Set-of-Mark Prompting Unleashes
Extraordinary Visual Grounding in GPT-4V
Abstract
We present Set-of-Mark (SoM), a new visual prompting method, to unleash the visual grounding abilities of large multimodal models (LMMs), such as GPT-4V. As illustrated in Fig. 1 (right), we employ off-the-shelf interactive segmentation models, such as SAM, to partition an image into regions at different levels of granularity, and overlay these regions with a set of marks e.g., alphanumerics, masks, boxes. Using the marked image as input, GPT-4V can answer the questions that require visual grounding. We perform a comprehensive empirical study to validate the effectiveness of SoM on a wide range of fine-grained vision and multimodal tasks. For example, our experiments show that GPT-4V with SoM outperforms the state-of-the-art fully-finetuned referring segmentation model on RefCOCOg in a zero-shot setting.
Playground: https://som-gpt4v.github.io/

1 Introduction
In the past few years, we have witnessed a significant advancement in large language models (LLMs) [2, 3, 10, 44, 60, 35]. In particular, Generative Pre-trained Transformers or GPTs [2, 35] have led a number of breakthroughs in the industry and academia. Since the release of GPT-4, large multimodal models (LMMs) have gained a growing interest in the research community. A number of works strive to build multimodal GPT-4 based on open-sourced models [28, 63, 57, 12, 48, 51, 20]. Recently, GPT-4V(ision) is released and attracts immediate attention from the community for its outstanding multimodal perception and reasoning capability. Its superiority and generality are showcased in [50]. Despite the unprecedented, strong, vision-language understanding capabilities, GPT-4V’s fine-grained visual grounding ability is relatively weak, or yet to be unleashed. For example, GPT-4V can hardly produce a sequence of accurate coordinates for a dog in the image111https://blog.roboflow.com/gpt-4-vision/, or a few traffic lights [54].
Our study is motivated by addressing the failed cases of GPT-4V on fine-grained vision tasks, such as object referring. In principle, these tasks require the model to have rich semantic understanding and accurate spatial understanding of visual contents. However, prompting GPT-4V to produce a sequence of tokens that contains textual description and numeric coordinates not only hurts the natural fluency in LLMs but also dismisses the spatial understanding ability in vision models used by LMMs, as pointed out by [7]. Therefore, in this study we focus on improving visual inputs by proposing a new visual prompting method to unleash the visual grounding capability of LMMs. Visual prompting has been explored for various vision and multimodal tasks [9, 19, 65, 46, 42]. These works can be categorized into two categories. One is to encode visual prompts such as point, box, and stroke into latent features, which are then used to prompt the vision models [65, 19]. The other is to overlay visual marks directly onto the input images. The overlaid marks could be a red circle [42], a highlighted region [49], or a few circles with arrows [50]. Although these studies demonstrate the promise of pixel-level visual prompting, they are limited to visually referring to one or a few objects. Moreover, all these marks are not easily “speakable” by LLMs, thus impeding the grounding capability for GPT-4V.
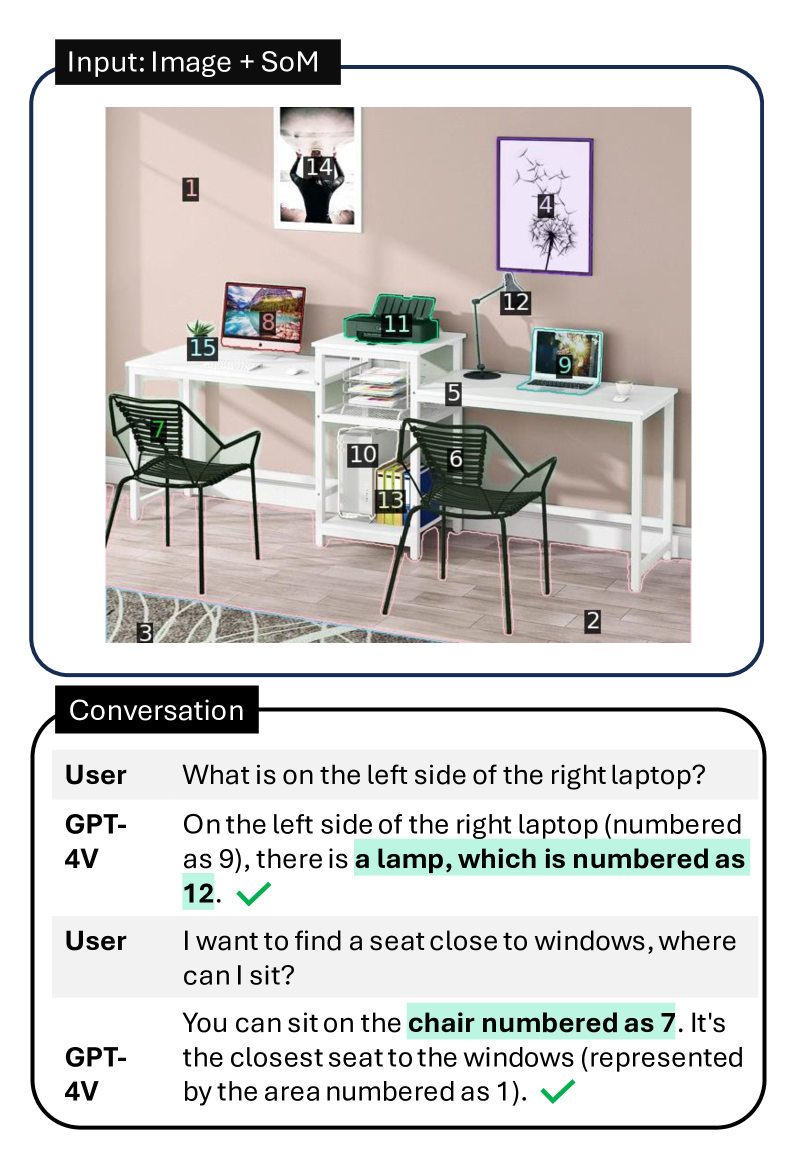
In this paper we present a new prompting mechanism called Set-of-Mark (SoM) prompting , i.e. simply adding a set of visual marks on top of image regions. We first partition an input image into a set of semantically meaningful regions. Then, we overlay each region with a mark of various formats such as numbers, alphabets, masks, or boxes. We perform an empirical study to validate whether GPT-4V could better ground the regions given these interpretable and “spreadable” visual marks. Our experiments show that SoM can drastically unleash the grounding capability of GPT-4V. As shown in Fig. 1, compared to the standard prompting, SoM helps GPT-4V accurately ground its answers in corresponding regions, e.g., the right laptop is “9” and the lamp is “12”. Likewise, it can also associate the chair on the left with “7”. Note that no information about the marks is leaked to the conversation with GPT-4V, which indicates that the model can not only understand the semantics of the visual marks but also know how and when to associate visual contents with marks. To the best of our knowledge, this is the first study to demonstrate that the emergent visual grounding ability of GPT-4V can be unleashed by visual prompting, SoM. To summarize, our main contributions are:
-
•
We propose a simple yet effective visual prompting, Set-of-Mark (SoM), for LMMs, and show empirically that SoM effectively unleashes the grounding ability of GPT-4V.
