Animatable 3D Gaussian: Fast and High-Quality Reconstruction of Multiple Human Avatars
Abstract
Neural radiance fields are capable of reconstructing high-quality drivable human avatars but are expensive to train and render. To reduce consumption, we propose Animatable 3D Gaussian, which learns human avatars from input images and poses. We extend 3D Gaussians to dynamic human scenes by modeling a set of skinned 3D Gaussians and a corresponding skeleton in canonical space and deforming 3D Gaussians to posed space according to the input poses. We introduce hash-encoded shape and appearance to speed up training and propose time-dependent ambient occlusion to achieve high-quality reconstructions in scenes containing complex motions and dynamic shadows. On both novel view synthesis and novel pose synthesis tasks, our method outperforms existing methods in terms of training time, rendering speed, and reconstruction quality. Our method can be easily extended to multi-human scenes and achieve comparable novel view synthesis results on a scene with ten people in only 25 seconds of training. For video and code, please see https://jimmyyliu.github.io/Animatable-3D-Gaussian/.
![[Uncaptioned image]](x1.png)
1 Introduction
Real-time rendering and fast reconstruction of a high-quality digital human has a variety of applications in various fields, such as virtual reality, gaming, sports broadcasting, and telepresence. Existing methods often take considerable time for training, and none of them can achieve high-quality reconstruction and real-time rendering in a very short training time.
Recent methods [26, 5, 37] implicitly reconstruct high-quality human avatars using neural radiance fields [35]. However, implicit neural radiance fields inevitably lead to artifacts in the synthesized novel views as they require modeling the entire space including empty space. Some of these methods [5, 37] require high memory and time consumption due to multilayer perceptron and complex point sampling for each ray. When it comes to datasets with dynamic illumination and shadow, the reconstruction quality of these methods [26, 5, 37] is significantly degraded. This decline is attributed to the inherent incapacity of these methods to accommodate the dynamic alterations in illumination and shadow.
In this paper, we aim to acquire high-fidelity human avatars from a monocular or sparse-view video sequence in seconds and to render high-quality novel view and pose at interactive rates (170 FPS for resolution). To this end, we introduce a novel neural representation using 3D Gaussians (3D-GS [28]) for dynamic humans, named Animatable 3D Gaussian, overcoming the problem of artifacts in implicit neural radiance fields. In order to deform 3D Gaussians to the posed space, we model a set of skinned 3D Gaussians and a corresponding skeleton in canonical space. We use hash-encoded shape and appearance to accelerate convergence speed and avoid overfitting. For low memory and time consumption of rendering, we use the 3D Gaussian rasterizer [28] to rasterize the deformed 3D Gaussians instead of volume rendering. To handle the dynamic illumination and shadow, we suggest modeling time-dependent ambient occlusion for each timestamp.
Since the public dataset [1] contains few pose and shadow changes, we create a new dataset named GalaBasketball in order to show the performance of our method under complex motion and dynamic shadows. We evaluate our method on both public and our created dataset and compare it with state-of-the-art methods [26, 5]. Our method is able to reconstruct better-quality human avatars in a shorter time. Moreover, our method can be extended to multi-human scenes and performs well.
In summary, the major contributions of our work are:
-
•
We propose Animatable 3D Gaussian, a novel neural representation using 3D Gaussians for dynamic humans, which enables 3D Gaussians to perform well in dynamic human scenes.
-
•
We present a novel pipeline for human reconstruction that can acquire higher-fidelity human avatars with lower memory and time consumption than state-of-the-art methods [26, 5].
-
•
We propose a time-dependent ambient occlusion module to reconstruct the dynamic shadows, which allows our method to obtain high-fidelity human avatars from scenes with complex motions and dynamic shadows.
2 Related Work
3D Human Reconstruction. Reconstructing 3D human has been a popular research topic in recent years. Traditional methods achieve high-fidelity reconstruction by means of depth sensors [9, 14, 42, 19] and dense camera arrays [11, 12], but expensive hardware requirements limit the application of these methods. Recent methods [1, 2, 18, 48, 20, 21, 47] utilize parametric mesh templates as a prior, such as SMPL [33]. By optimizing mesh templates, these methods are able to reconstruct 3D human bodies of different shapes. However, they have limitations in reconstructing details such as hair and fabric.
The emergence of neural radiance fields [35] has made neural representations popular in the field of human reconstruction. Many works [5, 26, 37, 3, 7, 6, 8, 10, 13, 15, 22, 23, 24, 25, 27, 29, 39, 40, 34, 32] have used neural representations to model 3D human shapes and appearances in a canonical space and then used deformation fields to deform the model into a posed space for rendering. These approaches achieve high-quality reconstruction results but require high memory and time consumption, as they typically require complex implicit representations, deformation algorithms, and volume rendering. One of these works InstantAvatar [26] is fast but suffers from artifacts in synthetic images. Our approach solves the problems of previous methods by combining parametric templates and implicit expressions to achieve fast and high-quality human reconstruction.
