LayoutXLM: Multimodal Pre-training for
Multilingual Visually-rich Document Understanding
Abstract
Multimodal pre-training with text, layout, and image has achieved SOTA performance for visually-rich document understanding tasks recently, which demonstrates the great potential for joint learning across different modalities. In this paper, we present LayoutXLM, a multimodal pre-trained model for multilingual document understanding, which aims to bridge the language barriers for visually-rich document understanding. To accurately evaluate LayoutXLM, we also introduce a multilingual form understanding benchmark dataset named XFUND, which includes form understanding samples in 7 languages (Chinese, Japanese, Spanish, French, Italian, German, Portuguese), and key-value pairs are manually labeled for each language. Experiment results show that the LayoutXLM model has significantly outperformed the existing SOTA cross-lingual pre-trained models on the XFUND dataset. The pre-trained LayoutXLM model and the XFUND dataset are publicly available at https://aka.ms/layoutxlm.
1 Introduction
Multimodal pre-training for visually-rich Document Understanding (VrDU) has achieved new SOTA performance on several public benchmarks recently (Xu et al., 2020a, b), including form understanding (Jaume et al., 2019), receipt understanding (Park et al., 2019), complex layout understanding (Graliński et al., 2020), document image classification (Harley et al., 2015) and document VQA task Mathew et al. (2020), due to the advantage that text, layout and image information is jointly learned end-to-end in a single framework. Meanwhile, we are well aware of the demand from the non-English world since nearly 40% of digital documents on the web are in non-English languages. Simply translating these documents automatically with machine translation services might help, but it is often not satisfactory due to the poor translation quality on document images (Afli and Way, 2016). Therefore, it is vital to pre-train the LayoutLM model using real document datasets around the world for the multilingual VrDU task.
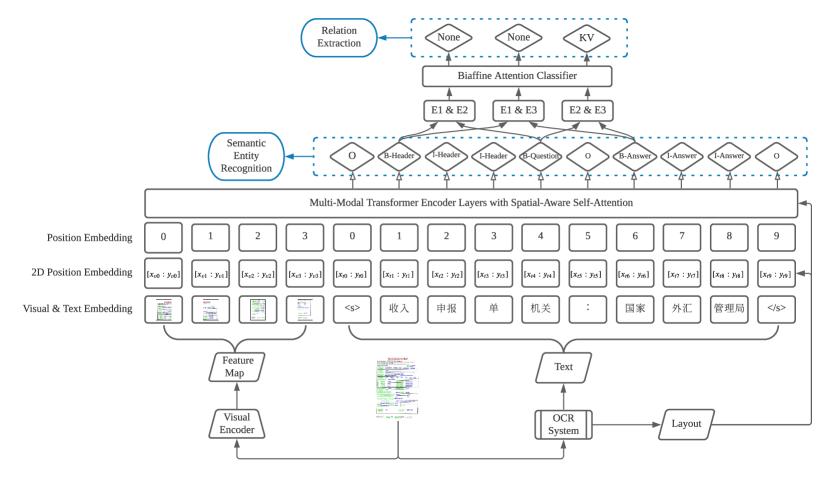
Multilingual pre-trained models such as mBERT (Devlin et al., 2018), XLM (Lample and Conneau, 2019), XLM-RoBERTa (Conneau et al., 2020), mBART (Liu et al., 2020), and the recent InfoXLM (Chi et al., 2020) and mT5 (Xue et al., 2020) have pushed many SOTA results on cross-lingual natural language understanding tasks by pre-training the Transformer models on different languages. These models have successfully bridged the language barriers in a number of cross-lingual transfer benchmarks such as XNLI (Conneau et al., 2018) and XTREME (Hu et al., 2020). Although a large amount of multilingual text data has been used in these cross-lingual pre-trained models, text-only multilingual models cannot be easily used in the VrDU tasks because they are usually fragile in analyzing the documents due to the format/layout diversity of documents in different countries, and even different regions in the same country. Hence, to accurately understand these visually-rich documents in various languages, it is crucial to pre-train the multilingual models with not only textual information but also layout and image information in a multimodal framework.