-
•
We have developed a new suite of evaluation benchmarks to examine the grounding ability of GPT-4V and other LMMs. For each image in the dataset, we employ off-the-shelf segmentation models to segment an image into regions, and overlay each region with visual marks, such as numeric numbers.
-
•
We have conducted quantitative and qualitative analysis to validate the effectiveness of SoM on a wide range of vision tasks. Our experiments show that SoM significantly improves GPT-4V’s performance on complex visual tasks that require grounding. For example, GPT-4V with SoM outperforms the state-of-the-art fully-finetuned referring segmentation model on RefCOCOg in a zero-shot setting.
2 Set-of-Mark Prompting
This section introduces Set-of-Mark Prompting and explains how it can be applied to prompt the LMMs, GPT-4V in particular.
2.1 Problem Definition
Typically, LMMs take an image and a text query of length of , as input, and generate a sequence of textual output with length , , formulated as:
| (1) |
Given the versatility of current LLMs used in LMMs, the input and output texts can be comprised of different types of characters (e.g., both alphabetic and numeric), and also multilingual. A large number of works have attempted to improve prompt engineering on the input text to endow more reasoning capability in LLMs [47, 53].
In contrast to prompt engineering for LLMs, the goal of this study is to develop a new prompting method for input images to unleash visual grounding ability of LMMs. In other words, we strive to equip a LMM with the ability to see location-by-location. This necessitates two essential properties for the prompting strategy:
-
•
The method should be able to partition an image into a set of semantically meaningful regions to align with the textual outputs, an ability known as grounding.
-
•
The auxiliary information cast to the input image should be both interpretable and speakable by the LMM, so that it can be described in its textual outputs.
With this in mind, we develop Set-of-Mark Prompting, a simple prompting method of overlaying a number of marks to the meaningful regions in an image. This operation augments the input image to a marked image while keeping the other inputs to LMMs unchanged, as shown in Fig. 2. Mathematically, Eq. (1) becomes
| (2) |
Although it is straightforward to apply SoM to all LMMs, we find that not all LMMs have the ability to “speak out” about the marks. Actually, we find that only GPT-4V, when equiped with SoM, shows the emergent grounding ability and significantly outperforms the other LMMs. In what follows, we will explain how we partition an image into regions and mark the image regions in SoM.
2.2 Image Partition
Given an input image, we need to extract meaningful and semantically aligned regions. Ideally, the extraction should be automatic or semi-automatic to avoid extra burden on users. To achieve this, we employ a suite of image segmentation tools. To support different use cases, the segmentation tools need to possess the following properties:
-
•
Strong performance: the region partition should be precise enough to convey fine-grained spatial layout information to GPT-4V. In this sense, we choose one of the state-of-the-art image segmentation models MaskDINO [24].
-
•
Open vocabulary: the segmentation models should be open-vocabulary so that they can recognize objects out of predefined vocabulary. As such, we opt for the advanced models like SEEM [65].
-
•
Rich granularity: Finally, the region of interest might be not only a full object but also a part of it. Therefore, we also employ SAM [19] and Semantic-SAM [21].
We have collected a suite of image segmentation models that offers a comprehensive toolbox for a user to partition arbitrary images. Most of models are interactive and promotable such that users can customize the SoM prompts interactively.
Based on our image partition toolkit, we divide an input image of size into regions , which are represented by binary masks. We show some SoM examples in Fig. 3 generated using our toolbox.

2.3 Set-of-Mark Generation
Once we obtain image partition , we need to generate for each region a mark that is useful for grounding by GPT-4V. We consider two factors, the types and locations of marks.
Mark Type.
As we discussed earlier, the mark type depends on whether they can be interpreted by GPT-4V. In this work, we consider alphanumeric in that it is not only compact enough to not occupy much image space but recognizable by GPT-4V (using its OCR capability). Besides, we also consider boxes and mask boundaries as auxiliary marks. In addition, we note that the mark types should be image-dependent to avoid any conflicts with the original image contents. For example, given an arithmetic image full of numbers, the numeric marks should be avoided, while the alphabetic characters should be not used for a screenshot of a document. We leave the automatically determining which mark types to use and how to combine them to future work. Fig. 4 shows different mark types and the interpreted outputs from GPT-4V.
Mark Location.
