MMBench: Is Your Multi-modal Model an All-around Player?
Abstract
Large vision-language models have recently achieved remarkable progress, exhibiting great perception and reasoning abilities concerning visual information. However, how to effectively evaluate these large vision-language models remains a major obstacle, hindering future model development. Traditional benchmarks like VQAv2 or COCO Caption provide quantitative performance measurements but suffer from a lack of fine-grained ability assessment and non-robust evaluation metrics. Recent subjective benchmarks, such as OwlEval, offer comprehensive evaluations of a model’s abilities by incorporating human labor, but they are not scalable and display significant bias. In response to these challenges, we propose MMBench, a novel multi-modality benchmark. MMBench methodically develops a comprehensive evaluation pipeline, primarily comprised of two elements. The first element is a meticulously curated dataset that surpasses existing similar benchmarks in terms of the number and variety of evaluation questions and abilities. The second element introduces a novel CircularEval strategy and incorporates the use of ChatGPT. This implementation is designed to convert free-form predictions into pre-defined choices, thereby facilitating a more robust evaluation of the model’s predictions. MMBench is a systematically-designed objective benchmark for robustly evaluating the various abilities of vision-language models. We hope MMBench will assist the research community in better evaluating their models and encourage future advancements in this domain. Project page: https://opencompass.org.cn/MMBench.
1 Introduction
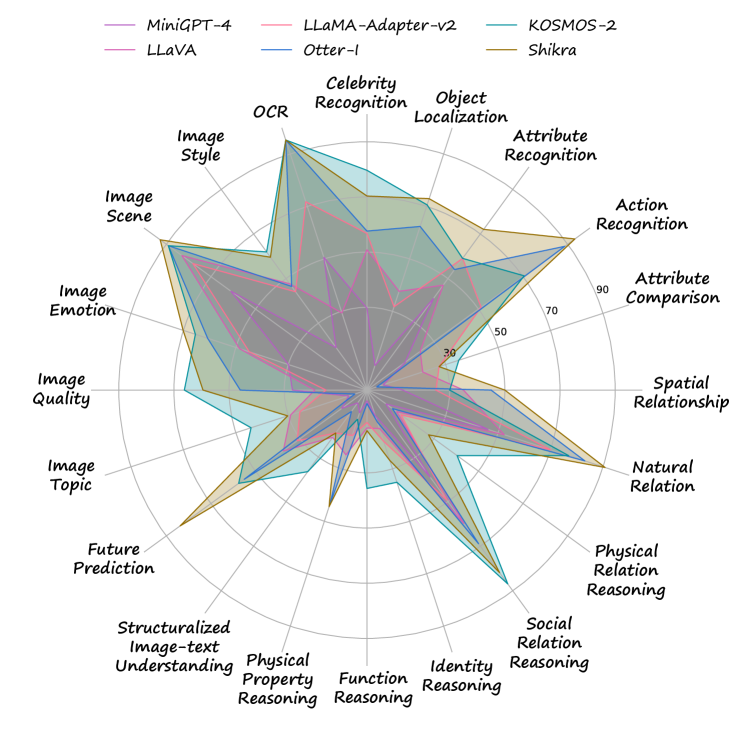
Recently, notable progress has been achieved within the realm of large language models (LLMs). For instance, the latest large language models, such as OpenAI’s ChatGPT and GPT-4 [31], have demonstrated remarkable reasoning capabilities that are comparable to, and in some cases, even surpass human capabilities. Drawing inspiration from these promising advancements in LLMs, the field of large vision-language models (LVLMs) has experienced a revolutionary transformation. Notable works, such as MiniGPT-4 [46], Otter [23, 22], and LLaVA [27], have demonstrated enhanced capabilities in terms of image content recognition and reasoning within the domain of vision-language models, surpassing the achievements of earlier models. Nevertheless, the majority of current studies tend to emphasize showcasing qualitative examples, rather than undertaking comprehensive quantitative experiments to thoroughly assess their model performance. The lack of quantitative assessment poses a considerable challenge for comparing various models. Addressing this concern, recent studies have explored two approaches. The first approach involves utilizing existing public datasets [15, 6] for objective quantitative evaluation. Alternatively, some studies leverage human resources [40, 39] for subjective quantitative evaluation. However, it is worth noting that both approaches exhibit inherent limitations.
A multitude of public datasets, such as VQAv2 [15], COCO Caption [6], GQA [20], OK-VQA [29], have long served as valuable resources for the quantitative evaluation of vision-language models. These datasets offer objective metrics, including accuracy, BLEU, CIDEr, etc. However, when employed to evaluate more advanced LVLMs, these benchmarks encounter the following challenges:
-
(1).
The existing evaluation metrics require an exact match between the prediction and the reference target, leading to potential limitations. For instance, in the Visual Question Answering (VQA) task, even if the prediction is “bicycle” while the reference answer is “bike”, the existing metric would assign a negative score to the current prediction, despite its correctness. Consequently, this issue results in a considerable number of false-negative samples.
-
(2).
Current public datasets predominantly focus on evaluating a model’s performance on specific tasks, offering limited insights into the fine-grained capabilities of these models. Additionally, they provide minimal feedback regarding potential avenues for future optimization.
Given the aforementioned challenges, recent studies, such as mPLUG-Owl [40] and LVLM-eHub [39] propose human-involved subjective evaluation strategies, aiming to address existing methods’ limitations by incorporating human judgment and perception in the evaluation process. mPLUG-Owl comprises 82 artificially constructed open-ended questions related to 50 images sourced from existing datasets. After predictions are generated by both mPLUG-Owl and another vision-language (VL) model, human annotators will assess the quality of these predictions. Similarly, inspired by FastChat [43], LVLM-eHub develops an online platform where two models are prompted to answer a question related to an image. A participant then compares the answers provided by the two models. These subjective evaluation strategies offer several advantages, consists of accurate matching (humans can accurately match a prediction to the target, even if presented in different formats) and comprehensive assessment (humans tend to compare two predictions based on various ability dimensions, such as the model’s ability to correctly recognize objects in the image or comprehend the relationships between them). The final score is calculated as the average score across different abilities, enabling a comprehensive evaluation of various model capabilities.
While subjective evaluation allows for a more comprehensive assessment of a model’s abilities, it also introduces new challenges that need to be addressed. Firstly, human evaluations are inherently biased. Consequently, it becomes challenging to reproduce the results presented in a paper with a different group of annotators. Also, the existing subjective evaluation strategies face scalability issues. Employing annotators for model evaluation after each experiment is an expensive endeavor. Moreover, evaluation datasets with a small scale can result in statistical instability. To ensure a robust evaluation, collecting more data becomes necessary, which in turn demands a significant amount of human labor.
In light of the challenges faced by conventional objective and subjective benchmarks, we propose MMBench, a systematically designed objective evaluation benchmark to robustly evaluate different abilities of large vision-language models. Currently, MMBench contains approximately 3000 single-choice questions covering 20 different ability dimensions, such as object localization and social reasoning, for vision-language models. Each ability dimension includes more than 75 questions, enabling a balanced and comprehensive evaluation of various abilities. The ability dimensions are not static and will expand as we continue to work on them. Since the instruction-following ability of current vision-language models is weak and they cannot directly output choice labels (A, B, C, etc), we cannot directly compare their output to the ground truth. In order to reduce the number of false-negative samples, we employ ChatGPT to match a model’s prediction to one of the choices in a multiple-choice question and then output the label for the matched choice. We compare ChatGPT-based choice matching to that of humans and find that ChatGPT can perfectly match human evaluations for 87% of ambiguous cases, demonstrating its good alignment and robustness as an evaluator. Besides, to make the evaluation more robust, we propose a novel evaluation strategy, named CircularEval (details in Sec. 4.1). We comprehensively evaluate 14 well-known vision-language models on MMBench and report their performance on different ability dimensions. Additionally, we undertook comparative assessments between Bard, the contemporary largest multimodal model with our benchmarked open-sourced VLMs. The performance ranking offers a direct comparison between various models and provides valuable feedback for future optimization. In summary, our main contributions are three-fold:
-
Systematically-constructed Dataset: In order to thoroughly evaluate the capacity of a VLM, we have meticulously crafted a systematic framework that encompasses three distinct levels of abilities. Within these defined ability levels, we have carefully curated a dataset, comprised of a total of 2,974 meticulously selected questions, which collectively cover a diverse spectrum of 20 fine-grained skills.
-
Robust Evaluation: We introduce a novel circular evaluation strategy (CircularEval) to improve the robustness of our evaluation process. After that, ChatGPT is employed to match model’s prediction with given choices, which can successfully extract choices even from predictions of a VLM with poor instruction-following capability.
-
Analysis and Observations: We perform a comprehensive evaluation of 14 well-known vision-language models using MMBench, and the results are reported across various ability dimensions (refer to Figure 1). The observations(see Sec.5.3) derived from this analysis, including the training data selection, model architecture design and fine-tuning strategy, provide insights to the research community for future exploration.
2 Related Work
2.1 Multi-modal Datasets
Large-scale vision-language models have shown promising potential in multi-modality tasks such as complex scene understanding and visual question answering. Though qualitative results so far are encouraging, quantitative evaluation is of great necessity to systematically evaluate and compare the abilities of different VLMs. Recent works evaluated their models on numerous existing public multi-modality datasets. COCO Caption [6], Nocaps [2], and Flickr30k [41] provide human-generated image captions and the corresponding task is to understand image content and describe it in the form of text. Visual question answering datasets, such as GQA [20], OK-VQA [29], VQAv2 [15] and Vizwiz [16], contain question-answer pairs related to the given image, used to measure the model’s ability on visual perception and reasoning. Some datasets provide more challenging question-answering scenarios by incorporating additional tasks. For example, TextVQA [36] proposes questions about text shown in the image, thus involving the OCR task into question-answering. ScienceQA [28] focuses on scientific topics, requiring the model to integrate commensense into reasoning. Youcook2 [45] replaces images with video clips, introducing additional temporal information. However, the aforementioned datasets are designed on specific domains, and can only evaluate the model’s performance on one or several tasks. Besides, different data formats and evaluation metrics across datasets make it more difficult to comprehensively assess model’s capability. Ye et al. [40] built an instruction evaluation set, OwlEval, consisting of several kinds of visual-related tasks, but in a limited size. Fu et al. [12] built MME, which is a evaluation dataset containing multi-modality Yes / No questions. However, the exact-matching based evaluation and non-rigorous evaluation setting make it harder to reveal the real performance gap between VLMs. Different from previous works, in this paper, we propose a novel multi-modal benchmark MMBench , which is built based on measuring abilities rather than performing specific tasks, aimed to better evaluating models once and for all.