To this end, we present a multimodal pre-trained model for multilingual VrDU tasks in this paper, aka LayoutXLM, which is a multilingual extension of the recent LayoutLMv2 model (Xu et al., 2020a). LayoutLMv2 integrates the image information in the pre-training stage by taking advantage of the Transformer architecture to learn the cross-modality interaction between visual and textual information. In addition, LayoutLMv2 uses two new training objectives in addition to the masked visual-language model, which are the image-text matching and image masking prediction tasks. In this way, the pre-trained models absorb cross-modal knowledge from different document types, where the local invariance among the layout and formats is preserved. Inspired by the LayoutLMv2 model, LayoutXLM adopts the same architecture for the multimodal pre-training initialized by a SOTA multilingual pre-trained InfoXLM model (Chi et al., 2020). In addition, we pre-train the model with the IIT-CDIP dataset (Lewis et al., 2006) as well as a great number of publicly available digital-born multilingual PDF files from the internet, which helps the LayoutXLM model to learn from real-world documents. In this way, the model obtains textual and visual signals from a variety of document templates/layouts/formats in different languages, thereby taking advantage of the local invariance property from both textual, visual and linguistic perspectives. Furthermore, to facilitate the evaluation of the pre-trained LayoutXLM model, we employ human annotators to label a multilingual form understanding dataset, which contains 7 languages, including Chinese, Japanese, Spanish, French, Italian, German, Portuguese, and introduces a multilingual benchmark dataset named XFUND for each language where key-value pairs are annotated. Experiment results show that the pre-trained LayoutXLM outperforms several SOTA cross-lingual pre-trained models on the XFUND benchmark dataset, which also demonstrates the potential of the multimodal pre-training strategy for multilingual document understanding.

The contributions of this paper are summarized as follows:
-
•
We propose LayoutXLM, a multimodal pre-trained model for multilingual document understanding, which is trained with large-scale real-world scanned/digital-born documents.
-
•
We also introduce XFUND, a multilingual form understanding benchmark dataset that includes human-labeled forms with key-value pairs in 7 languages (Chinese, Japanese, Spanish, French, Italian, German, Portuguese).
-
•
LayoutXLM has outperformed other SOTA multilingual baseline models on the XFUND dataset, which demonstrates the great potential for the multimodal pre-training for the multilingual VrDU task. The pre-trained LayoutXLM model and the XFUND dataset are publicly available at https://aka.ms/layoutxlm.
2 Approach
In this section, we introduce the model architecture, pre-training objectives, and pre-training dataset. We follow the LayoutLMv2 Xu et al. (2020a) architecture and transfer the model to large-scale multilingual document datasets.
2.1 Model Architecture
Similar to the LayoutLMv2 framework, we built the LayoutXLM model with a multimodal Transformer architecture. The framework is shown in Figure 1. The model accepts information from three different modalities, including text, layout, and image, which are encoded respectively with text embedding, layout embedding, and visual embedding layers. The text and image embeddings are concatenated, then plus the layout embedding to get the input embedding. The input embeddings are encoded by a multimodal Transformer with the spatial-ware self-attention mechanism. Finally, the output contextual representation can be utilized for the following task-specific layers. For brevity, we refer to Xu et al. (2020a) for further details on architecture.
2.2 Pre-training
The pre-training objectives of LayoutLMv2 have shown effectiveness in modeling visually-rich documents. Therefore, we naturally adapt this pre-training framework to multilingual document pre-training. Following the idea of cross-modal alignment, our pre-training framework for document understanding contains three pre-training objectives, which are Multilingual Masked Visual-Language Modeling (text-layout alignment), Text-Image Alignment (fine-grained text-image alignment), and Text-Image Matching (coarse-grained text-image alignment).
Multilingual Masked Visual-Language Modeling
The Masked Visual-Language Modeling (MVLM) is originally proposed in the vanilla LayoutLM and also used in LayoutLMv2, aiming to model the rich text in visually-rich documents. In this pre-training objective, the model is required to predict the masked text token based on its remaining text context and whole layout clues. Similar to the LayoutLM/LayoutLMv2, we train the LayoutXLM with the Multilingual Masked Visual-Language Modeling objective (MMVLM).
In LayoutLM/LayoutLMv2, an English word is treated as the basic unit, and its layout information is obtained by extracting the bounding box of each word with OCR tools, then subtokens of each word share the same layout information. However, for LayoutXLM, this strategy is not applicable because the definition of the linguistic unit is different from language to language. To prevent the language-specific pre-processing, we decide to obtain the character-level bounding boxes. After the tokenization using SentencePiece with a unigram language model, we calculate the bounding box of each token by merging the bounding boxes of all characters it contains. In this way, we can efficiently unify the multilingual multimodal inputs.
