles both forward and back propagation. As the network becomes deeper, an information bottleneck may occur, leading to loss functions that fail to produce useful gradients. In such cases, auxiliary reversible branch employs reversible functions to preserve information integrity and mitigate information loss in the main branch. Additionally, multi-level auxiliary information addresses the issue of error accumulation from the deep supervision mechanism, improving the learning capacity of the model through the introduction of supplementary information at different levels. Notably, research [26] highlighted the efficacy of PGI in preserving information during training, particularly in scenarios with limited features. This provides the theoretical basis for the YOLOv9 model to have excellent performance in fracture detection tasks.
3.1.2 Generalized Efficient Layer Aggregation Network
To enhance information integration and propagation efficiency in model training, YOLOv9 introduced a novel lightweight network architecture named Generalized Efficient Layer Aggregation Network (GELAN). GELAN integrates CSPNet [39] and ELAN [40] to efficiently aggregate network information, reducing information loss in propagation and enhancing inter-layer information interaction. This architecture is particularly suitable for fracture detection in environments with limited computing resources due to its lower parameters and computational complexity.
3.2 Data Processing and Augmentation
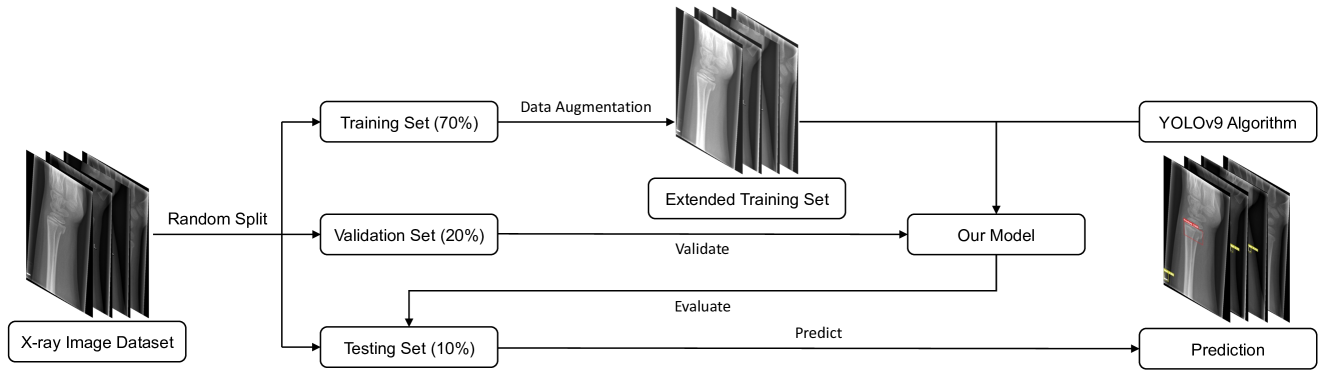
Fig 2 illustrates the flowchart of the experiments conducted in this study. Since the publisher of the GRAZPEDWRI-DX [20] dataset did not provide predefined training, validation, and test sets, we randomly assigned 70% to training set, 20% to validation set, and 10% to test set during the data processing. Moreover, due to the limited brightness diversity of low-featured X-ray images, models trained only on these images may not generalize well to X-ray images in other environments. To enhance the robustness of the model, we employed data augmentation techniques to extend the training set. Specifically, we fine-tuned the contrast and luminance of the X-ray images using the addWeighted function from the OpenCV library.