2.2 Multi-modal Models
Benefit from the success of LLMs e.g. GPTs [34, 4, 32], LLaMA [38], and Vicuna [7], multi-modal models also achieve great improvements recently. Flamingo [3] is one of the early attempts on introducing LLMs into vision-language pretraining. To be conditioned well on visual features, it inserts several gated cross-attention dense blocks between pretrained language encoder layers. OpenFlamingo [3] provides an open-source version of it. BLIP-2 [24] proposes a Querying Transformer (Q-former) to bridge the modality gap between the frozen image encoder and large language encoder. After that, InstructBLIP [8] extend BLIP-2 [24] with vision-language instruction tuning and achieve better performance. VisualGLM [9] also adopts Q-former [24] to bridge the visual model and language encoder, GLM [9]. LLaVA [27] adopt GPT4 [31] only with language inputs to generate instruction-following data for vision-language tuning. Otter [23] also constructs an instruction-tuning dataset to improve the ability of instruction-following for OpenFlamingo. MiniGPT-4 [46] believes the ability of GPT4 [31] comes from advanced LLMs and proposes to adopt only one project layer to align the visual representation with the language model. Although it is trained in high computational efficiency, it demonstrates some capabilities similar to GPT4 [31]. mPLUG-Owl [40] proposes another learning paradigm by first tuning the visual encoder to summarize and align visual features and then tuning the language model with LoRA [18]. In this paper, after thoroughly evaluating them on the proposed MMBench and other public datasets, we provide some insights for future multi-modal research.
3 MMBench
There exist two unique characteristics that differentiate MMBench with existing benchmarks for multi-modality understanding: i) MMBench adopts problems from various sources to evaluate diversified abilities in a hierarchical taxonomy; ii) MMBench applies a robust, LLM-based evaluation strategy, which can well handle the free-form outputs of multi-modality models and yield trustworthy evaluation results with affordable cost. This section we will focus on the first characteristic of MMBench , and we organize the subsequent content as follows: In Sec. 3.1, we present the hierarchical ability taxonomy of MMBench and discuss the design philosophy behind. In Sec. 3.2, we briefly introduce how we collect the MMBench questions, and provide some statistics of MMBench .
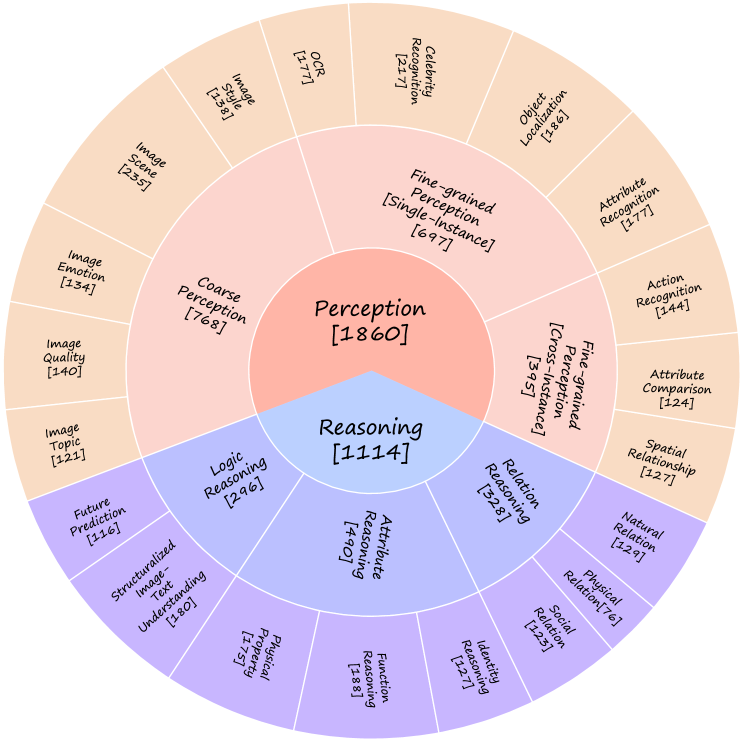
3.1 The Hierachical Ability Taxonomy of MMBench
Humans possess remarkable perception and reasoning capabilities, allowing them to understand and interact with the world. These abilities have been crucial in human evolution and serve as a foundation for complex cognitive processes. Perception refers to gathering information from sensory inputs, while reasoning involves drawing conclusions based on this information. Together, they form the basis of most tasks in the real world, including recognizing objects, solving problems, and making decisions [30, 11]. In pursuit of genuine general artificial intelligence, vision-language models are also expected to exhibit strong perception and reasoning abilities. Therefore, we incorporate Perception and Reasoning as our top-level ability dimensions in our ability taxonomy, referred to as L-1 ability dimension. For L-2 abilities, we derive: 1. Coarse Perception, 2. Fine-grained Single-instance Perception, 3. Fine-grained Cross-instance Perception from L-1 Perception; and 1. Attribute Reasoning, 2. Relation Reasoning, 3. Logic Reasoning from L-1 Reasoning. To make our benchmark as fine-grained as possible to produce informative feedbacks for developing multi-modality models. We further derive L-3 ability dimensions from L-2 ones.
Figure 2 provides an overview of the existing multimodal abilities to be evaluated in MMBench . Currently, this benchmark contains 20 distinct leaf abilities (with no derivated ability dimension), offering a comprehensive assessment of various fine-grained perception and reasoning capabilities. Table 14 gives the individual definitions of these leaf abilities, while Appendix D illustrates each of these abilities through specific examples. Note that the displayed taxonomy is not the final version. We will further extend the ability taxonomy to make it more comprehensive.
3.2 Data Collection and Statistics
In the current version of MMBench , we collect vision-language QAs in the format of multiple choice problems for each L-3 ability. A multiple choice problem corresponds to a quadruple . denotes the question, represents a set with () choices , corresponds to the image associated to the question, and is the correct answer. In the appendix, we visualize data samples corresponding to each L-3 ability. Our data—which include images, choices, and questions—are collected from multiple sources. A comprehensive breakdown of these sources is provided in Table 1. In the initial or “cold-start" phase of our data collection process, we assemble a suite of 10 to 50 multiple-choice problems for each L-3 ability. These problems serve as exemplars, illustrating the specific types of problems related to the evaluation of each respective ability. Subsequently, the annotators leverage these exemplars to expand the collection of multiple-choice problems pertaining to each L-3 ability. By referring to these exemplars, the annotators ensure the collected problems remain relevant and appropriate for assessing the targeted abilities. It is noteworthy that some data samples originate from public datasets such as COCO-Caption [6], which has been used by several public vision-language models in pre-training. Regardless, evaluation on MMBench can still be considered as out-domain evaluation [8] for two primary reasons: Firstly, our data is gathered from the validation sets of these public datasets, not their training sets. Secondly, data samples procured from these public datasets constitute less than 10% of all MMBench data samples.
Data Statistics. In the present study, we have gathered a total of 2,974 data samples spanning across 20 distinct L-3 abilities. We depict the problem counts of all 3 levels of abilities in Figure 2. To ensure a balanced and comprehensive evaluation for each ability, we try to maintain an even distribution among problems associated with different abilities during data collection.
Data Splits. We follow the standard practice employed in previous works [29] to split MMBench into dev and test subsets at a ratio of 4:6. For the dev subset, we make all data samples publicly available along with the ground truth answers for all questions. For the test subset, only the data samples are released, while the ground truth answers remain confidential. To obtain the evaluation results on the test subset, one needs to submit the predictions to MMBench evaluation server.
| Image Source | Question Source | Choice and Answer Source |
| W3C School [1] | customize | matched code;unmatched code |
| Places [44] | customize | image-paired scene category;unpaired scene category |
| TextVQA [36] | TextVQA | ground-truth answer;unpaired answer |
| ARAS [10] | customize | image-paired action category;unpaired action category |
| CLEVR [21] | CLEVR | ground-truth answer;unpaired answer |
| PISC [25] | customize | image-paired social relation;unpaired social relation |
| KonIQ-10k [17] | customize | image-paired description;unpaired description |
| VSR [26] | customize | image-paired description;unpaired description |
| LLaVA [27] | ChatGPT generated | ChatGPT generated |
| COCO-Caption [6] | customize | image-paired description;unpaired description |
| ScienceQA [28] | ScienceQA | ground-truth answer;unpaired answer |
| Internet | customize | customize; customize |
4 Evaluation Strategy
In MMBench we propose a new evaluation strategy that yields robust evaluation results with an affordable cost. At a strategic level, we adopt the Circular Evaluation strategy, which feeds a question to a VLM multiple times (with different prompts) and checks if the VLM succeeds in solving the question in all attempts. To deal with the free-form VLMs’ outputs, we propose to utilize ChatGPT as a helper for choice extraction. We conduct extensive experiments to study the ChatGPT-involved evaluation procedure. The results well support the effectiveness of ChatGPT as a choice extractor. Without specifications, we use gpt-3.5-turbo-0613 as the choice extractor in all of the following experiments.

4.1 The Circular Evaluation Strategy
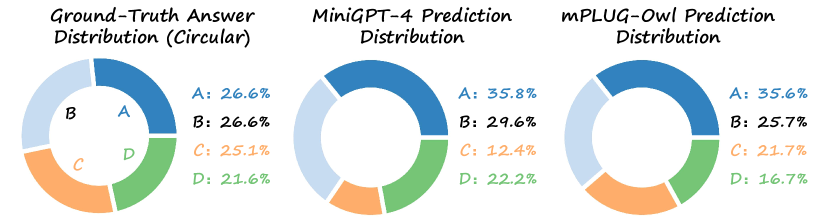
MMBench incorporates a diverse range of problems aimed at assessing the multifaceted capabilities of vision-language models (VLMs). These problems are presented as single-choice questions. The formulation poses an evaluation challenge: random guessing can lead to 25% Top-1 accuracy for 4-choice questions, potentially reducing the discernible performance differences between various VLMs. Besides, we noticed that VLMs may perfer to predict a certain choice among all given choices (Figure 4), which further amplify the bias in evaluation. To this end, we introduce a more robust evaluation strategy termed Circular Evaluation (or CircularEval). Under this setting, each question is fed to a VLM times ( equals to the choice number). Each time circular shifting is applied to the choices and the answer to generate a new prompt for VLMs (an example in Figure 3). A VLM is considered successful in solving a question only if it correctly predicts the answer in all rotational passes. Note that CircularEval doesn’t necessarily requires inference cost. By definition, if the VLM made a wrong prediction in one pass, we can directly drop the following passes and say the VLM failed this question. CircularEval achieves a good trade-off between the robustness and the evaluation cost.