Text-Image Alignment
The Text-Image Alignment (TIA) task is designed to help the model capture the fine-grained alignment relationship between text and image. We randomly select some text lines and then cover their corresponding image regions on the document image. The model needs to predict a binary label for each token based on whether it is covered or not.
Text-Image Matching
For Text-Image Matching (TIM), we aim to align the high-level semantic representation between text and image. To this end, we require the model to predict whether the text and image come from the same document page.
2.3 Pre-training Data
The LayoutXLM model is pre-trained with documents in 53 languages. Figure 2 shows the distribution of pre-training languages. In this section, we briefly describe the pipeline for preparing the large-scale multilingual document collection.
Data Collection
To collect a large-scale multilingual visually-rich document collection, we download and process publicly available multilingual digital-born PDF documents following the principles and policies of Common Crawl111https://commoncrawl.org. Using digital-born PDF documents can benefit the collecting and pre-processing steps. On the one hand, we do not have to identify scanned documents among the natural images. On the other hand, we can directly extract accurate text with corresponding layout information with off-the-shelf PDF parsers and save time for running expensive OCR tools.
Pre-processing
The pre-processing step is needed to clean the dataset since the raw multilingual PDFs are often noisy. We use an open-source PDF parser called PyMuPDF222https://github.com/pymupdf/PyMuPDF to extract text, layout, and document images from PDF documents. After PDF parsing, we discard the documents with less than 200 characters. We use the language detector from the BlingFire333https://github.com/microsoft/BlingFire library and split data per language. Following CCNet (Wenzek et al., 2019), we classify the document as the corresponding language if the language score is higher than 0.5. Otherwise, unclear PDF files with a language score of less than 0.5 are discarded.
Data Sampling
After splitting the data per language, we use the same sampling probability as XLM Lample and Conneau (2019) to sample the batches from different languages. Following InfoXLM (Chi et al., 2020), we use alpha = 0.7 for LayoutXLM to make a reasonable compromise between performance on high- and low-resource languages. The brief language distribution is shown in Figure 2. Finally, we follow this distribution and sample a multilingual document dataset with 22 million visually rich documents. In addition, we also sample 8 million scanned English documents from the IIT-CDIP dataset so that we totally use 30 million documents to pre-train the LayoutXLM, where the model can benefit from the visual information of both scanned and digital-born document images.


3 XFUND: A Multilingual Form Understanding Benchmark
In recent years, many evaluation datasets for document understanding tasks have been proposed, such as PublayNet Zhong et al. (2019), FUNSD Jaume et al. (2019), SROIE444https://rrc.cvc.uab.es/?ch=13, TableBank Li et al. (2020a), DocBank Li et al. (2020b), DocVQA Mathew et al. (2020) etc. They have successfully helped to evaluate the proposed neural network models and show the performance gap between the deep learning models and human beings, which significantly empowers the development of document understanding research. However, almost all of these evaluations and benchmarks are solely focused on English documents, which limits the research for non-English document understanding tasks. To this end, we introduce a new benchmark for multilingual Form Understanding, or XFUND, by extending the FUNSD dataset to 7 other languages, including Chinese, Japanese, Spanish, French, Italian, German, and Portuguese, where sampled documents are shown in Figure 3. Next, we introduce the key-value extraction task in our benchmark, as well as data collection, labeling pipeline, and the data statistics.
3.1 Task description
Key-value extraction is one of the most critical tasks in form understanding. Similar to FUNSD, we define this task with two sub-tasks, which are semantic entity recognition and relation extraction.
Semantic Entity Recognition
Given a visually-rich document , we acquire discrete token set , where each token consists of a word and its bounding box coordinates . is the semantic entity labels where the tokens are classified into. Semantic entity recognition is the task of extracting semantic entities and classifying them into given entity types. In other words, we intend to find a function , where is the predicted semantic entity set:
Relation Extraction
Equipped with the document and the semantic entity label set , relation extraction aims to predict the relation between any two predicted semantic entities. Defining as the semantic relation labels, we intend to find a function , where is the predicted semantic relation set:
where and are two semantic entities. In this work, we mainly focus on the key-value relation extraction.
