MAXIM: Multi-Axis MLP for Image Processing
Abstract
Recent progress on Transformers and multi-layer perceptron (MLP) models provide new network architectural designs for computer vision tasks. Although these models proved to be effective in many vision tasks such as image recognition, there remain challenges in adapting them for low-level vision. The inflexibility to support high-resolution images and limitations of local attention are perhaps the main bottlenecks. In this work, we present a multi-axis MLP based architecture called MAXIM, that can serve as an efficient and flexible general-purpose vision backbone for image processing tasks. MAXIM uses a UNet-shaped hierarchical structure and supports long-range interactions enabled by spatially-gated MLPs. Specifically, MAXIM contains two MLP-based building blocks: a multi-axis gated MLP that allows for efficient and scalable spatial mixing of local and global visual cues, and a cross-gating block, an alternative to cross-attention, which accounts for cross-feature conditioning. Both these modules are exclusively based on MLPs, but also benefit from being both global and ‘fully-convolutional’, two properties that are desirable for image processing. Our extensive experimental results show that the proposed MAXIM model achieves state-of-the-art performance on more than ten benchmarks across a range of image processing tasks, including denoising, deblurring, deraining, dehazing, and enhancement while requiring fewer or comparable numbers of parameters and FLOPs than competitive models. The source code and trained models will be available at https://github.com/google-research/maxim.
1 Introduction
Image processing tasks, such as restoration and enhancement, are important computer vision problems, which aim to produce a desired output from a degraded input. Various types of degradations may require different image enhancement treatments, such as denoising, deblurring, super-resolution, dehazing, low-light enhancement, and so on. Given the increased availability of curated large-scale training datasets, recent high-performing approaches [110, 111, 125, 50, 20, 15, 60, 61, 17, 52, 22] based on highly designed convolutional neural network (CNN) have demonstrated state-of-the-art (SOTA) performance on many tasks.
 |
 |
 |
Improving the architectural design of the underlying model is one of the keys to improving the performance of most computer vision tasks, including image restoration. Numerous researchers have invented or borrowed individual modules or building blocks and implemented them into low-level vision tasks, including residual learning [120, 43, 95], dense connections [121, 95], hierarchical structures [42, 41, 37], multi-stage frameworks [111, 16, 34, 113], and attention mechanisms [110, 111, 66, 91].
Recent research explorations on Vision Transformers (ViT) [24, 11, 57] have exemplified their great potential as alternatives to the go-to CNN models. The elegance of ViT [24] has also motivated similar model designs with simpler global operators such as MLP-Mixer [87], gMLP [54], GFNet [76], and FNet [44], to name a few. Despite successful applications to many high-level tasks [24, 57, 89, 4, 104, 102, 85], the efficacy of these global models on low-level enhancement and restoration problems has not been studied extensively. The pioneering works on Transformers for low-level vision [15, 10] directly applied full self-attention, which only accepts relatively small patches of fixed sizes (e.g., 4848). Such a strategy will inevitably cause patch boundary artifacts when applied on larger images using cropping [15]. Local-attention based Transformers [52, 97] ameliorate this issue, but they are also constrained to have limited sizes of receptive field, or to lose non-locality [93, 24], which is a compelling property of Transformers and MLP models relative to hierarchical CNNs.
To overcome these issues, we propose a generic image processing network, dubbed MAXIM, for low-level vision tasks. A key design element of MAXIM is the use of multi-axis approach (Sec. 3.2) that captures both local and global interactions in parallel. By mixing information on a single axis for each branch, this MLP-based operator becomes ‘fully-convolutional’ and scales linearly with respect to image size, which significantly increases its flexibility for dense image processing tasks. We also define and build a pure MLP-based cross-gating module, which adaptively gate the skip-connections in the neck of MAXIM using the same multi-axis approach, and which further boosts performance. Inspired by recent restoration models, we develop a simple but effective multi-stage, multi-scale architecture consisting of a stack of MAXIM backbones. MAXIM achieves strong performance on a range of image processing tasks, while requiring very few number of parameters and FLOPs. Our contributions are:
-
•
A novel and generic architecture for image processing, dubbed MAXIM, using a stack of encoder-decoder backbones, supervised by a multi-scale, multi-stage loss.
-
•
A multi-axis gated MLP module tailored for low-level vision tasks, which always enjoys a global receptive field, with linear complexity relative to image size.
-
•
A cross gating block that cross-conditions two separate features, which is also global and fully-convolutional.
-
•
Extensive experiments show that MAXIM achieves SOTA results on more than 10 datasets including denoising, deblurring, deraining, dehazing, and enhancement.
2 Related Work
Restoration models. Driven by recent enormous efforts on building vision benchmarks, learning-based models, especially CNN models, have been developed that attain state-of-the-art performance on a wide variety of image enhancement tasks [111, 16, 37, 50, 81, 17, 15, 52]. These increased performance gains can be mainly attributed to novel architecture designs, and/or task-specific modules and units. For instance, UNet [80] has incubated many successful encoder-decoder designs [111, 37, 20] for image restoration that improve on earlier single-scale feature processing models [120, 45]. Advanced components developed for high-level vision tasks have been brought into low-level vision tasks as well. Residual and dense connections [120, 43, 95, 121, 95], the multi-scale feature learning [41, 97, 20], attention mechanisms [110, 111, 66, 91, 121], and non-local networks [93, 53, 121] are such good examples. Recently, multi-stage networks [111, 16, 34, 113] have attained promising results relative to the aforementioned single-stage models on the challenging deblurring and deraining tasks [23, 34, 111]. These multi-stage frameworks are generally inspired by their success on higher-level problems such as pose estimation [18, 48], action segmentation [25, 47], and image generation [116, 117].
Low-level vision Transformers. Transformers were originally proposed for NLP tasks [90], where multi-head self-attention and feed-forward MLP layers are stacked to capture non-local interactions between words. Dosovitskiy et al. coined the term Vision Transformer (ViT) [24], and demonstrated the first pure Transformer model for image recognition. Several recent studies explored Transformers for low-level vision problems, e.g., the pioneering pre-trained image processing Transformer (IPT) [15]. Similar to ViT, IPT directly applies vanilla Transformers to image patches. The authors of [10] presented a spatial-temporal convolutional self-attention network that exploits local information for video super-resolution. More recently, Swin-IR [52] and UFormer [97] apply efficient window-based local attention models on a range of image restoration tasks.
MLP vision models. More recently, several authors have argued that when using a patch-based architecture as in ViT, the necessity of complex self-attention mechanisms becomes questionable. For instance, MLP-Mixer [87] adopts a simple token-mixing MLP to replace self-attention in ViT, resulting in an all-MLP architecture. The authors of [54] proposed the gMLP, which applies a spatial gating unit on visual tokens. ResMLP [88] adopts an Affine transformation as a substitute to Layer Normalization for acceleration. Very recent techniques such as FNet [44] and GFNet [76] demonstrate the simple Fourier Transform can be used as a competitive alternative to either self-attention or MLPs.

3 Our Approach: MAXIM
We present, to the best of our knowledge, the first effective general-purpose MLP architecture for low-level vision, which we call Multi-AXIs MLP for image processing (MAXIM). Unlike previous low-level Transformers [15, 10, 52, 97], MAXIM has several desired properties, making it intriguing for image processing tasks. First, MAXIM expresses global receptive fields on arbitrarily large images with linear complexity; Second, it directly supports arbitrary input resolutions, i.e., being fully-convolutional; Lastly, it provides a balanced design of local (Conv) and global (MLP) blocks, outperforming SOTA methods without the necessity for large-scale pre-training [15].
3.1 Main Backbone
The MAXIM backbone (Fig. 2a) follows the encoder-decoder design principles that originated with UNet [80]. We have observed that operators having small footprints such as Conv3x3 are essential to the performance of UNet-like networks. Thus, we rely on a hybrid model design for each block (Fig. 2b) – Conv for local, and MLP for long-range interactions – to make the most of them.
To allow long-range spatial mixing at different scales, we insert the multi-axis gated MLP block (MAB) into each encoder, decoder, and bottleneck (Fig. 2b), with a residual channel attention block (RCAB) [100, 111] (LayerNorm-Conv-LeakyReLU-Conv-SE [31]) stacked subsequently. Inspired by the gated filtering of skip connections [67, 71], we extend the gated MLP (gMLP) to build a cross gating block (CGB, Fig. 2c), which is an efficient 2nd-order alternative to cross-attention (3rd-order correlations), to interact, or condition two distinct features. We leverage the global features from Bottleneck (Fig. 2a) to gate the skip connections, while propagating the refined global features upwards to the next CGB. Multi-scale feature fusion [84, 110, 20] (red and blue lines) is utilized to aggregate multi-level information in the EncoderCGB and CGBDecoder dataflow.
3.2 Multi-Axis Gated MLP
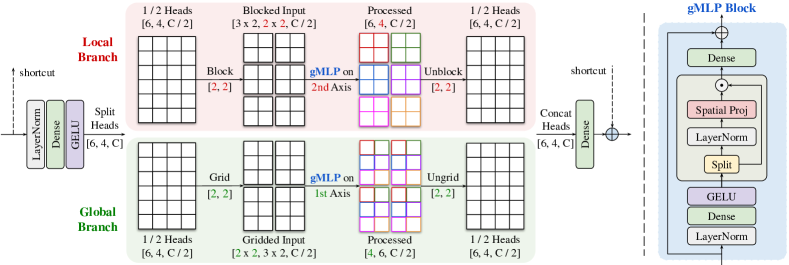
Our work is inspired by the multi-axis blocked self-attention proposed in [123], which performs attention on more than a single axis. The attentions performed on two axes on blocked images correspond to two forms of sparse self-attention, namely regional and dilated attention. Despite capturing local and global information in parallel, this module cannot accommodate image restoration or enhancement tasks where the test images are often of arbitrary sizes.