4.2 ChatGPT-involved Choice Extraction
In our initial attempts to solve the MMBench questions, we observed that the instruction-following capabilities of various VLMs is limited. Though problems are presented as clear single-choice questions with well-formated options, many VLMs still output the answers in free-form text (e.g., model’s direct output can be The correct answer is [choice "A" content], but not A). Extracting choices from free-form predictions is easy for human beings, but difficult with rule-based matching. Thus we design a universal evaluation strategy for all VLMs with different instruction-following capabilities:
Step 1. Matching Prediction. Extract choices from VLM predictions with exact matching. As an example, for ‘C’, we try to match "C", "C.", "C)", "C,", "C).", etc. with all words in the VLM’s output. Once matched, we successfully extracted the model’s choice111‘A’ may serve has an article in a sentence. Thus we skip this candidate during matching a sentence. .
Step 2. Matching ChatGPT’s output. If Step 1 fails, we then try to extract the choice with ChatGPT. We provide GPT with the question, options, and model prediciton, and then, we request ChatGPT to align the prediction with one of the given options, and subsequently produce the label of the corresponding option.
Step 3. Fallback: Random Assignment. If step 2 can still not extract the choice, we label the prediction with a random choice among all valid choices and ‘X’. Additionally, a comment message will be added to denote that ChatGPT failed to parse the model prediction. This step is never encountered is our preliminary feasibility analysis (Sec. 4.3), but we still add it for pipeline integrity.
ChatGPT-based choice extraction. To utilize ChatGPT as the choice extractor, we query it with the following template including the question, options and the corresponding VLM’s prediction:
We then get the prediction’s option (e.g. A) from GPT’s response. For most questions, GPT-3.5 is capable of returning a single character (e.g., A, B, C) as the answer. For each input, we compare the model’s label prediction (after GPT’s similarity readout) with the actual ground truth label. If the prediction matches the label, the test sample is considered correct.
4.3 ChatGPT as the Judge: A Feasibility Analysis
| Model Name | Step-1 | Step-2 |
| LLaMA-Adapter [13] | 1.0% | 100.0% |
| OpenFlamingo [3] | 98.6% | 100.0% |
| VisualGLM [9] | 14.9% | 100.0% |
| MiniGPT-4 [46] | 71.6% | 100.0% |
| LLaVA [27] | 9.9% | 100.0% |
| Otter-I [23] | 100.0% | 100.0% |
| InstructBLIP [8] | 91.2% | 100.0% |
| mPLUG-Owl [40] | 42.6% | 100.0% |
We first conduct pilot experiments to study the effectiveness of ChatGPT as the judge. To keep the setting simple, for MMBench , we sample a subset with 1000 samples and use the vanilla single-pass evaluation strategy to evaluate 8 selected VLMs. We also include traditional VQA benchmarks in the study.
Instruction following capabilities of different VLMs vary a lot. ChatGPT-involved choice extraction plays a vital role in MMBench evaluation, especially for VLMs with poor instruction following capabilities. In Table 2, we demonstrate the success rate of step 1 and step 2 of our evaluation strategy. Step 1 success rate (matching choices with VLM predictions) is directly related to the VLM’s instruction-following capability. Table 2 shows that the step-1 success rates of different VLMs vary a lot, covering a wide range from 1.0% to 100.0%.
However, with ChatGPT choice extractor equipped, the step-2 success rates of all VLMs reach nearly 100%, which enables a fair comparison of different VLMs on MMBench . Another point worth noting is, the instruction following capability and the overall multi-modality modeling capability is not necessarily correlated. OpenFlamingo [3] demonstrates the best instruction following capability among all VLMs, while also achieving one of the worst performance on MMBench (Table 5).
Human v.s ChatGPT: alignment in choice extraction.
For VLM predictions that cannot be parsed with exact matching, we adopt ChatGPT as the choice extractor. To validate its efficacy, we sample a subset of MMBench , which contains 103 questions and 824 () question-answer pairs. We keep only the QA pairs that can not be parsed by the evaluation step 1, which yield 376 data samples. With the help of 6 volunteers, we perform manual choice extraction to these data samples222The human annotations will be released. .
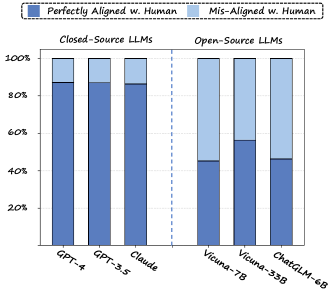
In Figure 5, we report the alignment rate (extracted choices are exactly the same) between ChatGPT and Human. Specifically, ChatGPT (GPT-3.5) achieves 87.0% alignment rate, while the more powerful GPT-4 achieves a slightly better 87.2%. We further conduct an ablation study to learn the effect of using various LLMs as the choice extractor. GPT-4 and ChatGPT take the lead among all LLMs. Claude achieves a very close alignment rate (86.4%) compared to ChatGPT. Existing open-source LLMs adapted from LLaMA [13] and GLM [9] achieves poor performance on the choice matching task. Further scaling the architecture (e.g. from Vicuna-7B to Vicuna-33B) only leads to limited improvements. We adopt ChatGPT as the choice extractor in our evaluation for a good performance-cost trade-off.
Mis-aligned cases analysis. Due to the newly introduced pseudo choice ‘X’, sometimes humans and LLMs can make different decisions when doing choice extraction due to different matching thresholds. For example, agent may match the prediction with a given choice since is the most similar choice to ; while agent can output choice since he / she thinks is not similar enough to any choice. Based on that observation, we divide the 50 ChatGPT mis-aligned cases into two categories:

Case I. Human or ChatGPT fails to match the prediction with given choices and outputs an ‘X’. 70% misaligned samples belong to that case.
Case II. Human and ChatGPT successfully match the prediction with given choices, but the matching results are different. 30% misaligned samples belong to that case.
In the two cases, I means the judgement of human and ChatGPT are less aligned (may due to different evaluation standards), while II means the judgement of human and ChatGPT is completely different. We manually investigate 15 samples in Case-II, and find that: 1. In 7 samples, ChatGPT did the right match while human did the wrong one; 2. In 6 samples, the model’s prediction is ambiguous and related to multiple choices; 3. In 2 samples, human did the right match while ChatGPT did the wrong one. The results support that ChatGPT can have strong capability in choice matching, even when compared with human annotators. We visualize Case-II samples in Figure 6.
ChatGPT-based evaluation for existing multi-modal tasks. To demonstrate ChatGPT is a general evaluator, we also validate our ChatGPT-based evaluation paradigm on existing multi-modality tasks, including GQA [20], OK-VQA [29], and Text-VQA [36]. Given the ground-truth answer, we use GPT3.5 to score the VLM’s prediction333The score will be an integer in [1, 2, 3, 4, 5]. 1 means completely wrong, while 5 means completely correct. We provide the prompt used for marking in Appendix. . For each benchmark, we randomly select 1000 testing samples and evaluate with exact match (the traditional paradigm) and GPT-based match, respectively, and list the results in Table 3. Basically, GPT-based evaluation demonstrates the same trend compared to the exact-match accuracy on all tasks. On GQA, two algorithms demonstrate very close performance under GPT-based evaluation. In further investigation, we find the reason is that GPT succeed in matching slightly different answers (compared to GT) generated by MiniGPT-4, while exact matching fails (examples in Table 7).
| Dataset | GQA [20] | OK-VQA [29] | Text-VQA [36] | |||
| Model | Flamingo | MiniGPT-4 | Flamingo | MiniGPT-4 | Flamingo | MiniGPT-4 |
| Accuracy | 33.6% | 22.4% | 42.6% | 21.9% | 22.9% | 9.8% |
| Average GPT score | 2.75 | 2.74 | 2.79 | 1.97 | 1.92 | 1.54 |
5 Evaluation Results
5.1 VLM Inference Setting
Currently, we adopt the traditional zero-shot setting for VLM inference, primarily due to the limited compatibility of existing VLMs with few-shot evaluation settings. However, we have noticed the great potential of few-shot evaluation protocols in LLMs [19]. In future work, we specifically plan to construct a subset of data samples designated for few-shot evaluation. We anticipate that few-shot evaluation will evolve into a standard assessment strategy, akin to the approach employed in LLMs.