| Model |
|
|
|
|
|
|
||||||||||||
| YOLOv8[16] | 43.61 | 164.9 | 62 | 63.63 | 40.41 | 7.7 | ||||||||||||
| YOLOv8+SA[22] | 43.64 | 165.4 | 63 | 64.25 | 41.64 | 8.0 | ||||||||||||
| YOLOv8+ECA[23] | 43.64 | 165.5 | 65 | 64.26 | 41.94 | 7.7 | ||||||||||||
| YOLOv8+GAM[24] | 49.29 | 183.5 | 65 | 64.26 | 41.00 | 12.7 | ||||||||||||
| YOLOv8+ResGAM[38] | 49.29 | 183.5 | 64 | 64.98 | 41.75 | 18.1 | ||||||||||||
| YOLOv8+ResCBAM[25] | 53.87 | 196.2 | 64 | 65.78 | 42.16 | 8.7 | ||||||||||||
| YOLOv9-C (Ours) | 51.02 | 239.0 | 66 | 65.57 | 43.70 | 12.7 | ||||||||||||
| YOLOv9-E (Ours) | 69.42 | 244.9 | 66 | 65.62 | 43.73 | 16.1 |
Note: The model size of all YOLOv8 and its variants listed in the table is large. [t1n1]Speed is the total time for preprocessing, inference, and post-processing.
4 Experiment
4.1 Dataset
GRAZPEDWRI-DX [20] is a public dataset provided by the Medical University of Graz, which contains 20,327 X-ray images of pediatric wrist trauma. These X-ray images were collected by a team of pediatric radiologists at the University Hospital Graz from 2008 to 2018. The dataset comprises 6,091 patients and 10,643 studies, with a total of 74,459 labeled images, representing 67,771 labeled objects.
4.2 Experiment setup
The experiments in this paper utilized one single NVIDIA GeForce RTX 3090 GPU, employing Python with the PyTorch framework. Before training our model, we employed the YOLOv9 model weights pretrained on the MS COCO 2017 [27] dataset. In the training process, we trained the model using the SGD [41] optimizer, with a weight decay rate set to 5e-4 and a momentum of 0.937. We followed the research [21] to set the initial learning rate to 1e-2, the number of epochs to 100. Due to resource limitations (24GB memory) imposed by a single GPU, a batch size of 16 was employed for training the model.
4.3 Experimental Results
To evaluate the performance of YOLOv9 and other SOTA models in real diagnostic scenarios, this study compares model size (parameters and floating-point operations per second), accuracy (F1 score, mean average precision at 50% (mAP 50), and mean average precision from 50% to 95% (mAP 50-95)), and inference time. It is widely recognized that using larger input image sizes improves prediction accuracy but also requires more computational resources. Therefore, we conducted two experiments with input image sizes of 640 and 1024 for various scenarios, and the results are presented in Tables 1 and 2. With the input size of 640, both YOLOv9-C (Compact) and YOLOv9-E (Extended) demonstrate significantly improved mAP, while maintaining a reasonable inference speed. Specifically, YOLOv9-E achieves mAP 50-95 of 43.32%, which is 4.4% higher than 41.49% achieved by the current SOTA model YOLOv8+SA. When the input image size is 1024, the mAP 50-95 of YOLOv9-E reaches 43.73%, which also obtains the SOTA performance. However, due to the increased inference time, it is more suitable for deployment on devices with high computing resources.
5 Conclusion
The models of YOLO series can serve as CAD to assist radiologists and surgeons in interpreting X-ray images. However, the predictions from the previous models are often unsatisfactory due to the low features of X-ray images. This paper first introduces the application of YOLOv9 to fracture detection, addressing the issue of information loss during model training by employing the newly proposed PGI and GELAN. Experimental results indicate that the YOLOv9 model achieves SOTA performance on the GRAZPEDWRI-DX dataset, proving the effectiveness of this method.
This research is supported by National Science and Technology Council of Taiwan, under Grant Number: NSTC 112-2221-E-032-037-MY2.