3.2 Data Collection and Labeling
Form Templates
Forms are usually used to collect information in different business scenarios. In order to avoid the sensitive information leak with the real-world documents, we collect the documents publicly available on the internet and remove the content within the documents while only keeping the templates to manually fill in synthetic information. We collect form templates in 7 languages from the internet. After that, the human annotators manually fill synthetic information into these form templates following corresponding requirements. Each template is allowed to be used only once, which means each form is different from the others. Besides, since the original FUNSD documents contain both digitally filled-out forms and handwritten forms, we also ask annotators to fill in the forms by typing or handwriting. The completed forms are finally scanned into document images for further OCR processing and key-value labeling.
Key-value Pairs
Key-value pairs are also annotated by human annotators. Equipped with the synthetic forms, we use Microsoft Read API555https://docs.microsoft.com/en-us/azure/cognitive-services/computer-vision/overview-ocr to generate OCR tokens with bounding boxes. With a GUI annotation tool, annotators are shown the original document images and the bounding boxes visualization of all OCR tokens. The annotators are asked to group the discrete tokens into entities and assign pre-defined labels to the entities. Also, if two entities are related, they should be linked together as a key-value pair.
3.3 Dataset Statistics
The XFUND benchmark includes 7 languages with 1,393 fully annotated forms. Each language includes 199 forms, where the training set includes 149 forms, and the test set includes 50 forms. Detailed information is shown in Table 1.
3.4 Baselines
Semantic Entity Recognition
For this task, we simply follow the typical sequence labeling paradigm with BIO labeling format and build task-specific layers over the text part of LayoutXLM.
Relation Extraction
Following Bekoulis et al. (2018) , we first incrementally construct the set of relation candidates by producing all possible pairs of given semantic entities. For every pair, the representation of the head/tail entity is the concatenation of the first token vector in each entity and the entity type embedding obtained with a specific type embedding layer. After respectively projected by two FFN layers, the representations of head and tail are concatenated and then fed into a bi-affine classifier.
4 Experiments
In this section, we introduce the experiment settings for pre-training LayoutXLM. To verify the effectiveness of the pre-trained LayoutXLM model, we evaluate all the pre-trained models on our human-labeled XFUND benchmark.
4.1 Settings
Pre-training LayoutXLM
Following the original LayoutLMv2 recipe, we train LayoutXLM models with two model sizes. For the LayoutXLMBASE model, we use a 12-layer Transformer encoder with 12 heads and set the hidden size to . For the LayoutXLMLARGE model, we increase the layer number to 24 with 16 heads and hidden size to . ResNeXt101-FPN is used as a visual backbone in both models. Finally, the number of parameters in these two models are approximately 345M and 625M. During the pre-training stage, we first initialize the Transformer encoder along with text embeddings from InfoXLM and initialize the visual embedding layer with a Mask-RCNN model trained on PubLayNet. The rest of the parameters are initialized randomly. Our models are trained with 64 Nvidia V100 GPUs.
Fine-tuning on XFUND
We conduct experiments on the XFUND benchmark. Besides the experiments of typical language-specific fine-tuning, we also design two additional settings to demonstrate the ability to transfer knowledge among different languages, which are zero-shot transfer learning and multitask fine-tuning. Specifically, (1) language-specific fine-tuning refers to the typical fine-tuning paradigm of fine-tuning on language X and testing on language X. (2) Zero-shot transfer learning means the models are trained on English data only and evaluated on each target language. (3) Multitask fine-tuning requires the model to train on data in all languages. We evaluate models in these three settings over two sub-tasks in XFUND: semantic entity recognition and relation extraction, and compare LayoutXLM to two strong cross-lingual language models: XLM-R and InfoXLM.
