Training robust and generalizable quantum models
Abstract
Adversarial robustness and generalization are both crucial properties of reliable machine learning models. In this paper, we study these properties in the context of quantum machine learning based on Lipschitz bounds. We derive tailored, parameter-dependent Lipschitz bounds for quantum models with trainable encoding, showing that the norm of the data encoding has a crucial impact on the robustness against perturbations in the input data. Further, we derive a bound on the generalization error which explicitly depends on the parameters of the data encoding. Our theoretical findings give rise to a practical strategy for training robust and generalizable quantum models by regularizing the Lipschitz bound in the cost. Further, we show that, for fixed and non-trainable encodings as frequently employed in quantum machine learning, the Lipschitz bound cannot be influenced by tuning the parameters. Thus, trainable encodings are crucial for systematically adapting robustness and generalization during training. With numerical results, we demonstrate that, indeed, Lipschitz bound regularization leads to substantially more robust and generalizable quantum models.
Robustness of machine learning (ML) models is an increasingly important property, especially when operating on real-world data subject to perturbations. In practice, there are various possible sources of perturbations such as noisy data acquisition or adversarial attacks. The latter are tiny but carefully chosen manipulations of the data, and they can lead to dramatic misclassification in neural networks [1, 2]. As a result, much research has been devoted to better understanding and improving adversarial robustness [3, 4, 5]. It is well-known that robustness is closely connected to generalization [1, 2, 6, 7, 8], i.e. the ability of a model to extrapolate beyond the training data. Intuitively, if a model is robust then small input changes only cause small output changes, thus counteracting the risk of overfitting.
A Lipschitz bound of a model is any satisfying
| (1) |
for all . By definition, Lipschitz bounds quantify the worst-case output change that can be caused by data perturbations and, thus, they provide a useful measure of adversarial robustness. Therefore, they are a well-established tool for characterizing robustness and generalization properties of ML models [2, 6, 9, 10, 11, 12, 13, 14, 15]. Lipschitz bounds cannot only be used to better understand these two properties, but they also allow to improve them by regularizing the Lipschitz bound during training [2, 6, 16, 17, 18].
In this paper, we study the interplay of robustness and generalization in quantum machine learning (QML). Variational quantum circuits are a well-studied class of quantum models [19, 20, 21] and they promise benefits over classical ML in various aspects including trainability, expressivity, and generalization performance [22, 23]. Data re-uploading circuits generalize the classical variational circuits by concatenating a data encoding and a parametrized quantum circuit not only once but repeatedly, thus iterating between data- and parameter-dependent gates [24]. This alternation provides substantial improvements on expressivity, leading to a universal quantum classifier even in the single-qubit case [24, 25].
Just as in the classical case, robustness is crucial for quantum models. First, if QML is to provide benefits over classical ML, it is necessary to implement QML circuits which are robust w.r.t. quantum errors occurring due to imperfect hardware in the noisy intermediate-scale quantum (NISQ) era [26]. Questions of robustness of quantum models against such hardware errors have been studied, e.g., in [27, 28]. Lipschitz bounds can be used to study robustness of quantum algorithms against certain types of hardware errors, e.g., coherent control errors [29].
However, robustness against hardware errors is entirely different from and independent of the robustness of a quantum model against data perturbations, which will be the subject of this paper. The latter type of robustness has been studied in the context of quantum adversarial machine learning [30, 31]. Not surprisingly, just like their classical counterparts, quantum models are also vulnerable to adversarial attacks, both when operating based on classical data [32, 33] and quantum data [34, 32, 35, 36, 37, 38, 39]. To mitigate these attacks, it is desirable to design training schemes encouraging adversarial robustness of the resulting quantum model. Existing approaches in this direction include solving an (adversarial) min-max optimization problem during training [32] or adding adversarial examples to the training data set [40]. Our results contribute to quantum adversarial machine learning by studying the robustness of quantum models via Lipschitz bounds, leading to a training scheme for robust quantum models based on Lipschitz bound regularization. We demonstrate the robustness benefits of the proposed regularization with numerical results.
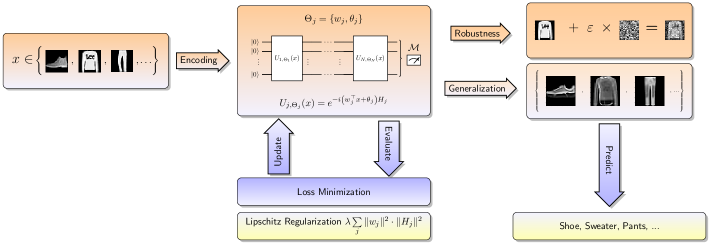
Besides robustness, another important aspect of any quantum model is its ability to generalize to unseen data [42, 43]. In particular, various works have shown generalization bounds [22, 44, 45, 46, 47], i.e., bounds on the expected risk of a model depending on its performance on the training data. While these bounds provide insights into possibilities for constructing quantum models that generalize well, they also face inherent limitations due to their uniform nature [48].
In the present paper, we derive a novel generalization bound which explicitly depends on the parameters of the quantum model, highlighting the role of the data encoding for generalizability. We show with numerical results that regularizing the Lipschitz bound indeed leads to substantial improvements in generalization performance. Finally, given that the derived Lipschitz bound mainly depends on the norm of the data encoding, our results show the importance and benefits of trainable encodings over quantum circuits with a priori fixed encoding as frequently used in variational QML [49, 19, 20, 21, 22, 25].
Results
Quantum models and their Lipschitz bounds. We consider parametrized unitary operators of the form of
| (2) |
with input data , trainable parameters , and Hermitian generators .