Given an image of size , we need to find good mark locations for all regions. A straightforward way is to derive the center coordinate of -th mask, and overlay the marks there. However, this inevitably introduces some overlaps or conflicts that may confuse GPT-4V, especially for images with dense objects, e.g., two objects centered around similar locations or concave regions, as shown in Fig. 5.



To mitigate the problem, we propose a mark allocation algorithm as illustrated in the algorithm on the right side of Fig. 5. Given the set of masks , we first calculate the areas for all and sort them in an ascending order (line 6). This strategy ensures that smaller regions are considered before large regions. To further avoid the potential overlaps, for -th mask, we exclude the region that is covered by any masks (line 8). The resulting mask is then fed to a distance transform algorithm, which helps to find the location inside the mask where the minimal distance to all boundary points is maximal. In practice, however, a region may be so small that the mark could cover the (almost) whole region. In this case, we move the marks off the region slightly. We find that GPT-4V can still build a decent association between the marks and regions.
Once we determine the mark type and locations for all regions, we overlay mark to region at location . We make sure that each mark is unique so that the full set are distinguishable and speakable by LLMs.
2.4 Interleaved Prompt
Thus far we have obtained a new image with overlaid marks. Additionally, we have a set of region-mark pairs . Given the additional cues in , we can use either a plain text prompt or interleaved ones to prompt LMMs:
-
•
Plain Text Prompt. We can use plain text prompts as usual without any explicit reference to the marks/regions in the image. As shown in Fig. 1, even without any special textual prompt, GPT-4V can automatically ground itself in the regions and corresponding marks. It can be used in a wide range of scenarios where users do not have specific regions of interest.
-
•
Interleaved Text Prompt. We can use interleaved ones by injecting the marks into the text directly. Since the marks are interpretable to LMMs, we can seamlessly blend them into the original text prompt to make a symbolic reference.
Examples of applying these two types of text prompts based on SoM are demonstrated in Fig. 6. Note that for each question, we use a new chat window to avoid context leakage during the conversation. In real-world scenarios, the above two text prompting strategies can be combined and used in multi-round conversations with GPT-4V to significantly enrich human-AI interaction. Moreover, users can also opt to draw the marks by themselves or revise the marks generated using the toolbox.
3 SoM Prompting for Vision
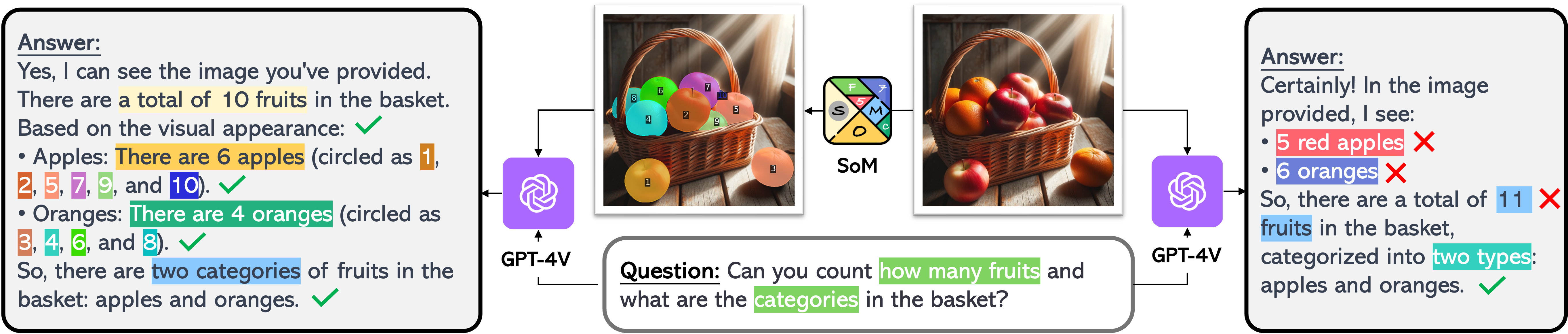
We highlight that the unique merit of using SoM to prompt GPT-4V is that it can produce outputs beyond texts. Since each mark is exclusively associated with an image region represented by a mask, we can trace back the masks for any mentioned marks in the text outputs. Consider the example in Fig. 7, the GPT-4V response on the left side contains the names and details of four regions. It can induce the one-to-one mappings between marks and text description, i.e., . Given that , we can further associate textual description with the masks for all regions. Finally, we can bridge the triplets for all regions, i.e., . The ability to produce paired texts and masks allows the SoM prompted GPT-4V to produce plausible visually grounded texts and more importantly support a variety of fine-grained vision tasks, which are challenging for the vanilla GPT-4V model.
Vision Tasks.
We quantitatively examine the performance of SoM prompted GPT-4V. With simple prompt engineering, it can be readily used in, but not limited to, a wide range of vision tasks such as
-
•
Open-vocabulary Image Segmentation: We ask GPT-4V to exhaustively tell the categories for all marked regions and the categories that are selected from a predetermined pool.
-
•
Referring Segmentation: Given a referring expression, the task for GPT-4V is selecting the top-matched region from the candidates produced by our image partition toolbox.
-
•
Phrase Grounding: Slightly different from referring segmentation, phrase grounding uses a complete sentence consisting of multiple noun phrases. We ask GPT-4V to allocate the corresponding regions for all labeled phrases.
-
•
Video Object Segmentation: It takes two images as input. The first image is the query image which contains a few objects of interest to identify in the second image. Given that GPT-4V supports multiple images as input, our prompting method can also be applied to ground visual objects across frames in a video.
We show how we prompt GPT-4V using SoM for the above vision tasks in Fig. 7. It is worth noting that SoM can be applied to broader tasks, such as region captioning, keypoint localization, and part segmentation, etc. Due to the limited access (quota) to GPT-4V, we focus on the aforementioned vision tasks and leave the explorations to other tasks for future work. We present the detailed empirical study in the next section.
