打赏本站
微信
 支付宝
支付宝

支付宝
深度神经网络 (DNN) 继续取得重大进展,解决从图像分类到翻译或强化学习的任务。该领域备受关注的一方面是在资源受限的环境(例如移动或嵌入式设备)中有效地执行深度模型。本文重点关注这个问题,提出了两种新的压缩方法,联合利用权重量化和将较大的教师网络蒸馏为较小的学生网络 ...

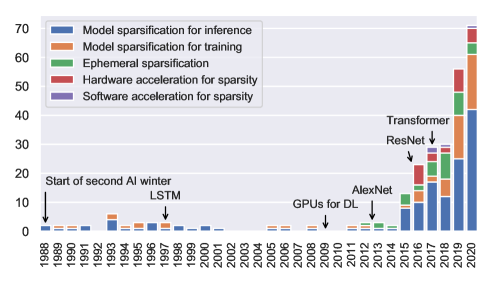
深度学习不断增长的能源和性能成本促使社区通过有选择地修剪组件来减小神经网络的规模。与生物网络类似,稀疏网络的泛化能力与原始密集网络一样好,甚至更好。稀疏性可以减少常规网络的内存占用以适应移动设备,并缩短不断增长的网络的训练时间 ...
本文研究了 OpenAI 发布的 Whisper 自动语音识别(ASR)模型的上下文学习能力。提出了一种新颖的基于语音的上下文学习(SICL)方法用于测试时适应,该方法可以仅用少量标记的语音样本来降低单词错误率(WER),而无需梯度下降。使用汉语方言进行的语言级适应实验表明,当将 SICL 应用到孤立词 ASR 时,使用任意大小的 Whisper 模型在两种方言上都可以实现一致且相当大的相对 WE ...
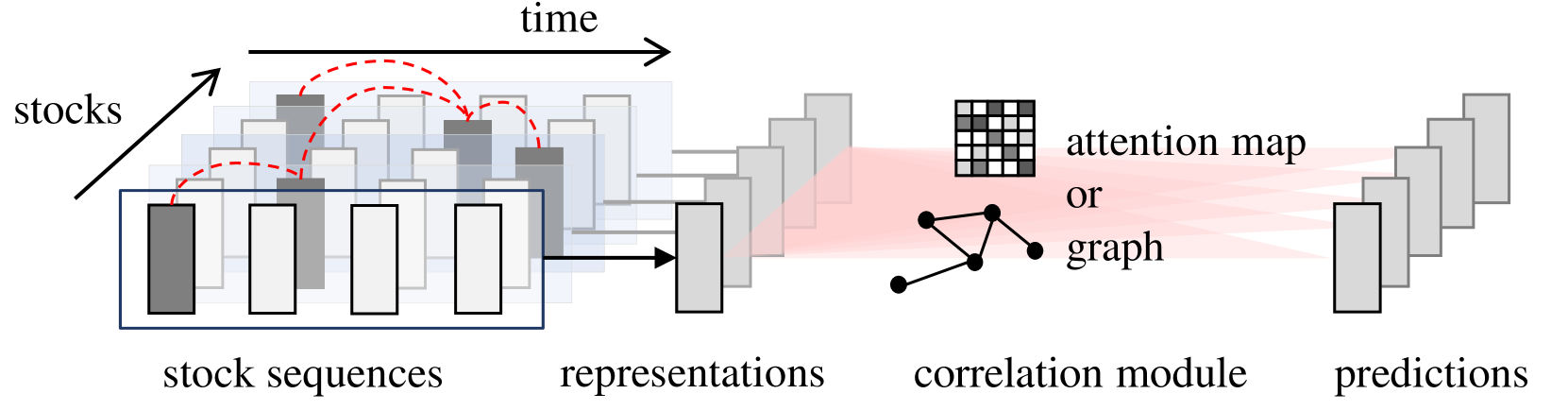
由于股市的高波动性,几十年来,股价预测一直是一个极具挑战性的问题。最近的努力致力于对复杂的股票相关性进行建模以进行联合股价预测。现有的作品共享一个共同的神经架构,该架构从单个股票系列中学习时间模式,然后混合时间表示以建立股票相关性 ...