We improve the ‘multi-axis’ concept for image processing tasks, by building a (split-head) multi-axis gated MLP block (MAB), as shown in Fig. 3. Instead of applying multi-axis attention in a single layer [123], we split in half the heads first, each being partitioned independently. In the local branch, the half head of a feature of size is blocked into a tensor of shape , representing partitioning into non-overlapping windows each with size of ; in the global branch, the other half head is gridded into the shape using a fixed grid, with each window having size . For visualization, we set in Fig. 3. To make it fully-convolutional, we only apply the gated MLP (gMLP) block [54] on a single axis of each branch – the nd axis for the local branch and the st axis for the global branch – while sharing parameters on the other spatial axes. Intuively, applying multi-axis gMLPs in parallel correspond to local and global (dilated) mixing of spatial information, respectively. Finally, the processed heads are concatenated and projected to reduce the number of channels, which are further combined using the long skip-connection from the input. It is worth noting that this approach provides an advantage for our model over methods that process fixed-size image patches [15] by avoiding patch boundary artifacts.
Complexity analysis. The computational complexity of our proposed Multi-Axis gMLP block (MAB) is:
| (1) |
which is linear with respect to image size , while other global models like ViT, Mixer, and gMLP are quadratic.
Universality of the multi-axis approach. Our proposed parallel multi-axis module (Fig. 3) presents a principled way to apply 1D operators on 2D images in a scalable manner. It also allows for significant flexibility and universality. For example, a straightforward replacement of a gMLP with a spatial MLP [87], self-attention [24], or even Fourier Transform [76, 44] leads to a family of MAXIM variants (see Sec. 4.3D), all sharing globality and fully-convolutionality. It is also easily extensible to any future 1D operator that may be defined on, e.g., Language models.
3.3 Cross Gating MLP Block
A common improvement over UNet is to leverage contextual features to selectively gate feature propagation in skip-connections [67, 71], which is often achieved by using cross-attention [90, 13]. Here we build an effective alternative, namely cross-gating block (CGB, Fig. 2c), as an extension of MAB (Sec. 3.2) which can only process a single feature. CGB can be regarded as a more general conditioning layer that interacts with multiple features [90, 70, 13]. We follow similar design patterns as those used in MAB.
To be more specific, let be two input features, and be the features projected after the first Dense layers in Fig. 2c. Input projections are then applied:
| (2) |
where is the activation [30], is Layer Normalization [5], and are MLP projection matrices. The multi-axis blocked gating weights are computed from , respectively, but applied reciprocally:
| (3) |
where represents element-wise multiplication, and the function extracts multi-axis cross gating weights from the input using our proposed multi-axis approach (Sec. 3.2):
| (4) |
where denotes concatenation. Here are two independent heads split from along the channel dimension, where represents the projected features after activation:
| (5) |
and are spatial projection matrices applied on the 2nd and 1st axis of the blocked/gridded features having fixed window size (), and fixed grid size of (), respectively. Finally, we adopt residual connection from the inputs, following an output channel-projection that maintains the same channel dimensions as the inputs (), using projection matrices , , denoted by
| (6) |
The complexity of CGB is also tightly-bounded by Eq. 1.
3.4 Multi-Stage Multi-Scale Framework
We further adopt a multi-stage framework because we find it more effective, as compared to scaling up the model width or height (see ablation Sec. 4.3A). We deem full resolution processing [69, 77, 16] a better approach than a multi-patch hierarchy [83, 111, 113], since the latter would potentially induce boundary effects across patches. To impose stronger supervision, we apply a multi-scale approach [48, 18, 20] at each stage to help the network learn. We leverage the supervised attention module [111] to propagate attentive features progressively along the stages. We leverage the cross-gating block (Sec. 3.3) for cross-stage feature fusion. We refer the reader to Fig. 9 for details.
| SIDD [2] | DND [72] | Average | ||||
|---|---|---|---|---|---|---|
| Method | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM |
| DnCNN [120] | 23.66 | 0.583 | 32.43 | 0.790 | 28.04 | 0.686 |
| MLP [7] | 24.71 | 0.641 | 34.23 | 0.833 | 29.47 | 0.737 |
| BM3D [21] | 35.65 | 0.685 | 34.51 | 0.851 | 35.08 | 0.768 |
| CBDNet* [29] | 30.78 | 0.801 | 38.06 | 0.942 | 34.42 | 0.872 |
| RIDNet* [3] | 38.71 | 0.951 | 39.26 | 0.953 | 38.99 | 0.952 |
| AINDNet* [38] | 38.95 | 0.952 | 39.37 | 0.951 | 39.16 | 0.952 |
| VDN [107] | 39.28 | 0.956 | 39.38 | 0.952 | 39.33 | 0.954 |
| SADNet* [12] | 39.46 | 0.957 | 39.59 | 0.952 | 39.53 | 0.955 |
| CycleISP* [109] | 39.52 | 0.957 | 39.56 | 0.956 | 39.54 | 0.957 |
| MIRNet [110] | 39.72 | 0.959 | 39.88 | 0.956 | 39.80 | 0.958 |
| MPRNet [111] | 39.71 | 0.958 | 39.80 | 0.954 | 39.76 | 0.956 |
| MAXIM-3S | 39.96 | 0.960 | 39.84 | 0.954 | 39.90 | 0.957 |
Formally, given an input image , we first extract its multi-scale variants by downscaling: . MAXIM predicts multi-scale restored outputs at each stage of stages, yielding a total of outputs: . Despite being multi-stage, MAXIM is trained end-to-end with losses accumulating across stages and scales:
| (7) |
where denotes (bilinearly-rescaled) multi-scale target images, and is the Charbonnier loss [111]:
| (8) |
where we set . is the frequency reconstruction loss that enforces high-frequency details [35, 20]:
| (9) |
where represents the 2D Fast Fourier Transform. We used as the weighting factor in all experiments.
4 Experiments
We aim at building a generic backbone for a broad spectrum of image processing tasks. Thus, we evaluated MAXIM on five different tasks: (1) denoising, (2) deblurring, (3) deraining, (4) dehazing, and (5) enhancement (retouching) on 17 different datasets (summarized in Tab. 8. More comprehensive results and visualizations can be found in Sec. A.6.
4.1 Experimental Setup
Datasets and metrics. We measured PSNR and SSIM [96] metrics between ground truth and predicted images to make quantitative comparisons. We used SIDD [2] and DND [72] for denoising, GoPro [62], HIDE [81], and RealBlur [79] for debluring, a combined dataset Rain13k used in [111] for deraining. The RESIDE [46] is used for dehazing, while Five-K[8] and LOL [98] are evaluated for enhancement.

|
|||||||
|---|---|---|---|---|---|---|---|
| Input | Target | VDN [107] | DANet [108] | MIRNet [110] | CycleISP [109] | MPRNet [111] | MAXIM-3S |
| GoPro [62] | HIDE [81] | Average | ||||
|---|---|---|---|---|---|---|
| Method | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM |
| DeblurGAN [40] | 28.70 | 0.858 | 24.51 | 0.871 | 26.61 | 0.865 |
| Nah et al. [62] | 29.08 | 0.914 | 25.73 | 0.874 | 27.41 | 0.894 |
| Zhang et al. [118] | 29.19 | 0.931 | - | - | - | - |
| DeblurGAN-v2 [41] | 29.55 | 0.934 | 26.61 | 0.875 | 28.08 | 0.905 |
| SRN [86] | 30.26 | 0.934 | 28.36 | 0.915 | 29.31 | 0.925 |
| Shen et al. [81] | - | - | 28.89 | 0.930 | - | - |
| Gao et al. [28] | 30.90 | 0.935 | 29.11 | 0.913 | 30.01 | 0.924 |
| DBGAN [119] | 31.10 | 0.942 | 28.94 | 0.915 | 30.02 | 0.929 |
| MT-RNN [69] | 31.15 | 0.945 | 29.15 | 0.918 | 30.15 | 0.932 |
| DMPHN [113] | 31.20 | 0.940 | 29.09 | 0.924 | 30.15 | 0.932 |
| Suin et al. [83] | 31.85 | 0.948 | 29.98 | 0.930 | 30.92 | 0.939 |
| MPRNet [111] | 32.66 | 0.959 | 30.96 | 0.939 | 31.81 | 0.949 |
| Pretrained-IPT [15] | 32.58 | - | - | - | - | - |
| MIMO-UNet+ [20] | 32.45 | 0.957 | 29.99 | 0.930 | 31.22 | 0.944 |
| HINet [16] | 32.71 | 0.959 | 30.32 | 0.932 | 31.52 | 0.946 |
| MAXIM-3S | 32.86 | 0.961 | 32.83 | 0.956 | 32.85 | 0.959 |
| RealBlur-R [79] | RealBlur-J [79] | Average | ||||
| Method | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM |
| Hu et al. [33] | 33.67 | 0.916 | 26.41 | 0.803 | 30.04 | 0.860 |
| Nah et al. [62] | 32.51 | 0.841 | 27.87 | 0.827 | 30.19 | 0.834 |
| DeblurGAN [40] | 33.79 | 0.903 | 27.97 | 0.834 | 30.88 | 0.869 |
| Pan et al. [68] | 34.01 | 0.916 | 27.22 | 0.790 | 30.62 | 0.853 |
| Xu et al. [103] | 34.46 | 0.937 | 27.14 | 0.830 | 30.8 | 0.884 |
| DeblurGAN-v2 [41] | 35.26 | 0.944 | 28.70 | 0.866 | 31.98 | 0.905 |
| Zhang et al. [118] | 35.48 | 0.947 | 27.80 | 0.847 | 31.64 | 0.897 |
| SRN [86] | 35.66 | 0.947 | 28.56 | 0.867 | 32.11 | 0.907 |
| DMPHN [113] | 35.70 | 0.948 | 28.42 | 0.860 | 32.06 | 0.904 |
| MPRNet [111] | 35.99 | 0.952 | 28.70 | 0.873 | 32.35 | 0.913 |
| MAXIM-3S | 35.78 | 0.947 | 28.83 | 0.875 | 32.31 | 0.911 |
| †DeblurGAN-v2 | 36.44 | 0.935 | 29.69 | 0.870 | 33.07 | 0.903 |
| †SRN [86] | 38.65 | 0.965 | 31.38 | 0.909 | 35.02 | 0.937 |
| †MPRNet [111] | 39.31 | 0.972 | 31.76 | 0.922 | 35.54 | 0.947 |
| †MIMO-UNet+ [20] | - | - | 32.05 | 0.921 | - | - |
| †MAXIM-3S | 39.45 | 0.962 | 32.84 | 0.935 | 36.15 | 0.949 |

|
|||||||
|---|---|---|---|---|---|---|---|
| Input | Target | DMPHN [113] | Suin et al. [83] | MPRNet [111] | HINet [16] | MIMO-UNet [20] | MAXIM-3S |
Training details. Our proposed MAXIM model is end-to-end trainable and requires neither large-scale pretraining nor progressive training. The network is trained on random-cropped patches. We train different iterations for each task. We used random horizontal and vertical flips, rotation, and MixUp [112] with probability for data augmentation. We used the Adam optimizer [39] with an initial learning rate of , which are steadily decreased to with the cosine annealing decay [59]. When testing, we padded the input images to be a multiplier of using symmetric padding on both sides. After inference, we cropped the padded image back to original size. More training details on each task can be found in Sec. A.1.
