Are we really making much progress? Revisiting, benchmarking, and refining heterogeneous graph neural networks
Abstract.
11footnotetext: Equal contribution.44footnotetext: Corresponding Author.Heterogeneous graph neural networks (HGNNs) have been blossoming in recent years, but the unique data processing and evaluation setups used by each work obstruct a full understanding of their advancements. In this work, we present a systematical reproduction of 12 recent HGNNs by using their official codes, datasets, settings, and hyperparameters, revealing surprising findings about the progress of HGNNs. We find that the simple homogeneous GNNs, e.g., GCN and GAT, are largely underestimated due to improper settings. GAT with proper inputs can generally match or outperform all existing HGNNs across various scenarios. To facilitate robust and reproducible HGNN research, we construct the Heterogeneous Graph Benchmark (HGB)111All codes and data are available at https://github.com/THUDM/HGB, and the HGB leaderboard is at https://www.biendata.xyz/hgb., consisting of 11 diverse datasets with three tasks. HGB standardizes the process of heterogeneous graph data splits, feature processing, and performance evaluation. Finally, we introduce a simple but very strong baseline Simple-HGN—which significantly outperforms all previous models on HGB—to accelerate the advancement of HGNNs in the future.
1. Introduction
As graph neural networks (GNNs) (Kipf and Welling, 2017; Battaglia et al., 2018) have already occupied the centre stage of graph mining research within recent years, the researchers begin to pay attention to their potential on heterogeneous graphs (a.k.a., Heterogeneous Information Networks) (Hu et al., 2020b; Dong et al., 2017; Wang et al., 2019b; Yun et al., 2019; Fu et al., 2020; Yang et al., 2020b). Heterogeneous graphs consist of multiple types of nodes and edges with different side information, connecting the novel and effective graph-learning algorithms to the noisy and complex industrial scenarios, e.g., recommendation.
To tackle the challenge of heterogeneity, various heterogeneous GNNs (HGNNs) (Wang et al., 2019b; Yun et al., 2019; Yang et al., 2020b) have been proposed to address the relevant tasks, including node classification, link prediction, and knowledge-aware recommendation. Take node classification for example, numerous HGNNs, such as HAN (Wang et al., 2019b), GTN (Yun et al., 2019), RSHN (Zhu et al., 2019), HetGNN (Zhang et al., 2019), MAGNN (Fu et al., 2020), HGT (Hu et al., 2020a), and HetSANN (Hong et al., 2020) were developed within the last two years.
Despite various new models developed, our understanding of how they actually make progress has been thus far limited by the unique data processing and settings adopted by each of them. To fully picture the advancements in this field, we comprehensively reproduce the experiments of 12 most popular HGNN models by using the codes, datasets, experimental settings, hyperparameters released by their original papers. Surprisingly, we find that the results generated by these state-of-the-art HGNNs are not as exciting as promised (Cf. Table 1), that is:
-
(1)
The performance of simple homogeneous GNNs, i.e., GCN (Kipf and Welling, 2017) and GAT (Veličković et al., 2017), is largely underestimated. Even vanilla GAT can outperform existing HGNNs in most cases with proper inputs.
-
(2)
Performances of some previous works are mistakenly reported due to inappropriate settings or data leakage.
Our further investigation also suggests:
-
(3)
Meta-paths are not necessary in most heterogeneous datasets.
-
(4)
There is still considerable room for improvements in HGNNs.
In our opinion, the above situation occurs largely because the individual data and experimental setup by each work obstructs a fair and consistent validation of different techniques, thus greatly hindering the advancements of HGNNs.
To facilitate robust and open HGNN developments, we build the Heterogeneous Graph Benchmark (HGB). HGB currently contains 11 heterogeneous graph datasets that vary in heterogeneity (the number of node and edge types), tasks (node classification, link prediction, and knowledge-aware recommendation), and domain (e.g., academic graphs, user-item graphs, and knowledge graphs). HGB provides a unified interface for data loading, feature processing, and evaluation, offering a convenient and consistent way to compare HGNN models. Similar to OGB (Hu et al., 2020c), HGB also hosts a leaderboard (https://www.biendata.xyz/hgb) for publicizing reproducible state-of-the-art HGNNs.
Finally, inspired by GAT’s significance in Table 1, we take GAT as backbone to design an extremely simple HGNN model—Simple-HGN. Simple-HGN can be viewed as GAT enhanced by three existing techniques: (1) learnable type embedding to leverage type information, (2) residual connections to enhance modeling power, and (3) normalization on the output embedddings. In ablation studies, these techniques steadily improve the performance. Experimental results on HGB suggest that Simple-HGN can consistently outperform previous HGNNs on three tasks across 11 datasets, making it to date the first HGNN model that is significantly better than the vanilla GAT.
To sum up, this work makes the following contributions:
-
•
We revisit HGNNs and identify issues blocking progress;
-
•
We benchmark HGNNs by HGB for robust developments;
-
•
We refine HGNNs by designing the Simple-HGN model.
| HAN (Wang et al., 2019b) | GTN (Yun et al., 2019) | RSHN (Zhu et al., 2019) | HetGNN (Zhang et al., 2019) | MAGNN (Fu et al., 2020) | ||||||||||
| Dataset | ACM | DBLP | ACM | IMDB | AIFB | MUTAG | BGS | MC (10%) | MC (30%) | DBLP | ||||
| Metric | Macro-F1 | Micro-F1 | Macro-F1 | Macro-F1 | Macro-F1 | Accuracy | Accuracy | Accuracy | Macro-F1 | Micro-F1 | Macro-F1 | Micro-F1 | Macro-F1 | Micro-F1 |
| model* | 91.89 | 91.85 | 94.18 | 92.68 | 60.92 | 97.22 | 82.35 | 93.10 | 97.8 | 97.9 | 98.1 | 98.2 | 93.13 | 93.61 |
| GCN* | 89.31 | 89.45 | 87.30 | 91.60 | 56.89 | - | - | - | - | - | - | - | 88.00 | 88.51 |
| GAT* | 90.55 | 90.55 | 93.71 | 92.33 | 58.14 | 91.67 | 72.06 | 66.32 | 96.2 | 96.3 | 96.5 | 96.5 | 91.05 | 91.61 |
| model | 90.94 | 90.96 | 92.95 | 92.28 | 57.532.22 | 97.22 | 82.35 | 93.10 | 97.06 | 97.11 | 97.34 | 97.37 | 92.81 | 93.36 |
| GCN | 92.25 | 92.29 | 91.48 | 92.28 | 59.111.73 | 97.22 | 79.41 | 96.55 | 91.88 | 92.04 | 95.37 | 95.57 | 88.31 | 89.37 |
| GAT | 92.08 | 92.15 | 94.18 | 92.49 | 58.861.73 | 100 | 80.88 | 100 | 98.25 | 98.30 | 98.42 | 98.50 | 94.40 | 94.78 |
2. Preliminaries
2.1. Heterogeneous Graph
A heterogeneous graph (Sun and Han, 2012) can be defined as , where is the set of nodes and is the set of edges. Each node has a type , and each edge has a type . The sets of possible node types and edge types are denoted by and , respectively. When , the graph degenerates into an ordinary homogeneous graph.
2.2. Graph Neural Networks
GNNs aim to learn a representation vector for each node after L-layer transformations, based on the graph structure and the initial node feature . The final representation can serve various downstream tasks, e.g., node classification, graph classification (after pooling), and link prediction.
Graph Convolution Network (GCN) (Kipf and Welling, 2017) is the pioneer of GNN models, where the layer is defined as
| (1) |
where is the representation of all nodes after the layer. is a trainable weight matrix. is the activation function, and is the normalized adjacency matrix with self-connections.