| lang | split | header | question | answer | other | total |
| ZH | training | 229 | 3,692 | 4,641 | 1,666 | 10,228 |
| testing | 58 | 1,253 | 1,732 | 586 | 3,629 | |
| JA | training | 150 | 2,379 | 3,836 | 2,640 | 9,005 |
| testing | 58 | 723 | 1,280 | 1,322 | 3,383 | |
| ES | training | 253 | 3,013 | 4,254 | 3,929 | 11,449 |
| testing | 90 | 909 | 1,218 | 1,196 | 3,413 | |
| FR | training | 183 | 2,497 | 3,427 | 2,709 | 8,816 |
| testing | 66 | 1,023 | 1,281 | 1,131 | 3,501 | |
| IT | training | 166 | 3,762 | 4,932 | 3,355 | 12,215 |
| testing | 65 | 1,230 | 1,599 | 1,135 | 4,029 | |
| DE | training | 155 | 2,609 | 3,992 | 1,876 | 8,632 |
| testing | 59 | 858 | 1,322 | 650 | 2,889 | |
| PT | training | 185 | 3,510 | 5,428 | 2,531 | 11,654 |
| testing | 59 | 1,288 | 1,940 | 882 | 4,169 |
| Model | FUNSD | ZH | JA | ES | FR | IT | DE | PT | Avg. | |
|---|---|---|---|---|---|---|---|---|---|---|
| SER | 0.667 | 0.8774 | 0.7761 | 0.6105 | 0.6743 | 0.6687 | 0.6814 | 0.6818 | 0.7047 | |
| 0.6852 | 0.8868 | 0.7865 | 0.6230 | 0.7015 | 0.6751 | 0.7063 | 0.7008 | 0.7207 | ||
| 0.794 | 0.8924 | 0.7921 | 0.7550 | 0.7902 | 0.8082 | 0.8222 | 0.7903 | 0.8056 | ||
| 0.7074 | 0.8925 | 0.7817 | 0.6515 | 0.7170 | 0.7139 | 0.711 | 0.7241 | 0.7374 | ||
| 0.7325 | 0.8955 | 0.7904 | 0.6740 | 0.7140 | 0.7152 | 0.7338 | 0.7212 | 0.7471 | ||
| 0.8225 | 0.9161 | 0.8033 | 0.7830 | 0.8098 | 0.8275 | 0.8361 | 0.8273 | 0.8282 | ||
| RE | 0.2659 | 0.5105 | 0.5800 | 0.5295 | 0.4965 | 0.5305 | 0.5041 | 0.3982 | 0.4769 | |
| 0.2920 | 0.5214 | 0.6000 | 0.5516 | 0.4913 | 0.5281 | 0.5262 | 0.4170 | 0.4910 | ||
| 0.5483 | 0.7073 | 0.6963 | 0.6896 | 0.6353 | 0.6415 | 0.6551 | 0.5718 | 0.6432 | ||
| 0.3473 | 0.6475 | 0.6798 | 0.6330 | 0.6080 | 0.6171 | 0.6189 | 0.5762 | 0.5910 | ||
| 0.3679 | 0.6775 | 0.6604 | 0.6346 | 0.6096 | 0.6659 | 0.6057 | 0.5800 | 0.6002 | ||
| 0.6404 | 0.7888 | 0.7255 | 0.7666 | 0.7102 | 0.7691 | 0.6843 | 0.6796 | 0.7206 |
| Model | FUNSD | ZH | JA | ES | FR | IT | DE | PT | Avg. | |
|---|---|---|---|---|---|---|---|---|---|---|
| SER | 0.667 | 0.4144 | 0.3023 | 0.3055 | 0.371 | 0.2767 | 0.3286 | 0.3936 | 0.3824 | |
| 0.6852 | 0.4408 | 0.3603 | 0.3102 | 0.4021 | 0.2880 | 0.3587 | 0.4502 | 0.4119 | ||
| 0.794 | 0.6019 | 0.4715 | 0.4565 | 0.5757 | 0.4846 | 0.5252 | 0.539 | 0.5561 | ||
| 0.7074 | 0.5205 | 0.3939 | 0.3627 | 0.4672 | 0.3398 | 0.418 | 0.4997 | 0.4637 | ||
| 0.7325 | 0.5536 | 0.4132 | 0.3689 | 0.4909 | 0.3598 | 0.4363 | 0.5126 | 0.4835 | ||
| 0.8225 | 0.6896 | 0.519 | 0.4976 | 0.6135 | 0.5517 | 0.5905 | 0.6077 | 0.6115 | ||
| RE | 0.2659 | 0.1601 | 0.2611 | 0.2440 | 0.2240 | 0.2374 | 0.2288 | 0.1996 | 0.2276 | |
| 0.2920 | 0.2405 | 0.2851 | 0.2481 | 0.2454 | 0.2193 | 0.2027 | 0.2049 | 0.2423 | ||
| 0.5483 | 0.4494 | 0.4408 | 0.4708 | 0.4416 | 0.4090 | 0.3820 | 0.3685 | 0.4388 | ||
| 0.3473 | 0.2421 | 0.3037 | 0.2843 | 0.2897 | 0.2496 | 0.2617 | 0.2333 | 0.2765 | ||
| 0.3679 | 0.3156 | 0.3364 | 0.3185 | 0.3189 | 0.2720 | 0.2953 | 0.2554 | 0.3100 | ||
| 0.6404 | 0.5531 | 0.5696 | 0.5780 | 0.5615 | 0.5184 | 0.4890 | 0.4795 | 0.5487 |
| Model | FUNSD | ZH | JA | ES | FR | IT | DE | PT | Avg. | |
|---|---|---|---|---|---|---|---|---|---|---|
| SER | 0.6633 | 0.883 | 0.7786 | 0.6223 | 0.7035 | 0.6814 | 0.7146 | 0.6726 | 0.7149 | |
| 0.6538 | 0.8741 | 0.7855 | 0.5979 | 0.7057 | 0.6826 | 0.7055 | 0.6796 | 0.7106 | ||
| 0.7924 | 0.8973 | 0.7964 | 0.7798 | 0.8173 | 0.821 | 0.8322 | 0.8241 | 0.8201 | ||
| 0.7151 | 0.8967 | 0.7828 | 0.6615 | 0.7407 | 0.7165 | 0.7431 | 0.7449 | 0.7502 | ||