Depending on the choice of , the operator acts on either one or multiple qubits. The operators give rise to the parametrized quantum circuit
| (3) |
where comprises the set of trainable parameters. The quantum model considered in this paper consists of applied to and followed by a measurement w.r.t. the observable , i.e.,
| (4) |
compare Figure 1. Note that each of the unitary operators involves the full data vector , i.e., the data are loaded repeatedly into the circuit, a strategy that is commonly referred to as data re-uploading [24]. The encoding of the data into each is realized via an affine function , where both and are trainable parameters. Hence, we refer to (4) as a quantum model with trainable encoding. Such trainable encodings are a generalization of common quantum models [49, 19, 20, 21, 22, 25], for which the ’s are fixed (typically unit vectors) and only the ’s are trained. In particular, our analysis results apply equally to these fixed-encoding quantum models. Later in the paper, we demonstrate with both theoretical and numerical results that trainable encodings can yield significant robustness and generalization improvements in comparison to fixed (i.e., non-trainable) encodings.
Our results make use of Lipschitz bounds defined in (1). A Lipschitz bound quantifies the maximum perturbation of that can be caused by input variations. For the quantum model , we can state the following Lipschitz bound
| (5) |
The formal derivation can be found in Supplementary Section 1-B.
For a given set of parameters , (5) allows to compute the Lipschitz bound of the corresponding quantum model. Note that depends only on but it is independent of . This fact plays an important role for potential benefits of trainable encodings since the parameters are not optimized during training for fixed-encoding circuits.
Robustness of quantum models. Suppose we want to evaluate the quantum model at , i.e., we are interested in the value , but we can only access at some perturbed input with an unknown . Such a setup can arise due to various reasons, e.g., may be the output of some physical process which can only be accessed via noisy sensors. The perturbation may also be the result of an adversarial attack, i.e., a perturbation aiming to cause a misclassification by choosing such that
| (6) |
is maximized. In either case, to correctly classify despite the perturbation, we require that is close to , meaning that (6) is small. According to (1), a Lipschitz bound of quantifies exactly this difference, implying that the maximum possible deviation of from is bounded as
| (7) |
This shows that smaller Lipschitz bounds imply better (worst-case) robustness of models against data perturbations. Thus, using (5), the robustness of the quantum model is mainly influenced by the parameters of the data encoding , , and by the observable . In particular, smaller values of and lead to a more robust model.
We now apply this theoretical insight to train robust quantum models using a Lipschitz bound regularization. More precisely, we consider a supervised learning setup with loss and training data set of size . The following optimization problem can thus be used to train the quantum model
| (8) |
In order to ensure that not only admits a small training loss but is also robust and generalizes well, we add a regularization term, leading to the regularized optimization problem
| (9) |
Regularizing the parameters encourages small norms of the data encoding and, thereby, small values of the Lipschitz bound . The hyperparameter allows to trade off between the two objectives of a small training loss and robustness/generalization in the cost function. Note that the regularization does not involve the ’s since they do not influence the Lipschitz bound (5), an issue we will discuss in more detail later in the paper. Moreover, we do not introduce an explicit dependence of the regularization on since we do not optimize over the observable in this paper. We note that penalty terms similar to the proposed regularization can be used for handling hard constraints in binary optimization via the quantum approximate optimization algorithm [50, 51]. Indeed, the above regularization can be interpreted as a penalty-based relaxation of the corresponding constrained training problem, i.e., of training a quantum model with Lipschitz bound below a specific value.

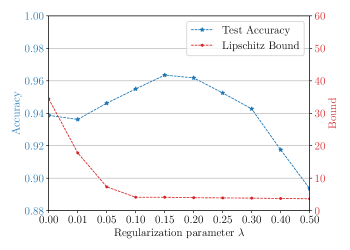
We now evaluate our theoretical findings based on a 2D classification problem, which we call the circle classification problem [52]: within a domain of , a circle with radius is drawn, and all data points inside the circle are labeled with , whereas points outside are labeled with , see Figure 6 in the Supplementary Section 3. For the quantum model with trainable encoding, we use general SU(2) operators and encode into the first two rotation angles. We repeat this encoding for each of the considered qubits, followed by nearest neighbour entangling gates based on CNOTs. Such a layer is then repeated times. As observable, we use . The resulting circuit is illustrated in Figure 4.
The numerical results for the robustness simulations are shown in Figure 2, where we compare the worst-case test accuracy and Lipschitz bound of three trained models with different regularization parameter . Additionally, the plot shows the accuracy of a quantum model with fixed encoding for the same numbers of qubits and layers (see (16) and Supplementary Section 3 for details). The worst-case test accuracy of all models is obtained by sampling different noise samples from and, thereby, it approximates the accuracy resulting from an adversarial attack norm-bounded by . As expected, all four models deteriorate with increasing noise level. For zero noise level , the model with the largest regularization parameter (and, hence, the smallest Lipschitz bound ) has a smaller test accuracy than the non-regularized model with . This can be explained by a decrease in the training accuracy that is caused via the additional regularization in the cost. For increasing noise levels, however, the enhanced robustness outweighs the loss of training performance and, therefore, the model with outperforms the model with . The fixed-encoding model achieves comparable performance to the trainable-encoding model with for small noise and the worst performance among all models for high noise. These observations can be explained by the reduced expressivity yet high Lipschitz bound of the fixed-encoding model. Finally, the model with almost consistently outperforms the model with and, in particular, it yields a higher test accuracy for small noise levels. This can be explained by the improved generalization performance caused by the regularization, an effect we discuss in more detail in the following.
