打赏本站
微信
 支付宝
支付宝

支付宝
Transformer 和多层感知器 (MLP) 模型的最新进展为计算机视觉任务提供了新的网络架构设计。尽管这些模型被证明在图像识别等许多视觉任务中是有效的,但将它们适应低级视觉仍然存在挑战。支持高分辨率图像的不灵活性和局部注意力的限制可能是主要瓶颈 ...
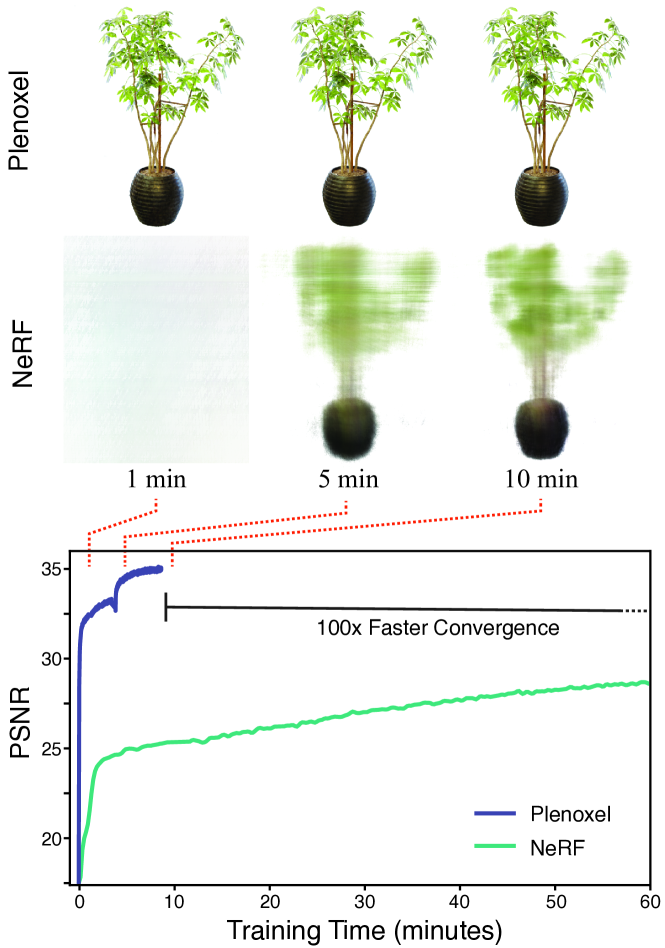
我们介绍 Plenoxels(全光体素),一种用于照片级真实感视图合成的系统。 Plenoxels 将场景表示为具有球谐函数的稀疏 3D 网格。这种表示可以通过梯度方法和正则化从校准图像中进行优化,而无需任何神经组件 ...
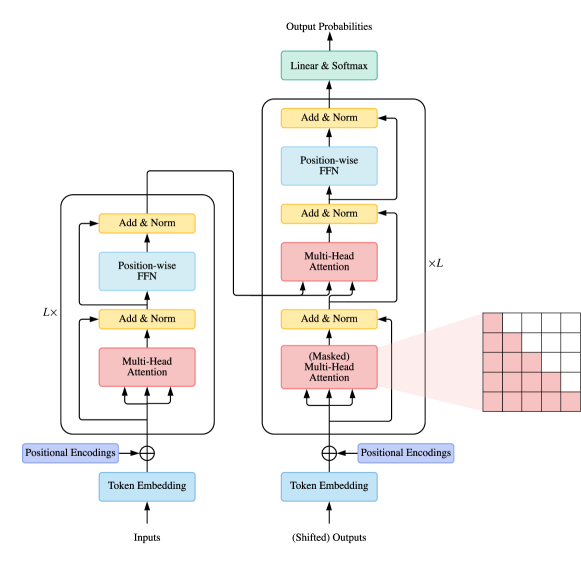
Transformer 在自然语言处理、计算机视觉、音频处理等许多人工智能领域取得了巨大成功。因此,自然引起学术界和工业界研究人员的广泛兴趣。到目前为止,Transformer 的变体种类繁多(a. ...
Meta 的 LLaMA 系列已成为最强大的开源大型语言模型 (LLM) 系列之一。值得注意的是,LLaMA3 模型最近已发布,并通过对超过 15T Token 的数据进行超大规模预训练,在各种方面取得了令人印象深刻的性能。鉴于 LLM 低位量化在资源有限的场景中的广泛应用,我们探索了 LLaMA3 在量化为低位宽时的功能 ...