4 Experiments
4.1 Experimental Setup
Implementation.
We do not need to train any models for our method. However, due to the limited quota and absence of GPT-4V API, we have to exhaustively send the SoM augmented images to the ChatGPT interface. The authors in this work used a divide-and-conquer strategy to run the experiments and evaluations. For each instance, we use a new chat window so that there is no context leakage during the evaluation. In this sense, all the reported results for our method are zero-shot. Unless otherwise mentioned, we always use the numeric numbers as the marks for reporting the main results. The usage of other mark types is shown in our ablation and qualitative studies.
Benchmarks.
Given the limited quota of GPT-4V, it is not possible for now to fully evaluate the validation set in each individual vision task as we listed above. Consequently, we select a small subset of validation data from each dataset for our study. For each image in the datasets, we overlay a set of marks on the regions extracted using our image partition toolbox. Depending on the specific task, we exploit different partition tools to propose regions. In Table 1, we list the setup for each task.
Comparisons.
We compare our method with:
-
•
GPT-4V baseline predicting coordinates. We use this as our baseline model. By default, GPT-4V can neither predict boxes nor generate masks. Following prior practice, we prompt the model to predict box coordinates. Comparing with the default GPT-4V baseline helps to inspect the benefit of our proposed Set-of-Mark Prompting.
-
•
State-of-the-art specialist models. For each of the vision tasks, a number of methods have been proposed. We choose state-of-the-art and representative methods for comparison. More specifically, MaskDINO [24] for generic segmentation on COCO, OpenSeeD [55] for zeroshot segmentation on ADE20K, Grounding DINO [31] and GLIPv2 [56] for phrase grounding on Flick30K, Grounding DINO and PolyFormer [29] for referring expression comprehension, PolyFormer and SEEM [65] for referring expression segmentation and SegGPT [46] for video object segmentation. We attempt to shed light on the gap between the strongest generalist vision model GPT-4V and specialist models that are sophisticatedly designed and trained with the take-specific data.
-
•
Open-sourced LMMs. We quantitatively evaluate one of the state-of-the-art open-sourced LMMs, LLaVa-1.5 [27], and qualitatively compare with MiniGPT-v2 [5] in our study. Note that both models are trained with a good amount of data from the targeted vision tasks. We are the first to compare closed- and open-sourced LMMs on vision benchmarks.
| Vision Task | Dataset | #Images | #Instances | Marks | Metric |
| Generic Segmentation | COCO [26] | 100 | 567 | Number & Mask | Precision |
| OV Segmentation | ADE20K [62] | 100 | 488 | Number & Mask | Precision |
| Phrase Grounding | Flickr30K [38] | 100 | 274 | Number & Box | Recall@1 |
| Referring Expression Segmentation | RefCOCO [18] | 100 | 177 | Number & Mask | mIoU |
| Referring Expression Comprehension | RefCOCO [18] | 100 | 177 | Number & Mask | ACC@0.5 |
| Video Object Segmentation | DAVIS [37] | 71 | 157 | Number & Mask | J&F |
4.2 Quantitative Results
We present the experimental results in Table 2.
| Model | LMM | Zero-shot | OV Segmentation | RefCOCOg | Phrase Grounding | VOS | ||
| COCO | ADE20K | REC | RES | Flickr30K | DAVIS2017 | |||
| MaskDINO [23] | ✗ | ✗ | 80.7 | - | n/a | n/a | n/a | n/a |
| OpenSeeD [55] | ✗ | ✓ | - | 23.4 | n/a | n/a | n/a | n/a |
| GLIPv2 [56] | ✗ | ✗ | - | - | - | - | n/a | |
| GDINO [31] | ✗ | ✗ | n/a | n/a | n/a | 90.5 | n/a | |
| X-Decoder [64] | ✗ | ✗ | - | - | - | n/a | 62.8 | |
| PolyFormer [29] | ✗ | ✗ | n/a | n/a | 67.2 | n/a | n/a | |
| SegGPT [46] | ✗ | ✓ | n/a | n/a | n/a | n/a | n/a | 75.6 |
| SEEM [65] | ✗ | ✗ | - | - | - | - | 62.8 | |
| RedCircle [42] | ✓ | ✓ | n/a | n/a | n/a | n/a | n/a | |
| FGVP [49] | ✓ | ✓ | n/a | n/a | n/a | n/a | n/a | |
| Shikra [6] | ✓ | ✗ | n/a | n/a | n/a | 77.4 | n/a | |
| LLaVA-1.5 [27] | ✓ | ✗ | n/a | n/a | 63.3 | n/a | n/a | n/a |
| MiniGPT-v2 [5] | ✓ | ✗ | n/a | n/a | n/a | n/a | n/a | |
| Ferret [54] | ✓ | ✗ | n/a | n/a | * | n/a | 81.1 | n/a |
| GPT-4V [36] | ✓ | ✓ | n/a | n/a | 25.7 | n/a | n/a | n/a |
| GPT-4V [36] + SoM (Ours) | ✓ | ✓ | 75.7 | 63.4 | 86.4 | 75.6 | 89.2 | 78.8 |
Image Segmentation
On image segmentation tasks, we evaluate the classification precision of GPT-4V + SoM and compare it with the strong segmentation model MaskDINO on COCO Panoptic segmentation dataset and OpenSeeD on ADE20K Panoptic segmentation dataset. For MaskDINO and OpenSeeD, we give them GT boxes and evaluate the output class. For GPT-4V + SoM, we overlay GT masks with alpha=0.4 and 0.2 for COCO and OpenSeeD, respectively, and add the ID number on each mask. We provide GPT-4V with the vocabulary of the datasets and ask it select a class label for each region. The results show that zero-shot performance of GPT-4V + SoM is close to the performance of fine-tuned MaskDINO and is much higher than the zero-shot performance of OpenSeeD on ADE20K. The similar performance on COCO and ADE20K for GPT-4V indicates its strong generalization ability to a wide of visual and semantic domains.