Architectural configuration. We designed two MAXIM variants: a two-stage model called MAXIM-2S, and a three-stage model, MAXIM-3S, for different tasks. We start with initial channels for feature extraction, with 3 downsampling layers, where the features contract from , , , to processed by two Bottlenecks (Fig. 2a), then symmetrically expanded back to full resolution. The number of parameters and required FLOPs of MAXIM-2S and MAXIM-3S, when applied on a image are shown in the last two rows of Tab. 7A.
4.2 Main Results
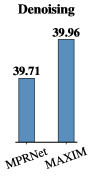
Denoising. We report in Tab. 1 numerical comparisons on the SIDD [2] and DND [72] datasets. As may be seen, our method outperformed previous SOTA techniques, e.g., MIRNet [110] by 0.24 dB of PSNR on SIDD while obtaining competitive PSNR (39.84 dB) on DND. Fig. 4 shows visual results on SIDD. Our method clearly removes real noise while maintaining fine details, yielding visually pleasant results to the other methods.
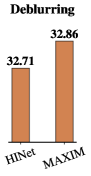
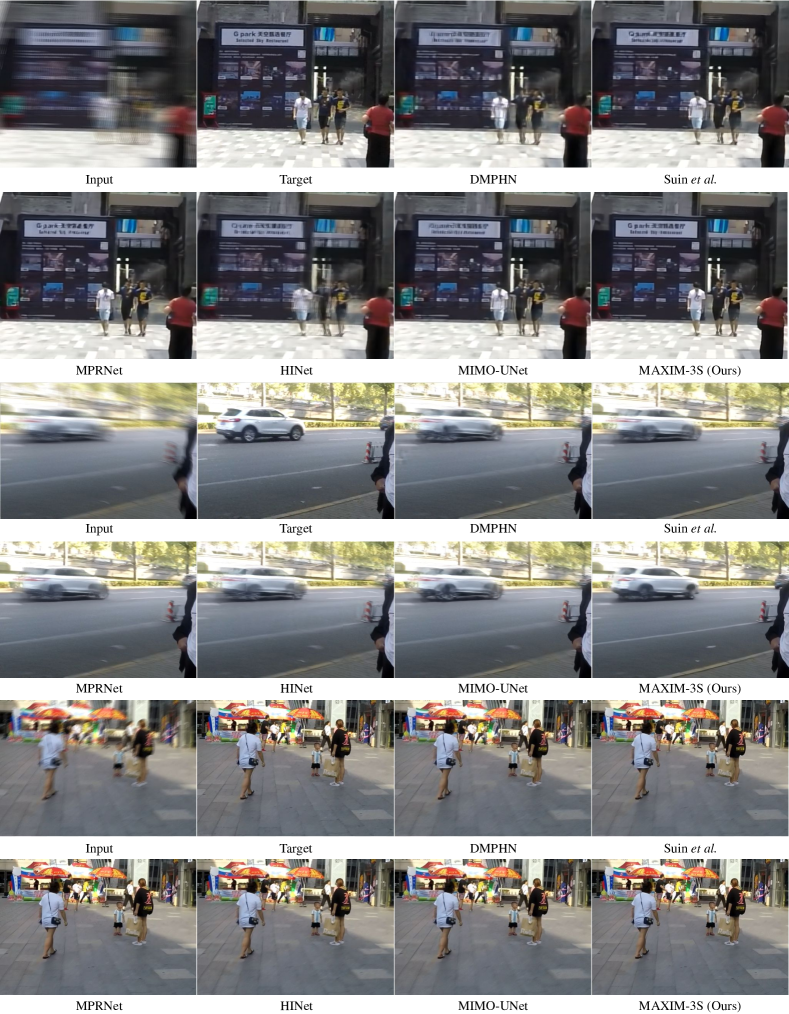
Deblurring. Tab. 2 shows the quantitative comparison of MAXIM-3S against SOTA deblurring methods on two synthetic blur datasets: GoPro [62] and HIDE [81]. Our method achieves 0.15 dB gain in PSNR over the previous best model HINet [16]. It is notable that the GoPro-trained MAXIM-3S model generalizes extremely well on the HIDE dataset, setting new SOTA PSNR values: 32.83 dB. We also evaluated on real-world blurry images from RealBlur [79] under two settings: (1) directly applied the GoPro-trained model on RealBlur, and (2) fine-tuned the model on RealBlur. Under setting (1), MAXIM-3S ranked first on RealBlur-J subset while obtaining the top two performance on RealBlur-R. Fig. 5 shows visual comparisons of the evaluated models on GoPro [62], HIDE [81] and RealBlur [79], respectively. It may be observed that our model recovers text extremely well, which may be attributed to the use of multi-axis MLP module within each block that globally aggregates repeated patterns across various scales.

|
|||||||
|---|---|---|---|---|---|---|---|
| Input | Target | RESCAN [49] | PreNet [77] | MSPFN [34] | MPRNet [111] | HINet [16] | MAXIM-2S |

|
|||||||
|---|---|---|---|---|---|---|---|
| Input | Target | GCANet [14] | GridDehaze [55] | DuRN [56] | MSBDN [23] | FFA-Net [74] | MAXIM-2S |
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

|
|||||||
| Input | Target | CycleGAN [124] | Exposure [32] | DPE [19] | EnlightenGAN | UEGAN [65] | MAXIM-2S |

|
|||||||
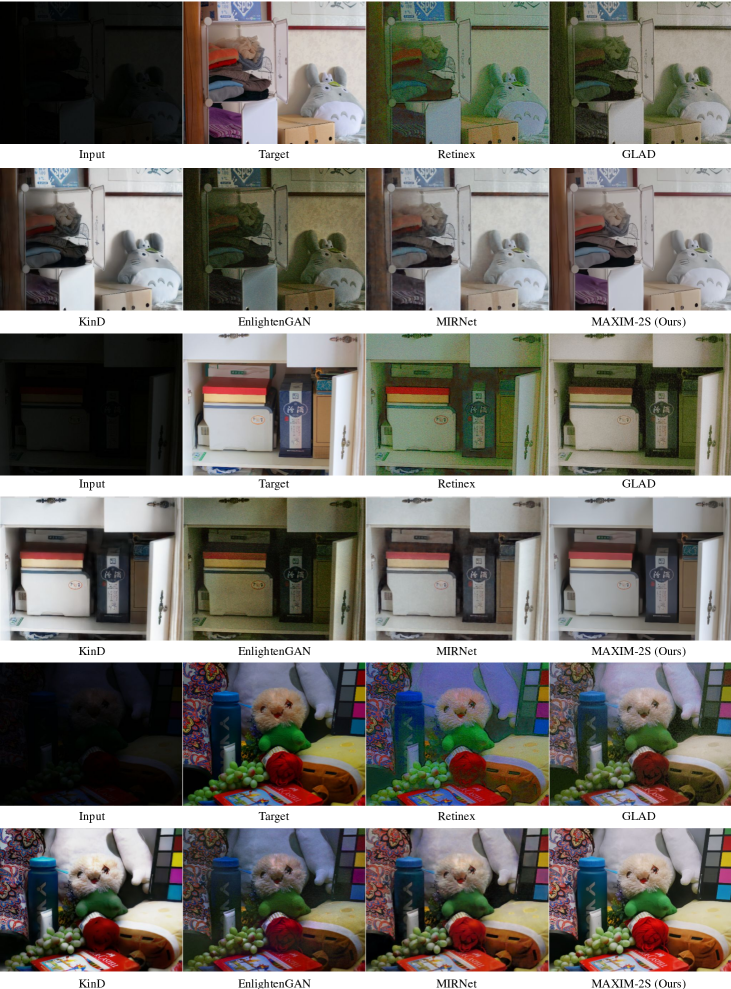
| Input | Target | Retinex [98] | GLAD [92] | KinD [122] | EnlightenGAN | MIRNet [110] | MAXIM-2S |
Deraining. Following previous work [34, 111], we computed the performance metrics using the Y channel (in YCbCr color space). Tab. 5 shows quantitative comparisons with previous methods. As may be seen, our model improved over the SOTA performances on all datasets. The average PSNR gain of our model over the previous best model HINet [16] is 0.24 dB. We demonstrate some challenging examples in Fig. 6, which demonstrates that our method consistently delivered faithfully recovered images without introducing any noticeable visual artifacts.