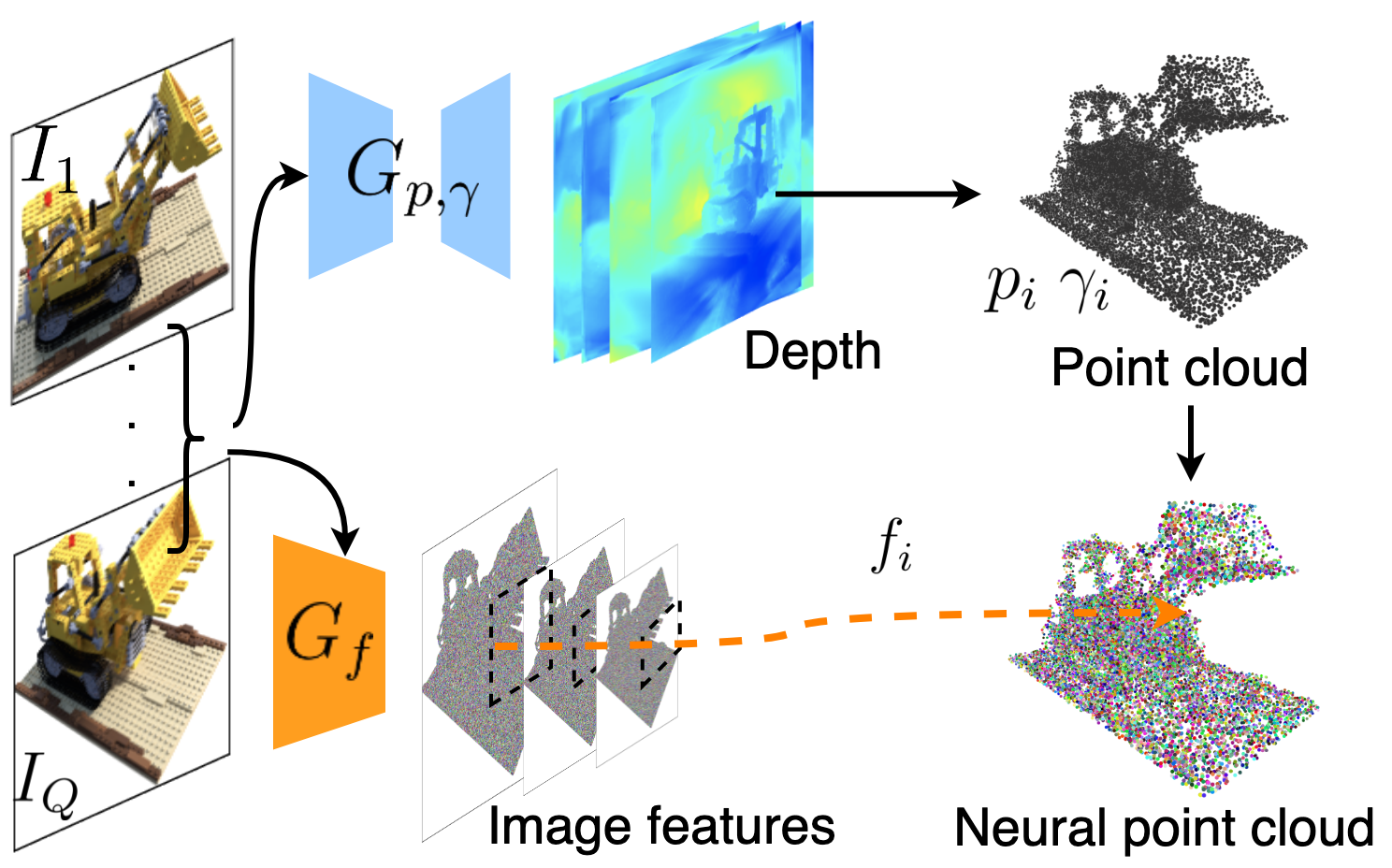
NeRF 等体积神经渲染方法可生成高质量的视图合成结果,但针对每个场景进行优化,导致重建时间过长。另一方面,深度多视图立体方法可以通过直接网络推理快速重建场景几何形状。 Point-NeRF 通过使用神经 3D 点云以及相关的神经特征来对辐射场进行建模,从而结合了这两种方法的优点 ...
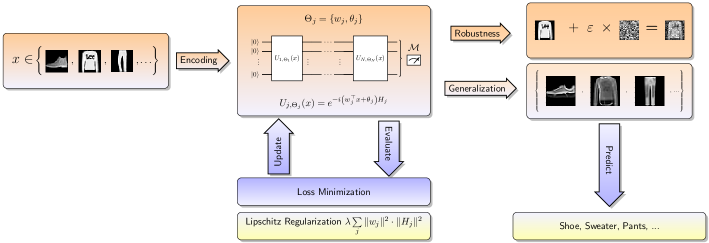
对抗性鲁棒性和泛化性都是可靠机器学习模型的关键属性。在本文中,我们在基于 Lipschitz 界限的量子机器学习背景下研究这些属性。我们为具有可训练编码的量子模型推导了定制的、参数相关的 Lipschitz 界限,表明数据编码的范数对输入数据扰动的鲁棒性具有至关重要的影响 ...
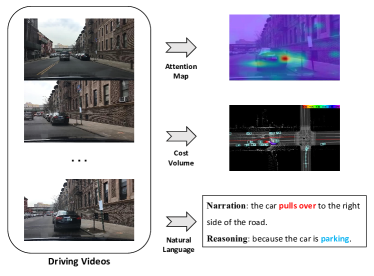
端到端自动驾驶在交通行业具有巨大潜力。然而,自动决策过程缺乏透明度和可解释性阻碍了其在实践中的工业采用。早期已经有一些尝试使用注意力图或成本量来获得更好的模型可解释性,但这对普通乘客来说很难理解 ...
传统的图像拼接方法倾向于利用日益复杂的几何特征(点、线、边缘等)来获得更好的性能。然而,这些手工制作的特征仅适用于具有足够几何结构的特定自然场景 ...