| 0.7246 | 0.8919 | 0.7998 | 0.6702 | 0.7376 | 0.7180 | 0.7523 | 0.7332 | 0.7534 | ||
| 0.8068 | 0.9155 | 0.8216 | 0.8055 | 0.8384 | 0.8372 | 0.853 | 0.8650 | 0.8429 | ||
| RE | 0.3638 | 0.6797 | 0.6829 | 0.6828 | 0.6727 | 0.6937 | 0.6887 | 0.6082 | 0.6341 | |
| 0.3699 | 0.6493 | 0.6473 | 0.6828 | 0.6831 | 0.6690 | 0.6384 | 0.5763 | 0.6145 | ||
| 0.6671 | 0.8241 | 0.8142 | 0.8104 | 0.8221 | 0.8310 | 0.7854 | 0.7044 | 0.7823 | ||
| 0.4246 | 0.7316 | 0.7350 | 0.7513 | 0.7532 | 0.7520 | 0.7111 | 0.6582 | 0.6896 | ||
| 0.4543 | 0.7311 | 0.7510 | 0.7644 | 0.7549 | 0.7504 | 0.7356 | 0.6875 | 0.7037 | ||
| 0.7683 | 0.9000 | 0.8621 | 0.8592 | 0.8669 | 0.8675 | 0.8263 | 0.8160 | 0.8458 |
4.2 Results
We evaluate the LayoutXLM model on language-specific fine-tuning tasks, and the results are shown in Table 2. Compared with the pre-trained models such as XLM-R and InfoXLM, the LayoutXLM LARGE model achieves the highest F1 scores in both SER and RE tasks. The significant improvement shows LayoutXLM’s capability to transfer knowledge obtained from pre-training to downstream tasks, which further confirms the effectiveness of our multilingual pre-training framework.
For the cross-lingual zero-shot transfer, we present the evaluation results in Table 3. Although the model are only fine-tuned on FUNSD dataset (in English), it can still transfer the knowledge to different languages. In addition, it is observed that the LayoutXLM model significantly outperforms the other text-based models. This verifies that LayoutXLM can capture the common layout invariance among different languages and transfer to other languages for form understanding.
Finally, Table 4 shows the evaluation results on the multitask learning. In this setting, the pre-trained LayoutXLM model is fine-tuned with all 8 languages simultaneously and evaluated on each specific language, in order to investigate whether improvements can be obtained by multilingual fine-tuning. We observe that the multitask learning further improves the model performance compared to the language-specific fine-tuning, which also confirms that document understanding can benefit from the layout invariance among different languages.
5 Related Work
Multimodal pre-training has become popular in recent years due to its successful applications in vision-language representation learning. Lu et al. (2019) proposed ViLBERT for learning task-agnostic joint representations of image content and natural language by extending the popular BERT architecture to a multimodal two-stream model. Su et al. (2020) proposed VL-BERT that adopts the Transformer model as the backbone, and extends it to take both visual and linguistic embedded features as input. Li et al. (2019) propose VisualBERT consists of a stack of Transformer layers that implicitly align elements of an input text and regions in an associated input image with self-attention. Chen et al. (2020) introduced UNITER that learns through large-scale pre-training over four image-text datasets (COCO, Visual Genome, Conceptual Captions, and SBU Captions), which can power heterogeneous downstream V+L tasks with joint multimodal embeddings. Li et al. (2020c) proposed a new learning method Oscar (Object-Semantics Aligned Pre-training), which uses object tags detected in images as anchor points to significantly ease the learning of alignments. Inspired by these vision-language pre-trained models, we would like to introduce the vision-language pre-training into the document intelligence area, where the text, layout, and image information can be jointly learned to benefit the VrDU tasks.