5.2 Main Results
We select 14 different multi-modality models and benchmark them on MMBench . The models we have selected cover a broad spectrum of strategies and architectures, effectively illustrating the current state-of-the-art in multimodal understanding. To facilitate a fair comparison, we mainly examine the "light" versions of all multimodal models — those with a total amount of parameters below 10B — when multiple variants exist. For further reference, we also evaluate larger variants (e.g. 13B) of some selected models, and report their performance. Please refer to Table 15 for detailed information regarding the architecture and the total parameters of these models.
| Eval \VLM | OpenFlamingo | LLaMA-Adapter | MiniGPT-4 | MMGPT | InstructBLIP | VisualGLM | LLaVA | mPLUG-Owl |
| VanillaEval | 34.6% | 62.6% | 50.3% | 49.1% | 61.3% | 60.4% | 56.1% | 67.3% |
| CircularEval | 4.6% | 41.2% | 24.3% | 15.3% | 36.0% | 38.1% | 38.7% | 49.4% |
| -30.0% | -21.4% | -26.0% | -33.8% | -25.3% | -22.3% | -17.4% | -17.9% | |
| Eval \VLM | OpenFlamingo v2 | -G2PT | MiniGPT-4-13B | Otter-I | InstructBLIP-13B | PandaGPT | Kosmos-2* | Shikra |
| VanillaEval | 40.0% | 61.3% | 61.3% | 68.8% | 64.4% | 55.2% | 58.2% | 69.9% |
| CircularEval | 6.6% | 43.2% | 42.3% | 51.4% | 44.0% | 33.5% | 58.2% | 58.8% |
| -33.4% | -18.1% | -19.0% | -17.4% | -20.4% | -21.7% | 0.0%* | -11.1% |
Before delving deeper into concrete evaluation results, we first compare our CircularEval (infer a question multiple passes, consistency as a must) with VanillaEval (infer a question only once). In Table 4, we present the results with two evaluation strategies on MMBench dev split. For most VLMs, switching from VanillaEval to CircularEval leads to a significant drop in model accuracy. Besides, different conclusions can be drawn from two evaluation results. An an example, InstructBLIP outperforms LLaVA in VanillaEval, but with CircularEval we have the opposite conclusion. In following experiments, We adopt CircularEval as our default evaluation strategy, which is a more reasonable and well-defined evaluation paradigm.
| VLM | Overall | LR | AR | RR | FP-S | FP-C | CP |
| OpenFlamingo [3] | 4.6% | 6.7% | 8.0% | 0.0% | 6.7% | 2.8% | 2.0% |
| OpenFlamingo v2 [3] | 6.6% | 4.2% | 15.4% | 0.9% | 8.1% | 1.4% | 5.0% |
| MMGPT [14] | 15.3% | 2.5% | 26.4% | 13.0% | 14.1% | 3.4% | 20.8% |
| MiniGPT-4 [46] | 24.3% | 7.5% | 31.3% | 4.3% | 30.3% | 9.0% | 35.6% |
| InstructBLIP [8] | 36.0% | 14.2% | 46.3% | 22.6% | 37.0% | 21.4% | 49.0% |
| VisualGLM [9] | 38.1% | 10.8% | 44.3% | 35.7% | 43.8% | 23.4% | 47.3% |
| LLaVA [27] | 38.7% | 16.7% | 48.3% | 30.4% | 45.5% | 32.4% | 40.6% |
| LLaMA-Adapter [42] | 41.2% | 11.7% | 35.3% | 29.6% | 47.5% | 38.6% | 56.4% |
| -G2PT | 43.2% | 13.3% | 38.8% | 40.9% | 46.5% | 38.6% | 58.1% |
| mPLUG-Owl [40] | 49.4% | 16.7% | 53.2% | 47.8% | 50.2% | 40.7% | 64.1% |
| Otter-I [23, 22] | 51.4% | 32.5% | 56.7% | 53.9% | 46.8% | 38.6% | 65.4% |
| Shikra [5] | 58.8% | 25.8% | 56.7% | 58.3% | 57.2% | 57.9% | 75.8% |
| Kosmos-2∗ [33] | 59.2% | 46.7% | 55.7% | 43.5% | 64.3% | 49.0% | 72.5% |
| PandaGPT [37] | 33.5% | 10.0% | 38.8% | 23.5% | 27.9% | 35.2% | 48.3% |
| MiniGPT-4-13B [46] | 42.3% | 20.8% | 50.7% | 30.4% | 49.5% | 26.2% | 50.7% |
| InstructBLIP-13B [8] | 44.0% | 19.1% | 54.2% | 34.8% | 47.8% | 24.8% | 56.4% |
| VLM | Overall | LR | AR | RR | FP-S | FP-C | CP |
| OpenFlamingo [3] | 4.3% | 9.1% | 11.4% | 3.3% | 2.5% | 1.6% | 1.5% |
| OpenFlamingo v2 [3] | 5.7% | 11.4% | 12.8% | 1.4% | 5.5% | 0.8% | 4.0% |
| MMGPT [14] | 16.0% | 1.1% | 23.9% | 20.7% | 18.3% | 5.2% | 18.2% |
| MiniGPT-4 [46] | 23.0% | 13.6% | 32.9% | 8.9% | 28.7% | 11.2% | 28.3% |
| VisualGLM [9] | 33.5% | 11.4% | 48.8% | 27.7% | 35.8% | 17.6% | 41.5% |
| InstructBLIP [8] | 33.9% | 21.6% | 47.4% | 22.5% | 33.0% | 24.4% | 41.1% |
| LLaVA [27] | 36.2% | 15.9% | 53.6% | 28.6% | 41.8% | 20.0% | 40.4% |
| LLaMA-Adapter [42] | 39.5% | 13.1% | 47.4% | 23.0% | 45.0% | 33.2% | 50.6% |
| -G2PT | 39.8% | 14.8% | 46.7% | 31.5% | 41.8% | 34.4% | 49.8% |
| mPLUG-Owl [40] | 46.6% | 19.9% | 56.1% | 39.0% | 53.0% | 26.8% | 59.4% |
| Otter-I [23, 22] | 48.3% | 22.2% | 63.3% | 39.4% | 46.8% | 36.4% | 60.6% |
| Kosmos-2∗ [33] | 58.2% | 48.6% | 59.9% | 34.7% | 65.6% | 47.9% | 70.4% |
| Shikra [5] | 60.2% | 33.5% | 69.6% | 53.1% | 61.8% | 50.4% | 71.7% |
| PandaGPT [37] | 30.6% | 15.3% | 41.5% | 22.0% | 20.3% | 20.4% | 47.9% |
| MiniGPT-4-13B [46] | 42.3% | 17.0% | 62.6% | 30.0% | 49.8% | 19.6% | 50.6% |
| InstructBLIP-13B [8] | 43.1% | 17.0% | 59.5% | 36.2% | 45.8% | 24.0% | 53.8% |
We exhaustively evaluate the eight models on the existing 20 leaf abilities of MMBench . In Table 5 and Table 6, we report the models’ overall performance and the performance in six L-2 abilities, namely Logical Reasoning (LR), Attribute Reasoning (AR), Relation Reasoning (RR), Fine-grained Perception (Cross Instance) (FP-C), Fine-grained Perception (Single Instance) (FP-S), and Coarse Perception (CP). These results offer valuable insights into the individual strengths and limitations of each model in different aspects of multi-modality understanding.
As demonstrated in Table 6 and Table 5, Shikra and Kosmos-2 yield superior results, significantly outperforming other models in nearly all L-2 abilities. Second to the two models, mPLUG-Owl, Otter-I, and LLaMA-Adapter444According to the authors who submitted the evaluation results, the evaluated model is LLaMA-Adapter trained with LAION400M [35] for visual-language pre-training and LLaVA–I [27] for instruction tuning. also exhibit noteworthy performances, and are comparable to each other. After that, four models (Otter-I, InstructBLIP, VisualGLM, LLaVA) are roughly at the same level of overall performance, but with strengths in different L2 abilities. Among all 14 models, OpenFlamingo, MMGPT, and MiniGPT-4 (7B) demonstrate lower overall performance compared to the other models. Furthermore, it is apparent that model scaling enhances performance metrics. This is evident as MiniGPT-4-13B outperforms MiniGPT-4 by an impressive 19.3%, and InstructBLIP-13B outperforms its predecessor, InstructBLIP, by a notable 9.2%.
The assessment on MMBench reveals that each multi-modality model exhibits unique strengths and weaknesses across different levels of abilities. This observation highlights the importance of carefully selecting and fine-tuning multi-modality models based on the specific requirements and objectives of a given task. Moreover, the identified limitations in some abilities suggest potential directions for further research and development in multi-modality AI systems.
For a more in-depth understanding, we provide a comprehensive analysis of the L3 abilities in Table 8, allowing readers to examine the very details of MMBench and gain deeper insights into the performance disparities among the evaluated models.
5.3 Analysis
With the comprehensive evaluation, we observe some interesting facts, which is expected to provide insights for future optimization.
Existing VLMs have limited instruction-following capabilities. For the sake of efficient evaluation, we guide each model to output only the label for each option, for instance, A, B, C, or D. However, we observe that these models often generate a full sentence corresponding to one option or a sentence semantically akin to one of the options. This tendency is the primary reason for employing ChatGPT for choice extraction. To improve the usability of multi-modality models to empower diversified applications, pursuing stronger instruction-following ability can be a significant direction.
The overall performance of existing VLMs is still limited. The strict CircularEval strategy reveals that the overall performance of existing VLMs is not satisfying. In experiments, all VLMs, except Kosmos-2 and Shikra, failed to reach 50% Top-1 accuracy on MMBench test for multiple choice questions with at most 4 choices. Potential reasons are two fold: 1. Current VLMs are not robust enough to produce the same prediction with slightly different prompts (performance under CircularEval is much worse than the performance under VanillaEval, see Table 4). 2. The capabilities of current VLMs are still quite limited and can be further improved. We hope that MMBench and our evaluation strategy can serve as important resource for the development, iteration and optimization of VLMs in the future.
Cross-Instance Understanding and Logic Reasoning are extremely difficult. An examination of our evaluation results reveals that cross-instance understanding—specifically relation reasoning (RR) and cross-instance fine-grained perception (FP-C)—poses a significant challenge for existing Visual Language Models (VLMs). The average accuracy for cross-instance fine-grained perception across all models is 27.7% and 23.4% on the dev and test splits respectively, significantly lower than that of single-instance fine-grained perception (FP-S). A similar disparity can be observed between relation reasoning (RR) and attribute reasoning (AR) as evidenced in Tables 6 and 5. Furthermore, when compared to other L-2 abilities, the logical reasoning (LR) capability of existing models appears strikingly weak, with an average accuracy of only 17.8%. The results indicate that improving the cross-instance understanding and logic reasoning capabilities of VLMs can be a significant and promising direction.
The introduction of object localization data is anticipated to enhance model performance. Among various models, Kosmos-2 and Shikra notably excel, offering significant improvements across almost all L-2 capabilities, particularly in logical reasoning and cross-instance fine-grained perception. Compared to other models, both Kosmos-2 and Shikra incorporate object localization within their training datasets. The integration of localization data infuses more detailed object-specific information into the models, allowing them to comprehend the dynamic states of objects more effectively. Moreover, it aids in elucidating relationships and interactions between distinct objects. This strategy contributes substantively to the enhancement of the models’ capabilities in logical reasoning and cross-instance fine-grained perception.