Accelerating Neural Rendering. Since the rendering speed of vanilla NeRF [35] is very slow, it takes several seconds to obtain an image and more time to train. Recent works [36, 4, 16, 36, 38, 28, 17, 45, 31, 30, 49, 44, 43] have been devoted to improving the speed of neural rendering. Plenoxels [16] proposes the utilization of a sparse volume, accompanied by density and spherical harmonic coefficients, for rendering purposes. TensoRF [4] decomposes the voxel grid into an aggregate of vector coefficients, aiming to reduce the size of the model for efficiency. Instant-NGP [36] introduces multi-resolution hash encoding to accomplish fast rendering. 3D-GS [28] represents each scene as a collection of scalable semi-transparent ellipsoids to achieve real-time rendering. These methods are mainly used for the reconstruction of static scenes. For dynamic scenes, FPO[45] presents a novel combination of NeRF, PlenOctree[49] representation, volumetric fusion, and Fourier transform to tackle efficient neural modeling and real-time rendering of dynamic scenes. InstantAvatar [26] applies hash encoding on 3d avatar reconstruction tasks for fast rendering. Such methods require high memory costs and suffer from artifacts. In this paper, we extend 3D-GS from static scenes to dynamic human scenes.
3 Preliminary
In this section, we briefly review the representation and pipeline of 3D Gaussian rasterization [28] in Sec. 3.1, and pose-based deformation in Sec. 3.2.
3.1 3D Gaussian Rasterization
Kerbl et al. [28] proposed to represent each scene as a collection of 3D Gaussians. Each 3D Gaussian is defined as:
| (1) |
where represents the geometric center of a 3D Gaussian distribution, is a rotation matrix, is a scaling matrix that scales the Gaussian in three dimensions, denotes the opacity of the center, and refers to a set of spherical harmonic coefficients used for modeling view-dependent color distribution following standard practice [16].
The opacity of position in the vicinity of a 3D Gaussian is defined as:
| (2) |
where the covariance matrix is decomposed into the rotation matrix and the scaling matrix :
| (3) |
Following the approach of Zwicker et al. [51], 3D Gaussians are projected to 2D image space as follows:
| (4) |
where is a viewing transformation and is the Jacobian of the affine approximation of the projective transformation.
Subsequently, the projected Gaussians are sorted based on their depths and rasterized to neighboring pixels according to Eq. (2). Each pixel receives a depth-sorted list of colors and opacities . The final pixel color is computed by blending N ordered points overlapping the pixel:
| (5) |
3.2 Pose-guided Deformation
We define each frame within the video sequence as a posed space with a timestamp and deform points from canonical space to posed space via linear blend skinning. We use a skinning weight field to model articulation. The skinning weight field [33] is defined as:
| (6) |
where is the count of bones and is a point in canonical space.
Target bone transformations in frame can be calculated from the input poses and the corresponding skeleton as follows:
| (7) |
where refers to the rotation Euler Angle of each joint in frame (world rotation for and local rotation for the rest), is the world translation in frame , and is the local position of each joint in canonical space. Please refer to the supplementary materials for the detailed calculation process.
Then we can deform points in canonical space to the posed space via linear blend skinning:
| (8) |
where refers to a point in frame .
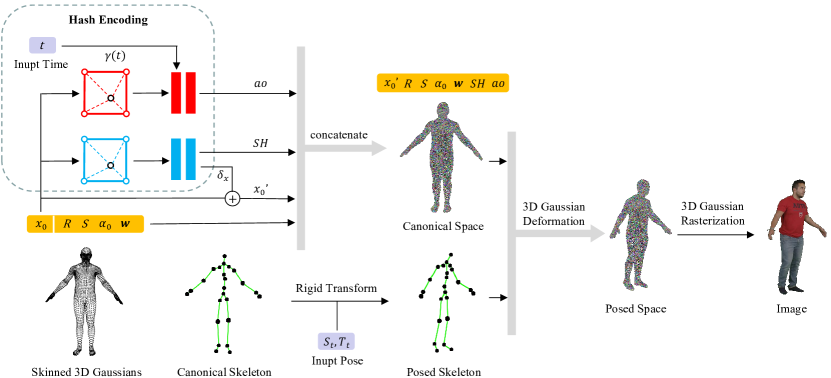
4 Method
Given a video sequence with one or more moving humans and their poses , we reconstruct an animatable 3D Gaussian representation for each person in seconds. For multi-view video sequences, we reconstruct time-dependent ambient occlusion to achieve high-quality novel view synthesis.