Generalization of quantum models. The Lipschitz bound (5) not only influences robustness but also has a crucial impact on generalization properties of the quantum model . Intuitively, a smaller Lipschitz bound implies a smaller variability of and, therefore, reduces the risk of overfitting. This intuition is made formal via the following generalization bound.
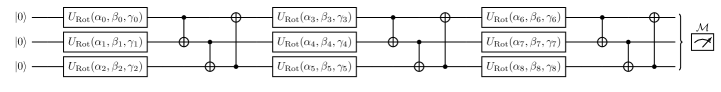
Theorem 1.
(informal version) Consider a supervised learning setup with loss and data set of size drawn according to the probability distribution . For the quantum model from (4), define the expected risk
| (10) |
and the empirical risk
| (11) |
The generalization error of is bounded as
| (12) |
for some .
The detailed version and proof of Theorem 1 are provided in Supplementary Section 2. Generalization bounds as in (12) quantify the ability of to generalize beyond the available data. The bound (12) directly depends on the data encoding via and on the observable via . In particular, achieves a small generalization error if its Lipschitz bound is small and the size of the data set is large. Note, however, the following fundamental trade-off: A too small Lipschitz bound may limit the expressivity of and, therefore, lead to a high empirical risk , in which case the generalization bound (12) is meaningless. In conclusion, Theorem 1 implies a small expected risk if is large, is small, and has a small empirical risk . In contrast to existing generalization bounds [22, 44, 45, 46, 47], the bound (12) explicitly involves the Lipschitz bound (5), i.e., the norm of the data encoding.
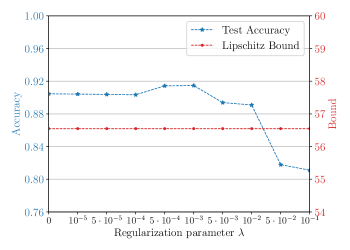
We evaluate the generalization performance of the trainable encoding again on the circle classification problem. The training setup is identical to the robustness simulations and the numerical results are shown in Figure 3, where we plot the test accuracy and Lipschitz bound depending on the regularization parameter . Increasing the regularization parameter decreases the Lipschitz bound of the trained model. In accordance with the generalization bound (12), this reduction of improves generalization performance with the maximum test accuracy at . Beyond this value, the regularization causes a too small Lipschitz bound, limiting expressivity and, therefore, decreasing the training accuracy. As a result, the test accuracy decreases as well. This illustrates the role of as a hyperparameter: Regularization does not always improve performance, but there is a sweet spot for at which both superior generalization and robustness over the unregularized setup (i.e., ) can be obtained. In practice, the hyperparameter can be tuned, e.g., via cross-validation.
Benefits of trainable encodings. A popular class of quantum models is obtained by constructing circuits which alternate between data- and parameter-dependent gates, i.e., replacing in (3) by
| (13) |
compare [49, 19, 20, 21, 22, 25]. The unitary operators are given by
| (14) | ||||
| (15) |
for trainable parameters and generators , . Figure 5 depicts the circuit representation of the corresponding quantum model
| (16) |
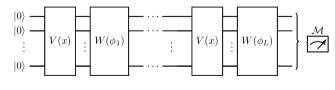
It is not hard to show that the parametrized quantum circuit in (3) generalizes the one in (13). Indeed, in (2) reduces to either
| (17) |
for suitable choices of , , and . Note that the data encoding of the quantum model is fixed a priori via the choice of and, in particular, it cannot be influenced during training. Therefore, we refer to as a quantum model with fixed encoding, in contrast to in (4) which contains trainable parameters and, therefore, a trainable encoding.
Benefits of trainable encodings for the expressivity of quantum models have been demonstrated numerically in [53, 54, 55] and theoretically in [24, 25]. In the following, we discuss the importance of trainable encodings for robustness and generalization. Recall that the Lipschitz bound (5), which we showed to be a crucial quantifier of robustness and generalization of quantum models, only depends on the observable and on the data encoding , , but it is independent of the parameters . Hence, in the quantum model with fixed encoding, the Lipschitz bound (5) cannot be influenced during training and, instead, is fixed a priori via the choice of the Hermitian generators . As a result, training has a limited effect on robustness and generalization properties of fixed-encoding quantum models.
The distinction between trainable and fixed data encodings becomes even more apparent when expressing quantum models as Fourier series [25]. In this case, fixed-encoding quantum models choose the frequencies of the Fourier basis functions before the training and only optimize over their coefficients. On the contrary, trainable-encoding quantum models simultaneously optimize over the frequencies and the coefficients which, according to the Lipschitz bound (5), is key for influencing robustness and generalization properties.
These insights confirm the observation by [56, 57, 58] that fixed-encoding quantum models are neither sensitive to data perturbations nor to overfitting. On the one hand, resilience against these two phenomena is a desirable property. However, the above discussion also implies that Lipschitz bound regularization, which is a systematic and effective tool for influencing robustness and generalization [2, 6, 16, 17, 18], cannot be implemented for fixed-encoding quantum models to improve robustness and generalization. The detrimental effect of this fact is illustrated by our robustness simulations in Figure 2. Here, the fixed-encoding model has a considerably higher Lipschitz bound than all the considered trainable-encoding models. This implies a significantly worse robustness w.r.t. data perturbations and, therefore, leads to a rapidly decreasing test accuracy for larger noise levels. Further, regularizing the parameters as suggested, e.g., by [59], does not affect the Lipschitz bound and, therefore, cannot be used to improve the robustness. In Supplementary Section 3, we study the effect of a regularization of on generalization. We find that the influence of regularizing the ’s on the test accuracy is limited and likely dependent on the specific ground-truth distribution generating the data and the chosen circuit ansatz.