Graph Attention Network (GAT) (Veličković et al., 2017) later replaces the average aggregation from neighbors, i.e., , as a weighted one, where the weight for each edge is from an attention mechanism as (layer mark is omitted for simplicity)
| (2) |
where and are learnable weights and represents the neighbors of node . Multi-head attention technique (Vaswani et al., 2017) is also used to improve the performance.
Many following works (Abu-El-Haija et al., 2019; Xu et al., 2018a; Ding et al., 2018; Feng et al., 2020) improve GCN and GAT furthermore, with focuses on homogeneous graphs. Actually, these homogeneous GNNs can also handle heterogeneous graphs by simply ignoring the node and edge types.
2.3. Meta-Paths in Heterogeneous Graphs
Meta-paths (Sun and Han, 2012; Sun et al., 2011) have been widely used for mining and learning with heterogeneous graphs. A meta-path is a path with a pre-defined (node or edge) types pattern, i.e., , where and . Researchers believe that these composite patterns imply different and useful semantics. For instance, “authorpaperauthor” meta-path defines the “co-author” relationship, and “useritemuseritem” indicates the first user may be a potential costumer of the last item.
Given a meta-path , we can re-connect the nodes in to get a meta-path neighbor graph . Edge exists in if and only if there is at least one path between and following the meta-path in the original graph .
3. Issues with Existing Heterogeneous GNNs
We analyze popular heterogeneous GNNs (HGNNs) organized by the tasks that they aim to address. For each HGNN, the analysis will be emphasized on its defects found in the process of reproducing its result by using its official code, the same datasets, settings, and hyperparameters as its original paper, which is summarized in Table 1.
3.1. Node Classification
3.1.1. HAN (Wang et al., 2019b).
Heterogeneous graph attention network (HAN) is among the early attempts to tackle with heterogeneous graphs. Firstly, HAN needs multiple meta-paths selected by human experts. Then HAN uses a hierarchical attention mechanism to capture both node-level and semantic-level importance. For each meta-path, the node-level attention is achieved by a GAT on its corresponding meta-path neighbor graph. And the semantic-level attention, which gives the final representation, refers to a weighted average of the node-level results from all meta-path neighbor graphs.
A defect of HAN is its unfair comparison between HAN and GAT. Since HAN can be seen as a weighted ensemble of GATs on many meta-path neighbor graphs, a comparison with the vanilla GAT is essential to prove its effectiveness. However, the GCN and GAT baselines in this paper take only one meta-path neighbor graph as input, losing a large part of information in the original graph, even though they report the result of the best meta-path neighbor graph.
To make a fair comparison, we feed the original graph into GAT by ignoring the types and only keeping the features of the target-type nodes. We find that this simple homogeneous approach consistently outperforms HAN, suggesting that the homogeneous GNNs are largely underestimated (See Table 1 for details).
Most of the following works also follow HAN’s setting to compare with homogeneous GNNs, suffering from the “information missing in homogeneous baselines” problem, which leads to a positive cognitive deviation on the performance progress of HGNNs.
3.1.2. GTN (Yun et al., 2019).
Graph transformer network (GTN) is able to discover valuable meta-paths automatically, instead of depending on manual selection like HAN. The intuition is that a meta-path neighbor graph can be obtained by multiplying the adjacency matrices of several sub-graphs. Therefore, GTN uses a soft sub-graph selection and matrix multiplication step to generate meta-path neighbor graphs, and then encodes the graphs by GCNs.
The main drawback of GTN is that it consumes gigantic amount of time and memory. For example, it needs 120 GB memory and 12 hours to train a GTN on DBLP with only 18,000 nodes. In contrast, GCN and GAT only take 1 GB memory and 10 seconds of time.
Moreover, when we test the GTN and GAT five times using the official codes of GTN, we find from Table 1 that their average scores are not significantly different, though GTN consumes time and memory of GAT.
3.1.3. RSHN (Zhu et al., 2019)
Relation structure-aware heterogeneous graph neural network (RSHN) builds coarsened line graph to obtain edge features first, then uses a novel Message Passing Neural Network (MPNN) (Gilmer et al., 2017) to propagate node and edge features.
The experiments in RSHN have serious problems according to the official code. First, it does not use validation set, and just tune hyperparameters on test set. Second, it reports the accuracy at the epoch with best accuracy on test set in the paper. As shown in Table 1, our well-tuned GAT can even reach 100% accuracy under this improper setting on the AIFB and BGS datasets, which is far better than the 91.67% and 66.32% reported in their paper.
3.1.4. HetGNN (Zhang et al., 2019)
Heterogeneous graph neural network (HetGNN) first uses random walks with restart to generate neighbors for nodes, and then leverages Bi-LSTM to aggregate node features for each type and among types.
HetGNN has the same “information missing in homogeneous baselines” problem as HAN: when comparing it with GAT, a sampled graph instead of the original full graph is fed to GAT. As demonstrated in Table 1, GAT with correct inputs gets clearly better performance.
3.1.5. MAGNN (Fu et al., 2020)
Meta-path aggregated graph neural network (MAGNN) is an enhanced HAN. The motivation is that when HAN deals with meta-path neighbor graphs, it only considers two endpoints of the meta-paths but ignores the intermediate nodes. MAGNN proposes several meta-path encoders to encode all the information along the path, instead of only the endpoints.
However, there are two problems in the experiments of MAGNN. First, MAGNN inherits the “information missing in homogeneous baselines” problem from HAN, and also underperforms GAT with correct inputs.
More seriously, MAGNN has a data leakage problem in link prediction, because it uses batch normalization, and loads positive and negative links sequentially during both training and testing periods. In this way, samples in a minibatch are either all positive or all negative, and the mean and variance in batch normalization will provide extra information. If we shuffle the test set to make each minibatch contains both positive and negative samples randomly, the AUC of MAGNN drops dramatically from 98.91 to 71.49 on the Last.fm dataset.
3.1.6. HGT (Hu et al., 2020a)
Heterogeneous graph transformer (HGT) proposes a transformer-based model for handling large academic heterogeneous graphs with heterogeneous subgraph sampling. As HGT mainly focuses on handling web-scale graphs via graph sampling strategy (Hamilton et al., 2017; Yang et al., 2020a), the datasets used in its paper (¿ 10,000,000 nodes) are unaffordable for most HGNNs, unless adapting them by subgraph sampling. To eliminate the impact of subgraph sampling techniques on the performance, we apply HGT with its official code on the relatively small datasets that are not used in its paper, producing mixed results when compared to GAT (See Table 3).
3.1.7. HetSANN (Hong et al., 2020)
Attention-based graph neural network for heterogeneous structural learning (HetSANN) uses a type-specific graph attention layer for the aggregation of local information, avoiding manually selecting meta-paths. HetSANN is reported to have promising performance in the paper.
However, the datasets and preprocessing details are not released with the official codes, and responses from its authors are not received as of the submission of this work. Therefore, we directly apply HetSANN with standard hyperparameter-tuning, giving unpromising results on other datasets (See Table 3).
3.2. Link Prediction
3.2.1. RGCN (Schlichtkrull et al., 2018)
Relational graph convolutional network (RGCN) extends GCN to relational (multiple edge types) graphs. The convolution in RGCN can be interpreted as a weighted sum of ordinary graph convolution with different edge types. For each node , the layer of convolution are defined as follows,
| (3) |
where is a normalization constant and s are learnable parameters.