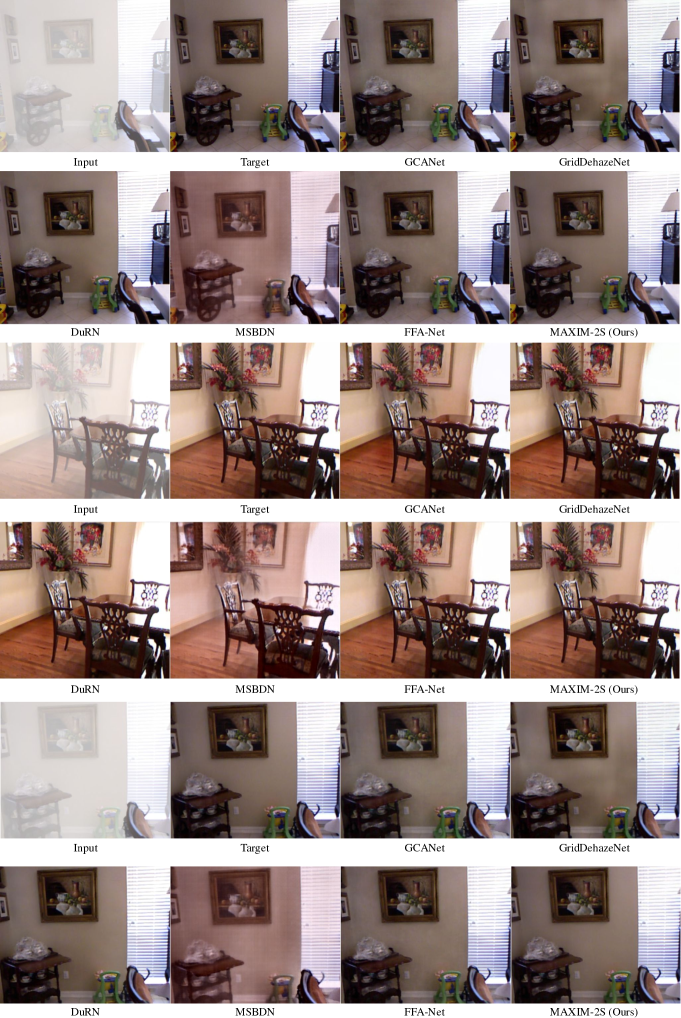
Dehazing. We report our comparisons against SOTA models in Tab. 5. Our model surpassed the previous best model by 0.94 dB and 0.62 dB of PSNR on the SOTS [46] indoor and outdoor sets. Fig. 7 shows that our model recovered images of better quality on both flat regions as well as textures, while achieving a harmonious global tone.
Enhancement / Retouching. As Tab. 6 illustrates, our model achieved the best PSNR and SSIM values on FiveK [8] and LOL [98], respectively. As the top row of Fig. 8 suggests, MAXIM recovered diverse naturalistic colors as compared to other techniques. Regarding the bottom example, while MIRNet [110] obtained a higher PSNR, we consistently observed that our model attains visually better quality with sharper details and less noise. Moreover, the far more perceptually relevant SSIM index indicates a significant advantage of MAXIM-2S relative to MIRNet.
Other benchmarks. Due to space limitations, we detail the outcomes of our experiments on the REDS deblurring [63] and the Raindrop removal task [73] in Sec. A.5.
4.3 Ablation
We conduct extensive ablation studies to validate the proposed multi-axis gated MLP block, cross-gating block, and multi-stage multi-scale architecture. The evaluations were performed on the GoPro dataset [62] trained on image patches of size for iterations. We used the MAXIM-2S model as the test-bed for Ablation-A and -B.
A. Individual components. We conducted an ablation by progressively adding (1) inter-stage cross-gating blocks (CGBIS), (2) a supervised attention module (SAM), (3) cross-stage cross-gating blocks (CGBCS, and (4) the multi-scale supervision (MS-Sp). Tab. 7A indicates a PSNR gain of 0.25, 0.63, 0.36, 0.26 dB for each respective component.
| FiveK [8] | LOL [98] | ||||
|---|---|---|---|---|---|
| Method | PSNR | SSIM | Method | PSNR | SSIM |
| CycleGAN [124] | 18.23 | 0.835 | Retinex [98] | 16.77 | 0.559 |
| Exposure [32] | 22.35 | 0.861 | GLAD [92] | 19.71 | 0.703 |
| EnlightenGAN | 17.74 | 0.828 | EnlightenGAN | 17.48 | 0.657 |
| DPE [19] | 24.08 | 0.922 | KinD [122] | 20.37 | 0.804 |
| UEGAN [65] | 25.00 | 0.929 | MIRNet [110] | 24.14 | 0.830 |
| MAXIM-2S | 26.15 | 0.945 | MAXIM-2S | 23.43 | 0.863 |
B. Effects of multi-axis approach. We further examined the necessity of our proposed multi-axis approach, as shown in Tab. 7B. We conducted experiments over (1) baseline UNet, (2) by adding the local branch of MAB (MAB), (3) by adding the global branch of MAB (MAB), (4) by adding the local branch of CGB (CGB), (5) by adding the global branch of CGB (CGB). Note that the huge jump (+1.04 dB) of PSNR by adding MAB can be largely attributed to the addition of input and output channel projection layers, because we also observe a high performance of 31.42 dB PSNR if only MAB is added. Overall, we observed a major improvement when including MAB, and a relatively minor gain when adding CGB.
C. Why multi-stage? Towards understanding this, we scaled up MAXIM in terms of width (channels), depth (downscaling steps), and the number of stages. Tab. 7C suggests that packing the backbone into multi-stages yields the best performance vs. complexity tradeoff (32.44 dB, 22.2 M, 339.2 G), compared to making it wider or deeper.
D. Beyond gMLP: the MAXIM families. As described in Sec. 3.2, our proposed multi-axis approach (Fig. 3) offers a scalable way of applying any 1D operators on (high-resolution) images, with linear complexity relative to image size while maintaining fully-convolutional. We conducted a pilot study using MAXIM-1S and -2S on SIDD [2] to explore the MAXIM families: MAXIM-FFT, -MLP, -gMLP (modeled in this paper), -SA, where we use the Fourier Transform filter [76, 44], spatial MLP [87], gMLP [54], and self-attention [24] on spatial axes using the same multi-axis approach (Fig. 3). As Tab. 7D shows, the gMLP and self-attention variants achieved the best performance, while the FFT and MLP families were more computationally efficient. We leave deeper explorations to future works.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
5 Conclusion
We have presented a generic network for restoration or enhancement tasks, dubbed MAXIM, inspired by recently popular MLP-based global models. Our work suggests an effective and efficient approach for applying gMLP to low-level vision tasks to gain global attention, a missing attribute of basic CNNs. Our gMLP initialization of the MAXIM family significantly advances state-of-the-arts in several image enhancement and restoration tasks with moderate complexity. We demonstrate a few applications, but there are many more possibilities beyond the scope of this work which could significantly benefit by using MAXIM. Our future work includes exploring more efficient models for extremely high-resolution image processing, as well as training large models that can adapt on multiple tasks.
Broader impacts. The proposed model can be used as an effective tool to enhance and retouch daily photos. However, enhancing techniques such as denoising and deblurring are vulnerable to malicious use for privacy concerns. The models trained on specific data may express bias. These issues should be responsibly taken care of by researchers.
6 Acknowledgment
We thank Junjie Ke, Mauricio Delbracio, Sungjoon Choi, Irene Zhu, Innfarn Yoo, Huiwen Chang, and Ce Liu for valuable discussions and feedback.
Appendix A Appendix
A.1 Datasets and Training Details
All the datasets used in the paper are summarized in Tab. 8. We describe details of training for each dataset in the following. Note that we used the loss for the dehazing task while using the loss defined in the main paper for all the other tasks.
Image Denoising. We trained our model on high-resolution images provided in SIDD [2] and evaluated on 1,280 () and 1,000 () images provided by authors of SIDD [2] and DND [72], respectively. The results on DND were obtained via the online server [1]. We cropped the training images into patches with a stride of 256 to prepare the training patches. We trained the MAXIM-3S model for 600k steps with a batch size of 256.