In this section, we first introduce our animatable 3D Gaussian representation in Sec. 4.1. Then we deform 3D Gaussians from canonical space to posed space, as introduced in Sec. 3.2 and Sec. 4.2. Finally, we run 3D Gaussian rasterization (Sec. 3.1) to render an image for specific camera parameters. Moreover, we propose to build time-dependent ambient occlusion (Sec. 4.3) for multi-view, multi-person, and wide-range motion tasks, which enables our algorithm to fit dynamic shadows caused by occlusion. The pipeline of the proposed method is illustrated in Fig. 2.
4.1 Animatable 3D Gaussian in Canonical Space
3D Gaussians with Skeleton. We bind 3D Gaussians to a corresponding skeleton to enable the linear skinning algorithm in Eq. (8). The proposed animatable 3D Gaussian representation consists of a set of skinned 3D Gaussians and a corresponding skeleton mentioned in Eq. (7). The skinned 3D Gaussian is adapted from the static 3D Gaussian in Eq. (1) and defined as follows:
| (9) |
where is the skinning weights, and is the vertex displacement.
Directly optimizing the skinning weights from random initialization is a significant challenge. Instead, we treat the skinning weights as a strong prior for a generic human body model unrelated to any specific human shape. In practice, we initialize the skinning weights and positions of Gaussian points using a standard skinned model as discussed in Sec. 4.4. During optimization, the skinning weights are kept fixed, while the vertex displacement and skeleton are optimized to capture the shape and motion of an individual accurately. We shift the Gaussian center before implementing pose-based deformation in Eq. (8):
| (10) |
Hash-encoded Shape and Appearance. We note that using per-vertex colors performs poorly in deformable dynamic scenes [28]. Since the deformation of Gaussians from canonical space to posed space is initially uncertain, it needs more samples and iterations to reach convergence. Moreover, rendering based on 3D Gaussian rasterization can only backpropagate the gradient to a finite number of Gaussians in a single iteration, which leads to a slow or even divergent optimization process for dynamic scenes. To address this issue, we suggest sampling spherical harmonic coefficients for each vertex from a continuous parameter field, which is able to affect all neighboring Gaussians in a single optimization. Similarly, using unconstrained per-vertex displacement can easily cause the optimization process to diverge in dynamic scenes. Therefore, we also model a parameter field for vertex displacement. For the remaining parameters in Eq. (9), we store them in each point to preserve the ability of the 3D Gaussian to fit different shapes. We define the parameter fields as follows:
| (11) |
Since our animatable 3D Gaussian representation is initialized by a standard human body model, the centers of 3D Gaussians are uniformly distributed near the human surface. We only need to sample at fixed positions near the surface of the human body in the parameter fields. This allows for significant compression of the hash table for the hash encoding [36]. Thus, we choose the hash encoding to model our parameter field to reduce the time and storage consumption.
Optionally, we provide UV-encoded spherical harmonic coefficients, allowing fast processing of custom human models with UV coordinate mappings. UV encoding potentially achieves higher reconstruction quality compared to hash encoding. The UV mapping for spherical harmonic coefficients is defined as follows:
| (12) |
where is the UV coordinate of a 3D Gaussian.
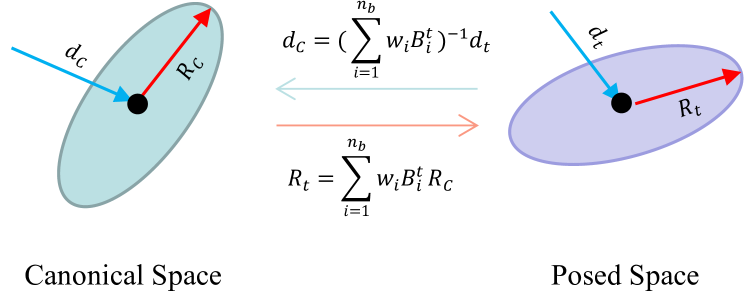
4.2 3D Gaussian Deformation
We use poses to guide the deformation of 3D Gaussians illustrated in Fig. 3. We introduce pose-based deformation which transforms the point position from the canonical space to the posed space in Sec. 3.2. For 3D Gaussians, we also need to deform their orientation to achieve a consistent anisotropic Gaussian distribution at different poses. Using the same orientation in different poses causes the 3D Gaussian to degenerate into Gaussian spheres. Same as Eq. (8), we apply the linear blend skinning to the rotation of 3D Gaussians as follows:
| (13) |
where is the rotation in canonical space and is the rotation in posed space in frame .
The view direction for the computation of color based on spherical harmonics should be deformed to canonical space, in order to achieve consistent anisotropic colors. Hence, we apply the inverse transformation of the linear blend skinning to the view direction:
| (14) |
where is the direction in canonical space and is the direction in posed space in frame .
We implement the mentioned transformations by extending the 3D Gaussian rasterizer [28] and explicitly derive the gradients for all parameters. This makes the time overhead for the pose-based deformation of 3D Gaussians almost negligible.