To conclude, our results show that training the encoding in quantum models not only increases the expressivity but also leads to superior robustness and generalization properties.
Discussion
In this paper, we study robustness and generalization properties of quantum models based on Lipschitz bounds. Lipschitz bounds are a well-established tool in the classical ML literature which not only quantify adversarial robustness but are also closely connected to generalization performance. We derive Lipschitz bounds based on the size of the data encoding which we then use to study robustness and generalization properties. Given that our generalization bound explicitly involves the parameters of the data encoding, it is not a uniform bound. As a result, it may allow to overcome some of the limitations of uniform QML generalization bounds [48]. Further, our theoretical results highlight the role of trainable encodings combined with regularization techniques for obtaining robust and generalizable quantum models. The numerical results confirm our theoretical findings, showing the existence of a sweet spot for the regularization parameter for which our training scheme improves both robustness as well as generalization compared to a non-regularized training scheme. It is important to emphasize that these numerical results with specific choices of rotation and entangling gates are mainly used for illustration, but our theoretical framework applies to all quantum models that can be written as in (4) and, hence, also allow for different rotation gates, entangling layers, or even parametrized multi-qubit gates.
While our results indicate the potential of using Lipschitz bounds in QML, there are various promising directions for future research. First and foremost, transferring existing research on Lipschitz bounds in classical ML to the QML setting provides a systematic framework for handling robustness and generalization, beyond the first results presented in this paper. In particular, although we focus on variational quantum models, the basic principles of our results are transferrable to different quantum models, including quantum kernel methods [20, 21] or linear quantum models [23]. Further, while we have emphasized the importance of trainable encodings, the considered quantum model only employs a specific, affine encoding . Extending our results to more general, possibly nonlinear encodings provides a promising avenue for designing powerful quantum models. Classical neural networks are ideal candidates for realizing a nonlinear encoding, given the extensive research in classical ML on their Lipschitz properties [2, 6, 9, 10, 11, 12, 13, 14, 15]. Finally, we plan to validate our theoretical findings for more complex classification tasks and on real quantum hardware.
Code Availability
The source code for the numerical case studies, as well as the data generation and analysis scripts are publicly accessible on GitHub via https://github.com/daniel-fink-de/training-robust-and-generalizable-quantum-models.
Acknowledgment
This work was funded by Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy - EXC 2075 - 390740016. We acknowledge the support by the Stuttgart Center for Simulation Science (SimTech). This work was also supported by the German Federal Ministry of Economic Affairs and Climate Action through the project AutoQML (grant no. 01MQ22002A).
References
- [1] I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” arXiv:1412.6572, 2014.
- [2] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, “Intriguing properties of neural networks,” arXiv:1312.6199, 2014.
- [3] E. Wong and Z. Kolter, “Provable defenses against adversarial examples via the convex outer adversarial polytope,” in Proc. International Conference on Machine Learning, 2018, pp. 5283–5292.
- [4] Y. Tsuzuku, I. Sato, and M. Sugiyama, “Lipschitz-margin training: Scalable certification of perturbation invariance for deep neural networks,” in Proc. Advances in Neural Information Processing Systems, 2018, pp. 6541–6550.
- [5] A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” arXiv:1706.06083, 2019.
- [6] A. Krogh and J. Hertz, “A simple weight decay can improve generalization,” in Advances in Neural Information Processing Systems, vol. 4, 1991. [Online]. Available: https://proceedings.neurips.cc/paper/1991/file/8eefcfdf5990e441f0fb6f3fad709e21-Paper.pdf
- [7] H. Xu and S. Mannor, “Robustness and generalization,” Mach. Learn., vol. 86, no. 3, pp. 391–423, 2012.
- [8] N. Papernot, P. McDaniel, X. Wu, S. Jha, and A. Swami, “Distillation as a defense to adversarial perturbations against deep neural networks,” in Proc. IEEE Symposium on Security and Privacy (SP), 2016, pp. 582–597.
- [9] U. von Luxburg and O. Bousquet, “Distance-based classification with Lipschitz functions,” Journal of Machine Learning Research, vol. 5, pp. 669–695, 2004.
- [10] P. Bartlett, D. J. Foster, and M. Telgarsky, “Spectrally-normalized margin bounds for neural networks,” in Advances in Neural Information Processing Systems, vol. 30, 2017, pp. 6240–6249.
- [11] B. Neyshabur, S. Bhojanapalli, D. McAllester, and N. Srebro, “Exploring generalization in deep learning,” in Advances in Neural Information Processing Systems, 2017, pp. 5947–5956.
- [12] J. Sokolić, R. Giryes, G. Sapiro, and M. R. D. Rodrigues, “Robust large margin deep neural networks,” IEEE Trans. Signal Processing, vol. 65, no. 16, pp. 4265–4280, 2017.
- [13] T.-W. Weng, H. Zhang, P.-Y. Chen, J. Yi, D. Su, Y. Gao, C.-J. Hsieh, and L. Daniel, “Evaluating the robustness of neural networks: an extreme value theory approach,” in Proc. 6th Int. Conf. Learning Representations (ICLR), 2018.
- [14] W. Ruan, X. Huang, and M. Kwiatkowska, “Reachability analysis of deep neural networks with provable guarantees,” in Proc. 27th Int. joint Conf. Artificial Intelligence (IJCAI), 2018, pp. 2651–2659.