Image Deblurring. We trained our model on 2,103 image pairs from GoPro [62]. To demonstrate generalization ability, we evaluated our GoPro trained model on 1,111 pairs of the GoPro evaluation set, 2,025 images in the HIDE dataset [81], as well as the RealBlur dataset [79], which contains 980 paired images of camera JPEG output and RAW images, respectively. We cropped training images from GoPro into patches with a stride of 128 to generate training patches. We trained our MAXIM-3S model over 600k steps with a batch size of 256. For evaluation on RealBlur setting (2) (see main paper), we loaded the GoPro pre-trained checkpoint and fine-tuned for 70k and 15k iterations on RealBlur-J and RealBlur-R, respectively. Additionally, we trained our model on 24,000 images from the REDS dataset of the NTIRE 2021 Image Deblurring Challenge Track 2 JPEG artifacts [63]. For evaluation, we followed the settings in the NTIRE 2021 Challenge on Image Deblurring [64], i.e., we used 300 images in the validation set of REDS. We trained from scratch for 10k epochs on REDS [63].
| Task | Dataset | #Train | #Test | Test Dubname |
|---|---|---|---|---|
| Denoising | SIDD [2] | 320 | 40 | SIDD |
| DND [72] | 0 | 50 | DND | |
| Deblurring | GoPro [62] | 2103 | 1111 | GoPro |
| HIDE [81] | 0 | 2025 | HIDE | |
| RealBlur-J [79] | 3758 | 980 | RealBlur-J | |
| RealBlur-R [79] | 3758 | 980 | RealBlur-R | |
| REDS [63] | 24000 | 300 | REDS | |
| Deraining | Rain14000 [27] | 11200 | 2800 | Test2800 |
| Rain1800 [105] | 1800 | 0 | - | |
| Rain800 [115] | 700 | 98 | Test100 | |
| Rain100H [105] | 0 | 100 | Rain100H | |
| Rain100L [105] | 0 | 100 | Rain100L | |
| Rain1200 [114] | 0 | 1200 | Test1200 | |
| Rain12 [51] | 12 | 0 | - | |
| Raindrop [73] | 861 | 58 | Raindrop-A | |
| Raindrop [73] | 0 | 239 | Raindrop-B | |
| Dehazing | RESIDE-ITS [46] | 13990 | 500 | SOTS-Indoor |
| RESIDE-OTS [46] | 313950 | 500 | SOTS-Outdoor | |
| Enhancement | MIT-Adobe FiveK [8] | 4500 | 500 | FiveK |
| (Retouching) | LOL [98] | 485 | 15 | LOL |
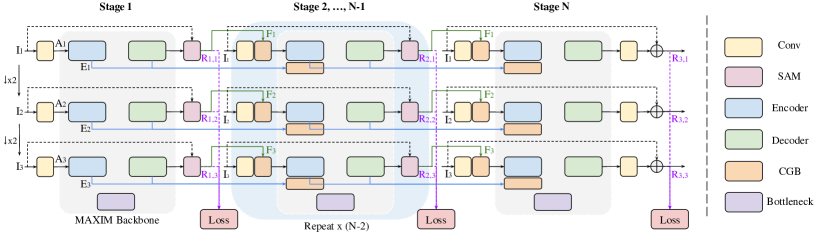
Image Deraining. Following [111, 34], we used a composite training set containing 13,712 clean-rain image pairs collected from multiple datasets [27, 105, 115, 105, 114, 51]. Evaluation was performed on five test sets, Rain100H [105], Rain100L [105], Test100 [115], Test1200 [114], and Test2800 [27]. We trained our MAXIM-2S model over 500k steps with a batch size of 512. For the raindrop removal task, we trained MAXIM-2S on 861 pairs of training images in Raindrop dataset [73] for 80k steps with a batch size of 512, and evaluate on testset A (58 images) and testset B (239 images), respectively.
Image Dehazing. The RESIDE dataset [46] contains two subsets: Indoor Training Set (ITS) which contains 13,990 hazy images generated from 1399 clean ones, and Outdoor Training Set (OTS) that consists of 313,950 hazing images synthesized from 8,970 haze-free outdoor scenes. We evaluated our model on the Synthetic Objective Testing Set (SOTS) [46]: 500 indoor images for ITS-trained, and 500 outdoor images for OTS-trained models, respectively. We trained for 10k and 500 epochs on RESIDE-ITS and RESIDE-OTS using the loss.
Image Enhancement. We used the MIT-Adobe FiveK [8] dataset provided by [65] for the retouching evaluation: the first 4,500 images for training and the rest 500 for testing. We cropped training images into patches with a stride of 256. We also used the LOL dataset [98] which includes 500 pairs of images for low-light enhancement. We trained our model on 485 training images and evaluated on 15 test images. We trained for 14k and 180k steps on FiveK and LOL, respectively.
A.2 Architecture Details
Our proposed general multi-stage and multi-scale framework is illustrated in Fig. 9, where each stage uses a single-stage MAXIM backbone, which is illustrated in the main paper. We leveraged the multi-scale input-output approach [20] to deeply supervise each stage. Specifically, given an input image , we used the nearest neighbour downscaling method [20] to generate multi-scale input variants: , while we adopted a bilinear downscaler to produce the ground truth variants: . For each stage, we extracted shallow features from the inputs at each scale using Conv3x3. Except for the first stage, we fused the shallow features with attention features coming from the previous supervised attention module (SAM) [111] using a cross gating block (CGB). We also employed cross-stage feature fusion [111, 16] to help later stages, where the intermediate Encoder and Decoder features from the previous stage are fused with features encoded at the current stage using a CGB (blue lines in Fig. 9).
A.2.1 Configurations
The detailed specifications of the Encoder part for a single-stage MAXIM are shown in Tab. 9. We also provide the input and output shapes of each block and layer. Here Conv3x3_s1_w32 means a Conv layer with 3x3 kernels, stride 1, and 32 channels. MAB and RCAB are the two major components in Encoder / Decoder / Bottleneck. Note that in Bottleneck blocks, we use (Conv1x1) layers to replace Conv3x3 in RCAB.
| Depth | Input shape | Output Shape | Layers |
|---|---|---|---|
| 1 | Conv3x3_s1_w32 | ||
| 1 | CGB* () | ||
| 1 | Conv1x1_s1_w32 | ||
| 1 | { | ||
| 1 | Conv3x3_s2_w32 | ||
| 2 | Conv3x3_s1_w64 | ||
| 2 | CGB* () | ||
| 2 | Conv1x1_s1_w64 | ||
| 2 | { | ||
| 2 | Conv3x3_s2_w64 | ||
| 3 | Conv3x3_s1_w128 | ||
| 3 | CGB* () | ||
| 3 | Conv1x1_s1_w128 | ||
| 3 | { | ||
| 3 | Conv3x3_s2_w128 | ||
| 4 | Conv1x1_s1_w256 | ||
| 4 | { | ||
| 4 | Conv1x1_s1_w256 | ||
| 4 | { |
The Decoder part of MAXIM is symmetric with respect to Tab. 9, and has the same configuration. For the CGB necks, we used for the depths 1 and 2, while is adopted for depth 3. Basically, we set the block and grid sizes as for high-resolution stages (i.e. feature size ) and for low-resolution stages (i.e. feature size ). Consequently, the input images need to have both dimensions to be divisible by 64, requiring the images to be padded by a multiplier of 64 during the inference.
A.2.2 Comparison with Other MLPs
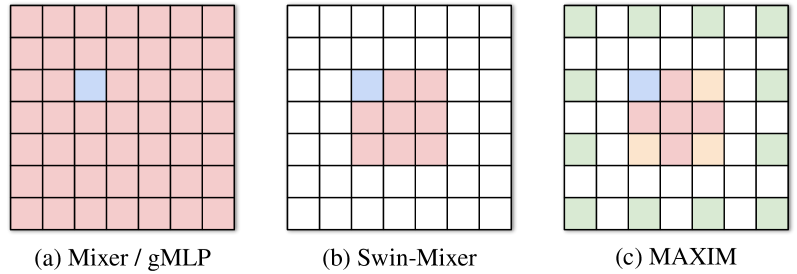
In Fig. 10, we show a visual comparison of the approximated effective receptive fields among recent MLP models: MLP-Mixer [87], gMLP [54], Swin-Mixer [57], and our proposed MAXIM. Our approach achieves sparse interactions to obtain both local (red in Fig. 10c) and global dilated (green) spatial communications. Moreover, as shown in Tab. 10, unlike previous MLP models, MAXIM obtains both global and fully-convolutional properties with a linear complexity with respect to the number of pixels .
A.3 JAX Implementations
Here we provide a JAX [6] implementation of the key component of MAXIM, namely the multi-axis gated MLP block (MAB), in Algorithm 1.
A.4 Performance vs. Complexity
We demonstrate the performance vs. complexity trade-off in Tab. 11 as compared with other competing methods for all the tasks. As it can be seen, our model obtains state-of-the-art performance at a very moderate complexity. On denoising, for example, MAXIM-3S has only FLOPs and parameters of MIRNet [110]; on deblurring, our MAXIM-3S model requires only of the number of parameters of the previous best model HINet [16], and merely of the number of parameters of the Transformer model IPT [15]. It is also worth noting that unlike IPT, our model requires no large-scale pre-training to obtain leading performance, making it attractive for low-level tasks where datasets are often at limited scale.
| Model | Complexity | Fully-conv | Global |
|---|---|---|---|
| MLP-Mixer [87] | ✗ | ✓ | |
| gMLP [54] | ✗ | ✓ | |
| Swin-Mixer [57] | ✓ | ✗ | |
| MAXIM (ours) | ✓ | ✓ |
A.5 Additional Experiments
Due to limited space in the main paper, we also show experimental results on deblurring and raindrop removal.
Deblurring on REDS [63]. Tab. 12 shows quantitative comparisons of MAXIM-3S against the winning solution, HINet [16], and a leading model, MPRNet [111] on the REDS dataset of NTIRE 2021 Image Deblurring Challenge Track 2 JPEG artifacts [63]. The metrics are computed and averaged on 300 validation images. Our MAXIM-3S model surpasses HINet by 0.1 dB of PSNR.
| Task | Dataset | Model | PSNR | Params | FLOPs |
|---|---|---|---|---|---|
| Denoise | SIDD [2] | MPRNet [111] | 39.71 | 15.7M | 1176G |
| MIRNet [110] | 39.72 | 31.7M | 1572G | ||
| MAXIM-3S | 39.96 | 22.2M | 339G | ||
| Deblur | GoPro [62] | MPRNet [111] | 32.66 | 20.1M | 1554G |
| HINet [16] | 32.71 | 88.7M | 341G | ||
| IPT [15] | 32.58 | 114M | 1188G | ||
| MAXIM-3S | 32.86 | 22.2M | 339G | ||
| Derain | Rain13k (Average) | MSPFN [34] | 30.75 | 21.7M | - |
| MPRNet [111] | 32.73 | 3.64M | 297G | ||
| MAXIM-2S | 33.24 | 14.1M | 216G | ||
| Dehaze | Indoor [46] | MSBDN [23] | 33.79 | 31.3M | 83G |
| FFA-Net [74] | 36.36 | 4.5M | 576G | ||
| MAXIM-2S | 39.72 | 14.1M | 216G | ||
| Enhance | LOL [98] | MIRNet [110] | 24.14 | 31.7M | 1572G |
| MAXIM-2S | 23.43 | 14.1M | 216G |
| REDS [63] | ||
|---|---|---|
| Method | PSNR | SSIM |
| MPRNet [111] | 28.79 | 0.911 |
| HINet [16] | 28.83 | 0.862 |
| MAXIM-3S | 28.93 | 0.865 |
| Raindrop-A [73] | Raindrop-B [73] | |||
|---|---|---|---|---|
| Method | PSNR | SSIM | PSNR | SSIM |
| AGAN [73] | 31.62 | 0.921 | 25.05 | 0.811 |
| DuRN [56] | 31.24 | 0.926 | 25.32 | 0.817 |
| Quan [75] | 31.36 | 0.928 | - | - |
| MAXIM-2S | 31.87 | 0.935 | 25.74 | 0.827 |
Raindrop removal [73]. Apart from the rain streak removal task reported in the main paper, we also evaluated our MAXIM model on the raindrop removal task. As can be seen in Tab. 13, our model achieved the best performance: 31.87 dB and 25.74 dB PSNR on Raindrop testset A and B.