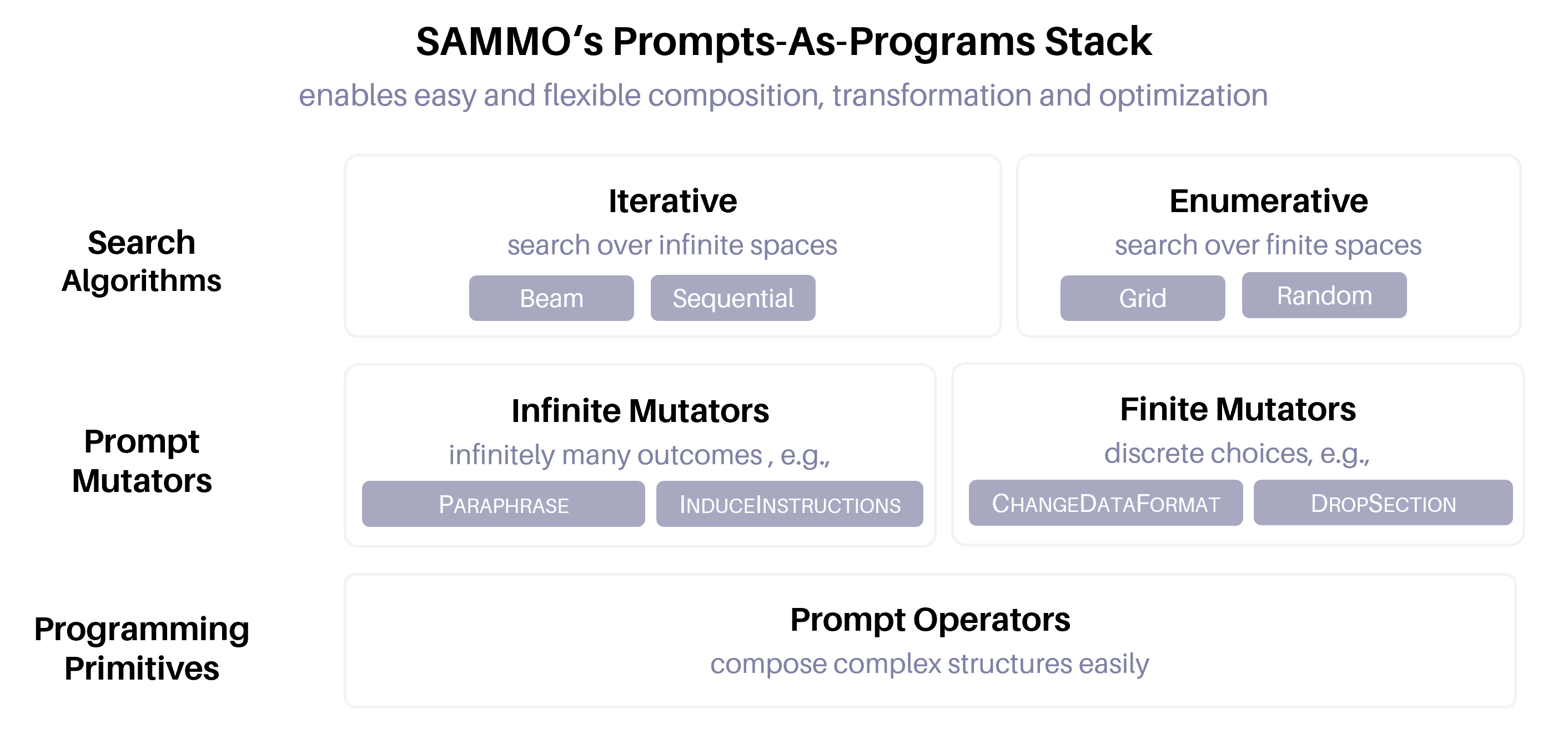
大型语言模型 (LLM) 现在可以处理更长、更复杂的输入,这有助于使用更详细的提示。但是,提示通常需要进行一些调整才能提高部署性能。最近的工作提出了自动提示优化方法,但随着提示复杂性和LLM强度的增加,许多提示优化技术不再足够,需要一种新的方法来优化{\em元提示程序} ...