- [15] C. Wei and T. Ma, “Data-dependent sample complexity of deep neural networks via Lipschitz augmentation,” in Advances in Neural Information Processing Systems, 2019, pp. 9725–9736.
- [16] M. Hein and M. Andriushchenko, “Formal guarantees on the robustness of a classifier against adversarial manipulation,” in Proc. Advances in Neural Information Processing Systems, 2017, pp. 2266–2276.
- [17] H. Gouk, E. Frank, B. Pfahringer, and M. Cree, “Regularisation of neural networks by enforcing Lipschitz continuity,” Machine Learning, vol. 110, pp. 393–416, 2021.
- [18] P. Pauli, A. Koch, J. Berberich, P. Kohler, and F. Allgöwer, “Training robust neural networks using Lipschitz bounds,” IEEE Control Systems Lett., vol. 6, pp. 121–126, 2022.
- [19] M. Benedetti, E. Lloyd, S. Sack, and M. Fiorentini, “Parameterized quantum circuits as machine learning models,” Quantum Sci. Technol., vol. 4, p. 043001, 2019.
- [20] V. Havlíček, A. D. Córcoles, K. Temme, A. W. Harrow, A. Kandala, J. M. Chow, and J. M. Gambetta, “Supervised learning with quantum-enhanced feature spaces,” Nature, vol. 567, pp. 209–212, 2019.
- [21] M. Schuld and N. Killoran, “Quantum machine learning in feature Hilbert spaces,” Physical Review Letters, vol. 122, p. 040504, 2019.
- [22] A. Abbas, D. Sutter, C. Zoufal, A. Lucchi, A. Figalli, and S. Woerner, “The power of quantum neural networks,” Nature Computational Science, vol. 1, pp. 403–409, 2021.
- [23] S. Jerbi, L. J. Fiderer, H. P. Nautrup, J. M. Kübler, H. J. Briegel, and V. Dunjko, “Quantum machine learning beyond kernel methods,” Nature Communications, vol. 14, p. 517, 2023.
- [24] A. Pérez-Salinas, A. Cervera-Lierta, E. Gil-Fuster, and J. I. Latorre, “Data re-uploading for a universal quantum classifier,” Quantum, vol. 4, p. 226, 2020.
- [25] M. Schuld, R. Sweke, and J. J. Meyer, “Effect of data encoding on the expressive power of variational quantum-machine-learning models,” Physical Review A, vol. 103, p. 032430, 2021.
- [26] J. Preskill, “Quantum computing in the NISQ era and beyond,” Quantum, vol. 2, p. 79, 2018.
- [27] R. LaRose and B. Coyle, “Robust data encodings for quantum classifiers,” Physical Review A, vol. 102, p. 032420, 2020.
- [28] L. Cincio, K. Rudinger, M. Sarovar, and P. J. Coles, “Machine learning of noise-resilient quantum circuits,” PRX Quantum, vol. 2, p. 010324, 2021.
- [29] J. Berberich, D. Fink, and C. Holm, “Robustness of quantum algorithms against coherent control errors,” arXiv:2303.00618, 2023.
- [30] D. Edwards and D. B. Rawat, “Quantum adversarial machine learning: status, challenges and perspectives,” in Proc. 2nd IEEE Int. Conf. Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA), 2020, pp. 128–133.
- [31] M. T. West, S.-L. Tsang, J. S. Low, C. D. Hill, C. Leckie, L. C. L. Hollenberg, S. M. Erfani, and M. Usman, “Towards quantum enhanced adversarial robustness in machine learning,” arXiv:2306.12688, 2023.
- [32] S. Lu, L.-M. Duan, and D.-L. Deng, “Quantum adversarial machine learning,” Physical Review Research, vol. 2, p. 033212, 2020.
- [33] M. T. West, S. M. Erfani, C. Leckie, M. Sevior, L. C. L. Hollenberg, and M. Usman, “Benchmarking adversarially robust quantum machine learning at scale,” arXiv:2211.12681, 2022.
- [34] N. Liu and P. Wittek, “Vulnerability of quantum classification to adversarial perturbations,” Physical Review A, vol. 101, p. 062331, 2020.
- [35] H. Liao, I. Convy, W. J. Huggins, and K. B. Whaley, “Robust in practice: adversarial attacks on quantum machine learning,” Physical Review A, vol. 103, p. 042427, 2021.
- [36] Y. Du, M.-H. Hsieh, T. Liu, D. Tao, and N. Liu, “Quantum noise protects quantum classifiers against adversaries,” Physical Review Research, vol. 3, p. 023153, 2021.
- [37] J. Guan, W. Fang, and M. Ying, “Robustness verification of quantum classifiers,” in Proc. Int. Conf. Computer Aided Verification, 2021, pp. 151–174.
- [38] M. Weber, N. Liu, B. Li, C. Zhang, and Z. Zhao, “Optimal provable robustness of quantum classification via quantum hypothesis testing,” Quantum Information, vol. 7, p. 76, 2021.
- [39] W. Gong and D.-L.-. Deng, “Universal adversarial examples and perturbations for quantum classifiers,” National Science Review, vol. 9, no. 6, p. nwab130, 2022.
- [40] W. Ren, W. Li, S. Xu, K. Wang, W. Jiang, F. Jin, X. Zhu, J. Chen, Z. Song, P. Zhang, H. Dong, X. Zhang, J. Deng, Y. Gao, C. Zhang, Y. Wu, B. Zhang, Q. Guo, H. Li, Z. Wang, J. Biamonte, C. Song, D.-L. Deng, and H. Wang, “Experimental quantum adversarial learning with programmable superconducting qubits,” arXiv:2204.01738, 2022.