3.2.2. GATNE (Cen et al., 2019)
General attributed multiplex heterogeneous network embedding (GATNE) leverages the graph convolution operation to aggregate the embeddings from neighbors. It relies on Skip-gram to learn a general embedding, a specific embedding and an attribute embedding respectively, and finally fuses all of them. In fact, GATNE is more a network embedding algorithm than a GNN-style model.
3.3. Knowledge-Aware Recommendation
Recommendation is a main application for Heterogeneous GNNs, but most related works (Fan et al., 2019b, a; Niu et al., 2020; Liu et al., 2020) only focus on their specific industrial data, resulting in non-open datasets and limited transferability of the models. Knowledge-aware recommendation is an emerging sub-field, aiming to improve recommendation by linking items with entities in an open knowledge graph. In this paper, we mainly survey and benchmark models on this topic.
3.3.1. KGCN (Wang et al., 2019d) and KGNN-LS (Wang et al., 2019c)
KGCN enhances the item representation by performing aggregations among its corresponding entity neighborhood in a knowledge graph. KGNN-LS further poses a label smoothness assumption, which posits that similar items in the knowledge graph are likely to have similar user preference. It adds a regularization term to help learn such a personalized weighted knowledge graph.
3.3.2. KGAT (Wang et al., 2019a)
KGAT shares a generally similar idea with KGCN. The main difference lies in an auxiliary loss for knowledge graph reconstruction and the pretrained BPR-MF (Rendle et al., 2009) features as inputs. Although not detailed in its paper, an important contribution of KGAT is to introduce the pretrained features into this tasks, which greatly improves the performance. Based on this finding, we successfully simplify KGAT and obtain similar or even better performance (See Table 5, denoted as KGAT).
3.4. Summary
In summary, the prime common issue of existing HGNNs is the lack of fair comparison with homogeneous GNNs and other works—to some extent—encourage the new models to equip themselves with novel yet redundant modules, instead of focusing more on progress in performance. Additionally, a non-negligible proportion of works have individual issues, e.g., data leakage (Fu et al., 2020), tuning on test set (Zhu et al., 2019), and two-order-of-magnitude more memory and time consumption without effectiveness improvements (Yun et al., 2019).
In light of the significant discrepancy, we take the initiative to setup a heterogeneous graph benchmark (HGB) with these three tasks on diverse datasets for open, reproducible heterogeneous graph research (See §4). Inspired by the promising advantages of the simple GAT over dedicated and relatively-complex heterogeneous GNN models, we present a simple heterogeneous GNN model with GAT as backbone, offering promising results on HGB (See §5).
4. Heterogeneous Graph Benchmark
4.1. Motivation and Overview
Issues with current datasets. Several types of datasets—academic networks (e.g., ACM, DBLP), information networks (e.g., IMDB, Reddit), and recommendation graphs (e.g., Amazon, MovieLens)—are the most frequently-used datasets, but the detailed task settings could be quite different in different papers. For instance, HAN (Wang et al., 2019b) and GTN (Yun et al., 2019) discard the citation links in ACM, while others use the original version. Besides, different splits of the dataset also contribute to uncomparable results. Finally, the recent graph benchmark OGB (Hu et al., 2020c) mostly focuses on benchmarking graph machine learning methods on homogeneous graphs and is not dedicated to heterogeneous graphs.
Issues with current pipelines. To fulfill a task, components outsides HGNNs can also play critical roles. For example, MAGNN (Fu et al., 2020) finds that not all types of node features are useful, and a pre-selection based on validation set could be helpful (See § 4.3). RGCN (Schlichtkrull et al., 2018) uses DistMult (Yang et al., 2014) instead of dot product for training in link prediction. We need to control the other components in the pipeline for fair comparison.
HGB. In view of these practical issues, we present the heterogeneous graph benchmark (HGB) for open, reproducible heterogeneous GNN research. We standardize the process of data splits, feature processing, and performance evaluation, by establishing the HGB pipeline “feature preprocessing HGNN encoder downstream decoder”. For each model, HGB selects the best fit feature preprocessing and downstream decoder based on its performance on validation set.
4.2. Dataset Construction
HGB collects 11 widely-recognized medium-scale datasets with predefined meta-paths from previous works, making it available to all kinds of HGNNs. The statistics are summarized in Table 2.
4.2.1. Node Classification
Node Classification follows a transductive setting, where all edges are available during training and node labels are split according to 24% for training, 6% for validation and 70% for test in each dataset.
-
•
DBLP222http://web.cs.ucla.edu/~yzsun/data/ is a bibliography website of computer science. We use a commonly used subset in 4 areas with nodes representing authors, papers, terms and venues.
-
•
IMDB333https://www.kaggle.com/karrrimba/movie-metadatacsv is a website about movies and related information. A subset from Action, Comedy, Drama, Romance and Thriller classes is used.
-
•
ACM is also a citation network. We use the subset hosted in HAN (Wang et al., 2019b), but preserve all edges including paper citations and references.
-
•
Freebase (Bollacker et al., 2008) is a huge knowledge graph. We sample a subgraph of 8 genres of entities with about 1,000,000 edges following the procedure of a previous survey (Yang et al., 2020c).
4.2.2. Link Prediction
Link prediction is formulated as a binary classification problem in HGB. The edges are split according to 81% for training, 9% for validation and 10% for test. Then the graph is reconstructed only by edges in the training set. For negative node pairs in testing, we firstly tried uniform sampling and found that most models could easily make a nearly perfect prediction (See Appendix B). Finally, we sample 2-hop neighbors for negative node pairs, of which are 1:1 ratio to the positive pairs in the test set.
-
•
Amazon is an online purchasing platform. We use the subset preprocessed by GATNE (Cen et al., 2019), containing electronics category products with co-viewing and co-purchasing links between them.
-
•
LastFM is an online music website. We use the subset released by HetRec 2011 (Cantador et al., 2011), and preprocess the dataset by filtering out the users and tags with only one link.
-
•
PubMed444https://pubmed.ncbi.nlm.nih.gov is a biomedical literature library. We use the subset constructed by HNE (Yang et al., 2020c).
4.2.3. Knowledge-aware recommendation
We randomly split 20% of user-item interactions as test set for each user, and for the left 80% interactions as training set.
-
•
Amazon-book is a subset of Amazon-review555http://jmcauley.ucsd.edu/data/amazon/ related to books.
-
•
LastFM is a subset extracted from last.fm with timestamp from January, 2015 to June, 2015.
-
•
Yelp-2018666https://www.yelp.com/dataset is a dataset adapted from 2018 edition of the Yelp challenge. Local businesses like restaurants and bars are seen as items.
-
•
Movielens is a subset of Movielens-20M777https://grouplens.org/datasets/movielens/, which is a widely used dataset for recommendation.
To assure the quality of dataset, we use 10-core setting to filter low-frequency nodes. To align items to knowledge graph entities, we adopt the same procedure as (Wang et al., 2019d, a).
| Node Classification | #Nodes | #Node Types | #Edges | #Edge Types | Target | #Classes |
| DBLP | 26,128 | 4 | 239,566 | 6 | author | 4 |
| IMDB | 21,420 | 4 | 86,642 | 6 | movie | 5 |
| ACM | 10,942 | 4 | 547,872 | 8 | paper | 3 |
| Freebase | 180,098 | 8 | 1,057,688 | 36 | book | 7 |
| Link Prediction | Target | |||||
| Amazon | 10,099 | 1 | 148,659 | 2 | product-product | |
| LastFM | 20,612 | 3 | 141,521 | 3 | user-artist | |
| PubMed | 63,109 | 4 | 244,986 | 10 | disease-disease | |
| Recommendation | Amazon-book | LastFM | Movielens | Yelp-2018 | |
| #Users | 70,679 | 23,566 | 37,385 | 45,919 | |
| #Items | 24,915 | 48,123 | 6,182 | 45,538 | |
| #Interactions | 846,434 | 3,034,763 | 539,300 | 1,183,610 | |
| #Entities | 113,487 | 106,389 | 24,536 | 136,499 | |
| #Relations | 39 | 9 | 20 | 42 | |
| #Triplets | 2,557,746 | 464,567 | 237,155 | 1,853,704 |
4.3. Feature Preprocessing
As pointed out in § 4.1, the preprocessing for input features has a great impact on the performance. Our preprocessing methods are as follows.