Multilingual pre-trained models have pushed many SOTA results on cross-lingual natural language understanding tasks by pre-training the Transformer models on different languages. These models have successfully bridged the language barriers in a number of cross-lingual transfer benchmarks such as XNLI (Conneau et al., 2018) and XTREME (Hu et al., 2020). Devlin et al. (2018) introduced a new language representation model called BERT and extend to a multilingual version called mBERT, which is designed to pre-train deep bidirectional representations from the unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks. Lample and Conneau (2019) proposed two methods to learn cross-lingual language models (XLMs): one unsupervised that only relies on monolingual data, and one supervised that leverages parallel data with a new cross-lingual language model objective. Conneau et al. (2020) proposed to train a Transformer-based masked language model on one hundred languages, using more than two terabytes of filtered CommonCrawl data, which significantly outperforms mBERT on a variety of cross-lingual benchmarks. Recently, Chi et al. (2020) formulated cross-lingual language model pre-training as maximizing mutual information between multilingual-multi-granularity texts. The unified view helps to better understand the existing methods for learning cross-lingual representations, and the information-theoretic framework inspires to propose a pre-training task based on contrastive learning. Liu et al. (2020) presented mBART – a sequence-to-sequence denoising auto-encoder pre-trained on large-scale monolingual corpora in many languages using the BART objective. Xue et al. (2020) introduced mT5, a multilingual variant of T5 that was pre-trained on a new Common Crawl-based dataset covering 101 languages. The pre-trained LayoutXLM model is built on the multilingual textual models as the initialization, which benefits the VrDU tasks in different languages worldwide.
6 Conclusion
In this paper, we present LayoutXLM, a multimodal pre-trained model for multilingual visually-rich document understanding. The LayoutXLM model is pre-trained with 30 million scanned and digital-born documents in 53 languages. Meanwhile, we also introduce the multilingual form understanding benchmark XFUND, which includes key-value labeled forms in 7 languages. Experimental results have illustrated that the pre-trained LayoutXLM model has significantly outperformed the SOTA baselines for multilingual document understanding, which bridges the language gap in real-world document understanding tasks. We make LayoutXLM and XFUND publicly available to advance the document understanding research.
For future research, we will further enlarge the multilingual training data to cover more languages as well as more document layouts and templates. In addition, as there are a great number of business documents with the same content but in different languages, we will also investigate how to leverage the contrastive learning of parallel documents for the multilingual pre-training.
References
- Afli and Way (2016) Haithem Afli and Andy Way. 2016. Integrating optical character recognition and machine translation of historical documents. In Proceedings of the Workshop on Language Technology Resources and Tools for Digital Humanities (LT4DH), pages 109–116, Osaka, Japan. The COLING 2016 Organizing Committee.
- Bekoulis et al. (2018) Giannis Bekoulis, Johannes Deleu, Thomas Demeester, and Chris Develder. 2018. Joint entity recognition and relation extraction as a multi-head selection problem. Expert Syst. Appl., 114:34–45.
- Chen et al. (2020) Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu. 2020. Uniter: Universal image-text representation learning.
- Chi et al. (2020) Zewen Chi, Li Dong, Furu Wei, Nan Yang, Saksham Singhal, Wenhui Wang, Xia Song, Xian-Ling Mao, Heyan Huang, and Ming Zhou. 2020. Infoxlm: An information-theoretic framework for cross-lingual language model pre-training.
- Conneau et al. (2020) Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2020. Unsupervised cross-lingual representation learning at scale.
- Conneau et al. (2018) Alexis Conneau, Ruty Rinott, Guillaume Lample, Adina Williams, Samuel R. Bowman, Holger Schwenk, and Veselin Stoyanov. 2018. Xnli: Evaluating cross-lingual sentence representations. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Graliński et al. (2020) Filip Graliński, Tomasz Stanisławek, Anna Wróblewska, Dawid Lipiński, Agnieszka Kaliska, Paulina Rosalska, Bartosz Topolski, and Przemysław Biecek. 2020. Kleister: A novel task for information extraction involving long documents with complex layout.