A.6 More Visual Comparisons
Denoising. Fig. 12 shows denoising results of our model compared with SOTA models on SIDD [2]. Our model recovers more details, yielding visually pleasant outputs.
Deblurring. The visual results on GoPro [62], HIDE [81], RealBlur-J [79], and REDS [63] are shown in Fig. 13, Fig. 14, Fig. 15, and Fig. 16, respectively. Our model outperformed other competing methods on both synthetic and real-world deblurring benchmarks.
Deraining. Qualitative comparisons of our model against SOTA methods on deraining are shown in Fig. 17, Fig. 18, Fig. 19, and Fig. 20.
Raindrop removal. We provide visual comparisons of the raindrop removal task on the Raindrop testset A and B [73] in Fig. 21 and Fig. 22.
Dehazing. We provide dehazing comparisons on the SOTS [46] indoor and outdoor sets in Fig. 23 and Fig. 24.
Retouching. Fig. 25 shows additional comparisons of our model with competing methods on the Five-K dataset [8] provided by [65] for retouching results.
Low-light enhancement. Fig. 26 demonstrates the evaluations on the LOL [98] test set for low-light enhancement.
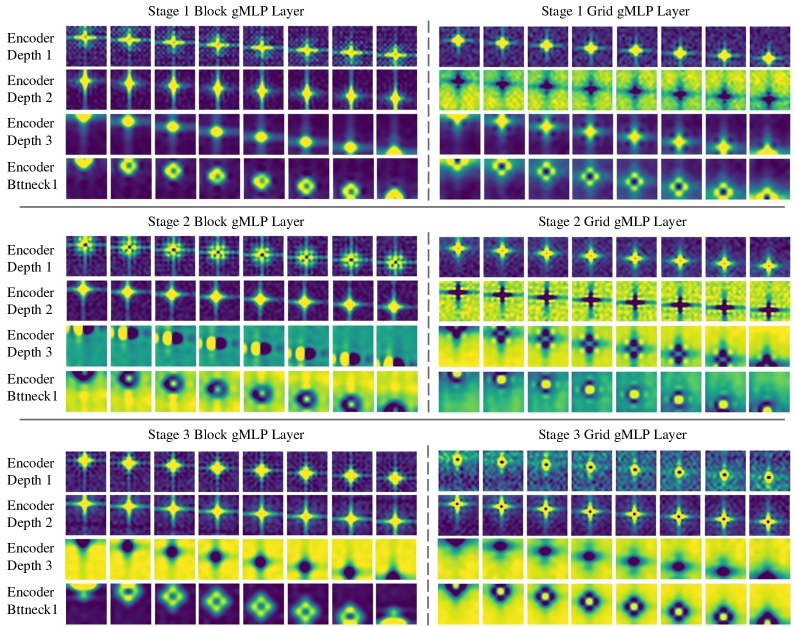
A.7 Weight Visualizations
Fig. 11 visualizes the spatial projection matrices of the block gMLP and the grid gMLP layers of each stage of MAXIM-3S trained on GoPro [62]. Similar to [54], we also observed that the weights after learning exhibit locality and spatial invariance. Surprisingly, the global grid gMLP layer also learns to perform ‘local’ operations (but on the uniform dilated grid). The spatial weights of block gMLP and grid gMLP in the same layer often demonstrate similar or coupled shapes, which may be attributed to the parallel-branch design in the multi-axis gMLP block. However, we have not observed a clear trend on how these filters at different stages vary.
A.8 Limitations and Discussions
One potential limitation of our model, which is shared with the existing SOTA, is the relatively inadequate generalization to real-world examples. This perhaps can be attributed to the training examples provided by the existing synthesized image restoration benchmarks. Creating more realistic, large-scale datasets through data-generation schemes [82, 94] can improve this shortcoming. Also, we observe that our model tends to slightly overfit certain benchmarks, because we did not apply a strong regularization (e.g., dropout) during training. Even though we find that regularization may result in a small reduction in performance for our models on these benchmarks we evaluated, it is worth exploring in future to effectively improve the generalization of our restoration models.
It is worth mentioning that our model is able to generate high quality sharp images, which are visually comparable to the state-of-the-art generative models [123, 36]. Notably, our model produces more conservative results without hallucinating many nonexistent details, delivering more reliable results than generative models.












References
- [1] Darmstadt noise dataset. https://noise.visinf.tu-darmstadt.de/benchmark, 2017. Accessed: 2021-10-30.
- [2] Abdelrahman Abdelhamed, Stephen Lin, and Michael S Brown. A high-quality denoising dataset for smartphone cameras. In CVPR, pages 1692–1700, 2018.
- [3] Saeed Anwar and Nick Barnes. Real image denoising with feature attention. In CVPR, pages 3155–3164, 2019.
- [4] Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, and Cordelia Schmid. Vivit: A video vision transformer. arXiv preprint arXiv:2103.15691, 2021.
- [5] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- [6] James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018.
- [7] Harold C Burger, Christian J Schuler, and Stefan Harmeling. Image denoising: Can plain neural networks compete with bm3d? In CVPR, pages 2392–2399. IEEE, 2012.
- [8] Vladimir Bychkovsky, Sylvain Paris, Eric Chan, and Frédo Durand. Learning photographic global tonal adjustment with a database of input/output image pairs. In CVPR, pages 97–104. IEEE, 2011.
- [9] Bolun Cai, Xiangmin Xu, Kui Jia, Chunmei Qing, and Dacheng Tao. Dehazenet: An end-to-end system for single image haze removal. IEEE TIP, 25(11):5187–5198, 2016.
- [10] Jiezhang Cao, Yawei Li, Kai Zhang, and Luc Van Gool. Video super-resolution transformer. arXiv preprint arXiv:2106.06847, 2021.
- [11] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In ECCV, pages 213–229. Springer, 2020.
- [12] Meng Chang, Qi Li, Huajun Feng, and Zhihai Xu. Spatial-adaptive network for single image denoising. In ECCV, pages 171–187. Springer, 2020.
- [13] Chun-Fu Chen, Quanfu Fan, and Rameswar Panda. Crossvit: Cross-attention multi-scale vision transformer for image classification. arXiv preprint arXiv:2103.14899, 2021.
- [14] Dongdong Chen, Mingming He, Qingnan Fan, Jing Liao, Liheng Zhang, Dongdong Hou, Lu Yuan, and Gang Hua. Gated context aggregation network for image dehazing and deraining. In 2019 IEEE winter conference on applications of computer vision (WACV), pages 1375–1383. IEEE, 2019.
- [15] Hanting Chen, Yunhe Wang, Tianyu Guo, Chang Xu, Yiping Deng, Zhenhua Liu, Siwei Ma, Chunjing Xu, Chao Xu, and Wen Gao. Pre-trained image processing transformer. In CVPR, pages 12299–12310, 2021.
- [16] Liangyu Chen, Xin Lu, Jie Zhang, Xiaojie Chu, and Chengpeng Chen. Hinet: Half instance normalization network for image restoration. In CVPRW, pages 182–192, 2021.
- [17] Li-Heng Chen, Christos G Bampis, Zhi Li, Andrey Norkin, and Alan C Bovik. Proxiqa: A proxy approach to perceptual optimization of learned image compression. IEEE TIP, 30:360–373, 2020.
- [18] Yilun Chen, Zhicheng Wang, Yuxiang Peng, Zhiqiang Zhang, Gang Yu, and Jian Sun. Cascaded pyramid network for multi-person pose estimation. In CVPR, pages 7103–7112, 2018.
- [19] Yu-Sheng Chen, Yu-Ching Wang, Man-Hsin Kao, and Yung-Yu Chuang. Deep photo enhancer: Unpaired learning for image enhancement from photographs with gans. In CVPR, pages 6306–6314, 2018.
- [20] Sung-Jin Cho, Seo-Won Ji, Jun-Pyo Hong, Seung-Won Jung, and Sung-Jea Ko. Rethinking coarse-to-fine approach in single image deblurring. In ICCV, pages 4641–4650, 2021.
- [21] Kostadin Dabov, Alessandro Foi, Vladimir Katkovnik, and Karen Egiazarian. Image denoising by sparse 3-d transform-domain collaborative filtering. IEEE TIP, 16(8):2080–2095, 2007.
- [22] Mauricio Delbracio, Hossein Talebi, and Peyman Milanfar. Projected distribution loss for image enhancement. ICCP, 2021.
- [23] Hang Dong, Jinshan Pan, Lei Xiang, Zhe Hu, Xinyi Zhang, Fei Wang, and Ming-Hsuan Yang. Multi-scale boosted dehazing network with dense feature fusion. In CVPR, pages 2157–2167, 2020.