Linear Transformation. As the input feature of different types of nodes may vary in dimension, we use a linear layer with bias for each node type to map all node features to a shared feature space. The parameters in these linear layers will be optimized along with the following HGNN.
Useful Types Selection. In many datasets, only features of a part of types are useful to the task. We can select a subset of node types to keep their features, and replace the features of nodes of other types as one-hot vectors. Combined with linear transformation, the replacement is equivalent to learn an individual embedding for each node of the unselected types. Ideally, we should enumerate all subsets of types and report the best one based on the performance on the validation set, but due to the high consumption to train the model times, we decide to only enumerate three choices, i.e. using all given node features, using only features of target node type, or replacing all node features as one-hot vectors.
4.4. Downstream Decoders and Loss function
4.4.1. Node Classification
After setting the final dimension of HGNNs the same as the number of classes, we then adopt the most usual loss functions. For single-label classification, we use softmax and cross-entropy loss. For multi-label datasets, i.e. IMDB in HGB, we use a sigmoid activation and binary cross-entropy loss.
4.4.2. Link Prediction
As RGCN (Battaglia et al., 2018) suggests, DistMult (Yang et al., 2014) performs better than direct dot product, due to multiple types of edges, i.e. for node pair and a target edge type ,
| (4) |
where is a learnable square matrix (sometimes regularized with diagonal matrix) for type . We find that DistMult outperforms dot product sometimes even when there is only single type of edge to predict. We try both dot product and DistMult decoders, and report the best results. The loss function is binary cross-entropy.
4.4.3. Knowledge-aware Recommendation
Recommendation is similar to link prediction, but differs in data distribution and focuses more on ranking. We define the similarity function between nodes based on dot product. As mentioned in § 3.3.2, pretrained BPR-MF embeddings are of vital importance. We incorporate the BPR-MF embeddings via a bias term in to avoid modification on the input or architectures of other models, i.e.,
| (5) |
Following KGAT (Wang et al., 2019a), we opt for BPR (Rendle et al., 2009) loss for training.
| (6) |
where is a positive pair, and is a negative pair sampled at random.
4.5. Evaluation Settings
We evaluate all methods for all datasets by running 5 times with different random seeds, and reporting the average score and standard deviation.
4.5.1. Node Classification
We evaluate node classification with Macro-F1 and Micro-F1 metrics for both multi-class (DBLP, ACM, Freebase) and multi-label (IMDB) datasets. The implementation is based on sklearn888https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html.
4.5.2. Link Prediction
We evaluate link prediction with ROC-AUC (area under the ROC curve) and MRR (mean reciprocal rank) metrics. Since we usually need to determine a threshold when to classify a pair as positive for the score given by decoder, ROC-AUC can evaluate the performance under difference threshold at a whole scope. MRR can evaluate the ranking performance for different methods. Following (Yang et al., 2020c), we calculate MRR scores clustered by the head of pairs in test set, and return the average of them as MRR performance.
4.5.3. Knowledge-aware Recommendation
Recommendation task focuses more on ranking instead of classification. Therefore, we adopt recall@20 and ndcg@20 as our evaluation metrics. The average metrics for all users in test set are reported as benchmark performance.
5. A Simple Heterogeneous GNN
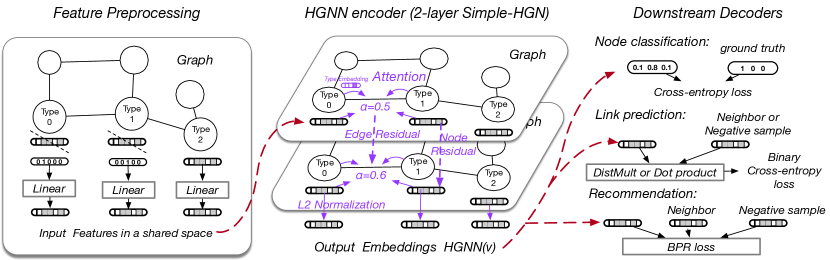
Inspired by the advantage of the simple GAT over advanced and dedicated heterogeneous GNNs, we present Simple-HGN, a simple and effective method for modeling heterogeneous graph. Simple-HGN adopts GAT as backbone with enhancements from the redesign of three well-known techniques: Learnable edge-type embedding, residual connections, and normalization on the output embeddings. Figure 1 illustrates the full pipeline with Simple-HGN .
5.1. Learnable Edge-type Embedding
Though GAT has powerful capacity in modeling homogeneous graphs, it may be not optimal for heterogeneous graphs due to the neglect of node or edge types. To tackle this problem, we extend the original graph attention mechanism by including edge type information into attention calculation. Specifically, at each layer, we allocate a dimensional embedding for each edge type , and use both edge type embeddings and node embeddings to calculate the attention score as follows999We omit the superscript in this equation for the sake of brevity.:
| (7) |
where represents the type of edge between node and node , and is a learnable matrix to transform type embeddings.