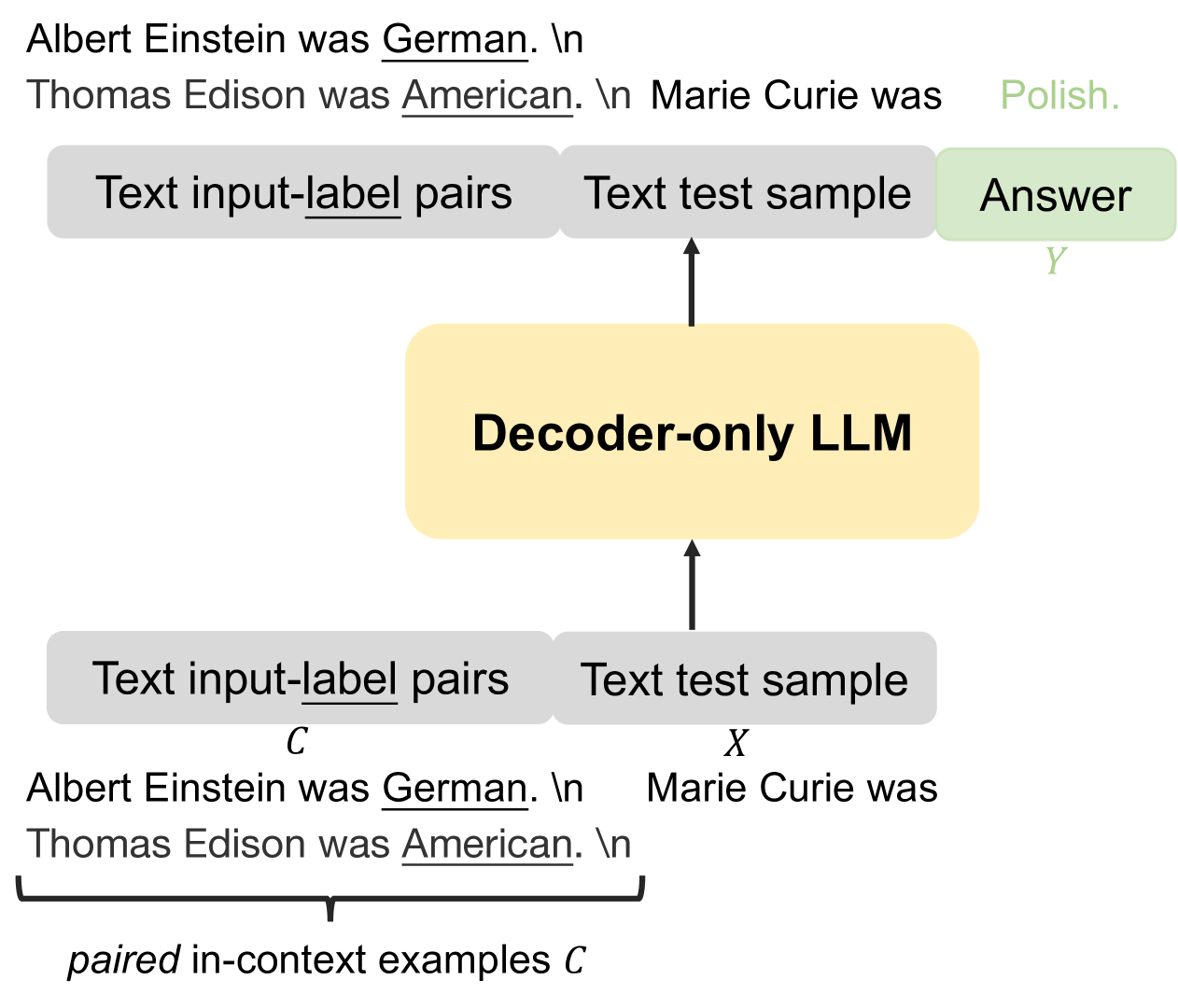
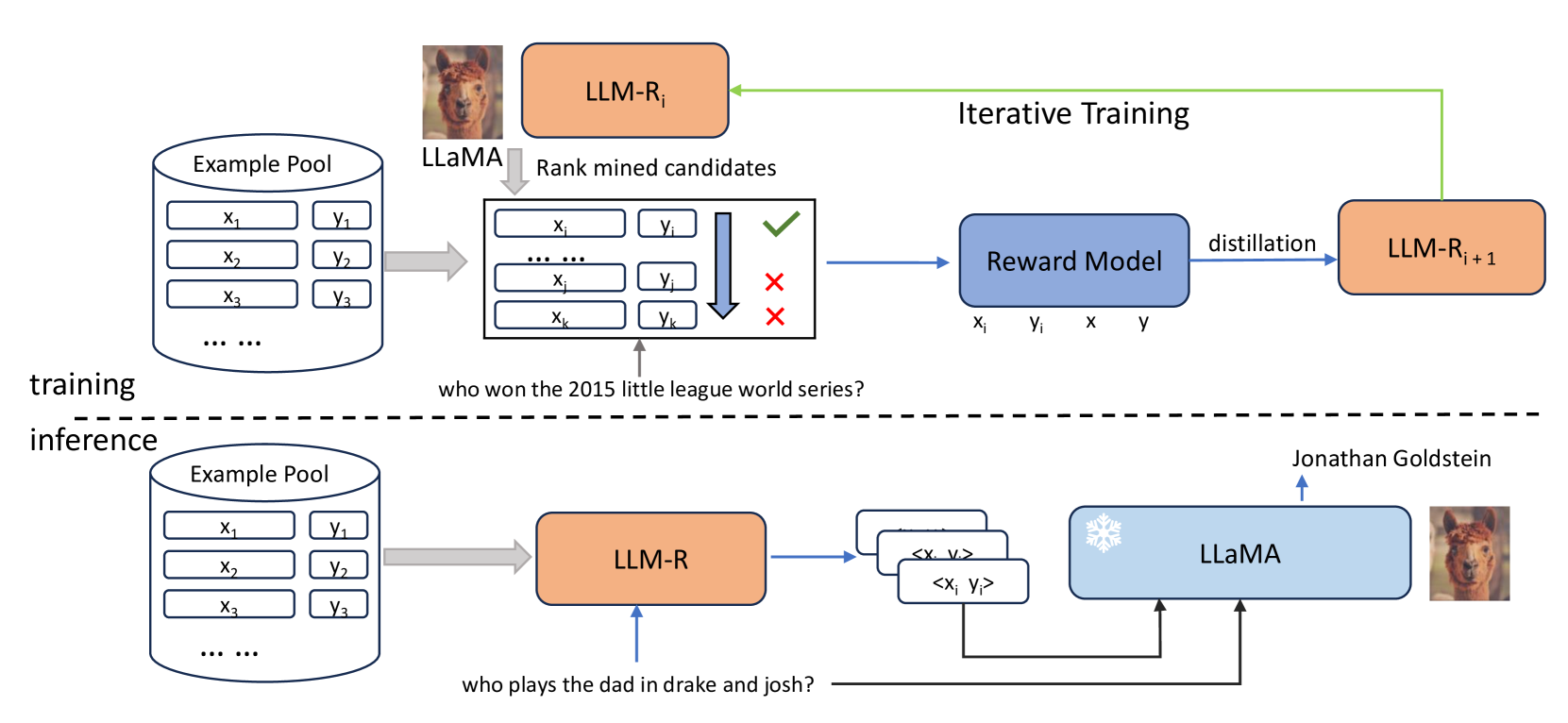
大型语言模型(LLM)已经证明了它们在上下文中学习的能力,使它们能够基于一些输入输出示例执行各种任务。然而,情境学习的有效性在很大程度上取决于所选示例的质量。在本文中,我们提出了一种新颖的框架来迭代训练密集检索器,该检索器可以为 LLM 识别高质量的上下文示例 ...