4.3 Time-dependent Ambient Occlusion
We propose a time-dependent ambient occlusion module to address the issue of dynamic shadows in specific scenes. We additionally model an ambient occlusion factor on top of the skinned 3D Gaussian in Eq. (9) as follows:
| (15) |
We calculate the color after considering the ambient occlusion for each individual Gaussian as follows:
| (16) |
where refers to the spherical harmonics.
As discussed in Sec. 4.1, we also employ hash encoding for the ambient occlusion , since shadows should be continuously modeled in space. Furthermore, we introduce an additional input of the positional encoding [35] of time in the MLP module of the hashing encoding [36] in order to capture time-dependent ambient occlusion. The parameter field for ambient occlusion is defined as:
| (17) |
where function refers to the positional encoding used in NeRF [35].
At the beginning of training, we use a fixed ambient occlusion to allow the model to learn time-independent spherical harmonic coefficients. We start optimizing the ambient occlusion after the color stabilizes.
| male-3-casual | male-4-casual | female-3-casual | female-4-casual | |||||||||
| PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | |
| Anim-NeRF [5] (5 minutes) | 23.17 | 0.9266 | 0.0784 | 22.30 | 0.9235 | 0.0911 | 22.37 | 0.9311 | 0.0784 | 23.18 | 0.9292 | 0.0687 |
| InstantAvatar [26] (30 seconds) | 26.56 | 0.9301 | 0.1190 | 26.10 | 0.9289 | 0.1397 | 22.37 | 0.8427 | 0.2687 | 26.32 | 0.9281 | 0.1333 |
| Ours (30 seconds) | 29.06 | 0.9704 | 0.0264 | 26.16 | 0.9554 | 0.0491 | 24.59 | 0.9535 | 0.0399 | 27.26 | 0.9634 | 0.0281 |
| InstantAvatar [26] (5 seconds) | 17.30 | 0.7980 | 0.3473 | 16.44 | 0.7960 | 0.3508 | 17.22 | 0.8185 | 0.3262 | 14.91 | 0.7606 | 0.3878 |
| Ours (5 seconds) | 22.84 | 0.9395 | 0.0632 | 18.88 | 0.9103 | 0.1175 | 20.51 | 0.9301 | 0.0764 | 20.63 | 0.9246 | 0.0737 |
4.4 Optimization Details
Animatable 3D Gaussian Initialization. The initialization of the 3D Gaussian has a significant impact on the quality of optimization results. Improper initialization can even lead to divergence in the optimization process. For static 3D Gaussians [28], the Structure-from-Motion (SFM [41]) method is used to obtain the initial 3D Gaussian point cloud, which provides a very good and dense initialization.
However, for dynamic scenes, obtaining an initial point cloud using SFM is a huge challenge. Therefore, we use a standard skinned model to initialize our deformable 3D Gaussian representation. This standard skinned model should include a set of positions and skinning weights , and a skeleton corresponding to the input poses. We recommend upsampling the vertices of the input model to around 100,000 to achieve high reconstruction quality. Specifically, for the SMPL model [33], we randomly sample K additional points (we set K=20 based on experimental results) within the neighborhood of each vertex and directly copy their skinning parameters to get a model of around 140,000 points.
Loss Function. The proposed animatable 3D Gaussian representation is capable of accurately fitting dynamic scenes containing moving humans, thus eliminating the need for additional regularization losses. We directly employ a combination of and D-SSIM term:
| (18) |
where we use following the best practices of the static 3D Gaussian [28].

| PSNR | SSIM | LPIPS | |
|---|---|---|---|
| w/o hash-SH | 25.38 | 0.9478 | 0.0504 |
| w/o hash-vd | 22.08 | 0.8994 | 0.1678 |
| w/o J-optimize | 21.45 | 0.9311 | 0.0781 |
| ours | 26.77 | 0.9607 | 0.0359 |
5 Experiments
We evaluate the speed and quality (PSNR, SSIM [46], and LPIPS [50]) of our method on monocular scenes (Sec. 5.1) and multi-view scenes (Sec. 5.2). Comparative experiments with state-of-the-art methods [26, 5] show the superiority of our method. In addition, we provide extensive ablation studies of our methods. In all experiments, we evaluate our approach and InstantAvatar [26] on a single RTX 3090 while Anim-NeRF on RTX 3090.
5.1 Monocular Scenes
We use the PeopleSnapshot [1] dataset to evaluate the performance of our method in single-human, monocular scenes. Following the previous approach [26], we downsample the images to resolution and use the SMPL [33] model for initialization. We do not use any predicted body parameters but a generic template. Since this dataset does not contain timestamps and drastic shading variations, we do not use the time-dependent ambient occlusion module.
Comparison. We provide quantitative comparisons in Tab. 1 and visual comparisons in Fig. 4. Compared to InstantAvatar [26] and Anim-NeRF [5], our method achieves higher reconstruction quality in a shorter training time (5s and 30s). As shown in Fig. 4, our method solves the problem of artifacts that have occurred in the previous methods. Moreover, our method achieves the fastest training and rendering speed. For resolution images, we reach a training speed of 50 FPS and a rendering speed of 170 FPS.