| DBLP | IMDB | ACM | Freebase | |||||
| Macro-F1 | Micro-F1 | Macro-F1 | Micro-F1 | Macro-F1 | Micro-F1 | Macro-F1 | Micro-F1 | |
| RGCN | 91.520.50 | 92.070.50 | 58.850.26 | 62.050.15 | 91.550.74 | 91.410.75 | 46.780.77 | 58.331.57 |
| HAN | 91.670.49 | 92.050.62 | 57.740.96 | 64.630.58 | 90.890.43 | 90.790.43 | 21.311.68 | 54.771.40 |
| GTN | 93.520.55 | 93.970.54 | 60.470.98 | 65.140.45 | 91.310.70 | 91.200.71 | - | - |
| RSHN | 93.340.58 | 93.810.55 | 59.853.21 | 64.221.03 | 90.501.51 | 90.321.54 | - | - |
| HetGNN | 91.760.43 | 92.330.41 | 48.250.67 | 51.160.65 | 85.910.25 | 86.050.25 | - | - |
| MAGNN | 93.280.51 | 93.760.45 | 56.493.20 | 64.671.67 | 90.880.64 | 90.770.65 | - | - |
| HetSANN | 78.552.42 | 80.561.50 | 49.471.21 | 57.680.44 | 90.020.35 | 89.910.37 | - | - |
| HGT | 93.010.23 | 93.490.25 | 63.001.19 | 67.200.57 | 91.120.76 | 91.000.76 | 29.282.52 | 60.511.16 |
| GCN | 90.840.32 | 91.470.34 | 57.881.18 | 64.820.64 | 92.170.24 | 92.120.23 | 27.843.13 | 60.230.92 |
| GAT | 93.830.27 | 93.390.30 | 58.941.35 | 64.860.43 | 92.260.94 | 92.190.93 | 40.742.58 | 65.260.80 |
| Simple-HGN | 94.010.24 | 94.460.22 | 63.531.36 | 67.360.57 | 93.420.44 | 93.350.45 | 47.721.48 | 66.290.45 |
| Amazon | LastFM | PubMed | ||||
| ROC-AUC | MRR | ROC-AUC | MRR | ROC-AUC | MRR | |
| RGCN | 86.340.28 | 93.920.16 | 57.210.09 | 77.680.17 | 78.290.18 | 90.260.24 |
| GATNE | 77.390.50 | 92.040.36 | 66.870.16 | 85.930.63 | 63.390.65 | 80.050.22 |
| HetGNN | 77.740.24 | 91.790.03 | 62.090.01 | 83.560.14 | 73.630.01 | 84.000.04 |
| MAGNN | - | - | 56.810.05 | 72.930.59 | - | - |
| HGT | 88.262.06 | 93.870.65 | 54.990.28 | 74.961.46 | 80.120.93 | 90.850.33 |
| GCN | 92.840.34 | 97.050.12 | 59.170.31 | 79.380.65 | 80.480.81 | 90.990.56 |
| GAT | 91.650.80 | 96.580.26 | 58.560.66 | 77.042.11 | 78.051.77 | 90.020.53 |
| Simple-HGN | 93.400.62 | 96.940.29 | 67.590.23 | 90.810.32 | 83.390.39 | 92.070.26 |
| Amazon-Book | LastFM | Yelp-2018 | MovieLens | |||||
| recall@20 | ndcg@20 | recall@20 | ndcg@20 | recall@20 | ndcg@20 | recall@20 | ndcg@20 | |
| KGCN | 0.14640.0002 | 0.07690.0002 | 0.08190.0002 | 0.07050.0002 | 0.06830.0003 | 0.04310.0003 | 0.42370.0008 | 0.27530.0005 |
| KGNN-LS | 0.14480.0003 | 0.07590.0001 | 0.08060.0003 | 0.06950.0002 | 0.06710.0003 | 0.04220.0002 | 0.42180.0008 | 0.27410.0005 |
| KGAT | 0.15070.0003 | 0.08020.0004 | 0.08770.0003 | 0.07490.0003 | 0.06970.0002 | 0.04500.0001 | 0.45320.0004 | 0.30070.0008 |
| KGAT | 0.14860.0003 | 0.07900.0002 | 0.08900.0002 | 0.07620.0002 | 0.07150.0001 | 0.04600.0001 | 0.45530.0003 | 0.30310.0006 |
| Simple-HGN | 0.15870.0011 | 0.08540.0005 | 0.09170.0006 | 0.07970.0003 | 0.07320.0003 | 0.04660.0003 | 0.46180.0007 | 0.30900.0007 |
5.2. Residual Connection
GNNs are hard to be deep due to the over-smoothing and gradient vanishing problems (Li et al., 2018; Xu et al., 2018b). A famous solution to mitigate this problem in computer vision is residual connection (He et al., 2016). However, the original GCN paper (Kipf and Welling, 2017) showed a negative result for residual connection on graph convolution. Recent study (Li et al., 2020) finds that well-designed pre-activation implementation could make residual connection great again in GNNs.
Node Residual. We add pre-activation residual connection for node representation across layers. The aggregation at the layer can be expressed as
| (8) |
where is the attention weight about edge and is an activation function (ELU (Clevert et al., 2015) by default). When the dimension changes in the th layer, an additional learnable linear transformation is needed, i.e.,
| (9) |
Edge Residual. Recently, Realformer (He et al., 2020) reveals that residual connection on attention scores is also helpful. After getting the raw attention scores via Eq. (7), we add residual connections to them,
| (10) |
where hyperparameter is a scaling factor.
Multi-head Attention. Similar to GAT, we adopt multi-head attention to enhance model’s expressive capacity. Specifically, we perform independent attention mechanisms according to Equation (8), and concatenate their results as the final representation. The corresponding updating rule is:
| (11) |
| (12) |
| (13) |
where denotes concatenation operation, and is attention score computed by the linear transformation according to Equation (9).
Usually the output dimension cannot be divided exactly by the number of heads. Following GAT, we no longer use concatenation but adopt averaging for the representation in the final () layer, i.e.,
| (14) |
Adaptation for Link Prediction. We slightly modify the model architecture for better performance on link prediction. Edge residual is removed and the final embedding is the concatenation of embeddings from all the layers. This adapted version is similar to JKNet (Xu et al., 2018b).
| Task | Node Classification | Link Prediction | Recommendation | |||
| Dataset | IMDB | Last.fm | Movielens-20M | |||
| Metric | Macro-F1 | Micro-F1 | ROC-AUC | MRR | recall@20 | ndcg@20 |
| Simple-HGN | 63.531.36 | 67.360.57 | 67.590.23 | 90.810.32 | 0.46260.0006 | 0.35320.0005 |
| w.o. type embedding | 63.041.00 | 67.060.40 | 67.610.13 | 90.520.13 | 0.46320.0005 | 0.35370.0007 |
| w.o. L2 normalization | 58.061.62 | 65.330.69 | 61.070.96 | 82.511.56 | 0.38370.0187 | 0.28160.0173 |
| w.o. residual connections | 61.612.34 | 66.281.11 | 63.330.78 | 84.130.62 | 0.42610.0004 | 0.31920.0006 |
5.3. Normalization
We find that an normalization on the output embedding is extremely useful, i.e.,
| (15) |
where is the output embedding of node and is the final representation from Equation (14).
The normalization on the output embedding is very common for retrieval-based tasks, because the dot product will be equivalent to the cosine similarity after normalization. But we also find its improvements for classification tasks, which was also observed in computer vision (Ranjan et al., 2017). Additionally, it suggests to multiply a scaling parameter to the output embedding (Ranjan et al., 2017). We find that tuning an appropriate indeed improves the performance, but it varies a lot in different datasets. We thus keep the form of Eq. (15) for simplicity.
6. Experiments
We benchmark results for 1) all HGNNs discussed in Section 3, 2) GCN and GAT, and 3) Simple-HGN on HGB. All experiments are reported with the average and the standard variance of five runs.
6.1. Benchmark
Tables 3, 4, and 5 report results for node classification, link prediction, and knowledge-aware recommendation, respectively. The results show that under fair comparison, 1) the simple homogeneous GAT can matches the best HGNNs in most cases, and 2) inherited from GAT, Simple-HGN consistently outperforms all advanced HGNNs methods for node classification on four datasets, link prediction on three datasets, and knowledge-aware recommendation on three datasets.
Implementations of all previous HGNNs are based on their official codes to avoid errors introduced by re-implementation. The only modification occurs on their data loading interfaces and downstream decoders, if necessary, to make their codes adapt to the HGB pipeline.