References
- [1] authorChung, S.W., et al.: titleAutomated detection and classification of the proximal humerus fracture by using deep learning algorithm. journalActa orthopaedica volume89(number4), pages468–473 (year2018)
- [2] authorChoi, J.W., et al.: titleUsing a dual-input convolutional neural network for automated detection of pediatric supracondylar fracture on conventional radiography. journalInvestigative radiology volume55(number2), pages101–110 (year2020)
- [3] authorTanzi, L., et al.: titleHierarchical fracture classification of proximal femur x-ray images using a multistage deep learning approach. journalEuropean journal of radiology volume133, pages109373 (year2020)
- [4] authorAdams, S.J., et al.: titleArtificial intelligence solutions for analysis of x-ray images. journalCanadian Association of Radiologists Journal volume72(number1), pages60–72 (year2021)
- [5] authorGan, K., et al.: titleArtificial intelligence detection of distal radius fractures: a comparison between the convolutional neural network and professional assessments. journalActa orthopaedica volume90(number4), pages394–400 (year2019)
- [6] authorYahalomi, E., authorChernofsky, M., authorWerman, M.: titleDetection of distal radius fractures trained by a small set of x-ray images and faster r-cnn. In: booktitleIntelligent Computing: Proceedings of the 2019 Computing Conference, Volume 1, pp. pages971–981. organizationSpringer (year2019)
- [7] authorBlüthgen, C., et al.: titleDetection and localization of distal radius fractures: Deep learning system versus radiologists. journalEuropean journal of radiology volume126, pages108925 (year2020)
- [8] authorRedmon, J., et al.: titleYou only look once: Unified, real-time object detection. In: booktitleProceedings of the IEEE conference on computer vision and pattern recognition, pp. pages779–788. (year2016)
- [9] authorBochkovskiy, A., authorWang, C.Y., authorLiao, H.Y.M.: titleYolov4: Optimal speed and accuracy of object detection. journalarXiv preprint arXiv:2004.10934 (year2020)
- [10] authorGe, Z., et al.: titleYolox: Exceeding yolo series in 2021. journalarXiv preprint arXiv:2107.08430 (year2021)
- [11] authorWang, C.Y., authorYeh, I.H., authorLiao, H.Y.M.: titleYou only learn one representation: Unified network for multiple tasks. journalarXiv preprint arXiv:2105.04206 (year2021)
- [12] authorGlenn, J.: titleUltralytics yolov5. GitHub. howpublishedhttps://github.com/ultralytics/yolov5 (year2022)
- [13] authorLi, C., et al.: titleYolov6: A single-stage object detection framework for industrial applications. journalarXiv preprint arXiv:2209.02976 (year2022)
- [14] authorJu, R.Y., et al.: titleResolution enhancement processing on low quality images using swin transformer based on interval dense connection strategy. journalMultimedia Tools and Applications pp. pages1–17. (year2023)
- [15] authorWang, C.Y., authorBochkovskiy, A., authorLiao, H.Y.M.: titleYolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In: booktitleProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. pages7464–7475. (year2023)
- [16] authorGlenn, J.: titleUltralytics yolov8. GitHub. howpublishedhttps://github.com/ultralytics/ultralytics (year2023)
- [17] authorSamothai, P., et al.: titleThe evaluation of bone fracture detection of yolo series. In: booktitle2022 37th International Technical Conference on Circuits/Systems, Computers and Communications (ITC-CSCC), pp. pages1054–1057. organizationIEEE (year2022)
- [18] authorHržić, F., et al.: titleFracture recognition in paediatric wrist radiographs: An object detection approach. journalMathematics volume10(number16), pages2939 (year2022)
- [19] authorSu, Z., et al.: titleSkeletal fracture detection with deep learning: A comprehensive review. journalDiagnostics volume13(number20), pages3245 (year2023)
- [20] authorNagy, E., et al.: titleA pediatric wrist trauma x-ray dataset (grazpedwri-dx) for machine learning. journalScientific Data volume9(number1), pages222 (year2022)
- [21] authorJu, R.Y., authorCai, W.: titleFracture detection in pediatric wrist trauma x-ray images using yolov8 algorithm. journalarXiv preprint arXiv:2304.05071 (year2023)