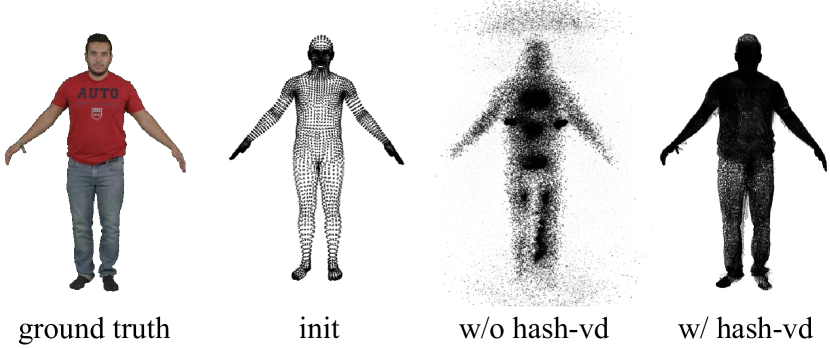
Ablation Study. Tab. 2 quantitatively illustrates that our proposed hash-encoded spherical harmonic coefficients, hash-encoded vertex displacement, and joint optimization, can improve the quality of the reconstruction in a short period of training time (30s). We also visualize the point cloud optimization results in Fig. 5 to show the effect of hash-encoded vertex displacement.
| idle | dribble | shot | turn | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | |
| InstantAvatar [26] (5 minutes) | 29.86 | 0.9607 | 0.0575 | 27.25 | 0.9435 | 0.0903 | 29.22 | 0.9461 | 0.0709 | 32.20 | 0.9705 | 0.0371 |
| Ours: w/o ao (50 seconds) | 37.38 | 0.9941 | 0.0042 | 36.53 | 0.9909 | 0.0059 | 37.07 | 0.9908 | 0.0067 | 36.77 | 0.9927 | 0.0062 |
| Ours: hash-SH (70 seconds) | 39.85 | 0.9957 | 0.0032 | 38.52 | 0.9934 | 0.0043 | 39.11 | 0.9933 | 0.0051 | 39.25 | 0.9951 | 0.0041 |
| Ours: uv-SH (60 seconds) | 40.75 | 0.9964 | 0.0029 | 38.53 | 0.9935 | 0.0042 | 39.44 | 0.9936 | 0.0049 | 39.74 | 0.9953 | 0.0038 |



5.2 Multi-View Scenes
There are few pose and shadow changes in the PeopleSnapshot [1] dataset. In order to demonstrate the reconstruction performance of the proposed method in scenes containing complex motions and dynamic shadows, we create a dataset called GalaBasketball, which is synthesized from several player models with different shapes and appearances. The GalaBasketball dataset consists of four single-human and three multi-human scenes, providing six uniformly surrounded cameras as a training set and one camera as a test set. For the single-human scenes, we provide an additional set of actions to evaluate the novel pose synthesis capability. Moreover, We provide a standard skinned model corresponding to the GalaBasketball dataset for initialization, which does not resemble any of the players in the dataset in terms of geometry and appearance.
Novel View Synthesis. As shown in Tab. 3 and Fig. 6, we evaluate the ability of our method under different settings to synthesize novel views on the single-human scenes of GalaBasketball. Compared with InstantAvatar [26], our approach under any setting achieves a higher-quality synthesis of novel views in a shorter training time and significantly eliminates artifacts. This proves that our animatable 3D Gaussian representation can be trained under complex motion variations and obtain high-quality human avatars. In contrast, InstantAvatar suffers from artifacts and achieves low synthesis quality, because skin weights fail to converge to the ground truth under complex motion variations.
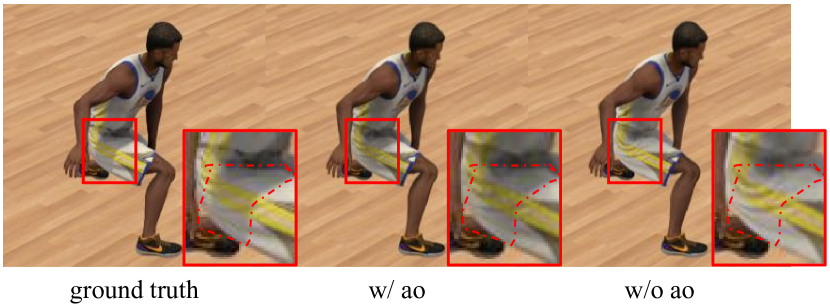
We also provide our ablation studies in Tab. 3. The time-dependent ambient occlusion helps our method achieve higher novel view synthesis quality, which fits time-dependent shadow changes as shown in Fig. 7. In addition, we provide UV mapping for the standard model to evaluate the performance of our UV-encoded spherical harmonic coefficients. The result shows that using UV-encoded spherical harmonic coefficients can improve the speed and quality compared with hash-encoded if permitted.