Referring
For referring tasks, we evaluate RES and REC on RefCOCOg. We use MaskDINO to propose masks and overlay the masks and numbers on the images. We use mIoU as the evaluation metric and compare it with state-of-the-art specialist PolyFormer [29] and SEEM [65]. Accordingly, GPT-4V + SoM outperforms PolyFormer by a large margin. Note that the performance of PolyFormer is evaluated on our dataset for apple-to-apple comparison. For REC, we convert the masks into boxes for our method. When prompting GPT-4V to directly output the coordinates, we attain significantly poor performance (25.7), which verifies our earlier hypothesis. Once augmented with SoM, GPT-4V beats both specialists such as Grounding DINO and Polyformer and recent open-source LMM including Shikra, LLaVA-1.5, MiniGPT-v2, and Ferret.
Phrase Grounding
For phrase grounding on Flickr30K, we use Grounding DINO to generate box proposals for each image. We use a threshold of 0.27 to filter redundant boxes, then we use SAM to predict a mask for each box. We draw boxes, masks, and numbers on the images. We give GPT-4V a caption and the noun phrases of the caption for each image and let GPT-4V to ground each noun phrase to a region. Our zero-shot performance is comparable with SOTA models GLIPv2 and Grounding DINO.
Video Object Segmentation
We evaluate DAVIS2017 [39] for the video segmentation task. To get the mask proposals of each video frame, we use MaskDINO [24]. The predicted masks are then overlayed on the corresponding frames with numeric labels following our SoM. We follow the semi-supervised setting to use the first frame masks as the reference and segment all the other frames of the same video. As GPT-4V can take in multiple images, we prompt GPT-4V with the first frame and the current frame to do segmentation by comparing similar objects across images. As shown in the last column of Table 2, GPT-4V achieves the best tracking performance (78.8 J&F) compared with other generalist vision models.
4.3 Ablation Study
Mark type.
We study how the choice of mark types affects the final performance for the phrase grounding task on Flickr30k. We compare two types of marks. The first is numbers and masks and the second is numbers, masks, and boxes. As shown in Table 4, the scheme of adding extra boxes can improve the performance significantly.
Golden mark location.
The extracted regions from our toolbox may often come with some errors. In this study, we investigate how GPT-4V behaves when we generate the marks with ground-truth annotations. Specifically, we replace the predicted segmentation masks with ground-truth ones in our RefCOCOg validation set. This means GPT-4V only needs to select one from regions for annotated phrases. As expected, the performance for referring segmentation can be further improved, especially when the segmentation model has some missed regions. The results are shown in Table 4, which shows using ground-truth masks in our SoM improves the RefCOCOg performance by mIoU. We also observe that most failure cases when using GT masks are not the GPT-4V’s problem, but the annotation itself is ambiguous or incorrect.
4.4 Qualitative Observations
When running through this work, we observed several intriguing qualitative findings.

The “golden” annotations are not always golden.
When evaluating SoM, we find that a few human annotations in datasets are incorrect. Some examples are shown in Fig. 8 (a,b,c). For example, human users annotate several people while the referring expression is “the legs of a person sitting on the couch” or only one truck is annotated for referring to “truck race”. In contrast, GPT-4V with SoM yields correct answers. This implies that the “golden” labels in vision datasets may be subject to some noises while GPT-4V could be a good judge to help find the ambiguous annotations for further cleaning.
The centered marks are not always the best.
By default, our mark allocation algorithm finds the center for each region. However, we observe that putting marks at the central locations does not necessarily bring the best performance. For example in Fig. 8 (e), there are two marks, one is for the person and the other one for the backpack. When being asked which one is the person, GPT-4V gives the mark for the backpack which is located at the upper part of the human body. A similar situation also happens in the second image where there is a background spanning the whole image. An example is shown in 8 (f), where the center of the grassland (labeled 2) is on the person (labeled 1). These results indicate that the focus of GPT-4V to understand visual contents is not necessarily at the center. Developing a better mark allocation algorithm should be considered.
Dynamitc selection of mark types.
In realistic scenarios, we find dynamically determining which type of mark to use is important. For example, an image of arithmetic problems usually contains many numbers. In this case, overlaying numeric marks on to will confuse the GPT-4V. Likewise, for a screenshot of a document, it might be not rational to overlay more alphabets on the image. As a result, to fully leverage the visual capability of GPT-4V, users may need to carefully design the SoM prompts before sending the image.
5 Related Work
We discuss related work from the perspective of prompting.
LLMs and Prompting.
We have witnessed significant progress in large language models (LLMs) [2, 3, 10, 44, 60, 35]. Of particular, Generative Pre-trained Transformers, commonly known as GPTs [2, 35], have led to a breakthrough in the realm of natural language processing. Despite the size of LLMs growing dramatically, eliciting reasoning capabilities still requires more sophisticatedly designed queries, i.e., prompting. In the past, a number of works attempted to do prompt engineering to endow more capability for LLMs. In-context learning is a main-stream way to teach LLMs to follow specific instructions as instantiated by a few examples [2, 15] As a follow-up, some other techniques such as chain-of-thought and tree-of-thought [47, 53] are proposed to enhance the arithmetic, commonsense, and symbolic reasoning tasks. Analogous to these works, our Set-of-Mark Prompting can be considered as a way of prompting the model to look at the image regions location-by-location. However, it also differs in that no in-context examples are needed in our method.