6 Conclusion
The inherent limitations of traditional benchmarks (VQAv2, COCO Caption, etc.) and subjective benchmarks (mPLUG-Owl, etc.), underscore the need for an innovative evaluation paradigm in vision-language understanding. To address this, we introduce MMBench , a multi-modality benchmark that proposes an objective evaluation pipeline of 2,974 multiple-choice questions covering 20 ability dimensions. To produce robust and reliable evaluation results, we introduce a new evaluation strategy named CircularEval. The strategy is much stricter than the vanilla 1-pass evaluation and can yield reliable evaluation results with an affordable cost. Additionally, we leverage ChatGPT to compare model predictions with target choices, which enables a fair comparison among VLMs with different levels of instruction-following capabilities. Compreshensive studies on both MMBench and public benchmark indicate the feasiblility of using ChatGPT as the judge. We hope MMBench can aid the research community in optimizing their models and inspire future progress.
7 Acknowledgement
We would like to express our great gratitude to community contributors for their contributions. Li Dong and Zhiliang Peng from Microsoft Research Asia have provided the inference results of Kosmos-2 on MMBench . Furthermore, we are thankful to Peng Gao and Peng Xu from Shanghai AI Laboratory, for supplying the inference results of -G2PT and LLaMA-Adapter. We are also grateful to Zhao Zhang and Keqin Chen from SenseTime for their provision of the inference results of Shikra. Moreover, our gratitude goes to Jiaye Ge, also at the Shanghai AI Laboratory, for orchestrating the data collection process and ensuring the timely delivery of the dataset. Yixiao Fang also merits our appreciation for his assistance in inferring MMGPT on MMBench. Lastly, we are indebted to Jun Xu and Xiaoqin Du from Shanghai AI Laboratory, whose support was instrumental in the construction of the MMBench webpage and leaderboard.
Appendix A GPT-based VQA evaluation
Prompt used for GPT-based GQA [20] evaluation:
Prompt used for GPT-based OK-VQA [29] and Text-VQA [36] evaluation:
Many MiniGPT-4 GQA answers can not be matched with exact matching, but can be matched with GPT-based evaluation. Here we provide some examples:
| Question | GroundTruth | MiniGPT-4 Answer | GPT Score |
| On which side of the picture is the leather bag? | right | leather bag is on right side | 5 |
| Who is wearing a shirt? | girl | woman is wearing shirt | 5 |
| What is the pen made of? | plastic | pen is made of plastic## | 5 |
| What does the male person ride on? | bike | bicycle | 4 |
| Is the microwave silver and rectangular? | Yes | microwave is silver and rectangular | 5 |
| How does the silver lamp appear to be, on or off? | off | silver lamp appears to be off ## | 5 |
Appendix B Evaluation Results at L-3 Granularity
In Tables 8, 9, 10, 11, 12 and 13, we present the performance of VLMs on all 20 L-3 abilities. We noticed that the rankings on the L-3 abilities are more diversified. Besides the leading VLMs Shikra and Kosmos-2, other VLMs, including mPKUG-Owl, InstructBLIP-13B, MiniGPT-4-13B, Otter-I, also achieve the first place in one / more sub-tasks on the dev / test split of OmniMMBench.
| Split | VLM | CP |
|
|
|
|
|
||||||||||
| DEV | OpenFlamingo | 2.0% | 0.0% | 1.9% | 0.0% | 1.9% | 8.3% | ||||||||||
| OpenFlamingo v2 | 5.0% | 3.8% | 3.8% | 4.0% | 3.7% | 13.9% | |||||||||||
| MMGPT | 20.8% | 3.8% | 21.0% | 56.0% | 13.0% | 8.3% | |||||||||||
| MiniGPT-4 | 35.6% | 15.1% | 53.3% | 32.0% | 20.4% | 41.7% | |||||||||||
| LLaVA | 40.6% | 30.2% | 43.8% | 70.0% | 22.2% | 33.3% | |||||||||||
| VisualGLM | 47.3% | 37.7% | 73.3% | 50.0% | 0.0% | 52.8% | |||||||||||
| PandaGPT | 48.3% | 30.2% | 69.5% | 62.0% | 1.9% | 63.9% | |||||||||||
| InstructBLIP | 49.0% | 49.1% | 65.7% | 50.0% | 5.6% | 63.9% | |||||||||||
| MiniGPT-4-13B | 50.7% | 64.2% | 61.9% | 56.0% | 3.7% | 61.1% | |||||||||||
| InstructBLIP-13B | 56.4% | 73.6% | 73.3% | 58.0% | 11.1% | 47.2% | |||||||||||
| LLaMA-Adapter | 56.4% | 45.3% | 75.2% | 76.0% | 3.7% | 69.4% | |||||||||||
| -G2PT | 58.1% | 47.2% | 80.0% | 60.0% | 20.4% | 63.9% | |||||||||||
| mPLUG-Owl | 64.1% | 73.6% | 72.4% | 84.0% | 16.7% | 69.4% | |||||||||||
| Otter-I | 65.4% | 64.2% | 84.8% | 70.0% | 16.7% | 77.8% | |||||||||||
| Kosmos-2 | 72.5% | 69.8% | 82.9% | 82.0% | 40.7% | 80.6% | |||||||||||
| Shikra | 75.8% | 62.3% | 96.2% | 86.0% | 37.0% | 80.6% | |||||||||||
| TEST | OpenFlamingo | 1.5% | 0.0% | 4.6% | 0.0% | 1.2% | 0.0% | ||||||||||
| OpenFlamingo v2 | 4.0% | 1.2% | 5.4% | 3.6% | 2.3% | 7.1% | |||||||||||
| MMGPT | 18.3% | 3.5% | 30.0% | 35.7% | 7.0% | 9.4% | |||||||||||
| MiniGPT-4 | 28.3% | 9.4% | 46.2% | 19.0% | 7.0% | 50.6% | |||||||||||
| LLaVA | 40.4% | 37.6% | 52.3% | 47.6% | 29.1% | 29.4% | |||||||||||
| InstructBLIP | 41.1% | 34.1% | 61.5% | 35.7% | 0.0% | 63.5% | |||||||||||
| VisualGLM | 41.5% | 30.6% | 68.5% | 41.7% | 0.0% | 52.9% | |||||||||||
| PandaGPT | 47.9% | 38.8% | 66.2% | 38.1% | 17.4% | 69.4% | |||||||||||
| -G2PT | 49.8% | 41.2% | 75.4% | 38.1% | 20.9% | 60.0% | |||||||||||
| LLaMA-Adapter | 50.6% | 31.8% | 70.0% | 44.0% | 25.6% | 71.8% | |||||||||||
| MiniGPT-4-13B | 50.6% | 62.4% | 75.4% | 38.1% | 4.7% | 60.0% | |||||||||||
| InstructBLIP-13B | 53.8% | 61.2% | 71.5% | 41.7% | 5.8% | 80.0% | |||||||||||
| mPLUG-Owl | 59.4% | 71.8% | 75.4% | 54.8% | 17.4% | 69.4% | |||||||||||
| Otter-I | 60.6% | 62.4% | 83.1% | 46.4% | 4.7% | 95.3% | |||||||||||
| Kosmos-2 | 70.4% | 70.6% | 76.9% | 61.9% | 44.2% | 95.3% | |||||||||||
| Shikra | 71.7% | 72.9% | 90.8% | 59.5% | 30.2% | 95.3% |
| Split | VLM | FP-S |
|
|
|
OCR | ||||||
| DEV | OpenFlamingo | 6.7% | 2.5% | 10.4% | 4.0% | 15.0% | ||||||
| OpenFlamingo v2 | 8.1% | 1.2% | 14.3% | 10.1% | 5.0% | |||||||
| MMGPT | 14.1% | 1.2% | 10.4% | 27.3% | 15.0% | |||||||
| PandaGPT | 27.9% | 14.8% | 50.6% | 23.2% | 22.5% | |||||||
| MiniGPT-4 | 30.3% | 7.4% | 50.6% | 35.4% | 25.0% | |||||||
| InstructBLIP | 37.0% | 6.2% | 51.9% | 47.5% | 45.0% | |||||||
| VisualGLM | 43.8% | 19.8% | 41.6% | 67.7% | 37.5% | |||||||
| LLaVA | 45.5% | 8.6% | 64.9% | 59.6% | 47.5% | |||||||
| -G2PT | 46.5% | 11.1% | 71.4% | 63.6% | 27.5% | |||||||
| Otter-I | 46.8% | 16.0% | 61.0% | 58.6% | 52.5% | |||||||
| LLaMA-Adapter | 47.5% | 17.3% | 68.8% | 59.6% | 37.5% | |||||||
| InstructBLIP-13B | 47.8% | 14.8% | 55.8% | 69.7% | 45.0% | |||||||
| MiniGPT-4-13B | 49.5% | 28.4% | 54.5% | 68.7% | 35.0% | |||||||
| mPLUG-Owl | 50.2% | 18.5% | 63.6% | 70.7% | 37.5% | |||||||
| Shikra | 57.2% | 32.1% | 75.3% | 63.6% | 57.5% | |||||||
| Kosmos-2 | 64.3% | 38.3% | 71.4% | 80.8% | 62.5% | |||||||
| TEST | OpenFlamingo | 2.5% | 2.9% | 3.0% | 1.7% | 2.6% | ||||||
| OpenFlamingo v2 | 5.5% | 2.9% | 7.0% | 8.5% | 2.6% | |||||||
| MMGPT | 18.2% | 3.8% | 23.0% | 28.0% | 16.9% | |||||||
| PandaGPT | 20.2% | 7.6% | 37.0% | 19.5% | 16.9% | |||||||
| MiniGPT-4 | 28.7% | 8.6% | 41.0% | 29.7% | 39.0% | |||||||
| InstructBLIP | 33.0% | 2.9% | 41.0% | 40.7% | 51.9% | |||||||
| VisualGLM | 35.8% | 8.6% | 40.0% | 52.5% | 41.6% | |||||||
| -G2PT | 41.8% | 17.1% | 56.0% | 59.3% | 29.9% | |||||||
| LLaVA | 41.8% | 13.3% | 47.0% | 50.8% | 59.7% | |||||||
| LLaMA-Adapter | 45.0% | 15.2% | 59.0% | 56.8% | 49.4% | |||||||
| InstructBLIP-13B | 45.8% | 5.7% | 45.0% | 65.3% | 71.4% | |||||||