Novel Pose Synthesis. We render the images using the other set of actions different from the training set and compare our novel pose synthesis results with InstantAvatar in Fig. 8. Since the novel pose synthesis task does not have a timestamp, we do not use the time-dependent ambient occlusion. The result shows that our reconstructed human avatar achieves high synthesis quality in novel poses, while InstantAvatar still suffers from artifacts.
Multi-Human Scenes. We extend our method to multi-human scenes by rendering multiple human avatars simultaneously on a single RTX 3090, while the existing methods [5, 26] can not be extended to multi-human scenes due to the limitations of implementation and memory. Fig. 9 shows the high-quality novel view synthesis results of our method in the multi-human scenes of GalaBasketball, including two double-human scenes and a 5v5 scene. Our method achieves a training speed of 40 FPS and a rendering speed of 110 FPS on double-human scenes ( resolution). On the 5v5 scene ( resolution), our method reaches a training speed of 10 FPS and a rendering speed of 40 FPS. Please refer to the supplementary materials for free-viewpoint video results.
6 Conclusion
We propose a method for high-quality human reconstruction in seconds. The reconstructed human avatar can be used for real-time novel view synthesis and novel pose synthesis. Our method consists of the Animatable 3D Gaussian representation in canonical space and pose-based 3D Gaussian deformation, which extends 3D Gaussian [28] to deformable humans. Our proposed time-dependent ambient occlusion achieves high-quality reconstruction results in scenes containing complex motions and dynamic shadows. Compared to the state-of-the-art methods [5, 26], our method takes less training time, renders faster, and yields better reconstruction results. Moreover, our approach can be easily extended to multi-human scenes.
Limitations and Future Work. To implement optional modules, our approach uses multiple MLPs. However, in specific tasks, multiple MLPS can be merged into one to further reduce training consumption. Due to the complexity of the dynamic scenes, we do not add or remove Gaussian points during the training process, which leads to the quality of the reconstruction greatly affected by the number of initialized points, and reduces the reconstruction quality in the high-frequency region. At last, inaccurate pose input may cause the performance degradation of our method. Optimizing the input pose by other regularization methods may solve this problem and even enable human reconstruction without input pose.
References
- Alldieck et al. [2018a] Thiemo Alldieck, Marcus Magnor, Weipeng Xu, Christian Theobalt, and Gerard Pons-Moll. Detailed human avatars from monocular video. In 2018 International Conference on 3D Vision (3DV), pages 98–109. IEEE, 2018a.
- Alldieck et al. [2018b] Thiemo Alldieck, Marcus Magnor, Weipeng Xu, Christian Theobalt, and Gerard Pons-Moll. Video based reconstruction of 3d people models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8387–8397, 2018b.
- Bergman et al. [2022] Alexander Bergman, Petr Kellnhofer, Wang Yifan, Eric Chan, David Lindell, and Gordon Wetzstein. Generative neural articulated radiance fields. Advances in Neural Information Processing Systems, 35:19900–19916, 2022.
- Chen et al. [2022a] Anpei Chen, Zexiang Xu, Andreas Geiger, Jingyi Yu, and Hao Su. Tensorf: Tensorial radiance fields. In European Conference on Computer Vision, pages 333–350. Springer, 2022a.
- Chen et al. [2021a] Jianchuan Chen, Ying Zhang, Di Kang, Xuefei Zhe, Linchao Bao, Xu Jia, and Huchuan Lu. Animatable neural radiance fields from monocular rgb videos. arXiv preprint arXiv:2106.13629, 2021a.
- Chen et al. [2021b] Xu Chen, Yufeng Zheng, Michael J Black, Otmar Hilliges, and Andreas Geiger. Snarf: Differentiable forward skinning for animating non-rigid neural implicit shapes. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11594–11604, 2021b.
- Chen et al. [2022b] Xu Chen, Tianjian Jiang, Jie Song, Jinlong Yang, Michael J Black, Andreas Geiger, and Otmar Hilliges. gdna: Towards generative detailed neural avatars. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20427–20437, 2022b.
- Chibane et al. [2020] Julian Chibane, Thiemo Alldieck, and Gerard Pons-Moll. Implicit functions in feature space for 3d shape reconstruction and completion. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6970–6981, 2020.
- Collet et al. [2015] Alvaro Collet, Ming Chuang, Pat Sweeney, Don Gillett, Dennis Evseev, David Calabrese, Hugues Hoppe, Adam Kirk, and Steve Sullivan. High-quality streamable free-viewpoint video. ACM Transactions on Graphics (ToG), 34(4):1–13, 2015.
- Corona et al. [2021] Enric Corona, Albert Pumarola, Guillem Alenya, Gerard Pons-Moll, and Francesc Moreno-Noguer. Smplicit: Topology-aware generative model for clothed people. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11875–11885, 2021.