Visual and Multimodal Prompting.
In earlier works on interactive image segmentation [34, 8, 9], the spatial prompting is used so that the model can take multiple user inputs (e.g., clicks) to gradually refine the mask. Recently, the pioneering work SAM [19] and its variants [43, 11] have proposed a unified model to support different types of prompting modes including points, boxes, and texts. In SEEM [65], the authors proposed a novel visual sampler to expand to visual prompting across images. Likewise, PerSAM [58] and SAM-PT [41] finetune SAM to support personalized segmentation and point tracking. Another line of work directly generates the prompts on the input images. In [1], image inpainting is used as the prompting to teach the model to predict dense outputs given example images and corresponding outputs, both in pixel space. Painter [45] and SegGPT [46] share similar spirits while using masked image modeling for decoding pixels in continuous space. Visual prompting can be also applied to multimodal models like CLIP [40]. RedCircle [42] draws a red circle on an image to focus the vision model on the enclosed region. In [49], the authors enhance the prompts by specifically segmenting and highlighting a target object in the image. Both methods then ask CLIP model to measure the similarity between the prompted image and a number of textual concepts.
LMMs and Prompting.
In a short time, large multimodal models (LMMs) have emerged as a new line of research in the community. The goal is to build a generalist multimodal system that behaves as LLMs that can perceive and reason with multimodal inputs [28, 63, 57, 12, 59, 48, 51, 6, 20, 5, 54]. Earlier works like MiniGPT-4 [5] and LLaVa [28] proposed a simple yet effective way to connect vision and LLMs followed by an instruction tuning. Later, a similar training strategy is applied to video tasks [33, 4] and fine-grained vision tasks [6, 59, 20, 5, 54]. Please refer to [20] for a more comprehensive review of LMMs. Thus far, prompting LMMs is rarely explored in academia, partially because most of the recent open-sourced models are of limited capacity and thus incapable of such emerging capability [47]. Most recently, GPT-4V [36] was released followed by a comprehensive qualitative study on it [50]. The authors in [50] used a similar prompting strategy as in RedCircle [42] to prompt GPT-4V. However, it only shows some referring capability of GPT-4V with hand-drawn circles or arrows, let alone a comprehensive quantitative study.
6 Discussion
The mystery in GPT-4V.
It is still mysterious why the proposed Set-of-Mark Prompting could work so well with GPT-4V. Out of curiosity, we also ran some examples on other open-sourced LMMs such as LLaVa-1.5 and MiniGPT-v2. However, both models can hardly interpret the marks and ground themselves on those marks. We hypothesize a few reasons for the extraordinary visual grounding capability exhibited in GPT-4V. First, scale matters. We believe the scale of model and training data used in GPT-4V is several orders of magnitude than the aforementioned open-sourced LMMs. Second, the data curation strategy is probably another secret sauce for GPT-4V. GPT-4V could automatically associate the image regions and marks without any explicit prompt in texts. Such kind of data could be probably from literature figures, charts, etc, which are usually clearly labeled or marked [1]. We doubt that GPT-4V specifically employs fine-grained vision data as covered in this work. Note that the amount is extremely limited, and annotating more such kinds of data is costly, not to mention the quality is hard to control. In the end, we note that all the above suspicions are not grounded on the facts but on some empirical studies as we conducted above.
Connecting visual and LLMs prompting.
Despite the unknowns behind GPT-4V. Our work does take one of the first steps to connect visual prompting and LLMs prompting. In the past, many works have studied how to make vision models more promptable, which is isolated from the text promptings to LLMs. The barrier is mainly due to the language bottleneck in that we can hardly express the visual promptings precisely in language. For example, the shape/location/color of a randomly drawn stroke on the image can be hardly described verbally, unless we can encode the visual prompts and finetune the whole model [54]. However, given the limited fine-grained training data and inferior open-sourced large vision and language models. We still see a clear gap. At the current stage, our proposed Set-of-Mark Prompting demonstrates a simple yet only feasible way to inherit all existing capabilities of the strongest LMM while unleashing its strongly aspired grounding capability. We hope this work as the first to seamlessly connect visual and language prompting, could help to pave the road towards more capable LMMs.
Scaling data via Set-of-Mark Prompting with GPT-4V.
In the past, the whole community has strived to build fine-grained, open-vocabulary vision systems, spanning from detection [17, 61, 25, 56, 52, 31] to segmentation [16, 64, 14], and further expand to 3D [32, 13, 30]. Though tremendous progress, we have been struggling with how to map the rich semantic knowledge from CLIP to the fine-grained domains. This is mainly due to the extremely limited number of fine-grained semantic annotations, which is still a considerable challenge to the current LMMs. As we already see, the feasibility of scaling data with fine-grained spatial has been demonstrated in SAM [19] and Semantic-SAM [22], but how to further annotate these regions with semantic labels is still an open problem. In the light of the study in this work, we are envisioning the potential of using GPT-4V plus our Set-of-Mark Prompting to intensively scale up the multimodal data which has both fine-grained spatial and detailed language description.
7 Conclusion
We have presented Set-of-Mark Prompting, a simple yet effective visual prompting mechanism for LMMs, particularly GPT-4V. We show that simply overlaying a number of symbolic marks on a set of regions of an input image can unleash the visual grounding ability of GPT-4V. We present a comprehensive empirical study on a wide range of fine-grained vision tasks to demonstrate that SoM-prompted GPT-4V is superior to fully-finetuned specialist models and other open-sourced LMMs. Moreover, our qualitative results show that GPT-4V with SoM possesses extraordinary fine-grained multimodal perception, cognition, and reasoning capabilities across the board. We hope that SoM would inspire future works on multimodal prompting for LMMs and pave the road towards multimodal AGI.