- [24] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021.
- [25] Yazan Abu Farha and Jurgen Gall. Ms-tcn: Multi-stage temporal convolutional network for action segmentation. In CVPR, pages 3575–3584, 2019.
- [26] Xueyang Fu, Jiabin Huang, Xinghao Ding, Yinghao Liao, and John Paisley. Clearing the skies: A deep network architecture for single-image rain removal. IEEE TIP, 26(6):2944–2956, 2017.
- [27] Xueyang Fu, Jiabin Huang, Delu Zeng, Yue Huang, Xinghao Ding, and John Paisley. Removing rain from single images via a deep detail network. In CVPR, pages 3855–3863, 2017.
- [28] Hongyun Gao, Xin Tao, Xiaoyong Shen, and Jiaya Jia. Dynamic scene deblurring with parameter selective sharing and nested skip connections. In CVPR, pages 3848–3856, 2019.
- [29] Shi Guo, Zifei Yan, Kai Zhang, Wangmeng Zuo, and Lei Zhang. Toward convolutional blind denoising of real photographs. In CVPR, pages 1712–1722, 2019.
- [30] Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016.
- [31] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7132–7141, 2018.
- [32] Yuanming Hu, Hao He, Chenxi Xu, Baoyuan Wang, and Stephen Lin. Exposure: A white-box photo post-processing framework. ACM TOG, 37(2):1–17, 2018.
- [33] Zhe Hu, Sunghyun Cho, Jue Wang, and Ming-Hsuan Yang. Deblurring low-light images with light streaks. In CVPR, pages 3382–3389, 2014.
- [34] Kui Jiang, Zhongyuan Wang, Peng Yi, Chen Chen, Baojin Huang, Yimin Luo, Jiayi Ma, and Junjun Jiang. Multi-scale progressive fusion network for single image deraining. In CVPR, pages 8346–8355, 2020.
- [35] Liming Jiang, Bo Dai, Wayne Wu, and Chen Change Loy. Focal frequency loss for image reconstruction and synthesis. In ICCV, pages 13919–13929, 2021.
- [36] Yifan Jiang, Shiyu Chang, and Zhangyang Wang. Transgan: Two transformers can make one strong gan. arXiv preprint arXiv:2102.07074, 1(3), 2021.
- [37] Yifan Jiang, Xinyu Gong, Ding Liu, Yu Cheng, Chen Fang, Xiaohui Shen, Jianchao Yang, Pan Zhou, and Zhangyang Wang. Enlightengan: Deep light enhancement without paired supervision. IEEE TIP, 30:2340–2349, 2021.
- [38] Yoonsik Kim, Jae Woong Soh, Gu Yong Park, and Nam Ik Cho. Transfer learning from synthetic to real-noise denoising with adaptive instance normalization. In CVPR, pages 3482–3492, 2020.
- [39] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [40] Orest Kupyn, Volodymyr Budzan, Mykola Mykhailych, Dmytro Mishkin, and Jiří Matas. Deblurgan: Blind motion deblurring using conditional adversarial networks. In CVPR, pages 8183–8192, 2018.
- [41] Orest Kupyn, Tetiana Martyniuk, Junru Wu, and Zhangyang Wang. Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better. In ICCV, pages 8878–8887, 2019.
- [42] Wei-Sheng Lai, Jia-Bin Huang, Narendra Ahuja, and Ming-Hsuan Yang. Deep laplacian pyramid networks for fast and accurate super-resolution. In CVPR, pages 624–632, 2017.
- [43] Christian Ledig, Lucas Theis, Ferenc Huszár, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, et al. Photo-realistic single image super-resolution using a generative adversarial network. In CVPR, pages 4681–4690, 2017.
- [44] James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, and Santiago Ontanon. Fnet: Mixing tokens with fourier transforms. arXiv preprint arXiv:2105.03824, 2021.
- [45] Boyi Li, Xiulian Peng, Zhangyang Wang, Jizheng Xu, and Dan Feng. Aod-net: All-in-one dehazing network. In ICCV, pages 4770–4778, 2017.
- [46] Boyi Li, Wenqi Ren, Dengpan Fu, Dacheng Tao, Dan Feng, Wenjun Zeng, and Zhangyang Wang. Benchmarking single-image dehazing and beyond. IEEE TIP, 28(1):492–505, 2019.
- [47] Shi-Jie Li, Yazan AbuFarha, Yun Liu, Ming-Ming Cheng, and Juergen Gall. Ms-tcn++: Multi-stage temporal convolutional network for action segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–1, 2020.
- [48] Wenbo Li, Zhicheng Wang, Binyi Yin, Qixiang Peng, Yuming Du, Tianzi Xiao, Gang Yu, Hongtao Lu, Yichen Wei, and Jian Sun. Rethinking on multi-stage networks for human pose estimation. arXiv preprint arXiv:1901.00148, 2019.
- [49] Xia Li, Jianlong Wu, Zhouchen Lin, Hong Liu, and Hongbin Zha. Recurrent squeeze-and-excitation context aggregation net for single image deraining. In ECCV, pages 254–269, 2018.
- [50] Yinxiao Li, Pengchong Jin, Feng Yang, Ce Liu, Ming-Hsuan Yang, and Peyman Milanfar. Comisr: Compression-informed video super-resolution. In ICCV, 2021.
- [51] Yu Li, Robby T Tan, Xiaojie Guo, Jiangbo Lu, and Michael S Brown. Rain streak removal using layer priors. In CVPR, pages 2736–2744, 2016.
- [52] Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration using swin transformer. In IEEE Int. Conf. Comput. Vis. Worksh., 2021.
- [53] Ding Liu, Bihan Wen, Yuchen Fan, Chen Change Loy, and Thomas S Huang. Non-local recurrent network for image restoration. arXiv preprint arXiv:1806.02919, 2018.
- [54] Hanxiao Liu, Zihang Dai, David R So, and Quoc V Le. Pay attention to mlps. arXiv preprint arXiv:2105.08050, 2021.
- [55] Xiaohong Liu, Yongrui Ma, Zhihao Shi, and Jun Chen. Griddehazenet: Attention-based multi-scale network for image dehazing. In ICCV, pages 7314–7323, 2019.
- [56] Xing Liu, Masanori Suganuma, Zhun Sun, and Takayuki Okatani. Dual residual networks leveraging the potential of paired operations for image restoration. In CVPR, pages 7007–7016, 2019.
- [57] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. ICCV, 2021.
- [58] Zheng Liu, Botao Xiao, Muhammad Alrabeiah, Keyan Wang, and Jun Chen. Single image dehazing with a generic model-agnostic convolutional neural network. IEEE Signal Processing Letters, 26(6):833–837, 2019.
- [59] Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983, 2016.
- [60] Erik Matlin and Peyman Milanfar. Removal of haze and noise from a single image. In Computational Imaging X, volume 8296, page 82960T. International Society for Optics and Photonics, 2012.
- [61] Zibo Meng, Runsheng Xu, and Chiu Man Ho. Gia-net: Global information aware network for low-light imaging. In European Conference on Computer Vision, pages 327–342. Springer, 2020.
- [62] Seungjun Nah, Tae Hyun Kim, and Kyoung Mu Lee. Deep multi-scale convolutional neural network for dynamic scene deblurring. In CVPR, pages 3883–3891, 2017.
- [63] Seungjun Nah, Sanghyun Son, Suyoung Lee, Radu Timofte, and Kyoung Mu Lee. Ntire 2021 challenge on image deblurring. In CVPR Workshops, pages 149–165, June 2021.
- [64] Seungjun Nah, Sanghyun Son, Suyoung Lee, Radu Timofte, and Kyoung Mu Lee. Ntire 2021 challenge on image deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 149–165, 2021.
- [65] Zhangkai Ni, Wenhan Yang, Shiqi Wang, Lin Ma, and Sam Kwong. Towards unsupervised deep image enhancement with generative adversarial network. IEEE TIP, 29:9140–9151, 2020.
- [66] Ben Niu, Weilei Wen, Wenqi Ren, Xiangde Zhang, Lianping Yang, Shuzhen Wang, Kaihao Zhang, Xiaochun Cao, and Haifeng Shen. Single image super-resolution via a holistic attention network. In ECCV, pages 191–207. Springer, 2020.
- [67] Ozan Oktay, Jo Schlemper, Loic Le Folgoc, Matthew Lee, Mattias Heinrich, Kazunari Misawa, Kensaku Mori, Steven McDonagh, Nils Y Hammerla, Bernhard Kainz, et al. Attention u-net: Learning where to look for the pancreas. arXiv preprint arXiv:1804.03999, 2018.
- [68] Jinshan Pan, Deqing Sun, Hanspeter Pfister, and Ming-Hsuan Yang. Blind image deblurring using dark channel prior. In CVPR, pages 1628–1636, 2016.
- [69] Dongwon Park, Dong Un Kang, Jisoo Kim, and Se Young Chun. Multi-temporal recurrent neural networks for progressive non-uniform single image deblurring with incremental temporal training. In ECCV, pages 327–343. Springer, 2020.
- [70] Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. In AAAI, volume 32, 2018.
- [71] Olivier Petit, Nicolas Thome, Clement Rambour, Loic Themyr, Toby Collins, and Luc Soler. U-net transformer: self and cross attention for medical image segmentation. In International Workshop on Machine Learning in Medical Imaging, pages 267–276. Springer, 2021.
- [72] Tobias Plotz and Stefan Roth. Benchmarking denoising algorithms with real photographs. In CVPR, pages 1586–1595, 2017.
- [73] Rui Qian, Robby T Tan, Wenhan Yang, Jiajun Su, and Jiaying Liu. Attentive generative adversarial network for raindrop removal from a single image. In CVPR, pages 2482–2491, 2018.