- [41] H. Xiao, K. Rasul, and R. Vollgraf, “Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithms,” arXiv:1708.07747, 2017.
- [42] M. Cerezo, G. Verdon, H.-Y. Huang, L. Cincio, and P. J. Coles, “Challenges and opportunities in quantum machine learning,” Nature Computational Science, vol. 2, pp. 567–576, 2022.
- [43] E. Peters and M. Schuld, “Generalization despite overfitting in quantum machine learning models,” arXiv:2209.05523, 2022.
- [44] H.-Y. Huang, M. Bourghton, M. Mohseni, R. Babbush, S. Boixo, H. Neven, and J. R. McClean, “Power of data in quantum machine learning,” Nature communications, vol. 12, no. 1, pp. 1–9, 2021.
- [45] L. Banchi, J. Pereira, and S. Pirandola, “Generalization in quantum machine learning: a quantum information standpoint,” PRX Quantum, vol. 2, p. 040321, 2021.
- [46] M. C. Caro, E. Gil-Fuster, J. J. Meyer, J. Eisert, and R. Sweke, “Encoding-dependent generalization bounds for parametrized quantum circuits,” arXiv:2106.03880, 2021.
- [47] S. Jerbi, C. Gyurik, S. C. Marshall, R. Molteni, and V. Dunjko, “Shadows of quantum machine learning,” arXiv:2306.00061, 2023.
- [48] E. Gil-Fuster, J. Eisert, and C. Bravo-Prieto, “Understanding quantum machine learning also requires rethinking generalization,” arXiv:2306.13461, 2023.
- [49] M. Schuld and F. Petruccione, Machine learning with quantum computers. Springer, 2021.
- [50] E. Farhi, J. Goldstone, and S. Gutmann, “A quantum approximate optimization algorithm,” arXiv:1411.4028, 2014.
- [51] S. Hadfield, Z. Wang, E. G. Rieffel, B. O’Gorman, D. Venturelli, and R. Biswas, “Quantum approximate optimization with hard and soft constraints,” in Proc. 2nd Int. Workshop on Post Moores Era Supercomputing, 2017, pp. 15–21.
- [52] S. Ahmed, “Tutorial: Data reuploading circuits,” https://pennylane.ai/qml/demos/tutorial˙data˙reuploading˙classifier/, 2021.
- [53] F. J. Gil Vidal and D. O. Theis, “Input redundancy for parameterized quantum circuits,” Frontiers in Physics, vol. 8, p. 297, 2020.
- [54] E. Ovalle-Magallanes, D. E. Alvarado-Carrillo, J. G. Avina-Cervantes, I. Cruz-Aceves, and J. Ruiz-Pinales, “Quantum angle encoding with learnable rotation applied to quantum-classical convolutional neural networks,” Applied Soft Computing, vol. 141, p. 110307, 2023.
- [55] B. Jaderberg, A. A. Gentile, Y. A. Berrada, E. Shishenina, and V. E. Elfving, “Let quantum neural networks choose their own frequencies,” arXiv:2309.03279, 2023.
- [56] K. Mitarai, M. Negoro, M. Kitagawa, and K. Fujii, “Quantum circuit learning,” Physical Review A, vol. 98, p. 032309, 2018.
- [57] M. Schuld, A. Bocharov, K. Svore, and N. Wiebe, “Circuit-centric quantum classifiers,” Physical Review A, vol. 101, p. 032308, 2020.
- [58] C.-C. Chen, M. Watabe, K. Shiba, M. Sogabe, K. Sakamoto, and T. Sogabe, “On the expressibility and overfitting of quantum circuit learning,” ACM Transactions on Quantum Computing, vol. 2, no. 2, p. 8, 2021.
- [59] Y. Du, M.-H. Hsieh, T. Liu, S. You, and D. Tao, “Learnability of quantum neural networks,” PRX Quantum, vol. 2, p. 040337, 2021.
- [60] T. M. Apostol, Mathematical Analysis. Pearson Education, 1974, 2nd edition.
- [61] M. Mohri, A. Rostamizadeh, and A. Talwalkar, Foundations of machine learning, 2nd ed., Adaptive Computation and Machine Learning. MIT Press, Cambridge, MA, 2018.
- [62] V. Bergholm, J. Izaac, M. Schuld, C. Gogolin, S. Ahmed, V. Ajith, M. S. Alam, G. Alonso-Linaje, B. AkashNarayanan, A. Asadi, J. M. Arrazola, U. Azad, S. Banning, C. Blank, T. R. Bromley, B. A. Cordier, J. Ceroni, A. Delgado, O. D. Matteo, A. Dusko, T. Garg, D. Guala, A. Hayes, R. Hill, A. Ijaz, T. Isacsson, D. Ittah, S. Jahangiri, P. Jain, E. Jiang, A. Khandelwal, K. Kottmann, R. A. Lang, C. Lee, T. Loke, A. Lowe, K. McKiernan, J. J. Meyer, J. A. Montañez-Barrera, R. Moyard, Z. Niu, L. J. O’Riordan, S. Oud, A. Panigrahi, C.-Y. Park, D. Polatajko, N. Quesada, C. Roberts, N. Sá, I. Schoch, B. Shi, S. Shu, S. Sim, A. Singh, I. Strandberg, J. Soni, A. Száva, S. Thabet, R. A. Vargas-Hernández, T. Vincent, N. Vitucci, M. Weber, D. Wierichs, R. Wiersema, M. Willmann, V. Wong, S. Zhang, and N. Killoran, “Pennylane: Automatic differentiation of hybrid quantum-classical computations,” arXiv:1811.04968, 2018.