- Debevec et al. [2000] Paul Debevec, Tim Hawkins, Chris Tchou, Haarm-Pieter Duiker, Westley Sarokin, and Mark Sagar. Acquiring the reflectance field of a human face. In Proceedings of the 27th annual conference on Computer graphics and interactive techniques, pages 145–156, 2000.
- Debevec et al. [2023] Paul E Debevec, Camillo J Taylor, and Jitendra Malik. Modeling and rendering architecture from photographs: A hybrid geometry-and image-based approach. In Seminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 465–474. 2023.
- Dong et al. [2022] Zijian Dong, Chen Guo, Jie Song, Xu Chen, Andreas Geiger, and Otmar Hilliges. Pina: Learning a personalized implicit neural avatar from a single rgb-d video sequence. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20470–20480, 2022.
- Dou et al. [2016] Mingsong Dou, Sameh Khamis, Yury Degtyarev, Philip Davidson, Sean Ryan Fanello, Adarsh Kowdle, Sergio Orts Escolano, Christoph Rhemann, David Kim, Jonathan Taylor, et al. Fusion4d: Real-time performance capture of challenging scenes. ACM Transactions on Graphics (ToG), 35(4):1–13, 2016.
- Feng et al. [2022] Yao Feng, Jinlong Yang, Marc Pollefeys, Michael J Black, and Timo Bolkart. Capturing and animation of body and clothing from monocular video. In SIGGRAPH Asia 2022 Conference Papers, pages 1–9, 2022.
- Fridovich-Keil et al. [2022] Sara Fridovich-Keil, Alex Yu, Matthew Tancik, Qinhong Chen, Benjamin Recht, and Angjoo Kanazawa. Plenoxels: Radiance fields without neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5501–5510, 2022.
- Garbin et al. [2021] Stephan J Garbin, Marek Kowalski, Matthew Johnson, Jamie Shotton, and Julien Valentin. Fastnerf: High-fidelity neural rendering at 200fps. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14346–14355, 2021.
- Guo et al. [2021] Chen Guo, Xu Chen, Jie Song, and Otmar Hilliges. Human performance capture from monocular video in the wild. In 2021 International Conference on 3D Vision (3DV), pages 889–898. IEEE, 2021.
- Guo et al. [2019] Kaiwen Guo, Peter Lincoln, Philip Davidson, Jay Busch, Xueming Yu, Matt Whalen, Geoff Harvey, Sergio Orts-Escolano, Rohit Pandey, Jason Dourgarian, et al. The relightables: Volumetric performance capture of humans with realistic relighting. ACM Transactions on Graphics (ToG), 38(6):1–19, 2019.
- Habermann et al. [2019] Marc Habermann, Weipeng Xu, Michael Zollhoefer, Gerard Pons-Moll, and Christian Theobalt. Livecap: Real-time human performance capture from monocular video. ACM Transactions On Graphics (TOG), 38(2):1–17, 2019.
- Habermann et al. [2020] Marc Habermann, Weipeng Xu, Michael Zollhofer, Gerard Pons-Moll, and Christian Theobalt. Deepcap: Monocular human performance capture using weak supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5052–5063, 2020.
- He et al. [2020] Tong He, John Collomosse, Hailin Jin, and Stefano Soatto. Geo-pifu: Geometry and pixel aligned implicit functions for single-view human reconstruction. Advances in Neural Information Processing Systems, 33:9276–9287, 2020.
- He et al. [2021] Tong He, Yuanlu Xu, Shunsuke Saito, Stefano Soatto, and Tony Tung. Arch++: Animation-ready clothed human reconstruction revisited. In Proceedings of the IEEE/CVF international conference on computer vision, pages 11046–11056, 2021.
- Huang et al. [2020] Zeng Huang, Yuanlu Xu, Christoph Lassner, Hao Li, and Tony Tung. Arch: Animatable reconstruction of clothed humans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3093–3102, 2020.
- Jiang et al. [2022a] Boyi Jiang, Yang Hong, Hujun Bao, and Juyong Zhang. Selfrecon: Self reconstruction your digital avatar from monocular video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5605–5615, 2022a.
- Jiang et al. [2023] Tianjian Jiang, Xu Chen, Jie Song, and Otmar Hilliges. Instantavatar: Learning avatars from monocular video in 60 seconds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16922–16932, 2023.
- Jiang et al. [2022b] Wei Jiang, Kwang Moo Yi, Golnoosh Samei, Oncel Tuzel, and Anurag Ranjan. Neuman: Neural human radiance field from a single video. In European Conference on Computer Vision, pages 402–418. Springer, 2022b.
- Kerbl et al. [2023] Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics (ToG), 42(4):1–14, 2023.