| Otter-I | 46.8% | 11.4% | 54.0% | 57.6% | 68.8% | |||||||
| MiniGPT-4-13B | 49.8% | 21.0% | 64.0% | 55.9% | 61.0% | |||||||
| mPLUG-Owl | 53.0% | 16.2% | 63.0% | 78.0% | 51.9% | |||||||
| Shikra | 61.8% | 27.6% | 72.0% | 70.3% | 81.8% | |||||||
| Kosmos-2 | 65.6% | 40.4% | 59.0% | 79.7% | 86.8% |
| Split | VLM | FP-C |
|
|
|
||||||
| DEV | OpenFlamingo v2 | 1.4% | 2.2% | 2.3% | 0.0% | ||||||
| OpenFlamingo | 2.8% | 2.2% | 0.0% | 5.4% | |||||||
| MMGPT | 3.4% | 2.2% | 2.3% | 5.4% | |||||||
| MiniGPT-4 | 9.0% | 0.0% | 11.4% | 14.3% | |||||||
| InstructBLIP | 21.4% | 6.7% | 11.4% | 41.1% | |||||||
| VisualGLM | 23.4% | 0.0% | 31.8% | 35.7% | |||||||
| InstructBLIP-13B | 24.8% | 6.7% | 36.4% | 30.4% | |||||||
| MiniGPT-4-13B | 26.2% | 20.0% | 20.5% | 35.7% | |||||||
| LLaVA | 32.4% | 6.7% | 38.6% | 48.2% | |||||||
| PandaGPT | 35.2% | 11.1% | 25.0% | 62.5% | |||||||
| LLaMA-Adapter | 38.6% | 11.1% | 47.7% | 53.6% | |||||||
| Otter-I | 38.6% | 15.6% | 4.5% | 83.9% | |||||||
| -G2PT | 38.6% | 6.7% | 45.5% | 58.9% | |||||||
| mPLUG-Owl | 40.7% | 13.3% | 27.3% | 73.2% | |||||||
| Kosmos-2 | 49.0% | 31.1% | 56.8% | 57.1% | |||||||
| Shikra | 57.9% | 33.3% | 45.5% | 87.5% | |||||||
| TEST | OpenFlamingo v2 | 0.8% | 0.0% | 0.0% | 2.3% | ||||||
| OpenFlamingo | 1.6% | 1.2% | 3.8% | 0.0% | |||||||
| MMGPT | 5.2% | 3.7% | 3.8% | 8.0% | |||||||
| MiniGPT-4 | 11.2% | 9.8% | 6.2% | 17.0% | |||||||
| VisualGLM | 17.6% | 7.3% | 8.8% | 35.2% | |||||||
| MiniGPT-4-13B | 19.6% | 17.1% | 8.8% | 31.8% | |||||||
| LLaVA | 20.0% | 14.6% | 21.2% | 23.9% | |||||||
| PandaGPT | 20.4% | 12.2% | 15.0% | 33.0% | |||||||
| InstructBLIP-13B | 24.0% | 9.8% | 17.5% | 43.2% | |||||||
| InstructBLIP | 24.4% | 9.8% | 2.5% | 58.0% | |||||||
| mPLUG-Owl | 26.8% | 18.3% | 22.5% | 38.6% | |||||||
| LLaMA-Adapter | 33.2% | 19.5% | 27.5% | 51.1% | |||||||
| -G2PT | 34.4% | 19.5% | 33.8% | 48.9% | |||||||
| Otter-I | 36.4% | 12.2% | 3.8% | 88.6% | |||||||
| Kosmos-2 | 47.9% | 35.1% | 35.0% | 70.5% | |||||||
| Shikra | 50.4% | 26.8% | 27.5% | 93.2% |
| Split | VLM | AR |
|
|
|
||||||
| DEV | OpenFlamingo | 8.0% | 10.7% | 8.6% | 2.2% | ||||||
| OpenFlamingo v2 | 15.4% | 14.7% | 8.6% | 28.9% | |||||||
| MMGPT | 26.4% | 24.0% | 9.9% | 60.0% | |||||||
| MiniGPT-4 | 31.3% | 14.7% | 19.8% | 80.0% | |||||||
| LLaMA-Adapter | 35.3% | 16.0% | 32.1% | 73.3% | |||||||
| -G2PT | 38.8% | 20.0% | 38.3% | 71.1% | |||||||
| PandaGPT | 38.8% | 16.0% | 46.9% | 62.2% | |||||||
| VisualGLM | 44.3% | 18.7% | 50.6% | 75.6% | |||||||
| InstructBLIP | 46.3% | 17.3% | 51.9% | 84.4% | |||||||
| LLaVA | 48.3% | 25.3% | 53.1% | 77.8% | |||||||
| MiniGPT-4-13B | 50.7% | 30.7% | 49.4% | 86.7% | |||||||
| mPLUG-Owl | 53.2% | 18.7% | 66.7% | 86.7% | |||||||
| InstructBLIP-13B | 54.2% | 30.7% | 56.8% | 88.9% | |||||||
| Kosmos-2 | 55.7% | 33.3% | 56.8% | 91.1% | |||||||
| Otter-I | 56.7% | 29.3% | 61.7% | 93.3% | |||||||
| Shikra | 56.7% | 30.7% | 63.0% | 88.9% | |||||||
| TEST | OpenFlamingo | 11.4% | 14.0% | 9.3% | 11.0% | ||||||
| OpenFlamingo v2 | 12.8% | 9.0% | 7.5% | 24.4% | |||||||
| MMGPT | 23.9% | 13.0% | 12.1% | 52.4% | |||||||
| MiniGPT-4 | 32.9% | 13.0% | 29.9% | 61.0% | |||||||
| PandaGPT | 41.5% | 15.0% | 42.1% | 73.2% | |||||||
| -G2PT | 46.7% | 31.0% | 38.3% | 76.8% | |||||||
| LLaMA-Adapter | 47.4% | 25.0% | 44.9% | 78.0% | |||||||
| InstructBLIP | 47.4% | 17.0% | 52.3% | 78.0% | |||||||
| VisualGLM | 48.8% | 26.0% | 44.9% | 81.7% | |||||||
| LLaVA | 53.6% | 35.0% | 48.6% | 82.9% | |||||||
| mPLUG-Owl | 56.1% | 23.0% | 59.8% | 91.5% | |||||||
| InstructBLIP-13B | 59.5% | 24.0% | 67.3% | 92.7% | |||||||
| Kosmos-2 | 59.9% | 30.0% | 65.4% | 89.0% | |||||||
| MiniGPT-4-13B | 62.6% | 35.0% | 67.3% | 90.2% | |||||||
| Otter-I | 63.3% | 45.0% | 60.7% | 89.0% | |||||||
| Shikra | 69.6% | 50.0% | 70.1% | 92.7% |
| Split | VLM | LR |
|
|
|||
| DEV | MMGPT | 2.5% | 2.6% | 2.4% | |||
| OpenFlamingo v2 | 4.2% | 5.1% | 2.4% | ||||
| OpenFlamingo | 6.7% | 9.0% | 2.4% | ||||
| MiniGPT-4 | 7.5% | 5.1% | 11.9% | ||||
| PandaGPT | 10.0% | 10.3% | 9.5% | ||||
| VisualGLM | 10.8% | 12.8% | 7.1% | ||||
| LLaMA-Adapter | 11.7% | 7.7% | 19.0% | ||||
| -G2PT | 13.3% | 10.3% | 19.0% | ||||
| InstructBLIP | 14.2% | 14.1% | 14.3% | ||||
| mPLUG-Owl | 16.7% | 10.3% | 28.6% | ||||
| LLaVA | 16.7% | 17.9% | 14.3% | ||||
| InstructBLIP-13B | 19.2% | 19.2% | 19.0% | ||||
| MiniGPT-4-13B | 20.8% | 20.5% | 21.4% | ||||
| Shikra | 25.8% | 16.7% | 42.9% | ||||
| Otter-I | 32.5% | 20.5% | 54.8% | ||||
| Kosmos-2 | 46.7% | 43.6% | 52.4% | ||||
| TEST | MMGPT | 1.1% | 0.0% | 2.7% | |||
| OpenFlamingo | 9.1% | 1.0% | 20.3% | ||||
| VisualGLM | 11.4% | 3.9% | 21.6% | ||||
| OpenFlamingo v2 | 11.4% | 2.9% | 23.0% | ||||
| LLaMA-Adapter | 13.1% | 11.8% | 14.9% | ||||
| MiniGPT-4 | 13.6% | 3.9% | 27.0% | ||||
| -G2PT | 14.8% | 6.9% | 25.7% | ||||
| PandaGPT | 15.3% | 6.9% | 27.0% | ||||
| LLaVA | 15.9% | 13.7% | 18.9% | ||||
| InstructBLIP-13B | 17.0% | 5.9% | 32.4% | ||||
| MiniGPT-4-13B | 17.0% | 6.9% | 31.1% | ||||
| mPLUG-Owl | 19.9% | 5.9% | 39.2% | ||||
| InstructBLIP | 21.6% | 4.9% | 44.6% | ||||
| Otter-I | 22.2% | 4.9% | 45.9% | ||||
| Shikra | 33.5% | 14.7% | 59.5% | ||||
| Kosmos-2 | 48.6% | 35.6% | 66.2% |
| Split | VLM | RR |
|
|
|
|||
| DEV | OpenFlamingo | 0.0% | 0.0% | 0.0% | 0.0% | |||
| OpenFlamingo v2 | 0.9% | 0.0% | 0.0% | 2.1% | ||||
| MiniGPT-4 | 4.3% | 2.3% | 8.3% | 4.2% | ||||
| MMGPT | 13.0% | 14.0% | 0.0% | 18.8% | ||||
| InstructBLIP | 22.6% | 34.9% | 8.3% | 18.8% | ||||
| PandaGPT | 23.5% | 20.9% | 8.3% | 33.3% | ||||
| LLaMA-Adapter | 29.6% | 37.2% | 16.7% | 29.2% | ||||
| MiniGPT-4-13B | 30.4% | 53.5% | 8.3% | 20.8% | ||||
| LLaVA | 30.4% | 37.2% | 12.5% | 33.3% | ||||
| InstructBLIP-13B | 34.8% | 55.8% | 8.3% | 29.2% | ||||
| VisualGLM | 35.7% | 62.8% | 8.3% | 25.0% | ||||
| -G2PT | 40.9% | 60.5% | 16.7% | 35.4% | ||||
| Kosmos-2 | 43.5% | 76.7% | 29.2% | 20.8% | ||||
| mPLUG-Owl | 47.8% | 69.8% | 8.3% | 47.9% | ||||
| Otter-I | 53.9% | 76.7% | 20.8% | 50.0% | ||||
| Shikra | 58.3% | 93.0% | 20.8% | 45.8% | ||||
| TEST | OpenFlamingo v2 | 1.4% | 1.2% | 3.8% | 0.0% | |||
| OpenFlamingo | 3.3% | 0.0% | 11.5% | 1.2% | ||||
| MiniGPT-4 | 8.9% | 11.2% | 5.8% | 8.6% | ||||
| MMGPT | 20.7% | 27.5% | 3.8% | 24.7% | ||||
| PandaGPT | 22.1% | 27.5% | 9.6% | 24.7% | ||||
| InstructBLIP | 22.5% | 27.5% | 11.5% | 24.7% | ||||
| LLaMA-Adapter | 23.0% | 31.2% | 19.2% | 17.3% | ||||
| VisualGLM | 27.7% | 46.2% | 3.8% | 24.7% | ||||
| LLaVA | 28.6% | 37.5% | 21.2% | 24.7% | ||||
| MiniGPT-4-13B | 30.0% | 43.8% | 21.2% | 22.2% | ||||
| -G2PT | 31.5% | 57.5% | 15.4% | 16.0% | ||||
| Kosmos-2 | 34.7% | 57.5% | 36.5% | 11.1% | ||||
| InstructBLIP-13B | 36.2% | 47.5% | 25.0% | 32.1% | ||||
| mPLUG-Owl | 39.0% | 61.3% | 15.4% | 32.1% | ||||
| Otter-I | 39.4% | 55.0% | 9.6% | 43.2% | ||||
| Shikra | 53.1% | 83.8% | 19.2% | 44.4% |
Appendix C Google Bard vs. OpenSource VLMs: A Quantitative Comparison
In March 2023, Google launched Bard, a lightweight and optimized version of LaMDA based on Transformer. Similar to ChatGPT, Bard is a close-sourced model and provide service to users via web UI. In July 2023, Google announced the latest update of Bard, which is capable of processing image input. In order to provide an overview of Bard’s multi-modal ability, we evaluate it on the test split of MMBench as below and compare it with other state-of-the-art VLMs.