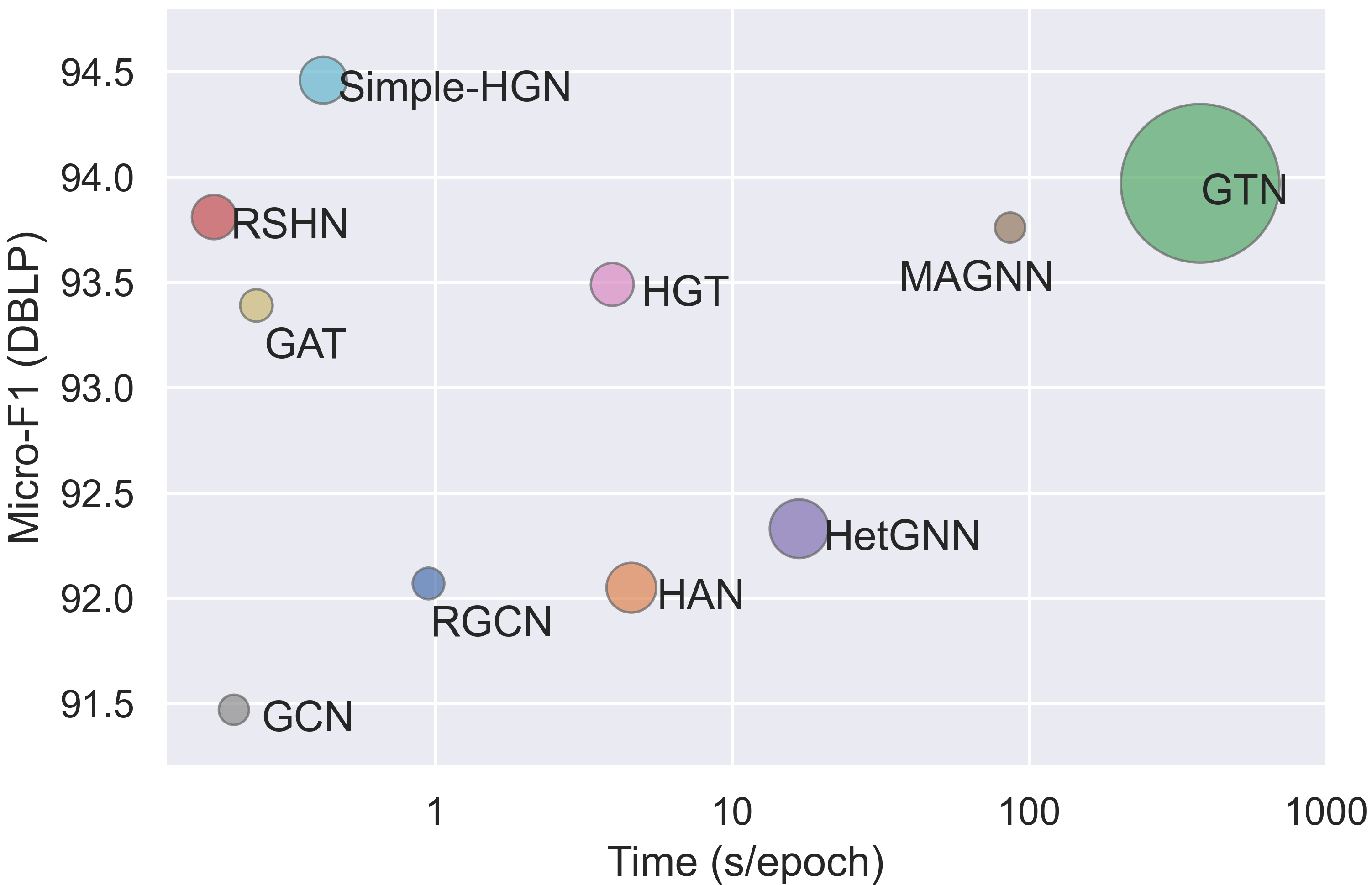
6.2. Time and Memory Consumption
We test the time and memory consumption of all available HGNNs for node classification on the DBLP dataset. The results are showed in Figure 2. It is worth noting that we only measure the time consumption of one epoch for each model, but the needed number of epochs until convergence could be various and hard to exactly define. HetSANN is omitted due to our failure to get a reasonable Micro-F1 score.
6.3. Ablation Studies
The ablation studies on all the three tasks are summarized in Table 6. Residual connection and normalization consistently improve performance, but type embedding only slightly boosts the performance on node classification, although it is the best way in our experiments to encode type information explicitly under the GAT framework. We will discuss the possible reasons in § 7.
7. Discussion and Conclusion
In this work, we identify the neglected issues in heterogeneous GNNs, setup the heterogeneous graph benchmark (HGB), and introduce a simple and strong baseline Simple-HGN. The goal of this work is to understand and advance the developments of heterogeneous GNNs by facilitating reproducible and robust research.
Notwithstanding the extensive and promising results, there are still open questions remaining for heterogeneous GNNs and broadly heterogeneous graph representation learning.
Is explicit type information useful? Ablation studies in Table 6 suggest the type embeddings only bring minor improvements. We hypothesize that the main reason is that the heterogeneity of node features already implies the different node and edge types. Another possibility is that the current graph attention mechanism (Veličković et al., 2017) is too weak to fuse the type information with feature information. We leave this question for future study.
Are meta-paths or variants still useful in GNNs? Meta-paths (Sun and Han, 2012) are proposed to separate different semantics with human prior. However, the premise of (graph) neural networks is to avoid the feature engineering process by extracting implicit and useful features underlying the data. Results in previous sections also suggest that meta-path based GNNs do not generate outperformance over the homogeneous GAT. Are there better ways to leverage meta-paths in heterogeneous GNNs than existing attempts? Will meta-paths still be necessary for heterogeneous GNNs in the future and what are the substitutions?
Acknowledgements.
The work is supported by the NSFC for Distinguished Young Scholar (61825602) and NSFC (61836013). The authors would like to thank Haonan Wang from UIUC and Hongxia Yang from Alibaba for their kind feedbacks.References
- (1)
- Abu-El-Haija et al. (2019) Sami Abu-El-Haija, Bryan Perozzi, Amol Kapoor, Nazanin Alipourfard, Kristina Lerman, Hrayr Harutyunyan, Greg Ver Steeg, and Aram Galstyan. 2019. Mixhop: Higher-order graph convolutional architectures via sparsified neighborhood mixing. In ICML’19. PMLR, 21–29.
- Battaglia et al. (2018) Peter W Battaglia, Jessica B Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez, Vinicius Zambaldi, Mateusz Malinowski, Andrea Tacchetti, David Raposo, Adam Santoro, Ryan Faulkner, et al. 2018. Relational inductive biases, deep learning, and graph networks. arXiv preprint arXiv:1806.01261 (2018).
- Bollacker et al. (2008) Kurt Bollacker, Colin Evans, Praveen Paritosh, Tim Sturge, and Jamie Taylor. 2008. Freebase: a collaboratively created graph database for structuring human knowledge. In SIGMOD’08. 1247–1250.
- Cantador et al. (2011) Iván Cantador, Peter Brusilovsky, and Tsvi Kuflik. 2011. Second workshop on information heterogeneity and fusion in recommender systems (HetRec2011). In RecSys’11. 387–388.
- Cen et al. (2019) Yukuo Cen, Xu Zou, Jianwei Zhang, Hongxia Yang, Jingren Zhou, and Jie Tang. 2019. Representation learning for attributed multiplex heterogeneous network. In KDD’19. 1358–1368.
- Clevert et al. (2015) Djork-Arné Clevert, Thomas Unterthiner, and Sepp Hochreiter. 2015. Fast and accurate deep network learning by exponential linear units (elus). arXiv preprint arXiv:1511.07289 (2015).
- Ding et al. (2018) Ming Ding, Jie Tang, and Jie Zhang. 2018. Semi-supervised learning on graphs with generative adversarial nets. In CIKM’18. 913–922.
- Dong et al. (2017) Yuxiao Dong, Nitesh V Chawla, and Ananthram Swami. 2017. metapath2vec: Scalable Representation Learning for Heterogeneous Networks. In KDD ’17. ACM, 135–144.
- Fan et al. (2019b) Shaohua Fan, Junxiong Zhu, Xiaotian Han, Chuan Shi, Linmei Hu, Biyu Ma, and Yongliang Li. 2019b. Metapath-guided heterogeneous graph neural network for intent recommendation. In KDD’19. 2478–2486.