- Li et al. [2022] Ruilong Li, Julian Tanke, Minh Vo, Michael Zollhöfer, Jürgen Gall, Angjoo Kanazawa, and Christoph Lassner. Tava: Template-free animatable volumetric actors. In European Conference on Computer Vision, pages 419–436. Springer, 2022.
- Lindell et al. [2021] David B Lindell, Julien NP Martel, and Gordon Wetzstein. Autoint: Automatic integration for fast neural volume rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14556–14565, 2021.
- Liu et al. [2020] Lingjie Liu, Jiatao Gu, Kyaw Zaw Lin, Tat-Seng Chua, and Christian Theobalt. Neural sparse voxel fields. Advances in Neural Information Processing Systems, 33:15651–15663, 2020.
- Liu et al. [2021] Lingjie Liu, Marc Habermann, Viktor Rudnev, Kripasindhu Sarkar, Jiatao Gu, and Christian Theobalt. Neural actor: Neural free-view synthesis of human actors with pose control. ACM transactions on graphics (TOG), 40(6):1–16, 2021.
- Loper et al. [2023] Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi-person linear model. In Seminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 851–866. 2023.
- Mihajlovic et al. [2021] Marko Mihajlovic, Yan Zhang, Michael J Black, and Siyu Tang. Leap: Learning articulated occupancy of people. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10461–10471, 2021.
- Mildenhall et al. [2021] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021.
- Müller et al. [2022] Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding. ACM Transactions on Graphics (ToG), 41(4):1–15, 2022.
- Peng et al. [2021] Sida Peng, Yuanqing Zhang, Yinghao Xu, Qianqian Wang, Qing Shuai, Hujun Bao, and Xiaowei Zhou. Neural body: Implicit neural representations with structured latent codes for novel view synthesis of dynamic humans. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9054–9063, 2021.
- Reiser et al. [2021] Christian Reiser, Songyou Peng, Yiyi Liao, and Andreas Geiger. Kilonerf: Speeding up neural radiance fields with thousands of tiny mlps. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14335–14345, 2021.
- Saito et al. [2019] Shunsuke Saito, Zeng Huang, Ryota Natsume, Shigeo Morishima, Angjoo Kanazawa, and Hao Li. Pifu: Pixel-aligned implicit function for high-resolution clothed human digitization. In Proceedings of the IEEE/CVF international conference on computer vision, pages 2304–2314, 2019.
- Saito et al. [2020] Shunsuke Saito, Tomas Simon, Jason Saragih, and Hanbyul Joo. Pifuhd: Multi-level pixel-aligned implicit function for high-resolution 3d human digitization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 84–93, 2020.
- Schonberger and Frahm [2016] Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4104–4113, 2016.
- Su et al. [2020] Zhuo Su, Lan Xu, Zerong Zheng, Tao Yu, Yebin Liu, and Lu Fang. Robustfusion: Human volumetric capture with data-driven visual cues using a rgbd camera. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part IV 16, pages 246–264. Springer, 2020.
- Sun et al. [2022] Cheng Sun, Min Sun, and Hwann-Tzong Chen. Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5459–5469, 2022.
- Wang et al. [2022a] Angtian Wang, Peng Wang, Jian Sun, Adam Kortylewski, and Alan Yuille. Voge: a differentiable volume renderer using gaussian ellipsoids for analysis-by-synthesis. In The Eleventh International Conference on Learning Representations, 2022a.
- Wang et al. [2022b] Liao Wang, Jiakai Zhang, Xinhang Liu, Fuqiang Zhao, Yanshun Zhang, Yingliang Zhang, Minye Wu, Jingyi Yu, and Lan Xu. Fourier plenoctrees for dynamic radiance field rendering in real-time. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13524–13534, 2022b.
- Wang et al. [2004] Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 13(4):600–612, 2004.
- Xiang et al. [2020] Donglai Xiang, Fabian Prada, Chenglei Wu, and Jessica Hodgins. Monoclothcap: Towards temporally coherent clothing capture from monocular rgb video. In 2020 International Conference on 3D Vision (3DV), pages 322–332. IEEE, 2020.
- Xu et al. [2018] Weipeng Xu, Avishek Chatterjee, Michael Zollhöfer, Helge Rhodin, Dushyant Mehta, Hans-Peter Seidel, and Christian Theobalt. Monoperfcap: Human performance capture from monocular video. ACM Transactions on Graphics (ToG), 37(2):1–15, 2018.
- Yu et al. [2021] Alex Yu, Ruilong Li, Matthew Tancik, Hao Li, Ren Ng, and Angjoo Kanazawa. Plenoctrees for real-time rendering of neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5752–5761, 2021.
- Zhang et al. [2018] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018.
- Zwicker et al. [2001] Matthias Zwicker, Hanspeter Pfister, Jeroen Van Baar, and Markus Gross. Ewa volume splatting. In Proceedings Visualization, 2001. VIS’01., pages 29–538. IEEE, 2001.