- [22] authorZhang, Q.L., authorYang, Y.B.: titleSa-net: Shuffle attention for deep convolutional neural networks. In: booktitleICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. pages2235–2239. organizationIEEE (year2021)
- [23] authorWang, Q., et al.: titleEca-net: Efficient channel attention for deep convolutional neural networks. In: booktitleProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. pages11534–11542. (year2020)
- [24] authorLiu, Y., authorShao, Z., authorHoffmann, N.: titleGlobal attention mechanism: Retain information to enhance channel-spatial interactions. journalarXiv preprint arXiv:2112.05561 (year2021)
- [25] authorWoo, S., et al.: titleCbam: Convolutional block attention module. In: booktitleProceedings of the European conference on computer vision (ECCV), pp. pages3–19. (year2018)
- [26] authorWang, C.Y., authorYeh, I.H., authorLiao, H.Y.M.: titleYolov9: Learning what you want to learn using programmable gradient information. journalarXiv preprint arXiv:2402.13616 (year2024)
- [27] authorLin, T.Y., et al.: titleMicrosoft coco: Common objects in context. In: booktitleComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pp. pages740–755. organizationSpringer (year2014)
- [28] authorSon, D.M., et al.: titleCombined deep learning techniques for mandibular fracture diagnosis assistance. journalLife volume12(number11), pages1711 (year2022)
- [29] authorRonneberger, O., authorFischer, P., authorBrox, T.: titleU-net: Convolutional networks for biomedical image segmentation. In: booktitleMedical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, pp. pages234–241. organizationSpringer (year2015)
- [30] authorJeon, Y.D., et al.: titleDeep learning model based on you only look once algorithm for detection and visualization of fracture areas in three-dimensional skeletal images. journalDiagnostics volume14(number1), pages11 (year2023)
- [31] authorAhmed, A., et al.: titleEnhancing wrist abnormality detection with yolo: Analysis of state-of-the-art single-stage detection models. journalBiomedical Signal Processing and Control volume93, pages106144 (year2024)
- [32] authorWarin, K., et al.: titleAssessment of deep convolutional neural network models for mandibular fracture detection in panoramic radiographs. journalInternational Journal of Oral and Maxillofacial Surgery volume51(number11), pages1488–1494 (year2022)
- [33] authorGaikwad, D., et al.: titleIdentification of cervical spine fracture using deep learning. journalAustralian Journal of Multi-Disciplinary Engineering pp. pages1–9. (year2024)
- [34] authorZou, J., authorArshad, M.R.: titleDetection of whole body bone fractures based on improved yolov7. journalBiomedical Signal Processing and Control volume91, pages105995 (year2024)
- [35] authorHu, J., authorShen, L., authorSun, G.: titleSqueeze-and-excitation networks. In: booktitleProceedings of the IEEE conference on computer vision and pattern recognition, pp. pages7132–7141. (year2018)
- [36] authorAbedeen, I., et al.: titleFracatlas: A dataset for fracture classification, localization and segmentation of musculoskeletal radiographs. journalScientific Data volume10(number1), pages521 (year2023)
- [37] authorMoon, G., et al.: titleComputer aided facial bone fracture diagnosis (ca-fbfd) system based on object detection model. journalIEEE Access volume10, pages79061–79070 (year2022)
- [38] authorChien, C.T., et al.: titleYolov8-am: Yolov8 with attention mechanisms for pediatric wrist fracture detection. journalarXiv preprint arXiv:2402.09329 (year2024)
- [39] authorWang, C.Y., et al.: titleCspnet: A new backbone that can enhance learning capability of cnn. In: booktitleProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pp. pages390–391. (year2020)
- [40] authorWang, C.Y., authorLiao, H.Y.M., authorYeh, I.H.: titleDesigning network design strategies through gradient path analysis. journalarXiv preprint arXiv:2211.04800 (year2022)
- [41] authorRuder, S.: titleAn overview of gradient descent optimization algorithms. journalarXiv preprint arXiv:1609.04747 (year2016)