- Fan et al. (2019a) Wenqi Fan, Yao Ma, Qing Li, Yuan He, Eric Zhao, Jiliang Tang, and Dawei Yin. 2019a. Graph neural networks for social recommendation. In WWW’19. 417–426.
- Feng et al. (2020) Wenzheng Feng, Jie Zhang, Yuxiao Dong, Yu Han, Huanbo Luan, Qian Xu, Qiang Yang, Evgeny Kharlamov, and Jie Tang. 2020. Graph Random Neural Networks for Semi-Supervised Learning on Graphs. NeurIPS 33 (2020).
- Fu et al. (2020) Xinyu Fu, Jiani Zhang, Ziqiao Meng, and Irwin King. 2020. MAGNN: metapath aggregated graph neural network for heterogeneous graph embedding. In WWW’20.
- Gilmer et al. (2017) Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. 2017. Neural message passing for quantum chemistry. In ICML’17. PMLR, 1263–1272.
- Hamilton et al. (2017) William L Hamilton, Rex Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs. arXiv preprint arXiv:1706.02216 (2017).
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In CVPR’16.
- He et al. (2020) Ruining He, Anirudh Ravula, Bhargav Kanagal, and Joshua Ainslie. 2020. RealFormer: Transformer Likes Residual Attention. arXiv preprint arXiv:2012.11747 (2020).
- Hong et al. (2020) Huiting Hong, Hantao Guo, Yucheng Lin, Xiaoqing Yang, Zang Li, and Jieping Ye. 2020. An attention-based graph neural network for heterogeneous structural learning. In AAAI’20, Vol. 34. 4132–4139.
- Hu et al. (2020c) Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. 2020c. Open graph benchmark: Datasets for machine learning on graphs. arXiv preprint arXiv:2005.00687 (2020).
- Hu et al. (2020b) Ziniu Hu, Yuxiao Dong, Kuansan Wang, Kai-Wei Chang, and Yizhou Sun. 2020b. GPT-GNN: Generative Pre-Training of Graph Neural Networks. In KDD.
- Hu et al. (2020a) Ziniu Hu, Yuxiao Dong, Kuansan Wang, and Yizhou Sun. 2020a. Heterogeneous graph transformer. In WWW’20. 2704–2710.
- Kipf and Welling (2017) Thomas N Kipf and Max Welling. 2017. Semi-supervised classification with graph convolutional networks. In ICLR’17.
- Li et al. (2020) Guohao Li, Chenxin Xiong, Ali Thabet, and Bernard Ghanem. 2020. Deepergcn: All you need to train deeper gcns. arXiv preprint arXiv:2006.07739 (2020).
- Li et al. (2018) Qimai Li, Zhichao Han, and Xiao-Ming Wu. 2018. Deeper insights into graph convolutional networks for semi-supervised learning. In AAAI’18, Vol. 32.
- Liu et al. (2020) Danyang Liu, Jianxun Lian, Shiyin Wang, Ying Qiao, Jiun-Hung Chen, Guangzhong Sun, and Xing Xie. 2020. KRED: Knowledge-Aware Document Representation for News Recommendations. In RecSys’20. 200–209.
- Niu et al. (2020) Xichuan Niu, Bofang Li, Chenliang Li, Rong Xiao, Haochuan Sun, Hongbo Deng, and Zhenzhong Chen. 2020. A Dual Heterogeneous Graph Attention Network to Improve Long-Tail Performance for Shop Search in E-Commerce. In KDD’20. 3405–3415.
- Ranjan et al. (2017) Rajeev Ranjan, Carlos D Castillo, and Rama Chellappa. 2017. L2-constrained softmax loss for discriminative face verification. arXiv preprint arXiv:1703.09507 (2017).
- Rendle et al. (2009) Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. 2009. BPR: Bayesian personalized ranking from implicit feedback. In UAI’09. 452–461.
- Schlichtkrull et al. (2018) Michael Schlichtkrull, Thomas N Kipf, Peter Bloem, Rianne Van Den Berg, Ivan Titov, and Max Welling. 2018. Modeling relational data with graph convolutional networks. In ESWC’18. Springer, 593–607.
- Sun and Han (2012) Yizhou Sun and Jiawei Han. 2012. Mining Heterogeneous Information Networks: Principles and Methodologies. Morgan and Claypool Publishers.
- Sun et al. (2011) Yizhou Sun, Jiawei Han, Xifeng Yan, Philip S Yu, and Tianyi Wu. 2011. Pathsim: Meta path-based top-k similarity search in heterogeneous information networks. PVLDB 4, 11 (2011), 992–1003.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. NeurIPS 30 (2017), 5998–6008.
- Veličković et al. (2017) Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. 2017. Graph attention networks. arXiv preprint arXiv:1710.10903 (2017).
- Wang et al. (2019c) Hongwei Wang, Fuzheng Zhang, Mengdi Zhang, Jure Leskovec, Miao Zhao, Wenjie Li, and Zhongyuan Wang. 2019c. Knowledge-aware graph neural networks with label smoothness regularization for recommender systems. In KDD’19. 968–977.
- Wang et al. (2019d) Hongwei Wang, Miao Zhao, Xing Xie, Wenjie Li, and Minyi Guo. 2019d. Knowledge graph convolutional networks for recommender systems. In WWW’19. 3307–3313.
- Wang et al. (2019a) Xiang Wang, Xiangnan He, Yixin Cao, Meng Liu, and Tat-Seng Chua. 2019a. Kgat: Knowledge graph attention network for recommendation. In KDD’19. 950–958.
- Wang et al. (2019b) Xiao Wang, Houye Ji, Chuan Shi, Bai Wang, Yanfang Ye, Peng Cui, and Philip S Yu. 2019b. Heterogeneous graph attention network. In WWW’19.
- Xu et al. (2018a) Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. 2018a. How Powerful are Graph Neural Networks?. In ICLR’18.
- Xu et al. (2018b) Keyulu Xu, Chengtao Li, Yonglong Tian, Tomohiro Sonobe, Ken-ichi Kawarabayashi, and Stefanie Jegelka. 2018b. Representation Learning on Graphs with Jumping Knowledge Networks. ICML (2018), 5449–5458.
- Yang et al. (2014) Bishan Yang, Wen-tau Yih, Xiaodong He, Jianfeng Gao, and Li Deng. 2014. Embedding entities and relations for learning and inference in knowledge bases. arXiv preprint arXiv:1412.6575 (2014).
- Yang et al. (2020b) Carl Yang, Aditya Pal, Andrew Zhai, Nikil Pancha, Jiawei Han, Charles Rosenberg, and Jure Leskovec. 2020b. MultiSage: Empowering GCN with Contextualized Multi-Embeddings on Web-Scale Multipartite Networks. In KDD’20. 2434–2443.
- Yang et al. (2020c) Carl Yang, Yuxin Xiao, Yu Zhang, Yizhou Sun, and Jiawei Han. 2020c. Heterogeneous Network Representation Learning: A Unified Framework with Survey and Benchmark. TKDE (2020).
- Yang et al. (2020a) Zhen Yang, Ming Ding, Chang Zhou, Hongxia Yang, Jingren Zhou, and Jie Tang. 2020a. Understanding negative sampling in graph representation learning. In KDD’20. 1666–1676.
- Yun et al. (2019) Seongjun Yun, Minbyul Jeong, Raehyun Kim, Jaewoo Kang, and Hyunwoo J Kim. 2019. Graph Transformer Networks. In NeurIPS’19.
- Zhang et al. (2019) Chuxu Zhang, Dongjin Song, Chao Huang, Ananthram Swami, and Nitesh V Chawla. 2019. Heterogeneous graph neural network. In KDD’19. 793–803.