Acknowledgement
We thank Fangrui Zhu for the thoughtful discussions.
References
- [1] Amir Bar, Yossi Gandelsman, Trevor Darrell, Amir Globerson, and Alexei Efros. Visual prompting via image inpainting. Advances in Neural Information Processing Systems, 35:25005–25017, 2022.
- [2] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners, 2020.
- [3] Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
- [4] Guo Chen, Yin-Dong Zheng, Jiahao Wang, Jilan Xu, Yifei Huang, Junting Pan, Yi Wang, Yali Wang, Yu Qiao, Tong Lu, and Limin Wang. Videollm: Modeling video sequence with large language models, 2023.
- [5] Jun Chen, Deyao Zhu, Xiaoqian Shen, Xiang Li, Zechu Liu, Pengchuan Zhang, Raghuraman Krishnamoorthi, Vikas Chandra, Yunyang Xiong, and Mohamed Elhoseiny. Minigpt-v2: Large language model as a unified interface for vision-language multi-task learning. github, 2023.
- [6] Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multimodal llm’s referential dialogue magic, 2023.
- [7] Ting Chen, Saurabh Saxena, Lala Li, David J. Fleet, and Geoffrey Hinton. Pix2seq: A language modeling framework for object detection, 2022.
- [8] Xi Chen, Zhiyan Zhao, Feiwu Yu, Yilei Zhang, and Manni Duan. Conditional diffusion for interactive segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7345–7354, 2021.
- [9] Xi Chen, Zhiyan Zhao, Yilei Zhang, Manni Duan, Donglian Qi, and Hengshuang Zhao. Focalclick: Towards practical interactive image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1300–1309, 2022.
- [10] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- [11] Haixing Dai, Chong Ma, Zhengliang Liu, Yiwei Li, Peng Shu, Xiaozheng Wei, Lin Zhao, Zihao Wu, Dajiang Zhu, Wei Liu, et al. Samaug: Point prompt augmentation for segment anything model. arXiv preprint arXiv:2307.01187, 2023.
- [12] Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning, 2023.
- [13] Runyu Ding, Jihan Yang, Chuhui Xue, Wenqing Zhang, Song Bai, and Xiaojuan Qi. Pla: Language-driven open-vocabulary 3d scene understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7010–7019, 2023.
- [14] Zheng Ding, Jieke Wang, and Zhuowen Tu. Open-vocabulary panoptic segmentation with maskclip. arXiv preprint arXiv:2208.08984, 2022.
- [15] Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, and Zhifang Sui. A survey for in-context learning. arXiv preprint arXiv:2301.00234, 2022.
- [16] Golnaz Ghiasi, Xiuye Gu, Yin Cui, and Tsung-Yi Lin. Scaling open-vocabulary image segmentation with image-level labels. In European Conference on Computer Vision, pages 540–557. Springer, 2022.
- [17] Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, and Yin Cui. Open-vocabulary object detection via vision and language knowledge distillation. arXiv preprint arXiv:2104.13921, 2021.
- [18] Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. Referitgame: Referring to objects in photographs of natural scenes. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 787–798, 2014.
- [19] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. Segment anything, 2023.
- [20] Chunyuan Li, Zhe Gan, Zhengyuan Yang, Jianwei Yang, Linjie Li, Lijuan Wang, and Jianfeng Gao. Multimodal foundation models: From specialists to general-purpose assistants. arXiv preprint arXiv:2309.10020, 2023.
- [21] Feng Li, Hao Zhang, Peize Sun, Xueyan Zou, Shilong Liu, Jianwei Yang, Chunyuan Li, Lei Zhang, and Jianfeng Gao. Semantic-sam: Segment and recognize anything at any granularity, 2023.
- [22] Feng Li, Hao Zhang, Peize Sun, Xueyan Zou, Shilong Liu, Jianwei Yang, Chunyuan Li, Lei Zhang, and Jianfeng Gao. Semantic-sam: Segment and recognize anything at any granularity. arXiv preprint arXiv:2307.04767, 2023.
- [23] Feng Li, Hao Zhang, Huaizhe xu, Shilong Liu, Lei Zhang, Lionel M. Ni, and Heung-Yeung Shum. Mask dino: Towards a unified transformer-based framework for object detection and segmentation, 2022.
- [24] Feng Li, Hao Zhang, Huaizhe Xu, Shilong Liu, Lei Zhang, Lionel M Ni, and Heung-Yeung Shum. Mask dino: Towards a unified transformer-based framework for object detection and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3041–3050, 2023.
- [25] Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. Grounded language-image pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10965–10975, 2022.
- [26] Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft coco: Common objects in context, 2015.
- [27] Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning, 2023.
- [28] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023.
- [29] Jiang Liu, Hui Ding, Zhaowei Cai, Yuting Zhang, Ravi Kumar Satzoda, Vijay Mahadevan, and R. Manmatha. Polyformer: Referring image segmentation as sequential polygon generation, 2023.
- [30] Kunhao Liu, Fangneng Zhan, Jiahui Zhang, Muyu Xu, Yingchen Yu, Abdulmotaleb El Saddik, Christian Theobalt, Eric Xing, and Shijian Lu. 3d open-vocabulary segmentation with foundation models. arXiv preprint arXiv:2305.14093, 2023.
- [31] Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding dino: Marrying dino with grounded pre-training for open-set object detection, 2023.
- [32] Yuheng Lu, Chenfeng Xu, Xiaobao Wei, Xiaodong Xie, Masayoshi Tomizuka, Kurt Keutzer, and Shanghang Zhang. Open-vocabulary 3d detection via image-level class and debiased cross-modal contrastive learning. arXiv preprint arXiv:2207.01987, 2022.