The test split of MMBench includes 1798 questions. During testing, we find that Bard refuses to process images containing human faces. For a fair comparison, we remove questions that Bard refuse to answer and discard questions that evaluate four human-related capabilities (Image Emotion, Identity Reasoning, Social Relation, and Action Recognition) in the test split. After filtering, we build a subset of 1226 samples and 16 leaf ability dimensions.
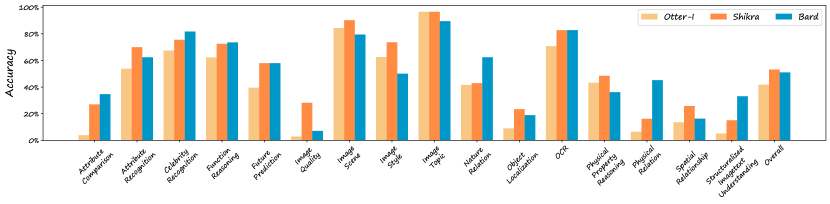
We compare Bard with two state-of-the-art VLMs that perform well on MMBench, namely Shikra and Otter-I. The result is shown in Figure 7. Bard attains an impressive overall accuracy of 51%, positioning itself among the top-tier VLMs proposed to date. Notably, Bard excels in answering questions that involve common sense reasoning. It achieves 62.3% accuracy on Nature Relation questions and 45.2% accuracy on Physical Relation questions, outperforming its counterparts, e.g. Otter-I and Shikra, by a substantial margin. Meanwhile, an analysis reveals that Bard’s performance is comparatively lower in tasks requiring spatial perception, such as Spatial Relationship and Object Localization. This observation aligns with expectations, considering that Shikra incorporates visual grounding tasks into its training data to enhance its localization capabilities, a facet potentially not integrated into Bard’s training process.

To complement the quantitative analysis in Figure 8, we also provide some qualitative examples of Bard. Some good cases are demonstrated in Figure 8. In the left-hand example, Bard adeptly processes intricate scenes, distills key information, and arrives at a reasonable conclusion. Notably, the majority of VLMs subjected to our testing fail to deliver the correct response to this particular question. In the right-hand example, Bard recognizes the correct concept from cartoon, sidestepping any potential confusion arising from the harmonious interaction between a snake and a mouse. This highlights Bard’s exceptional common sense reasoning ability.

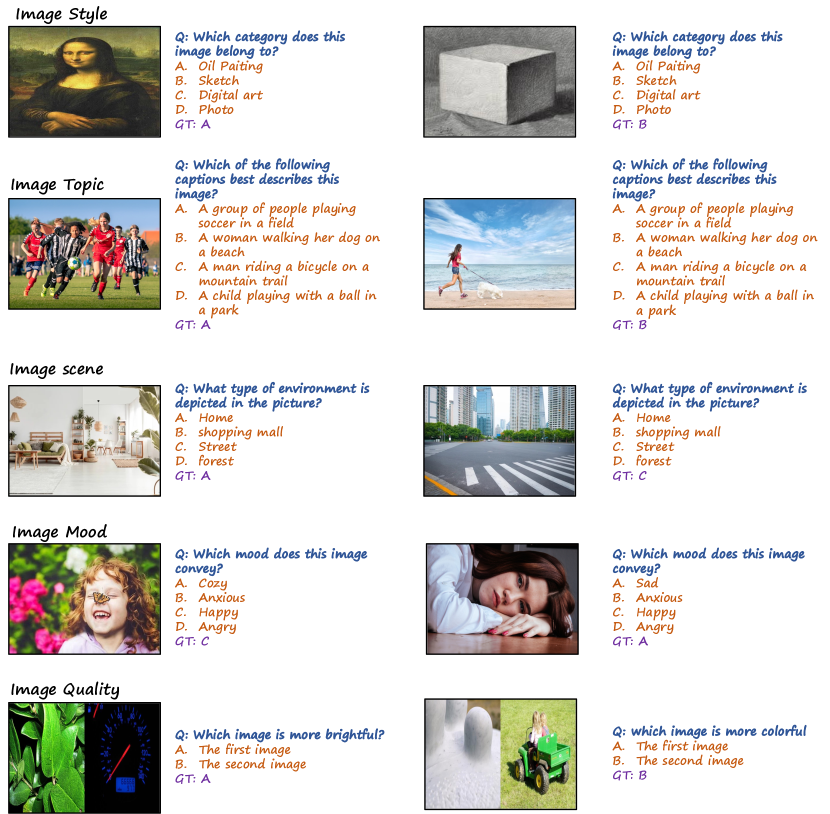
In Figure 9, we present illustrative examples that highlight Bard’s performance shortcomings. These instances originate from both image style and image quality tasks. The former entails the model to discern image categories, while the latter involves assessing visual attributes, such as brightness, across a pair of images. A shared characteristic between these tasks is the insignificance of image content concerning the task’s objectives. Bard performs bad on the two tasks, achieving 50% and 7% accuracy on each tasks respectively. The accompanying tables within these cases visually demonstrate Bard’s tendency to excessively focus on semantic concepts and depicted objects within the provided text and image, leaving it struggling to effectively address inquiries regarding holistic styles and attributes.
Last but not least, in all the aforementioned examples, Bard consistently delivers well-structured responses, frequently utilizing bullet-point lists and tables to enhance clarity. Moreover, across a majority of the questions, Bard adheres to a consistent response format: presenting the predicted option initially, subsequently offering a comprehensive rationale, and culminating by enumerating the reasons for the incorrectness of alternative choices. From the perspective of being a chatbot, Bard undeniably stands out as one of the most exceptional multi-modal chatbots.
Appendix D Examples in MMBench
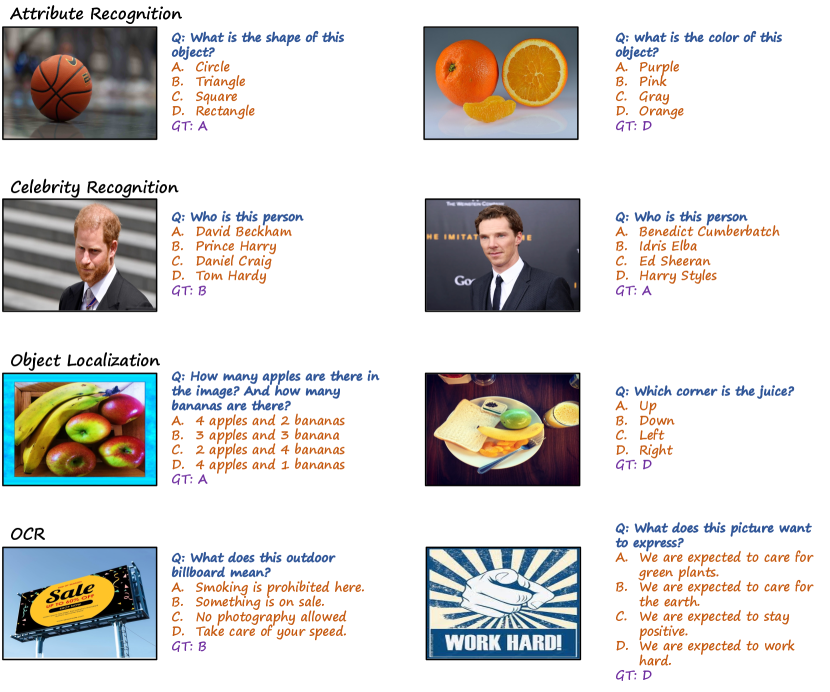
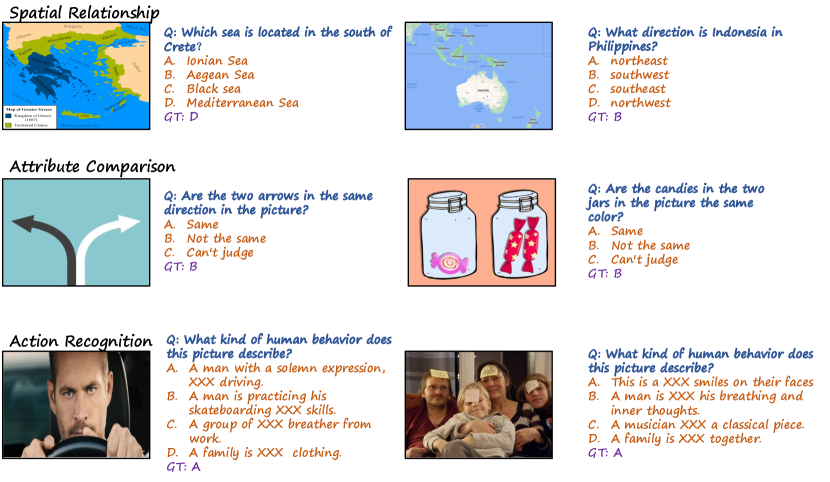
In the Figures 10, 11, 12, 15, 13 and 14, we illustruate some examples in MMBench , grouped by the L-2 abilities.