- Zhu et al. (2019) Shichao Zhu, Chuan Zhou, Shirui Pan, Xingquan Zhu, and Bin Wang. 2019. Relation structure-aware heterogeneous graph neural network. In ICDM’19.
Appendix A Time and Memory Consumption
Appendix B Random negative
The distribution of negative samples of test set in link prediction task has a great impact on the performance score. The results with random negative test in our benchmark are shown in Table 7. As we can see, the scores are greater than those in Table 4 by a large margin. Most works (Cen et al., 2019; Fu et al., 2020; Zhang et al., 2019) evaluate link prediction with randomly sampled negative pairs, which are easy to distinguish from the positive pairs for most methods. However, in real world scenarios, we usually need to discriminate positive and negative node pairs with similar characters, instead of random ones, due to the widely used “retrieve then re-rank” industrial pipeline. Therefore, we choose to use sampled 2-hop neighbors as our negative test set in benchmark.
| Amazon | Last.fm | PubMed | ||||
| ROC-AUC | MRR | ROC-AUC | MRR | ROC-AUC | MRR | |
| RGCN | 89.760.33 | 95.760.22 | 81.900.29 | 96.680.14 | 88.320.08 | 96.890.20 |
| GATNE | 96.670.08 | 98.680.06 | 87.420.22 | 96.350.24 | 78.360.92 | 90.640.49 |
| HetGNN | 95.510.39 | 97.910.08 | 87.350.02 | 96.150.18 | 84.140.01 | 91.000.03 |
| MAGNN | - | - | 76.500.21 | 85.680.04 | - | - |
| HGT | 91.702.31 | 96.070.68 | 80.490.78 | 95.480.38 | 90.290.68 | 97.310.09 |
| GCN | 98.570.21 | 99.770.02 | 84.710.1 | 96.600.12 | 86.061.23 | 98.800.56 |
| GAT | 98.450.11 | 99.610.22 | 83.552.11 | 91.455.66 | 87.571.23 | 98.380.11 |
| Simple-HGN | 98.740.25 | 99.520.08 | 91.040.22 | 99.210.15 | 91.400.30 | 96.040.25 |
Appendix C Hyper-parameters
We search learning rate within in all cases, and for weight decay rate. We set dropout rate as 0.1 in recommendation, and 0.5 in node classification and link prediction by default. For batch size, we will try , unless the code of the author has special requirements. For training epoch, we will use early stop mechanism based on the evaluation on validation set to promise fully training.
For brevity, we will denote some variables. Suppose dimension of embeddings for graph layers as , dimension of edge embeddings as , dimension of attention vector (if exists) as , number of graph layers as , number of attention heads as , negative slope of LeakyReLU as .
For input feature type, we use to denote using all given features, to denote using only target node features, and to denote all nodes with one-hot features.
C.1. Simple-HGN
C.1.1. Node classification
We set , , for all datasets. For DBLP, ACM and Freebase datasets, we set , . For IMDB dataset, we set , . We set for IMDB, for ACM, and for DBLP and Freebase.
C.1.2. Link prediction
We set , , , , for all datasets. For Amazon and PubMed, we use DistMult as decoder, and set . For LastFM, we use dot product as decoder, and set . We use for all datasets.
C.1.3. Recommendation
For all datasets, we set , , , , as suggested in (Wang et al., 2019a).
C.2. HAN
C.2.1. Node classification
We set , , and for all datasets. For input feature type, we use in Freebase, and in other datasets. We have also tried larger , but the vairation of performance becoms very large. Therefore, we keep as suggested in HAN’s code.
C.3. GTN
C.3.1. Node classification
We use adaptive learning rate suggested in their paper for all datasets. We set , number of GTN channels as 2. For DBLP and ACM, we set . For IMDB dataset, we set .
Moreover, as suggested in GTN paper, we aggregate the keyword node information as attribute to neighbors and use the left sub-graph to do node classification. We also tried to use the whole graph for GTN. Unfortunately, it collapse in that case, which indicates GTN is sensitive to the graph structure.
C.4. RSHN
For IMDB and DBLP, we set and . For ACM, we and . We use for ACM, IMDB and DBLP respectively.
C.5. HetGNN
C.5.1. Node classification
We set , , and batch size as 200 for all datasets. For random walk, we set walk length as 30 and the window size as 5.
C.5.2. Link prediction
We set , , and batch size as 200 for all datasets. For random walk, we set walk length as 30 and the window size as 5.
C.6. MAGNN
We set , and in all cases.
C.6.1. Node classification
We use in all cases. For DBLP and ACM datasets, we set batch size as 8, and number of neighbor samples as 100. For IMDB dataset, we use full batch training.
C.6.2. Link prediction
We set batch size as 8, and number of neighbor samples as 100 for LastFM. For other datasets, we failed to adapt the MAGNN code to them because there is too much hard-coding.
C.7. HetSANN
C.7.1. Node classification
For ACM, we set , , and . For IMDB, we set , , and . For DBLP, we set , , and .
C.8. HGT
C.8.1. Node Classification
We use layer normalization in each layer, and set , for all datasets. is set to 2, 3, 3, 5 for ACM, DBLP, Freebase and IMDB respectively. For input feature type, we use in Freebase, in IMDB and DBLP, and in ACM.
C.8.2. Link Prediction
For all datasets, we use layer normalization in each layer, and set , , and DistMult as decoder.
C.9. GCN
C.9.1. Node classification
We set for all datasets. We set for DBLP, ACM and Freebase, and for IMDB. We use for DBLP and Freebase, and for ACM and IMDB.
C.9.2. Link prediction
We set , , and for all datasets.
C.10. GAT
C.10.1. Node classification
We set , for all datasets. For DBLP, ACM and Freebase, we set and . For IMDB, we set and . We use for DBLP and Freebase, for ACM, and for IMDB.
C.10.2. Link prediction
We set , , and for all datasets.
C.11. RGCN
C.11.1. Node classification
We set for all datasets. For ACM, we set , . For DBLP and Freebase, we set , . For IMDB, we set , .
C.11.2. Link prediction
We set , and for all datasets.
C.12. GATNE
C.12.1. Link prediction
We set , , , for all datasets.
For random walk, we set walk length as 30 and the window size as 5. For neighbor sampling, we set negative samples for optimization as 5, neighbor samples for aggregation as 10.
C.13. KGCN and KGNN-LS
C.13.1. Recommendation
For all datasets, we set and . We also tried to stack more graph layers, but performance deteriorates when we do that, which is also found in (Wang et al., 2019d; Wang et al., 2019c) experiments. We use sum aggregator because it has best overall performance as reported in (Wang et al., 2019d).
C.14. KGAT
C.14.1. Recommendation
We set , , for all datasets. For attention mechanism, we keep the Bi-Interaction aggregator according to their official code.
Appendix D Meta-paths
The meta-paths used in benchmark experiments are shown in Table 8. We try to select meta-paths following prior works. For example, meta-paths in DBLP, IMDB and LastFM are from (Fu et al., 2020). Meta-paths in ACM dataset are based on (Wang et al., 2019b), and we also add some meta-paths related to citation and reference relation, which are not used in (Wang et al., 2019b). For Freebase dataset, we first count the most frequent meta-paths with length from 2 to 4, and then manually select 7 of them according to the performance on validation set.
| Dataset | Meta-path | Meaning | |||||||||||||||
| DBLP |
|
|
|||||||||||||||
| IMDB |
|
|
|||||||||||||||
| ACM |
|
|
|||||||||||||||
| Freebase |
|
|
|||||||||||||||
| LastFM |
|
|