- [74] Xu Qin, Zhilin Wang, Yuanchao Bai, Xiaodong Xie, and Huizhu Jia. Ffa-net: Feature fusion attention network for single image dehazing. In AAAI, volume 34, pages 11908–11915, 2020.
- [75] Yuhui Quan, Shijie Deng, Yixin Chen, and Hui Ji. Deep learning for seeing through window with raindrops. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2463–2471, 2019.
- [76] Yongming Rao, Wenliang Zhao, Zheng Zhu, Jiwen Lu, and Jie Zhou. Global filter networks for image classification. arXiv preprint arXiv:2107.00645, 2021.
- [77] Dongwei Ren, Wangmeng Zuo, Qinghua Hu, Pengfei Zhu, and Deyu Meng. Progressive image deraining networks: A better and simpler baseline. In CVPR, pages 3937–3946, 2019.
- [78] Wenqi Ren, Lin Ma, Jiawei Zhang, Jinshan Pan, Xiaochun Cao, Wei Liu, and Ming-Hsuan Yang. Gated fusion network for single image dehazing. In CVPR, 2018.
- [79] Jaesung Rim, Haeyun Lee, Jucheol Won, and Sunghyun Cho. Real-world blur dataset for learning and benchmarking deblurring algorithms. In ECCV, pages 184–201. Springer, 2020.
- [80] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015.
- [81] Ziyi Shen, Wenguan Wang, Xiankai Lu, Jianbing Shen, Haibin Ling, Tingfa Xu, and Ling Shao. Human-aware motion deblurring. In ICCV, pages 5572–5581, 2019.
- [82] Sanghyun Son, Jaeha Kim, Wei-Sheng Lai, Ming-Hsuan Yang, and Kyoung Mu Lee. Toward real-world super-resolution via adaptive downsampling models. IEEE transactions on pattern analysis and machine intelligence, 2021.
- [83] Maitreya Suin, Kuldeep Purohit, and AN Rajagopalan. Spatially-attentive patch-hierarchical network for adaptive motion deblurring. In CVPR, pages 3606–3615, 2020.
- [84] Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deep high-resolution representation learning for human pose estimation. In CVPR, pages 5693–5703, 2019.
- [85] Peize Sun, Yi Jiang, Rufeng Zhang, Enze Xie, Jinkun Cao, Xinting Hu, Tao Kong, Zehuan Yuan, Changhu Wang, and Ping Luo. Transtrack: Multiple-object tracking with transformer. arXiv preprint arXiv:2012.15460, 2020.
- [86] Xin Tao, Hongyun Gao, Xiaoyong Shen, Jue Wang, and Jiaya Jia. Scale-recurrent network for deep image deblurring. In CVPR, pages 8174–8182, 2018.
- [87] Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, et al. Mlp-mixer: An all-mlp architecture for vision. arXiv preprint arXiv:2105.01601, 2021.
- [88] Hugo Touvron, Piotr Bojanowski, Mathilde Caron, Matthieu Cord, Alaaeldin El-Nouby, Edouard Grave, Gautier Izacard, Armand Joulin, Gabriel Synnaeve, Jakob Verbeek, et al. Resmlp: Feedforward networks for image classification with data-efficient training. arXiv preprint arXiv:2105.03404, 2021.
- [89] Ashish Vaswani, Prajit Ramachandran, Aravind Srinivas, Niki Parmar, Blake Hechtman, and Jonathon Shlens. Scaling local self-attention for parameter efficient visual backbones. In CVPR, pages 12894–12904, 2021.
- [90] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS, pages 5998–6008, 2017.
- [91] Tianyu Wang, Xin Yang, Ke Xu, Shaozhe Chen, Qiang Zhang, and Rynson WH Lau. Spatial attentive single-image deraining with a high quality real rain dataset. In CVPR, pages 12270–12279, 2019.
- [92] Wenjing Wang, Chen Wei, Wenhan Yang, and Jiaying Liu. Gladnet: Low-light enhancement network with global awareness. In 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), pages 751–755. IEEE, 2018.
- [93] Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. In CVPR, pages 7794–7803, 2018.
- [94] Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1905–1914, 2021.
- [95] Xintao Wang, Ke Yu, Shixiang Wu, Jinjin Gu, Yihao Liu, Chao Dong, Yu Qiao, and Chen Change Loy. Esrgan: Enhanced super-resolution generative adversarial networks. In IEEE Eur. Conf. Comput. Vis. Worksh., pages 0–0, 2018.
- [96] Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE TIP, 13:600–612, 2004.
- [97] Zhendong Wang, Xiaodong Cun, Jianmin Bao, and Jianzhuang Liu. Uformer: A general u-shaped transformer for image restoration. arXiv preprint arXiv:2106.03106, 2021.
- [98] Chen Wei, Wenjing Wang, Wenhan Yang, and Jiaying Liu. Deep retinex decomposition for low-light enhancement. arXiv preprint arXiv:1808.04560, 2018.
- [99] Wei Wei, Deyu Meng, Qian Zhao, Zongben Xu, and Ying Wu. Semi-supervised transfer learning for image rain removal. In CVPR, pages 3877–3886, 2019.
- [100] Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon. Cbam: Convolutional block attention module. In ECCV, pages 3–19, 2018.
- [101] Haiyan Wu, Yanyun Qu, Shaohui Lin, Jian Zhou, Ruizhi Qiao, Zhizhong Zhang, Yuan Xie, and Lizhuang Ma. Contrastive learning for compact single image dehazing. In CVPR, pages 10551–10560, 2021.
- [102] Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. Segformer: Simple and efficient design for semantic segmentation with transformers. arXiv preprint arXiv:2105.15203, 2021.
- [103] Li Xu, Shicheng Zheng, and Jiaya Jia. Unnatural l0 sparse representation for natural image deblurring. In CVPR, pages 1107–1114, 2013.
- [104] Runsheng Xu, Hao Xiang, Zhengzhong Tu, Xin Xia, Ming-Hsuan Yang, and Jiaqi Ma. V2x-vit: Vehicle-to-everything cooperative perception with vision transformer. arXiv preprint arXiv:2203.10638, 2022.
- [105] Wenhan Yang, Robby T Tan, Jiashi Feng, Jiaying Liu, Zongming Guo, and Shuicheng Yan. Deep joint rain detection and removal from a single image. In CVPR, pages 1357–1366, 2017.
- [106] Rajeev Yasarla and Vishal M Patel. Uncertainty guided multi-scale residual learning-using a cycle spinning cnn for single image de-raining. In CVPR, pages 8405–8414, 2019.
- [107] Zongsheng Yue, Hongwei Yong, Qian Zhao, Lei Zhang, and Deyu Meng. Variational denoising network: Toward blind noise modeling and removal. arXiv preprint arXiv:1908.11314, 2019.
- [108] Zongsheng Yue, Qian Zhao, Lei Zhang, and Deyu Meng. Dual adversarial network: Toward real-world noise removal and noise generation. In ECCV, pages 41–58. Springer, 2020.
- [109] Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming-Hsuan Yang, and Ling Shao. Cycleisp: Real image restoration via improved data synthesis. In CVPR, pages 2696–2705, 2020.
- [110] Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming-Hsuan Yang, and Ling Shao. Learning enriched features for real image restoration and enhancement. In ECCV, pages 492–511. Springer, 2020.
- [111] Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming-Hsuan Yang, and Ling Shao. Multi-stage progressive image restoration. In CVPR, pages 14821–14831, 2021.
- [112] Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412, 2017.
- [113] Hongguang Zhang, Yuchao Dai, Hongdong Li, and Piotr Koniusz. Deep stacked hierarchical multi-patch network for image deblurring. In CVPR, pages 5978–5986, 2019.
- [114] He Zhang and Vishal M Patel. Density-aware single image de-raining using a multi-stream dense network. In CVPR, pages 695–704, 2018.
- [115] He Zhang, Vishwanath Sindagi, and Vishal M Patel. Image de-raining using a conditional generative adversarial network. IEEE TCSVT, 30(11):3943–3956, 2019.
- [116] Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, and Dimitris N Metaxas. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In ICCV, pages 5907–5915, 2017.
- [117] Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, and Dimitris N Metaxas. Stackgan++: Realistic image synthesis with stacked generative adversarial networks. IEEE TPAMI, 41(8):1947–1962, 2018.
- [118] Jiawei Zhang, Jinshan Pan, Jimmy Ren, Yibing Song, Linchao Bao, Rynson WH Lau, and Ming-Hsuan Yang. Dynamic scene deblurring using spatially variant recurrent neural networks. In CVPR, pages 2521–2529, 2018.
- [119] Kaihao Zhang, Wenhan Luo, Yiran Zhong, Lin Ma, Bjorn Stenger, Wei Liu, and Hongdong Li. Deblurring by realistic blurring. In CVPR, pages 2737–2746, 2020.
- [120] Kai Zhang, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE TIP, 26(7):3142–3155, 2017.
- [121] Yulun Zhang, Yapeng Tian, Yu Kong, Bineng Zhong, and Yun Fu. Residual dense network for image super-resolution. In CVPR, pages 2472–2481, 2018.
- [122] Yonghua Zhang, Jiawan Zhang, and Xiaojie Guo. Kindling the darkness: A practical low-light image enhancer. In ACM MM, pages 1632–1640, 2019.
- [123] Long Zhao, Zizhao Zhang, Ting Chen, Dimitris N Metaxas, and Han Zhang. Improved transformer for high-resolution gans. arXiv preprint arXiv:2106.07631, 2021.
- [124] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. In ICCV, pages 2223–2232, 2017.
- [125] Xiang Zhu, Filip Šroubek, and Peyman Milanfar. Deconvolving psfs for a better motion deblurring using multiple images. In European Conference on Computer Vision, pages 636–647. Springer, 2012.