- [33] Chenyang Lyu, Minghao Wu, Longyue Wang, Xinting Huang, Bingshuai Liu, Zefeng Du, Shuming Shi, and Zhaopeng Tu. Macaw-llm: Multi-modal language modeling with image, audio, video, and text integration, 2023.
- [34] Kevin McGuinness and Noel E O’connor. A comparative evaluation of interactive segmentation algorithms. Pattern Recognition, 43(2):434–444, 2010.
- [35] OpenAI. Gpt-4 technical report, 2023.
- [36] OpenAI. Gpt-4v(ision) system card, 2023.
- [37] Federico Perazzi, Jordi Pont-Tuset, Brian McWilliams, Luc Van Gool, Markus Gross, and Alexander Sorkine-Hornung. A benchmark dataset and evaluation methodology for video object segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 724–732, 2016.
- [38] Bryan A. Plummer, Liwei Wang, Chris M. Cervantes, Juan C. Caicedo, Julia Hockenmaier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models, 2016.
- [39] Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Arbeláez, Alex Sorkine-Hornung, and Luc Van Gool. The 2017 davis challenge on video object segmentation. arXiv preprint arXiv:1704.00675, 2017.
- [40] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021.
- [41] Frano Rajič, Lei Ke, Yu-Wing Tai, Chi-Keung Tang, Martin Danelljan, and Fisher Yu. Segment anything meets point tracking. arXiv preprint arXiv:2307.01197, 2023.
- [42] Aleksandar Shtedritski, Christian Rupprecht, and Andrea Vedaldi. What does clip know about a red circle? visual prompt engineering for vlms, 2023.
- [43] Lv Tang, Haoke Xiao, and Bo Li. Can sam segment anything? when sam meets camouflaged object detection. arXiv preprint arXiv:2304.04709, 2023.
- [44] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- [45] Xinlong Wang, Wen Wang, Yue Cao, Chunhua Shen, and Tiejun Huang. Images speak in images: A generalist painter for in-context visual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6830–6839, 2023.
- [46] Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, and Tiejun Huang. Seggpt: Segmenting everything in context, 2023.
- [47] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837, 2022.
- [48] Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, and Nan Duan. Visual chatgpt: Talking, drawing and editing with visual foundation models. arXiv preprint arXiv:2303.04671, 2023.
- [49] Lingfeng Yang, Yueze Wang, Xiang Li, Xinlong Wang, and Jian Yang. Fine-grained visual prompting, 2023.
- [50] Zhengyuan Yang, Linjie Li, Kevin Lin, Jianfeng Wang, Chung-Ching Lin, Zicheng Liu, and Lijuan Wang. The dawn of lmms: Preliminary explorations with gpt-4v(ision), 2023.
- [51] Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. Mm-react: Prompting chatgpt for multimodal reasoning and action. arXiv preprint arXiv:2303.11381, 2023.
- [52] Lewei Yao, Jianhua Han, Youpeng Wen, Xiaodan Liang, Dan Xu, Wei Zhang, Zhenguo Li, Chunjing Xu, and Hang Xu. Detclip: Dictionary-enriched visual-concept paralleled pre-training for open-world detection. Advances in Neural Information Processing Systems, 35:9125–9138, 2022.
- [53] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. arXiv preprint arXiv:2305.10601, 2023.
- [54] Haoxuan You, Haotian Zhang, Zhe Gan, Xianzhi Du, Bowen Zhang, Zirui Wang, Liangliang Cao, Shih-Fu Chang, and Yinfei Yang. Ferret: Refer and ground anything anywhere at any granularity, 2023.
- [55] Hao Zhang, Feng Li, Xueyan Zou, Shilong Liu, Chunyuan Li, Jianfeng Gao, Jianwei Yang, and Lei Zhang. A simple framework for open-vocabulary segmentation and detection, 2023.
- [56] Haotian Zhang, Pengchuan Zhang, Xiaowei Hu, Yen-Chun Chen, Liunian Harold Li, Xiyang Dai, Lijuan Wang, Lu Yuan, Jenq-Neng Hwang, and Jianfeng Gao. Glipv2: Unifying localization and vision-language understanding, 2022.
- [57] Renrui Zhang, Jiaming Han, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, Peng Gao, and Yu Qiao. Llama-adapter: Efficient fine-tuning of language models with zero-init attention. arXiv preprint arXiv:2303.16199, 2023.
- [58] Renrui Zhang, Zhengkai Jiang, Ziyu Guo, Shilin Yan, Junting Pan, Hao Dong, Peng Gao, and Hongsheng Li. Personalize segment anything model with one shot. arXiv preprint arXiv:2305.03048, 2023.
- [59] Shilong Zhang, Peize Sun, Shoufa Chen, Min Xiao, Wenqi Shao, Wenwei Zhang, Yu Liu, Kai Chen, and Ping Luo. Gpt4roi: Instruction tuning large language model on region-of-interest, 2023.
- [60] Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
- [61] Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chunyuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, et al. Regionclip: Region-based language-image pretraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16793–16803, 2022.
- [62] Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017.
- [63] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023.
- [64] Xueyan Zou, Zi-Yi Dou, Jianwei Yang, Zhe Gan, Linjie Li, Chunyuan Li, Xiyang Dai, Harkirat Behl, Jianfeng Wang, Lu Yuan, Nanyun Peng, Lijuan Wang, Yong Jae Lee, and Jianfeng Gao. Generalized decoding for pixel, image, and language, 2022.
- [65] Xueyan Zou, Jianwei Yang, Hao Zhang, Feng Li, Linjie Li, Jianfeng Gao, and Yong Jae Lee. Segment everything everywhere all at once. arXiv preprint arXiv:2304.06718, 2023.
Appendix A Use Cases
Combining GPT-4V with the proposed SoM prompting, we run many realistic use cases to check its generality and merit in comparison with the original GPT-4V.