- Harley et al. (2015) Adam W Harley, Alex Ufkes, and Konstantinos G Derpanis. 2015. Evaluation of deep convolutional nets for document image classification and retrieval. In International Conference on Document Analysis and Recognition (ICDAR).
- Hu et al. (2020) Junjie Hu, Sebastian Ruder, Aditya Siddhant, Graham Neubig, Orhan Firat, and Melvin Johnson. 2020. Xtreme: A massively multilingual multi-task benchmark for evaluating cross-lingual generalization.
- Jaume et al. (2019) Guillaume Jaume, Hazim Kemal Ekenel, and Jean-Philippe Thiran. 2019. Funsd: A dataset for form understanding in noisy scanned documents. 2019 International Conference on Document Analysis and Recognition Workshops (ICDARW).
- Lample and Conneau (2019) Guillaume Lample and Alexis Conneau. 2019. Cross-lingual language model pretraining.
- Lewis et al. (2006) D. Lewis, G. Agam, S. Argamon, O. Frieder, D. Grossman, and J. Heard. 2006. Building a test collection for complex document information processing. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’06, page 665–666, New York, NY, USA. Association for Computing Machinery.
- Li et al. (2019) Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, and Kai-Wei Chang. 2019. Visualbert: A simple and performant baseline for vision and language.
- Li et al. (2020a) Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou, and Zhoujun Li. 2020a. TableBank: Table benchmark for image-based table detection and recognition. In Proceedings of the 12th Language Resources and Evaluation Conference, pages 1918–1925, Marseille, France. European Language Resources Association.
- Li et al. (2020b) Minghao Li, Yiheng Xu, Lei Cui, Shaohan Huang, Furu Wei, Zhoujun Li, and Ming Zhou. 2020b. DocBank: A benchmark dataset for document layout analysis. In Proceedings of the 28th International Conference on Computational Linguistics, pages 949–960, Barcelona, Spain (Online). International Committee on Computational Linguistics.
- Li et al. (2020c) Xiujun Li, Xi Yin, Chunyuan Li, Pengchuan Zhang, Xiaowei Hu, Lei Zhang, Lijuan Wang, Houdong Hu, Li Dong, Furu Wei, Yejin Choi, and Jianfeng Gao. 2020c. Oscar: Object-semantics aligned pre-training for vision-language tasks.
- Liu et al. (2020) Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, and Luke Zettlemoyer. 2020. Multilingual denoising pre-training for neural machine translation.
- Lu et al. (2019) Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. 2019. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks.
- Mathew et al. (2020) Minesh Mathew, Dimosthenis Karatzas, R. Manmatha, and C. V. Jawahar. 2020. Docvqa: A dataset for vqa on document images.
- Park et al. (2019) Seunghyun Park, Seung Shin, Bado Lee, Junyeop Lee, Jaeheung Surh, Minjoon Seo, and Hwalsuk Lee. 2019. Cord: A consolidated receipt dataset for post-ocr parsing.
- Su et al. (2020) Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, and Jifeng Dai. 2020. Vl-bert: Pre-training of generic visual-linguistic representations.
- Wenzek et al. (2019) Guillaume Wenzek, Marie-Anne Lachaux, Alexis Conneau, Vishrav Chaudhary, Francisco Guzmán, Armand Joulin, and Edouard Grave. 2019. Ccnet: Extracting high quality monolingual datasets from web crawl data. CoRR, abs/1911.00359.
- Xu et al. (2020a) Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, and Lidong Zhou. 2020a. Layoutlmv2: Multi-modal pre-training for visually-rich document understanding.
- Xu et al. (2020b) Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, and Ming Zhou. 2020b. Layoutlm: Pre-training of text and layout for document image understanding. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD ’20, page 1192–1200, New York, NY, USA. Association for Computing Machinery.
- Xue et al. (2020) Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. 2020. mt5: A massively multilingual pre-trained text-to-text transformer.
- Zhong et al. (2019) Xu Zhong, Jianbin Tang, and Antonio Jimeno Yepes. 2019. Publaynet: largest dataset ever for document layout analysis. In 2019 International Conference on Document Analysis and Recognition (ICDAR), pages 1015–1022. IEEE.