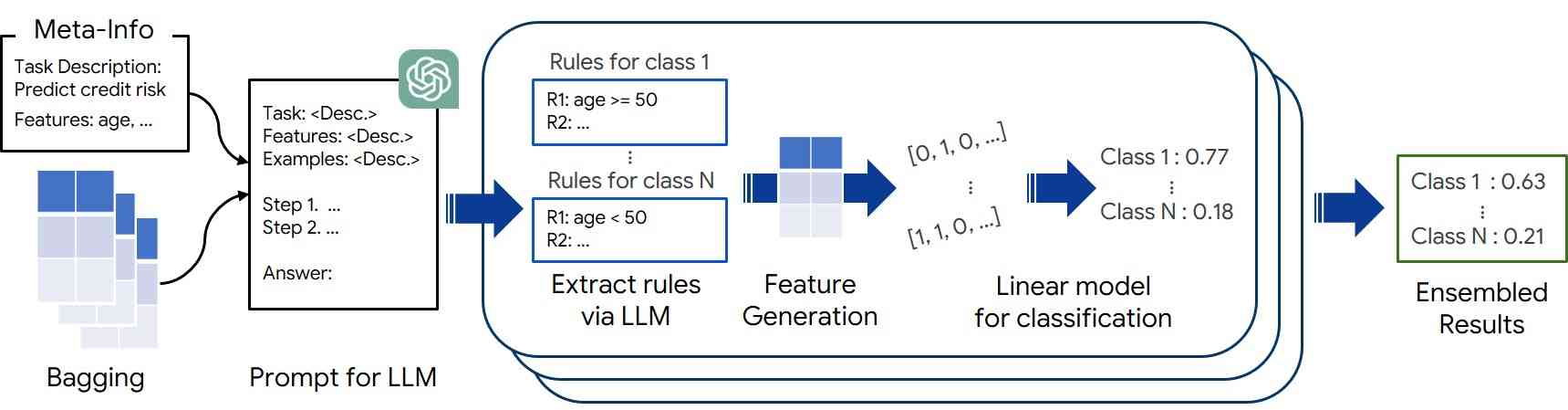
大型语言模型(LLM)具有解决具有挑战性和看不见的推理问题的卓越能力,在表格学习方面拥有巨大的潜力,这对于许多现实世界的应用程序至关重要。在本文中,我们提出了一种新颖的上下文学习框架 FeatLLM,该框架采用 LLM 作为特征工程师来生成最适合表格预测的输入数据集。生成的特征用于通过简单的下游机器学习模型(例如线性回归)推断类别可能性,并产生高性能的小样本学习 ...
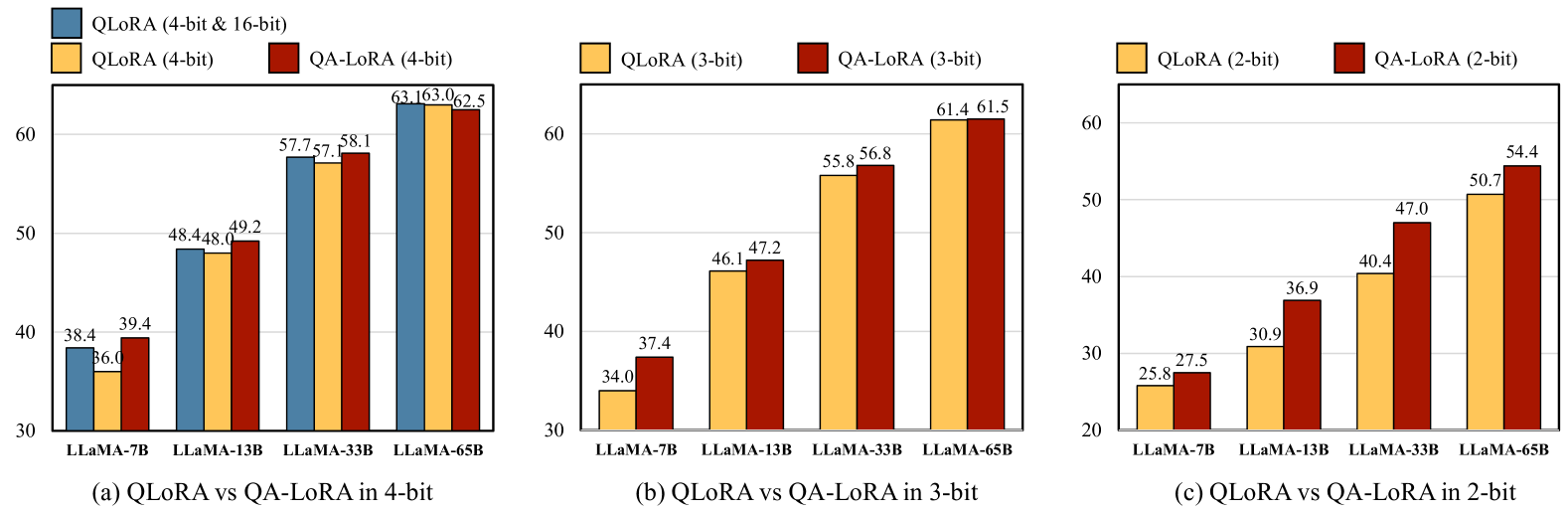
近年来,大型语言模型(LLM)迅速发展。尽管LLM在许多语言理解任务中具有很强的能力,但繁重的计算负担在很大程度上限制了LLM的应用,特别是当需要将它们部署到边缘设备上时。在本文中,我们提出了一种量化感知低秩自适应(QA-LoRA)算法 ...