- [63] D. P. Kingma and J. Ba, “Adam: a method for stochastic optimization,” arXiv:1412.6980, 2014.
- [64] Dask Development Team, “Dask: Library for dynamic task scheduling,” https://dask.org, 2016.
Supplementary material
1 Lipschitz bounds of quantum models
In this section, we study Lipschitz bounds of quantum models as in (4). We first derive a Lipschitz bound which is less tight than (5) but can be shown using a simple concatenation argument (Section 1-A). Next, in Section 1-B, we prove that (5) is indeed a Lipschitz bound.
1-A Simple Lipschitz bound based on concatenation
Before stating the result, we introduce the notation
| (18) |
Theorem 2.
The following is a Lipschitz bound of :
| (19) |
Proof.
Our proof relies on the fact that a Lipschitz bound of a concatenated function can be obtained based on the product of the individual Lipschitz bounds. To be precise, suppose can be written as , where denotes concatenation and each admits a Lipschitz bound , . Then, for arbitrary input arguments of , we obtain
| (20) |
We now prove that (19) is a Lipschitz bound by representing as a concatenation of the three functions
| (21) | ||||
| (22) | ||||
| (23) |
More precisely, it holds that
| (24) |
Hence, any set of Lipschitz bounds , , for the three functions , , gives rise to a Lipschitz bound of as their product:
| (25) |
Therefore, in the following, we will derive individual Lipschitz bounds , ,
and .
Lipschitz bound of :
Note that
| (26) |
Using , we infer
| (27) |
Thus, is a Lipschitz bound of .
Lipschitz bound of :
It follows from [29, Theorem 2.2] that
is a Lipschitz bound of .
Lipschitz bound of :
Given the linear form of , we directly obtain that
is a Lipschitz bound.
∎
1-B Proof that (5) is a Lipschitz bound
We first derive a Lipschitz bound on the parametrized unitary . To this end, we compute its differential
| (28) | ||||
Note that each term can be written as the concatenation of the two maps and defined by
| (29) | ||||
| (30) |
To be precise, it holds that . The differentials of the two maps and are given by
| (31) | ||||
where denotes the differential of at applied to , and similarly for . Thus, we have
| (32) | ||||
Inserting this into (28), we obtain
| (33) |
We have thus shown that the Jacobian of the map is given by
| (34) |
Using that has unit norm, that the ’s are unitary, as well as the triangle inequality, the norm of is bounded as
| (35) |
Thus, is a Lipschitz bound of [60, p. 356].
2 Full version and proof of Theorem 1
We first state the main result in a general supervised learning setup, before applying it to the quantum model considered in this paper. Consider a supervised learning setup with data samples drawn independently and identically distributed from according to some probability distribution . We define the -covering number of as follows.
Definition 2.1.
(adapted from [7, Definition 1]) We say that is an -cover of , if, for all , there exists such that . The -covering number of is
| (36) |
For a generic model , a loss function , and the training data , we define the expected loss and the empirical loss by
| (37) |
and
| (38) |
respectively. The following result states a generalization bound of .
Lemma 2.1.
Suppose
-
1.
the loss is nonnegative and admits a Lipschitz bound ,
-
2.
is compact such that is finite, and
-
3.
is a Lipschitz bound of .
Then, for any , with probability at least the generalization error of is bounded as
| (39) | ||||
Proof.
For the following proof, we invoke the concept of -robustness (adapted from [7, Definition 2]): The classifier is -robust for and , if can be partitioned into disjoint sets, denoted by , such that the following holds: For all , , , if , then
| (40) |
This property quantifies robustness of in the following sense: The set can be partitioned into a number of subsets such that, if a newly drawn sample lies in the same subset as a testing sample , then their associated loss values are close. Let us now proceed by noting that, for any , , and , it holds that
| (41) | ||||
where we use the Lipschitz bound of , the triangle inequality, and the Lipschitz bound of , respectively. Using [7, Theorem 6], we infer that is -robust for all . It now follows from [7, Theorem 1] that, for any , with probability at least inequality (39) holds. ∎
Let us now combine the Lipschitz bound (5) and Lemma 2.1 to state a tailored generalization bound for the considered class of quantum models , thus proving Theorem 1.
Theorem 2.1.
Suppose
-
1.
the loss is nonnegative and admits a Lipschitz bound and
-
2.
is compact such that is finite.
Then, for any , with probability at least the generalization error of is bounded as
| (42) |
Theorem 2.1 shows that the size of the data encoding and of the observable directly influences the generalization performance of the quantum model . In particular, for smaller values of and , the expected loss is closer to the empirical loss. The right-hand side of (42) contains two terms: The first one depends on the parameters of the quantum model and characterizes its robustness via the Lipschitz bound (5), whereas the second term decays with increasing data length . While (39) holds for arbitrary values of , it is not immediate which value of leads to the smallest possible bound: Smaller values of decrease the first term but increase in the second term (and vice versa).
In contrast to existing QML generalization bounds [22, 44, 45, 46, 47], Theorem 2.1 explicitly highlights the role of the Lipschitz bound. Using the additional flexibility of the parameter , it can be shown that the generalization bound (42) converges to zero when the data length approaches infinity. To this end, we use [61, Lemma 6.27] to upper bound the covering number
| (43) |
where is the radius of the smallest ball containing . Inserting (43) into (42) and choosing depending on as , we infer
| (44) |
which indeed converges to zero for .
3 Numerics: setup and further results
In the following, we provide details regarding the setup of our numerical results (Section 3-A) and we present further numerical results regarding parameter regularization in quantum models with fixed encoding (Section 3-B).