Appendix E Definition of Each Ability
In Table 14, we introduce the definition of each ability.
| Name | Ability |
| Image Style | Determine which type of image it belongs to, such as photos, paintings, CT scans, etc. |
| Image Scene | Determine which environment is shown in the image, such as indoors, outdoors, forest, city, mountains, waterfront, sunny day, rainy day, etc. |
| Image Emotion | Determine which subjective emotion is conveyed by the overall image, such as cold, cheerful, sad, or oppressive. |
| Image Quality | Determine the objective quality of the image, such as whether it is blurry, bright or dark, contrast, etc. |
| Image Topic | Determine what the subject of the image is, such as scenery, portrait, close-up of an object, text, etc. |
| Object Localization | For a single object, determine its position in the image (such as top, bottom, etc.), its absolute coordinates in the image, count the number of objects, and the orientation of the object |
| Attribute Recognition | Recognition of texture, shape, appearance characteristics, emotions, category, celebrities, famous places and objects, optical characters |
| Celebrity Recognition | Recognition of celebrities, landmarks, and common items. |
| OCR | Recognition of text, formula, and sheet in the image. |
| Spatial Relationship | Determine the relative position between objects in image. |
| Attribute Comparison | Compare attributes of different objects in image, such as shape, color, etc. |
| Action Recognition | Recognizing human actions, including pose motion, human-object interaction, and human-human interaction. |
| Structuralized Image-Text Understanding | Structured understanding of images and text, including parsing the content of charts (such as the trends of multiple bars in a bar chart), understanding the code in an image, etc. |
| Physical Property Reasoning | Predict the physical property of an object. Examples: the physical property of concentrated sulfuric acid is that it is volatile, the physical property of water is its fluidity, etc. |
| Function Reasoning | Predict the function of an object. Examples: the function of a broom is to sweep the floor, the function of a spatula is to cook, the function of a pen is to write, etc. |
| Identity Reasoning | Predict the identity of a person. Example: by observing a person’s clothing and appearance, one may infer his / her occupation and social status |
| Social Relation | Relations in human society or relations defined from the human perspective. Examples: Inter-person relations, such as father and son, husband and wife, friend, hostile, etc. |
| Physical Relation | All relationships that exist in the physical world, 3D spatial relationships and the connections between objects are. |
| Nature Relation | Other abstract relationships that exist in nature. Examples: predation, symbiosis, coexistence, etc. |
| Future Prediction | Predict what will happen in the future. Examples: if it is thundering in the sky now, it can be predicted that it will rain soon (physical phenomenon); if someone raises their fist, it means they are going to hit someone (event occurrence); if someone’s face becomes serious, it means they are going to get angry (emotional change). |
Appendix F Details of the evaluated models
| VLM | Language Backbone | Vision Backbone | Overall Parameters | Trainable Parameters |
| OpenFlamingo | LLaMA 7B | CLIP ViT-L/14 | 9B | 1.3B |
| OpenFlamingov2 | MPT 7B | CLIP ViT-L/14 | 9B | 1.3B |
| MMGPT | LLaMA 7B | CLIP ViT-L/14 | 9B | 22.5M |
| MiniGPT-4 | Vicuna 7B | EVA-G | 8B | 11.9M |
| MiniGPT-4-13B | Vicuna 13B | EVA-G | 14B | 11.9M |
| PandaGPT | Vicuna 13B | ImageBind ViT-H/14 | 14B | 28.8M |
| VisualGLM | ChatGLM 6B | EVA-CLIP | 8B | 0.2B |
| InstructBLIP | Vicuna 7B | EVA-G | 8B | 0.2B |
| InstructBLIP-13B | Vicuna 13B | EVA-G | 14B | 0.2B |
| Otter-I | LLaMA 7B | CLIP ViT-L/14 | 9B | 1.3B |
| LLaVA | LLaMA 7B | CLIP ViT-L/14 | 7.2B | 7B |
| LLaMA-Adapter | LLaMA 7B | CLIP ViT-L/14 | 7.2B | 1.2M |
| mPLUG-Owl | LLaMA 7B | CLIP ViT-L/14 | 7.2B | 0.4B |
| KOSMOS-2 | Decoder Only 1.3B | CLIP ViT-L/14 | 1.6B | 1.6B |
| Shikra | LLaMA 7B | CLIP ViT-L/14 | 7.2B | 6.7B |
| -G2PT | LLaMA 7B | ViT-G | 7B | 8B |
References
- [1] W3c school. In https://www.w3schools.com/, 2023.
- [2] Harsh Agrawal, Karan Desai, Yufei Wang, Xinlei Chen, Rishabh Jain, Mark Johnson, Dhruv Batra, Devi Parikh, Stefan Lee, and Peter Anderson. Nocaps: Novel object captioning at scale. In Proceedings of the IEEE/CVF international conference on computer vision, pages 8948–8957, 2019.
- [3] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing Systems, 35:23716–23736, 2022.
- [4] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- [5] Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multimodal llm’s referential dialogue magic. arXiv preprint arXiv:2306.15195, 2023.
- [6] Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco captions: Data collection and evaluation server. arXiv preprint arXiv:1504.00325, 2015.
- [7] Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023), 2023.
- [8] Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. arXiv preprint arXiv:2305.06500, 2023.
- [9] Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. Glm: General language model pretraining with autoregressive blank infilling. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 320–335, 2022.
- [10] Haodong Duan, Yue Zhao, Kai Chen, Yuanjun Xiong, and Dahua Lin. Mitigating representation bias in action recognition: Algorithms and benchmarks, 2022.
- [11] Jerry A Fodor. The modularity of mind. MIT press, 1983.
- [12] Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Zhenyu Qiu, Wei Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, and Rongrong Ji. Mme: A comprehensive evaluation benchmark for multimodal large language models. ArXiv, abs/2306.13394, 2023.
- [13] Peng Gao, Jiaming Han, Renrui Zhang, Ziyi Lin, Shijie Geng, Aojun Zhou, Wei Zhang, Pan Lu, Conghui He, Xiangyu Yue, et al. Llama-adapter v2: Parameter-efficient visual instruction model. arXiv preprint arXiv:2304.15010, 2023.
- [14] Tao Gong, Chengqi Lyu, Shilong Zhang, Yudong Wang, Miao Zheng, Qian Zhao, Kuikun Liu, Wenwei Zhang, Ping Luo, and Kai Chen. Multimodal-gpt: A vision and language model for dialogue with humans, 2023.
- [15] Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017.
- [16] Danna Gurari, Qing Li, Abigale J Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P Bigham. Vizwiz grand challenge: Answering visual questions from blind people. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3608–3617, 2018.
- [17] V. Hosu, H. Lin, T. Sziranyi, and D. Saupe. Koniq-10k: An ecologically valid database for deep learning of blind image quality assessment. IEEE Transactions on Image Processing, 29:4041–4056, 2020.
- [18] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- [19] Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Jiayi Lei, et al. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models. arXiv preprint arXiv:2305.08322, 2023.
- [20] Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709, 2019.
- [21] Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2901–2910, 2017.
- [22] Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Fanyi Pu, Jingkang Yang, Chunyuan Li, and Ziwei Liu. Mimic-it: Multi-modal in-context instruction tuning. 2023.
- [23] Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Jingkang Yang, and Ziwei Liu. Otter: A multi-modal model with in-context instruction tuning. arXiv preprint arXiv:2305.03726, 2023.
- [24] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023.
- [25] Junnan Li, Yongkang Wong, Qi Zhao, and Mohan S Kankanhalli. Dual-glance model for deciphering social relationships. In Proceedings of the IEEE international conference on computer vision, pages 2650–2659, 2017.
- [26] Fangyu Liu, Guy Edward Toh Emerson, and Nigel Collier. Visual spatial reasoning. Transactions of the Association for Computational Linguistics, 2023.
- [27] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023.
- [28] Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. Advances in Neural Information Processing Systems, 35:2507–2521, 2022.
- [29] Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. Ok-vqa: A visual question answering benchmark requiring external knowledge. In Proceedings of the IEEE/cvf conference on computer vision and pattern recognition, pages 3195–3204, 2019.
- [30] Mike Oaksford and Nick Chater. Bayesian rationality: The probabilistic approach to human reasoning. Oxford University Press, 2007.
- [31] OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023.
- [32] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- [33] Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding multimodal large language models to the world. arXiv preprint arXiv:2306.14824, 2023.
- [34] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- [35] Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv preprint arXiv:2111.02114, 2021.
- [36] Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317–8326, 2019.
- [37] Yixuan Su, Tian Lan, Huayang Li, Jialu Xu, Yan Wang, and Deng Cai. Pandagpt: One model to instruction-follow them all. arXiv preprint arXiv:2305.16355, 2023.
- [38] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- [39] Peng Xu, Wenqi Shao, Kaipeng Zhang, Peng Gao, Shuo Liu, Meng Lei, Fanqing Meng, Siyuan Huang, Yu Jiao Qiao, and Ping Luo. Lvlm-ehub: A comprehensive evaluation benchmark for large vision-language models. 2023.
- [40] Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, et al. mplug-owl: Modularization empowers large language models with multimodality. arXiv preprint arXiv:2304.14178, 2023.
- [41] Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics, 2:67–78, 2014.
- [42] Renrui Zhang, Jiaming Han, Chris Liu, Peng Gao, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, and Yu Qiao. Llama-adapter: Efficient fine-tuning of language models with zero-init attention, 2023.
- [43] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric. P Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023.
- [44] Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017.
- [45] Luowei Zhou, Chenliang Xu, and Jason Corso. Towards automatic learning of procedures from web instructional videos. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018.
- [46] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023.