3-A Numerical setup
All numerical simulations within this work were performed using the Python QML library PennyLane [62]. As device, we used the noiseless simulator ”lightning.qubit” together with the adjoint differentiation method, to enable fast and memory efficient gradient computations. In order to solve the optimization problem in (9), we apply the ADAM optimizer using a learning rate of and the suggested values for all other hyperparameters [63]. Furthermore, we run epochs throughout and train models based on different initial parameters for varying regularization parameters . Adding the regularization does not introduce significant computational overhead as the evaluation of the cost only involves a weighted sum of the terms . As final model, we take the set of parameters for the model with minimal cost over all runs and epochs. Furthermore, the training as well as the robustness and generalization analysis were parallelized using Dask [64].
For the trainable encoding model, the classical data is encoded into the quantum circuit with a general unitary parametrized by 3 Euler angles with
| (45) | ||||
| (46) | ||||
| (47) |
in PennyLane is implemented by the following decomposition
| (48) | ||||
| (49) |
In our numerical case study we set for all since this 1) still allows to reach arbitrary points on the Bloch sphere and 2) enables an easier comparison to fixed-encoding quantum models. In order to introduce entanglement in a hardware-efficient way, we use a ring of CNOTs. The considered circuit shown in Figure 4 involves three layers of rotations and entanglement, which we observed to be a good trade-off between expressivity and generalization. More precisely, in our simulations, fewer layers were not sufficient to accurately solve the classification task, whereas more layers led to higher degrees of overfitting. For the fixed-encoding quantum models as in (16), we use a similar -layer ansatz, encoding the two entries of the 2D data points into the first and second angle , of the rotation gates, followed by a parametrized rotation with three free parameters. We also perform a classical data pre processing, scaling the input domain from to , such that the full possible range of the rotation angles can be utilized.
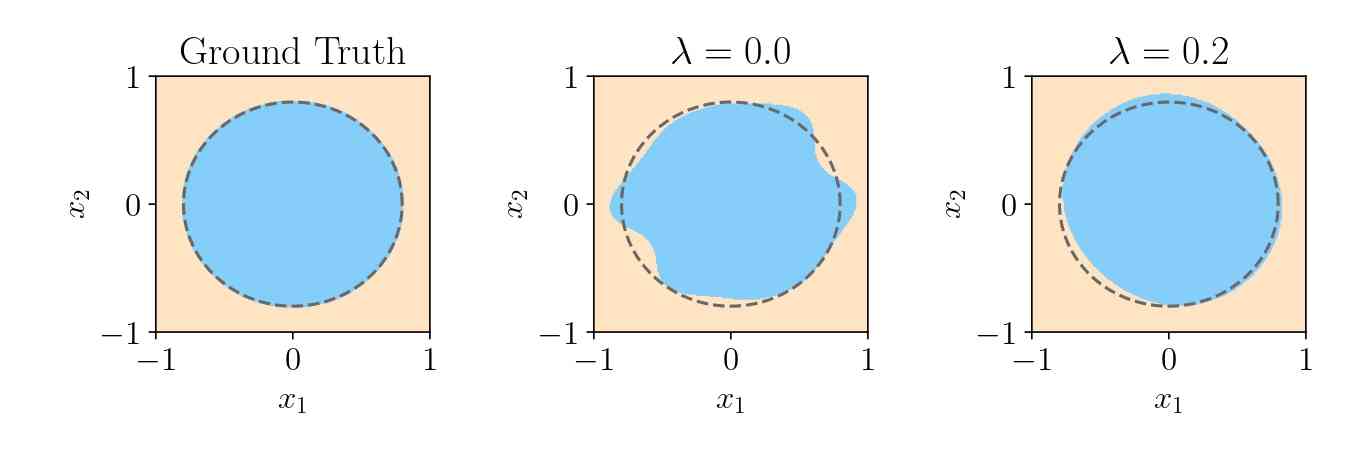
In Figure 6, we plot the ground truth and the decision boundaries for the two quantum models corresponding to and . As expected, the decision boundary resulting from the regularized training is significantly smoother than the unregularized one, explaining the superior robustness and generalization of the former.
3-B Regularization in quantum models with fixed encoding
In the main text, we have seen that the Lipschitz bound of the quantum model with fixed encoding in (16) cannot be adapted by changing the parameters . As a result, it is not possible to use Lipschitz bound regularization for improving robustness and generalization. In the following, we investigate whether regularization of can instead be used to improve generalization performance. More precisely, we consider the same numerical setup as for our generalization results with trainable encoding depicted in Figure 3. The main difference is that we consider a fixed-encoding quantum model which is trained via the following regularized training problem
| (50) |
The regularization with hyperparameter aims at keeping the norms of the angles small. Figure 7 depicts the test accuracy and Lipschitz bound of the resulting quantum model for different regularization parameters . First, note that the Lipschitz bound is indeed constant for all choices of due to the fixed encoding. Comparing Figures 3 and 7, we see that the trainable encoding yields a significantly higher test accuracy in comparison to the fixed encoding. Moreover, the influence of the regularization parameter on the test accuracy is much less pronounced for the fixed encoding than for the trainable encoding, confirming our previous discussion on the benefits of trainable encodings. The test accuracy is not entirely independent of since 1) regularization of the parameters influences the optimization and can improve or deteriorate convergence and 2) biasing towards zero may be beneficial if the underlying ground-truth distribution is better approximated by a quantum model with small values . Whether 2) brings practical benefits is, however, highly problem-specific as it depends on the distribution generating the data and on the circuit ansatz.